Explore Tenstorrent hardware & software for the first time
Six chapters from first boot to first model.
6 chapters · 41 min read time
What to Know About Your Workstation
Your workstation is a Tenstorrent Quietbox 2: four AI accelerators inside, an operating system you may not have used before, and the software stack already configured and waiting. The machine is ready to go — what’s left is knowing what you’ve got.
This guide doesn’t assume you know Linux, or Python, or what a PCIe slot is. It assumes you’re curious, and that curiosity is enough.
What’s Inside
The Tenstorrent Quietbox 2 (QB2) is a workstation with two Blackhole p300c cards — four Blackhole chips in total — on PCIe. Each p300c is a dual-chip card, and each chip is independent — four separate devices from the software’s point of view, connected to a standard CPU running Ubuntu 24.04 LTS.
| What | Detail |
|---|---|
| AI chips | 2× Blackhole p300c cards (4 Blackhole chips) |
| Tensix cores per chip | 120 (12×10 compute grid) |
| Connection | PCIe Gen4 (4 independent devices) |
| OS | Ubuntu 24.04 LTS |
| Pre-installed | TTNN, vLLM, tt-smi, drivers, Python venvs |
| Source tree | Not included — ~/tt-metal has venvs, not source |
The chips don’t share memory. When you open device 0, you’re talking to one Blackhole chip. To use all four together, you use ttnn.CreateDevices({0, 1, 2, 3}) — not four separate open_device() calls.

What Ships Pre-Installed
Tenstorrent ships the QB2 ready to serve models. You don’t install drivers. You don’t compile anything. The full stack is already there:
- Kernel driver — loaded automatically at boot, makes the chips visible to software
tt-smi— hardware monitoring tool, lives at/usr/bin/tt-smi- TTNN Python environment — pre-built venv at
~/tt-metal/python_env/ - vLLM — in the main tenstorrent venv at
~/.tenstorrent-venv/ - TT-Forge/XLA — container wrapper at
~/.local/bin/tt-forge - tt-studio — the no-code web UI for serving models, pre-installed (launch with
tt-studio) - A ready-to-run model — Qwen3-32B, weights pre-cached on disk, deployable from tt-studio with no download (your fastest path to a first token: launch
tt-studio, pick it, click Run) - Firmware — already flashed to all four chips
What’s intentionally absent: the ~/tt-metal source code. The environments are there; the source isn’t. You can build models, run inference, and work with the full API stack without it. Building from source is a later chapter — a much later chapter.
Physical Tour
The QB2 looks like a standard tower workstation. On the inside:
- CPU and motherboard running Ubuntu 24.04 LTS
- Two Blackhole p300c cards (four Blackhole chips total)
- RAM sized for production inference workloads
- Storage for model weights — but watch it carefully (more on that in Chapter 2)
The chips run warm under load. Fans will get louder when you run inference. This is correct. The cooling is designed for sustained operation at full chip temperature.
One Blackhole chip. You have four, on two p300c cards.
Next: First Boot →
First Boot
Power on. Ubuntu loads. You log in. Now what?
Everything from here happens in a terminal. That’s the command line — a text window where you type instructions and the machine responds. On a QB2, the terminal is your instrument panel. Learning its three or four most-used commands will get you surprisingly far.
Finding a Terminal
If you’re looking at the GNOME desktop:
- Press
Ctrl+Alt+T— opens a terminal on most Ubuntu setups - Or press the Super key (Windows key), type
terminal, press Enter - Or right-click the desktop and choose “Open Terminal”
Once a terminal window is open, you’re in the right place. It shows a prompt ending in $ — everything you type goes after that.
The Three Commands You Need Right Now
Check disk space first. Models are large. This is non-negotiable to understand before you do anything else:
df -h ~This shows your home directory’s disk usage. The Size column is total, Avail is what’s free. You need room — at minimum 3 GB for a small model (Qwen3-0.6B), 20+ GB for anything like Llama-3.1-8B. If you’re under 5 GB free, stop here and figure out where the space went before continuing.
Check internet connectivity:
ping -c 3 google.comIf this fails, check your network cable or go to Settings → Network. Everything else in this guide requires internet access for model downloads.
Update the package list (do this once after first boot):
sudo apt updatesudo means “run as administrator.” Ubuntu will ask for your password. This doesn’t install or change anything — it just refreshes the list of what’s available. You’ll see a lot of text scroll by. That’s normal.

Ubuntu: What You Should Know
The QB2 runs Ubuntu 24.04 LTS. If this is your first time with it:
- Package manager is
apt— install things withsudo apt install <name> - Files are case-sensitive:
Model.pyandmodel.pyare different files - Your home directory is
~— short for/home/yourusername sudoruns a command as administrator — use it only when a command tells you to
Your Login, Password, and SSH
Many QB2 units ship with a default login — username ttuser, password ttuser. If that’s how yours arrived, change the password the moment you’re in, before the machine is reachable on a shared network:
passwdIt asks for the current password (ttuser), then a new one twice.
Turn on SSH
Later in this guide — and on every other path — you reach the QB2 from your own laptop over SSH: forwarding a model server’s port back to your machine, copying files, running commands remotely. SSH isn’t always running on a fresh box, so turn it on once:
# Install and enable the SSH server
sudo apt install -y openssh-server
sudo systemctl enable --now ssh
# Confirm it's listening
systemctl status sshThen find the address other machines use to reach you:
hostname -I # the QB2's IP address on your network
hostname # its name — often <name>.localFrom your laptop you can now run ssh ttuser@<that-ip>. This is what makes the remote-access steps in Serving Models on QB2 — and bringing tt-studio’s web UI to your own browser — work.
ufw firewall is installed but inactive by default, so nothing on the QB2 is blocked out of the box. If you or your IT team turn it on (sudo ufw status tells you), remember to allow SSH with sudo ufw allow 22/tcp — and any service port you forward later, like 8000 for the inference server.
Python: A Field Guide to the Confusion
This is where new Linux users often hit a wall. Ubuntu ships with its own Python. The Tenstorrent software has its own Python environments. These are separate and don’t mix. Here’s the landscape:
What exists on your system
| Name | Location | What it is |
|---|---|---|
| System Python | /usr/bin/python3 |
Ubuntu’s built-in Python — don’t pip install here |
| TTNN venv | ~/tt-metal/python_env/ |
Pre-built environment for TTNN and the Direct API |
| Tenstorrent venv | ~/.tenstorrent-venv/ |
Main venv with vLLM and other tools |
| TT-Forge (TT-XLA) | pip wheel in a Python 3.12 venv | Compile PyTorch/JAX models — install it yourself (see TT-Forge) |
Why does this matter?
Ubuntu 24.04 enforces what’s called externally-managed Python — the system Python is protected. If you try to pip install something directly, Ubuntu will refuse with an error about breaking system packages. This is intentional. It protects you.
The right move is always: activate the correct venv, then install inside it. The Tenstorrent venvs already have everything you need for this guide, so you won’t need to install much.
What which python3 tells you
Before running any Python code, check which Python is active:
which python3If you see /usr/bin/python3 — you’re using the system Python. Tenstorrent imports will fail.
If you see something like /home/yourname/tt-metal/python_env/bin/python3 — you’re inside the right venv. Go ahead.
pip, pyenv, uv — a brief map
You may encounter other Python tools in documentation or online:
pip— Python package installer. Works inside a venv. Fine to use there.pyenv— manages multiple Python versions (3.10, 3.11, etc.). The QB2 doesn’t need it — the venvs handle version isolation.virtualenv/python -m venv— creates isolated environments. The Tenstorrent venvs were built this way.uv— a fast, modern alternative to pip and virtualenv. Works, but the QB2 docs and this guide use standard venv activation.
For this guide: ignore pyenv, ignore uv. Activate the venv Tenstorrent provides. That’s all you need.

Activating and deactivating
# Activate the TTNN environment
source ~/tt-metal/python_env/bin/activate
# Your prompt now shows (python_env) — you're inside
# Deactivate when done
deactivateThe (python_env) prefix in your prompt is the signal. When it’s there, Python calls and imports go to the right place. When it’s not, they don’t.
/etc/profile.d/ that activate an environment automatically at login. Run which python3 before sourcing any venv to see what's already active — activating on top of an active venv is messy.
Next: Is This Thing On? →
Is This Thing On?
Before running a model, confirm the hardware is alive and the software can see it. One command, four chips, zero guessing.
Reading Your Hardware with tt-smi
tt-smi is the Tenstorrent System Management Interface. Your window into the chips. Run it in snapshot mode to get JSON instead of the interactive TUI:
tt-smi -sA healthy QB2 returns four entries — one per Blackhole chip:
{
"device_info": [
{
"board_type": "BLACKHOLE",
"board_id": "AA-BHXY-0001",
"pcie_speed": "GEN4",
"pcie_width": "x16",
"temperature": { "asic": 44.1, "inlet": 31.0 },
"voltage": { "core": 0.85 },
"power": { "total": 42.0 }
}
]
}Four entries in device_info means four chips, all alive. Check it directly:
tt-smi -s | python3 -m json.tool | grep board_typeYou should see "BLACKHOLE" printed four times.

Reading the Output
A healthy QB2 shows four entries in device_info. Look at each one for:
"board_type": "BLACKHOLE"— confirms chip family. If you see anything else, something’s wrong."pcie_speed": "GEN4"— PCIe link is up at full speed. GEN3 would mean a slot compatibility issue."pcie_width": "x16"— full-width link. Narrower means lower bandwidth.- Temperature in the 35–55°C range — normal at idle. Higher under load is fine.
Count the entries:
tt-smi -s | python3 -c "import sys,json; d=json.load(sys.stdin); print(len(d['device_info']), 'devices')"If you see 4 devices, move on. The QB2 is ready.
tt-studio, pick it from the Deploy dropdown, and chat. No download. Full walkthrough in Your First Model.
If You See Fewer Than Four
A missing device usually means one of three things:
PCIe link not established:
dmesg | grep -i tenstorrent | tail -20Look for errors about PCIe enumeration or firmware loading failure. A loose card is possible — the QB2 ships with cards seated, but transit happens.
Firmware mismatch:
tt-smi -s | python3 -m json.tool | grep -i fw_versionIf firmware versions differ across devices, or show 0.0.0, you may need to reflash. See the tt-flash documentation for instructions.
Driver not loaded:
lsmod | grep tenstorrentIf nothing prints, the kernel driver isn’t loaded. This shouldn’t happen on a stock QB2, but if it does:
sudo modprobe tenstorrentWatching in Real Time
For a live view of all four chips while running inference:
tt-smiThis opens the interactive TUI — press q to quit. You’ll see per-chip utilization, temperature, and memory usage update live. Useful when a model is running and you want to see all four chips light up.
For something richer than the built-in TUI, tt-toplike renders the same telemetry as live ASCII art — every chip’s power, temperature, and DRAM state, animated:
This is what active inference looks like inside one chip. Four of these run in parallel on a QB2.
Next: Installing the Stack →
Installing the Stack
On a QB2 from Tenstorrent, this is already done. The venvs are there, the driver is loaded, the firmware is flashed. This chapter is for understanding what exists and where — so you know which environment to activate when, and what to do if something’s missing.
Installing the Tenstorrent Software Stack
On a QB2 from Tenstorrent, the stack is already there. This section is for installing on a fresh Ubuntu system, or understanding what the installer put where.
Prerequisites: Ubuntu 24.04 LTS (or 22.04), internet connection, sudo access.
sudo apt update && sudo apt install -y curl jq
/bin/bash -c "$(curl -fsSL https://github.com/tenstorrent/tt-installer/releases/latest/download/install.sh)"The installer handles drivers, firmware, kernel modules, and all three Python environments. Accept the defaults — they’re right for a QB2.
After it finishes, reboot:
sudo rebootWhat ends up on your QB2
| Path | What it is |
|---|---|
~/tt-metal/python_env/ |
TTNN / Direct API venv (pre-installed on QB2) |
~/.tenstorrent-venv/ |
Main Python environment with vLLM and other tools |
~/.local/bin/tt-forge |
Optional Forge container wrapper — only if you opted in; for most users Forge installs as a pip wheel instead |
~/.local/bin/tt-smi |
Hardware monitoring CLI (on PATH) |
~/models/ |
Model weights storage (create it: mkdir -p ~/models) |
As of tt-installer v3.2.0, Docker is the default container runtime (Podman is still supported — pass --install-container-runtime=podman). The Metalium container installs by default. Forge is not installed by default — the TT-Forge docs install it as a pip wheel (pip install pjrt-plugin-tt … then tt-forge-install); tt-installer’s --install-forge-container is an optional convenience, not the recommended path. See the TT-Forge chapter for the full install. On a QB2 that shipped from Tenstorrent, the TTNN venv at ~/tt-metal/python_env/ is pre-built. The ~/tt-metal/ directory contains compiled environments — not the tt-metal source code.

What You Have
On a QB2 from Tenstorrent, the stack is pre-installed. Here’s your map:
| Component | Location | When to use it |
|---|---|---|
| TTNN venv | ~/tt-metal/python_env/ |
Direct API work, TTNN operations, cookbook examples |
| vLLM | vllm in ~/.tenstorrent-venv/ |
Serving models via HTTP, OpenAI-compatible API |
| Forge / TT-XLA | pip wheel in a Python 3.12 venv (install it yourself) | Compile PyTorch/JAX models — not part of a default install, see TT-Forge |
tt-smi |
~/.local/bin/tt-smi (on PATH) |
Hardware monitoring, always available |
| Model storage | ~/models/ (convention) |
Where you put downloaded model weights |
| Scratch space | ~/tt-scratchpad/ |
Working directory for scripts and experiments |
Installing on a fresh Ubuntu machine? A default tt-installer run gets you the driver, the Python tools (tt-smi / tt-flash in ~/.tenstorrent-venv or ~/.local/bin/), and the tt-metalium container with its tt-metalium wrapper. It does not install Forge — the TT-Forge docs have you install that as a pip wheel (pip install pjrt-plugin-tt … then tt-forge-install). See TT-Forge for the full walkthrough. The paths here reflect a configured QB2; a fresh install may differ slightly.
Create the scratch directory if it doesn’t exist yet:
mkdir -p ~/tt-scratchpad ~/modelsThe Three Environments, Explained
TTNN (~/tt-metal/python_env/)
This is the workhorse. Use it for direct Python API work — opening devices, running TTNN operations, the cookbook examples in this guide.
source ~/tt-metal/python_env/bin/activate
# prompt changes to (python_env)
python3 -c "import ttnn; print('TTNN ready')"
deactivatevLLM (in ~/.tenstorrent-venv)
Use this to run a model as a server with an OpenAI-compatible HTTP API. vLLM is available in the main tenstorrent venv:
source ~/.tenstorrent-venv/bin/activate
vllm serve ~/models/Qwen3-0.6B --port 8000Or use tt-studio for a no-code UI that handles vLLM startup automatically.
TT-Forge — install it yourself with pip
Unlike TTNN and vLLM, Forge is not something a stock install hands you. The TT-Forge docs install it as a pip wheel into a Python 3.12 venv — TT-XLA is the frontend for PyTorch and JAX:
source ~/.tenstorrent-venv/bin/activate
pip install pjrt-plugin-tt --extra-index-url https://pypi.eng.aws.tenstorrent.com/
tt-forge-installModels then compile via torch.compile(model, backend="tt") (PyTorch) or jax.jit (JAX). Prebuilt Docker images and an ONNX frontend exist too — the TT-Forge chapter has the full walkthrough.
Confirming Each Environment Works
Run this check sequence:
# TTNN
source ~/tt-metal/python_env/bin/activate
python3 -c "import ttnn; print('✓ TTNN')" && deactivate
# vLLM (in the main tenstorrent venv)
source ~/.tenstorrent-venv/bin/activate
python3 -c "import vllm; print('✓ vLLM')" && deactivate
# Check for the tt-smi binary
which tt-smi && tt-smi --versionAll three should respond without errors. If TTNN import fails, the venv may not be set up — check docs.tenstorrent.com for the current setup guide. If tt-smi isn’t found, add ~/.local/bin to your PATH (see below).

~/tt-metal/ contains the pre-built TTNN Python environment and compiled shared libraries. The source code — C++ kernels, the build system — isn't there by default, and most users never need it. If you want to build from source (for kernel modification or upstream contributions), the build-tt-metal lesson walks through it.
Installing tt-smi if it’s Missing
On a QB2 it shouldn’t be missing, but on another Ubuntu system:
# Option A — public PyPI (any machine, no PPA needed):
pip install tt-smi
# Option B — via apt (requires Tenstorrent PPA, set up by tt-installer):
sudo apt install tt-smiBoth install the same tool. Option A works anywhere with Python; option B integrates with your system package manager. On a freshly installed Ubuntu machine without tt-installer, option A is the easier path.
Disk Space and Model Storage
Models consume significant disk space. Plan accordingly:
| Model | Size on disk |
|---|---|
| Qwen3-0.6B | ~1.5 GB |
| Qwen3-8B | ~16 GB |
| Llama-3.1-8B-Instruct | ~16 GB |
| Llama-3.1-70B | ~140 GB |
The convention across all Tenstorrent documentation is ~/models/<model-name>/. Nothing enforces this — you can store models anywhere and point --model at any path — but using the convention means every tutorial command works without substitution.
Check space before any download:
df -h ~/modelsNext: Your First Model →
Your First Model
Everything up to now was preparation. This is the part where the machine does something interesting. Four chips, waiting. One small model, about to arrive.
Running Your First Model
tt-studio, pick Qwen3-32B from the Deploy Model dropdown, click Run. The first deploy takes a few minutes (no multi-GB download — the weights are already there). You enter a Hugging Face token once; the model is gated even though the weights are local.
This chapter takes the other path — the hands-on one, where you talk to a chip directly in Python and pull a tiny model down yourself. The starter is Qwen/Qwen3-0.6B — no license gate, 1.5 GB, runs on any Tenstorrent hardware.
First, activate the TTNN environment and verify the hardware is accessible:
source ~/tt-metal/python_env/bin/activateYour prompt will change to show (python_env). That which python3 will now point into the venv, not /usr/bin/python3. Check it:
which python3
# → /home/yourname/tt-metal/python_env/bin/python3Now do the handshake — open a device, confirm it responds, close it:
python3 -c "
import ttnn
device = ttnn.open_device(device_id=0)
print('Device open:', device)
ttnn.close_device(device)
print('Done.')
"If you see Device open: without errors, chip 0 is alive and responding. Repeat with device_id=1, 2, 3 to verify all four.
ttnn.CreateDevices({0, 1, 2, 3}) — not four separate open_device() calls. Opening and closing devices individually can cause dispatch core errors on multi-chip configs.
Download a model
Use the hf CLI (part of the huggingface_hub package already installed in the venv):
# hf — not huggingface-cli. The command is hf.
hf download Qwen/Qwen3-0.6B --local-dir ~/models/Qwen3-0.6BThis creates ~/models/Qwen3-0.6B/ with the HuggingFace-format weights (~1.5 GB). Check your disk first:
df -h ~You need at least 3 GB free for this model alone. Larger models (Llama-3.1-8B) need 16+ GB.

What Just Happened
When that Python snippet ran without errors, the Blackhole chip opened a dispatch channel through the PCIe link, initialized its RISC-V cores, and confirmed it can receive work. Nothing computed yet. But the handshake — software to silicon — is the prerequisite for everything else.
ttnn.open_device(0) — what happens inside the chip.
Serving a Model with vLLM
The fastest path to actually generating text is vLLM. It handles model loading, tokenization, batching, and presents an OpenAI-compatible HTTP API.
source ~/.tenstorrent-venv/bin/activate
# Make sure the model is downloaded first (see above)
# Then start the server:
python3 -m vllm.entrypoints.openai.api_server \
--model ~/models/Qwen3-0.6B \
--port 8000You’ll see initialization messages as the model loads. This takes a minute or two on first run — the model weights are being compiled for the Blackhole architecture. Subsequent runs are faster.
Once you see INFO: Application startup complete, the server is ready. In a new terminal:
curl -s http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen3-0.6B",
"messages": [{"role": "user", "content": "What makes the Tenstorrent Blackhole chip different?"}]
}' | python3 -m json.toolThe response is JSON. The answer is in choices[0].message.content.
"think": false to the request to skip extended reasoning), and requires no Hugging Face license. Start here before trying larger models.
Using tt-studio (the Web UI)
tt-studio
tt-studio is a web interface for running models on QB2 without writing a line of code. It handles model selection, container lifecycle, and inference end-to-end — open a browser, pick a model, get tokens back. It’s the lowest-effort path to your first token on a QB2.
Start it with the pre-installed wrapper command:
tt-studioThen open http://localhost:3000 in your browser, pick a model from the Deploy Model dropdown, and click Run. On a QB2, Qwen3-32B is already there with its weights pre-cached — its first deploy skips the multi-GB download and is ready in a few minutes. Other models download on first use; after that, every run loads fast from the on-disk cache. (tt-studio v2.8.0 also fixed the cold first-chat delay after an idle model, so that first token comes back quickly.)
tt-studio is a convenience command the QB2 ships. Under the hood it launches the same stack you'd get by cloning the repo and running python3 run.py — that sets up the submodule and .env, prompts for your Hugging Face token, selects the right Docker overlays for your hardware, and brings up the Django + React app plus the model containers, then serves the UI at localhost:3000. On any other machine, that clone-and-run.py flow is how you'd start it.
What’s happening under the hood: tt-studio is a UI sitting on top of tt-inference-server. When you select a model and click Run, tt-studio spins up a Docker container running the TT fork of vLLM on port 8000. Your browser talks to tt-studio; tt-studio talks to that container. tt-local-generator routes through the same container — both are UIs sitting on top of tt-inference-server, just with different front ends.
To access tt-studio from your laptop while the QB2 is on your network, forward the port over SSH:
ssh -L 3000:localhost:3000 user@qb2-hostnameThen open http://localhost:3000 on your local machine as if you were sitting in front of the QB2.
For a deeper look at how the inference server is wired up, the tt-vscode-toolkit lesson on tt-inference-server walks through the architecture interactively — Docker flags, model download, port mapping, and what logs to watch on first boot.

Multi-Device: Using All Four Chips
To spread a model across all four Blackhole chips, use CreateDevices instead of open_device:
source ~/tt-metal/python_env/bin/activate
python3 -c "
import ttnn
devices = ttnn.CreateDevices({0, 1, 2, 3})
print('All devices:', devices)
ttnn.CloseDevices(devices)
print('Done.')
"CreateDevices handles the mesh configuration that lets the chips coordinate. Models loaded this way can distribute layers across chips, increasing the effective memory pool and throughput. Large models (Llama-3.1-70B) require this — they don’t fit on one chip’s memory alone.
CreateDevices spans all four chips: a large model's layers spread across them for more memory and throughput. (A small model like Qwen3-0.6B runs happily on one chip.)
Next: What Comes Next →
What Comes Next
You unboxed a machine that most people have never touched. You confirmed four Blackhole chips were alive and talking to the system. You navigated Python environments that would trip up someone who wasn’t paying attention. You ran a model on accelerator hardware and watched tokens come back. That’s not a tutorial warmup — that’s the actual thing.
The rest is up to you.

Tools in Your World
The QB2 ships with a full stack, but the ecosystem is bigger. Start with tt-toplike — htop for your chips, except the telemetry comes alive as ASCII art:
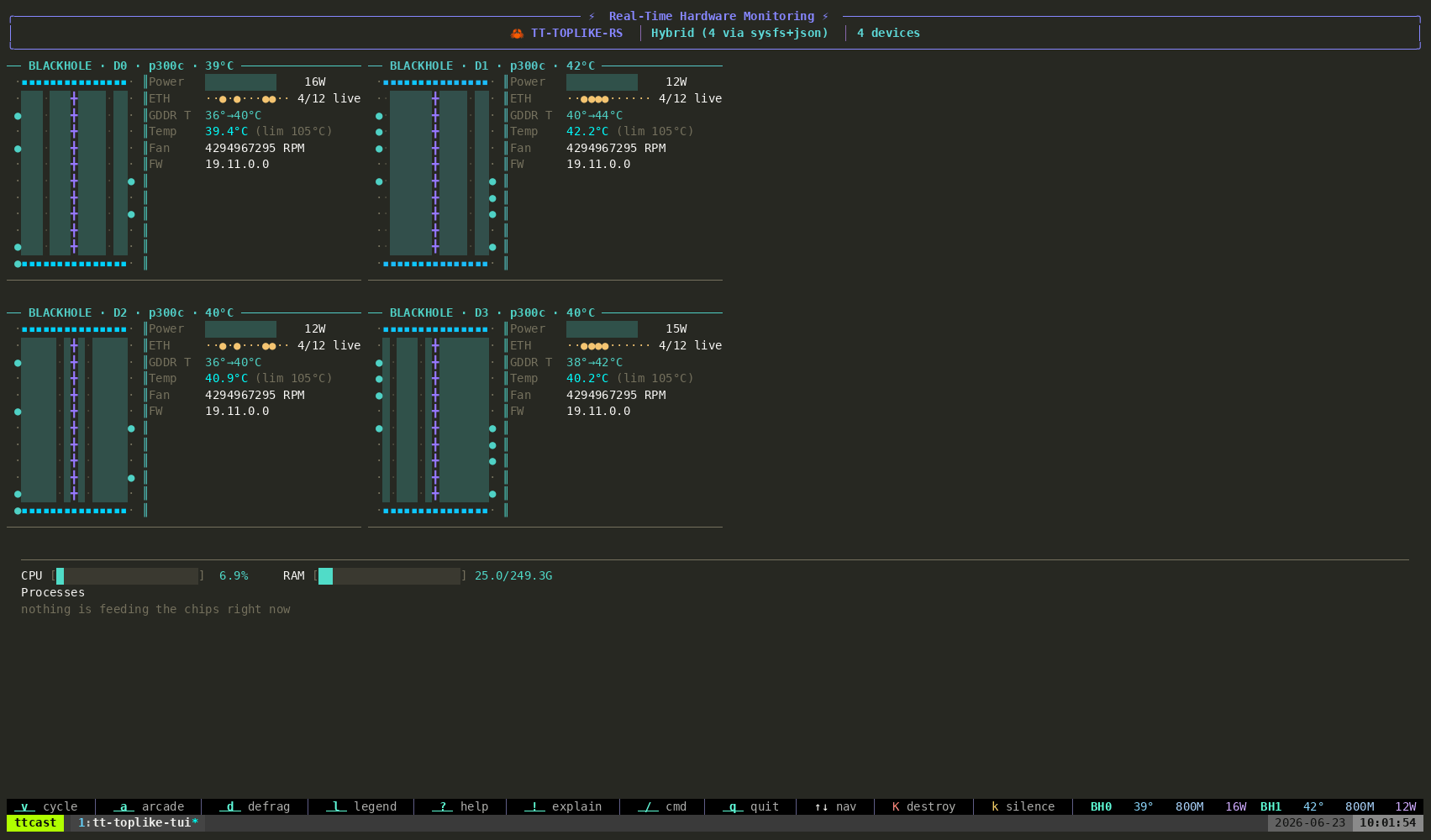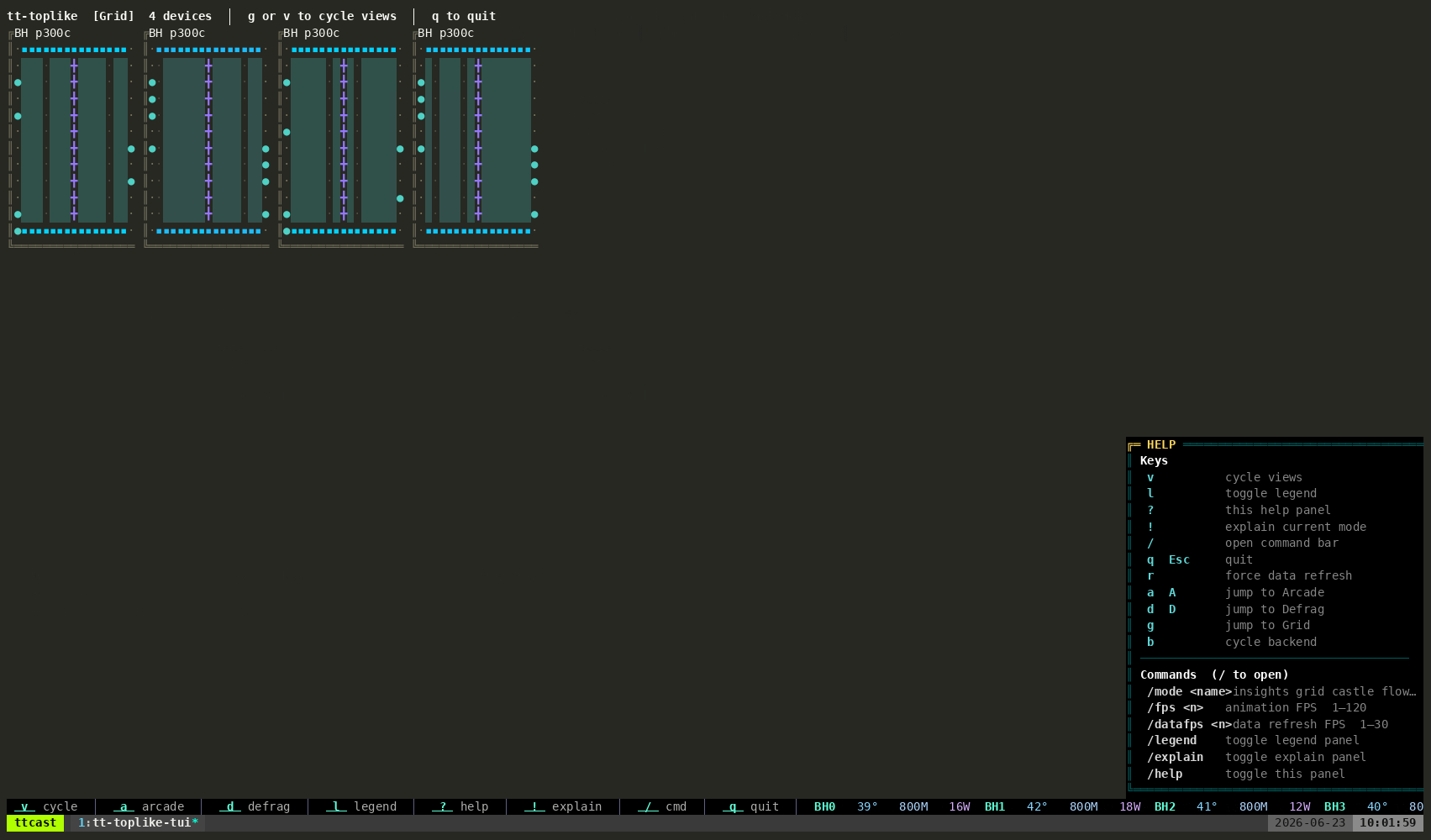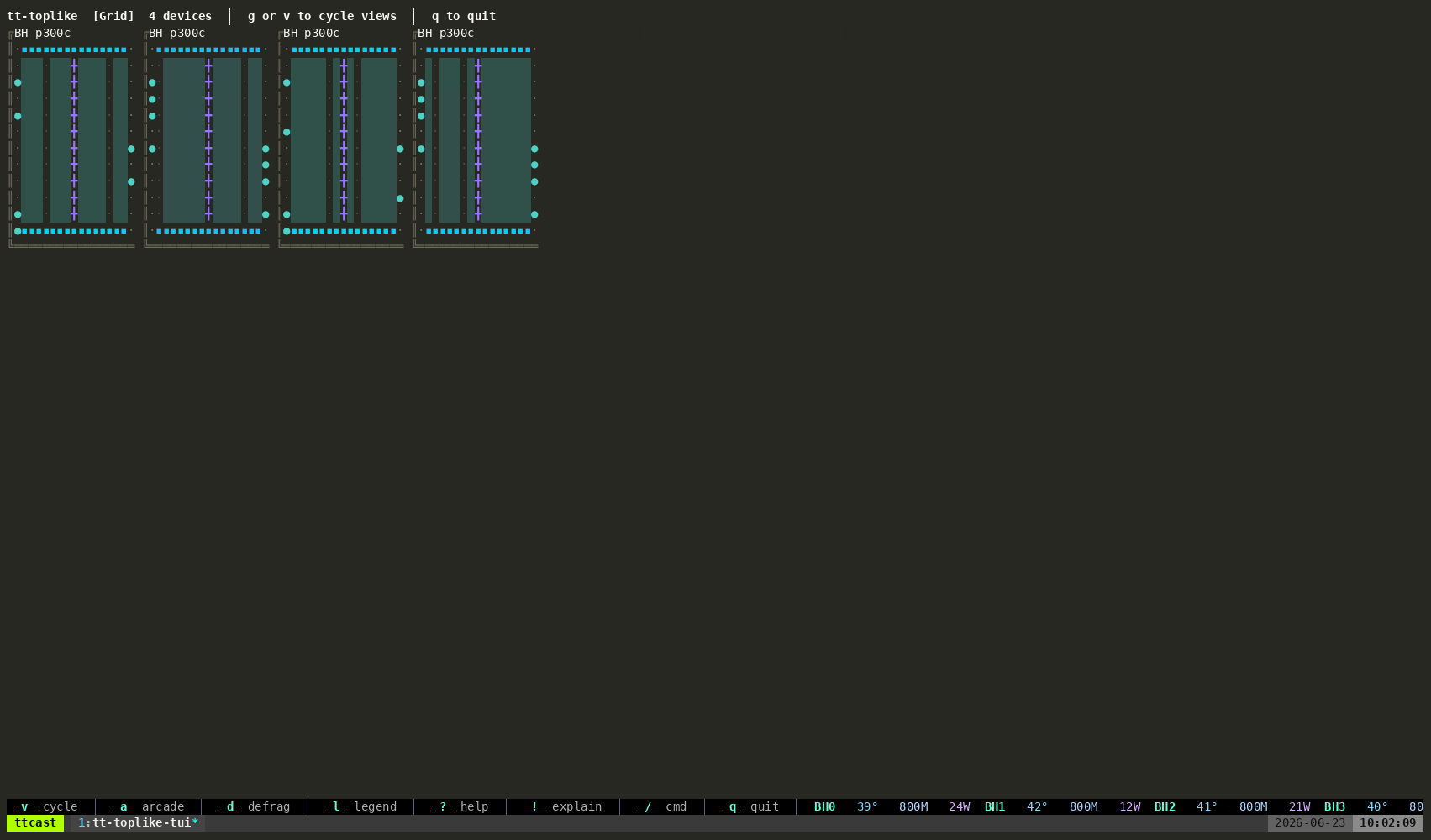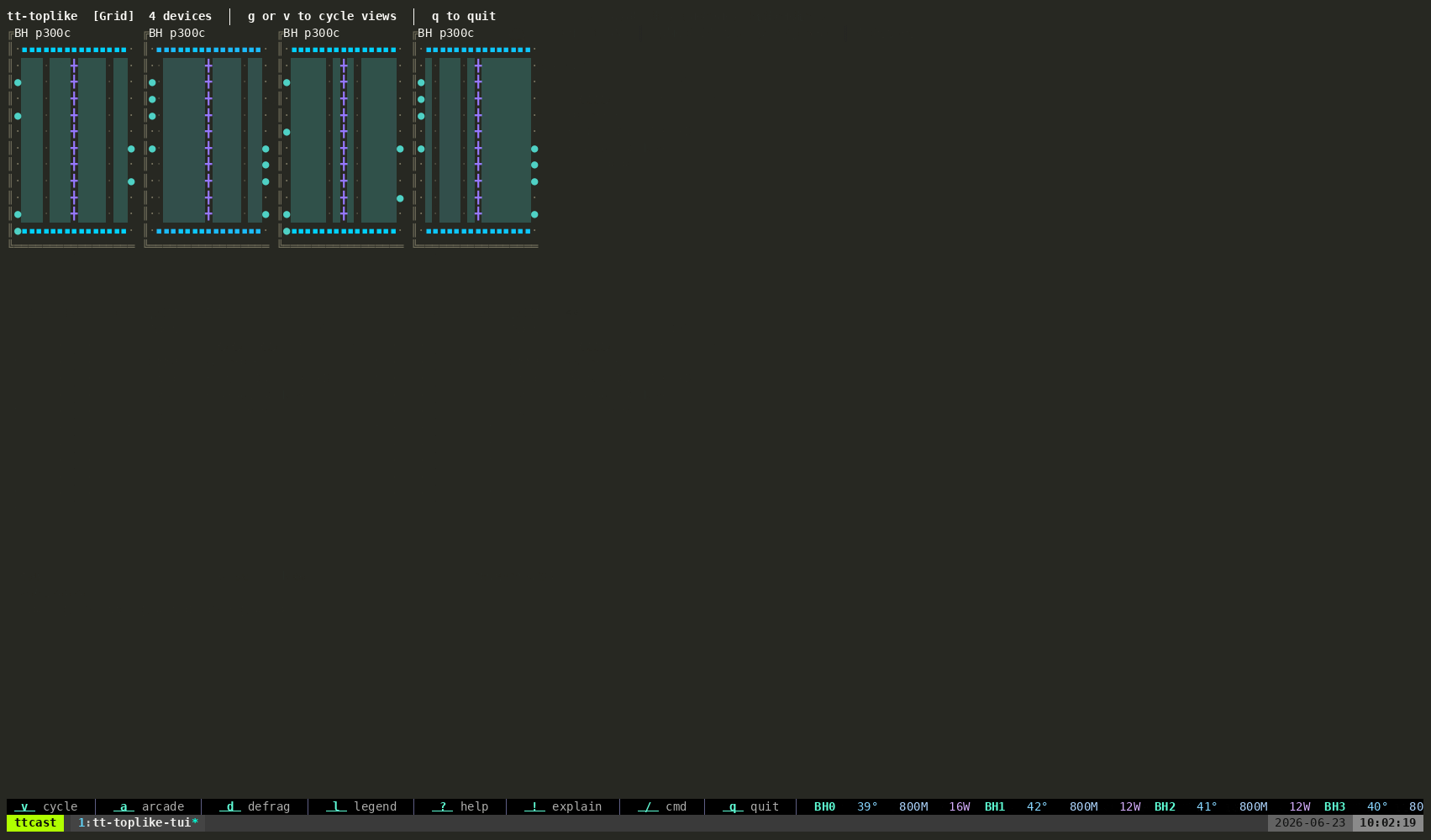
Where to Go From Here
Pick a thing you want to do and jump straight in.
Choose Your Next Track
The QB2 is a beginning. There’s a lot of surface area here, and you’ve only scratched it.