Advanced User Guide
Software Stack Overview
PyBuda is largely divided into two main components, the compiler and the runtime. Below is an overview of each component respectively.
PyBuda Compiler Architecture
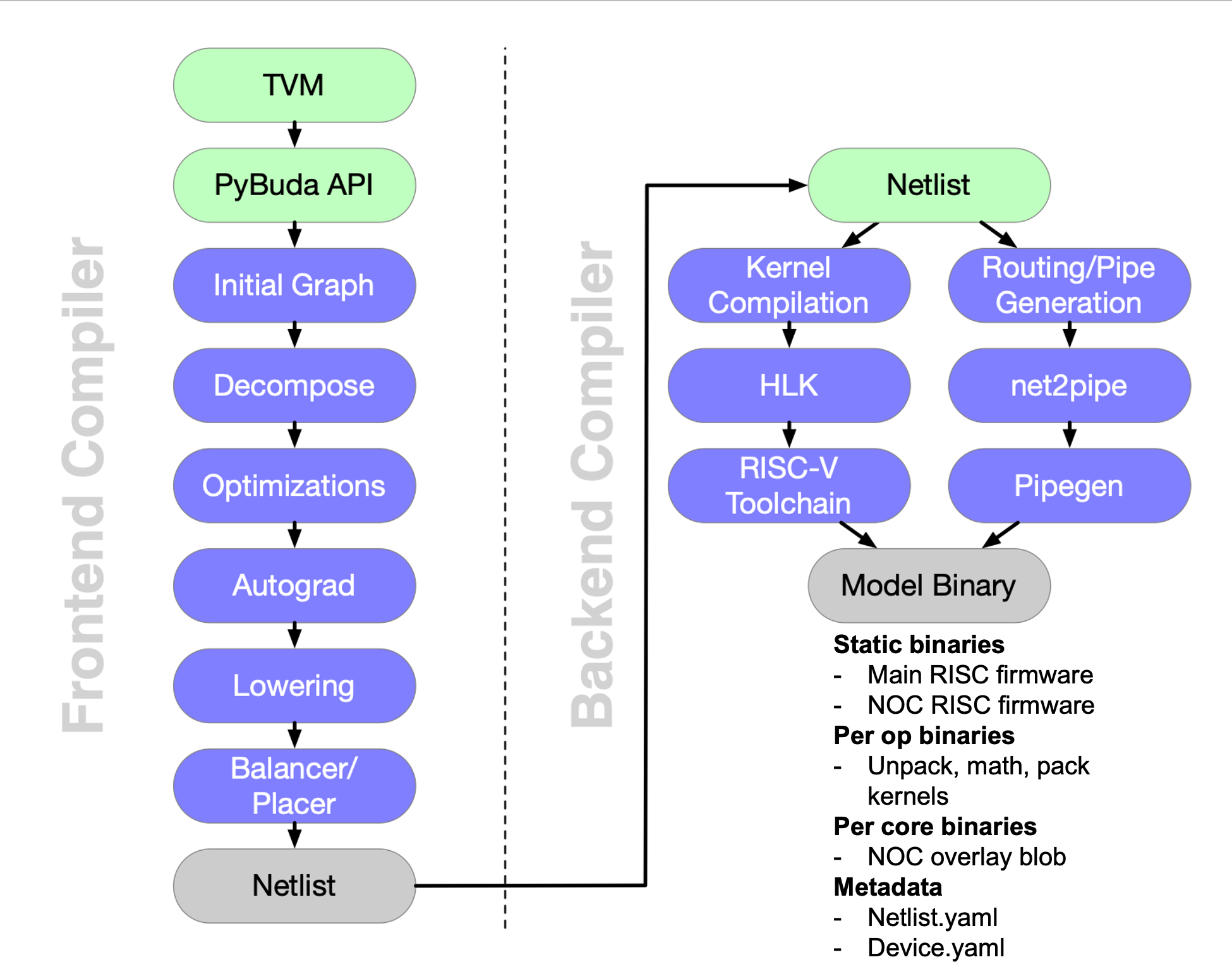
The PyBuda compiler is largely broken into 2 halves, frontend and backend as depicted in the image above. Each piece respectively is organized in passes that iteratively transform the framework model into something executable by the hardware.
Frontend Passes
TVM: PyBuda is itself an ML framework, but typically it’s more convenient to run models that have already been written to target another framework. We use TVM to abstract our compiler over many popular frameworks so it is often the primary entry point. We’ve written and maintain a TVM backend that targets PyBuda API.
PyBuda API: It’s also possible to express your model directly in PyBuda. Most internal tests are written directly in PyBuda.
Initial Graph: This isn’t really a compile pass, but rather an execution trace of the model with dummy tensors. From this trace we are able to build a rich graph datastructure that the frontend compiler uses to perform transformations over.
Decompose: This pass allows us to implement high level ops, such as
softmaxin terms of lower level ops. Decomposition in this context is breaking apart high level ops and replacing them in the graph with a new subgraph that implements the original op. This pass calls top level hooks into python making it very easy to add new decompositions into the compiler.Optimizations: This is a collection of passes that perform many kinds of optimizations including constant folding, op reordering, and reshape cancelation.
Autograd: We have our own autograd pass which gives us the opportunity to annotate our graph datastructure in a way to help future passes best target our HW. With this information our placement pass can leverage some unique properties about TT architecture to make training more efficient. This pass is only enabled if training is enabled.
Lowering: Up until this point we’ve been using operators in a high level IR that we call PyBuda IR. Lowering does a few things, but it’s main purpose is to lower this high level IR (PyBuda IR) to a low level IR (Buda IR) where this Buda IR is the core set of operations that are backed by HW kernels implemented by our backend compiler. Lowering is also where we perform data format selection and snap tensor sizes to tile granularity (i.e. 32x32 multiples on the RxC dims).
Balancer/Placer: Finally, our graph is ready to be scheduled onto the HW. Balancer and Placer are tightly coupled datastructures that together determine how operations will be laid out onto the device core grid and how many resources to assign to each operation.
Netlist: Netlist is the intermediate representation that serves as the API boundary between the frontend and the backend. It is a textual, human readable, yaml format that describes how operations are to be scheduled onto the chip.
Backend Passes
The backend is divided into two disjoint compile paths. Abstractly, if you imagine a graph datastructure with nodes and edges, the left path (kernel compilation) is compiling the nodes or math operations in the graph whereas the right path is compiling the edges or data movement operations.
Kernel Compilation: This path walks the netlist and extracts the set of operations specified and compiles the associated kernel implementations. Compilation here means compiling High Level Kernels (HLKs) implemented in C++ and using a kernel programming library called LLK (low level kernel) via a RISCV compiler toolchain. This is the actual machine code that will run on the Tensix core hardware.
Routing/Pipe Generation: This path first flows through
net2pipewhich extracts the op connectivity information from the netlist and generates a data movement program. This program is expressed in an IR that feeds into pipegen, the backend of this compile stage which implements the lowering of this IR into an executable that runs on a piece of hardware called overlay.
Compiler Configuration
PyBuda compiler is highly configurable via the CompilerConfig class. Instead of programming this class directly, most configs have convenience top level functions, all of which update in place a global instance of the CompilerConfig. Users can create their own CompilerConfig and explicitly pass it in for compile, but most examples simply use the global config object since there is rarely a need for multiple instances. Global config meaning config = pybuda.config._get_global_compiler_config().
Below are some common overrides with brief descriptions for each and organized in levels of increasing control. Level 1 configs are the first, low hanging fruit configs to reach for while tuning the desired compile output, whereas, Level 3 would be for power users that want explicit control over fine grained compiler decisions.
Note that there are compiler configurations that are present in the dataclass, but not listed in the tables below, this is intentional for a number of potential reasons. Some are for debugging / internal developement only and some overrides are deprecated and have not yet been removed from the compiler. We are working towards better organizing our override system to reflect the level system outlined below, move the development flags into a special area, and remove the deprecated configs.
Level 1
Level 1
Configuration |
Description |
Usage |
|---|---|---|
|
Streaming in this context means dividing the tensor into chunks along either the row or column dimension to stage the computation. This implies that the computation is spread out temporally (hence the |
|
|
Enable compiler pass that performs automatic fusing of subgraphs. This pass will fuse together groups of ops into a single kernel that executes as a single op in the pipeline. |
By default true, might be useful to disable to workaround an undesirable fused result, but by and large it should be true. To disable: |
|
Used in conjunction with |
|
|
Used in conjunction with |
|
|
When enabled, this will allow the compiler to execute tensor manipulation (TMs) operations on host. The compiler uses heuristics to maximize TMs that are done on host so it may include some compute light operations (i.e. add) if it allows for more TMs to be included. No operations deeper than |
|
|
The maximum depth of operation (operations between it and graph input/output) for it to be included in TM fallback search. Any operations deeper than this will be performed on device. |
|
|
Enabling host-side convolution prestiding (occurs during host-tilizer) for more efficient first convolution layer. For example, this can transform a 7x7 conv into a 4x4 one by reordering and stacking the channels during tilizing. |
By default this is set to true, but in some cases where the host CPU might be a bottleneck in performing the data reordering it might need to be disabled: |
|
Enable or Disable Tilize Op on the embedded platform |
By default this is set to true, but in some cases where the host CPU might be a bottleneck in performing the tilize operation so it might need to be disabled: |
- |
If set to true/false, place parameters in dram by default i.e. |
In batch=1 cases, where parameters are only used once it could be desirable to keep the parameters in DRAM rather than first copying them to L1. By default the compiler only does this for batch=1, otherwise always tries to copy the parameters to L1, given they fit. This can also be overridden on a per-op level via |
|
Please refer to the AMP section in the Pybuda user guide for detailed information about AMP and its capabilities. |
|
- |
It is generally recommended to reach for AMP before using explicit overrides, but we also have the ability to override op or buffer data types for output and accumulate data formats. |
|
- |
Please refer to the Data Formats and Math Fidelity section of the documentation. |
|
|
We support 2 performance trace levels |
|
|
Default enabled, normalizes the activations before performing the exponentiation to avoid infinties / numerical instability. This normalization step is costly and in some cases, depending on the nature of the data at this particular point in the network, might not be needed. |
To disable, for extra perf at the cost of potential numerical instability: |
|
Used in the context of offline compilation of |
- |
|
If true, input queue backing memory will reside in host RAM in a special device visibible mmio region. If false, the input queue will be first copied to device RAM. It’s almost always desirable to program this to true to avoid the overhead of copy to device RAM. |
By default true, to disable: |
|
If true, output queue backing memory will reside in host RAM in a special device visibible mmio region. If false, the output queue will be copied from device RAM to the host. It’s almost always desirable to program this to true to avoid the overhead of copy from device RAM. |
By default true, to disable: |
|
Override the op grid shape. It generally correlates that the larger the grid shape, i.e. more core resources given to the op, the faster the op will run. It should be one of the first overrides to reach for when trying to tune the placement of ops on the device grid. |
|
Level 2
Level 2
Configuration |
Description |
Usage |
|---|---|---|
|
Override the factors that the compiler automatically visits during regular compilation. Streaming in this context means dividing the tensor into chunks along either the row or column dimension to stage the computation. This implies that the computation is spread out temporally (hence the |
Used in conjunction with |
|
See |
Used in conjunction with |
|
Cache the output of TVM (front end of PyBuda compiler which translates framework (i.e. PyTorch) models into an IR that PyBuda understands), so that next time model is executed, TVM conversion can be skipped. |
Setting environment variable |
|
Used in conjunction with |
|
|
Used in conjunction with |
|
|
Reload the generated python module before PyBuda compilation. As part of converting TVM ir into PyBuda, it is serialized into a python module. |
Set |
- |
Today our backend implementation of |
|
|
Tell the compiler that some outputs from the model are inputs to the subsequent iteration, thus they should be kept on device. This is useful for implementing past cache generative models. |
|
- |
Force the specified op name to break to a new epoch during placement. This also implies that all subsequent nodes scheduled after the specified one will also belong to a subsequent epoch. |
All of the following are equivalent: |
- |
Akin to |
All of the following are equivalent: |
|
The list of op names supplied will not participate in the automatic fusion pass. |
|
- |
Please refer to the Pybuda Automatic Mixed Precision section in the user guide. |
Please refer to the Pybuda Automatic Mixed Precision section in the user guide. |
- |
Instruct pybuda compiler to schedule ops in a way that respects the given partial ordering. The compiler will ensure to schedule op_order[i] before op_order[i+1] in the final schedule. |
|
|
Used to program the tti format depending on the runtime to be used. |
- |
|
Set the algorithm to use for DRAM placement. Valid values are: ROUND_ROBIN, ROUND_ROBIN_FLIP_FLOP, GREATEST_CAPACITY, CLOSEST. DRAM placement is the process of allocating DRAM queues and intelligently assigning these queues to DRAM channels depending on the cores that they’re accessed from. |
This configuration might be |
|
Override the op placement on the device core grid. |
|
Level 3
Level 3
Configuration |
Description |
Usage |
|---|---|---|
|
GraphSolver self cut is a feature used to resolve op to op connection incompatibility which would otherwise result in compiler constraint violation. Incompatibility is resolved with queue insertion between two affected ops. There are four valid settings for |
Example of usage: |
|
Setting |
|
|
A fracture group describes pybuda a subgraph to be fractured and along specified dimension(s). This is called sharding in some other frameworks/papers. |
Typically useful for multichip configurations where you want a single op (i.e. a very large matmul) to span multiple chips for more parallelization. |
backend_opt_level |
An integer between |
- |
|
Given a dict of dram queue names to |
This can be useful when the |
- |
These two configuration options insert DRAM queues or no-op ops between the specified edge. This is useful in situations where a subgraph has a fork/join or skip-connect topology, especially ones where the paths are not balanced in terms of number of ops. This runs into a pipelining issue where the short path must wait for the long path to finish in order to make forward progress. These two configurations can help explicitly balance these situations to mitigate pipeline bubbles, or in some cases even deadlocks. These APIs should be required by defualt, we have an fork/join graph pass that does this automatically. |
- |
|
See |
Used in conjunction with |
|
Override the programming of |
|
|
Override the number of input back buffers there are, by default the compiler will opportunistically try to reclaim L1 for additional input buffering which can help performance because the op is able to prefetch more and mitigate data movement overheads or pipeline bubbles. This is what the fork/join automatic compiler pass reaches to first before inserting buffering nops or DRAM queues. Even outside the scope of fork/join, additional input buffering can help performance. In the typical case the compiler will simply set this value to 2, i.e. double buffered. |
|
|
For convolution only, fracture the convolution into multiple ops along the kernel window dimensions. |
|
Tools & Debug
Reportify
Reportify is a UI tool that we use visualize certain datastructures a device resources. It is not only useful as an internal developer tool, but also for external users to get a better understanding of the transformations that the compiler has done and then using that information to potentially feed back into the compiler via overrides to make different decisions.
Reportify is a webserver that typically runs on the same remote machine as the compiler. It’s pointed to a special local directory that the PyBuda compiler populates with all kinds of reports and debug information that the reportify server then serves as UI. Refer to the README.md in the reportify source repo for installing and setting up a webserver instance.
Home Page
When you go to the reportify address in your browser, you’ll get the above landing page. Each row entry represents a different module compilation or test, note that successive compilations clobber previous results.
Clicking on a row brings you to a list of report types associated with this compilation. The 2 most common report types that are used are typically Buda Reports: Passes and Placement Reports.
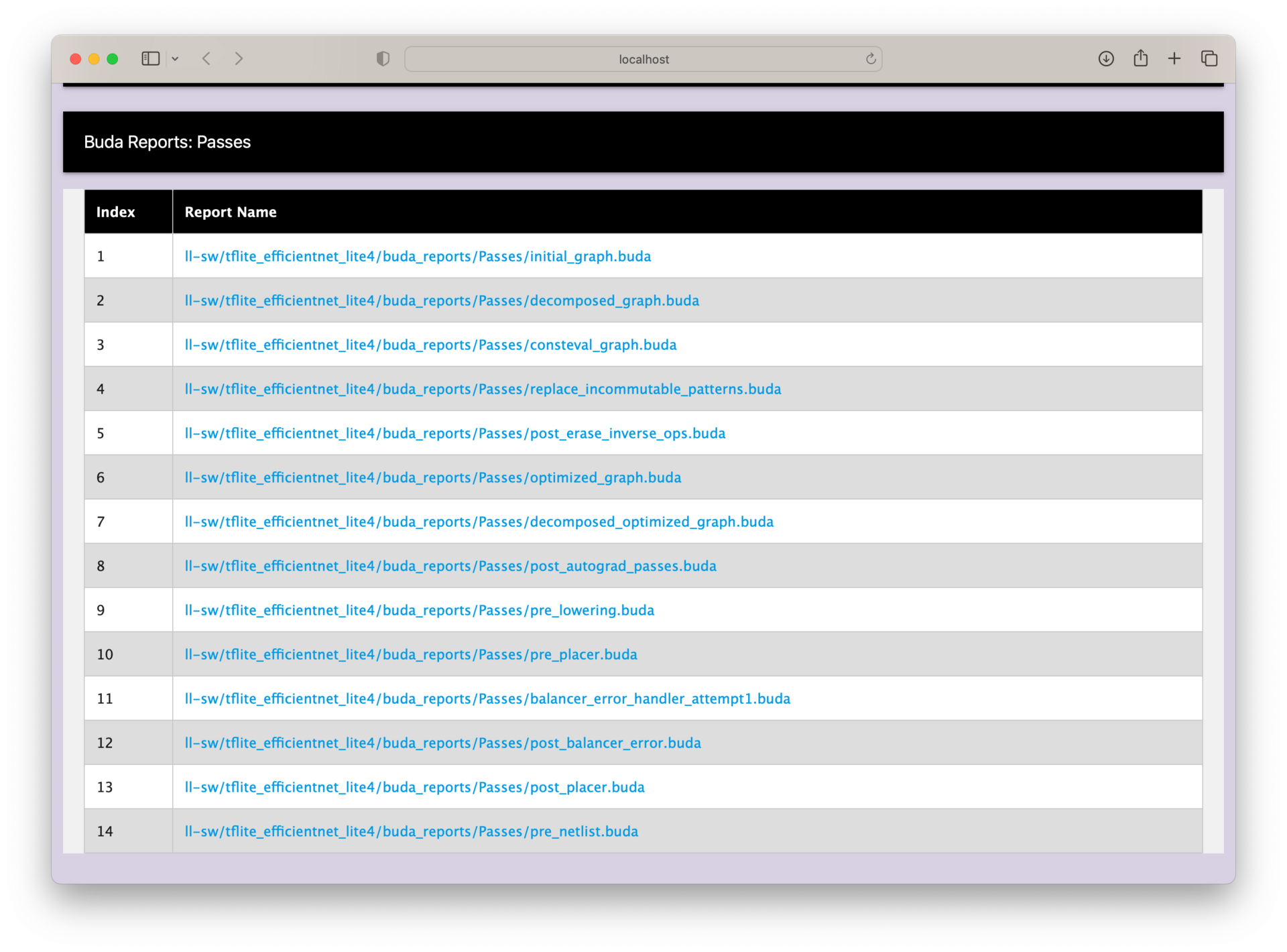
When clicking on the Buda Reports: Passes tab, we get a dropdown list of different graph passes to look at. Each entry corresponds to a high level graph pass that the compiler ran and generated a report for. We’ll look in detail at 2 of the graph passes, initial_graph and post_placer.
When you first click on a graph to visualize, reportify will be fully zoomed out to fit the entire graph inside the window. Point your cursor to a section of graph you wish to zoom into and use the scroll wheel to zoom.
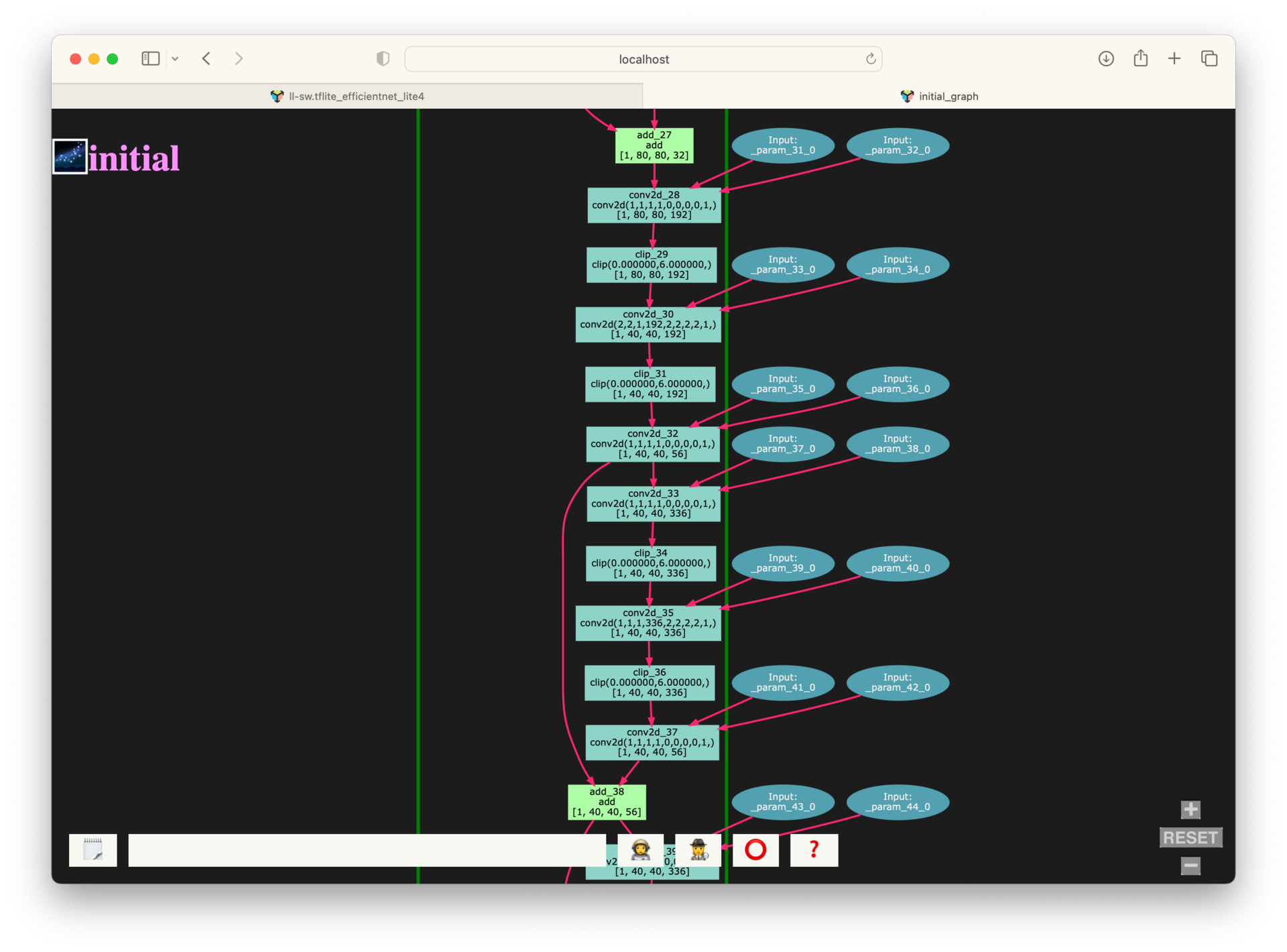
Here we can better see a section of the initial graph. The initial graph is less of a graph pass and is rather a direct representation of the initial graph data structure that the compiler generated from tracing the module. Graph input and output queues are typically drawn with ovals, light blue for activations and dark blue for parameters. Operations in the graph are denoted by rectangles and are annotated with the op’s name, internal compiler attributes associated with this op, and lastly the op’s shape in brackets.
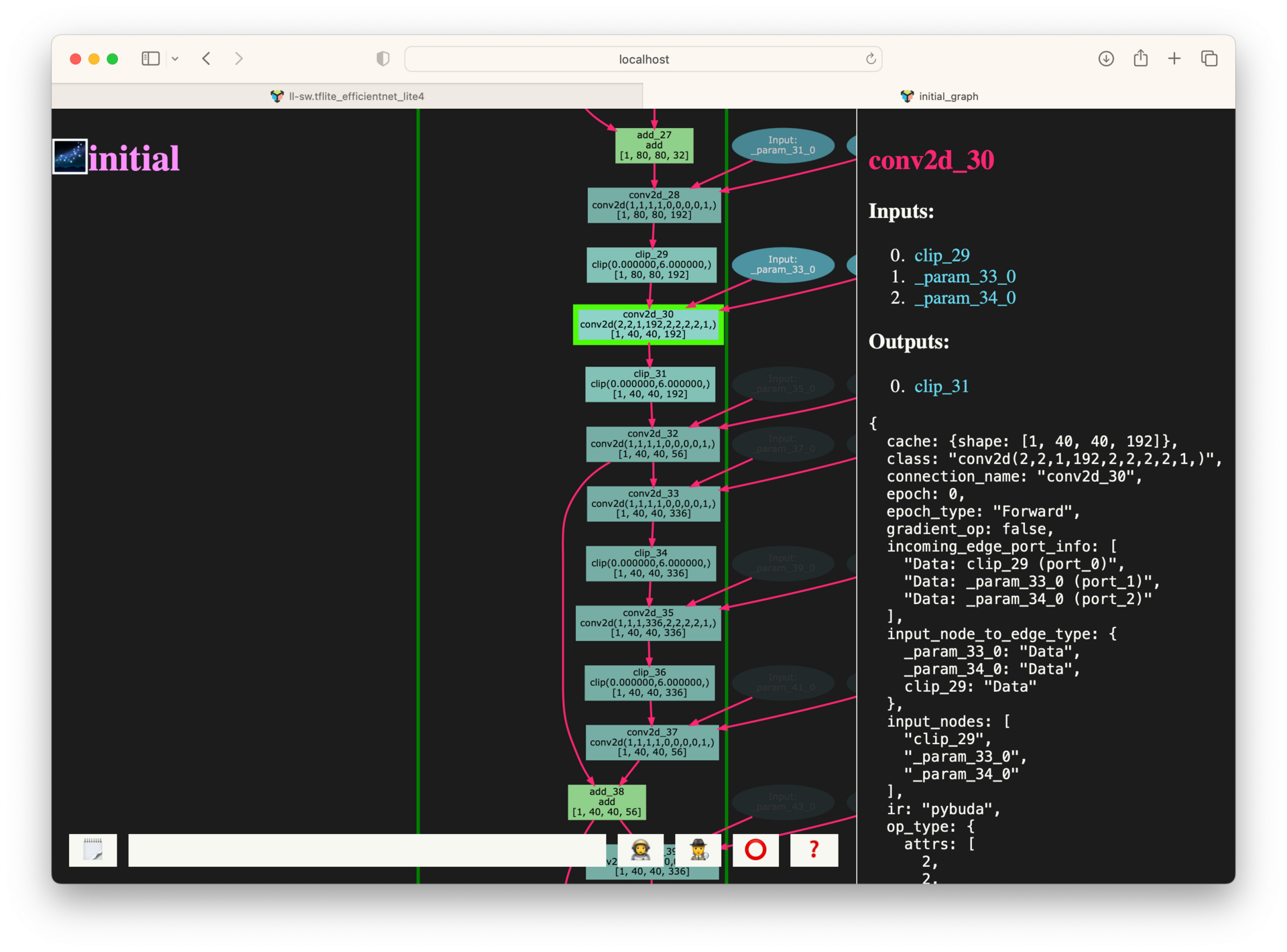
Clicking on a node in the graph brings up a dialog with tons of additional information and metadata about the node.
Let’s step out of the initial graph, and next take a look at another important graph pass, post_placer.
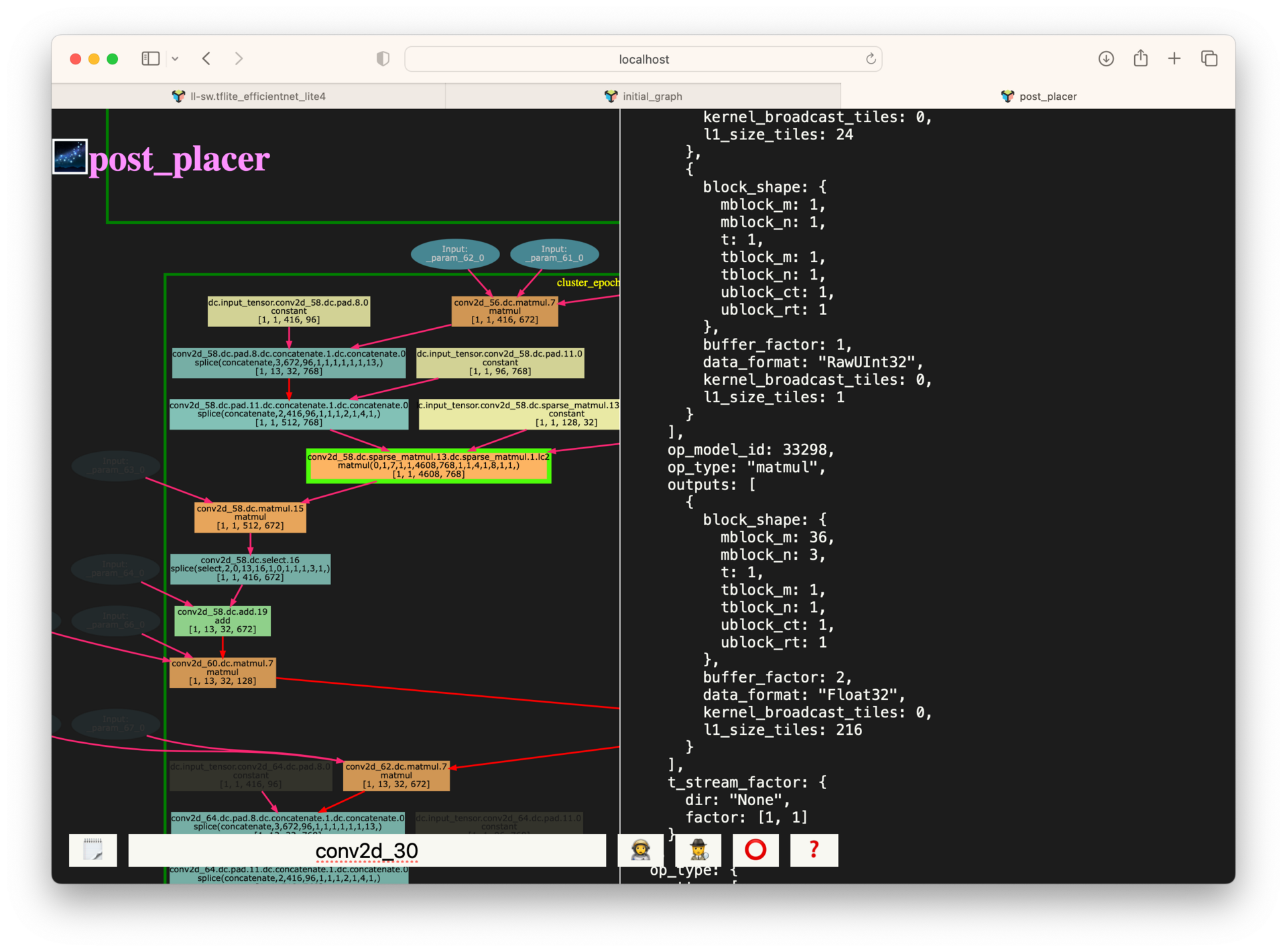
The post-placer graph is at the other end of the spectrum from the initial graph, this represents the fully lowered and placed graph. Here, I’ve already zoomed into an area of subgraph and clicked on a node. This graph is particularly useful for gathering additional metadata about the placement, low level blocking and tile allocation amounts for each op. This data is directly used to populate the netlist yaml, the IR format passed to the backend during the final compilation step.
Placement Reports
Ok, let’s step back to the report type’s page and this time take a look at a different report type, Placement Reports.
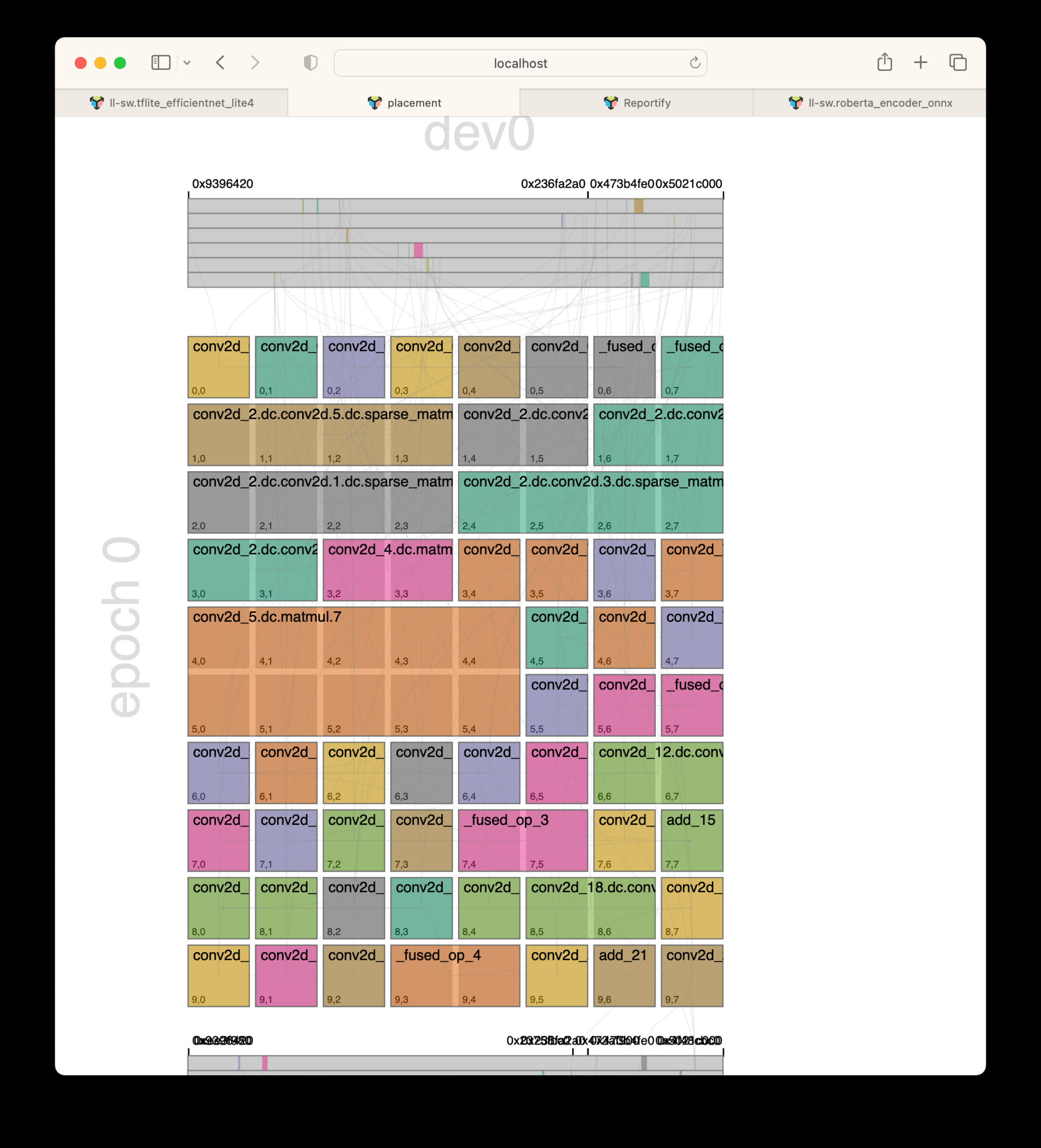
This report type displays a top level view of the device grid and how operations have been placed with respect to each other. We can see the orange matmul in the middle has been placed onto a 2x5 grid, meaning it uses 10 cores worth of resources during this epoch execution, whereas, most other ops on this epoch are on a 1x1 grid, using only a single core.
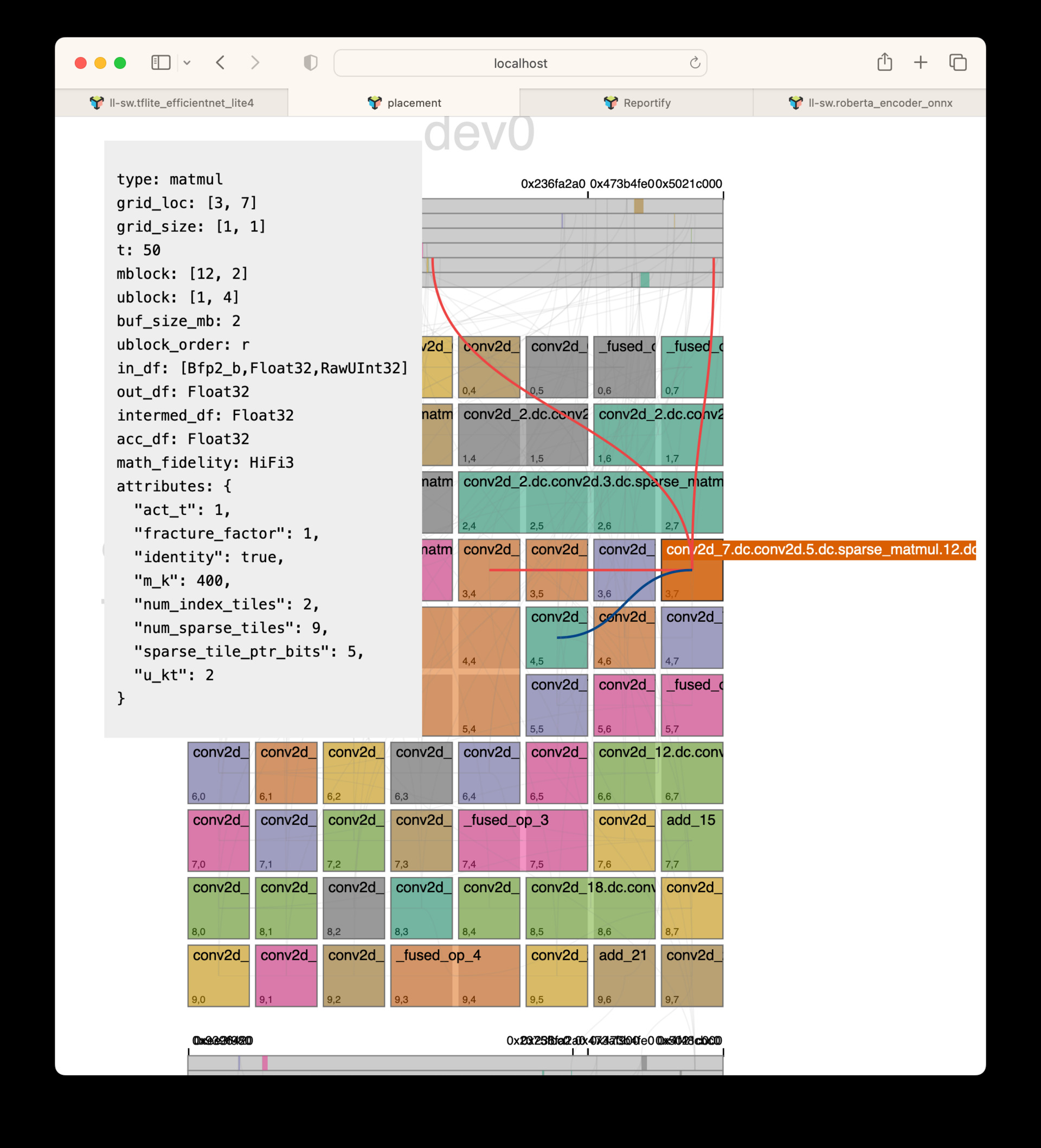
When hovering over an op with your cursor, a dialog pops up with all of the netlist information about this op. The input edges, in orange, and output edges, in blue, are also highlighted to visualize the source and destinations of data with respect to this op. This UI is incredibly useful to see what placement decisions the compiler made.
Perf Analyzer (Terminal App)
Overview
With the environment variable TT_BACKEND_PERF_ANALYZER, we can collect some very detailed information about op and pipe performance on silicon. This app helps by providing:
Data collected from multiple sources, presented in an interactive tabular form within a terminal
Quick epoch and model overview to highlight problem areas immediately
Highlighting of problem areas - very low utilization, bad u_kt choice
A way to save performance data into a single file for off-line analysis
Usage
To generate data used by the app, run any pybuda test with PYBUDA_OP_PERF=1 and TT_BACKEND_PERF_ANALYZER=1 env variables. PYBUDA_OP_PERF=1 is optional, and not available if a test is run from backend only (please ensure that you don’t have a leftover op_perf.csv file lying around in that case, as the app will try to pick it up). Alternatively, if using pybuda benchmark.py, run with –perf_analysis to automatically set the above env variables. Once the data has been generated, run the analysis app and give it the netlist name:
pybuda/pybuda/tools/perf_analysis.py -n your_netlist.yaml
The app will look for performance data in tt_build, and op_perf.csv in the current directory. This corresponds to a typical pybuda test or model run, and should work for the backend runs, too, minus the op_perf.csv file. Use –save to save data to a binary file, and then subsequently run with –load from any other location or machine. Full set of command line options is below:
usage: perf_analysis.py [-h] [-n NETLIST] [-s] [--save SAVE] [--load LOAD]
Perf analyzer collects performance data from various sources and displays it in terminal. To use, run any pybuda test with PYBUDA_OP_PERF=1 and TT_BACKEND_PERF_ANALYZER=1 switches to generate
data, and then run this script in pybuda root, providing the netlist.
optional arguments:
-h, --help show this help message and exit
-n NETLIST, --netlist NETLIST
Model netlist
-s, --spatial_epochs Show individual spatial epochs instead of temporal ones. Caution - overall performance estimate on multi-chip runs will not be accurate in this mode.
--save SAVE Save collected data into provided file
--load LOAD Load data from a previously saved file, instead of from current workspace
UI
Most of the data is presented in tables. The app will use the available terminal size, and will automatically fill the window as it is resized. Columns and rows that don’t fit on the screen are not shown, but arrow keys can be used to scroll through the data to show what doesn’t fit. Op names are shortened to about 50 characters, but pressing F will toggle the full names. Pressing ‘H’ will open up a help window with more information about the current screen.
Summary
The app initially opens up in the summary screen:
Note: Most of this information can be seen inside the app by pressing the ‘H’ key for help
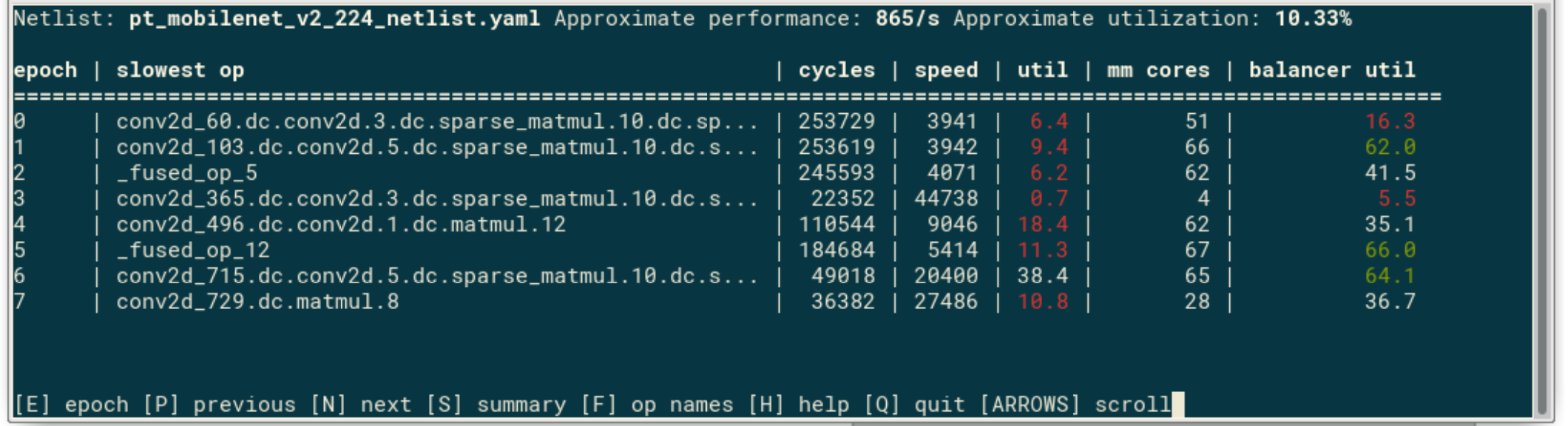
At the top, the screen shows the netlist name, and approximate performance and utilization calculated from the collected data. The overall performance of the model is based purely on the slowest ops in each epoch. Assuming the batch number is high enough to make epoch reconfiguration and pipeline fill/drain negligible, and that there are no major delays due to data transfer between host and the device, this should be a reasonable, albeit slightly optimistic, approximation. The overall utilization is similarly calculated using math utilizations measured on each core and could be optimistic if other delays are not negligible. A known limitation is that current backend measurement doesn’t take into account fork-join delays, so if overall performance, or a particular epoch performance here looks much better than the real measured time, it could be a sign of a fork-join problem. The fields in the summary table are:
cycles: Pipeline stage cycles, i.e. the cycles of the slowest op
speed: The number of inputs/s this epoch is processing
util: The math utilization of the pipeline this epoch, in steady state
mm cores: The number of cores occupied by matrix multiplication ops
balancer util: Similar to util, but calculated using estimated op speeds given to the compiler/balancer. This measures how well balancer did its job, given the information it was given.
Epoch Analysis
Pressing ‘N’ moves to the user to the next epoch, or, if on the summary screen, first epoch. Alternatively, pressing ‘E’ lets you enter the epoch number and jump to it directly.
Note: Most of this information can be seen inside the app by pressing the ‘H’ key for help
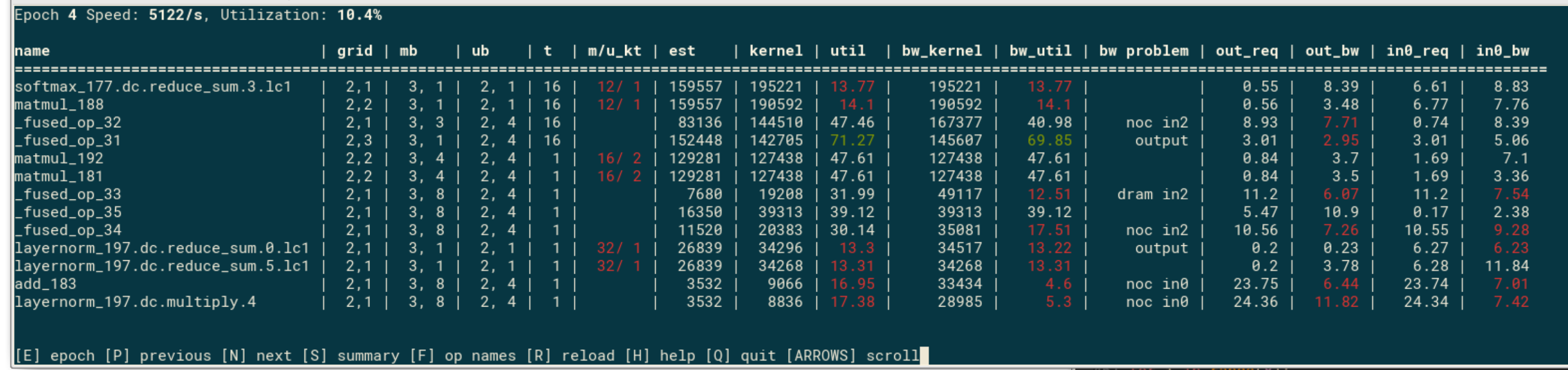
This window shows op performance and utilization for each op in the current epoch. Use P/N keys to move to previous/next epoch, and arrow keys to scroll the rows and columns of the table if it doesn’t fit on the screen. Use F to toggle between full op names and shortened version. The performance values in the table are measured on silicon using backend perf analyzer. The table is sorted with the slowest op at the top. Some of the key fields in the table are:
est: The estimated cycles for the op, given to the compiler/balancer.
kernel: The measured time kernel took to execute, with infinite input/output bandwidths.
bw_kernel: The measure time for the kernel with real pipes feeding data in/out of the core. This is the “real” time it took for the op to complete.
bw problem: Identifies the cause of the bw slowdown - input vs output pipe, and if input, then noc vs dram
in/out columns: Bandwidths, in bytes/cycle, required for the kernel to run at full speed, and measured with real pipes.
Note: A known limitation is that current backend measurement doesn’t take into account fork-join delays, so if overall performance, or a particular epoch performance here looks much better than the real measured time, it could be a sign of a fork-join problem.
Example Workflow / Compiler Feedback
Let’s consider an example performance report:

Let’s look at this initial epoch:

Just taking a look down the kernel column here we can see that _fused_op_0 took 4-6x longer to execute that all other ops on this epoch, so this is definitely something we should look into. Let’s take a look at the placement report for this epoch:
_fused_op_0 we can see in the bottom left hand corner on the 2x1 grid. If we hover over this op we can see its connections:
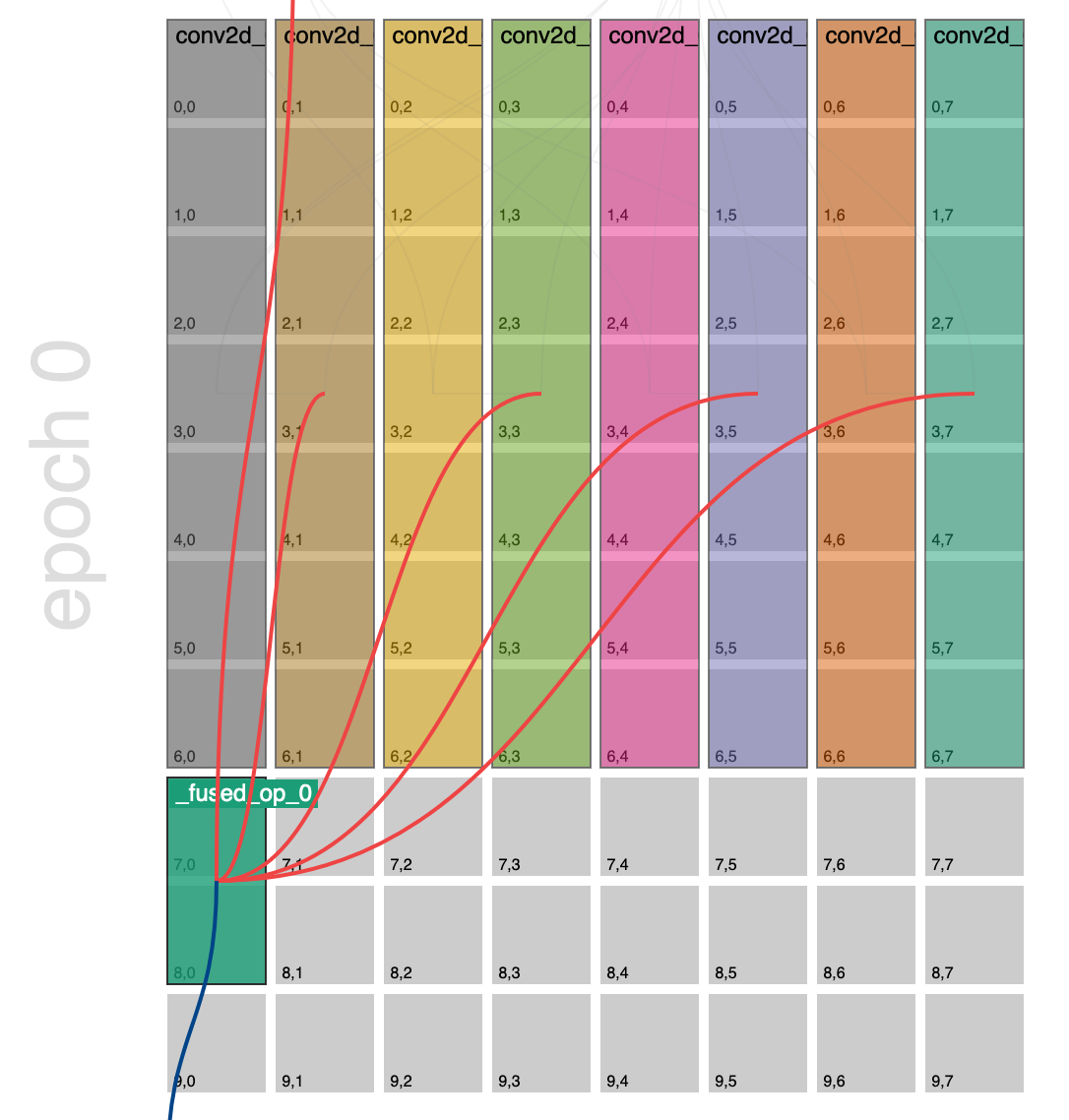
We can see that this op is gathering from 4 different producer ops, so we’d really like to make this fused op run at around the same speed so that it’ able to keep up with its producers. From a data movement perspective, this is also not great because the producer cores are on a 7x1 grid and this consumer is on a 2x1 grid. If we mentally map how the tensor has be chunked onto the producer core grid, i.e. 7 chunks vertically, and then how this maps to the consumer core, i.e. 2 chunks vertically, each consumer core will have to do a lot of gathering. Specifically, in this example, each consumer core will have to gather across 3.5 producer cores respectively in order to reconstruct the input tensor for this operation. As a general rule of thumb, the closer to a 1-1 mapping of producer cores to consumer cores the better for data movement. In BUDA we call this mismatch in core grids (and block shapes) between producer/consumer pairs reblocking. So more accurately, data movement is most efficient when the amount of reblocking (mismatch in grids and block shapes) is minimized.
So what to do now? In looking at the placement report we can see that there is a ribbon of ops along the top 7 rows, because of this these ops are balanced for the 2 reasons we discussed previously, 1) their kernel execution times are balanced because all ops have the same number of core resources allocated to them and 2) reblocking has been minimized because their core grids and block shapes match (note: block shapes can be seen by inspecting the netlist or hovering over the op in the placement graph). Ideally, if we had another column on the device grid, we could also place _fused_op_0 just to the right of the next op and also give it a 7x1 core grid. However, we do not, but we do have a bunch of available cores along the bottom. We can use 2 compiler overrides to reclaim those cores for our _fused_op_0.
# Ask the compiler to only consider grid shapes of 7x1 for _fused_op_0
pybuda.config.override_op_size('_fused_op_0', (7, 1))
# Ask the compiler to transpose the op grid, effectively swapping the rows and columns of the grid orientation
pybuda.config.override_op_placement('_fused_op_0', transpose_op=True)
After rerunning the test, let’s refresh our placement report and take a look if our settings took effect:
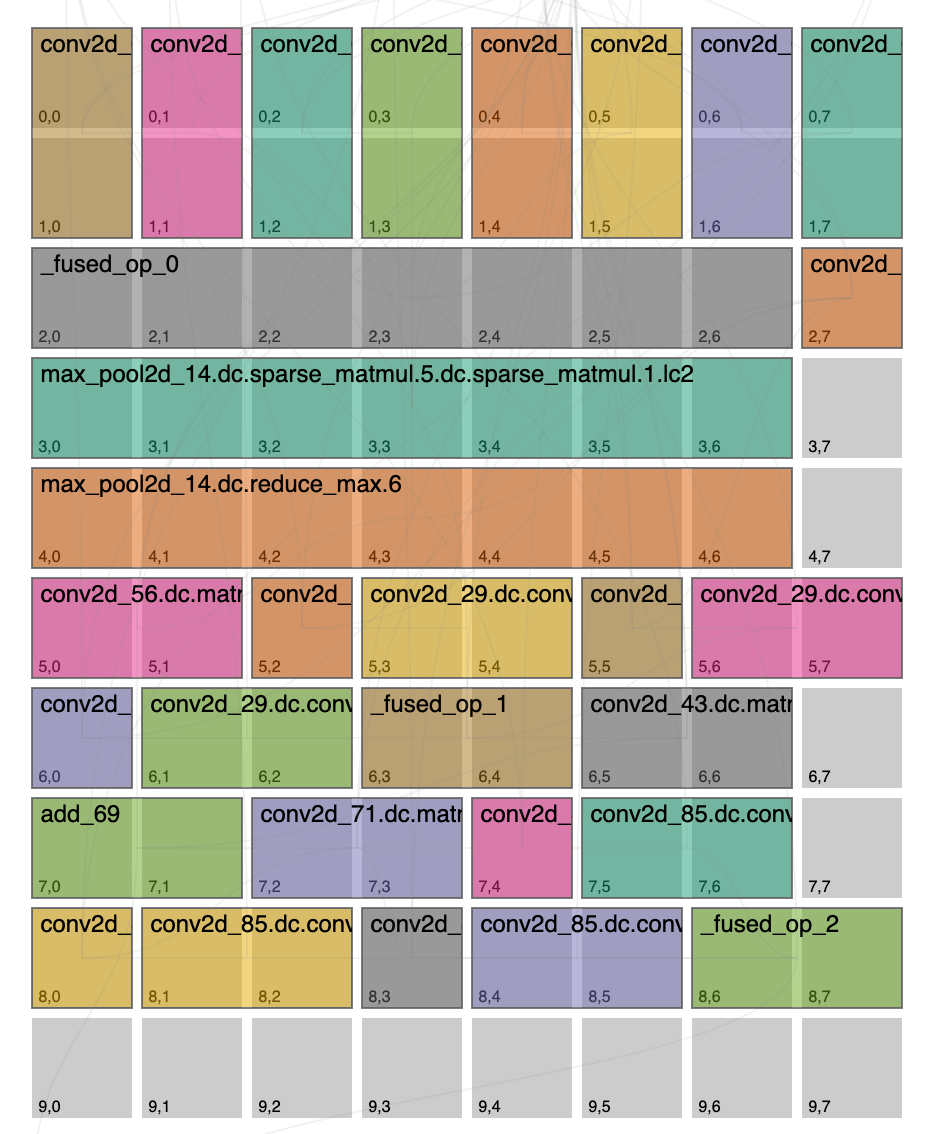
Things look quite different! First let’s notice that _fused_op_0 is on a transposed 7x1 grid, so our override worked. But also notice that this decision had a cascading effect, after we chose this the compiler realized that in order to be balanced we can actually give fewer cores to the producer operations preceding the _fused_op_0 and that it was now better to minimize reblocking on the outgoing edges from the fused op into the max pool operation which can now fit on this epoch. This outlines a complicated tradeoff that the compiler needs to calculate, is it better to assign more cores on average for all ops and have more epochs, or is it better to assign fewer cores on average for all ops and have fewer epochs. Even within an epoch there’s many decisions to be made, i.e. which edges will have the most impact by optimizing for their data movement, often times this is to the detriment of another op or connection.
So did we do better? From the summary view we can see that this override changed the network from running at 742 samples/sec to 1105 samples/sec, so ~1.5x speedup overall.

Let’s jump into epoch 0 and take a closer look:

A couple of interesting things to note, _fused_op_0 is now too fast, it’s kernel execution time lower than its immediate connections so it’d almost certainly be better to reduce this now. We should also note that overall, epoch 0 is actually executing slower, but we were able to fit many more ops on this epoch (seen in the placement graph above) so overall this was a net win.
Now, we could stop here, but it’s often interesting to try many experiments. We might be happy with our original graph, with the exception of the fused op, we can get back to something closer to our original placement by being more explicit:
pybuda.config.override_op_size('conv2d_0.dc.conv2d.3.dc.conv2d.1.dc.sparse_matmul.9.dc.sparse_matmul.1.lc2', (7, 1))
pybuda.config.override_op_size('conv2d_0.dc.conv2d.3.dc.conv2d.1.dc.matmul.11', (7, 1))
pybuda.config.override_op_size('conv2d_0.dc.conv2d.3.dc.conv2d.3.dc.sparse_matmul.9.dc.sparse_matmul.1.lc2', (7, 1))
pybuda.config.override_op_size('conv2d_0.dc.conv2d.3.dc.conv2d.3.dc.matmul.11', (7, 1))
pybuda.config.override_op_size('conv2d_0.dc.conv2d.3.dc.conv2d.5.dc.sparse_matmul.9.dc.sparse_matmul.1.lc2', (7, 1))
pybuda.config.override_op_size('conv2d_0.dc.conv2d.3.dc.conv2d.5.dc.matmul.11', (7, 1))
pybuda.config.override_op_size('conv2d_0.dc.conv2d.3.dc.conv2d.7.dc.sparse_matmul.9.dc.sparse_matmul.1.lc2', (7, 1))
pybuda.config.override_op_size('conv2d_0.dc.conv2d.3.dc.conv2d.7.dc.matmul.11', (7, 1))
pybuda.config.override_op_size('_fused_op_0', (7, 1))
pybuda.config.override_op_placement('_fused_op_0', transpose_op=True)
We refresh our placement graph and see:
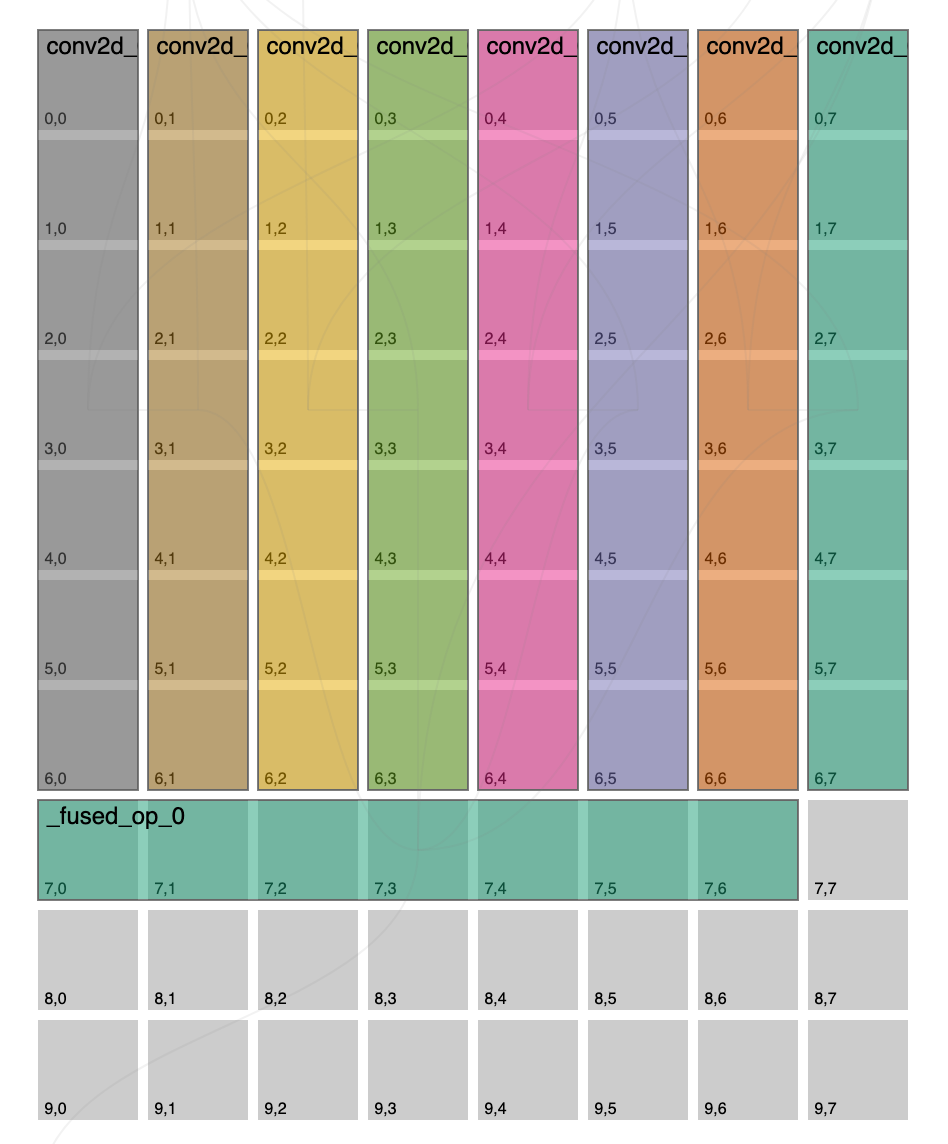
Now we really have what we originally intended to try, but how did we do? Let’s look at perf analyzer again:

Overall we’re at 763 samples/sec so not much better from our original 742 samples/sec. Let’s look at the epoch we changed:

Alright so looking at the kernel column we’re looking much better, if we look at this epoch runtime we’re at 5642 samples/sec so much better than originally at 4556 samples/sec. So then why did our previous attempt do so much better? We need to take a step back and take a look at the execution as a whole, across all epochs. It turned out to be better to have a slower epoch 0 if it meant we could squeeze more ops onto it, this then allieviates future epochs from having to do more work, or potentially eliminates entire epochs that would have existed.
Some key takeaways from this workflow include:
Kernel runtimes within an epoch should be balanced and can be manually tweaked by overridding grid size.
Efficient data movement can be achieved by minimizing reblocking by using grid size and placement overrides.
Performance issues/differences can be reasoned about, by running multiple experiments, comparing results, and looking at the placement solution holistically.
DeBUDA (Low level device debug)
Please reference the official DeBuda documentation here.
Comparison To GPU Programming Model
Tenstorrent device architecture differs from GPUs in a few fundamental ways, including:
Memory model:
Streaming architecture, no random access pointers. In fact the BUDA software architecture allows kernels to be written in a way that’s entirely decoupled from the way that memory was laid out from the producer core. This completely alleviates kernel variation explosion.
Kernel threading is abstracted away, instead kernels are written as though they are executing sequentially on a single core.
Execution model:
Tile based operations, tenstorrent HW works on 32x32 local chunks of data at a time.
SFPU HW provides SIMD like programming model.
The amount of parallelism can be decided on a per-op level enabling larger ops to use more resources and lighter ops to use fewer resources.
Scalability:
Same compiler for 1x1 device grid configuration can be scaled up to galaxy sized systems, 1000s of cores.
No need to support custom model types / manual model fracturing.
No kernel explosion, having to write the same kernel for all kinds of different access patterns.