tt-torch
NOTE: TT-Torch is deprecated. To work with PyTorch and the various features available in TT-Torch, please see the documentation for TT-XLA.
tt-torch is a PyTorch2.0 and torch-mlir based front-end for tt-mlir.
tt-torch uses venv to keep track of all dependencies. After compiling you can activate the venv by running from the project root directory:
source env/activate
The currently supported models can be found here. There is a brief demo showing how to use the compiler in demos/resnet/resnet50_demo.py
The general compile flow is:
- Pytorch model -> torch.compile which creates an fx graph
- Several compiler passes on the fx graph including consteval and dead code removal
- Conversion to torch-mlir -> torch-backend-mlir -> stableHLO through torch-mlir
- Conversion to TTIR -> TTNN -> flatbuffer through tt-mlir
- Creating executor with flatbuffer and passing back to user
- Copying inputs to device and executing flatbuffer through tt-mlir on each user invocation
In order to speed up model bring-up, users have the option of compiling models op-by-op. This allows in-parallel testing of the model since compilation does not stop at the first error. If enabled, see Controlling Compilation, after step 2, compilation stops and the fx graph is passed to the executor which is returned to the user. Upon execution, whenever a new, unique op is seen (based on op-type and shape on inputs), a new fx graph is created with just one operation, inputs and outputs. This small graph then proceeds through steps 3-4 and is executed in place.
Results of each unique op execution are stored in a json file to be later parsed into either a spreadsheet, or uploaded to a database.
Op-by-op execution is currently performed on the pytorch fx graph, we'll be adding support for op-by-op on the stableHLO graph soon to allow op-by-op bringup of onnx models.
The repository uses pre-commit, read more about it here.
Getting Started
NOTE: TT-Torch is deprecated. To work with PyTorch and the various features available in TT-Torch, please see the documentation for TT-XLA.
This document walks you through how to set up TT-Torch. TT-Torch is TT-Forge's front end for converting PyTorch models to different levels of Intermediate Representation (IR) all the way down to TTNN. This is the main Getting Started page. There are two additional Getting Started pages depending on what you want to do. They are all described here, with links provided to each.
The following topics are covered:
- Setup Options
- Configuring Hardware
- Installing a Wheel and Running an Example
- Other Setup Options
- Where to Go Next
NOTE: If you encounter issues, please request assistance on the TT-Torch Issues page.
Setup Options
TT-Torch can be used to run PyTorch models. Because TT-Torch is open source, you can also develop and add features to it. Setup instructions differ based on the task. You have the following options, listed in order of difficulty:
- Installing a Wheel and Running an Example - You should choose this option if you want to run models.
- Using a Docker Container to Run an Example - Choose this option if you want to keep the environment for running models separate from your existing environment.
- Building from Source - This option is best if you want to develop TT-Torch further. It's a more complex process you are unlikely to need if you want to stick with running a model.
Configuring Hardware
Before setup can happen, you must configure your hardware. You can skip this section if you already completed the configuration steps. Otherwise, this section of the walkthrough shows you how to do a quick setup using TT-Installer.
-
Configure your hardware with TT-Installer using the Quick Installation section here.
-
Reboot your machine.
-
Make sure hugepages is enabled:
sudo systemctl enable --now 'dev-hugepages\x2d1G.mount'
sudo systemctl enable --now tenstorrent-hugepages.service
-
Please ensure that after you run the TT-Installer script, after you complete reboot and set up hugepages, you activate the virtual environment it sets up -
source ~/.tenstorrent-venv/bin/activate. -
After your environment is running, to check that everything is configured, type the following:
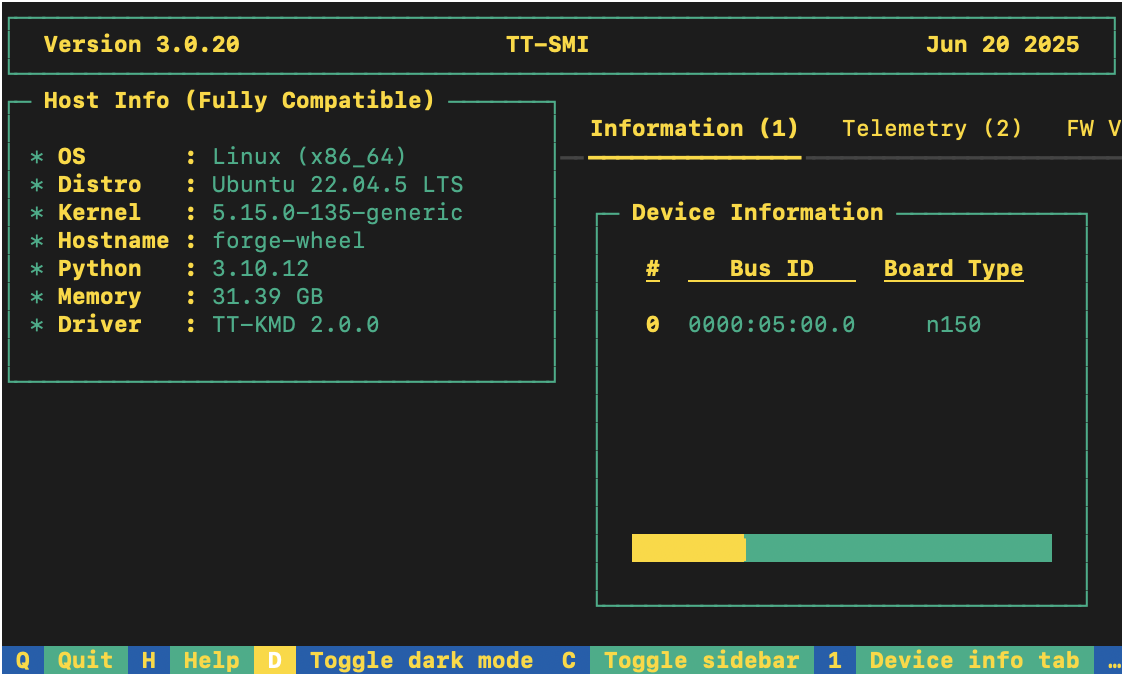
tt-smi
You should see the Tenstorrent System Management Interface. It allows you to view real-time stats, diagnostics, and health info about your Tenstorrent device.
Installing a Wheel and Running an Example
This section walks you through downloading and installing a wheel. You can install the wheel wherever you would like if it is for running a model. For this walkthrough, the resnet50_demo.py demo is used.
- Make sure you are in an active virtual environment. This walkthrough uses the same environment you activated to look at TT-SMI in the Configuring Hardware section. If you are using multiple TT-Forge front ends to run models, you may want to set up a separate virtual environment instead. For example:
python3 -m venv .tt-torch-venv
source .tt-torch-venv/bin/activate
- Download and install the wheel in your active virtual environment:
pip install tt-torch --pre --extra-index-url https://pypi.eng.aws.tenstorrent.com/
- Before you run a model, download and install the MPI implementation:
wget -q https://github.com/dmakoviichuk-tt/mpi-ulfm/releases/download/v5.0.7-ulfm/openmpi-ulfm_5.0.7-1_amd64.deb -O /tmp/openmpi-ulfm.deb && \
sudo apt install -y /tmp/openmpi-ulfm.deb
- Install the other packages you need for the demo:
pip install pillow
pip install tabulate
pip install requests
- Clone the TT-Forge repo:
git clone https://github.com/tenstorrent/tt-forge.git
-
Navigate into tt-forge/demos/tt-torch. You are now ready to try running a model.
-
Run the demo:
python resnet50_demo.py
If all goes well, you should get a list of top five predictions for what the example image is, with the top one being a cat.
Other Setup Options
If you want to keep your environment completely separate in a Docker container, or you want to develop TT-Torch further, this section links you to the pages with those options:
Where to Go Next
Now that you have set up the TT-Torch wheel, you can compile and run other demos. See the TT-Torch folder in the TT-Forge repo for other demos you can try.
Getting Started with Docker
NOTE: TT-Torch is deprecated. To work with PyTorch and the various features available in TT-Torch, please see the documentation for TT-XLA.
This document walks you through how to set up TT-Torch using a Docker image. There are two other available options for getting started:
- Installing a Wheel - if you do not want to use Docker, and prefer to use a virtual environment by itself instead, use this method.
- Building From Source - if you plan to develop TT-Torch further, you must build from source, and should use this method.
Configuring Hardware
Before setup can happen, you must configure your hardware. You can skip this section if you already completed the configuration steps. Otherwise, this section of the walkthrough shows you how to do a quick setup using TT-Installer.
-
Configure your hardware with TT-Installer using the Quick Installation section here.
-
Reboot your machine.
-
Make sure hugepages is enabled:
sudo systemctl enable --now 'dev-hugepages\x2d1G.mount'
sudo systemctl enable --now tenstorrent-hugepages.service
-
Please ensure that after you run the TT-Installer script, after you complete reboot and set up hugepages, you activate the virtual environment it sets up -
source ~/.tenstorrent-venv/bin/activate. -
When your environment is running, to check that everything is configured, type the following:
tt-smi
You should see the Tenstorrent System Management Interface. It allows you to view real-time stats, diagnostics, and health info about your Tenstorrent device.
Setting up the Docker Container
This section walks through the installation steps for using a Docker container for your project.
To install, do the following:
- Install Docker if you do not already have it:
sudo apt update
sudo apt install docker.io -y
sudo systemctl start docker
sudo systemctl enable docker
- Test that Docker is installed:
docker --version
- Add your user to the Docker group:
sudo usermod -aG docker $USER
newgrp docker
- Run the Docker container:
docker run -it --rm \
--device /dev/tenstorrent \
-v /dev/hugepages-1G:/dev/hugepages-1G \
ghcr.io/tenstorrent/tt-torch-slim:latest
NOTE: You cannot isolate devices in containers. You must pass through all devices even if you are only using one. You can do this by passing
--device /dev/tenstorrent. Do not try to pass--device /dev/tenstorrent/1or similar, as this type of device-in-container isolation will result in fatal errors later on during execution.
- If you want to check that it is running, open a new tab with the Same Command option and run the following:
docker ps
If all goes well, you are now ready to move on to the next section, and run your first demo model.
Running Models in Docker
This section shows you how to run a model using Docker. The provided example is from the TT-Forge repo. Do the following:
- Inside your running Docker container, clone the TT-Forge repo:
git clone https://github.com/tenstorrent/tt-forge.git
- Set the path for Python:
export PYTHONPATH=/tt-forge:$PYTHONPATH
- Navigate into TT-Forge and run the following command:
git submodule update --init --recursive
- For this set up, the resnet50_demo.py model is used. It requires additional dependencies be installed. Install the following:
pip install pillow
pip install tabulate
pip install requests
- Navigate into tt-forge/demos/tt-torch and run the model:
python resnet50_demo.py
If all goes well, you should get a list of top five predictions for what the example image is, with the top one being a cat.
Where to Go Next
Now that you have set up TT-Forge-FE, you can compile and run your own models, or continue trying demos from the TT-Torch folder in the TT-Forge repo.
Getting Started
NOTE: TT-Torch is deprecated. To work with PyTorch and the various features available in TT-Torch, please see the documentation for TT-XLA.
This document describes how to build the TT-Torch project on your local machine. You must build from source if you want to develop for TT-Torch. If you only want to run models, please choose one of the following sets of instructions instead:
- Installing a Wheel and Running an Example - You should choose this option if you want to run models.
- Using a Docker Container to Run an Example - Choose this option if you want to keep the environment separate from your existing environment.
The following topics are covered:
NOTE: If you encounter issues, please request assistance on the TT-Torch Issues page.
Configuring Hardware
Before setup can happen, you must configure your hardware. You can skip this section if you already completed the configuration steps. Otherwise, this section of the walkthrough shows you how to do a quick setup using TT-Installer.
-
Configure your hardware with TT-Installer using the Quick Installation section here.
-
Reboot your machine.
-
Please ensure that after you run this script, after you complete reboot, you activate the virtual environment it sets up -
source ~/.tenstorrent-venv/bin/activate. -
After your environment is running, to check that everything is configured, type the following:
tt-smi
You should see the Tenstorrent System Management Interface. It allows you to view real-time stats, diagnostics, and health info about your Tenstorrent device.
System Dependencies
TT-Torch has the following system dependencies:
- Ubuntu 22.04
- Python 3.11
- python3.11-venv
- Clang 17
- GCC 11
- Ninja
- CMake 4.0.3
Installing Python
If your system already has Python installed, make sure it is Python 3.11 or higher:
python3 --version
If not, install Python:
sudo apt install python3.11
Installing CMake 4.0.3
This section walks you through installing CMake 4 or higher.
- Install CMake 4.0.3:
pip install cmake==4.0.3
- Check that the correct version of CMake is installed:
cmake --version
If you see cmake version 4.0.3 you are ready for the next section.
Installing LLVM 17 Toolchain
This section walks you through installing LLVM 17 Toolchain.
- Download LLVM 17 Toolchain Installation Script:
wget https://apt.llvm.org/llvm.sh
chmod u+x llvm.sh
sudo ./llvm.sh 17
- Install C++ Standard Library (libc++) Development Files for LLVM 17:
sudo apt install -y libc++-17-dev libc++abi-17-dev
- Symlink Clang:
sudo ln -s /usr/bin/clang-17 /usr/bin/clang
sudo ln -s /usr/bin/clang++-17 /usr/bin/clang++
- Check that the selected GCC candidate using Clang 17 is using 11:
clang -v
- Look for the line that starts with:
Selected GCC installation:. If it is something other than GCC 11, and you do not see GCC 11 listed as an option, please install GCC 11 using:
sudo apt-get install gcc-11 lib32stdc++-11-dev lib32gcc-11-dev
- If you see GCC 12 listed as installed and listed as the default choice, uninstall it with:
sudo rm -rf /usr/bin/../lib/gcc/x86_64-linux-gnu/12
Installing Dependencies
Install additional dependencies required by TT-Torch that were not installed by the TT-Installer script:
sudo apt-get install -y \
libhwloc-dev \
libtbb-dev \
libcapstone-dev \
pkg-config \
linux-tools-generic \
ninja-build \
libgtest-dev \
ccache \
doxygen \
graphviz \
patchelf \
libyaml-cpp-dev \
libboost-all-dev \
lcov \
protobuf-compiler
Install OpenMPI:
sudo wget -q https://github.com/dmakoviichuk-tt/mpi-ulfm/releases/download/v5.0.7-ulfm/openmpi-ulfm_5.0.7-1_amd64.deb -O /tmp/openmpi-ulfm.deb && sudo apt install /tmp/openmpi-ulfm.deb
NOTE: If you want to run a test which uses
cv2(i.e. YOLOv10), please install libgl.
How to Build From Source
This section describes how to build TT-Torch. You need to build TT-Torch whether you plan to do development work, or run models.
- Clone the TT-Torch repo:
git clone https://github.com/tenstorrent/tt-torch.git
cd tt-torch
- Create a toolchain directory and make the account you are using the owner:
sudo mkdir -p /opt/ttmlir-toolchain
sudo chown -R $USER /opt/ttmlir-toolchain
- Build the toolchain for TT-Torch (this build step only needs to be done once):
cd third_party
cmake -B toolchain -DBUILD_TOOLCHAIN=ON
cd -
NOTE: This step takes a long time to complete.
- Build TT-Torch:
source env/activate
cmake -G Ninja -B build
cmake --build build
cmake --install build
NOTE: It takes a while for everything to build.
After the build completes, you are ready to run a test model.
Running a Test Model
You can test your installation by running the resnet50_demo.py:
python demos/resnet/resnet50_demo.py
For additional tests and models, please follow Testing.
Testing
NOTE: TT-Torch is deprecated. To work with PyTorch and the various features available in TT-Torch, please see the documentation for TT-XLA.
This document walks you through how to test tt-torch after building from source or installing from wheel
Infrastructure
tt-torch uses pytest for all unit and model tests.
Unit Tests
- PyTorch unit tests are located under tests/torch
- Onnx unit tests are located under tests/onnx
You can check that everything is working with a basic unit test:
# If building tt-torch from source
pytest -svv tests/torch/test_basic.py
# If installing tt-torch from wheel
pip install pytest
curl -s https://raw.githubusercontent.com/tenstorrent/tt-torch/main/tests/torch/test_basic.py -o test_basic.py
pytest -svv test_basic.py
NOTE: If you are using a multiple device setup, we encourage you to run the following tests:
tests/torch/test_basic_async.pytests/torch/test_basic_multichip.py
Running the resnet Demo
You can also try a demo:
# If building tt-torch from source
python demos/resnet/resnet50_demo.py
# If installing tt-torch from wheel
pip install pytest
curl -s https://raw.githubusercontent.com/tenstorrent/tt-torch/main/demos/resnet/resnet50_demo.py -o resnet50_demo.py
python resnet50_demo.py
Compiling and Running a Model
Once you have your torch.nn.Module compile the model:
import torch
import tt_torch
class MyModel(torch.nn.Module):
def __init__(self):
...
def forward(self, ...):
...
model = MyModel()
model = torch.compile(model, backend="tt-legacy")
inputs = ...
outputs = model(inputs)
Example - Add Two Tensors
Here is an example of a small model which adds its inputs running through tt-torch. Try it out!
import torch
import tt_torch
class AddTensors(torch.nn.Module):
def forward(self, x, y):
return x + y
model = AddTensors()
tt_model = torch.compile(model, backend="tt-legacy")
x = torch.ones(5, 5)
y = torch.ones(5, 5)
print(tt_model(x, y))
Testing With Experimental Flow
We are experimenting with torch-xla as a method of capturing and executing PyTorch models. We plan to eventually use torch-xla as the main execution engine for tt-torch.
Experimental torch.compile Backend ("tt-experimental")
import torch
import tt_torch
class AddTensors(torch.nn.Module):
def forward(self, x, y):
return x + y
model = AddTensors()
tt_model = torch.compile(model, backend="tt-experimental")
x = torch.ones(5, 5)
y = torch.ones(5, 5)
print(tt_model(x, y))
Experimental Eager Execution
torch-xla allows us to execute PyTorch models eagerly using the .to(device) infrastructure.
import torch
import tt_torch
class AddTensors(torch.nn.Module):
def forward(self, x, y):
return x + y
model = AddTensors()
model = model.to("xla")
x = torch.ones(5, 5, device="xla")
y = torch.ones(5, 5, device="xla")
print(model(x, y).to("cpu"))
Model Zoo
You can view our model zoo under tests/models
Please see overview for an explanation on how to control model tests.
You can always run pytest --collect-only to view available pytest names under test file.
/userhome/tt-torch$ pytest --collect-only tests/models/resnet
====================================================================== test session starts =======================================================================
platform linux -- Python 3.10.12, pytest-8.4.0, pluggy-1.6.0
rootdir: /userhome/tt-torch
configfile: pyproject.toml
plugins: cov-6.2.1
collected 12 items
<Dir tt-torch>
<Package tests>
<Dir models>
<Dir resnet>
<Module test_resnet.py>
<Function test_resnet[single_device-op_by_op_stablehlo-train]>
<Function test_resnet[single_device-op_by_op_stablehlo-eval]>
<Function test_resnet[single_device-op_by_op_torch-train]>
<Function test_resnet[single_device-op_by_op_torch-eval]>
<Function test_resnet[single_device-full-train]>
<Function test_resnet[single_device-full-eval]>
<Function test_resnet[data_parallel-op_by_op_stablehlo-train]>
<Function test_resnet[data_parallel-op_by_op_stablehlo-eval]>
<Function test_resnet[data_parallel-op_by_op_torch-train]>
<Function test_resnet[data_parallel-op_by_op_torch-eval]>
<Function test_resnet[data_parallel-full-train]>
<Function test_resnet[data_parallel-full-eval]>
Controlling Compiler Behavior
NOTE: TT-Torch is deprecated. To work with PyTorch and the various features available in TT-Torch, please see the documentation for TT-XLA.
You can use the following environment variables to override default behavior:
| Environment Variable | Behavior | Default |
|---|---|---|
| TT_TORCH_COMPILE_DEPTH | Sets the maximum compile depth, see tt_torch/tools/utils.py for options. | EXECUTE |
| TT_TORCH_VERIFY_OP_BY_OP | Sets whether to verify the output of each compiled op against pytorch when running with compile depth EXECUTE_OP_BY_OP. | False |
| TT_TORCH_VERIFY_INTERMEDIATES | Sets whether to verify runtime intermediates during execution. | False |
| TT_TORCH_CONSTEVAL | Enables evaluation of constant expressions (consteval) in the Torch FX graph prior to compilation. | False |
| TT_TORCH_CONSTEVAL_PARAMETERS | Extends consteval to include parameters (e.g., model weights) as well as embedded constants. | False |
| TT_TORCH_INLINE_PARAMETERS | Inlines parameters in the MLIR module (and thus flatbuffer executable) rather than requiring them as inputs. NOTE: The maximum size of a flatbuffer is 2GB so this will cause compilation to fail for sufficiently large models | False |
| TT_TORCH_IR_LOG_LEVEL | Enables printing MLIR from Torch to TTNN. It supports two modes; INFO and DEBUG. INFO prints MLIR for all conversions steps (Torch, StableHLO, TTIR and TTNN MLIR graphs). DEBUG prints intermediate MLIR for all passes (IR dump before and after each pass) additionally. Be warned, DEBUG IR printing forces single core compile, so it is much slower. | Disable |
Controlling Compiler Behavior Programatically
Instead of using the above environment variables, compiler behavior can be configured programatically as well.
Here is an example of enabling consteval:
from tt_torch.dynamo.backend import BackendOptions
from tt_torch.tools.utils import CompilerConfig
import tt_torch
import torch
class MyModel(torch.nn.Module):
def __init__(self):
...
def foward(self, ...):
...
model = MyModel()
cc = CompilerConfig()
cc.enable_consteval = True
cc.consteval_parameters = True # This will enable constant folding on the parameters in addition to any constants
options = BackendOptions()
options.compiler_config = cc
model = torch.compile(model, backend="tt-legacy", options=options)
inputs = ...
outputs = model(inputs)
Pre-Commit
NOTE: TT-Torch is deprecated. To work with PyTorch and the various features available in TT-Torch, please see the documentation for TT-XLA.
Pre-Commit applies a Git hook to the local repository, ensuring linting is checked and applied on every git commit action. Install it from the root of the repository using:
source env/activate
pre-commit install
If you have already made commits before installing the pre-commit hooks, you can run the following to “catch up”:
pre-commit run --all-files
For more information visit pre-commit
Profiling
Introduction
tt-torch uses the tt-metal Tracy fork to collect profiling data. Tracy is a single process profiler, and uses a client-server model to trace both host calls and on-device operation performance. tt-torch implements a wrapper called tt_profile.py with custom orchestration logic to handle the spawning of the Tracy capture server and the client workload to be profiled, as well as report generation and data postprocessing functionality.
The output of tt_profile.py is a CSV report displaying a table of operations executed on device and rich timing, memory usage and configuration data associated with them.
Note: Paths in this document are given relative to the repo root.
Prerequisites
NOTE: TT-Torch is deprecated. To work with PyTorch and the various features available in TT-Torch, please see the documentation for TT-XLA.
In the tt-torch building step (Getting Started), it is required to configure your cmake build with the additional cmake directive TT_RUNTIME_ENABLE_PERF_TRACE=ON (i.e. run: cmake -G Ninja -B build -DTT_RUNTIME_ENABLE_PERF_TRACE=ON).
Usage
The tt_profile.py tool is the recommended entrypoint for profiling workloads in tt-torch.
tt_profile.py [-h] [-o OUTPUT_PATH] [-p PORT] "test_command"
Note: The test_command must be quoted!
As a minimal example, the following command will run and tt_profile the MNIST test:
python tt_torch/tools/tt_profile.py "pytest -svv tests/models/mnist/test_mnist.py::test_mnist_train[single_device-full-eval]"
The report is created at results/perf/device_ops_perf_trace.csv by default, unless an output path is specified.
If tt-torch is installed using a wheel, the tt_profile command will be registered in the environment in which tt-torch is installed. Users can simply run tt_profile "<pytest or other command>" without providing a path to the profiler source file.
Limitations
- Tracy is a single process profiler and will not work with multiprocessed workflows. This includes tests parameterized by
op_by_op_shloandop_by_op_torch, which break down a model into individual ops and run them serially in separate processes. - To view traces, you can use
install/tt-metal/generated/profiler/.logs/tracy_profile_log_host.tracy.- This is a
.tracyfile that can be consumed by the tt-metal Tracy GUI and produce visual profiling traces of host and device activity. - You must use the tt-metal Tracy GUI to view this file. Refer to the GUI section in the tt-metal profiling documentation. Other sections are not applicable to tt-torch profiling.
- This is a
Troubleshooting
tt-torch/install/tt-metal/tools/profiler/bin/capture-release -o tracy_profile_log_host.tracy -f -p 8086' timed out after X seconds- Tracy uses a client-server model to communicate profiling data between the Tracy capture server and the client being profiled.
- Communication between client and server is done on a given port (default: 8086) as specified with the
-poption. - If there are multiple tracy clients/server processes active at once or previous processes are left dangling, or other processes on host occupying port 8086, there may be contention and unexpected behaviour including capture server timeouts.
- This may be addressed by manually specifying an unused port with the -p option to
tt_profile.py.
How to add model tests?
NOTE: TT-Torch is deprecated. To work with PyTorch and the various features available in TT-Torch, please see the documentation for TT-XLA.
Requirements
Following the instructions on this page will show you how to build your environment and run a demo.
TT-Torch Backend in a Nutshell
ModelTester and OnnxModelTester
Our testing framework uses ModelTester, OnnxModelTester defined under tests/utils.py
ModelTester and OnnxModelTester are designed to facilitate the testing of PyTorch and ONNX models, respectively. These classes provide a structured framework for loading models, preparing inputs, running inference, and verifying the accuracy of the outputs.
ModelTester
The ModelTester class serves as a base class for testing PyTorch models. It handles common testing procedures and provides abstract methods that derived classes can implement for specific model loading and input preparation.
Derived classes must implement the following abstract methods:
_load_model(): This method should load the PyTorch model to be tested and return the model object._load_inputs(): This method should load or generate the input data for the model and return it. The input should be a Torch object._extract_outputs()(optional): This method should return a tuple of torch tensors based on the outputs ifModelTester_extract_outputsfails.
OnnxModelTester
The OnnxModelTester class inherits from ModelTester and extends it to specifically handle testing of ONNX models.
Derived classes must implement the following abstract methods:
_load_model(): This method should load the Onnx model to be tested and return the model object._load_inputs(): This method should load or generate the input data for the model and return it. The input should be a Torch object._extract_outputs()(optional): This method should return a tuple of torch tensors based on the outputs ifModelTester_extract_outputsfails.
Backend
Backends are described under tt_torch/dynamo/backend.py and tt_torch/onnx_compile/onnx_compile.py There are a few factors determining which backend to use:
class CompileDepth(Enum):
TORCH_FX = 1
STABLEHLO = 2
TTNN_IR = 3
COMPILE_OP_BY_OP = 4
EXECUTE_OP_BY_OP = 5
EXECUTE = 6
class OpByOpBackend(Enum):
TORCH = 1
STABLEHLO = 2
Backends for Torch Models:
- Op by Op Flows (
COMPILE_OP_BY_OP/EXECUTE_OP_BY_OP):OpByOpBackend=TORCH--> usesTorchExecutorOpByOpBackend=STABLEHLO--> usesStablehloExecutor
- Other Compile Depths:
- Only
OpByOpBackend=TORCHis allowed. - Uses
Executor
- Only
Backends for ONNX Models:
- Op by Op Flows (
COMPILE_OP_BY_OP/EXECUTE_OP_BY_OP): OnlyOpByOpBackend=STABLEHLOis allowed. UsesStablehloExecutor - Other Compile Depths:
Only
OpByOpBackend=STABLEHLOis allowed. UsesOnnxExecutor
Executor
TT-Torch provides a set of executor classes that handle different types of models (ONNX, PyTorch) and compilation strategies (full compilation, op-by-op, etc.). The executor classes form a hierarchy, with specialized executors for different scenarios.
Executor (Base)
├── OpByOpExecutor
│ ├── TorchExecutor
│ └── StablehloExecutor
└── OnnxExecutor
Executor,OnnxExecutorandOpByOpExecutorare defined under tt_torch/dynamo/executor.pyTorchExecutoris defined under tt_torch/dynamo/torch_backend.pyStablehloExecutoris defined under tt_torch/dynamo/shlo_backend.py
Executor (Base Class)
The Executor class is the foundation for all executor implementations. It provides the basic framework for:
- Managing model representations (PyTorch programs, etc.)
- Converting input types between different formats
- Handling constants and model parameters
- Executing compiled models via TT-MLIR
- Managing device resources
- Verifying execution results
Key methods:
__call__: Main entry point for executing the modelset_binary: Sets the compiled binary for executiontypecast_inputs: Converts inputs to hardware-supported typesregister_intermediate_callback: Sets up callbacks for runtime verification
OpByOpExecutor
OpByOpExecutor extends the base Executor to support operation-by-operation compilation and execution. This allows for:
- Detailed profiling of individual operations
- Verification of each operation's outputs
- Debugging specific operations that might fail
Key methods:
compile_op: Compiles a single operationrun_op: Executes a single compiled operation
TorchExecutor
TorchExecutor is specialized for handling PyTorch models in an op-by-op fashion. It:
- Processes PyTorch FX graph modules node by node
- Converts PyTorch operations to StableHLO
- Compares outputs with golden (PyTorch) outputs for verification
Key methods:
get_stable_hlo_graph: Converts a PyTorch operation to StableHLO IRrun_gm_op_by_op: Executes a graph module operation by operation
StablehloExecutor
StablehloExecutor specializes in executing models through the StableHLO IR. It can:
- Process ONNX models converted to StableHLO
- Process PyTorch models converted to StableHLO
- Execute individual StableHLO operations
Key methods:
add_program: Adds a PyTorch program to the executoradd_onnx_model_proto: Adds an ONNX model to the executorget_stable_hlo_graph: Prepares a StableHLO operation for compilationshlo_op_by_op: Executes StableHLO operations individually
OnnxExecutor
OnnxExecutor is designed for handling ONNX models. It can:
- Execute ONNX models using ONNX Runtime
- Execute ONNX models converted to TT-MLIR binaries
CompilerConfig
This class manages settings for running models on Tenstorrent devices. Key aspects include:
- Compilation Depth: Defines the level of the compilation pipeline to reach.
- Profiling: Enables the collection of performance data for individual operations.
- Verification: Controls various checks and validations during compilation.
- Environment Overrides: Allows configuration through environment variables. This is explained in detail under Controlling Compiler Behaviour
Please see tt_torch/tools/utils.py for detailed information.
How to Write a Test?
The following is an example test body:
# Insert SPDX licensing. Pre-commit will insert if it is missing
# SPDX-FileCopyrightText: (c) 2025 Tenstorrent AI ULC
#
# SPDX-License-Identifier: Apache-2.0
# some base imports that are required for all tests:
import torch
import pytest
import onnx # for Onnx Tests
from tests.utils import ModelTester # for PyTorch Tests
from tests.utils import OnnxModelTester # for Onnx Tests
from tt_torch.tools.utils import CompilerConfig, CompileDepth, OpByOpBackend
class ThisTester(ModelTester): # or class ThisTester(OnnxModelTester):
def _load_model(self):
model = ....
return model
def _load_inputs(self):
inputs = ...
return inputs
# you can pytest parameterize certain arguments. i.e. Mode, OpByOpBackend, Model Name
@pytest.mark.parametrize(
"mode",
["train", "eval"],
)
@pytest.mark.parametrize(
"model_name",
[
"model_name_0",
"model_name_1",
],
)
@pytest.mark.parametrize(
"op_by_op",
[OpByOpBackend.STABLEHLO, OpByOpBackend.TORCH, None],
ids=["op_by_op_stablehlo", "op_by_op_torch", "full"],
)
# For PyTorch Tests
def <test_name>(record_property, model_name, mode, op_by_op):
cc = CompilerConfig()
cc.enable_consteval = True
cc.consteval_parameters = True
if op_by_op:
cc.compile_depth = CompileDepth.EXECUTE_OP_BY_OP
if op_by_op == OpByOpBackend.STABLEHLO:
cc.op_by_op_backend = OpByOpBackend.STABLEHLO
tester = ThisTester(
model_name,
mode,
compiler_config=cc,
record_property_handle=record_property,
)
results = tester.test_model()
if mode == "eval":
# code to evaluate the output is as expected
tester.finalize()
# For Onnx Tests:
def <test_name>(record_property, model_name, mode, op_by_op):
cc = CompilerConfig()
if op_by_op:
cc.compile_depth = CompileDepth.EXECUTE_OP_BY_OP
cc.op_by_op_backend = OpByOpBackend.STABLEHLO
tester = ThisTester(
model_name,
mode,
compiler_config=cc,
record_property_handle=record_property,
model_group="red",
)
results = tester.test_model()
if mode == "eval":
# code to evaluate the output is as expected
tester.finalize()
You can find example tests under tests/models
Note: please make sure to distinguish Onnx tests by appending _onnx to test names. i.e. test_EfficientNet_onnx.py
Test Run Nodes
-
op-by-op flow: This will break down model into graphs and break down graphs into ops, compiling and executing unique (first seen occurrence) ops independently. Results are written to .json file and and optionally converted to XLS file for reporting, as post-processing step. The op-by-op flow is typically used for bringing up new models and debugging and you should start there, especially if the model is a new, untested architecture or your have reason to believe it will not work end-to-end out of the box. Engaged with
cc.compile_depth = CompileDepth.EXECUTE_OP_BY_OPin test, typically driven by pytest params[op_by_op_torch-eval]. -
full end-to-end flow: This is the typical compile + execute of the model that typically includes functional correctness checking. Engaged with
cc.compile_depth = CompileDepth.EXECUTEin test, typically driven by pytest params[full-eval].
Where to Add Tests on tt-torch GitHub CI?
If you're a Tenstorrent internal developer and have a new model that is either running fully/correctly or still needs some work (compiler support, runtime support, etc), it should be added to CI in the same PR you add the model. Below is guide for where to add it.
Case 1: The New Model Test Runs Correctly End-to-end
If you've tried it and it runs – great!
- Add it to run in "nightly full model execute list" in
.github/workflows/run-full-model-execution-tests-nightly.ymlwhile ideally balancing existing groups of tests. Example:
tests/models/Qwen/test_qwen2_casual_lm.py::test_qwen2_casual_lm[full-eval]
- Also add it to "weekly op-by-op-flow list" in
.github/workflows/run-op-by-op-flow-tests-weekly.ymlwhere we less frequently run tests that have all ops passing through toEXECUTEdepth in op-by-op flow. Example:
tests/models/Qwen/test_qwen2_casual_lm.py::test_qwen2_casual_lm[op_by_op_torch-eval]
Case 2: The New Model Test Runs End-to-end but Encounters a PCC/ATOL/Checker Error
This is okay, there is still value in running the model.
- Follow previous section instructions for adding it to "nightly full model execute" and "weekly op-by-op-flow list" but first open a GitHub issue (follow template and
models_pcc_issuelabel like the example below) to track the PCC/ATOL/Checker error, reference it in the test body so it can be tracked/debugged, and disable PCC/ATOL/Token checking as needed. Example:
# TODO Enable checking - https://github.com/tenstorrent/tt-torch/issues/490
assert_pcc=False,
assert_atol=False,
Case 3: The New Model Test Does Not Run Correctly End-to-end
No problem. If your end-to-end model hits a compiler failure (unsupported op, etc) or runtime assert of any kind, this is why the op-by-op flow exists. The op-by-op flow is designed to flag per-op compile/runtime failures (which are perfectly fine) but is expected to return overall passed status.
- Go ahead and run the op-by-op flow locally (or on CI) for your model, and if the pytest finishes without fatal errors, add it to the "nightly op-by-op flow list" (a new or existing group) in
.github/workflows/run-op-by-op-flow-tests-nightly.ymlwhere individual ops will be tracked/debugged and later promoted to "nightly full model execute list" once ready. Example:
tests/models/t5/test_t5.py::test_t5[op_by_op_torch-t5-large-eval]
-
It is helpful if you can run
python results/parse_op_by_op_results.py(will generateresults/models_op_per_op.xlsxfor all models you've recently run in op-by-op-flow) and include the XLS file in your PR. This XLS file contains op-by-op-flow results and is also generated in Nightly regression for all work-in-progress models in.github/workflows/run-op-by-op-flow-tests-nightly.yml. -
If your model is reported in
results/models_op_per_op.xlsxas being able to compile all ops successfully (ie. all ops can compile to status6: CONVERTED_TO_TTNN, but some hit runtime7: EXECUTEfailures) then it should also be added to "nightly e2e compile list" in.github/workflows/run-e2e-compile-tests.ymlwhich stops before executing the model viaTT_TORCH_COMPILE_DEPTH=TTNN_IR pytest ...
How to Load Test Files into/from Large File System (LFS)
We have set up access to a AWS S3 bucket to be able to load and access model related files for testing. We can load files into our S3 bucket and access them from the tester scripts. You will need access to S3 bucket portal to add files. If you don't have an AWS account or access to the S3 bucket please reach out to the tt-torch community leader. Then, depending on if the test is running on CI or locally we will be able to load the files from the CI/IRD LFS caches that automatically sync up with contents in S3 bucket.
Load Files into S3 Bucket
Access S3 bucket portal, if you don't have access to the S3 bucket please reach out to the tt-torch community leader, and load file from local dir. Please add files following this structure:
test_files
├── pytorch
│ ├── huggingface
│ │ ├── meta-llama
│ │ │ ├── Llama-3.1-70B
│ │ │ │ └── <hugginface files>
│ │ │ ├── Llama-2-7b-hf
│ │ │ │ └── <hugginface files>
│ │ │ └── ...
│ │ └── ...
│ ├── yolov10
│ │ └── yolov10.pt
│ └── ...
└── onnx
├── ViT
│ └── ViT.onnx
└── ...
Load Files from S3 Bucket
Once files is loaded into S3 bucket we can access the file using a helper function from the tt-forge-models repo:
def get_file(path):
from third_party.tt_forge_models.tools.utils import get_file
class ThisTester(ModelTester):
def _load_model(self):
file = get_file("test_files/pytorch/yoloyv10/yolov_10n.pt")
...
The path arg should be the full path of the file in the S3 bucket. DO NOT use the S3 URL
Loading Files Locally
Locally get_file(path) will pull files directly from an IRD LFS cache. The IRD LFS cache is set up to sync up with S3 bucket every 5-10 minutes. You will need to set the IRD_LF_CACHE environment variable to the appropriate address. Contact tt-torch community leader for IRD LF cache address.
File/s will be downloaded into a local cache so next time you want to access the same file we won't have to load from the IRD cache or download it again. The default location for the local cache is ~/.cache/lfcache/. If you want to redirect files to a custom cache path set the LOCAL_LF_CACHE env variable to the desired path.
If you can't be granted access to the IRD LF cache you have two options:
- We can use
path=urlto download files. DO NOT use the S3 URL. - We can use
path=<local_path>where local path is a relative path of the file in your local cache (~/.cache/lfcache/<local_path>orLOCAL_LF_CACHE/<local_path>).
Loading Files from CI
Once a file has been loaded into ther S3 bucket the CI's shared DOCKER_CACHE_DIR has been set up to sync up with the contents of the S3 bucket every hour. get_file() will fetch the file from the DOCKER_CACHE_DIR.
Supported Models
NOTE: TT-Torch is deprecated. To work with PyTorch and the various features available in TT-Torch, please see the documentation for TT-XLA.
The following models can be currently run through tt-torch as of Feb 3rd, 2025. Please note, there is a known bug causing incorrect output for some models. The PCC is displayed at the end of each test below. This issue will be addressed soon.
| Model Name | Variant | Pytest Command |
|---|---|---|
| Albert | Masked LM Base | tests/models/albert/test_albert_masked_lm.py::test_albert_masked_lm[single_device-full-albert/albert-base-v2-eval] |
| Masked LM Large | tests/models/albert/test_albert_masked_lm.py::test_albert_masked_lm[single_device-full-albert/albert-large-v2-eval] | |
| Masked LM XLarge | tests/models/albert/test_albert_masked_lm.py::test_albert_masked_lm[single_device-full-albert/albert-xlarge-v2-eval] | |
| Masked LM XXLarge | tests/models/albert/test_albert_masked_lm.py::test_albert_masked_lm[single_device-full-albert/albert-xxlarge-v2-eval] | |
| Sequence Classification Base | tests/models/albert/test_albert_sequence_classification.py::test_albert_sequence_classification[single_device-full-textattack/albert-base-v2-imdb-eval] | |
| Token Classification Base | tests/models/albert/test_albert_token_classification.py::test_albert_token_classification[single_device-full-albert/albert-base-v2-eval] | |
| Autoencoder | (linear) | tests/models/autoencoder_linear/test_autoencoder_linear.py::test_autoencoder_linear[full-eval] |
| DistilBert | base uncased | tests/models/distilbert/test_distilbert.py::test_distilbert[full-distilbert-base-uncased-eval] |
| Llama | 3B | tests/models/llama/test_llama_3b.py::test_llama_3b[full-meta-llama/Llama-3.2-3B-eval] |
| MLPMixer | tests/models/mlpmixer/test_mlpmixer.py::test_mlpmixer[full-eval] | |
| MNist | pytest -svv tests/models/mnist/test_mnist.py::test_mnist_train[single_device-full-eval] | |
| MobileNet V2 | tests/models/MobileNetV2/test_MobileNetV2.py::test_MobileNetV2[full-eval] | |
| TorchVision | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-mobilenet_v2] | |
| MobileNet V3 | Small TorchVision | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-mobilenet_v3_small] |
| Large TorchVision | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-mobilenet_v3_large] | |
| OpenPose | tests/models/openpose/test_openpose_v2.py::test_openpose_v2[full-eval] | |
| Preciever_IO | tests/models/perceiver_io/test_perceiver_io.py::test_perceiver_io[full-eval] | |
| ResNet | 18 | tests/models/resnet/test_resnet.py::test_resnet[single_device-full-eval] |
| 18 TorchVision | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-resnet18] | |
| 34 TorchVision | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-resnet34] | |
| 50 | tests/models/resnet50/test_resnet50.py::test_resnet[single_device-full-eval] | |
| 50 TorchVision | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-resnet50] | |
| 101 TorchVision | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-resnet101] | |
| 152 TorchVision | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-resnet152] | |
| Wide ResNet | 50 | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-wide_resnet50_2] |
| 101 | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-wide_resnet101_2] | |
| ResNext | 50 | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-resnext50_32x4d] |
| 101_32x8d | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-resnext101_32x8d] | |
| 101_64x4d | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-resnext101_64x4d] | |
| Regnet | y 400 | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-regnet_y_400mf] |
| y 800 | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-regnet_y_800mf] | |
| y 1 6 | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-regnet_y_1_6gf] | |
| y 3 2 | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-regnet_y_3_2gf] | |
| y 8 | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-regnet_y_8gf] | |
| y 16 | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-regnet_y_16gf] | |
| y 32 | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-regnet_y_32gf] | |
| x 400 | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-regnet_x_400mf] | |
| x 800 | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-regnet_x_800mf] | |
| x 1 6 | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-regnet_x_1_6gf] | |
| x 3 2 | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-regnet_x_3_2gf] | |
| x 8 | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-regnet_x_8gf] | |
| x 16 | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-regnet_x_16gf] | |
| x 32 | tests/models/torchvision/test_torchvision_image_classification.py::test_torchvision_image_classification[single_device-full-regnet_x_32gf] | |
| Yolo | V3 | tests/models/yolov3/test_yolov3.py::test_yolov3[full-eval] |
Ops Documentation
NOTE: TT-Torch is deprecated. To work with PyTorch and the various features available in TT-Torch, please see the documentation for TT-XLA.
This section contains documentation for Ops operations.
Stablehlo Documentation
NOTE: TT-Torch is deprecated. To work with PyTorch and the various features available in TT-Torch, please see the documentation for TT-XLA.
This section contains documentation for Stablehlo operations.
arith.constant
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1]>, | aten::_safe_softmax | 4 |
stablehlo.add::ttnn.add
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[256,256]>, Tensor<[256,256]>, | ttnn.add | aten::add.Tensor | 6 |
| 1 | Tensor<[1,1,32,32]>, Tensor<[1,1,32,32]>, | ttnn.add | aten::add.Tensor | 4 |
| 2 | Tensor<[1,32,1]>, Tensor<[1,32,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 3 | Tensor<[1,32,32,128]>, Tensor<[1,32,32,128]>, | ttnn.add | aten::add.Tensor | 5 |
| 4 | Tensor<[1,32,32,32]>, Tensor<[1,32,32,32]>, | ttnn.add | aten::add.Tensor | 4 |
| 5 | Tensor<[1,32,4096]>, Tensor<[1,32,4096]>, | ttnn.add | aten::add.Tensor | 5 |
| 6 | Tensor<[32]>, Tensor<[32]>, | ttnn.add | aten::arange | 4 |
| 7 | Tensor<[32,1]>, Tensor<[32,1]>, | ttnn.add | aten::triu | 4 |
| 8 | Tensor<[1,7,768]>, Tensor<[1,7,768]>, | ttnn.add | aten::add.Tensor | 5 |
| 9 | Tensor<[7]>, Tensor<[7]>, | ttnn.add | aten::add.Tensor | 4 |
| 10 | Tensor<[1,7,1]>, Tensor<[1,7,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 11 | Tensor<[7,2304]>, Tensor<[7,2304]>, | ttnn.add | aten::add.Tensor | 4 |
| 12 | Tensor<[1,12,7,7]>, Tensor<[1,12,7,7]>, | ttnn.add | aten::add.Tensor | 4 |
| 13 | Tensor<[7,768]>, Tensor<[7,768]>, | ttnn.add | aten::add.Tensor | 4 |
| 14 | Tensor<[7,3072]>, Tensor<[7,3072]>, | ttnn.add | aten::add.Tensor | 4 |
| 15 | Tensor<[1,7,3072]>, Tensor<[1,7,3072]>, | ttnn.add | aten::add.Tensor | 5 |
| 16 | Tensor<[1]>, Tensor<[1]>, | ttnn.add | aten::arange | 4 |
| 17 | Tensor<[1,32,112,112]>, Tensor<[1,32,112,112]>, | ttnn.add | aten::add.Tensor | 4 |
| 18 | Tensor<[64]>, Tensor<[64]>, | ttnn.add | aten::add.Tensor | 4 |
| 19 | Tensor<[1,64,112,112]>, Tensor<[1,64,112,112]>, | ttnn.add | aten::add.Tensor | 4 |
| 20 | Tensor<[1,64,56,56]>, Tensor<[1,64,56,56]>, | ttnn.add | aten::add.Tensor | 4 |
| 21 | Tensor<[128]>, Tensor<[128]>, | ttnn.add | aten::add.Tensor | 4 |
| 22 | Tensor<[1,128,56,56]>, Tensor<[1,128,56,56]>, | ttnn.add | aten::add.Tensor | 4 |
| 23 | Tensor<[1,128,28,28]>, Tensor<[1,128,28,28]>, | ttnn.add | aten::add.Tensor | 4 |
| 24 | Tensor<[256]>, Tensor<[256]>, | ttnn.add | aten::add.Tensor | 4 |
| 25 | Tensor<[1,256,28,28]>, Tensor<[1,256,28,28]>, | ttnn.add | aten::add.Tensor | 4 |
| 26 | Tensor<[512]>, Tensor<[512]>, | ttnn.add | aten::add.Tensor | 4 |
| 27 | Tensor<[1,512,28,28]>, Tensor<[1,512,28,28]>, | ttnn.add | aten::add.Tensor | 4 |
| 28 | Tensor<[1,19,28,28]>, Tensor<[1,19,28,28]>, | ttnn.add | aten::convolution | 4 |
| 29 | Tensor<[1,38,28,28]>, Tensor<[1,38,28,28]>, | ttnn.add | aten::convolution | 4 |
| 30 | Tensor<[256,512]>, Tensor<[256,512]>, | ttnn.add | aten::add.Tensor | 4 |
| 31 | Tensor<[1,256,1]>, Tensor<[1,256,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 32 | Tensor<[1,256,512]>, Tensor<[1,256,512]>, | ttnn.add | aten::add.Tensor | 4 |
| 33 | Tensor<[1,1000]>, Tensor<[1,1000]>, | ttnn.add | aten::add.Tensor | 4 |
| 34 | Tensor<[1,1024,512]>, Tensor<[1,1024,512]>, | ttnn.add | aten::convolution | 4 |
| 35 | Tensor<[1,256,256]>, Tensor<[1,256,256]>, | ttnn.add | aten::gelu | 4 |
| 36 | Tensor<[1,64,1,1]>, Tensor<[1,64,1,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 37 | Tensor<[1,64,360,640]>, Tensor<[1,64,360,640]>, | ttnn.add | aten::add.Tensor | 4 |
| 38 | Tensor<[1,64,180,320]>, Tensor<[1,64,180,320]>, | ttnn.add | aten::add.Tensor | 4 |
| 39 | Tensor<[1,256,1,1]>, Tensor<[1,256,1,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 40 | Tensor<[1,256,180,320]>, Tensor<[1,256,180,320]>, | ttnn.add | aten::add.Tensor | 4 |
| 41 | Tensor<[1,128,1,1]>, Tensor<[1,128,1,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 42 | Tensor<[1,128,180,320]>, Tensor<[1,128,180,320]>, | ttnn.add | aten::add.Tensor | 4 |
| 43 | Tensor<[1,128,90,160]>, Tensor<[1,128,90,160]>, | ttnn.add | aten::add.Tensor | 4 |
| 44 | Tensor<[1,512,1,1]>, Tensor<[1,512,1,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 45 | Tensor<[1,512,90,160]>, Tensor<[1,512,90,160]>, | ttnn.add | aten::add.Tensor | 4 |
| 46 | Tensor<[1,256,90,160]>, Tensor<[1,256,90,160]>, | ttnn.add | aten::add.Tensor | 4 |
| 47 | Tensor<[1,256,45,80]>, Tensor<[1,256,45,80]>, | ttnn.add | aten::add.Tensor | 4 |
| 48 | Tensor<[1,1024,1,1]>, Tensor<[1,1024,1,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 49 | Tensor<[1,1024,45,80]>, Tensor<[1,1024,45,80]>, | ttnn.add | aten::add.Tensor | 4 |
| 50 | Tensor<[1,512,45,80]>, Tensor<[1,512,45,80]>, | ttnn.add | aten::add.Tensor | 4 |
| 51 | Tensor<[1,512,23,40]>, Tensor<[1,512,23,40]>, | ttnn.add | aten::add.Tensor | 4 |
| 52 | Tensor<[1,2048,1,1]>, Tensor<[1,2048,1,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 53 | Tensor<[1,2048,23,40]>, Tensor<[1,2048,23,40]>, | ttnn.add | aten::add.Tensor | 4 |
| 54 | Tensor<[23]>, Tensor<[23]>, | ttnn.add | aten::add.Tensor | 4 |
| 55 | Tensor<[40]>, Tensor<[40]>, | ttnn.add | aten::add.Tensor | 4 |
| 56 | Tensor<[1,1,40]>, Tensor<[1,1,40]>, | ttnn.add | aten::add.Tensor | 4 |
| 57 | Tensor<[1,23,1]>, Tensor<[1,23,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 58 | Tensor<[920,1,256]>, Tensor<[920,1,256]>, | ttnn.add | aten::add.Tensor | 5 |
| 59 | Tensor<[920,256]>, Tensor<[920,256]>, | ttnn.add | aten::add.Tensor | 4 |
| 60 | Tensor<[920,1,1]>, Tensor<[920,1,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 61 | Tensor<[920,2048]>, Tensor<[920,2048]>, | ttnn.add | aten::add.Tensor | 4 |
| 62 | Tensor<[100,1,256]>, Tensor<[100,1,256]>, | ttnn.add | aten::add.Tensor | 5 |
| 63 | Tensor<[100,256]>, Tensor<[100,256]>, | ttnn.add | aten::add.Tensor | 4 |
| 64 | Tensor<[100,1,1]>, Tensor<[100,1,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 65 | Tensor<[100,2048]>, Tensor<[100,2048]>, | ttnn.add | aten::add.Tensor | 4 |
| 66 | Tensor<[6,1,100,92]>, Tensor<[6,1,100,92]>, | ttnn.add | aten::add.Tensor | 4 |
| 67 | Tensor<[6,1,100,256]>, Tensor<[6,1,100,256]>, | ttnn.add | aten::add.Tensor | 4 |
| 68 | Tensor<[6,1,100,4]>, Tensor<[6,1,100,4]>, | ttnn.add | aten::add.Tensor | 4 |
| 69 | Tensor<[8,920,920]>, Tensor<[8,920,920]>, | ttnn.add | aten::baddbmm | 4 |
| 70 | Tensor<[8,100,920]>, Tensor<[8,100,920]>, | ttnn.add | aten::baddbmm | 4 |
| 71 | Tensor<[1,256,23,40]>, Tensor<[1,256,23,40]>, | ttnn.add | aten::convolution | 4 |
| 72 | Tensor<[1,10]>, Tensor<[1,10]>, | ttnn.add | aten::add.Tensor | 5 |
| 73 | Tensor<[1,10,768]>, Tensor<[1,10,768]>, | ttnn.add | aten::add.Tensor | 5 |
| 74 | Tensor<[1,10,1]>, Tensor<[1,10,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 75 | Tensor<[10,768]>, Tensor<[10,768]>, | ttnn.add | aten::add.Tensor | 4 |
| 76 | Tensor<[1,12,10,10]>, Tensor<[1,12,10,10]>, | ttnn.add | aten::add.Tensor | 4 |
| 77 | Tensor<[10,3072]>, Tensor<[10,3072]>, | ttnn.add | aten::add.Tensor | 4 |
| 78 | Tensor<[10,250002]>, Tensor<[10,250002]>, | ttnn.add | aten::add.Tensor | 4 |
| 79 | Tensor<[1,10,3072]>, Tensor<[1,10,3072]>, | ttnn.add | aten::gelu | 4 |
| 80 | Tensor<[1,1280]>, Tensor<[1,1280]>, | ttnn.add | aten::add.Tensor | 4 |
| 81 | Tensor<[1,32,1,1]>, Tensor<[1,32,1,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 82 | Tensor<[1,320,64,64]>, Tensor<[1,320,64,64]>, | ttnn.add | aten::add.Tensor | 4 |
| 83 | Tensor<[1,320]>, Tensor<[1,320]>, | ttnn.add | aten::add.Tensor | 4 |
| 84 | Tensor<[1,4096,1]>, Tensor<[1,4096,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 85 | Tensor<[1,4096,320]>, Tensor<[1,4096,320]>, | ttnn.add | aten::add.Tensor | 4 |
| 86 | Tensor<[4096,320]>, Tensor<[4096,320]>, | ttnn.add | aten::add.Tensor | 4 |
| 87 | Tensor<[4096,2560]>, Tensor<[4096,2560]>, | ttnn.add | aten::add.Tensor | 4 |
| 88 | Tensor<[1,320,32,32]>, Tensor<[1,320,32,32]>, | ttnn.add | aten::add.Tensor | 4 |
| 89 | Tensor<[1,640]>, Tensor<[1,640]>, | ttnn.add | aten::add.Tensor | 4 |
| 90 | Tensor<[1,640,32,32]>, Tensor<[1,640,32,32]>, | ttnn.add | aten::add.Tensor | 4 |
| 91 | Tensor<[1,1024,1]>, Tensor<[1,1024,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 92 | Tensor<[1,1024,640]>, Tensor<[1,1024,640]>, | ttnn.add | aten::add.Tensor | 4 |
| 93 | Tensor<[1024,640]>, Tensor<[1024,640]>, | ttnn.add | aten::add.Tensor | 4 |
| 94 | Tensor<[1024,5120]>, Tensor<[1024,5120]>, | ttnn.add | aten::add.Tensor | 4 |
| 95 | Tensor<[1,640,16,16]>, Tensor<[1,640,16,16]>, | ttnn.add | aten::add.Tensor | 4 |
| 96 | Tensor<[1,1280,16,16]>, Tensor<[1,1280,16,16]>, | ttnn.add | aten::add.Tensor | 4 |
| 97 | Tensor<[1,256,1280]>, Tensor<[1,256,1280]>, | ttnn.add | aten::add.Tensor | 4 |
| 98 | Tensor<[256,1280]>, Tensor<[256,1280]>, | ttnn.add | aten::add.Tensor | 4 |
| 99 | Tensor<[256,10240]>, Tensor<[256,10240]>, | ttnn.add | aten::add.Tensor | 4 |
| 100 | Tensor<[1,1280,8,8]>, Tensor<[1,1280,8,8]>, | ttnn.add | aten::add.Tensor | 4 |
| 101 | Tensor<[1,64,1]>, Tensor<[1,64,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 102 | Tensor<[1,64,1280]>, Tensor<[1,64,1280]>, | ttnn.add | aten::add.Tensor | 4 |
| 103 | Tensor<[64,1280]>, Tensor<[64,1280]>, | ttnn.add | aten::add.Tensor | 4 |
| 104 | Tensor<[64,10240]>, Tensor<[64,10240]>, | ttnn.add | aten::add.Tensor | 4 |
| 105 | Tensor<[1,2560,8,8]>, Tensor<[1,2560,8,8]>, | ttnn.add | aten::add.Tensor | 4 |
| 106 | Tensor<[16]>, Tensor<[16]>, | ttnn.add | aten::add.Tensor | 4 |
| 107 | Tensor<[1,2560,16,16]>, Tensor<[1,2560,16,16]>, | ttnn.add | aten::add.Tensor | 4 |
| 108 | Tensor<[1,1920,16,16]>, Tensor<[1,1920,16,16]>, | ttnn.add | aten::add.Tensor | 4 |
| 109 | Tensor<[1,1920,32,32]>, Tensor<[1,1920,32,32]>, | ttnn.add | aten::add.Tensor | 4 |
| 110 | Tensor<[1,1280,32,32]>, Tensor<[1,1280,32,32]>, | ttnn.add | aten::add.Tensor | 4 |
| 111 | Tensor<[1,960,32,32]>, Tensor<[1,960,32,32]>, | ttnn.add | aten::add.Tensor | 4 |
| 112 | Tensor<[1,960,64,64]>, Tensor<[1,960,64,64]>, | ttnn.add | aten::add.Tensor | 4 |
| 113 | Tensor<[1,640,64,64]>, Tensor<[1,640,64,64]>, | ttnn.add | aten::add.Tensor | 4 |
| 114 | Tensor<[160]>, Tensor<[160]>, | ttnn.add | aten::arange.start | 4 |
| 115 | Tensor<[1,4,64,64]>, Tensor<[1,4,64,64]>, | ttnn.add | aten::convolution | 4 |
| 116 | Tensor<[1,4096,1280]>, Tensor<[1,4096,1280]>, | ttnn.add | aten::gelu | 4 |
| 117 | Tensor<[1,1024,2560]>, Tensor<[1,1024,2560]>, | ttnn.add | aten::gelu | 4 |
| 118 | Tensor<[1,256,5120]>, Tensor<[1,256,5120]>, | ttnn.add | aten::gelu | 4 |
| 119 | Tensor<[1,64,5120]>, Tensor<[1,64,5120]>, | ttnn.add | aten::gelu | 4 |
| 120 | Tensor<[1280]>, Tensor<[1280]>, | ttnn.add | aten::index.Tensor | 4 |
| 121 | Tensor<[640]>, Tensor<[640]>, | ttnn.add | aten::index.Tensor | 4 |
| 122 | Tensor<[1,25,768]>, Tensor<[1,25,768]>, | ttnn.add | aten::add.Tensor | 5 |
| 123 | Tensor<[1,25,1]>, Tensor<[1,25,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 124 | Tensor<[25,768]>, Tensor<[25,768]>, | ttnn.add | aten::add.Tensor | 4 |
| 125 | Tensor<[1,12,25,25]>, Tensor<[1,12,25,25]>, | ttnn.add | aten::add.Tensor | 4 |
| 126 | Tensor<[25,3072]>, Tensor<[25,3072]>, | ttnn.add | aten::add.Tensor | 4 |
| 127 | Tensor<[25,2]>, Tensor<[25,2]>, | ttnn.add | aten::add.Tensor | 4 |
| 128 | Tensor<[1,1]>, Tensor<[1,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 129 | Tensor<[1,25,3072]>, Tensor<[1,25,3072]>, | ttnn.add | aten::gelu | 4 |
| 130 | Tensor<[1,1445,192]>, Tensor<[1,1445,192]>, | ttnn.add | aten::add.Tensor | 5 |
| 131 | Tensor<[1,1445,1]>, Tensor<[1,1445,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 132 | Tensor<[1445,192]>, Tensor<[1445,192]>, | ttnn.add | aten::add.Tensor | 4 |
| 133 | Tensor<[1445,768]>, Tensor<[1445,768]>, | ttnn.add | aten::add.Tensor | 4 |
| 134 | Tensor<[100,192]>, Tensor<[100,192]>, | ttnn.add | aten::add.Tensor | 4 |
| 135 | Tensor<[100,92]>, Tensor<[100,92]>, | ttnn.add | aten::add.Tensor | 4 |
| 136 | Tensor<[100,4]>, Tensor<[100,4]>, | ttnn.add | aten::add.Tensor | 4 |
| 137 | Tensor<[1,192,32,42]>, Tensor<[1,192,32,42]>, | ttnn.add | aten::convolution | 4 |
| 138 | Tensor<[1,1445,768]>, Tensor<[1,1445,768]>, | ttnn.add | aten::gelu | 4 |
| 139 | Tensor<[1,256,14,14]>, Tensor<[1,256,14,14]>, | ttnn.add | aten::add.Tensor | 4 |
| 140 | Tensor<[1,512,7,7]>, Tensor<[1,512,7,7]>, | ttnn.add | aten::add.Tensor | 4 |
| 141 | Tensor<[1,8,768]>, Tensor<[1,8,768]>, | ttnn.add | aten::add.Tensor | 5 |
| 142 | Tensor<[1,8,1]>, Tensor<[1,8,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 143 | Tensor<[1,12,8,8]>, Tensor<[1,12,8,8]>, | ttnn.add | aten::add.Tensor | 4 |
| 144 | Tensor<[1,768,8]>, Tensor<[1,768,8]>, | ttnn.add | aten::add.Tensor | 5 |
| 145 | Tensor<[1,768]>, Tensor<[1,768]>, | ttnn.add | aten::add.Tensor | 4 |
| 146 | Tensor<[1,3]>, Tensor<[1,3]>, | ttnn.add | aten::add.Tensor | 4 |
| 147 | Tensor<[1,3072,8]>, Tensor<[1,3072,8]>, | ttnn.add | aten::convolution | 4 |
| 148 | Tensor<[1,2048,768]>, Tensor<[1,2048,768]>, | ttnn.add | aten::add.Tensor | 4 |
| 149 | Tensor<[1,2048,1]>, Tensor<[1,2048,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 150 | Tensor<[2048,256]>, Tensor<[2048,256]>, | ttnn.add | aten::add.Tensor | 4 |
| 151 | Tensor<[2048,1280]>, Tensor<[2048,1280]>, | ttnn.add | aten::add.Tensor | 4 |
| 152 | Tensor<[1,8,256,2048]>, Tensor<[1,8,256,2048]>, | ttnn.add | aten::add.Tensor | 4 |
| 153 | Tensor<[256,768]>, Tensor<[256,768]>, | ttnn.add | aten::add.Tensor | 4 |
| 154 | Tensor<[2048,768]>, Tensor<[2048,768]>, | ttnn.add | aten::add.Tensor | 4 |
| 155 | Tensor<[2048,262]>, Tensor<[2048,262]>, | ttnn.add | aten::add.Tensor | 4 |
| 156 | Tensor<[2048]>, Tensor<[2048]>, | ttnn.add | aten::arange.start | 4 |
| 157 | Tensor<[1,256,56,56]>, Tensor<[1,256,56,56]>, | ttnn.add | aten::add.Tensor | 4 |
| 158 | Tensor<[1024]>, Tensor<[1024]>, | ttnn.add | aten::add.Tensor | 4 |
| 159 | Tensor<[1,1024,14,14]>, Tensor<[1,1024,14,14]>, | ttnn.add | aten::add.Tensor | 4 |
| 160 | Tensor<[1,512,14,14]>, Tensor<[1,512,14,14]>, | ttnn.add | aten::add.Tensor | 4 |
| 161 | Tensor<[1,2048,7,7]>, Tensor<[1,2048,7,7]>, | ttnn.add | aten::add.Tensor | 4 |
| 162 | Tensor<[12]>, Tensor<[12]>, | ttnn.add | aten::add.Tensor | 4 |
| 163 | Tensor<[1,193,768]>, Tensor<[1,193,768]>, | ttnn.add | aten::add.Tensor | 5 |
| 164 | Tensor<[1,201,1]>, Tensor<[1,201,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 165 | Tensor<[1,201,768]>, Tensor<[1,201,768]>, | ttnn.add | aten::add.Tensor | 4 |
| 166 | Tensor<[201,768]>, Tensor<[201,768]>, | ttnn.add | aten::add.Tensor | 4 |
| 167 | Tensor<[1,12,201,201]>, Tensor<[1,12,201,201]>, | ttnn.add | aten::add.Tensor | 4 |
| 168 | Tensor<[201,3072]>, Tensor<[201,3072]>, | ttnn.add | aten::add.Tensor | 4 |
| 169 | Tensor<[1,1536]>, Tensor<[1,1536]>, | ttnn.add | aten::add.Tensor | 4 |
| 170 | Tensor<[1,3129]>, Tensor<[1,3129]>, | ttnn.add | aten::add.Tensor | 4 |
| 171 | Tensor<[1,768,12,16]>, Tensor<[1,768,12,16]>, | ttnn.add | aten::convolution | 4 |
| 172 | Tensor<[1,201,3072]>, Tensor<[1,201,3072]>, | ttnn.add | aten::gelu | 4 |
| 173 | Tensor<[1,128]>, Tensor<[1,128]>, | ttnn.add | aten::add.Tensor | 4 |
| 174 | Tensor<[1,32,26,26]>, Tensor<[1,32,26,26]>, | ttnn.add | aten::convolution | 4 |
| 175 | Tensor<[1,64,24,24]>, Tensor<[1,64,24,24]>, | ttnn.add | aten::convolution | 4 |
| 176 | Tensor<[19]>, Tensor<[19]>, | ttnn.add | aten::add.Tensor | 4 |
| 177 | Tensor<[1,19]>, Tensor<[1,19]>, | ttnn.add | aten::add.Tensor | 4 |
| 178 | Tensor<[1,19,1024]>, Tensor<[1,19,1024]>, | ttnn.add | aten::add.Tensor | 5 |
| 179 | Tensor<[1,19,1]>, Tensor<[1,19,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 180 | Tensor<[19,1024]>, Tensor<[19,1024]>, | ttnn.add | aten::add.Tensor | 4 |
| 181 | Tensor<[1,16,19,19]>, Tensor<[1,16,19,19]>, | ttnn.add | aten::add.Tensor | 4 |
| 182 | Tensor<[19,4096]>, Tensor<[19,4096]>, | ttnn.add | aten::add.Tensor | 4 |
| 183 | Tensor<[1,19,4096]>, Tensor<[1,19,4096]>, | ttnn.add | aten::gelu | 4 |
| 184 | Tensor<[14]>, Tensor<[14]>, | ttnn.add | aten::add.Tensor | 4 |
| 185 | Tensor<[1,14,56,56]>, Tensor<[1,14,56,56]>, | ttnn.add | aten::add.Tensor | 4 |
| 186 | Tensor<[24]>, Tensor<[24]>, | ttnn.add | aten::add.Tensor | 4 |
| 187 | Tensor<[1,24,56,56]>, Tensor<[1,24,56,56]>, | ttnn.add | aten::add.Tensor | 4 |
| 188 | Tensor<[1,40,56,56]>, Tensor<[1,40,56,56]>, | ttnn.add | aten::add.Tensor | 4 |
| 189 | Tensor<[68]>, Tensor<[68]>, | ttnn.add | aten::add.Tensor | 4 |
| 190 | Tensor<[1,68,56,56]>, Tensor<[1,68,56,56]>, | ttnn.add | aten::add.Tensor | 4 |
| 191 | Tensor<[1,16,28,28]>, Tensor<[1,16,28,28]>, | ttnn.add | aten::add.Tensor | 4 |
| 192 | Tensor<[28]>, Tensor<[28]>, | ttnn.add | aten::add.Tensor | 4 |
| 193 | Tensor<[1,28,28,28]>, Tensor<[1,28,28,28]>, | ttnn.add | aten::add.Tensor | 4 |
| 194 | Tensor<[46]>, Tensor<[46]>, | ttnn.add | aten::add.Tensor | 4 |
| 195 | Tensor<[1,46,28,28]>, Tensor<[1,46,28,28]>, | ttnn.add | aten::add.Tensor | 4 |
| 196 | Tensor<[78]>, Tensor<[78]>, | ttnn.add | aten::add.Tensor | 4 |
| 197 | Tensor<[1,78,28,28]>, Tensor<[1,78,28,28]>, | ttnn.add | aten::add.Tensor | 4 |
| 198 | Tensor<[134]>, Tensor<[134]>, | ttnn.add | aten::add.Tensor | 4 |
| 199 | Tensor<[1,134,28,28]>, Tensor<[1,134,28,28]>, | ttnn.add | aten::add.Tensor | 4 |
| 200 | Tensor<[20]>, Tensor<[20]>, | ttnn.add | aten::add.Tensor | 4 |
| 201 | Tensor<[1,20,28,28]>, Tensor<[1,20,28,28]>, | ttnn.add | aten::add.Tensor | 4 |
| 202 | Tensor<[34]>, Tensor<[34]>, | ttnn.add | aten::add.Tensor | 4 |
| 203 | Tensor<[1,34,28,28]>, Tensor<[1,34,28,28]>, | ttnn.add | aten::add.Tensor | 4 |
| 204 | Tensor<[58]>, Tensor<[58]>, | ttnn.add | aten::add.Tensor | 4 |
| 205 | Tensor<[1,58,28,28]>, Tensor<[1,58,28,28]>, | ttnn.add | aten::add.Tensor | 4 |
| 206 | Tensor<[98]>, Tensor<[98]>, | ttnn.add | aten::add.Tensor | 4 |
| 207 | Tensor<[1,98,28,28]>, Tensor<[1,98,28,28]>, | ttnn.add | aten::add.Tensor | 4 |
| 208 | Tensor<[168]>, Tensor<[168]>, | ttnn.add | aten::add.Tensor | 4 |
| 209 | Tensor<[1,168,28,28]>, Tensor<[1,168,28,28]>, | ttnn.add | aten::add.Tensor | 4 |
| 210 | Tensor<[320]>, Tensor<[320]>, | ttnn.add | aten::add.Tensor | 4 |
| 211 | Tensor<[1,320,28,28]>, Tensor<[1,320,28,28]>, | ttnn.add | aten::add.Tensor | 4 |
| 212 | Tensor<[1,40,14,14]>, Tensor<[1,40,14,14]>, | ttnn.add | aten::add.Tensor | 4 |
| 213 | Tensor<[1,68,14,14]>, Tensor<[1,68,14,14]>, | ttnn.add | aten::add.Tensor | 4 |
| 214 | Tensor<[116]>, Tensor<[116]>, | ttnn.add | aten::add.Tensor | 4 |
| 215 | Tensor<[1,116,14,14]>, Tensor<[1,116,14,14]>, | ttnn.add | aten::add.Tensor | 4 |
| 216 | Tensor<[196]>, Tensor<[196]>, | ttnn.add | aten::add.Tensor | 4 |
| 217 | Tensor<[1,196,14,14]>, Tensor<[1,196,14,14]>, | ttnn.add | aten::add.Tensor | 4 |
| 218 | Tensor<[334]>, Tensor<[334]>, | ttnn.add | aten::add.Tensor | 4 |
| 219 | Tensor<[1,334,14,14]>, Tensor<[1,334,14,14]>, | ttnn.add | aten::add.Tensor | 4 |
| 220 | Tensor<[1,640,14,14]>, Tensor<[1,640,14,14]>, | ttnn.add | aten::add.Tensor | 4 |
| 221 | Tensor<[1,160,7,7]>, Tensor<[1,160,7,7]>, | ttnn.add | aten::add.Tensor | 4 |
| 222 | Tensor<[272]>, Tensor<[272]>, | ttnn.add | aten::add.Tensor | 4 |
| 223 | Tensor<[1,272,7,7]>, Tensor<[1,272,7,7]>, | ttnn.add | aten::add.Tensor | 4 |
| 224 | Tensor<[462]>, Tensor<[462]>, | ttnn.add | aten::add.Tensor | 4 |
| 225 | Tensor<[1,462,7,7]>, Tensor<[1,462,7,7]>, | ttnn.add | aten::add.Tensor | 4 |
| 226 | Tensor<[1,1024,7,7]>, Tensor<[1,1024,7,7]>, | ttnn.add | aten::add.Tensor | 4 |
| 227 | Tensor<[1,32,512,512]>, Tensor<[1,32,512,512]>, | ttnn.add | aten::add.Tensor | 4 |
| 228 | Tensor<[1,64,256,256]>, Tensor<[1,64,256,256]>, | ttnn.add | aten::add.Tensor | 4 |
| 229 | Tensor<[1,32,256,256]>, Tensor<[1,32,256,256]>, | ttnn.add | aten::add.Tensor | 4 |
| 230 | Tensor<[1,128,128,128]>, Tensor<[1,128,128,128]>, | ttnn.add | aten::add.Tensor | 4 |
| 231 | Tensor<[1,64,128,128]>, Tensor<[1,64,128,128]>, | ttnn.add | aten::add.Tensor | 4 |
| 232 | Tensor<[1,256,64,64]>, Tensor<[1,256,64,64]>, | ttnn.add | aten::add.Tensor | 4 |
| 233 | Tensor<[1,128,64,64]>, Tensor<[1,128,64,64]>, | ttnn.add | aten::add.Tensor | 4 |
| 234 | Tensor<[1,512,32,32]>, Tensor<[1,512,32,32]>, | ttnn.add | aten::add.Tensor | 4 |
| 235 | Tensor<[1,256,32,32]>, Tensor<[1,256,32,32]>, | ttnn.add | aten::add.Tensor | 4 |
| 236 | Tensor<[1,1024,16,16]>, Tensor<[1,1024,16,16]>, | ttnn.add | aten::add.Tensor | 4 |
| 237 | Tensor<[1,512,16,16]>, Tensor<[1,512,16,16]>, | ttnn.add | aten::add.Tensor | 4 |
| 238 | Tensor<[1,256,16,16]>, Tensor<[1,256,16,16]>, | ttnn.add | aten::add.Tensor | 4 |
| 239 | Tensor<[1,128,32,32]>, Tensor<[1,128,32,32]>, | ttnn.add | aten::add.Tensor | 4 |
| 240 | Tensor<[1,255,16,16]>, Tensor<[1,255,16,16]>, | ttnn.add | aten::convolution | 4 |
| 241 | Tensor<[1,255,32,32]>, Tensor<[1,255,32,32]>, | ttnn.add | aten::convolution | 4 |
| 242 | Tensor<[1,255,64,64]>, Tensor<[1,255,64,64]>, | ttnn.add | aten::convolution | 4 |
| 243 | Tensor<[1,1,256,256]>, Tensor<[1,1,256,256]>, | ttnn.add | aten::convolution | 4 |
| 244 | Tensor<[1,4,14,14]>, Tensor<[1,4,14,14]>, | ttnn.add | aten::convolution | 4 |
| 245 | Tensor<[1,16,14,14]>, Tensor<[1,16,14,14]>, | ttnn.add | aten::convolution | 4 |
| 246 | Tensor<[1,1,28,28]>, Tensor<[1,1,28,28]>, | ttnn.add | aten::convolution | 4 |
| 247 | Tensor<[1,32,1536]>, Tensor<[1,32,1536]>, | ttnn.add | aten::add.Tensor | 4 |
| 248 | Tensor<[32,4608]>, Tensor<[32,4608]>, | ttnn.add | aten::add.Tensor | 4 |
| 249 | Tensor<[1,16,32,32]>, Tensor<[1,16,32,32]>, | ttnn.add | aten::add.Tensor | 4 |
| 250 | Tensor<[32,1536]>, Tensor<[32,1536]>, | ttnn.add | aten::add.Tensor | 4 |
| 251 | Tensor<[32,6144]>, Tensor<[32,6144]>, | ttnn.add | aten::add.Tensor | 4 |
| 252 | Tensor<[1,32,6144]>, Tensor<[1,32,6144]>, | ttnn.add | aten::add.Tensor | 4 |
| 253 | Tensor<[16,32,32]>, Tensor<[16,32,32]>, | ttnn.add | aten::baddbmm | 4 |
| 254 | Tensor<[1,16,768]>, Tensor<[1,16,768]>, | ttnn.add | aten::add.Tensor | 5 |
| 255 | Tensor<[1,16,1]>, Tensor<[1,16,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 256 | Tensor<[16,768]>, Tensor<[16,768]>, | ttnn.add | aten::add.Tensor | 4 |
| 257 | Tensor<[1,12,16,16]>, Tensor<[1,12,16,16]>, | ttnn.add | aten::add.Tensor | 4 |
| 258 | Tensor<[16,3072]>, Tensor<[16,3072]>, | ttnn.add | aten::add.Tensor | 4 |
| 259 | Tensor<[1,16,3072]>, Tensor<[1,16,3072]>, | ttnn.add | aten::gelu | 4 |
| 260 | Tensor<[1,64,224,224]>, Tensor<[1,64,224,224]>, | ttnn.add | aten::add.Tensor | 4 |
| 261 | Tensor<[1,128,112,112]>, Tensor<[1,128,112,112]>, | ttnn.add | aten::add.Tensor | 4 |
| 262 | Tensor<[1,1,224,224]>, Tensor<[1,1,224,224]>, | ttnn.add | aten::convolution | 4 |
| 263 | Tensor<[1,19200,1]>, Tensor<[1,19200,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 264 | Tensor<[1,19200,64]>, Tensor<[1,19200,64]>, | ttnn.add | aten::add.Tensor | 4 |
| 265 | Tensor<[19200,64]>, Tensor<[19200,64]>, | ttnn.add | aten::add.Tensor | 4 |
| 266 | Tensor<[1,300,1]>, Tensor<[1,300,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 267 | Tensor<[1,300,64]>, Tensor<[1,300,64]>, | ttnn.add | aten::add.Tensor | 4 |
| 268 | Tensor<[300,64]>, Tensor<[300,64]>, | ttnn.add | aten::add.Tensor | 4 |
| 269 | Tensor<[19200,256]>, Tensor<[19200,256]>, | ttnn.add | aten::add.Tensor | 4 |
| 270 | Tensor<[1,4800,1]>, Tensor<[1,4800,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 271 | Tensor<[1,4800,128]>, Tensor<[1,4800,128]>, | ttnn.add | aten::add.Tensor | 4 |
| 272 | Tensor<[4800,128]>, Tensor<[4800,128]>, | ttnn.add | aten::add.Tensor | 4 |
| 273 | Tensor<[1,300,128]>, Tensor<[1,300,128]>, | ttnn.add | aten::add.Tensor | 4 |
| 274 | Tensor<[300,128]>, Tensor<[300,128]>, | ttnn.add | aten::add.Tensor | 4 |
| 275 | Tensor<[4800,512]>, Tensor<[4800,512]>, | ttnn.add | aten::add.Tensor | 4 |
| 276 | Tensor<[1,1200,1]>, Tensor<[1,1200,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 277 | Tensor<[1,1200,320]>, Tensor<[1,1200,320]>, | ttnn.add | aten::add.Tensor | 4 |
| 278 | Tensor<[1200,320]>, Tensor<[1200,320]>, | ttnn.add | aten::add.Tensor | 4 |
| 279 | Tensor<[1,300,320]>, Tensor<[1,300,320]>, | ttnn.add | aten::add.Tensor | 4 |
| 280 | Tensor<[300,320]>, Tensor<[300,320]>, | ttnn.add | aten::add.Tensor | 4 |
| 281 | Tensor<[1200,1280]>, Tensor<[1200,1280]>, | ttnn.add | aten::add.Tensor | 4 |
| 282 | Tensor<[1,300,512]>, Tensor<[1,300,512]>, | ttnn.add | aten::add.Tensor | 4 |
| 283 | Tensor<[300,512]>, Tensor<[300,512]>, | ttnn.add | aten::add.Tensor | 4 |
| 284 | Tensor<[300,2048]>, Tensor<[300,2048]>, | ttnn.add | aten::add.Tensor | 4 |
| 285 | Tensor<[30]>, Tensor<[30]>, | ttnn.add | aten::add.Tensor | 4 |
| 286 | Tensor<[30,1]>, Tensor<[30,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 287 | Tensor<[1,64,30,40]>, Tensor<[1,64,30,40]>, | ttnn.add | aten::add.Tensor | 5 |
| 288 | Tensor<[1,32,30,40]>, Tensor<[1,32,30,40]>, | ttnn.add | aten::add.Tensor | 4 |
| 289 | Tensor<[60]>, Tensor<[60]>, | ttnn.add | aten::add.Tensor | 4 |
| 290 | Tensor<[60,1]>, Tensor<[60,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 291 | Tensor<[80]>, Tensor<[80]>, | ttnn.add | aten::add.Tensor | 4 |
| 292 | Tensor<[1,64,60,80]>, Tensor<[1,64,60,80]>, | ttnn.add | aten::add.Tensor | 5 |
| 293 | Tensor<[1,32,60,80]>, Tensor<[1,32,60,80]>, | ttnn.add | aten::add.Tensor | 4 |
| 294 | Tensor<[120]>, Tensor<[120]>, | ttnn.add | aten::add.Tensor | 4 |
| 295 | Tensor<[120,1]>, Tensor<[120,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 296 | Tensor<[1,64,120,160]>, Tensor<[1,64,120,160]>, | ttnn.add | aten::add.Tensor | 5 |
| 297 | Tensor<[1,32,120,160]>, Tensor<[1,32,120,160]>, | ttnn.add | aten::add.Tensor | 4 |
| 298 | Tensor<[240]>, Tensor<[240]>, | ttnn.add | aten::add.Tensor | 4 |
| 299 | Tensor<[240,1]>, Tensor<[240,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 300 | Tensor<[1,64,240,320]>, Tensor<[1,64,240,320]>, | ttnn.add | aten::add.Tensor | 5 |
| 301 | Tensor<[480]>, Tensor<[480]>, | ttnn.add | aten::add.Tensor | 4 |
| 302 | Tensor<[480,1]>, Tensor<[480,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 303 | Tensor<[1,64,480,640]>, Tensor<[1,64,480,640]>, | ttnn.add | aten::add.Tensor | 5 |
| 304 | Tensor<[1,64,15,20]>, Tensor<[1,64,15,20]>, | ttnn.add | aten::convolution | 4 |
| 305 | Tensor<[1,256,120,160]>, Tensor<[1,256,120,160]>, | ttnn.add | aten::convolution | 4 |
| 306 | Tensor<[1,128,60,80]>, Tensor<[1,128,60,80]>, | ttnn.add | aten::convolution | 4 |
| 307 | Tensor<[1,128,15,20]>, Tensor<[1,128,15,20]>, | ttnn.add | aten::convolution | 4 |
| 308 | Tensor<[1,512,60,80]>, Tensor<[1,512,60,80]>, | ttnn.add | aten::convolution | 4 |
| 309 | Tensor<[1,320,30,40]>, Tensor<[1,320,30,40]>, | ttnn.add | aten::convolution | 4 |
| 310 | Tensor<[1,320,15,20]>, Tensor<[1,320,15,20]>, | ttnn.add | aten::convolution | 4 |
| 311 | Tensor<[1,1280,30,40]>, Tensor<[1,1280,30,40]>, | ttnn.add | aten::convolution | 4 |
| 312 | Tensor<[1,512,15,20]>, Tensor<[1,512,15,20]>, | ttnn.add | aten::convolution | 4 |
| 313 | Tensor<[1,2048,15,20]>, Tensor<[1,2048,15,20]>, | ttnn.add | aten::convolution | 4 |
| 314 | Tensor<[1,2,30,40]>, Tensor<[1,2,30,40]>, | ttnn.add | aten::convolution | 4 |
| 315 | Tensor<[1,2,60,80]>, Tensor<[1,2,60,80]>, | ttnn.add | aten::convolution | 4 |
| 316 | Tensor<[1,2,120,160]>, Tensor<[1,2,120,160]>, | ttnn.add | aten::convolution | 4 |
| 317 | Tensor<[1,1,480,640]>, Tensor<[1,1,480,640]>, | ttnn.add | aten::convolution | 4 |
| 318 | Tensor<[1,19200,256]>, Tensor<[1,19200,256]>, | ttnn.add | aten::gelu | 4 |
| 319 | Tensor<[1,4800,512]>, Tensor<[1,4800,512]>, | ttnn.add | aten::gelu | 4 |
| 320 | Tensor<[1,1200,1280]>, Tensor<[1,1200,1280]>, | ttnn.add | aten::gelu | 4 |
| 321 | Tensor<[1,300,2048]>, Tensor<[1,300,2048]>, | ttnn.add | aten::gelu | 4 |
| 322 | Tensor<[1,197,768]>, Tensor<[1,197,768]>, | ttnn.add | aten::add.Tensor | 5 |
| 323 | Tensor<[1,197,1]>, Tensor<[1,197,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 324 | Tensor<[197,768]>, Tensor<[197,768]>, | ttnn.add | aten::add.Tensor | 4 |
| 325 | Tensor<[197,3072]>, Tensor<[197,3072]>, | ttnn.add | aten::add.Tensor | 4 |
| 326 | Tensor<[1,768,14,14]>, Tensor<[1,768,14,14]>, | ttnn.add | aten::convolution | 4 |
| 327 | Tensor<[1,197,3072]>, Tensor<[1,197,3072]>, | ttnn.add | aten::gelu | 4 |
| 328 | Tensor<[1,16384,1]>, Tensor<[1,16384,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 329 | Tensor<[1,16384,32]>, Tensor<[1,16384,32]>, | ttnn.add | aten::add.Tensor | 4 |
| 330 | Tensor<[16384,32]>, Tensor<[16384,32]>, | ttnn.add | aten::add.Tensor | 4 |
| 331 | Tensor<[1,256,32]>, Tensor<[1,256,32]>, | ttnn.add | aten::add.Tensor | 4 |
| 332 | Tensor<[256,32]>, Tensor<[256,32]>, | ttnn.add | aten::add.Tensor | 4 |
| 333 | Tensor<[16384,128]>, Tensor<[16384,128]>, | ttnn.add | aten::add.Tensor | 4 |
| 334 | Tensor<[1,4096,64]>, Tensor<[1,4096,64]>, | ttnn.add | aten::add.Tensor | 4 |
| 335 | Tensor<[4096,64]>, Tensor<[4096,64]>, | ttnn.add | aten::add.Tensor | 4 |
| 336 | Tensor<[1,256,64]>, Tensor<[1,256,64]>, | ttnn.add | aten::add.Tensor | 4 |
| 337 | Tensor<[256,64]>, Tensor<[256,64]>, | ttnn.add | aten::add.Tensor | 4 |
| 338 | Tensor<[4096,256]>, Tensor<[4096,256]>, | ttnn.add | aten::add.Tensor | 4 |
| 339 | Tensor<[1,1024,160]>, Tensor<[1,1024,160]>, | ttnn.add | aten::add.Tensor | 4 |
| 340 | Tensor<[1024,160]>, Tensor<[1024,160]>, | ttnn.add | aten::add.Tensor | 4 |
| 341 | Tensor<[1,256,160]>, Tensor<[1,256,160]>, | ttnn.add | aten::add.Tensor | 4 |
| 342 | Tensor<[256,160]>, Tensor<[256,160]>, | ttnn.add | aten::add.Tensor | 4 |
| 343 | Tensor<[256,1024]>, Tensor<[256,1024]>, | ttnn.add | aten::add.Tensor | 4 |
| 344 | Tensor<[1,16384,256]>, Tensor<[1,16384,256]>, | ttnn.add | aten::add.Tensor | 4 |
| 345 | Tensor<[128,1]>, Tensor<[128,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 346 | Tensor<[1,256,128,128]>, Tensor<[1,256,128,128]>, | ttnn.add | aten::add.Tensor | 5 |
| 347 | Tensor<[1,4096,256]>, Tensor<[1,4096,256]>, | ttnn.add | aten::add.Tensor | 4 |
| 348 | Tensor<[1,1024,256]>, Tensor<[1,1024,256]>, | ttnn.add | aten::add.Tensor | 4 |
| 349 | Tensor<[1,32,128,128]>, Tensor<[1,32,128,128]>, | ttnn.add | aten::convolution | 4 |
| 350 | Tensor<[1,32,16,16]>, Tensor<[1,32,16,16]>, | ttnn.add | aten::convolution | 4 |
| 351 | Tensor<[1,64,64,64]>, Tensor<[1,64,64,64]>, | ttnn.add | aten::convolution | 4 |
| 352 | Tensor<[1,64,16,16]>, Tensor<[1,64,16,16]>, | ttnn.add | aten::convolution | 4 |
| 353 | Tensor<[1,160,32,32]>, Tensor<[1,160,32,32]>, | ttnn.add | aten::convolution | 4 |
| 354 | Tensor<[1,160,16,16]>, Tensor<[1,160,16,16]>, | ttnn.add | aten::convolution | 4 |
| 355 | Tensor<[1,150,128,128]>, Tensor<[1,150,128,128]>, | ttnn.add | aten::convolution | 4 |
| 356 | Tensor<[1,16384,128]>, Tensor<[1,16384,128]>, | ttnn.add | aten::gelu | 4 |
| 357 | Tensor<[1,256,1024]>, Tensor<[1,256,1024]>, | ttnn.add | aten::gelu | 4 |
| 358 | Tensor<[1,1,7,7]>, Tensor<[1,1,7,7]>, | ttnn.add | aten::add.Tensor | 4 |
| 359 | Tensor<[1,7,4544]>, Tensor<[1,7,4544]>, | ttnn.add | aten::add.Tensor | 4 |
| 360 | Tensor<[1,71,7,64]>, Tensor<[1,71,7,64]>, | ttnn.add | aten::add.Tensor | 5 |
| 361 | Tensor<[1,1,7,64]>, Tensor<[1,1,7,64]>, | ttnn.add | aten::add.Tensor | 5 |
| 362 | Tensor<[1,71,7,7]>, Tensor<[1,71,7,7]>, | ttnn.add | aten::add.Tensor | 4 |
| 363 | Tensor<[1,7,18176]>, Tensor<[1,7,18176]>, | ttnn.add | aten::gelu | 4 |
| 364 | Tensor<[7,1]>, Tensor<[7,1]>, | ttnn.add | aten::triu | 4 |
| 365 | Tensor<[1,16,112,112]>, Tensor<[1,16,112,112]>, | ttnn.add | aten::add.Tensor | 4 |
| 366 | Tensor<[96]>, Tensor<[96]>, | ttnn.add | aten::add.Tensor | 4 |
| 367 | Tensor<[1,96,112,112]>, Tensor<[1,96,112,112]>, | ttnn.add | aten::add.Tensor | 4 |
| 368 | Tensor<[1,96,56,56]>, Tensor<[1,96,56,56]>, | ttnn.add | aten::add.Tensor | 4 |
| 369 | Tensor<[144]>, Tensor<[144]>, | ttnn.add | aten::add.Tensor | 4 |
| 370 | Tensor<[1,144,56,56]>, Tensor<[1,144,56,56]>, | ttnn.add | aten::add.Tensor | 4 |
| 371 | Tensor<[1,144,28,28]>, Tensor<[1,144,28,28]>, | ttnn.add | aten::add.Tensor | 4 |
| 372 | Tensor<[1,32,28,28]>, Tensor<[1,32,28,28]>, | ttnn.add | aten::add.Tensor | 4 |
| 373 | Tensor<[192]>, Tensor<[192]>, | ttnn.add | aten::add.Tensor | 4 |
| 374 | Tensor<[1,192,28,28]>, Tensor<[1,192,28,28]>, | ttnn.add | aten::add.Tensor | 4 |
| 375 | Tensor<[1,192,14,14]>, Tensor<[1,192,14,14]>, | ttnn.add | aten::add.Tensor | 4 |
| 376 | Tensor<[1,64,14,14]>, Tensor<[1,64,14,14]>, | ttnn.add | aten::add.Tensor | 4 |
| 377 | Tensor<[384]>, Tensor<[384]>, | ttnn.add | aten::add.Tensor | 4 |
| 378 | Tensor<[1,384,14,14]>, Tensor<[1,384,14,14]>, | ttnn.add | aten::add.Tensor | 4 |
| 379 | Tensor<[1,96,14,14]>, Tensor<[1,96,14,14]>, | ttnn.add | aten::add.Tensor | 4 |
| 380 | Tensor<[576]>, Tensor<[576]>, | ttnn.add | aten::add.Tensor | 4 |
| 381 | Tensor<[1,576,14,14]>, Tensor<[1,576,14,14]>, | ttnn.add | aten::add.Tensor | 4 |
| 382 | Tensor<[1,576,7,7]>, Tensor<[1,576,7,7]>, | ttnn.add | aten::add.Tensor | 4 |
| 383 | Tensor<[960]>, Tensor<[960]>, | ttnn.add | aten::add.Tensor | 4 |
| 384 | Tensor<[1,960,7,7]>, Tensor<[1,960,7,7]>, | ttnn.add | aten::add.Tensor | 4 |
| 385 | Tensor<[1,320,7,7]>, Tensor<[1,320,7,7]>, | ttnn.add | aten::add.Tensor | 4 |
| 386 | Tensor<[1,1280,7,7]>, Tensor<[1,1280,7,7]>, | ttnn.add | aten::add.Tensor | 4 |
| 387 | Tensor<[1,12,128]>, Tensor<[1,12,128]>, | ttnn.add | aten::add.Tensor | 5 |
| 388 | Tensor<[1,12,1]>, Tensor<[1,12,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 389 | Tensor<[12,768]>, Tensor<[12,768]>, | ttnn.add | aten::add.Tensor | 4 |
| 390 | Tensor<[1,12,12,12]>, Tensor<[1,12,12,12]>, | ttnn.add | aten::add.Tensor | 4 |
| 391 | Tensor<[1,12,768]>, Tensor<[1,12,768]>, | ttnn.add | aten::add.Tensor | 5 |
| 392 | Tensor<[12,3072]>, Tensor<[12,3072]>, | ttnn.add | aten::add.Tensor | 4 |
| 393 | Tensor<[1,12,3072]>, Tensor<[1,12,3072]>, | ttnn.add | aten::add.Tensor | 5 |
| 394 | Tensor<[12,2]>, Tensor<[12,2]>, | ttnn.add | aten::add.Tensor | 4 |
| 395 | Tensor<[1,9,128]>, Tensor<[1,9,128]>, | ttnn.add | aten::add.Tensor | 5 |
| 396 | Tensor<[1,9,1]>, Tensor<[1,9,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 397 | Tensor<[9,768]>, Tensor<[9,768]>, | ttnn.add | aten::add.Tensor | 4 |
| 398 | Tensor<[1,12,9,9]>, Tensor<[1,12,9,9]>, | ttnn.add | aten::add.Tensor | 4 |
| 399 | Tensor<[1,9,768]>, Tensor<[1,9,768]>, | ttnn.add | aten::add.Tensor | 5 |
| 400 | Tensor<[9,3072]>, Tensor<[9,3072]>, | ttnn.add | aten::add.Tensor | 4 |
| 401 | Tensor<[1,9,3072]>, Tensor<[1,9,3072]>, | ttnn.add | aten::add.Tensor | 5 |
| 402 | Tensor<[9,128]>, Tensor<[9,128]>, | ttnn.add | aten::add.Tensor | 4 |
| 403 | Tensor<[9,30000]>, Tensor<[9,30000]>, | ttnn.add | aten::add.Tensor | 4 |
| 404 | Tensor<[9,2048]>, Tensor<[9,2048]>, | ttnn.add | aten::add.Tensor | 4 |
| 405 | Tensor<[1,16,9,9]>, Tensor<[1,16,9,9]>, | ttnn.add | aten::add.Tensor | 4 |
| 406 | Tensor<[1,9,2048]>, Tensor<[1,9,2048]>, | ttnn.add | aten::add.Tensor | 5 |
| 407 | Tensor<[9,8192]>, Tensor<[9,8192]>, | ttnn.add | aten::add.Tensor | 4 |
| 408 | Tensor<[1,9,8192]>, Tensor<[1,9,8192]>, | ttnn.add | aten::add.Tensor | 5 |
| 409 | Tensor<[9,1024]>, Tensor<[9,1024]>, | ttnn.add | aten::add.Tensor | 4 |
| 410 | Tensor<[1,9,1024]>, Tensor<[1,9,1024]>, | ttnn.add | aten::add.Tensor | 5 |
| 411 | Tensor<[9,4096]>, Tensor<[9,4096]>, | ttnn.add | aten::add.Tensor | 4 |
| 412 | Tensor<[1,9,4096]>, Tensor<[1,9,4096]>, | ttnn.add | aten::add.Tensor | 5 |
| 413 | Tensor<[1,64,9,9]>, Tensor<[1,64,9,9]>, | ttnn.add | aten::add.Tensor | 4 |
| 414 | Tensor<[9,16384]>, Tensor<[9,16384]>, | ttnn.add | aten::add.Tensor | 4 |
| 415 | Tensor<[1,9,16384]>, Tensor<[1,9,16384]>, | ttnn.add | aten::add.Tensor | 5 |
| 416 | Tensor<[1,2]>, Tensor<[1,2]>, | ttnn.add | aten::add.Tensor | 4 |
| 417 | Tensor<[1,14,128]>, Tensor<[1,14,128]>, | ttnn.add | aten::add.Tensor | 5 |
| 418 | Tensor<[1,14,1]>, Tensor<[1,14,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 419 | Tensor<[14,768]>, Tensor<[14,768]>, | ttnn.add | aten::add.Tensor | 4 |
| 420 | Tensor<[1,12,14,14]>, Tensor<[1,12,14,14]>, | ttnn.add | aten::add.Tensor | 4 |
| 421 | Tensor<[1,14,768]>, Tensor<[1,14,768]>, | ttnn.add | aten::add.Tensor | 5 |
| 422 | Tensor<[14,3072]>, Tensor<[14,3072]>, | ttnn.add | aten::add.Tensor | 4 |
| 423 | Tensor<[1,14,3072]>, Tensor<[1,14,3072]>, | ttnn.add | aten::add.Tensor | 5 |
| 424 | Tensor<[14,2]>, Tensor<[14,2]>, | ttnn.add | aten::add.Tensor | 4 |
| 425 | Tensor<[1,50,768]>, Tensor<[1,50,768]>, | ttnn.add | aten::add.Tensor | 5 |
| 426 | Tensor<[1,50,1]>, Tensor<[1,50,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 427 | Tensor<[50,768]>, Tensor<[50,768]>, | ttnn.add | aten::add.Tensor | 4 |
| 428 | Tensor<[50,3072]>, Tensor<[50,3072]>, | ttnn.add | aten::add.Tensor | 4 |
| 429 | Tensor<[2,7,512]>, Tensor<[2,7,512]>, | ttnn.add | aten::add.Tensor | 4 |
| 430 | Tensor<[2,7,1]>, Tensor<[2,7,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 431 | Tensor<[2,1,7,7]>, Tensor<[2,1,7,7]>, | ttnn.add | aten::add.Tensor | 5 |
| 432 | Tensor<[14,512]>, Tensor<[14,512]>, | ttnn.add | aten::add.Tensor | 4 |
| 433 | Tensor<[2,8,7,7]>, Tensor<[2,8,7,7]>, | ttnn.add | aten::add.Tensor | 4 |
| 434 | Tensor<[14,2048]>, Tensor<[14,2048]>, | ttnn.add | aten::add.Tensor | 4 |
| 435 | Tensor<[2]>, Tensor<[2]>, | ttnn.add | aten::arange | 4 |
| 436 | Tensor<[1,197,1024]>, Tensor<[1,197,1024]>, | ttnn.add | aten::add.Tensor | 4 |
| 437 | Tensor<[197,1024]>, Tensor<[197,1024]>, | ttnn.add | aten::add.Tensor | 4 |
| 438 | Tensor<[27]>, Tensor<[27]>, | ttnn.add | aten::add.Tensor | 4 |
| 439 | Tensor<[27,1]>, Tensor<[27,1]>, | ttnn.add | aten::add.Tensor | 4 |
| 440 | Tensor<[1,16,27,27]>, Tensor<[1,16,27,27]>, | ttnn.add | aten::add.Tensor | 5 |
| 441 | Tensor<[196,196]>, Tensor<[196,196]>, | ttnn.add | aten::add.Tensor | 4 |
| 442 | Tensor<[1,16,197,197]>, Tensor<[1,16,197,197]>, | ttnn.add | aten::add.Tensor | 5 |
| 443 | Tensor<[197,4096]>, Tensor<[197,4096]>, | ttnn.add | aten::add.Tensor | 4 |
| 444 | Tensor<[1,1024]>, Tensor<[1,1024]>, | ttnn.add | aten::add.Tensor | 4 |
| 445 | Tensor<[197]>, Tensor<[197]>, | ttnn.add | aten::arange | 4 |
| 446 | Tensor<[1,197,4096]>, Tensor<[1,197,4096]>, | ttnn.add | aten::gelu | 4 |
| 447 | Tensor<[1,12,27,27]>, Tensor<[1,12,27,27]>, | ttnn.add | aten::add.Tensor | 5 |
| 448 | Tensor<[1,12,197,197]>, Tensor<[1,12,197,197]>, | ttnn.add | aten::add.Tensor | 5 |
| 449 | Tensor<[1,64]>, Tensor<[1,64]>, | ttnn.add | aten::add.Tensor | 4 |
| 450 | Tensor<[1,12]>, Tensor<[1,12]>, | ttnn.add | aten::add.Tensor | 4 |
| 451 | Tensor<[1,784]>, Tensor<[1,784]>, | ttnn.add | aten::add.Tensor | 4 |
stablehlo.and::ttnn.and
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[19]>, Tensor<[19]>, | ttnn.and | aten::logical_and | 5 |
| 1 | Tensor<[197]>, Tensor<[197]>, | ttnn.and | aten::logical_and | 5 |
stablehlo.broadcast_in_dim
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,32,32,32]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 1 | Tensor<[1,32,32,1]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 2 | Scalar, dims: [] | aten::_safe_softmax | 4 | |
| 3 | Tensor<[1,1,32,32]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 4 | Tensor<[1,1,1,32]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 5 | Tensor<[1,32,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 6 | Tensor<[32]>, dims: [0] | aten::arange | 4 | |
| 7 | Tensor<[1,1,32]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 8 | Tensor<[32,128,32]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 9 | Tensor<[32,32,128]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 10 | Tensor<[32]>, dims: [1] | aten::gt.Tensor | 4 | |
| 11 | Tensor<[32,1]>, dims: [0, 1] | aten::gt.Tensor | 4 | |
| 12 | Tensor<[1,32,32,128]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 13 | Tensor<[1,32,128,32]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 14 | Tensor<[1,32,128]>, dims: [0, 1, 2] | aten::mul.Tensor | 4 | |
| 15 | Tensor<[1,32,4096]>, dims: [0, 1, 2] | aten::mul.Tensor | 4 | |
| 16 | Tensor<[4096]>, dims: [2] | aten::mul.Tensor | 4 | |
| 17 | Tensor<[1,1,32,128]>, dims: [0, 1, 2, 3] | aten::mul.Tensor | 4 | |
| 18 | Tensor<[1,32]>, dims: [0, 1] | aten::triu | 4 | |
| 19 | Tensor<[32,32]>, dims: [0, 1] | aten::triu | 4 | |
| 20 | Tensor<[1,12,7,7]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 21 | Tensor<[1,12,7,1]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 22 | Tensor<[7]>, dims: [0] | aten::add.Tensor | 4 | |
| 23 | Tensor<[1,7,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 24 | Tensor<[1,7,768]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 25 | Tensor<[768]>, dims: [2] | aten::add.Tensor | 4 | |
| 26 | Tensor<[7,2304]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 27 | Tensor<[2304]>, dims: [1] | aten::add.Tensor | 4 | |
| 28 | Tensor<[1,1,7,7]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 29 | Tensor<[7,768]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 30 | Tensor<[768]>, dims: [1] | aten::add.Tensor | 4 | |
| 31 | Tensor<[7,3072]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 32 | Tensor<[3072]>, dims: [1] | aten::add.Tensor | 4 | |
| 33 | Tensor<[1,7,3072]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 34 | Tensor<[1]>, dims: [0] | aten::arange | 4 | |
| 35 | Tensor<[12,64,7]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 36 | Tensor<[12,7,64]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 37 | Tensor<[1,7]>, dims: [0, 1] | aten::eq.Scalar | 4 | |
| 38 | Tensor<[1,1,1,7]>, dims: [0, 1, 2, 3] | aten::expand | 4 | |
| 39 | Tensor<[7]>, dims: [1] | aten::lt.Tensor | 4 | |
| 40 | Tensor<[7,1]>, dims: [0, 1] | aten::lt.Tensor | 4 | |
| 41 | Tensor<[1,12,7,64]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 42 | Tensor<[1,12,64,7]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 43 | Tensor<[2304]>, dims: [0] | aten::mul.Tensor | 4 | |
| 44 | Tensor<[768]>, dims: [0] | aten::mul.Tensor | 4 | |
| 45 | Tensor<[3072]>, dims: [0] | aten::mul.Tensor | 4 | |
| 46 | Tensor<[7,7]>, dims: [0, 1] | aten::where.self | 4 | |
| 47 | Tensor<[1,32,112,112]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 48 | Tensor<[32,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 49 | Tensor<[64]>, dims: [0] | aten::add.Tensor | 4 | |
| 50 | Tensor<[1,64,112,112]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 51 | Tensor<[64,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 52 | Tensor<[1,64,56,56]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 53 | Tensor<[128]>, dims: [0] | aten::add.Tensor | 4 | |
| 54 | Tensor<[1,128,56,56]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 55 | Tensor<[128,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 56 | Tensor<[1,128,28,28]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 57 | Tensor<[256]>, dims: [0] | aten::add.Tensor | 4 | |
| 58 | Tensor<[1,256,28,28]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 59 | Tensor<[256,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 60 | Tensor<[512]>, dims: [0] | aten::add.Tensor | 4 | |
| 61 | Tensor<[1,512,28,28]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 62 | Tensor<[512,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 63 | Tensor<[1,19,28,28]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 64 | Tensor<[19,1,1]>, dims: [1, 2, 3] | aten::convolution | 4 | |
| 65 | Tensor<[1,38,28,28]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 66 | Tensor<[38,1,1]>, dims: [1, 2, 3] | aten::convolution | 4 | |
| 67 | Tensor<[256,512]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 68 | Tensor<[512]>, dims: [1] | aten::add.Tensor | 4 | |
| 69 | Tensor<[1,256,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 70 | Tensor<[1,256,512]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 71 | Tensor<[512]>, dims: [2] | aten::add.Tensor | 4 | |
| 72 | Tensor<[256,256]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 73 | Tensor<[256]>, dims: [1] | aten::add.Tensor | 4 | |
| 74 | Tensor<[1,1000]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 75 | Tensor<[1000]>, dims: [1] | aten::add.Tensor | 4 | |
| 76 | Tensor<[1,1024,512]>, dims: [0, 1, 2] | aten::convolution | 4 | |
| 77 | Tensor<[1024,1]>, dims: [1, 2] | aten::convolution | 4 | |
| 78 | Tensor<[256,1]>, dims: [1, 2] | aten::convolution | 4 | |
| 79 | Tensor<[1,512]>, dims: [0, 1] | aten::mean.dim | 4 | |
| 80 | Tensor<[1000]>, dims: [0] | aten::mul.Tensor | 4 | |
| 81 | Tensor<[8,920,920]>, dims: [0, 1, 2] | aten::_softmax | 4 | |
| 82 | Tensor<[8,920,1]>, dims: [0, 1, 2] | aten::_softmax | 4 | |
| 83 | Tensor<[8,100,100]>, dims: [0, 1, 2] | aten::_softmax | 4 | |
| 84 | Tensor<[8,100,1]>, dims: [0, 1, 2] | aten::_softmax | 4 | |
| 85 | Tensor<[8,100,920]>, dims: [0, 1, 2] | aten::_softmax | 4 | |
| 86 | Tensor<[1,64,1,1]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 87 | Tensor<[1,64,360,640]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 88 | Tensor<[1,64,180,320]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 89 | Tensor<[1,256,1,1]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 90 | Tensor<[1,256,180,320]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 91 | Tensor<[1,128,1,1]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 92 | Tensor<[1,128,180,320]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 93 | Tensor<[1,128,90,160]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 94 | Tensor<[1,512,1,1]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 95 | Tensor<[1,512,90,160]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 96 | Tensor<[1,256,90,160]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 97 | Tensor<[1,256,45,80]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 98 | Tensor<[1,1024,1,1]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 99 | Tensor<[1,1024,45,80]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 100 | Tensor<[1,512,45,80]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 101 | Tensor<[1,512,23,40]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 102 | Tensor<[1,2048,1,1]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 103 | Tensor<[1,2048,23,40]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 104 | Tensor<[23]>, dims: [0] | aten::add.Tensor | 4 | |
| 105 | Tensor<[40]>, dims: [0] | aten::add.Tensor | 4 | |
| 106 | Tensor<[1,1,40]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 107 | Tensor<[1,23,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 108 | Tensor<[920,1,256]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 109 | Tensor<[256]>, dims: [2] | aten::add.Tensor | 4 | |
| 110 | Tensor<[920,256]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 111 | Tensor<[920,1,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 112 | Tensor<[920,2048]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 113 | Tensor<[2048]>, dims: [1] | aten::add.Tensor | 4 | |
| 114 | Tensor<[100,256]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 115 | Tensor<[100,1,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 116 | Tensor<[100,1,256]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 117 | Tensor<[100,2048]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 118 | Tensor<[6,1,100,92]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 119 | Tensor<[92]>, dims: [3] | aten::add.Tensor | 4 | |
| 120 | Tensor<[6,1,100,256]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 121 | Tensor<[256]>, dims: [3] | aten::add.Tensor | 4 | |
| 122 | Tensor<[6,1,100,4]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 123 | Tensor<[4]>, dims: [3] | aten::add.Tensor | 4 | |
| 124 | Tensor<[8,32,920]>, dims: [0, 1, 2] | aten::baddbmm | 4 | |
| 125 | Tensor<[8,1,920]>, dims: [0, 1, 2] | aten::baddbmm | 4 | |
| 126 | Tensor<[920,256,256]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 127 | Tensor<[8,920,32]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 128 | Tensor<[8,32,100]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 129 | Tensor<[8,100,32]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 130 | Tensor<[6,256,92]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 131 | Tensor<[6,256,256]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 132 | Tensor<[1,256,23,40]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 133 | Tensor<[1,23,40]>, dims: [0, 1, 2] | aten::div.Tensor | 4 | |
| 134 | Tensor<[1,23,40,1]>, dims: [0, 1, 2, 3] | aten::div.Tensor | 4 | |
| 135 | Tensor<[128]>, dims: [3] | aten::div.Tensor | 4 | |
| 136 | Tensor<[256,256]>, dims: [1, 2] | aten::expand | 5 | |
| 137 | Tensor<[1,1,1,920]>, dims: [0, 1, 2, 3] | aten::expand | 5 | |
| 138 | Tensor<[256,92]>, dims: [2, 3] | aten::expand | 5 | |
| 139 | Tensor<[256,256]>, dims: [2, 3] | aten::expand | 5 | |
| 140 | Tensor<[1,1,1,1]>, dims: [0, 1, 2, 3] | aten::index.Tensor | 4 | |
| 141 | Tensor<[1,1,1]>, dims: [1, 2, 3] | aten::index.Tensor | 4 | |
| 142 | Tensor<[23,1]>, dims: [2, 3] | aten::index.Tensor | 4 | |
| 143 | Tensor<[40]>, dims: [3] | aten::index.Tensor | 4 | |
| 144 | Tensor<[2048]>, dims: [0] | aten::mul.Tensor | 4 | |
| 145 | Tensor<[1,920]>, dims: [0, 1] | aten::where.self | 4 | |
| 146 | Tensor<[1,12,10,10]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 147 | Tensor<[1,12,10,1]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 148 | Tensor<[1,10]>, dims: [0, 1] | aten::add.Tensor | 5 | |
| 149 | Tensor<[1,10,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 150 | Tensor<[1,10,768]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 151 | Tensor<[10,768]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 152 | Tensor<[1,1,10,10]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 153 | Tensor<[10,3072]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 154 | Tensor<[10,250002]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 155 | Tensor<[250002]>, dims: [1] | aten::add.Tensor | 4 | |
| 156 | Tensor<[12,64,10]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 157 | Tensor<[12,10,64]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 158 | Tensor<[1,1,1,10]>, dims: [0, 1, 2, 3] | aten::expand | 4 | |
| 159 | Tensor<[1,12,10,64]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 160 | Tensor<[1,12,64,10]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 161 | Tensor<[250002]>, dims: [0] | aten::mul.Tensor | 4 | |
| 162 | Tensor<[1,8,4096,4096]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 163 | Tensor<[1,8,4096,1]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 164 | Tensor<[1,8,4096,9]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 165 | Tensor<[1,8,1024,1024]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 166 | Tensor<[1,8,1024,1]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 167 | Tensor<[1,8,1024,9]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 168 | Tensor<[1,8,256,256]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 169 | Tensor<[1,8,256,1]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 170 | Tensor<[1,8,256,9]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 171 | Tensor<[1,8,64,64]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 172 | Tensor<[1,8,64,1]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 173 | Tensor<[1,8,64,9]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 174 | Tensor<[1,1280]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 175 | Tensor<[1280]>, dims: [1] | aten::add.Tensor | 4 | |
| 176 | Tensor<[1,32,1,1]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 177 | Tensor<[1,320,64,64]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 178 | Tensor<[1,320,1,1]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 179 | Tensor<[1,320]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 180 | Tensor<[320]>, dims: [1] | aten::add.Tensor | 4 | |
| 181 | Tensor<[1,4096,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 182 | Tensor<[1,4096,320]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 183 | Tensor<[320]>, dims: [2] | aten::add.Tensor | 4 | |
| 184 | Tensor<[4096,320]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 185 | Tensor<[4096,2560]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 186 | Tensor<[2560]>, dims: [1] | aten::add.Tensor | 4 | |
| 187 | Tensor<[1,320,32,32]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 188 | Tensor<[1,640]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 189 | Tensor<[640]>, dims: [1] | aten::add.Tensor | 4 | |
| 190 | Tensor<[1,640,32,32]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 191 | Tensor<[1,640,1,1]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 192 | Tensor<[1,1024,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 193 | Tensor<[1,1024,640]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 194 | Tensor<[640]>, dims: [2] | aten::add.Tensor | 4 | |
| 195 | Tensor<[1024,640]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 196 | Tensor<[1024,5120]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 197 | Tensor<[5120]>, dims: [1] | aten::add.Tensor | 4 | |
| 198 | Tensor<[1,640,16,16]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 199 | Tensor<[1,1280,16,16]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 200 | Tensor<[1,1280,1,1]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 201 | Tensor<[1,256,1280]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 202 | Tensor<[1280]>, dims: [2] | aten::add.Tensor | 4 | |
| 203 | Tensor<[256,1280]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 204 | Tensor<[256,10240]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 205 | Tensor<[10240]>, dims: [1] | aten::add.Tensor | 4 | |
| 206 | Tensor<[1,1280,8,8]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 207 | Tensor<[1,64,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 208 | Tensor<[1,64,1280]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 209 | Tensor<[64,1280]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 210 | Tensor<[64,10240]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 211 | Tensor<[1,2560,8,8]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 212 | Tensor<[1,2560,1,1]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 213 | Tensor<[16]>, dims: [0] | aten::add.Tensor | 4 | |
| 214 | Tensor<[1,2560,16,16]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 215 | Tensor<[1,1920,16,16]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 216 | Tensor<[1,1920,1,1]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 217 | Tensor<[1,1920,32,32]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 218 | Tensor<[1,1280,32,32]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 219 | Tensor<[1,960,32,32]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 220 | Tensor<[1,960,1,1]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 221 | Tensor<[1,960,64,64]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 222 | Tensor<[1,640,64,64]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 223 | Tensor<[160]>, dims: [0] | aten::arange.start | 4 | |
| 224 | Tensor<[8,40,4096]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 225 | Tensor<[8,4096,40]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 226 | Tensor<[8,40,9]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 227 | Tensor<[8,9,40]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 228 | Tensor<[8,80,1024]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 229 | Tensor<[8,1024,80]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 230 | Tensor<[8,80,9]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 231 | Tensor<[8,9,80]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 232 | Tensor<[8,160,256]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 233 | Tensor<[8,256,160]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 234 | Tensor<[8,160,9]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 235 | Tensor<[8,9,160]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 236 | Tensor<[8,160,64]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 237 | Tensor<[8,64,160]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 238 | Tensor<[320,1,1]>, dims: [1, 2, 3] | aten::convolution | 4 | |
| 239 | Tensor<[640,1,1]>, dims: [1, 2, 3] | aten::convolution | 4 | |
| 240 | Tensor<[1280,1,1]>, dims: [1, 2, 3] | aten::convolution | 4 | |
| 241 | Tensor<[1,4,64,64]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 242 | Tensor<[4,1,1]>, dims: [1, 2, 3] | aten::convolution | 4 | |
| 243 | Tensor<[1280]>, dims: [0] | aten::index.Tensor | 4 | |
| 244 | Tensor<[16,1]>, dims: [2, 3] | aten::index.Tensor | 4 | |
| 245 | Tensor<[16]>, dims: [3] | aten::index.Tensor | 4 | |
| 246 | Tensor<[32,1]>, dims: [2, 3] | aten::index.Tensor | 4 | |
| 247 | Tensor<[32]>, dims: [3] | aten::index.Tensor | 4 | |
| 248 | Tensor<[640]>, dims: [0] | aten::index.Tensor | 4 | |
| 249 | Tensor<[64,1]>, dims: [2, 3] | aten::index.Tensor | 4 | |
| 250 | Tensor<[64]>, dims: [3] | aten::index.Tensor | 4 | |
| 251 | Tensor<[1,8,4096,40]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 252 | Tensor<[1,8,40,4096]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 253 | Tensor<[1,8,40,9]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 254 | Tensor<[1,8,1024,80]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 255 | Tensor<[1,8,80,1024]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 256 | Tensor<[1,8,80,9]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 257 | Tensor<[1,8,256,160]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 258 | Tensor<[1,8,160,256]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 259 | Tensor<[1,8,160,9]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 260 | Tensor<[1,8,64,160]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 261 | Tensor<[1,8,160,64]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 262 | Tensor<[1,1]>, dims: [0, 1] | aten::mul.Tensor | 4 | |
| 263 | Tensor<[1,160]>, dims: [0, 1] | aten::mul.Tensor | 4 | |
| 264 | Tensor<[1,32,10,4096]>, dims: [0, 1, 2, 3] | aten::mul.Tensor | 4 | |
| 265 | Tensor<[320]>, dims: [0] | aten::mul.Tensor | 4 | |
| 266 | Tensor<[2560]>, dims: [0] | aten::mul.Tensor | 4 | |
| 267 | Tensor<[1,32,10,1024]>, dims: [0, 1, 2, 3] | aten::mul.Tensor | 4 | |
| 268 | Tensor<[1,32,20,1024]>, dims: [0, 1, 2, 3] | aten::mul.Tensor | 4 | |
| 269 | Tensor<[5120]>, dims: [0] | aten::mul.Tensor | 4 | |
| 270 | Tensor<[1,32,20,256]>, dims: [0, 1, 2, 3] | aten::mul.Tensor | 4 | |
| 271 | Tensor<[1,32,40,256]>, dims: [0, 1, 2, 3] | aten::mul.Tensor | 4 | |
| 272 | Tensor<[10240]>, dims: [0] | aten::mul.Tensor | 4 | |
| 273 | Tensor<[1,32,40,64]>, dims: [0, 1, 2, 3] | aten::mul.Tensor | 4 | |
| 274 | Tensor<[1,32,80,64]>, dims: [0, 1, 2, 3] | aten::mul.Tensor | 4 | |
| 275 | Tensor<[1,32,80,256]>, dims: [0, 1, 2, 3] | aten::mul.Tensor | 4 | |
| 276 | Tensor<[1,32,60,256]>, dims: [0, 1, 2, 3] | aten::mul.Tensor | 4 | |
| 277 | Tensor<[1,32,60,1024]>, dims: [0, 1, 2, 3] | aten::mul.Tensor | 4 | |
| 278 | Tensor<[1,32,40,1024]>, dims: [0, 1, 2, 3] | aten::mul.Tensor | 4 | |
| 279 | Tensor<[1,32,30,1024]>, dims: [0, 1, 2, 3] | aten::mul.Tensor | 4 | |
| 280 | Tensor<[1,32,30,4096]>, dims: [0, 1, 2, 3] | aten::mul.Tensor | 4 | |
| 281 | Tensor<[1,32,20,4096]>, dims: [0, 1, 2, 3] | aten::mul.Tensor | 4 | |
| 282 | Tensor<[1,12,25,25]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 283 | Tensor<[1,12,25,1]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 284 | Tensor<[1,25,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 285 | Tensor<[1,25,768]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 286 | Tensor<[25,768]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 287 | Tensor<[1,1,25,25]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 288 | Tensor<[25,3072]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 289 | Tensor<[25,2]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 290 | Tensor<[2]>, dims: [1] | aten::add.Tensor | 4 | |
| 291 | Tensor<[1]>, dims: [1] | aten::add.Tensor | 4 | |
| 292 | Tensor<[12,64,25]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 293 | Tensor<[12,25,64]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 294 | Tensor<[1,1,1,25]>, dims: [0, 1, 2, 3] | aten::expand | 4 | |
| 295 | Tensor<[1,12,25,64]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 296 | Tensor<[1,12,64,25]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 297 | Tensor<[2]>, dims: [0] | aten::mul.Tensor | 4 | |
| 298 | Tensor<[1,3,1445,1445]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 299 | Tensor<[1,3,1445,1]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 300 | Tensor<[1,1445,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 301 | Tensor<[1,1445,192]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 302 | Tensor<[192]>, dims: [2] | aten::add.Tensor | 4 | |
| 303 | Tensor<[1445,192]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 304 | Tensor<[192]>, dims: [1] | aten::add.Tensor | 4 | |
| 305 | Tensor<[1445,768]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 306 | Tensor<[100,192]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 307 | Tensor<[100,92]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 308 | Tensor<[92]>, dims: [1] | aten::add.Tensor | 4 | |
| 309 | Tensor<[100,4]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 310 | Tensor<[4]>, dims: [1] | aten::add.Tensor | 4 | |
| 311 | Tensor<[3,64,1445]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 312 | Tensor<[3,1445,64]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 313 | Tensor<[1,192,32,42]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 314 | Tensor<[192,1,1]>, dims: [1, 2, 3] | aten::convolution | 4 | |
| 315 | Tensor<[1,3,1445,64]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 316 | Tensor<[1,3,64,1445]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 317 | Tensor<[192]>, dims: [0] | aten::mul.Tensor | 4 | |
| 318 | Tensor<[92]>, dims: [0] | aten::mul.Tensor | 4 | |
| 319 | Tensor<[4]>, dims: [0] | aten::mul.Tensor | 4 | |
| 320 | Tensor<[1,256,14,14]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 321 | Tensor<[1,512,7,7]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 322 | Tensor<[1,12,8,8]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 323 | Tensor<[1,12,8,1]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 324 | Tensor<[1,8,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 325 | Tensor<[1,8,768]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 326 | Tensor<[1,1,1,8]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 327 | Tensor<[1,768]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 328 | Tensor<[1,3]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 329 | Tensor<[3]>, dims: [1] | aten::add.Tensor | 4 | |
| 330 | Tensor<[12,64,8]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 331 | Tensor<[12,8,64]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 332 | Tensor<[1,768,8]>, dims: [0, 1, 2] | aten::convolution | 4 | |
| 333 | Tensor<[768,1]>, dims: [1, 2] | aten::convolution | 4 | |
| 334 | Tensor<[1,3072,8]>, dims: [0, 1, 2] | aten::convolution | 4 | |
| 335 | Tensor<[3072,1]>, dims: [1, 2] | aten::convolution | 4 | |
| 336 | Tensor<[3]>, dims: [0] | aten::mul.Tensor | 4 | |
| 337 | Tensor<[1,8,256,2048]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 338 | Tensor<[1,8,2048,256]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 339 | Tensor<[1,8,2048,1]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 340 | Tensor<[1,2048,768]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 341 | Tensor<[2048,768]>, dims: [1, 2] | aten::add.Tensor | 4 | |
| 342 | Tensor<[1,2048,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 343 | Tensor<[2048,256]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 344 | Tensor<[2048,1280]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 345 | Tensor<[1,1,1,2048]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 346 | Tensor<[256,768]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 347 | Tensor<[2048,768]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 348 | Tensor<[2048,262]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 349 | Tensor<[262]>, dims: [1] | aten::add.Tensor | 4 | |
| 350 | Tensor<[8,32,2048]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 351 | Tensor<[8,2048,160]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 352 | Tensor<[8,32,256]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 353 | Tensor<[8,256,96]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 354 | Tensor<[256,1280]>, dims: [1, 2] | aten::expand | 5 | |
| 355 | Tensor<[1,256,56,56]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 356 | Tensor<[1024]>, dims: [0] | aten::add.Tensor | 4 | |
| 357 | Tensor<[1,1024,14,14]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 358 | Tensor<[1024,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 359 | Tensor<[1,512,14,14]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 360 | Tensor<[1,2048,7,7]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 361 | Tensor<[2048,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 362 | Tensor<[1,12,201,201]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 363 | Tensor<[1,12,201,1]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 364 | Tensor<[12]>, dims: [0] | aten::add.Tensor | 4 | |
| 365 | Tensor<[1,201,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 366 | Tensor<[1,201,768]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 367 | Tensor<[201,768]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 368 | Tensor<[1,1,1,201]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 369 | Tensor<[201,3072]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 370 | Tensor<[1,1536]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 371 | Tensor<[1536]>, dims: [1] | aten::add.Tensor | 4 | |
| 372 | Tensor<[1,3129]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 373 | Tensor<[3129]>, dims: [1] | aten::add.Tensor | 4 | |
| 374 | Tensor<[12,64,201]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 375 | Tensor<[12,201,64]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 376 | Tensor<[1,768,12,16]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 377 | Tensor<[768,1,1]>, dims: [1, 2, 3] | aten::convolution | 4 | |
| 378 | Tensor<[12,1]>, dims: [0, 1] | aten::expand | 4 | |
| 379 | Tensor<[1,16]>, dims: [0, 1] | aten::expand | 4 | |
| 380 | Tensor<[12,1]>, dims: [2, 3] | aten::index.Tensor | 4 | |
| 381 | Tensor<[1536]>, dims: [0] | aten::mul.Tensor | 4 | |
| 382 | Tensor<[3129]>, dims: [0] | aten::mul.Tensor | 4 | |
| 383 | Tensor<[1,192]>, dims: [0, 1] | aten::rsub.Scalar | 4 | |
| 384 | Tensor<[1,128]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 385 | Tensor<[128]>, dims: [1] | aten::add.Tensor | 4 | |
| 386 | Tensor<[10]>, dims: [1] | aten::add.Tensor | 4 | |
| 387 | Tensor<[1,32,26,26]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 388 | Tensor<[1,64,24,24]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 389 | Tensor<[10]>, dims: [0] | aten::mul.Tensor | 4 | |
| 390 | Tensor<[16,19,19]>, dims: [0, 1, 2] | aten::_softmax | 4 | |
| 391 | Tensor<[16,19,1]>, dims: [0, 1, 2] | aten::_softmax | 4 | |
| 392 | Tensor<[19]>, dims: [0] | aten::add.Tensor | 4 | |
| 393 | Tensor<[1,19]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 394 | Tensor<[1,19,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 395 | Tensor<[1,19,1024]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 396 | Tensor<[1024]>, dims: [2] | aten::add.Tensor | 4 | |
| 397 | Tensor<[19,1024]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 398 | Tensor<[1024]>, dims: [1] | aten::add.Tensor | 4 | |
| 399 | Tensor<[1,16,19,19]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 400 | Tensor<[1,1,19,19]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 401 | Tensor<[19,4096]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 402 | Tensor<[4096]>, dims: [1] | aten::add.Tensor | 4 | |
| 403 | Tensor<[16,64,19]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 404 | Tensor<[16,19,64]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 405 | Tensor<[1,1,1,19]>, dims: [0, 1, 2, 3] | aten::expand | 4 | |
| 406 | Tensor<[19]>, dims: [1] | aten::lt.Tensor | 4 | |
| 407 | Tensor<[19,1]>, dims: [0, 1] | aten::lt.Tensor | 4 | |
| 408 | Tensor<[4096]>, dims: [0] | aten::mul.Tensor | 4 | |
| 409 | Tensor<[19,256008]>, dims: [0, 1] | aten::sub.Tensor | 4 | |
| 410 | Tensor<[19,19]>, dims: [0, 1] | aten::where.self | 4 | |
| 411 | Tensor<[14]>, dims: [0] | aten::add.Tensor | 4 | |
| 412 | Tensor<[1,14,56,56]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 413 | Tensor<[14,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 414 | Tensor<[24]>, dims: [0] | aten::add.Tensor | 4 | |
| 415 | Tensor<[1,24,56,56]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 416 | Tensor<[24,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 417 | Tensor<[1,40,56,56]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 418 | Tensor<[40,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 419 | Tensor<[68]>, dims: [0] | aten::add.Tensor | 4 | |
| 420 | Tensor<[1,68,56,56]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 421 | Tensor<[68,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 422 | Tensor<[1,16,28,28]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 423 | Tensor<[16,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 424 | Tensor<[28]>, dims: [0] | aten::add.Tensor | 4 | |
| 425 | Tensor<[1,28,28,28]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 426 | Tensor<[28,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 427 | Tensor<[46]>, dims: [0] | aten::add.Tensor | 4 | |
| 428 | Tensor<[1,46,28,28]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 429 | Tensor<[46,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 430 | Tensor<[78]>, dims: [0] | aten::add.Tensor | 4 | |
| 431 | Tensor<[1,78,28,28]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 432 | Tensor<[78,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 433 | Tensor<[134]>, dims: [0] | aten::add.Tensor | 4 | |
| 434 | Tensor<[1,134,28,28]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 435 | Tensor<[134,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 436 | Tensor<[20]>, dims: [0] | aten::add.Tensor | 4 | |
| 437 | Tensor<[1,20,28,28]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 438 | Tensor<[20,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 439 | Tensor<[34]>, dims: [0] | aten::add.Tensor | 4 | |
| 440 | Tensor<[1,34,28,28]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 441 | Tensor<[34,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 442 | Tensor<[58]>, dims: [0] | aten::add.Tensor | 4 | |
| 443 | Tensor<[1,58,28,28]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 444 | Tensor<[58,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 445 | Tensor<[98]>, dims: [0] | aten::add.Tensor | 4 | |
| 446 | Tensor<[1,98,28,28]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 447 | Tensor<[98,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 448 | Tensor<[168]>, dims: [0] | aten::add.Tensor | 4 | |
| 449 | Tensor<[1,168,28,28]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 450 | Tensor<[168,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 451 | Tensor<[1,320,28,28]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 452 | Tensor<[1,40,14,14]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 453 | Tensor<[1,68,14,14]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 454 | Tensor<[116]>, dims: [0] | aten::add.Tensor | 4 | |
| 455 | Tensor<[1,116,14,14]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 456 | Tensor<[116,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 457 | Tensor<[196]>, dims: [0] | aten::add.Tensor | 4 | |
| 458 | Tensor<[1,196,14,14]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 459 | Tensor<[196,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 460 | Tensor<[334]>, dims: [0] | aten::add.Tensor | 4 | |
| 461 | Tensor<[1,334,14,14]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 462 | Tensor<[334,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 463 | Tensor<[1,640,14,14]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 464 | Tensor<[1,160,7,7]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 465 | Tensor<[160,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 466 | Tensor<[272]>, dims: [0] | aten::add.Tensor | 4 | |
| 467 | Tensor<[1,272,7,7]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 468 | Tensor<[272,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 469 | Tensor<[462]>, dims: [0] | aten::add.Tensor | 4 | |
| 470 | Tensor<[1,462,7,7]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 471 | Tensor<[462,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 472 | Tensor<[1,1024,7,7]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 473 | Tensor<[1,32,512,512]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 474 | Tensor<[1,64,256,256]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 475 | Tensor<[1,32,256,256]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 476 | Tensor<[1,128,128,128]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 477 | Tensor<[1,64,128,128]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 478 | Tensor<[1,256,64,64]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 479 | Tensor<[1,128,64,64]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 480 | Tensor<[1,512,32,32]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 481 | Tensor<[1,256,32,32]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 482 | Tensor<[1,1024,16,16]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 483 | Tensor<[1,512,16,16]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 484 | Tensor<[1,256,16,16]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 485 | Tensor<[1,128,32,32]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 486 | Tensor<[1,255,16,16]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 487 | Tensor<[255,1,1]>, dims: [1, 2, 3] | aten::convolution | 4 | |
| 488 | Tensor<[1,255,32,32]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 489 | Tensor<[1,255,64,64]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 490 | Tensor<[1,1,256,256]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 491 | Tensor<[1,4,14,14]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 492 | Tensor<[1,16,14,14]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 493 | Tensor<[1,1,28,28]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 494 | Tensor<[1,16,32,32]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 495 | Tensor<[1,16,32,1]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 496 | Tensor<[1,32,1536]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 497 | Tensor<[1536]>, dims: [2] | aten::add.Tensor | 4 | |
| 498 | Tensor<[32,4608]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 499 | Tensor<[4608]>, dims: [1] | aten::add.Tensor | 4 | |
| 500 | Tensor<[32,1536]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 501 | Tensor<[32,6144]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 502 | Tensor<[6144]>, dims: [1] | aten::add.Tensor | 4 | |
| 503 | Tensor<[1,32,6144]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 504 | Tensor<[16,96,32]>, dims: [0, 1, 2] | aten::baddbmm | 4 | |
| 505 | Tensor<[16,32,32]>, dims: [0, 1, 2] | aten::baddbmm | 4 | |
| 506 | Tensor<[16,1,32]>, dims: [0, 1, 2] | aten::baddbmm | 4 | |
| 507 | Tensor<[16,32,96]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 508 | Tensor<[16,1]>, dims: [1, 2] | aten::mul.Tensor | 4 | |
| 509 | Tensor<[4608]>, dims: [0] | aten::mul.Tensor | 4 | |
| 510 | Tensor<[6144]>, dims: [0] | aten::mul.Tensor | 4 | |
| 511 | Tensor<[1,12,16,16]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 512 | Tensor<[1,12,16,1]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 513 | Tensor<[1,16,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 514 | Tensor<[1,16,768]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 515 | Tensor<[16,768]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 516 | Tensor<[1,1,16,16]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 517 | Tensor<[16,3072]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 518 | Tensor<[12,64,16]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 519 | Tensor<[12,16,64]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 520 | Tensor<[1,1,1,16]>, dims: [0, 1, 2, 3] | aten::expand | 4 | |
| 521 | Tensor<[1,12,16,64]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 522 | Tensor<[1,12,64,16]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 523 | Tensor<[1,64,224,224]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 524 | Tensor<[1,128,112,112]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 525 | Tensor<[1,1,224,224]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 526 | Tensor<[1,1,19200,300]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 527 | Tensor<[1,1,19200,1]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 528 | Tensor<[1,2,4800,300]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 529 | Tensor<[1,2,4800,1]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 530 | Tensor<[1,5,1200,300]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 531 | Tensor<[1,5,1200,1]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 532 | Tensor<[1,8,300,300]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 533 | Tensor<[1,8,300,1]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 534 | Tensor<[1,19200,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 535 | Tensor<[1,19200,64]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 536 | Tensor<[64]>, dims: [2] | aten::add.Tensor | 4 | |
| 537 | Tensor<[19200,64]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 538 | Tensor<[64]>, dims: [1] | aten::add.Tensor | 4 | |
| 539 | Tensor<[1,300,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 540 | Tensor<[1,300,64]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 541 | Tensor<[300,64]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 542 | Tensor<[19200,256]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 543 | Tensor<[1,4800,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 544 | Tensor<[1,4800,128]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 545 | Tensor<[128]>, dims: [2] | aten::add.Tensor | 4 | |
| 546 | Tensor<[4800,128]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 547 | Tensor<[1,300,128]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 548 | Tensor<[300,128]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 549 | Tensor<[4800,512]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 550 | Tensor<[1,1200,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 551 | Tensor<[1,1200,320]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 552 | Tensor<[1200,320]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 553 | Tensor<[1,300,320]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 554 | Tensor<[300,320]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 555 | Tensor<[1200,1280]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 556 | Tensor<[1,300,512]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 557 | Tensor<[300,512]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 558 | Tensor<[300,2048]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 559 | Tensor<[30]>, dims: [0] | aten::add.Tensor | 4 | |
| 560 | Tensor<[30,1]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 561 | Tensor<[1,64,30,40]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 562 | Tensor<[1,32,30,40]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 563 | Tensor<[60]>, dims: [0] | aten::add.Tensor | 4 | |
| 564 | Tensor<[60,1]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 565 | Tensor<[80]>, dims: [0] | aten::add.Tensor | 4 | |
| 566 | Tensor<[1,64,60,80]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 567 | Tensor<[1,32,60,80]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 568 | Tensor<[120]>, dims: [0] | aten::add.Tensor | 4 | |
| 569 | Tensor<[120,1]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 570 | Tensor<[1,64,120,160]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 571 | Tensor<[1,32,120,160]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 572 | Tensor<[240]>, dims: [0] | aten::add.Tensor | 4 | |
| 573 | Tensor<[240,1]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 574 | Tensor<[480]>, dims: [0] | aten::add.Tensor | 4 | |
| 575 | Tensor<[480,1]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 576 | Tensor<[1,64,300]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 577 | Tensor<[1,256,64]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 578 | Tensor<[2,64,300]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 579 | Tensor<[2,300,64]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 580 | Tensor<[1,512,128]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 581 | Tensor<[5,64,300]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 582 | Tensor<[5,300,64]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 583 | Tensor<[1,1280,320]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 584 | Tensor<[8,64,300]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 585 | Tensor<[8,300,64]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 586 | Tensor<[1,2048,512]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 587 | Tensor<[1,64,15,20]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 588 | Tensor<[1,256,120,160]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 589 | Tensor<[1,128,60,80]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 590 | Tensor<[1,128,15,20]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 591 | Tensor<[1,512,60,80]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 592 | Tensor<[1,320,30,40]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 593 | Tensor<[1,320,15,20]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 594 | Tensor<[1,1280,30,40]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 595 | Tensor<[1,512,15,20]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 596 | Tensor<[1,2048,15,20]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 597 | Tensor<[1,2,30,40]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 598 | Tensor<[2,1,1]>, dims: [1, 2, 3] | aten::convolution | 4 | |
| 599 | Tensor<[1,2,60,80]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 600 | Tensor<[1,2,120,160]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 601 | Tensor<[1,64,480,640]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 602 | Tensor<[1,1,480,640]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 603 | Tensor<[256,64]>, dims: [1, 2] | aten::expand | 5 | |
| 604 | Tensor<[512,128]>, dims: [1, 2] | aten::expand | 5 | |
| 605 | Tensor<[1280,320]>, dims: [1, 2] | aten::expand | 5 | |
| 606 | Tensor<[2048,512]>, dims: [1, 2] | aten::expand | 5 | |
| 607 | Tensor<[30,1]>, dims: [2, 3] | aten::index.Tensor | 4 | |
| 608 | Tensor<[60,1]>, dims: [2, 3] | aten::index.Tensor | 4 | |
| 609 | Tensor<[80]>, dims: [3] | aten::index.Tensor | 4 | |
| 610 | Tensor<[120,1]>, dims: [2, 3] | aten::index.Tensor | 4 | |
| 611 | Tensor<[160]>, dims: [3] | aten::index.Tensor | 4 | |
| 612 | Tensor<[240,1]>, dims: [2, 3] | aten::index.Tensor | 4 | |
| 613 | Tensor<[320]>, dims: [3] | aten::index.Tensor | 4 | |
| 614 | Tensor<[480,1]>, dims: [2, 3] | aten::index.Tensor | 4 | |
| 615 | Tensor<[640]>, dims: [3] | aten::index.Tensor | 4 | |
| 616 | Tensor<[1,1,30,40]>, dims: [0, 1, 2, 3] | aten::mul.Tensor | 4 | |
| 617 | Tensor<[1,1,60,80]>, dims: [0, 1, 2, 3] | aten::mul.Tensor | 4 | |
| 618 | Tensor<[1,1,120,160]>, dims: [0, 1, 2, 3] | aten::mul.Tensor | 4 | |
| 619 | Tensor<[1,64,240,320]>, dims: [0, 1, 2, 3] | aten::mul.Tensor | 4 | |
| 620 | Tensor<[1,12,197,197]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 621 | Tensor<[1,12,197,1]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 622 | Tensor<[1,197,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 623 | Tensor<[1,197,768]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 624 | Tensor<[197,768]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 625 | Tensor<[197,3072]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 626 | Tensor<[12,64,197]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 627 | Tensor<[12,197,64]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 628 | Tensor<[1,768,14,14]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 629 | Tensor<[1,12,197,64]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 630 | Tensor<[1,12,64,197]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 631 | Tensor<[1,1,16384,256]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 632 | Tensor<[1,1,16384,1]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 633 | Tensor<[1,2,4096,256]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 634 | Tensor<[1,2,4096,1]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 635 | Tensor<[1,5,1024,256]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 636 | Tensor<[1,5,1024,1]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 637 | Tensor<[1,16384,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 638 | Tensor<[1,16384,32]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 639 | Tensor<[32]>, dims: [2] | aten::add.Tensor | 4 | |
| 640 | Tensor<[16384,32]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 641 | Tensor<[1,256,32]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 642 | Tensor<[256,32]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 643 | Tensor<[16384,128]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 644 | Tensor<[1,4096,64]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 645 | Tensor<[4096,64]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 646 | Tensor<[256,64]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 647 | Tensor<[4096,256]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 648 | Tensor<[1,1024,160]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 649 | Tensor<[160]>, dims: [2] | aten::add.Tensor | 4 | |
| 650 | Tensor<[1024,160]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 651 | Tensor<[160]>, dims: [1] | aten::add.Tensor | 4 | |
| 652 | Tensor<[1,256,160]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 653 | Tensor<[256,160]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 654 | Tensor<[1,256,256]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 655 | Tensor<[256,1024]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 656 | Tensor<[1,16384,256]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 657 | Tensor<[128,1]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 658 | Tensor<[1,4096,256]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 659 | Tensor<[1,1024,256]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 660 | Tensor<[1,256,128,128]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 661 | Tensor<[1,32,256]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 662 | Tensor<[1,128,32]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 663 | Tensor<[2,32,256]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 664 | Tensor<[2,256,32]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 665 | Tensor<[5,32,256]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 666 | Tensor<[5,256,32]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 667 | Tensor<[1,640,160]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 668 | Tensor<[8,256,32]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 669 | Tensor<[1,64,256]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 670 | Tensor<[1,160,256]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 671 | Tensor<[1,32,128,128]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 672 | Tensor<[1,32,16,16]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 673 | Tensor<[1,64,64,64]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 674 | Tensor<[1,64,16,16]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 675 | Tensor<[1,160,32,32]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 676 | Tensor<[1,160,16,16]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 677 | Tensor<[1,150,128,128]>, dims: [0, 1, 2, 3] | aten::convolution | 4 | |
| 678 | Tensor<[150,1,1]>, dims: [1, 2, 3] | aten::convolution | 4 | |
| 679 | Tensor<[128,32]>, dims: [1, 2] | aten::expand | 5 | |
| 680 | Tensor<[640,160]>, dims: [1, 2] | aten::expand | 5 | |
| 681 | Tensor<[1024,256]>, dims: [1, 2] | aten::expand | 5 | |
| 682 | Tensor<[32,256]>, dims: [1, 2] | aten::expand | 5 | |
| 683 | Tensor<[64,256]>, dims: [1, 2] | aten::expand | 5 | |
| 684 | Tensor<[160,256]>, dims: [1, 2] | aten::expand | 5 | |
| 685 | Tensor<[128,1]>, dims: [2, 3] | aten::index.Tensor | 4 | |
| 686 | Tensor<[1,71,7,7]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 687 | Tensor<[1,71,7,1]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 688 | Tensor<[1,7,4544]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 689 | Tensor<[4544]>, dims: [2] | aten::add.Tensor | 4 | |
| 690 | Tensor<[1,1,7]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 691 | Tensor<[71,64,7]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 692 | Tensor<[71,7,64]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 693 | Tensor<[1,1,64,7]>, dims: [0, 1, 2, 3] | aten::expand | 5 | |
| 694 | Tensor<[1,1,7,64]>, dims: [0, 1, 2, 3] | aten::expand | 5 | |
| 695 | Tensor<[7,1,1]>, dims: [1, 2, 3] | aten::index.Tensor | 4 | |
| 696 | Tensor<[1,1]>, dims: [2, 3] | aten::index.Tensor | 4 | |
| 697 | Tensor<[1,71,7,64]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 698 | Tensor<[1,7,64]>, dims: [0, 1, 2] | aten::mul.Tensor | 4 | |
| 699 | Tensor<[1,16,112,112]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 700 | Tensor<[96]>, dims: [0] | aten::add.Tensor | 4 | |
| 701 | Tensor<[1,96,112,112]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 702 | Tensor<[96,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 703 | Tensor<[1,96,56,56]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 704 | Tensor<[144]>, dims: [0] | aten::add.Tensor | 4 | |
| 705 | Tensor<[1,144,56,56]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 706 | Tensor<[144,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 707 | Tensor<[1,144,28,28]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 708 | Tensor<[1,32,28,28]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 709 | Tensor<[1,192,28,28]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 710 | Tensor<[1,192,14,14]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 711 | Tensor<[1,64,14,14]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 712 | Tensor<[384]>, dims: [0] | aten::add.Tensor | 4 | |
| 713 | Tensor<[1,384,14,14]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 714 | Tensor<[384,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 715 | Tensor<[1,96,14,14]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 716 | Tensor<[576]>, dims: [0] | aten::add.Tensor | 4 | |
| 717 | Tensor<[1,576,14,14]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 718 | Tensor<[576,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 719 | Tensor<[1,576,7,7]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 720 | Tensor<[960]>, dims: [0] | aten::add.Tensor | 4 | |
| 721 | Tensor<[1,960,7,7]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 722 | Tensor<[960,1,1]>, dims: [1, 2, 3] | aten::add.Tensor | 4 | |
| 723 | Tensor<[1,320,7,7]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 724 | Tensor<[1,1280,7,7]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 725 | Tensor<[1,12,12,12]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 726 | Tensor<[1,12,12,1]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 727 | Tensor<[1,12,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 728 | Tensor<[1,12,128]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 729 | Tensor<[12,768]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 730 | Tensor<[1,1,12,12]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 731 | Tensor<[1,12,768]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 732 | Tensor<[12,3072]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 733 | Tensor<[1,12,3072]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 734 | Tensor<[12,2]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 735 | Tensor<[12,64,12]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 736 | Tensor<[12,12,64]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 737 | Tensor<[1,1,1,12]>, dims: [0, 1, 2, 3] | aten::expand | 4 | |
| 738 | Tensor<[1,12,12,64]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 739 | Tensor<[1,12,64,12]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 740 | Tensor<[1,12,9,9]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 741 | Tensor<[1,12,9,1]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 742 | Tensor<[1,9,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 743 | Tensor<[1,9,128]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 744 | Tensor<[9,768]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 745 | Tensor<[1,1,9,9]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 746 | Tensor<[1,9,768]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 747 | Tensor<[9,3072]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 748 | Tensor<[1,9,3072]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 749 | Tensor<[9,128]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 750 | Tensor<[9,30000]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 751 | Tensor<[30000]>, dims: [1] | aten::add.Tensor | 4 | |
| 752 | Tensor<[12,64,9]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 753 | Tensor<[12,9,64]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 754 | Tensor<[1,1,1,9]>, dims: [0, 1, 2, 3] | aten::expand | 4 | |
| 755 | Tensor<[1,12,9,64]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 756 | Tensor<[1,12,64,9]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 757 | Tensor<[30000]>, dims: [0] | aten::mul.Tensor | 4 | |
| 758 | Tensor<[1,16,9,9]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 759 | Tensor<[1,16,9,1]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 760 | Tensor<[9,2048]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 761 | Tensor<[1,9,2048]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 762 | Tensor<[2048]>, dims: [2] | aten::add.Tensor | 4 | |
| 763 | Tensor<[9,8192]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 764 | Tensor<[8192]>, dims: [1] | aten::add.Tensor | 4 | |
| 765 | Tensor<[1,9,8192]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 766 | Tensor<[16,128,9]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 767 | Tensor<[16,9,128]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 768 | Tensor<[1,16,9,128]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 769 | Tensor<[1,16,128,9]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 770 | Tensor<[8192]>, dims: [0] | aten::mul.Tensor | 4 | |
| 771 | Tensor<[9,1024]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 772 | Tensor<[1,9,1024]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 773 | Tensor<[9,4096]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 774 | Tensor<[1,9,4096]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 775 | Tensor<[16,64,9]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 776 | Tensor<[16,9,64]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 777 | Tensor<[1,16,9,64]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 778 | Tensor<[1,16,64,9]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 779 | Tensor<[1,64,9,9]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 780 | Tensor<[1,64,9,1]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 781 | Tensor<[9,16384]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 782 | Tensor<[16384]>, dims: [1] | aten::add.Tensor | 4 | |
| 783 | Tensor<[1,9,16384]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 784 | Tensor<[64,64,9]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 785 | Tensor<[64,9,64]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 786 | Tensor<[1,64,9,64]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 787 | Tensor<[1,64,64,9]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 788 | Tensor<[16384]>, dims: [0] | aten::mul.Tensor | 4 | |
| 789 | Tensor<[1,2]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 790 | Tensor<[1,12,14,14]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 791 | Tensor<[1,12,14,1]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 792 | Tensor<[1,14,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 793 | Tensor<[1,14,128]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 794 | Tensor<[14,768]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 795 | Tensor<[1,1,14,14]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 796 | Tensor<[1,14,768]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 797 | Tensor<[14,3072]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 798 | Tensor<[1,14,3072]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 799 | Tensor<[14,2]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 800 | Tensor<[12,64,14]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 801 | Tensor<[12,14,64]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 802 | Tensor<[1,1,1,14]>, dims: [0, 1, 2, 3] | aten::expand | 4 | |
| 803 | Tensor<[1,12,14,64]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 804 | Tensor<[1,12,64,14]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 805 | Tensor<[1,12,50,50]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 806 | Tensor<[1,12,50,1]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 807 | Tensor<[2,8,7,7]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 808 | Tensor<[2,8,7,1]>, dims: [0, 1, 2, 3] | aten::_safe_softmax | 4 | |
| 809 | Tensor<[1,50,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 810 | Tensor<[1,50,768]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 811 | Tensor<[50,768]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 812 | Tensor<[50,3072]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 813 | Tensor<[2,7,512]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 814 | Tensor<[1,7,512]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 815 | Tensor<[2,7,1]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 816 | Tensor<[14,512]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 817 | Tensor<[2,1,7,7]>, dims: [0, 1, 2, 3] | aten::add.Tensor | 4 | |
| 818 | Tensor<[14,2048]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 819 | Tensor<[12,64,50]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 820 | Tensor<[12,50,64]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 821 | Tensor<[16,64,7]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 822 | Tensor<[16,7,64]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 823 | Tensor<[2,512]>, dims: [0, 1] | aten::div.Tensor | 4 | |
| 824 | Tensor<[2,1]>, dims: [0, 1] | aten::div.Tensor | 4 | |
| 825 | Tensor<[2,1,1,7]>, dims: [0, 1, 2, 3] | aten::expand | 4 | |
| 826 | Tensor<[1,12,50,64]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 827 | Tensor<[1,12,64,50]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 828 | Tensor<[2,8,7,64]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 829 | Tensor<[2,8,64,7]>, dims: [0, 1, 2, 3] | aten::mul.Scalar | 4 | |
| 830 | Tensor<[1,50,3072]>, dims: [0, 1, 2] | aten::mul.Tensor | 4 | |
| 831 | Tensor<[2,7,2048]>, dims: [0, 1, 2] | aten::mul.Tensor | 4 | |
| 832 | Tensor<[1,16,197,197]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 833 | Tensor<[1,16,197,1]>, dims: [0, 1, 2, 3] | aten::_softmax | 4 | |
| 834 | Tensor<[1,197,1024]>, dims: [0, 1, 2] | aten::add.Tensor | 4 | |
| 835 | Tensor<[197,1024]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 836 | Tensor<[27]>, dims: [0] | aten::add.Tensor | 4 | |
| 837 | Tensor<[27,1]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 838 | Tensor<[196,196]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 839 | Tensor<[197,4096]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 840 | Tensor<[1,1024]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 841 | Tensor<[197]>, dims: [0] | aten::arange | 4 | |
| 842 | Tensor<[16,64,197]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 843 | Tensor<[16,197,64]>, dims: [0, 1, 2] | aten::bmm | 4 | |
| 844 | Tensor<[14,1]>, dims: [0, 1] | aten::expand | 4 | |
| 845 | Tensor<[1,14]>, dims: [0, 1] | aten::expand | 4 | |
| 846 | Tensor<[27,1]>, dims: [2, 3] | aten::index.Tensor | 4 | |
| 847 | Tensor<[27]>, dims: [3] | aten::index.Tensor | 4 | |
| 848 | Tensor<[1,16,27,27]>, dims: [0, 1, 2, 3] | aten::mul.Tensor | 4 | |
| 849 | Tensor<[2,196,1]>, dims: [0, 1, 2] | aten::sub.Tensor | 4 | |
| 850 | Tensor<[2,1,196]>, dims: [0, 1, 2] | aten::sub.Tensor | 4 | |
| 851 | Tensor<[1,197]>, dims: [0, 1] | aten::where.self | 4 | |
| 852 | Tensor<[196,197]>, dims: [0, 1] | aten::where.self | 4 | |
| 853 | Tensor<[197,1]>, dims: [0, 1] | aten::where.self | 4 | |
| 854 | Tensor<[197,197]>, dims: [0, 1] | aten::where.self | 4 | |
| 855 | Tensor<[12,1,1]>, dims: [1, 2, 3] | aten::index.Tensor | 4 | |
| 856 | Tensor<[1,12,27,27]>, dims: [0, 1, 2, 3] | aten::mul.Tensor | 4 | |
| 857 | Tensor<[1,64]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 858 | Tensor<[1,12]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 859 | Tensor<[12]>, dims: [1] | aten::add.Tensor | 4 | |
| 860 | Tensor<[1,784]>, dims: [0, 1] | aten::add.Tensor | 4 | |
| 861 | Tensor<[784]>, dims: [1] | aten::add.Tensor | 4 | |
| 862 | Tensor<[784]>, dims: [0] | aten::mul.Tensor | 4 |
stablehlo.ceil::ttnn.ceil
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Scalar, | ttnn.ceil | aten::arange | 4 |
stablehlo.clamp::ttnn.clamp
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,1024,512]>, Tensor<[1,1024,512]>, | ttnn.clamp | aten::gelu | 4 |
| 1 | Tensor<[1,256,256]>, Tensor<[1,256,256]>, | ttnn.clamp | aten::gelu | 4 |
| 2 | Tensor<[1,10,3072]>, Tensor<[1,10,3072]>, | ttnn.clamp | aten::gelu | 4 |
| 3 | Tensor<[1,10,768]>, Tensor<[1,10,768]>, | ttnn.clamp | aten::gelu | 4 |
| 4 | Tensor<[1,4096,1280]>, Tensor<[1,4096,1280]>, | ttnn.clamp | aten::gelu | 4 |
| 5 | Tensor<[1,1024,2560]>, Tensor<[1,1024,2560]>, | ttnn.clamp | aten::gelu | 4 |
| 6 | Tensor<[1,256,5120]>, Tensor<[1,256,5120]>, | ttnn.clamp | aten::gelu | 4 |
| 7 | Tensor<[1,64,5120]>, Tensor<[1,64,5120]>, | ttnn.clamp | aten::gelu | 4 |
| 8 | Tensor<[1,25,3072]>, Tensor<[1,25,3072]>, | ttnn.clamp | aten::gelu | 4 |
| 9 | Tensor<[1,1445,768]>, Tensor<[1,1445,768]>, | ttnn.clamp | aten::gelu | 4 |
| 10 | Tensor<[1,3072,8]>, Tensor<[1,3072,8]>, | ttnn.clamp | aten::gelu | 4 |
| 11 | Tensor<[1,256,1280]>, Tensor<[1,256,1280]>, | ttnn.clamp | aten::gelu | 4 |
| 12 | Tensor<[1,2048,768]>, Tensor<[1,2048,768]>, | ttnn.clamp | aten::gelu | 4 |
| 13 | Tensor<[1,201,3072]>, Tensor<[1,201,3072]>, | ttnn.clamp | aten::gelu | 4 |
| 14 | Tensor<[1,1536]>, Tensor<[1,1536]>, | ttnn.clamp | aten::gelu | 4 |
| 15 | Tensor<[1,19,4096]>, Tensor<[1,19,4096]>, | ttnn.clamp | aten::gelu | 4 |
| 16 | Tensor<[1,16,3072]>, Tensor<[1,16,3072]>, | ttnn.clamp | aten::gelu | 4 |
| 17 | Scalar, Tensor<[30]>, Scalar, | ttnn.clamp | aten::clamp | 4 |
| 18 | Scalar, Tensor<[30,1]>, Scalar, | ttnn.clamp | aten::clamp | 4 |
| 19 | Scalar, Tensor<[40]>, Scalar, | ttnn.clamp | aten::clamp | 4 |
| 20 | Scalar, Tensor<[60]>, Scalar, | ttnn.clamp | aten::clamp | 4 |
| 21 | Scalar, Tensor<[60,1]>, Scalar, | ttnn.clamp | aten::clamp | 4 |
| 22 | Scalar, Tensor<[80]>, Scalar, | ttnn.clamp | aten::clamp | 4 |
| 23 | Scalar, Tensor<[120]>, Scalar, | ttnn.clamp | aten::clamp | 4 |
| 24 | Scalar, Tensor<[120,1]>, Scalar, | ttnn.clamp | aten::clamp | 4 |
| 25 | Scalar, Tensor<[160]>, Scalar, | ttnn.clamp | aten::clamp | 4 |
| 26 | Scalar, Tensor<[240]>, Scalar, | ttnn.clamp | aten::clamp | 4 |
| 27 | Scalar, Tensor<[240,1]>, Scalar, | ttnn.clamp | aten::clamp | 4 |
| 28 | Scalar, Tensor<[320]>, Scalar, | ttnn.clamp | aten::clamp | 4 |
| 29 | Scalar, Tensor<[480]>, Scalar, | ttnn.clamp | aten::clamp | 4 |
| 30 | Scalar, Tensor<[480,1]>, Scalar, | ttnn.clamp | aten::clamp | 4 |
| 31 | Scalar, Tensor<[640]>, Scalar, | ttnn.clamp | aten::clamp | 4 |
| 32 | Tensor<[1,19200,256]>, Tensor<[1,19200,256]>, | ttnn.clamp | aten::gelu | 4 |
| 33 | Tensor<[1,4800,512]>, Tensor<[1,4800,512]>, | ttnn.clamp | aten::gelu | 4 |
| 34 | Tensor<[1,1200,1280]>, Tensor<[1,1200,1280]>, | ttnn.clamp | aten::gelu | 4 |
| 35 | Tensor<[1,300,2048]>, Tensor<[1,300,2048]>, | ttnn.clamp | aten::gelu | 4 |
| 36 | Tensor<[1,197,3072]>, Tensor<[1,197,3072]>, | ttnn.clamp | aten::gelu | 4 |
| 37 | Scalar, Tensor<[128]>, Scalar, | ttnn.clamp | aten::clamp | 4 |
| 38 | Scalar, Tensor<[128,1]>, Scalar, | ttnn.clamp | aten::clamp | 4 |
| 39 | Tensor<[1,16384,128]>, Tensor<[1,16384,128]>, | ttnn.clamp | aten::gelu | 4 |
| 40 | Tensor<[1,4096,256]>, Tensor<[1,4096,256]>, | ttnn.clamp | aten::gelu | 4 |
| 41 | Tensor<[1,1024,640]>, Tensor<[1,1024,640]>, | ttnn.clamp | aten::gelu | 4 |
| 42 | Tensor<[1,256,1024]>, Tensor<[1,256,1024]>, | ttnn.clamp | aten::gelu | 4 |
| 43 | Tensor<[1,7,18176]>, Tensor<[1,7,18176]>, | ttnn.clamp | aten::gelu | 4 |
| 44 | Scalar, Tensor<[27]>, Scalar, | ttnn.clamp | aten::clamp | 4 |
| 45 | Scalar, Tensor<[27,1]>, Scalar, | ttnn.clamp | aten::clamp | 4 |
| 46 | Tensor<[1,197,4096]>, Tensor<[1,197,4096]>, | ttnn.clamp | aten::gelu | 4 |
stablehlo.compare::ttnn.?
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,32,32,32]>, Tensor<[1,32,32,32]>, | ttnn.eq | aten::_safe_softmax | 4 |
| 1 | Tensor<[1,1,32,32]>, Tensor<[1,1,32,32]>, | ttnn.eq | aten::eq.Scalar | 4 |
| 2 | Tensor<[32,32]>, Tensor<[32,32]>, | ttnn.gt | aten::gt.Tensor | 4 |
| 3 | Tensor<[1,12,7,7]>, Tensor<[1,12,7,7]>, | ttnn.eq | aten::_safe_softmax | 4 |
| 4 | Tensor<[1,7]>, Tensor<[1,7]>, | ttnn.eq | aten::eq.Scalar | 4 |
| 5 | Tensor<[7,7]>, Tensor<[7,7]>, | ttnn.lt | aten::lt.Tensor | 4 |
| 6 | Tensor<[1,12,10,10]>, Tensor<[1,12,10,10]>, | ttnn.eq | aten::_safe_softmax | 4 |
| 7 | Tensor<[1,10]>, Tensor<[1,10]>, | ttnn.ne | aten::ne.Scalar | 4 |
| 8 | Tensor<[1,8,4096,4096]>, Tensor<[1,8,4096,4096]>, | ttnn.eq | aten::_safe_softmax | 4 |
| 9 | Tensor<[1,8,4096,9]>, Tensor<[1,8,4096,9]>, | ttnn.eq | aten::_safe_softmax | 4 |
| 10 | Tensor<[1,8,1024,1024]>, Tensor<[1,8,1024,1024]>, | ttnn.eq | aten::_safe_softmax | 4 |
| 11 | Tensor<[1,8,1024,9]>, Tensor<[1,8,1024,9]>, | ttnn.eq | aten::_safe_softmax | 4 |
| 12 | Tensor<[1,8,256,256]>, Tensor<[1,8,256,256]>, | ttnn.eq | aten::_safe_softmax | 4 |
| 13 | Tensor<[1,8,256,9]>, Tensor<[1,8,256,9]>, | ttnn.eq | aten::_safe_softmax | 4 |
| 14 | Tensor<[1,8,64,64]>, Tensor<[1,8,64,64]>, | ttnn.eq | aten::_safe_softmax | 4 |
| 15 | Tensor<[1,8,64,9]>, Tensor<[1,8,64,9]>, | ttnn.eq | aten::_safe_softmax | 4 |
| 16 | Tensor<[1,12,25,25]>, Tensor<[1,12,25,25]>, | ttnn.eq | aten::_safe_softmax | 4 |
| 17 | Tensor<[1,3,1445,1445]>, Tensor<[1,3,1445,1445]>, | ttnn.eq | aten::_safe_softmax | 4 |
| 18 | Tensor<[19]>, Tensor<[19]>, | ttnn.lt | aten::lt.Scalar | 4 |
| 19 | Tensor<[19,19]>, Tensor<[19,19]>, | ttnn.lt | aten::lt.Tensor | 4 |
| 20 | Tensor<[1,12,16,16]>, Tensor<[1,12,16,16]>, | ttnn.eq | aten::_safe_softmax | 4 |
| 21 | Tensor<[1,12,197,197]>, Tensor<[1,12,197,197]>, | ttnn.eq | aten::_safe_softmax | 4 |
| 22 | Tensor<[1,71,7,7]>, Tensor<[1,71,7,7]>, | ttnn.eq | aten::_safe_softmax | 4 |
| 23 | Tensor<[1,1,7,7]>, Tensor<[1,1,7,7]>, | ttnn.eq | aten::eq.Scalar | 4 |
| 24 | Tensor<[1,12,12,12]>, Tensor<[1,12,12,12]>, | ttnn.eq | aten::_safe_softmax | 4 |
| 25 | Tensor<[1,12,9,9]>, Tensor<[1,12,9,9]>, | ttnn.eq | aten::_safe_softmax | 4 |
| 26 | Tensor<[1,16,9,9]>, Tensor<[1,16,9,9]>, | ttnn.eq | aten::_safe_softmax | 4 |
| 27 | Tensor<[1,64,9,9]>, Tensor<[1,64,9,9]>, | ttnn.eq | aten::_safe_softmax | 4 |
| 28 | Tensor<[1,12,14,14]>, Tensor<[1,12,14,14]>, | ttnn.eq | aten::_safe_softmax | 4 |
| 29 | Tensor<[1,12,50,50]>, Tensor<[1,12,50,50]>, | ttnn.eq | aten::_safe_softmax | 4 |
| 30 | Tensor<[2,8,7,7]>, Tensor<[2,8,7,7]>, | ttnn.eq | aten::_safe_softmax | 4 |
| 31 | Tensor<[197]>, Tensor<[197]>, | ttnn.ge | aten::ge.Scalar | 4 |
stablehlo.concatenate::ttnn.concat
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,32,64]>, Tensor<[1,32,64]>, dim: 2 | ttnn.concat | aten::cat | 5 |
| 1 | Tensor<[1,32,32,64]>, Tensor<[1,32,32,64]>, dim: 3 | ttnn.concat | aten::cat | 5 |
| 2 | Tensor<[1,1]>, Tensor<[1,1]>, dim: 1 | ttnn.concat | aten::index.Tensor | 4 |
| 3 | Tensor<[1,128,28,28]>, Tensor<[1,19,28,28]>, Tensor<[1,38,28,28]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 4 | Tensor<[1,23,40,128]>, Tensor<[1,23,40,128]>, dim: 3 | ttnn.concat | aten::cat | 5 |
| 5 | Tensor<[1,1,23,40,1]>, Tensor<[1,1,23,40,1]>, Tensor<[1,1,23,40,1]>, Tensor<[1,1,23,40,1]>, dim: 4 | ttnn.concat | aten::index.Tensor | 4 |
| 6 | Tensor<[1,23,40,64,1]>, Tensor<[1,23,40,64,1]>, dim: 4 | ttnn.concat | aten::stack | 5 |
| 7 | Tensor<[1,100,1,256]>, Tensor<[1,100,1,256]>, Tensor<[1,100,1,256]>, Tensor<[1,100,1,256]>, Tensor<[1,100,1,256]>, Tensor<[1,100,1,256]>, dim: 0 | ttnn.concat | aten::stack | 5 |
| 8 | Tensor<[1,160]>, Tensor<[1,160]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 9 | Tensor<[1,1280,8,8]>, Tensor<[1,1280,8,8]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 10 | Tensor<[1,1280,16,16]>, Tensor<[1,1280,16,16]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 11 | Tensor<[1,1280,16,16]>, Tensor<[1,640,16,16]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 12 | Tensor<[1,1280,32,32]>, Tensor<[1,640,32,32]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 13 | Tensor<[1,640,32,32]>, Tensor<[1,640,32,32]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 14 | Tensor<[1,640,32,32]>, Tensor<[1,320,32,32]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 15 | Tensor<[1,640,64,64]>, Tensor<[1,320,64,64]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 16 | Tensor<[1,320,64,64]>, Tensor<[1,320,64,64]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 17 | Tensor<[1,1280,16,16,1]>, Tensor<[1,1280,16,16,1]>, Tensor<[1,1280,16,16,1]>, Tensor<[1,1280,16,16,1]>, dim: 4 | ttnn.concat | aten::index.Tensor | 4 |
| 18 | Tensor<[1,1280,32,32,1]>, Tensor<[1,1280,32,32,1]>, Tensor<[1,1280,32,32,1]>, Tensor<[1,1280,32,32,1]>, dim: 4 | ttnn.concat | aten::index.Tensor | 4 |
| 19 | Tensor<[1,640,64,64,1]>, Tensor<[1,640,64,64,1]>, Tensor<[1,640,64,64,1]>, Tensor<[1,640,64,64,1]>, dim: 4 | ttnn.concat | aten::index.Tensor | 4 |
| 20 | Tensor<[1,1,192]>, Tensor<[1,1344,192]>, Tensor<[1,100,192]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 21 | Tensor<[1,8,768]>, Tensor<[1,193,768]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 22 | Tensor<[1,8]>, Tensor<[1,193]>, dim: 1 | ttnn.concat | aten::cat | 4 |
| 23 | Tensor<[1,1,12,16,1]>, Tensor<[1,1,12,16,1]>, Tensor<[1,1,12,16,1]>, Tensor<[1,1,12,16,1]>, dim: 4 | ttnn.concat | aten::index.Tensor | 4 |
| 24 | Tensor<[12,16,1]>, Tensor<[12,16,1]>, dim: 2 | ttnn.concat | aten::stack | 4 |
| 25 | Tensor<[19,1,1]>, Tensor<[19,1,1]>, dim: 2 | ttnn.concat | aten::gather | 4 |
| 26 | Tensor<[1,14,56,56]>, Tensor<[1,64,56,56]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 27 | Tensor<[1,14,56,56]>, Tensor<[1,24,56,56]>, Tensor<[1,64,56,56]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 28 | Tensor<[1,14,56,56]>, Tensor<[1,40,56,56]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 29 | Tensor<[1,14,56,56]>, Tensor<[1,24,56,56]>, Tensor<[1,40,56,56]>, Tensor<[1,64,56,56]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 30 | Tensor<[1,14,56,56]>, Tensor<[1,14,56,56]>, Tensor<[1,14,56,56]>, Tensor<[1,14,56,56]>, Tensor<[1,68,56,56]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 31 | Tensor<[1,16,28,28]>, Tensor<[1,128,28,28]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 32 | Tensor<[1,16,28,28]>, Tensor<[1,28,28,28]>, Tensor<[1,128,28,28]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 33 | Tensor<[1,16,28,28]>, Tensor<[1,46,28,28]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 34 | Tensor<[1,16,28,28]>, Tensor<[1,28,28,28]>, Tensor<[1,46,28,28]>, Tensor<[1,128,28,28]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 35 | Tensor<[1,16,28,28]>, Tensor<[1,78,28,28]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 36 | Tensor<[1,16,28,28]>, Tensor<[1,28,28,28]>, Tensor<[1,78,28,28]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 37 | Tensor<[1,16,28,28]>, Tensor<[1,28,28,28]>, Tensor<[1,46,28,28]>, Tensor<[1,78,28,28]>, Tensor<[1,128,28,28]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 38 | Tensor<[1,16,28,28]>, Tensor<[1,16,28,28]>, Tensor<[1,16,28,28]>, Tensor<[1,16,28,28]>, Tensor<[1,16,28,28]>, Tensor<[1,16,28,28]>, Tensor<[1,16,28,28]>, Tensor<[1,16,28,28]>, Tensor<[1,134,28,28]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 39 | Tensor<[1,20,28,28]>, Tensor<[1,256,28,28]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 40 | Tensor<[1,20,28,28]>, Tensor<[1,34,28,28]>, Tensor<[1,256,28,28]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 41 | Tensor<[1,20,28,28]>, Tensor<[1,58,28,28]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 42 | Tensor<[1,20,28,28]>, Tensor<[1,34,28,28]>, Tensor<[1,58,28,28]>, Tensor<[1,256,28,28]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 43 | Tensor<[1,20,28,28]>, Tensor<[1,98,28,28]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 44 | Tensor<[1,20,28,28]>, Tensor<[1,34,28,28]>, Tensor<[1,98,28,28]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 45 | Tensor<[1,20,28,28]>, Tensor<[1,34,28,28]>, Tensor<[1,58,28,28]>, Tensor<[1,98,28,28]>, Tensor<[1,256,28,28]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 46 | Tensor<[1,20,28,28]>, Tensor<[1,20,28,28]>, Tensor<[1,20,28,28]>, Tensor<[1,20,28,28]>, Tensor<[1,20,28,28]>, Tensor<[1,20,28,28]>, Tensor<[1,20,28,28]>, Tensor<[1,20,28,28]>, Tensor<[1,168,28,28]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 47 | Tensor<[1,40,14,14]>, Tensor<[1,320,14,14]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 48 | Tensor<[1,40,14,14]>, Tensor<[1,68,14,14]>, Tensor<[1,320,14,14]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 49 | Tensor<[1,40,14,14]>, Tensor<[1,116,14,14]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 50 | Tensor<[1,40,14,14]>, Tensor<[1,68,14,14]>, Tensor<[1,116,14,14]>, Tensor<[1,320,14,14]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 51 | Tensor<[1,40,14,14]>, Tensor<[1,196,14,14]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 52 | Tensor<[1,40,14,14]>, Tensor<[1,68,14,14]>, Tensor<[1,196,14,14]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 53 | Tensor<[1,40,14,14]>, Tensor<[1,68,14,14]>, Tensor<[1,116,14,14]>, Tensor<[1,196,14,14]>, Tensor<[1,320,14,14]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 54 | Tensor<[1,40,14,14]>, Tensor<[1,40,14,14]>, Tensor<[1,40,14,14]>, Tensor<[1,40,14,14]>, Tensor<[1,40,14,14]>, Tensor<[1,40,14,14]>, Tensor<[1,40,14,14]>, Tensor<[1,40,14,14]>, Tensor<[1,334,14,14]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 55 | Tensor<[1,160,7,7]>, Tensor<[1,640,7,7]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 56 | Tensor<[1,160,7,7]>, Tensor<[1,272,7,7]>, Tensor<[1,640,7,7]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 57 | Tensor<[1,160,7,7]>, Tensor<[1,160,7,7]>, Tensor<[1,462,7,7]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 58 | Tensor<[1,256,32,32]>, Tensor<[1,512,32,32]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 59 | Tensor<[1,128,64,64]>, Tensor<[1,256,64,64]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 60 | Tensor<[1,256,32,32,1]>, Tensor<[1,256,32,32,1]>, Tensor<[1,256,32,32,1]>, Tensor<[1,256,32,32,1]>, dim: 4 | ttnn.concat | aten::index.Tensor | 4 |
| 61 | Tensor<[1,128,64,64,1]>, Tensor<[1,128,64,64,1]>, Tensor<[1,128,64,64,1]>, Tensor<[1,128,64,64,1]>, dim: 4 | ttnn.concat | aten::index.Tensor | 4 |
| 62 | Tensor<[1,256,32,32]>, Tensor<[1,256,32,32]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 63 | Tensor<[1,128,64,64]>, Tensor<[1,128,64,64]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 64 | Tensor<[1,64,128,128]>, Tensor<[1,64,128,128]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 65 | Tensor<[1,32,256,256]>, Tensor<[1,32,256,256]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 66 | Tensor<[1,512,28,28]>, Tensor<[1,512,28,28]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 67 | Tensor<[1,256,56,56]>, Tensor<[1,256,56,56]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 68 | Tensor<[1,128,112,112]>, Tensor<[1,128,112,112]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 69 | Tensor<[1,64,224,224]>, Tensor<[1,64,224,224]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 70 | Tensor<[1,64,30,40]>, Tensor<[1,64,30,40]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 71 | Tensor<[1,64,60,80]>, Tensor<[1,64,60,80]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 72 | Tensor<[1,64,120,160]>, Tensor<[1,64,120,160]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 73 | Tensor<[1,64,30,40,1]>, Tensor<[1,64,30,40,1]>, Tensor<[1,64,30,40,1]>, Tensor<[1,64,30,40,1]>, dim: 4 | ttnn.concat | aten::index.Tensor | 4 |
| 74 | Tensor<[1,64,60,80,1]>, Tensor<[1,64,60,80,1]>, Tensor<[1,64,60,80,1]>, Tensor<[1,64,60,80,1]>, dim: 4 | ttnn.concat | aten::index.Tensor | 4 |
| 75 | Tensor<[1,64,120,160,1]>, Tensor<[1,64,120,160,1]>, Tensor<[1,64,120,160,1]>, Tensor<[1,64,120,160,1]>, dim: 4 | ttnn.concat | aten::index.Tensor | 4 |
| 76 | Tensor<[1,64,240,320,1]>, Tensor<[1,64,240,320,1]>, Tensor<[1,64,240,320,1]>, Tensor<[1,64,240,320,1]>, dim: 4 | ttnn.concat | aten::index.Tensor | 4 |
| 77 | Tensor<[1,64,480,640,1]>, Tensor<[1,64,480,640,1]>, Tensor<[1,64,480,640,1]>, Tensor<[1,64,480,640,1]>, dim: 4 | ttnn.concat | aten::index.Tensor | 4 |
| 78 | Tensor<[1,1,768]>, Tensor<[1,196,768]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 79 | Tensor<[1,256,128,128]>, Tensor<[1,256,128,128]>, Tensor<[1,256,128,128]>, Tensor<[1,256,128,128]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 80 | Tensor<[1,256,128,128,1]>, Tensor<[1,256,128,128,1]>, Tensor<[1,256,128,128,1]>, Tensor<[1,256,128,128,1]>, dim: 4 | ttnn.concat | aten::index.Tensor | 4 |
| 81 | Tensor<[1,7,32]>, Tensor<[1,7,32]>, dim: 2 | ttnn.concat | aten::cat | 5 |
| 82 | Tensor<[1,71,7,32]>, Tensor<[1,71,7,32]>, dim: 3 | ttnn.concat | aten::cat | 5 |
| 83 | Tensor<[1,1,7,32]>, Tensor<[1,1,7,32]>, dim: 3 | ttnn.concat | aten::cat | 5 |
| 84 | Tensor<[1,7,1,64,1]>, Tensor<[1,7,1,64,1]>, Tensor<[1,7,1,64,1]>, Tensor<[1,7,1,64,1]>, dim: 4 | ttnn.concat | aten::index.Tensor | 4 |
| 85 | Tensor<[1,1,768]>, Tensor<[1,49,768]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 86 | Tensor<[2,1]>, Tensor<[2,1]>, dim: 1 | ttnn.concat | aten::index.Tensor | 4 |
| 87 | Tensor<[1,1,1024]>, Tensor<[1,196,1024]>, dim: 1 | ttnn.concat | aten::cat | 5 |
| 88 | Tensor<[729,16]>, Tensor<[3,16]>, dim: 0 | ttnn.concat | aten::cat | 5 |
| 89 | Tensor<[1,16,27,27,1]>, Tensor<[1,16,27,27,1]>, Tensor<[1,16,27,27,1]>, Tensor<[1,16,27,27,1]>, dim: 4 | ttnn.concat | aten::index.Tensor | 4 |
| 90 | Tensor<[1,14,14]>, Tensor<[1,14,14]>, dim: 0 | ttnn.concat | aten::stack | 4 |
| 91 | Tensor<[729,12]>, Tensor<[3,12]>, dim: 0 | ttnn.concat | aten::cat | 5 |
| 92 | Tensor<[1,12,27,27,1]>, Tensor<[1,12,27,27,1]>, Tensor<[1,12,27,27,1]>, Tensor<[1,12,27,27,1]>, dim: 4 | ttnn.concat | aten::index.Tensor | 4 |
stablehlo.constant
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Scalar, | aten::_safe_softmax | 4 | |
| 1 | Tensor<[32]>, | aten::arange | 4 | |
| 2 | Tensor<[32,1]>, | aten::triu | 4 | |
| 3 | Tensor<[7]>, | aten::add.Tensor | 4 | |
| 4 | Tensor<[1]>, | aten::arange | 4 | |
| 5 | Tensor<[1,7]>, | aten::eq.Scalar | 4 | |
| 6 | Tensor<[64]>, | aten::reciprocal | 5 | |
| 7 | Tensor<[128]>, | aten::reciprocal | 5 | |
| 8 | Tensor<[256]>, | aten::reciprocal | 5 | |
| 9 | Tensor<[512]>, | aten::reciprocal | 5 | |
| 10 | Tensor<[1,32,112,112]>, | aten::relu | 4 | |
| 11 | Tensor<[1,64,112,112]>, | aten::relu | 4 | |
| 12 | Tensor<[1,64,56,56]>, | aten::relu | 4 | |
| 13 | Tensor<[1,128,56,56]>, | aten::relu | 4 | |
| 14 | Tensor<[1,128,28,28]>, | aten::relu | 4 | |
| 15 | Tensor<[1,256,28,28]>, | aten::relu | 4 | |
| 16 | Tensor<[1,512,28,28]>, | aten::relu | 4 | |
| 17 | Tensor<[1,1024,512]>, | aten::gelu | 4 | |
| 18 | Tensor<[1,256,256]>, | aten::gelu | 4 | |
| 19 | Tensor<[1,720,1280]>, | aten::ones | 4 | |
| 20 | Tensor<[1,64,360,640]>, | aten::relu | 4 | |
| 21 | Tensor<[1,64,180,320]>, | aten::relu | 4 | |
| 22 | Tensor<[1,256,180,320]>, | aten::relu | 4 | |
| 23 | Tensor<[1,128,180,320]>, | aten::relu | 4 | |
| 24 | Tensor<[1,128,90,160]>, | aten::relu | 4 | |
| 25 | Tensor<[1,512,90,160]>, | aten::relu | 4 | |
| 26 | Tensor<[1,256,90,160]>, | aten::relu | 4 | |
| 27 | Tensor<[1,256,45,80]>, | aten::relu | 4 | |
| 28 | Tensor<[1,1024,45,80]>, | aten::relu | 4 | |
| 29 | Tensor<[1,512,45,80]>, | aten::relu | 4 | |
| 30 | Tensor<[1,512,23,40]>, | aten::relu | 4 | |
| 31 | Tensor<[1,2048,23,40]>, | aten::relu | 4 | |
| 32 | Tensor<[920,1,2048]>, | aten::relu | 4 | |
| 33 | Tensor<[100,1,2048]>, | aten::relu | 4 | |
| 34 | Tensor<[6,1,100,256]>, | aten::relu | 4 | |
| 35 | Tensor<[1,1]>, | aten::select_scatter | 4 | |
| 36 | Tensor<[1,3,720,1280]>, | aten::zeros | 5 | |
| 37 | Tensor<[1,10]>, | aten::add.Tensor | 5 | |
| 38 | Tensor<[1,10,3072]>, | aten::gelu | 4 | |
| 39 | Tensor<[1,10,768]>, | aten::gelu | 4 | |
| 40 | Tensor<[1,4096,1280]>, | aten::gelu | 4 | |
| 41 | Tensor<[1,1024,2560]>, | aten::gelu | 4 | |
| 42 | Tensor<[1,256,5120]>, | aten::gelu | 4 | |
| 43 | Tensor<[1,64,5120]>, | aten::gelu | 4 | |
| 44 | Tensor<[1280]>, | aten::index.Tensor | 4 | |
| 45 | Tensor<[640]>, | aten::index.Tensor | 4 | |
| 46 | Tensor<[1,25,3072]>, | aten::gelu | 4 | |
| 47 | Tensor<[1,1445,768]>, | aten::gelu | 4 | |
| 48 | Tensor<[1,100,192]>, | aten::relu | 4 | |
| 49 | Tensor<[1,256,14,14]>, | aten::relu | 4 | |
| 50 | Tensor<[1,512,7,7]>, | aten::relu | 4 | |
| 51 | Tensor<[1,3072,8]>, | aten::gelu | 4 | |
| 52 | Tensor<[2048]>, | aten::arange.start | 4 | |
| 53 | Tensor<[1,256,1280]>, | aten::gelu | 4 | |
| 54 | Tensor<[1,2048,768]>, | aten::gelu | 4 | |
| 55 | Tensor<[1024]>, | aten::reciprocal | 5 | |
| 56 | Tensor<[1,256,56,56]>, | aten::relu | 4 | |
| 57 | Tensor<[1,1024,14,14]>, | aten::relu | 4 | |
| 58 | Tensor<[1,512,14,14]>, | aten::relu | 4 | |
| 59 | Tensor<[1,2048,7,7]>, | aten::relu | 4 | |
| 60 | Tensor<[1,193]>, | aten::full_like | 4 | |
| 61 | Tensor<[1,201,3072]>, | aten::gelu | 4 | |
| 62 | Tensor<[1,1536]>, | aten::gelu | 4 | |
| 63 | Tensor<[1,192]>, | aten::rsub.Scalar | 4 | |
| 64 | Tensor<[1,8]>, | aten::zeros_like | 4 | |
| 65 | Tensor<[1,32,26,26]>, | aten::relu | 4 | |
| 66 | Tensor<[1,64,24,24]>, | aten::relu | 4 | |
| 67 | Tensor<[1,128]>, | aten::relu | 4 | |
| 68 | Tensor<[19]>, | aten::add.Tensor | 4 | |
| 69 | Tensor<[1,19]>, | aten::add.Tensor | 4 | |
| 70 | Tensor<[1,19,4096]>, | aten::gelu | 4 | |
| 71 | Tensor<[14]>, | aten::reciprocal | 5 | |
| 72 | Tensor<[24]>, | aten::reciprocal | 5 | |
| 73 | Tensor<[40]>, | aten::reciprocal | 5 | |
| 74 | Tensor<[68]>, | aten::reciprocal | 5 | |
| 75 | Tensor<[16]>, | aten::reciprocal | 5 | |
| 76 | Tensor<[28]>, | aten::reciprocal | 5 | |
| 77 | Tensor<[46]>, | aten::reciprocal | 5 | |
| 78 | Tensor<[78]>, | aten::reciprocal | 5 | |
| 79 | Tensor<[134]>, | aten::reciprocal | 5 | |
| 80 | Tensor<[20]>, | aten::reciprocal | 5 | |
| 81 | Tensor<[34]>, | aten::reciprocal | 5 | |
| 82 | Tensor<[58]>, | aten::reciprocal | 5 | |
| 83 | Tensor<[98]>, | aten::reciprocal | 5 | |
| 84 | Tensor<[168]>, | aten::reciprocal | 5 | |
| 85 | Tensor<[320]>, | aten::reciprocal | 5 | |
| 86 | Tensor<[116]>, | aten::reciprocal | 5 | |
| 87 | Tensor<[196]>, | aten::reciprocal | 5 | |
| 88 | Tensor<[334]>, | aten::reciprocal | 5 | |
| 89 | Tensor<[160]>, | aten::reciprocal | 5 | |
| 90 | Tensor<[272]>, | aten::reciprocal | 5 | |
| 91 | Tensor<[462]>, | aten::reciprocal | 5 | |
| 92 | Tensor<[1,32,256,256]>, | aten::relu | 4 | |
| 93 | Tensor<[1,64,128,128]>, | aten::relu | 4 | |
| 94 | Tensor<[1,128,64,64]>, | aten::relu | 4 | |
| 95 | Tensor<[1,256,32,32]>, | aten::relu | 4 | |
| 96 | Tensor<[1,512,16,16]>, | aten::relu | 4 | |
| 97 | Tensor<[1,16,28,28]>, | aten::relu | 4 | |
| 98 | Tensor<[1,4,14,14]>, | aten::relu | 4 | |
| 99 | Tensor<[1,16,14,14]>, | aten::relu | 4 | |
| 100 | Tensor<[1,32]>, | aten::sub.Tensor | 4 | |
| 101 | Tensor<[1,16,3072]>, | aten::gelu | 4 | |
| 102 | Tensor<[1,64,224,224]>, | aten::relu | 4 | |
| 103 | Tensor<[1,128,112,112]>, | aten::relu | 4 | |
| 104 | Tensor<[30,1]>, | aten::add.Tensor | 4 | |
| 105 | Tensor<[60,1]>, | aten::add.Tensor | 4 | |
| 106 | Tensor<[80]>, | aten::add.Tensor | 4 | |
| 107 | Tensor<[120,1]>, | aten::add.Tensor | 4 | |
| 108 | Tensor<[240,1]>, | aten::add.Tensor | 4 | |
| 109 | Tensor<[480,1]>, | aten::add.Tensor | 4 | |
| 110 | Tensor<[30]>, | aten::arange | 4 | |
| 111 | Tensor<[60]>, | aten::arange | 4 | |
| 112 | Tensor<[120]>, | aten::arange | 4 | |
| 113 | Tensor<[240]>, | aten::arange | 4 | |
| 114 | Tensor<[480]>, | aten::arange | 4 | |
| 115 | Tensor<[1,19200,256]>, | aten::gelu | 4 | |
| 116 | Tensor<[1,4800,512]>, | aten::gelu | 4 | |
| 117 | Tensor<[1,1200,1280]>, | aten::gelu | 4 | |
| 118 | Tensor<[1,300,2048]>, | aten::gelu | 4 | |
| 119 | Tensor<[1,64,30,40]>, | aten::relu | 4 | |
| 120 | Tensor<[1,32,30,40]>, | aten::relu | 4 | |
| 121 | Tensor<[1,64,60,80]>, | aten::relu | 4 | |
| 122 | Tensor<[1,32,60,80]>, | aten::relu | 4 | |
| 123 | Tensor<[1,64,120,160]>, | aten::relu | 4 | |
| 124 | Tensor<[1,32,120,160]>, | aten::relu | 4 | |
| 125 | Tensor<[1,64,480,640]>, | aten::relu | 4 | |
| 126 | Tensor<[1,197,3072]>, | aten::gelu | 4 | |
| 127 | Tensor<[128,1]>, | aten::add.Tensor | 4 | |
| 128 | Tensor<[1,16384,128]>, | aten::gelu | 4 | |
| 129 | Tensor<[1,4096,256]>, | aten::gelu | 4 | |
| 130 | Tensor<[1,1024,640]>, | aten::gelu | 4 | |
| 131 | Tensor<[1,256,1024]>, | aten::gelu | 4 | |
| 132 | Tensor<[1,256,128,128]>, | aten::relu | 4 | |
| 133 | Tensor<[1,7,18176]>, | aten::gelu | 4 | |
| 134 | Tensor<[7,1]>, | aten::triu | 4 | |
| 135 | Tensor<[96]>, | aten::reciprocal | 5 | |
| 136 | Tensor<[144]>, | aten::reciprocal | 5 | |
| 137 | Tensor<[192]>, | aten::reciprocal | 5 | |
| 138 | Tensor<[384]>, | aten::reciprocal | 5 | |
| 139 | Tensor<[576]>, | aten::reciprocal | 5 | |
| 140 | Tensor<[960]>, | aten::reciprocal | 5 | |
| 141 | Tensor<[2]>, | aten::arange | 4 | |
| 142 | Tensor<[27,1]>, | aten::add.Tensor | 4 | |
| 143 | Tensor<[27]>, | aten::add.Tensor | 4 | |
| 144 | Tensor<[196,196]>, | aten::add.Tensor | 4 | |
| 145 | Tensor<[197]>, | aten::arange | 4 | |
| 146 | Tensor<[1,197,4096]>, | aten::gelu | 4 | |
| 147 | Tensor<[197,197]>, | aten::zeros | 4 | |
| 148 | Tensor<[12]>, | aten::index.Tensor | 4 | |
| 149 | Tensor<[1,64]>, | aten::relu | 4 | |
| 150 | Tensor<[1,12]>, | aten::relu | 4 |
stablehlo.convert
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1]>, | aten::_safe_softmax | 4 | |
| 1 | Scalar, | aten::_safe_softmax | 4 | |
| 2 | Tensor<[1,1,1,32]>, | aten::add.Tensor | 4 | |
| 3 | Tensor<[1,1,32,32]>, | aten::add.Tensor | 4 | |
| 4 | Tensor<[1,32,4096]>, | aten::embedding | 4 | |
| 5 | Tensor<[32,32]>, | aten::mul.Tensor | 5 | |
| 6 | Tensor<[1,1,32]>, | prims::convert_element_type | 4 | |
| 7 | Tensor<[1,32,128]>, | prims::convert_element_type | 5 | |
| 8 | Tensor<[1,32,32,128]>, | prims::convert_element_type | 5 | |
| 9 | Tensor<[768]>, | aten::add.Tensor | 4 | |
| 10 | Tensor<[1,1,7,7]>, | aten::add.Tensor | 4 | |
| 11 | Tensor<[1,7,768]>, | aten::embedding | 4 | |
| 12 | Tensor<[7,7]>, | prims::convert_element_type | 5 | |
| 13 | Tensor<[2304]>, | prims::convert_element_type | 5 | |
| 14 | Tensor<[7,768]>, | prims::convert_element_type | 5 | |
| 15 | Tensor<[768,2304]>, | prims::convert_element_type | 5 | |
| 16 | Tensor<[7,2304]>, | prims::convert_element_type | 5 | |
| 17 | Tensor<[1,12,7,64]>, | prims::convert_element_type | 5 | |
| 18 | Tensor<[768,768]>, | prims::convert_element_type | 5 | |
| 19 | Tensor<[3072]>, | prims::convert_element_type | 5 | |
| 20 | Tensor<[768,3072]>, | prims::convert_element_type | 5 | |
| 21 | Tensor<[7,3072]>, | prims::convert_element_type | 5 | |
| 22 | Tensor<[3072,768]>, | prims::convert_element_type | 5 | |
| 23 | Tensor<[1,7]>, | prims::convert_element_type | 5 | |
| 24 | Tensor<[32,1,1]>, | aten::add.Tensor | 4 | |
| 25 | Tensor<[64,1,1]>, | aten::add.Tensor | 4 | |
| 26 | Tensor<[128,1,1]>, | aten::add.Tensor | 4 | |
| 27 | Tensor<[256,1,1]>, | aten::add.Tensor | 4 | |
| 28 | Tensor<[512,1,1]>, | aten::add.Tensor | 4 | |
| 29 | Tensor<[1,32,112,112]>, | aten::sub.Tensor | 4 | |
| 30 | Tensor<[1,64,112,112]>, | aten::sub.Tensor | 4 | |
| 31 | Tensor<[1,64,56,56]>, | aten::sub.Tensor | 4 | |
| 32 | Tensor<[1,128,56,56]>, | aten::sub.Tensor | 4 | |
| 33 | Tensor<[1,128,28,28]>, | aten::sub.Tensor | 4 | |
| 34 | Tensor<[1,256,28,28]>, | aten::sub.Tensor | 4 | |
| 35 | Tensor<[1,512,28,28]>, | aten::sub.Tensor | 4 | |
| 36 | Tensor<[32]>, | prims::convert_element_type | 5 | |
| 37 | Tensor<[64]>, | prims::convert_element_type | 5 | |
| 38 | Tensor<[128]>, | prims::convert_element_type | 5 | |
| 39 | Tensor<[256]>, | prims::convert_element_type | 5 | |
| 40 | Tensor<[512]>, | prims::convert_element_type | 5 | |
| 41 | Tensor<[1,1024,512]>, | aten::gelu | 4 | |
| 42 | Tensor<[1,256,256]>, | aten::gelu | 4 | |
| 43 | Tensor<[1,256,512]>, | aten::sub.Tensor | 4 | |
| 44 | Tensor<[256,768]>, | prims::convert_element_type | 5 | |
| 45 | Tensor<[768,512]>, | prims::convert_element_type | 5 | |
| 46 | Tensor<[256,512]>, | prims::convert_element_type | 5 | |
| 47 | Tensor<[512,256]>, | prims::convert_element_type | 5 | |
| 48 | Tensor<[256,256]>, | prims::convert_element_type | 5 | |
| 49 | Tensor<[1000]>, | prims::convert_element_type | 5 | |
| 50 | Tensor<[1,512]>, | prims::convert_element_type | 5 | |
| 51 | Tensor<[512,1000]>, | prims::convert_element_type | 5 | |
| 52 | Tensor<[1,1000]>, | prims::convert_element_type | 5 | |
| 53 | Tensor<[8,920,920]>, | aten::_softmax | 4 | |
| 54 | Tensor<[8,100,100]>, | aten::_softmax | 4 | |
| 55 | Tensor<[8,100,920]>, | aten::_softmax | 4 | |
| 56 | Tensor<[1,23,40]>, | aten::cumsum | 4 | |
| 57 | Tensor<[920,1,256]>, | aten::sub.Tensor | 4 | |
| 58 | Tensor<[100,1,256]>, | aten::sub.Tensor | 4 | |
| 59 | Tensor<[1,3,720,1280]>, | aten::zeros | 5 | |
| 60 | Tensor<[1,1,720,1280]>, | prims::convert_element_type | 5 | |
| 61 | Tensor<[23]>, | prims::convert_element_type | 4 | |
| 62 | Tensor<[40]>, | prims::convert_element_type | 4 | |
| 63 | Tensor<[1,1,23,40]>, | prims::convert_element_type | 5 | |
| 64 | Tensor<[1,256,23,40]>, | prims::convert_element_type | 5 | |
| 65 | Tensor<[920,256]>, | prims::convert_element_type | 5 | |
| 66 | Tensor<[2048]>, | prims::convert_element_type | 5 | |
| 67 | Tensor<[256,2048]>, | prims::convert_element_type | 5 | |
| 68 | Tensor<[920,2048]>, | prims::convert_element_type | 5 | |
| 69 | Tensor<[2048,256]>, | prims::convert_element_type | 5 | |
| 70 | Tensor<[100,256]>, | prims::convert_element_type | 5 | |
| 71 | Tensor<[100,2048]>, | prims::convert_element_type | 5 | |
| 72 | Tensor<[1,1,10,10]>, | aten::add.Tensor | 4 | |
| 73 | Tensor<[1,10]>, | aten::cumsum | 4 | |
| 74 | Tensor<[1,10,768]>, | aten::embedding | 4 | |
| 75 | Tensor<[1,10,3072]>, | aten::gelu | 4 | |
| 76 | Tensor<[10,768]>, | prims::convert_element_type | 5 | |
| 77 | Tensor<[1,12,10,64]>, | prims::convert_element_type | 5 | |
| 78 | Tensor<[10,3072]>, | prims::convert_element_type | 5 | |
| 79 | Tensor<[250002]>, | prims::convert_element_type | 5 | |
| 80 | Tensor<[768,250002]>, | prims::convert_element_type | 5 | |
| 81 | Tensor<[10,250002]>, | prims::convert_element_type | 5 | |
| 82 | Tensor<[1,320,1,1]>, | aten::add.Tensor | 4 | |
| 83 | Tensor<[320]>, | aten::add.Tensor | 4 | |
| 84 | Tensor<[640]>, | aten::add.Tensor | 4 | |
| 85 | Tensor<[1,640,1,1]>, | aten::add.Tensor | 4 | |
| 86 | Tensor<[1280]>, | aten::add.Tensor | 4 | |
| 87 | Tensor<[1,1280,1,1]>, | aten::add.Tensor | 4 | |
| 88 | Tensor<[1,2560,1,1]>, | aten::add.Tensor | 4 | |
| 89 | Tensor<[1,1920,1,1]>, | aten::add.Tensor | 4 | |
| 90 | Tensor<[1,960,1,1]>, | aten::add.Tensor | 4 | |
| 91 | Tensor<[1,4096,1280]>, | aten::gelu | 4 | |
| 92 | Tensor<[1,1024,2560]>, | aten::gelu | 4 | |
| 93 | Tensor<[1,256,5120]>, | aten::gelu | 4 | |
| 94 | Tensor<[1,64,5120]>, | aten::gelu | 4 | |
| 95 | Tensor<[1,32,10,4096]>, | aten::sub.Tensor | 4 | |
| 96 | Tensor<[1,4096,320]>, | aten::sub.Tensor | 4 | |
| 97 | Tensor<[1,32,10,1024]>, | aten::sub.Tensor | 4 | |
| 98 | Tensor<[1,32,20,1024]>, | aten::sub.Tensor | 4 | |
| 99 | Tensor<[1,1024,640]>, | aten::sub.Tensor | 4 | |
| 100 | Tensor<[1,32,20,256]>, | aten::sub.Tensor | 4 | |
| 101 | Tensor<[1,32,40,256]>, | aten::sub.Tensor | 4 | |
| 102 | Tensor<[1,256,1280]>, | aten::sub.Tensor | 4 | |
| 103 | Tensor<[1,32,40,64]>, | aten::sub.Tensor | 4 | |
| 104 | Tensor<[1,64,1280]>, | aten::sub.Tensor | 4 | |
| 105 | Tensor<[1,32,80,64]>, | aten::sub.Tensor | 4 | |
| 106 | Tensor<[1,32,80,256]>, | aten::sub.Tensor | 4 | |
| 107 | Tensor<[1,32,60,256]>, | aten::sub.Tensor | 4 | |
| 108 | Tensor<[1,32,60,1024]>, | aten::sub.Tensor | 4 | |
| 109 | Tensor<[1,32,40,1024]>, | aten::sub.Tensor | 4 | |
| 110 | Tensor<[1,32,30,1024]>, | aten::sub.Tensor | 4 | |
| 111 | Tensor<[1,32,30,4096]>, | aten::sub.Tensor | 4 | |
| 112 | Tensor<[1,32,20,4096]>, | aten::sub.Tensor | 4 | |
| 113 | Tensor<[1,1]>, | prims::convert_element_type | 4 | |
| 114 | Tensor<[1,320]>, | prims::convert_element_type | 5 | |
| 115 | Tensor<[320,1280]>, | prims::convert_element_type | 5 | |
| 116 | Tensor<[1,1280]>, | prims::convert_element_type | 5 | |
| 117 | Tensor<[1280,1280]>, | prims::convert_element_type | 5 | |
| 118 | Tensor<[1,320,64,64]>, | prims::convert_element_type | 5 | |
| 119 | Tensor<[1280,320]>, | prims::convert_element_type | 5 | |
| 120 | Tensor<[1,8,4096,40]>, | prims::convert_element_type | 5 | |
| 121 | Tensor<[4096,320]>, | prims::convert_element_type | 5 | |
| 122 | Tensor<[320,320]>, | prims::convert_element_type | 5 | |
| 123 | Tensor<[1,8,9,40]>, | prims::convert_element_type | 5 | |
| 124 | Tensor<[2560]>, | prims::convert_element_type | 5 | |
| 125 | Tensor<[320,2560]>, | prims::convert_element_type | 5 | |
| 126 | Tensor<[4096,2560]>, | prims::convert_element_type | 5 | |
| 127 | Tensor<[4096,1280]>, | prims::convert_element_type | 5 | |
| 128 | Tensor<[1,320,32,32]>, | prims::convert_element_type | 5 | |
| 129 | Tensor<[1280,640]>, | prims::convert_element_type | 5 | |
| 130 | Tensor<[1,640]>, | prims::convert_element_type | 5 | |
| 131 | Tensor<[1,640,32,32]>, | prims::convert_element_type | 5 | |
| 132 | Tensor<[1,8,1024,80]>, | prims::convert_element_type | 5 | |
| 133 | Tensor<[1024,640]>, | prims::convert_element_type | 5 | |
| 134 | Tensor<[640,640]>, | prims::convert_element_type | 5 | |
| 135 | Tensor<[1,8,9,80]>, | prims::convert_element_type | 5 | |
| 136 | Tensor<[5120]>, | prims::convert_element_type | 5 | |
| 137 | Tensor<[640,5120]>, | prims::convert_element_type | 5 | |
| 138 | Tensor<[1024,5120]>, | prims::convert_element_type | 5 | |
| 139 | Tensor<[1024,2560]>, | prims::convert_element_type | 5 | |
| 140 | Tensor<[2560,640]>, | prims::convert_element_type | 5 | |
| 141 | Tensor<[1,640,16,16]>, | prims::convert_element_type | 5 | |
| 142 | Tensor<[1,1280,16,16]>, | prims::convert_element_type | 5 | |
| 143 | Tensor<[1,8,256,160]>, | prims::convert_element_type | 5 | |
| 144 | Tensor<[256,1280]>, | prims::convert_element_type | 5 | |
| 145 | Tensor<[1,8,9,160]>, | prims::convert_element_type | 5 | |
| 146 | Tensor<[10240]>, | prims::convert_element_type | 5 | |
| 147 | Tensor<[1280,10240]>, | prims::convert_element_type | 5 | |
| 148 | Tensor<[256,10240]>, | prims::convert_element_type | 5 | |
| 149 | Tensor<[256,5120]>, | prims::convert_element_type | 5 | |
| 150 | Tensor<[5120,1280]>, | prims::convert_element_type | 5 | |
| 151 | Tensor<[1,1280,8,8]>, | prims::convert_element_type | 5 | |
| 152 | Tensor<[1,8,64,160]>, | prims::convert_element_type | 5 | |
| 153 | Tensor<[64,1280]>, | prims::convert_element_type | 5 | |
| 154 | Tensor<[64,10240]>, | prims::convert_element_type | 5 | |
| 155 | Tensor<[64,5120]>, | prims::convert_element_type | 5 | |
| 156 | Tensor<[1,2560,8,8]>, | prims::convert_element_type | 5 | |
| 157 | Tensor<[16]>, | prims::convert_element_type | 4 | |
| 158 | Tensor<[1,2560,16,16]>, | prims::convert_element_type | 5 | |
| 159 | Tensor<[1,1920,16,16]>, | prims::convert_element_type | 5 | |
| 160 | Tensor<[1,1280,32,32]>, | prims::convert_element_type | 5 | |
| 161 | Tensor<[1,1920,32,32]>, | prims::convert_element_type | 5 | |
| 162 | Tensor<[1,960,32,32]>, | prims::convert_element_type | 5 | |
| 163 | Tensor<[1,640,64,64]>, | prims::convert_element_type | 5 | |
| 164 | Tensor<[1,960,64,64]>, | prims::convert_element_type | 5 | |
| 165 | Tensor<[1,1,25,25]>, | aten::add.Tensor | 4 | |
| 166 | Tensor<[1,25,768]>, | aten::embedding | 4 | |
| 167 | Tensor<[1,25,3072]>, | aten::gelu | 4 | |
| 168 | Tensor<[25,768]>, | prims::convert_element_type | 5 | |
| 169 | Tensor<[1,12,25,64]>, | prims::convert_element_type | 5 | |
| 170 | Tensor<[25,3072]>, | prims::convert_element_type | 5 | |
| 171 | Tensor<[2]>, | prims::convert_element_type | 5 | |
| 172 | Tensor<[768,2]>, | prims::convert_element_type | 5 | |
| 173 | Tensor<[25,2]>, | prims::convert_element_type | 5 | |
| 174 | Tensor<[1,768]>, | prims::convert_element_type | 5 | |
| 175 | Tensor<[768,1]>, | prims::convert_element_type | 5 | |
| 176 | Tensor<[192]>, | aten::add.Tensor | 4 | |
| 177 | Tensor<[1,1445,768]>, | aten::gelu | 4 | |
| 178 | Tensor<[1,1445,192]>, | aten::sub.Tensor | 4 | |
| 179 | Tensor<[1445,192]>, | prims::convert_element_type | 5 | |
| 180 | Tensor<[192,192]>, | prims::convert_element_type | 5 | |
| 181 | Tensor<[1,3,1445,64]>, | prims::convert_element_type | 5 | |
| 182 | Tensor<[192,768]>, | prims::convert_element_type | 5 | |
| 183 | Tensor<[1445,768]>, | prims::convert_element_type | 5 | |
| 184 | Tensor<[768,192]>, | prims::convert_element_type | 5 | |
| 185 | Tensor<[100,192]>, | prims::convert_element_type | 5 | |
| 186 | Tensor<[92]>, | prims::convert_element_type | 5 | |
| 187 | Tensor<[192,92]>, | prims::convert_element_type | 5 | |
| 188 | Tensor<[100,92]>, | prims::convert_element_type | 5 | |
| 189 | Tensor<[4]>, | prims::convert_element_type | 5 | |
| 190 | Tensor<[192,4]>, | prims::convert_element_type | 5 | |
| 191 | Tensor<[100,4]>, | prims::convert_element_type | 5 | |
| 192 | Tensor<[1,256,14,14]>, | aten::sub.Tensor | 4 | |
| 193 | Tensor<[1,512,7,7]>, | aten::sub.Tensor | 4 | |
| 194 | Tensor<[1,12,8,8]>, | aten::_softmax | 4 | |
| 195 | Tensor<[1,8,768]>, | aten::embedding | 4 | |
| 196 | Tensor<[1,3072,8]>, | aten::gelu | 4 | |
| 197 | Tensor<[1,1,1,8]>, | prims::convert_element_type | 4 | |
| 198 | Tensor<[3]>, | prims::convert_element_type | 5 | |
| 199 | Tensor<[768,3]>, | prims::convert_element_type | 5 | |
| 200 | Tensor<[1,3]>, | prims::convert_element_type | 5 | |
| 201 | Tensor<[1,8,256,2048]>, | aten::_softmax | 4 | |
| 202 | Tensor<[1,8,256,256]>, | aten::_softmax | 4 | |
| 203 | Tensor<[1,8,2048,256]>, | aten::_softmax | 4 | |
| 204 | Tensor<[1,2048,768]>, | aten::embedding | 4 | |
| 205 | Tensor<[2048,768]>, | aten::embedding | 4 | |
| 206 | Tensor<[1,1,1,2048]>, | prims::convert_element_type | 4 | |
| 207 | Tensor<[1280,256]>, | prims::convert_element_type | 5 | |
| 208 | Tensor<[768,256]>, | prims::convert_element_type | 5 | |
| 209 | Tensor<[768,1280]>, | prims::convert_element_type | 5 | |
| 210 | Tensor<[2048,1280]>, | prims::convert_element_type | 5 | |
| 211 | Tensor<[1280,768]>, | prims::convert_element_type | 5 | |
| 212 | Tensor<[1024,1,1]>, | aten::add.Tensor | 4 | |
| 213 | Tensor<[2048,1,1]>, | aten::add.Tensor | 4 | |
| 214 | Tensor<[1,256,56,56]>, | aten::sub.Tensor | 4 | |
| 215 | Tensor<[1,1024,14,14]>, | aten::sub.Tensor | 4 | |
| 216 | Tensor<[1,512,14,14]>, | aten::sub.Tensor | 4 | |
| 217 | Tensor<[1,2048,7,7]>, | aten::sub.Tensor | 4 | |
| 218 | Tensor<[1024]>, | prims::convert_element_type | 5 | |
| 219 | Tensor<[1,2048]>, | prims::convert_element_type | 5 | |
| 220 | Tensor<[2048,1000]>, | prims::convert_element_type | 5 | |
| 221 | Tensor<[1,12,201,201]>, | aten::_softmax | 4 | |
| 222 | Tensor<[1,193,768]>, | aten::embedding | 4 | |
| 223 | Tensor<[1,201,3072]>, | aten::gelu | 4 | |
| 224 | Tensor<[1,1536]>, | aten::gelu | 4 | |
| 225 | Tensor<[1536]>, | aten::mul.Tensor | 4 | |
| 226 | Tensor<[1,201,768]>, | aten::sub.Tensor | 4 | |
| 227 | Tensor<[1,1,384,512]>, | prims::convert_element_type | 4 | |
| 228 | Tensor<[12]>, | prims::convert_element_type | 4 | |
| 229 | Tensor<[1,1,12,16]>, | prims::convert_element_type | 4 | |
| 230 | Tensor<[1,1,1,201]>, | prims::convert_element_type | 4 | |
| 231 | Tensor<[201,768]>, | prims::convert_element_type | 5 | |
| 232 | Tensor<[201,3072]>, | prims::convert_element_type | 5 | |
| 233 | Tensor<[768,1536]>, | prims::convert_element_type | 5 | |
| 234 | Tensor<[3129]>, | prims::convert_element_type | 5 | |
| 235 | Tensor<[1536,3129]>, | prims::convert_element_type | 5 | |
| 236 | Tensor<[1,3129]>, | prims::convert_element_type | 5 | |
| 237 | Tensor<[1,9216]>, | prims::convert_element_type | 5 | |
| 238 | Tensor<[9216,128]>, | prims::convert_element_type | 5 | |
| 239 | Tensor<[1,128]>, | prims::convert_element_type | 5 | |
| 240 | Tensor<[10]>, | prims::convert_element_type | 5 | |
| 241 | Tensor<[128,10]>, | prims::convert_element_type | 5 | |
| 242 | Tensor<[16,19,19]>, | aten::_softmax | 4 | |
| 243 | Tensor<[1,19,1024]>, | aten::embedding | 4 | |
| 244 | Tensor<[19]>, | aten::floor_divide | 4 | |
| 245 | Tensor<[1,19,4096]>, | aten::gelu | 4 | |
| 246 | Tensor<[19,1024]>, | aten::index_select | 4 | |
| 247 | Tensor<[19,19]>, | prims::convert_element_type | 5 | |
| 248 | Tensor<[1,1,19,19]>, | prims::convert_element_type | 4 | |
| 249 | Tensor<[1024,1024]>, | prims::convert_element_type | 5 | |
| 250 | Tensor<[4096]>, | prims::convert_element_type | 5 | |
| 251 | Tensor<[1024,4096]>, | prims::convert_element_type | 5 | |
| 252 | Tensor<[19,4096]>, | prims::convert_element_type | 5 | |
| 253 | Tensor<[4096,1024]>, | prims::convert_element_type | 5 | |
| 254 | Tensor<[19,256008]>, | prims::convert_element_type | 5 | |
| 255 | Tensor<[14,1,1]>, | aten::add.Tensor | 4 | |
| 256 | Tensor<[24,1,1]>, | aten::add.Tensor | 4 | |
| 257 | Tensor<[40,1,1]>, | aten::add.Tensor | 4 | |
| 258 | Tensor<[68,1,1]>, | aten::add.Tensor | 4 | |
| 259 | Tensor<[16,1,1]>, | aten::add.Tensor | 4 | |
| 260 | Tensor<[28,1,1]>, | aten::add.Tensor | 4 | |
| 261 | Tensor<[46,1,1]>, | aten::add.Tensor | 4 | |
| 262 | Tensor<[78,1,1]>, | aten::add.Tensor | 4 | |
| 263 | Tensor<[134,1,1]>, | aten::add.Tensor | 4 | |
| 264 | Tensor<[20,1,1]>, | aten::add.Tensor | 4 | |
| 265 | Tensor<[34,1,1]>, | aten::add.Tensor | 4 | |
| 266 | Tensor<[58,1,1]>, | aten::add.Tensor | 4 | |
| 267 | Tensor<[98,1,1]>, | aten::add.Tensor | 4 | |
| 268 | Tensor<[168,1,1]>, | aten::add.Tensor | 4 | |
| 269 | Tensor<[320,1,1]>, | aten::add.Tensor | 4 | |
| 270 | Tensor<[116,1,1]>, | aten::add.Tensor | 4 | |
| 271 | Tensor<[196,1,1]>, | aten::add.Tensor | 4 | |
| 272 | Tensor<[334,1,1]>, | aten::add.Tensor | 4 | |
| 273 | Tensor<[640,1,1]>, | aten::add.Tensor | 4 | |
| 274 | Tensor<[160,1,1]>, | aten::add.Tensor | 4 | |
| 275 | Tensor<[272,1,1]>, | aten::add.Tensor | 4 | |
| 276 | Tensor<[462,1,1]>, | aten::add.Tensor | 4 | |
| 277 | Tensor<[1,14,56,56]>, | aten::sub.Tensor | 4 | |
| 278 | Tensor<[1,24,56,56]>, | aten::sub.Tensor | 4 | |
| 279 | Tensor<[1,40,56,56]>, | aten::sub.Tensor | 4 | |
| 280 | Tensor<[1,68,56,56]>, | aten::sub.Tensor | 4 | |
| 281 | Tensor<[1,16,28,28]>, | aten::sub.Tensor | 4 | |
| 282 | Tensor<[1,28,28,28]>, | aten::sub.Tensor | 4 | |
| 283 | Tensor<[1,46,28,28]>, | aten::sub.Tensor | 4 | |
| 284 | Tensor<[1,78,28,28]>, | aten::sub.Tensor | 4 | |
| 285 | Tensor<[1,134,28,28]>, | aten::sub.Tensor | 4 | |
| 286 | Tensor<[1,20,28,28]>, | aten::sub.Tensor | 4 | |
| 287 | Tensor<[1,34,28,28]>, | aten::sub.Tensor | 4 | |
| 288 | Tensor<[1,58,28,28]>, | aten::sub.Tensor | 4 | |
| 289 | Tensor<[1,98,28,28]>, | aten::sub.Tensor | 4 | |
| 290 | Tensor<[1,168,28,28]>, | aten::sub.Tensor | 4 | |
| 291 | Tensor<[1,320,28,28]>, | aten::sub.Tensor | 4 | |
| 292 | Tensor<[1,40,14,14]>, | aten::sub.Tensor | 4 | |
| 293 | Tensor<[1,68,14,14]>, | aten::sub.Tensor | 4 | |
| 294 | Tensor<[1,116,14,14]>, | aten::sub.Tensor | 4 | |
| 295 | Tensor<[1,196,14,14]>, | aten::sub.Tensor | 4 | |
| 296 | Tensor<[1,334,14,14]>, | aten::sub.Tensor | 4 | |
| 297 | Tensor<[1,640,14,14]>, | aten::sub.Tensor | 4 | |
| 298 | Tensor<[1,160,7,7]>, | aten::sub.Tensor | 4 | |
| 299 | Tensor<[1,272,7,7]>, | aten::sub.Tensor | 4 | |
| 300 | Tensor<[1,462,7,7]>, | aten::sub.Tensor | 4 | |
| 301 | Tensor<[1,1024,7,7]>, | aten::sub.Tensor | 4 | |
| 302 | Tensor<[14]>, | prims::convert_element_type | 5 | |
| 303 | Tensor<[24]>, | prims::convert_element_type | 5 | |
| 304 | Tensor<[68]>, | prims::convert_element_type | 5 | |
| 305 | Tensor<[28]>, | prims::convert_element_type | 5 | |
| 306 | Tensor<[46]>, | prims::convert_element_type | 5 | |
| 307 | Tensor<[78]>, | prims::convert_element_type | 5 | |
| 308 | Tensor<[134]>, | prims::convert_element_type | 5 | |
| 309 | Tensor<[20]>, | prims::convert_element_type | 5 | |
| 310 | Tensor<[34]>, | prims::convert_element_type | 5 | |
| 311 | Tensor<[58]>, | prims::convert_element_type | 5 | |
| 312 | Tensor<[98]>, | prims::convert_element_type | 5 | |
| 313 | Tensor<[168]>, | prims::convert_element_type | 5 | |
| 314 | Tensor<[116]>, | prims::convert_element_type | 5 | |
| 315 | Tensor<[196]>, | prims::convert_element_type | 5 | |
| 316 | Tensor<[334]>, | prims::convert_element_type | 5 | |
| 317 | Tensor<[160]>, | prims::convert_element_type | 5 | |
| 318 | Tensor<[272]>, | prims::convert_element_type | 5 | |
| 319 | Tensor<[462]>, | prims::convert_element_type | 5 | |
| 320 | Tensor<[1,1024]>, | prims::convert_element_type | 5 | |
| 321 | Tensor<[1024,1000]>, | prims::convert_element_type | 5 | |
| 322 | Tensor<[1,32,512,512]>, | aten::sub.Tensor | 4 | |
| 323 | Tensor<[1,64,256,256]>, | aten::sub.Tensor | 4 | |
| 324 | Tensor<[1,32,256,256]>, | aten::sub.Tensor | 4 | |
| 325 | Tensor<[1,128,128,128]>, | aten::sub.Tensor | 4 | |
| 326 | Tensor<[1,64,128,128]>, | aten::sub.Tensor | 4 | |
| 327 | Tensor<[1,256,64,64]>, | aten::sub.Tensor | 4 | |
| 328 | Tensor<[1,128,64,64]>, | aten::sub.Tensor | 4 | |
| 329 | Tensor<[1,512,32,32]>, | aten::sub.Tensor | 4 | |
| 330 | Tensor<[1,256,32,32]>, | aten::sub.Tensor | 4 | |
| 331 | Tensor<[1,1024,16,16]>, | aten::sub.Tensor | 4 | |
| 332 | Tensor<[1,512,16,16]>, | aten::sub.Tensor | 4 | |
| 333 | Tensor<[1,256,16,16]>, | aten::sub.Tensor | 4 | |
| 334 | Tensor<[1,128,32,32]>, | aten::sub.Tensor | 4 | |
| 335 | Tensor<[1,32,1536]>, | aten::embedding | 4 | |
| 336 | Tensor<[16,1,32]>, | prims::convert_element_type | 5 | |
| 337 | Tensor<[4608]>, | prims::convert_element_type | 5 | |
| 338 | Tensor<[32,1536]>, | prims::convert_element_type | 5 | |
| 339 | Tensor<[1536,4608]>, | prims::convert_element_type | 5 | |
| 340 | Tensor<[32,4608]>, | prims::convert_element_type | 5 | |
| 341 | Tensor<[1,16,32,32]>, | prims::convert_element_type | 5 | |
| 342 | Tensor<[1536,1536]>, | prims::convert_element_type | 5 | |
| 343 | Tensor<[6144]>, | prims::convert_element_type | 5 | |
| 344 | Tensor<[1536,6144]>, | prims::convert_element_type | 5 | |
| 345 | Tensor<[32,6144]>, | prims::convert_element_type | 5 | |
| 346 | Tensor<[6144,1536]>, | prims::convert_element_type | 5 | |
| 347 | Tensor<[1,1,16,16]>, | aten::add.Tensor | 4 | |
| 348 | Tensor<[1,16,768]>, | aten::embedding | 4 | |
| 349 | Tensor<[1,16,3072]>, | aten::gelu | 4 | |
| 350 | Tensor<[16,768]>, | prims::convert_element_type | 5 | |
| 351 | Tensor<[1,12,16,64]>, | prims::convert_element_type | 5 | |
| 352 | Tensor<[16,3072]>, | prims::convert_element_type | 5 | |
| 353 | Tensor<[1,64,224,224]>, | aten::sub.Tensor | 4 | |
| 354 | Tensor<[1,128,112,112]>, | aten::sub.Tensor | 4 | |
| 355 | Tensor<[1,1,19200,300]>, | aten::_softmax | 4 | |
| 356 | Tensor<[1,2,4800,300]>, | aten::_softmax | 4 | |
| 357 | Tensor<[1,5,1200,300]>, | aten::_softmax | 4 | |
| 358 | Tensor<[1,8,300,300]>, | aten::_softmax | 4 | |
| 359 | Tensor<[1,19200,256]>, | aten::gelu | 4 | |
| 360 | Tensor<[1,4800,512]>, | aten::gelu | 4 | |
| 361 | Tensor<[1,1200,1280]>, | aten::gelu | 4 | |
| 362 | Tensor<[1,300,2048]>, | aten::gelu | 4 | |
| 363 | Tensor<[1,19200,64]>, | aten::sub.Tensor | 4 | |
| 364 | Tensor<[1,300,64]>, | aten::sub.Tensor | 4 | |
| 365 | Tensor<[1,4800,128]>, | aten::sub.Tensor | 4 | |
| 366 | Tensor<[1,300,128]>, | aten::sub.Tensor | 4 | |
| 367 | Tensor<[1,1200,320]>, | aten::sub.Tensor | 4 | |
| 368 | Tensor<[1,300,320]>, | aten::sub.Tensor | 4 | |
| 369 | Tensor<[1,300,512]>, | aten::sub.Tensor | 4 | |
| 370 | Tensor<[30,1]>, | aten::sub.Tensor | 4 | |
| 371 | Tensor<[1,64,30,40]>, | aten::sub.Tensor | 4 | |
| 372 | Tensor<[1,32,30,40]>, | aten::sub.Tensor | 4 | |
| 373 | Tensor<[80]>, | aten::sub.Tensor | 4 | |
| 374 | Tensor<[60,1]>, | aten::sub.Tensor | 4 | |
| 375 | Tensor<[1,64,60,80]>, | aten::sub.Tensor | 4 | |
| 376 | Tensor<[1,32,60,80]>, | aten::sub.Tensor | 4 | |
| 377 | Tensor<[120,1]>, | aten::sub.Tensor | 4 | |
| 378 | Tensor<[1,64,120,160]>, | aten::sub.Tensor | 4 | |
| 379 | Tensor<[1,32,120,160]>, | aten::sub.Tensor | 4 | |
| 380 | Tensor<[240,1]>, | aten::sub.Tensor | 4 | |
| 381 | Tensor<[480,1]>, | aten::sub.Tensor | 4 | |
| 382 | Tensor<[19200,64]>, | prims::convert_element_type | 5 | |
| 383 | Tensor<[64,64]>, | prims::convert_element_type | 5 | |
| 384 | Tensor<[300,64]>, | prims::convert_element_type | 5 | |
| 385 | Tensor<[64,256]>, | prims::convert_element_type | 5 | |
| 386 | Tensor<[19200,256]>, | prims::convert_element_type | 5 | |
| 387 | Tensor<[4800,128]>, | prims::convert_element_type | 5 | |
| 388 | Tensor<[128,128]>, | prims::convert_element_type | 5 | |
| 389 | Tensor<[300,128]>, | prims::convert_element_type | 5 | |
| 390 | Tensor<[128,512]>, | prims::convert_element_type | 5 | |
| 391 | Tensor<[4800,512]>, | prims::convert_element_type | 5 | |
| 392 | Tensor<[1200,320]>, | prims::convert_element_type | 5 | |
| 393 | Tensor<[300,320]>, | prims::convert_element_type | 5 | |
| 394 | Tensor<[1200,1280]>, | prims::convert_element_type | 5 | |
| 395 | Tensor<[300,512]>, | prims::convert_element_type | 5 | |
| 396 | Tensor<[512,512]>, | prims::convert_element_type | 5 | |
| 397 | Tensor<[512,2048]>, | prims::convert_element_type | 5 | |
| 398 | Tensor<[300,2048]>, | prims::convert_element_type | 5 | |
| 399 | Tensor<[1,64,15,20]>, | prims::convert_element_type | 5 | |
| 400 | Tensor<[30]>, | prims::convert_element_type | 4 | |
| 401 | Tensor<[60]>, | prims::convert_element_type | 4 | |
| 402 | Tensor<[120]>, | prims::convert_element_type | 4 | |
| 403 | Tensor<[240]>, | prims::convert_element_type | 4 | |
| 404 | Tensor<[1,64,240,320]>, | prims::convert_element_type | 5 | |
| 405 | Tensor<[480]>, | prims::convert_element_type | 4 | |
| 406 | Tensor<[1,64,480,640]>, | prims::convert_element_type | 5 | |
| 407 | Tensor<[1,197,3072]>, | aten::gelu | 4 | |
| 408 | Tensor<[1,197,768]>, | aten::sub.Tensor | 4 | |
| 409 | Tensor<[1,3,224,224]>, | prims::convert_element_type | 5 | |
| 410 | Tensor<[197,768]>, | prims::convert_element_type | 5 | |
| 411 | Tensor<[1,12,197,64]>, | prims::convert_element_type | 5 | |
| 412 | Tensor<[197,3072]>, | prims::convert_element_type | 5 | |
| 413 | Tensor<[768,1000]>, | prims::convert_element_type | 5 | |
| 414 | Tensor<[1,1,16384,256]>, | aten::_softmax | 4 | |
| 415 | Tensor<[1,2,4096,256]>, | aten::_softmax | 4 | |
| 416 | Tensor<[1,5,1024,256]>, | aten::_softmax | 4 | |
| 417 | Tensor<[1,16384,128]>, | aten::gelu | 4 | |
| 418 | Tensor<[1,4096,256]>, | aten::gelu | 4 | |
| 419 | Tensor<[1,256,1024]>, | aten::gelu | 4 | |
| 420 | Tensor<[1,16384,32]>, | aten::sub.Tensor | 4 | |
| 421 | Tensor<[1,256,32]>, | aten::sub.Tensor | 4 | |
| 422 | Tensor<[1,4096,64]>, | aten::sub.Tensor | 4 | |
| 423 | Tensor<[1,256,64]>, | aten::sub.Tensor | 4 | |
| 424 | Tensor<[1,1024,160]>, | aten::sub.Tensor | 4 | |
| 425 | Tensor<[1,256,160]>, | aten::sub.Tensor | 4 | |
| 426 | Tensor<[128,1]>, | aten::sub.Tensor | 4 | |
| 427 | Tensor<[1,256,128,128]>, | aten::sub.Tensor | 4 | |
| 428 | Tensor<[16384,32]>, | prims::convert_element_type | 5 | |
| 429 | Tensor<[256,32]>, | prims::convert_element_type | 5 | |
| 430 | Tensor<[32,128]>, | prims::convert_element_type | 5 | |
| 431 | Tensor<[16384,128]>, | prims::convert_element_type | 5 | |
| 432 | Tensor<[4096,64]>, | prims::convert_element_type | 5 | |
| 433 | Tensor<[256,64]>, | prims::convert_element_type | 5 | |
| 434 | Tensor<[4096,256]>, | prims::convert_element_type | 5 | |
| 435 | Tensor<[1024,160]>, | prims::convert_element_type | 5 | |
| 436 | Tensor<[160,160]>, | prims::convert_element_type | 5 | |
| 437 | Tensor<[256,160]>, | prims::convert_element_type | 5 | |
| 438 | Tensor<[160,640]>, | prims::convert_element_type | 5 | |
| 439 | Tensor<[256,1024]>, | prims::convert_element_type | 5 | |
| 440 | Tensor<[1,1,1,7]>, | aten::add.Tensor | 4 | |
| 441 | Tensor<[4544]>, | aten::add.Tensor | 4 | |
| 442 | Tensor<[1,7,4544]>, | aten::embedding | 4 | |
| 443 | Tensor<[1,7,18176]>, | aten::gelu | 4 | |
| 444 | Tensor<[1,1,7]>, | prims::convert_element_type | 4 | |
| 445 | Tensor<[1,7,64]>, | prims::convert_element_type | 5 | |
| 446 | Tensor<[1,71,7,64]>, | prims::convert_element_type | 5 | |
| 447 | Tensor<[1,1,7,64]>, | prims::convert_element_type | 5 | |
| 448 | Tensor<[96,1,1]>, | aten::add.Tensor | 4 | |
| 449 | Tensor<[144,1,1]>, | aten::add.Tensor | 4 | |
| 450 | Tensor<[192,1,1]>, | aten::add.Tensor | 4 | |
| 451 | Tensor<[384,1,1]>, | aten::add.Tensor | 4 | |
| 452 | Tensor<[576,1,1]>, | aten::add.Tensor | 4 | |
| 453 | Tensor<[960,1,1]>, | aten::add.Tensor | 4 | |
| 454 | Tensor<[1280,1,1]>, | aten::add.Tensor | 4 | |
| 455 | Tensor<[1,16,112,112]>, | aten::sub.Tensor | 4 | |
| 456 | Tensor<[1,96,112,112]>, | aten::sub.Tensor | 4 | |
| 457 | Tensor<[1,96,56,56]>, | aten::sub.Tensor | 4 | |
| 458 | Tensor<[1,144,56,56]>, | aten::sub.Tensor | 4 | |
| 459 | Tensor<[1,144,28,28]>, | aten::sub.Tensor | 4 | |
| 460 | Tensor<[1,32,28,28]>, | aten::sub.Tensor | 4 | |
| 461 | Tensor<[1,192,28,28]>, | aten::sub.Tensor | 4 | |
| 462 | Tensor<[1,192,14,14]>, | aten::sub.Tensor | 4 | |
| 463 | Tensor<[1,64,14,14]>, | aten::sub.Tensor | 4 | |
| 464 | Tensor<[1,384,14,14]>, | aten::sub.Tensor | 4 | |
| 465 | Tensor<[1,96,14,14]>, | aten::sub.Tensor | 4 | |
| 466 | Tensor<[1,576,14,14]>, | aten::sub.Tensor | 4 | |
| 467 | Tensor<[1,576,7,7]>, | aten::sub.Tensor | 4 | |
| 468 | Tensor<[1,960,7,7]>, | aten::sub.Tensor | 4 | |
| 469 | Tensor<[1,320,7,7]>, | aten::sub.Tensor | 4 | |
| 470 | Tensor<[1,1280,7,7]>, | aten::sub.Tensor | 4 | |
| 471 | Tensor<[96]>, | prims::convert_element_type | 5 | |
| 472 | Tensor<[144]>, | prims::convert_element_type | 5 | |
| 473 | Tensor<[384]>, | prims::convert_element_type | 5 | |
| 474 | Tensor<[576]>, | prims::convert_element_type | 5 | |
| 475 | Tensor<[960]>, | prims::convert_element_type | 5 | |
| 476 | Tensor<[1280,1000]>, | prims::convert_element_type | 5 | |
| 477 | Tensor<[1,1,12,12]>, | aten::add.Tensor | 4 | |
| 478 | Tensor<[1,12,128]>, | aten::embedding | 4 | |
| 479 | Tensor<[1,12,768]>, | aten::sub.Tensor | 4 | |
| 480 | Tensor<[12,128]>, | prims::convert_element_type | 5 | |
| 481 | Tensor<[128,768]>, | prims::convert_element_type | 5 | |
| 482 | Tensor<[12,768]>, | prims::convert_element_type | 5 | |
| 483 | Tensor<[1,12,12,64]>, | prims::convert_element_type | 5 | |
| 484 | Tensor<[12,3072]>, | prims::convert_element_type | 5 | |
| 485 | Tensor<[12,2]>, | prims::convert_element_type | 5 | |
| 486 | Tensor<[1,1,9,9]>, | aten::add.Tensor | 4 | |
| 487 | Tensor<[1,9,128]>, | aten::embedding | 4 | |
| 488 | Tensor<[1,9,768]>, | aten::sub.Tensor | 4 | |
| 489 | Tensor<[9,128]>, | prims::convert_element_type | 5 | |
| 490 | Tensor<[9,768]>, | prims::convert_element_type | 5 | |
| 491 | Tensor<[1,12,9,64]>, | prims::convert_element_type | 5 | |
| 492 | Tensor<[9,3072]>, | prims::convert_element_type | 5 | |
| 493 | Tensor<[768,128]>, | prims::convert_element_type | 5 | |
| 494 | Tensor<[30000]>, | prims::convert_element_type | 5 | |
| 495 | Tensor<[128,30000]>, | prims::convert_element_type | 5 | |
| 496 | Tensor<[9,30000]>, | prims::convert_element_type | 5 | |
| 497 | Tensor<[1,9,2048]>, | aten::sub.Tensor | 4 | |
| 498 | Tensor<[128,2048]>, | prims::convert_element_type | 5 | |
| 499 | Tensor<[9,2048]>, | prims::convert_element_type | 5 | |
| 500 | Tensor<[2048,2048]>, | prims::convert_element_type | 5 | |
| 501 | Tensor<[1,16,9,128]>, | prims::convert_element_type | 5 | |
| 502 | Tensor<[8192]>, | prims::convert_element_type | 5 | |
| 503 | Tensor<[2048,8192]>, | prims::convert_element_type | 5 | |
| 504 | Tensor<[9,8192]>, | prims::convert_element_type | 5 | |
| 505 | Tensor<[8192,2048]>, | prims::convert_element_type | 5 | |
| 506 | Tensor<[2048,128]>, | prims::convert_element_type | 5 | |
| 507 | Tensor<[1,9,1024]>, | aten::sub.Tensor | 4 | |
| 508 | Tensor<[128,1024]>, | prims::convert_element_type | 5 | |
| 509 | Tensor<[9,1024]>, | prims::convert_element_type | 5 | |
| 510 | Tensor<[1,16,9,64]>, | prims::convert_element_type | 5 | |
| 511 | Tensor<[9,4096]>, | prims::convert_element_type | 5 | |
| 512 | Tensor<[1024,128]>, | prims::convert_element_type | 5 | |
| 513 | Tensor<[1,9,4096]>, | aten::sub.Tensor | 4 | |
| 514 | Tensor<[128,4096]>, | prims::convert_element_type | 5 | |
| 515 | Tensor<[4096,4096]>, | prims::convert_element_type | 5 | |
| 516 | Tensor<[1,64,9,64]>, | prims::convert_element_type | 5 | |
| 517 | Tensor<[16384]>, | prims::convert_element_type | 5 | |
| 518 | Tensor<[4096,16384]>, | prims::convert_element_type | 5 | |
| 519 | Tensor<[9,16384]>, | prims::convert_element_type | 5 | |
| 520 | Tensor<[16384,4096]>, | prims::convert_element_type | 5 | |
| 521 | Tensor<[4096,128]>, | prims::convert_element_type | 5 | |
| 522 | Tensor<[1,2]>, | prims::convert_element_type | 5 | |
| 523 | Tensor<[1,1,14,14]>, | aten::add.Tensor | 4 | |
| 524 | Tensor<[1,14,128]>, | aten::embedding | 4 | |
| 525 | Tensor<[1,14,768]>, | aten::sub.Tensor | 4 | |
| 526 | Tensor<[14,128]>, | prims::convert_element_type | 5 | |
| 527 | Tensor<[14,768]>, | prims::convert_element_type | 5 | |
| 528 | Tensor<[1,12,14,64]>, | prims::convert_element_type | 5 | |
| 529 | Tensor<[14,3072]>, | prims::convert_element_type | 5 | |
| 530 | Tensor<[14,2]>, | prims::convert_element_type | 5 | |
| 531 | Tensor<[2,1,7,7]>, | aten::add.Tensor | 4 | |
| 532 | Tensor<[1,50,768]>, | aten::embedding | 4 | |
| 533 | Tensor<[2,7,512]>, | aten::embedding | 4 | |
| 534 | Tensor<[1,7,512]>, | aten::embedding | 4 | |
| 535 | Tensor<[50,768]>, | prims::convert_element_type | 5 | |
| 536 | Tensor<[1,12,50,64]>, | prims::convert_element_type | 5 | |
| 537 | Tensor<[50,3072]>, | prims::convert_element_type | 5 | |
| 538 | Tensor<[14,512]>, | prims::convert_element_type | 5 | |
| 539 | Tensor<[2,8,7,64]>, | prims::convert_element_type | 5 | |
| 540 | Tensor<[14,2048]>, | prims::convert_element_type | 5 | |
| 541 | Tensor<[2048,512]>, | prims::convert_element_type | 5 | |
| 542 | Tensor<[2,7]>, | prims::convert_element_type | 4 | |
| 543 | Tensor<[1,16,197,197]>, | aten::_softmax | 4 | |
| 544 | Tensor<[197]>, | aten::floor_divide | 4 | |
| 545 | Tensor<[1,197,4096]>, | aten::gelu | 4 | |
| 546 | Tensor<[1,197,1024]>, | aten::sub.Tensor | 4 | |
| 547 | Tensor<[27]>, | aten::sub.Tensor | 4 | |
| 548 | Tensor<[27,1]>, | aten::sub.Tensor | 4 | |
| 549 | Tensor<[197,1024]>, | prims::convert_element_type | 5 | |
| 550 | Tensor<[1,16,27,27]>, | prims::convert_element_type | 5 | |
| 551 | Tensor<[197,4096]>, | prims::convert_element_type | 5 | |
| 552 | Tensor<[1,12,197,197]>, | aten::_softmax | 4 | |
| 553 | Tensor<[1,12,27,27]>, | prims::convert_element_type | 5 | |
| 554 | Tensor<[1,784]>, | prims::convert_element_type | 5 | |
| 555 | Tensor<[784,128]>, | prims::convert_element_type | 5 | |
| 556 | Tensor<[128,64]>, | prims::convert_element_type | 5 | |
| 557 | Tensor<[1,64]>, | prims::convert_element_type | 5 | |
| 558 | Tensor<[64,12]>, | prims::convert_element_type | 5 | |
| 559 | Tensor<[1,12]>, | prims::convert_element_type | 5 | |
| 560 | Tensor<[12,3]>, | prims::convert_element_type | 5 | |
| 561 | Tensor<[3,12]>, | prims::convert_element_type | 5 | |
| 562 | Tensor<[12,64]>, | prims::convert_element_type | 5 | |
| 563 | Tensor<[64,128]>, | prims::convert_element_type | 5 | |
| 564 | Tensor<[784]>, | prims::convert_element_type | 5 | |
| 565 | Tensor<[128,784]>, | prims::convert_element_type | 5 |
stablehlo.convolution::ttnn.conv2d
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,3,224,224]>, Tensor<[32,3,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 1 | Tensor<[1,32,112,112]>, Tensor<[32,1,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 32 | ttnn.conv2d | aten::convolution | 5 |
| 2 | Tensor<[1,32,112,112]>, Tensor<[64,32,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 3 | Tensor<[1,64,112,112]>, Tensor<[64,1,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 64 | ttnn.conv2d | aten::convolution | 5 |
| 4 | Tensor<[1,64,56,56]>, Tensor<[128,64,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 5 | Tensor<[1,128,56,56]>, Tensor<[128,1,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 128 | ttnn.conv2d | aten::convolution | 5 |
| 6 | Tensor<[1,128,56,56]>, Tensor<[128,128,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 7 | Tensor<[1,128,56,56]>, Tensor<[128,1,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 128 | ttnn.conv2d | aten::convolution | 5 |
| 8 | Tensor<[1,128,28,28]>, Tensor<[256,128,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 9 | Tensor<[1,256,28,28]>, Tensor<[256,1,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 256 | ttnn.conv2d | aten::convolution | 5 |
| 10 | Tensor<[1,256,28,28]>, Tensor<[256,256,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 11 | Tensor<[1,256,28,28]>, Tensor<[512,256,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 12 | Tensor<[1,512,28,28]>, Tensor<[512,1,3,3]>, stride: [1, 1] pad: [[2, 2], [2, 2]] rhs_dilate: [2, 2] batch_group_count: 1 feature_group_count: 512 | ttnn.conv2d | aten::convolution | 5 |
| 13 | Tensor<[1,512,28,28]>, Tensor<[512,512,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 14 | Tensor<[1,512,28,28]>, Tensor<[512,1,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 512 | ttnn.conv2d | aten::convolution | 5 |
| 15 | Tensor<[1,512,28,28]>, Tensor<[128,512,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 16 | Tensor<[1,128,28,28]>, Tensor<[128,1,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 128 | ttnn.conv2d | aten::convolution | 5 |
| 17 | Tensor<[1,128,28,28]>, Tensor<[128,128,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 18 | Tensor<[1,128,28,28]>, Tensor<[128,128,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 19 | Tensor<[1,128,28,28]>, Tensor<[512,128,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 20 | Tensor<[1,512,28,28]>, Tensor<[19,512,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 21 | Tensor<[1,512,28,28]>, Tensor<[38,512,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 22 | Tensor<[1,185,28,28]>, Tensor<[128,185,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 23 | Tensor<[1,128,28,28]>, Tensor<[128,128,3,3]>, stride: [1, 1] pad: [[2, 2], [2, 2]] rhs_dilate: [2, 2] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 24 | Tensor<[1,128,28,28]>, Tensor<[19,128,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 25 | Tensor<[1,128,28,28]>, Tensor<[38,128,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 26 | Tensor<[1,256,512]>, Tensor<[1024,256,1]>, stride: [1] pad: [[0, 0]] rhs_dilate: [1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 27 | Tensor<[1,1024,512]>, Tensor<[256,1024,1]>, stride: [1] pad: [[0, 0]] rhs_dilate: [1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 28 | Tensor<[1,3,720,1280]>, Tensor<[64,3,7,7]>, stride: [2, 2] pad: [[3, 3], [3, 3]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 29 | Tensor<[1,64,180,320]>, Tensor<[64,64,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 30 | Tensor<[1,64,180,320]>, Tensor<[64,64,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 31 | Tensor<[1,64,180,320]>, Tensor<[256,64,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 32 | Tensor<[1,256,180,320]>, Tensor<[64,256,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 33 | Tensor<[1,256,180,320]>, Tensor<[128,256,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 34 | Tensor<[1,128,180,320]>, Tensor<[128,128,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 35 | Tensor<[1,128,90,160]>, Tensor<[512,128,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 36 | Tensor<[1,256,180,320]>, Tensor<[512,256,1,1]>, stride: [2, 2] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 37 | Tensor<[1,512,90,160]>, Tensor<[128,512,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 38 | Tensor<[1,128,90,160]>, Tensor<[128,128,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 39 | Tensor<[1,512,90,160]>, Tensor<[256,512,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 40 | Tensor<[1,256,90,160]>, Tensor<[256,256,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 41 | Tensor<[1,256,45,80]>, Tensor<[1024,256,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 42 | Tensor<[1,512,90,160]>, Tensor<[1024,512,1,1]>, stride: [2, 2] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 43 | Tensor<[1,1024,45,80]>, Tensor<[256,1024,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 44 | Tensor<[1,256,45,80]>, Tensor<[256,256,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 45 | Tensor<[1,1024,45,80]>, Tensor<[512,1024,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 46 | Tensor<[1,512,45,80]>, Tensor<[512,512,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 47 | Tensor<[1,512,23,40]>, Tensor<[2048,512,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 48 | Tensor<[1,1024,45,80]>, Tensor<[2048,1024,1,1]>, stride: [2, 2] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 49 | Tensor<[1,2048,23,40]>, Tensor<[512,2048,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 50 | Tensor<[1,512,23,40]>, Tensor<[512,512,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 51 | Tensor<[1,2048,23,40]>, Tensor<[256,2048,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 52 | Tensor<[1,4,64,64]>, Tensor<[320,4,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 53 | Tensor<[1,320,64,64]>, Tensor<[320,320,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 54 | Tensor<[1,320,64,64]>, Tensor<[320,320,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 55 | Tensor<[1,320,64,64]>, Tensor<[320,320,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 56 | Tensor<[1,320,32,32]>, Tensor<[640,320,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 57 | Tensor<[1,640,32,32]>, Tensor<[640,640,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 58 | Tensor<[1,320,32,32]>, Tensor<[640,320,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 59 | Tensor<[1,640,32,32]>, Tensor<[640,640,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 60 | Tensor<[1,640,32,32]>, Tensor<[640,640,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 61 | Tensor<[1,640,16,16]>, Tensor<[1280,640,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 62 | Tensor<[1,1280,16,16]>, Tensor<[1280,1280,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 63 | Tensor<[1,640,16,16]>, Tensor<[1280,640,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 64 | Tensor<[1,1280,16,16]>, Tensor<[1280,1280,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 65 | Tensor<[1,1280,16,16]>, Tensor<[1280,1280,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 66 | Tensor<[1,1280,8,8]>, Tensor<[1280,1280,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 67 | Tensor<[1,1280,8,8]>, Tensor<[1280,1280,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 68 | Tensor<[1,2560,8,8]>, Tensor<[1280,2560,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 69 | Tensor<[1,2560,8,8]>, Tensor<[1280,2560,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 70 | Tensor<[1,2560,16,16]>, Tensor<[1280,2560,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 71 | Tensor<[1,2560,16,16]>, Tensor<[1280,2560,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 72 | Tensor<[1,1920,16,16]>, Tensor<[1280,1920,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 73 | Tensor<[1,1920,16,16]>, Tensor<[1280,1920,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 74 | Tensor<[1,1280,32,32]>, Tensor<[1280,1280,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 75 | Tensor<[1,1920,32,32]>, Tensor<[640,1920,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 76 | Tensor<[1,1920,32,32]>, Tensor<[640,1920,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 77 | Tensor<[1,1280,32,32]>, Tensor<[640,1280,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 78 | Tensor<[1,1280,32,32]>, Tensor<[640,1280,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 79 | Tensor<[1,960,32,32]>, Tensor<[640,960,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 80 | Tensor<[1,960,32,32]>, Tensor<[640,960,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 81 | Tensor<[1,640,64,64]>, Tensor<[640,640,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 82 | Tensor<[1,960,64,64]>, Tensor<[320,960,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 83 | Tensor<[1,960,64,64]>, Tensor<[320,960,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 84 | Tensor<[1,640,64,64]>, Tensor<[320,640,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 85 | Tensor<[1,640,64,64]>, Tensor<[320,640,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 86 | Tensor<[1,320,64,64]>, Tensor<[4,320,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 87 | Tensor<[1,3,512,672]>, Tensor<[192,3,16,16]>, stride: [16, 16] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 88 | Tensor<[1,3,224,224]>, Tensor<[64,3,7,7]>, stride: [2, 2] pad: [[3, 3], [3, 3]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 89 | Tensor<[1,64,56,56]>, Tensor<[64,64,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 90 | Tensor<[1,64,56,56]>, Tensor<[128,64,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 91 | Tensor<[1,64,56,56]>, Tensor<[128,64,1,1]>, stride: [2, 2] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 92 | Tensor<[1,128,28,28]>, Tensor<[256,128,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 93 | Tensor<[1,256,14,14]>, Tensor<[256,256,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 94 | Tensor<[1,128,28,28]>, Tensor<[256,128,1,1]>, stride: [2, 2] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 95 | Tensor<[1,256,14,14]>, Tensor<[512,256,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 96 | Tensor<[1,512,7,7]>, Tensor<[512,512,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 97 | Tensor<[1,256,14,14]>, Tensor<[512,256,1,1]>, stride: [2, 2] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 98 | Tensor<[1,768,8]>, Tensor<[768,192,1]>, stride: [1] pad: [[0, 0]] rhs_dilate: [1] batch_group_count: 1 feature_group_count: 4 | ttnn.conv2d | aten::convolution | 4 |
| 99 | Tensor<[1,768,8]>, Tensor<[768,768,1]>, stride: [1] pad: [[0, 0]] rhs_dilate: [1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 100 | Tensor<[1,768,8]>, Tensor<[3072,192,1]>, stride: [1] pad: [[0, 0]] rhs_dilate: [1] batch_group_count: 1 feature_group_count: 4 | ttnn.conv2d | aten::convolution | 4 |
| 101 | Tensor<[1,3072,8]>, Tensor<[768,768,1]>, stride: [1] pad: [[0, 0]] rhs_dilate: [1] batch_group_count: 1 feature_group_count: 4 | ttnn.conv2d | aten::convolution | 4 |
| 102 | Tensor<[1,64,56,56]>, Tensor<[64,64,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 103 | Tensor<[1,64,56,56]>, Tensor<[256,64,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 104 | Tensor<[1,256,56,56]>, Tensor<[64,256,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 105 | Tensor<[1,256,56,56]>, Tensor<[128,256,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 106 | Tensor<[1,128,56,56]>, Tensor<[128,128,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 107 | Tensor<[1,256,56,56]>, Tensor<[512,256,1,1]>, stride: [2, 2] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 108 | Tensor<[1,512,28,28]>, Tensor<[256,512,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 109 | Tensor<[1,256,28,28]>, Tensor<[256,256,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 110 | Tensor<[1,256,14,14]>, Tensor<[1024,256,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 111 | Tensor<[1,512,28,28]>, Tensor<[1024,512,1,1]>, stride: [2, 2] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 112 | Tensor<[1,1024,14,14]>, Tensor<[256,1024,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 113 | Tensor<[1,1024,14,14]>, Tensor<[512,1024,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 114 | Tensor<[1,512,14,14]>, Tensor<[512,512,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 115 | Tensor<[1,512,7,7]>, Tensor<[2048,512,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 116 | Tensor<[1,1024,14,14]>, Tensor<[2048,1024,1,1]>, stride: [2, 2] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 117 | Tensor<[1,2048,7,7]>, Tensor<[512,2048,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 118 | Tensor<[1,3,384,512]>, Tensor<[768,3,32,32]>, stride: [32, 32] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 119 | Tensor<[1,1,28,28]>, Tensor<[32,1,3,3]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 120 | Tensor<[1,32,26,26]>, Tensor<[64,32,3,3]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 121 | Tensor<[1,32,112,112]>, Tensor<[64,32,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 122 | Tensor<[1,64,56,56]>, Tensor<[14,64,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 123 | Tensor<[1,78,56,56]>, Tensor<[24,78,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 124 | Tensor<[1,24,56,56]>, Tensor<[14,24,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 125 | Tensor<[1,102,56,56]>, Tensor<[40,102,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 126 | Tensor<[1,40,56,56]>, Tensor<[14,40,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 127 | Tensor<[1,54,56,56]>, Tensor<[24,54,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 128 | Tensor<[1,142,56,56]>, Tensor<[68,142,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 129 | Tensor<[1,124,56,56]>, Tensor<[128,124,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 130 | Tensor<[1,128,28,28]>, Tensor<[16,128,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 131 | Tensor<[1,144,28,28]>, Tensor<[28,144,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 132 | Tensor<[1,28,28,28]>, Tensor<[16,28,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 133 | Tensor<[1,172,28,28]>, Tensor<[46,172,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 134 | Tensor<[1,46,28,28]>, Tensor<[16,46,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 135 | Tensor<[1,62,28,28]>, Tensor<[28,62,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 136 | Tensor<[1,218,28,28]>, Tensor<[78,218,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 137 | Tensor<[1,78,28,28]>, Tensor<[16,78,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 138 | Tensor<[1,94,28,28]>, Tensor<[28,94,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 139 | Tensor<[1,122,28,28]>, Tensor<[46,122,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 140 | Tensor<[1,296,28,28]>, Tensor<[134,296,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 141 | Tensor<[1,262,28,28]>, Tensor<[256,262,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 142 | Tensor<[1,256,28,28]>, Tensor<[20,256,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 143 | Tensor<[1,276,28,28]>, Tensor<[34,276,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 144 | Tensor<[1,34,28,28]>, Tensor<[20,34,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 145 | Tensor<[1,310,28,28]>, Tensor<[58,310,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 146 | Tensor<[1,58,28,28]>, Tensor<[20,58,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 147 | Tensor<[1,78,28,28]>, Tensor<[34,78,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 148 | Tensor<[1,368,28,28]>, Tensor<[98,368,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 149 | Tensor<[1,98,28,28]>, Tensor<[20,98,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 150 | Tensor<[1,118,28,28]>, Tensor<[34,118,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 151 | Tensor<[1,152,28,28]>, Tensor<[58,152,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 152 | Tensor<[1,466,28,28]>, Tensor<[168,466,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 153 | Tensor<[1,328,28,28]>, Tensor<[320,328,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 154 | Tensor<[1,320,14,14]>, Tensor<[40,320,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 155 | Tensor<[1,360,14,14]>, Tensor<[68,360,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 156 | Tensor<[1,68,14,14]>, Tensor<[40,68,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 157 | Tensor<[1,428,14,14]>, Tensor<[116,428,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 158 | Tensor<[1,116,14,14]>, Tensor<[40,116,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 159 | Tensor<[1,156,14,14]>, Tensor<[68,156,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 160 | Tensor<[1,544,14,14]>, Tensor<[196,544,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 161 | Tensor<[1,196,14,14]>, Tensor<[40,196,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 162 | Tensor<[1,236,14,14]>, Tensor<[68,236,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 163 | Tensor<[1,304,14,14]>, Tensor<[116,304,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 164 | Tensor<[1,740,14,14]>, Tensor<[334,740,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 165 | Tensor<[1,654,14,14]>, Tensor<[640,654,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 166 | Tensor<[1,640,7,7]>, Tensor<[160,640,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 167 | Tensor<[1,800,7,7]>, Tensor<[272,800,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 168 | Tensor<[1,272,7,7]>, Tensor<[160,272,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 169 | Tensor<[1,1072,7,7]>, Tensor<[462,1072,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 170 | Tensor<[1,782,7,7]>, Tensor<[1024,782,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 171 | Tensor<[1,3,512,512]>, Tensor<[32,3,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 172 | Tensor<[1,32,512,512]>, Tensor<[64,32,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 173 | Tensor<[1,64,256,256]>, Tensor<[32,64,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 174 | Tensor<[1,32,256,256]>, Tensor<[64,32,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 175 | Tensor<[1,64,256,256]>, Tensor<[128,64,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 176 | Tensor<[1,128,128,128]>, Tensor<[64,128,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 177 | Tensor<[1,64,128,128]>, Tensor<[128,64,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 178 | Tensor<[1,128,128,128]>, Tensor<[256,128,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 179 | Tensor<[1,256,64,64]>, Tensor<[128,256,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 180 | Tensor<[1,128,64,64]>, Tensor<[256,128,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 181 | Tensor<[1,256,64,64]>, Tensor<[512,256,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 182 | Tensor<[1,512,32,32]>, Tensor<[256,512,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 183 | Tensor<[1,256,32,32]>, Tensor<[512,256,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 184 | Tensor<[1,512,32,32]>, Tensor<[1024,512,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 185 | Tensor<[1,1024,16,16]>, Tensor<[512,1024,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 186 | Tensor<[1,512,16,16]>, Tensor<[1024,512,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 187 | Tensor<[1,1024,16,16]>, Tensor<[255,1024,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 188 | Tensor<[1,512,16,16]>, Tensor<[256,512,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 189 | Tensor<[1,768,32,32]>, Tensor<[256,768,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 190 | Tensor<[1,512,32,32]>, Tensor<[255,512,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 191 | Tensor<[1,256,32,32]>, Tensor<[128,256,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 192 | Tensor<[1,384,64,64]>, Tensor<[128,384,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 193 | Tensor<[1,256,64,64]>, Tensor<[255,256,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 194 | Tensor<[1,3,256,256]>, Tensor<[32,3,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 195 | Tensor<[1,32,256,256]>, Tensor<[32,32,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 196 | Tensor<[1,32,128,128]>, Tensor<[64,32,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 197 | Tensor<[1,64,128,128]>, Tensor<[64,64,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 198 | Tensor<[1,64,64,64]>, Tensor<[128,64,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 199 | Tensor<[1,128,64,64]>, Tensor<[128,128,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 200 | Tensor<[1,128,32,32]>, Tensor<[256,128,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 201 | Tensor<[1,256,32,32]>, Tensor<[256,256,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 202 | Tensor<[1,256,16,16]>, Tensor<[512,256,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 203 | Tensor<[1,512,16,16]>, Tensor<[512,512,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 204 | Tensor<[1,512,16,16]>, Tensor<[2,2,256,512]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] lhs_dilate: [2, 2] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 205 | Tensor<[1,512,32,32]>, Tensor<[256,512,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 206 | Tensor<[1,256,32,32]>, Tensor<[2,2,128,256]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] lhs_dilate: [2, 2] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 207 | Tensor<[1,256,64,64]>, Tensor<[128,256,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 208 | Tensor<[1,128,64,64]>, Tensor<[2,2,64,128]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] lhs_dilate: [2, 2] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 209 | Tensor<[1,128,128,128]>, Tensor<[64,128,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 210 | Tensor<[1,64,128,128]>, Tensor<[2,2,32,64]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] lhs_dilate: [2, 2] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 211 | Tensor<[1,64,256,256]>, Tensor<[32,64,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 212 | Tensor<[1,32,256,256]>, Tensor<[1,32,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 213 | Tensor<[1,1,28,28]>, Tensor<[16,1,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 214 | Tensor<[1,16,14,14]>, Tensor<[4,16,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 215 | Tensor<[1,4,7,7]>, Tensor<[2,2,16,4]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] lhs_dilate: [2, 2] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 216 | Tensor<[1,16,14,14]>, Tensor<[2,2,1,16]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] lhs_dilate: [2, 2] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 217 | Tensor<[1,3,224,224]>, Tensor<[64,3,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 218 | Tensor<[1,64,224,224]>, Tensor<[64,64,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 219 | Tensor<[1,64,112,112]>, Tensor<[128,64,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 220 | Tensor<[1,128,112,112]>, Tensor<[128,128,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 221 | Tensor<[1,128,56,56]>, Tensor<[256,128,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 222 | Tensor<[1,256,56,56]>, Tensor<[256,256,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 223 | Tensor<[1,256,28,28]>, Tensor<[512,256,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 224 | Tensor<[1,512,28,28]>, Tensor<[512,512,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 225 | Tensor<[1,512,14,14]>, Tensor<[1024,512,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 226 | Tensor<[1,1024,14,14]>, Tensor<[1024,1024,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 227 | Tensor<[1,1024,14,14]>, Tensor<[2,2,512,1024]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] lhs_dilate: [2, 2] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 228 | Tensor<[1,1024,28,28]>, Tensor<[512,1024,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 229 | Tensor<[1,512,28,28]>, Tensor<[2,2,256,512]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] lhs_dilate: [2, 2] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 230 | Tensor<[1,512,56,56]>, Tensor<[256,512,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 231 | Tensor<[1,256,56,56]>, Tensor<[2,2,128,256]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] lhs_dilate: [2, 2] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 232 | Tensor<[1,256,112,112]>, Tensor<[128,256,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 233 | Tensor<[1,128,112,112]>, Tensor<[2,2,64,128]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] lhs_dilate: [2, 2] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 234 | Tensor<[1,128,224,224]>, Tensor<[64,128,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 235 | Tensor<[1,64,224,224]>, Tensor<[1,64,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 236 | Tensor<[1,3,480,640]>, Tensor<[64,3,7,7]>, stride: [4, 4] pad: [[3, 3], [3, 3]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 237 | Tensor<[1,64,120,160]>, Tensor<[64,64,8,8]>, stride: [8, 8] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 238 | Tensor<[1,256,120,160]>, Tensor<[256,1,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 256 | ttnn.conv2d | aten::convolution | 4 |
| 239 | Tensor<[1,64,120,160]>, Tensor<[128,64,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 240 | Tensor<[1,128,60,80]>, Tensor<[128,128,4,4]>, stride: [4, 4] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 241 | Tensor<[1,512,60,80]>, Tensor<[512,1,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 512 | ttnn.conv2d | aten::convolution | 4 |
| 242 | Tensor<[1,128,60,80]>, Tensor<[320,128,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 243 | Tensor<[1,320,30,40]>, Tensor<[320,320,2,2]>, stride: [2, 2] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 244 | Tensor<[1,1280,30,40]>, Tensor<[1280,1,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1280 | ttnn.conv2d | aten::convolution | 4 |
| 245 | Tensor<[1,320,30,40]>, Tensor<[512,320,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 246 | Tensor<[1,2048,15,20]>, Tensor<[2048,1,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 2048 | ttnn.conv2d | aten::convolution | 4 |
| 247 | Tensor<[1,512,15,20]>, Tensor<[64,512,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 248 | Tensor<[1,320,30,40]>, Tensor<[64,320,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 249 | Tensor<[1,128,30,40]>, Tensor<[64,128,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 250 | Tensor<[1,64,30,40]>, Tensor<[32,64,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 251 | Tensor<[1,32,30,40]>, Tensor<[2,32,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 252 | Tensor<[1,128,60,80]>, Tensor<[64,128,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 253 | Tensor<[1,128,60,80]>, Tensor<[64,128,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 254 | Tensor<[1,64,60,80]>, Tensor<[32,64,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 255 | Tensor<[1,32,60,80]>, Tensor<[2,32,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 256 | Tensor<[1,128,120,160]>, Tensor<[64,128,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 257 | Tensor<[1,64,120,160]>, Tensor<[32,64,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 258 | Tensor<[1,32,120,160]>, Tensor<[2,32,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 259 | Tensor<[1,64,480,640]>, Tensor<[64,64,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 260 | Tensor<[1,64,480,640]>, Tensor<[1,64,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 261 | Tensor<[1,3,224,224]>, Tensor<[768,3,16,16]>, stride: [16, 16] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 262 | Tensor<[1,3,512,512]>, Tensor<[32,3,7,7]>, stride: [4, 4] pad: [[3, 3], [3, 3]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 263 | Tensor<[1,32,128,128]>, Tensor<[32,32,8,8]>, stride: [8, 8] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 264 | Tensor<[1,128,128,128]>, Tensor<[128,1,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 128 | ttnn.conv2d | aten::convolution | 4 |
| 265 | Tensor<[1,32,128,128]>, Tensor<[64,32,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 266 | Tensor<[1,64,64,64]>, Tensor<[64,64,4,4]>, stride: [4, 4] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 267 | Tensor<[1,256,64,64]>, Tensor<[256,1,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 256 | ttnn.conv2d | aten::convolution | 4 |
| 268 | Tensor<[1,64,64,64]>, Tensor<[160,64,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 269 | Tensor<[1,160,32,32]>, Tensor<[160,160,2,2]>, stride: [2, 2] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 270 | Tensor<[1,640,32,32]>, Tensor<[640,1,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 640 | ttnn.conv2d | aten::convolution | 4 |
| 271 | Tensor<[1,160,32,32]>, Tensor<[256,160,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 272 | Tensor<[1,1024,16,16]>, Tensor<[1024,1,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1024 | ttnn.conv2d | aten::convolution | 4 |
| 273 | Tensor<[1,1024,128,128]>, Tensor<[256,1024,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 274 | Tensor<[1,256,128,128]>, Tensor<[150,256,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
| 275 | Tensor<[1,32,112,112]>, Tensor<[16,32,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 276 | Tensor<[1,16,112,112]>, Tensor<[96,16,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 277 | Tensor<[1,96,112,112]>, Tensor<[96,1,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 96 | ttnn.conv2d | aten::convolution | 5 |
| 278 | Tensor<[1,96,56,56]>, Tensor<[24,96,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 279 | Tensor<[1,24,56,56]>, Tensor<[144,24,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 280 | Tensor<[1,144,56,56]>, Tensor<[144,1,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 144 | ttnn.conv2d | aten::convolution | 5 |
| 281 | Tensor<[1,144,56,56]>, Tensor<[24,144,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 282 | Tensor<[1,144,56,56]>, Tensor<[144,1,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 144 | ttnn.conv2d | aten::convolution | 5 |
| 283 | Tensor<[1,144,28,28]>, Tensor<[32,144,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 284 | Tensor<[1,32,28,28]>, Tensor<[192,32,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 285 | Tensor<[1,192,28,28]>, Tensor<[192,1,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 192 | ttnn.conv2d | aten::convolution | 5 |
| 286 | Tensor<[1,192,28,28]>, Tensor<[32,192,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 287 | Tensor<[1,192,28,28]>, Tensor<[192,1,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 192 | ttnn.conv2d | aten::convolution | 5 |
| 288 | Tensor<[1,192,14,14]>, Tensor<[64,192,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 289 | Tensor<[1,64,14,14]>, Tensor<[384,64,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 290 | Tensor<[1,384,14,14]>, Tensor<[384,1,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 384 | ttnn.conv2d | aten::convolution | 5 |
| 291 | Tensor<[1,384,14,14]>, Tensor<[64,384,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 292 | Tensor<[1,384,14,14]>, Tensor<[96,384,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 293 | Tensor<[1,96,14,14]>, Tensor<[576,96,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 294 | Tensor<[1,576,14,14]>, Tensor<[576,1,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 576 | ttnn.conv2d | aten::convolution | 5 |
| 295 | Tensor<[1,576,14,14]>, Tensor<[96,576,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 296 | Tensor<[1,576,14,14]>, Tensor<[576,1,3,3]>, stride: [2, 2] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 576 | ttnn.conv2d | aten::convolution | 5 |
| 297 | Tensor<[1,576,7,7]>, Tensor<[160,576,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 298 | Tensor<[1,160,7,7]>, Tensor<[960,160,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 299 | Tensor<[1,960,7,7]>, Tensor<[960,1,3,3]>, stride: [1, 1] pad: [[1, 1], [1, 1]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 960 | ttnn.conv2d | aten::convolution | 5 |
| 300 | Tensor<[1,960,7,7]>, Tensor<[160,960,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 301 | Tensor<[1,960,7,7]>, Tensor<[320,960,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 302 | Tensor<[1,320,7,7]>, Tensor<[1280,320,1,1]>, stride: [1, 1] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 303 | Tensor<[1,3,224,224]>, Tensor<[768,3,32,32]>, stride: [32, 32] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 5 |
| 304 | Tensor<[1,3,224,224]>, Tensor<[1024,3,16,16]>, stride: [16, 16] pad: [[0, 0], [0, 0]] rhs_dilate: [1, 1] batch_group_count: 1 feature_group_count: 1 | ttnn.conv2d | aten::convolution | 4 |
stablehlo.cosine::ttnn.cos
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,32,128]>, | ttnn.cos | aten::cos | 4 |
| 1 | Tensor<[1,23,40,64]>, | ttnn.cos | aten::cos | 4 |
| 2 | Tensor<[1,160]>, | ttnn.cos | aten::cos | 4 |
| 3 | Tensor<[1,7,64]>, | ttnn.cos | aten::cos | 4 |
stablehlo.divide::ttnn.div
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,32,32,32]>, Tensor<[1,32,32,32]>, | ttnn.div | aten::_safe_softmax | 4 |
| 1 | Scalar, Scalar, | ttnn.div | aten::arange | 4 |
| 2 | Tensor<[1,32,1]>, Tensor<[1,32,1]>, | ttnn.div | aten::mean.dim | 4 |
| 3 | Tensor<[1,12,7,7]>, Tensor<[1,12,7,7]>, | ttnn.div | aten::_safe_softmax | 4 |
| 4 | Tensor<[32]>, Tensor<[32]>, | ttnn.div | aten::reciprocal | 5 |
| 5 | Tensor<[64]>, Tensor<[64]>, | ttnn.div | aten::reciprocal | 5 |
| 6 | Tensor<[128]>, Tensor<[128]>, | ttnn.div | aten::reciprocal | 5 |
| 7 | Tensor<[256]>, Tensor<[256]>, | ttnn.div | aten::reciprocal | 5 |
| 8 | Tensor<[512]>, Tensor<[512]>, | ttnn.div | aten::reciprocal | 5 |
| 9 | Tensor<[1,1024,512]>, Tensor<[1,1024,512]>, | ttnn.div | aten::gelu | 4 |
| 10 | Tensor<[1,256,256]>, Tensor<[1,256,256]>, | ttnn.div | aten::gelu | 4 |
| 11 | Tensor<[1,512]>, Tensor<[1,512]>, | ttnn.div | aten::mean.dim | 4 |
| 12 | Tensor<[8,920,920]>, Tensor<[8,920,920]>, | ttnn.div | aten::_softmax | 4 |
| 13 | Tensor<[8,100,100]>, Tensor<[8,100,100]>, | ttnn.div | aten::_softmax | 4 |
| 14 | Tensor<[8,100,920]>, Tensor<[8,100,920]>, | ttnn.div | aten::_softmax | 4 |
| 15 | Tensor<[1,23,40]>, Tensor<[1,23,40]>, | ttnn.div | aten::div.Tensor | 4 |
| 16 | Tensor<[1,23,40,128]>, Tensor<[1,23,40,128]>, | ttnn.div | aten::div.Tensor | 4 |
| 17 | Tensor<[1,12,10,10]>, Tensor<[1,12,10,10]>, | ttnn.div | aten::_safe_softmax | 4 |
| 18 | Tensor<[1,10,3072]>, Tensor<[1,10,3072]>, | ttnn.div | aten::gelu | 4 |
| 19 | Tensor<[1,10,768]>, Tensor<[1,10,768]>, | ttnn.div | aten::gelu | 4 |
| 20 | Tensor<[1,8,4096,4096]>, Tensor<[1,8,4096,4096]>, | ttnn.div | aten::_safe_softmax | 4 |
| 21 | Tensor<[1,8,4096,9]>, Tensor<[1,8,4096,9]>, | ttnn.div | aten::_safe_softmax | 4 |
| 22 | Tensor<[1,8,1024,1024]>, Tensor<[1,8,1024,1024]>, | ttnn.div | aten::_safe_softmax | 4 |
| 23 | Tensor<[1,8,1024,9]>, Tensor<[1,8,1024,9]>, | ttnn.div | aten::_safe_softmax | 4 |
| 24 | Tensor<[1,8,256,256]>, Tensor<[1,8,256,256]>, | ttnn.div | aten::_safe_softmax | 4 |
| 25 | Tensor<[1,8,256,9]>, Tensor<[1,8,256,9]>, | ttnn.div | aten::_safe_softmax | 4 |
| 26 | Tensor<[1,8,64,64]>, Tensor<[1,8,64,64]>, | ttnn.div | aten::_safe_softmax | 4 |
| 27 | Tensor<[1,8,64,9]>, Tensor<[1,8,64,9]>, | ttnn.div | aten::_safe_softmax | 4 |
| 28 | Tensor<[160]>, Tensor<[160]>, | ttnn.div | aten::div.Tensor | 4 |
| 29 | Tensor<[1,320,64,64]>, Tensor<[1,320,64,64]>, | ttnn.div | aten::div.Tensor | 4 |
| 30 | Tensor<[1,4096,320]>, Tensor<[1,4096,320]>, | ttnn.div | aten::div.Tensor | 4 |
| 31 | Tensor<[1,640,32,32]>, Tensor<[1,640,32,32]>, | ttnn.div | aten::div.Tensor | 4 |
| 32 | Tensor<[1,1024,640]>, Tensor<[1,1024,640]>, | ttnn.div | aten::div.Tensor | 4 |
| 33 | Tensor<[1,1280,16,16]>, Tensor<[1,1280,16,16]>, | ttnn.div | aten::div.Tensor | 4 |
| 34 | Tensor<[1,256,1280]>, Tensor<[1,256,1280]>, | ttnn.div | aten::div.Tensor | 4 |
| 35 | Tensor<[1,1280,8,8]>, Tensor<[1,1280,8,8]>, | ttnn.div | aten::div.Tensor | 4 |
| 36 | Tensor<[1,64,1280]>, Tensor<[1,64,1280]>, | ttnn.div | aten::div.Tensor | 4 |
| 37 | Tensor<[1,4096,1280]>, Tensor<[1,4096,1280]>, | ttnn.div | aten::gelu | 4 |
| 38 | Tensor<[1,1024,2560]>, Tensor<[1,1024,2560]>, | ttnn.div | aten::gelu | 4 |
| 39 | Tensor<[1,256,5120]>, Tensor<[1,256,5120]>, | ttnn.div | aten::gelu | 4 |
| 40 | Tensor<[1,64,5120]>, Tensor<[1,64,5120]>, | ttnn.div | aten::gelu | 4 |
| 41 | Tensor<[1,12,25,25]>, Tensor<[1,12,25,25]>, | ttnn.div | aten::_safe_softmax | 4 |
| 42 | Tensor<[1,25,3072]>, Tensor<[1,25,3072]>, | ttnn.div | aten::gelu | 4 |
| 43 | Tensor<[1,3,1445,1445]>, Tensor<[1,3,1445,1445]>, | ttnn.div | aten::_safe_softmax | 4 |
| 44 | Tensor<[1,1445,768]>, Tensor<[1,1445,768]>, | ttnn.div | aten::gelu | 4 |
| 45 | Tensor<[1,512,1,1]>, Tensor<[1,512,1,1]>, | ttnn.div | aten::mean.dim | 4 |
| 46 | Tensor<[1,12,8,8]>, Tensor<[1,12,8,8]>, | ttnn.div | aten::_softmax | 4 |
| 47 | Tensor<[1,3072,8]>, Tensor<[1,3072,8]>, | ttnn.div | aten::gelu | 4 |
| 48 | Tensor<[1,8,256,2048]>, Tensor<[1,8,256,2048]>, | ttnn.div | aten::_softmax | 4 |
| 49 | Tensor<[1,8,2048,256]>, Tensor<[1,8,2048,256]>, | ttnn.div | aten::_softmax | 4 |
| 50 | Tensor<[1,2048,768]>, Tensor<[1,2048,768]>, | ttnn.div | aten::gelu | 4 |
| 51 | Tensor<[1,2048,1,1]>, Tensor<[1,2048,1,1]>, | ttnn.div | aten::mean.dim | 4 |
| 52 | Tensor<[1024]>, Tensor<[1024]>, | ttnn.div | aten::reciprocal | 5 |
| 53 | Tensor<[2048]>, Tensor<[2048]>, | ttnn.div | aten::reciprocal | 5 |
| 54 | Tensor<[1,12,201,201]>, Tensor<[1,12,201,201]>, | ttnn.div | aten::_softmax | 4 |
| 55 | Tensor<[1,201,3072]>, Tensor<[1,201,3072]>, | ttnn.div | aten::gelu | 4 |
| 56 | Tensor<[1,1536]>, Tensor<[1,1536]>, | ttnn.div | aten::gelu | 4 |
| 57 | Tensor<[16,19,19]>, Tensor<[16,19,19]>, | ttnn.div | aten::_softmax | 4 |
| 58 | Tensor<[19]>, Tensor<[19]>, | ttnn.div | aten::floor_divide | 4 |
| 59 | Tensor<[1,19,4096]>, Tensor<[1,19,4096]>, | ttnn.div | aten::gelu | 4 |
| 60 | Tensor<[1,1024,1,1]>, Tensor<[1,1024,1,1]>, | ttnn.div | aten::mean.dim | 4 |
| 61 | Tensor<[14]>, Tensor<[14]>, | ttnn.div | aten::reciprocal | 5 |
| 62 | Tensor<[24]>, Tensor<[24]>, | ttnn.div | aten::reciprocal | 5 |
| 63 | Tensor<[40]>, Tensor<[40]>, | ttnn.div | aten::reciprocal | 5 |
| 64 | Tensor<[68]>, Tensor<[68]>, | ttnn.div | aten::reciprocal | 5 |
| 65 | Tensor<[16]>, Tensor<[16]>, | ttnn.div | aten::reciprocal | 5 |
| 66 | Tensor<[28]>, Tensor<[28]>, | ttnn.div | aten::reciprocal | 5 |
| 67 | Tensor<[46]>, Tensor<[46]>, | ttnn.div | aten::reciprocal | 5 |
| 68 | Tensor<[78]>, Tensor<[78]>, | ttnn.div | aten::reciprocal | 5 |
| 69 | Tensor<[134]>, Tensor<[134]>, | ttnn.div | aten::reciprocal | 5 |
| 70 | Tensor<[20]>, Tensor<[20]>, | ttnn.div | aten::reciprocal | 5 |
| 71 | Tensor<[34]>, Tensor<[34]>, | ttnn.div | aten::reciprocal | 5 |
| 72 | Tensor<[58]>, Tensor<[58]>, | ttnn.div | aten::reciprocal | 5 |
| 73 | Tensor<[98]>, Tensor<[98]>, | ttnn.div | aten::reciprocal | 5 |
| 74 | Tensor<[168]>, Tensor<[168]>, | ttnn.div | aten::reciprocal | 5 |
| 75 | Tensor<[320]>, Tensor<[320]>, | ttnn.div | aten::reciprocal | 5 |
| 76 | Tensor<[116]>, Tensor<[116]>, | ttnn.div | aten::reciprocal | 5 |
| 77 | Tensor<[196]>, Tensor<[196]>, | ttnn.div | aten::reciprocal | 5 |
| 78 | Tensor<[334]>, Tensor<[334]>, | ttnn.div | aten::reciprocal | 5 |
| 79 | Tensor<[640]>, Tensor<[640]>, | ttnn.div | aten::reciprocal | 5 |
| 80 | Tensor<[272]>, Tensor<[272]>, | ttnn.div | aten::reciprocal | 5 |
| 81 | Tensor<[462]>, Tensor<[462]>, | ttnn.div | aten::reciprocal | 5 |
| 82 | Tensor<[1,16,32,32]>, Tensor<[1,16,32,32]>, | ttnn.div | aten::_softmax | 4 |
| 83 | Tensor<[1,12,16,16]>, Tensor<[1,12,16,16]>, | ttnn.div | aten::_safe_softmax | 4 |
| 84 | Tensor<[1,16,3072]>, Tensor<[1,16,3072]>, | ttnn.div | aten::gelu | 4 |
| 85 | Tensor<[1,1,19200,300]>, Tensor<[1,1,19200,300]>, | ttnn.div | aten::_softmax | 4 |
| 86 | Tensor<[1,2,4800,300]>, Tensor<[1,2,4800,300]>, | ttnn.div | aten::_softmax | 4 |
| 87 | Tensor<[1,5,1200,300]>, Tensor<[1,5,1200,300]>, | ttnn.div | aten::_softmax | 4 |
| 88 | Tensor<[1,8,300,300]>, Tensor<[1,8,300,300]>, | ttnn.div | aten::_softmax | 4 |
| 89 | Tensor<[1,19200,256]>, Tensor<[1,19200,256]>, | ttnn.div | aten::gelu | 4 |
| 90 | Tensor<[1,4800,512]>, Tensor<[1,4800,512]>, | ttnn.div | aten::gelu | 4 |
| 91 | Tensor<[1,1200,1280]>, Tensor<[1,1200,1280]>, | ttnn.div | aten::gelu | 4 |
| 92 | Tensor<[1,300,2048]>, Tensor<[1,300,2048]>, | ttnn.div | aten::gelu | 4 |
| 93 | Tensor<[1,12,197,197]>, Tensor<[1,12,197,197]>, | ttnn.div | aten::_safe_softmax | 4 |
| 94 | Tensor<[1,197,3072]>, Tensor<[1,197,3072]>, | ttnn.div | aten::gelu | 4 |
| 95 | Tensor<[1,1,16384,256]>, Tensor<[1,1,16384,256]>, | ttnn.div | aten::_softmax | 4 |
| 96 | Tensor<[1,2,4096,256]>, Tensor<[1,2,4096,256]>, | ttnn.div | aten::_softmax | 4 |
| 97 | Tensor<[1,5,1024,256]>, Tensor<[1,5,1024,256]>, | ttnn.div | aten::_softmax | 4 |
| 98 | Tensor<[1,16384,128]>, Tensor<[1,16384,128]>, | ttnn.div | aten::gelu | 4 |
| 99 | Tensor<[1,4096,256]>, Tensor<[1,4096,256]>, | ttnn.div | aten::gelu | 4 |
| 100 | Tensor<[1,256,1024]>, Tensor<[1,256,1024]>, | ttnn.div | aten::gelu | 4 |
| 101 | Tensor<[1,71,7,7]>, Tensor<[1,71,7,7]>, | ttnn.div | aten::_safe_softmax | 4 |
| 102 | Tensor<[1,7,18176]>, Tensor<[1,7,18176]>, | ttnn.div | aten::gelu | 4 |
| 103 | Tensor<[1,1280,1,1]>, Tensor<[1,1280,1,1]>, | ttnn.div | aten::mean.dim | 4 |
| 104 | Tensor<[96]>, Tensor<[96]>, | ttnn.div | aten::reciprocal | 5 |
| 105 | Tensor<[144]>, Tensor<[144]>, | ttnn.div | aten::reciprocal | 5 |
| 106 | Tensor<[192]>, Tensor<[192]>, | ttnn.div | aten::reciprocal | 5 |
| 107 | Tensor<[384]>, Tensor<[384]>, | ttnn.div | aten::reciprocal | 5 |
| 108 | Tensor<[576]>, Tensor<[576]>, | ttnn.div | aten::reciprocal | 5 |
| 109 | Tensor<[960]>, Tensor<[960]>, | ttnn.div | aten::reciprocal | 5 |
| 110 | Tensor<[1280]>, Tensor<[1280]>, | ttnn.div | aten::reciprocal | 5 |
| 111 | Tensor<[1,12,12,12]>, Tensor<[1,12,12,12]>, | ttnn.div | aten::_safe_softmax | 4 |
| 112 | Tensor<[1,12,9,9]>, Tensor<[1,12,9,9]>, | ttnn.div | aten::_safe_softmax | 4 |
| 113 | Tensor<[1,16,9,9]>, Tensor<[1,16,9,9]>, | ttnn.div | aten::_safe_softmax | 4 |
| 114 | Tensor<[1,64,9,9]>, Tensor<[1,64,9,9]>, | ttnn.div | aten::_safe_softmax | 4 |
| 115 | Tensor<[1,12,14,14]>, Tensor<[1,12,14,14]>, | ttnn.div | aten::_safe_softmax | 4 |
| 116 | Tensor<[1,12,50,50]>, Tensor<[1,12,50,50]>, | ttnn.div | aten::_safe_softmax | 4 |
| 117 | Tensor<[2,8,7,7]>, Tensor<[2,8,7,7]>, | ttnn.div | aten::_safe_softmax | 4 |
| 118 | Tensor<[2,512]>, Tensor<[2,512]>, | ttnn.div | aten::div.Tensor | 4 |
| 119 | Tensor<[1,16,197,197]>, Tensor<[1,16,197,197]>, | ttnn.div | aten::_softmax | 4 |
| 120 | Tensor<[197]>, Tensor<[197]>, | ttnn.div | aten::floor_divide | 4 |
| 121 | Tensor<[1,197,4096]>, Tensor<[1,197,4096]>, | ttnn.div | aten::gelu | 4 |
| 122 | Tensor<[1,1024]>, Tensor<[1,1024]>, | ttnn.div | aten::mean.dim | 4 |
| 123 | Tensor<[1,768]>, Tensor<[1,768]>, | ttnn.div | aten::mean.dim | 4 |
stablehlo.dot_general::ttnn.matmul
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,64,1]>, Tensor<[1,1,32]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 1 | Tensor<[32,32,128]>, Tensor<[32,128,32]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 2 | Tensor<[32,32,32]>, Tensor<[32,32,128]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 3 | Tensor<[32,4096]>, Tensor<[4096,4096]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 4 | Tensor<[32,4096]>, Tensor<[4096,11008]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 5 | Tensor<[32,11008]>, Tensor<[11008,4096]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 6 | Tensor<[32,4096]>, Tensor<[4096,32000]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 7 | Tensor<[12,7,64]>, Tensor<[12,64,7]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 8 | Tensor<[12,7,7]>, Tensor<[12,7,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 9 | Tensor<[7,768]>, Tensor<[768,2304]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 10 | Tensor<[7,768]>, Tensor<[768,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 11 | Tensor<[7,768]>, Tensor<[768,3072]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 12 | Tensor<[7,3072]>, Tensor<[3072,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 13 | Tensor<[7,768]>, Tensor<[768,2]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 14 | Tensor<[256,768]>, Tensor<[768,512]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 15 | Tensor<[256,512]>, Tensor<[512,256]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 16 | Tensor<[256,256]>, Tensor<[256,512]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 17 | Tensor<[1,512]>, Tensor<[512,1000]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 18 | Tensor<[8,920,32]>, Tensor<[8,32,920]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::baddbmm | 4 |
| 19 | Tensor<[8,100,32]>, Tensor<[8,32,920]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::baddbmm | 4 |
| 20 | Tensor<[920,1,256]>, Tensor<[920,256,256]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 21 | Tensor<[8,920,920]>, Tensor<[8,920,32]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 22 | Tensor<[8,100,32]>, Tensor<[8,32,100]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 23 | Tensor<[8,100,100]>, Tensor<[8,100,32]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 24 | Tensor<[8,100,920]>, Tensor<[8,920,32]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 25 | Tensor<[6,100,256]>, Tensor<[6,256,92]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 26 | Tensor<[6,100,256]>, Tensor<[6,256,256]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 27 | Tensor<[920,256]>, Tensor<[256,256]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 28 | Tensor<[920,256]>, Tensor<[256,2048]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 29 | Tensor<[920,2048]>, Tensor<[2048,256]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 30 | Tensor<[100,256]>, Tensor<[256,256]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 31 | Tensor<[100,256]>, Tensor<[256,2048]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 32 | Tensor<[100,2048]>, Tensor<[2048,256]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 33 | Tensor<[600,256]>, Tensor<[256,256]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 34 | Tensor<[600,256]>, Tensor<[256,4]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 35 | Tensor<[12,10,64]>, Tensor<[12,64,10]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 36 | Tensor<[12,10,10]>, Tensor<[12,10,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 37 | Tensor<[10,768]>, Tensor<[768,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 38 | Tensor<[10,768]>, Tensor<[768,3072]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 39 | Tensor<[10,3072]>, Tensor<[3072,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 40 | Tensor<[10,768]>, Tensor<[768,250002]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 41 | Tensor<[8,4096,40]>, Tensor<[8,40,4096]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 42 | Tensor<[8,4096,4096]>, Tensor<[8,4096,40]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 43 | Tensor<[8,4096,40]>, Tensor<[8,40,9]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 44 | Tensor<[8,4096,9]>, Tensor<[8,9,40]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 45 | Tensor<[8,1024,80]>, Tensor<[8,80,1024]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 46 | Tensor<[8,1024,1024]>, Tensor<[8,1024,80]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 47 | Tensor<[8,1024,80]>, Tensor<[8,80,9]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 48 | Tensor<[8,1024,9]>, Tensor<[8,9,80]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 49 | Tensor<[8,256,160]>, Tensor<[8,160,256]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 50 | Tensor<[8,256,256]>, Tensor<[8,256,160]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 51 | Tensor<[8,256,160]>, Tensor<[8,160,9]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 52 | Tensor<[8,256,9]>, Tensor<[8,9,160]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 53 | Tensor<[8,64,160]>, Tensor<[8,160,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 54 | Tensor<[8,64,64]>, Tensor<[8,64,160]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 55 | Tensor<[8,64,160]>, Tensor<[8,160,9]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 56 | Tensor<[8,64,9]>, Tensor<[8,9,160]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 57 | Tensor<[1,320]>, Tensor<[320,1280]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 58 | Tensor<[1,1280]>, Tensor<[1280,1280]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 59 | Tensor<[1,1280]>, Tensor<[1280,320]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 60 | Tensor<[4096,320]>, Tensor<[320,320]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 61 | Tensor<[9,768]>, Tensor<[768,320]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 62 | Tensor<[4096,320]>, Tensor<[320,2560]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 63 | Tensor<[4096,1280]>, Tensor<[1280,320]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 64 | Tensor<[1,1280]>, Tensor<[1280,640]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 65 | Tensor<[1024,640]>, Tensor<[640,640]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 66 | Tensor<[9,768]>, Tensor<[768,640]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 67 | Tensor<[1024,640]>, Tensor<[640,5120]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 68 | Tensor<[1024,2560]>, Tensor<[2560,640]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 69 | Tensor<[256,1280]>, Tensor<[1280,1280]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 70 | Tensor<[9,768]>, Tensor<[768,1280]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 71 | Tensor<[256,1280]>, Tensor<[1280,10240]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 72 | Tensor<[256,5120]>, Tensor<[5120,1280]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 73 | Tensor<[64,1280]>, Tensor<[1280,1280]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 74 | Tensor<[64,1280]>, Tensor<[1280,10240]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 75 | Tensor<[64,5120]>, Tensor<[5120,1280]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 76 | Tensor<[12,25,64]>, Tensor<[12,64,25]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 77 | Tensor<[12,25,25]>, Tensor<[12,25,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 78 | Tensor<[25,768]>, Tensor<[768,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 79 | Tensor<[25,768]>, Tensor<[768,3072]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 80 | Tensor<[25,3072]>, Tensor<[3072,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 81 | Tensor<[25,768]>, Tensor<[768,2]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 82 | Tensor<[1,768]>, Tensor<[768,1]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 83 | Tensor<[3,1445,64]>, Tensor<[3,64,1445]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 84 | Tensor<[3,1445,1445]>, Tensor<[3,1445,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 85 | Tensor<[1445,192]>, Tensor<[192,192]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 86 | Tensor<[1445,192]>, Tensor<[192,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 87 | Tensor<[1445,768]>, Tensor<[768,192]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 88 | Tensor<[100,192]>, Tensor<[192,192]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 89 | Tensor<[100,192]>, Tensor<[192,92]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 90 | Tensor<[100,192]>, Tensor<[192,4]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 91 | Tensor<[12,8,64]>, Tensor<[12,64,8]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 92 | Tensor<[12,8,8]>, Tensor<[12,8,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 93 | Tensor<[1,768]>, Tensor<[768,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 94 | Tensor<[1,768]>, Tensor<[768,3]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 95 | Tensor<[8,256,32]>, Tensor<[8,32,2048]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 96 | Tensor<[8,256,2048]>, Tensor<[8,2048,160]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 97 | Tensor<[8,256,32]>, Tensor<[8,32,256]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 98 | Tensor<[8,2048,32]>, Tensor<[8,32,256]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 99 | Tensor<[8,2048,256]>, Tensor<[8,256,96]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 100 | Tensor<[256,1280]>, Tensor<[1280,256]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 101 | Tensor<[2048,768]>, Tensor<[768,256]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 102 | Tensor<[2048,768]>, Tensor<[768,1280]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 103 | Tensor<[256,1280]>, Tensor<[1280,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 104 | Tensor<[2048,768]>, Tensor<[768,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 105 | Tensor<[2048,768]>, Tensor<[768,262]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 106 | Tensor<[1,2048]>, Tensor<[2048,1000]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 107 | Tensor<[12,201,64]>, Tensor<[12,64,201]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 108 | Tensor<[12,201,201]>, Tensor<[12,201,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 109 | Tensor<[201,768]>, Tensor<[768,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 110 | Tensor<[201,768]>, Tensor<[768,3072]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 111 | Tensor<[201,3072]>, Tensor<[3072,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 112 | Tensor<[1,768]>, Tensor<[768,1536]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 113 | Tensor<[1,1536]>, Tensor<[1536,3129]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 114 | Tensor<[1,9216]>, Tensor<[9216,128]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 115 | Tensor<[1,128]>, Tensor<[128,10]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 116 | Tensor<[16,19,64]>, Tensor<[16,64,19]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 117 | Tensor<[16,19,19]>, Tensor<[16,19,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 118 | Tensor<[19,1024]>, Tensor<[1024,1024]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 119 | Tensor<[19,1024]>, Tensor<[1024,4096]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 120 | Tensor<[19,4096]>, Tensor<[4096,1024]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 121 | Tensor<[19,1024]>, Tensor<[1024,256008]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 122 | Tensor<[1,1024]>, Tensor<[1024,1000]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 123 | Tensor<[16,32,96]>, Tensor<[16,96,32]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::baddbmm | 4 |
| 124 | Tensor<[16,32,32]>, Tensor<[16,32,96]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 125 | Tensor<[32,1536]>, Tensor<[1536,4608]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 126 | Tensor<[32,1536]>, Tensor<[1536,1536]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 127 | Tensor<[32,1536]>, Tensor<[1536,6144]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 128 | Tensor<[32,6144]>, Tensor<[6144,1536]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 129 | Tensor<[32,1536]>, Tensor<[1536,250880]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 130 | Tensor<[12,16,64]>, Tensor<[12,64,16]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 131 | Tensor<[12,16,16]>, Tensor<[12,16,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 132 | Tensor<[16,768]>, Tensor<[768,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 133 | Tensor<[16,768]>, Tensor<[768,3072]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 134 | Tensor<[16,3072]>, Tensor<[3072,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 135 | Tensor<[1,19200,64]>, Tensor<[1,64,300]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 136 | Tensor<[1,19200,300]>, Tensor<[1,300,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 137 | Tensor<[1,19200,256]>, Tensor<[1,256,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 138 | Tensor<[2,4800,64]>, Tensor<[2,64,300]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 139 | Tensor<[2,4800,300]>, Tensor<[2,300,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 140 | Tensor<[1,4800,512]>, Tensor<[1,512,128]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 141 | Tensor<[5,1200,64]>, Tensor<[5,64,300]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 142 | Tensor<[5,1200,300]>, Tensor<[5,300,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 143 | Tensor<[1,1200,1280]>, Tensor<[1,1280,320]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 144 | Tensor<[8,300,64]>, Tensor<[8,64,300]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 145 | Tensor<[8,300,300]>, Tensor<[8,300,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 146 | Tensor<[1,300,2048]>, Tensor<[1,2048,512]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 147 | Tensor<[19200,64]>, Tensor<[64,64]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 148 | Tensor<[300,64]>, Tensor<[64,64]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 149 | Tensor<[19200,64]>, Tensor<[64,256]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 150 | Tensor<[4800,128]>, Tensor<[128,128]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 151 | Tensor<[300,128]>, Tensor<[128,128]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 152 | Tensor<[4800,128]>, Tensor<[128,512]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 153 | Tensor<[1200,320]>, Tensor<[320,320]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 154 | Tensor<[300,320]>, Tensor<[320,320]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 155 | Tensor<[1200,320]>, Tensor<[320,1280]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 156 | Tensor<[300,512]>, Tensor<[512,512]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 157 | Tensor<[300,512]>, Tensor<[512,2048]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 158 | Tensor<[12,197,64]>, Tensor<[12,64,197]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 159 | Tensor<[12,197,197]>, Tensor<[12,197,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 160 | Tensor<[197,768]>, Tensor<[768,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 161 | Tensor<[197,768]>, Tensor<[768,3072]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 162 | Tensor<[197,3072]>, Tensor<[3072,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 163 | Tensor<[1,768]>, Tensor<[768,1000]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 164 | Tensor<[1,16384,32]>, Tensor<[1,32,256]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 165 | Tensor<[1,16384,256]>, Tensor<[1,256,32]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 166 | Tensor<[1,16384,128]>, Tensor<[1,128,32]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 167 | Tensor<[2,4096,32]>, Tensor<[2,32,256]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 168 | Tensor<[2,4096,256]>, Tensor<[2,256,32]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 169 | Tensor<[1,4096,256]>, Tensor<[1,256,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 170 | Tensor<[5,1024,32]>, Tensor<[5,32,256]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 171 | Tensor<[5,1024,256]>, Tensor<[5,256,32]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 172 | Tensor<[1,1024,640]>, Tensor<[1,640,160]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 173 | Tensor<[8,256,256]>, Tensor<[8,256,32]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 174 | Tensor<[1,256,1024]>, Tensor<[1,1024,256]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 175 | Tensor<[1,4096,64]>, Tensor<[1,64,256]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 176 | Tensor<[1,1024,160]>, Tensor<[1,160,256]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 177 | Tensor<[1,256,256]>, Tensor<[1,256,256]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 178 | Tensor<[16384,32]>, Tensor<[32,32]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 179 | Tensor<[256,32]>, Tensor<[32,32]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 180 | Tensor<[16384,32]>, Tensor<[32,128]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 181 | Tensor<[4096,64]>, Tensor<[64,64]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 182 | Tensor<[256,64]>, Tensor<[64,64]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 183 | Tensor<[4096,64]>, Tensor<[64,256]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 184 | Tensor<[1024,160]>, Tensor<[160,160]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 185 | Tensor<[256,160]>, Tensor<[160,160]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 186 | Tensor<[1024,160]>, Tensor<[160,640]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 187 | Tensor<[256,256]>, Tensor<[256,256]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 188 | Tensor<[256,256]>, Tensor<[256,1024]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 189 | Tensor<[1,32,1]>, Tensor<[1,1,7]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 190 | Tensor<[71,7,64]>, Tensor<[71,64,7]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 191 | Tensor<[71,7,7]>, Tensor<[71,7,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 192 | Tensor<[7,4544]>, Tensor<[4544,4672]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 193 | Tensor<[7,4544]>, Tensor<[4544,4544]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 194 | Tensor<[7,4544]>, Tensor<[4544,18176]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 195 | Tensor<[7,18176]>, Tensor<[18176,4544]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 196 | Tensor<[7,4544]>, Tensor<[4544,65024]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 197 | Tensor<[1,1280]>, Tensor<[1280,1000]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 198 | Tensor<[12,12,64]>, Tensor<[12,64,12]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 199 | Tensor<[12,12,12]>, Tensor<[12,12,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 200 | Tensor<[12,128]>, Tensor<[128,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 201 | Tensor<[12,768]>, Tensor<[768,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 202 | Tensor<[12,768]>, Tensor<[768,3072]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 203 | Tensor<[12,3072]>, Tensor<[3072,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 204 | Tensor<[12,768]>, Tensor<[768,2]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 205 | Tensor<[12,9,64]>, Tensor<[12,64,9]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 206 | Tensor<[12,9,9]>, Tensor<[12,9,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 207 | Tensor<[9,128]>, Tensor<[128,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 208 | Tensor<[9,768]>, Tensor<[768,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 209 | Tensor<[9,768]>, Tensor<[768,3072]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 210 | Tensor<[9,3072]>, Tensor<[3072,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 211 | Tensor<[9,768]>, Tensor<[768,128]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 212 | Tensor<[9,128]>, Tensor<[128,30000]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 213 | Tensor<[16,9,128]>, Tensor<[16,128,9]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 214 | Tensor<[16,9,9]>, Tensor<[16,9,128]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 215 | Tensor<[9,128]>, Tensor<[128,2048]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 216 | Tensor<[9,2048]>, Tensor<[2048,2048]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 217 | Tensor<[9,2048]>, Tensor<[2048,8192]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 218 | Tensor<[9,8192]>, Tensor<[8192,2048]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 219 | Tensor<[9,2048]>, Tensor<[2048,128]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 220 | Tensor<[16,9,64]>, Tensor<[16,64,9]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 221 | Tensor<[16,9,9]>, Tensor<[16,9,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 222 | Tensor<[9,128]>, Tensor<[128,1024]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 223 | Tensor<[9,1024]>, Tensor<[1024,1024]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 224 | Tensor<[9,1024]>, Tensor<[1024,4096]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 225 | Tensor<[9,4096]>, Tensor<[4096,1024]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 226 | Tensor<[9,1024]>, Tensor<[1024,128]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 227 | Tensor<[64,9,64]>, Tensor<[64,64,9]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 228 | Tensor<[64,9,9]>, Tensor<[64,9,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 229 | Tensor<[9,128]>, Tensor<[128,4096]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 230 | Tensor<[9,4096]>, Tensor<[4096,4096]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 231 | Tensor<[9,4096]>, Tensor<[4096,16384]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 232 | Tensor<[9,16384]>, Tensor<[16384,4096]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 233 | Tensor<[9,4096]>, Tensor<[4096,128]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 234 | Tensor<[1,768]>, Tensor<[768,2]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 235 | Tensor<[12,14,64]>, Tensor<[12,64,14]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 236 | Tensor<[12,14,14]>, Tensor<[12,14,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 237 | Tensor<[14,128]>, Tensor<[128,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 238 | Tensor<[14,768]>, Tensor<[768,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 239 | Tensor<[14,768]>, Tensor<[768,3072]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 240 | Tensor<[14,3072]>, Tensor<[3072,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 241 | Tensor<[14,768]>, Tensor<[768,2]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 242 | Tensor<[12,50,64]>, Tensor<[12,64,50]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 243 | Tensor<[12,50,50]>, Tensor<[12,50,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 244 | Tensor<[16,7,64]>, Tensor<[16,64,7]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 245 | Tensor<[16,7,7]>, Tensor<[16,7,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 246 | Tensor<[50,768]>, Tensor<[768,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 247 | Tensor<[50,768]>, Tensor<[768,3072]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 248 | Tensor<[50,3072]>, Tensor<[3072,768]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 249 | Tensor<[14,512]>, Tensor<[512,512]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 250 | Tensor<[14,512]>, Tensor<[512,2048]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 251 | Tensor<[14,2048]>, Tensor<[2048,512]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 252 | Tensor<[1,768]>, Tensor<[768,512]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 253 | Tensor<[2,512]>, Tensor<[512,512]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 254 | Tensor<[2,512]>, Tensor<[512,1]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 255 | Tensor<[16,197,64]>, Tensor<[16,64,197]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 256 | Tensor<[16,197,197]>, Tensor<[16,197,64]>, batching_dims: [0] x [0] contracting_dims: [2] x [1] | ttnn.matmul | aten::bmm | 4 |
| 257 | Tensor<[197,1024]>, Tensor<[1024,1024]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 258 | Tensor<[197,1024]>, Tensor<[1024,4096]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 259 | Tensor<[197,4096]>, Tensor<[4096,1024]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 260 | Tensor<[1,784]>, Tensor<[784,128]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 261 | Tensor<[1,128]>, Tensor<[128,64]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 262 | Tensor<[1,64]>, Tensor<[64,12]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 263 | Tensor<[1,12]>, Tensor<[12,3]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 264 | Tensor<[1,3]>, Tensor<[3,12]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 265 | Tensor<[1,12]>, Tensor<[12,64]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 266 | Tensor<[1,64]>, Tensor<[64,128]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
| 267 | Tensor<[1,128]>, Tensor<[128,784]>, contracting_dims: [1] x [0] | ttnn.matmul | aten::mm | 5 |
stablehlo.dynamic_iota::ttnn.arange
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1]>, dim: 0 | ttnn.arange | aten::arange | 4 |
stablehlo.exponential::ttnn.exp
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,32,32,32]>, | ttnn.exp | aten::_safe_softmax | 4 |
| 1 | Tensor<[1,12,7,7]>, | ttnn.exp | aten::_safe_softmax | 4 |
| 2 | Tensor<[1,128,28,28]>, | ttnn.exp | aten::elu | 4 |
| 3 | Tensor<[8,920,920]>, | ttnn.exp | aten::_softmax | 4 |
| 4 | Tensor<[8,100,100]>, | ttnn.exp | aten::_softmax | 4 |
| 5 | Tensor<[8,100,920]>, | ttnn.exp | aten::_softmax | 4 |
| 6 | Tensor<[1,12,10,10]>, | ttnn.exp | aten::_safe_softmax | 4 |
| 7 | Tensor<[1,8,4096,4096]>, | ttnn.exp | aten::_safe_softmax | 4 |
| 8 | Tensor<[1,8,4096,9]>, | ttnn.exp | aten::_safe_softmax | 4 |
| 9 | Tensor<[1,8,1024,1024]>, | ttnn.exp | aten::_safe_softmax | 4 |
| 10 | Tensor<[1,8,1024,9]>, | ttnn.exp | aten::_safe_softmax | 4 |
| 11 | Tensor<[1,8,256,256]>, | ttnn.exp | aten::_safe_softmax | 4 |
| 12 | Tensor<[1,8,256,9]>, | ttnn.exp | aten::_safe_softmax | 4 |
| 13 | Tensor<[1,8,64,64]>, | ttnn.exp | aten::_safe_softmax | 4 |
| 14 | Tensor<[1,8,64,9]>, | ttnn.exp | aten::_safe_softmax | 4 |
| 15 | Tensor<[160]>, | ttnn.exp | aten::exp | 5 |
| 16 | Tensor<[1,12,25,25]>, | ttnn.exp | aten::_safe_softmax | 4 |
| 17 | Tensor<[1,3,1445,1445]>, | ttnn.exp | aten::_safe_softmax | 4 |
| 18 | Tensor<[1,12,8,8]>, | ttnn.exp | aten::_softmax | 4 |
| 19 | Tensor<[1,8,256,2048]>, | ttnn.exp | aten::_softmax | 4 |
| 20 | Tensor<[1,8,2048,256]>, | ttnn.exp | aten::_softmax | 4 |
| 21 | Tensor<[1,12,201,201]>, | ttnn.exp | aten::_softmax | 4 |
| 22 | Tensor<[1,10]>, | ttnn.exp | aten::exp | 5 |
| 23 | Tensor<[16,19,19]>, | ttnn.exp | aten::_softmax | 4 |
| 24 | Tensor<[19,256008]>, | ttnn.exp | aten::exp | 5 |
| 25 | Tensor<[1,16,32,32]>, | ttnn.exp | aten::_softmax | 4 |
| 26 | Tensor<[1,12,16,16]>, | ttnn.exp | aten::_safe_softmax | 4 |
| 27 | Tensor<[1,1,19200,300]>, | ttnn.exp | aten::_softmax | 4 |
| 28 | Tensor<[1,2,4800,300]>, | ttnn.exp | aten::_softmax | 4 |
| 29 | Tensor<[1,5,1200,300]>, | ttnn.exp | aten::_softmax | 4 |
| 30 | Tensor<[1,8,300,300]>, | ttnn.exp | aten::_softmax | 4 |
| 31 | Tensor<[1,12,197,197]>, | ttnn.exp | aten::_safe_softmax | 4 |
| 32 | Tensor<[1,1,16384,256]>, | ttnn.exp | aten::_softmax | 4 |
| 33 | Tensor<[1,2,4096,256]>, | ttnn.exp | aten::_softmax | 4 |
| 34 | Tensor<[1,5,1024,256]>, | ttnn.exp | aten::_softmax | 4 |
| 35 | Tensor<[1,71,7,7]>, | ttnn.exp | aten::_safe_softmax | 4 |
| 36 | Tensor<[1,12,12,12]>, | ttnn.exp | aten::_safe_softmax | 4 |
| 37 | Tensor<[1,12,9,9]>, | ttnn.exp | aten::_safe_softmax | 4 |
| 38 | Tensor<[1,16,9,9]>, | ttnn.exp | aten::_safe_softmax | 4 |
| 39 | Tensor<[1,64,9,9]>, | ttnn.exp | aten::_safe_softmax | 4 |
| 40 | Tensor<[1,12,14,14]>, | ttnn.exp | aten::_safe_softmax | 4 |
| 41 | Tensor<[1,12,50,50]>, | ttnn.exp | aten::_safe_softmax | 4 |
| 42 | Tensor<[2,8,7,7]>, | ttnn.exp | aten::_safe_softmax | 4 |
| 43 | Scalar, | ttnn.exp | aten::exp | 5 |
| 44 | Tensor<[1,16,197,197]>, | ttnn.exp | aten::_softmax | 4 |
stablehlo.floor::ttnn.floor
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[128]>, | ttnn.floor | aten::floor_divide | 4 |
| 1 | Tensor<[19]>, | ttnn.floor | aten::floor_divide | 4 |
| 2 | Tensor<[197]>, | ttnn.floor | aten::floor_divide | 4 |
stablehlo.gather::ttnn.embedding
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[32000,4096]>, Tensor<[1,32]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 1 | Tensor<[50257,768]>, Tensor<[1,7]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 2 | Tensor<[1024,768]>, Tensor<[1,7]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 3 | Tensor<[1,7,2]>, Tensor<[1,2]>, offset_dims: [1] collapsed_slice_dims: [0, 1] start_index_map: [0, 1] index_vector_dim: 1 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index.Tensor | 4 |
| 4 | Tensor<[1,1,720,1280]>, Tensor<[1,1,23,40,4]>, collapsed_slice_dims: [0, 1, 2, 3] start_index_map: [0, 1, 2, 3] index_vector_dim: 4 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index.Tensor | 4 |
| 5 | Tensor<[250002,768]>, Tensor<[1,10]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 6 | Tensor<[1,768]>, Tensor<[1,10]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 7 | Tensor<[514,768]>, Tensor<[1,10]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 8 | Tensor<[1,1280,8,8]>, Tensor<[1,1280,16,16,4]>, collapsed_slice_dims: [0, 1, 2, 3] start_index_map: [0, 1, 2, 3] index_vector_dim: 4 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index.Tensor | 4 |
| 9 | Tensor<[1,1280,16,16]>, Tensor<[1,1280,32,32,4]>, collapsed_slice_dims: [0, 1, 2, 3] start_index_map: [0, 1, 2, 3] index_vector_dim: 4 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index.Tensor | 4 |
| 10 | Tensor<[1,640,32,32]>, Tensor<[1,640,64,64,4]>, collapsed_slice_dims: [0, 1, 2, 3] start_index_map: [0, 1, 2, 3] index_vector_dim: 4 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index.Tensor | 4 |
| 11 | Tensor<[30522,768]>, Tensor<[1,25]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 12 | Tensor<[2,768]>, Tensor<[1,25]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 13 | Tensor<[512,768]>, Tensor<[1,25]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 14 | Tensor<[30528,768]>, Tensor<[1,8]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 15 | Tensor<[512,768]>, Tensor<[1,8]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 16 | Tensor<[2,768]>, Tensor<[1,8]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 17 | Tensor<[262,768]>, Tensor<[1,2048]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 18 | Tensor<[2048,768]>, Tensor<[2048]>, offset_dims: [1] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 1 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 19 | Tensor<[30522,768]>, Tensor<[1,8]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 20 | Tensor<[40,768]>, Tensor<[1,8]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 21 | Tensor<[2,768]>, Tensor<[1,193]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 22 | Tensor<[1,1,384,512]>, Tensor<[1,1,12,16,4]>, collapsed_slice_dims: [0, 1, 2, 3] start_index_map: [0, 1, 2, 3] index_vector_dim: 4 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index.Tensor | 4 |
| 23 | Tensor<[256008,1024]>, Tensor<[1,19]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 24 | Tensor<[19,256008]>, Tensor<[19,1,2]>, collapsed_slice_dims: [0, 1] start_index_map: [0, 1] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::gather | 4 |
| 25 | Tensor<[2050,1024]>, Tensor<[19]>, offset_dims: [1] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 1 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index_select | 4 |
| 26 | Tensor<[1,256,16,16]>, Tensor<[1,256,32,32,4]>, collapsed_slice_dims: [0, 1, 2, 3] start_index_map: [0, 1, 2, 3] index_vector_dim: 4 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index.Tensor | 4 |
| 27 | Tensor<[1,128,32,32]>, Tensor<[1,128,64,64,4]>, collapsed_slice_dims: [0, 1, 2, 3] start_index_map: [0, 1, 2, 3] index_vector_dim: 4 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index.Tensor | 4 |
| 28 | Tensor<[250880,1536]>, Tensor<[1,32]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 29 | Tensor<[30522,768]>, Tensor<[1,16]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 30 | Tensor<[512,768]>, Tensor<[1,16]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 31 | Tensor<[1,64,15,20]>, Tensor<[1,64,30,40,4]>, collapsed_slice_dims: [0, 1, 2, 3] start_index_map: [0, 1, 2, 3] index_vector_dim: 4 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index.Tensor | 4 |
| 32 | Tensor<[1,64,30,40]>, Tensor<[1,64,60,80,4]>, collapsed_slice_dims: [0, 1, 2, 3] start_index_map: [0, 1, 2, 3] index_vector_dim: 4 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index.Tensor | 4 |
| 33 | Tensor<[1,64,60,80]>, Tensor<[1,64,120,160,4]>, collapsed_slice_dims: [0, 1, 2, 3] start_index_map: [0, 1, 2, 3] index_vector_dim: 4 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index.Tensor | 4 |
| 34 | Tensor<[1,64,120,160]>, Tensor<[1,64,240,320,4]>, collapsed_slice_dims: [0, 1, 2, 3] start_index_map: [0, 1, 2, 3] index_vector_dim: 4 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index.Tensor | 4 |
| 35 | Tensor<[1,64,240,320]>, Tensor<[1,64,480,640,4]>, collapsed_slice_dims: [0, 1, 2, 3] start_index_map: [0, 1, 2, 3] index_vector_dim: 4 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index.Tensor | 4 |
| 36 | Tensor<[1,256,128,128]>, Tensor<[1,256,128,128,4]>, collapsed_slice_dims: [0, 1, 2, 3] start_index_map: [0, 1, 2, 3] index_vector_dim: 4 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index.Tensor | 4 |
| 37 | Tensor<[1,256,64,64]>, Tensor<[1,256,128,128,4]>, collapsed_slice_dims: [0, 1, 2, 3] start_index_map: [0, 1, 2, 3] index_vector_dim: 4 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index.Tensor | 4 |
| 38 | Tensor<[1,256,32,32]>, Tensor<[1,256,128,128,4]>, collapsed_slice_dims: [0, 1, 2, 3] start_index_map: [0, 1, 2, 3] index_vector_dim: 4 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index.Tensor | 4 |
| 39 | Tensor<[1,256,16,16]>, Tensor<[1,256,128,128,4]>, collapsed_slice_dims: [0, 1, 2, 3] start_index_map: [0, 1, 2, 3] index_vector_dim: 4 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index.Tensor | 4 |
| 40 | Tensor<[65024,4544]>, Tensor<[1,7]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 41 | Tensor<[1,7,73,64]>, Tensor<[1,7,1,64,4]>, collapsed_slice_dims: [0, 1, 2, 3] start_index_map: [0, 1, 2, 3] index_vector_dim: 4 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index.Tensor | 4 |
| 42 | Tensor<[30000,128]>, Tensor<[1,12]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 43 | Tensor<[2,128]>, Tensor<[1,12]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 44 | Tensor<[512,128]>, Tensor<[1,12]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 45 | Tensor<[30000,128]>, Tensor<[1,9]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 46 | Tensor<[2,128]>, Tensor<[1,9]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 47 | Tensor<[512,128]>, Tensor<[1,9]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 48 | Tensor<[30000,128]>, Tensor<[1,14]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 49 | Tensor<[2,128]>, Tensor<[1,14]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 50 | Tensor<[512,128]>, Tensor<[1,14]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 51 | Tensor<[50,768]>, Tensor<[1,50]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 52 | Tensor<[49408,512]>, Tensor<[2,7]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 53 | Tensor<[77,512]>, Tensor<[1,7]>, offset_dims: [2] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 2 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::embedding | 4 |
| 54 | Tensor<[2,7,512]>, Tensor<[2,2]>, offset_dims: [1] collapsed_slice_dims: [0, 1] start_index_map: [0, 1] index_vector_dim: 1 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index.Tensor | 4 |
| 55 | Tensor<[1,16,27,27]>, Tensor<[1,16,27,27,4]>, collapsed_slice_dims: [0, 1, 2, 3] start_index_map: [0, 1, 2, 3] index_vector_dim: 4 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index.Tensor | 4 |
| 56 | Tensor<[732,16]>, Tensor<[38809,1]>, offset_dims: [1] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 1 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index.Tensor | 4 |
| 57 | Tensor<[1,12,27,27]>, Tensor<[1,12,27,27,4]>, collapsed_slice_dims: [0, 1, 2, 3] start_index_map: [0, 1, 2, 3] index_vector_dim: 4 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index.Tensor | 4 |
| 58 | Tensor<[732,12]>, Tensor<[38809,1]>, offset_dims: [1] collapsed_slice_dims: [0] start_index_map: [0] index_vector_dim: 1 indices_are_sorted: false slice_sizes: array<i64 | ttnn.embedding | aten::index.Tensor | 4 |
stablehlo.iota::ttnn.arange
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[19,1,1]>, Tensor<[19,1,1]>, dim: 0 | ttnn.arange | aten::gather | 4 |
stablehlo.log::ttnn.log
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,1]>, | ttnn.log | aten::log | 4 |
| 1 | Tensor<[19,1]>, | ttnn.log | aten::log | 4 |
stablehlo.logistic::ttnn.sigmoig
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,32,11008]>, | ttnn.sigmoig | aten::silu | 4 |
| 1 | Tensor<[6,1,100,4]>, | ttnn.sigmoig | aten::sigmoid | 4 |
| 2 | Tensor<[1,1280]>, | ttnn.sigmoig | aten::silu | 4 |
| 3 | Tensor<[1,320,64,64]>, | ttnn.sigmoig | aten::silu | 4 |
| 4 | Tensor<[1,320,32,32]>, | ttnn.sigmoig | aten::silu | 4 |
| 5 | Tensor<[1,640,32,32]>, | ttnn.sigmoig | aten::silu | 4 |
| 6 | Tensor<[1,640,16,16]>, | ttnn.sigmoig | aten::silu | 4 |
| 7 | Tensor<[1,1280,16,16]>, | ttnn.sigmoig | aten::silu | 4 |
| 8 | Tensor<[1,1280,8,8]>, | ttnn.sigmoig | aten::silu | 4 |
| 9 | Tensor<[1,2560,8,8]>, | ttnn.sigmoig | aten::silu | 4 |
| 10 | Tensor<[1,2560,16,16]>, | ttnn.sigmoig | aten::silu | 4 |
| 11 | Tensor<[1,1920,16,16]>, | ttnn.sigmoig | aten::silu | 4 |
| 12 | Tensor<[1,1920,32,32]>, | ttnn.sigmoig | aten::silu | 4 |
| 13 | Tensor<[1,1280,32,32]>, | ttnn.sigmoig | aten::silu | 4 |
| 14 | Tensor<[1,960,32,32]>, | ttnn.sigmoig | aten::silu | 4 |
| 15 | Tensor<[1,960,64,64]>, | ttnn.sigmoig | aten::silu | 4 |
| 16 | Tensor<[1,640,64,64]>, | ttnn.sigmoig | aten::silu | 4 |
| 17 | Tensor<[1,100,4]>, | ttnn.sigmoig | aten::sigmoid | 4 |
| 18 | Tensor<[1,1,256,256]>, | ttnn.sigmoig | aten::sigmoid | 4 |
| 19 | Tensor<[1,2,30,40]>, | ttnn.sigmoig | aten::sigmoid | 4 |
| 20 | Tensor<[1,2,60,80]>, | ttnn.sigmoig | aten::sigmoid | 4 |
| 21 | Tensor<[1,2,120,160]>, | ttnn.sigmoig | aten::sigmoid | 4 |
| 22 | Tensor<[1,1,480,640]>, | ttnn.sigmoig | aten::sigmoid | 4 |
| 23 | Tensor<[1,50,3072]>, | ttnn.sigmoig | aten::sigmoid | 4 |
| 24 | Tensor<[2,7,2048]>, | ttnn.sigmoig | aten::sigmoid | 4 |
stablehlo.maximum::ttnn.maximum
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,128,28,28]>, Tensor<[1,128,28,28]>, | ttnn.maximum | aten::elu | 4 |
| 1 | Tensor<[1,32,112,112]>, Tensor<[1,32,112,112]>, | ttnn.maximum | aten::relu | 4 |
| 2 | Tensor<[1,64,112,112]>, Tensor<[1,64,112,112]>, | ttnn.maximum | aten::relu | 4 |
| 3 | Tensor<[1,64,56,56]>, Tensor<[1,64,56,56]>, | ttnn.maximum | aten::relu | 4 |
| 4 | Tensor<[1,128,56,56]>, Tensor<[1,128,56,56]>, | ttnn.maximum | aten::relu | 4 |
| 5 | Tensor<[1,256,28,28]>, Tensor<[1,256,28,28]>, | ttnn.maximum | aten::relu | 4 |
| 6 | Tensor<[1,512,28,28]>, Tensor<[1,512,28,28]>, | ttnn.maximum | aten::relu | 4 |
| 7 | Tensor<[1,64,360,640]>, Tensor<[1,64,360,640]>, | ttnn.maximum | aten::relu | 4 |
| 8 | Tensor<[1,64,180,320]>, Tensor<[1,64,180,320]>, | ttnn.maximum | aten::relu | 4 |
| 9 | Tensor<[1,256,180,320]>, Tensor<[1,256,180,320]>, | ttnn.maximum | aten::relu | 4 |
| 10 | Tensor<[1,128,180,320]>, Tensor<[1,128,180,320]>, | ttnn.maximum | aten::relu | 4 |
| 11 | Tensor<[1,128,90,160]>, Tensor<[1,128,90,160]>, | ttnn.maximum | aten::relu | 4 |
| 12 | Tensor<[1,512,90,160]>, Tensor<[1,512,90,160]>, | ttnn.maximum | aten::relu | 4 |
| 13 | Tensor<[1,256,90,160]>, Tensor<[1,256,90,160]>, | ttnn.maximum | aten::relu | 4 |
| 14 | Tensor<[1,256,45,80]>, Tensor<[1,256,45,80]>, | ttnn.maximum | aten::relu | 4 |
| 15 | Tensor<[1,1024,45,80]>, Tensor<[1,1024,45,80]>, | ttnn.maximum | aten::relu | 4 |
| 16 | Tensor<[1,512,45,80]>, Tensor<[1,512,45,80]>, | ttnn.maximum | aten::relu | 4 |
| 17 | Tensor<[1,512,23,40]>, Tensor<[1,512,23,40]>, | ttnn.maximum | aten::relu | 4 |
| 18 | Tensor<[1,2048,23,40]>, Tensor<[1,2048,23,40]>, | ttnn.maximum | aten::relu | 4 |
| 19 | Tensor<[920,1,2048]>, Tensor<[920,1,2048]>, | ttnn.maximum | aten::relu | 4 |
| 20 | Tensor<[100,1,2048]>, Tensor<[100,1,2048]>, | ttnn.maximum | aten::relu | 4 |
| 21 | Tensor<[6,1,100,256]>, Tensor<[6,1,100,256]>, | ttnn.maximum | aten::relu | 4 |
| 22 | Tensor<[1,100,192]>, Tensor<[1,100,192]>, | ttnn.maximum | aten::relu | 4 |
| 23 | Tensor<[1,256,14,14]>, Tensor<[1,256,14,14]>, | ttnn.maximum | aten::relu | 4 |
| 24 | Tensor<[1,512,7,7]>, Tensor<[1,512,7,7]>, | ttnn.maximum | aten::relu | 4 |
| 25 | Tensor<[1,256,56,56]>, Tensor<[1,256,56,56]>, | ttnn.maximum | aten::relu | 4 |
| 26 | Tensor<[1,1024,14,14]>, Tensor<[1,1024,14,14]>, | ttnn.maximum | aten::relu | 4 |
| 27 | Tensor<[1,512,14,14]>, Tensor<[1,512,14,14]>, | ttnn.maximum | aten::relu | 4 |
| 28 | Tensor<[1,2048,7,7]>, Tensor<[1,2048,7,7]>, | ttnn.maximum | aten::relu | 4 |
| 29 | Tensor<[1,32,26,26]>, Tensor<[1,32,26,26]>, | ttnn.maximum | aten::relu | 4 |
| 30 | Tensor<[1,64,24,24]>, Tensor<[1,64,24,24]>, | ttnn.maximum | aten::relu | 4 |
| 31 | Tensor<[1,128]>, Tensor<[1,128]>, | ttnn.maximum | aten::relu | 4 |
| 32 | Tensor<[1,16,19,19]>, Tensor<[1,16,19,19]>, | ttnn.maximum | aten::maximum | 4 |
| 33 | Tensor<[1,14,56,56]>, Tensor<[1,14,56,56]>, | ttnn.maximum | aten::hardtanh | 4 |
| 34 | Tensor<[1,24,56,56]>, Tensor<[1,24,56,56]>, | ttnn.maximum | aten::hardtanh | 4 |
| 35 | Tensor<[1,40,56,56]>, Tensor<[1,40,56,56]>, | ttnn.maximum | aten::hardtanh | 4 |
| 36 | Tensor<[1,68,56,56]>, Tensor<[1,68,56,56]>, | ttnn.maximum | aten::hardtanh | 4 |
| 37 | Tensor<[1,16,28,28]>, Tensor<[1,16,28,28]>, | ttnn.maximum | aten::hardtanh | 4 |
| 38 | Tensor<[1,28,28,28]>, Tensor<[1,28,28,28]>, | ttnn.maximum | aten::hardtanh | 4 |
| 39 | Tensor<[1,46,28,28]>, Tensor<[1,46,28,28]>, | ttnn.maximum | aten::hardtanh | 4 |
| 40 | Tensor<[1,78,28,28]>, Tensor<[1,78,28,28]>, | ttnn.maximum | aten::hardtanh | 4 |
| 41 | Tensor<[1,134,28,28]>, Tensor<[1,134,28,28]>, | ttnn.maximum | aten::hardtanh | 4 |
| 42 | Tensor<[1,20,28,28]>, Tensor<[1,20,28,28]>, | ttnn.maximum | aten::hardtanh | 4 |
| 43 | Tensor<[1,34,28,28]>, Tensor<[1,34,28,28]>, | ttnn.maximum | aten::hardtanh | 4 |
| 44 | Tensor<[1,58,28,28]>, Tensor<[1,58,28,28]>, | ttnn.maximum | aten::hardtanh | 4 |
| 45 | Tensor<[1,98,28,28]>, Tensor<[1,98,28,28]>, | ttnn.maximum | aten::hardtanh | 4 |
| 46 | Tensor<[1,168,28,28]>, Tensor<[1,168,28,28]>, | ttnn.maximum | aten::hardtanh | 4 |
| 47 | Tensor<[1,320,28,28]>, Tensor<[1,320,28,28]>, | ttnn.maximum | aten::hardtanh | 4 |
| 48 | Tensor<[1,40,14,14]>, Tensor<[1,40,14,14]>, | ttnn.maximum | aten::hardtanh | 4 |
| 49 | Tensor<[1,68,14,14]>, Tensor<[1,68,14,14]>, | ttnn.maximum | aten::hardtanh | 4 |
| 50 | Tensor<[1,116,14,14]>, Tensor<[1,116,14,14]>, | ttnn.maximum | aten::hardtanh | 4 |
| 51 | Tensor<[1,196,14,14]>, Tensor<[1,196,14,14]>, | ttnn.maximum | aten::hardtanh | 4 |
| 52 | Tensor<[1,334,14,14]>, Tensor<[1,334,14,14]>, | ttnn.maximum | aten::hardtanh | 4 |
| 53 | Tensor<[1,640,14,14]>, Tensor<[1,640,14,14]>, | ttnn.maximum | aten::hardtanh | 4 |
| 54 | Tensor<[1,160,7,7]>, Tensor<[1,160,7,7]>, | ttnn.maximum | aten::hardtanh | 4 |
| 55 | Tensor<[1,272,7,7]>, Tensor<[1,272,7,7]>, | ttnn.maximum | aten::hardtanh | 4 |
| 56 | Tensor<[1,462,7,7]>, Tensor<[1,462,7,7]>, | ttnn.maximum | aten::hardtanh | 4 |
| 57 | Tensor<[1,1024,7,7]>, Tensor<[1,1024,7,7]>, | ttnn.maximum | aten::hardtanh | 4 |
| 58 | Tensor<[1,32,512,512]>, Tensor<[1,32,512,512]>, | ttnn.maximum | aten::leaky_relu | 4 |
| 59 | Tensor<[1,64,256,256]>, Tensor<[1,64,256,256]>, | ttnn.maximum | aten::leaky_relu | 4 |
| 60 | Tensor<[1,32,256,256]>, Tensor<[1,32,256,256]>, | ttnn.maximum | aten::leaky_relu | 4 |
| 61 | Tensor<[1,128,128,128]>, Tensor<[1,128,128,128]>, | ttnn.maximum | aten::leaky_relu | 4 |
| 62 | Tensor<[1,64,128,128]>, Tensor<[1,64,128,128]>, | ttnn.maximum | aten::leaky_relu | 4 |
| 63 | Tensor<[1,256,64,64]>, Tensor<[1,256,64,64]>, | ttnn.maximum | aten::leaky_relu | 4 |
| 64 | Tensor<[1,128,64,64]>, Tensor<[1,128,64,64]>, | ttnn.maximum | aten::leaky_relu | 4 |
| 65 | Tensor<[1,512,32,32]>, Tensor<[1,512,32,32]>, | ttnn.maximum | aten::leaky_relu | 4 |
| 66 | Tensor<[1,256,32,32]>, Tensor<[1,256,32,32]>, | ttnn.maximum | aten::leaky_relu | 4 |
| 67 | Tensor<[1,1024,16,16]>, Tensor<[1,1024,16,16]>, | ttnn.maximum | aten::leaky_relu | 4 |
| 68 | Tensor<[1,512,16,16]>, Tensor<[1,512,16,16]>, | ttnn.maximum | aten::leaky_relu | 4 |
| 69 | Tensor<[1,256,16,16]>, Tensor<[1,256,16,16]>, | ttnn.maximum | aten::leaky_relu | 4 |
| 70 | Tensor<[1,128,32,32]>, Tensor<[1,128,32,32]>, | ttnn.maximum | aten::leaky_relu | 4 |
| 71 | Tensor<[1,4,14,14]>, Tensor<[1,4,14,14]>, | ttnn.maximum | aten::relu | 4 |
| 72 | Tensor<[1,16,14,14]>, Tensor<[1,16,14,14]>, | ttnn.maximum | aten::relu | 4 |
| 73 | Tensor<[1,64,224,224]>, Tensor<[1,64,224,224]>, | ttnn.maximum | aten::relu | 4 |
| 74 | Tensor<[1,128,112,112]>, Tensor<[1,128,112,112]>, | ttnn.maximum | aten::relu | 4 |
| 75 | Tensor<[1,64,30,40]>, Tensor<[1,64,30,40]>, | ttnn.maximum | aten::relu | 4 |
| 76 | Tensor<[1,32,30,40]>, Tensor<[1,32,30,40]>, | ttnn.maximum | aten::relu | 4 |
| 77 | Tensor<[1,64,60,80]>, Tensor<[1,64,60,80]>, | ttnn.maximum | aten::relu | 4 |
| 78 | Tensor<[1,32,60,80]>, Tensor<[1,32,60,80]>, | ttnn.maximum | aten::relu | 4 |
| 79 | Tensor<[1,64,120,160]>, Tensor<[1,64,120,160]>, | ttnn.maximum | aten::relu | 4 |
| 80 | Tensor<[1,32,120,160]>, Tensor<[1,32,120,160]>, | ttnn.maximum | aten::relu | 4 |
| 81 | Tensor<[1,64,480,640]>, Tensor<[1,64,480,640]>, | ttnn.maximum | aten::relu | 4 |
| 82 | Tensor<[1,256,128,128]>, Tensor<[1,256,128,128]>, | ttnn.maximum | aten::relu | 4 |
| 83 | Tensor<[1,96,112,112]>, Tensor<[1,96,112,112]>, | ttnn.maximum | aten::hardtanh | 4 |
| 84 | Tensor<[1,96,56,56]>, Tensor<[1,96,56,56]>, | ttnn.maximum | aten::hardtanh | 4 |
| 85 | Tensor<[1,144,56,56]>, Tensor<[1,144,56,56]>, | ttnn.maximum | aten::hardtanh | 4 |
| 86 | Tensor<[1,144,28,28]>, Tensor<[1,144,28,28]>, | ttnn.maximum | aten::hardtanh | 4 |
| 87 | Tensor<[1,192,28,28]>, Tensor<[1,192,28,28]>, | ttnn.maximum | aten::hardtanh | 4 |
| 88 | Tensor<[1,192,14,14]>, Tensor<[1,192,14,14]>, | ttnn.maximum | aten::hardtanh | 4 |
| 89 | Tensor<[1,384,14,14]>, Tensor<[1,384,14,14]>, | ttnn.maximum | aten::hardtanh | 4 |
| 90 | Tensor<[1,576,14,14]>, Tensor<[1,576,14,14]>, | ttnn.maximum | aten::hardtanh | 4 |
| 91 | Tensor<[1,576,7,7]>, Tensor<[1,576,7,7]>, | ttnn.maximum | aten::hardtanh | 4 |
| 92 | Tensor<[1,960,7,7]>, Tensor<[1,960,7,7]>, | ttnn.maximum | aten::hardtanh | 4 |
| 93 | Tensor<[1,1280,7,7]>, Tensor<[1,1280,7,7]>, | ttnn.maximum | aten::hardtanh | 4 |
| 94 | Tensor<[1,64]>, Tensor<[1,64]>, | ttnn.maximum | aten::relu | 4 |
| 95 | Tensor<[1,12]>, Tensor<[1,12]>, | ttnn.maximum | aten::relu | 4 |
stablehlo.minimum::ttnn.minimum
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,128,28,28]>, Tensor<[1,128,28,28]>, | ttnn.minimum | aten::elu | 4 |
| 1 | Tensor<[1,32,112,112]>, Tensor<[1,32,112,112]>, | ttnn.minimum | aten::hardtanh | 4 |
| 2 | Tensor<[1,64,112,112]>, Tensor<[1,64,112,112]>, | ttnn.minimum | aten::hardtanh | 4 |
| 3 | Tensor<[1,14,56,56]>, Tensor<[1,14,56,56]>, | ttnn.minimum | aten::hardtanh | 4 |
| 4 | Tensor<[1,24,56,56]>, Tensor<[1,24,56,56]>, | ttnn.minimum | aten::hardtanh | 4 |
| 5 | Tensor<[1,40,56,56]>, Tensor<[1,40,56,56]>, | ttnn.minimum | aten::hardtanh | 4 |
| 6 | Tensor<[1,68,56,56]>, Tensor<[1,68,56,56]>, | ttnn.minimum | aten::hardtanh | 4 |
| 7 | Tensor<[1,128,56,56]>, Tensor<[1,128,56,56]>, | ttnn.minimum | aten::hardtanh | 4 |
| 8 | Tensor<[1,16,28,28]>, Tensor<[1,16,28,28]>, | ttnn.minimum | aten::hardtanh | 4 |
| 9 | Tensor<[1,28,28,28]>, Tensor<[1,28,28,28]>, | ttnn.minimum | aten::hardtanh | 4 |
| 10 | Tensor<[1,46,28,28]>, Tensor<[1,46,28,28]>, | ttnn.minimum | aten::hardtanh | 4 |
| 11 | Tensor<[1,78,28,28]>, Tensor<[1,78,28,28]>, | ttnn.minimum | aten::hardtanh | 4 |
| 12 | Tensor<[1,134,28,28]>, Tensor<[1,134,28,28]>, | ttnn.minimum | aten::hardtanh | 4 |
| 13 | Tensor<[1,256,28,28]>, Tensor<[1,256,28,28]>, | ttnn.minimum | aten::hardtanh | 4 |
| 14 | Tensor<[1,20,28,28]>, Tensor<[1,20,28,28]>, | ttnn.minimum | aten::hardtanh | 4 |
| 15 | Tensor<[1,34,28,28]>, Tensor<[1,34,28,28]>, | ttnn.minimum | aten::hardtanh | 4 |
| 16 | Tensor<[1,58,28,28]>, Tensor<[1,58,28,28]>, | ttnn.minimum | aten::hardtanh | 4 |
| 17 | Tensor<[1,98,28,28]>, Tensor<[1,98,28,28]>, | ttnn.minimum | aten::hardtanh | 4 |
| 18 | Tensor<[1,168,28,28]>, Tensor<[1,168,28,28]>, | ttnn.minimum | aten::hardtanh | 4 |
| 19 | Tensor<[1,320,28,28]>, Tensor<[1,320,28,28]>, | ttnn.minimum | aten::hardtanh | 4 |
| 20 | Tensor<[1,40,14,14]>, Tensor<[1,40,14,14]>, | ttnn.minimum | aten::hardtanh | 4 |
| 21 | Tensor<[1,68,14,14]>, Tensor<[1,68,14,14]>, | ttnn.minimum | aten::hardtanh | 4 |
| 22 | Tensor<[1,116,14,14]>, Tensor<[1,116,14,14]>, | ttnn.minimum | aten::hardtanh | 4 |
| 23 | Tensor<[1,196,14,14]>, Tensor<[1,196,14,14]>, | ttnn.minimum | aten::hardtanh | 4 |
| 24 | Tensor<[1,334,14,14]>, Tensor<[1,334,14,14]>, | ttnn.minimum | aten::hardtanh | 4 |
| 25 | Tensor<[1,640,14,14]>, Tensor<[1,640,14,14]>, | ttnn.minimum | aten::hardtanh | 4 |
| 26 | Tensor<[1,160,7,7]>, Tensor<[1,160,7,7]>, | ttnn.minimum | aten::hardtanh | 4 |
| 27 | Tensor<[1,272,7,7]>, Tensor<[1,272,7,7]>, | ttnn.minimum | aten::hardtanh | 4 |
| 28 | Tensor<[1,462,7,7]>, Tensor<[1,462,7,7]>, | ttnn.minimum | aten::hardtanh | 4 |
| 29 | Tensor<[1,1024,7,7]>, Tensor<[1,1024,7,7]>, | ttnn.minimum | aten::hardtanh | 4 |
| 30 | Tensor<[1,32,512,512]>, Tensor<[1,32,512,512]>, | ttnn.minimum | aten::leaky_relu | 4 |
| 31 | Tensor<[1,64,256,256]>, Tensor<[1,64,256,256]>, | ttnn.minimum | aten::leaky_relu | 4 |
| 32 | Tensor<[1,32,256,256]>, Tensor<[1,32,256,256]>, | ttnn.minimum | aten::leaky_relu | 4 |
| 33 | Tensor<[1,128,128,128]>, Tensor<[1,128,128,128]>, | ttnn.minimum | aten::leaky_relu | 4 |
| 34 | Tensor<[1,64,128,128]>, Tensor<[1,64,128,128]>, | ttnn.minimum | aten::leaky_relu | 4 |
| 35 | Tensor<[1,256,64,64]>, Tensor<[1,256,64,64]>, | ttnn.minimum | aten::leaky_relu | 4 |
| 36 | Tensor<[1,128,64,64]>, Tensor<[1,128,64,64]>, | ttnn.minimum | aten::leaky_relu | 4 |
| 37 | Tensor<[1,512,32,32]>, Tensor<[1,512,32,32]>, | ttnn.minimum | aten::leaky_relu | 4 |
| 38 | Tensor<[1,256,32,32]>, Tensor<[1,256,32,32]>, | ttnn.minimum | aten::leaky_relu | 4 |
| 39 | Tensor<[1,1024,16,16]>, Tensor<[1,1024,16,16]>, | ttnn.minimum | aten::leaky_relu | 4 |
| 40 | Tensor<[1,512,16,16]>, Tensor<[1,512,16,16]>, | ttnn.minimum | aten::leaky_relu | 4 |
| 41 | Tensor<[1,256,16,16]>, Tensor<[1,256,16,16]>, | ttnn.minimum | aten::leaky_relu | 4 |
| 42 | Tensor<[1,128,32,32]>, Tensor<[1,128,32,32]>, | ttnn.minimum | aten::leaky_relu | 4 |
| 43 | Tensor<[1,96,112,112]>, Tensor<[1,96,112,112]>, | ttnn.minimum | aten::hardtanh | 4 |
| 44 | Tensor<[1,96,56,56]>, Tensor<[1,96,56,56]>, | ttnn.minimum | aten::hardtanh | 4 |
| 45 | Tensor<[1,144,56,56]>, Tensor<[1,144,56,56]>, | ttnn.minimum | aten::hardtanh | 4 |
| 46 | Tensor<[1,144,28,28]>, Tensor<[1,144,28,28]>, | ttnn.minimum | aten::hardtanh | 4 |
| 47 | Tensor<[1,192,28,28]>, Tensor<[1,192,28,28]>, | ttnn.minimum | aten::hardtanh | 4 |
| 48 | Tensor<[1,192,14,14]>, Tensor<[1,192,14,14]>, | ttnn.minimum | aten::hardtanh | 4 |
| 49 | Tensor<[1,384,14,14]>, Tensor<[1,384,14,14]>, | ttnn.minimum | aten::hardtanh | 4 |
| 50 | Tensor<[1,576,14,14]>, Tensor<[1,576,14,14]>, | ttnn.minimum | aten::hardtanh | 4 |
| 51 | Tensor<[1,576,7,7]>, Tensor<[1,576,7,7]>, | ttnn.minimum | aten::hardtanh | 4 |
| 52 | Tensor<[1,960,7,7]>, Tensor<[1,960,7,7]>, | ttnn.minimum | aten::hardtanh | 4 |
| 53 | Tensor<[1,1280,7,7]>, Tensor<[1,1280,7,7]>, | ttnn.minimum | aten::hardtanh | 4 |
stablehlo.multiply::ttnn.multiply
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[32]>, Tensor<[32]>, | ttnn.multiply | aten::arange | 4 |
| 1 | Tensor<[1,32,32,128]>, Tensor<[1,32,32,128]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 2 | Tensor<[1,32,128,32]>, Tensor<[1,32,128,32]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 3 | Tensor<[32,32]>, Tensor<[32,32]>, | ttnn.multiply | aten::mul.Tensor | 5 |
| 4 | Tensor<[1,32,128]>, Tensor<[1,32,128]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 5 | Tensor<[1,32,4096]>, Tensor<[1,32,4096]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 6 | Tensor<[1,32,11008]>, Tensor<[1,32,11008]>, | ttnn.multiply | aten::mul.Tensor | 5 |
| 7 | Tensor<[7]>, Tensor<[7]>, | ttnn.multiply | aten::arange | 4 |
| 8 | Tensor<[1]>, Tensor<[1]>, | ttnn.multiply | aten::arange | 4 |
| 9 | Tensor<[1,12,7,64]>, Tensor<[1,12,7,64]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 10 | Tensor<[1,12,64,7]>, Tensor<[1,12,64,7]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 11 | Tensor<[1,7,768]>, Tensor<[1,7,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 12 | Tensor<[7,2304]>, Tensor<[7,2304]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 13 | Tensor<[2304]>, Tensor<[2304]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 14 | Tensor<[7,768]>, Tensor<[7,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 15 | Tensor<[768]>, Tensor<[768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 16 | Tensor<[7,3072]>, Tensor<[7,3072]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 17 | Tensor<[3072]>, Tensor<[3072]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 18 | Tensor<[1,7,3072]>, Tensor<[1,7,3072]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 19 | Tensor<[1,128,28,28]>, Tensor<[1,128,28,28]>, | ttnn.multiply | aten::elu | 4 |
| 20 | Tensor<[1,32,112,112]>, Tensor<[1,32,112,112]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 21 | Tensor<[64]>, Tensor<[64]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 22 | Tensor<[1,64,112,112]>, Tensor<[1,64,112,112]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 23 | Tensor<[1,64,56,56]>, Tensor<[1,64,56,56]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 24 | Tensor<[128]>, Tensor<[128]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 25 | Tensor<[1,128,56,56]>, Tensor<[1,128,56,56]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 26 | Tensor<[256]>, Tensor<[256]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 27 | Tensor<[1,256,28,28]>, Tensor<[1,256,28,28]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 28 | Tensor<[512]>, Tensor<[512]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 29 | Tensor<[1,512,28,28]>, Tensor<[1,512,28,28]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 30 | Tensor<[1,1024,512]>, Tensor<[1,1024,512]>, | ttnn.multiply | aten::gelu | 4 |
| 31 | Tensor<[1,256,256]>, Tensor<[1,256,256]>, | ttnn.multiply | aten::gelu | 4 |
| 32 | Tensor<[256,512]>, Tensor<[256,512]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 33 | Tensor<[1,256,512]>, Tensor<[1,256,512]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 34 | Tensor<[256,256]>, Tensor<[256,256]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 35 | Tensor<[1,1000]>, Tensor<[1,1000]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 36 | Tensor<[1000]>, Tensor<[1000]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 37 | Tensor<[23]>, Tensor<[23]>, | ttnn.multiply | aten::arange | 4 |
| 38 | Tensor<[40]>, Tensor<[40]>, | ttnn.multiply | aten::arange | 4 |
| 39 | Tensor<[8,920,920]>, Tensor<[8,920,920]>, | ttnn.multiply | aten::baddbmm | 4 |
| 40 | Tensor<[8,100,920]>, Tensor<[8,100,920]>, | ttnn.multiply | aten::baddbmm | 4 |
| 41 | Tensor<[1,64,1,1]>, Tensor<[1,64,1,1]>, | ttnn.multiply | aten::mul.Tensor | 5 |
| 42 | Tensor<[1,64,360,640]>, Tensor<[1,64,360,640]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 43 | Tensor<[1,64,180,320]>, Tensor<[1,64,180,320]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 44 | Tensor<[1,256,1,1]>, Tensor<[1,256,1,1]>, | ttnn.multiply | aten::mul.Tensor | 5 |
| 45 | Tensor<[1,256,180,320]>, Tensor<[1,256,180,320]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 46 | Tensor<[1,128,1,1]>, Tensor<[1,128,1,1]>, | ttnn.multiply | aten::mul.Tensor | 5 |
| 47 | Tensor<[1,128,180,320]>, Tensor<[1,128,180,320]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 48 | Tensor<[1,128,90,160]>, Tensor<[1,128,90,160]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 49 | Tensor<[1,512,1,1]>, Tensor<[1,512,1,1]>, | ttnn.multiply | aten::mul.Tensor | 5 |
| 50 | Tensor<[1,512,90,160]>, Tensor<[1,512,90,160]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 51 | Tensor<[1,256,90,160]>, Tensor<[1,256,90,160]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 52 | Tensor<[1,256,45,80]>, Tensor<[1,256,45,80]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 53 | Tensor<[1,1024,1,1]>, Tensor<[1,1024,1,1]>, | ttnn.multiply | aten::mul.Tensor | 5 |
| 54 | Tensor<[1,1024,45,80]>, Tensor<[1,1024,45,80]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 55 | Tensor<[1,512,45,80]>, Tensor<[1,512,45,80]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 56 | Tensor<[1,512,23,40]>, Tensor<[1,512,23,40]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 57 | Tensor<[1,2048,1,1]>, Tensor<[1,2048,1,1]>, | ttnn.multiply | aten::mul.Tensor | 5 |
| 58 | Tensor<[1,2048,23,40]>, Tensor<[1,2048,23,40]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 59 | Tensor<[1,23,40]>, Tensor<[1,23,40]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 60 | Tensor<[8,920,32]>, Tensor<[8,920,32]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 61 | Tensor<[920,256]>, Tensor<[920,256]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 62 | Tensor<[920,1,256]>, Tensor<[920,1,256]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 63 | Tensor<[920,2048]>, Tensor<[920,2048]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 64 | Tensor<[2048]>, Tensor<[2048]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 65 | Tensor<[100,256]>, Tensor<[100,256]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 66 | Tensor<[8,100,32]>, Tensor<[8,100,32]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 67 | Tensor<[100,1,256]>, Tensor<[100,1,256]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 68 | Tensor<[100,2048]>, Tensor<[100,2048]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 69 | Tensor<[1,10,3072]>, Tensor<[1,10,3072]>, | ttnn.multiply | aten::gelu | 4 |
| 70 | Tensor<[1,10,768]>, Tensor<[1,10,768]>, | ttnn.multiply | aten::gelu | 4 |
| 71 | Tensor<[1,12,10,64]>, Tensor<[1,12,10,64]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 72 | Tensor<[1,12,64,10]>, Tensor<[1,12,64,10]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 73 | Tensor<[1,10]>, Tensor<[1,10]>, | ttnn.multiply | aten::mul.Tensor | 5 |
| 74 | Tensor<[10,768]>, Tensor<[10,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 75 | Tensor<[10,3072]>, Tensor<[10,3072]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 76 | Tensor<[10,250002]>, Tensor<[10,250002]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 77 | Tensor<[250002]>, Tensor<[250002]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 78 | Tensor<[16]>, Tensor<[16]>, | ttnn.multiply | aten::arange | 4 |
| 79 | Tensor<[160]>, Tensor<[160]>, | ttnn.multiply | aten::arange.start | 4 |
| 80 | Tensor<[1,4096,1280]>, Tensor<[1,4096,1280]>, | ttnn.multiply | aten::gelu | 4 |
| 81 | Tensor<[1,1024,2560]>, Tensor<[1,1024,2560]>, | ttnn.multiply | aten::gelu | 4 |
| 82 | Tensor<[1,256,5120]>, Tensor<[1,256,5120]>, | ttnn.multiply | aten::gelu | 4 |
| 83 | Tensor<[1,64,5120]>, Tensor<[1,64,5120]>, | ttnn.multiply | aten::gelu | 4 |
| 84 | Tensor<[1280]>, Tensor<[1280]>, | ttnn.multiply | aten::index.Tensor | 4 |
| 85 | Tensor<[640]>, Tensor<[640]>, | ttnn.multiply | aten::index.Tensor | 4 |
| 86 | Tensor<[1,8,4096,40]>, Tensor<[1,8,4096,40]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 87 | Tensor<[1,8,40,4096]>, Tensor<[1,8,40,4096]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 88 | Tensor<[1,8,40,9]>, Tensor<[1,8,40,9]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 89 | Tensor<[1,8,1024,80]>, Tensor<[1,8,1024,80]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 90 | Tensor<[1,8,80,1024]>, Tensor<[1,8,80,1024]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 91 | Tensor<[1,8,80,9]>, Tensor<[1,8,80,9]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 92 | Tensor<[1,8,256,160]>, Tensor<[1,8,256,160]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 93 | Tensor<[1,8,160,256]>, Tensor<[1,8,160,256]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 94 | Tensor<[1,8,160,9]>, Tensor<[1,8,160,9]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 95 | Tensor<[1,8,64,160]>, Tensor<[1,8,64,160]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 96 | Tensor<[1,8,160,64]>, Tensor<[1,8,160,64]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 97 | Tensor<[1,160]>, Tensor<[1,160]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 98 | Tensor<[1,1280]>, Tensor<[1,1280]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 99 | Tensor<[1,32,10,4096]>, Tensor<[1,32,10,4096]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 100 | Tensor<[1,320,64,64]>, Tensor<[1,320,64,64]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 101 | Tensor<[1,320]>, Tensor<[1,320]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 102 | Tensor<[320]>, Tensor<[320]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 103 | Tensor<[1,4096,320]>, Tensor<[1,4096,320]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 104 | Tensor<[4096,320]>, Tensor<[4096,320]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 105 | Tensor<[4096,2560]>, Tensor<[4096,2560]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 106 | Tensor<[2560]>, Tensor<[2560]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 107 | Tensor<[1,32,10,1024]>, Tensor<[1,32,10,1024]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 108 | Tensor<[1,320,32,32]>, Tensor<[1,320,32,32]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 109 | Tensor<[1,640]>, Tensor<[1,640]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 110 | Tensor<[1,32,20,1024]>, Tensor<[1,32,20,1024]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 111 | Tensor<[1,640,32,32]>, Tensor<[1,640,32,32]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 112 | Tensor<[1,1024,640]>, Tensor<[1,1024,640]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 113 | Tensor<[1024,640]>, Tensor<[1024,640]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 114 | Tensor<[1024,5120]>, Tensor<[1024,5120]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 115 | Tensor<[5120]>, Tensor<[5120]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 116 | Tensor<[1,32,20,256]>, Tensor<[1,32,20,256]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 117 | Tensor<[1,640,16,16]>, Tensor<[1,640,16,16]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 118 | Tensor<[1,32,40,256]>, Tensor<[1,32,40,256]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 119 | Tensor<[1,1280,16,16]>, Tensor<[1,1280,16,16]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 120 | Tensor<[1,256,1280]>, Tensor<[1,256,1280]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 121 | Tensor<[256,1280]>, Tensor<[256,1280]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 122 | Tensor<[256,10240]>, Tensor<[256,10240]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 123 | Tensor<[10240]>, Tensor<[10240]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 124 | Tensor<[1,32,40,64]>, Tensor<[1,32,40,64]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 125 | Tensor<[1,1280,8,8]>, Tensor<[1,1280,8,8]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 126 | Tensor<[1,64,1280]>, Tensor<[1,64,1280]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 127 | Tensor<[64,1280]>, Tensor<[64,1280]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 128 | Tensor<[64,10240]>, Tensor<[64,10240]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 129 | Tensor<[1,32,80,64]>, Tensor<[1,32,80,64]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 130 | Tensor<[1,2560,8,8]>, Tensor<[1,2560,8,8]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 131 | Tensor<[1,32,80,256]>, Tensor<[1,32,80,256]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 132 | Tensor<[1,2560,16,16]>, Tensor<[1,2560,16,16]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 133 | Tensor<[1,32,60,256]>, Tensor<[1,32,60,256]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 134 | Tensor<[1,1920,16,16]>, Tensor<[1,1920,16,16]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 135 | Tensor<[1,32,60,1024]>, Tensor<[1,32,60,1024]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 136 | Tensor<[1,1920,32,32]>, Tensor<[1,1920,32,32]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 137 | Tensor<[1,32,40,1024]>, Tensor<[1,32,40,1024]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 138 | Tensor<[1,1280,32,32]>, Tensor<[1,1280,32,32]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 139 | Tensor<[1,32,30,1024]>, Tensor<[1,32,30,1024]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 140 | Tensor<[1,960,32,32]>, Tensor<[1,960,32,32]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 141 | Tensor<[1,32,30,4096]>, Tensor<[1,32,30,4096]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 142 | Tensor<[1,960,64,64]>, Tensor<[1,960,64,64]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 143 | Tensor<[1,32,20,4096]>, Tensor<[1,32,20,4096]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 144 | Tensor<[1,640,64,64]>, Tensor<[1,640,64,64]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 145 | Tensor<[1,25,3072]>, Tensor<[1,25,3072]>, | ttnn.multiply | aten::gelu | 4 |
| 146 | Tensor<[1,12,25,64]>, Tensor<[1,12,25,64]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 147 | Tensor<[1,12,64,25]>, Tensor<[1,12,64,25]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 148 | Tensor<[1,25,768]>, Tensor<[1,25,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 149 | Tensor<[25,768]>, Tensor<[25,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 150 | Tensor<[25,3072]>, Tensor<[25,3072]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 151 | Tensor<[25,2]>, Tensor<[25,2]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 152 | Tensor<[2]>, Tensor<[2]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 153 | Tensor<[1,1]>, Tensor<[1,1]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 154 | Tensor<[1,1445,768]>, Tensor<[1,1445,768]>, | ttnn.multiply | aten::gelu | 4 |
| 155 | Tensor<[1,3,1445,64]>, Tensor<[1,3,1445,64]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 156 | Tensor<[1,3,64,1445]>, Tensor<[1,3,64,1445]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 157 | Tensor<[1,1445,192]>, Tensor<[1,1445,192]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 158 | Tensor<[1445,192]>, Tensor<[1445,192]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 159 | Tensor<[192]>, Tensor<[192]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 160 | Tensor<[1445,768]>, Tensor<[1445,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 161 | Tensor<[100,192]>, Tensor<[100,192]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 162 | Tensor<[100,92]>, Tensor<[100,92]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 163 | Tensor<[92]>, Tensor<[92]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 164 | Tensor<[100,4]>, Tensor<[100,4]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 165 | Tensor<[4]>, Tensor<[4]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 166 | Tensor<[1,256,14,14]>, Tensor<[1,256,14,14]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 167 | Tensor<[1,512,7,7]>, Tensor<[1,512,7,7]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 168 | Tensor<[1,3072,8]>, Tensor<[1,3072,8]>, | ttnn.multiply | aten::gelu | 4 |
| 169 | Tensor<[1,1,1,8]>, Tensor<[1,1,1,8]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 170 | Tensor<[1,8,768]>, Tensor<[1,8,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 171 | Tensor<[1,768]>, Tensor<[1,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 172 | Tensor<[1,3]>, Tensor<[1,3]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 173 | Tensor<[3]>, Tensor<[3]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 174 | Tensor<[1,2048,768]>, Tensor<[1,2048,768]>, | ttnn.multiply | aten::gelu | 4 |
| 175 | Tensor<[1,1,1,2048]>, Tensor<[1,1,1,2048]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 176 | Tensor<[2048,256]>, Tensor<[2048,256]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 177 | Tensor<[2048,1280]>, Tensor<[2048,1280]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 178 | Tensor<[256,768]>, Tensor<[256,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 179 | Tensor<[2048,768]>, Tensor<[2048,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 180 | Tensor<[1,256,56,56]>, Tensor<[1,256,56,56]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 181 | Tensor<[1024]>, Tensor<[1024]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 182 | Tensor<[1,1024,14,14]>, Tensor<[1,1024,14,14]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 183 | Tensor<[1,512,14,14]>, Tensor<[1,512,14,14]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 184 | Tensor<[1,2048,7,7]>, Tensor<[1,2048,7,7]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 185 | Tensor<[12]>, Tensor<[12]>, | ttnn.multiply | aten::arange | 4 |
| 186 | Tensor<[1,201,3072]>, Tensor<[1,201,3072]>, | ttnn.multiply | aten::gelu | 4 |
| 187 | Tensor<[1,1536]>, Tensor<[1,1536]>, | ttnn.multiply | aten::gelu | 4 |
| 188 | Tensor<[1,1,1,201]>, Tensor<[1,1,1,201]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 189 | Tensor<[1,201,768]>, Tensor<[1,201,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 190 | Tensor<[201,768]>, Tensor<[201,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 191 | Tensor<[201,3072]>, Tensor<[201,3072]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 192 | Tensor<[1536]>, Tensor<[1536]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 193 | Tensor<[1,3129]>, Tensor<[1,3129]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 194 | Tensor<[3129]>, Tensor<[3129]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 195 | Tensor<[1,128]>, Tensor<[1,128]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 196 | Tensor<[10]>, Tensor<[10]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 197 | Tensor<[19]>, Tensor<[19]>, | ttnn.multiply | aten::arange | 4 |
| 198 | Tensor<[1,19,4096]>, Tensor<[1,19,4096]>, | ttnn.multiply | aten::gelu | 4 |
| 199 | Tensor<[1,19,1024]>, Tensor<[1,19,1024]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 200 | Tensor<[19,1024]>, Tensor<[19,1024]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 201 | Tensor<[19,4096]>, Tensor<[19,4096]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 202 | Tensor<[4096]>, Tensor<[4096]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 203 | Tensor<[14]>, Tensor<[14]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 204 | Tensor<[1,14,56,56]>, Tensor<[1,14,56,56]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 205 | Tensor<[24]>, Tensor<[24]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 206 | Tensor<[1,24,56,56]>, Tensor<[1,24,56,56]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 207 | Tensor<[1,40,56,56]>, Tensor<[1,40,56,56]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 208 | Tensor<[68]>, Tensor<[68]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 209 | Tensor<[1,68,56,56]>, Tensor<[1,68,56,56]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 210 | Tensor<[1,16,28,28]>, Tensor<[1,16,28,28]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 211 | Tensor<[28]>, Tensor<[28]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 212 | Tensor<[1,28,28,28]>, Tensor<[1,28,28,28]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 213 | Tensor<[46]>, Tensor<[46]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 214 | Tensor<[1,46,28,28]>, Tensor<[1,46,28,28]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 215 | Tensor<[78]>, Tensor<[78]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 216 | Tensor<[1,78,28,28]>, Tensor<[1,78,28,28]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 217 | Tensor<[134]>, Tensor<[134]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 218 | Tensor<[1,134,28,28]>, Tensor<[1,134,28,28]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 219 | Tensor<[20]>, Tensor<[20]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 220 | Tensor<[1,20,28,28]>, Tensor<[1,20,28,28]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 221 | Tensor<[34]>, Tensor<[34]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 222 | Tensor<[1,34,28,28]>, Tensor<[1,34,28,28]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 223 | Tensor<[58]>, Tensor<[58]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 224 | Tensor<[1,58,28,28]>, Tensor<[1,58,28,28]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 225 | Tensor<[98]>, Tensor<[98]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 226 | Tensor<[1,98,28,28]>, Tensor<[1,98,28,28]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 227 | Tensor<[168]>, Tensor<[168]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 228 | Tensor<[1,168,28,28]>, Tensor<[1,168,28,28]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 229 | Tensor<[1,320,28,28]>, Tensor<[1,320,28,28]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 230 | Tensor<[1,40,14,14]>, Tensor<[1,40,14,14]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 231 | Tensor<[1,68,14,14]>, Tensor<[1,68,14,14]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 232 | Tensor<[116]>, Tensor<[116]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 233 | Tensor<[1,116,14,14]>, Tensor<[1,116,14,14]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 234 | Tensor<[196]>, Tensor<[196]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 235 | Tensor<[1,196,14,14]>, Tensor<[1,196,14,14]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 236 | Tensor<[334]>, Tensor<[334]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 237 | Tensor<[1,334,14,14]>, Tensor<[1,334,14,14]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 238 | Tensor<[1,640,14,14]>, Tensor<[1,640,14,14]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 239 | Tensor<[1,160,7,7]>, Tensor<[1,160,7,7]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 240 | Tensor<[272]>, Tensor<[272]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 241 | Tensor<[1,272,7,7]>, Tensor<[1,272,7,7]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 242 | Tensor<[462]>, Tensor<[462]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 243 | Tensor<[1,462,7,7]>, Tensor<[1,462,7,7]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 244 | Tensor<[1,1024,7,7]>, Tensor<[1,1024,7,7]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 245 | Tensor<[1,32,512,512]>, Tensor<[1,32,512,512]>, | ttnn.multiply | aten::leaky_relu | 4 |
| 246 | Tensor<[1,64,256,256]>, Tensor<[1,64,256,256]>, | ttnn.multiply | aten::leaky_relu | 4 |
| 247 | Tensor<[1,32,256,256]>, Tensor<[1,32,256,256]>, | ttnn.multiply | aten::leaky_relu | 4 |
| 248 | Tensor<[1,128,128,128]>, Tensor<[1,128,128,128]>, | ttnn.multiply | aten::leaky_relu | 4 |
| 249 | Tensor<[1,64,128,128]>, Tensor<[1,64,128,128]>, | ttnn.multiply | aten::leaky_relu | 4 |
| 250 | Tensor<[1,256,64,64]>, Tensor<[1,256,64,64]>, | ttnn.multiply | aten::leaky_relu | 4 |
| 251 | Tensor<[1,128,64,64]>, Tensor<[1,128,64,64]>, | ttnn.multiply | aten::leaky_relu | 4 |
| 252 | Tensor<[1,512,32,32]>, Tensor<[1,512,32,32]>, | ttnn.multiply | aten::leaky_relu | 4 |
| 253 | Tensor<[1,256,32,32]>, Tensor<[1,256,32,32]>, | ttnn.multiply | aten::leaky_relu | 4 |
| 254 | Tensor<[1,1024,16,16]>, Tensor<[1,1024,16,16]>, | ttnn.multiply | aten::leaky_relu | 4 |
| 255 | Tensor<[1,512,16,16]>, Tensor<[1,512,16,16]>, | ttnn.multiply | aten::leaky_relu | 4 |
| 256 | Tensor<[1,256,16,16]>, Tensor<[1,256,16,16]>, | ttnn.multiply | aten::leaky_relu | 4 |
| 257 | Tensor<[1,128,32,32]>, Tensor<[1,128,32,32]>, | ttnn.multiply | aten::leaky_relu | 4 |
| 258 | Tensor<[16,32,32]>, Tensor<[16,32,32]>, | ttnn.multiply | aten::baddbmm | 4 |
| 259 | Tensor<[1,32,1536]>, Tensor<[1,32,1536]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 260 | Tensor<[1,32]>, Tensor<[1,32]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 261 | Tensor<[1,16,32]>, Tensor<[1,16,32]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 262 | Tensor<[32,4608]>, Tensor<[32,4608]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 263 | Tensor<[4608]>, Tensor<[4608]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 264 | Tensor<[32,1536]>, Tensor<[32,1536]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 265 | Tensor<[32,6144]>, Tensor<[32,6144]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 266 | Tensor<[6144]>, Tensor<[6144]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 267 | Tensor<[1,32,6144]>, Tensor<[1,32,6144]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 268 | Tensor<[1,16,3072]>, Tensor<[1,16,3072]>, | ttnn.multiply | aten::gelu | 4 |
| 269 | Tensor<[1,12,16,64]>, Tensor<[1,12,16,64]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 270 | Tensor<[1,12,64,16]>, Tensor<[1,12,64,16]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 271 | Tensor<[1,16,768]>, Tensor<[1,16,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 272 | Tensor<[16,768]>, Tensor<[16,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 273 | Tensor<[16,3072]>, Tensor<[16,3072]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 274 | Tensor<[1,64,224,224]>, Tensor<[1,64,224,224]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 275 | Tensor<[1,128,112,112]>, Tensor<[1,128,112,112]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 276 | Tensor<[30]>, Tensor<[30]>, | ttnn.multiply | aten::arange | 4 |
| 277 | Tensor<[60]>, Tensor<[60]>, | ttnn.multiply | aten::arange | 4 |
| 278 | Tensor<[80]>, Tensor<[80]>, | ttnn.multiply | aten::arange | 4 |
| 279 | Tensor<[120]>, Tensor<[120]>, | ttnn.multiply | aten::arange | 4 |
| 280 | Tensor<[240]>, Tensor<[240]>, | ttnn.multiply | aten::arange | 4 |
| 281 | Tensor<[480]>, Tensor<[480]>, | ttnn.multiply | aten::arange | 4 |
| 282 | Tensor<[1,19200,256]>, Tensor<[1,19200,256]>, | ttnn.multiply | aten::gelu | 4 |
| 283 | Tensor<[1,4800,512]>, Tensor<[1,4800,512]>, | ttnn.multiply | aten::gelu | 4 |
| 284 | Tensor<[1,1200,1280]>, Tensor<[1,1200,1280]>, | ttnn.multiply | aten::gelu | 4 |
| 285 | Tensor<[1,300,2048]>, Tensor<[1,300,2048]>, | ttnn.multiply | aten::gelu | 4 |
| 286 | Tensor<[1,19200,64]>, Tensor<[1,19200,64]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 287 | Tensor<[19200,64]>, Tensor<[19200,64]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 288 | Tensor<[1,300,64]>, Tensor<[1,300,64]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 289 | Tensor<[300,64]>, Tensor<[300,64]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 290 | Tensor<[19200,256]>, Tensor<[19200,256]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 291 | Tensor<[1,4800,128]>, Tensor<[1,4800,128]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 292 | Tensor<[4800,128]>, Tensor<[4800,128]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 293 | Tensor<[1,300,128]>, Tensor<[1,300,128]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 294 | Tensor<[300,128]>, Tensor<[300,128]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 295 | Tensor<[4800,512]>, Tensor<[4800,512]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 296 | Tensor<[1,1200,320]>, Tensor<[1,1200,320]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 297 | Tensor<[1200,320]>, Tensor<[1200,320]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 298 | Tensor<[1,300,320]>, Tensor<[1,300,320]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 299 | Tensor<[300,320]>, Tensor<[300,320]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 300 | Tensor<[1200,1280]>, Tensor<[1200,1280]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 301 | Tensor<[1,300,512]>, Tensor<[1,300,512]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 302 | Tensor<[300,512]>, Tensor<[300,512]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 303 | Tensor<[300,2048]>, Tensor<[300,2048]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 304 | Tensor<[1,64,30,40]>, Tensor<[1,64,30,40]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 305 | Tensor<[1,32,30,40]>, Tensor<[1,32,30,40]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 306 | Tensor<[1,64,60,80]>, Tensor<[1,64,60,80]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 307 | Tensor<[1,32,60,80]>, Tensor<[1,32,60,80]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 308 | Tensor<[1,64,120,160]>, Tensor<[1,64,120,160]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 309 | Tensor<[1,32,120,160]>, Tensor<[1,32,120,160]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 310 | Tensor<[1,64,240,320]>, Tensor<[1,64,240,320]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 311 | Tensor<[1,64,480,640]>, Tensor<[1,64,480,640]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 312 | Tensor<[1,1,480,640]>, Tensor<[1,1,480,640]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 313 | Tensor<[1,197,3072]>, Tensor<[1,197,3072]>, | ttnn.multiply | aten::gelu | 4 |
| 314 | Tensor<[1,12,197,64]>, Tensor<[1,12,197,64]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 315 | Tensor<[1,12,64,197]>, Tensor<[1,12,64,197]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 316 | Tensor<[1,197,768]>, Tensor<[1,197,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 317 | Tensor<[197,768]>, Tensor<[197,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 318 | Tensor<[197,3072]>, Tensor<[197,3072]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 319 | Tensor<[1,16384,128]>, Tensor<[1,16384,128]>, | ttnn.multiply | aten::gelu | 4 |
| 320 | Tensor<[1,4096,256]>, Tensor<[1,4096,256]>, | ttnn.multiply | aten::gelu | 4 |
| 321 | Tensor<[1,256,1024]>, Tensor<[1,256,1024]>, | ttnn.multiply | aten::gelu | 4 |
| 322 | Tensor<[1,16384,32]>, Tensor<[1,16384,32]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 323 | Tensor<[16384,32]>, Tensor<[16384,32]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 324 | Tensor<[1,256,32]>, Tensor<[1,256,32]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 325 | Tensor<[256,32]>, Tensor<[256,32]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 326 | Tensor<[16384,128]>, Tensor<[16384,128]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 327 | Tensor<[1,4096,64]>, Tensor<[1,4096,64]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 328 | Tensor<[4096,64]>, Tensor<[4096,64]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 329 | Tensor<[1,256,64]>, Tensor<[1,256,64]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 330 | Tensor<[256,64]>, Tensor<[256,64]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 331 | Tensor<[4096,256]>, Tensor<[4096,256]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 332 | Tensor<[1,1024,160]>, Tensor<[1,1024,160]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 333 | Tensor<[1024,160]>, Tensor<[1024,160]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 334 | Tensor<[1,256,160]>, Tensor<[1,256,160]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 335 | Tensor<[256,160]>, Tensor<[256,160]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 336 | Tensor<[256,1024]>, Tensor<[256,1024]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 337 | Tensor<[1,256,128,128]>, Tensor<[1,256,128,128]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 338 | Tensor<[1,7,18176]>, Tensor<[1,7,18176]>, | ttnn.multiply | aten::gelu | 4 |
| 339 | Tensor<[1,71,7,64]>, Tensor<[1,71,7,64]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 340 | Tensor<[1,1,64,7]>, Tensor<[1,1,64,7]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 341 | Tensor<[7,7]>, Tensor<[7,7]>, | ttnn.multiply | aten::mul.Tensor | 5 |
| 342 | Tensor<[1,7,64]>, Tensor<[1,7,64]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 343 | Tensor<[1,7,4544]>, Tensor<[1,7,4544]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 344 | Tensor<[1,1,7,64]>, Tensor<[1,1,7,64]>, | ttnn.multiply | aten::mul.Tensor | 5 |
| 345 | Tensor<[1,16,112,112]>, Tensor<[1,16,112,112]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 346 | Tensor<[96]>, Tensor<[96]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 347 | Tensor<[1,96,112,112]>, Tensor<[1,96,112,112]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 348 | Tensor<[1,96,56,56]>, Tensor<[1,96,56,56]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 349 | Tensor<[144]>, Tensor<[144]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 350 | Tensor<[1,144,56,56]>, Tensor<[1,144,56,56]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 351 | Tensor<[1,144,28,28]>, Tensor<[1,144,28,28]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 352 | Tensor<[1,32,28,28]>, Tensor<[1,32,28,28]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 353 | Tensor<[1,192,28,28]>, Tensor<[1,192,28,28]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 354 | Tensor<[1,192,14,14]>, Tensor<[1,192,14,14]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 355 | Tensor<[1,64,14,14]>, Tensor<[1,64,14,14]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 356 | Tensor<[384]>, Tensor<[384]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 357 | Tensor<[1,384,14,14]>, Tensor<[1,384,14,14]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 358 | Tensor<[1,96,14,14]>, Tensor<[1,96,14,14]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 359 | Tensor<[576]>, Tensor<[576]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 360 | Tensor<[1,576,14,14]>, Tensor<[1,576,14,14]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 361 | Tensor<[1,576,7,7]>, Tensor<[1,576,7,7]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 362 | Tensor<[960]>, Tensor<[960]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 363 | Tensor<[1,960,7,7]>, Tensor<[1,960,7,7]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 364 | Tensor<[1,320,7,7]>, Tensor<[1,320,7,7]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 365 | Tensor<[1,1280,7,7]>, Tensor<[1,1280,7,7]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 366 | Tensor<[1,12,12,64]>, Tensor<[1,12,12,64]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 367 | Tensor<[1,12,64,12]>, Tensor<[1,12,64,12]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 368 | Tensor<[1,12,128]>, Tensor<[1,12,128]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 369 | Tensor<[12,768]>, Tensor<[12,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 370 | Tensor<[1,12,768]>, Tensor<[1,12,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 371 | Tensor<[12,3072]>, Tensor<[12,3072]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 372 | Tensor<[1,12,3072]>, Tensor<[1,12,3072]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 373 | Tensor<[12,2]>, Tensor<[12,2]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 374 | Tensor<[1,12,9,64]>, Tensor<[1,12,9,64]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 375 | Tensor<[1,12,64,9]>, Tensor<[1,12,64,9]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 376 | Tensor<[1,9,128]>, Tensor<[1,9,128]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 377 | Tensor<[9,768]>, Tensor<[9,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 378 | Tensor<[1,9,768]>, Tensor<[1,9,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 379 | Tensor<[9,3072]>, Tensor<[9,3072]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 380 | Tensor<[1,9,3072]>, Tensor<[1,9,3072]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 381 | Tensor<[9,128]>, Tensor<[9,128]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 382 | Tensor<[9,30000]>, Tensor<[9,30000]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 383 | Tensor<[30000]>, Tensor<[30000]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 384 | Tensor<[1,16,9,128]>, Tensor<[1,16,9,128]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 385 | Tensor<[1,16,128,9]>, Tensor<[1,16,128,9]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 386 | Tensor<[9,2048]>, Tensor<[9,2048]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 387 | Tensor<[1,9,2048]>, Tensor<[1,9,2048]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 388 | Tensor<[9,8192]>, Tensor<[9,8192]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 389 | Tensor<[8192]>, Tensor<[8192]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 390 | Tensor<[1,9,8192]>, Tensor<[1,9,8192]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 391 | Tensor<[1,16,9,64]>, Tensor<[1,16,9,64]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 392 | Tensor<[1,16,64,9]>, Tensor<[1,16,64,9]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 393 | Tensor<[9,1024]>, Tensor<[9,1024]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 394 | Tensor<[1,9,1024]>, Tensor<[1,9,1024]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 395 | Tensor<[9,4096]>, Tensor<[9,4096]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 396 | Tensor<[1,9,4096]>, Tensor<[1,9,4096]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 397 | Tensor<[1,64,9,64]>, Tensor<[1,64,9,64]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 398 | Tensor<[1,64,64,9]>, Tensor<[1,64,64,9]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 399 | Tensor<[9,16384]>, Tensor<[9,16384]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 400 | Tensor<[16384]>, Tensor<[16384]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 401 | Tensor<[1,9,16384]>, Tensor<[1,9,16384]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 402 | Tensor<[1,2]>, Tensor<[1,2]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 403 | Tensor<[1,12,14,64]>, Tensor<[1,12,14,64]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 404 | Tensor<[1,12,64,14]>, Tensor<[1,12,64,14]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 405 | Tensor<[1,14,128]>, Tensor<[1,14,128]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 406 | Tensor<[14,768]>, Tensor<[14,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 407 | Tensor<[1,14,768]>, Tensor<[1,14,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 408 | Tensor<[14,3072]>, Tensor<[14,3072]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 409 | Tensor<[1,14,3072]>, Tensor<[1,14,3072]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 410 | Tensor<[14,2]>, Tensor<[14,2]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 411 | Tensor<[1,12,50,64]>, Tensor<[1,12,50,64]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 412 | Tensor<[1,12,64,50]>, Tensor<[1,12,64,50]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 413 | Tensor<[2,8,7,64]>, Tensor<[2,8,7,64]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 414 | Tensor<[2,8,64,7]>, Tensor<[2,8,64,7]>, | ttnn.multiply | aten::mul.Scalar | 4 |
| 415 | Tensor<[1,50,768]>, Tensor<[1,50,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 416 | Tensor<[50,768]>, Tensor<[50,768]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 417 | Tensor<[50,3072]>, Tensor<[50,3072]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 418 | Tensor<[1,50,3072]>, Tensor<[1,50,3072]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 419 | Tensor<[2,7,512]>, Tensor<[2,7,512]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 420 | Tensor<[14,512]>, Tensor<[14,512]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 421 | Tensor<[14,2048]>, Tensor<[14,2048]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 422 | Tensor<[2,7,2048]>, Tensor<[2,7,2048]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 423 | Tensor<[2,1]>, Tensor<[2,1]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 424 | Tensor<[27]>, Tensor<[27]>, | ttnn.multiply | aten::arange | 4 |
| 425 | Tensor<[197]>, Tensor<[197]>, | ttnn.multiply | aten::arange | 4 |
| 426 | Tensor<[1,197,4096]>, Tensor<[1,197,4096]>, | ttnn.multiply | aten::gelu | 4 |
| 427 | Tensor<[1,197,1024]>, Tensor<[1,197,1024]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 428 | Tensor<[197,1024]>, Tensor<[197,1024]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 429 | Tensor<[1,16,27,27]>, Tensor<[1,16,27,27]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 430 | Tensor<[196,196]>, Tensor<[196,196]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 431 | Tensor<[197,4096]>, Tensor<[197,4096]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 432 | Tensor<[1,1024]>, Tensor<[1,1024]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 433 | Tensor<[1,12,27,27]>, Tensor<[1,12,27,27]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 434 | Tensor<[1,64]>, Tensor<[1,64]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 435 | Tensor<[1,12]>, Tensor<[1,12]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 436 | Tensor<[1,784]>, Tensor<[1,784]>, | ttnn.multiply | aten::mul.Tensor | 4 |
| 437 | Tensor<[784]>, Tensor<[784]>, | ttnn.multiply | aten::mul.Tensor | 4 |
stablehlo.negate::ttnn.neg
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,32,32,64]>, | ttnn.neg | aten::neg | 5 |
| 1 | Tensor<[19]>, | ttnn.neg | aten::neg | 5 |
| 2 | Tensor<[1,71,7,32]>, | ttnn.neg | aten::neg | 5 |
| 3 | Tensor<[1,1,7,32]>, | ttnn.neg | aten::neg | 5 |
stablehlo.not::ttnn.not
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,23,40]>, | ttnn.not | aten::bitwise_not | 5 |
stablehlo.power::ttnn.pow
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,32,4096]>, Tensor<[1,32,4096]>, | ttnn.pow | aten::pow.Tensor_Scalar | 4 |
| 1 | Tensor<[1,7,3072]>, Tensor<[1,7,3072]>, | ttnn.pow | aten::pow.Tensor_Scalar | 4 |
| 2 | Tensor<[128]>, Tensor<[128]>, | ttnn.pow | aten::pow.Scalar | 4 |
| 3 | Tensor<[16]>, Tensor<[16]>, | ttnn.pow | aten::pow.Tensor_Tensor | 4 |
| 4 | Tensor<[1,12,3072]>, Tensor<[1,12,3072]>, | ttnn.pow | aten::pow.Tensor_Scalar | 4 |
| 5 | Tensor<[1,9,3072]>, Tensor<[1,9,3072]>, | ttnn.pow | aten::pow.Tensor_Scalar | 4 |
| 6 | Tensor<[1,9,128]>, Tensor<[1,9,128]>, | ttnn.pow | aten::pow.Tensor_Scalar | 4 |
| 7 | Tensor<[1,9,8192]>, Tensor<[1,9,8192]>, | ttnn.pow | aten::pow.Tensor_Scalar | 4 |
| 8 | Tensor<[1,9,4096]>, Tensor<[1,9,4096]>, | ttnn.pow | aten::pow.Tensor_Scalar | 4 |
| 9 | Tensor<[1,9,16384]>, Tensor<[1,9,16384]>, | ttnn.pow | aten::pow.Tensor_Scalar | 4 |
| 10 | Tensor<[1,14,3072]>, Tensor<[1,14,3072]>, | ttnn.pow | aten::pow.Tensor_Scalar | 4 |
| 11 | Tensor<[1,512]>, Tensor<[1,512]>, | ttnn.pow | aten::pow.Tensor_Scalar | 4 |
| 12 | Tensor<[1,1]>, Tensor<[1,1]>, | ttnn.pow | aten::pow.Tensor_Scalar | 4 |
| 13 | Tensor<[2,512]>, Tensor<[2,512]>, | ttnn.pow | aten::pow.Tensor_Scalar | 4 |
| 14 | Tensor<[2,1]>, Tensor<[2,1]>, | ttnn.pow | aten::pow.Tensor_Scalar | 4 |
stablehlo.reduce_stablehlo.add::ttnn.sum
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,32,32,32]>, Scalar, dim: [3] | ttnn.sum | aten::_safe_softmax | 4 |
| 1 | Tensor<[1,32,4096]>, Scalar, dim: [2] | ttnn.sum | aten::mean.dim | 4 |
| 2 | Tensor<[1,12,7,7]>, Scalar, dim: [3] | ttnn.sum | aten::_safe_softmax | 4 |
| 3 | Tensor<[1,512,256]>, Scalar, dim: [2] | ttnn.sum | aten::mean.dim | 4 |
| 4 | Tensor<[8,920,920]>, Scalar, dim: [2] | ttnn.sum | aten::_softmax | 4 |
| 5 | Tensor<[8,100,100]>, Scalar, dim: [2] | ttnn.sum | aten::_softmax | 4 |
| 6 | Tensor<[8,100,920]>, Scalar, dim: [2] | ttnn.sum | aten::_softmax | 4 |
| 7 | Tensor<[1,12,10,10]>, Scalar, dim: [3] | ttnn.sum | aten::_safe_softmax | 4 |
| 8 | Tensor<[1,8,4096,4096]>, Scalar, dim: [3] | ttnn.sum | aten::_safe_softmax | 4 |
| 9 | Tensor<[1,8,4096,9]>, Scalar, dim: [3] | ttnn.sum | aten::_safe_softmax | 4 |
| 10 | Tensor<[1,8,1024,1024]>, Scalar, dim: [3] | ttnn.sum | aten::_safe_softmax | 4 |
| 11 | Tensor<[1,8,1024,9]>, Scalar, dim: [3] | ttnn.sum | aten::_safe_softmax | 4 |
| 12 | Tensor<[1,8,256,256]>, Scalar, dim: [3] | ttnn.sum | aten::_safe_softmax | 4 |
| 13 | Tensor<[1,8,256,9]>, Scalar, dim: [3] | ttnn.sum | aten::_safe_softmax | 4 |
| 14 | Tensor<[1,8,64,64]>, Scalar, dim: [3] | ttnn.sum | aten::_safe_softmax | 4 |
| 15 | Tensor<[1,8,64,9]>, Scalar, dim: [3] | ttnn.sum | aten::_safe_softmax | 4 |
| 16 | Tensor<[1,12,25,25]>, Scalar, dim: [3] | ttnn.sum | aten::_safe_softmax | 4 |
| 17 | Tensor<[1,3,1445,1445]>, Scalar, dim: [3] | ttnn.sum | aten::_safe_softmax | 4 |
| 18 | Tensor<[1,512,7,7]>, Scalar, dim: [2, | ttnn.sum | aten::mean.dim | 4 |
| 19 | Tensor<[1,12,8,8]>, Scalar, dim: [3] | ttnn.sum | aten::_softmax | 4 |
| 20 | Tensor<[1,8,256,2048]>, Scalar, dim: [3] | ttnn.sum | aten::_softmax | 4 |
| 21 | Tensor<[1,8,2048,256]>, Scalar, dim: [3] | ttnn.sum | aten::_softmax | 4 |
| 22 | Tensor<[1,2048,7,7]>, Scalar, dim: [2, | ttnn.sum | aten::mean.dim | 4 |
| 23 | Tensor<[1,12,201,201]>, Scalar, dim: [3] | ttnn.sum | aten::_softmax | 4 |
| 24 | Tensor<[1,12,16]>, Scalar, dim: [1] | ttnn.sum | aten::sum.dim_IntList | 4 |
| 25 | Tensor<[1,12,16]>, Scalar, dim: [2] | ttnn.sum | aten::sum.dim_IntList | 4 |
| 26 | Tensor<[1,10]>, Scalar, dim: [1] | ttnn.sum | aten::sum.dim_IntList | 5 |
| 27 | Tensor<[16,19,19]>, Scalar, dim: [2] | ttnn.sum | aten::_softmax | 4 |
| 28 | Tensor<[19]>, Scalar, dim: [0] | ttnn.sum | aten::sum | 4 |
| 29 | Tensor<[19,256008]>, Scalar, dim: [1] | ttnn.sum | aten::sum.dim_IntList | 5 |
| 30 | Tensor<[1,1024,7,7]>, Scalar, dim: [2, | ttnn.sum | aten::mean.dim | 4 |
| 31 | Tensor<[1,16,32,32]>, Scalar, dim: [3] | ttnn.sum | aten::_softmax | 4 |
| 32 | Tensor<[1,12,16,16]>, Scalar, dim: [3] | ttnn.sum | aten::_safe_softmax | 4 |
| 33 | Tensor<[1,1,19200,300]>, Scalar, dim: [3] | ttnn.sum | aten::_softmax | 4 |
| 34 | Tensor<[1,2,4800,300]>, Scalar, dim: [3] | ttnn.sum | aten::_softmax | 4 |
| 35 | Tensor<[1,5,1200,300]>, Scalar, dim: [3] | ttnn.sum | aten::_softmax | 4 |
| 36 | Tensor<[1,8,300,300]>, Scalar, dim: [3] | ttnn.sum | aten::_softmax | 4 |
| 37 | Tensor<[1,12,197,197]>, Scalar, dim: [3] | ttnn.sum | aten::_safe_softmax | 4 |
| 38 | Tensor<[1,1,16384,256]>, Scalar, dim: [3] | ttnn.sum | aten::_softmax | 4 |
| 39 | Tensor<[1,2,4096,256]>, Scalar, dim: [3] | ttnn.sum | aten::_softmax | 4 |
| 40 | Tensor<[1,5,1024,256]>, Scalar, dim: [3] | ttnn.sum | aten::_softmax | 4 |
| 41 | Tensor<[1,71,7,7]>, Scalar, dim: [3] | ttnn.sum | aten::_safe_softmax | 4 |
| 42 | Tensor<[1,1280,7,7]>, Scalar, dim: [2, | ttnn.sum | aten::mean.dim | 4 |
| 43 | Tensor<[1,12,12,12]>, Scalar, dim: [3] | ttnn.sum | aten::_safe_softmax | 4 |
| 44 | Tensor<[1,12,9,9]>, Scalar, dim: [3] | ttnn.sum | aten::_safe_softmax | 4 |
| 45 | Tensor<[1,16,9,9]>, Scalar, dim: [3] | ttnn.sum | aten::_safe_softmax | 4 |
| 46 | Tensor<[1,64,9,9]>, Scalar, dim: [3] | ttnn.sum | aten::_safe_softmax | 4 |
| 47 | Tensor<[1,12,14,14]>, Scalar, dim: [3] | ttnn.sum | aten::_safe_softmax | 4 |
| 48 | Tensor<[1,12,50,50]>, Scalar, dim: [3] | ttnn.sum | aten::_safe_softmax | 4 |
| 49 | Tensor<[2,8,7,7]>, Scalar, dim: [3] | ttnn.sum | aten::_safe_softmax | 4 |
| 50 | Tensor<[1,512]>, Scalar, dim: [1] | ttnn.sum | aten::sum.dim_IntList | 4 |
| 51 | Tensor<[2,512]>, Scalar, dim: [1] | ttnn.sum | aten::sum.dim_IntList | 4 |
| 52 | Tensor<[1,16,197,197]>, Scalar, dim: [3] | ttnn.sum | aten::_softmax | 4 |
| 53 | Tensor<[1,196,1024]>, Scalar, dim: [1] | ttnn.sum | aten::mean.dim | 4 |
| 54 | Tensor<[196,196,2]>, Scalar, dim: [2] | ttnn.sum | aten::sum.dim_IntList | 4 |
| 55 | Tensor<[1,196,768]>, Scalar, dim: [1] | ttnn.sum | aten::mean.dim | 4 |
stablehlo.reduce_stablehlo.and::ttnn.?
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,32,32,32]>, Scalar, dim: [3] | ttnn.? | aten::_safe_softmax | 4 |
| 1 | Tensor<[1,12,7,7]>, Scalar, dim: [3] | ttnn.? | aten::_safe_softmax | 4 |
| 2 | Tensor<[1,12,10,10]>, Scalar, dim: [3] | ttnn.? | aten::_safe_softmax | 4 |
| 3 | Tensor<[1,8,4096,4096]>, Scalar, dim: [3] | ttnn.? | aten::_safe_softmax | 4 |
| 4 | Tensor<[1,8,4096,9]>, Scalar, dim: [3] | ttnn.? | aten::_safe_softmax | 4 |
| 5 | Tensor<[1,8,1024,1024]>, Scalar, dim: [3] | ttnn.? | aten::_safe_softmax | 4 |
| 6 | Tensor<[1,8,1024,9]>, Scalar, dim: [3] | ttnn.? | aten::_safe_softmax | 4 |
| 7 | Tensor<[1,8,256,256]>, Scalar, dim: [3] | ttnn.? | aten::_safe_softmax | 4 |
| 8 | Tensor<[1,8,256,9]>, Scalar, dim: [3] | ttnn.? | aten::_safe_softmax | 4 |
| 9 | Tensor<[1,8,64,64]>, Scalar, dim: [3] | ttnn.? | aten::_safe_softmax | 4 |
| 10 | Tensor<[1,8,64,9]>, Scalar, dim: [3] | ttnn.? | aten::_safe_softmax | 4 |
| 11 | Tensor<[1,12,25,25]>, Scalar, dim: [3] | ttnn.? | aten::_safe_softmax | 4 |
| 12 | Tensor<[1,3,1445,1445]>, Scalar, dim: [3] | ttnn.? | aten::_safe_softmax | 4 |
| 13 | Tensor<[1,12,16,16]>, Scalar, dim: [3] | ttnn.? | aten::_safe_softmax | 4 |
| 14 | Tensor<[1,12,197,197]>, Scalar, dim: [3] | ttnn.? | aten::_safe_softmax | 4 |
| 15 | Tensor<[1,71,7,7]>, Scalar, dim: [3] | ttnn.? | aten::_safe_softmax | 4 |
| 16 | Tensor<[1,12,12,12]>, Scalar, dim: [3] | ttnn.? | aten::_safe_softmax | 4 |
| 17 | Tensor<[1,12,9,9]>, Scalar, dim: [3] | ttnn.? | aten::_safe_softmax | 4 |
| 18 | Tensor<[1,16,9,9]>, Scalar, dim: [3] | ttnn.? | aten::_safe_softmax | 4 |
| 19 | Tensor<[1,64,9,9]>, Scalar, dim: [3] | ttnn.? | aten::_safe_softmax | 4 |
| 20 | Tensor<[1,12,14,14]>, Scalar, dim: [3] | ttnn.? | aten::_safe_softmax | 4 |
| 21 | Tensor<[1,12,50,50]>, Scalar, dim: [3] | ttnn.? | aten::_safe_softmax | 4 |
| 22 | Tensor<[2,8,7,7]>, Scalar, dim: [3] | ttnn.? | aten::_safe_softmax | 4 |
stablehlo.reduce_stablehlo.maximum::ttnn.max
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,32,32,32]>, Scalar, dim: [3] | ttnn.max | aten::_safe_softmax | 4 |
| 1 | Tensor<[1,12,7,7]>, Scalar, dim: [3] | ttnn.max | aten::_safe_softmax | 4 |
| 2 | Tensor<[8,920,920]>, Scalar, dim: [2] | ttnn.max | aten::_softmax | 4 |
| 3 | Tensor<[8,100,100]>, Scalar, dim: [2] | ttnn.max | aten::_softmax | 4 |
| 4 | Tensor<[8,100,920]>, Scalar, dim: [2] | ttnn.max | aten::_softmax | 4 |
| 5 | Tensor<[1,12,10,10]>, Scalar, dim: [3] | ttnn.max | aten::_safe_softmax | 4 |
| 6 | Tensor<[1,8,4096,4096]>, Scalar, dim: [3] | ttnn.max | aten::_safe_softmax | 4 |
| 7 | Tensor<[1,8,4096,9]>, Scalar, dim: [3] | ttnn.max | aten::_safe_softmax | 4 |
| 8 | Tensor<[1,8,1024,1024]>, Scalar, dim: [3] | ttnn.max | aten::_safe_softmax | 4 |
| 9 | Tensor<[1,8,1024,9]>, Scalar, dim: [3] | ttnn.max | aten::_safe_softmax | 4 |
| 10 | Tensor<[1,8,256,256]>, Scalar, dim: [3] | ttnn.max | aten::_safe_softmax | 4 |
| 11 | Tensor<[1,8,256,9]>, Scalar, dim: [3] | ttnn.max | aten::_safe_softmax | 4 |
| 12 | Tensor<[1,8,64,64]>, Scalar, dim: [3] | ttnn.max | aten::_safe_softmax | 4 |
| 13 | Tensor<[1,8,64,9]>, Scalar, dim: [3] | ttnn.max | aten::_safe_softmax | 4 |
| 14 | Tensor<[1,12,25,25]>, Scalar, dim: [3] | ttnn.max | aten::_safe_softmax | 4 |
| 15 | Tensor<[1,3,1445,1445]>, Scalar, dim: [3] | ttnn.max | aten::_safe_softmax | 4 |
| 16 | Tensor<[1,12,8,8]>, Scalar, dim: [3] | ttnn.max | aten::_softmax | 4 |
| 17 | Tensor<[1,8,256,2048]>, Scalar, dim: [3] | ttnn.max | aten::_softmax | 4 |
| 18 | Tensor<[1,8,2048,256]>, Scalar, dim: [3] | ttnn.max | aten::_softmax | 4 |
| 19 | Tensor<[1,12,201,201]>, Scalar, dim: [3] | ttnn.max | aten::_softmax | 4 |
| 20 | Tensor<[1]>, Scalar, dim: [0] | ttnn.max | aten::max | 4 |
| 21 | Tensor<[1,10]>, Scalar, dim: [1] | ttnn.max | aten::amax | 5 |
| 22 | Tensor<[16,19,19]>, Scalar, dim: [2] | ttnn.max | aten::_softmax | 4 |
| 23 | Tensor<[19,256008]>, Scalar, dim: [1] | ttnn.max | aten::amax | 5 |
| 24 | Tensor<[1,16,32,32]>, Scalar, dim: [3] | ttnn.max | aten::_softmax | 4 |
| 25 | Tensor<[1,12,16,16]>, Scalar, dim: [3] | ttnn.max | aten::_safe_softmax | 4 |
| 26 | Tensor<[1,1,19200,300]>, Scalar, dim: [3] | ttnn.max | aten::_softmax | 4 |
| 27 | Tensor<[1,2,4800,300]>, Scalar, dim: [3] | ttnn.max | aten::_softmax | 4 |
| 28 | Tensor<[1,5,1200,300]>, Scalar, dim: [3] | ttnn.max | aten::_softmax | 4 |
| 29 | Tensor<[1,8,300,300]>, Scalar, dim: [3] | ttnn.max | aten::_softmax | 4 |
| 30 | Tensor<[1,12,197,197]>, Scalar, dim: [3] | ttnn.max | aten::_safe_softmax | 4 |
| 31 | Tensor<[1,1,16384,256]>, Scalar, dim: [3] | ttnn.max | aten::_softmax | 4 |
| 32 | Tensor<[1,2,4096,256]>, Scalar, dim: [3] | ttnn.max | aten::_softmax | 4 |
| 33 | Tensor<[1,5,1024,256]>, Scalar, dim: [3] | ttnn.max | aten::_softmax | 4 |
| 34 | Tensor<[1,71,7,7]>, Scalar, dim: [3] | ttnn.max | aten::_safe_softmax | 4 |
| 35 | Tensor<[1,12,12,12]>, Scalar, dim: [3] | ttnn.max | aten::_safe_softmax | 4 |
| 36 | Tensor<[1,12,9,9]>, Scalar, dim: [3] | ttnn.max | aten::_safe_softmax | 4 |
| 37 | Tensor<[1,16,9,9]>, Scalar, dim: [3] | ttnn.max | aten::_safe_softmax | 4 |
| 38 | Tensor<[1,64,9,9]>, Scalar, dim: [3] | ttnn.max | aten::_safe_softmax | 4 |
| 39 | Tensor<[1,12,14,14]>, Scalar, dim: [3] | ttnn.max | aten::_safe_softmax | 4 |
| 40 | Tensor<[1,12,50,50]>, Scalar, dim: [3] | ttnn.max | aten::_safe_softmax | 4 |
| 41 | Tensor<[2,8,7,7]>, Scalar, dim: [3] | ttnn.max | aten::_safe_softmax | 4 |
| 42 | Tensor<[1,16,197,197]>, Scalar, dim: [3] | ttnn.max | aten::_softmax | 4 |
stablehlo.reduce_window_stablehlo.add::ttnn.avg_pool2d
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,23,40]>, Scalar, | ttnn.avg_pool2d | aten::cumsum | 4 |
| 1 | Tensor<[1,10]>, Scalar, | ttnn.avg_pool2d | aten::cumsum | 4 |
| 2 | Tensor<[1,32]>, Scalar, | ttnn.avg_pool2d | aten::cumsum | 4 |
stablehlo.remainder::ttnn.remainder
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1]>, Tensor<[1]>, | ttnn.remainder | aten::remainder.Scalar | 4 |
stablehlo.reshape::ttnn.reshape
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,32,32]>, Tensor<[1,32,32,1]>, | ttnn.reshape | aten::_safe_softmax | 4 |
| 1 | Tensor<[1]>, Scalar, | ttnn.reshape | aten::_safe_softmax | 4 |
| 2 | Tensor<[1,64,32]>, Tensor<[1,64,32]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 3 | Tensor<[32,4096]>, Tensor<[1,32,4096]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 4 | Tensor<[32,11008]>, Tensor<[1,32,11008]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 5 | Tensor<[32,32000]>, Tensor<[1,32,32000]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 6 | Scalar, Tensor<[1]>, | ttnn.reshape | aten::arange | 4 |
| 7 | Tensor<[1,32]>, Tensor<[1,32,1]>, | ttnn.reshape | aten::mean.dim | 4 |
| 8 | Tensor<[32]>, Tensor<[32,1]>, | ttnn.reshape | aten::triu | 4 |
| 9 | Tensor<[32]>, Tensor<[1,32]>, | ttnn.reshape | aten::triu | 4 |
| 10 | Tensor<[32,32]>, Tensor<[1,32,32]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 11 | Tensor<[1,32,32]>, Tensor<[1,1,32,32]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 12 | Tensor<[1,32]>, Tensor<[1,1,32]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 13 | Tensor<[1,1,32]>, Tensor<[1,1,1,32]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 14 | Tensor<[64]>, Tensor<[1,64]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 15 | Tensor<[1,64]>, Tensor<[1,64,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 16 | Tensor<[1,32,128]>, Tensor<[1,1,32,128]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 17 | Tensor<[1,64,1]>, Tensor<[1,64,1]>, | ttnn.reshape | aten::view | 5 |
| 18 | Tensor<[1,1,32]>, Tensor<[1,1,32]>, | ttnn.reshape | aten::view | 5 |
| 19 | Tensor<[1,32,4096]>, Tensor<[32,4096]>, | ttnn.reshape | aten::view | 5 |
| 20 | Tensor<[1,32,4096]>, Tensor<[1,32,32,128]>, | ttnn.reshape | aten::view | 5 |
| 21 | Tensor<[1,32,32,128]>, Tensor<[32,32,128]>, | ttnn.reshape | aten::view | 5 |
| 22 | Tensor<[1,32,128,32]>, Tensor<[32,128,32]>, | ttnn.reshape | aten::view | 5 |
| 23 | Tensor<[32,32,32]>, Tensor<[1,32,32,32]>, | ttnn.reshape | aten::view | 5 |
| 24 | Tensor<[1,32,32,32]>, Tensor<[32,32,32]>, | ttnn.reshape | aten::view | 5 |
| 25 | Tensor<[32,32,128]>, Tensor<[1,32,32,128]>, | ttnn.reshape | aten::view | 5 |
| 26 | Tensor<[1,32,32,128]>, Tensor<[1,32,4096]>, | ttnn.reshape | aten::view | 5 |
| 27 | Tensor<[1,32,11008]>, Tensor<[32,11008]>, | ttnn.reshape | aten::view | 5 |
| 28 | Tensor<[1,12,7]>, Tensor<[1,12,7,1]>, | ttnn.reshape | aten::_safe_softmax | 4 |
| 29 | Tensor<[7,2]>, Tensor<[1,7,2]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 30 | Tensor<[1]>, Tensor<[1,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 31 | Tensor<[7]>, Tensor<[1,7]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 32 | Tensor<[7,7]>, Tensor<[1,7,7]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 33 | Tensor<[1,7,7]>, Tensor<[1,1,7,7]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 34 | Tensor<[1,7]>, Tensor<[1,1,7]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 35 | Tensor<[1,1,7]>, Tensor<[1,1,1,7]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 36 | Tensor<[1,7]>, Tensor<[1,7]>, | ttnn.reshape | aten::view | 4 |
| 37 | Tensor<[7]>, Tensor<[7,1]>, | ttnn.reshape | aten::view | 4 |
| 38 | Tensor<[1,7,768]>, Tensor<[7,768]>, | ttnn.reshape | aten::view | 5 |
| 39 | Tensor<[7,2304]>, Tensor<[1,7,2304]>, | ttnn.reshape | aten::view | 5 |
| 40 | Tensor<[1,7,768]>, Tensor<[1,7,12,64]>, | ttnn.reshape | aten::view | 5 |
| 41 | Tensor<[1,12,7,64]>, Tensor<[12,7,64]>, | ttnn.reshape | aten::view | 5 |
| 42 | Tensor<[1,12,64,7]>, Tensor<[12,64,7]>, | ttnn.reshape | aten::view | 5 |
| 43 | Tensor<[12,7,7]>, Tensor<[1,12,7,7]>, | ttnn.reshape | aten::view | 5 |
| 44 | Tensor<[1,12,7,7]>, Tensor<[12,7,7]>, | ttnn.reshape | aten::view | 5 |
| 45 | Tensor<[12,7,64]>, Tensor<[1,12,7,64]>, | ttnn.reshape | aten::view | 5 |
| 46 | Tensor<[1,7,12,64]>, Tensor<[1,7,768]>, | ttnn.reshape | aten::view | 5 |
| 47 | Tensor<[7,768]>, Tensor<[1,7,768]>, | ttnn.reshape | aten::view | 5 |
| 48 | Tensor<[7,3072]>, Tensor<[1,7,3072]>, | ttnn.reshape | aten::view | 5 |
| 49 | Tensor<[1,7,3072]>, Tensor<[7,3072]>, | ttnn.reshape | aten::view | 5 |
| 50 | Tensor<[1,7,768]>, Tensor<[1,7,768]>, | ttnn.reshape | aten::view | 5 |
| 51 | Tensor<[128]>, Tensor<[128,1,1]>, | ttnn.reshape | aten::convolution | 4 |
| 52 | Tensor<[512]>, Tensor<[512,1,1]>, | ttnn.reshape | aten::convolution | 4 |
| 53 | Tensor<[19]>, Tensor<[19,1,1]>, | ttnn.reshape | aten::convolution | 4 |
| 54 | Tensor<[38]>, Tensor<[38,1,1]>, | ttnn.reshape | aten::convolution | 4 |
| 55 | Tensor<[32,1]>, Tensor<[32,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 56 | Tensor<[64]>, Tensor<[64,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 57 | Tensor<[64,1]>, Tensor<[64,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 58 | Tensor<[128]>, Tensor<[128,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 59 | Tensor<[128,1]>, Tensor<[128,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 60 | Tensor<[256]>, Tensor<[256,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 61 | Tensor<[256,1]>, Tensor<[256,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 62 | Tensor<[512]>, Tensor<[512,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 63 | Tensor<[512,1]>, Tensor<[512,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 64 | Tensor<[1,16,16,16,16,3]>, Tensor<[1,256,768]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 65 | Tensor<[1024]>, Tensor<[1024,1]>, | ttnn.reshape | aten::convolution | 4 |
| 66 | Tensor<[1,3,256,256]>, Tensor<[1,3,16,16,16,16]>, | ttnn.reshape | aten::view | 4 |
| 67 | Tensor<[1,256,768]>, Tensor<[256,768]>, | ttnn.reshape | aten::view | 5 |
| 68 | Tensor<[256,512]>, Tensor<[1,256,512]>, | ttnn.reshape | aten::view | 5 |
| 69 | Tensor<[1,256,512]>, Tensor<[256,512]>, | ttnn.reshape | aten::view | 5 |
| 70 | Tensor<[256,256]>, Tensor<[1,256,256]>, | ttnn.reshape | aten::view | 5 |
| 71 | Tensor<[1,256,256]>, Tensor<[256,256]>, | ttnn.reshape | aten::view | 5 |
| 72 | Tensor<[8,920]>, Tensor<[8,920,1]>, | ttnn.reshape | aten::_softmax | 4 |
| 73 | Tensor<[8,100]>, Tensor<[8,100,1]>, | ttnn.reshape | aten::_softmax | 4 |
| 74 | Tensor<[920,1,256]>, Tensor<[920,1,256]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 75 | Tensor<[6,100,92]>, Tensor<[6,1,100,92]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 76 | Tensor<[6,1,100,92]>, Tensor<[6,100,92]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 77 | Tensor<[6,100,256]>, Tensor<[6,1,100,256]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 78 | Tensor<[6,1,100,256]>, Tensor<[6,100,256]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 79 | Tensor<[600,256]>, Tensor<[6,1,100,256]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 80 | Tensor<[6,1,100,256]>, Tensor<[600,256]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 81 | Tensor<[600,4]>, Tensor<[6,1,100,4]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 82 | Tensor<[6,1,100,4]>, Tensor<[600,4]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 83 | Tensor<[256]>, Tensor<[256,1,1]>, | ttnn.reshape | aten::convolution | 4 |
| 84 | Tensor<[1,1]>, Tensor<[1,1,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 85 | Tensor<[1,1,1]>, Tensor<[1,1,1,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 86 | Tensor<[1,1,23,40]>, Tensor<[1,1,23,40,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 87 | Tensor<[100,1,256]>, Tensor<[1,100,1,256]>, | ttnn.reshape | aten::repeat | 4 |
| 88 | Tensor<[1,100,1,256]>, Tensor<[1,100,1,1,256]>, | ttnn.reshape | aten::repeat | 4 |
| 89 | Tensor<[1,100,1,1,256]>, Tensor<[1,100,1,1,1,256]>, | ttnn.reshape | aten::repeat | 4 |
| 90 | Tensor<[1,100,1,1,1,256]>, Tensor<[100,1,1,1,256]>, | ttnn.reshape | aten::repeat | 4 |
| 91 | Tensor<[100,1,1,1,256]>, Tensor<[100,1,1,256]>, | ttnn.reshape | aten::repeat | 4 |
| 92 | Tensor<[100,1,1,256]>, Tensor<[100,1,256]>, | ttnn.reshape | aten::repeat | 4 |
| 93 | Tensor<[1,3,720,1280]>, Tensor<[3,720,1280]>, | ttnn.reshape | aten::select.int | 5 |
| 94 | Tensor<[1,720,1280]>, Tensor<[720,1280]>, | ttnn.reshape | aten::select.int | 4 |
| 95 | Tensor<[1,1,23,40]>, Tensor<[1,23,40]>, | ttnn.reshape | aten::select.int | 4 |
| 96 | Tensor<[1,1,100,4]>, Tensor<[1,100,4]>, | ttnn.reshape | aten::select.int | 4 |
| 97 | Tensor<[1,1,100,92]>, Tensor<[1,100,92]>, | ttnn.reshape | aten::select.int | 4 |
| 98 | Tensor<[3,720,1280]>, Tensor<[1,3,720,1280]>, | ttnn.reshape | aten::select_scatter | 4 |
| 99 | Tensor<[720,1280]>, Tensor<[1,720,1280]>, | ttnn.reshape | aten::select_scatter | 4 |
| 100 | Tensor<[1,23,40,64]>, Tensor<[1,23,40,64,1]>, | ttnn.reshape | aten::stack | 5 |
| 101 | Tensor<[1,720,1280]>, Tensor<[1,1,720,1280]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 102 | Tensor<[23]>, Tensor<[23,1]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 103 | Tensor<[1,23,40]>, Tensor<[1,23,40,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 104 | Tensor<[100,256]>, Tensor<[100,1,256]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 105 | Tensor<[64]>, Tensor<[1,64,1,1]>, | ttnn.reshape | aten::view | 5 |
| 106 | Tensor<[256]>, Tensor<[1,256,1,1]>, | ttnn.reshape | aten::view | 5 |
| 107 | Tensor<[128]>, Tensor<[1,128,1,1]>, | ttnn.reshape | aten::view | 5 |
| 108 | Tensor<[512]>, Tensor<[1,512,1,1]>, | ttnn.reshape | aten::view | 5 |
| 109 | Tensor<[1024]>, Tensor<[1,1024,1,1]>, | ttnn.reshape | aten::view | 5 |
| 110 | Tensor<[2048]>, Tensor<[1,2048,1,1]>, | ttnn.reshape | aten::view | 5 |
| 111 | Tensor<[1,23,40,64,2]>, Tensor<[1,23,40,128]>, | ttnn.reshape | aten::view | 5 |
| 112 | Tensor<[1,256,23,40]>, Tensor<[1,256,920]>, | ttnn.reshape | aten::view | 5 |
| 113 | Tensor<[1,23,40]>, Tensor<[1,920]>, | ttnn.reshape | aten::view | 4 |
| 114 | Tensor<[920,256,256]>, Tensor<[920,256,256]>, | ttnn.reshape | aten::view | 5 |
| 115 | Tensor<[920,1,256]>, Tensor<[920,8,32]>, | ttnn.reshape | aten::view | 5 |
| 116 | Tensor<[1,920]>, Tensor<[1,1,1,920]>, | ttnn.reshape | aten::view | 5 |
| 117 | Tensor<[1,8,1,920]>, Tensor<[8,1,920]>, | ttnn.reshape | aten::view | 5 |
| 118 | Tensor<[920,8,32]>, Tensor<[920,256]>, | ttnn.reshape | aten::view | 5 |
| 119 | Tensor<[920,256]>, Tensor<[920,1,256]>, | ttnn.reshape | aten::view | 5 |
| 120 | Tensor<[920,1,256]>, Tensor<[920,256]>, | ttnn.reshape | aten::view | 5 |
| 121 | Tensor<[920,2048]>, Tensor<[920,1,2048]>, | ttnn.reshape | aten::view | 5 |
| 122 | Tensor<[920,1,2048]>, Tensor<[920,2048]>, | ttnn.reshape | aten::view | 5 |
| 123 | Tensor<[100,1,256]>, Tensor<[100,256]>, | ttnn.reshape | aten::view | 5 |
| 124 | Tensor<[100,1,256]>, Tensor<[100,8,32]>, | ttnn.reshape | aten::view | 5 |
| 125 | Tensor<[100,8,32]>, Tensor<[100,256]>, | ttnn.reshape | aten::view | 5 |
| 126 | Tensor<[100,2048]>, Tensor<[100,1,2048]>, | ttnn.reshape | aten::view | 5 |
| 127 | Tensor<[100,1,2048]>, Tensor<[100,2048]>, | ttnn.reshape | aten::view | 5 |
| 128 | Tensor<[6,1,256,92]>, Tensor<[6,256,92]>, | ttnn.reshape | aten::view | 5 |
| 129 | Tensor<[6,1,256,256]>, Tensor<[6,256,256]>, | ttnn.reshape | aten::view | 5 |
| 130 | Tensor<[1,12,10]>, Tensor<[1,12,10,1]>, | ttnn.reshape | aten::_safe_softmax | 4 |
| 131 | Tensor<[1,10]>, Tensor<[1,1,10]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 132 | Tensor<[1,1,10]>, Tensor<[1,1,1,10]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 133 | Tensor<[1,10,768]>, Tensor<[10,768]>, | ttnn.reshape | aten::view | 5 |
| 134 | Tensor<[10,768]>, Tensor<[1,10,768]>, | ttnn.reshape | aten::view | 5 |
| 135 | Tensor<[1,10,768]>, Tensor<[1,10,12,64]>, | ttnn.reshape | aten::view | 5 |
| 136 | Tensor<[1,12,10,64]>, Tensor<[12,10,64]>, | ttnn.reshape | aten::view | 5 |
| 137 | Tensor<[1,12,64,10]>, Tensor<[12,64,10]>, | ttnn.reshape | aten::view | 5 |
| 138 | Tensor<[12,10,10]>, Tensor<[1,12,10,10]>, | ttnn.reshape | aten::view | 5 |
| 139 | Tensor<[1,12,10,10]>, Tensor<[12,10,10]>, | ttnn.reshape | aten::view | 5 |
| 140 | Tensor<[12,10,64]>, Tensor<[1,12,10,64]>, | ttnn.reshape | aten::view | 5 |
| 141 | Tensor<[1,10,12,64]>, Tensor<[1,10,768]>, | ttnn.reshape | aten::view | 5 |
| 142 | Tensor<[10,3072]>, Tensor<[1,10,3072]>, | ttnn.reshape | aten::view | 5 |
| 143 | Tensor<[1,10,3072]>, Tensor<[10,3072]>, | ttnn.reshape | aten::view | 5 |
| 144 | Tensor<[10,250002]>, Tensor<[1,10,250002]>, | ttnn.reshape | aten::view | 5 |
| 145 | Tensor<[1,8,4096]>, Tensor<[1,8,4096,1]>, | ttnn.reshape | aten::_safe_softmax | 4 |
| 146 | Tensor<[1,8,1024]>, Tensor<[1,8,1024,1]>, | ttnn.reshape | aten::_safe_softmax | 4 |
| 147 | Tensor<[1,8,256]>, Tensor<[1,8,256,1]>, | ttnn.reshape | aten::_safe_softmax | 4 |
| 148 | Tensor<[1,8,64]>, Tensor<[1,8,64,1]>, | ttnn.reshape | aten::_safe_softmax | 4 |
| 149 | Tensor<[4096,320]>, Tensor<[1,4096,320]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 150 | Tensor<[9,320]>, Tensor<[1,9,320]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 151 | Tensor<[1024,640]>, Tensor<[1,1024,640]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 152 | Tensor<[9,640]>, Tensor<[1,9,640]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 153 | Tensor<[256,1280]>, Tensor<[1,256,1280]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 154 | Tensor<[9,1280]>, Tensor<[1,9,1280]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 155 | Tensor<[64,1280]>, Tensor<[1,64,1280]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 156 | Tensor<[320]>, Tensor<[320,1,1]>, | ttnn.reshape | aten::convolution | 4 |
| 157 | Tensor<[640]>, Tensor<[640,1,1]>, | ttnn.reshape | aten::convolution | 4 |
| 158 | Tensor<[1280]>, Tensor<[1280,1,1]>, | ttnn.reshape | aten::convolution | 4 |
| 159 | Tensor<[4]>, Tensor<[4,1,1]>, | ttnn.reshape | aten::convolution | 4 |
| 160 | Tensor<[1280]>, Tensor<[1280,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 161 | Tensor<[1280,1]>, Tensor<[1280,1,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 162 | Tensor<[1,1280,16,16]>, Tensor<[1,1280,16,16,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 163 | Tensor<[1,1280,32,32]>, Tensor<[1,1280,32,32,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 164 | Tensor<[640]>, Tensor<[640,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 165 | Tensor<[640,1]>, Tensor<[640,1,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 166 | Tensor<[1,640,64,64]>, Tensor<[1,640,64,64,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 167 | Tensor<[160]>, Tensor<[1,160]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 168 | Tensor<[320]>, Tensor<[1,320]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 169 | Tensor<[1,320]>, Tensor<[1,320,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 170 | Tensor<[1,320,1]>, Tensor<[1,320,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 171 | Tensor<[1,640]>, Tensor<[1,640,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 172 | Tensor<[1,640,1]>, Tensor<[1,640,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 173 | Tensor<[640]>, Tensor<[1,640]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 174 | Tensor<[1,1280]>, Tensor<[1,1280,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 175 | Tensor<[1,1280,1]>, Tensor<[1,1280,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 176 | Tensor<[1280]>, Tensor<[1,1280]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 177 | Tensor<[2560]>, Tensor<[1,2560]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 178 | Tensor<[1,2560]>, Tensor<[1,2560,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 179 | Tensor<[1,2560,1]>, Tensor<[1,2560,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 180 | Tensor<[16]>, Tensor<[16,1]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 181 | Tensor<[1920]>, Tensor<[1,1920]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 182 | Tensor<[1,1920]>, Tensor<[1,1920,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 183 | Tensor<[1,1920,1]>, Tensor<[1,1920,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 184 | Tensor<[960]>, Tensor<[1,960]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 185 | Tensor<[1,960]>, Tensor<[1,960,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 186 | Tensor<[1,960,1]>, Tensor<[1,960,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 187 | Tensor<[1,320,64,64]>, Tensor<[1,32,10,4096]>, | ttnn.reshape | aten::view | 5 |
| 188 | Tensor<[1,32,10,4096]>, Tensor<[1,320,64,64]>, | ttnn.reshape | aten::view | 5 |
| 189 | Tensor<[1,64,64,320]>, Tensor<[1,4096,320]>, | ttnn.reshape | aten::view | 5 |
| 190 | Tensor<[1,4096,320]>, Tensor<[4096,320]>, | ttnn.reshape | aten::view | 5 |
| 191 | Tensor<[1,4096,320]>, Tensor<[1,4096,8,40]>, | ttnn.reshape | aten::view | 5 |
| 192 | Tensor<[1,8,4096,40]>, Tensor<[8,4096,40]>, | ttnn.reshape | aten::view | 5 |
| 193 | Tensor<[1,8,40,4096]>, Tensor<[8,40,4096]>, | ttnn.reshape | aten::view | 5 |
| 194 | Tensor<[8,4096,4096]>, Tensor<[1,8,4096,4096]>, | ttnn.reshape | aten::view | 5 |
| 195 | Tensor<[1,8,4096,4096]>, Tensor<[8,4096,4096]>, | ttnn.reshape | aten::view | 5 |
| 196 | Tensor<[8,4096,40]>, Tensor<[1,8,4096,40]>, | ttnn.reshape | aten::view | 5 |
| 197 | Tensor<[1,4096,8,40]>, Tensor<[1,4096,320]>, | ttnn.reshape | aten::view | 5 |
| 198 | Tensor<[1,9,768]>, Tensor<[9,768]>, | ttnn.reshape | aten::view | 5 |
| 199 | Tensor<[1,9,320]>, Tensor<[1,9,8,40]>, | ttnn.reshape | aten::view | 5 |
| 200 | Tensor<[1,8,40,9]>, Tensor<[8,40,9]>, | ttnn.reshape | aten::view | 5 |
| 201 | Tensor<[8,4096,9]>, Tensor<[1,8,4096,9]>, | ttnn.reshape | aten::view | 5 |
| 202 | Tensor<[1,8,4096,9]>, Tensor<[8,4096,9]>, | ttnn.reshape | aten::view | 5 |
| 203 | Tensor<[1,8,9,40]>, Tensor<[8,9,40]>, | ttnn.reshape | aten::view | 5 |
| 204 | Tensor<[4096,2560]>, Tensor<[1,4096,2560]>, | ttnn.reshape | aten::view | 5 |
| 205 | Tensor<[1,4096,1280]>, Tensor<[4096,1280]>, | ttnn.reshape | aten::view | 5 |
| 206 | Tensor<[1,4096,320]>, Tensor<[1,64,64,320]>, | ttnn.reshape | aten::view | 5 |
| 207 | Tensor<[1,320,32,32]>, Tensor<[1,32,10,1024]>, | ttnn.reshape | aten::view | 5 |
| 208 | Tensor<[1,32,10,1024]>, Tensor<[1,320,32,32]>, | ttnn.reshape | aten::view | 5 |
| 209 | Tensor<[1,640,32,32]>, Tensor<[1,32,20,1024]>, | ttnn.reshape | aten::view | 5 |
| 210 | Tensor<[1,32,20,1024]>, Tensor<[1,640,32,32]>, | ttnn.reshape | aten::view | 5 |
| 211 | Tensor<[1,32,32,640]>, Tensor<[1,1024,640]>, | ttnn.reshape | aten::view | 5 |
| 212 | Tensor<[1,1024,640]>, Tensor<[1024,640]>, | ttnn.reshape | aten::view | 5 |
| 213 | Tensor<[1,1024,640]>, Tensor<[1,1024,8,80]>, | ttnn.reshape | aten::view | 5 |
| 214 | Tensor<[1,8,1024,80]>, Tensor<[8,1024,80]>, | ttnn.reshape | aten::view | 5 |
| 215 | Tensor<[1,8,80,1024]>, Tensor<[8,80,1024]>, | ttnn.reshape | aten::view | 5 |
| 216 | Tensor<[8,1024,1024]>, Tensor<[1,8,1024,1024]>, | ttnn.reshape | aten::view | 5 |
| 217 | Tensor<[1,8,1024,1024]>, Tensor<[8,1024,1024]>, | ttnn.reshape | aten::view | 5 |
| 218 | Tensor<[8,1024,80]>, Tensor<[1,8,1024,80]>, | ttnn.reshape | aten::view | 5 |
| 219 | Tensor<[1,1024,8,80]>, Tensor<[1,1024,640]>, | ttnn.reshape | aten::view | 5 |
| 220 | Tensor<[1,9,640]>, Tensor<[1,9,8,80]>, | ttnn.reshape | aten::view | 5 |
| 221 | Tensor<[1,8,80,9]>, Tensor<[8,80,9]>, | ttnn.reshape | aten::view | 5 |
| 222 | Tensor<[8,1024,9]>, Tensor<[1,8,1024,9]>, | ttnn.reshape | aten::view | 5 |
| 223 | Tensor<[1,8,1024,9]>, Tensor<[8,1024,9]>, | ttnn.reshape | aten::view | 5 |
| 224 | Tensor<[1,8,9,80]>, Tensor<[8,9,80]>, | ttnn.reshape | aten::view | 5 |
| 225 | Tensor<[1024,5120]>, Tensor<[1,1024,5120]>, | ttnn.reshape | aten::view | 5 |
| 226 | Tensor<[1,1024,2560]>, Tensor<[1024,2560]>, | ttnn.reshape | aten::view | 5 |
| 227 | Tensor<[1,1024,640]>, Tensor<[1,32,32,640]>, | ttnn.reshape | aten::view | 5 |
| 228 | Tensor<[1,640,16,16]>, Tensor<[1,32,20,256]>, | ttnn.reshape | aten::view | 5 |
| 229 | Tensor<[1,32,20,256]>, Tensor<[1,640,16,16]>, | ttnn.reshape | aten::view | 5 |
| 230 | Tensor<[1,1280,16,16]>, Tensor<[1,32,40,256]>, | ttnn.reshape | aten::view | 5 |
| 231 | Tensor<[1,32,40,256]>, Tensor<[1,1280,16,16]>, | ttnn.reshape | aten::view | 5 |
| 232 | Tensor<[1,16,16,1280]>, Tensor<[1,256,1280]>, | ttnn.reshape | aten::view | 5 |
| 233 | Tensor<[1,256,1280]>, Tensor<[256,1280]>, | ttnn.reshape | aten::view | 5 |
| 234 | Tensor<[1,256,1280]>, Tensor<[1,256,8,160]>, | ttnn.reshape | aten::view | 5 |
| 235 | Tensor<[1,8,256,160]>, Tensor<[8,256,160]>, | ttnn.reshape | aten::view | 5 |
| 236 | Tensor<[1,8,160,256]>, Tensor<[8,160,256]>, | ttnn.reshape | aten::view | 5 |
| 237 | Tensor<[8,256,256]>, Tensor<[1,8,256,256]>, | ttnn.reshape | aten::view | 5 |
| 238 | Tensor<[1,8,256,256]>, Tensor<[8,256,256]>, | ttnn.reshape | aten::view | 5 |
| 239 | Tensor<[8,256,160]>, Tensor<[1,8,256,160]>, | ttnn.reshape | aten::view | 5 |
| 240 | Tensor<[1,256,8,160]>, Tensor<[1,256,1280]>, | ttnn.reshape | aten::view | 5 |
| 241 | Tensor<[1,9,1280]>, Tensor<[1,9,8,160]>, | ttnn.reshape | aten::view | 5 |
| 242 | Tensor<[1,8,160,9]>, Tensor<[8,160,9]>, | ttnn.reshape | aten::view | 5 |
| 243 | Tensor<[8,256,9]>, Tensor<[1,8,256,9]>, | ttnn.reshape | aten::view | 5 |
| 244 | Tensor<[1,8,256,9]>, Tensor<[8,256,9]>, | ttnn.reshape | aten::view | 5 |
| 245 | Tensor<[1,8,9,160]>, Tensor<[8,9,160]>, | ttnn.reshape | aten::view | 5 |
| 246 | Tensor<[256,10240]>, Tensor<[1,256,10240]>, | ttnn.reshape | aten::view | 5 |
| 247 | Tensor<[1,256,5120]>, Tensor<[256,5120]>, | ttnn.reshape | aten::view | 5 |
| 248 | Tensor<[1,256,1280]>, Tensor<[1,16,16,1280]>, | ttnn.reshape | aten::view | 5 |
| 249 | Tensor<[1,1280,8,8]>, Tensor<[1,32,40,64]>, | ttnn.reshape | aten::view | 5 |
| 250 | Tensor<[1,32,40,64]>, Tensor<[1,1280,8,8]>, | ttnn.reshape | aten::view | 5 |
| 251 | Tensor<[1,8,8,1280]>, Tensor<[1,64,1280]>, | ttnn.reshape | aten::view | 5 |
| 252 | Tensor<[1,64,1280]>, Tensor<[64,1280]>, | ttnn.reshape | aten::view | 5 |
| 253 | Tensor<[1,64,1280]>, Tensor<[1,64,8,160]>, | ttnn.reshape | aten::view | 5 |
| 254 | Tensor<[1,8,64,160]>, Tensor<[8,64,160]>, | ttnn.reshape | aten::view | 5 |
| 255 | Tensor<[1,8,160,64]>, Tensor<[8,160,64]>, | ttnn.reshape | aten::view | 5 |
| 256 | Tensor<[8,64,64]>, Tensor<[1,8,64,64]>, | ttnn.reshape | aten::view | 5 |
| 257 | Tensor<[1,8,64,64]>, Tensor<[8,64,64]>, | ttnn.reshape | aten::view | 5 |
| 258 | Tensor<[8,64,160]>, Tensor<[1,8,64,160]>, | ttnn.reshape | aten::view | 5 |
| 259 | Tensor<[1,64,8,160]>, Tensor<[1,64,1280]>, | ttnn.reshape | aten::view | 5 |
| 260 | Tensor<[8,64,9]>, Tensor<[1,8,64,9]>, | ttnn.reshape | aten::view | 5 |
| 261 | Tensor<[1,8,64,9]>, Tensor<[8,64,9]>, | ttnn.reshape | aten::view | 5 |
| 262 | Tensor<[64,10240]>, Tensor<[1,64,10240]>, | ttnn.reshape | aten::view | 5 |
| 263 | Tensor<[1,64,5120]>, Tensor<[64,5120]>, | ttnn.reshape | aten::view | 5 |
| 264 | Tensor<[1,64,1280]>, Tensor<[1,8,8,1280]>, | ttnn.reshape | aten::view | 5 |
| 265 | Tensor<[1,2560,8,8]>, Tensor<[1,32,80,64]>, | ttnn.reshape | aten::view | 5 |
| 266 | Tensor<[1,32,80,64]>, Tensor<[1,2560,8,8]>, | ttnn.reshape | aten::view | 5 |
| 267 | Tensor<[1,2560,16,16]>, Tensor<[1,32,80,256]>, | ttnn.reshape | aten::view | 5 |
| 268 | Tensor<[1,32,80,256]>, Tensor<[1,2560,16,16]>, | ttnn.reshape | aten::view | 5 |
| 269 | Tensor<[1,1920,16,16]>, Tensor<[1,32,60,256]>, | ttnn.reshape | aten::view | 5 |
| 270 | Tensor<[1,32,60,256]>, Tensor<[1,1920,16,16]>, | ttnn.reshape | aten::view | 5 |
| 271 | Tensor<[1,1920,32,32]>, Tensor<[1,32,60,1024]>, | ttnn.reshape | aten::view | 5 |
| 272 | Tensor<[1,32,60,1024]>, Tensor<[1,1920,32,32]>, | ttnn.reshape | aten::view | 5 |
| 273 | Tensor<[1,1280,32,32]>, Tensor<[1,32,40,1024]>, | ttnn.reshape | aten::view | 5 |
| 274 | Tensor<[1,32,40,1024]>, Tensor<[1,1280,32,32]>, | ttnn.reshape | aten::view | 5 |
| 275 | Tensor<[1,960,32,32]>, Tensor<[1,32,30,1024]>, | ttnn.reshape | aten::view | 5 |
| 276 | Tensor<[1,32,30,1024]>, Tensor<[1,960,32,32]>, | ttnn.reshape | aten::view | 5 |
| 277 | Tensor<[1,960,64,64]>, Tensor<[1,32,30,4096]>, | ttnn.reshape | aten::view | 5 |
| 278 | Tensor<[1,32,30,4096]>, Tensor<[1,960,64,64]>, | ttnn.reshape | aten::view | 5 |
| 279 | Tensor<[1,640,64,64]>, Tensor<[1,32,20,4096]>, | ttnn.reshape | aten::view | 5 |
| 280 | Tensor<[1,32,20,4096]>, Tensor<[1,640,64,64]>, | ttnn.reshape | aten::view | 5 |
| 281 | Tensor<[1,12,25]>, Tensor<[1,12,25,1]>, | ttnn.reshape | aten::_safe_softmax | 4 |
| 282 | Tensor<[1,1,768]>, Tensor<[1,768]>, | ttnn.reshape | aten::select.int | 4 |
| 283 | Tensor<[1,25,1]>, Tensor<[1,25]>, | ttnn.reshape | aten::squeeze.dim | 5 |
| 284 | Tensor<[1,25]>, Tensor<[1,1,25]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 285 | Tensor<[1,1,25]>, Tensor<[1,1,1,25]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 286 | Tensor<[1,25,768]>, Tensor<[25,768]>, | ttnn.reshape | aten::view | 5 |
| 287 | Tensor<[25,768]>, Tensor<[1,25,768]>, | ttnn.reshape | aten::view | 5 |
| 288 | Tensor<[1,25,768]>, Tensor<[1,25,12,64]>, | ttnn.reshape | aten::view | 5 |
| 289 | Tensor<[1,12,25,64]>, Tensor<[12,25,64]>, | ttnn.reshape | aten::view | 5 |
| 290 | Tensor<[1,12,64,25]>, Tensor<[12,64,25]>, | ttnn.reshape | aten::view | 5 |
| 291 | Tensor<[12,25,25]>, Tensor<[1,12,25,25]>, | ttnn.reshape | aten::view | 5 |
| 292 | Tensor<[1,12,25,25]>, Tensor<[12,25,25]>, | ttnn.reshape | aten::view | 5 |
| 293 | Tensor<[12,25,64]>, Tensor<[1,12,25,64]>, | ttnn.reshape | aten::view | 5 |
| 294 | Tensor<[1,25,12,64]>, Tensor<[1,25,768]>, | ttnn.reshape | aten::view | 5 |
| 295 | Tensor<[25,3072]>, Tensor<[1,25,3072]>, | ttnn.reshape | aten::view | 5 |
| 296 | Tensor<[1,25,3072]>, Tensor<[25,3072]>, | ttnn.reshape | aten::view | 5 |
| 297 | Tensor<[25,2]>, Tensor<[1,25,2]>, | ttnn.reshape | aten::view | 5 |
| 298 | Tensor<[1,25]>, Tensor<[1,25]>, | ttnn.reshape | aten::view | 5 |
| 299 | Tensor<[1,1]>, Tensor<[1]>, | ttnn.reshape | aten::view | 5 |
| 300 | Tensor<[1,3,1445]>, Tensor<[1,3,1445,1]>, | ttnn.reshape | aten::_safe_softmax | 4 |
| 301 | Tensor<[192]>, Tensor<[192,1,1]>, | ttnn.reshape | aten::convolution | 4 |
| 302 | Tensor<[1,1,192]>, Tensor<[1,192]>, | ttnn.reshape | aten::select.int | 4 |
| 303 | Tensor<[1,192]>, Tensor<[1,1,192]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 304 | Tensor<[1,192,32,42]>, Tensor<[1,192,1344]>, | ttnn.reshape | aten::view | 5 |
| 305 | Tensor<[1,192,4150]>, Tensor<[1,192,50,83]>, | ttnn.reshape | aten::view | 5 |
| 306 | Tensor<[1,1445,192]>, Tensor<[1445,192]>, | ttnn.reshape | aten::view | 5 |
| 307 | Tensor<[1445,192]>, Tensor<[1,1445,192]>, | ttnn.reshape | aten::view | 5 |
| 308 | Tensor<[1,1445,192]>, Tensor<[1,1445,3,64]>, | ttnn.reshape | aten::view | 5 |
| 309 | Tensor<[1,3,1445,64]>, Tensor<[3,1445,64]>, | ttnn.reshape | aten::view | 5 |
| 310 | Tensor<[1,3,64,1445]>, Tensor<[3,64,1445]>, | ttnn.reshape | aten::view | 5 |
| 311 | Tensor<[3,1445,1445]>, Tensor<[1,3,1445,1445]>, | ttnn.reshape | aten::view | 5 |
| 312 | Tensor<[1,3,1445,1445]>, Tensor<[3,1445,1445]>, | ttnn.reshape | aten::view | 5 |
| 313 | Tensor<[3,1445,64]>, Tensor<[1,3,1445,64]>, | ttnn.reshape | aten::view | 5 |
| 314 | Tensor<[1,1445,3,64]>, Tensor<[1,1445,192]>, | ttnn.reshape | aten::view | 5 |
| 315 | Tensor<[1445,768]>, Tensor<[1,1445,768]>, | ttnn.reshape | aten::view | 5 |
| 316 | Tensor<[1,1445,768]>, Tensor<[1445,768]>, | ttnn.reshape | aten::view | 5 |
| 317 | Tensor<[1,100,192]>, Tensor<[100,192]>, | ttnn.reshape | aten::view | 5 |
| 318 | Tensor<[100,192]>, Tensor<[1,100,192]>, | ttnn.reshape | aten::view | 5 |
| 319 | Tensor<[100,92]>, Tensor<[1,100,92]>, | ttnn.reshape | aten::view | 5 |
| 320 | Tensor<[100,4]>, Tensor<[1,100,4]>, | ttnn.reshape | aten::view | 5 |
| 321 | Tensor<[1,512]>, Tensor<[1,512,1,1]>, | ttnn.reshape | aten::mean.dim | 4 |
| 322 | Tensor<[1,512,1,1]>, Tensor<[1,512]>, | ttnn.reshape | aten::view | 5 |
| 323 | Tensor<[1,12,8]>, Tensor<[1,12,8,1]>, | ttnn.reshape | aten::_softmax | 4 |
| 324 | Tensor<[12,8,8]>, Tensor<[1,12,8,8]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 325 | Tensor<[12,8,64]>, Tensor<[1,12,8,64]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 326 | Tensor<[768]>, Tensor<[768,1]>, | ttnn.reshape | aten::convolution | 4 |
| 327 | Tensor<[3072]>, Tensor<[3072,1]>, | ttnn.reshape | aten::convolution | 4 |
| 328 | Tensor<[1,8]>, Tensor<[1,1,8]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 329 | Tensor<[1,1,8]>, Tensor<[1,1,1,8]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 330 | Tensor<[1,768,8]>, Tensor<[1,12,64,8]>, | ttnn.reshape | aten::view | 5 |
| 331 | Tensor<[1,12,8,64]>, Tensor<[12,8,64]>, | ttnn.reshape | aten::view | 5 |
| 332 | Tensor<[1,12,64,8]>, Tensor<[12,64,8]>, | ttnn.reshape | aten::view | 5 |
| 333 | Tensor<[1,12,8,8]>, Tensor<[12,8,8]>, | ttnn.reshape | aten::view | 5 |
| 334 | Tensor<[1,12,64,8]>, Tensor<[1,768,8]>, | ttnn.reshape | aten::view | 5 |
| 335 | Tensor<[1,8,2048]>, Tensor<[1,8,2048,1]>, | ttnn.reshape | aten::_softmax | 4 |
| 336 | Tensor<[8,256,2048]>, Tensor<[1,8,256,2048]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 337 | Tensor<[8,2048,256]>, Tensor<[1,8,2048,256]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 338 | Tensor<[8,2048,96]>, Tensor<[1,8,2048,96]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 339 | Tensor<[1,2048]>, Tensor<[1,1,2048]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 340 | Tensor<[1,1,2048]>, Tensor<[1,1,1,2048]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 341 | Tensor<[1,2048,768]>, Tensor<[2048,768]>, | ttnn.reshape | aten::view | 5 |
| 342 | Tensor<[2048,256]>, Tensor<[1,2048,256]>, | ttnn.reshape | aten::view | 5 |
| 343 | Tensor<[2048,1280]>, Tensor<[1,2048,1280]>, | ttnn.reshape | aten::view | 5 |
| 344 | Tensor<[1,256,256]>, Tensor<[1,256,8,32]>, | ttnn.reshape | aten::view | 5 |
| 345 | Tensor<[1,2048,256]>, Tensor<[1,2048,8,32]>, | ttnn.reshape | aten::view | 5 |
| 346 | Tensor<[1,2048,1280]>, Tensor<[1,2048,8,160]>, | ttnn.reshape | aten::view | 5 |
| 347 | Tensor<[1,8,256,32]>, Tensor<[8,256,32]>, | ttnn.reshape | aten::view | 5 |
| 348 | Tensor<[1,8,32,2048]>, Tensor<[8,32,2048]>, | ttnn.reshape | aten::view | 5 |
| 349 | Tensor<[1,8,256,2048]>, Tensor<[8,256,2048]>, | ttnn.reshape | aten::view | 5 |
| 350 | Tensor<[1,8,2048,160]>, Tensor<[8,2048,160]>, | ttnn.reshape | aten::view | 5 |
| 351 | Tensor<[1,8,32,256]>, Tensor<[8,32,256]>, | ttnn.reshape | aten::view | 5 |
| 352 | Tensor<[256,768]>, Tensor<[1,256,768]>, | ttnn.reshape | aten::view | 5 |
| 353 | Tensor<[1,256,768]>, Tensor<[1,256,8,96]>, | ttnn.reshape | aten::view | 5 |
| 354 | Tensor<[1,8,2048,32]>, Tensor<[8,2048,32]>, | ttnn.reshape | aten::view | 5 |
| 355 | Tensor<[1,8,2048,256]>, Tensor<[8,2048,256]>, | ttnn.reshape | aten::view | 5 |
| 356 | Tensor<[1,8,256,96]>, Tensor<[8,256,96]>, | ttnn.reshape | aten::view | 5 |
| 357 | Tensor<[1,2048,8,96]>, Tensor<[1,2048,768]>, | ttnn.reshape | aten::view | 5 |
| 358 | Tensor<[2048,768]>, Tensor<[1,2048,768]>, | ttnn.reshape | aten::view | 5 |
| 359 | Tensor<[2048,262]>, Tensor<[1,2048,262]>, | ttnn.reshape | aten::view | 5 |
| 360 | Tensor<[1,2048]>, Tensor<[1,2048,1,1]>, | ttnn.reshape | aten::mean.dim | 4 |
| 361 | Tensor<[1024,1]>, Tensor<[1024,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 362 | Tensor<[2048]>, Tensor<[2048,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 363 | Tensor<[2048,1]>, Tensor<[2048,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 364 | Tensor<[1,2048,1,1]>, Tensor<[1,2048]>, | ttnn.reshape | aten::view | 5 |
| 365 | Tensor<[1,12,201]>, Tensor<[1,12,201,1]>, | ttnn.reshape | aten::_softmax | 4 |
| 366 | Tensor<[12,201,201]>, Tensor<[1,12,201,201]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 367 | Tensor<[12,201,64]>, Tensor<[1,12,201,64]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 368 | Tensor<[768]>, Tensor<[768,1,1]>, | ttnn.reshape | aten::convolution | 4 |
| 369 | Tensor<[1,1,12,16]>, Tensor<[1,1,12,16,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 370 | Tensor<[1,1,12,16]>, Tensor<[1,12,16]>, | ttnn.reshape | aten::select.int | 4 |
| 371 | Tensor<[192,1]>, Tensor<[192]>, | ttnn.reshape | aten::select.int | 4 |
| 372 | Tensor<[12,16]>, Tensor<[12,16,1]>, | ttnn.reshape | aten::stack | 4 |
| 373 | Tensor<[1,384,512]>, Tensor<[1,1,384,512]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 374 | Tensor<[12]>, Tensor<[12,1]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 375 | Tensor<[12,16,2]>, Tensor<[1,12,16,2]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 376 | Tensor<[1,12,16,2]>, Tensor<[1,1,12,16,2]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 377 | Tensor<[1,201]>, Tensor<[1,1,201]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 378 | Tensor<[1,1,201]>, Tensor<[1,1,1,201]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 379 | Tensor<[1,768,144]>, Tensor<[1,768,12,12]>, | ttnn.reshape | aten::view | 5 |
| 380 | Tensor<[1,768,12,16]>, Tensor<[1,768,192]>, | ttnn.reshape | aten::view | 5 |
| 381 | Tensor<[16]>, Tensor<[1,16]>, | ttnn.reshape | aten::view | 4 |
| 382 | Tensor<[1,1,12,16,2]>, Tensor<[1,192,2]>, | ttnn.reshape | aten::view | 4 |
| 383 | Tensor<[1,1,12,16]>, Tensor<[1,192]>, | ttnn.reshape | aten::view | 4 |
| 384 | Tensor<[1,201,768]>, Tensor<[201,768]>, | ttnn.reshape | aten::view | 5 |
| 385 | Tensor<[201,768]>, Tensor<[1,201,768]>, | ttnn.reshape | aten::view | 5 |
| 386 | Tensor<[1,201,768]>, Tensor<[1,201,12,64]>, | ttnn.reshape | aten::view | 5 |
| 387 | Tensor<[1,12,201,64]>, Tensor<[12,201,64]>, | ttnn.reshape | aten::view | 5 |
| 388 | Tensor<[1,12,64,201]>, Tensor<[12,64,201]>, | ttnn.reshape | aten::view | 5 |
| 389 | Tensor<[1,12,201,201]>, Tensor<[12,201,201]>, | ttnn.reshape | aten::view | 5 |
| 390 | Tensor<[1,201,12,64]>, Tensor<[1,201,768]>, | ttnn.reshape | aten::view | 5 |
| 391 | Tensor<[201,3072]>, Tensor<[1,201,3072]>, | ttnn.reshape | aten::view | 5 |
| 392 | Tensor<[1,201,3072]>, Tensor<[201,3072]>, | ttnn.reshape | aten::view | 5 |
| 393 | Tensor<[32]>, Tensor<[32,1,1]>, | ttnn.reshape | aten::convolution | 4 |
| 394 | Tensor<[64]>, Tensor<[64,1,1]>, | ttnn.reshape | aten::convolution | 4 |
| 395 | Tensor<[1,64,12,12]>, Tensor<[1,9216]>, | ttnn.reshape | aten::view | 5 |
| 396 | Tensor<[16,19]>, Tensor<[16,19,1]>, | ttnn.reshape | aten::_softmax | 4 |
| 397 | Tensor<[1,19,16,64]>, Tensor<[1,19,1024]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 398 | Tensor<[19,256008]>, Tensor<[1,19,256008]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 399 | Tensor<[19]>, Tensor<[19,1]>, | ttnn.reshape | aten::amax | 5 |
| 400 | Tensor<[19,1]>, Tensor<[19,1,1]>, | ttnn.reshape | aten::gather | 4 |
| 401 | Tensor<[1,19]>, Tensor<[19]>, | ttnn.reshape | aten::squeeze.dim | 4 |
| 402 | Tensor<[19,1]>, Tensor<[19]>, | ttnn.reshape | aten::squeeze.dim | 5 |
| 403 | Tensor<[19]>, Tensor<[1,19]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 404 | Tensor<[19,19]>, Tensor<[1,19,19]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 405 | Tensor<[1,19,19]>, Tensor<[1,1,19,19]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 406 | Tensor<[1,19]>, Tensor<[1,1,19]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 407 | Tensor<[1,1,19]>, Tensor<[1,1,1,19]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 408 | Tensor<[1,19]>, Tensor<[1,19]>, | ttnn.reshape | aten::view | 4 |
| 409 | Tensor<[19,1024]>, Tensor<[1,19,1024]>, | ttnn.reshape | aten::view | 5 |
| 410 | Tensor<[1,19,1024]>, Tensor<[19,1024]>, | ttnn.reshape | aten::view | 5 |
| 411 | Tensor<[1,19,1024]>, Tensor<[1,19,16,64]>, | ttnn.reshape | aten::view | 5 |
| 412 | Tensor<[1,16,19,64]>, Tensor<[16,19,64]>, | ttnn.reshape | aten::view | 5 |
| 413 | Tensor<[16,19,19]>, Tensor<[1,16,19,19]>, | ttnn.reshape | aten::view | 5 |
| 414 | Tensor<[1,16,19,19]>, Tensor<[16,19,19]>, | ttnn.reshape | aten::view | 5 |
| 415 | Tensor<[16,19,64]>, Tensor<[1,16,19,64]>, | ttnn.reshape | aten::view | 5 |
| 416 | Tensor<[19,4096]>, Tensor<[1,19,4096]>, | ttnn.reshape | aten::view | 5 |
| 417 | Tensor<[1,19,4096]>, Tensor<[19,4096]>, | ttnn.reshape | aten::view | 5 |
| 418 | Tensor<[1,19,256008]>, Tensor<[19,256008]>, | ttnn.reshape | aten::view | 5 |
| 419 | Tensor<[1,1024]>, Tensor<[1,1024,1,1]>, | ttnn.reshape | aten::mean.dim | 4 |
| 420 | Tensor<[14]>, Tensor<[14,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 421 | Tensor<[14,1]>, Tensor<[14,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 422 | Tensor<[24]>, Tensor<[24,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 423 | Tensor<[24,1]>, Tensor<[24,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 424 | Tensor<[40]>, Tensor<[40,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 425 | Tensor<[40,1]>, Tensor<[40,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 426 | Tensor<[68]>, Tensor<[68,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 427 | Tensor<[68,1]>, Tensor<[68,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 428 | Tensor<[16,1]>, Tensor<[16,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 429 | Tensor<[28]>, Tensor<[28,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 430 | Tensor<[28,1]>, Tensor<[28,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 431 | Tensor<[46]>, Tensor<[46,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 432 | Tensor<[46,1]>, Tensor<[46,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 433 | Tensor<[78]>, Tensor<[78,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 434 | Tensor<[78,1]>, Tensor<[78,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 435 | Tensor<[134]>, Tensor<[134,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 436 | Tensor<[134,1]>, Tensor<[134,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 437 | Tensor<[20]>, Tensor<[20,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 438 | Tensor<[20,1]>, Tensor<[20,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 439 | Tensor<[34]>, Tensor<[34,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 440 | Tensor<[34,1]>, Tensor<[34,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 441 | Tensor<[58]>, Tensor<[58,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 442 | Tensor<[58,1]>, Tensor<[58,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 443 | Tensor<[98]>, Tensor<[98,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 444 | Tensor<[98,1]>, Tensor<[98,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 445 | Tensor<[168]>, Tensor<[168,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 446 | Tensor<[168,1]>, Tensor<[168,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 447 | Tensor<[320]>, Tensor<[320,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 448 | Tensor<[320,1]>, Tensor<[320,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 449 | Tensor<[116]>, Tensor<[116,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 450 | Tensor<[116,1]>, Tensor<[116,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 451 | Tensor<[196]>, Tensor<[196,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 452 | Tensor<[196,1]>, Tensor<[196,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 453 | Tensor<[334]>, Tensor<[334,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 454 | Tensor<[334,1]>, Tensor<[334,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 455 | Tensor<[160]>, Tensor<[160,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 456 | Tensor<[160,1]>, Tensor<[160,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 457 | Tensor<[272]>, Tensor<[272,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 458 | Tensor<[272,1]>, Tensor<[272,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 459 | Tensor<[462]>, Tensor<[462,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 460 | Tensor<[462,1]>, Tensor<[462,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 461 | Tensor<[1,1024,1,1]>, Tensor<[1,1024]>, | ttnn.reshape | aten::view | 5 |
| 462 | Tensor<[255]>, Tensor<[255,1,1]>, | ttnn.reshape | aten::convolution | 4 |
| 463 | Tensor<[1,256,32,32]>, Tensor<[1,256,32,32,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 464 | Tensor<[1,128,64,64]>, Tensor<[1,128,64,64,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 465 | Tensor<[1]>, Tensor<[1,1,1]>, | ttnn.reshape | aten::convolution | 4 |
| 466 | Tensor<[16]>, Tensor<[16,1,1]>, | ttnn.reshape | aten::convolution | 4 |
| 467 | Tensor<[1,16,32]>, Tensor<[1,16,32,1]>, | ttnn.reshape | aten::_softmax | 4 |
| 468 | Tensor<[1,32,16,96]>, Tensor<[1,32,1536]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 469 | Tensor<[32,250880]>, Tensor<[1,32,250880]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 470 | Tensor<[1,32,16,1,96]>, Tensor<[1,32,16,96]>, | ttnn.reshape | aten::select.int | 4 |
| 471 | Tensor<[1,16,32]>, Tensor<[16,1,32]>, | ttnn.reshape | aten::view | 5 |
| 472 | Tensor<[1,32,1536]>, Tensor<[32,1536]>, | ttnn.reshape | aten::view | 5 |
| 473 | Tensor<[32,4608]>, Tensor<[1,32,4608]>, | ttnn.reshape | aten::view | 5 |
| 474 | Tensor<[1,32,4608]>, Tensor<[1,32,16,3,96]>, | ttnn.reshape | aten::view | 5 |
| 475 | Tensor<[1,16,32,96]>, Tensor<[16,32,96]>, | ttnn.reshape | aten::view | 5 |
| 476 | Tensor<[16,32,32]>, Tensor<[1,16,32,32]>, | ttnn.reshape | aten::view | 5 |
| 477 | Tensor<[1,16,32,32]>, Tensor<[16,32,32]>, | ttnn.reshape | aten::view | 5 |
| 478 | Tensor<[16,32,96]>, Tensor<[1,16,32,96]>, | ttnn.reshape | aten::view | 5 |
| 479 | Tensor<[32,1536]>, Tensor<[1,32,1536]>, | ttnn.reshape | aten::view | 5 |
| 480 | Tensor<[32,6144]>, Tensor<[1,32,6144]>, | ttnn.reshape | aten::view | 5 |
| 481 | Tensor<[1,32,6144]>, Tensor<[32,6144]>, | ttnn.reshape | aten::view | 5 |
| 482 | Tensor<[1,12,16]>, Tensor<[1,12,16,1]>, | ttnn.reshape | aten::_safe_softmax | 4 |
| 483 | Tensor<[1,16]>, Tensor<[1,1,16]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 484 | Tensor<[1,1,16]>, Tensor<[1,1,1,16]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 485 | Tensor<[1,16,768]>, Tensor<[16,768]>, | ttnn.reshape | aten::view | 5 |
| 486 | Tensor<[16,768]>, Tensor<[1,16,768]>, | ttnn.reshape | aten::view | 5 |
| 487 | Tensor<[1,16,768]>, Tensor<[1,16,12,64]>, | ttnn.reshape | aten::view | 5 |
| 488 | Tensor<[1,12,16,64]>, Tensor<[12,16,64]>, | ttnn.reshape | aten::view | 5 |
| 489 | Tensor<[1,12,64,16]>, Tensor<[12,64,16]>, | ttnn.reshape | aten::view | 5 |
| 490 | Tensor<[12,16,16]>, Tensor<[1,12,16,16]>, | ttnn.reshape | aten::view | 5 |
| 491 | Tensor<[1,12,16,16]>, Tensor<[12,16,16]>, | ttnn.reshape | aten::view | 5 |
| 492 | Tensor<[12,16,64]>, Tensor<[1,12,16,64]>, | ttnn.reshape | aten::view | 5 |
| 493 | Tensor<[1,16,12,64]>, Tensor<[1,16,768]>, | ttnn.reshape | aten::view | 5 |
| 494 | Tensor<[16,3072]>, Tensor<[1,16,3072]>, | ttnn.reshape | aten::view | 5 |
| 495 | Tensor<[1,16,3072]>, Tensor<[16,3072]>, | ttnn.reshape | aten::view | 5 |
| 496 | Tensor<[1,1,19200]>, Tensor<[1,1,19200,1]>, | ttnn.reshape | aten::_softmax | 4 |
| 497 | Tensor<[1,2,4800]>, Tensor<[1,2,4800,1]>, | ttnn.reshape | aten::_softmax | 4 |
| 498 | Tensor<[1,5,1200]>, Tensor<[1,5,1200,1]>, | ttnn.reshape | aten::_softmax | 4 |
| 499 | Tensor<[1,8,300]>, Tensor<[1,8,300,1]>, | ttnn.reshape | aten::_softmax | 4 |
| 500 | Tensor<[1,19200,300]>, Tensor<[1,1,19200,300]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 501 | Tensor<[1,19200,64]>, Tensor<[1,1,19200,64]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 502 | Tensor<[1,19200,64]>, Tensor<[1,19200,64]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 503 | Tensor<[2,4800,300]>, Tensor<[1,2,4800,300]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 504 | Tensor<[2,4800,64]>, Tensor<[1,2,4800,64]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 505 | Tensor<[1,4800,128]>, Tensor<[1,4800,128]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 506 | Tensor<[5,1200,300]>, Tensor<[1,5,1200,300]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 507 | Tensor<[5,1200,64]>, Tensor<[1,5,1200,64]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 508 | Tensor<[1,1200,320]>, Tensor<[1,1200,320]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 509 | Tensor<[8,300,300]>, Tensor<[1,8,300,300]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 510 | Tensor<[8,300,64]>, Tensor<[1,8,300,64]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 511 | Tensor<[1,300,512]>, Tensor<[1,300,512]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 512 | Tensor<[2048]>, Tensor<[2048,1,1]>, | ttnn.reshape | aten::convolution | 4 |
| 513 | Tensor<[2]>, Tensor<[2,1,1]>, | ttnn.reshape | aten::convolution | 4 |
| 514 | Tensor<[1,64,30,40]>, Tensor<[1,64,30,40,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 515 | Tensor<[1,64,60,80]>, Tensor<[1,64,60,80,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 516 | Tensor<[1,64,120,160]>, Tensor<[1,64,120,160,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 517 | Tensor<[1,64,240,320]>, Tensor<[1,64,240,320,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 518 | Tensor<[1,64,480,640]>, Tensor<[1,64,480,640,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 519 | Tensor<[1,1,30,40]>, Tensor<[1,30,40]>, | ttnn.reshape | aten::select.int | 4 |
| 520 | Tensor<[1,1,60,80]>, Tensor<[1,60,80]>, | ttnn.reshape | aten::select.int | 4 |
| 521 | Tensor<[1,1,120,160]>, Tensor<[1,120,160]>, | ttnn.reshape | aten::select.int | 4 |
| 522 | Tensor<[1,1,480,640]>, Tensor<[1,480,640]>, | ttnn.reshape | aten::squeeze.dim | 5 |
| 523 | Tensor<[1,30,40]>, Tensor<[1,1,30,40]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 524 | Tensor<[1,60,80]>, Tensor<[1,1,60,80]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 525 | Tensor<[1,120,160]>, Tensor<[1,1,120,160]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 526 | Tensor<[1,64,120,160]>, Tensor<[1,64,19200]>, | ttnn.reshape | aten::view | 5 |
| 527 | Tensor<[1,19200,64]>, Tensor<[19200,64]>, | ttnn.reshape | aten::view | 5 |
| 528 | Tensor<[19200,64]>, Tensor<[1,19200,64]>, | ttnn.reshape | aten::view | 5 |
| 529 | Tensor<[1,19200,64]>, Tensor<[1,19200,1,64]>, | ttnn.reshape | aten::view | 5 |
| 530 | Tensor<[1,64,19200]>, Tensor<[1,64,120,160]>, | ttnn.reshape | aten::view | 5 |
| 531 | Tensor<[1,64,15,20]>, Tensor<[1,64,300]>, | ttnn.reshape | aten::view | 5 |
| 532 | Tensor<[1,300,64]>, Tensor<[300,64]>, | ttnn.reshape | aten::view | 5 |
| 533 | Tensor<[300,64]>, Tensor<[1,300,64]>, | ttnn.reshape | aten::view | 5 |
| 534 | Tensor<[1,300,64]>, Tensor<[1,300,1,64]>, | ttnn.reshape | aten::view | 5 |
| 535 | Tensor<[1,1,19200,64]>, Tensor<[1,19200,64]>, | ttnn.reshape | aten::view | 5 |
| 536 | Tensor<[1,1,64,300]>, Tensor<[1,64,300]>, | ttnn.reshape | aten::view | 5 |
| 537 | Tensor<[1,1,19200,300]>, Tensor<[1,19200,300]>, | ttnn.reshape | aten::view | 5 |
| 538 | Tensor<[1,1,300,64]>, Tensor<[1,300,64]>, | ttnn.reshape | aten::view | 5 |
| 539 | Tensor<[1,19200,1,64]>, Tensor<[1,19200,64]>, | ttnn.reshape | aten::view | 5 |
| 540 | Tensor<[19200,256]>, Tensor<[1,19200,256]>, | ttnn.reshape | aten::view | 5 |
| 541 | Tensor<[1,256,19200]>, Tensor<[1,256,120,160]>, | ttnn.reshape | aten::view | 5 |
| 542 | Tensor<[1,256,120,160]>, Tensor<[1,256,19200]>, | ttnn.reshape | aten::view | 5 |
| 543 | Tensor<[1,19200,256]>, Tensor<[1,19200,256]>, | ttnn.reshape | aten::view | 5 |
| 544 | Tensor<[1,256,64]>, Tensor<[1,256,64]>, | ttnn.reshape | aten::view | 5 |
| 545 | Tensor<[1,19200,64]>, Tensor<[1,120,160,64]>, | ttnn.reshape | aten::view | 5 |
| 546 | Tensor<[1,128,60,80]>, Tensor<[1,128,4800]>, | ttnn.reshape | aten::view | 5 |
| 547 | Tensor<[1,4800,128]>, Tensor<[4800,128]>, | ttnn.reshape | aten::view | 5 |
| 548 | Tensor<[4800,128]>, Tensor<[1,4800,128]>, | ttnn.reshape | aten::view | 5 |
| 549 | Tensor<[1,4800,128]>, Tensor<[1,4800,2,64]>, | ttnn.reshape | aten::view | 5 |
| 550 | Tensor<[1,128,4800]>, Tensor<[1,128,60,80]>, | ttnn.reshape | aten::view | 5 |
| 551 | Tensor<[1,128,15,20]>, Tensor<[1,128,300]>, | ttnn.reshape | aten::view | 5 |
| 552 | Tensor<[1,300,128]>, Tensor<[300,128]>, | ttnn.reshape | aten::view | 5 |
| 553 | Tensor<[300,128]>, Tensor<[1,300,128]>, | ttnn.reshape | aten::view | 5 |
| 554 | Tensor<[1,300,128]>, Tensor<[1,300,2,64]>, | ttnn.reshape | aten::view | 5 |
| 555 | Tensor<[1,2,4800,64]>, Tensor<[2,4800,64]>, | ttnn.reshape | aten::view | 5 |
| 556 | Tensor<[1,2,64,300]>, Tensor<[2,64,300]>, | ttnn.reshape | aten::view | 5 |
| 557 | Tensor<[1,2,4800,300]>, Tensor<[2,4800,300]>, | ttnn.reshape | aten::view | 5 |
| 558 | Tensor<[1,2,300,64]>, Tensor<[2,300,64]>, | ttnn.reshape | aten::view | 5 |
| 559 | Tensor<[1,4800,2,64]>, Tensor<[1,4800,128]>, | ttnn.reshape | aten::view | 5 |
| 560 | Tensor<[4800,512]>, Tensor<[1,4800,512]>, | ttnn.reshape | aten::view | 5 |
| 561 | Tensor<[1,512,4800]>, Tensor<[1,512,60,80]>, | ttnn.reshape | aten::view | 5 |
| 562 | Tensor<[1,512,60,80]>, Tensor<[1,512,4800]>, | ttnn.reshape | aten::view | 5 |
| 563 | Tensor<[1,4800,512]>, Tensor<[1,4800,512]>, | ttnn.reshape | aten::view | 5 |
| 564 | Tensor<[1,512,128]>, Tensor<[1,512,128]>, | ttnn.reshape | aten::view | 5 |
| 565 | Tensor<[1,4800,128]>, Tensor<[1,60,80,128]>, | ttnn.reshape | aten::view | 5 |
| 566 | Tensor<[1,320,30,40]>, Tensor<[1,320,1200]>, | ttnn.reshape | aten::view | 5 |
| 567 | Tensor<[1,1200,320]>, Tensor<[1200,320]>, | ttnn.reshape | aten::view | 5 |
| 568 | Tensor<[1200,320]>, Tensor<[1,1200,320]>, | ttnn.reshape | aten::view | 5 |
| 569 | Tensor<[1,1200,320]>, Tensor<[1,1200,5,64]>, | ttnn.reshape | aten::view | 5 |
| 570 | Tensor<[1,320,1200]>, Tensor<[1,320,30,40]>, | ttnn.reshape | aten::view | 5 |
| 571 | Tensor<[1,320,15,20]>, Tensor<[1,320,300]>, | ttnn.reshape | aten::view | 5 |
| 572 | Tensor<[1,300,320]>, Tensor<[300,320]>, | ttnn.reshape | aten::view | 5 |
| 573 | Tensor<[300,320]>, Tensor<[1,300,320]>, | ttnn.reshape | aten::view | 5 |
| 574 | Tensor<[1,300,320]>, Tensor<[1,300,5,64]>, | ttnn.reshape | aten::view | 5 |
| 575 | Tensor<[1,5,1200,64]>, Tensor<[5,1200,64]>, | ttnn.reshape | aten::view | 5 |
| 576 | Tensor<[1,5,64,300]>, Tensor<[5,64,300]>, | ttnn.reshape | aten::view | 5 |
| 577 | Tensor<[1,5,1200,300]>, Tensor<[5,1200,300]>, | ttnn.reshape | aten::view | 5 |
| 578 | Tensor<[1,5,300,64]>, Tensor<[5,300,64]>, | ttnn.reshape | aten::view | 5 |
| 579 | Tensor<[1,1200,5,64]>, Tensor<[1,1200,320]>, | ttnn.reshape | aten::view | 5 |
| 580 | Tensor<[1200,1280]>, Tensor<[1,1200,1280]>, | ttnn.reshape | aten::view | 5 |
| 581 | Tensor<[1,1280,1200]>, Tensor<[1,1280,30,40]>, | ttnn.reshape | aten::view | 5 |
| 582 | Tensor<[1,1280,30,40]>, Tensor<[1,1280,1200]>, | ttnn.reshape | aten::view | 5 |
| 583 | Tensor<[1,1200,1280]>, Tensor<[1,1200,1280]>, | ttnn.reshape | aten::view | 5 |
| 584 | Tensor<[1,1280,320]>, Tensor<[1,1280,320]>, | ttnn.reshape | aten::view | 5 |
| 585 | Tensor<[1,1200,320]>, Tensor<[1,30,40,320]>, | ttnn.reshape | aten::view | 5 |
| 586 | Tensor<[1,512,15,20]>, Tensor<[1,512,300]>, | ttnn.reshape | aten::view | 5 |
| 587 | Tensor<[1,300,512]>, Tensor<[300,512]>, | ttnn.reshape | aten::view | 5 |
| 588 | Tensor<[300,512]>, Tensor<[1,300,512]>, | ttnn.reshape | aten::view | 5 |
| 589 | Tensor<[1,300,512]>, Tensor<[1,300,8,64]>, | ttnn.reshape | aten::view | 5 |
| 590 | Tensor<[1,8,300,64]>, Tensor<[8,300,64]>, | ttnn.reshape | aten::view | 5 |
| 591 | Tensor<[1,8,64,300]>, Tensor<[8,64,300]>, | ttnn.reshape | aten::view | 5 |
| 592 | Tensor<[1,8,300,300]>, Tensor<[8,300,300]>, | ttnn.reshape | aten::view | 5 |
| 593 | Tensor<[1,300,8,64]>, Tensor<[1,300,512]>, | ttnn.reshape | aten::view | 5 |
| 594 | Tensor<[300,2048]>, Tensor<[1,300,2048]>, | ttnn.reshape | aten::view | 5 |
| 595 | Tensor<[1,2048,300]>, Tensor<[1,2048,15,20]>, | ttnn.reshape | aten::view | 5 |
| 596 | Tensor<[1,2048,15,20]>, Tensor<[1,2048,300]>, | ttnn.reshape | aten::view | 5 |
| 597 | Tensor<[1,300,2048]>, Tensor<[1,300,2048]>, | ttnn.reshape | aten::view | 5 |
| 598 | Tensor<[1,2048,512]>, Tensor<[1,2048,512]>, | ttnn.reshape | aten::view | 5 |
| 599 | Tensor<[1,300,512]>, Tensor<[1,15,20,512]>, | ttnn.reshape | aten::view | 5 |
| 600 | Tensor<[30]>, Tensor<[30,1]>, | ttnn.reshape | aten::view | 5 |
| 601 | Tensor<[60]>, Tensor<[60,1]>, | ttnn.reshape | aten::view | 5 |
| 602 | Tensor<[120]>, Tensor<[120,1]>, | ttnn.reshape | aten::view | 5 |
| 603 | Tensor<[240]>, Tensor<[240,1]>, | ttnn.reshape | aten::view | 5 |
| 604 | Tensor<[480]>, Tensor<[480,1]>, | ttnn.reshape | aten::view | 5 |
| 605 | Tensor<[1,12,197]>, Tensor<[1,12,197,1]>, | ttnn.reshape | aten::_safe_softmax | 4 |
| 606 | Tensor<[1,768,14,14]>, Tensor<[1,768,196]>, | ttnn.reshape | aten::view | 5 |
| 607 | Tensor<[1,197,768]>, Tensor<[197,768]>, | ttnn.reshape | aten::view | 5 |
| 608 | Tensor<[197,768]>, Tensor<[1,197,768]>, | ttnn.reshape | aten::view | 5 |
| 609 | Tensor<[1,197,768]>, Tensor<[1,197,12,64]>, | ttnn.reshape | aten::view | 5 |
| 610 | Tensor<[1,12,197,64]>, Tensor<[12,197,64]>, | ttnn.reshape | aten::view | 5 |
| 611 | Tensor<[1,12,64,197]>, Tensor<[12,64,197]>, | ttnn.reshape | aten::view | 5 |
| 612 | Tensor<[12,197,197]>, Tensor<[1,12,197,197]>, | ttnn.reshape | aten::view | 5 |
| 613 | Tensor<[1,12,197,197]>, Tensor<[12,197,197]>, | ttnn.reshape | aten::view | 5 |
| 614 | Tensor<[12,197,64]>, Tensor<[1,12,197,64]>, | ttnn.reshape | aten::view | 5 |
| 615 | Tensor<[1,197,12,64]>, Tensor<[1,197,768]>, | ttnn.reshape | aten::view | 5 |
| 616 | Tensor<[197,3072]>, Tensor<[1,197,3072]>, | ttnn.reshape | aten::view | 5 |
| 617 | Tensor<[1,197,3072]>, Tensor<[197,3072]>, | ttnn.reshape | aten::view | 5 |
| 618 | Tensor<[1,1,16384]>, Tensor<[1,1,16384,1]>, | ttnn.reshape | aten::_softmax | 4 |
| 619 | Tensor<[1,2,4096]>, Tensor<[1,2,4096,1]>, | ttnn.reshape | aten::_softmax | 4 |
| 620 | Tensor<[1,5,1024]>, Tensor<[1,5,1024,1]>, | ttnn.reshape | aten::_softmax | 4 |
| 621 | Tensor<[1,16384,256]>, Tensor<[1,1,16384,256]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 622 | Tensor<[1,16384,32]>, Tensor<[1,1,16384,32]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 623 | Tensor<[1,16384,32]>, Tensor<[1,16384,32]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 624 | Tensor<[2,4096,256]>, Tensor<[1,2,4096,256]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 625 | Tensor<[2,4096,32]>, Tensor<[1,2,4096,32]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 626 | Tensor<[1,4096,64]>, Tensor<[1,4096,64]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 627 | Tensor<[5,1024,256]>, Tensor<[1,5,1024,256]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 628 | Tensor<[5,1024,32]>, Tensor<[1,5,1024,32]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 629 | Tensor<[1,1024,160]>, Tensor<[1,1024,160]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 630 | Tensor<[8,256,32]>, Tensor<[1,8,256,32]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 631 | Tensor<[1,256,256]>, Tensor<[1,256,256]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 632 | Tensor<[1,16384,256]>, Tensor<[1,16384,256]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 633 | Tensor<[1,4096,256]>, Tensor<[1,4096,256]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 634 | Tensor<[1,1024,256]>, Tensor<[1,1024,256]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 635 | Tensor<[160]>, Tensor<[160,1,1]>, | ttnn.reshape | aten::convolution | 4 |
| 636 | Tensor<[1024]>, Tensor<[1024,1,1]>, | ttnn.reshape | aten::convolution | 4 |
| 637 | Tensor<[150]>, Tensor<[150,1,1]>, | ttnn.reshape | aten::convolution | 4 |
| 638 | Tensor<[1,256,128,128]>, Tensor<[1,256,128,128,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 639 | Tensor<[1,32,128,128]>, Tensor<[1,32,16384]>, | ttnn.reshape | aten::view | 5 |
| 640 | Tensor<[1,16384,32]>, Tensor<[16384,32]>, | ttnn.reshape | aten::view | 5 |
| 641 | Tensor<[16384,32]>, Tensor<[1,16384,32]>, | ttnn.reshape | aten::view | 5 |
| 642 | Tensor<[1,16384,32]>, Tensor<[1,16384,1,32]>, | ttnn.reshape | aten::view | 5 |
| 643 | Tensor<[1,32,16384]>, Tensor<[1,32,128,128]>, | ttnn.reshape | aten::view | 5 |
| 644 | Tensor<[1,32,16,16]>, Tensor<[1,32,256]>, | ttnn.reshape | aten::view | 5 |
| 645 | Tensor<[1,256,32]>, Tensor<[256,32]>, | ttnn.reshape | aten::view | 5 |
| 646 | Tensor<[256,32]>, Tensor<[1,256,32]>, | ttnn.reshape | aten::view | 5 |
| 647 | Tensor<[1,256,32]>, Tensor<[1,256,1,32]>, | ttnn.reshape | aten::view | 5 |
| 648 | Tensor<[1,1,16384,32]>, Tensor<[1,16384,32]>, | ttnn.reshape | aten::view | 5 |
| 649 | Tensor<[1,1,32,256]>, Tensor<[1,32,256]>, | ttnn.reshape | aten::view | 5 |
| 650 | Tensor<[1,1,16384,256]>, Tensor<[1,16384,256]>, | ttnn.reshape | aten::view | 5 |
| 651 | Tensor<[1,1,256,32]>, Tensor<[1,256,32]>, | ttnn.reshape | aten::view | 5 |
| 652 | Tensor<[1,16384,1,32]>, Tensor<[1,16384,32]>, | ttnn.reshape | aten::view | 5 |
| 653 | Tensor<[16384,128]>, Tensor<[1,16384,128]>, | ttnn.reshape | aten::view | 5 |
| 654 | Tensor<[1,128,16384]>, Tensor<[1,128,128,128]>, | ttnn.reshape | aten::view | 5 |
| 655 | Tensor<[1,128,128,128]>, Tensor<[1,128,16384]>, | ttnn.reshape | aten::view | 5 |
| 656 | Tensor<[1,16384,128]>, Tensor<[1,16384,128]>, | ttnn.reshape | aten::view | 5 |
| 657 | Tensor<[1,128,32]>, Tensor<[1,128,32]>, | ttnn.reshape | aten::view | 5 |
| 658 | Tensor<[1,16384,32]>, Tensor<[1,128,128,32]>, | ttnn.reshape | aten::view | 5 |
| 659 | Tensor<[1,64,64,64]>, Tensor<[1,64,4096]>, | ttnn.reshape | aten::view | 5 |
| 660 | Tensor<[1,4096,64]>, Tensor<[4096,64]>, | ttnn.reshape | aten::view | 5 |
| 661 | Tensor<[4096,64]>, Tensor<[1,4096,64]>, | ttnn.reshape | aten::view | 5 |
| 662 | Tensor<[1,4096,64]>, Tensor<[1,4096,2,32]>, | ttnn.reshape | aten::view | 5 |
| 663 | Tensor<[1,64,4096]>, Tensor<[1,64,64,64]>, | ttnn.reshape | aten::view | 5 |
| 664 | Tensor<[1,64,16,16]>, Tensor<[1,64,256]>, | ttnn.reshape | aten::view | 5 |
| 665 | Tensor<[1,256,64]>, Tensor<[256,64]>, | ttnn.reshape | aten::view | 5 |
| 666 | Tensor<[256,64]>, Tensor<[1,256,64]>, | ttnn.reshape | aten::view | 5 |
| 667 | Tensor<[1,256,64]>, Tensor<[1,256,2,32]>, | ttnn.reshape | aten::view | 5 |
| 668 | Tensor<[1,2,4096,32]>, Tensor<[2,4096,32]>, | ttnn.reshape | aten::view | 5 |
| 669 | Tensor<[1,2,32,256]>, Tensor<[2,32,256]>, | ttnn.reshape | aten::view | 5 |
| 670 | Tensor<[1,2,4096,256]>, Tensor<[2,4096,256]>, | ttnn.reshape | aten::view | 5 |
| 671 | Tensor<[1,2,256,32]>, Tensor<[2,256,32]>, | ttnn.reshape | aten::view | 5 |
| 672 | Tensor<[1,4096,2,32]>, Tensor<[1,4096,64]>, | ttnn.reshape | aten::view | 5 |
| 673 | Tensor<[4096,256]>, Tensor<[1,4096,256]>, | ttnn.reshape | aten::view | 5 |
| 674 | Tensor<[1,256,4096]>, Tensor<[1,256,64,64]>, | ttnn.reshape | aten::view | 5 |
| 675 | Tensor<[1,256,64,64]>, Tensor<[1,256,4096]>, | ttnn.reshape | aten::view | 5 |
| 676 | Tensor<[1,4096,64]>, Tensor<[1,64,64,64]>, | ttnn.reshape | aten::view | 5 |
| 677 | Tensor<[1,160,32,32]>, Tensor<[1,160,1024]>, | ttnn.reshape | aten::view | 5 |
| 678 | Tensor<[1,1024,160]>, Tensor<[1024,160]>, | ttnn.reshape | aten::view | 5 |
| 679 | Tensor<[1024,160]>, Tensor<[1,1024,160]>, | ttnn.reshape | aten::view | 5 |
| 680 | Tensor<[1,1024,160]>, Tensor<[1,1024,5,32]>, | ttnn.reshape | aten::view | 5 |
| 681 | Tensor<[1,160,1024]>, Tensor<[1,160,32,32]>, | ttnn.reshape | aten::view | 5 |
| 682 | Tensor<[1,160,16,16]>, Tensor<[1,160,256]>, | ttnn.reshape | aten::view | 5 |
| 683 | Tensor<[1,256,160]>, Tensor<[256,160]>, | ttnn.reshape | aten::view | 5 |
| 684 | Tensor<[256,160]>, Tensor<[1,256,160]>, | ttnn.reshape | aten::view | 5 |
| 685 | Tensor<[1,256,160]>, Tensor<[1,256,5,32]>, | ttnn.reshape | aten::view | 5 |
| 686 | Tensor<[1,5,1024,32]>, Tensor<[5,1024,32]>, | ttnn.reshape | aten::view | 5 |
| 687 | Tensor<[1,5,32,256]>, Tensor<[5,32,256]>, | ttnn.reshape | aten::view | 5 |
| 688 | Tensor<[1,5,1024,256]>, Tensor<[5,1024,256]>, | ttnn.reshape | aten::view | 5 |
| 689 | Tensor<[1,5,256,32]>, Tensor<[5,256,32]>, | ttnn.reshape | aten::view | 5 |
| 690 | Tensor<[1,1024,5,32]>, Tensor<[1,1024,160]>, | ttnn.reshape | aten::view | 5 |
| 691 | Tensor<[1,640,1024]>, Tensor<[1,640,32,32]>, | ttnn.reshape | aten::view | 5 |
| 692 | Tensor<[1,640,32,32]>, Tensor<[1,640,1024]>, | ttnn.reshape | aten::view | 5 |
| 693 | Tensor<[1,1024,640]>, Tensor<[1,1024,640]>, | ttnn.reshape | aten::view | 5 |
| 694 | Tensor<[1,640,160]>, Tensor<[1,640,160]>, | ttnn.reshape | aten::view | 5 |
| 695 | Tensor<[1,1024,160]>, Tensor<[1,32,32,160]>, | ttnn.reshape | aten::view | 5 |
| 696 | Tensor<[1,256,16,16]>, Tensor<[1,256,256]>, | ttnn.reshape | aten::view | 5 |
| 697 | Tensor<[1,256,8,32]>, Tensor<[1,256,256]>, | ttnn.reshape | aten::view | 5 |
| 698 | Tensor<[256,1024]>, Tensor<[1,256,1024]>, | ttnn.reshape | aten::view | 5 |
| 699 | Tensor<[1,1024,256]>, Tensor<[1,1024,16,16]>, | ttnn.reshape | aten::view | 5 |
| 700 | Tensor<[1,1024,16,16]>, Tensor<[1,1024,256]>, | ttnn.reshape | aten::view | 5 |
| 701 | Tensor<[1,256,1024]>, Tensor<[1,256,1024]>, | ttnn.reshape | aten::view | 5 |
| 702 | Tensor<[1,256,256]>, Tensor<[1,16,16,256]>, | ttnn.reshape | aten::view | 5 |
| 703 | Tensor<[1,32,256]>, Tensor<[1,32,256]>, | ttnn.reshape | aten::view | 5 |
| 704 | Tensor<[1,256,16384]>, Tensor<[1,256,128,128]>, | ttnn.reshape | aten::view | 5 |
| 705 | Tensor<[1,64,256]>, Tensor<[1,64,256]>, | ttnn.reshape | aten::view | 5 |
| 706 | Tensor<[1,160,256]>, Tensor<[1,160,256]>, | ttnn.reshape | aten::view | 5 |
| 707 | Tensor<[1,256,1024]>, Tensor<[1,256,32,32]>, | ttnn.reshape | aten::view | 5 |
| 708 | Tensor<[1,256,256]>, Tensor<[1,256,16,16]>, | ttnn.reshape | aten::view | 5 |
| 709 | Tensor<[1,71,7]>, Tensor<[1,71,7,1]>, | ttnn.reshape | aten::_safe_softmax | 4 |
| 710 | Tensor<[1,32,7]>, Tensor<[1,32,7]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 711 | Tensor<[7,4672]>, Tensor<[1,7,4672]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 712 | Tensor<[71,7,7]>, Tensor<[1,71,7,7]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 713 | Tensor<[71,7,64]>, Tensor<[1,71,7,64]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 714 | Tensor<[1,7,71,64]>, Tensor<[1,7,4544]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 715 | Tensor<[7,4544]>, Tensor<[1,7,4544]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 716 | Tensor<[7,18176]>, Tensor<[1,7,18176]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 717 | Tensor<[1,7,4544]>, Tensor<[7,4544]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 718 | Tensor<[7,65024]>, Tensor<[1,7,65024]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 719 | Tensor<[7,1]>, Tensor<[7,1,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 720 | Tensor<[1,7,1,64]>, Tensor<[1,7,1,64,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 721 | Tensor<[1,7,64]>, Tensor<[1,1,7,64]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 722 | Tensor<[1,32,1]>, Tensor<[1,32,1]>, | ttnn.reshape | aten::view | 5 |
| 723 | Tensor<[1,1,7]>, Tensor<[1,1,7]>, | ttnn.reshape | aten::view | 5 |
| 724 | Tensor<[1,7,4672]>, Tensor<[1,7,73,64]>, | ttnn.reshape | aten::view | 5 |
| 725 | Tensor<[1,71,7,64]>, Tensor<[1,71,7,64]>, | ttnn.reshape | aten::view | 5 |
| 726 | Tensor<[1,1,7,64]>, Tensor<[1,1,7,64]>, | ttnn.reshape | aten::view | 5 |
| 727 | Tensor<[1,71,7,64]>, Tensor<[71,7,64]>, | ttnn.reshape | aten::view | 5 |
| 728 | Tensor<[1,71,64,7]>, Tensor<[71,64,7]>, | ttnn.reshape | aten::view | 5 |
| 729 | Tensor<[1,71,7,7]>, Tensor<[71,7,7]>, | ttnn.reshape | aten::view | 5 |
| 730 | Tensor<[1,7,18176]>, Tensor<[7,18176]>, | ttnn.reshape | aten::view | 5 |
| 731 | Tensor<[1,1280]>, Tensor<[1,1280,1,1]>, | ttnn.reshape | aten::mean.dim | 4 |
| 732 | Tensor<[96]>, Tensor<[96,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 733 | Tensor<[96,1]>, Tensor<[96,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 734 | Tensor<[144]>, Tensor<[144,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 735 | Tensor<[144,1]>, Tensor<[144,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 736 | Tensor<[192]>, Tensor<[192,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 737 | Tensor<[192,1]>, Tensor<[192,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 738 | Tensor<[384]>, Tensor<[384,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 739 | Tensor<[384,1]>, Tensor<[384,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 740 | Tensor<[576]>, Tensor<[576,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 741 | Tensor<[576,1]>, Tensor<[576,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 742 | Tensor<[960]>, Tensor<[960,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 743 | Tensor<[960,1]>, Tensor<[960,1,1]>, | ttnn.reshape | aten::unsqueeze | 5 |
| 744 | Tensor<[1,1280,1,1]>, Tensor<[1,1280]>, | ttnn.reshape | aten::view | 5 |
| 745 | Tensor<[1,12,12]>, Tensor<[1,12,12,1]>, | ttnn.reshape | aten::_safe_softmax | 4 |
| 746 | Tensor<[1,12]>, Tensor<[1,1,12]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 747 | Tensor<[1,1,12]>, Tensor<[1,1,1,12]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 748 | Tensor<[1,12,128]>, Tensor<[12,128]>, | ttnn.reshape | aten::view | 5 |
| 749 | Tensor<[12,768]>, Tensor<[1,12,768]>, | ttnn.reshape | aten::view | 5 |
| 750 | Tensor<[1,12,768]>, Tensor<[12,768]>, | ttnn.reshape | aten::view | 5 |
| 751 | Tensor<[1,12,768]>, Tensor<[1,12,12,64]>, | ttnn.reshape | aten::view | 5 |
| 752 | Tensor<[1,12,12,64]>, Tensor<[12,12,64]>, | ttnn.reshape | aten::view | 5 |
| 753 | Tensor<[1,12,64,12]>, Tensor<[12,64,12]>, | ttnn.reshape | aten::view | 5 |
| 754 | Tensor<[12,12,12]>, Tensor<[1,12,12,12]>, | ttnn.reshape | aten::view | 5 |
| 755 | Tensor<[1,12,12,12]>, Tensor<[12,12,12]>, | ttnn.reshape | aten::view | 5 |
| 756 | Tensor<[12,12,64]>, Tensor<[1,12,12,64]>, | ttnn.reshape | aten::view | 5 |
| 757 | Tensor<[1,12,12,64]>, Tensor<[1,12,768]>, | ttnn.reshape | aten::view | 5 |
| 758 | Tensor<[12,3072]>, Tensor<[1,12,3072]>, | ttnn.reshape | aten::view | 5 |
| 759 | Tensor<[1,12,3072]>, Tensor<[12,3072]>, | ttnn.reshape | aten::view | 5 |
| 760 | Tensor<[12,2]>, Tensor<[1,12,2]>, | ttnn.reshape | aten::view | 5 |
| 761 | Tensor<[1,12,9]>, Tensor<[1,12,9,1]>, | ttnn.reshape | aten::_safe_softmax | 4 |
| 762 | Tensor<[1,9]>, Tensor<[1,1,9]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 763 | Tensor<[1,1,9]>, Tensor<[1,1,1,9]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 764 | Tensor<[1,9,128]>, Tensor<[9,128]>, | ttnn.reshape | aten::view | 5 |
| 765 | Tensor<[9,768]>, Tensor<[1,9,768]>, | ttnn.reshape | aten::view | 5 |
| 766 | Tensor<[1,9,768]>, Tensor<[1,9,12,64]>, | ttnn.reshape | aten::view | 5 |
| 767 | Tensor<[1,12,9,64]>, Tensor<[12,9,64]>, | ttnn.reshape | aten::view | 5 |
| 768 | Tensor<[1,12,64,9]>, Tensor<[12,64,9]>, | ttnn.reshape | aten::view | 5 |
| 769 | Tensor<[12,9,9]>, Tensor<[1,12,9,9]>, | ttnn.reshape | aten::view | 5 |
| 770 | Tensor<[1,12,9,9]>, Tensor<[12,9,9]>, | ttnn.reshape | aten::view | 5 |
| 771 | Tensor<[12,9,64]>, Tensor<[1,12,9,64]>, | ttnn.reshape | aten::view | 5 |
| 772 | Tensor<[1,9,12,64]>, Tensor<[1,9,768]>, | ttnn.reshape | aten::view | 5 |
| 773 | Tensor<[9,3072]>, Tensor<[1,9,3072]>, | ttnn.reshape | aten::view | 5 |
| 774 | Tensor<[1,9,3072]>, Tensor<[9,3072]>, | ttnn.reshape | aten::view | 5 |
| 775 | Tensor<[9,128]>, Tensor<[1,9,128]>, | ttnn.reshape | aten::view | 5 |
| 776 | Tensor<[9,30000]>, Tensor<[1,9,30000]>, | ttnn.reshape | aten::view | 5 |
| 777 | Tensor<[1,16,9]>, Tensor<[1,16,9,1]>, | ttnn.reshape | aten::_safe_softmax | 4 |
| 778 | Tensor<[9,2048]>, Tensor<[1,9,2048]>, | ttnn.reshape | aten::view | 5 |
| 779 | Tensor<[1,9,2048]>, Tensor<[9,2048]>, | ttnn.reshape | aten::view | 5 |
| 780 | Tensor<[1,9,2048]>, Tensor<[1,9,16,128]>, | ttnn.reshape | aten::view | 5 |
| 781 | Tensor<[1,16,9,128]>, Tensor<[16,9,128]>, | ttnn.reshape | aten::view | 5 |
| 782 | Tensor<[1,16,128,9]>, Tensor<[16,128,9]>, | ttnn.reshape | aten::view | 5 |
| 783 | Tensor<[16,9,9]>, Tensor<[1,16,9,9]>, | ttnn.reshape | aten::view | 5 |
| 784 | Tensor<[1,16,9,9]>, Tensor<[16,9,9]>, | ttnn.reshape | aten::view | 5 |
| 785 | Tensor<[16,9,128]>, Tensor<[1,16,9,128]>, | ttnn.reshape | aten::view | 5 |
| 786 | Tensor<[1,9,16,128]>, Tensor<[1,9,2048]>, | ttnn.reshape | aten::view | 5 |
| 787 | Tensor<[9,8192]>, Tensor<[1,9,8192]>, | ttnn.reshape | aten::view | 5 |
| 788 | Tensor<[1,9,8192]>, Tensor<[9,8192]>, | ttnn.reshape | aten::view | 5 |
| 789 | Tensor<[9,1024]>, Tensor<[1,9,1024]>, | ttnn.reshape | aten::view | 5 |
| 790 | Tensor<[1,9,1024]>, Tensor<[9,1024]>, | ttnn.reshape | aten::view | 5 |
| 791 | Tensor<[1,9,1024]>, Tensor<[1,9,16,64]>, | ttnn.reshape | aten::view | 5 |
| 792 | Tensor<[1,16,9,64]>, Tensor<[16,9,64]>, | ttnn.reshape | aten::view | 5 |
| 793 | Tensor<[1,16,64,9]>, Tensor<[16,64,9]>, | ttnn.reshape | aten::view | 5 |
| 794 | Tensor<[16,9,64]>, Tensor<[1,16,9,64]>, | ttnn.reshape | aten::view | 5 |
| 795 | Tensor<[1,9,16,64]>, Tensor<[1,9,1024]>, | ttnn.reshape | aten::view | 5 |
| 796 | Tensor<[9,4096]>, Tensor<[1,9,4096]>, | ttnn.reshape | aten::view | 5 |
| 797 | Tensor<[1,9,4096]>, Tensor<[9,4096]>, | ttnn.reshape | aten::view | 5 |
| 798 | Tensor<[1,64,9]>, Tensor<[1,64,9,1]>, | ttnn.reshape | aten::_safe_softmax | 4 |
| 799 | Tensor<[1,9,4096]>, Tensor<[1,9,64,64]>, | ttnn.reshape | aten::view | 5 |
| 800 | Tensor<[1,64,9,64]>, Tensor<[64,9,64]>, | ttnn.reshape | aten::view | 5 |
| 801 | Tensor<[1,64,64,9]>, Tensor<[64,64,9]>, | ttnn.reshape | aten::view | 5 |
| 802 | Tensor<[64,9,9]>, Tensor<[1,64,9,9]>, | ttnn.reshape | aten::view | 5 |
| 803 | Tensor<[1,64,9,9]>, Tensor<[64,9,9]>, | ttnn.reshape | aten::view | 5 |
| 804 | Tensor<[64,9,64]>, Tensor<[1,64,9,64]>, | ttnn.reshape | aten::view | 5 |
| 805 | Tensor<[1,9,64,64]>, Tensor<[1,9,4096]>, | ttnn.reshape | aten::view | 5 |
| 806 | Tensor<[9,16384]>, Tensor<[1,9,16384]>, | ttnn.reshape | aten::view | 5 |
| 807 | Tensor<[1,9,16384]>, Tensor<[9,16384]>, | ttnn.reshape | aten::view | 5 |
| 808 | Tensor<[1,12,14]>, Tensor<[1,12,14,1]>, | ttnn.reshape | aten::_safe_softmax | 4 |
| 809 | Tensor<[1,14,1]>, Tensor<[1,14]>, | ttnn.reshape | aten::squeeze.dim | 5 |
| 810 | Tensor<[1,14]>, Tensor<[1,1,14]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 811 | Tensor<[1,1,14]>, Tensor<[1,1,1,14]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 812 | Tensor<[1,14,128]>, Tensor<[14,128]>, | ttnn.reshape | aten::view | 5 |
| 813 | Tensor<[14,768]>, Tensor<[1,14,768]>, | ttnn.reshape | aten::view | 5 |
| 814 | Tensor<[1,14,768]>, Tensor<[14,768]>, | ttnn.reshape | aten::view | 5 |
| 815 | Tensor<[1,14,768]>, Tensor<[1,14,12,64]>, | ttnn.reshape | aten::view | 5 |
| 816 | Tensor<[1,12,14,64]>, Tensor<[12,14,64]>, | ttnn.reshape | aten::view | 5 |
| 817 | Tensor<[1,12,64,14]>, Tensor<[12,64,14]>, | ttnn.reshape | aten::view | 5 |
| 818 | Tensor<[12,14,14]>, Tensor<[1,12,14,14]>, | ttnn.reshape | aten::view | 5 |
| 819 | Tensor<[1,12,14,14]>, Tensor<[12,14,14]>, | ttnn.reshape | aten::view | 5 |
| 820 | Tensor<[12,14,64]>, Tensor<[1,12,14,64]>, | ttnn.reshape | aten::view | 5 |
| 821 | Tensor<[1,14,12,64]>, Tensor<[1,14,768]>, | ttnn.reshape | aten::view | 5 |
| 822 | Tensor<[14,3072]>, Tensor<[1,14,3072]>, | ttnn.reshape | aten::view | 5 |
| 823 | Tensor<[1,14,3072]>, Tensor<[14,3072]>, | ttnn.reshape | aten::view | 5 |
| 824 | Tensor<[14,2]>, Tensor<[1,14,2]>, | ttnn.reshape | aten::view | 5 |
| 825 | Tensor<[1,12,50]>, Tensor<[1,12,50,1]>, | ttnn.reshape | aten::_safe_softmax | 4 |
| 826 | Tensor<[2,8,7]>, Tensor<[2,8,7,1]>, | ttnn.reshape | aten::_safe_softmax | 4 |
| 827 | Tensor<[2,8,7,64]>, Tensor<[16,7,64]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 828 | Tensor<[2,8,64,7]>, Tensor<[16,64,7]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 829 | Tensor<[2]>, Tensor<[2,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 830 | Tensor<[2,7]>, Tensor<[2,1,7]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 831 | Tensor<[2,1,7]>, Tensor<[2,1,1,7]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 832 | Tensor<[1,768,7,7]>, Tensor<[1,768,49]>, | ttnn.reshape | aten::view | 5 |
| 833 | Tensor<[1,50,768]>, Tensor<[50,768]>, | ttnn.reshape | aten::view | 5 |
| 834 | Tensor<[50,768]>, Tensor<[1,50,768]>, | ttnn.reshape | aten::view | 5 |
| 835 | Tensor<[1,50,768]>, Tensor<[1,50,12,64]>, | ttnn.reshape | aten::view | 5 |
| 836 | Tensor<[1,12,50,64]>, Tensor<[12,50,64]>, | ttnn.reshape | aten::view | 5 |
| 837 | Tensor<[1,12,64,50]>, Tensor<[12,64,50]>, | ttnn.reshape | aten::view | 5 |
| 838 | Tensor<[12,50,50]>, Tensor<[1,12,50,50]>, | ttnn.reshape | aten::view | 5 |
| 839 | Tensor<[1,12,50,50]>, Tensor<[12,50,50]>, | ttnn.reshape | aten::view | 5 |
| 840 | Tensor<[12,50,64]>, Tensor<[1,12,50,64]>, | ttnn.reshape | aten::view | 5 |
| 841 | Tensor<[1,50,12,64]>, Tensor<[1,50,768]>, | ttnn.reshape | aten::view | 5 |
| 842 | Tensor<[50,3072]>, Tensor<[1,50,3072]>, | ttnn.reshape | aten::view | 5 |
| 843 | Tensor<[1,50,3072]>, Tensor<[50,3072]>, | ttnn.reshape | aten::view | 5 |
| 844 | Tensor<[2,7]>, Tensor<[2,7]>, | ttnn.reshape | aten::view | 4 |
| 845 | Tensor<[2,7,512]>, Tensor<[14,512]>, | ttnn.reshape | aten::view | 5 |
| 846 | Tensor<[14,512]>, Tensor<[2,7,512]>, | ttnn.reshape | aten::view | 5 |
| 847 | Tensor<[2,7,512]>, Tensor<[2,7,8,64]>, | ttnn.reshape | aten::view | 5 |
| 848 | Tensor<[16,7,7]>, Tensor<[2,8,7,7]>, | ttnn.reshape | aten::view | 5 |
| 849 | Tensor<[2,8,7,7]>, Tensor<[16,7,7]>, | ttnn.reshape | aten::view | 5 |
| 850 | Tensor<[16,7,64]>, Tensor<[2,8,7,64]>, | ttnn.reshape | aten::view | 5 |
| 851 | Tensor<[2,7,8,64]>, Tensor<[2,7,512]>, | ttnn.reshape | aten::view | 5 |
| 852 | Tensor<[14,2048]>, Tensor<[2,7,2048]>, | ttnn.reshape | aten::view | 5 |
| 853 | Tensor<[2,7,2048]>, Tensor<[14,2048]>, | ttnn.reshape | aten::view | 5 |
| 854 | Tensor<[1,16,197]>, Tensor<[1,16,197,1]>, | ttnn.reshape | aten::_softmax | 4 |
| 855 | Tensor<[197,1024]>, Tensor<[1,197,1024]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 856 | Tensor<[16,197,197]>, Tensor<[1,16,197,197]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 857 | Tensor<[16,197,64]>, Tensor<[1,16,197,64]>, | ttnn.reshape | aten::_unsafe_view | 5 |
| 858 | Tensor<[1,16,27,27]>, Tensor<[1,16,27,27,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 859 | Tensor<[38809]>, Tensor<[38809,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 860 | Tensor<[196,196,1]>, Tensor<[196,196]>, | ttnn.reshape | aten::select.int | 4 |
| 861 | Tensor<[1,197]>, Tensor<[197]>, | ttnn.reshape | aten::select.int | 4 |
| 862 | Tensor<[197,1]>, Tensor<[197]>, | ttnn.reshape | aten::select.int | 4 |
| 863 | Tensor<[196,196]>, Tensor<[196,196,1]>, | ttnn.reshape | aten::select_scatter | 4 |
| 864 | Tensor<[197]>, Tensor<[1,197]>, | ttnn.reshape | aten::select_scatter | 4 |
| 865 | Tensor<[197]>, Tensor<[197,1]>, | ttnn.reshape | aten::select_scatter | 4 |
| 866 | Tensor<[14,14]>, Tensor<[1,14,14]>, | ttnn.reshape | aten::stack | 4 |
| 867 | Tensor<[2,196]>, Tensor<[2,196,1]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 868 | Tensor<[2,196]>, Tensor<[2,1,196]>, | ttnn.reshape | aten::unsqueeze | 4 |
| 869 | Tensor<[1,1024,14,14]>, Tensor<[1,1024,196]>, | ttnn.reshape | aten::view | 5 |
| 870 | Tensor<[1,197,1024]>, Tensor<[197,1024]>, | ttnn.reshape | aten::view | 5 |
| 871 | Tensor<[1,197,1024]>, Tensor<[1,197,16,64]>, | ttnn.reshape | aten::view | 5 |
| 872 | Tensor<[1,16,197,64]>, Tensor<[16,197,64]>, | ttnn.reshape | aten::view | 5 |
| 873 | Tensor<[1,16,64,197]>, Tensor<[16,64,197]>, | ttnn.reshape | aten::view | 5 |
| 874 | Tensor<[729,16]>, Tensor<[1,27,27,16]>, | ttnn.reshape | aten::view | 5 |
| 875 | Tensor<[27]>, Tensor<[27,1]>, | ttnn.reshape | aten::view | 5 |
| 876 | Tensor<[1,27,27,16]>, Tensor<[729,16]>, | ttnn.reshape | aten::view | 5 |
| 877 | Tensor<[14]>, Tensor<[1,14]>, | ttnn.reshape | aten::view | 4 |
| 878 | Tensor<[2,14,14]>, Tensor<[2,196]>, | ttnn.reshape | aten::view | 4 |
| 879 | Tensor<[197,197]>, Tensor<[38809]>, | ttnn.reshape | aten::view | 4 |
| 880 | Tensor<[38809,16]>, Tensor<[197,197,16]>, | ttnn.reshape | aten::view | 5 |
| 881 | Tensor<[1,16,197,197]>, Tensor<[16,197,197]>, | ttnn.reshape | aten::view | 5 |
| 882 | Tensor<[1,197,16,64]>, Tensor<[1,197,1024]>, | ttnn.reshape | aten::view | 5 |
| 883 | Tensor<[197,4096]>, Tensor<[1,197,4096]>, | ttnn.reshape | aten::view | 5 |
| 884 | Tensor<[1,197,4096]>, Tensor<[197,4096]>, | ttnn.reshape | aten::view | 5 |
| 885 | Tensor<[12,1]>, Tensor<[12,1,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 886 | Tensor<[1,12,27,27]>, Tensor<[1,12,27,27,1]>, | ttnn.reshape | aten::index.Tensor | 4 |
| 887 | Tensor<[729,12]>, Tensor<[1,27,27,12]>, | ttnn.reshape | aten::view | 5 |
| 888 | Tensor<[1,27,27,12]>, Tensor<[729,12]>, | ttnn.reshape | aten::view | 5 |
| 889 | Tensor<[38809,12]>, Tensor<[197,197,12]>, | ttnn.reshape | aten::view | 5 |
stablehlo.reverse::ttnn.?
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[2,2,256,512]>, dims: [0, 1] | ttnn.? | aten::convolution | 4 |
| 1 | Tensor<[2,2,128,256]>, dims: [0, 1] | ttnn.? | aten::convolution | 4 |
| 2 | Tensor<[2,2,64,128]>, dims: [0, 1] | ttnn.? | aten::convolution | 4 |
| 3 | Tensor<[2,2,32,64]>, dims: [0, 1] | ttnn.? | aten::convolution | 4 |
| 4 | Tensor<[2,2,16,4]>, dims: [0, 1] | ttnn.? | aten::convolution | 4 |
| 5 | Tensor<[2,2,1,16]>, dims: [0, 1] | ttnn.? | aten::convolution | 4 |
| 6 | Tensor<[2,2,512,1024]>, dims: [0, 1] | ttnn.? | aten::convolution | 4 |
stablehlo.rng
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Scalar, Scalar, Tensor<[3]>, distribution: UNIFORM | aten::rand | 4 |
stablehlo.rsqrt::ttnn.rsqrt
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,32,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 1 | Tensor<[1,7,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 2 | Tensor<[1,1024,512]>, | ttnn.rsqrt | aten::gelu | 4 |
| 3 | Tensor<[1,256,256]>, | ttnn.rsqrt | aten::gelu | 4 |
| 4 | Tensor<[1,256,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 5 | Tensor<[1,64,1,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 6 | Tensor<[1,256,1,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 7 | Tensor<[1,128,1,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 8 | Tensor<[1,512,1,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 9 | Tensor<[1,1024,1,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 10 | Tensor<[1,2048,1,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 11 | Tensor<[920,1,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 12 | Tensor<[100,1,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 13 | Tensor<[1,10,3072]>, | ttnn.rsqrt | aten::gelu | 4 |
| 14 | Tensor<[1,10,768]>, | ttnn.rsqrt | aten::gelu | 4 |
| 15 | Tensor<[1,10,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 16 | Tensor<[1,4096,1280]>, | ttnn.rsqrt | aten::gelu | 4 |
| 17 | Tensor<[1,1024,2560]>, | ttnn.rsqrt | aten::gelu | 4 |
| 18 | Tensor<[1,256,5120]>, | ttnn.rsqrt | aten::gelu | 4 |
| 19 | Tensor<[1,64,5120]>, | ttnn.rsqrt | aten::gelu | 4 |
| 20 | Tensor<[1,32,1,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 21 | Tensor<[1,4096,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 22 | Tensor<[1,1024,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 23 | Tensor<[1,64,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 24 | Tensor<[1,25,3072]>, | ttnn.rsqrt | aten::gelu | 4 |
| 25 | Tensor<[1,25,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 26 | Tensor<[1,1445,768]>, | ttnn.rsqrt | aten::gelu | 4 |
| 27 | Tensor<[1,1445,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 28 | Tensor<[1,3072,8]>, | ttnn.rsqrt | aten::gelu | 4 |
| 29 | Tensor<[1,8,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 30 | Tensor<[1,256,1280]>, | ttnn.rsqrt | aten::gelu | 4 |
| 31 | Tensor<[1,2048,768]>, | ttnn.rsqrt | aten::gelu | 4 |
| 32 | Tensor<[1,2048,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 33 | Tensor<[1,201,3072]>, | ttnn.rsqrt | aten::gelu | 4 |
| 34 | Tensor<[1,1536]>, | ttnn.rsqrt | aten::gelu | 4 |
| 35 | Tensor<[1,201,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 36 | Tensor<[1,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 37 | Tensor<[1,19,4096]>, | ttnn.rsqrt | aten::gelu | 4 |
| 38 | Tensor<[1,19,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 39 | Tensor<[1,16,3072]>, | ttnn.rsqrt | aten::gelu | 4 |
| 40 | Tensor<[1,16,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 41 | Tensor<[1,19200,256]>, | ttnn.rsqrt | aten::gelu | 4 |
| 42 | Tensor<[1,4800,512]>, | ttnn.rsqrt | aten::gelu | 4 |
| 43 | Tensor<[1,1200,1280]>, | ttnn.rsqrt | aten::gelu | 4 |
| 44 | Tensor<[1,300,2048]>, | ttnn.rsqrt | aten::gelu | 4 |
| 45 | Tensor<[1,19200,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 46 | Tensor<[1,300,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 47 | Tensor<[1,4800,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 48 | Tensor<[1,1200,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 49 | Tensor<[1,197,3072]>, | ttnn.rsqrt | aten::gelu | 4 |
| 50 | Tensor<[1,197,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 51 | Tensor<[1,16384,128]>, | ttnn.rsqrt | aten::gelu | 4 |
| 52 | Tensor<[1,4096,256]>, | ttnn.rsqrt | aten::gelu | 4 |
| 53 | Tensor<[1,1024,640]>, | ttnn.rsqrt | aten::gelu | 4 |
| 54 | Tensor<[1,256,1024]>, | ttnn.rsqrt | aten::gelu | 4 |
| 55 | Tensor<[1,16384,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 56 | Tensor<[1,7,18176]>, | ttnn.rsqrt | aten::gelu | 4 |
| 57 | Tensor<[1,12,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 58 | Tensor<[1,9,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 59 | Tensor<[1,14,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 60 | Tensor<[1,50,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 61 | Tensor<[2,7,1]>, | ttnn.rsqrt | aten::rsqrt | 5 |
| 62 | Tensor<[1,197,4096]>, | ttnn.rsqrt | aten::gelu | 4 |
stablehlo.scatter::ttnn.scatter
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,3,720,1280]>, Tensor<[1,1]>, Tensor<[1,3,720,1280]>, update_window_dims: [1, 2, 3] inserted_window_dims: [0] scatter_dims_to_operand_dims: [0] index_vector_dim: 1> | ttnn.scatter | aten::select_scatter | 4 |
| 1 | Tensor<[1,720,1280]>, Tensor<[1,1]>, Tensor<[1,720,1280]>, update_window_dims: [1, 2] inserted_window_dims: [0] scatter_dims_to_operand_dims: [0] index_vector_dim: 1> | ttnn.scatter | aten::select_scatter | 4 |
| 2 | Tensor<[196,196,2]>, Tensor<[1,1]>, Tensor<[196,196,1]>, update_window_dims: [0, 1] inserted_window_dims: [2] scatter_dims_to_operand_dims: [2] index_vector_dim: 1> | ttnn.scatter | aten::select_scatter | 4 |
| 3 | Tensor<[197,197]>, Tensor<[1,1]>, Tensor<[1,197]>, update_window_dims: [1] inserted_window_dims: [0] scatter_dims_to_operand_dims: [0] index_vector_dim: 1> | ttnn.scatter | aten::select_scatter | 4 |
| 4 | Tensor<[197,197]>, Tensor<[1,1]>, Tensor<[197,1]>, update_window_dims: [0] inserted_window_dims: [1] scatter_dims_to_operand_dims: [1] index_vector_dim: 1> | ttnn.scatter | aten::select_scatter | 4 |
| 5 | Tensor<[197]>, Tensor<[1,1]>, Tensor<[1]>, inserted_window_dims: [0] scatter_dims_to_operand_dims: [0] index_vector_dim: 1> | ttnn.scatter | aten::select_scatter | 4 |
stablehlo.select::ttnn.where
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,32,32,32]>, Tensor<[1,32,32,32]>, | ttnn.where | aten::_safe_softmax | 4 |
| 1 | Tensor<[32,32]>, Tensor<[32,32]>, | ttnn.where | aten::triu | 4 |
| 2 | Tensor<[1,1,32,32]>, Tensor<[1,1,32,32]>, | ttnn.where | aten::where.self | 4 |
| 3 | Tensor<[1,12,7,7]>, Tensor<[1,12,7,7]>, | ttnn.where | aten::_safe_softmax | 4 |
| 4 | Tensor<[7,7]>, Tensor<[7,7]>, | ttnn.where | aten::where.self | 4 |
| 5 | Tensor<[1,1,7,7]>, Tensor<[1,1,7,7]>, | ttnn.where | aten::where.self | 4 |
| 6 | Tensor<[1,920]>, Tensor<[1,920]>, | ttnn.where | aten::where.self | 4 |
| 7 | Tensor<[1,12,10,10]>, Tensor<[1,12,10,10]>, | ttnn.where | aten::_safe_softmax | 4 |
| 8 | Tensor<[1,1,10,10]>, Tensor<[1,1,10,10]>, | ttnn.where | aten::where.self | 4 |
| 9 | Tensor<[1,8,4096,4096]>, Tensor<[1,8,4096,4096]>, | ttnn.where | aten::_safe_softmax | 4 |
| 10 | Tensor<[1,8,4096,9]>, Tensor<[1,8,4096,9]>, | ttnn.where | aten::_safe_softmax | 4 |
| 11 | Tensor<[1,8,1024,1024]>, Tensor<[1,8,1024,1024]>, | ttnn.where | aten::_safe_softmax | 4 |
| 12 | Tensor<[1,8,1024,9]>, Tensor<[1,8,1024,9]>, | ttnn.where | aten::_safe_softmax | 4 |
| 13 | Tensor<[1,8,256,256]>, Tensor<[1,8,256,256]>, | ttnn.where | aten::_safe_softmax | 4 |
| 14 | Tensor<[1,8,256,9]>, Tensor<[1,8,256,9]>, | ttnn.where | aten::_safe_softmax | 4 |
| 15 | Tensor<[1,8,64,64]>, Tensor<[1,8,64,64]>, | ttnn.where | aten::_safe_softmax | 4 |
| 16 | Tensor<[1,8,64,9]>, Tensor<[1,8,64,9]>, | ttnn.where | aten::_safe_softmax | 4 |
| 17 | Tensor<[1,12,25,25]>, Tensor<[1,12,25,25]>, | ttnn.where | aten::_safe_softmax | 4 |
| 18 | Tensor<[1,1,25,25]>, Tensor<[1,1,25,25]>, | ttnn.where | aten::where.self | 4 |
| 19 | Tensor<[1,3,1445,1445]>, Tensor<[1,3,1445,1445]>, | ttnn.where | aten::_safe_softmax | 4 |
| 20 | Tensor<[19,19]>, Tensor<[19,19]>, | ttnn.where | aten::where.self | 4 |
| 21 | Tensor<[1,1,19,19]>, Tensor<[1,1,19,19]>, | ttnn.where | aten::where.self | 4 |
| 22 | Tensor<[1,19]>, Tensor<[1,19]>, | ttnn.where | aten::where.self | 4 |
| 23 | Tensor<[19]>, Tensor<[19]>, | ttnn.where | aten::where.self | 4 |
| 24 | Tensor<[1,12,16,16]>, Tensor<[1,12,16,16]>, | ttnn.where | aten::_safe_softmax | 4 |
| 25 | Tensor<[1,1,16,16]>, Tensor<[1,1,16,16]>, | ttnn.where | aten::where.self | 4 |
| 26 | Tensor<[1,12,197,197]>, Tensor<[1,12,197,197]>, | ttnn.where | aten::_safe_softmax | 4 |
| 27 | Tensor<[1,71,7,7]>, Tensor<[1,71,7,7]>, | ttnn.where | aten::_safe_softmax | 4 |
| 28 | Tensor<[1,12,12,12]>, Tensor<[1,12,12,12]>, | ttnn.where | aten::_safe_softmax | 4 |
| 29 | Tensor<[1,1,12,12]>, Tensor<[1,1,12,12]>, | ttnn.where | aten::where.self | 4 |
| 30 | Tensor<[1,12,9,9]>, Tensor<[1,12,9,9]>, | ttnn.where | aten::_safe_softmax | 4 |
| 31 | Tensor<[1,1,9,9]>, Tensor<[1,1,9,9]>, | ttnn.where | aten::where.self | 4 |
| 32 | Tensor<[1,16,9,9]>, Tensor<[1,16,9,9]>, | ttnn.where | aten::_safe_softmax | 4 |
| 33 | Tensor<[1,64,9,9]>, Tensor<[1,64,9,9]>, | ttnn.where | aten::_safe_softmax | 4 |
| 34 | Tensor<[1,12,14,14]>, Tensor<[1,12,14,14]>, | ttnn.where | aten::_safe_softmax | 4 |
| 35 | Tensor<[1,1,14,14]>, Tensor<[1,1,14,14]>, | ttnn.where | aten::where.self | 4 |
| 36 | Tensor<[1,12,50,50]>, Tensor<[1,12,50,50]>, | ttnn.where | aten::_safe_softmax | 4 |
| 37 | Tensor<[2,8,7,7]>, Tensor<[2,8,7,7]>, | ttnn.where | aten::_safe_softmax | 4 |
| 38 | Tensor<[2,1,7,7]>, Tensor<[2,1,7,7]>, | ttnn.where | aten::where.self | 4 |
| 39 | Tensor<[196,197]>, Tensor<[196,197]>, | ttnn.where | aten::where.self | 4 |
| 40 | Tensor<[197,197]>, Tensor<[197,197]>, | ttnn.where | aten::where.self | 4 |
stablehlo.sine::ttnn.sin
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,32,128]>, | ttnn.sin | aten::sin | 4 |
| 1 | Tensor<[1,23,40,64]>, | ttnn.sin | aten::sin | 4 |
| 2 | Tensor<[1,160]>, | ttnn.sin | aten::sin | 4 |
| 3 | Tensor<[1,7,64]>, | ttnn.sin | aten::sin | 4 |
stablehlo.slice::ttnn.slice
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,32,32,128]>, indices: [0:1, 0:32, 0:32, 0:64] | ttnn.reshape | aten::slice.Tensor | 4 |
| 1 | Tensor<[1,32,32,128]>, indices: [0:1, 0:32, 0:32, 64:128] | ttnn.reshape | aten::slice.Tensor | 4 |
| 2 | Tensor<[1,7,2304]>, indices: [0:1, 0:7, 0:768] | ttnn.reshape | aten::slice.Tensor | 4 |
| 3 | Tensor<[1,7,2304]>, indices: [0:1, 0:7, 768:1536] | ttnn.reshape | aten::slice.Tensor | 4 |
| 4 | Tensor<[1,7,2304]>, indices: [0:1, 0:7, 1536:2304] | ttnn.reshape | aten::slice.Tensor | 4 |
| 5 | Tensor<[1,185,28,28]>, indices: [0:1, 0:128, 0:28, 0:28] | ttnn.reshape | aten::slice.Tensor | 4 |
| 6 | Tensor<[1,185,28,28]>, indices: [0:1, 128:185, 0:28, 0:28] | ttnn.reshape | aten::slice.Tensor | 4 |
| 7 | Tensor<[6,1,100,4]>, indices: [5:6, 0:1, 0:100, 0:4] | ttnn.reshape | aten::select.int | 4 |
| 8 | Tensor<[6,1,100,92]>, indices: [5:6, 0:1, 0:100, 0:92] | ttnn.reshape | aten::select.int | 4 |
| 9 | Tensor<[1,23,40]>, indices: [0:1, 22:23, 0:40] | ttnn.reshape | aten::slice.Tensor | 4 |
| 10 | Tensor<[1,23,40]>, indices: [0:1, 0:23, 39:40] | ttnn.reshape | aten::slice.Tensor | 4 |
| 11 | Tensor<[1,23,40,128]>, indices: [0:1, 0:23, 0:40, 0:128:2] | ttnn.reshape | aten::slice.Tensor | 4 |
| 12 | Tensor<[1,23,40,128]>, indices: [0:1, 0:23, 0:40, 1:128:2] | ttnn.reshape | aten::slice.Tensor | 4 |
| 13 | Tensor<[768,256]>, indices: [0:256, 0:256] | ttnn.reshape | aten::slice.Tensor | 4 |
| 14 | Tensor<[768,256]>, indices: [256:512, 0:256] | ttnn.reshape | aten::slice.Tensor | 4 |
| 15 | Tensor<[768,256]>, indices: [512:768, 0:256] | ttnn.reshape | aten::slice.Tensor | 4 |
| 16 | Tensor<[768]>, indices: [0:256] | ttnn.reshape | aten::slice.Tensor | 4 |
| 17 | Tensor<[768]>, indices: [256:512] | ttnn.reshape | aten::slice.Tensor | 4 |
| 18 | Tensor<[768]>, indices: [512:768] | ttnn.reshape | aten::slice.Tensor | 4 |
| 19 | Tensor<[1,514]>, indices: [0:1, 0:10] | ttnn.reshape | aten::slice.Tensor | 4 |
| 20 | Tensor<[1,320]>, indices: [0:1, 160:320] | ttnn.reshape | aten::slice.Tensor | 4 |
| 21 | Tensor<[1,320]>, indices: [0:1, 0:160] | ttnn.reshape | aten::slice.Tensor | 4 |
| 22 | Tensor<[1,4096,2560]>, indices: [0:1, 0:4096, 0:1280] | ttnn.reshape | aten::slice.Tensor | 4 |
| 23 | Tensor<[1,4096,2560]>, indices: [0:1, 0:4096, 1280:2560] | ttnn.reshape | aten::slice.Tensor | 4 |
| 24 | Tensor<[1,1024,5120]>, indices: [0:1, 0:1024, 0:2560] | ttnn.reshape | aten::slice.Tensor | 4 |
| 25 | Tensor<[1,1024,5120]>, indices: [0:1, 0:1024, 2560:5120] | ttnn.reshape | aten::slice.Tensor | 4 |
| 26 | Tensor<[1,256,10240]>, indices: [0:1, 0:256, 0:5120] | ttnn.reshape | aten::slice.Tensor | 4 |
| 27 | Tensor<[1,256,10240]>, indices: [0:1, 0:256, 5120:10240] | ttnn.reshape | aten::slice.Tensor | 4 |
| 28 | Tensor<[1,64,10240]>, indices: [0:1, 0:64, 0:5120] | ttnn.reshape | aten::slice.Tensor | 4 |
| 29 | Tensor<[1,64,10240]>, indices: [0:1, 0:64, 5120:10240] | ttnn.reshape | aten::slice.Tensor | 4 |
| 30 | Tensor<[1,25,768]>, indices: [0:1, 0:1, 0:768] | ttnn.reshape | aten::select.int | 4 |
| 31 | Tensor<[1,512]>, indices: [0:1, 0:25] | ttnn.reshape | aten::slice.Tensor | 4 |
| 32 | Tensor<[1,25,2]>, indices: [0:1, 0:25, 0:1] | ttnn.reshape | aten::slice.Tensor | 4 |
| 33 | Tensor<[1,25,2]>, indices: [0:1, 0:25, 1:2] | ttnn.reshape | aten::slice.Tensor | 4 |
| 34 | Tensor<[1,4251,192]>, indices: [0:1, 0:1, 0:192] | ttnn.reshape | aten::select.int | 4 |
| 35 | Tensor<[1,4251,192]>, indices: [0:1, 4151:4251, 0:192] | ttnn.reshape | aten::slice.Tensor | 4 |
| 36 | Tensor<[1,4251,192]>, indices: [0:1, 1:4151, 0:192] | ttnn.reshape | aten::slice.Tensor | 4 |
| 37 | Tensor<[1,1445,192]>, indices: [0:1, 1345:1445, 0:192] | ttnn.reshape | aten::slice.Tensor | 4 |
| 38 | Tensor<[1,8,768]>, indices: [0:1, 0:1, 0:768] | ttnn.reshape | aten::select.int | 4 |
| 39 | Tensor<[1,512]>, indices: [0:1, 0:8] | ttnn.reshape | aten::slice.Tensor | 4 |
| 40 | Tensor<[1,16]>, indices: [0:1, 0:1] | ttnn.reshape | aten::select.int | 4 |
| 41 | Tensor<[1,12]>, indices: [0:1, 0:1] | ttnn.reshape | aten::select.int | 4 |
| 42 | Tensor<[192,2]>, indices: [0:192, 0:1] | ttnn.reshape | aten::select.int | 4 |
| 43 | Tensor<[1,201,768]>, indices: [0:1, 0:1, 0:768] | ttnn.reshape | aten::select.int | 4 |
| 44 | Tensor<[1,40]>, indices: [0:1, 0:8] | ttnn.reshape | aten::slice.Tensor | 4 |
| 45 | Tensor<[1,145,768]>, indices: [0:1, 1:145, 0:768] | ttnn.reshape | aten::slice.Tensor | 4 |
| 46 | Tensor<[1,19]>, indices: [0:1, 18:19] | ttnn.reshape | aten::select.int | 4 |
| 47 | Tensor<[1,19]>, indices: [0:1, 1:19] | ttnn.reshape | aten::slice.Tensor | 4 |
| 48 | Tensor<[1,19]>, indices: [0:1, 0:18] | ttnn.reshape | aten::slice.Tensor | 4 |
| 49 | Tensor<[1,32,16,3,96]>, indices: [0:1, 0:32, 0:16, 0:1, 0:96] | ttnn.reshape | aten::select.int | 4 |
| 50 | Tensor<[1,32,16,3,96]>, indices: [0:1, 0:32, 0:16, 1:2, 0:96] | ttnn.reshape | aten::select.int | 4 |
| 51 | Tensor<[1,32,16,3,96]>, indices: [0:1, 0:32, 0:16, 2:3, 0:96] | ttnn.reshape | aten::select.int | 4 |
| 52 | Tensor<[1,512]>, indices: [0:1, 0:16] | ttnn.reshape | aten::slice.Tensor | 4 |
| 53 | Tensor<[1,2,30,40]>, indices: [0:1, 0:1, 0:30, 0:40] | ttnn.reshape | aten::select.int | 4 |
| 54 | Tensor<[1,2,30,40]>, indices: [0:1, 1:2, 0:30, 0:40] | ttnn.reshape | aten::select.int | 4 |
| 55 | Tensor<[1,2,60,80]>, indices: [0:1, 0:1, 0:60, 0:80] | ttnn.reshape | aten::select.int | 4 |
| 56 | Tensor<[1,2,60,80]>, indices: [0:1, 1:2, 0:60, 0:80] | ttnn.reshape | aten::select.int | 4 |
| 57 | Tensor<[1,2,120,160]>, indices: [0:1, 0:1, 0:120, 0:160] | ttnn.reshape | aten::select.int | 4 |
| 58 | Tensor<[1,2,120,160]>, indices: [0:1, 1:2, 0:120, 0:160] | ttnn.reshape | aten::select.int | 4 |
| 59 | Tensor<[1,197,768]>, indices: [0:1, 0:1, 0:768] | ttnn.reshape | aten::select.int | 4 |
| 60 | Tensor<[1,7,73,64]>, indices: [0:1, 0:7, 0:71, 0:64] | ttnn.reshape | aten::slice.Tensor | 4 |
| 61 | Tensor<[1,71,7,64]>, indices: [0:1, 0:71, 0:7, 0:32] | ttnn.reshape | aten::slice.Tensor | 4 |
| 62 | Tensor<[1,71,7,64]>, indices: [0:1, 0:71, 0:7, 32:64] | ttnn.reshape | aten::slice.Tensor | 4 |
| 63 | Tensor<[1,1,7,64]>, indices: [0:1, 0:1, 0:7, 0:32] | ttnn.reshape | aten::slice.Tensor | 4 |
| 64 | Tensor<[1,1,7,64]>, indices: [0:1, 0:1, 0:7, 32:64] | ttnn.reshape | aten::slice.Tensor | 4 |
| 65 | Tensor<[1,512]>, indices: [0:1, 0:12] | ttnn.reshape | aten::slice.Tensor | 4 |
| 66 | Tensor<[1,512]>, indices: [0:1, 0:9] | ttnn.reshape | aten::slice.Tensor | 4 |
| 67 | Tensor<[1,9,768]>, indices: [0:1, 0:1, 0:768] | ttnn.reshape | aten::select.int | 4 |
| 68 | Tensor<[1,512]>, indices: [0:1, 0:14] | ttnn.reshape | aten::slice.Tensor | 4 |
| 69 | Tensor<[1,14,2]>, indices: [0:1, 0:14, 0:1] | ttnn.reshape | aten::slice.Tensor | 4 |
| 70 | Tensor<[1,14,2]>, indices: [0:1, 0:14, 1:2] | ttnn.reshape | aten::slice.Tensor | 4 |
| 71 | Tensor<[1,50,768]>, indices: [0:1, 0:1, 0:768] | ttnn.reshape | aten::select.int | 4 |
| 72 | Tensor<[1,77]>, indices: [0:1, 0:7] | ttnn.reshape | aten::slice.Tensor | 4 |
| 73 | Tensor<[196,196,2]>, indices: [0:196, 0:196, 0:1] | ttnn.reshape | aten::select.int | 4 |
| 74 | Tensor<[196,196,2]>, indices: [0:196, 0:196, 1:2] | ttnn.reshape | aten::select.int | 4 |
| 75 | Tensor<[197,197]>, indices: [0:1, 0:197] | ttnn.reshape | aten::select.int | 4 |
| 76 | Tensor<[197,197]>, indices: [0:197, 0:1] | ttnn.reshape | aten::select.int | 4 |
| 77 | Tensor<[197]>, indices: [0:1] | ttnn.reshape | aten::select.int | 4 |
| 78 | Tensor<[732,16]>, indices: [0:729, 0:16] | ttnn.reshape | aten::slice.Tensor | 4 |
| 79 | Tensor<[732,16]>, indices: [729:732, 0:16] | ttnn.reshape | aten::slice.Tensor | 4 |
| 80 | Tensor<[197,197]>, indices: [1:197, 0:197] | ttnn.reshape | aten::slice.Tensor | 4 |
| 81 | Tensor<[196,197]>, indices: [0:196, 1:197] | ttnn.reshape | aten::slice.Tensor | 4 |
| 82 | Tensor<[1,197,1024]>, indices: [0:1, 1:197, 0:1024] | ttnn.reshape | aten::slice.Tensor | 4 |
| 83 | Tensor<[732,12]>, indices: [0:729, 0:12] | ttnn.reshape | aten::slice.Tensor | 4 |
| 84 | Tensor<[732,12]>, indices: [729:732, 0:12] | ttnn.reshape | aten::slice.Tensor | 4 |
| 85 | Tensor<[1,197,768]>, indices: [0:1, 1:197, 0:768] | ttnn.reshape | aten::slice.Tensor | 4 |
stablehlo.sqrt::ttnn.sqrt
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[32]>, | ttnn.sqrt | aten::sqrt | 5 |
| 1 | Tensor<[64]>, | ttnn.sqrt | aten::sqrt | 5 |
| 2 | Tensor<[128]>, | ttnn.sqrt | aten::sqrt | 5 |
| 3 | Tensor<[256]>, | ttnn.sqrt | aten::sqrt | 5 |
| 4 | Tensor<[512]>, | ttnn.sqrt | aten::sqrt | 5 |
| 5 | Tensor<[1024]>, | ttnn.sqrt | aten::sqrt | 5 |
| 6 | Tensor<[2048]>, | ttnn.sqrt | aten::sqrt | 5 |
| 7 | Tensor<[14]>, | ttnn.sqrt | aten::sqrt | 5 |
| 8 | Tensor<[24]>, | ttnn.sqrt | aten::sqrt | 5 |
| 9 | Tensor<[40]>, | ttnn.sqrt | aten::sqrt | 5 |
| 10 | Tensor<[68]>, | ttnn.sqrt | aten::sqrt | 5 |
| 11 | Tensor<[16]>, | ttnn.sqrt | aten::sqrt | 5 |
| 12 | Tensor<[28]>, | ttnn.sqrt | aten::sqrt | 5 |
| 13 | Tensor<[46]>, | ttnn.sqrt | aten::sqrt | 5 |
| 14 | Tensor<[78]>, | ttnn.sqrt | aten::sqrt | 5 |
| 15 | Tensor<[134]>, | ttnn.sqrt | aten::sqrt | 5 |
| 16 | Tensor<[20]>, | ttnn.sqrt | aten::sqrt | 5 |
| 17 | Tensor<[34]>, | ttnn.sqrt | aten::sqrt | 5 |
| 18 | Tensor<[58]>, | ttnn.sqrt | aten::sqrt | 5 |
| 19 | Tensor<[98]>, | ttnn.sqrt | aten::sqrt | 5 |
| 20 | Tensor<[168]>, | ttnn.sqrt | aten::sqrt | 5 |
| 21 | Tensor<[320]>, | ttnn.sqrt | aten::sqrt | 5 |
| 22 | Tensor<[116]>, | ttnn.sqrt | aten::sqrt | 5 |
| 23 | Tensor<[196]>, | ttnn.sqrt | aten::sqrt | 5 |
| 24 | Tensor<[334]>, | ttnn.sqrt | aten::sqrt | 5 |
| 25 | Tensor<[640]>, | ttnn.sqrt | aten::sqrt | 5 |
| 26 | Tensor<[160]>, | ttnn.sqrt | aten::sqrt | 5 |
| 27 | Tensor<[272]>, | ttnn.sqrt | aten::sqrt | 5 |
| 28 | Tensor<[462]>, | ttnn.sqrt | aten::sqrt | 5 |
| 29 | Tensor<[96]>, | ttnn.sqrt | aten::sqrt | 5 |
| 30 | Tensor<[144]>, | ttnn.sqrt | aten::sqrt | 5 |
| 31 | Tensor<[192]>, | ttnn.sqrt | aten::sqrt | 5 |
| 32 | Tensor<[384]>, | ttnn.sqrt | aten::sqrt | 5 |
| 33 | Tensor<[576]>, | ttnn.sqrt | aten::sqrt | 5 |
| 34 | Tensor<[960]>, | ttnn.sqrt | aten::sqrt | 5 |
| 35 | Tensor<[1280]>, | ttnn.sqrt | aten::sqrt | 5 |
stablehlo.subtract::ttnn.subtract
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,32,32,32]>, Tensor<[1,32,32,32]>, | ttnn.subtract | aten::_safe_softmax | 4 |
| 1 | Tensor<[1,12,7,7]>, Tensor<[1,12,7,7]>, | ttnn.subtract | aten::_safe_softmax | 4 |
| 2 | Tensor<[1,1,7,7]>, Tensor<[1,1,7,7]>, | ttnn.subtract | aten::rsub.Scalar | 4 |
| 3 | Tensor<[1,7,768]>, Tensor<[1,7,768]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 4 | Tensor<[1]>, Tensor<[1]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 5 | Tensor<[1,128,28,28]>, Tensor<[1,128,28,28]>, | ttnn.subtract | aten::elu | 4 |
| 6 | Tensor<[1,32,112,112]>, Tensor<[1,32,112,112]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 7 | Tensor<[1,64,112,112]>, Tensor<[1,64,112,112]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 8 | Tensor<[1,64,56,56]>, Tensor<[1,64,56,56]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 9 | Tensor<[1,128,56,56]>, Tensor<[1,128,56,56]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 10 | Tensor<[1,256,28,28]>, Tensor<[1,256,28,28]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 11 | Tensor<[1,512,28,28]>, Tensor<[1,512,28,28]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 12 | Tensor<[1,256,512]>, Tensor<[1,256,512]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 13 | Tensor<[8,920,920]>, Tensor<[8,920,920]>, | ttnn.subtract | aten::_softmax | 4 |
| 14 | Tensor<[8,100,100]>, Tensor<[8,100,100]>, | ttnn.subtract | aten::_softmax | 4 |
| 15 | Tensor<[8,100,920]>, Tensor<[8,100,920]>, | ttnn.subtract | aten::_softmax | 4 |
| 16 | Scalar, Scalar, | ttnn.subtract | aten::arange | 4 |
| 17 | Tensor<[1,64,1,1]>, Tensor<[1,64,1,1]>, | ttnn.subtract | aten::sub.Tensor | 5 |
| 18 | Tensor<[1,256,1,1]>, Tensor<[1,256,1,1]>, | ttnn.subtract | aten::sub.Tensor | 5 |
| 19 | Tensor<[1,128,1,1]>, Tensor<[1,128,1,1]>, | ttnn.subtract | aten::sub.Tensor | 5 |
| 20 | Tensor<[1,512,1,1]>, Tensor<[1,512,1,1]>, | ttnn.subtract | aten::sub.Tensor | 5 |
| 21 | Tensor<[1,1024,1,1]>, Tensor<[1,1024,1,1]>, | ttnn.subtract | aten::sub.Tensor | 5 |
| 22 | Tensor<[1,2048,1,1]>, Tensor<[1,2048,1,1]>, | ttnn.subtract | aten::sub.Tensor | 5 |
| 23 | Tensor<[920,1,256]>, Tensor<[920,1,256]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 24 | Tensor<[100,1,256]>, Tensor<[100,1,256]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 25 | Tensor<[1,12,10,10]>, Tensor<[1,12,10,10]>, | ttnn.subtract | aten::_safe_softmax | 4 |
| 26 | Tensor<[1,1,10,10]>, Tensor<[1,1,10,10]>, | ttnn.subtract | aten::rsub.Scalar | 4 |
| 27 | Tensor<[1,10,768]>, Tensor<[1,10,768]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 28 | Tensor<[1,8,4096,4096]>, Tensor<[1,8,4096,4096]>, | ttnn.subtract | aten::_safe_softmax | 4 |
| 29 | Tensor<[1,8,4096,9]>, Tensor<[1,8,4096,9]>, | ttnn.subtract | aten::_safe_softmax | 4 |
| 30 | Tensor<[1,8,1024,1024]>, Tensor<[1,8,1024,1024]>, | ttnn.subtract | aten::_safe_softmax | 4 |
| 31 | Tensor<[1,8,1024,9]>, Tensor<[1,8,1024,9]>, | ttnn.subtract | aten::_safe_softmax | 4 |
| 32 | Tensor<[1,8,256,256]>, Tensor<[1,8,256,256]>, | ttnn.subtract | aten::_safe_softmax | 4 |
| 33 | Tensor<[1,8,256,9]>, Tensor<[1,8,256,9]>, | ttnn.subtract | aten::_safe_softmax | 4 |
| 34 | Tensor<[1,8,64,64]>, Tensor<[1,8,64,64]>, | ttnn.subtract | aten::_safe_softmax | 4 |
| 35 | Tensor<[1,8,64,9]>, Tensor<[1,8,64,9]>, | ttnn.subtract | aten::_safe_softmax | 4 |
| 36 | Tensor<[1,32,10,4096]>, Tensor<[1,32,10,4096]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 37 | Tensor<[1,4096,320]>, Tensor<[1,4096,320]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 38 | Tensor<[1,32,10,1024]>, Tensor<[1,32,10,1024]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 39 | Tensor<[1,32,20,1024]>, Tensor<[1,32,20,1024]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 40 | Tensor<[1,1024,640]>, Tensor<[1,1024,640]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 41 | Tensor<[1,32,20,256]>, Tensor<[1,32,20,256]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 42 | Tensor<[1,32,40,256]>, Tensor<[1,32,40,256]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 43 | Tensor<[1,256,1280]>, Tensor<[1,256,1280]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 44 | Tensor<[1,32,40,64]>, Tensor<[1,32,40,64]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 45 | Tensor<[1,64,1280]>, Tensor<[1,64,1280]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 46 | Tensor<[1,32,80,64]>, Tensor<[1,32,80,64]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 47 | Tensor<[1,32,80,256]>, Tensor<[1,32,80,256]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 48 | Tensor<[1,32,60,256]>, Tensor<[1,32,60,256]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 49 | Tensor<[1,32,60,1024]>, Tensor<[1,32,60,1024]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 50 | Tensor<[1,32,40,1024]>, Tensor<[1,32,40,1024]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 51 | Tensor<[1,32,30,1024]>, Tensor<[1,32,30,1024]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 52 | Tensor<[1,32,30,4096]>, Tensor<[1,32,30,4096]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 53 | Tensor<[1,32,20,4096]>, Tensor<[1,32,20,4096]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 54 | Tensor<[1,12,25,25]>, Tensor<[1,12,25,25]>, | ttnn.subtract | aten::_safe_softmax | 4 |
| 55 | Tensor<[1,1,25,25]>, Tensor<[1,1,25,25]>, | ttnn.subtract | aten::rsub.Scalar | 4 |
| 56 | Tensor<[1,25,768]>, Tensor<[1,25,768]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 57 | Tensor<[1,3,1445,1445]>, Tensor<[1,3,1445,1445]>, | ttnn.subtract | aten::_safe_softmax | 4 |
| 58 | Tensor<[1,1445,192]>, Tensor<[1,1445,192]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 59 | Tensor<[1,256,14,14]>, Tensor<[1,256,14,14]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 60 | Tensor<[1,512,7,7]>, Tensor<[1,512,7,7]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 61 | Tensor<[1,12,8,8]>, Tensor<[1,12,8,8]>, | ttnn.subtract | aten::_softmax | 4 |
| 62 | Tensor<[1,1,1,8]>, Tensor<[1,1,1,8]>, | ttnn.subtract | aten::rsub.Scalar | 4 |
| 63 | Tensor<[1,8,768]>, Tensor<[1,8,768]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 64 | Tensor<[1,8,256,2048]>, Tensor<[1,8,256,2048]>, | ttnn.subtract | aten::_softmax | 4 |
| 65 | Tensor<[1,8,2048,256]>, Tensor<[1,8,2048,256]>, | ttnn.subtract | aten::_softmax | 4 |
| 66 | Tensor<[1,1,1,2048]>, Tensor<[1,1,1,2048]>, | ttnn.subtract | aten::rsub.Scalar | 4 |
| 67 | Tensor<[1,2048,768]>, Tensor<[1,2048,768]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 68 | Tensor<[1,256,56,56]>, Tensor<[1,256,56,56]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 69 | Tensor<[1,1024,14,14]>, Tensor<[1,1024,14,14]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 70 | Tensor<[1,512,14,14]>, Tensor<[1,512,14,14]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 71 | Tensor<[1,2048,7,7]>, Tensor<[1,2048,7,7]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 72 | Tensor<[1,12,201,201]>, Tensor<[1,12,201,201]>, | ttnn.subtract | aten::_softmax | 4 |
| 73 | Tensor<[1,192]>, Tensor<[1,192]>, | ttnn.subtract | aten::rsub.Scalar | 4 |
| 74 | Tensor<[1,1,1,201]>, Tensor<[1,1,1,201]>, | ttnn.subtract | aten::rsub.Scalar | 4 |
| 75 | Tensor<[1,201,768]>, Tensor<[1,201,768]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 76 | Tensor<[1,1536]>, Tensor<[1,1536]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 77 | Tensor<[1,10]>, Tensor<[1,10]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 78 | Tensor<[16,19,19]>, Tensor<[16,19,19]>, | ttnn.subtract | aten::_softmax | 4 |
| 79 | Tensor<[1,1,19,19]>, Tensor<[1,1,19,19]>, | ttnn.subtract | aten::rsub.Scalar | 4 |
| 80 | Tensor<[1,19,1024]>, Tensor<[1,19,1024]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 81 | Tensor<[19]>, Tensor<[19]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 82 | Tensor<[19,256008]>, Tensor<[19,256008]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 83 | Tensor<[1,14,56,56]>, Tensor<[1,14,56,56]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 84 | Tensor<[1,24,56,56]>, Tensor<[1,24,56,56]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 85 | Tensor<[1,40,56,56]>, Tensor<[1,40,56,56]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 86 | Tensor<[1,68,56,56]>, Tensor<[1,68,56,56]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 87 | Tensor<[1,16,28,28]>, Tensor<[1,16,28,28]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 88 | Tensor<[1,28,28,28]>, Tensor<[1,28,28,28]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 89 | Tensor<[1,46,28,28]>, Tensor<[1,46,28,28]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 90 | Tensor<[1,78,28,28]>, Tensor<[1,78,28,28]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 91 | Tensor<[1,134,28,28]>, Tensor<[1,134,28,28]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 92 | Tensor<[1,20,28,28]>, Tensor<[1,20,28,28]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 93 | Tensor<[1,34,28,28]>, Tensor<[1,34,28,28]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 94 | Tensor<[1,58,28,28]>, Tensor<[1,58,28,28]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 95 | Tensor<[1,98,28,28]>, Tensor<[1,98,28,28]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 96 | Tensor<[1,168,28,28]>, Tensor<[1,168,28,28]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 97 | Tensor<[1,320,28,28]>, Tensor<[1,320,28,28]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 98 | Tensor<[1,40,14,14]>, Tensor<[1,40,14,14]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 99 | Tensor<[1,68,14,14]>, Tensor<[1,68,14,14]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 100 | Tensor<[1,116,14,14]>, Tensor<[1,116,14,14]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 101 | Tensor<[1,196,14,14]>, Tensor<[1,196,14,14]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 102 | Tensor<[1,334,14,14]>, Tensor<[1,334,14,14]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 103 | Tensor<[1,640,14,14]>, Tensor<[1,640,14,14]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 104 | Tensor<[1,160,7,7]>, Tensor<[1,160,7,7]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 105 | Tensor<[1,272,7,7]>, Tensor<[1,272,7,7]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 106 | Tensor<[1,462,7,7]>, Tensor<[1,462,7,7]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 107 | Tensor<[1,1024,7,7]>, Tensor<[1,1024,7,7]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 108 | Tensor<[1,32,512,512]>, Tensor<[1,32,512,512]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 109 | Tensor<[1,64,256,256]>, Tensor<[1,64,256,256]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 110 | Tensor<[1,32,256,256]>, Tensor<[1,32,256,256]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 111 | Tensor<[1,128,128,128]>, Tensor<[1,128,128,128]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 112 | Tensor<[1,64,128,128]>, Tensor<[1,64,128,128]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 113 | Tensor<[1,256,64,64]>, Tensor<[1,256,64,64]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 114 | Tensor<[1,128,64,64]>, Tensor<[1,128,64,64]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 115 | Tensor<[1,512,32,32]>, Tensor<[1,512,32,32]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 116 | Tensor<[1,256,32,32]>, Tensor<[1,256,32,32]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 117 | Tensor<[1,1024,16,16]>, Tensor<[1,1024,16,16]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 118 | Tensor<[1,512,16,16]>, Tensor<[1,512,16,16]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 119 | Tensor<[1,256,16,16]>, Tensor<[1,256,16,16]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 120 | Tensor<[1,128,32,32]>, Tensor<[1,128,32,32]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 121 | Tensor<[1,16,32,32]>, Tensor<[1,16,32,32]>, | ttnn.subtract | aten::_softmax | 4 |
| 122 | Tensor<[1,32,1536]>, Tensor<[1,32,1536]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 123 | Tensor<[1,32]>, Tensor<[1,32]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 124 | Tensor<[1,12,16,16]>, Tensor<[1,12,16,16]>, | ttnn.subtract | aten::_safe_softmax | 4 |
| 125 | Tensor<[1,1,16,16]>, Tensor<[1,1,16,16]>, | ttnn.subtract | aten::rsub.Scalar | 4 |
| 126 | Tensor<[1,16,768]>, Tensor<[1,16,768]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 127 | Tensor<[1,64,224,224]>, Tensor<[1,64,224,224]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 128 | Tensor<[1,128,112,112]>, Tensor<[1,128,112,112]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 129 | Tensor<[1,1,19200,300]>, Tensor<[1,1,19200,300]>, | ttnn.subtract | aten::_softmax | 4 |
| 130 | Tensor<[1,2,4800,300]>, Tensor<[1,2,4800,300]>, | ttnn.subtract | aten::_softmax | 4 |
| 131 | Tensor<[1,5,1200,300]>, Tensor<[1,5,1200,300]>, | ttnn.subtract | aten::_softmax | 4 |
| 132 | Tensor<[1,8,300,300]>, Tensor<[1,8,300,300]>, | ttnn.subtract | aten::_softmax | 4 |
| 133 | Tensor<[1,19200,64]>, Tensor<[1,19200,64]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 134 | Tensor<[1,300,64]>, Tensor<[1,300,64]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 135 | Tensor<[1,4800,128]>, Tensor<[1,4800,128]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 136 | Tensor<[1,300,128]>, Tensor<[1,300,128]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 137 | Tensor<[1,1200,320]>, Tensor<[1,1200,320]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 138 | Tensor<[1,300,320]>, Tensor<[1,300,320]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 139 | Tensor<[1,300,512]>, Tensor<[1,300,512]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 140 | Tensor<[30]>, Tensor<[30]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 141 | Tensor<[40]>, Tensor<[40]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 142 | Tensor<[1,64,30,40]>, Tensor<[1,64,30,40]>, | ttnn.subtract | aten::sub.Tensor | 5 |
| 143 | Tensor<[30,1]>, Tensor<[30,1]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 144 | Tensor<[1,32,30,40]>, Tensor<[1,32,30,40]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 145 | Tensor<[60]>, Tensor<[60]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 146 | Tensor<[80]>, Tensor<[80]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 147 | Tensor<[1,64,60,80]>, Tensor<[1,64,60,80]>, | ttnn.subtract | aten::sub.Tensor | 5 |
| 148 | Tensor<[60,1]>, Tensor<[60,1]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 149 | Tensor<[1,32,60,80]>, Tensor<[1,32,60,80]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 150 | Tensor<[120]>, Tensor<[120]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 151 | Tensor<[160]>, Tensor<[160]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 152 | Tensor<[1,64,120,160]>, Tensor<[1,64,120,160]>, | ttnn.subtract | aten::sub.Tensor | 5 |
| 153 | Tensor<[120,1]>, Tensor<[120,1]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 154 | Tensor<[1,32,120,160]>, Tensor<[1,32,120,160]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 155 | Tensor<[240]>, Tensor<[240]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 156 | Tensor<[320]>, Tensor<[320]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 157 | Tensor<[1,64,240,320]>, Tensor<[1,64,240,320]>, | ttnn.subtract | aten::sub.Tensor | 5 |
| 158 | Tensor<[240,1]>, Tensor<[240,1]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 159 | Tensor<[480]>, Tensor<[480]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 160 | Tensor<[640]>, Tensor<[640]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 161 | Tensor<[1,64,480,640]>, Tensor<[1,64,480,640]>, | ttnn.subtract | aten::sub.Tensor | 5 |
| 162 | Tensor<[480,1]>, Tensor<[480,1]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 163 | Tensor<[1,12,197,197]>, Tensor<[1,12,197,197]>, | ttnn.subtract | aten::_safe_softmax | 4 |
| 164 | Tensor<[1,197,768]>, Tensor<[1,197,768]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 165 | Tensor<[1,1,16384,256]>, Tensor<[1,1,16384,256]>, | ttnn.subtract | aten::_softmax | 4 |
| 166 | Tensor<[1,2,4096,256]>, Tensor<[1,2,4096,256]>, | ttnn.subtract | aten::_softmax | 4 |
| 167 | Tensor<[1,5,1024,256]>, Tensor<[1,5,1024,256]>, | ttnn.subtract | aten::_softmax | 4 |
| 168 | Tensor<[1,16384,32]>, Tensor<[1,16384,32]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 169 | Tensor<[1,256,32]>, Tensor<[1,256,32]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 170 | Tensor<[1,4096,64]>, Tensor<[1,4096,64]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 171 | Tensor<[1,256,64]>, Tensor<[1,256,64]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 172 | Tensor<[1,1024,160]>, Tensor<[1,1024,160]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 173 | Tensor<[1,256,160]>, Tensor<[1,256,160]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 174 | Tensor<[1,256,256]>, Tensor<[1,256,256]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 175 | Tensor<[128]>, Tensor<[128]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 176 | Tensor<[1,256,128,128]>, Tensor<[1,256,128,128]>, | ttnn.subtract | aten::sub.Tensor | 5 |
| 177 | Tensor<[128,1]>, Tensor<[128,1]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 178 | Tensor<[1,71,7,7]>, Tensor<[1,71,7,7]>, | ttnn.subtract | aten::_safe_softmax | 4 |
| 179 | Tensor<[1,7,4544]>, Tensor<[1,7,4544]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 180 | Tensor<[1,16,112,112]>, Tensor<[1,16,112,112]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 181 | Tensor<[1,96,112,112]>, Tensor<[1,96,112,112]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 182 | Tensor<[1,96,56,56]>, Tensor<[1,96,56,56]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 183 | Tensor<[1,144,56,56]>, Tensor<[1,144,56,56]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 184 | Tensor<[1,144,28,28]>, Tensor<[1,144,28,28]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 185 | Tensor<[1,32,28,28]>, Tensor<[1,32,28,28]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 186 | Tensor<[1,192,28,28]>, Tensor<[1,192,28,28]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 187 | Tensor<[1,192,14,14]>, Tensor<[1,192,14,14]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 188 | Tensor<[1,64,14,14]>, Tensor<[1,64,14,14]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 189 | Tensor<[1,384,14,14]>, Tensor<[1,384,14,14]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 190 | Tensor<[1,96,14,14]>, Tensor<[1,96,14,14]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 191 | Tensor<[1,576,14,14]>, Tensor<[1,576,14,14]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 192 | Tensor<[1,576,7,7]>, Tensor<[1,576,7,7]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 193 | Tensor<[1,960,7,7]>, Tensor<[1,960,7,7]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 194 | Tensor<[1,320,7,7]>, Tensor<[1,320,7,7]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 195 | Tensor<[1,1280,7,7]>, Tensor<[1,1280,7,7]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 196 | Tensor<[1,12,12,12]>, Tensor<[1,12,12,12]>, | ttnn.subtract | aten::_safe_softmax | 4 |
| 197 | Tensor<[1,1,12,12]>, Tensor<[1,1,12,12]>, | ttnn.subtract | aten::rsub.Scalar | 4 |
| 198 | Tensor<[1,12,128]>, Tensor<[1,12,128]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 199 | Tensor<[1,12,768]>, Tensor<[1,12,768]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 200 | Tensor<[1,12,9,9]>, Tensor<[1,12,9,9]>, | ttnn.subtract | aten::_safe_softmax | 4 |
| 201 | Tensor<[1,1,9,9]>, Tensor<[1,1,9,9]>, | ttnn.subtract | aten::rsub.Scalar | 4 |
| 202 | Tensor<[1,9,128]>, Tensor<[1,9,128]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 203 | Tensor<[1,9,768]>, Tensor<[1,9,768]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 204 | Tensor<[1,16,9,9]>, Tensor<[1,16,9,9]>, | ttnn.subtract | aten::_safe_softmax | 4 |
| 205 | Tensor<[1,9,2048]>, Tensor<[1,9,2048]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 206 | Tensor<[1,9,1024]>, Tensor<[1,9,1024]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 207 | Tensor<[1,64,9,9]>, Tensor<[1,64,9,9]>, | ttnn.subtract | aten::_safe_softmax | 4 |
| 208 | Tensor<[1,9,4096]>, Tensor<[1,9,4096]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 209 | Tensor<[1,12,14,14]>, Tensor<[1,12,14,14]>, | ttnn.subtract | aten::_safe_softmax | 4 |
| 210 | Tensor<[1,1,14,14]>, Tensor<[1,1,14,14]>, | ttnn.subtract | aten::rsub.Scalar | 4 |
| 211 | Tensor<[1,14,128]>, Tensor<[1,14,128]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 212 | Tensor<[1,14,768]>, Tensor<[1,14,768]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 213 | Tensor<[1,12,50,50]>, Tensor<[1,12,50,50]>, | ttnn.subtract | aten::_safe_softmax | 4 |
| 214 | Tensor<[2,8,7,7]>, Tensor<[2,8,7,7]>, | ttnn.subtract | aten::_safe_softmax | 4 |
| 215 | Tensor<[2,1,7,7]>, Tensor<[2,1,7,7]>, | ttnn.subtract | aten::rsub.Scalar | 4 |
| 216 | Tensor<[1,50,768]>, Tensor<[1,50,768]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 217 | Tensor<[1,768]>, Tensor<[1,768]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 218 | Tensor<[2,7,512]>, Tensor<[2,7,512]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 219 | Tensor<[1,16,197,197]>, Tensor<[1,16,197,197]>, | ttnn.subtract | aten::_softmax | 4 |
| 220 | Tensor<[1,197,1024]>, Tensor<[1,197,1024]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 221 | Tensor<[27]>, Tensor<[27]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 222 | Tensor<[1,16,27,27]>, Tensor<[1,16,27,27]>, | ttnn.subtract | aten::sub.Tensor | 5 |
| 223 | Tensor<[27,1]>, Tensor<[27,1]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 224 | Tensor<[2,196,196]>, Tensor<[2,196,196]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 225 | Tensor<[197]>, Tensor<[197]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 226 | Tensor<[1,1024]>, Tensor<[1,1024]>, | ttnn.subtract | aten::sub.Tensor | 4 |
| 227 | Tensor<[1,12,27,27]>, Tensor<[1,12,27,27]>, | ttnn.subtract | aten::sub.Tensor | 5 |
stablehlo.tanh::ttnn.tanh
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,7,3072]>, | ttnn.tanh | aten::tanh | 4 |
| 1 | Tensor<[1,768]>, | ttnn.tanh | aten::tanh | 4 |
| 2 | Tensor<[1,32,6144]>, | ttnn.tanh | aten::tanh | 4 |
| 3 | Tensor<[1,12,3072]>, | ttnn.tanh | aten::tanh | 4 |
| 4 | Tensor<[1,9,3072]>, | ttnn.tanh | aten::tanh | 4 |
| 5 | Tensor<[1,9,128]>, | ttnn.tanh | aten::tanh | 4 |
| 6 | Tensor<[1,9,8192]>, | ttnn.tanh | aten::tanh | 4 |
| 7 | Tensor<[1,9,4096]>, | ttnn.tanh | aten::tanh | 4 |
| 8 | Tensor<[1,9,16384]>, | ttnn.tanh | aten::tanh | 4 |
| 9 | Tensor<[1,14,3072]>, | ttnn.tanh | aten::tanh | 4 |
stablehlo.transpose::ttnn.permute
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[1,64,32]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 1 | Tensor<[4096,4096]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 2 | Tensor<[1,32,32,128]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 3 | Tensor<[1,32,32,128]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 4 | Tensor<[11008,4096]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 5 | Tensor<[4096,11008]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 6 | Tensor<[32000,4096]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 7 | Tensor<[1,7,12,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 8 | Tensor<[1,12,7,64]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 9 | Tensor<[1,12,7,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 10 | Tensor<[2,768]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 11 | Tensor<[1,3,16,16,16,16]>, dims: [0, 2, 4, 3, 5, 1] | ttnn.permute | aten::permute | 4 |
| 12 | Tensor<[1,256,512]>, dims: [0, 2, 1] | ttnn.permute | aten::permute | 4 |
| 13 | Tensor<[512,768]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 14 | Tensor<[256,512]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 15 | Tensor<[512,256]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 16 | Tensor<[1000,512]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 17 | Tensor<[1,23,40,256]>, dims: [0, 3, 1, 2] | ttnn.permute | aten::permute | 4 |
| 18 | Tensor<[1,256,920]>, dims: [2, 0, 1] | ttnn.permute | aten::permute | 4 |
| 19 | Tensor<[256,256]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 20 | Tensor<[920,8,32]>, dims: [1, 0, 2] | ttnn.permute | aten::transpose.int | 4 |
| 21 | Tensor<[8,920,32]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 22 | Tensor<[8,920,32]>, dims: [1, 0, 2] | ttnn.permute | aten::transpose.int | 4 |
| 23 | Tensor<[2048,256]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 24 | Tensor<[256,2048]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 25 | Tensor<[100,8,32]>, dims: [1, 0, 2] | ttnn.permute | aten::transpose.int | 4 |
| 26 | Tensor<[8,100,32]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 27 | Tensor<[8,100,32]>, dims: [1, 0, 2] | ttnn.permute | aten::transpose.int | 4 |
| 28 | Tensor<[6,100,1,256]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 29 | Tensor<[92,256]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 30 | Tensor<[4,256]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 31 | Tensor<[1,10,12,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 32 | Tensor<[768,768]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 33 | Tensor<[1,12,10,64]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 34 | Tensor<[1,12,10,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 35 | Tensor<[3072,768]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 36 | Tensor<[768,3072]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 37 | Tensor<[250002,768]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 38 | Tensor<[1,320,64,64]>, dims: [0, 2, 3, 1] | ttnn.permute | aten::permute | 4 |
| 39 | Tensor<[1,64,64,320]>, dims: [0, 3, 1, 2] | ttnn.permute | aten::permute | 4 |
| 40 | Tensor<[1,640,32,32]>, dims: [0, 2, 3, 1] | ttnn.permute | aten::permute | 4 |
| 41 | Tensor<[1,32,32,640]>, dims: [0, 3, 1, 2] | ttnn.permute | aten::permute | 4 |
| 42 | Tensor<[1,1280,16,16]>, dims: [0, 2, 3, 1] | ttnn.permute | aten::permute | 4 |
| 43 | Tensor<[1,16,16,1280]>, dims: [0, 3, 1, 2] | ttnn.permute | aten::permute | 4 |
| 44 | Tensor<[1,1280,8,8]>, dims: [0, 2, 3, 1] | ttnn.permute | aten::permute | 4 |
| 45 | Tensor<[1,8,8,1280]>, dims: [0, 3, 1, 2] | ttnn.permute | aten::permute | 4 |
| 46 | Tensor<[1280,320]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 47 | Tensor<[1280,1280]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 48 | Tensor<[320,1280]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 49 | Tensor<[320,320]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 50 | Tensor<[1,4096,8,40]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 51 | Tensor<[1,8,4096,40]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 52 | Tensor<[1,8,4096,40]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 53 | Tensor<[320,768]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 54 | Tensor<[1,9,8,40]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 55 | Tensor<[1,8,9,40]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 56 | Tensor<[2560,320]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 57 | Tensor<[640,1280]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 58 | Tensor<[640,640]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 59 | Tensor<[1,1024,8,80]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 60 | Tensor<[1,8,1024,80]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 61 | Tensor<[1,8,1024,80]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 62 | Tensor<[640,768]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 63 | Tensor<[1,9,8,80]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 64 | Tensor<[1,8,9,80]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 65 | Tensor<[5120,640]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 66 | Tensor<[640,2560]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 67 | Tensor<[1,256,8,160]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 68 | Tensor<[1,8,256,160]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 69 | Tensor<[1,8,256,160]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 70 | Tensor<[1280,768]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 71 | Tensor<[1,9,8,160]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 72 | Tensor<[1,8,9,160]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 73 | Tensor<[10240,1280]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 74 | Tensor<[1280,5120]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 75 | Tensor<[1,64,8,160]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 76 | Tensor<[1,8,64,160]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 77 | Tensor<[1,8,64,160]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 78 | Tensor<[1,25,12,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 79 | Tensor<[1,12,25,64]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 80 | Tensor<[1,12,25,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 81 | Tensor<[1,768]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 82 | Tensor<[1,1445,3,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 83 | Tensor<[1,3,1445,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 84 | Tensor<[1,192,1344]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 85 | Tensor<[1,4150,192]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 86 | Tensor<[192,192]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 87 | Tensor<[1,3,1445,64]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 88 | Tensor<[768,192]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 89 | Tensor<[192,768]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 90 | Tensor<[92,192]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 91 | Tensor<[4,192]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 92 | Tensor<[1,8,768]>, dims: [0, 2, 1] | ttnn.permute | aten::permute | 4 |
| 93 | Tensor<[1,12,64,8]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::permute | 4 |
| 94 | Tensor<[1,12,8,64]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::permute | 4 |
| 95 | Tensor<[1,768,8]>, dims: [0, 2, 1] | ttnn.permute | aten::permute | 4 |
| 96 | Tensor<[3,768]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 97 | Tensor<[1,256,8,32]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 98 | Tensor<[1,2048,8,32]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 99 | Tensor<[1,2048,8,160]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 100 | Tensor<[1,256,8,96]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 101 | Tensor<[1,8,2048,96]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 102 | Tensor<[256,1280]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 103 | Tensor<[256,768]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 104 | Tensor<[1,8,2048,32]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 105 | Tensor<[1,8,256,32]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 106 | Tensor<[768,1280]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 107 | Tensor<[262,768]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 108 | Tensor<[1000,2048]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 109 | Tensor<[1,201,12,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 110 | Tensor<[1,12,201,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 111 | Tensor<[1,144,768]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 112 | Tensor<[1,768,192]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 113 | Tensor<[1,12,201,64]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 114 | Tensor<[1536,768]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 115 | Tensor<[3129,1536]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 116 | Tensor<[128,9216]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 117 | Tensor<[10,128]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 118 | Tensor<[1024,1024]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 119 | Tensor<[1,19,16,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 120 | Tensor<[16,19,64]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 121 | Tensor<[1,16,19,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 122 | Tensor<[4096,1024]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 123 | Tensor<[1024,4096]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 124 | Tensor<[256008,1024]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 125 | Tensor<[1000,1024]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 126 | Tensor<[512,256,2,2]>, dims: [2, 3, 1, 0] | ttnn.permute | aten::convolution | 4 |
| 127 | Tensor<[256,128,2,2]>, dims: [2, 3, 1, 0] | ttnn.permute | aten::convolution | 4 |
| 128 | Tensor<[128,64,2,2]>, dims: [2, 3, 1, 0] | ttnn.permute | aten::convolution | 4 |
| 129 | Tensor<[64,32,2,2]>, dims: [2, 3, 1, 0] | ttnn.permute | aten::convolution | 4 |
| 130 | Tensor<[4,16,2,2]>, dims: [2, 3, 1, 0] | ttnn.permute | aten::convolution | 4 |
| 131 | Tensor<[16,1,2,2]>, dims: [2, 3, 1, 0] | ttnn.permute | aten::convolution | 4 |
| 132 | Tensor<[1,16,32,96]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 133 | Tensor<[4608,1536]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 134 | Tensor<[1,32,16,96]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 135 | Tensor<[16,32,96]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 136 | Tensor<[1536,1536]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 137 | Tensor<[6144,1536]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 138 | Tensor<[1536,6144]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 139 | Tensor<[250880,1536]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 140 | Tensor<[1,16,12,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 141 | Tensor<[1,12,16,64]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 142 | Tensor<[1,12,16,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 143 | Tensor<[1024,512,2,2]>, dims: [2, 3, 1, 0] | ttnn.permute | aten::convolution | 4 |
| 144 | Tensor<[1,19200,1,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 145 | Tensor<[1,19200,64]>, dims: [0, 2, 1] | ttnn.permute | aten::permute | 4 |
| 146 | Tensor<[1,64,300]>, dims: [0, 2, 1] | ttnn.permute | aten::permute | 4 |
| 147 | Tensor<[1,300,1,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 148 | Tensor<[1,1,19200,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 149 | Tensor<[1,120,160,64]>, dims: [0, 3, 1, 2] | ttnn.permute | aten::permute | 4 |
| 150 | Tensor<[1,4800,2,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 151 | Tensor<[1,4800,128]>, dims: [0, 2, 1] | ttnn.permute | aten::permute | 4 |
| 152 | Tensor<[1,128,300]>, dims: [0, 2, 1] | ttnn.permute | aten::permute | 4 |
| 153 | Tensor<[1,300,2,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 154 | Tensor<[1,2,4800,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 155 | Tensor<[1,60,80,128]>, dims: [0, 3, 1, 2] | ttnn.permute | aten::permute | 4 |
| 156 | Tensor<[1,1200,5,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 157 | Tensor<[1,1200,320]>, dims: [0, 2, 1] | ttnn.permute | aten::permute | 4 |
| 158 | Tensor<[1,320,300]>, dims: [0, 2, 1] | ttnn.permute | aten::permute | 4 |
| 159 | Tensor<[1,300,5,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 160 | Tensor<[1,5,1200,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 161 | Tensor<[1,30,40,320]>, dims: [0, 3, 1, 2] | ttnn.permute | aten::permute | 4 |
| 162 | Tensor<[1,300,8,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 163 | Tensor<[1,8,300,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 164 | Tensor<[1,15,20,512]>, dims: [0, 3, 1, 2] | ttnn.permute | aten::permute | 4 |
| 165 | Tensor<[1,64,19200]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 166 | Tensor<[64,64]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 167 | Tensor<[1,1,300,64]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 168 | Tensor<[256,64]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 169 | Tensor<[1,19200,256]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 170 | Tensor<[1,256,19200]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 171 | Tensor<[64,256]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 172 | Tensor<[1,128,4800]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 173 | Tensor<[128,128]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 174 | Tensor<[1,2,300,64]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 175 | Tensor<[512,128]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 176 | Tensor<[1,4800,512]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 177 | Tensor<[1,512,4800]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 178 | Tensor<[128,512]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 179 | Tensor<[1,320,1200]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 180 | Tensor<[1,5,300,64]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 181 | Tensor<[1,1200,1280]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 182 | Tensor<[1,1280,1200]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 183 | Tensor<[1,512,300]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 184 | Tensor<[512,512]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 185 | Tensor<[1,8,300,64]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 186 | Tensor<[2048,512]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 187 | Tensor<[1,300,2048]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 188 | Tensor<[1,2048,300]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 189 | Tensor<[512,2048]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 190 | Tensor<[1,197,12,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 191 | Tensor<[1,12,197,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 192 | Tensor<[1,768,196]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 193 | Tensor<[1,12,197,64]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 194 | Tensor<[1000,768]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 195 | Tensor<[1,16384,1,32]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 196 | Tensor<[1,16384,32]>, dims: [0, 2, 1] | ttnn.permute | aten::permute | 4 |
| 197 | Tensor<[1,32,256]>, dims: [0, 2, 1] | ttnn.permute | aten::permute | 4 |
| 198 | Tensor<[1,256,1,32]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 199 | Tensor<[1,1,16384,32]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 200 | Tensor<[1,128,128,32]>, dims: [0, 3, 1, 2] | ttnn.permute | aten::permute | 4 |
| 201 | Tensor<[1,4096,2,32]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 202 | Tensor<[1,4096,64]>, dims: [0, 2, 1] | ttnn.permute | aten::permute | 4 |
| 203 | Tensor<[1,64,256]>, dims: [0, 2, 1] | ttnn.permute | aten::permute | 4 |
| 204 | Tensor<[1,256,2,32]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 205 | Tensor<[1,2,4096,32]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 206 | Tensor<[1,64,64,64]>, dims: [0, 3, 1, 2] | ttnn.permute | aten::permute | 4 |
| 207 | Tensor<[1,1024,5,32]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 208 | Tensor<[1,1024,160]>, dims: [0, 2, 1] | ttnn.permute | aten::permute | 4 |
| 209 | Tensor<[1,160,256]>, dims: [0, 2, 1] | ttnn.permute | aten::permute | 4 |
| 210 | Tensor<[1,256,5,32]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 211 | Tensor<[1,5,1024,32]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 212 | Tensor<[1,32,32,160]>, dims: [0, 3, 1, 2] | ttnn.permute | aten::permute | 4 |
| 213 | Tensor<[1,8,256,32]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 214 | Tensor<[1,16,16,256]>, dims: [0, 3, 1, 2] | ttnn.permute | aten::permute | 4 |
| 215 | Tensor<[1,16384,256]>, dims: [0, 2, 1] | ttnn.permute | aten::permute | 4 |
| 216 | Tensor<[1,4096,256]>, dims: [0, 2, 1] | ttnn.permute | aten::permute | 4 |
| 217 | Tensor<[1,1024,256]>, dims: [0, 2, 1] | ttnn.permute | aten::permute | 4 |
| 218 | Tensor<[1,256,256]>, dims: [0, 2, 1] | ttnn.permute | aten::permute | 4 |
| 219 | Tensor<[1,32,16384]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 220 | Tensor<[32,32]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 221 | Tensor<[1,1,256,32]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 222 | Tensor<[128,32]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 223 | Tensor<[1,16384,128]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 224 | Tensor<[1,128,16384]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 225 | Tensor<[32,128]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 226 | Tensor<[1,64,4096]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 227 | Tensor<[1,2,256,32]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 228 | Tensor<[1,256,4096]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 229 | Tensor<[1,160,1024]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 230 | Tensor<[160,160]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 231 | Tensor<[1,5,256,32]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 232 | Tensor<[640,160]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 233 | Tensor<[1,1024,640]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 234 | Tensor<[1,640,1024]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 235 | Tensor<[160,640]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 236 | Tensor<[1024,256]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 237 | Tensor<[1,256,1024]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 238 | Tensor<[256,1024]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 239 | Tensor<[256,32]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 240 | Tensor<[256,160]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 241 | Tensor<[4672,4544]>, dims: [1, 0] | ttnn.permute | aten::permute | 5 |
| 242 | Tensor<[1,71,7,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 243 | Tensor<[4544,4544]>, dims: [1, 0] | ttnn.permute | aten::permute | 5 |
| 244 | Tensor<[18176,4544]>, dims: [1, 0] | ttnn.permute | aten::permute | 5 |
| 245 | Tensor<[4544,18176]>, dims: [1, 0] | ttnn.permute | aten::permute | 5 |
| 246 | Tensor<[1,32,7]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 247 | Tensor<[1,7,71,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 248 | Tensor<[1,7,1,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 249 | Tensor<[1,1,7,64]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 250 | Tensor<[65024,4544]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 251 | Tensor<[1000,1280]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 252 | Tensor<[1,12,12,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 253 | Tensor<[768,128]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 254 | Tensor<[1,12,12,64]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 255 | Tensor<[1,9,12,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 256 | Tensor<[1,12,9,64]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 257 | Tensor<[1,12,9,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 258 | Tensor<[128,768]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 259 | Tensor<[30000,128]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 260 | Tensor<[1,9,16,128]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 261 | Tensor<[2048,128]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 262 | Tensor<[2048,2048]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 263 | Tensor<[1,16,9,128]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 264 | Tensor<[1,16,9,128]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 265 | Tensor<[8192,2048]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 266 | Tensor<[2048,8192]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 267 | Tensor<[128,2048]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 268 | Tensor<[1,9,16,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 269 | Tensor<[1024,128]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 270 | Tensor<[1,16,9,64]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 271 | Tensor<[1,16,9,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 272 | Tensor<[128,1024]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 273 | Tensor<[1,9,64,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 274 | Tensor<[4096,128]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 275 | Tensor<[1,64,9,64]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 276 | Tensor<[1,64,9,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 277 | Tensor<[16384,4096]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 278 | Tensor<[4096,16384]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 279 | Tensor<[128,4096]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 280 | Tensor<[1,14,12,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 281 | Tensor<[1,12,14,64]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 282 | Tensor<[1,12,14,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 283 | Tensor<[1,768,49]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 284 | Tensor<[1,50,12,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 285 | Tensor<[1,12,50,64]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 286 | Tensor<[1,12,50,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 287 | Tensor<[2,7,8,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 288 | Tensor<[2,8,7,64]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 289 | Tensor<[2,8,7,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::transpose.int | 4 |
| 290 | Tensor<[1,512]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 291 | Tensor<[2,1]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 292 | Tensor<[1,197,16,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 293 | Tensor<[1,27,27,16]>, dims: [0, 3, 1, 2] | ttnn.permute | aten::permute | 4 |
| 294 | Tensor<[1,16,27,27]>, dims: [0, 2, 3, 1] | ttnn.permute | aten::permute | 4 |
| 295 | Tensor<[2,196,196]>, dims: [1, 2, 0] | ttnn.permute | aten::permute | 4 |
| 296 | Tensor<[197,197,16]>, dims: [2, 0, 1] | ttnn.permute | aten::permute | 4 |
| 297 | Tensor<[1,16,197,64]>, dims: [0, 2, 1, 3] | ttnn.permute | aten::permute | 4 |
| 298 | Tensor<[1,1024,196]>, dims: [0, 2, 1] | ttnn.permute | aten::transpose.int | 4 |
| 299 | Tensor<[1,16,197,64]>, dims: [0, 1, 3, 2] | ttnn.permute | aten::transpose.int | 4 |
| 300 | Tensor<[1,27,27,12]>, dims: [0, 3, 1, 2] | ttnn.permute | aten::permute | 4 |
| 301 | Tensor<[1,12,27,27]>, dims: [0, 2, 3, 1] | ttnn.permute | aten::permute | 4 |
| 302 | Tensor<[197,197,12]>, dims: [2, 0, 1] | ttnn.permute | aten::permute | 4 |
| 303 | Tensor<[128,784]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 304 | Tensor<[64,128]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 305 | Tensor<[12,64]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 306 | Tensor<[3,12]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 307 | Tensor<[12,3]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 308 | Tensor<[64,12]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 309 | Tensor<[128,64]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
| 310 | Tensor<[784,128]>, dims: [1, 0] | ttnn.permute | aten::transpose.int | 5 |
tensor.empty
| STABLE HLO Input Variations | ttnn op | Torch Name | Status | |
|---|---|---|---|---|
| 0 | Tensor<[32,32]>, | aten::empty_strided | 4 | |
| 1 | Tensor<[7,7]>, | aten::empty_strided | 4 | |
| 2 | Tensor<[19,19]>, | aten::empty_strided | 4 |
TTNN OP Traces
NOTE: TT-Torch is deprecated. To work with PyTorch and the various features available in TT-Torch, please see the documentation for TT-XLA.
The following pages have traces of operations that are currently not being compiled correctly. They can be updated by running:
python tt_torch/tools/generate_md.py --excel_path <path to xlsx file> --md_dir docs/src/ops/ttnn --json_dir docs/src/ops/ttnn --failures_only
How to read these files?
The *.md/ *.json files store information related to ops from ttnn graphs. A TTNN Graph could look like the following
#device = #tt.device<workerGrid = #tt.grid<8x8, (d0, d1) -> (0, d0, d1)>, l1Map = (d0, d1)[s0, s1] -> (0, d0 floordiv s0, d1 floordiv s1, (d0 mod s0) * s1 + d1 mod s1), dramMap = (d0, d1)[s0, s1] -> (0, 0, ((((d0 floordiv s0) * 8 + d1 floordiv s1) * (s1 * s0) + (d0 mod s0) * s1 + d1 mod s1) floordiv 8192) mod 12, (((d0 floordiv s0) * 8 + d1 floordiv s1) * (s1 * s0) + (d0 mod s0) * s1 + d1 mod s1) floordiv 98304 + (((d0 floordiv s0) * 8 + d1 floordiv s1) * (s1 * s0) + (d0 mod s0) * s1 + d1 mod s1) mod 8192), meshShape = , chipIds = [0]>
#dram = #ttnn.buffer_type<dram>
#system_desc = #tt.system_desc<[{role = host, target_triple = ""x86_64-pc-linux-gnu""}], [{arch = <wormhole_b0>, grid = 8x8, l1_size = 1499136, num_dram_channels = 12, dram_channel_size = 1073741824, noc_l1_address_align_bytes = 16, pcie_address_align_bytes = 32, noc_dram_address_align_bytes = 32, l1_unreserved_base = 1024, erisc_l1_unreserved_base = 1024, dram_unreserved_base = 1024, dram_unreserved_end = 1073741824, physical_cores = {worker = [ 0x0, 0x1, 0x2, 0x3, 0x4, 0x5, 0x6, 0x7, 1x0, 1x1, 1x2, 1x3, 1x4, 1x5, 1x6, 1x7, 2x0, 2x1, 2x2, 2x3, 2x4, 2x5, 2x6, 2x7, 3x0, 3x1, 3x2, 3x3, 3x4, 3x5, 3x6, 3x7, 4x0, 4x1, 4x2, 4x3, 4x4, 4x5, 4x6, 4x7, 5x0, 5x1, 5x2, 5x3, 5x4, 5x5, 5x6, 5x7, 6x0, 6x1, 6x2, 6x3, 6x4, 6x5, 6x6, 6x7, 7x0, 7x1, 7x2, 7x3, 7x4, 7x5, 7x6, 7x7] dram = [ 8x0, 9x0, 10x0, 8x1, 9x1, 10x1, 8x2, 9x2, 10x2, 8x3, 9x3, 10x3]}, supported_data_types = [<f32>, <f16>, <bf16>, <bfp_f8>, <bfp_bf8>, <bfp_f4>, <bfp_bf4>, <bfp_f2>, <bfp_bf2>, <u32>, <u16>, <u8>], supported_tile_sizes = [ 4x16, 16x16, 32x16, 4x32, 16x32, 32x32], num_cbs = 32}], [0], [3 : i32], [ 0x0x0x0]>
#system_memory = #ttnn.buffer_type<system_memory>
#ttnn_layout = #ttnn.ttnn_layout<(d0, d1, d2, d3) -> (d0 * 14336 + d1 * 14 + d2, d3), <1x1>, memref<14336x14xbf16, #system_memory>>
#ttnn_layout1 = #ttnn.ttnn_layout<(d0, d1, d2, d3) -> (d0 * 3072 + d1 * 3 + d2, d3), <1x1>, memref<3145728x3xbf16, #system_memory>>
#ttnn_layout2 = #ttnn.ttnn_layout<(d0, d1, d2, d3) -> (d0 * 14336 + d1 * 14 + d2, d3), <1x1>, memref<448x1x!tt.tile<32x32, bf16>, #dram>, interleaved>
#ttnn_layout3 = #ttnn.ttnn_layout<(d0, d1, d2, d3) -> (d0 * 14336 + d1 * 1024 + d2, d3), <1x1>, memref<448x1x!tt.tile<32x32, bf16>, #dram>, interleaved>
#ttnn_layout4 = #ttnn.ttnn_layout<(d0, d1, d2, d3) -> (d0 * 196 + d1 * 14 + d2, d3), <1x1>, memref<7x32x!tt.tile<32x32, bf16>, #dram>, interleaved>
module attributes {tt.device = #device, tt.system_desc = #system_desc} {
func.func @main(%arg0: tensor<1x1024x14x14xbf16, #ttnn_layout>, %arg1: tensor<1024x1024x3x3xbf16, #ttnn_layout1>) -> tensor<1x1024x14x14xbf16, #ttnn_layout> {
%0 = ""ttnn.get_device""() <{mesh_shape = #ttnn<mesh_shape 1x1>}> : () -> !tt.device<#device>
%1 = ""ttnn.to_device""(%arg0, %0) <{memory_config = #ttnn.memory_config<<interleaved>, #dram, <<448x1>>>}> : (tensor<1x1024x14x14xbf16, #ttnn_layout>, !tt.device<#device>) -> tensor<1x1024x14x14xbf16, #ttnn_layout2>
%2 = ""ttnn.to_layout""(%1) <{layout = #ttnn.layout<tile>}> : (tensor<1x1024x14x14xbf16, #ttnn_layout2>) -> tensor<1x1024x14x14xbf16, #ttnn_layout2>
""ttnn.deallocate""(%1) <{force = false}> : (tensor<1x1024x14x14xbf16, #ttnn_layout2>) -> ()
%3 = ""ttnn.transpose""(%2) <{dim0 = 1 : si32, dim1 = 2 : si32}> : (tensor<1x1024x14x14xbf16, #ttnn_layout2>) -> tensor<1x14x1024x14xbf16, #ttnn_layout3>
""ttnn.deallocate""(%2) <{force = false}> : (tensor<1x1024x14x14xbf16, #ttnn_layout2>) -> ()
%4 = ""ttnn.transpose""(%3) <{dim0 = 2 : si32, dim1 = 3 : si32}> : (tensor<1x14x1024x14xbf16, #ttnn_layout3>) -> tensor<1x14x14x1024xbf16, #ttnn_layout4>
""ttnn.deallocate""(%3) <{force = false}> : (tensor<1x14x1024x14xbf16, #ttnn_layout3>) -> ()
%5 = ""ttnn.reshape""(%4) <{shape = [1 : i32, 1 : i32, 196 : i32, 1024 : i32]}> : (tensor<1x14x14x1024xbf16, #ttnn_layout4>) -> tensor<1x1x196x1024xbf16, #ttnn_layout4>
""ttnn.deallocate""(%4) <{force = false}> : (tensor<1x14x14x1024xbf16, #ttnn_layout4>) -> ()
%6 = ""ttnn.empty""(%0) <{dtype = #tt.supportedDataTypes<bf16>, layout = #ttnn.layout<tile>, memory_config = #ttnn.memory_config<<interleaved>, #dram, <<7x32>>>, shape = #ttnn.shape<1x1x196x1024>}> : (!tt.device<#device>) -> tensor<1x1x196x1024xbf16, #ttnn_layout4>
%7 = ""ttnn.conv2d""(%5, %arg1, %6, %0) <{batch_size = 1 : i32, dilation_height = 1 : i32, dilation_width = 1 : i32, groups = 1 : i32, in_channels = 1024 : i32, input_height = 14 : i32, input_width = 14 : i32, kernel_height = 3 : i32, kernel_width = 3 : i32, out_channels = 1024 : i32, padding_height = 1 : i32, padding_width = 1 : i32, stride_height = 1 : i32, stride_width = 1 : i32}> : (tensor<1x1x196x1024xbf16, #ttnn_layout4>, tensor<1024x1024x3x3xbf16, #ttnn_layout1>, tensor<1x1x196x1024xbf16, #ttnn_layout4>, !tt.device<#device>) -> tensor<1x1x196x1024xbf16, #ttnn_layout4>
""ttnn.deallocate""(%5) <{force = false}> : (tensor<1x1x196x1024xbf16, #ttnn_layout4>) -> ()
%8 = ""ttnn.reshape""(%7) <{shape = [1 : i32, 14 : i32, 14 : i32, 1024 : i32]}> : (tensor<1x1x196x1024xbf16, #ttnn_layout4>) -> tensor<1x14x14x1024xbf16, #ttnn_layout4>
""ttnn.deallocate""(%6) <{force = false}> : (tensor<1x1x196x1024xbf16, #ttnn_layout4>) -> ()
%9 = ""ttnn.transpose""(%8) <{dim0 = 2 : si32, dim1 = 3 : si32}> : (tensor<1x14x14x1024xbf16, #ttnn_layout4>) -> tensor<1x14x1024x14xbf16, #ttnn_layout3>
""ttnn.deallocate""(%8) <{force = false}> : (tensor<1x14x14x1024xbf16, #ttnn_layout4>) -> ()
%10 = ""ttnn.transpose""(%9) <{dim0 = 1 : si32, dim1 = 2 : si32}> : (tensor<1x14x1024x14xbf16, #ttnn_layout3>) -> tensor<1x1024x14x14xbf16, #ttnn_layout2>
""ttnn.deallocate""(%9) <{force = false}> : (tensor<1x14x1024x14xbf16, #ttnn_layout3>) -> ()
%11 = ""ttnn.from_device""(%10) : (tensor<1x1024x14x14xbf16, #ttnn_layout2>) -> tensor<1x1024x14x14xbf16, #ttnn_layout>
""ttnn.deallocate""(%10) <{force = false}> : (tensor<1x1024x14x14xbf16, #ttnn_layout2>) -> ()
%12 = ""ttnn.to_layout""(%11) <{layout = #ttnn.layout<row_major>}> : (tensor<1x1024x14x14xbf16, #ttnn_layout>) -> tensor<1x1024x14x14xbf16, #ttnn_layout>
""ttnn.deallocate""(%11) <{force = false}> : (tensor<1x1024x14x14xbf16, #ttnn_layout>) -> ()
return %12 : tensor<1x1024x14x14xbf16, #ttnn_layout>
}
}
Each line that starts with #number refers to an operation. The parser parses through all TTNN graphs generated by models under tt-torch and compiles all ops by the same name together.
Name
The name of the operation, i.e. ttnn.add, ttnn.matmul
Input/ Output Shapes
The shapes of the input/ output arguments to the operation, last element is the data type (i.e. bf16, i32)
Note: Some operations take the output as the last input.
Input/ Output Layouts
Please refer to tt-mlir tensor layout documentation
Mapping From/ To
i.e. (d0, d1, d2, d3) -> (d0 * 3072 + d1 * 3 + d2, d3)
Memory Config
i.e. <448x1x!tt.tile<32x32, bf16>, #dram>
- "tile" refers to tilized memory
- "dram" refers to dram memory
- "system_memory" refers to unformatted weight tensor on host
- "interleaved" refers to interleaved memory
Attributes
Parameters passed into the operation.
Runs on TTNN
Yes / No/ N/A
PCC
Pearson's correlation coefficient
ATOL
The tolerance on absolute differences
ttnn.add
This table is a trace for ttnn.add op. Traces are generated from nightly tt-torch runs. To see nightly runs: Nightly Runs
| Name | Input Shapes | Input Layouts | Attributes | Output Shapes | Output Layouts | PCC | ATOL |
|---|---|---|---|---|---|---|---|
| ttnn.add | tensor<[1,128,512,512,bf16]> tensor<[1,128,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 512 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 4096 + d1 * 32 + d2, d3), memory_config: (128, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,128,512,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 512 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,3,512,512,bf16]> tensor<[1,3,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1536 + d1 * 512 + d2, d3), memory_config: (48, 16, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 96 + d1 * 32 + d2, d3), memory_config: (3, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,3,512,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1536 + d1 * 512 + d2, d3), memory_config: (48, 16, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,4,14,14,bf16]> tensor<[1,4,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 128 + d1 * 32 + d2, d3), memory_config: (4, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 128 + d1 * 32 + d2, d3), memory_config: (4, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,4,14,14,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 128 + d1 * 32 + d2, d3), memory_config: (4, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,128,512,512,bf16]> tensor<[1,128,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 512 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 4096 + d1 * 32 + d2, d3), memory_config: (128, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,128,512,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 512 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,256,512,512,bf16]> tensor<[1,256,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 131072 + d1 * 512 + d2, d3), memory_config: (4096, 16, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,256,512,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 131072 + d1 * 512 + d2, d3), memory_config: (4096, 16, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,64,1024,1024,bf16]> tensor<[1,64,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 1024 + d2, d3), memory_config: (2048, 32, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2048 + d1 * 32 + d2, d3), memory_config: (64, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,64,1024,1024,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 1024 + d2, d3), memory_config: (2048, 32, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,64,256,256,bf16]> tensor<[1,64,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 16384 + d1 * 256 + d2, d3), memory_config: (512, 8, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2048 + d1 * 32 + d2, d3), memory_config: (64, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,64,256,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 16384 + d1 * 256 + d2, d3), memory_config: (512, 8, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,256,256,256,bf16]> tensor<[1,256,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 256 + d2, d3), memory_config: (2048, 8, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,256,256,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 256 + d2, d3), memory_config: (2048, 8, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,512,256,256,bf16]> tensor<[1,512,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 131072 + d1 * 256 + d2, d3), memory_config: (4096, 8, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 16384 + d1 * 32 + d2, d3), memory_config: (512, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,512,256,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 131072 + d1 * 256 + d2, d3), memory_config: (4096, 8, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,48,1024,1024,bf16]> tensor<[1,48,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 49152 + d1 * 1024 + d2, d3), memory_config: (1536, 32, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1536 + d1 * 32 + d2, d3), memory_config: (48, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,48,1024,1024,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 49152 + d1 * 1024 + d2, d3), memory_config: (1536, 32, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,98,256,256,bf16]> tensor<[1,98,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 25088 + d1 * 256 + d2, d3), memory_config: (784, 8, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 3136 + d1 * 32 + d2, d3), memory_config: (98, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,98,256,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 25088 + d1 * 256 + d2, d3), memory_config: (784, 8, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,480,640,bf16]> tensor<[1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 480 + d1 * 480 + d2, d3), memory_config: (15, 20, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,480,640,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 480 + d1 * 480 + d2, d3), memory_config: (15, 20, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,64,480,640,bf16]> tensor<[1,64,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 30720 + d1 * 480 + d2, d3), memory_config: (960, 20, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2048 + d1 * 32 + d2, d3), memory_config: (64, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,64,480,640,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 30720 + d1 * 480 + d2, d3), memory_config: (960, 20, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,64,128,128,bf16]> tensor<[1,64,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 128 + d2, d3), memory_config: (256, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2048 + d1 * 32 + d2, d3), memory_config: (64, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,64,128,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 128 + d2, d3), memory_config: (256, 4, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,7,25281,2,f32]> tensor<[1,256,7,25281,2,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 177184 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (5537, 1, 'tile<32x32, f32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'dram') | tensor<[1,256,7,25281,2,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[16,1,1,1,si32]> tensor<[16,250,250,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (16, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64000 + d1 * 256 + d2, d3), memory_config: (32000, 1, 'tile<32x32, si32>', 'dram') | tensor<[16,250,250,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64000 + d1 * 256 + d2, d3), memory_config: (32000, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,250,1,1,si32]> tensor<[16,250,250,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8000 + d1 * 32 + d2, d3), memory_config: (250, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64000 + d1 * 256 + d2, d3), memory_config: (32000, 1, 'tile<32x32, si32>', 'dram') | tensor<[16,250,250,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64000 + d1 * 256 + d2, d3), memory_config: (32000, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,1,1,si32]> tensor<[1,2640,768,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2027520 + d1 * 768 + d2, d3), memory_config: (63360, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,2640,768,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2027520 + d1 * 768 + d2, d3), memory_config: (63360, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,768,1,si32]> tensor<[1,2640,768,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 768 + d1 * 768 + d2, d3), memory_config: (24, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2027520 + d1 * 768 + d2, d3), memory_config: (63360, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,2640,768,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2027520 + d1 * 768 + d2, d3), memory_config: (63360, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,1,1,si32]> tensor<[1,300,4,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9600 + d1 * 32 + d2, d3), memory_config: (300, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,300,4,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9600 + d1 * 32 + d2, d3), memory_config: (300, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,4,1,si32]> tensor<[1,300,4,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9600 + d1 * 32 + d2, d3), memory_config: (300, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,300,4,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9600 + d1 * 32 + d2, d3), memory_config: (300, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,1,1,si32]> tensor<[1,300,80,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 28800 + d1 * 96 + d2, d3), memory_config: (900, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,300,80,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 28800 + d1 * 96 + d2, d3), memory_config: (900, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,80,1,si32]> tensor<[1,300,80,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 96 + d1 * 96 + d2, d3), memory_config: (3, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 28800 + d1 * 96 + d2, d3), memory_config: (900, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,300,80,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 28800 + d1 * 96 + d2, d3), memory_config: (900, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,6,1,1,si32]> tensor<[1,1,6,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,1,6,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,16,1,1,1,si32]> tensor<[1,16,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,16,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,1,1,1,si32]> tensor<[1,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,1,1,1,si32]> tensor<[1,16,6,192,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,16,6,192,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,16,1,1,1,si32]> tensor<[1,16,6,192,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,16,6,192,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,6,1,1,si32]> tensor<[1,16,6,192,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,16,6,192,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,1,192,1,si32]> tensor<[1,16,6,192,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 192 + d3, d4), memory_config: (6, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,16,6,192,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,6,1,1,si32]> tensor<[1,1,6,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,1,6,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,16,1,1,1,si32]> tensor<[1,16,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,16,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,1,1,1,si32]> tensor<[1,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,1,1,1,si32]> tensor<[1,16,6,192,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,16,6,192,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,16,1,1,1,si32]> tensor<[1,16,6,192,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,16,6,192,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,6,1,1,si32]> tensor<[1,16,6,192,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,16,6,192,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,1,192,1,si32]> tensor<[1,16,6,192,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 192 + d3, d4), memory_config: (6, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,16,6,192,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,1,1,3,1,1,si32]> tensor<[1,1,1,1,3,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,1,1,1,3,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,1,1,1,1,1,si32]> tensor<[1,1,1,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4 * 32 + d5, d6), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4 * 32 + d5, d6), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,1,1,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4 * 32 + d5, d6), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,1,1,1,1,1,si32]> tensor<[1,1,1,1,3,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4 * 32 + d5, d6), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,1,1,1,3,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,1,1,1,si32]> tensor<[1,256,7,25281,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,256,7,25281,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,256,1,1,1,si32]> tensor<[1,256,7,25281,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 8192 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (256, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,256,7,25281,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,1,1,1,si32]> tensor<[1,256,7,25281,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,256,7,25281,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,256,1,1,1,si32]> tensor<[1,256,7,25281,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 8192 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (256, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,256,7,25281,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,1,1,1,si32]> tensor<[1,256,7,25281,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,256,7,25281,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,256,1,1,1,si32]> tensor<[1,256,7,25281,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 8192 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (256, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,256,7,25281,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,25281,1,1,si32]> tensor<[1,1,25281,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 808992 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (25281, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 808992 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (25281, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,1,25281,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 808992 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (25281, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,7,1,1,1,si32]> tensor<[1,7,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 224 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (7, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 224 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (7, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,7,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 224 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (7, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,1,1,1,si32]> tensor<[1,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,1,1,1,si32]> tensor<[1,7,25281,2,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 5662944 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (176967, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,7,25281,2,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 5662944 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (176967, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,7,1,1,1,si32]> tensor<[1,7,25281,2,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 224 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (7, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 5662944 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (176967, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,7,25281,2,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 5662944 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (176967, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,25281,1,1,si32]> tensor<[1,7,25281,2,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 808992 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (25281, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 5662944 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (176967, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,7,25281,2,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 5662944 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (176967, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,1,2,1,si32]> tensor<[1,7,25281,2,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 5662944 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (176967, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,7,25281,2,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 5662944 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (176967, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[160,si32]> tensor<[160,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, si32>', 'dram') mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, si32>', 'dram') | tensor<[160,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,8,1,1,1,1,si32]> tensor<[1,8,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 256 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (8, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 256 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (8, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,8,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 256 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (8, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,1,1,1,1,si32]> tensor<[1,1,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,1,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,1,1,1,1,si32]> tensor<[1,8,160,160,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 6553600 + d1 * 819200 + d2 * 5120 + d3 * 32 + d4, d5), memory_config: (204800, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,8,160,160,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 6553600 + d1 * 819200 + d2 * 5120 + d3 * 32 + d4, d5), memory_config: (204800, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,8,1,1,1,1,si32]> tensor<[1,8,160,160,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 256 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (8, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 6553600 + d1 * 819200 + d2 * 5120 + d3 * 32 + d4, d5), memory_config: (204800, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,8,160,160,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 6553600 + d1 * 819200 + d2 * 5120 + d3 * 32 + d4, d5), memory_config: (204800, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,160,1,1,1,si32]> tensor<[1,8,160,160,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 5120 + d1 * 5120 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (160, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 6553600 + d1 * 819200 + d2 * 5120 + d3 * 32 + d4, d5), memory_config: (204800, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,8,160,160,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 6553600 + d1 * 819200 + d2 * 5120 + d3 * 32 + d4, d5), memory_config: (204800, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,1,160,1,1,si32]> tensor<[1,8,160,160,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 5120 + d1 * 5120 + d2 * 5120 + d3 * 32 + d4, d5), memory_config: (160, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 6553600 + d1 * 819200 + d2 * 5120 + d3 * 32 + d4, d5), memory_config: (204800, 1, 'tile<32x32, si32>', 'dram') | tensor<[1,8,160,160,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 6553600 + d1 * 819200 + d2 * 5120 + d3 * 32 + d4, d5), memory_config: (204800, 1, 'tile<32x32, si32>', 'dram') | nan | nan | |
| ttnn.add | tensor<[1,1,1,1,si32]> tensor<[1,256,7,25281,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, si32>', 'dram') | tensor<[1,256,7,25281,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, si32>', 'dram') | nan | nan |
ttnn.arange
This table is a trace for ttnn.arange op. Traces are generated from nightly tt-torch runs. To see nightly runs: Nightly Runs
| Name | Input Shapes | Input Layouts | Attributes | Output Shapes | Output Layouts | PCC | ATOL |
|---|---|---|---|---|---|---|---|
| ttnn.arange | !ttnn.device | dtype: #tt.supportedDataTypes end: 16 : i64 memory_config: #ttnn.memory_config<#dram, <<1x1>>, start: 0 : i64 step: 1 : i64 | tensor<[16,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 16, 'si32', 'dram') | nan | nan | |
| ttnn.arange | !ttnn.device | dtype: #tt.supportedDataTypes end: 250 : i64 memory_config: #ttnn.memory_config<#dram, <<1x8>>, start: 0 : i64 step: 1 : i64 | tensor<[250,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 250, 'si32', 'dram') | nan | nan | |
| ttnn.arange | !ttnn.device | dtype: #tt.supportedDataTypes end: 1 : i64 memory_config: #ttnn.memory_config<#dram, <<1x1>>, start: 0 : i64 step: 1 : i64 | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'dram') | nan | nan | |
| ttnn.arange | !ttnn.device | dtype: #tt.supportedDataTypes end: 768 : i64 memory_config: #ttnn.memory_config<#dram, <<1x24>>, start: 0 : i64 step: 1 : i64 | tensor<[768,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 768, 'si32', 'dram') | nan | nan | |
| ttnn.arange | !ttnn.device | dtype: #tt.supportedDataTypes end: 1 : i64 memory_config: #ttnn.memory_config<#dram, <<1x1>>, start: 0 : i64 step: 1 : i64 | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'dram') | nan | nan | |
| ttnn.arange | !ttnn.device | dtype: #tt.supportedDataTypes end: 4 : i64 memory_config: #ttnn.memory_config<#dram, <<1x1>>, start: 0 : i64 step: 1 : i64 | tensor<[4,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 4, 'si32', 'dram') | nan | nan | |
| ttnn.arange | !ttnn.device | dtype: #tt.supportedDataTypes end: 1 : i64 memory_config: #ttnn.memory_config<#dram, <<1x1>>, start: 0 : i64 step: 1 : i64 | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'dram') | nan | nan | |
| ttnn.arange | !ttnn.device | dtype: #tt.supportedDataTypes end: 80 : i64 memory_config: #ttnn.memory_config<#dram, <<1x3>>, start: 0 : i64 step: 1 : i64 | tensor<[80,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 80, 'si32', 'dram') | nan | nan | |
| ttnn.arange | !ttnn.device | dtype: #tt.supportedDataTypes end: 6 : i64 memory_config: #ttnn.memory_config<#dram, <<1x1>>, start: 0 : i64 step: 1 : i64 | tensor<[6,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'si32', 'dram') | nan | nan | |
| ttnn.arange | !ttnn.device | dtype: #tt.supportedDataTypes end: 16 : i64 memory_config: #ttnn.memory_config<#dram, <<1x1>>, start: 0 : i64 step: 1 : i64 | tensor<[16,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 16, 'si32', 'dram') | nan | nan | |
| ttnn.arange | !ttnn.device | dtype: #tt.supportedDataTypes end: 1 : i64 memory_config: #ttnn.memory_config<#dram, <<1x1>>, start: 0 : i64 step: 1 : i64 | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'dram') | nan | nan | |
| ttnn.arange | !ttnn.device | dtype: #tt.supportedDataTypes end: 6 : i64 memory_config: #ttnn.memory_config<#dram, <<1x1>>, start: 0 : i64 step: 1 : i64 | tensor<[6,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'si32', 'dram') | nan | nan | |
| ttnn.arange | !ttnn.device | dtype: #tt.supportedDataTypes end: 16 : i64 memory_config: #ttnn.memory_config<#dram, <<1x1>>, start: 0 : i64 step: 1 : i64 | tensor<[16,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 16, 'si32', 'dram') | nan | nan | |
| ttnn.arange | !ttnn.device | dtype: #tt.supportedDataTypes end: 1 : i64 memory_config: #ttnn.memory_config<#dram, <<1x1>>, start: 0 : i64 step: 1 : i64 | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'dram') | nan | nan | |
| ttnn.arange | !ttnn.device | dtype: #tt.supportedDataTypes end: 3 : i64 memory_config: #ttnn.memory_config<#dram, <<1x1>>, start: 0 : i64 step: 1 : i64 | tensor<[3,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 3, 'si32', 'dram') | nan | nan | |
| ttnn.arange | !ttnn.device | dtype: #tt.supportedDataTypes end: 1 : i64 memory_config: #ttnn.memory_config<#dram, <<1x1>>, start: 0 : i64 step: 1 : i64 | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'dram') | nan | nan | |
| ttnn.arange | !ttnn.device | dtype: #tt.supportedDataTypes end: 25281 : i64 memory_config: #ttnn.memory_config<#dram, <<1x791>>, start: 0 : i64 step: 1 : i64 | tensor<[25281,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 25281, 'si32', 'dram') | nan | nan | |
| ttnn.arange | !ttnn.device | dtype: #tt.supportedDataTypes end: 7 : i64 memory_config: #ttnn.memory_config<#dram, <<1x1>>, start: 0 : i64 step: 1 : i64 | tensor<[7,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 7, 'si32', 'dram') | nan | nan | |
| ttnn.arange | !ttnn.device | dtype: #tt.supportedDataTypes end: 1 : i64 memory_config: #ttnn.memory_config<#dram, <<1x1>>, start: 0 : i64 step: 1 : i64 | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'dram') | nan | nan | |
| ttnn.arange | !ttnn.device | dtype: #tt.supportedDataTypes end: 160 : i64 memory_config: #ttnn.memory_config<#dram, <<1x5>>, start: 0 : i64 step: 1 : i64 | tensor<[160,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 160, 'si32', 'dram') | nan | nan | |
| ttnn.arange | !ttnn.device | dtype: #tt.supportedDataTypes end: 8 : i64 memory_config: #ttnn.memory_config<#dram, <<1x1>>, start: 0 : i64 step: 1 : i64 | tensor<[8,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 8, 'si32', 'dram') | nan | nan | |
| ttnn.arange | !ttnn.device | dtype: #tt.supportedDataTypes end: 1 : i64 memory_config: #ttnn.memory_config<#dram, <<1x1>>, start: 0 : i64 step: 1 : i64 | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'dram') | nan | nan |
ttnn.concat
This table is a trace for ttnn.concat op. Traces are generated from nightly tt-torch runs. To see nightly runs: Nightly Runs
| Name | Input Shapes | Input Layouts | Attributes | Output Shapes | Output Layouts | PCC | ATOL |
|---|---|---|---|---|---|---|---|
| ttnn.concat | tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> tensor<[1,3,128,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 128 + d2, d3), memory_config: (12, 4, 'tile<32x32, bf16>', 'dram') | dim: 1 : si32 | tensor<[1,192,128,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 24576 + d1 * 128 + d2, d3), memory_config: (768, 4, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.concat | dim: 1 : si32 | nan | nan | ||||
| ttnn.concat | tensor<[16,250,250,1,bf16]> tensor<[16,250,250,1,bf16]> tensor<[16,250,250,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64000 + d1 * 256 + d2, d3), memory_config: (32000, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64000 + d1 * 256 + d2, d3), memory_config: (32000, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64000 + d1 * 256 + d2, d3), memory_config: (32000, 1, 'tile<32x32, bf16>', 'dram') | dim: 3 : si32 | tensor<[16,250,250,3,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64000 + d1 * 256 + d2, d3), memory_config: (32000, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.concat | tensor<[1,2640,768,1,bf16]> tensor<[1,2640,768,1,bf16]> tensor<[1,2640,768,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2027520 + d1 * 768 + d2, d3), memory_config: (63360, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2027520 + d1 * 768 + d2, d3), memory_config: (63360, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2027520 + d1 * 768 + d2, d3), memory_config: (63360, 1, 'tile<32x32, bf16>', 'dram') | dim: 3 : si32 | tensor<[1,2640,768,3,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2027520 + d1 * 768 + d2, d3), memory_config: (63360, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.concat | tensor<[1,300,4,1,bf16]> tensor<[1,300,4,1,bf16]> tensor<[1,300,4,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9600 + d1 * 32 + d2, d3), memory_config: (300, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9600 + d1 * 32 + d2, d3), memory_config: (300, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9600 + d1 * 32 + d2, d3), memory_config: (300, 1, 'tile<32x32, bf16>', 'dram') | dim: 3 : si32 | tensor<[1,300,4,3,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9600 + d1 * 32 + d2, d3), memory_config: (300, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.concat | tensor<[1,300,80,1,bf16]> tensor<[1,300,80,1,bf16]> tensor<[1,300,80,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 28800 + d1 * 96 + d2, d3), memory_config: (900, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 28800 + d1 * 96 + d2, d3), memory_config: (900, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 28800 + d1 * 96 + d2, d3), memory_config: (900, 1, 'tile<32x32, bf16>', 'dram') | dim: 3 : si32 | tensor<[1,300,80,3,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 28800 + d1 * 96 + d2, d3), memory_config: (900, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.concat | tensor<[1,16,6,192,1,bf16]> tensor<[1,16,6,192,1,bf16]> tensor<[1,16,6,192,1,bf16]> tensor<[1,16,6,192,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, bf16>', 'dram') | dim: 4 : si32 | tensor<[1,16,6,192,4,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.concat | tensor<[1,16,6,192,1,bf16]> tensor<[1,16,6,192,1,bf16]> tensor<[1,16,6,192,1,bf16]> tensor<[1,16,6,192,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, bf16>', 'dram') | dim: 4 : si32 | tensor<[1,16,6,192,4,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.concat | tensor<[1,1,1,1,3,1,1,bf16]> tensor<[1,1,1,1,3,1,1,bf16]> tensor<[1,1,1,1,3,1,1,bf16]> tensor<[1,1,1,1,3,1,1,bf16]> tensor<[1,1,1,1,3,1,1,bf16]> tensor<[1,1,1,1,3,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, bf16>', 'dram') | dim: 6 : si32 | tensor<[1,1,1,1,3,1,6,bf16]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.concat | tensor<[1,256,7,25281,1,bf16]> tensor<[1,256,7,25281,1,bf16]> tensor<[1,256,7,25281,1,bf16]> tensor<[1,256,7,25281,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') | dim: 4 : si32 | tensor<[1,256,7,25281,4,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.concat | tensor<[1,256,7,25281,1,bf16]> tensor<[1,256,7,25281,1,bf16]> tensor<[1,256,7,25281,1,bf16]> tensor<[1,256,7,25281,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') | dim: 4 : si32 | tensor<[1,256,7,25281,4,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.concat | tensor<[1,256,7,25281,1,bf16]> tensor<[1,256,7,25281,1,bf16]> tensor<[1,256,7,25281,1,bf16]> tensor<[1,256,7,25281,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') | dim: 4 : si32 | tensor<[1,256,7,25281,4,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.concat | tensor<[1,7,25281,2,1,bf16]> tensor<[1,7,25281,2,1,bf16]> tensor<[1,7,25281,2,1,bf16]> tensor<[1,7,25281,2,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 5662944 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (176967, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 5662944 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (176967, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 5662944 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (176967, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 5662944 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (176967, 1, 'tile<32x32, bf16>', 'dram') | dim: 4 : si32 | tensor<[1,7,25281,2,4,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 5662944 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (176967, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
ttnn.constant
This table is a trace for ttnn.constant op. Traces are generated from nightly tt-torch runs. To see nightly runs: Nightly Runs
| Name | Input Shapes | Input Layouts | Attributes | Output Shapes | Output Layouts | PCC | ATOL |
|---|---|---|---|---|---|---|---|
| ttnn.constant | value: dense<[[1.280000e+05], [5.120000e+02], [1.000000e+00]]> : tensor<3x1xf32> | tensor<[3,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (3, 1, 'f32', 'system_memory') | nan | nan | ||
| ttnn.constant | value: dense<[[1.689600e+05], [7.680000e+02], [1.000000e+00]]> : tensor<3x1xf32> | tensor<[3,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (3, 1, 'f32', 'system_memory') | nan | nan | ||
| ttnn.constant | value: dense<[[3.360000e+04], [4.000000e+00], [1.000000e+00]]> : tensor<3x1xf32> | tensor<[3,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (3, 1, 'f32', 'system_memory') | nan | nan | ||
| ttnn.constant | value: dense<[[6.720000e+05], [8.000000e+01], [1.000000e+00]]> : tensor<3x1xf32> | tensor<[3,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (3, 1, 'f32', 'system_memory') | nan | nan | ||
| ttnn.constant | value: dense<[[1.228800e+04], [7.680000e+02], [1.280000e+02], [1.000000e+00]]> : tensor<4x1xf32> | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (4, 1, 'f32', 'system_memory') | nan | nan | ||
| ttnn.constant | value: dense<[[6.144000e+03], [3.840000e+02], [6.400000e+01], [1.000000e+00]]> : tensor<4x1xf32> | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (4, 1, 'f32', 'system_memory') | nan | nan | ||
| ttnn.constant | value: dense<[[1.200000e+01], [1.200000e+01], [1.200000e+01], [1.200000e+01], [4.000000e+00], [1.000000e+00]]> : tensor<6x1xf32> | tensor<[6,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (6, 1, 'f32', 'system_memory') | nan | nan | ||
| ttnn.constant | value: dense<[[5.017600e+04], [1.960000e+02], [1.400000e+01], [1.000000e+00]]> : tensor<4x1xf32> | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (4, 1, 'f32', 'system_memory') | nan | nan | ||
| ttnn.constant | value: dense<[[2.007040e+05], [7.840000e+02], [2.800000e+01], [1.000000e+00]]> : tensor<4x1xf32> | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (4, 1, 'f32', 'system_memory') | nan | nan | ||
| ttnn.constant | value: dense<[[1.254400e+04], [4.900000e+01], [7.000000e+00], [1.000000e+00]]> : tensor<4x1xf32> | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (4, 1, 'f32', 'system_memory') | nan | nan | ||
| ttnn.constant | value: dense<[[7.078680e+05], [1.011240e+05], [4.000000e+00], [1.000000e+00]]> : tensor<4x1xf32> | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (4, 1, 'f32', 'system_memory') | nan | nan | ||
| ttnn.constant | value: dense<[[6.144000e+05], [7.680000e+04], [4.800000e+02], [3.000000e+00], [1.000000e+00]]> : tensor<5x1xf32> | tensor<[5,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (5, 1, 'f32', 'system_memory') | nan | nan |
ttnn.conv2d
This table is a trace for ttnn.conv2d op. Traces are generated from nightly tt-torch runs. To see nightly runs: Nightly Runs
| Name | Input Shapes | Input Layouts | Attributes | Output Shapes | Output Layouts | PCC | ATOL |
|---|---|---|---|---|---|---|---|
| ttnn.conv2d | tensor<[1,1,262144,128,bf16]> tensor<[128,128,3,3,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (262144, 128, 'bf16', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 3 + d2, d3), memory_config: (49152, 3, 'bf16', 'system_memory') | batch_size: 1 : i32 dilation: array<i32: 1, 1> groups: 1 : i32 in_channels: 128 : i32 input_height: 512 : i32 input_width: 512 : i32 kernel_size: array<i32: 3, 3> out_channels: 128 : i32 padding: array<i32: 1, 1> stride: array<i32: 1, 1> | tensor<[1,1,262144,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 4, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.conv2d | tensor<[1,1,262144,128,bf16]> tensor<[3,128,3,3,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (262144, 128, 'bf16', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 384 + d1 * 3 + d2, d3), memory_config: (1152, 3, 'bf16', 'system_memory') | batch_size: 1 : i32 dilation: array<i32: 1, 1> groups: 1 : i32 in_channels: 128 : i32 input_height: 512 : i32 input_width: 512 : i32 kernel_size: array<i32: 3, 3> out_channels: 3 : i32 padding: array<i32: 1, 1> stride: array<i32: 1, 1> | tensor<[1,1,262144,3,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.conv2d | tensor<[1,1,196,16,bf16]> tensor<[4,16,3,3,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 196 + d1 * 196 + d2, d3), memory_config: (196, 16, 'bf16', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 48 + d1 * 3 + d2, d3), memory_config: (192, 3, 'bf16', 'system_memory') | batch_size: 1 : i32 dilation: array<i32: 1, 1> groups: 1 : i32 in_channels: 16 : i32 input_height: 14 : i32 input_width: 14 : i32 kernel_size: array<i32: 3, 3> out_channels: 4 : i32 padding: array<i32: 1, 1> stride: array<i32: 1, 1> | tensor<[1,1,196,4,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 224 + d1 * 224 + d2, d3), memory_config: (7, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.conv2d | tensor<[1,1,262144,256,bf16]> tensor<[128,256,3,3,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (262144, 256, 'bf16', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 768 + d1 * 3 + d2, d3), memory_config: (98304, 3, 'bf16', 'system_memory') | batch_size: 1 : i32 dilation: array<i32: 1, 1> groups: 1 : i32 in_channels: 256 : i32 input_height: 512 : i32 input_width: 512 : i32 kernel_size: array<i32: 3, 3> out_channels: 128 : i32 padding: array<i32: 1, 1> stride: array<i32: 1, 1> | tensor<[1,1,262144,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 4, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.conv2d | tensor<[1,1,262144,256,bf16]> tensor<[256,256,3,3,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (262144, 256, 'bf16', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 768 + d1 * 3 + d2, d3), memory_config: (196608, 3, 'bf16', 'system_memory') | batch_size: 1 : i32 dilation: array<i32: 1, 1> groups: 1 : i32 in_channels: 256 : i32 input_height: 512 : i32 input_width: 512 : i32 kernel_size: array<i32: 3, 3> out_channels: 256 : i32 padding: array<i32: 1, 1> stride: array<i32: 1, 1> | tensor<[1,1,262144,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 8, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.conv2d | tensor<[1,1,1048576,3,bf16]> tensor<[64,3,3,3,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1048576 + d2, d3), memory_config: (1048576, 3, 'bf16', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9 + d1 * 3 + d2, d3), memory_config: (576, 3, 'bf16', 'system_memory') | batch_size: 1 : i32 dilation: array<i32: 1, 1> groups: 1 : i32 in_channels: 3 : i32 input_height: 1024 : i32 input_width: 1024 : i32 kernel_size: array<i32: 3, 3> out_channels: 64 : i32 padding: array<i32: 1, 1> stride: array<i32: 1, 1> | tensor<[1,1,1048576,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1048576 + d2, d3), memory_config: (32768, 2, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.conv2d | tensor<[1,1,65536,480,bf16]> tensor<[64,480,3,3,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (65536, 480, 'bf16', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1440 + d1 * 3 + d2, d3), memory_config: (92160, 3, 'bf16', 'system_memory') | batch_size: 1 : i32 dilation: array<i32: 1, 1> groups: 1 : i32 in_channels: 480 : i32 input_height: 256 : i32 input_width: 256 : i32 kernel_size: array<i32: 3, 3> out_channels: 64 : i32 padding: array<i32: 1, 1> stride: array<i32: 1, 1> | tensor<[1,1,65536,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 2, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.conv2d | tensor<[1,1,65536,512,bf16]> tensor<[256,512,3,3,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (65536, 512, 'bf16', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1536 + d1 * 3 + d2, d3), memory_config: (393216, 3, 'bf16', 'system_memory') | batch_size: 1 : i32 dilation: array<i32: 1, 1> groups: 1 : i32 in_channels: 512 : i32 input_height: 256 : i32 input_width: 256 : i32 kernel_size: array<i32: 3, 3> out_channels: 256 : i32 padding: array<i32: 1, 1> stride: array<i32: 1, 1> | tensor<[1,1,65536,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 8, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.conv2d | tensor<[1,1,65536,512,bf16]> tensor<[512,512,3,3,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (65536, 512, 'bf16', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1536 + d1 * 3 + d2, d3), memory_config: (786432, 3, 'bf16', 'system_memory') | batch_size: 1 : i32 dilation: array<i32: 1, 1> groups: 1 : i32 in_channels: 512 : i32 input_height: 256 : i32 input_width: 256 : i32 kernel_size: array<i32: 3, 3> out_channels: 512 : i32 padding: array<i32: 1, 1> stride: array<i32: 1, 1> | tensor<[1,1,65536,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.conv2d | tensor<[1,1,1048576,64,bf16]> tensor<[48,64,3,3,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1048576 + d2, d3), memory_config: (1048576, 64, 'bf16', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 192 + d1 * 3 + d2, d3), memory_config: (9216, 3, 'bf16', 'system_memory') | batch_size: 1 : i32 dilation: array<i32: 1, 1> groups: 1 : i32 in_channels: 64 : i32 input_height: 1024 : i32 input_width: 1024 : i32 kernel_size: array<i32: 3, 3> out_channels: 48 : i32 padding: array<i32: 1, 1> stride: array<i32: 1, 1> | tensor<[1,1,1048576,48,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1048576 + d2, d3), memory_config: (32768, 2, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.conv2d | tensor<[1,1,65536,64,bf16]> tensor<[98,64,7,7,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (65536, 64, 'bf16', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 448 + d1 * 7 + d2, d3), memory_config: (43904, 7, 'bf16', 'system_memory') | batch_size: 1 : i32 dilation: array<i32: 1, 1> groups: 1 : i32 in_channels: 64 : i32 input_height: 256 : i32 input_width: 256 : i32 kernel_size: array<i32: 7, 7> out_channels: 98 : i32 padding: array<i32: 3, 3> stride: array<i32: 1, 1> | tensor<[1,1,65536,98,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 4, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.conv2d | tensor<[1,1,307200,64,bf16]> tensor<[1,64,3,3,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 307200 + d2, d3), memory_config: (307200, 64, 'bf16', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 192 + d1 * 3 + d2, d3), memory_config: (192, 3, 'bf16', 'system_memory') | batch_size: 1 : i32 dilation: array<i32: 1, 1> groups: 1 : i32 in_channels: 64 : i32 input_height: 480 : i32 input_width: 640 : i32 kernel_size: array<i32: 3, 3> out_channels: 1 : i32 padding: array<i32: 1, 1> stride: array<i32: 1, 1> | tensor<[1,1,307200,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 307200 + d2, d3), memory_config: (9600, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.conv2d | tensor<[1,1,307200,64,bf16]> tensor<[64,64,3,3,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 307200 + d2, d3), memory_config: (307200, 64, 'bf16', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 192 + d1 * 3 + d2, d3), memory_config: (12288, 3, 'bf16', 'system_memory') | batch_size: 1 : i32 dilation: array<i32: 1, 1> groups: 1 : i32 in_channels: 64 : i32 input_height: 480 : i32 input_width: 640 : i32 kernel_size: array<i32: 3, 3> out_channels: 64 : i32 padding: array<i32: 1, 1> stride: array<i32: 1, 1> | tensor<[1,1,307200,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 307200 + d2, d3), memory_config: (9600, 2, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.conv2d | tensor<[1,1,16384,960,bf16]> tensor<[64,960,3,3,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 16384 + d1 * 16384 + d2, d3), memory_config: (16384, 960, 'bf16', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2880 + d1 * 3 + d2, d3), memory_config: (184320, 3, 'bf16', 'system_memory') | batch_size: 1 : i32 dilation: array<i32: 1, 1> groups: 1 : i32 in_channels: 960 : i32 input_height: 128 : i32 input_width: 128 : i32 kernel_size: array<i32: 3, 3> out_channels: 64 : i32 padding: array<i32: 1, 1> stride: array<i32: 1, 1> | tensor<[1,1,16384,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 16384 + d1 * 16384 + d2, d3), memory_config: (512, 2, 'tile<32x32, bf16>', 'dram') | nan | nan |
ttnn.embedding
This table is a trace for ttnn.embedding op. Traces are generated from nightly tt-torch runs. To see nightly runs: Nightly Runs
| Name | Input Shapes | Input Layouts | Attributes | Output Shapes | Output Layouts | PCC | ATOL |
|---|---|---|---|---|---|---|---|
| ttnn.embedding | tensor<[1000000,ui32]> tensor<[2048000,1,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1000000, 'ui32', 'dram') mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (64000, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1000000,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (31250, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.embedding | tensor<[2027520,ui32]> tensor<[168960,1,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 2027520, 'ui32', 'dram') mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (5280, 1, 'tile<32x32, bf16>', 'dram') | tensor<[2027520,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (63360, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.embedding | tensor<[1200,ui32]> tensor<[33600,1,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1200, 'ui32', 'dram') mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1050, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1200,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (38, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.embedding | tensor<[24000,ui32]> tensor<[672000,1,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 24000, 'ui32', 'dram') mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (21000, 1, 'tile<32x32, bf16>', 'dram') | tensor<[24000,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (750, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.embedding | tensor<[3,ui32]> tensor<[12,1,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 3, 'ui32', 'dram') mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | tensor<[3,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.embedding | tensor<[45303552,ui32]> tensor<[50176,1,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 45303552, 'ui32', 'dram') mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1568, 1, 'tile<32x32, bf16>', 'dram') | tensor<[45303552,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1415736, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.embedding | tensor<[45303552,ui32]> tensor<[200704,1,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 45303552, 'ui32', 'dram') mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (6272, 1, 'tile<32x32, bf16>', 'dram') | tensor<[45303552,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1415736, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.embedding | tensor<[45303552,ui32]> tensor<[12544,1,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 45303552, 'ui32', 'dram') mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (392, 1, 'tile<32x32, bf16>', 'dram') | tensor<[45303552,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1415736, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
ttnn.from_device
This table is a trace for ttnn.from_device op. Traces are generated from nightly tt-torch runs. To see nightly runs: Nightly Runs
| Name | Input Shapes | Input Layouts | Attributes | Output Shapes | Output Layouts | PCC | ATOL |
|---|---|---|---|---|---|---|---|
| ttnn.from_device | tensor<[1,1,262144,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 4, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,262144,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 4, 'tile<32x32, bf16>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,1,262144,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 4, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,262144,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 4, 'tile<32x32, bf16>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,1,196,16,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 224 + d1 * 224 + d2, d3), memory_config: (7, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,196,16,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 224 + d1 * 224 + d2, d3), memory_config: (7, 1, 'tile<32x32, bf16>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,1,262144,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 8, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,262144,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 8, 'tile<32x32, bf16>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,1,262144,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 8, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,262144,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 8, 'tile<32x32, bf16>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,1,1048576,3,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1048576 + d2, d3), memory_config: (32768, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,1048576,3,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1048576 + d2, d3), memory_config: (32768, 1, 'tile<32x32, bf16>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,1,65536,480,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 15, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,65536,480,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 15, 'tile<32x32, bf16>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,1,65536,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,65536,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,1,65536,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,65536,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,1,1048576,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1048576 + d2, d3), memory_config: (32768, 2, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,1048576,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1048576 + d2, d3), memory_config: (32768, 2, 'tile<32x32, bf16>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,1,65536,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 2, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,65536,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 2, 'tile<32x32, bf16>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,1,307200,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 307200 + d2, d3), memory_config: (9600, 2, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,307200,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 307200 + d2, d3), memory_config: (9600, 2, 'tile<32x32, bf16>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,1,307200,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 307200 + d2, d3), memory_config: (9600, 2, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,307200,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 307200 + d2, d3), memory_config: (9600, 2, 'tile<32x32, bf16>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,1,16384,960,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 16384 + d1 * 16384 + d2, d3), memory_config: (512, 30, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,16384,960,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 16384 + d1 * 16384 + d2, d3), memory_config: (512, 30, 'tile<32x32, bf16>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[16,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 16, 'si32', 'dram') | tensor<[16,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 16, 'si32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[250,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 250, 'si32', 'dram') | tensor<[250,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 250, 'si32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1000000,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 31250, 'tile<32x32, u32>', 'dram') | tensor<[1000000,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 31250, 'tile<32x32, u32>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'dram') | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[768,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 768, 'si32', 'dram') | tensor<[768,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 768, 'si32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[2027520,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 63360, 'tile<32x32, u32>', 'dram') | tensor<[2027520,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 63360, 'tile<32x32, u32>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'dram') | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[4,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 4, 'si32', 'dram') | tensor<[4,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 4, 'si32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1200,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 38, 'tile<32x32, u32>', 'dram') | tensor<[1200,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 38, 'tile<32x32, u32>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'dram') | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[80,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 80, 'si32', 'dram') | tensor<[80,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 80, 'si32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[24000,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 750, 'tile<32x32, u32>', 'dram') | tensor<[24000,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 750, 'tile<32x32, u32>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[6,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'si32', 'dram') | tensor<[6,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'si32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[6,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'ui32', 'dram') | tensor<[6,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'ui32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[16,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 16, 'si32', 'dram') | tensor<[16,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 16, 'si32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[16,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 16, 'ui32', 'dram') | tensor<[16,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 16, 'ui32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'dram') | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'dram') | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[6,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'si32', 'dram') | tensor<[6,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'si32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[6,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'ui32', 'dram') | tensor<[6,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'ui32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[16,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 16, 'si32', 'dram') | tensor<[16,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 16, 'si32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[16,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 16, 'ui32', 'dram') | tensor<[16,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 16, 'ui32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'dram') | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'dram') | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[3,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 3, 'si32', 'dram') | tensor<[3,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 3, 'si32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[3,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 3, 'ui32', 'dram') | tensor<[3,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 3, 'ui32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'dram') | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'dram') | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[3,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | tensor<[3,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[45303552,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1415736, 'tile<32x32, u32>', 'dram') | tensor<[45303552,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1415736, 'tile<32x32, u32>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[45303552,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1415736, 'tile<32x32, u32>', 'dram') | tensor<[45303552,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1415736, 'tile<32x32, u32>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[45303552,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1415736, 'tile<32x32, u32>', 'dram') | tensor<[45303552,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1415736, 'tile<32x32, u32>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[25281,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 25281, 'si32', 'dram') | tensor<[25281,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 25281, 'si32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[25281,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 25281, 'ui32', 'dram') | tensor<[25281,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 25281, 'ui32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[7,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 7, 'si32', 'dram') | tensor<[7,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 7, 'si32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[7,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 7, 'ui32', 'dram') | tensor<[7,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 7, 'ui32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'dram') | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'dram') | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[160,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 160, 'ui32', 'dram') | tensor<[160,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 160, 'ui32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[160,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 160, 'si32', 'dram') | tensor<[160,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 160, 'si32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[8,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 8, 'si32', 'dram') | tensor<[8,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 8, 'si32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[8,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 8, 'ui32', 'dram') | tensor<[8,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 8, 'ui32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'dram') | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'dram') | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,1,784,16,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 800 + d1 * 800 + d2, d3), memory_config: (25, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,784,16,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 800 + d1 * 800 + d2, d3), memory_config: (25, 1, 'tile<32x32, bf16>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,1,196,4,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 224 + d1 * 224 + d2, d3), memory_config: (7, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,196,4,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 224 + d1 * 224 + d2, d3), memory_config: (7, 1, 'tile<32x32, bf16>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,1,196,528,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 224 + d1 * 224 + d2, d3), memory_config: (7, 17, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,196,528,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 224 + d1 * 224 + d2, d3), memory_config: (7, 17, 'tile<32x32, bf16>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,256,7,25281,2,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'dram') | tensor<[1,256,7,25281,2,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'system_memory') | nan | nan | |
| ttnn.from_device | tensor<[1,256,7,25281,1,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45303552 + d1 * 176967 + d2 * 25281 + d3, d4), memory_config: (45303552, 1, 'f32', 'dram') | tensor<[1,256,7,25281,1,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45303552 + d1 * 176967 + d2 * 25281 + d3, d4), memory_config: (45303552, 1, 'f32', 'system_memory') | nan | nan |
ttnn.full
This table is a trace for ttnn.full op. Traces are generated from nightly tt-torch runs. To see nightly runs: Nightly Runs
| Name | Input Shapes | Input Layouts | Attributes | Output Shapes | Output Layouts | PCC | ATOL |
|---|---|---|---|---|---|---|---|
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[1,256,7,25281,2,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[16,250,250,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64000 + d1 * 256 + d2, d3), memory_config: (32000, 1, 'tile<32x32, u32>', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[1,2640,768,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2027520 + d1 * 768 + d2, d3), memory_config: (63360, 1, 'tile<32x32, u32>', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[1,300,4,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9600 + d1 * 32 + d2, d3), memory_config: (300, 1, 'tile<32x32, u32>', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[1,300,80,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 28800 + d1 * 96 + d2, d3), memory_config: (900, 1, 'tile<32x32, u32>', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 1.000000e+00 : f32 | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[16,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 16, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 1.000000e+00 : f32 | tensor<[16,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 16, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[6,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 1.000000e+00 : f32 | tensor<[6,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[1,16,6,192,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, u32>', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 1.000000e+00 : f32 | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[16,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 16, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 1.000000e+00 : f32 | tensor<[16,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 16, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[6,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 1.000000e+00 : f32 | tensor<[6,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[1,16,6,192,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, u32>', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 1.000000e+00 : f32 | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[3,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 3, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 1.000000e+00 : f32 | tensor<[3,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 3, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[1,1,1,1,3,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, u32>', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[1,256,7,25281,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, u32>', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[1,256,7,25281,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, u32>', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[1,256,7,25281,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, u32>', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 1.000000e+00 : f32 | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[7,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 7, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 1.000000e+00 : f32 | tensor<[7,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 7, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[25281,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 25281, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 1.000000e+00 : f32 | tensor<[25281,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 25281, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[1,7,25281,2,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 5662944 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (176967, 1, 'tile<32x32, u32>', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 1.000000e+00 : f32 | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[8,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 8, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 1.000000e+00 : f32 | tensor<[8,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 8, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[160,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 160, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 1.000000e+00 : f32 | tensor<[160,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 160, 'ui32', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[1,8,160,160,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 6553600 + d1 * 819200 + d2 * 5120 + d3 * 32 + d4, d5), memory_config: (204800, 1, 'tile<32x32, u32>', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[1,16,14,14,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 512 + d1 * 32 + d2, d3), memory_config: (16, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[1,16,28,28,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 512 + d1 * 32 + d2, d3), memory_config: (16, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[1,4,14,14,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 128 + d1 * 32 + d2, d3), memory_config: (4, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.full | !ttnn.device | fillValue: 0.000000e+00 : f32 | tensor<[1,256,7,25281,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, u32>', 'dram') | nan | nan |
ttnn.get_device
This table is a trace for ttnn.get_device op. Traces are generated from nightly tt-torch runs. To see nightly runs: Nightly Runs
| Name | Input Shapes | Input Layouts | Attributes | Output Shapes | Output Layouts | PCC | ATOL |
|---|---|---|---|---|---|---|---|
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc5) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc5) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc5) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc5) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc5) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc5) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc5) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc5) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc5) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc5) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc5) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc5) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc5) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc5) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc3) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc4) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc4) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc4) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc4) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc4) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc4) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc4) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc7) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc7) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc7) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc4) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc4) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc3) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc3) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc3) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc3) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc3) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc3) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc3) | nan | nan | |||
| ttnn.get_device | mesh_offset: #ttnn<mesh_offset 0x0> mesh_shape: #ttnn<mesh_shape 1x1> | !ttnn.device loc(#loc5) | nan | nan |
ttnn.matmul
This table is a trace for ttnn.matmul op. Traces are generated from nightly tt-torch runs. To see nightly runs: Nightly Runs
| Name | Input Shapes | Input Layouts | Attributes | Output Shapes | Output Layouts | PCC | ATOL |
|---|---|---|---|---|---|---|---|
| ttnn.matmul | tensor<[16,250,250,3,f32]> tensor<[3,1,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64000 + d1 * 256 + d2, d3), memory_config: (32000, 1, 'tile<32x32, f32>', 'dram') mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | transpose_a: False transpose_b: False | tensor<[16,250,250,1,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64000 + d1 * 256 + d2, d3), memory_config: (32000, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.matmul | tensor<[1,2640,768,3,f32]> tensor<[3,1,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2027520 + d1 * 768 + d2, d3), memory_config: (63360, 1, 'tile<32x32, f32>', 'dram') mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | transpose_a: False transpose_b: False | tensor<[1,2640,768,1,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2027520 + d1 * 768 + d2, d3), memory_config: (63360, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.matmul | tensor<[1,300,4,3,f32]> tensor<[3,1,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9600 + d1 * 32 + d2, d3), memory_config: (300, 1, 'tile<32x32, f32>', 'dram') mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | transpose_a: False transpose_b: False | tensor<[1,300,4,1,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9600 + d1 * 32 + d2, d3), memory_config: (300, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.matmul | tensor<[1,300,80,3,f32]> tensor<[3,1,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 28800 + d1 * 96 + d2, d3), memory_config: (900, 1, 'tile<32x32, f32>', 'dram') mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | transpose_a: False transpose_b: False | tensor<[1,300,80,1,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 28800 + d1 * 96 + d2, d3), memory_config: (900, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.matmul | tensor<[1,1,1,1,3,1,6,f32]> tensor<[6,1,f32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, f32>', 'dram') mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | transpose_a: False transpose_b: False | tensor<[1,1,1,1,3,1,1,f32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.matmul | tensor<[1,256,7,25281,4,f32]> tensor<[4,1,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'dram') mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | transpose_a: False transpose_b: False | tensor<[1,256,7,25281,1,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.matmul | tensor<[1,256,7,25281,4,f32]> tensor<[4,1,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'dram') mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | transpose_a: False transpose_b: False | tensor<[1,256,7,25281,1,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.matmul | tensor<[1,256,7,25281,4,f32]> tensor<[4,1,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'dram') mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | transpose_a: False transpose_b: False | tensor<[1,256,7,25281,1,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
ttnn.max_pool2d
This table is a trace for ttnn.max_pool2d op. Traces are generated from nightly tt-torch runs. To see nightly runs: Nightly Runs
| Name | Input Shapes | Input Layouts | Attributes | Output Shapes | Output Layouts | PCC | ATOL |
|---|---|---|---|---|---|---|---|
| ttnn.max_pool2d | tensor<[1,1,784,16,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 784 + d1 * 784 + d2, d3), memory_config: (784, 16, 'bf16', 'dram') | batch_size: 1 : si32 ceil_mode: False channels: 16 : si32 dilation: array<i32: 1, 1> input_height: 28 : si32 input_width: 28 : si32 kernel_size: array<i32: 2, 2> padding: array<i32: 0, 0> stride: array<i32: 2, 2> | tensor<[1,1,196,16,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 196 + d1 * 196 + d2, d3), memory_config: (196, 16, 'bf16', 'dram') | nan | nan |
| ttnn.max_pool2d | tensor<[1,1,196,4,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 196 + d1 * 196 + d2, d3), memory_config: (196, 4, 'bf16', 'dram') | batch_size: 1 : si32 ceil_mode: False channels: 4 : si32 dilation: array<i32: 1, 1> input_height: 14 : si32 input_width: 14 : si32 kernel_size: array<i32: 2, 2> padding: array<i32: 0, 0> stride: array<i32: 2, 2> | tensor<[1,1,49,4,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 49 + d1 * 49 + d2, d3), memory_config: (49, 4, 'bf16', 'dram') | nan | nan |
| ttnn.max_pool2d | tensor<[1,1,196,528,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 196 + d1 * 196 + d2, d3), memory_config: (196, 528, 'bf16', 'dram') | batch_size: 1 : si32 ceil_mode: False channels: 528 : si32 dilation: array<i32: 1, 1> input_height: 14 : si32 input_width: 14 : si32 kernel_size: array<i32: 3, 3> padding: array<i32: 1, 1> stride: array<i32: 1, 1> | tensor<[1,1,196,528,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 196 + d1 * 196 + d2, d3), memory_config: (196, 528, 'bf16', 'dram') | nan | nan |
ttnn.maximum
This table is a trace for ttnn.maximum op. Traces are generated from nightly tt-torch runs. To see nightly runs: Nightly Runs
| Name | Input Shapes | Input Layouts | Attributes | Output Shapes | Output Layouts | PCC | ATOL |
|---|---|---|---|---|---|---|---|
| ttnn.maximum | tensor<[1,16,14,14,bf16]> tensor<[1,16,14,14,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 512 + d1 * 32 + d2, d3), memory_config: (16, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 512 + d1 * 32 + d2, d3), memory_config: (16, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,16,14,14,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 512 + d1 * 32 + d2, d3), memory_config: (16, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.maximum | tensor<[1,16,28,28,bf16]> tensor<[1,16,28,28,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 512 + d1 * 32 + d2, d3), memory_config: (16, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 512 + d1 * 32 + d2, d3), memory_config: (16, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,16,28,28,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 512 + d1 * 32 + d2, d3), memory_config: (16, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.maximum | tensor<[1,4,14,14,bf16]> tensor<[1,4,14,14,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 128 + d1 * 32 + d2, d3), memory_config: (4, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 128 + d1 * 32 + d2, d3), memory_config: (4, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,4,14,14,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 128 + d1 * 32 + d2, d3), memory_config: (4, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
ttnn.multiply
This table is a trace for ttnn.multiply op. Traces are generated from nightly tt-torch runs. To see nightly runs: Nightly Runs
| Name | Input Shapes | Input Layouts | Attributes | Output Shapes | Output Layouts | PCC | ATOL |
|---|---|---|---|---|---|---|---|
| ttnn.multiply | tensor<[1,1,6,1,1,bf16]> tensor<[1,1,6,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,6,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.multiply | tensor<[1,16,1,1,1,bf16]> tensor<[1,16,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,16,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.multiply | tensor<[1,1,1,1,1,bf16]> tensor<[1,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.multiply | tensor<[1,1,6,1,1,bf16]> tensor<[1,1,6,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,6,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.multiply | tensor<[1,16,1,1,1,bf16]> tensor<[1,16,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,16,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.multiply | tensor<[1,1,1,1,1,bf16]> tensor<[1,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.multiply | tensor<[1,1,1,1,3,1,1,bf16]> tensor<[1,1,1,1,3,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,1,1,3,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.multiply | tensor<[1,1,1,1,1,1,1,bf16]> tensor<[1,1,1,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4 * 32 + d5, d6), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4 * 32 + d5, d6), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,1,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4 * 32 + d5, d6), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.multiply | tensor<[1,1,25281,1,1,bf16]> tensor<[1,1,25281,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 808992 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (25281, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 808992 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (25281, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,25281,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 808992 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (25281, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.multiply | tensor<[1,7,1,1,1,bf16]> tensor<[1,7,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 224 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (7, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 224 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (7, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,7,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 224 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (7, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.multiply | tensor<[1,1,1,1,1,bf16]> tensor<[1,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.multiply | tensor<[160,bf16]> tensor<[160,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, bf16>', 'dram') mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, bf16>', 'dram') | tensor<[160,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.multiply | tensor<[1,8,1,1,1,1,bf16]> tensor<[1,8,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 256 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (8, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 256 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (8, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,8,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 256 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (8, 1, 'tile<32x32, bf16>', 'dram') | nan | nan | |
| ttnn.multiply | tensor<[1,1,1,1,1,1,bf16]> tensor<[1,1,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | tensor<[1,1,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
ttnn.permute
This table is a trace for ttnn.permute op. Traces are generated from nightly tt-torch runs. To see nightly runs: Nightly Runs
| Name | Input Shapes | Input Layouts | Attributes | Output Shapes | Output Layouts | PCC | ATOL |
|---|---|---|---|---|---|---|---|
| ttnn.permute | tensor<[1,128,512,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 512 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 2, 3, 1> | tensor<[1,512,512,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 512 + d2, d3), memory_config: (8192, 4, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,512,512,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 512 + d2, d3), memory_config: (8192, 4, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 3, 1, 2> | tensor<[1,128,512,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 512 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,128,512,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 512 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 2, 3, 1> | tensor<[1,512,512,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 512 + d2, d3), memory_config: (8192, 4, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,512,512,3,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 512 + d2, d3), memory_config: (8192, 1, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 3, 1, 2> | tensor<[1,3,512,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1536 + d1 * 512 + d2, d3), memory_config: (48, 16, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,16,14,14,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 512 + d1 * 32 + d2, d3), memory_config: (16, 1, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 2, 3, 1> | tensor<[1,14,14,16,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 448 + d1 * 32 + d2, d3), memory_config: (14, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,14,14,4,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 448 + d1 * 32 + d2, d3), memory_config: (14, 1, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 3, 1, 2> | tensor<[1,4,14,14,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 128 + d1 * 32 + d2, d3), memory_config: (4, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,256,512,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 131072 + d1 * 512 + d2, d3), memory_config: (4096, 16, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 2, 3, 1> | tensor<[1,512,512,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 512 + d2, d3), memory_config: (8192, 8, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,512,512,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 512 + d2, d3), memory_config: (8192, 4, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 3, 1, 2> | tensor<[1,128,512,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 512 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,256,512,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 131072 + d1 * 512 + d2, d3), memory_config: (4096, 16, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 2, 3, 1> | tensor<[1,512,512,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 512 + d2, d3), memory_config: (8192, 8, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,512,512,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 512 + d2, d3), memory_config: (8192, 8, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 3, 1, 2> | tensor<[1,256,512,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 131072 + d1 * 512 + d2, d3), memory_config: (4096, 16, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,3,1024,1024,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 3072 + d1 * 1024 + d2, d3), memory_config: (96, 32, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 2, 3, 1> | tensor<[1,1024,1024,3,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1024 + d2, d3), memory_config: (32768, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,1024,1024,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1024 + d2, d3), memory_config: (32768, 2, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 3, 1, 2> | tensor<[1,64,1024,1024,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 1024 + d2, d3), memory_config: (2048, 32, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,480,256,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 122880 + d1 * 256 + d2, d3), memory_config: (3840, 8, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 2, 3, 1> | tensor<[1,256,256,480,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 256 + d2, d3), memory_config: (2048, 15, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,256,256,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 256 + d2, d3), memory_config: (2048, 2, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 3, 1, 2> | tensor<[1,64,256,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 16384 + d1 * 256 + d2, d3), memory_config: (512, 8, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,512,256,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 131072 + d1 * 256 + d2, d3), memory_config: (4096, 8, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 2, 3, 1> | tensor<[1,256,256,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 256 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,256,256,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 256 + d2, d3), memory_config: (2048, 8, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 3, 1, 2> | tensor<[1,256,256,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 256 + d2, d3), memory_config: (2048, 8, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,512,256,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 131072 + d1 * 256 + d2, d3), memory_config: (4096, 8, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 2, 3, 1> | tensor<[1,256,256,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 256 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,256,256,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 256 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 3, 1, 2> | tensor<[1,512,256,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 131072 + d1 * 256 + d2, d3), memory_config: (4096, 8, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,64,1024,1024,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 1024 + d2, d3), memory_config: (2048, 32, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 2, 3, 1> | tensor<[1,1024,1024,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1024 + d2, d3), memory_config: (32768, 2, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,1024,1024,48,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1024 + d2, d3), memory_config: (32768, 2, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 3, 1, 2> | tensor<[1,48,1024,1024,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 49152 + d1 * 1024 + d2, d3), memory_config: (1536, 32, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,64,256,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 16384 + d1 * 256 + d2, d3), memory_config: (512, 8, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 2, 3, 1> | tensor<[1,256,256,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 256 + d2, d3), memory_config: (2048, 2, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,256,256,98,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 256 + d2, d3), memory_config: (2048, 4, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 3, 1, 2> | tensor<[1,98,256,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 25088 + d1 * 256 + d2, d3), memory_config: (784, 8, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,64,480,640,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 30720 + d1 * 480 + d2, d3), memory_config: (960, 20, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 2, 3, 1> | tensor<[1,480,640,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 640 + d2, d3), memory_config: (9600, 2, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,480,640,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 640 + d2, d3), memory_config: (9600, 1, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 3, 1, 2> | tensor<[1,1,480,640,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 480 + d1 * 480 + d2, d3), memory_config: (15, 20, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,64,480,640,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 30720 + d1 * 480 + d2, d3), memory_config: (960, 20, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 2, 3, 1> | tensor<[1,480,640,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 640 + d2, d3), memory_config: (9600, 2, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,480,640,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 640 + d2, d3), memory_config: (9600, 2, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 3, 1, 2> | tensor<[1,64,480,640,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 30720 + d1 * 480 + d2, d3), memory_config: (960, 20, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,960,128,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 122880 + d1 * 128 + d2, d3), memory_config: (3840, 4, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 2, 3, 1> | tensor<[1,128,128,960,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 16384 + d1 * 128 + d2, d3), memory_config: (512, 30, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,128,128,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 16384 + d1 * 128 + d2, d3), memory_config: (512, 2, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 3, 1, 2> | tensor<[1,64,128,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 128 + d2, d3), memory_config: (256, 4, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,16,28,28,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 512 + d1 * 32 + d2, d3), memory_config: (16, 1, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 2, 3, 1> | tensor<[1,28,28,16,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 896 + d1 * 32 + d2, d3), memory_config: (28, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,14,14,16,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 448 + d1 * 32 + d2, d3), memory_config: (14, 1, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 3, 1, 2> | tensor<[1,16,14,14,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 512 + d1 * 32 + d2, d3), memory_config: (16, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,4,14,14,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 128 + d1 * 32 + d2, d3), memory_config: (4, 1, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 2, 3, 1> | tensor<[1,14,14,4,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 448 + d1 * 32 + d2, d3), memory_config: (14, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,7,7,4,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 224 + d1 * 32 + d2, d3), memory_config: (7, 1, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 3, 1, 2> | tensor<[1,4,7,7,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 128 + d1 * 32 + d2, d3), memory_config: (4, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,528,14,14,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 16896 + d1 * 32 + d2, d3), memory_config: (528, 1, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 2, 3, 1> | tensor<[1,14,14,528,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 448 + d1 * 32 + d2, d3), memory_config: (14, 17, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,14,14,528,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 448 + d1 * 32 + d2, d3), memory_config: (14, 17, 'tile<32x32, bf16>', 'dram') | permutation: array<i64: 0, 3, 1, 2> | tensor<[1,528,14,14,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 16896 + d1 * 32 + d2, d3), memory_config: (528, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.permute | tensor<[1,220,12,1,768,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 84480 + d1 * 384 + d2 * 32 + d3, d4), memory_config: (2640, 24, 'tile<32x32, f32>', 'dram') | permutation: array<i64: 1, 2, 4, 0, 3> | tensor<[220,12,768,1,1,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 294912 + d1 * 24576 + d2 * 32 + d3, d4), memory_config: (2027520, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
ttnn.reshape
This table is a trace for ttnn.reshape op. Traces are generated from nightly tt-torch runs. To see nightly runs: Nightly Runs
| Name | Input Shapes | Input Layouts | Attributes | Output Shapes | Output Layouts | PCC | ATOL |
|---|---|---|---|---|---|---|---|
| ttnn.reshape | tensor<[1,512,512,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 512 + d2, d3), memory_config: (8192, 4, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 1 : i32, 262144 : i32, 128 : i32] | tensor<[1,1,262144,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 4, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1,262144,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 4, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 512 : i32, 512 : i32, 128 : i32] | tensor<[1,512,512,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 512 + d2, d3), memory_config: (8192, 4, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[128,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 4, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 128 : i32, 1 : i32, 1 : i32] | tensor<[1,128,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 4096 + d1 * 32 + d2, d3), memory_config: (128, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,512,512,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 512 + d2, d3), memory_config: (8192, 4, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 1 : i32, 262144 : i32, 128 : i32] | tensor<[1,1,262144,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 4, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1,262144,3,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 1, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 512 : i32, 512 : i32, 3 : i32] | tensor<[1,512,512,3,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 512 + d2, d3), memory_config: (8192, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[3,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 3 : i32, 1 : i32, 1 : i32] | tensor<[1,3,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 96 + d1 * 32 + d2, d3), memory_config: (3, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,14,14,16,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 448 + d1 * 32 + d2, d3), memory_config: (14, 1, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 1 : i32, 196 : i32, 16 : i32] | tensor<[1,1,196,16,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 224 + d1 * 224 + d2, d3), memory_config: (7, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1,196,4,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 224 + d1 * 224 + d2, d3), memory_config: (7, 1, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 14 : i32, 14 : i32, 4 : i32] | tensor<[1,14,14,4,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 448 + d1 * 32 + d2, d3), memory_config: (14, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[4,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 4 : i32, 1 : i32, 1 : i32] | tensor<[1,4,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 128 + d1 * 32 + d2, d3), memory_config: (4, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,512,512,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 512 + d2, d3), memory_config: (8192, 8, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 1 : i32, 262144 : i32, 256 : i32] | tensor<[1,1,262144,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 8, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1,262144,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 4, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 512 : i32, 512 : i32, 128 : i32] | tensor<[1,512,512,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 512 + d2, d3), memory_config: (8192, 4, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[128,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 4, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 128 : i32, 1 : i32, 1 : i32] | tensor<[1,128,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 4096 + d1 * 32 + d2, d3), memory_config: (128, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,512,512,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 512 + d2, d3), memory_config: (8192, 8, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 1 : i32, 262144 : i32, 256 : i32] | tensor<[1,1,262144,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 8, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1,262144,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 8, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 512 : i32, 512 : i32, 256 : i32] | tensor<[1,512,512,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 512 + d2, d3), memory_config: (8192, 8, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[256,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 8, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 256 : i32, 1 : i32, 1 : i32] | tensor<[1,256,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1024,1024,3,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1024 + d2, d3), memory_config: (32768, 1, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 1 : i32, 1048576 : i32, 3 : i32] | tensor<[1,1,1048576,3,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1048576 + d2, d3), memory_config: (32768, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1,1048576,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1048576 + d2, d3), memory_config: (32768, 2, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 1024 : i32, 1024 : i32, 64 : i32] | tensor<[1,1024,1024,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1024 + d2, d3), memory_config: (32768, 2, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[64,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 2, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 64 : i32, 1 : i32, 1 : i32] | tensor<[1,64,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2048 + d1 * 32 + d2, d3), memory_config: (64, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,256,256,480,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 256 + d2, d3), memory_config: (2048, 15, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 1 : i32, 65536 : i32, 480 : i32] | tensor<[1,1,65536,480,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 15, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1,65536,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 2, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 256 : i32, 256 : i32, 64 : i32] | tensor<[1,256,256,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 256 + d2, d3), memory_config: (2048, 2, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[64,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 2, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 64 : i32, 1 : i32, 1 : i32] | tensor<[1,64,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2048 + d1 * 32 + d2, d3), memory_config: (64, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,256,256,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 256 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 1 : i32, 65536 : i32, 512 : i32] | tensor<[1,1,65536,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1,65536,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 8, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 256 : i32, 256 : i32, 256 : i32] | tensor<[1,256,256,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 256 + d2, d3), memory_config: (2048, 8, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[256,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 8, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 256 : i32, 1 : i32, 1 : i32] | tensor<[1,256,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,256,256,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 256 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 1 : i32, 65536 : i32, 512 : i32] | tensor<[1,1,65536,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1,65536,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 256 : i32, 256 : i32, 512 : i32] | tensor<[1,256,256,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 256 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[512,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 16, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 512 : i32, 1 : i32, 1 : i32] | tensor<[1,512,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 16384 + d1 * 32 + d2, d3), memory_config: (512, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1024,1024,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1024 + d2, d3), memory_config: (32768, 2, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 1 : i32, 1048576 : i32, 64 : i32] | tensor<[1,1,1048576,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1048576 + d2, d3), memory_config: (32768, 2, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1,1048576,48,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1048576 + d2, d3), memory_config: (32768, 2, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 1024 : i32, 1024 : i32, 48 : i32] | tensor<[1,1024,1024,48,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1024 + d2, d3), memory_config: (32768, 2, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[48,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 2, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 48 : i32, 1 : i32, 1 : i32] | tensor<[1,48,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1536 + d1 * 32 + d2, d3), memory_config: (48, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,256,256,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 256 + d2, d3), memory_config: (2048, 2, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 1 : i32, 65536 : i32, 64 : i32] | tensor<[1,1,65536,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 2, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1,65536,98,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 4, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 256 : i32, 256 : i32, 98 : i32] | tensor<[1,256,256,98,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 256 + d2, d3), memory_config: (2048, 4, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[98,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 4, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 98 : i32, 1 : i32, 1 : i32] | tensor<[1,98,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 3136 + d1 * 32 + d2, d3), memory_config: (98, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,480,640,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 640 + d2, d3), memory_config: (9600, 2, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 1 : i32, 307200 : i32, 64 : i32] | tensor<[1,1,307200,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 307200 + d2, d3), memory_config: (9600, 2, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1,307200,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 307200 + d2, d3), memory_config: (9600, 1, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 480 : i32, 640 : i32, 1 : i32] | tensor<[1,480,640,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 640 + d2, d3), memory_config: (9600, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,480,640,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 640 + d2, d3), memory_config: (9600, 2, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 1 : i32, 307200 : i32, 64 : i32] | tensor<[1,1,307200,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 307200 + d2, d3), memory_config: (9600, 2, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1,307200,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 307200 + d2, d3), memory_config: (9600, 2, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 480 : i32, 640 : i32, 64 : i32] | tensor<[1,480,640,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 640 + d2, d3), memory_config: (9600, 2, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[64,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 2, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 64 : i32, 1 : i32, 1 : i32] | tensor<[1,64,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2048 + d1 * 32 + d2, d3), memory_config: (64, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,128,128,960,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 16384 + d1 * 128 + d2, d3), memory_config: (512, 30, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 1 : i32, 16384 : i32, 960 : i32] | tensor<[1,1,16384,960,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 16384 + d1 * 16384 + d2, d3), memory_config: (512, 30, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1,16384,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 16384 + d1 * 16384 + d2, d3), memory_config: (512, 2, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 128 : i32, 128 : i32, 64 : i32] | tensor<[1,128,128,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 16384 + d1 * 128 + d2, d3), memory_config: (512, 2, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[64,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 2, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 64 : i32, 1 : i32, 1 : i32] | tensor<[1,64,1,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2048 + d1 * 32 + d2, d3), memory_config: (64, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[16,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | shape: [16 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[16,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (16, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[250,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 8, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 250 : i32, 1 : i32, 1 : i32] | tensor<[1,250,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8000 + d1 * 32 + d2, d3), memory_config: (250, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[16,250,250,ui32]> | mapping_from: (d0, d1, d2), mapping_to: (d0 * 256 + d1, d2), memory_config: (128, 8, 'tile<32x32, u32>', 'dram') | shape: [16 : i32, 250 : i32, 250 : i32, 1 : i32] | tensor<[16,250,250,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64000 + d1 * 256 + d2, d3), memory_config: (32000, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[16,250,512,f32]> | mapping_from: (d0, d1, d2), mapping_to: (d0 * 256 + d1, d2), memory_config: (128, 16, 'tile<32x32, f32>', 'dram') | shape: [2048000 : i32, 1 : i32] | tensor<[2048000,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (64000, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[16,250,250,1,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64000 + d1 * 256 + d2, d3), memory_config: (32000, 1, 'tile<32x32, f32>', 'dram') | shape: [1000000 : i32] | tensor<[1000000,f32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 31250, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1000000,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (31250, 1, 'tile<32x32, f32>', 'dram') | shape: [16 : i32, 250 : i32, 250 : i32] | tensor<[16,250,250,f32]> | mapping_from: (d0, d1, d2), mapping_to: (d0 * 256 + d1, d2), memory_config: (128, 8, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,2640,768,ui32]> | mapping_from: (d0, d1, d2), mapping_to: (d0 * 2656 + d1, d2), memory_config: (83, 24, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 2640 : i32, 768 : i32, 1 : i32] | tensor<[1,2640,768,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2027520 + d1 * 768 + d2, d3), memory_config: (63360, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[768,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 24, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 768 : i32, 1 : i32] | tensor<[1,1,768,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 768 + d1 * 768 + d2, d3), memory_config: (24, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,220,768,f32]> | mapping_from: (d0, d1, d2), mapping_to: (d0 * 224 + d1, d2), memory_config: (7, 24, 'tile<32x32, f32>', 'dram') | shape: [168960 : i32, 1 : i32] | tensor<[168960,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (5280, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,2640,768,1,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2027520 + d1 * 768 + d2, d3), memory_config: (63360, 1, 'tile<32x32, f32>', 'dram') | shape: [2027520 : i32] | tensor<[2027520,f32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 63360, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[2027520,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (63360, 1, 'tile<32x32, f32>', 'dram') | shape: [1 : i32, 2640 : i32, 768 : i32] | tensor<[1,2640,768,f32]> | mapping_from: (d0, d1, d2), mapping_to: (d0 * 2656 + d1, d2), memory_config: (83, 24, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,300,4,ui32]> | mapping_from: (d0, d1, d2), mapping_to: (d0 * 320 + d1, d2), memory_config: (10, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 300 : i32, 4 : i32, 1 : i32] | tensor<[1,300,4,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9600 + d1 * 32 + d2, d3), memory_config: (300, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[4,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 4 : i32, 1 : i32] | tensor<[1,1,4,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,8400,4,f32]> | mapping_from: (d0, d1, d2), mapping_to: (d0 * 8416 + d1, d2), memory_config: (263, 1, 'tile<32x32, f32>', 'dram') | shape: [33600 : i32, 1 : i32] | tensor<[33600,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1050, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,300,4,1,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9600 + d1 * 32 + d2, d3), memory_config: (300, 1, 'tile<32x32, f32>', 'dram') | shape: [1200 : i32] | tensor<[1200,f32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 38, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1200,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (38, 1, 'tile<32x32, f32>', 'dram') | shape: [1 : i32, 300 : i32, 4 : i32] | tensor<[1,300,4,f32]> | mapping_from: (d0, d1, d2), mapping_to: (d0 * 320 + d1, d2), memory_config: (10, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,300,80,ui32]> | mapping_from: (d0, d1, d2), mapping_to: (d0 * 320 + d1, d2), memory_config: (10, 3, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 300 : i32, 80 : i32, 1 : i32] | tensor<[1,300,80,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 28800 + d1 * 96 + d2, d3), memory_config: (900, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[80,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 3, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 80 : i32, 1 : i32] | tensor<[1,1,80,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 96 + d1 * 96 + d2, d3), memory_config: (3, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,8400,80,f32]> | mapping_from: (d0, d1, d2), mapping_to: (d0 * 8416 + d1, d2), memory_config: (263, 3, 'tile<32x32, f32>', 'dram') | shape: [672000 : i32, 1 : i32] | tensor<[672000,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (21000, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,300,80,1,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 28800 + d1 * 96 + d2, d3), memory_config: (900, 1, 'tile<32x32, f32>', 'dram') | shape: [24000 : i32] | tensor<[24000,f32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 750, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[24000,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (750, 1, 'tile<32x32, f32>', 'dram') | shape: [1 : i32, 300 : i32, 80 : i32] | tensor<[1,300,80,f32]> | mapping_from: (d0, d1, d2), mapping_to: (d0 * 320 + d1, d2), memory_config: (10, 3, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[6,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 6 : i32, 1 : i32, 1 : i32] | tensor<[1,1,6,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[16,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 16 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[1,16,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[1,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[192,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 1 : i32, 192 : i32, 1 : i32] | tensor<[1,1,1,192,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 192 + d3, d4), memory_config: (6, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,16,6,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 512 + d1 * 32 + d2, d3), memory_config: (16, 4, 'tile<32x32, bf16>', 'dram') | shape: [12288 : i32, 1 : i32] | tensor<[12288,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (384, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[6,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 6 : i32, 1 : i32, 1 : i32] | tensor<[1,1,6,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[16,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 16 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[1,16,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[1,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[192,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 1 : i32, 192 : i32, 1 : i32] | tensor<[1,1,1,192,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 192 + d3, d4), memory_config: (6, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,16,6,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 512 + d1 * 32 + d2, d3), memory_config: (16, 2, 'tile<32x32, bf16>', 'dram') | shape: [6144 : i32, 1 : i32] | tensor<[6144,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (192, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[3,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 1 : i32, 1 : i32, 3 : i32, 1 : i32, 1 : i32] | tensor<[1,1,1,1,3,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 1 : i32, 1 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[1,1,1,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4 * 32 + d5, d6), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1,1,1,3,4,f32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | shape: [12 : i32, 1 : i32] | tensor<[12,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1,1,1,3,1,1,f32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, f32>', 'dram') | shape: [3 : i32] | tensor<[3,f32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[3,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | shape: [1 : i32, 1 : i32, 1 : i32, 1 : i32, 3 : i32, 1 : i32] | tensor<[1,1,1,1,3,1,f32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[1,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,256,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 256 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[1,256,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 8192 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (256, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,256,7,25281,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 256 : i32, 7 : i32, 25281 : i32, 1 : i32] | tensor<[1,256,7,25281,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,256,14,14,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 1, 'tile<32x32, f32>', 'dram') | shape: [50176 : i32, 1 : i32] | tensor<[50176,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1568, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,256,7,25281,1,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'dram') | shape: [45303552 : i32] | tensor<[45303552,f32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1415736, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[45303552,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1415736, 1, 'tile<32x32, f32>', 'dram') | shape: [1 : i32, 256 : i32, 7 : i32, 25281 : i32] | tensor<[1,256,7,25281,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[1,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,256,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 256 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[1,256,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 8192 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (256, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,256,7,25281,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 256 : i32, 7 : i32, 25281 : i32, 1 : i32] | tensor<[1,256,7,25281,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,256,28,28,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 1, 'tile<32x32, f32>', 'dram') | shape: [200704 : i32, 1 : i32] | tensor<[200704,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (6272, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,256,7,25281,1,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'dram') | shape: [45303552 : i32] | tensor<[45303552,f32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1415736, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[45303552,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1415736, 1, 'tile<32x32, f32>', 'dram') | shape: [1 : i32, 256 : i32, 7 : i32, 25281 : i32] | tensor<[1,256,7,25281,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[1,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,256,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 256 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[1,256,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 8192 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (256, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,256,7,25281,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 256 : i32, 7 : i32, 25281 : i32, 1 : i32] | tensor<[1,256,7,25281,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,256,7,7,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 1, 'tile<32x32, f32>', 'dram') | shape: [12544 : i32, 1 : i32] | tensor<[12544,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (392, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,256,7,25281,1,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'dram') | shape: [45303552 : i32] | tensor<[45303552,f32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1415736, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[45303552,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1415736, 1, 'tile<32x32, f32>', 'dram') | shape: [1 : i32, 256 : i32, 7 : i32, 25281 : i32] | tensor<[1,256,7,25281,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[25281,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 791, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 25281 : i32, 1 : i32, 1 : i32] | tensor<[1,1,25281,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 808992 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (25281, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[7,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 7 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[1,7,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 224 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (7, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[1,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[2,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 1 : i32, 2 : i32, 1 : i32] | tensor<[1,1,1,2,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[8,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 8 : i32, 1 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[1,8,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 256 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (8, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 1 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[1,1,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[160,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 160 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[1,1,160,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 5120 + d1 * 5120 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (160, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[160,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 1 : i32, 160 : i32, 1 : i32, 1 : i32] | tensor<[1,1,1,160,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 5120 + d1 * 5120 + d2 * 5120 + d3 * 32 + d4, d5), memory_config: (160, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,28,28,16,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 896 + d1 * 32 + d2, d3), memory_config: (28, 1, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 1 : i32, 784 : i32, 16 : i32] | tensor<[1,1,784,16,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 800 + d1 * 800 + d2, d3), memory_config: (25, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1,196,16,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 224 + d1 * 224 + d2, d3), memory_config: (7, 1, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 14 : i32, 14 : i32, 16 : i32] | tensor<[1,14,14,16,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 448 + d1 * 32 + d2, d3), memory_config: (14, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,14,14,4,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 448 + d1 * 32 + d2, d3), memory_config: (14, 1, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 1 : i32, 196 : i32, 4 : i32] | tensor<[1,1,196,4,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 224 + d1 * 224 + d2, d3), memory_config: (7, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1,49,4,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64 + d1 * 64 + d2, d3), memory_config: (2, 1, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 7 : i32, 7 : i32, 4 : i32] | tensor<[1,7,7,4,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 224 + d1 * 32 + d2, d3), memory_config: (7, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,14,14,528,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 448 + d1 * 32 + d2, d3), memory_config: (14, 17, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 1 : i32, 196 : i32, 528 : i32] | tensor<[1,1,196,528,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 224 + d1 * 224 + d2, d3), memory_config: (7, 17, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,1,196,528,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 224 + d1 * 224 + d2, d3), memory_config: (7, 17, 'tile<32x32, bf16>', 'dram') | shape: [1 : i32, 14 : i32, 14 : i32, 528 : i32] | tensor<[1,14,14,528,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 448 + d1 * 32 + d2, d3), memory_config: (14, 17, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,256,7,25281,1,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'dram') | shape: [1 : i32, 256 : i32, 7 : i32, 25281 : i32] | tensor<[1,256,7,25281,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,256,7,25281,1,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'dram') | shape: [1 : i32, 256 : i32, 7 : i32, 25281 : i32] | tensor<[1,256,7,25281,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.reshape | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | shape: [1 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
ttnn.slice
This table is a trace for ttnn.slice op. Traces are generated from nightly tt-torch runs. To see nightly runs: Nightly Runs
| Name | Input Shapes | Input Layouts | Attributes | Output Shapes | Output Layouts | PCC | ATOL |
|---|---|---|---|---|---|---|---|
| ttnn.slice | tensor<[1,256,7,25281,2,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'dram') | begins: [0 : i32, 0 : i32, 0 : i32, 0 : i32, 0 : i32] ends: [1 : i32, 256 : i32, 7 : i32, 25281 : i32, 1 : i32] step: [1 : i32, 1 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[1,256,7,25281,1,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.slice | tensor<[1,256,7,25281,2,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45303552 + d1 * 176967 + d2 * 25281 + d3, d4), memory_config: (45303552, 2, 'f32', 'dram') | begins: [0 : i32, 0 : i32, 0 : i32, 0 : i32, 1 : i32] ends: [1 : i32, 256 : i32, 7 : i32, 25281 : i32, 2 : i32] step: [1 : i32, 1 : i32, 1 : i32, 1 : i32, 1 : i32] | tensor<[1,256,7,25281,1,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45303552 + d1 * 176967 + d2 * 25281 + d3, d4), memory_config: (45303552, 1, 'f32', 'dram') | nan | nan |
ttnn.to_device
This table is a trace for ttnn.to_device op. Traces are generated from nightly tt-torch runs. To see nightly runs: Nightly Runs
| Name | Input Shapes | Input Layouts | Attributes | Output Shapes | Output Layouts | PCC | ATOL |
|---|---|---|---|---|---|---|---|
| ttnn.to_device | tensor<[1,1,262144,128,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (262144, 128, 'bf16', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<262144x128>>, | tensor<[1,1,262144,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (262144, 128, 'bf16', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,1,262144,128,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (262144, 128, 'bf16', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<262144x128>>, | tensor<[1,1,262144,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (262144, 128, 'bf16', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,1,196,16,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 196 + d1 * 196 + d2, d3), memory_config: (196, 16, 'bf16', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<196x16>>, | tensor<[1,1,196,16,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 196 + d1 * 196 + d2, d3), memory_config: (196, 16, 'bf16', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,1,262144,256,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (262144, 256, 'bf16', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<262144x256>>, | tensor<[1,1,262144,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (262144, 256, 'bf16', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,1,262144,256,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (262144, 256, 'bf16', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<262144x256>>, | tensor<[1,1,262144,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (262144, 256, 'bf16', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,1,1048576,3,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1048576 + d2, d3), memory_config: (1048576, 3, 'bf16', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1048576x3>>, | tensor<[1,1,1048576,3,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1048576 + d2, d3), memory_config: (1048576, 3, 'bf16', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,1,65536,480,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (65536, 480, 'bf16', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<65536x480>>, | tensor<[1,1,65536,480,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (65536, 480, 'bf16', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,1,65536,512,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (65536, 512, 'bf16', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<65536x512>>, | tensor<[1,1,65536,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (65536, 512, 'bf16', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,1,65536,512,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (65536, 512, 'bf16', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<65536x512>>, | tensor<[1,1,65536,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (65536, 512, 'bf16', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,1,1048576,64,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1048576 + d2, d3), memory_config: (1048576, 64, 'bf16', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1048576x64>>, | tensor<[1,1,1048576,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1048576 + d2, d3), memory_config: (1048576, 64, 'bf16', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,1,65536,64,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (65536, 64, 'bf16', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<65536x64>>, | tensor<[1,1,65536,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (65536, 64, 'bf16', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,1,307200,64,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 307200 + d2, d3), memory_config: (307200, 64, 'bf16', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<307200x64>>, | tensor<[1,1,307200,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 307200 + d2, d3), memory_config: (307200, 64, 'bf16', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,1,307200,64,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 307200 + d2, d3), memory_config: (307200, 64, 'bf16', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<307200x64>>, | tensor<[1,1,307200,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 307200 + d2, d3), memory_config: (307200, 64, 'bf16', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,1,16384,960,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 16384 + d1 * 16384 + d2, d3), memory_config: (16384, 960, 'bf16', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<16384x960>>, | tensor<[1,1,16384,960,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 16384 + d1 * 16384 + d2, d3), memory_config: (16384, 960, 'bf16', 'dram') | nan | nan |
| ttnn.to_device | tensor<[3,1,f32]> !ttnn.device | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[3,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[16,si32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[16,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[250,si32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 8, 'tile<32x32, si32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x8>>, | tensor<[250,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 8, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1000000,ui32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1000000, 'ui32', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1000000>>, | tensor<[1000000,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1000000, 'ui32', 'dram') | nan | nan |
| ttnn.to_device | tensor<[3,1,f32]> !ttnn.device | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[3,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,si32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[768,si32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 24, 'tile<32x32, si32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x24>>, | tensor<[768,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 24, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[2027520,ui32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 2027520, 'ui32', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x2027520>>, | tensor<[2027520,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 2027520, 'ui32', 'dram') | nan | nan |
| ttnn.to_device | tensor<[3,1,f32]> !ttnn.device | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[3,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,si32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[4,si32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[4,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1200,ui32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1200, 'ui32', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1200>>, | tensor<[1200,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1200, 'ui32', 'dram') | nan | nan |
| ttnn.to_device | tensor<[3,1,f32]> !ttnn.device | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[3,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,si32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[80,si32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 3, 'tile<32x32, si32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x3>>, | tensor<[80,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 3, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[24000,ui32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 24000, 'ui32', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x24000>>, | tensor<[24000,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 24000, 'ui32', 'dram') | nan | nan |
| ttnn.to_device | tensor<[4,1,f32]> !ttnn.device | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[6,si32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[6,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[6,ui32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[6,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[16,si32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[16,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[16,ui32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[16,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,si32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,ui32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[4,1,f32]> !ttnn.device | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[6,si32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[6,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[6,ui32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[6,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[16,si32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[16,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[16,ui32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[16,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,si32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,ui32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[6,1,f32]> !ttnn.device | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[6,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[3,si32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[3,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[3,ui32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[3,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,si32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,ui32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[3,ui32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 3, 'ui32', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x3>>, | tensor<[3,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 3, 'ui32', 'dram') | nan | nan |
| ttnn.to_device | tensor<[4,1,f32]> !ttnn.device | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[45303552,ui32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 45303552, 'ui32', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x45303552>>, | tensor<[45303552,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 45303552, 'ui32', 'dram') | nan | nan |
| ttnn.to_device | tensor<[4,1,f32]> !ttnn.device | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[45303552,ui32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 45303552, 'ui32', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x45303552>>, | tensor<[45303552,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 45303552, 'ui32', 'dram') | nan | nan |
| ttnn.to_device | tensor<[4,1,f32]> !ttnn.device | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[45303552,ui32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 45303552, 'ui32', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x45303552>>, | tensor<[45303552,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 45303552, 'ui32', 'dram') | nan | nan |
| ttnn.to_device | tensor<[4,1,f32]> !ttnn.device | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[25281,si32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 791, 'tile<32x32, si32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x791>>, | tensor<[25281,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 791, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[25281,ui32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 791, 'tile<32x32, u32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x791>>, | tensor<[25281,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 791, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[7,si32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[7,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[7,ui32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[7,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,si32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,ui32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[5,1,f32]> !ttnn.device | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[5,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[160,ui32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, u32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x5>>, | tensor<[160,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[160,si32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, si32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x5>>, | tensor<[160,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[8,si32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[8,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[8,ui32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[8,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,si32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,ui32]> !ttnn.device | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1x1>>, | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,1,784,16,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 784 + d1 * 784 + d2, d3), memory_config: (784, 16, 'bf16', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<784x16>>, | tensor<[1,1,784,16,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 784 + d1 * 784 + d2, d3), memory_config: (784, 16, 'bf16', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,1,196,4,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 196 + d1 * 196 + d2, d3), memory_config: (196, 4, 'bf16', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<196x4>>, | tensor<[1,1,196,4,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 196 + d1 * 196 + d2, d3), memory_config: (196, 4, 'bf16', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,1,196,528,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 196 + d1 * 196 + d2, d3), memory_config: (196, 528, 'bf16', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<196x528>>, | tensor<[1,1,196,528,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 196 + d1 * 196 + d2, d3), memory_config: (196, 528, 'bf16', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,256,7,25281,2,f32]> !ttnn.device | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45303552 + d1 * 176967 + d2 * 25281 + d3, d4), memory_config: (45303552, 2, 'f32', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<45303552x2>>, | tensor<[1,256,7,25281,2,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45303552 + d1 * 176967 + d2 * 25281 + d3, d4), memory_config: (45303552, 2, 'f32', 'dram') | nan | nan |
| ttnn.to_device | tensor<[1,256,7,25281,1,f32]> !ttnn.device | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'system_memory') | memory_config: #ttnn.memory_config<#dram, <<1417472x1>>, | tensor<[1,256,7,25281,1,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
ttnn.to_layout
This table is a trace for ttnn.to_layout op. Traces are generated from nightly tt-torch runs. To see nightly runs: Nightly Runs
| Name | Input Shapes | Input Layouts | Attributes | Output Shapes | Output Layouts | PCC | ATOL |
|---|---|---|---|---|---|---|---|
| ttnn.to_layout | tensor<[1,1,262144,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 4, 'tile<32x32, bf16>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[1,1,262144,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (262144, 128, 'bf16', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,1,262144,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 4, 'tile<32x32, bf16>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[1,1,262144,128,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (262144, 128, 'bf16', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,1,196,16,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 224 + d1 * 224 + d2, d3), memory_config: (7, 1, 'tile<32x32, bf16>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[1,1,196,16,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 196 + d1 * 196 + d2, d3), memory_config: (196, 16, 'bf16', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,1,262144,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 8, 'tile<32x32, bf16>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[1,1,262144,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (262144, 256, 'bf16', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,1,262144,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (8192, 8, 'tile<32x32, bf16>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[1,1,262144,256,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 262144 + d1 * 262144 + d2, d3), memory_config: (262144, 256, 'bf16', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,1,1048576,3,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1048576 + d2, d3), memory_config: (32768, 1, 'tile<32x32, bf16>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[1,1,1048576,3,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1048576 + d2, d3), memory_config: (1048576, 3, 'bf16', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,1,65536,480,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 15, 'tile<32x32, bf16>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[1,1,65536,480,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (65536, 480, 'bf16', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,1,65536,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[1,1,65536,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (65536, 512, 'bf16', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,1,65536,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 16, 'tile<32x32, bf16>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[1,1,65536,512,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (65536, 512, 'bf16', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,1,1048576,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1048576 + d2, d3), memory_config: (32768, 2, 'tile<32x32, bf16>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[1,1,1048576,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 1048576 + d1 * 1048576 + d2, d3), memory_config: (1048576, 64, 'bf16', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,1,65536,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (2048, 2, 'tile<32x32, bf16>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[1,1,65536,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 65536 + d1 * 65536 + d2, d3), memory_config: (65536, 64, 'bf16', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,1,307200,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 307200 + d2, d3), memory_config: (9600, 2, 'tile<32x32, bf16>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[1,1,307200,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 307200 + d2, d3), memory_config: (307200, 64, 'bf16', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,1,307200,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 307200 + d2, d3), memory_config: (9600, 2, 'tile<32x32, bf16>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[1,1,307200,64,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 307200 + d1 * 307200 + d2, d3), memory_config: (307200, 64, 'bf16', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,1,16384,960,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 16384 + d1 * 16384 + d2, d3), memory_config: (512, 30, 'tile<32x32, bf16>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[1,1,16384,960,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 16384 + d1 * 16384 + d2, d3), memory_config: (16384, 960, 'bf16', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[3,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (3, 1, 'f32', 'system_memory') | layout: #ttnn.layout | tensor<[3,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[16,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 16, 'si32', 'system_memory') | layout: #ttnn.layout | tensor<[16,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[250,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 250, 'si32', 'system_memory') | layout: #ttnn.layout | tensor<[250,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 8, 'tile<32x32, si32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1000000,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 31250, 'tile<32x32, u32>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[1000000,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1000000, 'ui32', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[3,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (3, 1, 'f32', 'system_memory') | layout: #ttnn.layout | tensor<[3,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'system_memory') | layout: #ttnn.layout | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[768,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 768, 'si32', 'system_memory') | layout: #ttnn.layout | tensor<[768,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 24, 'tile<32x32, si32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[2027520,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 63360, 'tile<32x32, u32>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[2027520,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 2027520, 'ui32', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[3,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (3, 1, 'f32', 'system_memory') | layout: #ttnn.layout | tensor<[3,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'system_memory') | layout: #ttnn.layout | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[4,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 4, 'si32', 'system_memory') | layout: #ttnn.layout | tensor<[4,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1200,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 38, 'tile<32x32, u32>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[1200,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1200, 'ui32', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[3,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (3, 1, 'f32', 'system_memory') | layout: #ttnn.layout | tensor<[3,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'system_memory') | layout: #ttnn.layout | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[80,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 80, 'si32', 'system_memory') | layout: #ttnn.layout | tensor<[80,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 3, 'tile<32x32, si32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[24000,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 750, 'tile<32x32, u32>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[24000,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 24000, 'ui32', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (4, 1, 'f32', 'system_memory') | layout: #ttnn.layout | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[6,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'si32', 'system_memory') | layout: #ttnn.layout | tensor<[6,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[6,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'ui32', 'system_memory') | layout: #ttnn.layout | tensor<[6,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[16,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 16, 'si32', 'system_memory') | layout: #ttnn.layout | tensor<[16,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[16,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 16, 'ui32', 'system_memory') | layout: #ttnn.layout | tensor<[16,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'system_memory') | layout: #ttnn.layout | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'system_memory') | layout: #ttnn.layout | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (4, 1, 'f32', 'system_memory') | layout: #ttnn.layout | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[6,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'si32', 'system_memory') | layout: #ttnn.layout | tensor<[6,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[6,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'ui32', 'system_memory') | layout: #ttnn.layout | tensor<[6,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[16,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 16, 'si32', 'system_memory') | layout: #ttnn.layout | tensor<[16,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[16,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 16, 'ui32', 'system_memory') | layout: #ttnn.layout | tensor<[16,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'system_memory') | layout: #ttnn.layout | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'system_memory') | layout: #ttnn.layout | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[6,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (6, 1, 'f32', 'system_memory') | layout: #ttnn.layout | tensor<[6,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[3,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 3, 'si32', 'system_memory') | layout: #ttnn.layout | tensor<[3,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[3,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 3, 'ui32', 'system_memory') | layout: #ttnn.layout | tensor<[3,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'system_memory') | layout: #ttnn.layout | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'system_memory') | layout: #ttnn.layout | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[3,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[3,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 3, 'ui32', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (4, 1, 'f32', 'system_memory') | layout: #ttnn.layout | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[45303552,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1415736, 'tile<32x32, u32>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[45303552,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 45303552, 'ui32', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (4, 1, 'f32', 'system_memory') | layout: #ttnn.layout | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[45303552,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1415736, 'tile<32x32, u32>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[45303552,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 45303552, 'ui32', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (4, 1, 'f32', 'system_memory') | layout: #ttnn.layout | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[45303552,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1415736, 'tile<32x32, u32>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[45303552,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 45303552, 'ui32', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (4, 1, 'f32', 'system_memory') | layout: #ttnn.layout | tensor<[4,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[25281,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 25281, 'si32', 'system_memory') | layout: #ttnn.layout | tensor<[25281,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 791, 'tile<32x32, si32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[25281,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 25281, 'ui32', 'system_memory') | layout: #ttnn.layout | tensor<[25281,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 791, 'tile<32x32, u32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[7,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 7, 'si32', 'system_memory') | layout: #ttnn.layout | tensor<[7,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[7,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 7, 'ui32', 'system_memory') | layout: #ttnn.layout | tensor<[7,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'system_memory') | layout: #ttnn.layout | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'system_memory') | layout: #ttnn.layout | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[5,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (5, 1, 'f32', 'system_memory') | layout: #ttnn.layout | tensor<[5,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[160,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 160, 'ui32', 'system_memory') | layout: #ttnn.layout | tensor<[160,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, u32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[160,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 160, 'si32', 'system_memory') | layout: #ttnn.layout | tensor<[160,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, si32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[8,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 8, 'si32', 'system_memory') | layout: #ttnn.layout | tensor<[8,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[8,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 8, 'ui32', 'system_memory') | layout: #ttnn.layout | tensor<[8,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'si32', 'system_memory') | layout: #ttnn.layout | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'ui32', 'system_memory') | layout: #ttnn.layout | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,1,784,16,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 800 + d1 * 800 + d2, d3), memory_config: (25, 1, 'tile<32x32, bf16>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[1,1,784,16,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 784 + d1 * 784 + d2, d3), memory_config: (784, 16, 'bf16', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,1,196,16,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 196 + d1 * 196 + d2, d3), memory_config: (196, 16, 'bf16', 'dram') | layout: #ttnn.layout | tensor<[1,1,196,16,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 224 + d1 * 224 + d2, d3), memory_config: (7, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.to_layout | tensor<[1,1,196,4,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 224 + d1 * 224 + d2, d3), memory_config: (7, 1, 'tile<32x32, bf16>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[1,1,196,4,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 196 + d1 * 196 + d2, d3), memory_config: (196, 4, 'bf16', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,1,49,4,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 49 + d1 * 49 + d2, d3), memory_config: (49, 4, 'bf16', 'dram') | layout: #ttnn.layout | tensor<[1,1,49,4,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64 + d1 * 64 + d2, d3), memory_config: (2, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.to_layout | tensor<[1,1,196,528,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 224 + d1 * 224 + d2, d3), memory_config: (7, 17, 'tile<32x32, bf16>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[1,1,196,528,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 196 + d1 * 196 + d2, d3), memory_config: (196, 528, 'bf16', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,1,196,528,bf16]> !ttnn.device | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 196 + d1 * 196 + d2, d3), memory_config: (196, 528, 'bf16', 'dram') | layout: #ttnn.layout | tensor<[1,1,196,528,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 224 + d1 * 224 + d2, d3), memory_config: (7, 17, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.to_layout | tensor<[1,256,7,25281,2,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'system_memory') | layout: #ttnn.layout<row_major> | tensor<[1,256,7,25281,2,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45303552 + d1 * 176967 + d2 * 25281 + d3, d4), memory_config: (45303552, 2, 'f32', 'system_memory') | nan | nan |
| ttnn.to_layout | tensor<[1,256,7,25281,1,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45303552 + d1 * 176967 + d2 * 25281 + d3, d4), memory_config: (45303552, 1, 'f32', 'system_memory') | layout: #ttnn.layout | tensor<[1,256,7,25281,1,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'system_memory') | nan | nan |
ttnn.typecast
This table is a trace for ttnn.typecast op. Traces are generated from nightly tt-torch runs. To see nightly runs: Nightly Runs
| Name | Input Shapes | Input Layouts | Attributes | Output Shapes | Output Layouts | PCC | ATOL |
|---|---|---|---|---|---|---|---|
| ttnn.typecast | tensor<[16,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[16,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[16,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (16, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[16,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (16, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[16,250,250,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64000 + d1 * 256 + d2, d3), memory_config: (32000, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[16,250,250,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64000 + d1 * 256 + d2, d3), memory_config: (32000, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[250,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 8, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[250,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 8, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,250,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8000 + d1 * 32 + d2, d3), memory_config: (250, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,250,1,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8000 + d1 * 32 + d2, d3), memory_config: (250, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[16,250,250,si32]> | mapping_from: (d0, d1, d2), mapping_to: (d0 * 256 + d1, d2), memory_config: (128, 8, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[16,250,250,ui32]> | mapping_from: (d0, d1, d2), mapping_to: (d0 * 256 + d1, d2), memory_config: (128, 8, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[16,250,250,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64000 + d1 * 256 + d2, d3), memory_config: (32000, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[16,250,250,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64000 + d1 * 256 + d2, d3), memory_config: (32000, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[16,250,250,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64000 + d1 * 256 + d2, d3), memory_config: (32000, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[16,250,250,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64000 + d1 * 256 + d2, d3), memory_config: (32000, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[16,250,250,3,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64000 + d1 * 256 + d2, d3), memory_config: (32000, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[16,250,250,3,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64000 + d1 * 256 + d2, d3), memory_config: (32000, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[16,250,250,3,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64000 + d1 * 256 + d2, d3), memory_config: (32000, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[16,250,250,3,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 64000 + d1 * 256 + d2, d3), memory_config: (32000, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1000000,f32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 31250, 'tile<32x32, f32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1000000,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 31250, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[2048000,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (64000, 1, 'tile<32x32, f32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[2048000,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (64000, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1000000,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (31250, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1000000,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (31250, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,2640,768,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2027520 + d1 * 768 + d2, d3), memory_config: (63360, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,2640,768,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2027520 + d1 * 768 + d2, d3), memory_config: (63360, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,2640,768,si32]> | mapping_from: (d0, d1, d2), mapping_to: (d0 * 2656 + d1, d2), memory_config: (83, 24, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,2640,768,ui32]> | mapping_from: (d0, d1, d2), mapping_to: (d0 * 2656 + d1, d2), memory_config: (83, 24, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[768,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 24, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[768,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 24, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,768,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 768 + d1 * 768 + d2, d3), memory_config: (24, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,768,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 768 + d1 * 768 + d2, d3), memory_config: (24, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,2640,768,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2027520 + d1 * 768 + d2, d3), memory_config: (63360, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,2640,768,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2027520 + d1 * 768 + d2, d3), memory_config: (63360, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,2640,768,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2027520 + d1 * 768 + d2, d3), memory_config: (63360, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,2640,768,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2027520 + d1 * 768 + d2, d3), memory_config: (63360, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,2640,768,3,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2027520 + d1 * 768 + d2, d3), memory_config: (63360, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,2640,768,3,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2027520 + d1 * 768 + d2, d3), memory_config: (63360, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,2640,768,3,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2027520 + d1 * 768 + d2, d3), memory_config: (63360, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,2640,768,3,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 2027520 + d1 * 768 + d2, d3), memory_config: (63360, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[2027520,f32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 63360, 'tile<32x32, f32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[2027520,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 63360, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[168960,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (5280, 1, 'tile<32x32, f32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[168960,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (5280, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[2027520,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (63360, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[2027520,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (63360, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,300,4,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9600 + d1 * 32 + d2, d3), memory_config: (300, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,300,4,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9600 + d1 * 32 + d2, d3), memory_config: (300, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,300,4,si32]> | mapping_from: (d0, d1, d2), mapping_to: (d0 * 320 + d1, d2), memory_config: (10, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,300,4,ui32]> | mapping_from: (d0, d1, d2), mapping_to: (d0 * 320 + d1, d2), memory_config: (10, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[4,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[4,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,4,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,4,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,300,4,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9600 + d1 * 32 + d2, d3), memory_config: (300, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,300,4,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9600 + d1 * 32 + d2, d3), memory_config: (300, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,300,4,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9600 + d1 * 32 + d2, d3), memory_config: (300, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,300,4,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9600 + d1 * 32 + d2, d3), memory_config: (300, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,300,4,3,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9600 + d1 * 32 + d2, d3), memory_config: (300, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,300,4,3,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9600 + d1 * 32 + d2, d3), memory_config: (300, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,300,4,3,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9600 + d1 * 32 + d2, d3), memory_config: (300, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,300,4,3,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 9600 + d1 * 32 + d2, d3), memory_config: (300, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1200,f32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 38, 'tile<32x32, f32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1200,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 38, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[33600,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1050, 1, 'tile<32x32, f32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[33600,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1050, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1200,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (38, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1200,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (38, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,300,80,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 28800 + d1 * 96 + d2, d3), memory_config: (900, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,300,80,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 28800 + d1 * 96 + d2, d3), memory_config: (900, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,300,80,si32]> | mapping_from: (d0, d1, d2), mapping_to: (d0 * 320 + d1, d2), memory_config: (10, 3, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,300,80,ui32]> | mapping_from: (d0, d1, d2), mapping_to: (d0 * 320 + d1, d2), memory_config: (10, 3, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[80,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 3, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[80,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 3, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,80,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 96 + d1 * 96 + d2, d3), memory_config: (3, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,80,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 96 + d1 * 96 + d2, d3), memory_config: (3, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,300,80,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 28800 + d1 * 96 + d2, d3), memory_config: (900, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,300,80,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 28800 + d1 * 96 + d2, d3), memory_config: (900, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,300,80,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 28800 + d1 * 96 + d2, d3), memory_config: (900, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,300,80,1,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 28800 + d1 * 96 + d2, d3), memory_config: (900, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,300,80,3,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 28800 + d1 * 96 + d2, d3), memory_config: (900, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,300,80,3,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 28800 + d1 * 96 + d2, d3), memory_config: (900, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,300,80,3,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 28800 + d1 * 96 + d2, d3), memory_config: (900, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,300,80,3,f32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 28800 + d1 * 96 + d2, d3), memory_config: (900, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[24000,f32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 750, 'tile<32x32, f32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[24000,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 750, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[672000,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (21000, 1, 'tile<32x32, f32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[672000,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (21000, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[24000,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (750, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[24000,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (750, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[6,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[6,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,6,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,6,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,6,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,6,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,6,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,6,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[16,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[16,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,16,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,16,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,16,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,16,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,16,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,16,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,16,6,192,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,16,6,192,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[192,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[192,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,192,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 192 + d3, d4), memory_config: (6, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,192,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 192 + d3, d4), memory_config: (6, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,16,6,192,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,16,6,192,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,16,6,192,4,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,16,6,192,4,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | nan | nan | |||||
| ttnn.typecast | tensor<[6,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[6,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,6,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,6,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,6,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,6,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,6,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,6,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 32 + d3, d4), memory_config: (6, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[16,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[16,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,16,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,16,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,16,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,16,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,16,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,16,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 512 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (16, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,16,6,192,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,16,6,192,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[192,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[192,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 6, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,192,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 192 + d3, d4), memory_config: (6, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,192,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 192 + d1 * 192 + d2 * 192 + d3, d4), memory_config: (6, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,16,6,192,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,16,6,192,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,16,6,192,4,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,16,6,192,4,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 18432 + d1 * 1152 + d2 * 192 + d3, d4), memory_config: (576, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | nan | nan | |||||
| ttnn.typecast | tensor<[3,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[3,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,3,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,3,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,3,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,3,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,3,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,3,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4 * 32 + d5, d6), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4 * 32 + d5, d6), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4 * 32 + d5, d6), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4 * 32 + d5, d6), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4 * 32 + d5, d6), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4 * 32 + d5, d6), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,3,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,3,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,3,1,6,bf16]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,3,1,6,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,3,1,6,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,3,1,6,f32]> | mapping_from: (d0, d1, d2, d3, d4, d5, d6), mapping_to: (d0 * 96 + d1 * 96 + d2 * 96 + d3 * 96 + d4 * 32 + d5, d6), memory_config: (3, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[3,f32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[3,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[12,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[12,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[3,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[3,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,7,25281,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,7,25281,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,1,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 8192 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (256, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 8192 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (256, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,7,25281,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,7,25281,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,7,25281,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,7,25281,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,7,25281,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,7,25281,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,7,25281,4,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,7,25281,4,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,7,25281,4,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,7,25281,4,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[45303552,f32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1415736, 'tile<32x32, f32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[45303552,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1415736, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[50176,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1568, 1, 'tile<32x32, f32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[50176,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1568, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[45303552,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1415736, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[45303552,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1415736, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,7,25281,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,7,25281,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,1,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 8192 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (256, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 8192 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (256, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,7,25281,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,7,25281,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,7,25281,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,7,25281,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,7,25281,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,7,25281,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,7,25281,4,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,7,25281,4,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,7,25281,4,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,7,25281,4,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[45303552,f32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1415736, 'tile<32x32, f32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[45303552,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1415736, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[200704,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (6272, 1, 'tile<32x32, f32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[200704,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (6272, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[45303552,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1415736, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[45303552,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1415736, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,7,25281,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,7,25281,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,1,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 8192 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (256, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 8192 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (256, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,7,25281,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,7,25281,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,7,25281,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,7,25281,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,7,25281,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,7,25281,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,7,25281,4,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,7,25281,4,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,7,25281,4,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,7,25281,4,f32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 45359104 + d1 * 177184 + d2 * 25312 + d3, d4), memory_config: (1417472, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[45303552,f32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1415736, 'tile<32x32, f32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[45303552,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1415736, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[12544,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (392, 1, 'tile<32x32, f32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[12544,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (392, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[45303552,1,bf16]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1415736, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[45303552,1,f32]> | mapping_from: (d0, d1), mapping_to: (d0, d1), memory_config: (1415736, 1, 'tile<32x32, f32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[25281,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 791, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[25281,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 791, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,25281,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 808992 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (25281, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,25281,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 808992 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (25281, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,25281,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 808992 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (25281, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,25281,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 808992 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (25281, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,25281,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 808992 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (25281, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,25281,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 808992 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (25281, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[7,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[7,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,7,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 224 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (7, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,7,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 224 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (7, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,7,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 224 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (7, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,7,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 224 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (7, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,7,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 224 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (7, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,7,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 224 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (7, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,7,25281,2,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 5662944 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (176967, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,7,25281,2,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 5662944 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (176967, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[2,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[2,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,2,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,2,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3, d4), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,7,25281,2,1,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 5662944 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (176967, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,7,25281,2,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 5662944 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (176967, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,7,25281,2,4,bf16]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 5662944 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (176967, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,7,25281,2,4,si32]> | mapping_from: (d0, d1, d2, d3, d4), mapping_to: (d0 * 5662944 + d1 * 808992 + d2 * 32 + d3, d4), memory_config: (176967, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[160,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[160,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[160,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[160,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[160,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[160,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[160,bf16]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[160,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[8,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[8,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,8,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 256 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (8, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,8,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 256 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (8, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,8,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 256 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (8, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,8,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 256 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (8, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,8,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 256 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (8, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,8,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 256 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (8, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (1, 1, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 32 + d1 * 32 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,8,160,160,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 6553600 + d1 * 819200 + d2 * 5120 + d3 * 32 + d4, d5), memory_config: (204800, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,8,160,160,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 6553600 + d1 * 819200 + d2 * 5120 + d3 * 32 + d4, d5), memory_config: (204800, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[160,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[160,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 5, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,160,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 5120 + d1 * 5120 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (160, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,160,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 5120 + d1 * 5120 + d2 * 32 + d3 * 32 + d4, d5), memory_config: (160, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,160,1,1,ui32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 5120 + d1 * 5120 + d2 * 5120 + d3 * 32 + d4, d5), memory_config: (160, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,160,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 5120 + d1 * 5120 + d2 * 5120 + d3 * 32 + d4, d5), memory_config: (160, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,8,160,160,1,1,si32]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 6553600 + d1 * 819200 + d2 * 5120 + d3 * 32 + d4, d5), memory_config: (204800, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,8,160,160,1,1,bf16]> | mapping_from: (d0, d1, d2, d3, d4, d5), mapping_to: (d0 * 6553600 + d1 * 819200 + d2 * 5120 + d3 * 32 + d4, d5), memory_config: (204800, 1, 'tile<32x32, bf16>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,si32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,ui32]> | mapping_from: (d0), mapping_to: (0, d0), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,1,1,1,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,1,1,1,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 32 + d1 * 32 + d2, d3), memory_config: (1, 1, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,7,25281,ui32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, u32>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,7,25281,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, si32>', 'dram') | nan | nan |
| ttnn.typecast | tensor<[1,256,7,25281,bf16]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, bf16>', 'dram') | dtype: #tt.supportedDataTypes | tensor<[1,256,7,25281,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, si32>', 'dram') | nan | nan |
ttnn.where
This table is a trace for ttnn.where op. Traces are generated from nightly tt-torch runs. To see nightly runs: Nightly Runs
| Name | Input Shapes | Input Layouts | Attributes | Output Shapes | Output Layouts | PCC | ATOL |
|---|---|---|---|---|---|---|---|
| ttnn.where | tensor<[1,256,7,25281,si32]> tensor<[1,256,7,25281,si32]> tensor<[1,256,7,25281,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, si32>', 'dram') mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, si32>', 'dram') | tensor<[1,256,7,25281,si32]> | mapping_from: (d0, d1, d2, d3), mapping_to: (d0 * 8192 + d1 * 32 + d2, d3), memory_config: (256, 791, 'tile<32x32, si32>', 'dram') | nan | nan |