Introduction
Welcome to tt-mlir, Tenstorrent's open-source MLIR-based compiler infrastructure designed to optimize and deploy machine learning models and other computational workloads on Tenstorrent hardware. This documentation provides an overview of the key components, features, and usage of tt-mlir.
Architecture & Dialect Overview
tt-mlir is structured around several core dialects and components that facilitate the compilation process from high-level representations to low-level code generation. While the architecture diagram below illustrates Tenstorrent’s compiler flow, it also reflects the various dialect abstractions defined within tt-mlir.
tt-mlir is a library of reusable components that can be used to build compilers targeting Tenstorrent hardware. Other compiler technologies may choose to leverage whichever abstractions best suit their needs.
// TTIR: Named ops on tensors (akin to shlo, tosa, etc)
//
// This should be the default IR that users who need a higher-level abstraction
// over tensors.
//
// Example IR:
func.func @simple_linear(
%arg0: tensor<64x128xbf16>,
%arg1: tensor<128x64xbf16>,
%bias: tensor<64x64xbf16>) -> tensor<64x64xbf16> {
%0 = ttir.empty() : tensor<64x64xbf16>
%1 = "ttir.linear"(%arg0, %arg1, %bias, %0) : (tensor<64x128xbf16>, tensor<128x64xbf16>, tensor<64x64xbf16>, tensor<64x64xbf16>) -> tensor<64x64xbf16>
return %1 : tensor<64x64xbf16>
}
// TTNN: Named ops on tensors (akin to shlo, tosa, etc)
//
// The TTNN dialect models the tt-nn API (from the tt-metalium project)
// as closely as possible. It is intended to be a high-level IR over tensors.
//
// Example IR:
#ttnn_layout = #ttnn.ttnn_layout<(d0, d1) -> (d0, d1), <1x1>, memref<2x4x!ttcore.tile<32x32, bf16>, #dram>, <interleaved>>
#ttnn_layout1 = #ttnn.ttnn_layout<(d0, d1) -> (d0, d1), <1x1>, memref<4x2x!ttcore.tile<32x32, bf16>, #dram>, <interleaved>>
#ttnn_layout2 = #ttnn.ttnn_layout<(d0, d1) -> (d0, d1), <1x1>, memref<2x2x!ttcore.tile<32x32, bf16>, #dram>, <interleaved>>
func.func @simple_linear(
%arg0: tensor<64x128xbf16, #ttnn_layout>,
%arg1: tensor<128x64xbf16, #ttnn_layout1>,
%arg2: tensor<64x64xbf16, #ttnn_layout2>
) -> tensor<64x64xbf16, #ttnn_layout2> {
%0 = "ttnn.linear"(%arg0, %arg1, %arg2) <{
transpose_a = false,
transpose_b = false
}> : (tensor<64x128xbf16, #ttnn_layout>, tensor<128x64xbf16, #ttnn_layout1>, tensor<64x64xbf16, #ttnn_layout2>) -> tensor<64x64xbf16, #ttnn_layout2>
"ttnn.deallocate"(%arg2) <{force = false}> : (tensor<64x64xbf16, #ttnn_layout2>) -> ()
"ttnn.deallocate"(%arg1) <{force = false}> : (tensor<128x64xbf16, #ttnn_layout1>) -> ()
"ttnn.deallocate"(%arg0) <{force = false}> : (tensor<64x128xbf16, #ttnn_layout>) -> ()
return %0 : tensor<64x64xbf16, #ttnn_layout2>
}
// D2M: Generic compute dialect (akin to linalg)
//
// The D2M dialect models generic compute on tensors and memrefs,
// similar to linalg.generic, but with constructs that map well to
// the Tenstorrent execution model (e.g., sharded tensors, grids,
// explicit datamovement).
//
// Example IR:
#layout = #ttcore.metal_layout<logical_shape = 64x128, dim_alignments = 32x32, collapsed_intervals = dense<[[0, 1], [1, 2]]> : tensor<2x2xi64>, undef, l1>
#layout1 = #ttcore.metal_layout<logical_shape = 128x96, dim_alignments = 32x32, collapsed_intervals = dense<[[0, 1], [1, 2]]> : tensor<2x2xi64>, undef, l1>
#layout2 = #ttcore.metal_layout<logical_shape = 64x96, dim_alignments = 32x32, collapsed_intervals = dense<[[0, 1], [1, 2]]> : tensor<2x2xi64>, undef, l1>
#map = affine_map<(d0, d1, d2) -> (d0, d2)>
#map1 = affine_map<(d0, d1, d2) -> (d2, d1)>
#map2 = affine_map<(d0, d1, d2) -> (d0, d1)>
#parallel = #ttcore.iterator_type
#reduction = #ttcore.iterator_type
func.func @simple_matmul(
%arg0: tensor<64x128xbf16>,
%arg1: tensor<128x96xbf16>
) -> tensor<64x96xbf16> {
%0 = d2m.empty() : tensor<64x96xbf16>
%1 = d2m.empty() : tensor<1x1x2x4x!ttcore.tile<32x32, bf16>, #layout>
%2 = d2m.to_layout %arg0, %1 : tensor<64x128xbf16> into tensor<1x1x2x4x!ttcore.tile<32x32, bf16>, #layout> -> tensor<1x1x2x4x!ttcore.tile<32x32, bf16>, #layout>
%3 = d2m.empty() : tensor<1x1x4x3x!ttcore.tile<32x32, bf16>, #layout1>
%4 = d2m.to_layout %arg1, %3 : tensor<128x96xbf16> into tensor<1x1x4x3x!ttcore.tile<32x32, bf16>, #layout1> -> tensor<1x1x4x3x!ttcore.tile<32x32, bf16>, #layout1>
%5 = d2m.empty() : tensor<1x1x2x3x!ttcore.tile<32x32, bf16>, #layout2>
%6 = d2m.to_layout %0, %5 : tensor<64x96xbf16> into tensor<1x1x2x3x!ttcore.tile<32x32, bf16>, #layout2> -> tensor<1x1x2x3x!ttcore.tile<32x32, bf16>, #layout2>
%7 = d2m.generic {
block_factors = [1, 1, 1],
grid = #ttcore.grid<1x1>,
indexing_maps = [#map, #map1, #map2],
iterator_types = [#parallel, #parallel, #reduction],
threads = [#d2m.thread]
} ins(%2, %4 : tensor<1x1x2x4x!ttcore.tile<32x32, bf16>, #layout>, tensor<1x1x4x3x!ttcore.tile<32x32, bf16>, #layout1>)
outs(%6 : tensor<1x1x2x3x!ttcore.tile<32x32, bf16>, #layout2>) {
^compute0(%cb0: !d2m.cb>>, %cb1: !d2m.cb>>, %cb2: !d2m.cb>>):
%10 = d2m.wait %cb0 : >> -> tensor<2x4x!ttcore.tile<32x32, bf16>>
%11 = d2m.wait %cb1 : >> -> tensor<4x3x!ttcore.tile<32x32, bf16>>
%12 = d2m.reserve %cb2 : >> -> tensor<2x3x!ttcore.tile<32x32, bf16>>
%13 = linalg.generic {
indexing_maps = [#map, #map1, #map2],
iterator_types = ["parallel", "parallel", "reduction"]
} ins(%10, %11 : tensor<2x4x!ttcore.tile<32x32, bf16>>, tensor<4x3x!ttcore.tile<32x32, bf16>>) outs(%12 : tensor<2x3x!ttcore.tile<32x32, bf16>>) {
^bb0(%in: !ttcore.tile<32x32, bf16>, %in_0: !ttcore.tile<32x32, bf16>, %out: !ttcore.tile<32x32, bf16>):
%14 = "d2m.tile_matmul"(%in, %in_0, %out) : (!ttcore.tile<32x32, bf16>, !ttcore.tile<32x32, bf16>, !ttcore.tile<32x32, bf16>) -> !ttcore.tile<32x32, bf16>
linalg.yield %14 : !ttcore.tile<32x32, bf16>
} -> tensor<2x3x!ttcore.tile<32x32, bf16>>
d2m.yield %13 : (tensor<2x3x!ttcore.tile<32x32, bf16>>)
} : tensor<1x1x2x3x!ttcore.tile<32x32, bf16>, #layout2>
%8 = d2m.empty() : tensor<64x96xbf16>
%9 = d2m.to_layout %7, %8 : tensor<1x1x2x3x!ttcore.tile<32x32, bf16>, #layout2> into tensor<64x96xbf16> -> tensor<64x96xbf16>
return %9 : tensor<64x96xbf16>
}
// TTKernel: tt-metal device kernel dialect.
//
// The TTKernel dialect models low-level kernels that run on Tenstorrent
// devices. It exposes concepts such as circular buffers, tile registers,
// noc transactions and explicit synchronization. It is intended to be a
// 1-1 mapping to tt-metalium kernels.
//
// Example Datamovement Kernel IR:
func.func private @datamovement_kernel() attributes {
ttkernel.arg_spec = #ttkernel.arg_spec<ct_args = [
<arg_type = cb_port, operand_index = 0>,
<arg_type = cb_port, operand_index = 1>
]>,
ttkernel.thread = #ttkernel.thread<noc>
} {
%0 = ttkernel.get_compile_time_arg_val(0) : () -> !ttkernel.cb<1, !ttcore.tile<32x32, bf16>>
%1 = ttkernel.get_compile_time_arg_val(1) : () -> !ttkernel.cb<1024, bf16>
%c1_i32 = arith.constant 1 : i32
ttkernel.cb_reserve_back(%0, %c1_i32) : (!ttkernel.cb<1, !ttcore.tile<32x32, bf16>>, i32) -> ()
ttkernel.cb_push_back(%0, %c1_i32) : (!ttkernel.cb<1, !ttcore.tile<32x32, bf16>>, i32) -> ()
return
}
//
// Example Compute Kernel IR:
func.func private @compute_kernel8() attributes {
ttkernel.arg_spec = #ttkernel.arg_spec<ct_args = [
<arg_type = cb_port, operand_index = 0>,
<arg_type = cb_port, operand_index = 1>,
<arg_type = cb_port, operand_index = 2>
]>,
ttkernel.thread = #ttkernel.thread<compute>
} {
%0 = ttkernel.get_compile_time_arg_val(0) : () -> !ttkernel.cb<1, !ttcore.tile<32x32, bf16>>
%1 = ttkernel.get_compile_time_arg_val(1) : () -> !ttkernel.cb<1, !ttcore.tile<32x32, bf16>>
%2 = ttkernel.get_compile_time_arg_val(2) : () -> !ttkernel.cb<1, !ttcore.tile<32x32, bf16>>
%c0 = arith.constant 0 : index
%c1_i32 = arith.constant 1 : i32
%c1_i32_0 = arith.constant 1 : i32
%c1_i32_1 = arith.constant 1 : i32
%c1_i32_2 = arith.constant 1 : i32
%c0_i32 = arith.constant 0 : i32
"ttkernel.mm_block_init"(%0, %1, %2, %c0_i32, %c1_i32_1, %c1_i32, %c1_i32_0) : (!ttkernel.cb<1, !ttcore.tile<32x32, bf16>>, !ttkernel.cb<1, !ttcore.tile<32x32, bf16>>, !ttkernel.cb<1, !ttcore.tile<32x32, bf16>>, i32, i32, i32, i32) -> ()
%c4 = arith.constant 4 : index
%c1 = arith.constant 1 : index
%c0_3 = arith.constant 0 : index
scf.for %arg0 = %c0_3 to %c4 step %c1 {
%c1_i32_4 = arith.constant 1 : i32
ttkernel.cb_wait_front(%0, %c1_i32_4) : (!ttkernel.cb<1, !ttcore.tile<32x32, bf16>>, i32) -> ()
%c1_i32_5 = arith.constant 1 : i32
ttkernel.cb_wait_front(%1, %c1_i32_5) : (!ttkernel.cb<1, !ttcore.tile<32x32, bf16>>, i32) -> ()
%c1_i32_6 = arith.constant 1 : i32
ttkernel.cb_reserve_back(%2, %c1_i32_6) : (!ttkernel.cb<1, !ttcore.tile<32x32, bf16>>, i32) -> ()
ttkernel.tile_regs_acquire() : () -> ()
%3 = arith.cmpi ne, %arg0, %c0_3 : index
scf.if %3 {
ttkernel.copy_tile_init(%2) : (!ttkernel.cb<1, !ttcore.tile<32x32, bf16>>) -> ()
ttkernel.copy_tile(%2, %c0_3, %c0_3) : (!ttkernel.cb<1, !ttcore.tile<32x32, bf16>>, index, index) -> ()
}
"ttkernel.mm_block_init_short"(%0, %1, %c0_i32, %c1_i32_1, %c1_i32, %c1_i32_0) : (!ttkernel.cb<1, !ttcore.tile<32x32, bf16>>, !ttkernel.cb<1, !ttcore.tile<32x32, bf16>>, i32, i32, i32, i32) -> ()
%c0_7 = arith.constant 0 : index
%c0_8 = arith.constant 0 : index
"ttkernel.experimental.matmul_block"(%0, %1, %c0_7, %c0_8, %c0, %c0_i32, %c1_i32_1, %c1_i32, %c1_i32_0, %c1_i32_2) : (!ttkernel.cb<1, !ttcore.tile<32x32, bf16>>, !ttkernel.cb<1, !ttcore.tile<32x32, bf16>>, index, index, index, i32, i32, i32, i32, i32) -> ()
ttkernel.pack_tile(%c0_3, %2, %c0_3, true) : (index, !ttkernel.cb<1, !ttcore.tile<32x32, bf16>>, index) -> ()
ttkernel.cb_pop_front(%0, %c1_i32_4) : (!ttkernel.cb<1, !ttcore.tile<32x32, bf16>>, i32) -> ()
ttkernel.cb_pop_front(%1, %c1_i32_5) : (!ttkernel.cb<1, !ttcore.tile<32x32, bf16>>, i32) -> ()
ttkernel.cb_push_back(%2, %c1_i32_6) : (!ttkernel.cb<1, !ttcore.tile<32x32, bf16>>, i32) -> ()
%c1_i32_4 = arith.constant 1 : i32
ttkernel.cb_wait_front(%2, %c1_i32_4) : (!ttkernel.cb<1, !ttcore.tile<32x32, bf16>>, i32) -> ()
ttkernel.cb_pop_front(%2, %c1_i32_4) : (!ttkernel.cb<1, !ttcore.tile<32x32, bf16>>, i32) -> ()
}
return
}
// TTMetal: tt-metal host/device interop dialect.
//
// The TTMetal dialect models host-side operations for managing Tenstorrent
// devices, such as buffer allocation, data transfer, and enqueueing programs.
//
// Example IR:
func.func @simple_matmul(
%arg0: memref<64x128xbf16>,
%arg1: memref<128x96xbf16>
) -> memref<64x96xbf16> {
%0 = "ttmetal.create_buffer"() <{address = 13312 : i64}> : () -> memref<2x4x1x1x!ttcore.tile<32x32, bf16>, #ttcore.shard<2048x2048>, #ttcore.memory_space<l1>>
%1 = "ttmetal.create_buffer"() <{address = 1024 : i64}> : () -> memref<2x4x32x32xbf16, #ttcore.shard<64x2>, #ttcore.memory_space<l1>>
"ttmetal.enqueue_write_buffer"(%arg0, %1) : (memref<64x128xbf16>, memref<2x4x32x32xbf16, #ttcore.shard<64x2>, #ttcore.memory_space<l1>>) -> ()
"ttmetal.enqueue_program"(%1, %0, %1, %0) <{
cb_ports = array<i64: 0, 1>,
kernelConfigs = [
#ttmetal.noc_config<@datamovement_kernel0, #ttmetal.core_range<0x0, 2x4>, #ttmetal.kernel_args<ct_args = [<cb_port[0]>, <cb_port[1]>]>, noc0>,
#ttmetal.noc_config<@datamovement_kernel1, #ttmetal.core_range<0x0, 2x4>, #ttmetal.kernel_args< ct_args = [<cb_port[0]>, <cb_port[1]>]>, noc1>,
#ttmetal.compute_config<@compute_kernel2, #ttmetal.core_range<0x0, 2x4>, #ttmetal.kernel_args< ct_args = [<cb_port[0]>, <cb_port[1]>]>, hifi4, false, false, false, [default]>
],
operandSegmentSizes = array<i32: 2, 2>
}> : (memref<2x4x32x32xbf16, #ttcore.shard<64x2>, #ttcore.memory_space<l1>>, memref<2x4x1x1x!ttcore.tile<32x32, bf16>, #ttcore.shard<2048x2048>, #ttcore.memory_space<l1>>, memref<2x4x32x32xbf16, #ttcore.shard<64x2>, #ttcore.memory_space<l1>>, memref<2x4x1x1x!ttcore.tile<32x32, bf16>, #ttcore.shard<2048x2048>, #ttcore.memory_space<l1>>) -> ()
"ttmetal.deallocate_buffer"(%1) : (memref<2x4x32x32xbf16, #ttcore.shard<64x2>, #ttcore.memory_space<l1>>) -> ()
%2 = "ttmetal.create_buffer"() <{address = 11264 : i64}> : () -> memref<4x3x1x1x!ttcore.tile<32x32, bf16>, #ttcore.shard<2048x2048>, #ttcore.memory_space<l1>>
%3 = "ttmetal.create_buffer"() <{address = 1024 : i64}> : () -> memref<4x3x32x32xbf16, #ttcore.shard<64x2>, #ttcore.memory_space<l1>>
"ttmetal.enqueue_write_buffer"(%arg1, %3) : (memref<128x96xbf16>, memref<4x3x32x32xbf16, #ttcore.shard<64x2>, #ttcore.memory_space<l1>>) -> ()
"ttmetal.enqueue_program"(%3, %2, %3, %2) <{
cb_ports = array<i64: 0, 1>,
kernelConfigs = [
#ttmetal.noc_config<@datamovement_kernel3, #ttmetal.core_range<0x0, 4x3>,#ttmetal.kernel_args< ct_args = [<cb_port[0]>, <cb_port[1]>]>, noc0>,
#ttmetal.noc_config<@datamovement_kernel4, #ttmetal.core_range<0x0, 4x3>, #ttmetal.kernel_args< ct_args = [<cb_port[0]>, <cb_port[1]>]>, noc1>,
#ttmetal.compute_config<@compute_kernel5, #ttmetal.core_range<0x0, 4x3>, #ttmetal.kernel_args< ct_args = [<cb_port[0]>, <cb_port[1]>]>, hifi4, false, false, false, [default]>
],
operandSegmentSizes = array<i32: 2, 2>
}> : (memref<4x3x32x32xbf16, #ttcore.shard<64x2>, #ttcore.memory_space<l1>>, memref<4x3x1x1x!ttcore.tile<32x32, bf16>, #ttcore.shard<2048x2048>, #ttcore.memory_space<l1>>, memref<4x3x32x32xbf16, #ttcore.shard<64x2>, #ttcore.memory_space<l1>>, memref<4x3x1x1x!ttcore.tile<32x32, bf16>, #ttcore.shard<2048x2048>, #ttcore.memory_space<l1>>) -> ()
"ttmetal.deallocate_buffer"(%3) : (memref<4x3x32x32xbf16, #ttcore.shard<64x2>, #ttcore.memory_space<l1>>) -> ()
%4 = "ttmetal.create_buffer"() <{address = 9216 : i64}> : () -> memref<2x3x1x1x!ttcore.tile<32x32, bf16>, #ttcore.shard<2048x2048>, #ttcore.memory_space<l1>>
%5 = "ttmetal.create_buffer"() <{address = 1024 : i64}> : () -> memref<2x4x1x1x!ttcore.tile<32x32, bf16>, #ttcore.shard<2048x2048, 2>, #ttcore.memory_space<l1>>
"ttmetal.enqueue_program"(%0, %2, %4, %5, %6, %4) <{
cb_ports = array<i64: 0, 1, 2>,
kernelConfigs = [
#ttmetal.noc_config<@datamovement_kernel6, #ttmetal.core_range<0x0, 2x3>, #ttmetal.kernel_args< ct_args = [<cb_port[0]>, <cb_port[1]>, <cb_port[2]>, <semaphore[0]>, <semaphore[1]>, <semaphore[2]>, <semaphore[3]>, <buffer_address[0]>]>, noc0>,
#ttmetal.noc_config<@datamovement_kernel7, #ttmetal.core_range<0x0, 2x3>, #ttmetal.kernel_args< ct_args = [<cb_port[0]>, <cb_port[1]>, <cb_port[2]>, <semaphore[0]>, <semaphore[1]>, <semaphore[2]>, <semaphore[3]>, <buffer_address[1]>]>, noc1>,
#ttmetal.compute_config<@compute_kernel8, #ttmetal.core_range<0x0, 2x3>, #ttmetal.kernel_args< ct_args = [<cb_port[0]>, <cb_port[1]>, <cb_port[2]>]>, hifi4, false, false, false, [default]>
],
operandSegmentSizes = array<i32: 3, 3>
}> : (memref<2x4x1x1x!ttcore.tile<32x32, bf16>, #ttcore.shard<2048x2048>, #ttcore.memory_space<l1>>, memref<4x3x1x1x!ttcore.tile<32x32, bf16>, #ttcore.shard<2048x2048>, #ttcore.memory_space<l1>>, memref<2x3x1x1x!ttcore.tile<32x32, bf16>, #ttcore.shard<2048x2048>, #ttcore.memory_space<l1>>, memref<2x4x1x1x!ttcore.tile<32x32, bf16>, #ttcore.shard<2048x2048, 2>, #ttcore.memory_space<l1>>, memref<4x3x1x1x!ttcore.tile<32x32, bf16>, #ttcore.shard<2048x2048, 2>, #ttcore.memory_space<l1>>, memref<2x3x1x1x!ttcore.tile<32x32, bf16>, #ttcore.shard<2048x2048>, #ttcore.memory_space<l1>>) -> ()
"ttmetal.deallocate_buffer"(%6) : (memref<4x3x1x1x!ttcore.tile<32x32, bf16>, #ttcore.shard<2048x2048, 2>, #ttcore.memory_space<l1>>) -> ()
"ttmetal.deallocate_buffer"(%2) : (memref<4x3x1x1x!ttcore.tile<32x32, bf16>, #ttcore.shard<2048x2048>, #ttcore.memory_space<l1>>) -> ()
"ttmetal.deallocate_buffer"(%5) : (memref<2x4x1x1x!ttcore.tile<32x32, bf16>, #ttcore.shard<2048x2048, 2>, #ttcore.memory_space<l1>>) -> ()
"ttmetal.deallocate_buffer"(%0) : (memref<2x4x1x1x!ttcore.tile<32x32, bf16>, #ttcore.shard<2048x2048>, #ttcore.memory_space<l1>>) -> ()
%alloc = memref.alloc() : memref<64x96xbf16>
%7 = "ttmetal.create_buffer"() <{address = 1024 : i64}> : () -> memref<2x3x32x32xbf16, #ttcore.shard<64x2>, #ttcore.memory_space<l1>>
"ttmetal.enqueue_program"(%4, %7, %4, %7) <{
cb_ports = array<i64: 0, 1>,
kernelConfigs = [
#ttmetal.noc_config<@datamovement_kernel9, #ttmetal.core_range<0x0, 2x3>, #ttmetal.kernel_args< ct_args = [<cb_port[0]>, <cb_port[1]>]>, noc0>,
#ttmetal.noc_config<@datamovement_kernel10, #ttmetal.core_range<0x0, 2x3>, #ttmetal.kernel_args< ct_args = [<cb_port[0]>, <cb_port[1]>]>, noc1>,
#ttmetal.compute_config<@compute_kernel11, #ttmetal.core_range<0x0, 2x3>, #ttmetal.kernel_args< ct_args = [<cb_port[0]>, <cb_port[1]>]>, hifi4, false, false, false, [default]>
],
operandSegmentSizes = array<i32: 2, 2>
}> : (memref<2x3x1x1x!ttcore.tile<32x32, bf16>, #ttcore.shard<2048x2048>, #ttcore.memory_space<l1>>, memref<2x3x32x32xbf16, #ttcore.shard<64x2>, #ttcore.memory_space<l1>>, memref<2x3x1x1x!ttcore.tile<32x32, bf16>, #ttcore.shard<2048x2048>, #ttcore.memory_space<l1>>, memref<2x3x32x32xbf16, #ttcore.shard<64x2>, #ttcore.memory_space<l1>>) -> ()
"ttmetal.deallocate_buffer"(%4) : (memref<2x3x1x1x!ttcore.tile<32x32, bf16>, #ttcore.shard<2048x2048>, #ttcore.memory_space<l1>>) -> ()
"ttmetal.enqueue_read_buffer"(%7, %alloc) : (memref<2x3x32x32xbf16, #ttcore.shard<64x2>, #ttcore.memory_space<l1>>, memref<64x96xbf16>) -> ()
"ttmetal.finish"() : () -> ()
"ttmetal.deallocate_buffer"(%7) : (memref<2x3x32x32xbf16, #ttcore.shard<64x2>, #ttcore.memory_space<l1>>) -> ()
return %alloc : memref<64x96xbf16>
}
Related Tenstorrent Projects
Getting Started
This page walks you through the steps required to set up tt-mlir.
NOTE: If you have a build issue, you can file a bug here.
Prerequisites
Hardware Setup
Use this guide to set up your hardware - Hardware Setup.
System Dependencies
You can use tt-mlir with Ubuntu or Mac OS, however the runtime does not work on Mac OS. tt-mlir project has the following system dependencies:
- Ubuntu 24.04 OS or Mac OS
- Clang >= 14 & <= 18
- Ninja
- CMake 3.24 or higher
- Python 3.12
- python3.12-venv
Ubuntu
Install Clang, Ninja, CMake, and python3.12-venv:
sudo apt install git clang cmake ninja-build pip python3.12-venv
You should now have the required dependencies installed.
NOTE: If you intend to build with runtime enabled (
-DTTMLIR_ENABLE_RUNTIME=ON), you also need to install tt-metal dependencies which can be found here.
Full developer dependencies as packaged in our docker image:
apt-get update -qq
apt-get install -y -qq \
software-properties-common \
build-essential \
python3-pip \
git \
libhwloc-dev \
pandoc \
libtbb-dev \
libcapstone-dev \
pkg-config \
linux-tools-generic \
ninja-build \
wget \
libgtest-dev \
cmake \
ccache \
doxygen \
graphviz \
libyaml-cpp-dev \
curl \
jq \
sudo \
lcov \
zstd \
unzip
# Install Python 3.12 (native in Ubuntu 24.04)
apt-get install -y -qq python3.12 python3.12-dev python3.12-venv
# Setup / install metal dependencies
wget -q https://raw.githubusercontent.com/tenstorrent/tt-metal/${TT_METAL_DEPENDENCIES_COMMIT}/{install_dependencies.sh,tt_metal/sfpi-info.sh,tt_metal/sfpi-version}
chmod u+x sfpi-info.sh
bash install_dependencies.sh --docker
bash install_dependencies.sh --sfpi
# tt-metal's install_dependencies.sh --docker no longer installs ULFM OpenMPI,
# so install it here so libtt_metal.so links against the ULFM build instead of
# the system OpenMPI.
( source install_dependencies.sh --source-only && detect_os && distributed=1 && install_mpi_ulfm )
apt-get clean
rm -rf /var/lib/apt/lists/*
Mac OS
On MacOS we need to install the latest version of cmake, and ninja which can be done using Homebrew with (Docs for installing Homebrew: https://brew.sh).
brew install cmake ninja
Clone the tt-mlir Repo
- Clone the tt-mlir repo:
git clone https://github.com/tenstorrent/tt-mlir.git
- Navigate into the tt-mlir folder.
Environment Setup
There are two ways to set up the environment, either using a docker image or building the environment manually. The docker image is recommended on ubuntu since it is easier to set up and use.
Note: Docker path is only supported on ubuntu. For macos please use Setting up the Environment Manually.
Using a Docker Image
Please see Docker Notes for details on how to set up and use the docker image.
Once you have the docker image running and you are logged into the container, you should be ready to build.
Note: Docker path is only supported on ubuntu. For macos please use Setting up the Environment Manually.
Setting up the Environment Manually
This section explains how to manually build the environment so you can use tt-mlir. You only need to build this once, it builds llvm, flatbuffers, and a Python virtual environment. You can specify the LLVM build type by using -DLLVM_BUILD_TYPE=*. The default is MinSizeRel, and available options are listed here.
-
Navigate into the tt-mlir folder.
-
The environment gets installed into a toolchain directory, which is by default set to
/opt/ttmlir-toolchain, but can be overridden by setting (and persisting in your environment) the environment variableTTMLIR_TOOLCHAIN_DIR. You need to manually create the toolchain directory as follows:
export TTMLIR_TOOLCHAIN_DIR=/opt/ttmlir-toolchain/
sudo mkdir -p "${TTMLIR_TOOLCHAIN_DIR}"
sudo chown -R "${USER}" "${TTMLIR_TOOLCHAIN_DIR}"
- Please ensure that you do not already have an environment (venv) activated before running the following commands:
cmake -B env/build env -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++
cmake --build env/build
source env/activate
NOTE: The last command takes time to run, so give it time to complete.
Building the tt-mlir Project
In this step, you build the tt-mlir project:
source env/activate
cmake -G Ninja -B build
cmake --build build
You have now configured tt-mlir.
You can add different flags to your build. Here are some options to consider:
- To enable the ttnn/metal runtime add
-DTTMLIR_ENABLE_RUNTIME=ON. Clang 20 is the minimum required version when enabling the runtime. - To enable the ttnn/metal perf runtime add
-DTT_RUNTIME_ENABLE_PERF_TRACE=ON. - To accelerate the builds with ccache use
-DCMAKE_CXX_COMPILER_LAUNCHER=ccache. - To workaround OOM issues it can be useful to decrease the number of parallel jobs with
-DCMAKE_BUILD_PARALLEL_LEVEL=4. - If Python bindings aren't required for your project, you can accelerate builds further with the command
-DTTMLIR_ENABLE_BINDINGS_PYTHON=OFF. - To enable
tt-exploreradd the-DTT_RUNTIME_ENABLE_PERF_TRACE=ON,-DTTMLIR_ENABLE_RUNTIME=ON, and-DTT_RUNTIME_DEBUG=ON. - To enable optimizer pass that uses the op model library, add
-DTTMLIR_ENABLE_OPMODEL=ON. - The TTNN build is automatically integrated / handled by the tt-mlir cmake build system. For debugging and further information regarding the TTNN backend build step, please refer to TTNN Documentation.
- The runtime build depends on the
TT_METAL_RUNTIME_ROOTvariable, which is also set inenv/activatescript. For more information, please refer to TT-NN and TT-Metalium installation documentation.
| OS | Offline Compiler Only | Runtime Enabled Build | Runtime + Perf Enabled Build |
|---|---|---|---|
| Ubuntu 24.04 | ✅ | ✅ | ✅ |
| Ubuntu 20.04 | ✅ | ❌ | ❌ |
| MacOS | ✅ | ❌ | ❌ |
Test the Build
Use this step to check your build. Do the following:
source env/activate
cmake --build build -- check-ttmlir
Lint
Set up lint so you can spot errors and stylistic issues before runtime:
source env/activate
cmake --build build -- clang-tidy
Note for developers: You can run:
source env/activate cmake --build build -- clang-tidy-ciThis reproduces the
Lint (clang-tidy)CI job. It runsclang-tidyonly on committed files that have been modified relative to theorigin/mainbranch.
Pre-Commit
Pre-Commit applies a git hook to the local repository such that linting is checked and applied on every git commit action. Install from the root of the repository using:
source env/activate
pre-commit install
If you have already committed before installing the pre-commit hooks, you can run on all files to "catch up":
pre-commit run --all-files
For more information visit pre-commit
Docs
Build the documentation by doing the following:
-
Make sure you have
mdbook,doxygen,sphinx, andsphinx-markdown-builderinstalled. -
Build the docs:
source env/activate
cmake --build build -- docs
mdbook serve build/docs
NOTE:
mdbook servewill by default create a local server athttp://localhost:3000.
For more information about building the docs please read the full guide on building the docs.
Common Build Errors
TTMLIRPythonCAPI target requires changing an RPATH
CMake Error at /opt/ttmlir-toolchain/lib/cmake/llvm/AddLLVM.cmake:594 (add_library):
The install of the TTMLIRPythonCAPI target requires changing an RPATH from
the build tree, but this is not supported with the Ninja generator unless
on an ELF-based or XCOFF-based platform. The
CMAKE_BUILD_WITH_INSTALL_RPATH variable may be set to avoid this relinking
step.
If you get the above error, it means you tried to build with an old version of cmake or ninja and there is a stale file. To fix this, rm -rf your build directory, install a newer version of cmake/ninja, and then rebuild. If you installed ninja via sudo apt install ninja-build, it might still be not up-to-date (v1.10.0). You may use ninja in the python virtual environment, or install it via pip3 install -U ninja, either way the version 1.11.1.git.kitware.jobserver-1 should work.
clang++ is not a full path and was not found in the PATH
CMake Error at CMakeLists.txt:2 (project):
The CMAKE_CXX_COMPILER:
clang++
is not a full path and was not found in the PATH.
Tell CMake where to find the compiler by setting either the environment
variable "CXX" or the CMake cache entry CMAKE_CXX_COMPILER to the full path
to the compiler, or to the compiler name if it is in the PATH.
CMake Error at CMakeLists.txt:2 (project):
The CMAKE_C_COMPILER:
clang
is not a full path and was not found in the PATH.
Tell CMake where to find the compiler by setting either the environment
variable "CC" or the CMake cache entry CMAKE_C_COMPILER to the full path to
the compiler, or to the compiler name if it is in the PATH.
If you get the following error, it means you need to install clang which you can do with sudo apt install clang on Ubuntu.
tt-metal Update Failures
Failed to unstash changes in: '/path/to/tt-metal/src/tt-metal'
You will have to resolve the conflicts manually
This error occurs during CMake's ExternalProject update of tt-metal. The build system tries to apply changes using Git's stash mechanism, but fails due to conflicts. This can happen even if you haven't manually modified any files, as the build process itself may leave behind artifacts or partial changes from previous builds.
To resolve, run the following command:
rm -rf third_party/tt-metal
Then retry your build command. If the error persists, you may need to do the following:
-
Remove the build directory:
rm -rf build -
Run CMake commands again.
-
Run the above.
Common Runtime Errors
Debugging Python on Mac OS
When debugging python on macOS via lldb you may see an error like:
(lldb) r
error: process exited with status -1 (attach failed (Not allowed to attach to process. Look in the console messages (Console.app), near the debugserver entries, when the attach failed. The subsystem that denied t
he attach permission will likely have logged an informative message about why it was denied.))
For preinstalled macOS binaries you must manually codesign with debug entitlements.
Create file debuggee-entitlement.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>com.apple.security.cs.disable-library-validation</key>
<true/>
<key>com.apple.security.get-task-allow</key>
<true/>
</dict>
</plist>
Sign the binary:
sudo codesign -f -s - --entitlements debuggee-entitlement.xml /opt/ttmlir-toolchain/venv/bin/python
Working with Docker Images
Components:
- Dockerfile
- Workflow for building Docker image
- Project build using Docker image
Overview
We use docker images to prepare the project environment, install dependencies, tooling and prebuild toolchain. Project builds four docker images:
- Base image
tt-mlir-base-ubuntu-24-04Dockerfile.base - CI image
tt-mlir-ci-ubuntu-24-04Dockerfile.ci - Base IRD image
tt-mlir-base-ird-ubuntu-24-04Dockerfile.ird - IRD image
tt-mlir-ird-ubuntu-24-04Dockerfile.ird
Base image starts with a supported base image (Ubuntu 24.04) and installs dependencies for project build. From there, we build the CI image that contains the prebuild toolchain and is used in CI to shorten the build time. The IRD image contains dev tools such as GDB, vim and ssh which are used in IRD environments.
During the CI Docker build, the project is built and tests are run to ensure that everything is set up correctly. If any dependencies are missing, the Docker build will fail.
Using the Docker Image
Here is a typical command to run the latest developer (ird) docker image:
sudo docker run -it -d --rm \
--name my-docker \
--cap-add ALL \
--device /dev/tenstorrent/0:/dev/tenstorrent/0 \
-v /dev/hugepages:/dev/hugepages \
-v /dev/hugepages-1G:/dev/hugepages-1G \
ghcr.io/tenstorrent/tt-mlir/tt-mlir-ird-ubuntu-24-04:latest bash
Special attention should be paid to flags:
--device /dev/tenstorrent/0:/dev/tenstorrent/0: this is required to map the hardware device into the container. For machines with multiple devices, this flag can be specified multiple times or adjusted with the appropriate device number.-v /dev/hugepages:/dev/hugepages/-v /dev/hugepages-1G:/dev/hugepages-1G: this is required to map the hugepages volume into the container. For more information on hugepages, please refer to the Getting Started Guide.The base or CI image can also be used in the same way, but the IRD image is recommended for development.
Using the Docker Image via IRD (Internal Developers Only)
Internally we use a tool called IRD. As part of your reserve command, you
can specify the docker image to use:
ird reserve \
--docker-image ghcr.io/tenstorrent/tt-mlir/tt-mlir-ird-ubuntu-24-04:latest
See ird reserve --help for more information on the reserve command. Typical
ird usage might look like:
# list machine availability
ird list-machines
# reserve a machine
ird reserve \
--volumes /localdev/$USER:/localdev/$USER \
--docker-image ghcr.io/tenstorrent/tt-mlir/tt-mlir-ird-ubuntu-24-04:latest \
--timeout 720 \
wormhole_b0 \
--machine [MACHINE_NAME]
# list your currently reserved machines
ird list
# connect to the first reserved machine
ird connect-to 1
# release the first reserved machine
ird release 1
Building the Docker Image using GitHub Actions
The GitHub Actions workflow Build and Publish Docker Image builds the Docker images and uploads them to GitHub Packages at https://github.com/orgs/tenstorrent/packages?repo_name=tt-mlir. We use the git SHA we build from as the tag.
Building the Docker Image Locally
To test the changes and build the image locally, use the following command:
docker build -f .github/Dockerfile.base -t ghcr.io/tenstorrent/tt-mlir/tt-mlir-base-ubuntu-24-04:latest .
docker build -f .github/Dockerfile.ci -t ghcr.io/tenstorrent/tt-mlir/tt-mlir-ci-ubuntu-24-04:latest .
docker build -f .github/Dockerfile.ird --build-arg FROM_IMAGE=base -t ghcr.io/tenstorrent/tt-mlir/tt-mlir-ird-base-ubuntu-24-04:latest .
docker build -f .github/Dockerfile.ird --build-arg FROM_IMAGE=ci -t ghcr.io/tenstorrent/tt-mlir/tt-mlir-ird-ubuntu-24-04:latest .
Using the Image in GitHub Actions Jobs
The GitHub Actions workflow Build in Docker uses a Docker container for building:
container:
image: ghcr.io/${{ github.repository }}/tt-mlir-ci-ubuntu-24-04:latest
options: --user root
Running Virtualized Ubuntu VM on macOS
In some cases, like running a software simulated device, it can be beneficial to run the stack on a local macOS machine. This document covers the necessary setup and configuration steps to get a performant Ubuntu VM setup on Apple Silicon.
Prerequisite Steps
- UTM is the VM application we'll be using in this guide, so the first step is to download and install UTM.
- Ubuntu 24.04 ARM image download.
- Direct link: 64-bit ARM (ARMv8/AArch64) server install image
UTM Setup
- Launch UTM and click the
+button to start a new VM. - Choose
Virtualize(emulation works, but is unusably slow). - Under
PreconfiguredchooseLinux. - Check box
Use Apple Virtualizationand select the ubuntu iso we just downloaded forBoot ISO Image.
- Optionally check
Enable Rosettawhich can enable running ELF's compiled for x86 if you're interested. It's not required and additional steps are required for it to work.
- This step depends on your machine's capabilities, but it's recommended to give 16GB of memory and to use the default CPU Cores setting. Note this can be changed after initial setup if you want to go back and tweak settings.
- It's recommended to at least 128GB of storage, with LLVM installation and full SW stack we quickly reach 80 gigs of storage.
- Optionally choose a shared host/VM directory.
- Optionally name your new VM
ubuntu 24.04 arm64
VM Setup
- Boot your newly created VM!
- Run through the Ubuntu setup as you see fit, be sure that openssh is enabled which simplifies logging into your VM, but the rest of the defaults are sufficient.
- If you plan on using your VM via ssh you can retrieve the ip address
ip aand looking at theinetrow underenp0s1. Should look something likeinet 192.168.64.3. Another tip is to add this to the host's~/.ssh/config. - Install your normal developer tools as you see fit.
Software Stack Installation
The majority of the software install flow is the same, with the exception of a few caveats called out here.
- Installing metal deps needs the additional flags below:
git clone git@github.com:tenstorrent/tt-metal.git
cd tt-metal
sudo bash install_dependencies.sh --docker --no-distributed
--docker: Despite not being in a docker, this is the flag that turns off configuring hugepages which is not required for VM.--no-distributed: Currently the metal distributed feature requires a package version of openmpi that only supports x86.
- Install tt-mlir system dependencies as outlined by this step.
- The environment needs to be built manually as outlined here.
- We can then build tt-mlir per usual.
- If planning to run tests on software sim, let's build the ttrt tool.
- The following all works per usual:
Testing
To run tests:
source env/activate
cmake --build build -- check-ttmlir
Lit testing
llvm-lit tool is used for MLIR testing. With it you can:
# Query which tests are available
llvm-lit -sv ./build/test --show-tests
# Run an individual test:
llvm-lit -sv ./build/test/ttmlir/Dialect/TTIR/test_allocate.mlir
# Run a sub-suite:
llvm-lit -sv ./build/test/ttmlir/Dialect/TTIR
See the full
llvm-litdocumentation for more information.
EmitC testing
NOTE: This is a developer's guide on how to test EmitC as a feature. For usage of EmitC, please refer to ttnn-standalone docs.
Prerequisites
-
Activated virtual environment:
source env/activate -
Saved system descriptor file:
ttrt query --save-artifacts
Table of Contents
- Generate all EmitC tests and run them
- Generate a single EmitC test and run it
- Generate EmitC tests with Builder
Generate all EmitC tests and run them
-
Generate flatbuffers and .cpp files for EmitC tests
If you don't have SYSTEM_DESC_PATH environment variable exported, you can run:
SYSTEM_DESC_PATH=/path/to/system_desc.ttsys llvm-lit -sv test/ttmlir/EmitC/TTNNOr if you have SYSTEM_DESC_PATH exported, you can omit it:
llvm-lit -sv test/ttmlir/EmitC/TTNN -
Compile generated .cpp files to shared objects
tools/ttnn-standalone/ci_compile_dylib.py -
Run flatbuffers + shared objects and compare results
ttrt run --emitc build/test/ttmlir/EmitC/TTNN
Generate EmitC tests with Builder
Builder offers support for building EmitPy modules from ttir or stablehlo ops. Refer to Builder documentation.
Generate a single EmitC test and run it
-
Generate flatbuffers and .cpp files for EmitC test
SYSTEM_DESC_PATH=/path/to/system_desc.ttsys llvm-lit -sv test/ttmlir/EmitC/TTNN/eltwise_binary/add.mlir -
Compile generated .cpp files to shared objects
Assuming default build directory path:
tools/ttnn-standalone/ci_compile_dylib.py --file build/test/ttmlir/EmitC/TTNN/eltwise_binary/add.mlir.cpp -
Run the flatbuffer + shared object and compare results
ttrt emitc build/test/ttmlir/EmitC/TTNN/eltwise_binary/add.mlir.so --flatbuffer build/test/ttmlir/EmitC/TTNN/eltwise_binary/add.mlir.ttnn
Tools
The ttmlir project currently exposes the following tools:
ttmlir-opt: Thettmliroptimizer driver. This tool is used to run thettmlircompiler passes on a.mlirsource files and is central to developing and testing the compiler.ttmlir-translate: Thettmlirtranslation tool. This tool can convert from IR to external representation (and inverse). For example, IR in EmitC dialect can be converted into C++ code.ttrt: This tool is intended to be a swiss army knife for working with flatbuffers generated by the compiler. Its primary role is to inspect and run flatbuffer files.ttir-builder: This tool is for creating ttir operations. It provides support for those ops to be compiled into modules or directly to flatbuffer files.tt-explorer: Visualizer tool forttmlir-powered compiler results. Visualizes from emitted.mlirfiles to display compiled model, attributes, performance results, and provide a platform for human-driven overrides to gamify model tuning.ttnn-standalone: This tool is used to run C++ TTNN code outside of the compiler environment.
ttmlir-opt
The ttmlir optimizer driver. This tool is used to run the ttmlir compiler passes on a .mlir source files and is central to developing and testing the compiler.
Simple Test
./build/bin/ttmlir-opt --ttir-to-ttnn-runtime-pipeline test/ttmlir/Dialect/TTNN/simple_multiply.mlir
# Or
./build/bin/ttmlir-opt --ttir-to-ttmetal-pipeline test/ttmlir/Dialect/TTNN/simple_multiply.mlir
ttmlir-translate
The ttmlir-translate translation utility. Unlike ttmlir-opt tool which is used to run passes within the MLIR world, ttmlir-translate allows us to ingest something (e.g. code) into MLIR world, and also produce something (e.g. executable binary, or even code again) from MLIR.
Generate C++ code from MLIR
# First, let's run `ttmlir-opt` to convert to proper dialect
./build/bin/ttmlir-opt --ttir-to-emitc-pipeline test/ttmlir/Dialect/TTNN/eltwise/binary/multiply/simple_multiply.mlir -o c.mlir
# Now run `ttmlir-translate` to produce C++ code
./build/bin/ttmlir-translate --mlir-to-cpp c.mlir
Bonus: These two commands can be piped, to avoid writing a mlir file to disk, like so:
./build/bin/ttmlir-opt --ttir-to-emitc-pipeline test/ttmlir/Dialect/TTNN/eltwise/binary/multiply/simple_multiply.mlir | ./build/bin/ttmlir-translate -mlir-to-cpp
Generate flatbuffer file from MLIR
# First run `ttmlir-opt` to convert to proper dialect
./build/bin/ttmlir-opt --ttir-to-ttnn-runtime-pipeline test/ttmlir/Dialect/TTNN/eltwise/binary/multiply/simple_multiply.mlir -o ttnn.mlir
# Now run `ttmlir-translate` to produce flatbuffer file
./build/bin/ttmlir-translate --ttnn-to-flatbuffer ttnn.mlir -o out.ttnn
ttrt
This tool is intended to be a swiss army knife for working with flatbuffers generated by the compiler. Its primary role is to inspect and run flatbuffer files. It enables the running of flatbuffer files without a front-end runtime.
Building
- Build ttmlir
- Build
ttrt:
source env/activate
cmake --build build
ttrt --help
Building runtime mode
Add the following flags when building the compiler
-DTTMLIR_ENABLE_RUNTIME=ON
Building perf mode
Add the following flags when building the compiler
-DTTMLIR_ENABLE_RUNTIME=ON
-DTT_RUNTIME_ENABLE_PERF_TRACE=ON
LOGGER Levels
ttrt support logging at different logger levels. You will need to set env var TTRT_LOGGER_LEVEL in command line or a python script. By default, it's set to INFO.
TTRT_LOGGER_LEVEL=INFO
TTRT_LOGGER_LEVEL=CRITICAL
TTRT_LOGGER_LEVEL=ERROR
TTRT_LOGGER_LEVEL=WARNING
TTRT_LOGGER_LEVEL=DEBUG
tt-metal logging
ttrt runtime uses tt-metal for op execution and device interfacing. For more detailed logs, which can help in troubleshooting build or runtime issues, set env var TT_METAL_LOGGER_LEVEL. By default, it is set to FATAL.
export TT_METAL_LOGGER_LEVEL=DEBUG
Installing ttrt as python whls
Every time ttrt is built, it creates a whls file in build/tools/ttrt/build. Ex filename: ttrt-0.0.235-cp312-cp312-linux_x86_64.whl. You can take this whls file and install it in any docker container and in any venv outside of ttmlir. After which, you can use all the following functionality as the same.
- Download whls
- Create a python venv
python -m venv ttrt_env
source ttrt_env/bin/activate
- Install whls (replace with your version of the whls)
pip install build/tools/ttrt/build/ttrt-0.0.235-cp312-cp312-linux_x86_64.whl
Generating a flatbuffer
tt-mlir exposes a few ways to generate flatbuffers.
Generate a flatbuffer file from ttir-builder
ttir-builder is a tool for creating TTIR ops, converting them into MLIR modules, running passes to lower modules into backends, and translating to flatbuffers. See documentation for further instructions.
Generate a flatbuffer file from compiler
The compiler supports a pass to load a system descriptor to compile against. You can feed this pass into ttmlir-opt.
- Build ttmlir
- Generate ttsys file from the system you want to compile for using
ttrt. This will create asystem_desc.ttsysfile underttrt-artifactsfolder.
ttrt query --save-artifacts
- Use
ttmlir-opttool in compiler to feed system descriptor. See thettmlir-optdocumentation for more information on how to generate .mlir files.
./build/bin/ttmlir-opt --ttcore-register-device="system-desc-path=/path/to/system_desc.ttsys" --ttir-to-ttnn-runtime-pipeline test/ttmlir/Dialect/TTNN/simple_subtract.mlir -o ttnn.mlir
or (pipe path directly into ttir-to-ttnn-runtime-pipeline)
./build/bin/ttmlir-opt --ttir-to-ttnn-runtime-pipeline="system-desc-path=/path/to/system_desc.ttsys" test/ttmlir/Dialect/TTNN/simple_subtract_to_add.mlir -o ttnn.mlir
- Use
ttmlir-translatetool in compiler to generate the flatbuffer executable. See thettmlir-translatedocumentation for more information on how to generate flatbuffer files.
./build/bin/ttmlir-translate --ttnn-to-flatbuffer ttnn.mlir -o out.ttnn
- Run your test cases using
ttrt
ttrt run /path/to/out.ttnn
Generate flatbuffer files using llvm-lit
There are already existing .mlir test cases under test/ttmlir/Silicon. You can use llvm-lit tool to generate the corresponding ttnn and ttm files.
- Build ttmlir
- Generate ttsys file from the system you want to compile for using
ttrt. This will create asystem_desc.ttsysfile underttrt-artifactsfolder.
ttrt query --save-artifacts
- Export this file in your environment using
export SYSTEM_DESC_PATH=/path/to/system_desc.ttsys. Whenllvm-litis run, it will query this variable and generate the ttnn and ttm files using this system. Optionally, you can also provide this manually when runningllvm-lit. - Generate your test cases. This will generate all your ttnn and ttm files under
build/test/ttmlir/Silicon. ttnn files have a.ttnnfile extension and ttmetal files have a.ttmextension.
cmake --build build -- check-ttmlir
- (Optional) If you have a single .mlir file (or a directory of custom .mlir files) that you created using the compiler, and you want to generate the corresponding ttnn and ttm files for it, you can run
llvm-litstandalone to the path of your .mlir file or directory of .mlir files to generate the flatbuffer executables. You will have to make sure you add in the correctllvm-litconfigs into your .mlir file. See section on addingllvm-litconfig options inside a .mlir file to create flatbuffer binaries for more info. You must also make sure your .mlir test is found within test/ttmlir/Silicon folder (and point lit to the build folder)!
llvm-lit -v ./build/test/ttmlir/Silicon
or
SYSTEM_DESC_PATH=/path/to/system_desc.ttsys llvm-lit -v ./build/test/ttmlir/Silicon
- Run your test cases using
ttrt
ttrt run /path/to/test.ttnn
ttrt run /path/to/dir/of/flatbuffers
Adding llvm-lit config options inside a .mlir file to create flatbuffer binaries
Inside of your .mlir file, you can add certain config options that llvm-lit will use when running against that test case. For the purpose of generating flatbuffer executables, you can add --ttcore-register-device="system-desc-path=%system_desc_path%" which will tell llvm-lit to parse the system desc found from the environment flag set by export SYSTEM_DESC_PATH=/path/to/system_desc.ttsys. You can also paste a custom path to a system desc file as well.
// RUN: ttmlir-opt --ttcore-register-device="system-desc-path=%system_desc_path%" --ttnn-layout --convert-ttir-to-ttnn %s > %t.mlir
// RUN: FileCheck %s --input-file=%t.mlir
// RUN: ttmlir-translate --ttnn-to-flatbuffer %t.mlir > %t.ttnn
Adding new mlir test cases
You can copy your .mlir test file (with the appropriate llvm-lit config options for generating flatbuffer binaries) into test/ttmlir/Silicon. Then, follow generating flatbuffer files using llvm-lit to generate the executables to run!
Versioning
ttrt and flatbuffers have strict versioning check. When running a flatbuffer against ttrt, you have to make sure the flatbuffer was generated using the same version as ttrt (or vice versa). Major and Minor versions are manually set using github tags when releases are made. Patch versioning is the number of commits from the last major/minor tag.
vmajor.minor.patch
The flag --ignore-version can be used to bypass versioning checks. Use at your own risk; it can cause unpredictable errors.
Application APIs
ttrt --help
ttrt read
ttrt run
ttrt query
ttrt perf
ttrt check
ttrt emitpy
Command line usage
There are different ways you can use the APIs under ttrt. The first is via the command line as follows. All artifacts are saved under ttrt-artifacts folder under TT_MLIR_HOME environment variable. By default, all logging is printed to the terminal. You can specify a log file to dump output to.
read
Read sections of a binary file
ttrt read --help
ttrt read --section version out.ttnn
ttrt read --section system_desc out.ttnn
ttrt read --section mlir out.ttnn
ttrt read --section inputs out.ttnn
ttrt read --section outputs out.ttnn
ttrt read --section op_stats out.ttnn
ttrt read --section mesh_shape out.ttnn
ttrt read --section all out.ttnn --clean-artifacts
ttrt read --section all out.ttnn --save-artifacts
ttrt read --section all /dir/of/flatbuffers
ttrt read system_desc.ttsys
ttrt read --section system_desc system_desc.ttsys
ttrt read system_desc.ttsys --log-file ttrt.log
ttrt read out.ttnn --save-artifacts --artifact-dir /path/to/some/dir
ttrt read out.ttnn --result-file result.json
run
Run a binary file or a directory of binary files
Note: It's required to be on a system with silicon and to have a runtime enabled build -DTTMLIR_ENABLE_RUNTIME=ON.
ttrt run --help
ttrt run out.ttnn
ttrt run out.ttnn --seed 0
ttrt run out.ttnn --init arange
ttrt run out.ttnn --identity
ttrt run out.ttnn --identity --rtol 1 --atol 1
ttrt run out.ttnn --clean-artifacts
ttrt run out.ttnn --save-artifacts
ttrt run out.ttnn --loops 10
ttrt run --program-index all out.ttnn
ttrt run --program-index 0 out.ttnn
ttrt run /dir/of/flatbuffers
ttrt run /dir/of/flatbuffers --loops 10
ttrt run /dir/of/flatbuffers --log-file ttrt.log
ttrt run out.ttnn --save-artifacts --artifact-dir /path/to/some/dir
ttrt run out.ttnn --dump-kernels --kernel-source-dir /tmp
ttrt run out.ttnn --load-kernels --kernel-source-dir /tmp
ttrt run out.ttnn --result-file result.json
ttrt run out.ttnn --disable-golden
ttrt run out.ttnn --save-golden-tensors
ttrt run out.ttnn --print-input-output-tensors
ttrt run out.ttnn --debugger
ttrt run out.ttnn --memory --save-artifacts
ttrt run out.ttnn --memory --check-memory-leak
For info on running EmitC tests, see EmitC testing.
Run results
The run api saves a run_results.json file that records information about the run including any errors that were thrown and location of other saved run data.
{
[
{
"file_path": "ttnn/test_tan[f32-shape0]_ttnn.mlir.ttnn",
"result": "pass",
"exception": "",
"log_file": "ttrt.log",
"artifacts": "/home/$USER/tt-mlir/ttrt-artifacts",
"program_index": "all",
"program_results": {
"program_index_0": {
"loop_0": {
"total_duration_ns": 3269341588,
"total_ttnn_api_duration_ns": null,
"total_device_kernel_duration_ns": null
}
}
}
}
]
Golden checks
Golden checks are used to verify runtime op accuracy. They are run by default during the golden callback unless flag --disable-golden is used. If flag --save-artifacts is used, a golden results report will be saved under the artifacts directory.
{
"loc(\"/home/$USER/tt-mlir/test/python/golden/test_ttir_ops.py:74:id(0)\")": {
"expected_pcc": 0.99,
"actual_pcc": 0.0015917614829425491,
"atol": 1e-08,
"rtol": 1e-05,
"allclose": false,
"max": 8529.765625,
"mean_absolute_error": 6.644593238830566,
"root_mean_square_error": 100.30211639404297,
"cosine_similarity": 0.0016297339461743832
}
}
Memory
Memory callback functions are run when flag --memory is used. A memory report will be written under the artifacts directory that contains information on op memory usage.
{
"0": {
"loc": "loc(\"/home/$USER/tt-mlir/test/python/golden/test_ttir_ops.py:74:id(0)\")",
"debug_str": "%0 = \"ttnn.tan\"(%arg0) : (tensor<128x128xf32, #ttnn.ttnn_layout<(d0, d1) -> (d0, d1), <1x1>, memref<4x4x!ttcore.tile<32x32, f32>, #ttnn.buffer_type<dram>>, <interleaved>>>) -> tensor<128x128xf32, #ttnn.ttnn_layout<(d0, d1) -> (d0, d1), <1x1>, memref<4x4x!ttcore.tile<32x32, f32>, #ttnn.buffer_type<dram>>, <interleaved>>> loc(\"/home/$USER/tt-mlir/test/python/golden/test_ttir_ops.py:74:id(0)\")",
"dram": {
"num_banks": 12,
"total_bytes_per_bank": 1071181792,
"total_bytes_allocated_per_bank": 16384,
"total_bytes_free_per_bank": 1071167456,
"largest_contiguous_bytes_free_per_bank": 1071165408,
"block_table": [
{
"allocated": "yes",
"nextID": "1",
"prevID": "-1",
"size": "8192",
"address": "0",
"blockID": "0"
},
{
"allocated": "yes",
"nextID": "3",
"prevID": "0",
"size": "8192",
"address": "8192",
"blockID": "1"
},
{
"allocated": "no",
"nextID": "-1",
"prevID": "1",
"size": "1071165408",
"address": "16384",
"blockID": "3"
}
]
},
"l1": {
"num_banks": 64,
"total_bytes_per_bank": 1369120,
"total_bytes_allocated_per_bank": 0,
"total_bytes_free_per_bank": 1369120,
"largest_contiguous_bytes_free_per_bank": 1369120,
"block_table": [
{
"allocated": "no",
"nextID": "-1",
"prevID": "-1",
"size": "1369120",
"address": "0",
"blockID": "0"
}
]
},
"l1_small": {
"num_banks": 64,
"total_bytes_per_bank": 32768,
"total_bytes_allocated_per_bank": 0,
"total_bytes_free_per_bank": 32768,
"largest_contiguous_bytes_free_per_bank": 32768,
"block_table": [
{
"allocated": "no",
"nextID": "-1",
"prevID": "-1",
"size": "32768",
"address": "0",
"blockID": "0"
}
]
},
"trace": {
"num_banks": 12,
"total_bytes_per_bank": 0,
"total_bytes_allocated_per_bank": 0,
"total_bytes_free_per_bank": 0,
"largest_contiguous_bytes_free_per_bank": 0,
"block_table": [
{
"allocated": "no",
"nextID": "-1",
"prevID": "-1",
"size": "0",
"address": "0",
"blockID": "0"
}
]
}
}
}
Debugger
Enabling the --debugger flag sets a pbd trace to run after each op during the callback hook.
query
Query the system to obtain the system desc file (optionally store it to disk)
Note: It's required to be on a system with silicon and to have a runtime enabled build -DTTMLIR_ENABLE_RUNTIME=ON.
ttrt query --help
ttrt query
ttrt query --quiet
ttrt query --save-artifacts
ttrt query --clean-artifacts
ttrt query --save-artifacts --log-file ttrt.log
ttrt query --save-artifacts --artifact-dir /path/to/some/dir
ttrt query --result-file result.json
perf
Run performance mode of a binary file or a directory of binary files
Note: It's required to be on a system with silicon and to have a runtime enabled build -DTTMLIR_ENABLE_RUNTIME=ON. Also need perf enabled build -DTT_RUNTIME_ENABLE_PERF_TRACE=ON.
Note: You can collect host only related performance data via --host-only flag. By default, host and device side performance data are both collected.
If the saving artifacts flag is provided, perf mode will dump the following files in the artifacts directory
ops_perf_results.csv : compiled op performance results
OP CODE,OP TYPE,GLOBAL CALL COUNT,DEVICE ID,ATTRIBUTES,MATH FIDELITY,CORE COUNT,PARALLELIZATION STRATEGY,HOST START TS,HOST END TS,HOST DURATION [ns],DEVICE FW START CYCLE,DEVICE FW END CYCLE,OP TO OP LATENCY [ns],OP TO OP LATENCY BR/NRISC START [ns],DEVICE FW DURATION [ns],DEVICE KERNEL DURATION [ns],DEVICE KERNEL DURATION DM START [ns],DEVICE KERNEL DURATION PER CORE MIN [ns],DEVICE KERNEL DURATION PER CORE MAX [ns],DEVICE KERNEL DURATION PER CORE AVG [ns],DEVICE KERNEL FIRST TO LAST START [ns],DEVICE BRISC KERNEL DURATION [ns],DEVICE NCRISC KERNEL DURATION [ns],DEVICE TRISC0 KERNEL DURATION [ns],DEVICE TRISC1 KERNEL DURATION [ns],DEVICE TRISC2 KERNEL DURATION [ns],DEVICE ERISC KERNEL DURATION [ns],DEVICE COMPUTE CB WAIT FRONT [ns],DEVICE COMPUTE CB RESERVE BACK [ns],DISPATCH TOTAL CQ CMD OP TIME [ns],DISPATCH GO SEND WAIT TIME [ns],INPUT_0_W,INPUT_0_Z,INPUT_0_Y,INPUT_0_X,INPUT_0_LAYOUT,INPUT_0_DATATYPE,INPUT_0_MEMORY,OUTPUT_0_W,OUTPUT_0_Z,OUTPUT_0_Y,OUTPUT_0_X,OUTPUT_0_LAYOUT,OUTPUT_0_DATATYPE,OUTPUT_0_MEMORY,METAL TRACE ID,METAL TRACE REPLAY SESSION ID,COMPUTE KERNEL SOURCE,COMPUTE KERNEL HASH,DATA MOVEMENT KERNEL SOURCE,DATA MOVEMENT KERNEL HASH,BRISC MAX KERNEL SIZE [B],NCRISC MAX KERNEL SIZE [B],TRISC 0 MAX KERNEL SIZE [B],TRISC 1 MAX KERNEL SIZE [B],TRISC 2 MAX KERNEL SIZE [B],ERISC MAX KERNEL SIZE [B],PM IDEAL [ns],PM COMPUTE [ns],PM BANDWIDTH [ns],PM REQ I BW,PM REQ O BW,PM FPU UTIL (%),NOC UTIL (%),DRAM BW UTIL (%),NPE CONG IMPACT (%),LOC,CONST_EVAL_OP,PROGRAM_METADATA
UnaryDeviceOperation,tt_dnn_device,1024,0,{'bfp8_pack_precise': 'false'; 'fp32_dest_acc_en': 'true'; 'op_chain': '{UnaryWithParam(op_type=UnaryOpType::TAN;param={})}'; 'output_dtype': 'DataType::FLOAT32'; 'output_memory_config': 'MemoryConfig(memory_layout=TensorMemoryLayout::INTERLEAVED;buffer_type=BufferType::DRAM;shard_spec=std::nullopt;nd_shard_spec=std::nullopt;created_with_nd_shard_spec=0)'; 'preserve_fp32_precision': 'true'},HiFi4,16,,4556959654,4557518500,558846,9815181939513,9815181946491,0,0,6978,6314,6126,4982,6216,5652,335,6087,1375,1656,4957,465,,,,,,1,1,128,128,TILE,FLOAT32,DEV_1_DRAM_INTERLEAVED,1,1,128,128,TILE,FLOAT32,DEV_1_DRAM_INTERLEAVED,,,['ttnn/cpp/ttnn/operations/eltwise/unary/device/kernels/compute//eltwise_sfpu.cpp'],['eltwise_sfpu/3265258334475852953/'],['ttnn/cpp/ttnn/operations/eltwise/unary/device/kernels/dataflow/reader_unary_interleaved_start_id.cpp'; 'ttnn/cpp/ttnn/operations/eltwise/unary/device/kernels/dataflow/writer_unary_interleaved_start_id.cpp'],['reader_unary_interleaved_start_id/1146610629329498539/'; 'writer_unary_interleaved_start_id/1727642094059197364/'],708,736,1344,1568,1380,0,1,1,1,[],[],0.016,,,,"loc(""/home/$USER/tt-mlir/test/python/golden/test_ttir_ops.py:74:id(0)"")",false,"{'loop_number': 0, 'program_index': 0, 'disable_eth_dispatch': False, 'enable_program_cache': False, 'dump_device_rate': 1000}"
profile_log_device.csv : dump of all device side profiled results
tracy_ops_data.csv : op data results dumped in a readable format
tracy_ops_times.csv : op time results dumped in a readable format
tracy_profile_log_host.tracy : tracy profiled results file, this file can be fed into the tracy GUI
check
Check a binary file or a directory of binary files against a system desc (by default, uses the host machine)
Note: It's required to be on a system with silicon and to have a runtime enabled build -DTTMLIR_ENABLE_RUNTIME=ON.
ttrt check --help
ttrt check out.ttnn
ttrt check out.ttnn --system-desc /path/to/system_desc.ttsys
ttrt check out.ttnn --clean-artifacts
ttrt check out.ttnn --save-artifacts
ttrt check out.ttnn --log-file ttrt.log
ttrt check /dir/of/flatbuffers --system-desc /dir/of/system_desc
ttrt check --save-artifacts --artifact-dir /path/to/some/dir out.ttnn
ttrt check out.ttnn --result-file result.json
emitpy
Run a python file or a directory of python files. Optionally provide a binary file or directory of binary files for output tensor comparison.
Note: It's required to be on a system with silicon and to have a runtime enabled build -DTTMLIR_ENABLE_RUNTIME=ON.
ttrt emitpy --help
ttrt emitpy out.py
ttrt emitpy out.py --clean-artifacts
ttrt emitpy out.py --save-artifacts
ttrt emitpy out.py --loops 10
ttrt emitpy --program-index all out.py
ttrt emitpy --program-index 0 out.py
ttrt emitpy /dir/of/emitpy_modules
ttrt emitpy /dir/of/emitpy_modules --loops 10
ttrt emitpy /dir/of/emitpy_modules --log-file ttrt.log
ttrt emitpy /dir/of/emitpy_modules --flatbuffer /path/to/flatbuffer
ttrt emitpy out.py --save-artifacts --artifact-dir /path/to/some/dir
ttrt emitpy out.py --result-file result.json
ttrt emitpy out.py --print-input-output-tensors
ttrt emitpy out.py --memory --save-artifacts
For info on generating EmitPy tests through ttmlir-opt and ttmlir-translate, see EmitPy.
For info on generating EmitPy tests through ttir-builder, see ttir-builder.
emitpy results
The emitpy api saves a emitpy_results.json file that records information about the run including any errors that were thrown and location of other saved data.
[
{
"file_path": "ttir-builder-artifacts/emitpy/test_binary_ops[add-emitpy-f32-128x128]_ttnn.mlir.py",
"result": "pass",
"exception": "",
"log_file": "ttrt.log",
"artifacts": "/home/$USER/tt-mlir/ttrt-artifacts",
"program_index": "all"
}
]
emitc
Run a .so file or a directory of .so files. Optionally provide a binary file or directory of binary files for output tensor comparison.
Note: It's required to be on a system with silicon and to have a runtime enabled build -DTTMLIR_ENABLE_RUNTIME=ON.
ttrt emitc --help
ttrt emitc out.py
ttrt emitc out.py --clean-artifacts
ttrt emitc out.py --save-artifacts
ttrt emitc out.py --loops 10
ttrt emitc --program-index all out.py
ttrt emitc --program-index 0 out.py
ttrt emitc /dir/of/emitc_modules
ttrt emitc /dir/of/emitc_modules --loops 10
ttrt emitc /dir/of/emitc_modules --log-file ttrt.log
ttrt emitc /dir/of/emitc_modules --flatbuffer /path/to/flatbuffer
ttrt emitc out.py --save-artifacts --artifact-dir /path/to/some/dir
ttrt emitc out.py --result-file result.json
ttrt emitc out.py --print-input-output-tensors
ttrt emitc out.py --memory --save-artifacts
For info on generating EmitC tests through ttnn-standalone, see EmitC testing documentation.
For info on generating EmitC tests through ttir-builder, see ttir-builder documentation.
emitc results
The emitc api saves a emitc_results.json file that records information about the run including any errors that were thrown and location of other saved data.
[
{
"file_path": "ttir-builder-artifacts/emitc/test_reciprocal[emitc-f32-128x128]_ttnn.mlir.so",
"result": "pass",
"exception": "",
"log_file": "ttrt.log",
"artifacts": "/home/$USER/tt-mlir/ttrt-artifacts",
"program_index": "all"
}
]
gdb
You can relaunch ttrt inside of gdb which can be useful for debugging C++
runtime components.
ttrt --gdb run ...
ttrt --gdb perf ...
Using as a python package
The other way to use the APIs under ttrt is importing it as a library. This allows the user to use it in custom scripts.
Import ttrt as a python package
from ttrt.common.api import API
Setup API and register all features
API.initialize_apis()
Setup arguments
You can specify certain arguments to pass to each API, or use the default arguments provided
Args
This can be a dictionary of values to set inside your API instance. These are the same options as found via the command line. You can get the total list of support arguments via the ttrt --help command. Any argument not provided will be set to the default.
custom_args = {}
custom_args["--clean-artifacts"] = True
query_instance = API.Query(args=custom_args)
Logging
You can specify a specific logging module you want to set inside your API instance. The rationale behind this is to support different instances of different APIs, all being able to be logged to a different file. You can also customize the level of detail your log file contains.
from ttrt.common.util import Logger
import os
os.environ["LOGGER_LEVEL"] = "DEBUG"
log_file_name = "some_file_name.log"
custom_logger = Logger(log_file_name)
read_instance = API.Read(logger=custom_logger)
Artifacts
You can specify a specific artifacts directory to store all the generate metadata during the execution of any API run. This allows you to specify different artifact directories if you wish for different instances of APIs.
from ttrt.common.util import Artifacts
log_file_name = "some_file_name.log"
artifacts_folder_path = "/opt/folder"
custom_logger = Logger(log_file_name)
custom_artifacts = Artifacts(logger=custom_logger, artifacts_folder_path=artifacts_folder_path)
run_instance = API.Run(artifacts=custom_artifacts)
Execute API
Once all the arguments are setup, you can run your API instance with all your provided arguments. Note, APIs are stateless. Thus, subsequent calls to the same API instance will not preserve previous call artifacts. You can generate a new artifacts directory for subsequent runs if you wish to call the APIs multiple times, for example.
result_code, results = query_instance()
result_code, results = read_instance()
result_code, results = run_instance()
Putting it all together
You can do interesting stuff when combining all the above features into your python script
from ttrt.common.api import API
from ttrt.common.util import Logger
from ttrt.common.util import Artifacts
API.initialize_apis()
custom_args = {}
custom_args["--clean-artifacts"] = True
custom_args["--save-artifacts"] = True
custom_args["--loops"] = 10
custom_args["--init"] = "randn"
custom_args["binary"] = "/path/to/subtract.ttnn"
log_file_name = "some_file_name.log"
custom_logger = Logger(log_file_name)
artifacts_folder_path = "/opt/folder"
custom_artifacts = Artifacts(logger=custom_logger, artifacts_folder_path=artifacts_folder_path)
run_instance = API.Run(args=custom_args, logger=custom_logger, artifacts=custom_artifacts)
result_code, results = run_instance()
Runtime integration
The full set of ttrt.runtime exposed APIs and types can be found in runtime/python/runtime/runtime.cpp, however only the ones intended to be used for runtime customization through callback hooks are outlined here.
Callback hooks
MLIR Runtime exposes a feature to register python callback functions. Any two python functions can be provided - the first function will be executed before every op in MLIR Runtime, the second after every op. The following steps describe how to extend your application to register python functions. Callback functions are already implemented by default for pbd debugger implementation and gathering memory and golden check data as outlined in the run API section.
- Pybind DebugHooks C++ class, specifically
tt::runtime::debug::Hooks::get. Seeruntime/python/runtime/runtime.cppfor an example of howttrtpybinds it.
tt::runtime::debug::Hooks
tt::runtime::debug::Hooks::get
- Register callback functions in your python script. The following is registering the two callback functions written in
tools/ttrt/common/callback.py. The Debug Hooks get function has been exposed via pybind tottrt.runtime.DebugHooks.get
import ttrt.runtime
callback_env = ttrt.runtime.DebugHooks.get(pre_op_callback_runtime_config, post_op_callback_runtime_config)
- The callback function has a particular function signature, which looks like the following
def pre_op_callback_runtime_config(binary, program_context, op_context):
binary: reference to the binary you are currently running, ttrt.binary Binary object
program_context: reference to the program currently running, ttrt.runtime ProgramContext object
op_context: reference to the op that is currently running, ttrt.runtime OpContext object
- Each of these parameters has certain runtime APIs exposed which can only be called within the callback functions since they rely on the
op_contextvariable that is only available from runtime during callbacks.
import ttrt.runtime
loc = ttrt.runtime.get_op_loc_info(op_context) : get the location of the op as a string which is used as the key when indexing the golden tensors stored in the flatbuffer
op_debug_str = ttrt.runtime.get_op_debug_str(op_context) : get the op debug str (contains op metadata including op type, attributes, input tensor shapes and dtypes, memref with layout and buffer type, and loc)
op_golden_tensor = ttrt.runtime.get_debug_info_golden(binary, loc) : get the golden tensor from the binary as a ttrt.binary GoldenTensor object
op_output_tensor = ttrt.runtime.get_op_output_tensor(op_context, program_context) : get the currently running output tensor from device as a ttrt.runtime Tensor object, if this is called in a preOp function or the op doesn't output a tensor, an empty tensor will be returned.
Note: ttrt is not needed to implement this callback feature. It aims to provide an example of how this callback feature can be implemented for golden application.
FAQ
Flatbuffer version does not match ttrt version!
ttrt and flatbuffer have strict versioning that is checked during ttrt execution. You will have to generate a flatbuffer using the same version of ttrt (or vice versa). This mean you might have to build on the same branch on which the flatbuffer was generated or regenerate the flatbuffer using your current build.
System desc does not match flatbuffer!
Flatbuffers are compiled using a specific system desc (or default values if no system desc is provided). During runtime, the flatbuffer system desc is checked against the current system to ensure the system being run on supports the flatbuffer that was compiled. If you get this error, you will have to regenerate the flatbuffer using the system you want to run on. See generate a flatbuffer file from compiler section on how to do this.
I just want to test and push my commit! What do I do!
Follow these steps (on n150, n300, and llmbox)
- Build ttmlir (sample instructions - subject to change)
source env/activate
cmake -G Ninja -B build -DCMAKE_BUILD_TYPE=Release -DCMAKE_C_COMPILER=clang-20 -DCMAKE_CXX_COMPILER=clang++-20 -DCMAKE_CXX_COMPILER_LAUNCHER=ccache -DTTMLIR_ENABLE_RUNTIME=ON -DTT_RUNTIME_ENABLE_PERF_TRACE=ON
cmake --build build
- Query system
ttrt query --save-artifacts
- Export system desc file
export SYSTEM_DESC_PATH=/path/to/system_desc.ttsys (path dumped in previous command)
- Generate test cases
cmake --build build -- check-ttmlir
- Run test cases
ttrt run build/test/ttmlir/Silicon
- (Optional) Run perf test cases
ttrt perf build/test/ttmlir/Silicon
TTRT yields an ambiguous segmentation fault!
The ttrt toolchain has specific behaviors and requirements that can lead to build and runtime issues, particularly when dealing with version mismatches or out-of-sync dependencies.
Version Mismatch Due to Local Commits
The ttrt toolchain verifies whether the current system configuration matches the model’s compilation environment. This verification involves tracking the number of commits since the last synchronization. When local commits are made in your branch, it may trigger a version mismatch between the compiled model and the current environment. This mismatch may not be handled properly by the runtime (rt), leading to potential issues.
To resolve issues stemming from these synchronization problems, follow this workflow:
- Incremental build
# make some changes
# commit
cmake --build build
# note you need to generate system_desc and flatbuffer again once you do this
This incremental build should be sufficient. If it does not resolve the error, please file an issue and proceed with the following steps for now.
- Clear the existing build and dependencies:
rm -rf build third_party/tt-metal
This ensures that all previous build artifacts and dependencies are removed, preventing conflicts or stale files from affecting the new build.
-
Rebuild from scratch: After clearing the build directories, rebuild the project from the ground up. This ensures that the build process incorporates all the necessary components without any remnants of previous builds. Build Instructions
-
Switch build configurations: If switching from a Debug to a Release build (or vice versa), ensure that you clean the build environment before transitioning. This avoids inconsistencies between build configurations and potential issues with optimization levels or debugging symbols.
-
Re-acquire the IRD: By relinquishing and re-acquiring the IRD, you ensure that the correct toolchain is used for the new build. This step ensures synchronization between the model and the toolchain.
-
Enable Debug Logging for tt-metal: To gain more insight into potential issues, enable debugging by setting the TT_METAL_LOGGER_LEVEL to DEBUG. This will provide detailed logs, which can help in troubleshooting build or runtime issues.
export TT_METAL_LOGGER_LEVEL=DEBUG
ttir-builder
ttir-builder is a tool for creating TTIR operations. It provides support for MLIR modules to be generated from user-constructed ops, lowered into TTNN or TTMetal backends, and finally translated into executable flatbuffers. Or you can do all three at once!
Building
- Build tt-mlir
- Build
ttrt - Generate ttsys file from the system you want to compile for using
ttrt. This will create attrt-artifactsfolder containing asystem_desc.ttsysfile.
ttrt query --save-artifacts
- Export this file in your environment using
export SYSTEM_DESC_PATH=/path/to/system_desc.ttsys.builder.base.builder_utilsuses thesystem_desc.ttsysfile as it runs a pass over an MLIR module to the TTNN or TTMetal backend.
Getting started
TTIRBuilder is a builder class providing the API for creating TTIR ops. The python package builder contains everything needed to create ops through a TTIRBuilder object. builder.base.builder_utils contains the APIs for wrapping op-creating-functions into MLIR modules and flatbuffers files.
from builder.ttir.ttir_builder import TTIRBuilder
from builder.base.builder_utils import compile_ttir_to_flatbuffer
Creating a TTIR module
build_ttir_module defines an MLIR module specified as a python function. It wraps fn in a MLIR FuncOp then wraps that in an MLIR module, and finally ties arguments of that FuncOp to test function inputs. It will instantiate and pass a TTIRBuilder object as the last argument of fn. Each op returns an OpView type which is a type of Operand that can be passed into another builder op as an input.
def build_ttir_module(
fn: Callable,
inputs_shapes: List[Shape],
inputs_types: Optional[List[Union[torch.dtype, TypeInfo]]] = None,
mesh_name: str = "mesh",
mesh_dict: OrderedDict[str, int] = OrderedDict([("x", 1), ("y", 1)]),
module_dump: bool = False,
base: Optional[str] = None,
output_root: str = ".",
) -> Tuple[Module, TTIRBuilder]:
Example
from builder.base.builder import Operand
from builder.ttir.ttir_builder import TTIRBuilder
from builder.base.builder_utils import build_ttir_module
shapes = [(32, 32), (32, 32), (32, 32)]
def model(in0: Operand, in1: Operand, in2: Operand, builder: TTIRBuilder):
add_0 = builder.add(in0, in1)
multiply_1 = builder.multiply(in1, add_0)
return builder.multiply(multiply_1, in2)
module, builder = build_ttir_module(model, shapes)
Returns
An MLIR module containing an MLIR op graph defined by fn and the TTIRBuilder object used to create it
module {
func.func @model(%arg0: tensor<32x32xf32>, %arg1: tensor<32x32xf32>, %arg2: tensor<32x32xf32>) -> tensor<32x32xf32> {
%0 = "ttir.add"(%arg0, %arg1) : (tensor<32x32xf32>, tensor<32x32xf32>) -> tensor<32x32xf32>
%1 = "ttir.multiply"(%arg1, %0) : (tensor<32x32xf32>, tensor<32x32xf32>) -> tensor<32x32xf32>
%2 = "ttir.multiply"(%1, %arg2) : (tensor<32x32xf32>, tensor<32x32xf32>) -> tensor<32x32xf32>
return %2 : tensor<32x32xf32>
}
}
Running a pipeline
run_ttir_pipeline runs a pass on the TTIR module to lower it into a backend, using pipeline_fn. You can pass pipeline_fn in as one of the following: ttir_to_ttnn_runtime_pipeline, ttir_to_ttmetal_backend_pipeline (both found in ttmlir.passes), or a custom pipeline built with create_custom_pipeline_fn. The default if none is provided is the TTNN pipeline.
def run_ttir_pipeline(
module,
pipeline_fn: Callable,
pipeline_options: List[str] = [],
dump_to_file: bool = True,
output_file_name: str = "test.mlir",
system_desc_path: Optional[str] = None,
mesh_dict: OrderedDict[str, int] = None,
argument_types_string: Optional[str] = None,
)
TTNN example
Let's expand on our previous example
from ttmlir.passes import ttir_to_ttnn_runtime_pipeline
from builder.base.builder import Operand
from builder.ttir.ttir_builder import TTIRBuilder
from builder.base.builder_utils import build_ttir_module, run_ttir_pipeline
shapes = [(32, 32), (32, 32), (32, 32)]
def model(in0: Operand, in1: Operand, in2: Operand, builder: TTIRBuilder):
add_0 = builder.add(in0, in1)
multiply_1 = builder.multiply(in1, add_0)
return builder.multiply(multiply_1, in2)
module, builder = build_ttir_module(model, shapes)
ttnn_module = run_ttir_pipeline(module, ttir_to_ttnn_runtime_pipeline)
Returns
An MLIR module lowered into TTNN
#dram = #ttnn.buffer_type<dram>
#system_desc = #ttcore.system_desc<[{role = host, target_triple = "x86_64-pc-linux"}], [{arch = <wormhole_b0>, grid = 8x8, coord_translation_offsets = 18x18, l1_size = 1499136, num_dram_channels = 12, dram_channel_size = 1073741824, noc_l1_address_align_bytes = 16, pcie_address_align_bytes = 32, noc_dram_address_align_bytes = 32, l1_unreserved_base = 97248, erisc_l1_unreserved_base = 69632, dram_unreserved_base = 32, dram_unreserved_end = 1073158336, physical_helper_cores = {dram = [ 0x0, 0x1, 0x2, 0x3, 0x4, 0x5, 0x6, 0x7, 0x8, 0x9, 0x10, 0x11] eth_inactive = [ 16x18, 16x19, 16x20, 16x21, 16x22, 16x23, 16x24, 16x25, 17x19, 17x20, 17x22, 17x23, 17x24]}, supported_data_types = [<f32>, <f16>, <bf16>, <bfp_f8>, <bfp_bf8>, <bfp_f4>, <bfp_bf4>, <bfp_f2>, <bfp_bf2>, <u32>, <u16>, <u8>, <si32>], supported_tile_sizes = [ 4x16, 16x16, 32x16, 4x32, 16x32, 32x32], num_cbs = 32, num_compute_threads = 1, num_datamovement_threads = 2}], [0], [3 : i32], [ 0x0x0x0]>
#ttnn_layout = #ttnn.ttnn_layout<(d0, d1) -> (d0, d1), <1x1>, memref<1x1x!ttcore.tile<32x32, f32>, #dram>, <interleaved>>
module {
ttcore.device_module {
builtin.module attributes {ttcore.system_desc = #system_desc} {
ttcore.device @default_device = <workerGrid = #ttcore.grid<8x8, (d0, d1) -> (0, d0, d1)>, l1Map = (d0, d1, d2)[s0] -> (0, d0, d1, d2 + s0), dramMap = (d0, d1, d2)[s0, s1, s2, s3, s4, s5] -> (0, 0, (((d0 * s1) * (s2 * s3) + d1 * (s2 * s3) + d2) floordiv s4) mod 12, ((d0 * s1) * (s2 * s3) + d1 * (s2 * s3) + d2) floordiv (s4 * 12) + ((d0 * s1) * (s2 * s3) + d1 * (s2 * s3) + d2) mod s4 + s5), meshShape = , chipIds = [0]>
func.func @model(%arg0: tensor<32x32xf32, #ttnn_layout>, %arg1: tensor<32x32xf32, #ttnn_layout>, %arg2: tensor<32x32xf32, #ttnn_layout>) -> tensor<32x32xf32, #ttnn_layout> {
%0 = "ttnn.abs"(%arg0) : (tensor<32x32xf32, #ttnn_layout>) -> tensor<32x32xf32, #ttnn_layout>
"ttnn.deallocate"(%arg0) <{force = false}> : (tensor<32x32xf32, #ttnn_layout>) -> ()
%1 = "ttnn.multiply"(%arg1, %0) : (tensor<32x32xf32, #ttnn_layout>, tensor<32x32xf32, #ttnn_layout>) -> tensor<32x32xf32, #ttnn_layout>
"ttnn.deallocate"(%0) <{force = false}> : (tensor<32x32xf32, #ttnn_layout>) -> ()
"ttnn.deallocate"(%arg1) <{force = false}> : (tensor<32x32xf32, #ttnn_layout>) -> ()
%2 = "ttnn.multiply"(%1, %arg2) : (tensor<32x32xf32, #ttnn_layout>, tensor<32x32xf32, #ttnn_layout>) -> tensor<32x32xf32, #ttnn_layout>
"ttnn.deallocate"(%1) <{force = false}> : (tensor<32x32xf32, #ttnn_layout>) -> ()
"ttnn.deallocate"(%arg2) <{force = false}> : (tensor<32x32xf32, #ttnn_layout>) -> ()
return %2 : tensor<32x32xf32, #ttnn_layout>
}
}
}
}
TTMetal example
Let's use the same code for TTMetal that was used in the TTNN example but change the pipeline_fn to ttir_to_ttmetal_backend_pipeline. Only one or the other can be run on a module since run_ttir_pipeline modifies the module in place. Note that while all TTIR ops supported by builder can be lowered to TTNN, not all can be lowered to TTMetal yet. Adding documentation to specify what ops can be lowered to TTMetal is in the works.
from ttmlir.passes import ttir_to_ttmetal_backend_pipeline
ttmetal_module = run_ttir_pipeline(module, ttir_to_ttmetal_backend_pipeline)
Returns
An MLIR module lowered into TTMetal
#l1 = #ttcore.memory_space<l1>
#system_desc = #ttcore.system_desc<[{role = host, target_triple = "x86_64-pc-linux"}], [{arch = <wormhole_b0>, grid = 8x8, coord_translation_offsets = 18x18, l1_size = 1499136, num_dram_channels = 12, dram_channel_size = 1073741824, noc_l1_address_align_bytes = 16, pcie_address_align_bytes = 32, noc_dram_address_align_bytes = 32, l1_unreserved_base = 103712, erisc_l1_unreserved_base = 98304, dram_unreserved_base = 32, dram_unreserved_end = 1073119552, supported_data_types = [<f32>, <f16>, <bf16>, <bfp_f8>, <bfp_bf8>, <bfp_f4>, <bfp_bf4>, <bfp_f2>, <bfp_bf2>, <u32>, <u16>, <u8>, <si32>], supported_tile_sizes = [ 4x16, 16x16, 32x16, 4x32, 16x32, 32x32], dst_physical_size_tiles = 16, num_cbs = 64, num_compute_threads = 1, num_datamovement_threads = 2, dram_grid = 1x12, dram_bank_to_logical_worker_noc0 = [(7, 3), (0, 0), (4, 0), (5, 0), (0, 4), (7, 7), (1, 4), (3, 6), (6, 4), (2, 4), (4, 4), (5, 4)], dram_bank_to_logical_worker_noc1 = [(7, 3), (0, 0), (4, 0), (5, 0), (0, 4), (7, 7), (1, 4), (3, 6), (6, 4), (2, 4), (4, 4), (5, 4)]}], [0], [1 : i32], [ 0x0x0x0]>
module {
ttcore.device_module {
builtin.module attributes {ttcore.system_desc = #system_desc} {
ttcore.device @default_device = <workerGrid = #ttcore.grid<8x8, virt_to_physical_map = (d0, d1) -> (0, d0, d1), physical_to_virt_map = (d0, d1, d2) -> (d1, d2)>, dramGrid = #ttcore.grid<1x12>, l1Map = (d0, d1, d2)[s0] -> (0, d0, d1, d2 + s0), dramMap = (d0, d1, d2)[s0, s1, s2, s3, s4, s5, s6] -> (0, 0, (((d0 * s1) * (s2 * (s3 * s6)) + d1 * (s2 * (s3 * s6)) + d2) floordiv s4) mod 12, ((((d0 * s1) * (s2 * (s3 * s6)) + d1 * (s2 * (s3 * s6)) + d2) floordiv s4) floordiv 12) * s4 + ((d0 * s1) * (s2 * (s3 * s6)) + d1 * (s2 * (s3 * s6)) + d2) mod s4 + s5), meshShape = , chipIds = [0]>
func.func @model(%arg0: memref<32x32xf32>, %arg1: memref<32x32xf32>, %arg2: memref<32x32xf32>) -> memref<32x32xf32> attributes {tt.function_type = "forward_device"} {
%0 = "ttmetal.create_buffer"() <{address = 107808 : i64}> : () -> memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>
%1 = "ttmetal.create_buffer"() <{address = 103712 : i64}> : () -> memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>
"ttmetal.enqueue_write_buffer"(%arg0, %1) : (memref<32x32xf32>, memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>) -> ()
"ttmetal.enqueue_program"(%1, %0, %1, %0) <{cb_ports = array<i64: 0, 1>, kernelConfigs = [#ttmetal.noc_config<@datamovement_kernel0, #ttmetal.core_range<0x0, 1x1>, #ttmetal.kernel_args< >, noc0>, #ttmetal.compute_config<@compute_kernel1, #ttmetal.core_range<0x0, 1x1>, #ttmetal.kernel_args< ct_args = [<cb_port[1]>, <cb_port[0]>]>, hifi4, true, false, false, [default]>], operandSegmentSizes = array<i32: 2, 2>}> : (memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>, memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>) -> ()
"ttmetal.deallocate_buffer"(%1) : (memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>) -> ()
%2 = "ttmetal.create_buffer"() <{address = 103712 : i64}> : () -> memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>
%3 = "ttmetal.create_buffer"() <{address = 111904 : i64}> : () -> memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>
"ttmetal.enqueue_write_buffer"(%arg1, %3) : (memref<32x32xf32>, memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>) -> ()
"ttmetal.enqueue_program"(%3, %2, %3, %2) <{cb_ports = array<i64: 0, 1>, kernelConfigs = [#ttmetal.noc_config<@datamovement_kernel2, #ttmetal.core_range<0x0, 1x1>, #ttmetal.kernel_args< >, noc0>, #ttmetal.compute_config<@compute_kernel3, #ttmetal.core_range<0x0, 1x1>, #ttmetal.kernel_args< ct_args = [<cb_port[1]>, <cb_port[0]>]>, hifi4, true, false, false, [default]>], operandSegmentSizes = array<i32: 2, 2>}> : (memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>, memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>) -> ()
"ttmetal.deallocate_buffer"(%3) : (memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>) -> ()
%4 = "ttmetal.create_buffer"() <{address = 116000 : i64}> : () -> memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>
"ttmetal.enqueue_program"(%0, %2, %4, %0, %2, %4) <{cb_ports = array<i64: 0, 1, 2>, kernelConfigs = [#ttmetal.noc_config<@datamovement_kernel4, #ttmetal.core_range<0x0, 1x1>, #ttmetal.kernel_args< >, noc0>, #ttmetal.compute_config<@compute_kernel5, #ttmetal.core_range<0x0, 1x1>, #ttmetal.kernel_args< ct_args = [<cb_port[2]>, <cb_port[1]>, <cb_port[0]>]>, hifi4, true, false, false, [default]>], operandSegmentSizes = array<i32: 3, 3>}> : (memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>) -> ()
"ttmetal.deallocate_buffer"(%0) : (memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>) -> ()
"ttmetal.deallocate_buffer"(%2) : (memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>) -> ()
%5 = "ttmetal.create_buffer"() <{address = 111904 : i64}> : () -> memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>
%6 = "ttmetal.create_buffer"() <{address = 103712 : i64}> : () -> memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>
"ttmetal.enqueue_write_buffer"(%arg1, %6) : (memref<32x32xf32>, memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>) -> ()
"ttmetal.enqueue_program"(%6, %5, %6, %5) <{cb_ports = array<i64: 0, 1>, kernelConfigs = [#ttmetal.noc_config<@datamovement_kernel6, #ttmetal.core_range<0x0, 1x1>, #ttmetal.kernel_args< >, noc0>, #ttmetal.compute_config<@compute_kernel7, #ttmetal.core_range<0x0, 1x1>, #ttmetal.kernel_args< ct_args = [<cb_port[1]>, <cb_port[0]>]>, hifi4, true, false, false, [default]>], operandSegmentSizes = array<i32: 2, 2>}> : (memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>, memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>) -> ()
"ttmetal.deallocate_buffer"(%6) : (memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>) -> ()
%7 = "ttmetal.create_buffer"() <{address = 107808 : i64}> : () -> memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>
"ttmetal.enqueue_program"(%5, %4, %7, %5, %4, %7) <{cb_ports = array<i64: 0, 1, 2>, kernelConfigs = [#ttmetal.noc_config<@datamovement_kernel8, #ttmetal.core_range<0x0, 1x1>, #ttmetal.kernel_args< >, noc0>, #ttmetal.compute_config<@compute_kernel9, #ttmetal.core_range<0x0, 1x1>, #ttmetal.kernel_args< ct_args = [<cb_port[2]>, <cb_port[1]>, <cb_port[0]>]>, hifi4, true, false, false, [default]>], operandSegmentSizes = array<i32: 3, 3>}> : (memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>) -> ()
"ttmetal.deallocate_buffer"(%5) : (memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>) -> ()
"ttmetal.deallocate_buffer"(%4) : (memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>) -> ()
%8 = "ttmetal.create_buffer"() <{address = 111904 : i64}> : () -> memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>
%9 = "ttmetal.create_buffer"() <{address = 103712 : i64}> : () -> memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>
"ttmetal.enqueue_write_buffer"(%arg2, %9) : (memref<32x32xf32>, memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>) -> ()
"ttmetal.enqueue_program"(%9, %8, %9, %8) <{cb_ports = array<i64: 0, 1>, kernelConfigs = [#ttmetal.noc_config<@datamovement_kernel10, #ttmetal.core_range<0x0, 1x1>, #ttmetal.kernel_args< >, noc0>, #ttmetal.compute_config<@compute_kernel11, #ttmetal.core_range<0x0, 1x1>, #ttmetal.kernel_args< ct_args = [<cb_port[1]>, <cb_port[0]>]>, hifi4, true, false, false, [default]>], operandSegmentSizes = array<i32: 2, 2>}> : (memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>, memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>) -> ()
"ttmetal.deallocate_buffer"(%9) : (memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>) -> ()
%10 = "ttmetal.create_buffer"() <{address = 103712 : i64}> : () -> memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>
"ttmetal.enqueue_program"(%7, %8, %10, %7, %8, %10) <{cb_ports = array<i64: 0, 1, 2>, kernelConfigs = [#ttmetal.noc_config<@datamovement_kernel12, #ttmetal.core_range<0x0, 1x1>, #ttmetal.kernel_args< >, noc0>, #ttmetal.compute_config<@compute_kernel13, #ttmetal.core_range<0x0, 1x1>, #ttmetal.kernel_args< ct_args = [<cb_port[2]>, <cb_port[1]>, <cb_port[0]>]>, hifi4, true, false, false, [default]>], operandSegmentSizes = array<i32: 3, 3>}> : (memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>) -> ()
"ttmetal.deallocate_buffer"(%7) : (memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>) -> ()
"ttmetal.deallocate_buffer"(%8) : (memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>) -> ()
%alloc = memref.alloc() : memref<32x32xf32>
%11 = "ttmetal.create_buffer"() <{address = 107808 : i64}> : () -> memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>
"ttmetal.enqueue_program"(%10, %11, %10, %11) <{cb_ports = array<i64: 0, 1>, kernelConfigs = [#ttmetal.noc_config<@datamovement_kernel14, #ttmetal.core_range<0x0, 1x1>, #ttmetal.kernel_args< >, noc0>, #ttmetal.compute_config<@compute_kernel15, #ttmetal.core_range<0x0, 1x1>, #ttmetal.kernel_args< ct_args = [<cb_port[1]>, <cb_port[0]>]>, hifi4, true, false, false, [default]>], operandSegmentSizes = array<i32: 2, 2>}> : (memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>, memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>, memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>, memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>) -> ()
"ttmetal.deallocate_buffer"(%10) : (memref<1x1x1x1x!ttcore.tile<32x32, f32>, #ttcore.shard<4096x4096, 1>, #l1>) -> ()
"ttmetal.enqueue_read_buffer"(%11, %alloc) : (memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>, memref<32x32xf32>) -> ()
"ttmetal.finish"() : () -> ()
"ttmetal.deallocate_buffer"(%11) : (memref<1x1x32x32xf32, #ttcore.shard<128x4, 1>, #l1>) -> ()
return %alloc : memref<32x32xf32>
}
func.func private @datamovement_kernel0() attributes {tt.function_type = "kernel", ttkernel.arg_spec = #ttkernel.arg_spec< >, ttkernel.thread = #ttkernel.thread<noc>} {
return
}
func.func private @compute_kernel1() attributes {tt.function_type = "kernel", ttkernel.arg_spec = #ttkernel.arg_spec< ct_args = [<arg_type = cb_port, operand_index = 1>, <arg_type = cb_port, operand_index = 0>]>, ttkernel.thread = #ttkernel.thread<compute>} {
%0 = emitc.expression : () -> i32 {
%3 = "emitc.constant"() <{value = 1 : i32}> : () -> i32
yield %3 : i32
}
%1 = emitc.literal "get_compile_time_arg_val(0)" {ttkernel.cb_ctarg_idx = 0 : i32} : !emitc.opaque<"::tt::CB">
emitc.verbatim "CircularBuffer cb_ctarg_0({});" args %1 : !emitc.opaque<"::tt::CB">
%2 = emitc.literal "get_compile_time_arg_val(1)" {ttkernel.cb_ctarg_idx = 1 : i32} : !emitc.opaque<"::tt::CB">
emitc.verbatim "CircularBuffer cb_ctarg_1({});" args %2 : !emitc.opaque<"::tt::CB">
emitc.verbatim "cb_ctarg_1.reserve_back({});" args %0 : i32
emitc.verbatim "cb_ctarg_1.push_back({});" args %0 : i32
emitc.verbatim "cb_ctarg_1.wait_front({});" args %0 : i32
emitc.verbatim "cb_ctarg_0.reserve_back({});" args %0 : i32
emitc.call_opaque "compute_kernel_hw_startup"(%2, %1) : (!emitc.opaque<"::tt::CB">, !emitc.opaque<"::tt::CB">) -> ()
emitc.call_opaque "tilize_init"(%2, %0, %1) : (!emitc.opaque<"::tt::CB">, i32, !emitc.opaque<"::tt::CB">) -> ()
emitc.call_opaque "experimental::tilize_block"(%2, %1, %0, %0) : (!emitc.opaque<"::tt::CB">, !emitc.opaque<"::tt::CB">, i32, i32) -> ()
emitc.verbatim "cb_ctarg_1.pop_front({});" args %0 : i32
emitc.verbatim "cb_ctarg_0.push_back({});" args %0 : i32
emitc.verbatim "cb_ctarg_0.wait_front({});" args %0 : i32
emitc.verbatim "cb_ctarg_0.pop_front({});" args %0 : i32
return
}
func.func private @datamovement_kernel2() attributes {tt.function_type = "kernel", ttkernel.arg_spec = #ttkernel.arg_spec< >, ttkernel.thread = #ttkernel.thread<noc>} {
return
}
func.func private @compute_kernel3() attributes {tt.function_type = "kernel", ttkernel.arg_spec = #ttkernel.arg_spec< ct_args = [<arg_type = cb_port, operand_index = 1>, <arg_type = cb_port, operand_index = 0>]>, ttkernel.thread = #ttkernel.thread<compute>} {
%0 = emitc.expression : () -> i32 {
%3 = "emitc.constant"() <{value = 1 : i32}> : () -> i32
yield %3 : i32
}
%1 = emitc.literal "get_compile_time_arg_val(0)" {ttkernel.cb_ctarg_idx = 0 : i32} : !emitc.opaque<"::tt::CB">
emitc.verbatim "CircularBuffer cb_ctarg_0({});" args %1 : !emitc.opaque<"::tt::CB">
%2 = emitc.literal "get_compile_time_arg_val(1)" {ttkernel.cb_ctarg_idx = 1 : i32} : !emitc.opaque<"::tt::CB">
emitc.verbatim "CircularBuffer cb_ctarg_1({});" args %2 : !emitc.opaque<"::tt::CB">
emitc.verbatim "cb_ctarg_1.reserve_back({});" args %0 : i32
emitc.verbatim "cb_ctarg_1.push_back({});" args %0 : i32
emitc.verbatim "cb_ctarg_1.wait_front({});" args %0 : i32
emitc.verbatim "cb_ctarg_0.reserve_back({});" args %0 : i32
emitc.call_opaque "compute_kernel_hw_startup"(%2, %1) : (!emitc.opaque<"::tt::CB">, !emitc.opaque<"::tt::CB">) -> ()
emitc.call_opaque "tilize_init"(%2, %0, %1) : (!emitc.opaque<"::tt::CB">, i32, !emitc.opaque<"::tt::CB">) -> ()
emitc.call_opaque "experimental::tilize_block"(%2, %1, %0, %0) : (!emitc.opaque<"::tt::CB">, !emitc.opaque<"::tt::CB">, i32, i32) -> ()
emitc.verbatim "cb_ctarg_1.pop_front({});" args %0 : i32
emitc.verbatim "cb_ctarg_0.push_back({});" args %0 : i32
emitc.verbatim "cb_ctarg_0.wait_front({});" args %0 : i32
emitc.verbatim "cb_ctarg_0.pop_front({});" args %0 : i32
return
}
func.func private @datamovement_kernel4() attributes {tt.function_type = "kernel", ttkernel.arg_spec = #ttkernel.arg_spec< >, ttkernel.thread = #ttkernel.thread<noc>} {
return
}
func.func private @compute_kernel5() attributes {tt.function_type = "kernel", ttkernel.arg_spec = #ttkernel.arg_spec< ct_args = [<arg_type = cb_port, operand_index = 2>, <arg_type = cb_port, operand_index = 1>, <arg_type = cb_port, operand_index = 0>]>, ttkernel.thread = #ttkernel.thread<compute>} {
%0 = emitc.expression : () -> !emitc.size_t {
%6 = "emitc.constant"() <{value = 1 : index}> : () -> !emitc.size_t
yield %6 : !emitc.size_t
}
%1 = emitc.expression : () -> !emitc.size_t {
%6 = "emitc.constant"() <{value = 0 : index}> : () -> !emitc.size_t
yield %6 : !emitc.size_t
}
%2 = emitc.expression : () -> i32 {
%6 = "emitc.constant"() <{value = 1 : i32}> : () -> i32
yield %6 : i32
}
%3 = emitc.literal "get_compile_time_arg_val(0)" {ttkernel.cb_ctarg_idx = 0 : i32} : !emitc.opaque<"::tt::CB">
emitc.verbatim "CircularBuffer cb_ctarg_0({});" args %3 : !emitc.opaque<"::tt::CB">
%4 = emitc.literal "get_compile_time_arg_val(1)" {ttkernel.cb_ctarg_idx = 1 : i32} : !emitc.opaque<"::tt::CB">
emitc.verbatim "CircularBuffer cb_ctarg_1({});" args %4 : !emitc.opaque<"::tt::CB">
%5 = emitc.literal "get_compile_time_arg_val(2)" {ttkernel.cb_ctarg_idx = 2 : i32} : !emitc.opaque<"::tt::CB">
emitc.verbatim "CircularBuffer cb_ctarg_2({});" args %5 : !emitc.opaque<"::tt::CB">
emitc.call_opaque "init_sfpu"(%5, %3) : (!emitc.opaque<"::tt::CB">, !emitc.opaque<"::tt::CB">) -> ()
emitc.call_opaque "init_sfpu"(%5, %3) : (!emitc.opaque<"::tt::CB">, !emitc.opaque<"::tt::CB">) -> ()
emitc.call_opaque "init_sfpu"(%5, %3) : (!emitc.opaque<"::tt::CB">, !emitc.opaque<"::tt::CB">) -> ()
emitc.verbatim "cb_ctarg_2.reserve_back({});" args %2 : i32
emitc.verbatim "cb_ctarg_2.push_back({});" args %2 : i32
emitc.verbatim "cb_ctarg_2.wait_front({});" args %2 : i32
emitc.verbatim "cb_ctarg_1.reserve_back({});" args %2 : i32
emitc.verbatim "cb_ctarg_1.push_back({});" args %2 : i32
emitc.verbatim "cb_ctarg_1.wait_front({});" args %2 : i32
emitc.verbatim "cb_ctarg_0.reserve_back({});" args %2 : i32
emitc.call_opaque "tile_regs_acquire"() : () -> ()
emitc.call_opaque "copy_tile_init"(%5) : (!emitc.opaque<"::tt::CB">) -> ()
emitc.call_opaque "copy_tile"(%5, %1, %1) : (!emitc.opaque<"::tt::CB">, !emitc.size_t, !emitc.size_t) -> ()
emitc.call_opaque "copy_tile_init"(%4) : (!emitc.opaque<"::tt::CB">) -> ()
emitc.call_opaque "copy_tile"(%4, %1, %0) : (!emitc.opaque<"::tt::CB">, !emitc.size_t, !emitc.size_t) -> ()
emitc.call_opaque "add_binary_tile_init"() : () -> ()
emitc.call_opaque "add_binary_tile"(%1, %0, %1) : (!emitc.size_t, !emitc.size_t, !emitc.size_t) -> ()
emitc.call_opaque "tile_regs_commit"() : () -> ()
emitc.call_opaque "tile_regs_wait"() : () -> ()
emitc.call_opaque "pack_tile"(%1, %3, %1) {template_args = [true]} : (!emitc.size_t, !emitc.opaque<"::tt::CB">, !emitc.size_t) -> ()
emitc.call_opaque "tile_regs_release"() : () -> ()
emitc.verbatim "cb_ctarg_1.pop_front({});" args %2 : i32
emitc.verbatim "cb_ctarg_2.pop_front({});" args %2 : i32
emitc.verbatim "cb_ctarg_0.push_back({});" args %2 : i32
emitc.verbatim "cb_ctarg_0.wait_front({});" args %2 : i32
emitc.verbatim "cb_ctarg_0.pop_front({});" args %2 : i32
return
}
func.func private @datamovement_kernel6() attributes {tt.function_type = "kernel", ttkernel.arg_spec = #ttkernel.arg_spec< >, ttkernel.thread = #ttkernel.thread<noc>} {
return
}
func.func private @compute_kernel7() attributes {tt.function_type = "kernel", ttkernel.arg_spec = #ttkernel.arg_spec< ct_args = [<arg_type = cb_port, operand_index = 1>, <arg_type = cb_port, operand_index = 0>]>, ttkernel.thread = #ttkernel.thread<compute>} {
%0 = emitc.expression : () -> i32 {
%3 = "emitc.constant"() <{value = 1 : i32}> : () -> i32
yield %3 : i32
}
%1 = emitc.literal "get_compile_time_arg_val(0)" {ttkernel.cb_ctarg_idx = 0 : i32} : !emitc.opaque<"::tt::CB">
emitc.verbatim "CircularBuffer cb_ctarg_0({});" args %1 : !emitc.opaque<"::tt::CB">
%2 = emitc.literal "get_compile_time_arg_val(1)" {ttkernel.cb_ctarg_idx = 1 : i32} : !emitc.opaque<"::tt::CB">
emitc.verbatim "CircularBuffer cb_ctarg_1({});" args %2 : !emitc.opaque<"::tt::CB">
emitc.verbatim "cb_ctarg_1.reserve_back({});" args %0 : i32
emitc.verbatim "cb_ctarg_1.push_back({});" args %0 : i32
emitc.verbatim "cb_ctarg_1.wait_front({});" args %0 : i32
emitc.verbatim "cb_ctarg_0.reserve_back({});" args %0 : i32
emitc.call_opaque "compute_kernel_hw_startup"(%2, %1) : (!emitc.opaque<"::tt::CB">, !emitc.opaque<"::tt::CB">) -> ()
emitc.call_opaque "tilize_init"(%2, %0, %1) : (!emitc.opaque<"::tt::CB">, i32, !emitc.opaque<"::tt::CB">) -> ()
emitc.call_opaque "experimental::tilize_block"(%2, %1, %0, %0) : (!emitc.opaque<"::tt::CB">, !emitc.opaque<"::tt::CB">, i32, i32) -> ()
emitc.verbatim "cb_ctarg_1.pop_front({});" args %0 : i32
emitc.verbatim "cb_ctarg_0.push_back({});" args %0 : i32
emitc.verbatim "cb_ctarg_0.wait_front({});" args %0 : i32
emitc.verbatim "cb_ctarg_0.pop_front({});" args %0 : i32
return
}
func.func private @datamovement_kernel8() attributes {tt.function_type = "kernel", ttkernel.arg_spec = #ttkernel.arg_spec< >, ttkernel.thread = #ttkernel.thread<noc>} {
return
}
func.func private @compute_kernel9() attributes {tt.function_type = "kernel", ttkernel.arg_spec = #ttkernel.arg_spec< ct_args = [<arg_type = cb_port, operand_index = 2>, <arg_type = cb_port, operand_index = 1>, <arg_type = cb_port, operand_index = 0>]>, ttkernel.thread = #ttkernel.thread<compute>} {
%0 = emitc.expression : () -> !emitc.size_t {
%6 = "emitc.constant"() <{value = 1 : index}> : () -> !emitc.size_t
yield %6 : !emitc.size_t
}
%1 = emitc.expression : () -> !emitc.size_t {
%6 = "emitc.constant"() <{value = 0 : index}> : () -> !emitc.size_t
yield %6 : !emitc.size_t
}
%2 = emitc.expression : () -> i32 {
%6 = "emitc.constant"() <{value = 1 : i32}> : () -> i32
yield %6 : i32
}
%3 = emitc.literal "get_compile_time_arg_val(0)" {ttkernel.cb_ctarg_idx = 0 : i32} : !emitc.opaque<"::tt::CB">
emitc.verbatim "CircularBuffer cb_ctarg_0({});" args %3 : !emitc.opaque<"::tt::CB">
%4 = emitc.literal "get_compile_time_arg_val(1)" {ttkernel.cb_ctarg_idx = 1 : i32} : !emitc.opaque<"::tt::CB">
emitc.verbatim "CircularBuffer cb_ctarg_1({});" args %4 : !emitc.opaque<"::tt::CB">
%5 = emitc.literal "get_compile_time_arg_val(2)" {ttkernel.cb_ctarg_idx = 2 : i32} : !emitc.opaque<"::tt::CB">
emitc.verbatim "CircularBuffer cb_ctarg_2({});" args %5 : !emitc.opaque<"::tt::CB">
emitc.call_opaque "init_sfpu"(%5, %3) : (!emitc.opaque<"::tt::CB">, !emitc.opaque<"::tt::CB">) -> ()
emitc.call_opaque "init_sfpu"(%5, %3) : (!emitc.opaque<"::tt::CB">, !emitc.opaque<"::tt::CB">) -> ()
emitc.call_opaque "init_sfpu"(%5, %3) : (!emitc.opaque<"::tt::CB">, !emitc.opaque<"::tt::CB">) -> ()
emitc.verbatim "cb_ctarg_2.reserve_back({});" args %2 : i32
emitc.verbatim "cb_ctarg_2.push_back({});" args %2 : i32
emitc.verbatim "cb_ctarg_2.wait_front({});" args %2 : i32
emitc.verbatim "cb_ctarg_1.reserve_back({});" args %2 : i32
emitc.verbatim "cb_ctarg_1.push_back({});" args %2 : i32
emitc.verbatim "cb_ctarg_1.wait_front({});" args %2 : i32
emitc.verbatim "cb_ctarg_0.reserve_back({});" args %2 : i32
emitc.call_opaque "tile_regs_acquire"() : () -> ()
emitc.call_opaque "copy_tile_init"(%5) : (!emitc.opaque<"::tt::CB">) -> ()
emitc.call_opaque "copy_tile"(%5, %1, %1) : (!emitc.opaque<"::tt::CB">, !emitc.size_t, !emitc.size_t) -> ()
emitc.call_opaque "copy_tile_init"(%4) : (!emitc.opaque<"::tt::CB">) -> ()
emitc.call_opaque "copy_tile"(%4, %1, %0) : (!emitc.opaque<"::tt::CB">, !emitc.size_t, !emitc.size_t) -> ()
emitc.call_opaque "mul_binary_tile_init"() : () -> ()
emitc.call_opaque "mul_binary_tile"(%1, %0, %1) : (!emitc.size_t, !emitc.size_t, !emitc.size_t) -> ()
emitc.call_opaque "tile_regs_commit"() : () -> ()
emitc.call_opaque "tile_regs_wait"() : () -> ()
emitc.call_opaque "pack_tile"(%1, %3, %1) {template_args = [true]} : (!emitc.size_t, !emitc.opaque<"::tt::CB">, !emitc.size_t) -> ()
emitc.call_opaque "tile_regs_release"() : () -> ()
emitc.verbatim "cb_ctarg_1.pop_front({});" args %2 : i32
emitc.verbatim "cb_ctarg_2.pop_front({});" args %2 : i32
emitc.verbatim "cb_ctarg_0.push_back({});" args %2 : i32
emitc.verbatim "cb_ctarg_0.wait_front({});" args %2 : i32
emitc.verbatim "cb_ctarg_0.pop_front({});" args %2 : i32
return
}
func.func private @datamovement_kernel10() attributes {tt.function_type = "kernel", ttkernel.arg_spec = #ttkernel.arg_spec< >, ttkernel.thread = #ttkernel.thread<noc>} {
return
}
func.func private @compute_kernel11() attributes {tt.function_type = "kernel", ttkernel.arg_spec = #ttkernel.arg_spec< ct_args = [<arg_type = cb_port, operand_index = 1>, <arg_type = cb_port, operand_index = 0>]>, ttkernel.thread = #ttkernel.thread<compute>} {
%0 = emitc.expression : () -> i32 {
%3 = "emitc.constant"() <{value = 1 : i32}> : () -> i32
yield %3 : i32
}
%1 = emitc.literal "get_compile_time_arg_val(0)" {ttkernel.cb_ctarg_idx = 0 : i32} : !emitc.opaque<"::tt::CB">
emitc.verbatim "CircularBuffer cb_ctarg_0({});" args %1 : !emitc.opaque<"::tt::CB">
%2 = emitc.literal "get_compile_time_arg_val(1)" {ttkernel.cb_ctarg_idx = 1 : i32} : !emitc.opaque<"::tt::CB">
emitc.verbatim "CircularBuffer cb_ctarg_1({});" args %2 : !emitc.opaque<"::tt::CB">
emitc.verbatim "cb_ctarg_1.reserve_back({});" args %0 : i32
emitc.verbatim "cb_ctarg_1.push_back({});" args %0 : i32
emitc.verbatim "cb_ctarg_1.wait_front({});" args %0 : i32
emitc.verbatim "cb_ctarg_0.reserve_back({});" args %0 : i32
emitc.call_opaque "compute_kernel_hw_startup"(%2, %1) : (!emitc.opaque<"::tt::CB">, !emitc.opaque<"::tt::CB">) -> ()
emitc.call_opaque "tilize_init"(%2, %0, %1) : (!emitc.opaque<"::tt::CB">, i32, !emitc.opaque<"::tt::CB">) -> ()
emitc.call_opaque "experimental::tilize_block"(%2, %1, %0, %0) : (!emitc.opaque<"::tt::CB">, !emitc.opaque<"::tt::CB">, i32, i32) -> ()
emitc.verbatim "cb_ctarg_1.pop_front({});" args %0 : i32
emitc.verbatim "cb_ctarg_0.push_back({});" args %0 : i32
emitc.verbatim "cb_ctarg_0.wait_front({});" args %0 : i32
emitc.verbatim "cb_ctarg_0.pop_front({});" args %0 : i32
return
}
func.func private @datamovement_kernel12() attributes {tt.function_type = "kernel", ttkernel.arg_spec = #ttkernel.arg_spec< >, ttkernel.thread = #ttkernel.thread<noc>} {
return
}
func.func private @compute_kernel13() attributes {tt.function_type = "kernel", ttkernel.arg_spec = #ttkernel.arg_spec< ct_args = [<arg_type = cb_port, operand_index = 2>, <arg_type = cb_port, operand_index = 1>, <arg_type = cb_port, operand_index = 0>]>, ttkernel.thread = #ttkernel.thread<compute>} {
%0 = emitc.expression : () -> !emitc.size_t {
%6 = "emitc.constant"() <{value = 1 : index}> : () -> !emitc.size_t
yield %6 : !emitc.size_t
}
%1 = emitc.expression : () -> !emitc.size_t {
%6 = "emitc.constant"() <{value = 0 : index}> : () -> !emitc.size_t
yield %6 : !emitc.size_t
}
%2 = emitc.expression : () -> i32 {
%6 = "emitc.constant"() <{value = 1 : i32}> : () -> i32
yield %6 : i32
}
%3 = emitc.literal "get_compile_time_arg_val(0)" {ttkernel.cb_ctarg_idx = 0 : i32} : !emitc.opaque<"::tt::CB">
emitc.verbatim "CircularBuffer cb_ctarg_0({});" args %3 : !emitc.opaque<"::tt::CB">
%4 = emitc.literal "get_compile_time_arg_val(1)" {ttkernel.cb_ctarg_idx = 1 : i32} : !emitc.opaque<"::tt::CB">
emitc.verbatim "CircularBuffer cb_ctarg_1({});" args %4 : !emitc.opaque<"::tt::CB">
%5 = emitc.literal "get_compile_time_arg_val(2)" {ttkernel.cb_ctarg_idx = 2 : i32} : !emitc.opaque<"::tt::CB">
emitc.verbatim "CircularBuffer cb_ctarg_2({});" args %5 : !emitc.opaque<"::tt::CB">
emitc.call_opaque "init_sfpu"(%5, %3) : (!emitc.opaque<"::tt::CB">, !emitc.opaque<"::tt::CB">) -> ()
emitc.call_opaque "init_sfpu"(%5, %3) : (!emitc.opaque<"::tt::CB">, !emitc.opaque<"::tt::CB">) -> ()
emitc.call_opaque "init_sfpu"(%5, %3) : (!emitc.opaque<"::tt::CB">, !emitc.opaque<"::tt::CB">) -> ()
emitc.verbatim "cb_ctarg_2.reserve_back({});" args %2 : i32
emitc.verbatim "cb_ctarg_2.push_back({});" args %2 : i32
emitc.verbatim "cb_ctarg_2.wait_front({});" args %2 : i32
emitc.verbatim "cb_ctarg_1.reserve_back({});" args %2 : i32
emitc.verbatim "cb_ctarg_1.push_back({});" args %2 : i32
emitc.verbatim "cb_ctarg_1.wait_front({});" args %2 : i32
emitc.verbatim "cb_ctarg_0.reserve_back({});" args %2 : i32
emitc.call_opaque "tile_regs_acquire"() : () -> ()
emitc.call_opaque "copy_tile_init"(%5) : (!emitc.opaque<"::tt::CB">) -> ()
emitc.call_opaque "copy_tile"(%5, %1, %1) : (!emitc.opaque<"::tt::CB">, !emitc.size_t, !emitc.size_t) -> ()
emitc.call_opaque "copy_tile_init"(%4) : (!emitc.opaque<"::tt::CB">) -> ()
emitc.call_opaque "copy_tile"(%4, %1, %0) : (!emitc.opaque<"::tt::CB">, !emitc.size_t, !emitc.size_t) -> ()
emitc.call_opaque "mul_binary_tile_init"() : () -> ()
emitc.call_opaque "mul_binary_tile"(%1, %0, %1) : (!emitc.size_t, !emitc.size_t, !emitc.size_t) -> ()
emitc.call_opaque "tile_regs_commit"() : () -> ()
emitc.call_opaque "tile_regs_wait"() : () -> ()
emitc.call_opaque "pack_tile"(%1, %3, %1) {template_args = [true]} : (!emitc.size_t, !emitc.opaque<"::tt::CB">, !emitc.size_t) -> ()
emitc.call_opaque "tile_regs_release"() : () -> ()
emitc.verbatim "cb_ctarg_1.pop_front({});" args %2 : i32
emitc.verbatim "cb_ctarg_2.pop_front({});" args %2 : i32
emitc.verbatim "cb_ctarg_0.push_back({});" args %2 : i32
emitc.verbatim "cb_ctarg_0.wait_front({});" args %2 : i32
emitc.verbatim "cb_ctarg_0.pop_front({});" args %2 : i32
return
}
func.func private @datamovement_kernel14() attributes {tt.function_type = "kernel", ttkernel.arg_spec = #ttkernel.arg_spec< >, ttkernel.thread = #ttkernel.thread<noc>} {
return
}
func.func private @compute_kernel15() attributes {tt.function_type = "kernel", ttkernel.arg_spec = #ttkernel.arg_spec< ct_args = [<arg_type = cb_port, operand_index = 1>, <arg_type = cb_port, operand_index = 0>]>, ttkernel.thread = #ttkernel.thread<compute>} {
%0 = emitc.expression : () -> i32 {
%3 = "emitc.constant"() <{value = 1 : i32}> : () -> i32
yield %3 : i32
}
%1 = emitc.literal "get_compile_time_arg_val(0)" {ttkernel.cb_ctarg_idx = 0 : i32} : !emitc.opaque<"::tt::CB">
emitc.verbatim "CircularBuffer cb_ctarg_0({});" args %1 : !emitc.opaque<"::tt::CB">
%2 = emitc.literal "get_compile_time_arg_val(1)" {ttkernel.cb_ctarg_idx = 1 : i32} : !emitc.opaque<"::tt::CB">
emitc.verbatim "CircularBuffer cb_ctarg_1({});" args %2 : !emitc.opaque<"::tt::CB">
emitc.verbatim "cb_ctarg_1.reserve_back({});" args %0 : i32
emitc.verbatim "cb_ctarg_1.push_back({});" args %0 : i32
emitc.verbatim "cb_ctarg_1.wait_front({});" args %0 : i32
emitc.verbatim "cb_ctarg_0.reserve_back({});" args %0 : i32
emitc.call_opaque "compute_kernel_hw_startup"(%2, %1) : (!emitc.opaque<"::tt::CB">, !emitc.opaque<"::tt::CB">) -> ()
emitc.call_opaque "pack_untilize_init"(%2, %1) {template_args = [#emitc.opaque<"1">, #emitc.opaque<"1">]} : (!emitc.opaque<"::tt::CB">, !emitc.opaque<"::tt::CB">) -> ()
emitc.call_opaque "experimental::pack_untilize_block"(%2, %1, %0, %0) {template_args = [#emitc.opaque<"1">, #emitc.opaque<"1">]} : (!emitc.opaque<"::tt::CB">, !emitc.opaque<"::tt::CB">, i32, i32) -> ()
emitc.call_opaque "pack_untilize_uninit"(%1) : (!emitc.opaque<"::tt::CB">) -> ()
emitc.verbatim "cb_ctarg_1.pop_front({});" args %0 : i32
emitc.verbatim "cb_ctarg_0.push_back({});" args %0 : i32
emitc.verbatim "cb_ctarg_0.wait_front({});" args %0 : i32
emitc.verbatim "cb_ctarg_0.pop_front({});" args %0 : i32
return
}
}
}
}
Compiling into flatbuffer
compile_ttir_to_flatbuffer compiles a TTIRBuilder function fn straight to flatbuffer. This decorator is mainly a wrapper around the following functions, with each next function called on the output of the last: build_ttir_module, run_ttir_pipeline, and ttnn_to_flatbuffer_file, ttmetal_to_flatbuffer_file, ttir_to_emitpy_pipeline, or ttir_to_ttnn_emitc_pipeline as dictated by the target parameter.
def compile_ttir_to_flatbuffer(
fn: Callable,
inputs_shapes: List[Shape],
inputs_types: Optional[List[Union[torch.dtype, TypeInfo]]] = None,
system_desc_path: Optional[str] = None,
test_base: str = "test",
output_root: str = ".",
target: Literal["ttnn", "ttmetal", "emitc", "emitpy"] = "ttnn",
mesh_name: str = "mesh",
mesh_dict: OrderedDict[str, int] = OrderedDict([("x", 1), ("y", 1)]),
module_dump: bool = True,
argument_types_string: Optional[str] = None,
custom_pipeline: Optional[Union[Callable, str]] = None,
pipeline_options: List[str] = [],
print_ir: Union[bool, str] = False,
) -> str:
The executable flatbuffer is written to a file, compile_ttir_to_flatbuffer returns the file address of that flatbuffer.
TTNN example
Let's use our previous model function.
from builder.base.builder import Operand
from builder.ttir.ttir_builder import TTIRBuilder
from builder.base.builder_utils import compile_ttir_to_flatbuffer
shapes = [(32, 32), (32, 32), (32, 32)]
def model(in0: Operand, in1: Operand, in2: Operand, builder: TTIRBuilder):
add_0 = builder.add(in0, in1)
multiply_1 = builder.multiply(in1, add_0)
return builder.multiply(multiply_1, in2)
compile_ttir_to_flatbuffer(
model,
shapes,
target="ttnn",
)
TTMetal example
Let's once again use the same code for TTMetal that was used in the TTNN example but change the target to "ttmetal". Just as with run_ttir_pipeline, only one or the other can be run on a module since compile_ttir_to_flatbuffer modifies the module in place.
compile_ttir_to_flatbuffer(
model,
shapes,
target="ttmetal",
)
Integrating with other tt-mlir tools
Alternatives for file creation
- The
ttmlir-opttool runs a compiler pass on an.mlirfile. - The
ttmlir-translatecan generate a flatbuffer from an.mlirfile. llvm-litcan also be used to generate a flatbuffer from an existing.mlirfile.
Running models
ttrt
ttrt is intended to be a swiss army knife for working with flatbuffers.
tt-explorer
tt-explorer is a visualizer tool for ttmlir-powered compiler results.
ttnn-standalone
ttnn-standalone is a post-compile tuning/debugging tool.
llvm-lit
llvm-lit can also be used for MLIR testing.
Golden mode
Golden dataclass
TTIRBuilder provides support to code golden tensors into flatbuffers which will be used for comparison with TT device output in ttrt runtime. Golden is the dataclass used to store information about a golden tensor. Each TTIR op should have a matching PyTorch op (or golden function built from PyTorch ops) which should perform exactly the same operation, generating the same outputs given the same inputs. You can use TTIRBuilder helper functions to store input, intermediate, and output tensors within the flatbuffer. Input and output goldens are mapped with keys "input_" and "output_" followed by a tensor index: input_0. Intermediate output tensors are mapped to the location of the respective op creation.
GoldenCheckLevel Enum
TTIRBuilder stores an instance of the class GoldenCheckLevel(Enum) that dictates golden handling. It defaults to GoldenCheckLevel.OP_LEVEL. The exception is that TTIRBuilder CCL ops force the golden level to be set to GRAPH_LEVEL.
DISABLED : do not store goldens
OP_LEVEL : check every single op level goldens
GRAPH_LEVEL : check graph level goldens only
Check and set GoldenCheckLevel with TTIRBuilder APIs.
from builder.base.builder import Operand, GoldenCheckLevel
from builder.ttir.ttir_builder import TTIRBuilder
def model(in0: Operand, in1: Operand, in2: Operand, builder: TTIRBuilder):
builder.golden_check_level = GoldenCheckLevel.GRAPH_LEVEL
add_0 = builder.add(in0, in1)
multiply_1 = builder.multiply(in1, add_0)
return builder.multiply(multiply_1, in2)
Getting golden data
Unless otherwise specified in the GoldenCheckLevel, all input and output tensors will generate and store a golden in TTIRBuilder as a Golden type.
The TTIRBuilder API get_golden_map(self) is used to export golden data for flatbuffer construction. It returns a dictionary of golden tensor names and GoldenTensor objects.
To get info from a GoldenTensor object, use the attributes supported by ttmlir.passes: name, shape, strides, dtype, data.
from ttmlir.passes import GoldenTensor
from builder.ttir.ttir_builder import TTIRBuilder
shapes = [(32, 32), (32, 32), (32, 32)]
def model(in0: Operand, in1: Operand, in2: Operand, builder: TTIRBuilder):
add_0 = builder.add(in0, in1)
builder.print_goldens()
print(builder.get_golden_map())
return add0
Golden tensor:
tensor([[ 4.0450e+00, 1.4274e+00, 5.9156e-01, ..., -5.9834e-01,
-1.1830e-01, 1.2837e-01],
[ 2.3788e+00, 2.9242e-03, -5.2838e-02, ..., 1.8294e+00,
5.0348e+00, 9.7179e-01],
[ 1.5168e-02, 1.0577e-01, -3.0682e-01, ..., 6.7212e-01,
9.4523e-02, 5.3765e+00],
...,
[ 1.4241e-01, 1.1838e+00, -1.0601e+00, ..., 4.9099e-01,
4.2267e+00, 4.0610e-01],
[ 5.6630e-01, -1.3068e-01, -1.7771e-01, ..., 2.3862e+00,
3.9376e-01, 7.3140e-01],
[ 4.2420e+00, 1.7006e-01, -3.4861e-01, ..., 1.1471e-01,
1.6189e+00, -6.9106e-01]])
{'input_0': <ttmlir._mlir_libs._ttmlir.passes.GoldenTensor object at 0x7f77c70fa0d0>, 'output_0': <ttmlir._mlir_libs._ttmlir.passes.GoldenTensor object at 0x7f77c6fc9590>}
Setting golden data
Use TTIRBuilder API set_graph_input_output to set your own input and output golden tensors using PyTorch tensors. Keep in mind that this also sets graph inputs and outputs. There are some functions for which setting custom input tensors is required to pass PCC accuracy checks: ttir.tan, ttir.log, ttir.log1p. See example implementation and explanation in test/python/golden/test_ttir_ops.py.
set_graph_input_output(
self,
inputs: List[torch.Tensor],
outputs: Optional[List[torch.Tensor]] = None,
override: bool = False,
)
import torch
input_0 = torch.ones((32, 32))
output_0 = torch.zeros((32, 32))
builder.set_graph_input_output([input_0], [output_0], override=True)
Running flatbuffer with golden data in ttrt
Running flatbuffers in ttrt requires building and setting up the environment. Run these commands before creating MLIR modules or flatbuffers so the system description in the flatbuffers match your device.
cmake --build build
ttrt query --save-artifacts
export SYSTEM_DESC_PATH=/path/to/system_desc.ttsys
Set environment variable TTRT_LOGGER_LEVEL to DEBUG so ttrt logs golden comparison results and prints graph level golden tensors.
export TTRT_LOGGER_LEVEL=DEBUG
Finally run ttrt. Our example flatbuffer file (since we didn't specify otherwise) defaulted to file path ./builder-artifacts/ttir-builder/test_ttnn/test_ttnn.mlir.ttnn. --log-file ttrt.log and --save-golden-tensors are both optional flags. They ensure that all golden data produced by the ttrt run gets written to files.
ttrt run builder-artifacts/ttir-builder/test_ttnn/test_ttnn.mlir.ttnn --log-file ttrt.log --save-golden-tensors
Golden callbacks
The ttrt documentation contains a section on the callback function feature. Callback functions run between each op execution during runtime and contain op level golden analysis. They are also customizable and provide the flexibility for you to get creative with your golden usage.
builder.apis
Adding a new op to ttir-builder
ttir-builder is designed to only create ops supported in TTIR. At the moment, most but not all ops are supported, and new ops are still occasionally added to TTIR. Creating ttir-builder support for an op entails writing a function in tools/builder/ttir/ttir_builder.py that will create the op and its golden counterpart.
TTIR op factories
All ops are created when their relevant information is run through the _op_proxy function which provides a general interface for proxy-ing and creating ops.
def _op_proxy(
self,
op_ttir_function: Callable,
inputs: List[Operand],
unit_attrs: List[str] = None,
organize_ttir_args: Optional[Callable] = None,
organize_golden_args: Optional[Callable] = None,
output_shape: Optional[Shape] = None,
output_type: Optional[Type] = None,
output_create_fn: Optional[Callable] = None,
golden_kwargs: dict = {},
ttir_kwargs: dict = {},
skip_golden: bool = False,
)
Start by finding the TTIR op you wish to replicate in include/ttmlir/Dialect/TTIR/IR/TTIROps.td or the TTIR dialect documentation.
All op attributes should be included as arguments in your function and passed into a proxy function as keyword arguments using ttir_kwargs.
All input operands should be passed into a proxy function using the argument inputs. Output operands are considered inputs and can optionally be passed into inputs if their shape or datatype is relevant to the op's result operand. organize_ttir_args dictates what information gets passed into autogenerated file build/python_packages/ttmlir/dialects/_ttir_ops_gen.py and can be used if operand arguments require special handling.
Golden functions
Golden functions provide the reference implementation for TTIR operations using PyTorch. They are centralized in tools/golden/mapping.py and must be mapped to their corresponding TTIR operations. The _op_proxy function automatically retrieves the appropriate golden function based on the TTIR operation class. The skip_golden argument omits golden tensor creation and addition to the golden map. Since goldens are relied upon to set output_shape and output_type, setting skip_golden=True requires passing in output_shape and output_type to _op_proxy.
Writing a golden function
Before writing a golden function, you need to know exactly what the TTIR op does to its input data because you will have to replicate that exactly using PyTorch operations. This information is usually covered in TTIR documentation, but if not, you may have to do some detective work and trial and error. Get creative with keyword argument handling, using similar Pytorch operations, and maybe multiple operations. Google is your friend. If you have to figure out how to do something Pytorch doesn't, odds are someone online has encountered the same situation.
Golden functions should be implemented in tools/golden/mapping.py and follow this pattern:
- Simple operations: If PyTorch has an identical function, you can directly use it in the mappings
- Complex operations: Define a custom golden function that implements the behavior using PyTorch operations
Adding golden function mappings
All golden functions must be registered in the GOLDEN_MAPPINGS dictionary in tools/golden/mapping.py:
# In tools/golden/mapping.py
def cbrt_golden(input: torch.Tensor) -> torch.Tensor:
"""Golden function for cube root operation."""
golden_sign = torch.sign(input)
golden_cbrt = torch.pow(torch.abs(input), 1 / 3)
return golden_sign * golden_cbrt
# Add to GOLDEN_MAPPINGS dictionary in tools/goldens/mapping.py
GOLDEN_MAPPINGS: Dict[type, Callable] = {
# ... other mappings ...
ttir.CbrtOp: cbrt_golden,
# ... more mappings ...
}
Using golden functions in ops.py
In your operation implementation in ops.py, simply pass the TTIR operation class to _op_proxy. The golden function is automatically retrieved internally:
# In ops.py
from goldens import GOLDEN_MAPPINGS
def cbrt(self, in0: Operand, unit_attrs: Optional[List[str]] = None) -> OpView:
return self._op_proxy(
ttir.CbrtOp, # Golden function automatically retrieved from GOLDEN_MAPPINGS
[in0],
unit_attrs=unit_attrs,
)
Adding Silicon tests
Silicon tests are created in the test/python/golden directory.
pytest test/python/golden/test_ttir_ops.py
Be sure to file an issue for failing tests and add a pytest mark for any failing or unsupported tests. The pytest marks instruct CI to ignore tests.
pytest.mark.skip("Issue number") : skip flatbuffer creation for this test
pytest.mark.skip_config(config, ... reason=None): skip test if all of the specified targets/backends per config are present
The skip_config mark here is a little nuanced. By passing in a list of
strings representing targets and/or systems (e.g. ["ttmetal", "p150"]) this
mark will intelligently skip tests with that configuration. The example given
will skip tests lowered to ttmetal iff we are running on a p150 (i.e.
blackhole). This functionality will be expanded to include other axes of test
configuration, but target and system are sufficient for our needs at the
moment.
For tests exclusive to n300 or llmbox, use the following pytest marks or add them to their respective test files.
pytestmark = pytest.mark.n300
pytestmark = pytest.mark.llmbox
Running Silicon tests
Follow these steps. The directory test/python/golden contains tests for modules, individual ops, and various machines.
1. Build ttmlir
source env/activate
cmake -G Ninja -B build -DCMAKE_BUILD_TYPE=Release -DCMAKE_C_COMPILER=clang-17 -DCMAKE_CXX_COMPILER=clang++-17 -DCMAKE_CXX_COMPILER_LAUNCHER=ccache -DTTMLIR_ENABLE_RUNTIME=ON -DTT_RUNTIME_ENABLE_PERF_TRACE=ON
cmake --build build
2. Query system
ttrt query --save-artifacts
3. Export system desc file
export SYSTEM_DESC_PATH=/path/to/system_desc.ttsys (path dumped in previous command)
4. Generate test cases
pytest test/python/golden/test_ttir_ops.py
5. Run test cases
ttrt run builder-artifacts
Sphinx documentation
Docstrings
Sphinx generates documentation for builder ops from the docstrings in TTIRBuilder functions. This is the structure to follow when writing your docstring
"""
Creates ``ttir.add``.
*Elementwise addition operation.*
Performs elementwise addition between two tensors.
For each pair of corresponding elements, adds the element in the second
tensor to the element in the first tensor.
Mathematical definition: add(x, y) = x + y
.. code-block:: mlir
// Add corresponding elements
%result = ttir.add(%lhs, %rhs, %output) : tensor<3xf32>, tensor<3xf32>, tensor<3xf32> -> tensor<3xf32>
// Input tensors:
// lhs: [3.5, 0.0, -1.2]
// rhs: [1.5, 2.0, -3.2]
// Output tensor:
// [5.0, 2.0, -4.4]
Parameters
----------
in0 : Operand
First input tensor
in1 : Operand
Second input tensor
unit_attrs : *Optional[List[str]]*, optional
Optional list of unit attributes
Returns
-------
*OpView*
A tensor containing the elementwise sum of the inputs
"""
Autogen skip
All functions in TTIRBuilder are included in documentation by default. If your op is failing any of the tests, it can't yet be added to the documentation. Custom golden functions also must be excluded. Tag those functions with autodoc_skip.
@autodoc_skip
def bitwise_not(
self, in0: Operand, unit_attrs: Optional[List[str]] = None
) -> OpView:
stablehlo-builder
stablehlo-builder is a tool for creating stableHLO operations. It provides support for MLIR modules to be generated from user-constructed ops.
Getting started
StableHLOBuilder is a builder class providing the API for creating stableHLO ops. The python package builder contains everything needed to create ops through a StableHLOBuilder object. builder.base.builder_utils contains the APIs for wrapping op-creating-functions into MLIR modules and flatbuffers files.
from builder.stablehlo.stablehlo_builder import StableHLOBuilder
from builder.base.builder_utils import build_stablehlo_module, compile_stablehlo_to_flatbuffer
Creating a StableHLO module
build_stablehlo_module defines an MLIR module specified as a python function. It wraps fn in a MLIR FuncOp then wraps that in an MLIR module, and finally ties arguments of that FuncOp to test function inputs. It will instantiate and pass a StableHLOBuilder object as the last argument of fn. Each op returns an OpView type which is a type of Operand that can be passed into another builder op as an input.
def build_stablehlo_module(
fn: Callable,
inputs_shapes: List[Shape],
inputs_types: Optional[List[Union[torch.dtype, TypeInfo]]] = None,
mesh_name: str = "mesh",
mesh_dict: OrderedDict[str, int] = OrderedDict([("x", 1), ("y", 1)]),
module_dump: bool = False,
base: Optional[str] = None,
output_root: str = ".",
) -> Tuple[Module, StableHLOBuilder]:
Example
from builder.base.builder import Operand
from builder.stablehlo.stablehlo_builder import StableHLOBuilder
from builder.base.builder_utils import build_stablehlo_module
shapes = [(32, 32), (32, 32), (32, 32)]
def model(in0: Operand, in1: Operand, in2: Operand, builder: StableHLOBuilder):
return builder.add(in0, in1)
module, builder = build_stablehlo_module(model, shapes)
Returns
An MLIR module containing an MLIR op graph defined by fn and the StableHLOBuilder object used to create it
module {
func.func @model(%arg0: tensor<32x32xf32>, %arg1: tensor<32x32xf32>, %arg2: tensor<32x32xf32>) -> tensor<32x32xf32> {
%0 = stablehlo.add %arg0, %arg1 : tensor<32x32xf32>
return %0 : tensor<32x32xf32>
}
}
Creating a StableHLO module with Shardy annotations
StableHLOBuilder allows you to attach shardy annotations to the generated mlir graph.
Example
from builder.base.builder import Operand
from builder.stablehlo.stablehlo_builder import StableHLOBuilder
from builder.base.builder_utils import build_stablehlo_module
shapes = [(32, 32), (32, 32)]
def model(in0: Operand, in1: Operand, shlo_builder: StableHLOBuilder):
tensor_sharding_attr = shlo_builder.tensor_sharding_attr(
mesh_name="mesh",
dimension_shardings=[
shlo_builder.dimension_sharding_attr(
axes=[shlo_builder.axis_ref_attr(name="x")],
is_closed=True,
),
shlo_builder.dimension_sharding_attr(
axes=[shlo_builder.axis_ref_attr(name="y")],
is_closed=False,
)
]
)
shlo_builder.sharding_constraint(in0, tensor_sharding_attr=tensor_sharding_attr)
return shlo_builder.add(in0, in1)
module, shlo_builder = build_stablehlo_module(model, shapes, mesh_name="mesh", mesh_dict=OrderedDict([("x", 1), ("y", 8)]))
Returns
An MLIR module containing shardy annotations.
module {
sdy.mesh @mesh = <["x"=1, "y"=8]>
func.func @model(%arg0: tensor<32x32xf32>, %arg1: tensor<32x32xf32>) -> tensor<32x32xf32> {
%0 = sdy.sharding_constraint %arg0 <@mesh, [{"x"}, {"y", ?}]> : tensor<32x32xf32>
%1 = stablehlo.add %arg0, %arg1 : tensor<32x32xf32>
return %1 : tensor<32x32xf32>
}
}
Compiling into flatbuffer
compile_stablehlo_to_flatbuffer compiles a StableHLOBuilder function fn straight to flatbuffer. This decorator is mainly a wrapper around the following functions, with each next function called on the output of the last: build_stablehlo_module, _run_ttir_pipeline, and ttnn_to_flatbuffer_file, ttmetal_to_flatbuffer_file, or ttir_to_ttnn_emitc_pipeline as dictated by the target parameter.
def compile_stablehlo_to_flatbuffer(
fn: Callable,
inputs_shapes: List[Shape],
inputs_types: Optional[List[Union[torch.dtype, TypeInfo]]] = None,
system_desc_path: Optional[str] = None,
test_base: str = "test",
output_root: str = ".",
target: Literal["ttnn", "ttmetal", "emitc"] = "ttnn",
mesh_name: str = "mesh",
mesh_dict: OrderedDict[str, int] = OrderedDict([("x", 1), ("y", 1)]),
module_dump: bool = True,
argument_types_string: Optional[str] = None,
custom_pipeline: Optional[Union[Callable, str]] = None,
ttir_pipeline_options: List[str] = [],
shlo_pipeline_options: List[str] = [],
shlo_to_ttir_pipeline_options: List[str] = [],
print_ir: Union[bool, str] = False,
) -> str:
The executable flatbuffer is written to a file, compile_stablehlo_to_flatbuffer returns the file address of that flatbuffer.
TTNN example
Let's use our previous model function.
from builder.base.builder import Operand
from builder.stablehlo.stablehlo_builder import StableHLOBuilder
from builder.base.builder_utils import compile_stablehlo_to_flatbuffer
shapes = [(32, 32), (32, 32)]
def model(in0: Operand, in1: Operand, shlo_builder: StableHLOBuilder):
tensor_sharding_attr = shlo_builder.tensor_sharding_attr(
mesh_name="mesh",
dimension_shardings=[
shlo_builder.dimension_sharding_attr(
axes=[shlo_builder.axis_ref_attr(name="x")],
is_closed=True,
),
shlo_builder.dimension_sharding_attr(
axes=[shlo_builder.axis_ref_attr(name="y")],
is_closed=False,
)
]
)
shlo_builder.sharding_constraint(in0, tensor_sharding_attr=tensor_sharding_attr)
return shlo_builder.add(in0, in1)
compile_stablehlo_to_flatbuffer(
model,
shapes,
mesh_name="mesh",
mesh_dict=OrderedDict([("x", 1), ("y", 8)]),
target="ttnn",
)
TTMetal example
Let's once again use the same code for TTMetal that was used in the TTNN example but change the target to "ttmetal". Just as with _run_ttir_pipeline, only one or the other can be run on a module since compile_stablehlo_to_flatbuffer modifies the module in place.
compile_stablehlo_to_flatbuffer(
model,
shapes,
mesh_name="mesh",
mesh_dict=OrderedDict([("x", 1), ("y", 8)]),
target="ttmetal",
)
Integrating with other tt-mlir tools
Alternatives for file creation
- The
ttmlir-opttool runs a compiler pass on an.mlirfile. - The
ttmlir-translatecan generate a flatbuffer from an.mlirfile. llvm-litcan also be used to generate a flatbuffer from an existing.mlirfile.
Running models
ttrt
ttrt is intended to be a swiss army knife for working with flatbuffers.
tt-explorer
tt-explorer is a visualizer tool for ttmlir-powered compiler results.
ttnn-standalone
ttnn-standalone is a post-compile tuning/debugging tool.
llvm-lit
llvm-lit can also be used for MLIR testing.
Golden mode
Golden dataclass
StableHLOBuilder provides support to code golden tensors into flatbuffers which will be used for comparison with TT device output in ttrt runtime. Golden is the dataclass used to store information about a golden tensor. Each StableHLOBuilder op should have a matching PyTorch op (or golden function built from PyTorch ops) which should perform exactly the same operation, generating the same outputs given the same inputs. You can use StableHLOBuilder helper functions to store input, intermediate, and output tensors within the flatbuffer. Input and output goldens are mapped with keys "input_" and "output_" followed by a tensor index: input_0. Intermediate output tensors are mapped to the location of the respective op creation.
GoldenCheckLevel Enum
StableHLOBuilder stores an instance of the class GoldenCheckLevel(Enum) that dictates golden handling. It defaults to GoldenCheckLevel.OP_LEVEL.
DISABLED : do not store goldens
OP_LEVEL : check every single op level goldens
GRAPH_LEVEL : check graph level goldens only
Check and set GoldenCheckLevel with StableHLOBuilder APIs.
from builder.base.builder import Operand, GoldenCheckLevel
from builder.stablehlo.stablehlo_builder import StableHLOBuilder
def model(in0: Operand, in1: Operand, in2: Operand, builder: StableHLOBuilder):
builder.golden_check_level = GoldenCheckLevel.GRAPH_LEVEL
add_0 = builder.add(in0, in1)
multiply_1 = builder.multiply(in1, add_0)
return builder.multiply(multiply_1, in2)
Getting golden data
Unless otherwise specified in the GoldenCheckLevel, all input and output tensors will generate and store a golden in StableHLOBuilder as a Golden type.
The StableHLOBuilder API get_golden_map(self) is used to export golden data for flatbuffer construction. It returns a dictionary of golden tensor names and GoldenTensor objects.
To get info from a GoldenTensor object, use the attributes supported by ttmlir.passes: name, shape, strides, dtype, data.
from ttmlir.passes import GoldenTensor
from builder.stablehlo.stablehlo_builder import StableHLOBuilder
shapes = [(32, 32), (32, 32), (32, 32)]
def model(in0: Operand, in1: Operand, in2: Operand, builder: StableHLOBuilder):
add_0 = builder.add(in0, in1)
builder.print_goldens()
print(builder.get_golden_map())
return add0
Golden tensor:
tensor([[ 4.0450e+00, 1.4274e+00, 5.9156e-01, ..., -5.9834e-01,
-1.1830e-01, 1.2837e-01],
[ 2.3788e+00, 2.9242e-03, -5.2838e-02, ..., 1.8294e+00,
5.0348e+00, 9.7179e-01],
[ 1.5168e-02, 1.0577e-01, -3.0682e-01, ..., 6.7212e-01,
9.4523e-02, 5.3765e+00],
...,
[ 1.4241e-01, 1.1838e+00, -1.0601e+00, ..., 4.9099e-01,
4.2267e+00, 4.0610e-01],
[ 5.6630e-01, -1.3068e-01, -1.7771e-01, ..., 2.3862e+00,
3.9376e-01, 7.3140e-01],
[ 4.2420e+00, 1.7006e-01, -3.4861e-01, ..., 1.1471e-01,
1.6189e+00, -6.9106e-01]])
{'input_0': <ttmlir._mlir_libs._ttmlir.passes.GoldenTensor object at 0x7f77c70fa0d0>, 'output_0': <ttmlir._mlir_libs._ttmlir.passes.GoldenTensor object at 0x7f77c6fc9590>}
Setting golden data
Use StableHLOBuilder API set_graph_input_output to set your own input and output golden tensors using PyTorch tensors. Keep in mind that this also sets graph inputs and outputs.
set_graph_input_output(
self,
inputs: List[torch.Tensor],
outputs: Optional[List[torch.Tensor]] = None,
override: bool = False,
)
import torch
input_0 = torch.ones((32, 32))
output_0 = torch.zeros((32, 32))
builder.set_graph_input_output([input_0], [output_0], override=True)
Running flatbuffer with golden data in ttrt
Running flatbuffers in ttrt requires building and setting up the environment. Run these commands before creating MLIR modules or flatbuffers so the system description in the flatbuffers match your device.
cmake --build build
ttrt query --save-artifacts
export SYSTEM_DESC_PATH=/path/to/system_desc.ttsys
Set environment variable TTRT_LOGGER_LEVEL to DEBUG so ttrt logs golden comparison results and prints graph level golden tensors.
export TTRT_LOGGER_LEVEL=DEBUG
Finally run ttrt. Our example flatbuffer file (since we didn't specify otherwise) defaulted to file path ./builder-artifacts/stablehlo-builder/test_ttnn/test_ttnn.mlir.ttnn. --log-file ttrt.log and --save-golden-tensors are both optional flags. They ensure that all golden data produced by the ttrt run gets written to files.
ttrt run builder-artifacts/stablehlo-builder/test_ttnn/test_ttnn.mlir.ttnn --log-file ttrt.log --save-golden-tensors
Golden callbacks
The ttrt documentation contains a section on the callback function feature. Callback functions run between each op execution during runtime and contain op level golden analysis. They are also customizable and provide the flexibility for you to get creative with your golden usage.
Builder Testing
The tests for builder compilability & semantic correctness all live in
test/python/golden. pytest is used to orchestrate these tests. The basic
stages of each test are as follows:
- Compilation
- Builder Graph -> TTIR-MLIR
- TTIR-MLIR -> TTNN-MLIR or TTMetal-MLIR (depending on
targetparameter) - {TTNN,TTMetal}-MLIR -> Executable Flatbuffer
Test Structure
All op tests utilizing builder follow a similar structure. Here we use
reshape (from test/python/golden/test_ttir_ops.py) to demonstrate:
@pytest.mark.parametrize(
"input_shape,output_shape",
[
# [input_shape, output_shape]
((128, 128), (16384,)), # Flatten 2D to 1D
((24,), (2, 3, 4)), # Unflatten 1D to 3D
((2, 3, 4), (6, 4)), # 3D to 2D reshape
((128, 128), (64, 256)), # 2D to 2D different arrangement
((1, 1, 1), (1,)), # Edge case: all dimensions are 1
((10,), (10,)), # Identity reshape
((64, 512), (64, 1, 512)), # Common ML pattern: expand dims
((256, 256), (512, 128)), # Power of 2 reshape
((32, 3, 224, 224), (32, 150528)), # Large ML pattern: batch flatten
],
)
@pytest.mark.parametrize("dtype", [torch.float32, torch.int32], ids=["f32", "i32"])
@pytest.mark.parametrize("target", ["ttnn"])
def test_reshape(input_shape, output_shape, dtype: torch.dtype, request):
def reshape_wrapper(in0: Operand, builder: TTIRBuilder):
return builder.reshape(in0, output_shape)
compile_ttir_to_flatbuffer(
reshape_wrapper,
[input_shape],
[dtype],
target=target,
test_base=request.node.name,
output_root=request.config.getoption("--path"),
system_desc_path=request.config.getoption("--sys-desc"),
As seen above, each test is broadly split into 3 parts:
- Parametrizations to generate multiple tests for a single op, testing common patterns and edge cases.
- The test function (
Callable) (in this case, it isreshape_wrapper) that defines the builder graph to be compiled - A call to
compile_ttir_to_flatbuffer. This is where the test is actually executed and the graph compiled. The docstring forcompile_ttir_to_flatbufferexplains each parameter in detail
Parametrization Rules
NOTE: these rules are temporary, and may be relaxed completely upon completion of #4518
The builder tests make heavy utilization of pytests parametrization features
to reuse as much code as possible when just changing the inputs to different
ops. There are some special rules to follow when defining parametrizations for tests here:
-
All tests must be parametrized with the input shape of an op for reporting to pick up the shape, and it must be named one of
shapes,shape,input_shape, orinputs_shapes. This requirement is to allow these shapes to easily be dumped to a test report and ingested by some report analysis tool, so the dumper must know which parameters to look for. -
If input types are being parametrized, then they must be named one of
dtypes,dtype,inputs_dtypesfor the same reason as above. The arity of this must either match the arity of the shapes, or be exactly one element, which signals that all input tensors are to be marked as that type. -
If the test function itself is being parametrized (see
test_unary_opsintest/python/golden/test_ttir_ops.py), then that parameter must be namedtest_fn -
If you want to tie two semantic parameters together (e.g. stride and padding in a
conv2dop), do not parametrized them as tuples and unpack them in the function. This blinds the test reporter from the actual correct names of the parameters. Instead, usepytest.mark.parametrize's built in feature for tying multiple parameters together via a comma separated string.Good:
@pytest.mark.parametrize( "stride,padding,dilation,groups", [([2, 1], [2, 1], [2, 1], 2)] )Bad:
@pytest.mark.parametrize( "stride_padding_dilation_groups", [([2, 1], [2, 1], [2, 1], 2)] ) ... stride, padding, dilation, groups = stride_padding_dilation_groups -
If a different backend to
"ttnn"is desired, then it must be parametrized under the name"target". This is true even of test cases that don't need to be over multiple targets, since thedevicefixture must be able to read the target from the parameters to initialize the device for execution -
All tests must contain the
pytest.mark.frontendmark, denoting either"ttir"or"shlo". The easiest way to do this is by utilizing file wide marks (set thepytestmarkvariable to the mark or a list of marks you want to apply to every test in the file)
Marks
There are a number of custom marks provided for this test suite, most of them having to do with skipping tests on specific hardware or with specific parameter configurations. They are as follows:
x86_only: Skips a test if the host is not running x86 hardwareskip_config(...): Given a set of target and hardware params, this will skip the test if the specific config is met. For example,skip_config(["ttmetal", "p150"])will skip the test that targetsttmetalon allp150machines. This functions over set intersection, so something likeskip_config(["ttmetal"])will skip allttmetaltests that this test function generatesfrontend(fe):feis one of"ttir"or"shlo"and denotes for the test reporter which frontend builder this test is using
TT-Explorer
Welcome to the TT-Explorer wiki! TT-Explorer is a visualization and exploration tool included in the TT-MLIR repository. Based on Google's Model Explorer, TT-Explorer is adapted for use with Tenstorrent's custom, open-source compiler stack. Using TT-Explorer, you can:
- Analyze and inspect models
- Visualize models (attributes, performance results)
- Explore models across StableHLO (SHLO), TTIR, and TTNN dialects
- Interactively debug or experiment with IR-level overrides.
TT-Explorer is for use with TT-MLIR compiler results. It takes emitted MLIR files, converts them to JSON, and displays them. There are three main levels the emitted TT-MLIR file is likely to be from, and all are supported for TT-Explorer:
- SHLO - Portability layer between different ML frameworks (like TensorFlow, JAX, and PyTorch) and ML compilers (like XLA and IREE), ensuring compatibility across the ML ecosystem.
- TTIR - Mid-level intermediate representation (IR) that introduces hardware concepts like tensor tiling, memory layouts, and op fusion. Maps to hardware capabilities.
- TTNN - High-level, PyTorch style ops (for example,
ttnn.conv2d) used for writing and compiling models in a user-friendly format.
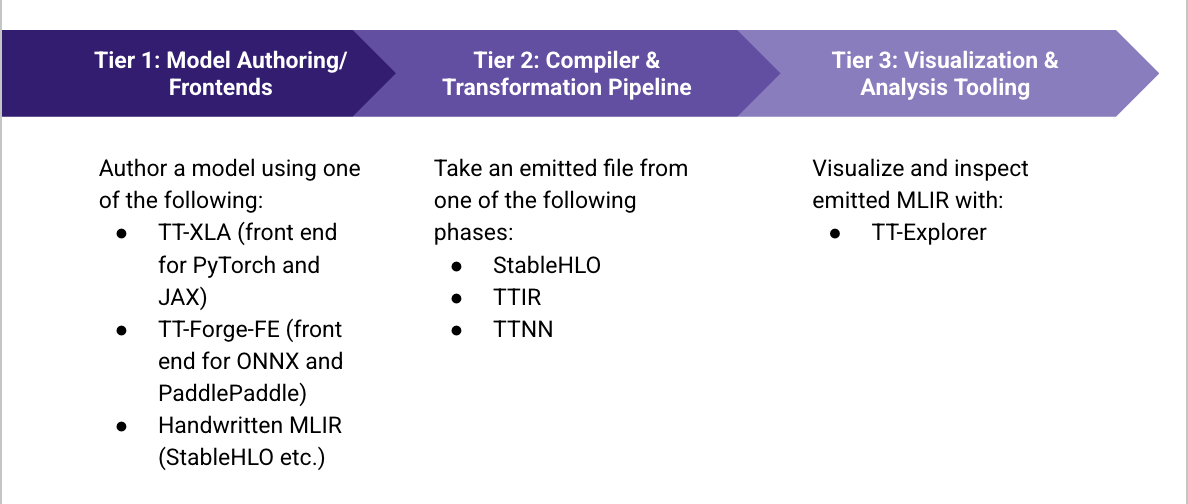
Prerequisites
- Configure your Tenstorrent hardware
- Configure the Tenstorrent software stack
Quick Start
This section explains how to install TT-Explorer. Do the following:
- TT-Explorer comes packaged as a tool in the TT-MLIR directory. Clone the TT-MLIR repo:
git clone https://github.com/tenstorrent/tt-mlir.git
-
Navigate into the tt-mlir directory.
-
The environment gets installed into a toolchain directory, which is by default set to
/opt/ttmlir-toolchain, but can be overridden by setting the environment variableTTMLIR_TOOLCHAIN_DIR. You need to manually create the toolchain directory as follows:
export TTMLIR_TOOLCHAIN_DIR=/opt/ttmlir-toolchain/
sudo mkdir -p "${TTMLIR_TOOLCHAIN_DIR}"
sudo chown -R "${USER}" "${TTMLIR_TOOLCHAIN_DIR}"
- Ensure you do not have a virtual environment activated already before running the following command:
source env/activate
NOTE: These commands can take some time to run. Also, please note that the virtual environment may not show at the end of this step.
- In this step, you build the TT-MLIR project. To build so that you can use TT-EXPLORER, the following flags must be included for your build:
-DTT_RUNTIME_ENABLE_PERF_TRACE=ON-DTTMLIR_ENABLE_RUNTIME=ON-DTT_RUNTIME_DEBUG=ON-DTTMLIR_ENABLE_STABLEHLO=ON
The commands are:
source env/activate
cmake -G Ninja -B build \
-DTT_RUNTIME_ENABLE_PERF_TRACE=ON \
-DTTMLIR_ENABLE_RUNTIME=ON \
-DTT_RUNTIME_DEBUG=ON \
-DTTMLIR_ENABLE_STABLEHLO=ON
- Build the
explorertarget in the tt-mlir directory:
cmake --build build -- explorer
-
Run
tt-explorerin the terminal to start att-explorerinstance. (Refer to the CLI section in the API for specifics)- Note:
tt-explorerrequires Pandas in addition to thett-mlirSystem Dependencies.
- Note:
-
Ensure the server has started in the
tt-explorershell instance. Check for the following message:Starting Model Explorer server at: http://localhost:8080
Running TT-Explorer CI Tests Locally
This section describes how to run CI tests as well as how to reproduce and debug failing CI tests locally. Make sure you are familiar with how to build and run TT-Explorer before starting this section.
TT-Explorer relies on tests that are present in the test/ directory as well as tests dynamically created through llvm-lit. Below are the steps to replicate the testing procedure seen in CI:
- Make sure you're in the
tt-mlirdirectory - You need to build the explorer target with
cmake --build build -- explorer - Run and save the system descriptor
ttrt query --save-artifacts - Save the system variable
export SYSTEM_DESC_PATH=$(pwd)/ttrt-artifacts/system_desc.ttsys - Run and generate ttnn + MLIR tests:
cmake --build build -- check-ttmlir - Save the relevant test directories:
export TT_EXPLORER_GENERATED_MLIR_TEST_DIRS=$(pwd)/build/test/python/golden/ttnn,$(pwd)/build/test/ttmlir/Silicon/TTNN/n150/perfexport TT_EXPLORER_GENERATED_TTNN_TEST_DIRS=$(pwd)/build/test/python/golden/ttnn
- Run the pytest for
tt-explorerwithpytest tools/explorer/test/run_tests.py
As a shell script it looks like this:
# Ensure you are present in the tt-mlir directory
source env/activate
# Build Tests
cmake --build build -- explorer
ttrt query --save-artifacts
export SYSTEM_DESC_PATH=$(pwd)/ttrt-artifacts/system_desc.ttsys
cmake --build build -- check-ttmlir
# Load Tests
export TT_EXPLORER_GENERATED_MLIR_TEST_DIRS=$(pwd)/build/test/python/golden/ttnn,$(pwd)/build/test/ttmlir/Silicon/TTNN/n150/perf
export TT_EXPLORER_GENERATED_TTNN_TEST_DIRS=$(pwd)/build/test/python/golden/ttnn
# Run Tests
pytest tools/explorer/test/run_tests.py
TT-Explorer UI
For general details about the UI, refer to Google's Model Explorer wiki. This page highlights unique UI elements added to the Tenstorrent fork of Google's Model Explorer.
Model Execution

TT-Explorer adds a toolbar to the top of the screen that features the following icons in order of appearance:
- Execute Model (Play icon)
- Model Execution Settings (Gear icon)
- Generated C Code (Angle Brackets icon)
- Log Messages (Comment Bubble icon)
Run / Execute

The play icon invokes the execute function which compiles and executes the model. The icon then displays as loading until execution is finished. Pressing the icon does the following:
- Runs the model through the
tt-mlirpipeline. - Updates the visualization with results from the server execution.
- Creates overlays on the graph after the model executes. These overlays use color to visually communicate how long different nodes take to complete during execution.
Performance Overlay
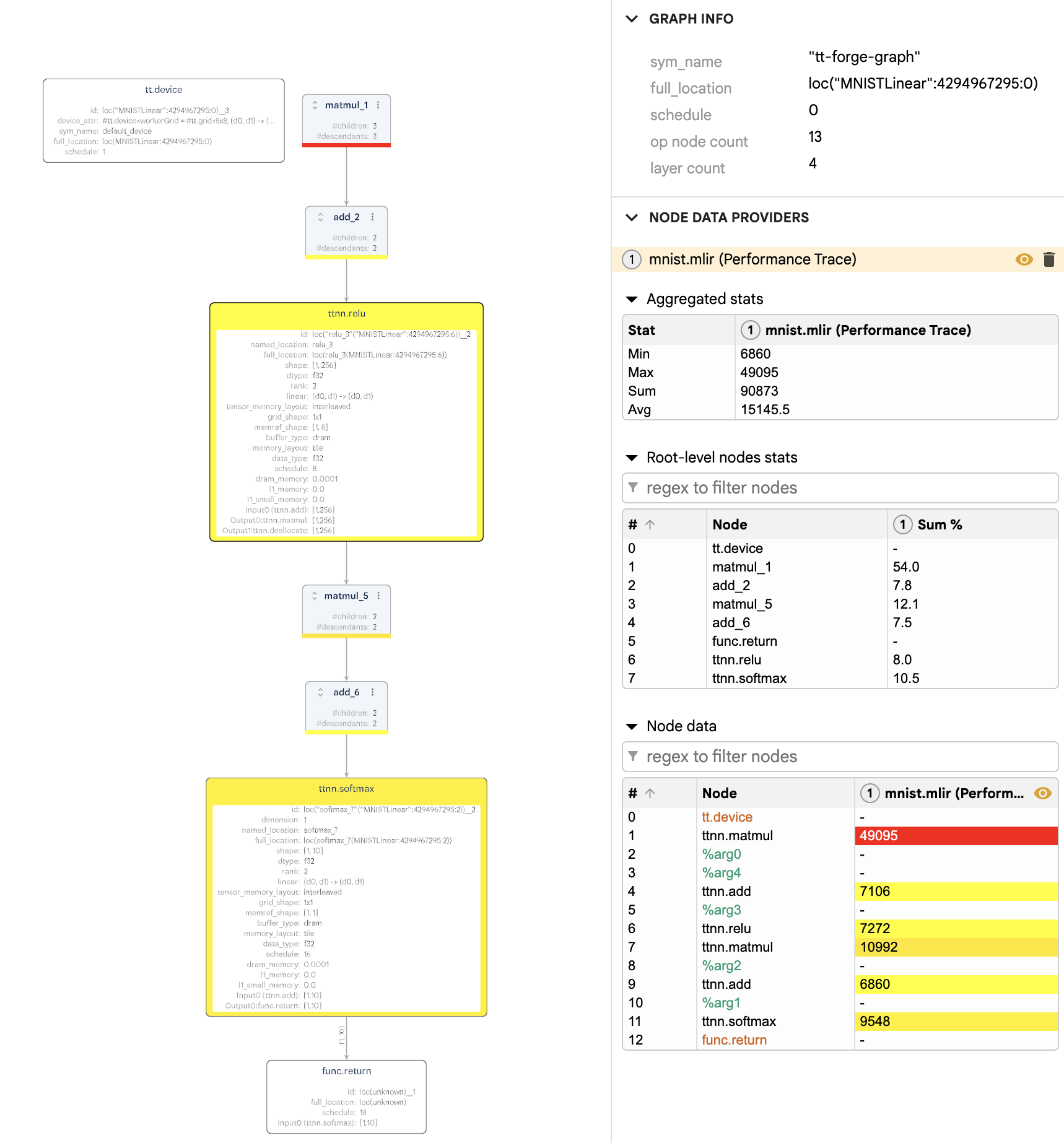
After every execution, the performance overlay appears. It uses a color gradient from yellow to red to represent the execution time of each node:
- Yellow nodes represent the fastest execution times (relative to other nodes).
- Red nodes indicate the slowest execution times.
This helps you quickly identify bottlenecks or costly operations in the model graph.
Accuracy Overlay
The accuracy overlay only appears after executing from a compatible flatbuffer (.ttnn file extension with debug info included). It shows a pass/fail status for each node based on a comparison against a "golden" (expected) reference:
- Green nodes passed the accuracy check
- Red nodes failed the check
This overlay is useful for validating that model outputs remain correct after transformations or optimizations.
The overlay value represents the difference between the actual Pearson Correlation Coefficient (PCC) for the node's output and the expected PCC from the golden reference. If the PCC difference is negative (lower than expected), the node fails the accuracy check. Otherwise it is considered accurate.
Advanced Settings

Clicking the gear icon opens a menu with advanced settings for model execution.
Optimization Policy
This dropdown provides a list of Optimization Policies which can be applied when lowering from a ttir module to an executable ttnn module.
Generate C++ Code
This toggle runs the EmitC pass in the tt-mlir compiler to generate TTNN C++ Code and make it available to you after running a model. The default value for this toggle is Off.
Code Icon

If the Generate C++ Code option is enabled, this button will become available to view and download the C++ code in a window within explorer.
Logs Icon

This button will open a window to view the shell logs while execution is running. If any errors occur they will be displayed here.
Overridden Fields
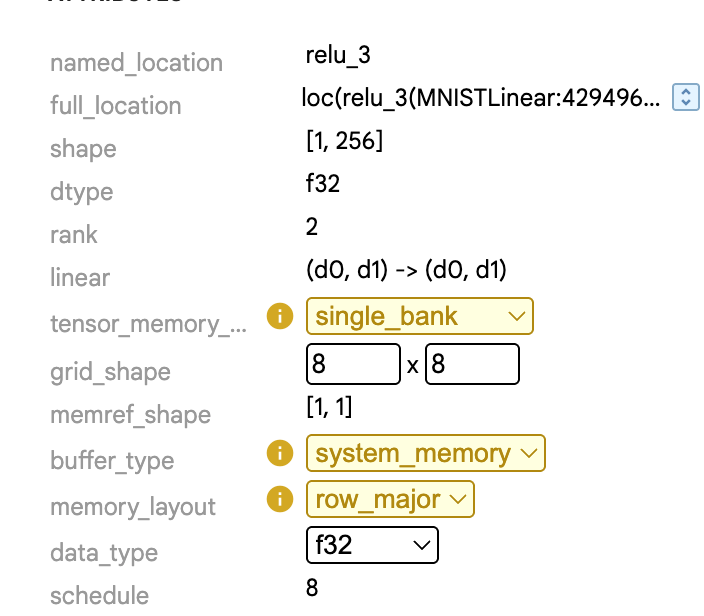
Certain nodes on the graph have attributes that are presented as editable fields. These are fields which have overrides available. This value can be changed and then sent to be recompiled, with invalid configurations resulting in errors.
tt-explorer CLI
This page details the command-line interface (CLI) for TT-Explorer. Through the CLI, you can:
- Start the server
- Configure the server's network settings
- Control whether the UI automatically opens in a browser
- Enable or disable model execution
You can also find a summary of supported input models, so you know what can be executed and visualized through the UI.
Input Models
Currently tt-explorer supports 3 types of models that can be executed/visualized.
| Input Type | Execution Support | Visualization Support |
|---|---|---|
.ttnn Flatbuffers with Debug Info | ✔️ | ✔️ |
.ttnn Flatbuffers without Debug Info | ❌ | ❌ |
.mlir TTIR Modules | ✔️ | ✔️ |
.mlir TTNN Modules | ❌ | ✔️ |
CLI
The CLI for tt-explorer provides a simple suite of options to start the UI:
tt-explorer -p <port> -u <url> -q
Options
-p, --port- Port that model-explorer server will be exposed to. Default is 8080.
-u, --url- Host URL Address for server. Default is "localhost".
-q, --no-browser- Create server without opening a browser tab.
-x, --no-model-execution- Disable execution of models from the UI.
Example usage:
tt-explorer -p 8000 -u 0.0.0.0 -q
This command will start the tt-explorer server on port 8000, accessible at the address 0.0.0.0, and without opening a browser tab.
tt-explorer - API
This page documents the TT-Adapter API, the programmatic interface provided by TT-Explorer, Tenstorrent’s fork of Google’s Model Explorer. While Model Explorer focuses on visualizing and interacting with machine learning models through its UI, TT-Explorer extends it with the ability to send commands, convert models, execute them, and query execution status programmatically, leveraging the same underlying graph structures and model representations that Model Explorer uses.
The TT-Adapter API enables automation of workflows, integration of model execution into scripts, and interaction with models on the server without relying on the UI. This reference explains request and response formats, supported commands, and how editable attributes are represented, providing all the details needed to work with TT-Explorer programmatically.
It is especially useful when managing multiple models, performing batch conversions, or integrating TT-Explorer functionality into automated pipelines — tasks that would be cumbersome or impractical through the UI alone.
TT-Adapter
This section provides a reference for the TT-Adapter REST API, as well as an explanation of how TT-Explorer creates an extensible API on top of Google's Model Explorer.
Building an API using Model Explorer
Google's Model Explorer defines the endpoint /apipost/v1/send_command as a generic command-receiving mechanism. This endpoint lets the server accept requests to perform operations on a model. Specifically, it:
- Accepts JSON commands describing an action (for example, convert a model or run an analysis).
- Parses commands to ensure they follow the correct format.
- Forwards the command to the installed adapter—here, TT-Adapter.
- Wraps the output in a standard JSON response that the UI (TT-Explorer’s interface) can interpret.
This endpoint provides the main communication channel between the client and server. Commands sent here are executed by the specified adapter and return a structured “adapter response,” allowing developers to interact programmatically with models through TT-Explorer.
Flow Overview
This section provides a general overview of how commands flow between the client and server.
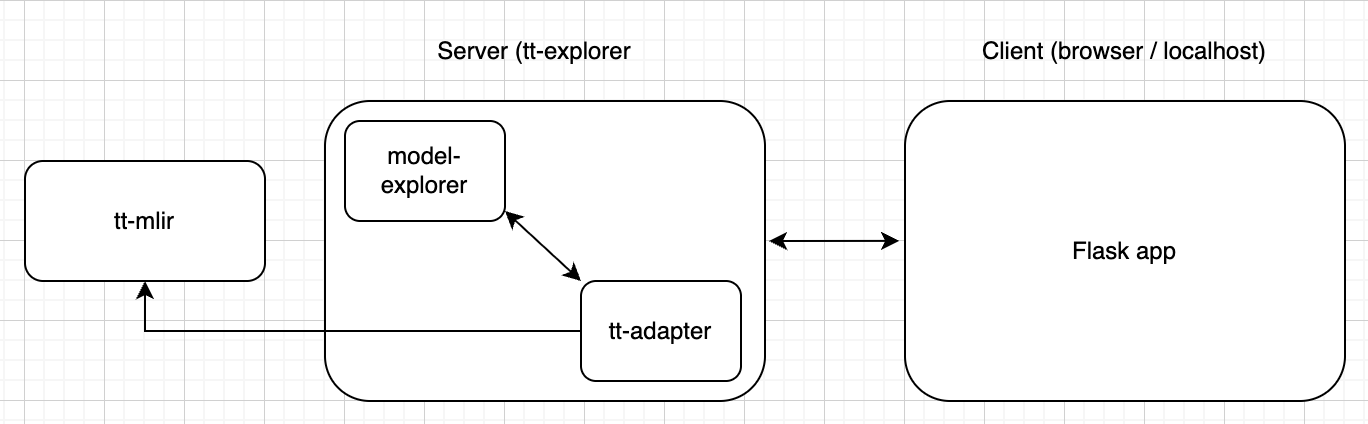
Flow for File Upload From Computer
-
Server starts the Flask app.
-
(This step occurs when uploading a file from your computer rather than using a link.) Client sends the uploaded file to the server.
-
Server sends confirmation the file uploaded.
-
Server (Backend) forwards commands to the TT-Adapter for execution.
-
TT-Adapter executes the model / graph operations locally (may reuse upstream code).
-
Adapter produces a raw response → Server processes it via
convert_adapter_response. -
Server returns JSON-wrapped results to the UI, which renders graphs, overlays, and status.
Flow for Link Upload
-
Server starts the Flask app.
-
Client sends the link to the file with a convert request (HTTP POST request).
-
Server sends an HTTP response to the UI, which renders graphs, overlays, and status.
-
Server (Backend) forwards commands to the TT-Adapter for execution.
-
TT-Adapter executes the model / graph operations locally (may reuse upstream code).
-
Adapter produces a raw response → Server processes it via
convert_adapter_response. -
Server returns JSON-wrapped results to the UI, which renders graphs, overlays, and status.
Sending Commands
Commands sent to the /apipost/v1/send_command endpoint must be formatted as JSON and follow a standard structure. The base structure is described using a Typescript interface for clarity, though in practice it is just a JSON object. Specific commands may add extra fields or restrict some values, but all fields in the base interface must still be present for the server to process the command correctly.
interface ExtensionCommand {
cmdId: string;
extensionId: string;
modelPath: string;
settings: Record<string, any>;
deleteAfterConversion: boolean;
}
On the server side, all functions that handle commands must follow this required parameter signature:
class TTAdapter(Adapter):
# ...
def my_adapter_fn(self, model_path: str, settings: dict):
# Parse model_path and settings objects as they are fed from send_command endpoint.
pass
Information does not persist between requests—each request gets a new instance of TT-Adapter. As all requests to the server are stateless, each command-handling function receives input only through its parameters (model_path and settings). Any data needed for execution must be passed in the request, and the client is responsible for keeping track of important information such as the path of an uploaded model or the locations of artifacts produced by the server.
This design ensures that each request is isolated and predictable, while the settings dictionary provides a flexible way to supply additional context for execution. For example, ModelRunner:initialize ignores its parameters entirely and performs a static initialization regardless of the values passed.
Example Request
Below is an example of the JSON request sent from the UI to the server:
{
// tt_adapter to invoke functions from TT-Adapter
"extensionId": "tt_adapter",
// Name of function to be run, "convert" is built into all adapters to convert some model to graph
"cmdId": "convert",
// Path to model on server to be fed into function
"modelPath": "/tmp/tmp80eg73we/mnist_sharding.mlir",
// Object holding custom settings to be fed into function
"settings": {
"const_element_count_limit": 16,
"edge_label_font_size": 7.5,
"artificial_layer_node_count_threshold": 1000,
"keep_layers_with_a_single_child": false,
"show_welcome_card": false,
"disallow_vertical_edge_labels": false,
"show_op_node_out_of_layer_edges_without_selecting": false,
"highlight_layer_node_inputs_outputs": false,
"hide_empty_node_data_entries": false
},
// `true` if file at `modelPath` is to be deleted after function run
"deleteAfterConversion": true
}
Adapter Response Processing
TT-Explorer extends Model Explorer with an adapter framework, but the original Model Explorer was not designed for this level of extensibility. As a result, adapter responses must be processed in a specific way before being returned to the client.
The function model_explorer.utils.convert_adapter_response is applied to the output of every adapter function. This ensures compatibility with the upstream (Google Model Explorer) implementation and enforces a consistent response format.
For compatibility, all responses sent from the server (the backend component of TT-Explorer that executes adapter commands) must:
- Be in JSON format
- Wrap the payload within a
graphsproperty
The TypeScript interface expected by the UI is as follows:
/** A response received from the extension. */
interface ExtensionResponse<
G extends Array<unknown> = Graph[],
E extends unknown = string
> {
graphs: G;
error?: E;
}
Custom adapter responses must conform to this structure. This restriction prevents the direct transfer of raw bytes through unsupported MIME types and requires the use of tt_adapter.utils.to_adapter_format, which converts any Python dict into a Model Explorer–compatible adapter response. While this framework works well for graphs, it makes building a fully extensible API more challenging. All responses must fit within the graphs JSON wrapper and adhere to a fixed structure.
Current API Reference
This section shows all the different API functions that are available:
convert
Standard built-in conversion function, converts TTIR Module into Model Explorer Graph. Also provides settings as a platform for overrides to be applied to the graph.
Request
// As this is the base request everything is based off,
// this interface only narrows down the command to be "convert".
interface AdapterConvertCommand extends ExtensionCommand {
cmdId: 'convert';
}
Response
// As this is the base response everything is based off,
// it is exactly the same as `ExtensionResponse`.
type AdapterConvertResponse = ExtensionResponse;
{
"graphs": [{
// Model Explorer Graph JSON Object
}]
}
initialize
Called from TTAdapter.__init__, used to Load SystemDesc into environment.
Request
interface InitializeCommand extends ExtensionCommand {
cmdId: 'initialize';
}
Response
type AdapterInitializeResponse = ExtensionResponse<[{
system_desc_path: string
}]>;
{
"graphs": [{
"system_desc_path": "<path to system_desc.ttsys>"
}]
}
execute
Called from TTAdapter.execute, executes a model.
Request
interface AdapterExecuteCommand extends ExtensionCommand {
cmdId: 'execute';
}
Response
// When the request is successful, we don't expect any response back.
// Thus, an empty array is returned for `graphs`.
type AdapterExecuteResponse = ExtensionResponse<[]>;
{
"graphs": []
}
status-check
Called from TTExplorer.status_check, it is used for checking the execution status of a model and update the UI accordingly.
Request
interface AdapterStatusCheckCommand extends ExtensionCommand {
cmdId: 'status_check';
}
Response
type AdapterStatusCheckResponse = ExtensionResponse<[{
isDone: boolean,
progress: number,
total?: number,
timeElapsed?: number,
currentStatus?: string,
error?: string,
stdout?: string,
log_file?: string
}]>;
{
"graphs": [{
"isDone": false,
"progress": 20,
"total": 100,
"timeElapsed": 234,
"stdout": "Executing model...\nPath: /path/to/model",
"log_file": "/path/to/log/on/the/server"
}]
}
Editable Attributes
To enable an attribute to be edited, a response coming from the server should contain the editable field on the attribute.
The typescript interface is as follows:
interface Graph {
nodes: GraphNode[];
// ...
}
interface GraphNode {
attrs?: Attribute[];
// ...
}
type EditableAttributeTypes = EditableIntAttribute | EditableValueListAttribute | EditableGridAttribute; // Attribute types are defined below...
interface Attribute {
key: string;
value: string;
editable?: EditableAttributeTypes; // <- the editable attribute information
// ...
}
EditableIntAttribute
This editable attribute represents a list of integer values. It expects the attribute value to be formatted as a string, starting with [ and ending with ], with all values separated by ,. Like the example below:
[1, 2, 3]
The typescript interface for the editable attribute is this:
interface EditableIntAttribute {
input_type: 'int_list';
min_value?: number = 0;
max_value?: number = 100;
step?: number = 1;
}
Both min_value and max_value define the accepted range of values, and step define the number to increment or decrement per step.
The default range of values is between 0 and 100, inclusive, and the default step is 1. Thus by default, the value will increment or decrement by 1 each time to a minimum of 0 and a maximum of 100.
Here is an example of what this attribute look like:
{
"graphs": [{
"nodes": [
{
"attrs": [
{
"key": "shape",
"value": "[8, 8]",
"editable": {
"input_type": "int_list",
"min_value": 8,
"max_value": 64,
"step": 8
}
}
]
}
]
}]
}
EditableValueListAttribute
This editable attribute define a fixed list of string values to display.
The typescript interface for the editable attribute is this:
interface EditableValueListAttribute {
input_type: 'value_list';
options: string[];
}
The options property provides the list of options to be displayed. The current value will be added to this list and any duplicates will be removed.
Here is an example of what this attribute look like:
{
"graphs": [{
"nodes": [
{
"attrs": [
{
"key": "chip_arch",
"value": "wormhole",
"editable": {
"input_type": "value_list",
"options": [
"wormhole",
"blackhole"
]
}
}
]
}
]
}]
}
EditableGridAttribute
The grid attribute is similar to to the integer list, with the main difference that you can specify a separator for the place the list will be split, and it doesn't need to be enclosed in bracket ([ and ]). The data for a grid attribute looks like this:
4x4x2
The typescript interface for the editable attribute is this:
interface EditableGridAttribute {
input_type: 'grid';
separator?: string = 'x';
min_value?: number = 0;
max_value?: number = 100;
step?: number = 1;
}
Both min_value and max_value define the accepted range of values, and step define the number to increment or decrement per step.
The default range of values is between 0 and 100, inclusive, and the default step is 1. Thus by default, the value will increment or decrement by 1 each time to a minimum of 0 and a maximum of 100.
The separator attribute defines the character used to split the string, it defaults to "x".
Here is an example of what this attribute look like:
{
"graphs": [{
"nodes": [
{
"attrs": [
{
"key": "grid",
"value": "4x4",
"editable": {
"input_type": "grid",
"min_value": 4,
"max_value": 64,
"step": 4,
"separator": "x"
}
}
]
}
]
}]
}
Attribute display type
To change how the attribute is displayed from plain text to something else, we do extend the attribute interface (presented above) with the display_type optional field.
type AttributeDisplayType = 'memory';
interface Attribute {
key: string;
value: string;
display_type?: AttributeDisplayType; // <- Optional, add a different display type.
// ...
}
If the display_type attribute is present, and it matches one of the available values, then the attribute will display differently than the others.
In the example below, the two attributes have different display types, one shows the regular, plain text display; and the other shows the memory display type, which renders it as a progress bar.

memory
Setting the display type to memory will make the attribute try to render as a progress bar.
The UI will then check the value property in the attribute for the following conditions:
- Is a double precision floating point number
- Is not
NaN - Is greater than or equal to
0 - Is less than or equal to
1
If all of the conditions are true, then the value will be rendered as a progress bar.
tt-explorer - Project Architecture
TT-Explorer is a tool for exploring, visualizing, and executing machine learning models on Tenstorrent hardware. It provides a Human-In-Loop interface that allows developers to:
- Inspect compiler results
- Apply configuration overrides
- Observe the effect of changes on model execution
Through TT-Explorer's interactive visualizations, users can examine model operations, performance traces, and execution results, providing insight into model behavior and supporting optimization efforts.
Software Architecture
TT-Explorer is structured around the TT-Forge compiler stack, which provides the compilation and transformation capabilities used to generate and visualize models for Tenstorrent hardware. The TT-RT runtime handles the backend execution of compiled models on hardware.
For visualization and interaction, TT-Explorer extends Google's Model Explorer, which serves as the primary UI and graph-rendering framework. Because Model Explorer is implemented in Python, TT-Explorer primarily makes use of Python bindings provided by TT-MLIR for direct access to compiler internals.
The overall system integrates these components:
Diagram transcript
Horizontal group labeled "Host side" at the top, with nodes from left to right connected to each other by arrows, and at the end connected to the next group. The nodes are:
- "AI Model", with an arrow labeled "Model binary file" to the next node.
- "TVM", with an arrow labeled "PyBUDA Graph" to the next node.
- "TT-Forge-ONNX", with an unlabeled arrow to the next node.
- "TT-MLIR", with an arrow labeled "MLIR file (.ttir, etc...)" to the "TT-Adapter" node on the next group.
Vertical group at the right side, unlabeled, with nodes from top down connected to each other by arrows, and with some arrows going to the next group. The group intersects with the "Host side" group at the "TT-MLIR" node. The nodes are:
- "TT-Adapter", with an arrow labeled "Flatbuffer w/ Model Binary" to the next node, an arrow labeled "Overrides JSON (to apply)" to the previous node, and an arrow labeled "HTTPS API (Overrides, MLIR -> JSON, etc...)" to and from the "Model Explorer" node on the next group.
- "TTRT", with an arrow labeled "HTTPS Server Call" to the next node.
- "Tracy Results", with an arrow labeled "Performance Trace" to the "UI" node on the next group.
Rectangular group labeled "Client Side", below "Host side" and left of unlabeled group, with interconnected nodes by arrows, and with some arrows going to the previous group. The nodes are:
- "Model Explorer", with an arrow labeled "HTTPS API (Overrides, MLIR -> JSON, etc...)" to and from the "TT-Adapter" node on the previous group, and an arrow labeled "Overrides (legal configurations)" to and from the next node.
- "UI", with an arrow labeled "Performance Trace" coming from the "Tracy Results" node on the previous group, an arrow labeled "Overrides (legal configurations)" to and from the previous node, and an unlabeled arrow going to the next node.
- "Notebook", with an arrow labeled "Scripted Overrides" going to the "Model Explorer" node on this group.
TT-Forge-ONNX (Front End)
TT-Forge ONNX is frontend which uses TVM to transform conventional AI models into the MLIR in the TTIR Dialect for ONNX and paddlepaddle models.
Ingests: AI Model defined in PyTorch, TF, etc… Emits: Rudimentary TTIR Module consisting of Ops from AI Model.
TT-MLIR
TT-MLIR currently defines the out-of-tree MLIR compiler created by Tenstorrent to specifically target TT Hardware as a backend. It comprises a platform of several dialects (TTIR, TTNN, TTMetal) and the passes and transformations to compile a model into an executable that can run on TT hardware. In the scope of tt-explorer the python bindings will be leveraged.
Ingests: TTIR Module, Overrides JSON Emits: Python Bindings to interface with TTIR Module, Overridden TTIR Modules, Flatbuffers
TT-Adapter
TT-Adapter is the adapter created for tt-explorer that parses TTIR Modules using the Python Bindings provided by TT-MLIR to create a graph legible by model-explorer. It also has an extensible REST endpoint that is leveraged to implement functionality, this endpoint acts as the main bridge between the Client and Host side processes.
It is the piece that connects Model Explorer, through a custom adapters that can visualize TTIR, to the rest of the architecture.
Ingests: TTIR Modules, TT-MLIR Python Bindings, REST API Calls Emits: Model-Explorer Graph, REST API Results
ttrt
TT-RT is the runtime library for TT-Forge, which provides an API to run Flatbuffers generated from TT-MLIR. These flatbuffers contain the compiled results of the TTIR module, and TTRT allows us to query and execute them. Particularly, a performance trace can be generated using Tracy, which is fed into model-explorer to visualize the performance of operations in the graph.
Ingests: Flatbuffers Emits: Performance Trace, Model Results
Model-Explorer
Model Explorer is the backbone of the client and visualization of these models. It is placed in the “Client” portion of the diagram as this is where most interactions with Model Explorer will happen. Due to the "client and server" architecture, tt-explorer will be run on the host, and so will the model-explorer instance.
The frontend will be a client of the REST API created by TT-Adapter and will use URLs from the model-explorer server to visualize the models.
Currently TT maintains a fork of model-explorer which has changes to the UI elements for overrides, graph execution, and displaying performance traces.
Ingests: Model Explorer Graph, User-Provided Overrides (UI), Performance Trace Emits: Overrides JSON, Model Visualization
These components all work together to provide the tt-explorer platform.
Client-Server Design Paradigm
Since performance traces and execution rely on Silicon machines, there is a push to decouple the execution and MLIR-environment heavy aspects of tt-explorer onto some host device with TT hardware on it. Then have a lightweight REST server, provided by TT-Adapter, to leverage the host device without having to constantly be on said host.
And finally connect to a client through a web interface, thus removing the need to run the client and server in the same machine.
This is very useful for cloud development (as is common Tenstorrent). In doing so, tt-explorer is a project that can be spun up in either a tt-mlir environment, or without one. The lightweight python version of tt-explorer provides a set of utilities that call upon and visualize models from the host, the host will start the server and serve the API to be consumed. The client can then be any browser that connects to that server.
tt-alchemist
tt-alchemist is a code generation tool that converts MLIR models to executable C++ or Python solutions for Tenstorrent AI accelerators.
Table of Contents
Support Matrix
Note: The tool is currently in development and is subject to frequent changes. Please refer to this document for most up-to-date information. Support matrix is provided below.
The following table summarizes the current support for code generation modes in tt-alchemist:
| C++ | Python | |
|---|---|---|
| standalone | ✅ Supported | ❌ Not yet supported |
| local | 🟨 Experimental support | 🟨 Experimental support |
Modes:
- standalone: Generates a self-contained solution with all necessary dependencies copied into the output directory. Useful for deployment and sharing.
- local: Generates code that uses libraries from the source tree, minimizing duplication and disk usage. Useful for development and debugging.
Note: Python codegen currently supports a small subset of operations compared to C++. Full support is being actively worked on and is coming soon.
Usage
The tool is compiled into a C++ library, with a thin CLI wrapper written in Python. This means that it can be distributed both as a C++ library, and as a CLI tool via Python wheel mechanism.
Using via CLI
To use via CLI, it is suggested to build the tool from source. Alternatively, look for tt-alchemist artifacts within CI runs.
# Assuming the user had already built the tt-mlir compiler and turned on the python virtual env
# Build the tt-alchemist lib, package into Python wheel, and install to active env
cmake --build build -- tt-alchemist
For all available CLI options and usage instructions, run:
tt-alchemist --help
All APIs today accept a .mlir file that describe a model in TTIR dialect.
Example usage:
# Generate a whole standalone C++ solution and run
tt-alchemist generate-cpp tools/tt-alchemist/test/models/mnist.mlir -o mnist_cpp --standalone
cd mnist_cpp
./run
# Similar to above, but use "local" libs from source dir - this saves on memory by not copying the whole dev package to the output dir
tt-alchemist generate-cpp tools/tt-alchemist/test/models/mnist.mlir -o mnist_cpp --local
cd mnist_cpp
./run
# Similarly for python
tt-alchemist generate-python tools/tt-alchemist/test/models/mnist.mlir -o mnist_python --local
cd mnist_python
./run
# Following APIs are intended to be used for debugging purposes
# Convert a mlir file to C++ code and print to console
tt-alchemist model-to-cpp tools/tt-alchemist/test/models/mnist.mlir
# Same, but for python (current support limited to few ops)
tt-alchemist model-to-python tools/tt-alchemist/test/models/mnist.mlir
Usage via lib
To use within another project (e.g. a frontend like tt-xla), build the library from source:
# Assuming the user had already built the tt-mlir compiler and turned on the python virtual env
# Build the tt-alchemist lib
cmake --build build -- tt-alchemist-lib
Then, you may call any of the APIs listed here.
ttnn-standalone
ttnn-standalone is a post-compile tuning/debugging tool.
Forge and third party ML models (PyTorch, Jax, ONNX, ...) can be compiled to a set of TTNN library op calls in C++. This generated code can then be used outside of the compiler environment. ttnn-standalone tool offers all the scaffolding needed to run the C++ code on device (build & run scripts).
Usage
# 1. Convert a model from TTIR dialect to EmitC dialect using ttmlir-opt
# 2. Translate the resulting EmitC dialect to C++ code using ttmlir-translate
# 3. Pipe the generated C++ code to a .cpp file
ttmlir-opt \
--ttir-to-emitc-pipeline \
test/ttmlir/EmitC/TTNN/sanity_add.mlir | \
ttmlir-translate \
--mlir-to-cpp > \
tools/ttnn-standalone/ttnn-standalone.cpp
# 1. Change dir to `tools/ttnn-standalone`
# 2. Use `run` script to compile and run the compiled binary
cd tools/ttnn-standalone
./run
Note: if you receive this error
-bash: ./run: Permission denied
running chmod +x run will set the execute permission on the script.
EmitPy
EmitPy is part of the tt-mlir compiler project. Its primary function is to translate MLIR IR from various dialects into human-readable, executable Python source code.
By representing Python language constructs within a dedicated EmitPy dialect, the project provides a structured pathway for lowering high-level computational graphs (e.g., from machine learning frameworks) into a familiar and flexible Python language, enabling rapid prototyping, debugging, and integration with Tenstorrent's TTNN open source library.
Current implementation enables support for MNIST and ResNet models.
Prerequisites
-
Activated virtual environment:
source env/activate
Usage
ttmlir-opt
# 1. Convert a model from TTIR dialect to EmitPy dialect using ttmlir-opt
# 2. Translate the resulting EmitPy dialect to Python code using ttmlir-translate
# 3. Pipe the generated Python code to a .py file
ttmlir-opt --ttir-to-emitpy-pipeline test/ttmlir/Dialect/EmitPy/ttir_to_emitpy_pipeline_sanity.mlir | \
ttmlir-translate --mlir-to-python > example.py
builder
Builder offers support for building EmitPy modules. ttrt offers support for running EmitPy modules.
Optimizer
Optimizer is the main component responsible for performance. It is a collection of passes with the two most important purposes being optimizing tensor memory layouts and selecting optimal operation configurations.
Prerequisites
To use the optimizer:
- A physical Tenstorrent device must be present on the machine
- Build of
tt-mlirmust be with OpModel support enabled:
cmake -G Ninja -B build -DTTMLIR_ENABLE_OPMODEL=ON
Basic Usage
Optimizer is disabled by default. To enable it, use the enable-optimizer option:
ttmlir-opt --ttir-to-ttnn-runtime-pipeline="enable-optimizer=true" input.mlir
Optimizer Options
The optimizer provides additional configuration options:
-
optimization-level(default:0)- 0: Optimizer disabled, 1: Optimizer enabled without sharding, 2: Full optimization with sharding
- Automatically sets
enable-optimizerandmemory-layout-analysis-enabledbased on level
-
enable-optimizer(default:false)- Enables the optimizer pass
- Must be set to
trueto use any other optimizer options
-
memory-layout-analysis-enabled(default:true)- Enables memory layout optimization
- Shards tensors to maximize usage of fast L1 memory instead of DRAM
-
max-legal-layouts(default:8)- Maximum number of different layouts to generate for each operation during analysis
- Higher values may provide better results but increase compile time
Example
# Enable optimizer with default settings
ttmlir-opt --ttir-to-ttnn-runtime-pipeline="enable-optimizer=true memory-layout-analysis-enabled=true max-legal-layouts=8" input.mlir
Design Documentation
For detailed information about the optimizer's architecture, algorithms, and implementation, see the TTNN Optimizer Design Specification.
PyKernel Guide
PyKernel is a Python interface for developing custom TTNN operations for Tenstorrent's AI accelerators. This guide explains how to use the PyKernel interface to implement your own TTNN operations.
Introduction to PyKernel
PyKernel provides a Python-based framework to define hardware-specific kernels that can be used with the TTNN framework. It allows developers to implement custom operations by defining compute kernels, reader/writer kernels, and control logic in a high-level Python interface.
The PyKernel framework consists of:
- PyKernelOp: Base class that manages kernel selection, compilation, and execution
- AST module: Decorators and utilities for defining kernels
- Types module: Type definitions for PyKernel operations
PyKernel Architecture
Foundationally, PyKernel is a compiler built on top of 3 core components, described below.
Python ast Frontend
The frontend of PyKernel is made to parse Python code and is enabled through using the ast (Abstract Syntax Tree) parser builtin to Python. By walking through the AST produced by this module, a MLIR module is created with the ttkernel dialect (among others such as arith, memref, scf). This MLIR module is then piped into the next step of the PyKernel compiler. For more information about the type of kernel code that can be parsed by the Frontend, refer to the ttkernel Op spec.
Direct To Metal (D2M) Kernel Code Generation
Another component of the tt-mlir project that PyKernel is built on is the D2M compiler infrastructure. This infrastructure enables dynamic generation of kernels to performantly execute ML models and is leveraged by providing the custom MLIR module created by the PyKernel frontend. The compilation flow runs a series of transformations on the MLIR module and lowers to the emitc dialect to translate the module into C++ code. This C++ code is the artifact that is consumed by the runtime to execute on Tenstorrent Hardware.
TTNN Generic Op
TTNN consists of Python bindings to precompiled kernels and operator factories that maintain API parity with PyTorch. The Generic Op extends this by operating directly on TTNN tensors and primitives but does not define its own factory or kernels. Instead, these must be supplied to the Generic Op to enable execution. PyKernel leverages this flexibility by injecting dynamically compiled C++ kernels into the Generic Op, allowing them to interface with TTNN data as if they were native “custom” ops. This mechanism serves as the integration layer that connects the compiler to TTNN.
Prerequisites
Before using PyKernel, ensure your environment is set up with:
- TT-MLIR built and installed
- Python 3.12 or newer
- Required Python packages
- TTMLIR_ENABLE_RUNTIME and TTMLIR_ENABLE_PYKERNEL flags set during build
Creating a Custom PyKernel Operation
To create a custom PyKernel operation, you need to:
- Create a class that inherits from
PyKernelOp - Implement the
define_core_rangesmethod to specify the grid of cores for the operation - Define kernels using the
@compute_thread(),@reader_thread(), or@writer_thread()decorators - Implement the
invokemethod to create and connect kernels - Define necessary circular buffers
- Create a program descriptor that combines kernels and circular buffers
Basic Structure
from pykernel.kernel_ast import *
from pykernel.op import PyKernelOp
from pykernel.kernel_types import *
import ttnn
import torch
class MyCustomOp(PyKernelOp):
# Define Core Grid
def define_core_ranges(self, tensors, options):
# Your logic to determine the core ranges
core_1 = ttnn.CoreCoord(0, 0)
core_2 = ttnn.CoreCoord(1, 1)
return ttnn.CoreRangeSet([ttnn.CoreRange(core_1, core_2)])
# Define compute kernel with appropriate decorator
@compute_thread()
def my_compute_kernel(cb_in: CircularBuffer, cb_out: CircularBuffer,
per_core_block_cnt: CompileTimeValue,
per_core_block_dim: CompileTimeValue):
# Kernel processing code here
return
# Define reader kernel
@reader_thread()
def reader_kernel(cb_in: CircularBuffer, cb_out: CircularBuffer,
src_addr, num_tiles, start_id):
# Reader kernel code here
return
# Define writer kernel
@writer_thread()
def writer_kernel(cb_in: CircularBuffer, cb_out: CircularBuffer,
dst_addr, num_tiles, start_id):
# Writer kernel code here
return
# The invoke method is the main entry point for kernel execution
def invoke(self, in_tensor, out_tensor, **options):
# Create circular buffers for input and output tensors
cb_in = self.create_cb(in_tensor, 0)
cb_out = self.create_cb(out_tensor, 1)
# Prepare parameters for kernels
start_id = 0
num_tiles = options["num_tiles"]
# Create kernels with appropriate parameters
kernels = [
self.create_kernel(
MyCustomOp.my_compute_kernel,
cb_in, cb_out,
per_core_block_cnt=num_tiles,
per_core_block_dim=1
),
self.create_kernel(
MyCustomOp.writer_kernel,
cb_in, cb_out,
out_tensor.buffer_address(),
num_tiles, start_id,
tensor_accessor_configs=[out_tensor],
),
self.create_kernel(
MyCustomOp.reader_kernel,
cb_in, cb_out,
in_tensor.buffer_address(),
num_tiles, start_id,
tensor_accessor_configs=[in_tensor],
)
]
# Create and return the program descriptor
return self.create_program(kernels, [cb_in, cb_out])
Kernel Types
PyKernel supports different types of kernels:
- Compute Kernels: Process data on the compute units (e.g., SFPU - Scalar Floating-Point Unit)
- Reader Kernels: Transfer data from memory to circular buffers
- Writer Kernels: Transfer data from circular buffers to memory
Each kernel type has a specific decorator:
@compute_thread()- For compute kernels that run on Tensix cores@reader_thread()- For reader kernels that transfer data from memory to circular buffers@writer_thread()- For writer kernels that transfer data from circular buffers to memory
These decorators handle the compilation of Python code into hardware-specific kernels. You can also use the older style decorators if needed:
@ttkernel_tensix_compile()- Equivalent to@compute_thread()@ttkernel_noc_compile()- For both reader and writer kernels
Runtime Arguments
In PyKernel, you can pass runtime arguments to your kernels to control their behavior on a per-core basis. There are two types of runtime arguments:
-
Single-Core Arguments (Common Runtime Arguments): These are scalar values (integers) that are broadcast to all cores in the grid. They are passed as
common_runtime_argsto thecreate_kernelmethod. -
Multi-Core Arguments (Runtime Arguments): These are lists of lists of integers, where each inner list corresponds to a core in the grid. This allows you to provide different values for each core. They are passed as
runtime_argsto thecreate_kernelmethod.
Single-Core Arguments
Single-core arguments are useful when all cores need the same value for a particular parameter. For example, num_tiles_per_core in the VecAdd example is a single-core argument because each core processes the same number of tiles.
Multi-Core Arguments
Multi-core arguments are necessary when each core requires a unique value. A common use case is distributing work across cores, where each core needs a different start_id to process its portion of the data. In the VecAdd example, start_id_multicore is a multi-core argument.
Default Core Range Behavior
If you do not override the define_core_ranges method in your PyKernelOp class, it will default to a single core at (0, 0). This is suitable for single-core operations like the EltwiseSFPU demo, where the entire operation runs on a single core.
Circular Buffers
Circular buffers are used to transfer data between kernels and memory. In the PyKernel framework, there are two aspects of circular buffers:
- CircularBuffer class: Used in kernel definitions to represent a circular buffer
- CB Descriptors: Used at runtime to configure the actual hardware circular buffers
CircularBuffer Class
The CircularBuffer class is defined in pykernel.types and is used in kernel definitions:
class CircularBuffer:
def __init__(self, cb_id, tensor_shape=(8, 128, 128), dtype="Float32"):
self.cb_id = cb_id
self.tensor_shape = tensor_shape
self.tile_shape = 32 # default to 32x32 tile shape
self.tilized_shape = self.get_tilized_memref_shape()
self.dtype = dtype
Creating Circular Buffers in the Invoke Method
In your custom operation's invoke method, you can create circular buffers using the create_cb helper method from the PyKernelOp base class:
def invoke(self, in_tensor, out_tensor, **options):
cb_in = self.create_cb(in_tensor, 0) # buffer_index=0
cb_out = self.create_cb(out_tensor, 1) # buffer_index=1
# Use cb_in and cb_out in kernel creation
# ...
return self.create_program(kernels, [cb_in, cb_out])
The create_cb method handles the creation of the necessary format descriptors and buffer descriptors based on the tensor properties:
Kernel Decorator Options
The kernel decorators (@compute_thread, @reader_thread, and @writer_thread) accept two optional boolean arguments:
verbose: When set toTrue, the PyKernel compiler will print the generated MLIR and the Python AST (Abstract Syntax Tree) during compilation. This is useful for debugging.optimize: When set toTrue, the PyKernel compiler will run an optimization pipeline on the generated MLIR before converting it to C++. This can improve the performance of your kernel.
Example: Vector Add Operation
The VecAdd operation adds two tensors element-wise. Let's examine a complete implementation based on the demo in test/pykernel/demo/vecadd_multicore_demo.py:
1. Define the Operation Class
from pykernel.kernel_ast import *
from pykernel.op import PyKernelOp
from pykernel.kernel_types import *
import ttnn
import torch
class VecAddMulticorePyKernelOp(PyKernelOp):
# Kernel implementations will go here
2. Define Core Ranges
The define_core_ranges method specifies the grid of cores that the operation will run on.
def define_core_ranges(self, tensors, options):
core_0 = ttnn.CoreCoord(0, 0)
if self.max_core_ranges is None:
core_1 = ttnn.CoreCoord(1, 1)
else:
core_1 = self.max_core_ranges
return ttnn.CoreRangeSet([ttnn.CoreRange(core_0, core_1)])
3. Define the Compute Kernel
@compute_thread()
def add_multicore(
cb_in0: CircularBuffer,
cb_in1: CircularBuffer,
cb_out: CircularBuffer,
num_tiles,
start_tile_id,
):
binary_op_init_common(cb_in0, cb_in1, cb_out)
add_tiles_init(cb_in0, cb_in1)
end_tile_id = start_tile_id + num_tiles
dst_reg = 0
for i in range(start_tile_id, end_tile_id, 1):
cb_wait_front(cb_in0, 1)
cb_wait_front(cb_in1, 1)
tile_regs_acquire()
add_tiles(cb_in0, cb_in1, 0, 0, dst_reg)
tile_regs_commit()
cb_reserve_back(cb_out, 1)
tile_regs_wait()
pack_tile(dst_reg, cb_out, 0)
tile_regs_release()
cb_push_back(cb_out, 1)
cb_pop_front(cb_in0, 1)
cb_pop_front(cb_in1, 1)
tile_regs_release()
return
4. Define Writer Kernel
@writer_thread()
def writer_multicore(
cb_out: CircularBuffer,
dst_addr,
num_tiles,
start_id,
):
onetile = 1
tile_bytes = get_tile_size(cb_out)
tensor_accessor_args = TensorAccessorArgs(cta_base=1, crta_base=0)
s0 = TensorAccessor(tensor_accessor_args, dst_addr, tile_bytes)
end_id = start_id + num_tiles
for i in range(start_id, end_id, onetile):
cb_wait_front(cb_out, onetile)
l1_read_addr = get_read_ptr(cb_out)
noc_async_write_tile(i, s0, l1_read_addr)
noc_async_write_barrier()
cb_pop_front(cb_out, onetile)
return
5. Define Reader Kernel
@reader_thread()
def reader_binary_interleaved(
cb_in0: CircularBuffer,
cb_in1: CircularBuffer,
src_addr0,
src_addr1,
num_tiles,
start_id,
):
onetile = 1
tile_bytes0 = get_tile_size(cb_in0)
tensor_accessor_args = TensorAccessorArgs(cta_base=2, crta_base=0)
s0 = TensorAccessor(tensor_accessor_args, src_addr0, tile_bytes0)
tile_bytes1 = get_tile_size(cb_in1)
tensor_accessor_args = TensorAccessorArgs(cta_base=3, crta_base=0)
s1 = TensorAccessor(tensor_accessor_args, src_addr1, tile_bytes1)
end_id = start_id + num_tiles
for i in range(start_id, end_id, onetile):
cb_reserve_back(cb_in0, onetile)
cb_reserve_back(cb_in1, onetile)
src0_write_addr = get_write_ptr(cb_in0)
src1_write_addr = get_write_ptr(cb_in1)
noc_async_read_tile(i, s0, src0_write_addr)
noc_async_read_tile(i, s1, src1_write_addr)
noc_async_read_barrier()
cb_push_back(cb_in0, onetile)
cb_push_back(cb_in1, onetile)
return
6. Implement the Invoke Method
The invoke method is the critical part that connects the kernels together and creates the program descriptor:
def invoke(self, a_tensor, b_tensor, out_tensor):
# Create circular buffers
cb_in0 = self.create_cb(a_tensor, 0)
cb_in1 = self.create_cb(b_tensor, 1)
cb_out = self.create_cb(out_tensor, 2)
num_tiles = ceil(max(map(lambda t: t.volume(), [a_tensor, b_tensor, out_tensor])) / 1024)
num_cores = self.get_core_ranges().num_cores()
num_tiles_per_core = int(num_tiles / num_cores)
# Define the multicore runtime arguments
start_id = 0
start_id_multicore = []
bb = self.get_core_ranges().bounding_box()
for i in range(bb.start.x, bb.end.x + 1):
start_id_multicore.append([])
for j in range(bb.start.y, bb.end.y + 1):
start_id_multicore[-1].append([start_id])
start_id += 1
# Create kernels with appropriate parameters
kernels = [
self.create_kernel(
VecAddMulticorePyKernelOp.add_multicore,
cb_in0,
cb_in1,
cb_out,
num_tiles_per_core,
start_id_multicore,
),
self.create_kernel(
VecAddMulticorePyKernelOp.writer_multicore,
cb_out,
out_tensor.buffer_address(),
num_tiles_per_core,
start_id_multicore,
tensor_accessor_configs=[out_tensor],
),
self.create_kernel(
VecAddMulticorePyKernelOp.reader_binary_interleaved,
cb_in0,
cb_in1,
a_tensor.buffer_address(),
b_tensor.buffer_address(),
num_tiles_per_core,
start_id_multicore,
tensor_accessor_configs=[a_tensor, b_tensor],
),
]
# Create and return the program descriptor
return self.create_program(kernels, [cb_in0, cb_in1, cb_out])
Running the VecAdd Demo
The VecAdd demo demonstrates adding two tensors element-wise. This can be run using the pykernel-demo target:
source env/activate
# Ensure the TTMLIR_ENABLE_RUNTIME and TTMLIR_ENABLE_PYKERNEL flags are set during build
cmake --build build -- pykernel-demo
Demo Breakdown
Let's examine how to use the PyKernel operation in practice:
# Open a device
device = ttnn.open_device(device_id=0)
# Define tensor shapes and data
num_tiles = 4
shape = [1, num_tiles, 32, 32]
data = torch.rand(shape).to(torch.bfloat16)
data2 = torch.rand(shape).to(torch.bfloat16)
# Configure memory
dram_memory_config = ttnn.DRAM_MEMORY_CONFIG
# Create input tensors
a_tensor = ttnn.from_torch(
data,
dtype=ttnn.bfloat16,
layout=ttnn.TILE_LAYOUT,
device=device,
memory_config=dram_memory_config,
)
b_tensor = ttnn.from_torch(
data2,
dtype=ttnn.bfloat16,
layout=ttnn.TILE_LAYOUT,
device=device,
memory_config=dram_memory_config,
)
# Create output tensor
output_tensor = ttnn.allocate_tensor_on_device(
ttnn.Shape(shape),
ttnn.bfloat16,
ttnn.TILE_LAYOUT,
device,
dram_memory_config,
)
# Create the custom operation
vecadd_op = VecAddMulticorePyKernelOp()
# Execute the operation with the tensors and options
output = vecadd_op(a_tensor, b_tensor, output_tensor)
# Compare with the built-in add operation
golden = ttnn.add(a_tensor, b_tensor)
# Convert to torch tensors for comparison
torch_golden = ttnn.to_torch(golden)
torch_output = ttnn.to_torch(output)
# Verify results
matching = torch.allclose(torch_golden, torch_output)
print(f"Tensors are matching: {matching}")
assert matching
This demo shows the complete workflow:
- Opens a device
- Creates input and output tensors with appropriate memory configuration
- Instantiates the
VecAddMulticorePyKernelOpclass - Executes the operation by calling the op with tensors
- Compares the result with the built-in TTNN implementation
Comparison with Native TTNN Operations
PyKernel operations integrate seamlessly with native TTNN operations. As shown in the demo, you can compare your custom PyKernel operation with built-in TTNN operations:
# Execute your custom PyKernel operation
output = vecadd_op(a_tensor, b_tensor, output_tensor)
# Execute the equivalent built-in TTNN operation
golden = ttnn.add(a_tensor, b_tensor)
# Convert both to torch tensors for comparison
torch_golden = ttnn.to_torch(golden)
torch_output = ttnn.to_torch(output)
# Verify the results match
matching = torch.allclose(torch_golden, torch_output)
print(f"Tensors are matching: {matching}")
assert matching
This approach allows you to:
- Validate your custom operation against known implementations
- Benchmark performance differences between custom and built-in operations
- Extend the TTNN framework with operations not available in the standard library
Building and Testing
To build and test PyKernel, you need to enable both the runtime and PyKernel components:
source env/activate
# Configure with PyKernel enabled
cmake -G Ninja -B build \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_C_COMPILER=clang-17 \
-DCMAKE_CXX_COMPILER=clang++-17 \
-DTTMLIR_ENABLE_RUNTIME=ON \
-DTTMLIR_ENABLE_PYKERNEL=ON
# Build the project
cmake --build build
# Run the PyKernel demo
cmake --build build -- pykernel-demo
The TTMLIR_ENABLE_RUNTIME and TTMLIR_ENABLE_PYKERNEL flags are essential for PyKernel functionality. Without these flags, the PyKernel components will not be built.
Best Practices
When developing with PyKernel, follow these best practices:
-
Separate concerns: Keep compute, reader, and writer kernels separate for better maintainability and reusability
-
Use appropriate decorators: Apply the correct decorator for each kernel type:
@compute_thread()for compute kernels@reader_thread()for reader kernels@writer_thread()for writer kernels
-
Implement the invoke method properly: The
invokemethod is critical as it connects all components:- Create circular buffers with appropriate parameters
- Set up kernel parameters correctly
- Create kernels with the right arguments
- Return a program descriptor that includes all kernels and circular buffers
-
Handle memory configurations: Be aware of memory types (DRAM vs L1) when creating kernels
-
Reuse kernels: Create reusable kernels for common operations to avoid code duplication
-
Leverage caching: PyKernelOp automatically caches compiled kernels for performance
-
Test thoroughly: Always compare results with reference implementations or built-in TTNN operations
-
Document parameters: Clearly document the expected parameters for your PyKernel operation
Running tt-mlir pykernel on macOS
Quick guide for building and running pykernel on macOS without runtime support (no hardware execution).
Setup
You'll need a system descriptor file. Grab one from a real system or use a mock one:
export SYSTEM_DESC_PATH=$(pwd)/system_desc.ttsys
Build Configuration
Configure with runtime disabled:
cmake -G Ninja -B build \
-DTTMLIR_ENABLE_RUNTIME=OFF \
-DTTMLIR_ENABLE_STABLEHLO=OFF \
-DTT_RUNTIME_ENABLE_PERF_TRACE=OFF \
-DTTMLIR_ENABLE_BINDINGS_PYTHON=ON \
-DTTMLIR_ENABLE_DEBUG_STRINGS=OFF \
-DTTMLIR_ENABLE_EXPLORER=OFF \
-DTTMLIR_ENABLE_RUNTIME_TESTS=OFF \
-DTTMLIR_ENABLE_PYKERNEL=ON \
-DCMAKE_BUILD_TYPE=Debug \
-DCMAKE_C_COMPILER=clang \
-DCMAKE_CXX_COMPILER=clang++ \
-DCMAKE_CXX_COMPILER_LAUNCHER=ccache \
-DCMAKE_BUILD_PARALLEL_LEVEL=4 \
-DFLATBUFFERS_COMPILER=/opt/homebrew/bin/flatc
Build
source env/activate
cmake --build build
Run Example
export SYSTEM_DESC_PATH=$(pwd)/system_desc.ttsys
source env/activate
python test/pykernel/gen/custom_dm_matmul.py
What works
The full compilation pipeline (Python → D2M → MLIR → TTKernel → EmitC) will run successfully. Hardware execution will not work due to no runtime support, but you can develop and test the compiler itself.
- Full MLIR compilation pipeline
- Kernel code generation
- All compiler passes
- No actual hardware execution (requires runtime + Tenstorrent hardware)
Summary
PyKernel provides a flexible and powerful way to implement custom operations for Tenstorrent hardware. By following the pattern outlined in this guide, you can create your own operations that integrate seamlessly with the TTNN framework.
Key components of the PyKernel framework:
- PyKernelOp base class: Handles kernel management, compilation, and caching
- Kernel decorators:
@compute_thread(),@reader_thread(), and@writer_thread() - CircularBuffer class: Represents circular buffers in kernel definitions
- invoke method: The critical implementation that connects kernels and creates the program
The workflow for creating a custom PyKernel operation is:
- Create a class that inherits from
PyKernelOp - Define compute, reader, and writer kernels with appropriate decorators
- Implement the
invokemethod to create circular buffers and connect kernels - Use the operation by instantiating your class and calling it with tensors and options
With PyKernel, you can extend the TTNN framework with custom operations that leverage the full power of Tenstorrent hardware while maintaining a clean, high-level Python interface.
ttnn.jit
ttnn.jit is a tool that allows TTNN model developers to leverage the Direct-To-Metal (D2M) compiler Just-In-Time (JIT) compile select portions of their model.
Table of Contents
Getting Started
Quickstart
Wheel install coming soon!
Building From Source
Build tt-mlir with the following flags:
-DTTMLIR_ENABLE_RUNTIME=ON -DTTMLIR_ENABLE_TTNN_JIT=ON
For profiling purposes, add the following flag to enable Tracy:
-DTT_RUNTIME_ENABLE_PERF_TRACE=ON
A Superset dashboard is available to track nightly JIT performance across a set of representative ops.
After building, make sure to generate a system descriptor using ttrt.
ttrt query --save-artifacts
export SYSTEM_DESC_PATH=`pwd`/ttrt-artifacts/system_desc.ttsys
How to use ttnn.jit
Take any Python TTNN subgraph such as the cosh composite operation:
def cosh(input_tensor):
e_pos_x = ttnn.exp(input_tensor)
e_neg_x = ttnn.exp(ttnn.neg(input_tensor))
nr_term = ttnn.add(e_pos_x, e_neg_x)
return ttnn.multiply(nr_term, 0.5)
def model(input_0, input_1):
x = cosh(input_0)
y = ttnn.exp(input_1)
return ttnn.matmul(x, y)
Simply decorate with @ttnn_jit.jit() to JIT compile through D2M. In this example, cosh will be compiled into a single fused kernel.
@ttnn_jit.jit()
def cosh(input_tensor):
e_pos_x = ttnn.exp(input_tensor)
e_neg_x = ttnn.exp(ttnn.neg(input_tensor))
nr_term = ttnn.add(e_pos_x, e_neg_x)
return ttnn.multiply(nr_term, 0.5)
def model(input_0, input_1):
x = cosh(input_0)
y = ttnn.exp(input_1)
return ttnn.matmul(x, y)
This demo is available here.
JIT Flags
| Flag | Type | Default | Description |
|---|---|---|---|
enable_cache | bool | False | Enables caching for compiled JIT graphs. |
math_fidelity | ttnn.MathFidelity | ttnn.MathFidelity.HiFi4 | Sets the math fidelity setting for the JIT graph. |
debug | bool | False | Enables debug prints during compilation and execution. |
compile_only | bool | False | Only compile runtime without execution. The resulting flatbuffer and kernel source files will be dumped to generated/ttnn-jit/<func_name>. |
memory_config | ttnn.MemoryConfig | None | Output memory configuration for the JIT function. If specified, the output tensor will use this exact layout. If unspecified, a maximally L1 block sharded layout will be used as default. |
fallback | bool | False | When enabled, falls back to running the original function eagerly through TTNN if JIT compilation or execution fails. Cannot be used together with compile_only. |
extra_pipeline_options | str | "" | Additional pipeline options passed to the D2M compilation pipeline. For advanced use only. Example: "test-buffer-size-policy=max". |
Current Support
Supported Operations
The following major categories of operations are supported:
- Unary Elementwise
- Binary Elementwise
- Unary Bitwise
- Binary Bitwise
- Matrix Multiplication
- Reductions
- Tensor Manipulation
- Data Movement
- Collective Communication (CCL)
Not every operation is supported within the above categories. Tensor manipulation, data movement, and CCL ops are currently supported at the IR generation level; end-to-end support through D2M may vary.
Supported Tensor Layouts
- Unary Elementwise and Bitwise
- Height, width, and block sharded tensors in L1 as well as DRAM interleaved.
- Binary Elementwise and Bitwise
- Height, width, and block sharded tensors in L1 as well as DRAM interleaved.
- If both operands are sharded, they must have identical shard specs.
- Matrix Multiplication:
- Block sharded tensors in L1 and DRAM interleaved.
- Reductions:
- Height, width, and block sharded tensors in L1.
- DRAM tensors are not supported.
Note: Only tiled tensors with tile-aligned dimensions are currently supported. Padding is not supported. Row-major layouts are not supported. ND sharded tensors are also supported.
Supported Datatypes
| Operation Category | Supported Datatypes |
|---|---|
| Unary Elementwise | f32, bf16, bfp8 |
| Binary Elementwise | f32, bf16, bfp8 |
| Unary Bitwise | int32 |
| Binary Bitwise | int32 |
| Matrix Multiplication | f32, bf16, bfp8 |
| Reductions | f32, bf16 |
| Tensor Manipulation | f32, bf16, bfp8 |
| Data Movement | f32, bf16, bfp8 |
| CCL | f32, bf16, bfp8 |
Notes
- The
memory_configarguments on individual JIT ops are ignored; only thememory_configpassed to the@ttnn_jit.jit()decorator is used. - See the current test suite for what is guaranteed to be working.
How It Works
The ttnn.jit decorator implements a three-step compilation and execution pipeline that transforms Python TTNN operations into optimized hardware kernels:
Step 1: Python Decorator
When you decorate a function with @ttnn_jit.jit(), the decorator wraps it in a JitFunction object. On the first call:
- The function's source code is rewritten so that
ttnn.*calls are redirected through JIT-aware handlers. - The rewritten function is executed, tracing each TTNN operation and converting it to its corresponding MLIR operation in the TTIR dialect.
The output is a valid MLIR module in the TTIR dialect. The previous cosh example will be compiled into TTIR operations like:
module {
func.func @cosh(%arg0: tensor<32x32xbf16, #ttnn_layout>) -> tensor<32x32xbf16, #ttnn_layout> {
%0 = "ttir.exp"(%arg0) : (tensor<32x32xbf16, #ttnn_layout>) -> tensor<32x32xbf16>
%1 = "ttir.neg"(%arg0) : (tensor<32x32xbf16, #ttnn_layout>) -> tensor<32x32xbf16>
%2 = "ttir.exp"(%1) : (tensor<32x32xbf16>) -> tensor<32x32xbf16>
%3 = "ttir.add"(%0, %2) : (tensor<32x32xbf16>, tensor<32x32xbf16>) -> tensor<32x32xbf16>
%cst = "ttir.full"() <{shape = array<i32: 32, 32>, fill_value = 5.000000e-01 : f32}> : () -> tensor<32x32xf32>
%4 = "ttir.multiply"(%3, %cst) : (tensor<32x32xbf16>, tensor<32x32xf32>) -> tensor<32x32xbf16>
%5 = ttir.empty() : tensor<32x32xbf16, #ttnn_layout>
%6 = ttir.to_layout %4, %5 : tensor<32x32xbf16> into tensor<32x32xbf16, #ttnn_layout> -> tensor<32x32xbf16, #ttnn_layout>
return %6 : tensor<32x32xbf16, #ttnn_layout>
}
}
Only function arguments and the final return value carry a #ttnn_layout encoding that specifies the exact tensor layout (sharding, memory space, grid). Intermediate results are left as bare tensor types; the D2M GridSelection pass infers optimal layouts for these during compilation.
Step 2: D2M Compilation Pipeline
The resulting MLIR module is then passed to the compiler:
- D2M Compilation: The
ttir-to-ttmetal-pipelineruns withttnn-mode- Generates custom kernels with techniques such as destination fusion and loop tiling.
- Wraps the generated kernels in
ttnn.genericoperations that contain the necessary host side program setup.
- Flatbuffer Serialization: The compiled IR is serialized to a FlatBuffer binary format via
ttnnToFlatbuffer()- This flatbuffer is returned to the decorator and cached as a
Binaryobject.
- This flatbuffer is returned to the decorator and cached as a
Each ttnn.generic op requires a ProgramDescriptor that contains everything needed to construct a TT-Metal Program.
- Circular buffer and Semaphore config.
- Kernel source code, common runtime, and compile-time argument setup.
Step 3: Runtime Execution
The decorator leverages the same MLIR runtime as ttrt. For our purposes, it is essentially just TTNN with additional machinery to execute the serialized ttnn.generic operations that wrap the custom D2M-generated kernels.
As shown in previously, interop with TTNN is seamless, allowing users to switch freely between JIT'ed and non-JIT'ed subgraphs of ttnn ops.
JIT Caching
The first invocation of a JIT'ed subgraph will compile and cache the resulting flatbuffer in a JitCache. The cache uses tensor metadata (shape, dtype, memory config, etc.) as the key. The compiled flatbuffer wrapped in an MLIR runtime Binary object is the cache entry.
Each JitFunction maintains its own JitCache, so different JIT configurations will have independent cache entries.
Constructing a ProgramDescriptor from a flatbuffer at runtime is expensive. To mitigate this, ProgramDescriptor instances are cached in a ProgramDescCache owned by the flatbuffer Binary object. The same cache key is also stored in the ProgramDescriptor as a custom_program_hash and passed to the TTNN runtime, allowing the ttnn.generic to reuse it for its ProgramCache.
See test_program_cache.py for a detailed example demonstrating cache hit/miss behavior.
Op Fusion
Fusion is a key optimization in the D2M compilation pipeline that can combine multiple D2M generic operations into a single op, generating fewer kernels, reducing overhead, and improving performance. This feature is currently always enabled and runs under-the-hood with no additional input/guidance required from the user.
At a Glance
- Fuses viable pairs of
d2m.genericops together to eliminate/reduce redundant ops/instructions - Saves dispatch time by reducing total number of kernels
- Reduces kernel execution time by reducing redundant
*_initop calls - Reorders op call sequence to minimize required DST memory and data movement
Fusion Zoo
Currently only supports elementwise ops as shown below. Currently at work on moving more ops from their cages into the Fusion Cage.
(If the figures aren't showing up, please install the support for the 'Mermaid' package in Markdown files)
graph LR
subgraph MatMul["MatMul"]
direction TB
title_mm["<b>MatMul</b>"]
in0_bm[in0] --> BlockMM((BlockMM))
in1_bm[in1] --> BlockMM
BlockMM --> out0_bm[out0]
in0_tm[in0] --> TileMM((TileMM))
in1_tm[in1] --> TileMM
TileMM --> out0_tm[out0]
end
subgraph Reductions
direction TB
title_red["<b>Reductions</b>"]
in0_r1[in0] --> Unary((Unary))
Unary --> out0_r1[out0]
in0_r2[in0] --> Binary((Binary))
in1_r2[in1] --> Binary
Binary --> out0_r2[out0]
end
subgraph TMs
direction TB
title_tms["<b>TMs</b>"]
in0_tm1[in0] --> Gather((Gather))
dots_in[". . ."] --> Gather
inN_tm1[inN] --> Gather
Gather --> out0_tm1[out0]
in0_tm2[in0] --> Scatter((Scatter))
Scatter --> out0_tm2[out0]
Scatter --> dots_out[". . ."]
Scatter --> outN_tm2[outN]
end
MatMul ~~~ Reductions ~~~ TMs
classDef purpleCircle fill:#9370db,stroke:#444,stroke-width:3px,color:#fff
classDef blueCircle fill:#4169e1,stroke:#444,stroke-width:3px,color:#fff
classDef yellowCircle fill:#ffd700,stroke:#444,stroke-width:3px,color:#000
classDef inputOutput fill:#fff,stroke:#444,stroke-width:1px
class BlockMM,TileMM purpleCircle
class Unary,Binary blueCircle
class Gather,Scatter yellowCircle
class in0_bm,in1_bm,out0_bm,in0_tm,in1_tm,out0_tm,in0_r1,out0_r1,in0_r2,in1_r2,out0_r2 inputOutput
class in0_tm1,dots_in,inN_tm1,out0_tm1,in0_tm2,out0_tm2,dots_out,outN_tm2 inputOutput
style MatMul fill:#fff,stroke:#444,stroke-width:3px,rx:15,ry:15
style Reductions fill:#fff,stroke:#444,stroke-width:3px,rx:15,ry:15
style TMs fill:#fff,stroke:#444,stroke-width:3px,rx:15,ry:15
graph TD
subgraph Elementwise
direction LR
subgraph Left[" "]
direction TB
title_left["<b>Elementwise</b>"]
in0_e1[in0] --> EltUnary1((Unary))
EltUnary1 --> out0_e1[out0]
in0_e2[in0] --> EltBinary1((Binary))
in1_e2[in1] --> EltBinary1
EltBinary1 --> out0_e2[out0]
end
subgraph Right[" "]
direction TB
in0_e3[in0] --> EltUnary3A((Unary))
EltUnary3A --> EltUnary3B((Unary))
EltUnary3B --> out0_e3[out0]
in0_e4[in0] --> EltUnary4((Unary))
EltUnary4 --> EltBinary4((Binary))
in1_e4[in1] --> EltBinary4
EltBinary4 --> out0_e4[out0]
in0_e5[in0] --> EltBinary5((Binary))
in1_e5[in1] --> EltBinary5
EltBinary5 --> EltUnary5((Unary))
EltUnary5 --> out0_e5[out0]
in0_e6[in0] --> EltBinary6A((Binary))
in1_e6[in1] --> EltBinary6A
in2_e6[in2] --> EltBinary6B((Binary))
in3_e6[in3] --> EltBinary6B
EltBinary6A --> EltBinary7((Binary))
EltBinary6B --> EltBinary7
EltBinary7 --> out0_e6[out0]
end
Left ~~~ Right
end
classDef greenCircle fill:#32cd32,stroke:#444,stroke-width:3px,color:#fff
classDef whiteCircle fill:#fff,stroke:#444,stroke-width:3px,color:#000
classDef inputOutput fill:#fff,stroke:#444,stroke-width:1px
class EltUnary1,EltUnary3A,EltUnary3B,EltUnary4,EltUnary5 greenCircle
class EltBinary1,EltBinary4,EltBinary5,EltBinary6A,EltBinary6B,EltBinary7 whiteCircle
class in0_e1,out0_e1,in0_e2,in1_e2,out0_e2,in0_e3,out0_e3,in0_e4,in1_e4,out0_e4 inputOutput
class in0_e5,in1_e5,out0_e5,in0_e6,in1_e6,in2_e6,in3_e6,out0_e6 inputOutput
style Elementwise fill:#fff,stroke:#444,stroke-width:3px,rx:15,ry:15
style Left fill:none,stroke:none
style Right fill:none,stroke:none
Limitations
- Only supports elementwise ops (no reductions/matmuls/TMs yet)
- Fused
d2m.genericcan't have more than 32 input/output tensors (CB limit)- If all tensors have data types with <= 16b, can fuse freely until we hit CB limit
- If any of the tensors being fused has a data type > 16b, can only fuse up-to and including 7 inputs
- Ops with 2+ inputs are currently lowered to loops that operate on 1xDST-tile at a time
- Can fuse aggressively and save on dispatch but less savings on redundant ops
- Major revisions incoming in later releases
- Can only fuse over op trees (i.e., can't fuse over tensors with multiple users)
- EXCEPTION: if the tensor is a func argument, it will go through separate "tilize"
d2m.generics; as far as the downstreamd2m.generics are concerned → the output of each "tilize" is a unique tensor
- EXCEPTION: if the tensor is a func argument, it will go through separate "tilize"
Examples of Current Supported Patterns
Unary Op Chains
- Fully fusable → Fewer kernels = fewer kernel dispatches
- Op loops iterate over 8xDST-Tile blocks
- Can use init hoisting to reduce
*_initop calls by 8x - DST is double buffered (benefits degrade dramatically as chain gets longer)
@ttnn_jit.jit()
def unary_chain(input_tensor):
res_0 = ttnn.abs(input_tensor)
res_1 = ttnn.sin(res_0)
res_2 = ttnn.neg(res_1)
output_tensor = ttnn.exp(res_2)
return output_tensor
Lowers to the singular d2m compute generic below:
d2m.generic { // . . . omitted . . .
^compute0(%cb0: !d2m.cb<memref<4x4x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<l1>>>, %cb1: !d2m.cb<memref<4x4x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<l1>>>):
// . . . omitted . . .
scf.for %arg1 = %c0 to %c4 step %c2 {
scf.for %arg2 = %c0 to %c4 step %c4 {
// . . . omitted . . .
affine.for %arg3 = 0 to 2 {
affine.for %arg4 = 0 to 4 {
%2 = affine.load %subview[%arg3, %arg4] : memref<2x4x!ttcore.tile<32x32, bf16>, strided<[4, 1], offset: ?>, #ttcore.memory_space<l1>>
affine.store %2, %dst[0, %arg3, %arg4] : memref<1x2x4x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
}
}
affine.for %arg3 = 0 to 2 {
affine.for %arg4 = 0 to 4 {
%2 = affine.load %dst[0, %arg3, %arg4] : memref<1x2x4x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%3 = "d2m.tile_abs"(%2) : (!ttcore.tile<32x32, bf16>) -> !ttcore.tile<32x32, bf16>
affine.store %3, %dst[%c0, %arg3, %arg4] : memref<1x2x4x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
}
}
// Shortened IR for 2 intermediate ops
// affine.for{affine.for{load --> "d2m.tile_sin" --> store}}
// affine.for{affine.for{load --> "d2m.tile_neg" --> store}}
affine.for %arg3 = 0 to 2 {
affine.for %arg4 = 0 to 4 {
%2 = affine.load %dst[%c0, %arg3, %arg4] : memref<1x2x4x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%3 = "d2m.tile_exp"(%2) : (!ttcore.tile<32x32, bf16>) -> !ttcore.tile<32x32, bf16>
affine.store %3, %dst[0, %arg3, %arg4] : memref<1x2x4x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
}
}
affine.for %arg3 = 0 to 2 {
affine.for %arg4 = 0 to 4 {
%2 = affine.load %dst[0, %arg3, %arg4] : memref<1x2x4x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
affine.store %2, %subview_4[%arg3, %arg4] : memref<2x4x!ttcore.tile<32x32, bf16>, strided<[4, 1], offset: ?>, #ttcore.memory_space<l1>>
}
}
}
}
}
Arbitrary Binary + Unary Op Trees
- Fully fusable → Fewer kernels = fewer kernel dispatches
- Op loops iterate over 1xDST-Tile blocks
- No init hoisting benefits
- Op tree is evaluated and op execution order is rescheduled to minimize number of required DST registers (minimize the max number of tensors that can be live at any point during execution)
- "loads" of input data tiles are moved to immediately before their users
Sample op tree to be fused and rescheduled:
@ttnn_jit.jit()
def add_tree_8_to_1(
in0, in1, in2, in3,
in4, in5, in6, in7
):
add_0_0 = builder.add(in0, in1)
add_0_1 = builder.add(in2, in3)
add_0_2 = builder.add(in4, in5)
# At this point we're storing 3 intermediate results in DST tiles
# Need 2 more DST tiles for inputs below
# +1 more DST tile for the result
# Peak usage of 6 DST tiles
add_0_3 = builder.add(in6, in7)
add_1_0 = builder.add(add_0_0, add_0_1)
add_1_1 = builder.add(add_0_2, add_0_3)
add_2_0 = builder.add(add_1_0, add_1_1)
Is rescheduled under-the-hood to the below snippet. This reordering will produce the exact same output as the original order i.e., reordering doesn't affect floating point rounding error accumulation.
# resolve one half of the op-tree
add_0_0 = builder.add(in0, in1)
add_0_1 = builder.add(in2, in3)
add_1_0 = builder.add(add_0_0, add_0_1)
# store add_1_0 as the result of this half of the tree
# THEN resolve other half
add_0_2 = builder.add(in4, in5)
# Storing add_1_0 and add_0_2 in intermediate in DST tiles
# Need 3 more DST tiles for add_0_3
# Peak usage of 5 DST-Tiles
add_0_3 = builder.add(in6, in7)
add_1_1 = builder.add(add_0_2, add_0_3)
# combine 2 results
add_2_0 = builder.add(add_1_0, add_1_1)
This will then lower into the following loop structure (assuming tensor sizes of 1024 x 1024 x bf16 and an 8x8 grid):
d2m.generic {// . . . omitted . . .
^compute0(%cb0: !d2m.cb<memref<4x4x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<l1>>>, %cb1: !d2m.cb<memref<4x4x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<l1>>>, %cb2: !d2m.cb<memref<4x4x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<l1>>>, %cb3: !d2m.cb<memref<4x4x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<l1>>>, %cb4: !d2m.cb<memref<4x4x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<l1>>>, %cb5: !d2m.cb<memref<4x4x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<l1>>>, %cb6: !d2m.cb<memref<4x4x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<l1>>>, %cb7: !d2m.cb<memref<4x4x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<l1>>>, %cb8: !d2m.cb<memref<4x4x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<l1>>>):
// . . . omitted . . .
scf.for %arg8 = %c0 to %c4 step %c1 {
scf.for %arg9 = %c0 to %c4 step %c1 {
// . . . omitted . . .
%dst = d2m.acquire_dst() : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
// Loads from l1/DRAM into DST are moved into the same loop as the compute ops
// Currently any d2m.generic with 3+ inputs will lower down to so that the inner loop nest operates on only 1xTile at a time.
// To be improved in later revisions
affine.for %arg10 = 0 to 1 {
affine.for %arg11 = 0 to 1 {
%9 = affine.load %subview[%arg10, %arg11] : memref<1x1x!ttcore.tile<32x32, bf16>, strided<[4, 1], offset: ?>, #ttcore.memory_space<l1>>
affine.store %9, %dst[0, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%10 = affine.load %dst[0, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%11 = affine.load %subview_18[%arg10, %arg11] : memref<1x1x!ttcore.tile<32x32, bf16>, strided<[4, 1], offset: ?>, #ttcore.memory_space<l1>>
affine.store %11, %dst[1, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%12 = affine.load %dst[1, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%13 = "d2m.tile_add"(%10, %12) : (!ttcore.tile<32x32, bf16>, !ttcore.tile<32x32, bf16>) -> !ttcore.tile<32x32, bf16>
affine.store %13, %dst[%c2, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%14 = affine.load %dst[%c2, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%15 = affine.load %subview_19[%arg10, %arg11] : memref<1x1x!ttcore.tile<32x32, bf16>, strided<[4, 1], offset: ?>, #ttcore.memory_space<l1>>
affine.store %15, %dst[0, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%16 = affine.load %dst[0, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%17 = affine.load %subview_20[%arg10, %arg11] : memref<1x1x!ttcore.tile<32x32, bf16>, strided<[4, 1], offset: ?>, #ttcore.memory_space<l1>>
affine.store %17, %dst[1, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%18 = affine.load %dst[1, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%19 = "d2m.tile_add"(%16, %18) : (!ttcore.tile<32x32, bf16>, !ttcore.tile<32x32, bf16>) -> !ttcore.tile<32x32, bf16>
affine.store %19, %dst[%c3, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%20 = affine.load %dst[%c3, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%21 = "d2m.tile_add"(%14, %20) : (!ttcore.tile<32x32, bf16>, !ttcore.tile<32x32, bf16>) -> !ttcore.tile<32x32, bf16>
affine.store %21, %dst[%c0, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%22 = affine.load %dst[%c0, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%23 = affine.load %subview_21[%arg10, %arg11] : memref<1x1x!ttcore.tile<32x32, bf16>, strided<[4, 1], offset: ?>, #ttcore.memory_space<l1>>
affine.store %23, %dst[2, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%24 = affine.load %dst[2, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%25 = affine.load %subview_22[%arg10, %arg11] : memref<1x1x!ttcore.tile<32x32, bf16>, strided<[4, 1], offset: ?>, #ttcore.memory_space<l1>>
affine.store %25, %dst[3, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%26 = affine.load %dst[3, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%27 = "d2m.tile_add"(%24, %26) : (!ttcore.tile<32x32, bf16>, !ttcore.tile<32x32, bf16>) -> !ttcore.tile<32x32, bf16>
affine.store %27, %dst[%c1, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%28 = affine.load %dst[%c1, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%29 = affine.load %subview_23[%arg10, %arg11] : memref<1x1x!ttcore.tile<32x32, bf16>, strided<[4, 1], offset: ?>, #ttcore.memory_space<l1>>
affine.store %29, %dst[2, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%30 = affine.load %dst[2, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%31 = affine.load %subview_24[%arg10, %arg11] : memref<1x1x!ttcore.tile<32x32, bf16>, strided<[4, 1], offset: ?>, #ttcore.memory_space<l1>>
affine.store %31, %dst[3, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%32 = affine.load %dst[3, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%33 = "d2m.tile_add"(%30, %32) : (!ttcore.tile<32x32, bf16>, !ttcore.tile<32x32, bf16>) -> !ttcore.tile<32x32, bf16>
affine.store %33, %dst[%c4, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%34 = affine.load %dst[%c4, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%35 = "d2m.tile_add"(%28, %34) : (!ttcore.tile<32x32, bf16>, !ttcore.tile<32x32, bf16>) -> !ttcore.tile<32x32, bf16>
affine.store %35, %dst[%c2, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%36 = affine.load %dst[%c2, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
%37 = "d2m.tile_add"(%22, %36) : (!ttcore.tile<32x32, bf16>, !ttcore.tile<32x32, bf16>) -> !ttcore.tile<32x32, bf16>
affine.store %37, %dst[1, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
}
}
// Stores from DST to L1/DRAM contained within their own loop
affine.for %arg10 = 0 to 1 {
affine.for %arg11 = 0 to 1 {
%9 = affine.load %dst[1, %arg10, %arg11] : memref<8x1x1x!ttcore.tile<32x32, bf16>, #ttcore.memory_space<dst>>
affine.store %9, %subview_25[%arg10, %arg11] : memref<1x1x!ttcore.tile<32x32, bf16>, strided<[4, 1], offset: ?>, #ttcore.memory_space<l1>>
}
}
}
}
}
Debugging FAQ
For debugging purposes, always build with -DCMAKE_BUILD_TYPE=Debug and decorate with debug=True to see IR outputs after each step.
AssertionError: Function ___ not supported
This indicates the decorated TTNN op is not supported yet in the TTNN dialect. Or you spelt it wrong, eg: ttnn.mul is not supported but ttnn.multiply is.
To start, check whether the desired TTNN op is supported in the tablegen. If not, please file an issue.
Note: as mentioned in Current Support, not every operation within each category is supported.
Failed to run pass manager
This means the compilation pipeline failed at a certain stage. The easiest way to debug is to copy the IR output from the tracing step (use debug=True), and manually run each individual pipeline:
ttmlir-opt --convert-ttnn-to-ttir *.mlir
ttmlir-opt --mlir-print-ir-after-all --ttir-to-ttmetal-pipeline="system-desc-path=${SYSTEM_DESC_PATH} ttnn-mode=true" *.mlir
ttmlir-translate --ttnn-to-flatbuffer *.mlir
For MLIR runtime and debug output:
export TTMLIR_RUNTIME_LOGGER_LEVEL=Trace
export TTRT_LOGGER_LEVEL=Debug
Creating Bug Repros for TTNN Using TT-MLIR Codegen
While developing in tt-mlir, it's not uncommon to encounter bugs originating in the TTNN library. To isolate and report such bugs, a practical approach is to use the C++ codegen feature (EmitC) to generate a minimal repro. This guide walks you through how to create such repros and integrate them into the tt-metal repository, where TTNN is developed.
Step-by-Step Guide
Note: If you run into issues while following these steps, check the Known Issues section at the end of this guide for common problems and solutions.
1. Generate C++ Code from TT-MLIR
Use the ttnn-standalone tool to run the compiler and emit C++ code.
📖 See
ttnn-standalonefor instructions on how to generate C++ code from your MLIR input using EmitC.
2. Scope Down the Repro
Once you've generated the C++ code:
- Use the
ttnn-standalonetool to run and debug it in isolation. - Reduce the repro to the minimal example that still triggers the bug.
- Confirm the issue still reproduces reliably.
3. Clone the TT-Metal Repository
Clone the tt-metal repo:
git clone git@github.com:tenstorrent/tt-metal.git
cd tt-metal
4. Add the Repro to the GTest Infrastructure
Place your .cpp file in:
tests/ttnn/unit_tests/gtests/emitc/
and add it to the cmake file:
tests/ttnn/unit_tests/gtests/CMakeLists.txt
like so:
set(EMITC_UNIT_TESTS_SRC
${CMAKE_CURRENT_SOURCE_DIR}/emitc/test_sanity.cpp
${CMAKE_CURRENT_SOURCE_DIR}/emitc/your_test_name.cpp # <<<===
)
Use the existing file test_sanity.cpp in that directory as a reference.
5. Modify the Repro for GTest
There are some modifications that need to be made in order to fit the GTest infra:
- Convert the
main()function to aTEST(...)macro:
TEST(EmitC, YourTestName) {
// Your original main function body here
}
- Remove any
returnstatements from theTEST(...)function body. - Replace
#include "ttnn-precompiled.hpp"with#include "emitc.hpp"
6. Build the TTNN EmitC Tests
First, activate the python virtual env, and set some env variables:
source python_env/bin/activate
export TT_METAL_RUNTIME_ROOT=$(pwd)
export PYTHONPATH=$(pwd)
Then, build the tests:
./build_metal.sh --build-ttnn-tests
Note: some unrelated gtests might fail here, we can ignore them.
7. Run the EmitC Unit Tests
To run all EmitC tests:
./build/test/ttnn/unit_tests_ttnn_emitc
To run a specific test:
./build/test/ttnn/unit_tests_ttnn_emitc --gtest_filter=EmitC.YourTestName
8. Share the Repro
- Create a branch with your changes.
- Open a GitHub issue or comment on an existing one.
- Link to your branch and include the instructions for running the repro
./build_metal.sh --build-ttnn-tests
./build/test/ttnn/unit_tests_ttnn_emitc
./build/test/ttnn/unit_tests_ttnn_emitc --gtest_filter=EmitC.YourTestName
Known Issues
-
Missing
sfpicompiler or other dependencies If you encounter errors about a missingsfpicompiler or other system-level dependencies, refer to the tt-metal installation guide for instructions on installing the required packages. -
TTNN test compilation failures If the build fails when compiling TTNN tests, inspect the specific tests that caused the failure. If the failures are unrelated to EmitC tests, they can typically be ignored — this is a known issue.
Python Bindings
This page aims to clarify, document, and de-mystify the tt-mlir python bindings. It will do so by first highlighting the mechanism with which these bindings are generated and exposed to users. It will then document the nuances of nanobind, and the different parts of these bindings that must be written in by hand. Finally, it will go through a hands-on example of how to add your own functionality to the tt-mlir python bindings.
nanobind
Nanobind is the successor of the ubiquitous pybind project. In almost the same syntactical form, it provides a framework to define InterOp between C++ and Python. For more information about nanobind specifically, I'd recommend reading through the documentation. MLIR (and by extension: tt-mlir) leverages nanobind to create bindings for the C++ framework of Dialects, Ops, Types, Attributes, and Passes to be used in Python.
MLIR in Python
This section highlights the machinery and configuration with which MLIR can be exposed to Python, while still maintaining functional interop with the C++ code. For more context and information feel free to read the MLIR Python Documentation.
C-API
While the documentation provides a very lack-lustre explanation as to why the C-API exists, I am here to provide my take on the existence and purpose of the MLIR CAPI.
RTTI
MLIR, being a part of the llvm-project, follows their "custom" RTTI. For this reason, the entire C++ portion of the project isn't built with RTTI to enable to custom functionality. nanobind, however, requires RTTI to perform a lot of the casting and transformation required to interop with Python. This conflict leads to the natural desire for an alternative.
C doesn't have RTTI, it's a stable language without the extra convenience and machinery presented in C++. If a C-API were present, the python bindings can link against the C-API, relying on externally defined NanobindAdaptors to do the type conversions using nanobind mechanisms instead of relying on the C++/LLVM RTTI for the Python bindings.
C++ ABI
The C++ Application Boundary Interface (ABI) proves to be a challenging barrier to accessing functionality from C++. Without a defined stable ABI, it becomes difficult to deal with some of the complexity required to package and InterOp with Python. Specifically, dealing with templates, inheritance, and RTTI can prove quite the challenge.
To simplify this process, C provides a relatively stable ABI. The C-API also acts as a wrapper around the complex C++ functions, providing a simple "trampoline" for Python to link against.
nanobind x C-API Functionality
In the previous section, I mentioned NanobindAdaptors. This file helps to define some of the key design decisions made when linking the Python bindings against the C-API instead of the underlying C++ API. Functionally, the Python bindings act as a "wrapper" around the CAPI, exposing the functionality through python.
include/mlir-c/Bindings/Python/Interop.h
This file is key to defining the InterOp between the C-API and Python w.r.t. maintaining and accessing information in a pointer. It exposes an AI that interfaces immediate data pointers with python capsules. PyCapsules are essentially thin wrappers around data pointers in Python. The critically contain data (void*), destructor method, and a name.
Within the Interop, the assumption is that the data's ownership and lifetime is managed by some bound object that was created in C++. This file merely provides the API with which the underlying data pointer is passed around as either a PyCapsule or the raw pointer, and this file provides the type conversion utilities to convert between Python and C from an underlying object.
include/mlir/CAPI/Wrap.h
This header defines the API to InterOp between C-API objects and their C++ equivalent. By calling wrap() on a C++ MLIR object to have the underlying data create a C-API object on the same memory, and unwrap() does it the other way around.
They key caveat with this wrapping/unwrapping is the ownership over the lifetime of the data itself. The constructors for almost all of the primitives have already been defined in C++. As such the syntax for creating a new C-API object is more the syntax of creating an object in C++ and wrapping it into a CAPI object. The lifetime of the pointer is therefore maintained by the CAPI object as it gets passed around in return objects.
include/mlir/Bindings/Python/NanobindAdaptors.h
As the CAPI object gets bounced around in memory, the ownership and lifetime of the data must eventually reach python to be controlled by the user. The implementation details are not relevant to this component as to how the data reaches python. This component provides the utility to create copies of the underlying data and send them through nanobind, effectively framing itself as the InterOp component between CAPI objects and their nanobind equivalents.
Through the carefully created contract between these components of the MLIR project, the IR primitives are exposed to Python, created in C++, and bounced off of the C-API. While I may have gleaned over the other supporting mechanisms in this explanation, explore the parent directories for these three files for a more detailed look into the semantics of ownership and such.
Defining the C-API.
For primitives to be defined for use in Python, they must first be implemented in C++. This is outside of the scope of the Python specific code, please refer to the rest of tt-mlir documentation for references on this. Once the C++ functionality is defined, the C-API must be constructed on top of this to serve as the "InterOp" layer.
get & Constructing C-API Objects
Since most constructors for IR primitives are created in C++, the goal is to construct objects in C++, but have the ownership exposed to Python. We do this through the creation of a Get function. The get function will essentially intake primitive C-types, and invoke the ::get operator in C++ to construct the object. A simple code example for the ttkernel.TileType is shown below:
include/ttmlir-c/TTTypes.h
// We export the function outside of the scope of "C" such that it can be defined later using C++ methods.
MLIR_CAPI_EXPORTED MlirType ttmlirTTTileTypeGet(MlirContext get, unsigned height, unsigned width, uin32_t dataType);
lib/CAPI/TTTypes.cpp
MlirType ttmlirTTTileTypeGet(MlirContext ctx, unsigned height, unsigned width, uint32_t dataType) {
// We return the **wrapped** created C++ object, transferring Ownership to the C-API
return wrap(
TileType::get(
unwrap(ctx), // Now we unwrap the MlirContext object to cast it to a mlir::MLIRContext object (w/o affecting ownership)
llvm::SmallVector<std::int64_t>{height, width}, // We construct the list here since a list isn't natively defined in the C-API,
static_cast<ttcore::DataType>(dataType) // Here we cast the int value to get the Enum value from `ttcore::DataType`
) // Invoking the builtin get operator to create and get the pointer for some object
);
}
The key details to note are the reliance on C++ methods in the get definition like initializer lists. By leveraging the InterOp the get method will return a pointer which can easily be represented in the C-API and owned as such, while masking the complexities of the C++ underneath from nanobind. Definitions such as these must either be written by hand (as shown above), or they can automatically be generated for certain IR primitives. We will learn more about that below.
Generating Bindings
This section will outline the mechanism with which bindings are generated, and the intricacies of this step.
Declaring Python Bindings
The first step to kicking off binding generation is to declare that they should exist for some dialect. MLIR provides a CMake module (AddMLIRPython) which exposes the following utility functions which can be declared to state what Python bindings are generated. For more information about the specific arguments and expected structure of these CMake functions refer to the AddMLIRPython module and python/CMakeLists.txt.
declare_mlir_python_sources
Overview
This function provides an interface to directly copy .py source files into the final built python module.
Key Arguments
ADD_TO_PARENTdefines the Parentnameto which this source will be added to, inheriting the location.
Usecases
- We use it to declare generic "Parents" which contain the generated/declared python files from many of the submodules within the dialects.
- We use it to directly copy over key test infrastructure like
ttir_builderas purely python programmed modules.
declare_mlir_dialect_python_bindings
Overview
This function is the key to invoking the mechanism to generate python bindings from Tablegen Definitions.
Key Arguments
TD_FILERelative toROOT_DIR, where the Tablegen Definition file to build bindings off of is located. Note: This currently just forwards the TD files frominclude/ttmlir/Dialect.SOURCESRaw python files associated with bindings. Note: These files will essentially forward the generated modules forward.GEN_ENUM_BINDINGS_TD_FILEifGEN_ENUM_BINDINGSisON, this will build enum bindings from the defined Tablegen file.DIALECT_NAMEWhat name the dialects should be generated under.
Usecases
- We use this CMake function to define and generate the bindings for the
ttkernel,ttir,tt, andttnndialects.
declare_mlir_python_extension
Overview
This is the CMake function used to link C++ Source Files + declared nanobinds into the generated python module.
Key Arguments
EMBED_CAPI_LINKS_LIBSThis is to declare the libraries used to link against the CAPI in the bindings. Learn more in the CAPI section below.PRIVATE_LINK_LIBSDeclares other libraries that are linked against the Python bindings.
Usecases
- We use this function to build and link all of our custom
nanobinds and hand-written Type/Attr bindings into thettmlirmodule.
add_mlir_python_common_capi_library
Overview
This function adds a shared library embedding all of the core CAPI libs needed to link against extensions.
add_mlir_python_modules
Overview
This is the final packaging function of the python bindings, linking all of the sources together and packaging it into a built module.
Building MLIR Primitives from Tablegen
The declare_mlir_dialect_python_bindings leverages a mechanism of the mlir-tblgen to build the python bindings for some defined dialect. What are the intricacies of this functionality?
mlir-tblgen
This tool parses .td Tablegen files to automatically generate C++ code to implement that functionality in MLIR. We leverage the Tablegen language to define our dialects in tt-mlir, and this tool is exactly what gets invoked to build and generate the code to functionally use this dialect in our codebase.
Trivial Constructors
To deal with automatically generating the functionality around an Operation, a certain amount of generality is needed to deem the problem trivial enough to generate. All of the IR primitives are thankfully able to be constructed from .td to their relevant C++ implementations. However, as shown in the TileType example, the conversion from simple C primitives (+ pre-defined MLIR C-API types) to C++ get functions isn't trivial. For this reason, we can start to analyze the IR primitives and deem which ones are trivial for C-API generation, and which must be implemented by hand.
enum- The enum type can be considered very generic. With the underlying data storage type being integral values, and an optional
Stringrepresentation in MLIR. By iterating over all of the user defined enum values, a very trivial constructor can be made to automatically generateenums.
- The enum type can be considered very generic. With the underlying data storage type being integral values, and an optional
operation- Operations are a unique case where the constructor isn't often generic enough; however, the
OperationStateexists as a strictly defined struct which contains all of the relevant construction details and implementation requirements for an operation. For this reason, while it is not trivial, it is generic enough that theOperationStatecan be relied on to form a mechanism which automatically generates C-API builders.
- Operations are a unique case where the constructor isn't often generic enough; however, the
Types/Attributes- Types and Attributes unfortunately receive the short end of the stick. Their constructors are wildly generic, and there is no baseline for what is required in the construction of a Type/Attr. For this reason, at the current moment these primitives aren't supported for automatic generation in
mlir-tblgen, and must be defined by hand.
- Types and Attributes unfortunately receive the short end of the stick. Their constructors are wildly generic, and there is no baseline for what is required in the construction of a Type/Attr. For this reason, at the current moment these primitives aren't supported for automatic generation in
Writing Bindings
With the understanding that not all bindings can be automatically generated for us, we can head into the intricacies of defining your own bindings for Types/Attrs.
LLVM-Style Pythonic "Type Information" + Casting
An important caveat to introduce before entering the domain of writing our own bindings is the understanding of how MLIR approaches the problem of downcasting w.r.t. IR primitives. Considering the C-API doesn't have an inheritance structure, Python is required to uphold the inheritance structure and hold the type information such that casting is possible between primitives and their specific implementation (ex: going from MlirAttribute -> TTNNLayoutAttr).
This mechanism can be exposed to Python in multiple different ways, where MLIR supports a specific implementation of an mlir_attribute_class and mlir_type_class which intake 2 additional C-API functions. To initialize a class using this structure the following functions are required:
myAttributeGet: to construct the Type/AttrmyAttributeGetTypeID: provides a unique static TypeID formyAttributeisAMyAttribute: boolean to see if higher level type is of the same type.
This will then provide an interface where in python a type can be cast by calling the constructor method of some downcasted type:
# Example to downcast using MLIR provided methods.
my_attribute = mlir.MyAttribute(attr: _mlir.ir.MlirAttribute)
Choosing a direct C++ structure instead of C-API
Those who are familiar with the tt-mlir python bindings may be aware that our code structure looks drastically different from this, why is that? The answer lies in the redundancy and lack of extensive use of the nanobind mechanisms around tt-mlir Python bindings.
As mentioned in the C-API section, the C-API is required to form the contract between C++ -> Python, to reduce the collisions with RTTI and the unstable ABI from C++. That being said, it's not unsupported to still directly access C++ members from nanobind and skip the C-API Builder functions, instead just opting to create in C++ directly and then wrap that result. This is the approach taken "consciously" in the tt-mlir python bindings.
What are the consequences of this design decision? The advantages?
Direct MLIR Casting Support
Instead of relying on Python for casting, and defining C-API functions to support this functionality; this approach allows us to directly use mlir::isa, mlir::cast, etc... in it's place.
For example, we support tt_attribute_class and tt_type_class, which leverage isa and dyn_cast to downcast to Types and Attrs by wrapping the Python types and operating on the underlying C++ types.
This also brings about some potential collisions with RTTI from nanobind. None are present in the bindings (as far as I know), but the bindings are exposed to this problem moving forward.
Simpler Initialization Structures
Instead of having to invoke a C-API function to define the get method in nanobind we can directly invoke the wrap(CppType::get(...)) functionality that the C-API ends up calling. The primary difference is the native support for complex data structures like vector and map through nanobind. Take for example the following initialization for an attribute:
// C-API Definition for myAttributeGet
MlirAttribute myAttributeGet(MlirContext ctx, int* array, size_t arraySize) {
return wrap(MyAttribute::get(ctx, std::vector<int>{array, array + arraySize}));
}
// nanobind direct invocation
tt_attribute_class(m, "MyAttribute")
.def_static("get", [](MlirContext ctx, std::vector<int> arr) {
return wrap(MyAttribure::get(ctx, arr));
})
// nanobind invocation through C-API
mlir_attribute_class(m, "MyAttribute", myAttributeGetTypeId, isAMyAttribute)
.def_static("get", [](MlirContext ctx, std::vector<int> arr) {
return myAttributeGet(ctx, arr.data(), arr.size());
})
// Note: While this may seem like a trivial change, the cost for retaining the function signature in C begins to grow very quickly. Especially when considering maps and more complex data structures.
Again, this does come with some nuances w.r.t. the ABI, but for our simple usecase of the bindings it can be considered acceptable...
Wait... why are we still defining the CAPI Builders Then?
This leads to an underlying question: What's the point of still defining the CAPI functions if we actually never end up using them? The answer is that we would ideally still maintain the infrastructure to backtrack our changes if we end up making more extensive use of the Python bindings and come across nasty ABI/RTTI issues, or MLIR upstreams significant changes to the Python bindings where we would have to leverage their architecture. With regards to the latter, I have asked some of the contributors and received "iffy" responses, with the general answer being that major changes are not planned for the MLIR Python bindings infrastructure.
That being said, for the low low cost of a few redundant functions being defined, we have a clear backup route in case the Python bindings blow up in our faces. I do think this argument is built on significant personal opinion, in the future we may change the strategy for the bindings. For now, it makes the structure of our python code cleaner, while having a clear route forward if something breaks.
Each MLIR project I've used as a reference approaches the problems differently. AFAIK the bindings are generally defined however the end user desires to invoke them :)
General Structure
Considering that mlir-tblgen will handle the generation of the underlying C++ code, we only need to define the C Builders and the nanobinds for each of the Types/Attrs we would like to add.
This often comprises of the following contributions:
- Declaring the C-API Header Function(s) in
include/ttmlir-c - Defining the C-API Function(s) in
lib/CAPI - Writing out the
nanobindfor that Type/Attr inpython/.
Example: Defining ttkernel Python Bindings
In this section, we will go through a worked example on the different steps required to expose functionality for the TTKernel dialect.
- We will continue while assuming that the TTKernel dialect has been defined using Tablegen and already has a valid target that compiles the C++ functionality. We will also assume that the current CMake build targets and functionality that uphold the rest of the
ttmlirdialects already exists. - Declare and register the TTKernel dialect in the C-API by calling the
MLIR_DECLARE_CAPI_DIALECT_REGISTRATION(TTKernel, ttkernel);macro ininclude/ttmlir-c/Dialects.h:
// File: include/ttmlir-c/Dialects.h
#include "mlir-c/IR.h"
#ifdef __cplusplus
extern "C" {
#endif
MLIR_DECLARE_CAPI_DIALECT_REGISTRATION(TTKernel, ttkernel);
#ifdef __cplusplus
}
#endif
- Declare CAPI Builder for all of the Types (namely only
CBTypeneeds to be implemented) ininclude/ttmlir-c/TTKernelTypes.h
// File: include/ttmlir-c/TTKernelTypes.h
#include "ttmlir-c/Dialects.h"
#ifdef __cplusplus
extern "C" {
#endif
MLIR_CAPI_EXPORTED MlirType ttmlirTTKernelCBTypeGet(
MlirContext ctx, uint64_t port, uint64_t address,
MlirType memrefType);
#ifdef __cplusplus
}
#endif
- Declare the CAPI builder target in
lib/CAPI/CMakeLists.txtby addingTTKernelTypes.cppas a source to TTMLIRCAPI. - Define the Dialect by formally applying the generated Dialect type into the
CAPI_DIALECT_REGISTRATIONmacro.
// File: lib/CAPI/Dialects.cpp
#include "ttmlir-c/Dialects.h"
#include "mlir/CAPI/Registration.h"
#include "ttmlir/Dialect/TTKernel/IR/TTKernel.h"
MLIR_DEFINE_CAPI_DIALECT_REGISTRATION(
TTKernel, ttkernel, mlir::tt::ttkernel::TTKernelDialect)
- Define the CAPI
getmethod forCBType
// File: lib/CAPI/TTKernelTypes.cpp
#include "ttmlir-c/TTKernelTypes.h"
#include "mlir/CAPI/IR.h"
#include "mlir/CAPI/Support.h"
#include "ttmlir/Dialect/TTKernel/IR/TTKernelOpsTypes.h"
using namespace mlir::tt::ttkernel;
MlirType ttmlirTTKernelCBTypeGet(MlirContext ctx, MlirType memrefType) {
return wrap(CBType::get(unwrap(ctx), mlir::cast<mlir::MemRefType>(unwrap(memrefType))));
}
- Define the
nanobindbuild target inpython/CMakeLists.txtby addingttkernelas a dialect, and providingTTkernelModule.cppas a source forTTMLIRPythonExtensions.Main.
# Define ttkernel dialect
declare_mlir_dialect_python_bindings(
ADD_TO_PARENT TTMLIRPythonSources.Dialects
ROOT_DIR "${TTMLIR_PYTHON_ROOT_DIR}"
TD_FILE dialects/TTKernelBinding.td
SOURCES dialects/ttkernel.py
DIALECT_NAME ttkernel
)
- Create
python/dialects/TTKernelBindings.tdto forward the tablegen for TTKernel to the CMake dialect target:
include "ttmlir/Dialect/TTKernel/IR/TTKernelOps.td"
- Create
nanobindmodule for TTKernel Dialect inpython/TTMLIRModule.cpp
// Representation of the Delta you have to add to TTMLIRModule.cpp in the correct locations
NB_MODULE(_ttmlir, m) {
m.doc() = "ttmlir main python extension";
m.def(
"register_dialect",
[](MlirContext context, bool load) {
MlirDialectHandle ttkernel_handle mlirGetDialectHandle__ttkernel__();
mlirDialectHandleRegisterDialect(ttkernel_handle, context);
if (load) {
mlirDialectHandleLoadDialect(ttkernel_handle, context);
}
},
py::arg("context"), py::arg("load") = true);
auto ttkernel_ir = m.def_submodule("ttkernel_ir", "TTKernel IR Bindings");
mlir::ttmlir::python::populateTTKernelModule(ttkernel_ir);
}
- Define
populateTTKernelModuleinpython/TTKernelModule.cpp
// File: python/TTKernelModule.cpp
#include <vector>
#include "ttmlir/Bindings/Python/TTMLIRModule.h"
#include "mlir/CAPI/IR.h"
#include "ttmlir-c/TTKernelTypes.h"
#include "ttmlir/Dialect/TTKernel/IR/TTKernelOpsTypes.h"
namespace mlir::ttmlir::python {
void populateTTKernelModule(py::module &m) {
tt_type_class<tt::ttkernel::CBType>(m, "CBType")
.def_static("get",
[](MlirContext ctx, uint64_t port, uint64_t address,
MlirType memrefType) {
return ttmlirTTKernelCBTypeGet(ctx, port, address,
memrefType);
// Note that for more complex constructors / out of ease this could also be defined using the wrap(CBType::get) style constructor.
})
.def_prop_ro("shape", [](tt::ttkernel::CBType &cb) {
cb.getShape().vec();
})
.def_prop_ro("memref", &tt::ttkernel::CBType::getMemref);
}
} // namespace mlir::ttmlir::python
- Finally, expose the built python bindings using a "trampoline" python file in
python/dialects/ttkernel.py
from ._ttkernel_ops_gen import *
from .._mlir_libs._ttmlir import register_dialect, ttkernel_ir as ir
# Import nanobind defined targets into ttkernel.ir, and the rest of the generated Ops into the top-level ttkernel python module.
Concluding The Example
While there are quite a few steps for adding a whole new dialect, often times more than not you will only need a subset of these steps to add a new Type/Attr to some existing dialect. Even less to modify the signature of some existing Type/Attr in the bindings.
Using the Python Bindings
This section will cover the basics of using the Python bindings. I think the folks at MLIR have produced documentation that can help you get up to speed quickly. This section will go over some of the nuances of using the python bindings that ttmlir has defined explicitly.
Interfacing with Generated Op Classes
The unfortunate reality is that documentation for autogenerated Ops isn't present. Fortunately, argument names are preserved and the function structure can be invoked by leveraging the help function in python. Iteratively running through the functions you want to implement can be helpful.
MLIRModuleLogger
Almost all of the python bindings behave exactly as expected coming from the ttmlir python bindings. A weird addition I think would provide some more context on nanobind and managed memory would be the MLIRModuleLogger.
This class is defined in C++ to attach to an existing MLIRContext, adding hooks to save the module to a std::vector<std::string, std::string>. Binding this forward through nanobind requires some delicacy about the state of this MLIRModuleLogger object. It needs to modify memory managed by C++, but it attaches to a context that exists in Python. This state management is done through nanobind owning and managing a thinly wrapped pointer to the C++ object by setting the return_value policy.
Using the Python bindings when traversing frequently through memory outside of the IR primitives requires some delicacy to ensure data is preserved and the code functions as intended.
Flatbuffers
Flatbuffers are the binary serialization format used by TTMLIR and they currently come in a few flavors (designated by the file extension):
.ttsys: A system description file that is the mechanism for supplying target information to the compiler. These can be collected on a target machine and downloaded to a development machine to enable cross-compilation..ttnn: A compiled binary file intended to be loaded and executed by the TTNN backend runtime..ttb: A compiled binary file intended to be loaded and executed by the TTMetal backend runtime (Unsupported).
LLVM Dependency Update
The TT-MLIR compiler has the following LLVM-related dependencies:
Dependency Hierarchy
- LLVM - Core LLVM infrastructure
- StableHLO - High-level operations dialect
- Depends on LLVM as an external dependency
- Shardy - Sharding and partitioning dialect
- Depends on StableHLO as an external dependency
Dependency Management
These projects are actively developed upstream, and our compiler code needs to occasionally update these dependencies to:
- Incorporate new features and optimizations
- Apply security patches and bug fixes
- Maintain compatibility with the broader LLVM ecosystem
Updating Cadence
We should update our compiler LLVM dependencies at least once every three months. The schedule for the next updates should be around:
- November 2025
- February 2026
- May 2026
Updating Dependencies
- Identify compatible versions across the dependency chain:
- Select the latest Shardy version from the main branch and record it as SHARDY_COMMIT

- On this commit of Shardy, we can obtain the used version of StableHLO:
STABLEHLO_COMMIT = "..."
- On this commit of StableHLO, we can obtain the used version of LLVM:
LLVM_COMMIT = "..."
- Prepare the development environment using the base tt-mlir IRD Ubuntu image. This clean Docker image lacks prebuilt dependencies, enabling fresh builds for dependency updates and troubleshooting:
ghcr.io/tenstorrent/tt-mlir/tt-mlir-base-ird-ubuntu-24-04:latest
- Synchronize with the latest tt-mlir main branch:
git pull
- Create uplift branch in the following format:
git checkout -b [alias]/[year]_[month]_llvm_dependency_update
# For example: sdjordjevic/2025_august_llvm_dependency_update
- Update dependency versions in the CMakeLists.txt configuration:
- LLVM_PROJECT_VERSION with LLVM_COMMIT obtained from step 1
- STABLEHLO_VERSION with STABLEHLO_COMMIT obtained from step 1
- SHARDY_VERSION with SHARDY_COMMIT obtained from step 1
- Build the local environment following this section of doc:
cmake -B env/build env
cmake --build env/build
- Build the tt-mlir compiler with runtime, optimizer and StableHLO enabled following this section of doc:
source env/activate
cmake -G Ninja -B build -DTTMLIR_ENABLE_RUNTIME=ON -DTTMLIR_ENABLE_OPMODEL=ON -DTTMLIR_ENABLE_STABLEHLO=ON -DCMAKE_CXX_COMPILER_LAUNCHER=ccache
cmake --build build
- Resolving Shardy patch compatibility issues:
- The most challenging aspect of dependency uplifts involves maintaining the Shardy patch. Since Shardy only supports Bazel builds, we maintain a custom patch to ensure CMake compatibility. Due to active upstream development, this patch typically requires updates during each dependency uplift. The most common error is something like this
CMake Error at /opt/ttmlir-toolchain/lib/cmake/llvm/AddLLVM.cmake:568 (add_library):
Cannot find source file:
constant_merger.cc
Tried extensions .c .C .c++ .cc .cpp .cxx .cu .mpp .m .M .mm .ixx .cppm
.ccm .cxxm .c++m .h .hh .h++ .hm .hpp .hxx .in .txx .f .F .for .f77 .f90
.f95 .f03 .hip .ispc
Call Stack (most recent call first):
/opt/ttmlir-toolchain/lib/cmake/mlir/AddMLIR.cmake:386 (llvm_add_library)
/opt/ttmlir-toolchain/src/shardy/shardy/dialect/sdy/transforms/export/CMakeLists.txt:35 (add_mlir_library)
- This indicates that library files have been renamed, moved, or deleted, requiring patch regeneration. To resolve this, navigate to the Shardy environment directory (e.g.,
/opt/ttmlir-toolchain/src/shardy/shardy/dialect/sdy/transforms/export/CMakeLists.txt) and update the library definition to reflect current .cc files. For example:
add_mlir_library(SdyTransformsExportPasses
close_shardings.cc
constant_or_scalar_merger.cc // Renamed from constant_merger.cc
drop_sharding_rules.cc
explicit_reshards_util.cc // Added as a new file, previously didn't exist
export_pipeline.cc
insert_explicit_reshards.cc
remove_propagation_debug_info.cc // Added as a new file, previously didn't exist
remove_sharding_groups.cc
reshard_to_collectives.cc
sharding_constraint_to_reshard.cc
sink_data_flow_edges.cc
update_non_divisible_input_output_shardings.cc // Removed temp_explicit_reshards_for_optimizations.cc as it doesn't exist anymore
- Another common error involves deleted libraries. If libraries were removed in the previous step, update the SHARDY_LIBS configuration for the TTMLIRCompilerStatic target:
CMake Error at /opt/ttmlir-toolchain/lib/cmake/llvm/AddLLVM.cmake:605 (add_dependencies):
The dependency target "SdyRoundtripImportShardyAttrs" of target
"obj.TTMLIRCompilerStatic" does not exist.
Call Stack (most recent call first):
/opt/ttmlir-toolchain/lib/cmake/mlir/AddMLIR.cmake:386 (llvm_add_library)
lib/CMakeLists.txt:71 (add_mlir_library)
- Missing symbol errors represent another category of common issues, typically manifesting as:
ld.lld: error: undefined symbol: mlir::sdy::log::LogMessageFatal::LogMessageFatal(mlir::sdy::log::LogMessageData)
>>> referenced by dialect.cc:265 (/opt/ttmlir-toolchain/src/shardy/shardy/dialect/sdy/ir/dialect.cc:265)
>>> dialect.cc.o:(mlir::sdy::MeshAttr::getAxisSize(llvm::StringRef) const) in archive lib/libSdyDialect.a
ld.lld: error: undefined symbol: mlir::sdy::log::LogMessage::stream()
>>> referenced by dialect.cc:265 (/opt/ttmlir-toolchain/src/shardy/shardy/dialect/sdy/ir/dialect.cc:265)
>>> dialect.cc.o:(mlir::sdy::MeshAttr::getAxisSize(llvm::StringRef) const) in archive lib/libSdyDialect.a
ld.lld: error: undefined symbol: mlir::sdy::log::LogMessageFatal::~LogMessageFatal()
>>> referenced by dialect.cc:265 (/opt/ttmlir-toolchain/src/shardy/shardy/dialect/sdy/ir/dialect.cc:265)
>>> dialect.cc.o:(mlir::sdy::MeshAttr::getAxisSize(llvm::StringRef) const) in archive lib/libSdyDialect.a
clang++-20: error: linker command failed with exit code 1 (use -v to see invocation)
- This error pattern is similar to the file renaming issue but occurs when new files are added to Bazel build targets without corresponding updates to our CMake equivalents. To resolve this, examine the Shardy environment directory (e.g.,
/opt/ttmlir-toolchain/src/shardy/shardy/common/CMakeLists.txt) and ensure all .cc files are included in the library definition. For example:
add_mlir_library(SdyCommonFileUtils
file_utils.cc
logging.cc // Added new file, previously didn't exist
save_module_op.cc
- After fixing the shardy patch errors locally in your shardy environment folder, we need to create a patch diff with all your changes in shardy directory. Follow these steps to produce the updated shardy patch:
# First we need to undo the commit from already applied patch so we can get the diffs
git reset --soft HEAD~1
# Produce the full diff patch including the staged changes from the previous patch (--cached)
git diff --cached > shardy.patch
# Copy generated patch to env folder to update the patch
cp shardy.patch ../../../tt-mlir/env/patches/
- Since patches are applied during environment builds, verification requires rebuilding both the environment and project:
cmake -B env/build env
cmake --build env/build
source env/activate
cmake -G Ninja -B build -DTTMLIR_ENABLE_RUNTIME=ON -DTTMLIR_ENABLE_OPMODEL=ON -DTTMLIR_ENABLE_STABLEHLO=ON -DCMAKE_CXX_COMPILER_LAUNCHER=ccache
cmake --build build
- Address MLIR and LLVM API compatibility issues:
- LLVM updates frequently introduce breaking changes to API signatures and interfaces
- Build failures typically manifest as incorrect function signatures or deprecated API usage
- Review compilation errors and update code to match current LLVM APIs
- Create and submit the update pull request:
- Commit all changes with descriptive messages
- Push the branch to the remote repository
- Create a PR with the title format: "[Year] [Month] LLVM Dependency Update"
- Verify CI pipeline success:
- Ensure all CI checks pass
- Confirm tt-mlir test suite completion without failures
- Validate frontend compatibility:
- Obtain the commit ID from your latest uplift branch commit:
- Execute On PR actions for each frontend repository:
- Run CI workflows from the main branch using the tt-mlir commit from step 1
CI
Our CI infrastructure is currently hosted in the cloud. Cloud machines are used and linked as GitHub runners.
Overview
CI automatically triggers on:
- Pull requests - validates code changes before merging
- Pushes to main - typically when PRs are merged
- Nightly runs - comprehensive testing with all components
- Uplift PRs - special PRs that update tt-metal to the latest version
The CI system automatically collects analytics data from each workflow run, including test results and code coverage. It also publishes the latest documentation to GitHub.
Builds
CI performs several types of builds:
Release Builds
- speedy - optimized for performance and speed
- tracy - includes runtime tracing and debug capabilities with performance measurements
Development Builds
- Debug build - includes unit tests and code coverage collection
- MacOS build - ensures cross-platform compatibility
- Wheels - Python package distributions
- Clang-tidy - static code analysis
Release builds include the runtime needed to execute on TT hardware, making them suitable for integration testing. The debug build runs unit tests and generates code coverage reports that are published to Codecov with detailed results linked in PR comments.
Release Build Components
Release builds do more than just compile tt-mlir - they also prepare tests, build tools, and create wheels. Components are configured in .github/settings/build.json:
{ "image": "tracy", "script": "explorer.sh" }
- image: Specifies which release build to use (
speedyortracy) - script: Build script located in
.github/build_scripts/ - if (optional): Links to optional components - only builds when that component is enabled
Before running build scripts, the workflow will activate the default TT-MLIR Python venv and set a number of useful environment variables:
- WORK_DIR - set to repo root
- BUILD_DIR - set to build artifacts
- INSTALL_DIR - set to install artifacts
- BUILD_NAME - name of the build image
Uploading Artifacts from Build Scripts
Build scripts can upload their output files as artifacts for later use in testing. This is especially important for optional components that may not always run.
How it works:
- Build scripts write artifact information to a JSON file specified by the
$UPLOAD_LISTenvironment variable - Each artifact entry contains a
name(identifier) andpath(file location) - The CI system automatically uploads these artifacts after the build completes
Example:
echo "{\"name\":\"ttrt-whl-$BUILD_NAME\",\"path\":\"$WORK_DIR/build/tools/ttrt/build/ttrt*.whl\"}," >> $UPLOAD_LIST
This example uploads Python wheel files with a descriptive name that includes the build type.
Please note
>>as it appends to existing list.
Optional Components
As the codebase grows, CI can become slow and bloated. To keep development efficient, some components are made optional and only run when needed:
When optional components run:
- ✅ Nightly builds (full testing)
- ✅ Uplift PRs (tt-metal version updates)
- ✅ PRs that modify the component's code
- ❌ Regular PRs (unless component files changed)
Good candidates for optional components:
- Mature, stable features that rarely break
- Legacy code that's still supported but not actively developed
- Rarely-used functionality where breakage isn't critical
- Time-intensive wheel builds (when functionality is tested elsewhere)
Configuring Optional Components
Define components in .github/settings/optional-components.yml:
component_name:
- path/to/files/*.py
- specific/file.py
- another/directory/**
The component name can then be referenced in build and test configurations in "if" field:
Example:
emitc:
- test/ttmlir/EmitC/**
- tools/ttnn-standalone/ci_compile_dylib.py
- include/ttmlir/Conversion/TTNNToEmitC/**
- lib/Conversion/TTNNToEmitC/**
Build example:
{ "image": "speedy", "script": "emitc.sh", "if": "emitc" }
Test example:
{ "runs-on": "n150", "image": "speedy", "script": "emitc.sh", "if": "emitc" }
This makes the EmitC component optional - it only builds/tests when EmitC-related files are modified in a PR.
Testing
Testing is performed inside the call-test.yml workflow as run-tests jobs. It uses a matrix strategy, which means that multiple jobs are created and executed on multiple machines using the same job task.
Tests
The tests are defined by a JSON file tests.json inside the .github/settings directory.
Each row in the JSON array represents a test that will execute on a specific machine using a specified (release) build image.
Example:
{ "runs-on": "n150", "image": "tracy", "script": "pykernel.sh" },
{ "runs-on": "n300", "image": "speedy", "script": "ttrt.sh", "args": ["run", "Silicon", "--non-zero"] },
runs-on
Specifies the machine on which the test suite will be executed. Currently supported runners are:
- n150 - Wormhole 1 chip card
- n300 - Wormhole 2 chip card
- llmbox - Loudbox machine with 4 N300 cards
- tg - Galaxy box
- p150 - Blackhole 1 chip card
It is expected that the list will expand soon as machines with blackhole chip family are added to the runner pool.
image
Specifies which release build image to use. It can be:
- speedy
- tracy
Please take a look at the Builds section for a more detailed description of the builds.
script
Test type. It is the name of the BASH script that executes the test. Scripts are located in the .github/test_scripts directory,
and it is possible to create new test types simply by adding scripts to the directory.
args (optional)
This field represents the arguments for the script. This can be omitted, a string, or a JSON array.
reqs (optional)
Specifies additional requirements for test execution. These arguments are passed as the REQUIREMENTS environment variable to the test script.
if (optional)
Specifies the name of optional component. The test will be executed only if optional component is enabled.
Using JSON arrays
The runs-on and image fields can be passed as JSON arrays. With arrays, one can define a test to execute on multiple machines and images. Examples:
{ "runs-on": ["n150","n300"],
"image": ["speedy","tracy"],
"script": "unit" }
Adding New Test
Usually, it is enough to add a single line to the test matrix and your tests will become part of the tt-mlir CI. Here is a checklist of what you should decide before adding it:
- On which TT hardware should your tests run? Put the specific hardware in the "runs-on" field.
- Do your tests run with
ttrtorpytestor any other standard type that other tests also use? Put this decision in the "script" field. - Refer to the test script you've put in the type for interpretation of
argsandreqsparameters.
Each line in the matrix MUST be unique! There is no point in running the same test with the same build image on the same type of hardware.
Consider
Here are a few things to consider:
- Design your
ttrttest so it is generated with a-- check_ttmlirCMake target. These will be generated at compile time and will be available for test jobs. - For pytest, use pytest test discovery to run all tests in subdirectories. In most cases, there is no need for two sets of tests.
- If you want to have separate test reports, do not add additional XML file paths and steps to upload these.
Use
${TTRT_REPORT_PATH}(for ttrt JSON files) or${TEST_REPORT_PATH}(for JUnit XML) because it will be automatically picked up and sent to analytics. - If separate reports are required, treat them as different tests. Add an additional line to the test matrix.
You can use a construct from this example:
cp run_results.json ${TTRT_REPORT_PATH%_*}_ttir_${TTRT_REPORT_PATH##*_}
Adding New Test Script
To design a new test script, add new files to .github/test_scripts
Make sure you set the execution flag for the new test script file (
chmod +x <file>)!
Before running test scripts, the workflow will activate the default TT-MLIR Python venv and set a number of useful environment variables:
- WORK_DIR - set to repo root
- BUILD_DIR - set to build artifacts
- INSTALL_DIR - set to install artifacts
- LD_LIBRARY_PATH - set to install artifacts
liband toolchainlibdirectories - SYSTEM_DESC_PATH - set to
system_desc.ttsyssystem descriptor file generated byttrt - TT_METAL_RUNTIME_ROOT - set to
tt-metalinstall directory - RUNS_ON - machine label script runs on
- IMAGE_NAME - name of the image script runs on
- RUN_ID - id of workflow run, see below.
Also, a soft link is created inside the build directory to the install directory.
Please make sure you implement cleanup logic inside your script and leave the script with the repo in the same state as before execution!
A good practice is to put some comments on how the script interprets arguments (and requirements if applicable).
For example builder.sh:
# arg $1: path to pytest test files
# arg $2: pytest marker expression to select tests to run
# arg $3: "run-ttrt" or predefined additional flags for pytest and ttrt
runttrt=""
TTRT_ARGS=""
PYTEST_ARGS=""
[[ "$RUNS_ON" != "n150" ]] && PYTEST_ARGS="$PYTEST_ARGS --require-exact-mesh"
for flag in $3; do
[[ "$flag" == "run-ttrt" ]] && runttrt=1
[[ "$flag" == "require-opmodel" ]] && PYTEST_ARGS="$PYTEST_ARGS --require-opmodel"
done
pytest "$1" -m "$2" $PYTEST_ARGS -v --junit-xml=$TEST_REPORT_PATH
if [[ "$runttrt" == "1" ]]; then
ttrt run $TTRT_ARGS ttir-builder-artifacts/
cp run_results.json ${TTRT_REPORT_PATH%_*}_ttir_${TTRT_REPORT_PATH##*_} || true
ttrt run $TTRT_ARGS stablehlo-builder-artifacts/
cp run_results.json ${TTRT_REPORT_PATH%_*}_stablehlo_${TTRT_REPORT_PATH##*_} || true
fi
This script has several types of flags that can be stated concurrently. Arguments are parsed as run-ttrt and other
possible flags for pytest or ttrt. This test uses TTRT_REPORT_PATH, but due to the fact that it has two ttrt runs, it inserts its type inside the filename.
The second example is pytest.sh script:
if [ -n "$REQUIREMENTS" ]; then
eval "pip install $REQUIREMENTS"
fi
export TT_EXPLORER_GENERATED_MLIR_TEST_DIRS=$BUILD_DIR/test/ttmlir/Silicon/TTNN/n150/perf,$BUILD_DIR/test/python/golden/ttnn
export TT_EXPLORER_GENERATED_TTNN_TEST_DIRS=$BUILD_DIR/test/python/golden/ttnn
pytest -ssv "$@" --junit-xml=$TEST_REPORT_PATH
This script uses $REQUIREMENTS to specify additional wheels to be installed. Note how it uses the eval command to expand bash variables where suitable. It also defines some additional environment variables using the provided ones.
Downloading Artifacts
If you need to download artifacts (e.g., wheels) from a workflow run, you can use the following command:
gh run download $RUN_ID --repo tenstorrent/tt-mlir --name <artifact_name>
This command downloads the specified artifact to the current directory. You can specify a different download location using the --dir <directory> option.
To download multiple artifacts matching a pattern, use the --pattern option instead of --name:
gh run download $RUN_ID --repo tenstorrent/tt-mlir --pattern "tt_*.whl"
Note: When using --pattern, artifacts are downloaded into separate subdirectories, even when --dir is specified.
CI Run (under the hood)
Test runs are prepared in the prepare-run job when the input test matrix is transformed into a job test matrix that will be used for test runs.
All jobs are grouped based on runs-on and image fields and then split (and balanced) into several runs based on test durations and target total time.
This is done to make efficient use of resources because there are many tests that last for just several seconds while preparation can take ~4 minutes.
So, tests are run in batches in the Run Test step with clear separation and summary. Lists of tests are displayed at the beginning, and one can search for test <number>
(number ranges from 1 to total number of tests) when needing to see test flow and test results for a particular test. Also, it is possible during development
to comment out tests in the JSON file of Test Matrix using the # character in a development branch and make test runs much faster, but
please do not forget to remove comments when a PR is created or finalized.
Test durations are collected after each push to main, and these are automatically used on each subsequent PR, Push, and other runs.
Additional Reading
This section contains pointers to reading material that may be useful for understanding the project.
MLIR
- https://llvm.org/docs/tutorial/MyFirstLanguageFrontend/index.html
- https://mlir.llvm.org/docs/Tutorials/Toy/
- https://www.jeremykun.com/2023/08/10/mlir-getting-started/
- https://arxiv.org/pdf/2002.11054
- https://ieeexplore.ieee.org/abstract/document/9370308
Dialects
- affine dialect
- Affine map is a really powerful primitive that can be used to describe most data movement patterns.
- It can also be used to describe memory layouts.
- linalg dialect
- tosa dialect
- tosa spec
- memref dialect
- torch-mlir
- onnx-mlir
- triton-mlir
Tablegen
LLVM Testing Framework Tools
Jax
Flatbuffer
Openxla Website
openxla
StableHLO
Contributor Covenant Code of Conduct
Our Pledge
We as members, contributors, and leaders pledge to make participation in our community a harassment-free experience for everyone, regardless of age, body size, visible or invisible disability, ethnicity, sex characteristics, gender identity and expression, level of experience, education, socio-economic status, nationality, personal appearance, race, religion, or sexual identity and orientation.
We pledge to act and interact in ways that contribute to an open, welcoming, diverse, inclusive, and healthy community.
Our Standards
Examples of behavior that contributes to a positive environment for our community include:
- Demonstrating empathy and kindness toward other people
- Being respectful of differing opinions, viewpoints, and experiences
- Giving and gracefully accepting constructive feedback
- Accepting responsibility and apologizing to those affected by our mistakes, and learning from the experience
- Focusing on what is best not just for us as individuals, but for the overall community
Examples of unacceptable behavior include:
- The use of sexualized language or imagery, and sexual attention or advances of any kind
- Trolling, insulting or derogatory comments, and personal or political attacks
- Public or private harassment
- Publishing others' private information, such as a physical or email address, without their explicit permission
- Other conduct which could reasonably be considered inappropriate in a professional setting
Enforcement Responsibilities
Community leaders are responsible for clarifying and enforcing our standards of acceptable behavior and will take appropriate and fair corrective action in response to any behavior that they deem inappropriate, threatening, offensive, or harmful.
Community leaders have the right and responsibility to remove, edit, or reject comments, commits, code, wiki edits, issues, and other contributions that are not aligned to this Code of Conduct, and will communicate reasons for moderation decisions when appropriate.
Scope
This Code of Conduct applies within all community spaces, and also applies when an individual is officially representing the community in public spaces. Examples of representing our community include using an official e-mail address, posting via an official social media account, or acting as an appointed representative at an online or offline event.
Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be reported to the community leaders responsible for enforcement at nsmith@tenstorrent.com or staylor@tenstorrent.com. All complaints will be reviewed and investigated promptly and fairly.
All community leaders are obligated to respect the privacy and security of the reporter of any incident.
Enforcement Guidelines
Community leaders will follow these Community Impact Guidelines in determining the consequences for any action they deem in violation of this Code of Conduct:
1. Correction
Community Impact: Use of inappropriate language or other behavior deemed unprofessional or unwelcome in the community.
Consequence: A private, written warning from community leaders, providing clarity around the nature of the violation and an explanation of why the behavior was inappropriate. A public apology may be requested.
2. Warning
Community Impact: A violation through a single incident or series of actions.
Consequence: A warning with consequences for continued behavior. No interaction with the people involved, including unsolicited interaction with those enforcing the Code of Conduct, for a specified period of time. This includes avoiding interactions in community spaces as well as external channels like social media. Violating these terms may lead to a temporary or permanent ban.
3. Temporary Ban
Community Impact: A serious violation of community standards, including sustained inappropriate behavior.
Consequence: A temporary ban from any sort of interaction or public communication with the community for a specified period of time. No public or private interaction with the people involved, including unsolicited interaction with those enforcing the Code of Conduct, is allowed during this period. Violating these terms may lead to a permanent ban.
4. Permanent Ban
Community Impact: Demonstrating a pattern of violation of community standards, including sustained inappropriate behavior, harassment of an individual, or aggression toward or disparagement of classes of individuals.
Consequence: A permanent ban from any sort of public interaction within the community.
Attribution
This Code of Conduct is adapted from the Contributor Covenant, version 2.0, available at https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
Community Impact Guidelines were inspired by Mozilla's code of conduct enforcement ladder.
For answers to common questions about this code of conduct, see the FAQ at https://www.contributor-covenant.org/faq. Translations are available at https://www.contributor-covenant.org/translations.
Project Structure
env: Contains the environment setup for building project dependencies, such as LLVM and Flatbuffersinclude/ttmlir: Public headers for the TTMLIR libraryDialect: MLIR dialect interfaces and definitions, dialects typically follow a common directory tree structure:IR: MLIR operation/type/attribute interfaces and definitionsPasses.[h|td]: MLIR pass interfaces and definitionsTransforms: Common MLIR transformations, typically invoked by passes
Target: Flatbuffer schema definitions. This defines the binary interface between the compiler and the runtime
lib: TTMLIR library implementationCAPI: C API for interfacing with the TTMLIR library, note this is needed for implementing the python bindings. Read more about it here: https://mlir.llvm.org/docs/Bindings/Python/#use-the-c-apiDialect: MLIR dialect implementations
runtime: Device runtime implementationinclude/tt/runtime: Public headers for the runtime interfacelib: Runtime implementationtools/python: Python bindings for the runtime, currently this is wherettrtis implemented
test: Test suitetools/ttmlir-opt: TTMLIR optimizer driver
Namespaces
mlir: On the compiler side, we use the MLIR namespace for all MLIR types and operations and subnamespace for our dialects.mlir::tt: Everything ttmlir related is underneath this namespace. Since we need to subnamespace undermlir, justmlir::ttseemed better thanmlir::ttmlirwhich feels redundant.mlir::tt::ttir: The TTIR dialect namespacemlir::tt::ttnn: The TTNN dialect namespacemlir::tt::ttmetal: The TTMetal dialect namespacemlir::tt::ttkernel: The TTKernel dialect namespace
tt::runtime: On the runtime side, we use thett::runtimenamespace for all runtime types and operations.tt::runtime::ttnn: The TTNN runtime namespacett::runtime::ttmetal: The TTMetal runtime namespace (not implemented)
Dialects Overview
Here is a brief overview of the dialects in the project, please refer to the individual dialect documentation for more details.:
ttcore: Common types such as,ttcore.tile,ttcore.metal_layout,ttcore.grid, etc. and enums such as, data formats, memory spaces, iterator types etc.ttir: A high level dialect that models the tensor compute graph on tenstorrent devices. Acceptstosaandlinalginput.ttir.generic: Generically describe compute work.ttir.to_layout: Convert between different tensor memory layouts and transfer between different memory spaces.tensor.pad: Pad a tensor with a value (ie. convs)ttir.yield: return result memref of computation in dispatch region body, lowers tottkernel.yieldttir.kernel: lowers to some backend kernel
ttnn: A TTNN dialect that models ttnn API.ttkernel: Tenstorrent kernel library operations.ttkernel.noc_async_readttkernel.noc_async_writettkernel.cb_push_backttkernel.[matmul|add|multiply]: Computations on tiles in source register space, store the result in dest register space.ttkernel.sfpu_*: Computations on tiles in dest register space using sfpu coprocessor.
ttmetal: Operations that dispatch work from host to device.ttmetal.enqueue_program: Dispatch a grid of compute work.
Guidelines
This page contains a collection of guidelines to help maintain consistency and quality across our project. Please refer to the following documents for detailed instructions on coding practices, as well as specific dialect guidelines.
TT-MLIR Coding Guidelines
This document outlines the coding standards used in the tt-mlir project. These guidelines are designed to enhance the readability and maintainability of our shared codebase. While these guidelines are not strict rules for every situation, they are essential for maintaining consistency across the repository.
Our long-term aim is to have the entire codebase adhere to these conventions.
Since our compiler is built on the LLVM MLIR framework, we strive to align closely with the LLVM coding style guidelines outlined here: LLVM Coding Standards.
Naming
Clear and descriptive names are crucial for code readability and preventing bugs. It’s important to choose names that accurately reflect the semantics and purpose of the underlying entities, within reason. Avoid abbreviations unless they are widely recognized. Once you settle on a name, ensure consistent capitalization throughout the codebase to avoid confusion.
The general naming rule is to use camel case for most names (for example, WorkaroundPass, isRankedTensor())
- Type Names
- Applies to classes, structs, enums, and typedefs.
- Should be nouns that describe the entity's purpose.
- Use upper camel case (for example, TTNNOptimizerOptions, DecompositionPass).
- Variable Names
- Should be nouns, as they represent state.
- Use lower camel case (for example, inputLayout).
- Function Names
- Represent actions and should be verb phrases
- Use lower camel case (for example, createTTNNOptimizer(), emitTTNNAsCpp()).
Includes
We prefer #includes to be listed in this order:
- Main Module Header
- Local/Private Headers
- LLVM project/subproject headers (clang/..., lldb/..., llvm/..., etc)
- System #includes
Each category should:
- Be sorted lexicographically by the full path.
- Be separated by a single blank line for clarity.
Only the standard lib header includes should use <> whereas all the others should use quotes "". Additionally, all project headers must use absolute paths (rooted at ttmlir) to prevent preprocessor and namespacing issues. For example, the following is preferred:
#include "ttmlir/module/something.h"
over:
#include "something.h"
Using TTIRToTTNN.cpp as an example, this is what includes would look like for us:
#include "ttmlir/Conversion/TTIRToTTNN/TTIRToTTNN.h" # main header
#include "ttmlir/Dialect/TTCore/IR/TTCoreOpsTypes.h" # these are local/private headers
#include "ttmlir/Dialect/TTNN/Utils/Utils.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h" # llvm project/subproj headers
#include "llvm/Support/LogicalResult.h"
#include <cstdio> # system includes
#include <algorithm>
Comments
Write comments as full sentences, starting with a capital letter and ending with a period. Comments should explain why the code exists, not just what it does. Use comments to clarify logic, assumptions, or any non-obvious aspects of the code.
Example of a comment:
// Initialize the buffer to store incoming data from the network.
In general, C++ style comments (//) should be used. Use C-style comments (/**/) only for when documenting the significance of constants used as actual parameters in a call:
object.callFunction(/*arg0=*/nullptr);
Every function, class, or non-trivial piece of logic should have a comment. Avoid redundant comments for self-explanatory code, but never leave complex code unexplained. Example of redundant comment:
// Increment the counter by 1. // Redundant, avoid.
counter++;
Ensure comments are accurate and reflect the current state of the code. Outdated or misleading comments can be worse than no comments at all.
All TODO comments should be marked with an alias as follows:
// TODO (your-alias): Refactor this loop for clarity. Issue: https://github.com/tenstorrent/tt-mlir/issues/XYZ
A TT-MLIR issue should be created and linked inline to track the TODO.
Code Denesting (Inversion)
Strive to minimize unnecessary indentation without compromising code clarity. One effective way to achieve this is by using early exits and the continue keyword in long loops.
Consider following example:
void doSomething(Operation *op)
{
if (op->getNumOperands() > 0
&& isDpsOp(op)
&& doSomethingDifferent(op)) {
// ... some long code ...
}
}
It is strongly recommended to format the code as follows:
void doSomething(Operation *op)
{
// ...
// We need to do something with the op that has more than 0 operands
if (op->getNumOperands() <= 0) {
return;
}
// We need something to do with the DPS op
if (!isDpsOp(op)) {
return;
}
// Just for example purposes
if (!doSomethingDifferent(op)) {
return;
}
// .. some long code ...
}
This reduces loop nesting, makes the reasoning behind the conditions clearer, and signals to the reader that there is no subsequent else to worry about, reducing cognitive load. This can significantly improve code readability and comprehension.
Braces for Control Flow Statements
Always use braces for the body of if, else, for, while, and do-while statements, even when the body contains only a single statement. This rule is enforced in CI via the readability-braces-around-statements clang-tidy check.
Example of incorrect style:
if (condition)
doSomething();
for (int i = 0; i < n; i++)
process(i);
for (int i = 0; i < n; i++)
if (condition)
doSomething();
Example of correct style:
if (condition) {
doSomething();
}
for (int i = 0; i < n; i++) {
process(i);
}
while (isRunning) {
update();
}
do {
processNext();
} while (hasMore);
Function Declaration and Definition Order
To improve code readability and maintainability, we should adopt a consistent approach for organizing function declarations and definitions within a file. The goal is to make it easier for readers to follow the logical flow of function dependencies.
Follow a bottom-up call order:
- Arrange functions so that lower-level helper functions are defined first, followed by higher-level functions that call them.
- This allows each function to be defined after its dependencies, making it clear which functions rely on which.
- For example, if function A calls A1 and A2, then the preferred order is:
void A1();
void A2();
void A(){
A1();
A2();
}
Group related functions together:
- If functions are only relevant to a specific “parent” function (for example, A1 and A2 are only called by A), place them directly before the “parent” function.
- If a function (like A2) is also called by other functions (for example, B), place it where it fits the overall bottom-up order.
Avoid mixed ordering:
- Mixing top-down and bottom-up call orders within the same file can make the code hard to read and maintain.
Example of a preferred order:
void A1() {
/*...*/
}
void A2() {
/*...*/
}
void B() {
A2(); // A2 is defined before B, so dependencies are clear.
}
void A() {
A1();
A2();
B();
}
Helper Functions
These coding guidelines address visibility and linkage of simple helper functions to ensure clarity, prevent linking errors, and improve maintainability:
-
If a helper function needs to be defined in a .cpp file, it should be declared static or wrapped inside an anonymous namespace.
-
If a helper function needs to be defined in a header file (for example, for templated or performance-critical code), it should be marked as inline.
[!NOTE] A significant concern with declaring functions as non-public (for example, static functions or functions in unnamed namespaces) is that they cannot be unit tested in isolation. This limitation hinders our ability to write focused, granular tests that verify the correctness of individual components and it also reduces test coverage.
Using Namespaces
Namespaces are an important part of C++ programming, providing a way to organize code and avoid naming conflicts. Choose namespace names that reflect the purpose or functionality of the code contained within.
Follow these guidelines when defining namespaces:
- Use lower-case letters for short, single-word names or those with a clear acronym (for example, ttnn, mlir).
- Use nested namespaces to group logically related code, avoiding too deep or unnecessarily complex hierarchy
Follow these guidelines when using namespaces:
- Do not use a using-directive to make all names from a namespace available because it pollutes the namespace.
// Forbidden -- This pollutes the namespace.
using namespace std;
- Avoid placing code in the global namespace to reduce the potential for name conflicts and ambiguity. Always use specific namespaces. If necessary to use something from the global namespace (such as std), use an explicit std:: prefix rather than importing everything using using namespace std;.
- Do not use namespace aliases at namespace scope in header files except in explicitly marked internal-only namespaces, because anything imported into a namespace in a header file becomes part of the public API exported by that file.
- Try to avoid mixing concepts from different namespaces in a single function or class. If a function belongs to one namespace but calls classes from others, ensure the relationships are clear.
- Wrap classes/structs declared in .cpp files inside of an anonymous namespace to avoid violating ODR. See LLVM docs for more detailed information.
Using Alternative Tokens (and, or, xor, etc.)
Although they are standard, we should avoid their use. They are very rarely used in practice and the C++ community widely uses the standard operators (&&, ||, !, etc.), as they are more familiar and easily recognizable to most C++ developers. Their usage can make the code harder to read and maintain, especially for developers who are not familiar with these alternatives. We should stick to the standard operators (&&, ||, !, etc.) for clarity, consistency, and compatibility with other C++ developers and tools.
Type Aliasing
When declaring type aliases in C++ prefer using over typedef. using provides better readability, especially for complex types, and supports alias templates. Here is an example:
// Preferred
using Callback = void(*)(int, double);
// Avoid
typedef void (*Callback)(int, double);
Choose alias names that clarify their role in the code. Avoid overly generic names that might obscure the type’s purpose. Do not create a type alias unless it significantly improves clarity or simplifies complex types.
Using auto to Deduce Type
Use auto only when it enhances code readability or maintainability. Avoid defaulting to “always use auto.” Instead, apply it thoughtfully in the following scenarios:
- When the type is immediately clear from the initializer, such as in cast
(...). - When the type is obvious from the context, making the code cleaner and more concise.
- When the type is already abstracted, such as with container typedefs like std::vector
::iterator.
In all other cases, prefer explicit type declarations to maintain clarity and ensure the code remains easy to understand.
Python Coding Guidelines
Python Version and Source Code Formatting
The current minimum version of Python required is 3.12 or higher. Python code in the tt-mlir repository should only use language features available in this version of Python.
The Python code within the tt-mlir repository should adhere to the formatting guidelines outlined in PEP 8.
For consistency and to limit churn, code should be automatically formatted with the black utility, which is PEP 8 compliant. Use its default rules. For example, avoid specifying --line-length even though it does not default to 80. The default rules can change between major versions of black. In order to avoid unnecessary churn in the formatting rules, we currently use black version 23.x.
When contributing a patch unrelated to formatting, you should format only the Python code that the patch modifies. When contributing a patch specifically for reformatting Python files, use black, which currently only supports formatting entire files.
Here is a quick example, but see the black documentation for details:
$ black test.py # format entire file
TTNN Dialect Contribution Guidelines
This document provides clear and consistent guidelines for contributing to the TTNN dialect, including operations, attributes, types, and other components. Following these ensures a streamlined development process, faster code reviews, and higher-quality code with fewer bugs.
General Principle: Model TTNN Library Closely
The TTNN dialect should closely reflect the TTNN library wherever practical, serving as the core guiding principle when contributing to the dialect. Whenever there's a need to deviate from this principle, it should be discussed with stakeholders.
Ops and Operands
Signature Selection
Ops in TTNN may have multiple signatures available - it's important to choose the right one when creating its model in the TTNN dialect. Going through an example, these are the available signatures for the ttnn::transpose op:
struct ExecuteTranspose {
static ttnn::Tensor invoke(
uint8_t queue_id,
const ttnn::Tensor& input_tensor,
const int64_t& dim1,
const int64_t& dim2,
const std::optional<MemoryConfig>& memory_config_arg,
const std::optional<float>& pad_value = 0.0f);
static ttnn::Tensor invoke(
const ttnn::Tensor& input_tensor,
const int64_t& dim1,
const int64_t& dim2,
const std::optional<MemoryConfig>& memory_config,
const std::optional<float>& pad_value = 0.0f);
static ttnn::Tensor invoke(
const ttnn::Tensor& input_tensor,
const int64_t& dim1,
const int64_t& dim2,
const std::optional<float>& pad_value = 0.0f);
};
The first and second signature differ only in the queue_id parameter - we don't model queues today, so the second signature has priority here. The second and third signature differ in memory_config parameter - the second signature is preferred as it is more robust: the parameter is optional so it can remain unused if it isn't needed.
Only one signature should be chosen. If the need would arise for more than one signature, it would be a precedent, and should be discussed with stakeholders.
Operand ordering
Operands in the TTNN dialect ops should match the ordering of the signature of the op being modelled. For the chosen signature of the ttnn::transpose op, the operands should look like this:
let arguments = (ins AnyRankedTensor:$input,
SI64Attr:$dim0,
SI64Attr:$dim1,
OptionalAttr<TTNN_MemoryConfigAttr>:$memory_config,
OptionalAttr<FloatAttr>:$pad_value);
Mixing types and attributes within the ordering is not an issue, this is valid:
let arguments = (ins TTNN_ShapeAttr:$shape,
OptionalAttr<TT_DataTypeAttr>:$dtype,
OptionalAttr<TTNN_LayoutAttr>:$layout,
Optional<TT_Device>:$device,
OptionalAttr<TTNN_MemoryConfigAttr>:$memory_config);
Following this guideline provides consistency with the TTNN lib.
Optional operands
If an operand is optional in the TTNN lib, it should be modelled as optional in the dialect.
Default-valued operands
If an operand has a default value in the TTNN lib, it should have a default value in the dialect.
ttnn::permute as an example:
static ttnn::Tensor invoke(
const ttnn::Tensor& input_tensor,
ttsl::Span<const int64_t> dims,
const std::optional<MemoryConfig>& memory_config,
const std::optional<float>& pad_value = 0.0f);
let arguments = (ins AnyRankedTensor:$input,
DenseI64ArrayAttr:$permutation,
OptionalAttr<TTNN_MemoryConfigAttr>:$memory_config,
DefaultValuedOptionalAttr<F32Attr, "0.0f">:$pad_value);
Numerical operands
Numerical operands should match in signedness and bit width. If an operand is a signed integer of width of 32 bits, SI32Attr should be used to model it.
Pointers and references
Pointers and references should be ignored. We do not want to model this level of detail at this point in time.
There were very few issues with these previously, and they were caused by inconsistencies in TTNN lib APIs.
Attrs vs Types
General guideline is that if a value is known at compile time, it should probably be an Attr. Example: dims in transpose op, pooling windows in a conv, etc. If the value is unknown at compile time (e.g. tensor) it should be a Type.
There's another consideration to account for: does the value need its own SSA? Remember, Attrs need something to latch onto, like an op or a Type, but Types need to be constructed, i.e. have their own SSA, in order to exist. Let's look at ttnn::Shape for example - in TTNN lib, these need to be constructed, so it naturally follows that they should have their own SSA value within the IR, implying that they should be implemented as Types. However, there are several downsides to this:
- More IR is produced
- Diminished readability as they're not attached to the object whose shape they're describing
- Not as easy to construct in code
- Runtime would need to keep track of all the Shape objects (it currently maps all SSAs, which are currently only tensors and devices)
One upside for implementing ttnn::Shape as a Type is that it would enable optimizing out multiple constructor calls for the same Shape.
It is agreed that we should prefer using Attrs in these scenarios. However, this guideline is not set in stone - stakeholders should be notified if anyone believes there's a need to implement an object as a Type.
Destination-passing style (DPS)
If the op in TTNN lib has the destination tensor, is should be modelled as DPS op.
An example signature, where the last operand is a destination tensor:
static Tensor invoke(
const Tensor& input_tensor,
float exponent,
const std::optional<MemoryConfig>& memory_config = std::nullopt,
const std::optional<Tensor>& optional_output_tensor = std::nullopt);
Variadic operands
Variadic<> type constraint should only be used for operands that are variadic in nature, e.g. a vector of tensors, like in ttnn::concat:
static ttnn::Tensor invoke(
const std::vector<ttnn::Tensor>& input_tensors,
int dim,
const std::optional<MemoryConfig>& memory_config = std::nullopt,
const std::optional<ttnn::Tensor>& optional_output_tensor = std::nullopt,
unsigned int groups = 1);
Operand naming
Operands should be named as they are in the TTNN lib. However, this guideline is not strict, and some reasonable deviations are acceptable.
Operand namespaces
Some operands are defined in a namespace nested within the TTNN namespace, i.e. ttnn::ccl::Topology, and some are in other but related namespaces, i.e. tt::tt_metal::MemoryConfig. While it would be ideal to model these completely accurately, it doesn’t provide value and we should pretend they’re all in the ttnn:: namespace for the sake of simplicity.
Adding an Op
This guide will walk you through the process of adding a new Op end to end in
tt-mlir, in this case we will be adding a matmul operation. Note that the matmul
op was added as part of the same changeset as this guide, it could be useful to
reference the diff alongside this guide to see the changes in full.
This guide will cover the following steps:
- Adding an Op
- 1. Define the Op in the TTIR frontend dialect
- 2. Define the Op in the TTNN backend dialect
- 3. Convert / Implement the Op in the TTNN passes
- 4. Add a compiler unit test for the Op
- 5. Define flatbuffer schema for the Op
- 6. Serialize the Op in the flatbuffer format
- 7. Add runtime support for the Op
- 8. Add a silicon unit test for the Op
- 9. Add an EmitC test for the Op
- 10. Add a builder test for the Op
- 11. Add CPU-hoisting support (if applicable)
1. Define the Op in the TTIR frontend dialect
We will start by defining the Op in the TTIR dialect. The TTIR Ops are defined
in a tablegen file located at include/ttmlir/Dialect/TTIR/IR/TTIROps.td.
Tablegen is a domain-specific language for defining ops/types/attributes in MLIR and LLVM, these definitions constitute the dialect's Operation Definition Specification (ODS).
Here is an example of defining matmul in the TTIR dialect:
def TTIR_MatmulOp : TTIR_NamedOp<"matmul"> {
let summary = "Matrix multiplication operation.";
let description = [{
The `matmul` operation computes the matrix multiplication of two tensors.
This operation performs matrix multiplication between tensors `a` and `b`. It supports optional
transposition of either input tensor before multiplication. For 2D tensors, this computes the standard
matrix product. For tensors with more dimensions, it applies batched matrix multiplication.
Example:
```mlir
// Basic matrix multiplication of 2D tensors
%a = ... : tensor<3x4xf32> // Matrix A with shape [3,4]
%b = ... : tensor<4x5xf32> // Matrix B with shape [4,5]
%result = ttir.matmul(%a, %b) :
(tensor<3x4xf32>, tensor<4x5xf32>) -> tensor<3x5xf32>
// Batched matrix multiplication with transposition
%a = ... : tensor<2x3x4xf32> // Batch of 2 matrices with shape [3,4]
%b = ... : tensor<2x5x4xf32> // Batch of 2 matrices with shape [5,4]
%result = ttir.matmul(%a, %b) {
transpose_a = false, // Don't transpose A
transpose_b = true // Transpose B before multiplication
} : (tensor<2x3x4xf32>, tensor<2x5x4xf32>) -> tensor<2x3x5xf32>
```
Inputs:
- `a` (Tensor): The first input tensor.
- `b` (Tensor): The second input tensor.
Attributes:
- `transpose_a` (Boolean, default=false): Whether to transpose tensor `a` before multiplication.
- `transpose_b` (Boolean, default=false): Whether to transpose tensor `b` before multiplication.
Output:
- `result` (Tensor): The result of the matrix multiplication.
Note: The inner dimensions of the input tensors must be compatible for matrix multiplication.
If `a` has shape [..., m, k] and `b` has shape [..., k, n], then the result will have shape [..., m, n].
If `transpose_a` is true, then `a` is treated as having shape [..., k, m].
If `transpose_b` is true, then `b` is treated as having shape [..., n, k].
}];
let arguments = (ins AnyRankedTensor:$a,
AnyRankedTensor:$b,
DefaultValuedAttr<BoolAttr, "false">:$transpose_a,
DefaultValuedAttr<BoolAttr, "false">:$transpose_b);
let results = (outs AnyRankedTensor:$result);
let hasVerifier = 1;
let hasCanonicalizer = 1;
}
There are many things to break down here, starting from the top:
defin tablegen is used to define a concrete type, this will have a 1-1 mapping to a C++ generated class, and for this particular case the build will end up generating filebuild/include/ttmlir/Dialect/TTIR/IR/TTIROps.h.inc.- It inherits from
class TTIR_DPSOp, classes in tablegen don't define a concrete type, but rather an interface that augment or constrain inheriteddefs.TTIR_DPSOpis a class that defines the common attributes for all TTIR Ops that implement Destination Passing Style (DPS) semantics. DPS just means that the result tensor is passed as an argument to the operation which will be critical for modeling buffer allocation / lifetimes. Note the 3rd argumentAnyRankedTensor:$output. - Next we have a list of
arguments. These arguments consist of a mixture ofTypes (i.e.AnyRankedTensor) andAttributes. Read more about Types & Attributes here.AnyRankedTensoris part of a tablegen standard library which type aliases to MLIR's builtin Tensor type, with the added constraint that the tensor has a static rank. As much as possible we want to use the builtin types and infrastructure provided by MLIR.
- Next we have a list of
resultsin this case just 1, which aliases theoutputtensor. One drawback of DPS is that the result tensor and the output tensor will appear to have different SSA names in the IR, but they really alias the same object. This can make writing some passes more cumbersome. - Next we have
extraClassDeclaration, which enables us to inject member functions, written directly in C++, into the generated class. We are doing this for this particular case in order to satisfy the DPS interface which requires an implementation for getting the mutated output tensor. - Finally, we have
hasVerifier = 1, this tells MLIR that we have a verifier function that will be called to validate the operation. This is a good practice to ensure that the IR is well formed.
We can now try building and opening the TTIROps.h.inc file to see the generated C++ code.
We will actually get a linker error because we have hasVerifier = 1 which
automatically declared a verifier function, but we need to go implement.
Let's head over to lib/Dialect/TTIR/IR/TTIROps.cpp and implement the verifier.
// MatmulOp verification
::mlir::LogicalResult mlir::tt::ttir::MatmulOp::verify() {
::mlir::RankedTensorType inputAType = getA().getType();
::mlir::RankedTensorType inputBType = getB().getType();
::mlir::RankedTensorType outputType = getType();
llvm::ArrayRef<int64_t> outputShape = outputType.getShape();
llvm::SmallVector<int64_t> inputAShape(inputAType.getShape());
llvm::SmallVector<int64_t> inputBShape(inputBType.getShape());
// Verify that the input A is at least 1D tensor.
if (inputAType.getRank() < 1) {
return emitOpError("Input A must be at least a 1D tensor");
}
// Verify that the input B is at least 1D tensor.
if (inputBType.getRank() < 1) {
return emitOpError("Input B must be at least a 1D tensor");
}
// If input A is a vector (1D tensor), 1 is prepended to its dimensions for
// the purpose of the matrix multiplication. After the matrix
// multiplication, the prepended dimension is removed. Otherwise, check if
// the LHS needs to be transposed.
if (inputAType.getRank() == 1) {
inputAShape.insert(inputAShape.begin(), 1);
} else if (getTransposeA()) {
std::swap(inputAShape[inputAShape.size() - 1],
inputAShape[inputAShape.size() - 2]);
}
// If input B is a vector (1D tensor), a 1 is appended to its dimensions for
// the purpose of the matrix-vector product and removed afterwards.
// Otherwise, check if the RHS needs to be transposed.
if (inputBType.getRank() == 1) {
inputBShape.push_back(1);
} else if (getTransposeB()) {
std::swap(inputBShape[inputBShape.size() - 1],
inputBShape[inputBShape.size() - 2]);
}
// Verify that the input A and input B has matching inner dimensions.
if (inputAShape[inputAShape.size() - 1] !=
inputBShape[inputBShape.size() - 2]) {
return emitOpError("Input A[-1](")
<< inputAShape[inputAShape.size() - 1] << ") and B[-2]("
<< inputBShape[inputBShape.size() - 2]
<< ") must have matching inner dimensions";
}
llvm::SmallVector<int64_t> expectedOutputShape;
// Verify that the batch dimensions are broadcast compatible and construct
// the expected output shape. If either of input A or input B is at most 2D
// tensors, the batch dimensions are trivially broadcast compatible.
if (inputAShape.size() > 2 || inputBShape.size() > 2) {
llvm::SmallVector<int64_t> inputABatchDims(inputAShape.begin(),
inputAShape.end() - 2);
llvm::SmallVector<int64_t> inputBBatchDims(inputBShape.begin(),
inputBShape.end() - 2);
// Verify that the batch dimensions of input A and B are broadcast
// compatible.
llvm::SmallVector<int64_t, 4> broadcastedShape;
if (!mlir::OpTrait::util::getBroadcastedShape(
inputABatchDims, inputBBatchDims, broadcastedShape)) {
return emitOpError("Batch dimensions of input A(" +
ttmlir::utils::join(inputABatchDims, ",") +
") and B(" +
ttmlir::utils::join(inputBBatchDims, ",") +
") are not broadcast compatible");
}
// Insert the broadcasted batch dimensions in the expected output shape.
expectedOutputShape = std::move(broadcastedShape);
}
// Insert the input A and B inner dimensions in expected output shape
// Consider the case where input A and B are vectors. In that case,
// the dimension 1 is omitted from the output shape.
if (inputAType.getRank() > 1) {
expectedOutputShape.push_back(inputAShape[inputAShape.size() - 2]);
}
if (inputBType.getRank() > 1) {
expectedOutputShape.push_back(inputBShape[inputBShape.size() - 1]);
}
// Check the case of a vector-vector product. At this moment we don't
// support scalars in IR, hence check that the output is at least 1D tensor
// of size 1.
if (expectedOutputShape.size() == 0) {
if (outputType.getRank() < 1) {
return emitOpError("Scalar output is not supported, output must be at "
"least a 1D tensor");
}
if (outputType.getRank() > 1 || outputType.getShape()[0] != 1) {
return emitOpError("Scalar output must be a 1D tensor of size 1");
}
return success();
}
// Verify that the output shape is correct.
if (outputShape.size() != expectedOutputShape.size()) {
return emitOpError("Output shape rank(")
<< outputShape.size()
<< ") must match the expected output shape rank("
<< expectedOutputShape.size() << ")";
}
// Verify each dim of the output shape.
for (auto [index, outputDim, expectedDim] : llvm::zip(
llvm::seq(outputShape.size()), outputShape, expectedOutputShape)) {
if (outputDim != expectedDim) {
return emitOpError("Output shape dimension[")
<< index << "](" << outputDim
<< ") doesn't match the expected output shape dimension[" << index
<< "](" << expectedDim << ")";
}
}
return success();
}
2. Define the Op in the TTNN backend dialect
Next we will define the Op in the TTNN dialect. TTNN Ops are defined in the same way, but in their respective set of dialect files. Refer to the previous section for details, the process is the same.
TTNNOps.td
def TTNN_MatmulOp : TTNN_Op<"matmul", [TTNN_ComputeKernelConfigOpInterface]> {
let arguments = (ins AnyRankedTensor:$a,
AnyRankedTensor:$b,
DefaultValuedAttr<BoolAttr, "false">:$transpose_a,
DefaultValuedAttr<BoolAttr, "false">:$transpose_b,
OptionalAttr<AnyAttrOf<[
TTNN_MatmulMultiCoreReuseProgramConfigAttr,
TTNN_MatmulMultiCoreReuseMultiCastProgramConfigAttr,
TTNN_MatmulMultiCoreReuseMultiCast1DProgramConfigAttr,
TTNN_MatmulMultiCoreReuseMultiCastDRAMShardedProgramConfigAttr
]>>:$matmul_program_config,
OptionalAttr<StrAttr>:$activation,
OptionalAttr<TTNN_DeviceComputeKernelConfig>:$compute_config);
let results = (outs AnyRankedTensor:$result);
let builders = [
OpBuilder<(ins "Type":$result, "Value":$a, "Value":$b,
"bool":$transpose_a, "bool":$transpose_b,
"Attribute":$matmul_program_config,
"StringAttr":$activation),
[{
build($_builder, $_state, result, a, b, transpose_a, transpose_b,
matmul_program_config, activation, /*compute_config=*/nullptr);
}]>
];
let hasVerifier = 1;
let hasCanonicalizer = 1;
}
TTNNOps.cpp
// MatmulOp verification
::mlir::LogicalResult mlir::tt::ttnn::MatmulOp::verify() {
::mlir::RankedTensorType inputAType = getA().getType();
::mlir::RankedTensorType inputBType = getB().getType();
::mlir::RankedTensorType outputType = getResult().getType();
llvm::ArrayRef<int64_t> outputShape = outputType.getShape();
// Verify that the input A is at least 1D tensor.
if (inputAType.getRank() < 1) {
return emitOpError("Input A must be at least a 1D tensor");
}
// Verify that the input B is at least 1D tensor.
if (inputBType.getRank() < 1) {
return emitOpError("Input B must be at least a 1D tensor");
}
MatmulAdjustedShapes adjustedShapes = getMatmulAdjustedInputShapes(
inputAType, inputBType, getTransposeA(), getTransposeB());
llvm::SmallVector<int64_t> inputAShape = std::move(adjustedShapes.inputA);
llvm::SmallVector<int64_t> inputBShape = std::move(adjustedShapes.inputB);
// Verify that the input A and input B has matching inner dimensions.
if (inputAShape[inputAShape.size() - 1] !=
inputBShape[inputBShape.size() - 2]) {
return emitOpError("Input A[-1](")
<< inputAShape[inputAShape.size() - 1] << ") and B[-2]("
<< inputBShape[inputBShape.size() - 2]
<< ") must have matching inner dimensions";
}
llvm::SmallVector<int64_t> expectedOutputShape;
// Verify that the batch dimensions are broadcast compatible and construct the
// expected output shape. If either of input A or input B is at most 2D
// tensors, the batch dimensions are trivially broadcast compatible.
if (inputAShape.size() > 2 || inputBShape.size() > 2) {
llvm::SmallVector<int64_t> inputABatchDims(inputAShape.begin(),
inputAShape.end() - 2);
llvm::SmallVector<int64_t> inputBBatchDims(inputBShape.begin(),
inputBShape.end() - 2);
// Verify that the batch dimensions of input A and B are broadcast
// compatible.
llvm::SmallVector<int64_t, 4> broadcastedShape;
if (!OpTrait::util::getBroadcastedShape(inputABatchDims, inputBBatchDims,
broadcastedShape)) {
return emitOpError("Batch dimensions of input A(" +
ttmlir::utils::join(inputABatchDims, ",") +
") and B(" +
ttmlir::utils::join(inputBBatchDims, ",") +
") are not broadcast compatible");
}
// Insert the broadcasted batch dimensions in the expected output shape.
expectedOutputShape = std::move(broadcastedShape);
}
// Insert the input A and B inner dimensions in expected output shape
// Consider the case where input A and B are vectors. In that case,
// the dimension 1 is omitted from the output shape.
if (inputAType.getRank() > 1) {
expectedOutputShape.push_back(inputAShape[inputAShape.size() - 2]);
}
if (inputBType.getRank() > 1) {
expectedOutputShape.push_back(inputBShape[inputBShape.size() - 1]);
}
// Check the case of a vector-vector product. At this moment we don't support
// scalars in IR, hence check that the output is at least 1D tensor of size 1.
if (expectedOutputShape.size() == 0) {
if (outputType.getRank() < 1) {
return emitOpError("Scalar output is not supported, output must be at "
"least a 1D tensor");
}
if (outputType.getRank() > 1 || outputType.getShape()[0] != 1) {
return emitOpError("Scalar output must be a 1D tensor of size 1");
}
return success();
}
// Verify that the output shape is correct.
if (outputShape.size() != expectedOutputShape.size()) {
return emitOpError("Output shape rank(")
<< outputShape.size()
<< ") must match the expected output shape rank("
<< expectedOutputShape.size() << ")";
}
// Verify each dim of the output shape.
for (auto [index, outputDim, expectedDim] : llvm::zip(
llvm::seq(outputShape.size()), outputShape, expectedOutputShape)) {
if (outputDim != expectedDim) {
return emitOpError("Output shape dimension[")
<< index << "](" << outputDim
<< ") doesn't match the expected output shape dimension[" << index
<< "](" << expectedDim << ")";
}
}
return success();
}
For more details on adding ops to the TTNN dialect, refer to TTNN Dialect Contribution Guidelines.
Adding constraint/runtime APIs
We need to implement two APIs when adding a TTNN Op, namely getOpConstraints and getOpRuntime.
More details about this can be found here.
3. Convert / Implement the Op in the TTNN passes
TTIR to TTNN
Next we will implement the conversion from the TTIR matmul Op to the TTNN matmul Op.
This is a trivial conversion, as the Ops are identical in their semantics, so
the changeset isn't going to be very instructive, but will at least point to the
files involved. The conversion is implemented in the ConvertTTIRToTTNNPass pass in
file lib/Conversion/TTIRToTTNN/TTIRToTTNNPass.cpp.
Zooming into class ConvertTTIRToTTNNPass we can see we implement the pass interface
via member function void runOnOperation() final. This function will be called
for every operation matching the type specified in the pass tablegen file. A
quick look at include/ttmlir/Conversion/Passes.td we can see:
def ConvertTTIRToTTNN: Pass<"convert-ttir-to-ttnn", "::mlir::ModuleOp"> {
This means that runOnOperation will be called for every ModuleOp in the
graph, usually there is only one ModuleOp which serves as the root of the
graph.
Inside runOnOperation is usually where we define a rewrite pattern set that
can match much more complicated patterns (nested inside of the ModuleOp's
regions)
than just a single operation. In runOperation method you will see the call to
method populateTTIRToTTNNPatterns(...) that actually generates rewrite patterns.
Method populateTTIRToTTNNPatterns(...) is defined
in lib/Conversion/TTIRToTTNN/TTIRToTTNN.cpp.
patterns
.add<TensorEmptyConversionPattern,
NamedFullConversionPattern<ttir::ZerosOp, ttnn::ZerosOp>,
NamedFullConversionPattern<ttir::OnesOp, ttnn::OnesOp>,
FullOpConversionPattern,
ToLayoutOpConversionPattern,
QuantizationOpConversionPattern<ttir::QuantizeUnrolledOp, ttnn::QuantizeOp>,
QuantizationOpConversionPattern<ttir::DequantizeUnrolledOp, ttnn::DequantizeOp>,
RequantizeOpConversionPattern,
ElementwiseBinaryOpConversionPattern<ttir::AddOp, ttnn::AddOp>,
ElementwiseBinaryOpConversionPattern<ttir::LogicalRightShiftOp, ttnn::LogicalRightShiftOp>,
ElementwiseBinaryOpConversionPattern<ttir::SubtractOp, ttnn::SubtractOp>,
ElementwiseBinaryOpConversionPattern<ttir::MultiplyOp, ttnn::MultiplyOp>,
ElementwiseBinaryOpConversionPattern<ttir::DivOp, ttnn::DivideOp>,
ElementwiseBinaryOpConversionPattern<ttir::EqualOp, ttnn::EqualOp>,
ElementwiseBinaryOpConversionPattern<ttir::NotEqualOp, ttnn::NotEqualOp>,
ElementwiseBinaryOpConversionPattern<ttir::GreaterEqualOp, ttnn::GreaterEqualOp>,
ElementwiseBinaryOpConversionPattern<ttir::GreaterThanOp, ttnn::GreaterThanOp>,
ElementwiseBinaryOpConversionPattern<ttir::LessEqualOp, ttnn::LessEqualOp>,
ElementwiseBinaryOpConversionPattern<ttir::LessThanOp, ttnn::LessThanOp>,
ElementwiseBinaryOpConversionPattern<ttir::LogicalAndOp, ttnn::LogicalAndOp>,
ElementwiseBinaryOpConversionPattern<ttir::LogicalOrOp, ttnn::LogicalOrOp>,
ElementwiseBinaryOpConversionPattern<ttir::LogicalXorOp, ttnn::LogicalXorOp>,
ElementwiseOpConversionPattern<ttir::BitwiseAndOp, ttnn::BitwiseAndOp>,
ElementwiseOpConversionPattern<ttir::LogicalLeftShiftOp, ttnn::LogicalLeftShiftOp>,
ElementwiseOpConversionPattern<ttir::BitwiseOrOp, ttnn::BitwiseOrOp>,
ElementwiseOpConversionPattern<ttir::BitwiseXorOp, ttnn::BitwiseXorOp>,
ElementwiseOpConversionPattern<ttir::MaximumOp, ttnn::MaximumOp>,
ElementwiseOpConversionPattern<ttir::MinimumOp, ttnn::MinimumOp>,
ElementwiseOpConversionPattern<ttir::RemainderOp, ttnn::RemainderOp>,
ElementwiseOpConversionPattern<ttir::Atan2Op, ttnn::Atan2Op>,
ElementwiseOpConversionPattern<ttir::AbsOp, ttnn::AbsOp>,
ElementwiseOpConversionPattern<ttir::CbrtOp, ttnn::CbrtOp>,
ElementwiseOpConversionPattern<ttir::FloorOp, ttnn::FloorOp>,
ElementwiseOpConversionPattern<ttir::IsFiniteOp, ttnn::IsFiniteOp>,
ElementwiseOpConversionPattern<ttir::LogicalNotOp, ttnn::LogicalNotOp>,
ElementwiseOpConversionPattern<ttir::BitwiseNotOp, ttnn::BitwiseNotOp>,
ElementwiseOpConversionPattern<ttir::MishOp, ttnn::MishOp>,
ElementwiseOpConversionPattern<ttir::NegOp, ttnn::NegOp>,
ElementwiseOpConversionPattern<ttir::ReluOp, ttnn::ReluOp>,
ElementwiseOpConversionPattern<ttir::Relu6Op, ttnn::Relu6Op>,
ElementwiseOpConversionPattern<ttir::GeluOp, ttnn::GeluOp>,
ElementwiseOpConversionPattern<ttir::SqrtOp, ttnn::SqrtOp>,
ElementwiseOpConversionPattern<ttir::RsqrtOp, ttnn::RsqrtOp>,
ElementwiseOpConversionPattern<ttir::SignOp, ttnn::SignOp>,
ElementwiseOpConversionPattern<ttir::SigmoidOp, ttnn::SigmoidOp>,
ElementwiseOpConversionPattern<ttir::HardsigmoidOp, ttnn::HardsigmoidOp>,
ElementwiseOpConversionPattern<ttir::SiluOp, ttnn::SiluOp>,
ElementwiseOpConversionPattern<ttir::Log1pOp, ttnn::Log1pOp>,
ElementwiseOpConversionPattern<ttir::ReciprocalOp, ttnn::ReciprocalOp>,
ElementwiseOpConversionPattern<ttir::ExpOp, ttnn::ExpOp>,
ElementwiseOpConversionPattern<ttir::ErfOp, ttnn::ErfOp>,
ElementwiseOpConversionPattern<ttir::ErfcOp, ttnn::ErfcOp>,
ElementwiseOpConversionPattern<ttir::LogOp, ttnn::LogOp>,
ElementwiseOpConversionPattern<ttir::CeilOp, ttnn::CeilOp>,
ElementwiseOpConversionPattern<ttir::SinOp, ttnn::SinOp>,
ElementwiseOpConversionPattern<ttir::AsinOp, ttnn::AsinOp>,
ElementwiseOpConversionPattern<ttir::AsinhOp, ttnn::AsinhOp>,
ElementwiseOpConversionPattern<ttir::CosOp, ttnn::CosOp>,
ElementwiseOpConversionPattern<ttir::AcosOp, ttnn::AcosOp>,
ElementwiseOpConversionPattern<ttir::Expm1Op, ttnn::Expm1Op>,
ElementwiseOpConversionPattern<ttir::WhereOp, ttnn::WhereOp>,
ElementwiseOpConversionPattern<ttir::TanOp, ttnn::TanOp>,
ElementwiseOpConversionPattern<ttir::TanhOp, ttnn::TanhOp>,
ElementwiseOpConversionPattern<ttir::AtanOp, ttnn::AtanOp>,
Pooling2dOpConversionPattern<ttir::MaxPool2dOp, ttnn::MaxPool2dOp>,
Pooling2dOpConversionPattern<ttir::MaxPool2dWithIndicesOp, ttnn::MaxPool2dWithIndicesOp>,
Pooling2dOpConversionPattern<ttir::AvgPool2dOp, ttnn::AvgPool2dOp>,
GlobalAvgPool2dOpConversionPattern,
ReductionOpConversionPattern<ttir::SumOp, ttnn::SumOp>,
ReductionOpConversionPattern<ttir::MeanOp, ttnn::MeanOp>,
ReductionOpConversionPattern<ttir::MaxOp, ttnn::MaxOp>,
ReductionOpConversionPattern<ttir::MinOp, ttnn::MinOp>,
ReductionProdOpConversionPattern,
ReductionArgMaxOpConversionPattern,
ElementwiseUnaryWithFloatParameterOpConversionPattern<ttir::LeakyReluOp, ttnn::LeakyReluOp>,
BroadcastOpConversionPattern,
PadOpConversionPattern,
PowOpConversionPattern,
EmbeddingOpConversionPattern,
EmbeddingBackwardOpConversionPattern,
RepeatOpConversionPattern,
CumSumOpConversionPattern,
CumProdOpConversionPattern,
RepeatInterleaveOpConversionPattern,
SoftmaxOpConversionPattern,
SortOpConversionPattern,
BitcastConvertOPConversionPattern,
TypecastOpConversionPattern,
ClampOpConversionPattern<ttir::ClampScalarOp, ttnn::ClampScalarOp>,
ClampOpConversionPattern<ttir::ClampTensorOp, ttnn::ClampTensorOp>,
ConcatOpConversionPattern,
ReshapeOpConversionPattern,
SliceOpConversionPattern<ttir::SliceStaticOp, ttnn::SliceStaticOp>,
SliceOpConversionPattern<ttir::SliceDynamicOp, ttnn::SliceDynamicOp>,
SqueezeOpConversionPattern,
UnsqueezeOpConversionPattern,
ConstantOpConversionPattern,
LinearOpConversionPattern,
BatchNormInferenceOpConversionPattern,
BatchNormTrainingOpConversionPattern,
RMSNormOpConversionPattern,
DistributedRMSNormOpConversionPattern,
DistributedLayerNormOpConversionPattern,
LayerNormOpConversionPattern,
GroupNormOpConversionPattern,
MatmulOpConversionPattern,
SparseMatmulOpConversionPattern,
AllToAllDispatchOpConversionPattern,
AllToAllDispatchMetadataOpConversionPattern,
AllToAllCombineOpConversionPattern,
SelectiveReduceCombineOpConversionPattern,
MoeExpertTokenRemapOpConversionPattern,
MoeGptOpConversionPattern,
MoeComputeOpConversionPattern,
Conv2dOpConversionPattern,
Conv3dOpConversionPattern,
ConvTranspose2dOpConversionPattern,
MeshShardOpConversionPattern,
AllReduceOpConversionPattern,
AllReduceAsyncOpConversionPattern,
AllGatherOpConversionPattern,
MeshPartitionOpConversionPattern,
ReduceScatterOpConversionPattern,
CollectivePermuteOpConversionPattern,
ArangeOpConversionPattern,
RandOpConversionPattern,
UpdateCacheOpConversionPattern,
PagedFillCacheOpConversionPattern,
PagedUpdateCacheOpConversionPattern,
SamplingOpConversionPattern,
FillCacheOpConversionPattern,
ScatterOpConversionPattern,
GatherOpConversionPattern,
PermuteOpConversionPattern,
UpsampleOpConversionPattern,
AllToAllOpConversionPattern,
CollectiveBroadcastOpConversionPattern,
ConcatenateHeadsOpConversionPattern,
ScaledDotProductAttentionOpConversionPattern,
ScaledDotProductAttentionDecodeOpConversionPattern,
PagedScaledDotProductAttentionDecodeOpConversionPattern,
PagedFlashMultiLatentAttentionDecodeOpConversionPattern,
SplitQueryKeyValueAndSplitHeadsOpConversionPattern,
GeluBackwardOpConversionPattern,
DropoutOpConversionPattern,
DebugOpConversionPattern<debug::DumpOp, ttnn::DumpTensorOp>,
TopKOpConversionPattern,
TopKRouterGptOpConversionPattern
>(typeConverter, ctx);
More information on rewrite patterns and their capabilities can be found in the MLIR documentation here and here.
For matmul, we defined a new conversion pattern that's generic to all binary ops
with arguments named a and b:
namespace {
class MatmulOpConversionPattern : public OpConversionPattern<ttir::MatmulOp> {
public:
using OpConversionPattern<ttir::MatmulOp>::OpConversionPattern;
LogicalResult
matchAndRewrite(ttir::MatmulOp op, OpAdaptor adaptor,
ConversionPatternRewriter &rewriter) const override {
auto newOp = rewriter.replaceOpWithNewOp<ttnn::MatmulOp>(
op, this->getTypeConverter()->convertType(op.getType()), adaptor.getA(),
adaptor.getB(), adaptor.getTransposeA(), adaptor.getTransposeB(),
/*matmul_program_config=*/nullptr, /*activation=*/nullptr);
if (auto attr = op->getAttr("ttcore.weight_dtype")) {
newOp->setAttr("ttcore.weight_dtype", attr);
}
return success();
}
};
} // namespace
Invoked as part of the rewrite set:
MatmulOpConversionPattern
TTNN to EmitC
Similarly, we also need to add a pattern to convert from TTNN dialect to EmitC dialect.
Method to populate rewrite patterns can be found in lib/Conversion/TTNNToEmitC/TTNNToEmitC.cpp:
void populateTTNNToEmitCPatterns(mlir::MLIRContext *ctx,
mlir::RewritePatternSet &patterns,
TypeConverter &typeConverter) {
// Device ops
//
patterns.add<TTDeviceOpConversionPattern>(typeConverter, ctx);
patterns.add<GetDeviceOpConversionPattern,
CreateGlobalSemaphoreOpConversionPattern,
ResetGlobalSemaphoreOpConversionPattern>(typeConverter, ctx);
// Memory ops
//
// clang-format off
patterns.add<ToLayoutOpConversionPattern,
ToMemoryConfigOpConversionPattern,
TypecastOpConversionPattern,
ToDeviceOpConversionPattern,
FromDeviceOpConversionPattern,
DeallocateOpConversionPattern>(typeConverter, ctx);
// clang-format on
// Tensor ops
//
// clang-format off
patterns.add<EmptyOpConversionPattern,
NamedFullOpConversionPattern<mlir::tt::ttnn::ZerosOp>,
NamedFullOpConversionPattern<mlir::tt::ttnn::OnesOp>,
FullOpConversionPattern,
DefaultOpConversionPattern<mlir::tt::ttnn::ArangeOp>,
DefaultOpConversionPattern<mlir::tt::ttnn::ConstantOp>,
RandOpConversionPattern,
AssignOpConversionPattern>(typeConverter, ctx);
// clang-format on
// Eltwise unary ops
//
patterns
.add<EltwiseUnaryOpConversionPattern<mlir::tt::ttnn::AbsOp>,
EltwiseUnaryCompositeOpConversionPattern<mlir::tt::ttnn::CbrtOp>,
ClampOpConversionPattern<::mlir::tt::ttnn::ClampScalarOp>,
ClampOpConversionPattern<mlir::tt::ttnn::ClampTensorOp>,
EltwiseUnaryOpConversionPattern<mlir::tt::ttnn::FloorOp>,
EltwiseUnaryOpConversionPattern<mlir::tt::ttnn::IsFiniteOp>,
EltwiseUnaryOpConversionPattern<mlir::tt::ttnn::LogicalNotOp>,
EltwiseUnaryOpConversionPattern<mlir::tt::ttnn::BitwiseNotOp>,
EltwiseUnaryOpConversionPattern<mlir::tt::ttnn::NegOp>,
EltwiseUnaryOpConversionPattern<mlir::tt::ttnn::ReluOp>,
EltwiseUnaryWithFastAndApproximateModeOpConversionPattern<
mlir::tt::ttnn::RsqrtOp>,
EltwiseUnaryOpConversionPattern<mlir::tt::ttnn::Relu6Op>,
EltwiseUnaryOpConversionPattern<mlir::tt::ttnn::HardsigmoidOp>,
EltwiseUnaryOpConversionPattern<mlir::tt::ttnn::SiluOp>,
EltwiseUnaryWithFastAndApproximateModeOpConversionPattern<
mlir::tt::ttnn::MishOp>,
ElementwiseUnaryWithFloatParameterOpConversionPattern<
mlir::tt::ttnn::LeakyReluOp>,
EltwiseUnaryWithFastAndApproximateModeOpConversionPattern<
mlir::tt::ttnn::GeluOp>,
EltwiseUnaryWithFastAndApproximateModeOpConversionPattern<
mlir::tt::ttnn::SqrtOp>,
EltwiseUnaryOpConversionPattern<mlir::tt::ttnn::SignOp>,
EltwiseUnaryWithVectorAndFastAndApproximateModeOpConversionPattern<
mlir::tt::ttnn::SigmoidOp>,
EltwiseUnaryCompositeWithFastAndApproximateModeOpConversionPattern<
mlir::tt::ttnn::Log1pOp>,
EltwiseUnaryOpConversionPattern<mlir::tt::ttnn::ReciprocalOp>,
EltwiseUnaryWithFastAndApproximateModeOpConversionPattern<
mlir::tt::ttnn::ExpOp>,
EltwiseUnaryWithFastAndApproximateModeOpConversionPattern<
mlir::tt::ttnn::ErfOp>,
EltwiseUnaryOpConversionPattern<mlir::tt::ttnn::ErfcOp>,
EltwiseUnaryOpConversionPattern<mlir::tt::ttnn::CeilOp>,
EltwiseUnaryOpConversionPattern<mlir::tt::ttnn::SinOp>,
EltwiseUnaryOpConversionPattern<mlir::tt::ttnn::AsinOp>,
EltwiseUnaryOpConversionPattern<mlir::tt::ttnn::AsinhOp>,
EltwiseUnaryOpConversionPattern<mlir::tt::ttnn::CosOp>,
EltwiseUnaryOpConversionPattern<mlir::tt::ttnn::AcosOp>,
EltwiseUnaryOpConversionPattern<mlir::tt::ttnn::Expm1Op>,
EltwiseUnaryOpConversionPattern<mlir::tt::ttnn::TanOp>,
EltwiseUnaryWithOutputAndApproxModeOpConversionPattern<
mlir::tt::ttnn::TanhOp>,
EltwiseUnaryOpConversionPattern<mlir::tt::ttnn::AtanOp>,
EltwiseUnaryWithFastAndApproximateModeOpConversionPattern<
mlir::tt::ttnn::LogOp>>(typeConverter, ctx);
// Eltwise binary ops
//
patterns.add<
EltwiseBinaryOpConversionPattern<mlir::tt::ttnn::AddOp>,
EltwiseBinaryOpConversionPattern<mlir::tt::ttnn::LogicalRightShiftOp>,
EltwiseBinaryOpConversionPattern<mlir::tt::ttnn::SubtractOp>,
EltwiseBinaryOpConversionPattern<mlir::tt::ttnn::MultiplyOp>,
EltwiseBinaryOpConversionPattern<mlir::tt::ttnn::LogicalAndOp>,
EltwiseBinaryOpConversionPattern<mlir::tt::ttnn::LogicalOrOp>,
EltwiseBinaryOpConversionPattern<mlir::tt::ttnn::LogicalXorOp>,
EltwiseBinaryCompositeOpConversionPattern<mlir::tt::ttnn::BitwiseAndOp>,
EltwiseBinaryCompositeOpConversionPattern<mlir::tt::ttnn::BitwiseOrOp>,
EltwiseBinaryCompositeOpConversionPattern<mlir::tt::ttnn::BitwiseXorOp>,
EltwiseBinaryOpConversionPattern<mlir::tt::ttnn::EqualOp>,
EltwiseBinaryOpConversionPattern<mlir::tt::ttnn::NotEqualOp>,
EltwiseBinaryOpConversionPattern<mlir::tt::ttnn::GreaterEqualOp>,
EltwiseBinaryOpConversionPattern<mlir::tt::ttnn::GreaterThanOp>,
EltwiseBinaryOpConversionPattern<mlir::tt::ttnn::LessEqualOp>,
EltwiseBinaryOpConversionPattern<mlir::tt::ttnn::LessThanOp>,
EltwiseBinaryNGCompositeOpConversionPattern<mlir::tt::ttnn::MaximumOp>,
EltwiseBinaryNGCompositeOpConversionPattern<mlir::tt::ttnn::MinimumOp>,
EltwiseBinaryOpConversionPattern<mlir::tt::ttnn::DivideOp>,
EltwiseBinaryCompositeOpConversionPattern<
mlir::tt::ttnn::LogicalLeftShiftOp>,
EltwiseBinaryNGCompositeOpConversionPattern<mlir::tt::ttnn::RemainderOp>,
EltwiseBinaryNGCompositeOpConversionPattern<mlir::tt::ttnn::PowTensorOp>,
EltwiseBinaryCompositeOpConversionPattern<mlir::tt::ttnn::Atan2Op>,
PowScalarOpConversionPattern>(typeConverter, ctx);
// Experimental binary backward ops
//
patterns.add<ExperimentalGeluBackwardOpConversionPattern>(typeConverter, ctx);
// Experimental dropout op
//
patterns.add<DropoutOpConversionPattern>(typeConverter, ctx);
// Eltwise ternary ops
//
patterns.add<EltwiseTernaryOpConversionPattern<mlir::tt::ttnn::WhereOp>>(
typeConverter, ctx);
// Tensor manipulation ops
//
patterns
.add<TransposeOpConversionPattern, ConcatOpConversionPattern,
ReshapeOpConversionPattern, RepeatOpConversionPattern,
RepeatInterleaveOpConversionPattern, SliceStaticOpConversionPattern,
SliceDynamicOpConversionPattern, SortOpConversionPattern,
PermuteOpConversionPattern, PadOpConversionPattern,
TTNNToEmitCTopKOpConversionPattern,
TTNNToEmitCSamplingOpConversionPattern, GatherOpConversionPattern>(
typeConverter, ctx);
// Quantization ops.
//
patterns.add<QuantizationOpConversionPattern<mlir::tt::ttnn::QuantizeOp>,
QuantizationOpConversionPattern<mlir::tt::ttnn::DequantizeOp>,
RequantizeOpConversionPattern>(typeConverter, ctx);
// Matmul ops
//
patterns.add<LinearOpConversionPattern, MatmulOpConversionPattern,
SparseMatmulOpConversionPattern>(typeConverter, ctx);
// Reduction ops
//
patterns.add<ReductionOpConversionPattern<mlir::tt::ttnn::SumOp>,
ReductionOpConversionPattern<mlir::tt::ttnn::MeanOp>,
ReductionOpConversionPattern<mlir::tt::ttnn::MaxOp>,
ReductionOpConversionPattern<mlir::tt::ttnn::MinOp>,
ProdOpConversionPattern, ArgMaxOpConversionPattern,
TTNNToEmitCTopKRouterGptOpConversionPattern>(typeConverter, ctx);
// Pooling ops
//
patterns.add<AvgPool2dOpConversionPattern>(typeConverter, ctx);
patterns.add<MaxPool2dOpConversionPattern>(typeConverter, ctx);
patterns.add<MaxPool2dWithIndicesOpConversionPattern>(typeConverter, ctx);
patterns.add<GlobalAvgPool2dOpConversionPattern>(typeConverter, ctx);
patterns.add<UpsampleOpConversionPattern>(typeConverter, ctx);
// Convolution ops
//
patterns.add<PrepareConv2dWeightsOpConversionPattern>(typeConverter, ctx);
patterns.add<PrepareConv2dBiasOpConversionPattern>(typeConverter, ctx);
patterns.add<PrepareConv3dWeightsOpConversionPattern>(typeConverter, ctx);
patterns.add<PrepareConvTranspose2dWeightsOpConversionPattern>(typeConverter,
ctx);
patterns.add<PrepareConvTranspose2dBiasOpConversionPattern>(typeConverter,
ctx);
patterns.add<Conv2dOpConversionPattern>(typeConverter, ctx);
patterns.add<Conv3dOpConversionPattern>(typeConverter, ctx);
patterns.add<ConvTranspose2dOpConversionPattern>(typeConverter, ctx);
// Other ops
//
patterns
.add<SoftmaxOpConversionPattern, EmbeddingOpConversionPattern,
DefaultOpConversionPattern<mlir::tt::ttnn::EmbeddingBackwardOp>,
CumSumOpConversionPattern, CumProdOpConversionPattern,
BatchNormInferenceOpConversionPattern,
BatchNormTrainingOpConversionPattern, RMSNormOpConversionPattern,
RMSNormPreAllGatherOpConversionPattern,
DistributedRMSNormOpConversionPattern, LayerNormOpConversionPattern,
LayerNormPreAllGatherOpConversionPattern,
LayerNormPostAllGatherOpConversionPattern,
GroupNormOpConversionPattern>(typeConverter, ctx);
// CCL ops
//
patterns.add<AllGatherOpConversionPattern>(typeConverter, ctx);
patterns.add<AllReduceOpConversionPattern>(typeConverter, ctx);
patterns.add<AllReduceAsyncOpConversionPattern>(typeConverter, ctx);
patterns.add<ReduceScatterOpConversionPattern>(typeConverter, ctx);
patterns.add<ScatterOpConversionPattern>(typeConverter, ctx);
patterns.add<MeshPartitionOpConversionPattern>(typeConverter, ctx);
patterns.add<DistributeTensorOpConversionPattern>(typeConverter, ctx);
patterns.add<AggregateTensorOpConversionPattern>(typeConverter, ctx);
patterns.add<PointToPointOpConversionPattern>(typeConverter, ctx);
patterns.add<AllToAllDispatchOpConversionPattern>(typeConverter, ctx);
patterns.add<AllToAllDispatchMetadataOpConversionPattern>(typeConverter, ctx);
patterns.add<AllToAllCombineOpConversionPattern>(typeConverter, ctx);
patterns.add<MoeExpertTokenRemapOpConversionPattern>(typeConverter, ctx);
patterns.add<MoeGptOpConversionPattern>(typeConverter, ctx);
// KV Cache ops
//
patterns.add<UpdateCacheOpConversionPattern>(typeConverter, ctx);
patterns.add<PagedUpdateCacheOpConversionPattern>(typeConverter, ctx);
patterns.add<PagedFillCacheOpConversionPattern>(typeConverter, ctx);
patterns.add<DefaultOpConversionPattern<mlir::tt::ttnn::FillCacheOp>>(
typeConverter, ctx);
// Tensor serialization ops
//
patterns.add<DumpTensorOpConversionPattern>(typeConverter, ctx);
patterns.add<LoadTensorOpConversionPattern>(typeConverter, ctx);
// Trace ops
//
patterns.add<WriteTensorOpConversionPattern>(typeConverter, ctx);
patterns.add<BeginTraceCaptureOpConversionPattern>(typeConverter, ctx);
patterns.add<EndTraceCaptureOpConversionPattern>(typeConverter, ctx);
patterns.add<CaptureOrExecuteTraceOpConversionPattern>(typeConverter, ctx);
patterns.add<ExecuteTraceOpConversionPattern>(typeConverter, ctx);
// Arith ops
//
patterns.add<ArithConstantOpConversionPattern>(typeConverter, ctx);
// Tuple ops
//
patterns.add<GetTupleElementOpConversionPattern>(typeConverter, ctx);
patterns.add<TupleOpConversionPattern>(typeConverter, ctx);
// LoadCached op
//
patterns.add<LoadCachedOpConversionPattern>(typeConverter, ctx);
// Module op
//
patterns.add<ModuleOpConversionPattern>(typeConverter, ctx);
// FuncOp
//
patterns.add<FuncOpConversionPattern>(typeConverter, ctx);
// Transformers ops
//
patterns.add<ConcatenateHeadsOpConversionPattern>(typeConverter, ctx);
patterns.add<SplitQueryKeyValueAndSplitHeadsOpConversionPattern>(
typeConverter, ctx);
patterns.add<RotaryEmbeddingLlamaOpConversionPattern>(typeConverter, ctx);
patterns.add<RotaryEmbeddingOpConversionPattern>(typeConverter, ctx);
patterns.add<NLPConcatHeadsDecodeOpConversionPattern>(typeConverter, ctx);
patterns.add<PagedScaledDotProductAttentionDecodeOpConversionPattern>(
typeConverter, ctx);
patterns.add<PagedFlashMultiLatentAttentionDecodeOpConversionPattern>(
typeConverter, ctx);
patterns.add<ScaledDotProductAttentionDecodeOpConversionPattern>(
typeConverter, ctx);
patterns.add<ScaledDotProductAttentionOpConversionPattern>(typeConverter,
ctx);
patterns.add<FlashMlaPrefillOpConversionPattern>(typeConverter, ctx);
patterns.add<NLPCreateQKVHeadsDecodeOpConversionPattern>(typeConverter, ctx);
}
Writing conversion patterns to EmitC is a little tricky at first. In general case, we will be converting an op that has operands (SSAs) and attributes (e.g. data type) as arguments. We want to flatten these arguments at call site.
We'll use EmitC's CallOpaqueOp as the target op. Let's take a look at our matmul IR within TTNN dialect:
"ttnn.matmul"(%2, %4, %5) : (tensor<64x128xbf16, #ttnn_layout4>, tensor<128x96xbf16, #ttnn_layout6>, tensor<64x96xbf16, #ttnn_layout7>) -> tensor<64x96xbf16, #ttnn_layout7>
Now let's look at matmul's call signature in TTNN lib:
static Tensor invoke(
const Tensor& input_tensor_a,
const Tensor& input_tensor_b,
const bool transpose_a = false,
const bool transpose_b = false,
const std::optional<const MemoryConfig>& memory_config = std::nullopt,
const std::optional<const DataType> dtype = std::nullopt,
const std::optional<const MatmulProgramConfig>& program_config = std::nullopt,
const std::optional<const std::string>& activation = std::nullopt,
const std::optional<const DeviceComputeKernelConfig> compute_kernel_config = std::nullopt,
const std::optional<const CoreGrid> core_grid = std::nullopt,
const std::optional<const tt::tt_metal::Tile>& output_tile = std::nullopt,
std::optional<Tensor> optional_output_tensor = std::nullopt,
const std::optional<const DeviceGlobalCircularBuffer>& global_cb = std::nullopt);
If we look closely, we'll notice that the IR has way less arguments than can be seen in the actual signature of the op - as we're lowering to EmitC, which gets translated into actual C++ code, we need to correct for this (ideally the op would be perfectly modelled with all the arguments, but that is not the case today).
We do this by filling in the gaps. EmitC's CallOpaqueOp takes in an array of attributes, and an array of operands, which need to be combined. The combining is done by extending the array of attributes with "pointers" into operands, like so:
llvm::SmallVector<mlir::Attribute> args{
emitter.emit(srcOp.getA()),
emitter.emit(srcOp.getB()),
emitter.emit(srcOp.getTransposeA()),
emitter.emit(srcOp.getTransposeB()),
emitter.emit(srcOp.getMemoryConfigAttr()),
emitter.emit(emitter.getOutputDtype(srcOp.getResult())),
/*program_config=*/emitter.emit(std::nullopt),
emitter.emit(srcOp.getActivation()),
emitter.emit(srcOp.getComputeConfig()),
};
Pointers are denoted with IndexTypes, wrapped into IntegerAttrs. Attributes are converted into EmitC's OpaqueAttr which can, for practical purposes, be treated as strings: a BoolAttr carrying "false" as value needs to be converted into an OpaqueAttr whose value is a string "false", which is what the convertBoolAttr function does.
This is our final converted EmitC CallOpaqueOp:
emitc.call_opaque "ttnn::matmul"(%3, %6, %9) {args = [0 : index, 1 : index, #emitc.opaque<"false">, #emitc.opaque<"false">, #emitc.opaque<"std::nullopt">, #emitc.opaque<"std::nullopt">, #emitc.opaque<"std::nullopt">, #emitc.opaque<"std::nullopt">, #emitc.opaque<"std::nullopt">, #emitc.opaque<"std::nullopt">, #emitc.opaque<"std::nullopt">, 2 : index]} : (!emitc.opaque<"ttnn::Tensor">, !emitc.opaque<"ttnn::Tensor">, !emitc.opaque<"ttnn::Tensor">) -> !emitc.opaque<"ttnn::Tensor">
which, when translated to C++ code, looks like:
ttnn::matmul(v6, v9, false, false, std::nullopt, std::nullopt, std::nullopt, std::nullopt, std::nullopt, std::nullopt, std::nullopt, v12);
Full conversion pattern for matmul op:
namespace {
class MatmulOpConversionPattern
: public TTNNToEmitCBaseOpConversionPattern<mlir::tt::ttnn::MatmulOp> {
public:
using TTNNToEmitCBaseOpConversionPattern<
mlir::tt::ttnn::MatmulOp>::TTNNToEmitCBaseOpConversionPattern;
LogicalResult
matchAndRewrite(mlir::tt::ttnn::MatmulOp srcOp,
mlir::tt::ttnn::MatmulOp::Adaptor adaptor,
ConversionPatternRewriter &rewriter) const override {
ttnn_to_emitc::EmitCTTNNEmitter<mlir::tt::ttnn::MatmulOp> emitter(
srcOp, adaptor, rewriter);
llvm::SmallVector<mlir::Attribute> args{
emitter.emit(srcOp.getA()),
emitter.emit(srcOp.getB()),
emitter.emit(srcOp.getTransposeA()),
emitter.emit(srcOp.getTransposeB()),
emitter.emit(srcOp.getMemoryConfigAttr()),
emitter.emit(emitter.getOutputDtype(srcOp.getResult())),
/*program_config=*/emitter.emit(std::nullopt),
emitter.emit(srcOp.getActivation()),
emitter.emit(srcOp.getComputeConfig()),
};
emitter.replaceOp(*this, args);
return success();
}
};
} // namespace
4. Add a compiler unit test for the Op
So far we have defined the Op in the TTIR and TTNN dialects,
implemented verifiers, and have conversion passes. Now we need to add a unit
test to ensure that the pass is working correctly. The compiler unit tests are located
in test/ttmlir/Dialect area. In this case we'll add a test under the TTNN
subdirectory since we are testing the ConvertTTIRToTTNNPass.
test/ttmlir/Dialect/TTNN/matmul/simple_matmul.mlir
// RUN: ttmlir-opt --ttir-to-ttnn-backend-pipeline -o %t %s
// RUN: FileCheck %s --input-file=%t
module {
func.func @forward(%arg0: tensor<64x128xbf16>, %arg1: tensor<128x96xbf16>) -> tensor<64x96xbf16> {
// CHECK: "ttnn.matmul"
%1 = "ttir.matmul"(%arg0, %arg1) : (tensor<64x128xbf16>, tensor<128x96xbf16>) -> tensor<64x96xbf16>
return %1 : tensor<64x96xbf16>
}
}
Unit tests in MLIR are typically written using a tool called
FileCheck, please refer to the llvm FileCheck documentation for a tutorial and more information about theRUNandCHECKdirectives.
A few things to point out specifically regarding tt-mlir dialects:
ttcore.system_desc: This is a 1-1 mapping to theSystemDescflatbuffer schema that is used to describe the system configuration. This is a required attribute tagged on the top level module for all tt-mlir dialects.- Pass
--ttnn-layoutis a prerequisite before runningconvert-ttir-to-ttnn. This pass is responsible for converting the input tensors to device memory space and tile layout before lowering to TTNN. - This test is asserting that
ttir.matmulconverts tottnn.matmul.
To run the test, you can use the following command:
cmake --build build -- check-ttmlir
You can also manually run ttmlir-opt on the test file to see the
resulting output:
./build/bin/ttmlir-opt --ttcore-register-device="system-desc-path=<PATH_TO_SYSTEM_DESC>" --ttir-to-ttnn-runtime-pipeline test/ttmlir/Dialect/TTNN/matmul/simple_matmul.mlir
5. Define flatbuffer schema for the Op
Next we will define the flatbuffer schema for the Op. The schema must capture all tensor inputs, outputs, and attributes of the Op, i.e. everything the runtime needs to execute the Op.
The schema can be placed in an existing .fbs file located in the include/ttmlir/Target/TTNN/operations directory.
If no suitable .fbs file exists for the operation category, feel free to create new .fbs files as needed. After creating a new .fbs file, remember to add a corresponding cmake target in the include/ttmlir/Target/TTNN/CMakeLists.txt file.
include/ttmlir/Target/TTNN/CMakeLists.txt
operations/matmul.fbs
In our case, we can add our schema to include/ttmlir/Target/TTNN/operations/matmul.fbs directly, without needing to create a new file.
include/ttmlir/Target/TTNN/operations/matmul.fbs
table MatmulOp {
a: tt.target.ttnn.TensorRef;
b: tt.target.ttnn.TensorRef;
out: tt.target.ttnn.TensorRef;
transpose_a: bool;
transpose_b: bool;
matmul_program_config: tt.target.ttnn.MatmulProgramConfig;
activation: string;
compute_config: tt.target.ttnn.DeviceComputeKernelConfig;
}
Type TensorRef, flatbuffer tables with suffix Ref are used to represent live values
during the runtime, decoupled from the underlying Desc suffixes which carry the
type and attribute information for the object.
After creating the schema for our new operation type, we need to register it in the OpType union
within program.fbs. This file serves as the main entry point for all program information,
where the OpType union collects and defines all supported operation types and their corresponding schemas.
include/ttmlir/Target/TTNN/program.fbs
MatmulOp,
If a new .fbs file was created, don't forget to include the new file in include/ttmlir/Target/TTNN/program.fbs.
include "ttmlir/Target/TTNN/operations/matmul.fbs";
More information about writing flatbuffer schemas can be found in the flatbuffers documentation
6. Serialize the Op in the flatbuffer format
In the previous section we defined the flatbuffer schema for the matmul
Op, now let's put our new schema definition to use. The schema is used as input
to a program called flatc which generates C++ code (or any language for that
matter) for serializing and deserializing the schema. This generated code can be
found in build/include/ttmlir/Target/TTNN/program_generated.h.
Let's head over to lib/Target/TTNN/TTNNToFlatbuffer.cpp to define
a createOp overloaded function that does the conversion from MLIR to flatbuffer:
::flatbuffers::Offset<::tt::target::ttnn::MatmulOp>
createOp(FlatbufferObjectCache &cache, MatmulOp op) {
auto a = cache.at<::tt::target::ttnn::TensorRef>(
getOperandThroughDPSOps(op.getA()));
auto b = cache.at<::tt::target::ttnn::TensorRef>(
getOperandThroughDPSOps(op.getB()));
auto output =
cache.getOrCreateNoSharding(op.getResult(), tensorValueToFlatbuffer,
/*local_shape*/ std::nullopt);
using MatmulConfigType = ::tt::target::ttnn::MatmulProgramConfig;
MatmulConfigType matmulProgramConfigType = MatmulConfigType::NONE;
::flatbuffers::Offset<void> matmulProgramConfigDesc;
if (auto matmulProgramConfig = op.getMatmulProgramConfigAttr()) {
if (auto config =
mlir::dyn_cast<ttnn::MatmulMultiCoreReuseProgramConfigAttr>(
matmulProgramConfig)) {
matmulProgramConfigType =
MatmulConfigType::MatmulMultiCoreReuseProgramConfig;
matmulProgramConfigDesc = toFlatbuffer(cache, config).Union();
} else if (auto config = mlir::dyn_cast<
ttnn::MatmulMultiCoreReuseMultiCastProgramConfigAttr>(
matmulProgramConfig)) {
matmulProgramConfigType =
MatmulConfigType::MatmulMultiCoreReuseMultiCastProgramConfig;
matmulProgramConfigDesc = toFlatbuffer(cache, config).Union();
} else if (auto config = mlir::dyn_cast<
ttnn::MatmulMultiCoreReuseMultiCast1DProgramConfigAttr>(
matmulProgramConfig)) {
matmulProgramConfigType =
MatmulConfigType::MatmulMultiCoreReuseMultiCast1DProgramConfig;
matmulProgramConfigDesc = toFlatbuffer(cache, config).Union();
} else if (
auto config = mlir::dyn_cast<
ttnn::MatmulMultiCoreReuseMultiCastDRAMShardedProgramConfigAttr>(
matmulProgramConfig)) {
matmulProgramConfigType = MatmulConfigType::
MatmulMultiCoreReuseMultiCastDRAMShardedProgramConfig;
matmulProgramConfigDesc = toFlatbuffer(cache, config).Union();
}
}
auto activation = toFlatbuffer(cache, op.getActivation()).value_or(0);
std::optional<
::flatbuffers::Offset<::tt::target::ttnn::DeviceComputeKernelConfig>>
computeConfig = toFlatbuffer(cache, op.getComputeConfig());
return ::tt::target::ttnn::CreateMatmulOp(
*cache.fbb, a, b, output, op.getTransposeA(), op.getTransposeB(),
matmulProgramConfigType, matmulProgramConfigDesc, activation,
computeConfig.value_or(0));
}
Lots of things are happening here, let's break it down:
FlatbufferObjectCache: This is a helper class that is used to cache objects in the flatbuffer that are created during the serialization process. This is necessary for managing value lifetimes and identifiers, at the same time it is an optimization to avoid having multiple copies of the same object. For example, aTensorRefwith multiple uses could naively be recreated, one for each use, but with the cache we can ensure that the object is only created once and all uses point to the same flatbuffer offset. The cache is passed around to all serialization functions and should be used whenever creating a new object.getOperandThroughDPSOps: In section 1. we discussed DPS semantics and the drawback of having the result alias the output tensor. This is one of those cases where we need to use a helper function to trace through the output operands to find the original SSA name in order to associate it with the originalTensorRef.CreateMatmulOp: The autogenerated function from the flatbuffer schema that actually serializes the data into the flatbuffer format.
We can finally generate a binary with our new Op! We can use the following command:
./build/bin/ttmlir-opt --ttcore-register-device="system-desc-path=<PATH_TO_SYSTEM_DESC>" --ttir-to-ttnn-runtime-pipeline test/ttmlir/Dialect/TTNN/matmul/simple_matmul.mlir | ./build/bin/ttmlir-translate --ttnn-to-flatbuffer -o out.ttnn
And we can inspect the with ttrt:
ttrt read out.ttnn
Note: If the above ttrt command yields a segfault, a clean build of your workspace may be required: Build Instructions
7. Add runtime support for the Op
Next, we want to add runtime support for the Op by parsing the flatbuffer and invoking the TTNN API.
runtime/lib/ttnn/operations/matmul/matmul.cpp
void run(const ::tt::target::ttnn::MatmulOp *op, ProgramContext &context) {
ProgramTensorPool &tensorPool = context.getTensorPool();
const ::ttnn::Tensor &lhs = tensorPool.getTTNNTensorAndValidate(op->a());
const ::ttnn::Tensor &rhs = tensorPool.getTTNNTensorAndValidate(op->b());
auto outputMemoryConfig =
::tt::runtime::ttnn::utils::createMemoryConfigIfNeeded(
::tt::runtime::ttnn::utils::getTensorRefMemoryConfig(op->out()));
LOG_ASSERT(::tt::runtime::ttnn::utils::inSystemMemory(op->out()) ||
outputMemoryConfig,
"Memory config must exist for device tensors");
::ttnn::DataType outputDataType = utils::getDataType(op->out());
std::optional<::ttnn::operations::matmul::MatmulProgramConfig>
matmulProgramConfig = utils::createMatmulProgramConfigIfNeeded(op);
std::optional<std::string> activation;
if (op->activation() && !programCarriesFusedActivation(matmulProgramConfig)) {
activation = op->activation()->str();
}
std::optional<::ttnn::DeviceComputeKernelConfig> computeConfig;
if (op->compute_config()) {
computeConfig =
utils::createDeviceComputeKernelConfig(op->compute_config());
}
::ttnn::Tensor output = ::ttnn::matmul(
lhs, rhs, op->transpose_a(), op->transpose_b(), outputMemoryConfig,
outputDataType, matmulProgramConfig,
/*activation=*/activation, /*compute_kernel_config=*/computeConfig,
/*core_grid=*/std::nullopt, /*output_tile=*/std::nullopt,
/* optional_output_tensor=*/std::nullopt);
tensorPool.insertTTNNTensorAndValidate(op->out(), output);
}
A couple things to note from above:
- Most runtime op functions will follow a similar pattern, they will take in
some additional datastructures for managing the program context.
- Program context tracks the state of the current program. It stores intermediate tensors and devices.
tensorPool.at(op->in0()->global_id()):global_idis a unique identifier for the tensor that was generated and managed by theFlatbufferObjectCache. This is how it's intended to be used by the runtime.- Some operations may belong to a larger set of operations. For example, any eltwise unary operations can
be added in
runtime/lib/ttnn/operations/eltwise/unary.cppdirectly without needing to create a new file.
If a new file is created for the op, we need to add a new source to runtime/lib/ttnn/operations/CMakeLists.txt and a new case to runtime/lib/ttnn/program_executor.cpp.
To update runtime/lib/ttnn/operations/CMakeLists.txt, include the path to the source file in TTNN_OPS_SRCS:
runtime/lib/ttnn/operations/CMakeLists.txt
${CMAKE_CURRENT_SOURCE_DIR}/matmul/matmul.cpp
To update runtime/lib/ttnn/program_executor.cpp, add a new case to the runOperation method of ProgramExecutor:
runtime/lib/ttnn/program_executor.cpp
case ::tt::target::ttnn::OpType::MatmulOp: {
return operations::matmul::run(op->type_as_MatmulOp(), getContext());
}
We can test our changes with ttrt (don't forget to rebuild ttrt):
ttrt run out.ttnn
8. Add a silicon unit test for the Op
After adding runtime support, we're ready to test our Op on silicon. All silicon tests are located
under test/ttmlir/Silicon. The process is similar to adding a compiler unit test.
In our specific case, we create a unit test here:
test/ttmlir/Silicon/TTNN/matmul/simple_matmul.mlir
// RUN: ttmlir-opt --ttir-to-ttnn-backend-pipeline="system-desc-path=%system_desc_path%" -o %t.mlir %s
// RUN: FileCheck %s --input-file=%t.mlir
// RUN: ttmlir-translate --ttnn-to-flatbuffer -o %t.ttnn %t.mlir
module {
func.func @forward(%arg0: tensor<64x128xbf16>, %arg1: tensor<128x96xbf16>) -> tensor<64x96xbf16> {
// CHECK: "ttnn.matmul"
%1 = "ttir.matmul"(%arg0, %arg1) : (tensor<64x128xbf16>, tensor<128x96xbf16>) -> tensor<64x96xbf16>
return %1 : tensor<64x96xbf16>
}
func.func @matmul_transpose_lhs(%arg0: tensor<64x128xbf16>, %arg1: tensor<64x128xbf16>) -> tensor<128x128xbf16> {
// CHECK: "ttnn.matmul"
%1 = "ttir.matmul"(%arg0, %arg1) <{transpose_a = true}>: (tensor<64x128xbf16>, tensor<64x128xbf16>) -> tensor<128x128xbf16>
return %1 : tensor<128x128xbf16>
}
func.func @matmul_transpose_rhs(%arg0: tensor<64x128xbf16>, %arg1: tensor<64x128xbf16>) -> tensor<64x64xbf16> {
// CHECK: "ttnn.matmul"
%1 = "ttir.matmul"(%arg0, %arg1) <{transpose_b = true}>: (tensor<64x128xbf16>, tensor<64x128xbf16>) -> tensor<64x64xbf16>
return %1 : tensor<64x64xbf16>
}
}
Couple things to point out about this process:
- Tests placed under
test/ttmlir/Dialectwill only test the compiler's capability of compiling the module. If you want the module to run on silicon in CI, the test must be placed undertest/ttmlir/Silicon. - Notice the differences between the compilation headers of
test/ttmlir/Silicon/TTNN/simple_matmul.mlirandtest/ttmlir/Dialect/TTNN/matmul/simple_matmul.mlir--ttir-to-ttnn-runtime-pipeline="system-desc-path=%system_desc_path%": Thesystem-desc-pathoption specifies the location of the system descriptor required for compiling the module. This is crucial for silicon tests, as modules compiled with different system descriptors may vary in silicon compatibility. Ensuring the system descriptor accurately reflects the target hardware is essential for running the module correctly.// RUN: ttmlir-translate --ttnn-to-flatbuffer %t.mlir > %t.ttnn: This runsttmlir-translatethat serializes the output mlir module to a flatbuffer binary. We added the logic for this serialization in the Serialize the Op in the flatbuffer format section.
9. Add an EmitC test for the Op
Op should be tested in the EmitC (C++ codegen) path as well.
TTNN EmitC tests live in the test/ttmlir/EmitC/TTNN path. In our case, the test is in test/ttmlir/EmitC/TTNN/matmul/matmul.mlir.
test/ttmlir/EmitC/TTNN/matmul/matmul.mlir
// TODO(dmilinkovic): re-enable CPU-hoisted const-eval once EmitC support for CPU-hoisted ops lands - issue #6100.
// RUN: ttmlir-opt --ttir-to-ttnn-common-pipeline="enable-cpu-hoisted-const-eval=false system-desc-path=%system_desc_path%" -o %t.mlir %s
//
// RUN: ttmlir-opt --ttnn-common-to-runtime-pipeline -o %t_rt.mlir %t.mlir
// RUN: ttmlir-translate --ttnn-to-flatbuffer -o %basename_t.ttnn %t_rt.mlir
//
// RUN: ttmlir-opt --ttnn-common-to-emitc-pipeline -o %t2.mlir %t.mlir
// RUN: ttmlir-translate --mlir-to-cpp -o %basename_t.cpp %t2.mlir
func.func @matmul(%arg0: tensor<64x128xbf16>, %arg1: tensor<128x96xbf16>) -> tensor<64x96xbf16> {
%1 = "ttir.matmul"(%arg0, %arg1) : (tensor<64x128xbf16>, tensor<128x96xbf16>) -> tensor<64x96xbf16>
return %1 : tensor<64x96xbf16>
}
The first two RUN lines create a flatbuffer. The third and forth convert to EmitC dialect, translate to C++, then output the result to matmul.mlir.cpp file.
Additionally, the op's header file operations/matmul/matmul.hpp should be added to the list of includes in tools/ttnn-standalone/ttnn-precompiled.hpp:
#include "operations/ccl/all_gather/all_gather.hpp"
#include "operations/ccl/all_to_all_combine/all_to_all_combine.hpp"
#include "operations/ccl/all_to_all_dispatch/all_to_all_dispatch.hpp"
#include "operations/ccl/ccl_host_types.hpp"
#include "operations/conv/conv2d/conv2d.hpp"
#include "operations/conv/conv2d/prepare_conv2d_weights.hpp"
#include "operations/conv/conv_transpose2d/conv_transpose2d.hpp"
#include "operations/core/core.hpp"
#include "operations/creation/creation.hpp"
#include "operations/data_movement/concat/concat.hpp"
#include "operations/data_movement/gather/gather.hpp"
#include "operations/data_movement/moe_expert_token_remap/moe_expert_token_remap.hpp"
#include "operations/data_movement/pad/pad.hpp"
#include "operations/data_movement/permute/permute.hpp"
#include "operations/data_movement/repeat/repeat.hpp"
#include "operations/data_movement/repeat_interleave/repeat_interleave.hpp"
#include "operations/data_movement/reshape_view/reshape.hpp"
#include "operations/data_movement/scatter/scatter.hpp"
#include "operations/data_movement/slice/slice.hpp"
#include "operations/data_movement/sort/sort.hpp"
#include "operations/data_movement/transpose/transpose.hpp"
#include "operations/eltwise/binary/binary.hpp"
#include "operations/eltwise/binary/binary_composite.hpp"
#include "operations/eltwise/quantization/quantization.hpp"
#include "operations/eltwise/unary/unary_composite.hpp"
#include "operations/embedding/embedding.hpp"
#include "operations/embedding_backward/embedding_backward.hpp"
#include "operations/experimental/ccl/all_reduce_async/all_reduce_async.hpp"
#include "operations/experimental/ccl/all_to_all_dispatch_metadata/all_to_all_dispatch_metadata.hpp"
#include "operations/experimental/ccl/moe_gpt/moe_gpt.hpp"
#include "operations/experimental/ccl/rms_allgather/rms_allgather.hpp"
#include "operations/experimental/conv3d/conv3d.hpp"
#include "operations/experimental/conv3d/prepare_conv3d_weights.hpp"
#include "operations/experimental/dropout/dropout.hpp"
#include "operations/experimental/transformer/nlp_concat_heads/nlp_concat_heads.hpp"
#include "operations/experimental/unary_backward/gelu_backward/gelu_backward.hpp"
#include "operations/kv_cache/kv_cache.hpp"
#include "operations/matmul/matmul.hpp"
#include "operations/normalization/batch_norm/batch_norm.hpp"
#include "operations/normalization/groupnorm/groupnorm.hpp"
#include "operations/normalization/layernorm/layernorm.hpp"
#include "operations/normalization/layernorm_distributed/layernorm_post_all_gather.hpp"
#include "operations/normalization/layernorm_distributed/layernorm_pre_all_gather.hpp"
#include "operations/normalization/rmsnorm/rmsnorm.hpp"
#include "operations/normalization/rmsnorm_distributed/rmsnorm_pre_all_gather.hpp"
#include "operations/normalization/softmax/softmax.hpp"
#include "operations/pool/generic/generic_pools.hpp"
#include "operations/pool/upsample/upsample.hpp"
#include "operations/rand/rand.hpp"
#include "operations/reduction/accumulation/cumsum/cumsum.hpp"
#include "operations/reduction/argmax/argmax.hpp"
#include "operations/reduction/generic/generic_reductions.hpp"
#include "operations/reduction/prod/prod.hpp"
#include "operations/trace.hpp"
#include "operations/transformer/concatenate_heads/concatenate_heads.hpp"
#include "operations/transformer/sdpa/sdpa.hpp"
#include "operations/transformer/sdpa_decode/sdpa_decode.hpp"
#include "operations/transformer/split_query_key_value_and_split_heads/split_query_key_value_and_split_heads.hpp"
#include "tt-metalium/bfloat16.hpp"
#include "ttnn/common/queue_id.hpp"
#include "ttnn/core.hpp"
#include "ttnn/device.hpp"
#include "ttnn/global_semaphore.hpp"
#include "ttnn/operations/copy/typecast/typecast.hpp"
#include "ttnn/operations/experimental/paged_cache/paged_cache.hpp"
#include "ttnn/operations/experimental/topk_router_gpt/topk_router_gpt.hpp"
#include "ttnn/operations/experimental/transformer/nlp_concat_heads_decode/nlp_concat_heads_decode.hpp"
#include "ttnn/operations/experimental/transformer/nlp_create_qkv_heads_decode/nlp_create_qkv_heads_decode.hpp"
#include "ttnn/operations/experimental/transformer/rotary_embedding/rotary_embedding.hpp"
#include "ttnn/operations/experimental/transformer/rotary_embedding_llama/rotary_embedding_llama.hpp"
#include "ttnn/operations/normalization/layernorm/layernorm.hpp"
#include "ttnn/operations/reduction/accumulation/cumprod/cumprod.hpp"
#include "ttnn/operations/reduction/topk/topk.hpp"
#include "ttnn/tensor/serialization.hpp"
#include "ttnn/tensor/tensor.hpp"
#include "ttnn/tensor/types.hpp"
#include "ttnn/types.hpp"
#include "workarounds.hpp"
10. Add a builder test for the Op
Builder tests verify end-to-end numerical correctness — they compile through the full TTIR → TTNN pipeline and execute on silicon, comparing results against PyTorch golden values. They complement the structural lit tests from steps 4 and 8.
10a. Add the op to ttir_builder.py
If the op does not yet have a builder method in
tools/builder/ttir/ttir_builder.py, add one now. This involves:
- Writing the builder method that calls
_op_proxywith the appropriate TTIR op class, operands, and keyword attributes. - Registering a golden function in
tools/golden/mapping.pyso_op_proxycan compare compiler output against the PyTorch reference.
Refer to Adding a new op to ttir-builder for
the full workflow, including how to write golden functions and register them in
GOLDEN_MAPPINGS.
10b. Write the builder test
Builder tests live under test/python/golden/ttir_ops/<category>/. Add a new
file (or extend an existing one) for the op. The test parametrizes over shapes,
dtypes, and target backends, then delegates to compile_and_execute_ttir which
builds the TTIR module, compiles it, runs it on device, and checks numerical
correctness against the golden.
test/python/golden/ttir_ops/matmul/test_matmul.py
# SPDX-FileCopyrightText: (c) 2026 Tenstorrent AI ULC
#
# SPDX-License-Identifier: Apache-2.0
import pytest
import torch
from typing import List, Optional
from conftest import x86_only, get_request_kwargs
from builder.base.builder_utils import Operand, Shape
from builder.ttir.ttir_builder import TTIRBuilder
from builder.base.builder_apis import compile_and_execute_ttir
from test_utils import (
XFail,
shapes_list_str,
)
pytestmark = pytest.mark.frontend("ttir")
@pytest.mark.parametrize(
"shapes",
[
[(128, 128), (128, 128)],
[(4, 128, 128), (4, 128, 128)],
# Batched matmul, no broadcast.
[(1, 1, 128, 128), (1, 1, 128, 128)],
[(2, 1, 128, 128), (2, 1, 128, 128)],
[(1, 2, 128, 128), (1, 2, 128, 128)],
[(2, 2, 128, 128), (2, 2, 128, 128)],
# RHS broadcast: supported only when the whole RHS is a single batch.
[(1, 4, 128, 128), (1, 1, 128, 128)],
[(4, 1, 128, 128), (1, 1, 128, 128)],
[(4, 8, 128, 128), (1, 1, 128, 128)],
[(1, 8, 128, 128), (1, 1, 128, 128)],
[(2, 4, 128, 128), (2, 1, 128, 128)] | XFail("partial RHS batch"),
[(4, 2, 128, 128), (1, 2, 128, 128)] | XFail("partial RHS batch"),
# LHS broadcast: never supported.
[(1, 1, 128, 128), (1, 4, 128, 128)] | XFail("LHS batch broadcast"),
[(2, 1, 128, 128), (2, 4, 128, 128)] | XFail("LHS batch broadcast"),
[(1, 1, 128, 128), (4, 1, 128, 128)] | XFail("LHS batch broadcast"),
[(1, 2, 128, 128), (4, 2, 128, 128)] | XFail("LHS batch broadcast"),
[(1, 1, 128, 128), (4, 8, 128, 128)] | XFail("LHS batch broadcast"),
],
ids=shapes_list_str,
)
@pytest.mark.parametrize("dtype", [torch.float32], ids=["f32"])
@pytest.mark.parametrize("transpose_a", [False, True])
@pytest.mark.parametrize("transpose_b", [False, True])
@pytest.mark.parametrize("target", ["ttnn", "emitpy"])
def test_matmul(
shapes: List[Shape],
dtype: torch.dtype,
transpose_a: bool,
transpose_b: bool,
target: str,
request,
device,
):
"""Matmul over square, batched, and batch-broadcast operand shapes.
The broadcast cases pin down which batched-matmul shapes tt-metal supports:
the ``XFail``-ed shapes are the ones metal cannot handle (partial RHS batch,
or any LHS batch broadcast). They do not exercise the broadcast-into-matmul
fold directly -- the builder emits a ``ttir.matmul`` with implicitly
mismatched batch dims, which never materializes a ``ttnn.repeat`` -- but
they are the ground truth the fold (``MatmulOp`` canonicalization in the
TTNN dialect) must respect: it may only ever produce shapes from the passing
set, never one of the ``XFail``-ed shapes.
"""
def module(builder: TTIRBuilder):
@builder.func(shapes, [dtype] * len(shapes))
def matmul(
in0: Operand,
in1: Operand,
builder: TTIRBuilder,
unit_attrs: Optional[List[str]] = None,
):
return builder.matmul(
in0,
in1,
transpose_a=transpose_a,
transpose_b=transpose_b,
unit_attrs=unit_attrs,
)
pipeline_options = []
compile_and_execute_ttir(
module,
**get_request_kwargs(request),
target=target,
device=device,
pipeline_options=pipeline_options,
)
@pytest.mark.parametrize(
"shapes",
[
[
(10, 64, 64),
(64, 64),
]
],
ids=shapes_list_str,
)
@pytest.mark.parametrize("dtype", [torch.float32], ids=["f32"])
@pytest.mark.parametrize("has_bias", [True, False], ids=["with_bias", "without_bias"])
@pytest.mark.parametrize("transpose_a", [False, True])
@pytest.mark.parametrize("transpose_b", [False, True])
@pytest.mark.parametrize("target", ["ttnn", "emitpy"])
def test_linear(
shapes: List[Shape],
dtype: torch.dtype,
has_bias: bool,
transpose_a: bool,
transpose_b: bool,
target: str,
request,
device,
):
bias_shape = None
if has_bias:
bias_shape = (shapes[1][-1],)
def module(builder: TTIRBuilder):
# Set up input shapes and types based on whether bias is used
if has_bias:
input_shapes = shapes + [bias_shape]
input_types = [dtype, dtype, dtype]
else:
input_shapes = shapes
input_types = [dtype, dtype]
@builder.func(input_shapes, input_types)
def linear(*args, unit_attrs: Optional[List[str]] = None):
# The builder is always passed as the last positional argument
builder = args[-1]
inputs = args[:-1]
in0 = inputs[0]
in1 = inputs[1]
bias = inputs[2] if len(inputs) > 2 else None
return builder.linear(
in0,
in1,
bias,
transpose_a=transpose_a,
transpose_b=transpose_b,
unit_attrs=unit_attrs,
)
compile_and_execute_ttir(
module,
**get_request_kwargs(request),
device=device,
target=target,
)
@x86_only
@pytest.mark.parametrize(
"shapes",
[
[(10, 64, 32), (32, 128), (128,)],
[(10, 20), (20, 30)],
],
ids=["3D_with_bias", "2D_no_bias"],
)
@pytest.mark.parametrize("dtype", [torch.float32], ids=["f32"])
@pytest.mark.parametrize("target", ["ttnn", "emitpy"])
def test_hoisted_linear(
shapes: List[Shape], dtype: torch.dtype, target: str, request, device
):
def module(builder: TTIRBuilder):
@builder.func(shapes, [dtype] * len(shapes))
def hoisted_linear(
*inputs,
unit_attrs: Optional[List[str]] = None,
):
builder = inputs[-1]
in0 = inputs[0]
in1 = inputs[1]
bias = inputs[2] if len(inputs) > 3 else None
return builder.linear(in0, in1, bias, unit_attrs=["ttir.should_hoist"])
compile_and_execute_ttir(
module,
**get_request_kwargs(request),
target=target,
device=device,
)
@x86_only
@pytest.mark.parametrize(
"shapes",
[
[(10, 20), (20, 30)],
[(5, 10, 20), (5, 20, 30)],
],
ids=["standard_2D_matmul", "3D_batched_matmul"],
)
@pytest.mark.parametrize("dtype", [torch.float32], ids=["f32"])
@pytest.mark.parametrize("target", ["ttnn", "emitpy"])
def test_hoisted_matmul(
shapes: List[Shape], dtype: torch.dtype, target: str, request, device
):
def module(builder: TTIRBuilder):
@builder.func(shapes, [dtype] * len(shapes))
def hoisted_matmul(
in0: Operand,
in1: Operand,
builder: TTIRBuilder,
unit_attrs: Optional[List[str]] = None,
):
return builder.matmul(in0, in1, unit_attrs=["ttir.should_hoist"])
compile_and_execute_ttir(
module,
**get_request_kwargs(request),
target=target,
device=device,
)
Key conventions:
pytestmark = pytest.mark.frontend("ttir")— required file-wide mark.- Shape parameters must be named
shape,shapes,input_shape, orinput_shapes; dtype parameters must be nameddtype,dtypes, orinput_dtypes. See Builder Testing for the full rules. targetmust be a parametrized dimension even for single-target tests (thedevicefixture reads it to initialise the right backend).- The inner
@builder.func([shapes], [dtypes])decorator wires up MLIR function arguments; the computation is expressed withbuilder.<op>(...)calls inside.
Run with:
pytest test/python/golden/ttir_ops/matmul/test_matmul.py
For full parametrization rules, skip marks (skip_config, x86_only), and
test-report requirements refer to Builder Testing.
11. Add CPU-hoisting support (if applicable)
CPU-hoisting moves selected TTIR ops off the device and executes them on the host CPU, improving
numerical precision (full f32/i32) and reducing peak DRAM/L1 usage. It is appropriate for standard
elementwise, reduction, normalization, and similar ops. Skip this step for complex,
model-specific ops (e.g., ScaledDotProductAttentionDecodeOp) that have no meaningful host
execution path and should always run on device.
Hoisted ops are lowered through two independent paths:
- Runtime target (flatbuffer path): TTIR → Linalg/TOSA → LLVM IR →
.sodylib, embedded in the flatbuffer and loaded at runtime viadlopen(). - EmitPy target: TTIR →
CallOpaqueOp("ttir_cpu.<op>")→ pure-torch implementation inttir_cpu.py.
11a. TTIR to Linalg/TOSA conversion pattern
Add a conversion pattern in lib/Conversion/TTIRToLinalg/ and register it in the appropriate
populate function. Elementwise ops typically lower to linalg.generic or a TOSA equivalent; see
existing patterns in the same directory for reference.
11b. TTIR to Linalg/TOSA lit test
Add test/ttmlir/Conversion/TTIRToLinalg/<op_name>.mlir. See existing tests in that directory
for the RUN/FileCheck boilerplate and CHECK conventions for both Linalg and TOSA targets.
11c. Decomposition alternative to 11a–11b (runtime path only)
If the op has no natural Linalg/TOSA equivalent but decomposes cleanly into ops that already have
Linalg support (e.g., DotGeneralOp → MatmulOp), steps 11a–11b can be skipped. Add the op as
illegal under DecompMode::CPUFallback in
lib/Conversion/TTIRToTTIRDecomposition/TTIRToTTIRDecompositionPass.cpp and add the decomposition
pattern under lib/Conversion/TTIRToTTIRDecomposition/. The runtime CPU pipeline runs this
decomposition before the Linalg lowering, and the hoisting validation uses the same check.
Note: decomposition does not help the EmitPy path — the EmitPy CPU pipeline has no prior decomposition step, so steps 11d–11e are still required.
11d. TTIR to EmitPy CPU conversion pattern
Add a pattern in lib/Conversion/TTIRToEmitPy/TTIRCPUToEmitPyPass.cpp. For elementwise ops,
use the existing generic templates; for ops with non-trivial attributes write a custom pattern
using EmitPyCallBuilder. See existing patterns in the same file for reference.
11e. Torch implementation in ttir_cpu
Add a pure-torch function to tools/tt-alchemist/templates/python/local/ttir_cpu.py mirroring
the TTIR op semantics (EmitPy target only — the runtime target goes through Linalg → LLVM). Use
**_ to absorb unused kwargs, builtins.* when a local name shadows a Python builtin, and
operate in float32 for reductions/normalization. Match TTIR semantics exactly — this is the
reference implementation for const-eval.
11f. Tests for CPU-hoisted ops
Linalg conversion lit test: run the test added in 11b:
llvm-lit test/ttmlir/Conversion/TTIRToLinalg/<op_name>.mlir
EmitPy lit test: add a function to test/ttmlir/EmitPy/cpu_hoisted_ops.mlir. The convention
is to run the op twice in one function — once tagged {ttir.should_hoist} and once on device —
then subtract the results, exercising both paths. Check for the expected ttir_cpu.<op> call in
the generated Python. See existing functions in that file for the pattern.
Builder test: add a test_cpu_hoistable_* test to
test/python/golden/ttir_ops/<category>/test_<category>.py, passing
unit_attrs=["ttir.should_hoist"] to the builder call and parametrizing over all three targets
(ttnn, ttmetal, emitpy). See existing test_cpu_hoistable_* tests for exact parametrization
and decorator patterns (e.g., @x86_only).
Adding OpConstraints and OpRuntime APIs to TTNN Operations
Overview
The TTNN Op Model Interface provides two key APIs for analyzing and optimizing operations:
getOpConstraints: Returns constraint information including memory requirements, layout compatibility, and operation feasibilitygetOpRuntime: Returns performance metrics including execution time estimates
These APIs enable the compiler to make informed decisions about operation placement, memory allocation, and performance optimization.
This guide walks you through best practices for implementing these APIs. It will cover the following steps:
Architecture
The implementation follows a layered architecture:
TTNNOpModelInterface.cpp (Operation-specific implementations)
↓
TTNNOpModel.h/.cpp (Core model implementations and helpers)
↓
Metal Backend (Runtime execution and constraint validation)
Important note: getOpConstraints and getOpRuntime API calls should be identical to regular op invocation path through runtime.
The only difference is that one call is generated from the IR while the other is from serialised FB. For example, you can compare:
The runtime code runtime/lib/ttnn/operations/conv/conv2d.cpp:
void run(const ::tt::target::ttnn::Conv2dOp *op, ProgramContext &context) {
// ...
}
With the constraint API implementation code lib/OpModel/TTNN/TTNNOpModel.cpp:
llvm::Expected<OpConstraints> OpModel<Conv2dOp>::getOpConstraints(/* args */){
// ...
}
// and:
llvm::Expected<size_t> OpModel<Conv2dOp>::getOpRuntime(/* args */){
// ...
}
And observe the similarities. This is very important to maintain throughout the lifetime of the project to guarantee consistency and functional correctness.
Implementation Steps
Step 1: Implement Operation-Specific Methods
Add your operation's implementation in lib/Dialect/TTNN/IR/TTNNOpModelInterface.cpp:
//===----------------------------------------------------------------------===//
// YourOp - TTNN Op Model Interface
//===----------------------------------------------------------------------===//
llvm::Expected<op_model::OpConstraints>
YourOp::getOpConstraints(const std::vector<TTNNLayoutAttr> &inputs,
const OpConfig &opConfig) {
// You can extract all input tensors' layouts from `inputs`.
// Other configurations can also be extracted from `opConfig`.
// All inputs/attrs can be extracted from YourOp's member functions.
// This layer is usually a wrapper to extract the op's necessary inputs/attrs
// and pass those information to TTNNOpModel.h.
return opConstraintsCache().getOrCompute(
op_model::OpModel<YourOp>::getOpConstraints, *this,
deviceGrid, /* other parameters */);
}
llvm::Expected<size_t>
YourOp::getOpRuntime(const std::vector<TTNNLayoutAttr> &inputs,
const OpConfig &opConfig) {
// Similar to the previous function.
return opRuntimeCache().getOrCompute(
op_model::OpModel<YourOp>::getOpRuntime, *this,
/* other parameters */);
}
Note: The codebase provides several template helpers for common operation patterns:
Unary Operations
// For simple unary operations (like ReluOp, SqrtOp, etc.)
return detail::getUnaryOpConstraints(*this, inputs, opConfig);
return detail::getUnaryOpRuntime(*this, inputs, opConfig);
Binary Operations
// For binary element-wise operations (like AddOp, MultiplyOp, etc.)
return detail::getBinaryOpConstraints(*this, inputs, opConfig);
return detail::getBinaryOpRuntime(*this, inputs, opConfig);
Ternary Operations
// For ternary operations (like WhereOp)
return detail::getTernaryOpConstraints(*this, inputs, opConfig);
return detail::getTernaryOpRuntime(*this, inputs, opConfig);
Reduction Operations
// For reduction operations (like SumOp, MeanOp, etc.)
return detail::getReductionOpConstraints(*this, inputs, opConfig);
return detail::getReductionOpRuntime(*this, inputs, opConfig);
Step 2: Add Core Model Implementation
Add the core implementation in include/ttmlir/OpModel/TTNN/TTNNOpModel.h:
template <>
struct OpModel<YourOp> {
static llvm::Expected<OpConstraints>
getOpConstraints(ttcore::GridAttr deviceGrid,
// ... operation-specific parameters ...
TTNNLayoutAttr outputLayout);
static llvm::Expected<size_t>
getOpRuntime(// ... operation-specific parameters ...
TTNNLayoutAttr outputLayout);
};
And the corresponding implementation in lib/OpModel/TTNN/TTNNOpModel.cpp:
llvm::Expected<OpConstraints>
OpModel<YourOp>::getOpConstraints(
ttcore::GridAttr deviceGrid,
// operation-specific parameters
llvm::ArrayRef<int64_t> inputShape, TTNNLayoutAttr inputLayout,
TTNNLayoutAttr outputLayout) {
#ifdef TTMLIR_ENABLE_OPMODEL
::tt::tt_metal::distributed::MeshDevice *device =
SingletonDeviceContext::getInstance().getDevice();
// 1. Convert inputs to TensorSpecs using ASSIGN_OR_RETURN.
// This macro unwraps llvm::Expected and returns the error
// on failure, avoiding repetitive error-checking boilerplate.
ASSIGN_OR_RETURN(::ttnn::TensorSpec inputSpec,
detail::convertToTensorSpec(device, inputShape, inputLayout));
// 2. Create query closure
// Here the ultimate goal is to enable the optimizer to call the
// invoke method of the op in tt-metal. This is achieved through
// creating a lambda that calls `query_op_constraints` which
// receives 3 arguments:
// 1. An op (eg. ::ttnn::yourOp). This is the op's backend
// found under tt-metal/src/tt-metal/ttnn/. The op usually
// has an 'invoke' method.
// 2. The device,
// 3. A variadic number of inputs that are converted to match
// the metal's definitions. The order and the types of these
// inputs are expected to match the invoke function of the
// op in metal.
auto yourOpQuery = [=]() {
return QUERY_OP_CONSTRAINTS(
::ttnn::yourOp, device, inputSpec,
/* other converted parameters */);
};
// 3. Call getOpConstraints and pass the callable.
return operation::getOpConstraints(inputLayout.getContext(), deviceGrid,
yourOpQuery);
#else
return OpConstraints{};
#endif // TTMLIR_ENABLE_OPMODEL
}
llvm::Expected<size_t>
OpModel<YourOp>::getOpRuntime(
// operation-specific parameters
llvm::ArrayRef<int64_t> inputShape, TTNNLayoutAttr inputLayout,
TTNNLayoutAttr outputLayout) {
#ifdef TTMLIR_ENABLE_OPMODEL
::tt::tt_metal::distributed::MeshDevice *device =
SingletonDeviceContext::getInstance().getDevice();
ASSIGN_OR_RETURN(::ttnn::TensorSpec inputSpec,
detail::convertToTensorSpec(device, inputShape, inputLayout));
auto yourOpQuery = [=]() {
return QUERY_OP_RUNTIME(
::ttnn::yourOp, device, inputSpec,
/* other converted parameters */);
};
return operation::getOpRuntime(yourOpQuery);
#else
return llvm::createStringError("Not Implemented");
#endif // TTMLIR_ENABLE_OPMODEL
}
Note: If the op's definition cannot be found by gcc you might need to #include the
related header file in OpModel/TTNN/MetalHeaders.h.
Note: The codebase provides several implementations for common operation patterns which is done through Explicit template instantiation.
Unary Operations
// For simple unary operations (like ReluOp, SqrtOp, etc.)
template struct UnaryEltwiseOpModel</* Op */>;
Binary Operations
// For binary element-wise operations (like AddOp, MultiplyOp, etc.)
template struct BinaryEltwiseOpModel</* Op */>;
Ternary Operations
// For ternary operations (like WhereOp)
template struct TernaryEltwiseOpModel</* Op */>;
Reduction Operations
// For reduction operations (like SumOp, MeanOp, etc.)
template struct ReductionOpModel</* Op */>;
Step 3: Add Unit Tests
Create tests in test/unittests/OpModel/TTNN/Op/TestOpModelInterface.cpp:
TEST_F(OpModelBase, YourOpInterface) {
// Create input tensors
auto input = createEmptyTensor({32, 64}, ttcore::DataType::Float32);
// Create operation
auto yourOp = builder.create<YourOp>(
loc, createRankedTensorType({32, 64}, ttcore::DataType::Float32),
input, /* other parameters */);
// Test constraints
auto constraintsExp = getOpConstraints(yourOp.getOperation());
if (constraintsExp) {
auto l1 = constraintsExp.get();
const auto &[cbSize, l1PeakSize, totalPeakSize, outputSize, outputLayout] = l1;
EXPECT_EQ(cbSize, /* some expected value */);
EXPECT_EQ(l1PeakSize, /* some expected value */);
EXPECT_EQ(totalPeakSize, /* some expected value */);
EXPECT_EQ(outputSize, /* some expected value */);
} else {
FAIL() << "Missing L1 constraints; Error="
<< llvm::toString(constraintsExp.takeError()) << std::endl;
}
auto runtimeExp = getOpRuntime(yourOp.getOperation());
if (runtimeExp) {
EXPECT_TRUE(runtimeExp.get() > 0);
} else {
FAIL() << llvm::toString(runtimeExp.takeError());
}
}
Step 4: Add Integration Tests
Create comprehensive tests in test/unittests/OpModel/TTNN/Lib/TestOpModelLib.cpp.
The following is one way of doing this, not the only possible test.
Note: For operations with additional parameters (like kernel size, stride, etc.), add them between the input and output tensors in the tuple definition and destructuring assignment.
template <typename OpTy>
class OpModelYourOpParam : public OpModelTest,
public ::testing::WithParamInterface<
std::tuple<detail::TestTensor, // input
detail::TestTensor, // output
detail::ExpectedResult>> {
protected:
void RunTest() {
auto [inputTensor, outputTensor, expectedResult] = GetParam();
// Create tensors with specified layouts
TTNNLayoutAttr inputLayout = createLayout(inputTensor);
TTNNLayoutAttr outputLayout = createLayout(outputTensor);
auto constraintsExp = OpModel<OpTy>::getOpConstraints(
CreateWorkerGrid(), /* pass the params according to TTNNOpModel.h interface */, outputLayout);
EXPECT_EQ(static_cast<bool>(constraintsExp), expectedResult.expectedLegal);
if (expectedResult.expectedLegal) {
const auto [cbSize, l1PeakSize, totalPeakSize, outputSize, outputLayout] =
constraintsExp.get();
EXPECT_EQ(cbSize, expectedResult.expectedCbSize);
EXPECT_EQ(l1PeakSize, expectedResult.expectedL1PeakSize);
EXPECT_EQ(totalPeakSize, expectedResult.expectedTotalPeakSize);
EXPECT_EQ(outputSize, expectedResult.expectedOutputSize);
} else {
// Must clean up the error
llvm::consumeError(constraintsExp.takeError());
}
auto runtimeExp =
OpModel<OpTy>::getOpRuntime(/* pass the params according to TTNNOpModel.h interface */, outputLayout);
EXPECT_EQ(static_cast<bool>(runtimeExp), expectedResult.expectedLegal);
if (expectedResult.expectedLegal) {
EXPECT_TRUE(runtimeExp.get() > 0);
} else {
llvm::consumeError(runtimeExp.takeError());
}
}
};
using OpModelYourOpParamTest = OpModelYourOpParam<YourOp>;
TEST_P(OpModelYourOpParamTest, YourOp) { RunTest(); }
INSTANTIATE_TEST_SUITE_P(
YourOpTests, OpModelYourOpParamTest,
::testing::Values(
std::make_tuple(
detail::TestTensor{{32, 64}, TensorMemoryLayout::INTERLEAVED, BufferType::DRAM},
detail::TestTensor{{32, 64}, TensorMemoryLayout::INTERLEAVED, BufferType::DRAM},
detail::ExpectedResult{true, 8192, 8192, 8192, 8192}),
// Add more test cases...
));
Key Considerations
Operations Not Supported by OpModel
If an operation does not need OpModel support (e.g., it has no metal backend
implementation, requires multi-device support, or simply doesn't benefit from
constraint analysis), mark it with the OpModelExempt trait in its TableGen
definition:
def TTNN_YourOp : TTNN_Op<"your_op", [OpModelExempt]> {
// ...
}
The OpModelExempt trait prevents the base op class from adding
DeclareOpInterfaceMethods<TTNN_OpModelInterface>, so no stub
implementation in TTNNOpModelInterface.cpp is needed.
We're keeping track of ops that lack OpModel support in this issue. Please either update the issue or add comments to it when exempting an op.
Device Grid Validation
Validate the device worker grid before proceeding using the
ASSIGN_OR_RETURN macro (defined in ttmlir/OpModel/TTNN/TTNNOpModel.h)
combined with detail::getValidatedDeviceGrid:
ASSIGN_OR_RETURN(ttcore::GridAttr deviceGrid,
detail::getValidatedDeviceGrid(op.getOperation()));
Caching
Use the provided caching mechanisms for computations:
// For getOpConstraints:
return opConstraintsCache().getOrCompute(
op_model::OpModel<YourOp>::getOpConstraints, *this,
/* parameters */);
// For getOpRuntime:
return opRuntimeCache().getOrCompute(
op_model::OpModel<YourOp>::getOpRuntime, *this,
/* parameters */);
Check Metal Backend Availability
Ensure your operation has a corresponding implementation in the tt-metal backend before implementing these APIs.
As mentioned before, the current metal header files are #included in MetalHeaders.h. If you are adding a
TTNNOp you might want to add an #include statement in that file to let the c++ compiler know where/how to find
the op's definition in metal.
Validate Input Assumptions
Always validate the number of input tensors, eg.:
assert(inputs.size() == 2); // for a binary op
assert(inputs.size() == 3); // for a ternary op
Example: Complete Implementation
Here's a complete example for a hypothetical CustomUnaryOp:
// In TTNNOpModelInterface.cpp
llvm::Expected<op_model::OpConstraints>
CustomUnaryOp::getOpConstraints(const std::vector<TTNNLayoutAttr> &inputs,
const OpConfig &opConfig) {
return detail::getUnaryOpConstraints(*this, inputs, opConfig);
}
llvm::Expected<size_t>
CustomUnaryOp::getOpRuntime(const std::vector<TTNNLayoutAttr> &inputs,
const OpConfig &opConfig) {
return detail::getUnaryOpRuntime(*this, inputs, opConfig);
}
// In TTNNOpModel.h
template <>
struct OpModel<CustomUnaryOp> : UnaryEltwiseOpModel<CustomUnaryOp> {};
// In TTNNOpModel.cpp
template <typename OpTy>
auto getOpSymbol() {
// ...
if constexpr (std::is_same_v<OpTy, CustomUnaryOp>) {
return ::ttnn::custom_unary_op; // metal's definition
}
// ...
}
// Explicit template instantiation
template struct UnaryEltwiseOpModel<CustomUnaryOp>;
// Add tests in TestOpModelInterface.cpp and TestOpModelLib.cpp
Decomposing an Op in TTIR
This guide explains how to add and decompose a new operation in the TTIR dialect. We’ll focus on adding an Index operation, which will be decomposed into the Slice operation. The decomposition is implemented as a conversion pass in MLIR since it allows us to mark operations or dialects as legal or illegal, type conversion...
This guide will cover the following steps:
1. Define the Op in the TTIR frontend dialect
The more information regarding this step can be found here: Define the Op in the TTIR frontend dialect
I updated the TTIROps.td as following:
def TTIR_IndexOp: TTIR_NamedOp<"index"> {
let summary = "Tensor indexing operation.";
let description = [{
The `index` operation extracts a sub-tensor (slice) from the input tensor along a specified dimension.
This operation selects elements from the input tensor along a single dimension based on the specified
begin, end, and step indices. It's similar to Python's slicing notation `tensor[:, begin:end:step, :]`
where the slicing is applied only to the specified dimension.
Example:
```mlir
// Extract elements with indices 1, 3, 5 from dimension 0 of a 1D tensor
%input = ... : tensor<6xf32> // Input tensor with values: [1, 2, 3, 4, 5, 6]
%result = ttir.index(%input) {
dim = 0 : i32, // Dimension to index
begin = 1 : i32, // Start index
end = 6 : i32, // End index (exclusive)
step = 2 : i32 // Step size
} : (tensor<6xf32>) -> tensor<3xf32>
// Result: [2, 4, 6]
// Extract columns 0 and 2 from a 2D tensor
%input = ... : tensor<3x4xf32> // Input tensor with values:
// [[1, 2, 3, 4],
// [5, 6, 7, 8],
// [9, 10, 11, 12]]
%result = ttir.index(%input) {
dim = 1 : i32, // Index along columns (dimension 1)
begin = 0 : i32, // Start from first column
end = 3 : i32, // End at third column (exclusive)
step = 2 : i32 // Take every other column
} : (tensor<3x4xf32>) -> tensor<3x2xf32>
// Result:
// [[1, 3],
// [5, 7],
// [9, 11]]
```
Inputs:
- `input` (Tensor): The input tensor to index.
Attributes:
- `dim` (Integer): The dimension along which to index.
- `begin` (Integer): The starting index.
- `end` (Integer): The ending index (exclusive).
- `step` (Integer): The step size between indices.
Output:
- `result` (Tensor): The indexed tensor.
Note: The shape of the output tensor is the same as the input tensor except for the indexed dimension,
which will have size `ceil((end - begin) / step)`. The indices selected will be `begin`, `begin + step`,
`begin + 2*step`, etc., up to but not including `end`.
}];
let arguments = (ins AnyRankedTensor:$input,
I32Attr:$dim,
I32Attr:$begin,
I32Attr:$end,
I32Attr:$step);
let results = (outs AnyRankedTensor:$result);
let hasVerifier = 1;
}
The verification function has been added as well:
// IndexOp verification
::mlir::LogicalResult mlir::tt::ttir::IndexOp::verify() {
::mlir::RankedTensorType inputType = getInput().getType();
::llvm::ArrayRef<int64_t> inputShape = inputType.getShape();
::mlir::RankedTensorType outputType = getType();
int32_t dim = getDim();
int32_t begin = getBegin();
int32_t end = getEnd();
int32_t step = getStep();
// Verify that the input is at least 1D tensor
if (inputType.getRank() < 1) {
return emitOpError("Input must be at least a 1D tensor");
}
// Validate that the output tensor has the same element type as the input
// tensor
if (inputType.getElementType() != outputType.getElementType()) {
return emitOpError(
"Output tensor must have the same element type as the input tensor");
}
// Verify the output tensor rank
if (inputType.getRank() != outputType.getRank()) {
return emitOpError(
"Output tensor must have the same rank as the input tensor");
}
// Verify that the dim attribute is within the bounds of the input tensor
if (dim < 0 || dim >= inputType.getRank()) {
return emitOpError() << "Invalid dimension index " << dim
<< ". Input tensor rank is " << inputType.getRank();
}
// Verify begin, end, step and the output tensor dimensions
int64_t dimSize = inputShape[dim];
// Adjust negative begin and end
int32_t adjustedBegin = (begin < 0) ? (begin + dimSize) : begin;
int32_t adjustedEnd = (end < 0) ? (end + dimSize) : end;
std::ostringstream inputShapeStream;
inputShapeStream << "(";
for (size_t i = 0; i < inputShape.size(); ++i) {
inputShapeStream << inputShape[i];
if (i != inputShape.size() - 1) {
inputShapeStream << ", ";
}
}
inputShapeStream << ")";
std::string inputShapeStr = inputShapeStream.str();
if (adjustedBegin < 0 || adjustedBegin >= dimSize) {
return emitOpError() << "Invalid begin index for dimension "
<< std::to_string(dim) << ". Expected value in range ["
<< std::to_string(-dimSize) << ", " << dimSize
<< "), got " << begin
<< ". Input shape: " << inputShapeStr;
}
if (adjustedEnd < 0 || adjustedEnd > dimSize) {
return emitOpError() << "Invalid end index for dimension "
<< std::to_string(dim) << ". Expected value in range ["
<< std::to_string(-dimSize) << ", " << dimSize
<< "], got " << end
<< ". Input shape: " << inputShapeStr;
}
auto formatValueMessage = [](int value, int adjustedValue) {
return value < 0 ? std::to_string(adjustedValue) + " (" +
std::to_string(value) + ")"
: std::to_string(value);
};
std::string beginValueMessage = formatValueMessage(begin, adjustedBegin);
std::string endValueMessage = formatValueMessage(end, adjustedEnd);
if (step == 0) {
return emitOpError("Step value for dimension " + std::to_string(dim) +
" cannot be zero");
}
if (step > 0 && adjustedBegin > adjustedEnd) {
return emitOpError() << "For positive step, begin index must be less "
"than or equal to end index for dimension "
<< dim << ". Got begin: " << beginValueMessage
<< ", end: " << endValueMessage << ", step: " << step
<< ", input shape: " << inputShapeStr;
}
if (step < 0 && adjustedBegin < adjustedEnd) {
return emitOpError() << "For negative step, begin index must be greater "
"than or equal to end index for dimension "
<< dim << ". Got begin: " << beginValueMessage
<< ", end: " << endValueMessage << ", step: " << step
<< ", input shape: " << inputShapeStr;
}
// Calculate the expected size of the output dimension
int32_t expectedDimSize =
(std::abs(adjustedEnd - adjustedBegin) + std::abs(step) - 1) /
std::abs(step);
if (outputType.getDimSize(dim) != expectedDimSize) {
return emitOpError() << "Mismatch in dimension " << std::to_string(dim)
<< " of the output tensor: expected size "
<< expectedDimSize << ", but got "
<< outputType.getDimSize(dim);
}
return success();
}
2. Create a conversion pattern
A conversion pattern defines how MLIR should rewrite the Op. It can be implemented in either C++ or TableGen. Currently, we only have the C++ implementation; TableGen format will be added in the future.
C++ conversion pattern
For the Index operation, we use the C++ conversion pattern because it involves changing the Op’s input types from integers to arrays, which TableGen lacks flexibility for.
// This transformation adjusts IndexOp attributes so that `begin`, `end`, and
// `step` become arrays, where each array element corresponds to a dimension of
// the input tensor. For dimensions other than the sliced dimension, default
// values are used.
//
namespace {
struct IndexToSliceConversionPattern
: public OpConversionPattern<ttir::IndexOp> {
using OpConversionPattern<ttir::IndexOp>::OpConversionPattern;
LogicalResult
matchAndRewrite(ttir::IndexOp op, OpAdaptor adaptor,
ConversionPatternRewriter &rewriter) const override {
auto inputType =
::mlir::dyn_cast<mlir::RankedTensorType>(adaptor.getInput().getType());
if (!inputType || !inputType.hasRank()) {
return failure();
}
int64_t rank = inputType.getRank();
int64_t dim = op.getDim();
int32_t begin = adaptor.getBegin();
int32_t end = adaptor.getEnd();
int64_t dimSize = inputType.getDimSize(dim);
// Normalize negative bounds so downstream slice folding composes canonical
// coordinates instead of raw Python-style negative offsets.
if (begin < 0) {
begin += dimSize;
}
if (end < 0) {
end += dimSize;
}
llvm::SmallVector<mlir::Attribute, 4> begins, ends, steps;
for (int64_t i = 0; i < rank; ++i) {
if (i == dim) {
begins.push_back(rewriter.getI32IntegerAttr(begin));
ends.push_back(rewriter.getI32IntegerAttr(end));
steps.push_back(rewriter.getI32IntegerAttr(adaptor.getStep()));
} else {
begins.push_back(rewriter.getI32IntegerAttr(0));
ends.push_back(rewriter.getI32IntegerAttr(inputType.getDimSize(i)));
steps.push_back(rewriter.getI32IntegerAttr(1));
}
}
auto newOp = rewriter.create<ttir::SliceStaticOp>(
op.getLoc(), getTypeConverter()->convertType(op.getType()),
adaptor.getInput(), rewriter.getArrayAttr(begins),
rewriter.getArrayAttr(ends), rewriter.getArrayAttr(steps));
rewriter.replaceOp(op, newOp.getResult());
return success();
}
};
} // namespace
The matchAndRewrite method from OpConversionPattern is implemented to replace the matched Op with the newly created Op. Since decomposition is implemented as a conversion pass, OpAdaptor is used to access the attributes of the original Op in their converted types. Finally, we instantiate the new Op and call the replaceOp method on ConversionPatternRewriter to replace the original Op.
Tablegen conversion pattern
TODO
3. Register the created conversion pattern
To register the new pattern, go to the populateTTIRToTTIRDecompositionPatterns function in TTIRToTTIRDecomposition.cpp and add it to RewritePatternSet using the add method. After that is done you should mark the decomposed op as illegal in runOnOperation method of TTIRToTTIRDecompositionPass in TTIRToTTIRDecompositionPass.cpp.
You should also add a silicon test like described here: Add a silicon unit test for the Op. This is how the silicon test for the Index operation looks like:
// RUN: ttmlir-opt --ttir-to-ttnn-backend-pipeline="system-desc-path=%system_desc_path%" -o %t.mlir %s
// RUN: FileCheck %s --input-file=%t.mlir
// RUN: ttmlir-translate --ttnn-to-flatbuffer -o %t.ttnn %t.mlir
module attributes {} {
func.func @forward(%arg0: tensor<4x32x32xbf16>) -> tensor<4x32x16xbf16> {
// CHECK: = "ttnn.slice_static"
%1 = "ttir.index"(%arg0) <{dim = 2: i32, begin = 0: i32, end = 32: i32, step = 2: i32}> : (tensor<4x32x32xbf16>) -> tensor<4x32x16xbf16>
return %1 : tensor<4x32x16xbf16>
}
}
Docs & Doxygen
Markdown documentation is built using mdbook and API documentation is built using doxygen, and sphinx, and sphinx-markdown-builder.
Markdown documentation (docs)
Requirements
The markdown documentation is built using mdbook and sphinx.
Build command
If not already installed, be sure to install sphinx-markdown-builder.
pip install sphinx-markdown-builder
To build the markdown docs use the docs target in CMake.
cmake -B build
cmake --build build -- docs
API documentation (doxygen)
This is a link to a doxygen autogenerated code reference. Doxygen
Requirements
The API documentation is built using doxygen and sphinx, here are the needed tools for building it:
Build command
To build the API docs use the doxygen target in CMake
cmake -B build
cmake --build build -- doxygen
Serving the docs locally
To start a server for local viewing of the docs, after building, run:
mdbook serve build/docs
mdbook will start a local server at http://localhost:3000 with the built docs.
Specifications
Specifications are documents that define the requirements for features or concepts that are particularly cross-cutting, complex, or require a high degree of coordination and planning. They are intended to be a living document that evolves as the feature is developed and should be maintained as the goto reference documentation for the feature or concept.
Specifications are written in markdown and are stored in the docs/src/specs
directory of the repository. Below is a template that should be used when
creating a new specification.
Specification Template
# [Title]
A brief description of the feature or concept that this specification is
defining.
## Motivation
A description of why this feature or concept is needed and what problem it is
solving. This section is best written by providing concrete examples and use
cases.
## Proposed Changes
A list of the components that will be impacted by this spec and a detailed
description of the changes that will be made to each respective component.
It should also call out any interactions between components and how they might
share an interface or communicate with each other.
## Test Plan
A brief description of how the feature or concept will be tested.
## Concerns
A list of concerns that have been identified during the design of this feature.
Runtime Stitching
Runtime stitching adds the ability for the runtime to stitch together multiple, independently compiled programs together at runtime, ie. without compiler knowledge of how the binary programs will be composed.
Motivation
In order to flexibly support arbitrary training schedules / composing multiple models together we want to have the ability for the runtime to stitch graphs together. To achieve this we need to define an ABI kind of interface between the compiler and the runtime.
Simple Example
mod_a = forge.compile(PyTorch_module_a)
mod_b = forge.compile(PyTorch_module_b)
for i in range(10):
outs_a = mod_a(ins_a)
outs_b = mod_b(outs_a)
mod_a and mod_b are 2 independent compile steps, during the compile step for
mod_a it should be completely unaware that mod_b will take place and vice-versa.
In order to achieve this we propose a new runtime concept called stitching:
- forge invokes compile step for
mod_a, tt-mlir compiler determines where the inputs (ins_a) should live, host, device dram, device l1. tt-mlir returns metadata to forge describing where it wants the tensors to reside before invoking flatbuffer submission. - forge invokes compile step for
mod_b, same happens as bullet 1 mod_ais invoked at runtime, forge runtime needs to inspect the compiler metadata to determine where the tensors should live. Runtime manually invokes a new data copy command to get the tenors to the correct memory space / correct memory address.- forge runtime invokes
mod_aprogram submit mod_bis invoked at runtime, this time it might be that the compiler left the tensor outputs in L1, so no data copy is needed to start runningmod_bsince the inputs are already in the correct location.
A more concrete usecase would be a training loop where there are often multiple graphs composed together. #82 Or when we eventually support torch 2.0, the torch runtime can arbitrarily break the graph anywhere.
Proposed Changes
Compiler Metadata
Compiler will encode the input tensor layout information directly into the flatbuffer tensor desc. The flatbuffer schema already exists to express this, we just need to adopt populating it instead of assuming a canonical host layout.
Compiler will decide where the tensors should live, host, device dram, device l1.
Runtime
- Runtime will inspect the tensor desc metadata to determine where the tensors need to end up / what layout they should be in before invoking the program.
- New runtime API
Tensor toLayout(Tensor tensor, ::tt::target::TensorDesc* tensorDesc); - Runtime will need to invoke
toLayouton all input tensors before invoking the program.
Test Plan
- Add a new test to the runtime gtest suite that verifies the runtime can correctly stitch together 2 independently compiled programs.
Concerns
- Tensors pass through device memory spaces (dram, L1) will have a dynamic address, some arbitrary run order of flatbuffer could cause tensors to end up in non-ideal locations in memory. Specifically, L1, a poorly placed tensor might not be able to be moved to a better location without a bounce through DRAM.
Tensor Layout
The tensor layout attribute captures how tensor data is sharded across a grid of devices, cores, and is laid out in memory.
Motivation / High level goals
- Logical shapes: Keep the original tensor shape and rank intact and agnostic to underlying storage layout. Keeping the logical shapes not only makes some graph transformations vastly simpler, in particular convs, but it makes the lowered IR much easier to read and reason about. The original tensor shapes leave breadcrumbs that make it much easier to map back to the input representation.
- Flexible sharding: Enable flexibility in choosing grid shape, to get better parallelization and avoid resharding. This is particularly important in cases where tensor shapes are not clean powers of two and would otherwise force our hand in choosing non-optimal grid shapes.
- Logical-Physical Isomorphism: Encode this information with just a few attributes to enable derived conversions from logical to physical layout and back.
- Explicit: A single source of truth.
- Enable a direct way to query padded regions.
An Example / Walkthrough
Let's consider a snippet of MLIR:
tensor<2x3x64x128xf32>
Here we've defined a 4 dimensional tensor using MLIR's builtin tensor type. This tensor type has an optional attribute called an Encoding, this attribute has been used by the TT dialect to encode the tensor's layout. This looks like:
tensor<2x3x64x128xf32,
#ttcore.metal_layout<
(d0, d1, d2, d3) -> (d0 * 192 + d1 * 64 + d2, d3),
undef,
<1x1>,
memref<384x128xf32, #ttcore.memory_space<l1>>
>
>
At the time of this writing there are 4 properties that make up a tensor layout:
linear: An affine map that defines how the logical tensor dimensions map to a grid shape. Note that the number of dims in the affine map must match exactly the rank of the original tensor, and the number of results must match exactly the rank of the grid shape.oob_val: A tracked out of bounds value that fills padding space.grid: The grid shape that this tensor is divided onto.memref: A memref that describes the physical footprint allocation of the shard. It must also have a shape with rank equal to grid.
This example isn't particularly complicated because it's only sharded to a 1x1 grid, the rest of the document will go into more details on the following topics:
Before we jump into more advanced topics there are two resources that could be useful to have at hand:
test/python/tensor_layout.py: Python test with many convenience functions for creating and experimenting with tensor layouts.- TTNN Interactive Visualizer: An interactive visualization tool that demonstrates the transformation. Note that this tool was created for TTNN tensor layout, but many of the same concepts transfer over.
Dimension Collapsing
Probably the most important concept in ttcore.metal_layout is dimension collapsing.
This is captured by the affine map linear property which provides a
mapping from tensor dim space to a reduced physical dimensional space. This
single-handedly touches on most of the tensor layout goals mentioned at the
beginning of the doc:
- Leaves tensor shapes intact
- Logical-Physical mapping, how the tensor is laid out in memory over a grid
- Enables more flexible sharding
- Explicit padding
To see how these goals are achieved we'll continue working on an explicit example, same one as above:
(d0, d1, d2, d3) -> (d0 * 192 + d1 * 64 + d2, d3)
To recap, we have our example 4d tensor (2, 3, 64, 128), which maps directly to the
LHS (d0, d1, d2, d3). We have our 2d grid shape (1, 1), notice the
affine-map RHS is also 2d, and this describes how tensor dims map to a lower dimensional
physical memory, overlaid on a grid. We'll see how this gets divided onto the grid later,
but first let's look at how this forms an affine-map iteration space. If we
index our tensor at say [1, 1, 6, 100], we can simply plugin those numbers
to get our remapped offset:
(1 * 192 + 1 * 64 + 6, 100) = (262, 100)
This remapped offset (262, 100) corresponds to the row and column index of the
collapsed physical memory.
By default, the dim range [0, -1) is collapsed, but the ttcore.metal_layout constructor
can actually take a programmable range called collapseIntervals.
collapseIntervals is a list of pairs, where each pair is a dim range interval,
left inclusive, right exclusive. Let's consider a few examples:
Instead of multiplying out real shapes, we will use
<>to represent a dimension join operator.
- 3D tensor onto a 2D grid and default
collapseIntervals=[(0, -1)]:
(d0, d1, d2) -> (d0 <> d1, d2)
- 4D tensor onto a 3D grid and
collapseIntervals=[(1, -1)]:
(d0, d1, d2, d3) -> (d0, d1 <> d2, d3)
- 4D tensor onto a 3D grid and
collapseIntervals=[(0, 2)]:
(d0, d1, d2, d3) -> (d0 <> d1, d2, d3)
- 7D tensor onto a 4D grid and
collapseIntervals=[(0, 3), (-3, -1)]:
(d0, d1, d2, d3, d4, d5, d6) -> (d0 <> d1 <> d2, d3, d4 <> d5, d6)
Multi-core
Let's consider the original example again, but on a larger grid than 1x1, say 2x4:
tensor<2x3x64x128xf32,
#ttcore.metal_layout<
(d0, d1, d2, d3) -> (d0 * 192 + d1 * 64 + d2, d3),
undef,
<2x4>,
memref<192x32xf32, #ttcore.memory_space<l1>>
>
>
The number of affine map results, grid shape, and memref shape all must have the same rank. We can see in this example by changing the grid shape we also changed the memref shape, we can always calculate the memref shape by plugging in the full tensor dims into our affine map and then dividing by grid shape.
(d0, d1, d2, d3) -> (d0 * 192 + d1 * 64 + d2, d3),
(2 - 1, 3 - 1, 64 - 1, 128 - 1) = (1 * 192 + 2 * 64 + 63, 127) = (383, 127)
Above we actually subtracted 1 in order to get the index of the last element of the tensor. Now we can simply add back 1 to get the size:
(383 + 1, 127 + 1) = (384, 128)
Finally, we divide the dims by the respective grid dims:
(384 / 2, 128 / 4) = (192, 32)
Here's a few more example mlir snippets:
tensor<8x300xf32,
#ttcore.metal_layout<(d0, d1) -> (d0, d1),
undef,
<1x2>,
memref<8x150xf32, #ttcore.memory_space<l1>>
>
>
tensor<8x96x32xf32,
#ttcore.metal_layout<(d0, d1, d2) -> (d0 * 96 + d1, d2),
undef,
<2x1>,
memref<384x32xf32, #ttcore.memory_space<l1>>
>
>
tensor<8x96x32xf32,
#ttcore.metal_layout<(d0, d1, d2) -> (d0 * 96 + d1, d1, d2),
undef,
<2x1x2>,
memref<384x96x16xf32, #ttcore.memory_space<l1>>
>
>
tensor<5x3x2x2x7x32x32xf32,
#ttcore.metal_layout<
(d0, d1, d2, d3, d4, d5, d6)
-> (d0 * 2688 + d1 * 896 + d2 * 448 + d3 * 224 + d4 * 32 + d5, d4, d5, d6),
undef,
<3x2x2x2>,
memref<4480x4x16x16xf32, #ttcore.memory_space<l1>>
>
>
A couple of final notes regarding grid shape:
- Grid shapes of rank > 2 are
perfectly legal. Not only it this useful for describing multi-device grid
topologies, but it is often convenient to have higher ranked grids to better
describe how a high rank tensor should be divided. The grid shape here is a
virtual grid shape, the
ttcore.deviceattribute will hold an additional affine map that defines how this virtual grid shape maps to a physical one. - Grid shapes where either columns or rows are > physical device grid is also
legal. Since this is only a virtual grid shape we could have some grid
1x64that maps to a physical8x8device grid (this particular example is called width sharding in TTNN).
Tilized
A tilized tensor is one with a memref that has a tile element type.
Given some tensor with scalar layout:
tensor<3x64x128xf32,
#ttcore.metal_layout<
(d0, d1, d2) -> (d0 * 64 + d1, d2),
undef,
<3x2>,
memref<64x64xf32, #ttcore.memory_space<l1>>
>
>
After tilizing we'll have:
tensor<3x64x128xf32,
#ttcore.metal_layout<
(d0, d1, d2) -> (d0 * 64 + d1, d2),
undef,
<3x2>,
memref<2x2x!ttcore.tile<32 x 32, bfp_bf8>, #ttcore.memory_space<l1>>
>
>
Notice the memref dim was ceilDiv'd by tile shape and the element type becomes
a ttcore.tile type. Also notice that the tensor shape and element type remains
intact.
Padding
Padding can be a bit of an overloaded term, but in this context it refers to an
out of bounds area in the physical memory allocation that has no real tensor
data in it. The contents of this area is tracked by oob_val and the padding
area can be automatically derived from the attributes of ttcore.metal_layout.
Padding is a necessary evil that arises when a tensor is not evenly divisible by a grid shape or tile shape. It can also arise due to minimum Noc addressing requirements.
Example of non-divisible grid:
tensor<53x63xf32,
#ttcore.metal_layout<
(d0, d1) -> (d0, d1),
undef,
<3x2>,
memref<18x32xf32, #ttcore.memory_space<l1>>
>
>
The grid dims always ceilDiv the affine map results, real tensor data will
entirely fill initial shards and the last shard in each dimension will be
partially filled.
In this particular example, we have 1 scalar row of padding on the last row of cores and 1 scalar column of padding on the last column of cores.
Taking the above example a step further, we could tilize it:
tensor<53x63xf32,
#ttcore.metal_layout<
(d0, d1) -> (d0, d1),
undef,
<3x2>,
memref<1x1x!ttcore.tile<32 x 32, bfp_bf8>, #ttcore.memory_space<l1>>
>
>
Tile dims also always ceilDiv the resulting memref shape. Notice now that
the padding is slightly more complicated. Our scalar shard shape was 18x32,
but this was further padded to 32x32 meaning that every core now has 14 rows
of padding except for the last row of cores which has 15 rows of padding.
Also note that there is an order of operations here, grid divides the scalar shape first and then we tilize. This is important because it can enable use cases that frequently arise in conv networks that would otherwise result in reshards in between every layer.
With affine map we can be even more flexible in how we pad, we can bump our
stride between dimensions. Consider tensor (w/ batch dim 2):
tensor<2x8x32xf32,
#ttcore.metal_layout<
(d0, d1, d2) -> (d0 * 8 + d1, d2),
undef,
<1x2>,
memref<16x16xf32, #ttcore.memory_space<l1>>
>
>
If we tilized the above tensor we'd end up with a memref shape of
1x1x!ttcore.tile<32x32>, that is, all batches are tightly packed within a single
tile. Let's say that for some reason, we do not want the batches (2) to be
tightly packed within a tile, perhaps the mathematical operation we're doing
requires the batch to be independently evaluated and thus the (S)FPU needs them
in separate tiles. We can adjust this by adjusting the stride of the affine
map:
(d0, d1, d2) -> (d0 * 32 + d1, d2),
Instead of striding by the number of logical rows, 8, we bump the stride up to
32 effectively pushing a gap between the collapsed rows and enabling each
batch to fall on a tile boundary.
Memory Spaces
At the time of writing this document there are 4 memory spaces:
System: Host memory space that is not device visible.SystemMMIO: Host memory space that is device visible.DeviceDRAM: DRAM local to the device.DeviceL1: SRAM on each core.
Something worth noting here is that a tensor must belong exclusively to only
one of these memory spaces at a time. For example, in order to stream tensor
data from DeviceDRAM to DeviceL1 you would need to either manually slice the
tensor into smaller tensors that do fit in L1 or have native support in the op's
kernel for double buffering a block (most TTNN ops already support this).
Multi-device
Multi-device can be naturally represented via a combination of two concepts
already touched on above, higher ranked grids and collapseIntervals. Let's
consider the following example with a 3d grid and collapseIntervals=[(1, -1)].
tensor<2x3x64x128xf32,
#ttcore.metal_layout<(d0, d1, d2, d3) -> (d0, d1 * 64 + d2, d3),
undef,
<2x2x4>,
memref<1x3x1x!ttcore.tile<32 x 32, bfp_bf8>, #ttcore.memory_space<l1>>
>
>
Here we've left the batch dim intact and started collapsing
at d1. This enables us to define a 3d grid where the outermost grid dim
divides the batch directly. This could map to a 2 device system where the batch
dim is evenly divided between 2 devices. Within each device this op runs on a
2x4 grid.
The high level takeaway here is that how a tensor is logically divided up is decoupled from its mapping to physical compute resources. This has a nice property that data parallel extends to any tensor dimension and is captured under the same grid primitive that also divides tensor rows and columns.
Test Plan
test/python/tensor_layout.py: Assertions forLayoutAttrto make sure it's spec compliant.- Sweep tests:
- Grid dim sweeps
- Tilize / untilize sweeps
- Padding sweeps
- Multi-device tests
Concerns
ttcore.metal_layoutis deliberately flexible and tries to capture as many problematic use-cases we've ran into in the past in a single, succinct representation. This flexibility will need to be further constrained by backends to avoid unsupported programming of this attribute.- Optimization solution space is potentially large with all of this flexibility.
Two things that I hope can help protect us here:
- By and large the heuristic we'll be following is just max the grid at all costs. This should really narrow down the solution space to only a handful of options and we only keep exploring if producers/consumers end up with nasty reblocking.
- We can constrain the optimizer heuristics as aggressively as possible in the beginning and just advertise the full flexible options to the UI model explorer. Hopefully this enables us to experiment with crazier grid layouts and prove it's worthwhile before writing an algorithm.
TTNN Tensor Layout
The above section of this document covers how the compiler models tensor layout. There are some slight differences in TTNN, but the high level idea of collapsing dims is still used.
Terms
shape: Always logical shape, n-dimensionalstride: Same as pytorch stride, but this is crucial for describing how n-dimensional data gets packed into a 2D physical layout. This 2D physical layout is always the inner dim (-1) wide and dims [0, N-1] are collapsed into rows derived from strideshard_shape: Also a logical shape, describes a 2d region that chunks physical_shape . Note this does not need to be a tile multiplephysical_shard_shape: The shard_shape padded out to tile_shapetile_shape: A programmable tile shape, though constraints must check that it's compatible with an op's usage, i.e. FPU/Noc compatiblegrid_shape: [divup(stride[0] // stride[-2], shard_shape[0]), divup(stride[-2], shard_shape[0])]
Mapping from the compiler
The compiler uses an affine map to explicitly track which dimensions are folded
together, but TTNN does not have affine maps so the representation is a bit more
implicit. TTNN captures the dimension collapsing in the stride attribute
where dimensions [0, N-1] are always collapsed. This is less flexible so the
compiler will have to enforce only collapsing supported dimensions when
targeting TTNN, or handle lowering in a different way. For example, in the
compiler we might want to represent data parallel over the tensor batch dim by
leaving d0 and collapsing d1 - d[-1]. TTNN doesn't support this in its
tensor layout representation, but this could be lowered to a TTNN mesh tensor
where the mesh could be sliced on the batch and each per-device tensor has d0
fully collapsed.
TTNN Example

Device
Device in tt-mlir is somewhat of an overloaded term and can refer to different
things depending on the context. This document will only speak to the compiler's
abstract representation of a device captured by attribute #ttcore.device.
Terms
There are many overloaded terms when talking about devices and grids, this document will use the following definitions:
- Physical Grid: A 2D array of tensix cores on a chip.
- Chip: A single physical chip with a Physical Grid of cores.
- Card: A PCIE or Ethernet card that may contain multiple Chips.
- System: A collection of Cards that are usually connected together on the
same host via PCIE or networked via ethernet. A system is represented by
SystemDescin the compiler. - Device: Device is always presented as a single entity to the enclosing scope, but it may be virtualized to abstract a multi-card System and part of its encoding carries a Logical Grid. Another way to think of device is a view over the system.
- Logical Grid or just Grid: Is a logical shape that abstracts one or more Physical Grids.
- Mesh Shape: Describes the virtual layout of the chips with respect to each other. In practice the mesh shape is used to derive the logical grid.
Motivation
The device attribute strives to achieve the following goals:
- Provide a convenient representation of a physical grid that decouples the logical division of tensors from the physical layout of the hardware. This not only simplifies reasoning about how tensors get divided into shards, but can also enable reinterpretations of the device grid for data layout optimization decoupled from the existing encoding of the tensor layouts.
- Following the first point, the device attribute should be able to represent many different forms of logical grids, from simple 2D grids, to more complex topologies like extra-wide grids or higher dimensional grids.
- Device attribute captures encoding both single chip and multi-chip systems under a single, virtualized representation.
- Enable many forms of data parallel execution strategies for single and multi chip systems under a single representation.
Scope
This document will cover how the device attribute is encoded and how it can be lowered to backend dialects. The document will not cover the algorithm for choosing the best, or even legal, device configurations for a given physical system.
Examples
All of the following examples will assume the physical hardware has an 8x8 physical
grid of cores. We will use notation [N, 8x8] to represent a N chip system,
each with an 8x8 physical grid.
#ttcore.device in is simplest, single chip form [1, 8x8], just maps directly 1-1 to the
underlying physical hardware device.
#ttcore.device<
workerGrid = #ttcore.grid<8x8, (d0, d1) -> (0, d0, d1)>,
meshShape = 1,
chipIds = [0]
>
Let's break down what each of these attributes mean:
workerGrid = #ttcore.grid<8x8, (d0, d1) -> (0, d0, d1)>: This is a 2D logical grid with dim 8x8. It's followed by an affine map(d0, d1) -> (0, d0, d1)that provides a mapping from the logical grid to the physical grid. In this case, the logical grid is the same as the physical grid, so the mapping is the identity function. The logical grid can have any rank, but the physical mapping is always 3D, with the first being the chip index, followed by the 2D physical core index within the chip.meshShape = 1: A shape provided as part of theDeviceAttrconstructor that describes the virtual layout of the chips with respect to each other. Note that in a multi-chip system, this grid encapsulates the entire system's grid shape, e.g. 8x16 grid could be made up of a 1x2 mesh of chips side-by-side. The mesh attribute configures how the above grid/map attributes are created such that they implement this mesh topology.chipIds = [0]: This is a list of chip indices. These chip indices directly reference the same chip indices in the system descriptor. TheSystemDescattribute that this is in reference to is tagged on the top levelModuleOp.
Specific examples that this document will cover:
- Data Parallel Over Batch
- Data Parallel Over 2d
- Data Parallel Over 2d and Batch
- Pipeline Parallel
- Reinterpreted Grids (Transpose)
- Reinterpreted Grids (Training Usecase)
- Reinterpreted Grids (Extra)
Before we move on to more complex examples, it's worth having on hand:
- The python test
test/python/device_attr.pywhich shows how all of these examples can actually be programmed for the device attribute.- The Tensor Layout spec as the following examples will demonstrate how tensor layout interacts with the logical device grid.
Note on Data Parallel: There is existing literature that explicitly distinguishes between data parallel and tensor parallel, oftentimes describing data parallel as duplicating the model across multiple devices and trivially dividing up the batch whereas tensor parallel refers to tensor data being distributed and potentially communicated between devices during execution. While this is true for multi-GPU/CPU systems, it is somewhat of an implementation detail and given the flexibility of tenstorrent hardware there is an opportunity to generalize this concept. In this document we will use the term data parallel to refer to any form of parallelism that divides any dimension of the tensor across multiple cores/chips.
Note on Constraints: Many of the examples below require careful virtualization of the underlying physical system, i.e. some device configurations might only work if the chips are connected via ethernet and with a particular topology, but these constraints are outside the scope of the examples and will be discussed further in the Backend Lowering and Constraints section.
Data Parallel Over Batch
Given a 2 chip system, [2, 8x8], we can represent a simple data parallel
logical grid that divides the batch dimension in half across the two chips.
This is denoted by meshShape = 2x1x1 which means the logical grid is 3D.
#ttcore.device<
workerGrid = #ttcore.grid<2x8x8, (d0, d1, d2) -> (d0, d1, d2)>,
meshShape = 2x1x1,
chipIds = [0, 1]
>
The affine map here is just identity, so dims d1 and d2 directly index
the physical grid and d0 indexes the chip.
Now we can consider some tensor that, importantly, has a grid of the same rank as the logical device grid:
tensor<16x3x64x128xf32,
#ttcore.metal_layout<(d0, d1, d2, d3) -> (d0, d1 * 64 + d2, d3),
undef,
<2x2x4>,
memref<8x3x1x!ttcore.tile<32 x 32, bfp_bf8>, #ttcore.memory_space<l1>>
>
>
If we map this tensor onto the above device, it will span across both chips, half of the batch dimension on each chip. Within each chip the tensor occupies a 2x4 grid out of the 8x8 physical grid available.
Data Parallel Over 2d
In this example we will consider a 2 chip system, [2, 8x8], and view it as
though the two chips are concatenated together side by side to form a single
8x16 grid. This is denoted by meshShape = 1x2 which means to concatenate
the chips in the second dimension.
#ttcore.device<
workerGrid = #ttcore.grid<8x16, (d0, d1) -> ((d0 floordiv 8) * 2 + d1 floordiv 8, d0, d1 mod 8)>,
meshShape = 1x2,
chipIds = [0, 1]
>
Here we can see that the affine map encodes an indexing pattern such that when we extend past 8 cores in the second dimension, we wrap around to the next chip.
Now we can consider some tensor that, importantly, has a grid of the same rank as the logical device grid:
tensor<256x1024xf32,
#ttcore.metal_layout<(d0, d1) -> (d0, d1),
undef,
<4x16>,
memref<2x2x!ttcore.tile<32 x 32, bfp_bf8>, #ttcore.memory_space<l1>>
>
>
This single tensor maps trivially onto the logical grid, spanning the upper half. Decoupled from the tensor's layout, under the hood the tensor is actually physically spanning across two chips.
Data Parallel Over 2d and Batch
The previous 2 examples can be composed together to form a logical grid that
divides tensor across multiple dimensions. Here we will consider a 4 chip
system [4, 8x8] and view it as a 2x8x16 grid. Note that the meshShape is
2x1x2 which means to concatenate the chips in the first and third dimensions.
#ttcore.device<
workerGrid = #ttcore.grid<2x8x16, (d0, d1, d2) -> (d0 * 2 + (d1 floordiv 8) * 2 + d2 floordiv 8, d1, d2 mod 8)>,
meshShape = 2x1x2,
chipIds = [0, 1, 2, 3]
>
We can evaluate the affine map to see that the chips are interpreted in chunks of
two, where groups [0, 1] and [2, 3] each form 8x16 grids and these 2 groups
concatenate to form a 2x8x16 grid.
We can consider the following tensor to map onto this grid:
tensor<64x256x1024xf32,
#ttcore.metal_layout<(d0, d1) -> (d0, d1),
undef,
<2x4x16>,
memref<32x2x2x!ttcore.tile<32 x 32, bfp_bf8>, #ttcore.memory_space<l1>>
>
>
Pipeline Parallel
Pipeline parallel in the scope of this spec isn't particularly interesting, it
is intended to be used in conjunction with the ttir.pipeline operation which
will group sections of the module's operations into groups to form pipeline regions
and will be covered in a separate spec.
What we can demonstrate here is how we can take multiple non-overlapping views of the system descriptor to form distinct virtual devices.
Given an 8 chip system [8, 8x8], we can form two virtual devices that each
take 4 chips and interpret them differently (though they could take the same
logical grid).
#ttcore.device<
workerGrid = #ttcore.grid<2x8x16, (d0, d1, d2) -> (d0 * 2 + (d1 floordiv 8) * 2 + d2 floordiv 8, d1, d2 mod 8)>,
meshShape = 2x1x2,
chipIds = [0, 1, 2, 3]
>
#ttcore.device<
workerGrid = #ttcore.grid<16x16, (d0, d1) -> ((d0 floordiv 8) * 2 + d1 floordiv 8, d0 mod 8, d1 mod 8)>,
meshShape = 2x2,
chipIds = [4, 5, 6, 7]
>
Reinterpreted Grids (Transpose)
One particularly interesting usecase that logical grids could enable is to reinterpret the grid as a form of data layout optimization. For example, if we wanted to transpose a tensor, instead of having to move the data around to implement transpose, we could instead reinterpret the grid as being transposed, leveraging the fact that the relevant data is already located on the correct cores/chips.
To keep things simple, let's consider a 1 chip system [1, 8x8], but it's not
too big a leap to see how this could map to multi-chip where the cost of moving
data is even higher.
Let's also consider a simple (totally contrived) eltwise unary graph:
a = exp(a)
aT = transpose(a)
relu(aT)
- We'll establish a regular, single chip, identity logical grid:
#ttcore.device<
workerGrid = #ttcore.grid<8x8, (d0, d1) -> (0, d0, d1)>,
meshShape = 1,
chipIds = [0]
>
- Execute
exp. - We'll reinterpret the grid as transposed:
#ttcore.device<
workerGrid = #ttcore.grid<8x8, (d0, d1) -> (0, d1, d0)>,
meshShape = 1,
chipIds = [0]
>
- Execute
transpose. Note that each core only needs to transpose their data locally. Eventually this could be implemented as a no-op by reindexing the tile visitation order of the successive operation. - Execute
relu.
It's important to note that we effectively implemented transpose without moving data anywhere.
Reinterpreted Grids (Extra)
For the sake of examples, here's a few more ways of reinterpreting the logical grid.
Extra Wide Grid
#ttcore.device<
workerGrid = #ttcore.grid<1x64, (d0, d1) -> (0, d0 * 8 + d1 floordiv 8, d1 mod 8)>,
meshShape = 1,
chipIds = [0]
>
Extra Tall + Transposed Grid
#ttcore.device<
workerGrid = #ttcore.grid<64x1, (d0, d1) -> (0, d1 * 8 + d0 floordiv 8, d0 mod 8)>,
meshShape = 1,
chipIds = [0]
>
Staircase
#ttcore.device<
workerGrid = #ttcore.grid<8x8, (d0, d1) -> (0, d0, (d0 + d1) mod 8)>,
meshShape = 1,
chipIds = [0]
>
This could be an interesting starting position for data in implementing matmul as a systolic array in a ring topology.
Lowering to TTNN
While the above device attribute encoding is quite flexible, this does not necessarily mean the target backend can actually support all of these interpretations. TTNN backend will be constrained to support only the specialized grid topologies that are supported by the API.
Grid/Shard Orientation
TODO
Multi-device
Please refer to TTNN Mesh Programming Docs for more information on how to program multi-device systems with TTNN API.
Multi-device TTNN dialect will try and stay as close to the TTNN API as possible. Let's consider what this looks like from the compiler and runtime perspectives:
Compiler
- Device Creation: The TTNN device in the compiler is exactly the same attribute
from the ttir dialect. It will encode the
meshShapeinto the flatbuffer which can be directly used to program::ttnn::MeshShape. - Tensor Layout: Again, the tensor layout is inherited in TTNN dialect from the
ttir dialect. The grid attribute in the tensor layout can be trivially
divided by
meshShapeto determine the shape of the tensor slice on each device. Broadcasting rules can be applied to determine which Distribution Strategy to use:- Mesh Sharded: If the tensor grid is > 1 along the
meshShapedimensions, the tensor will be sharded across the mesh devices. - Replication: If the tensor needs to be broadcasted for this op, by extension the tensor layout will be replicated across the mesh devices.
- Mesh Sharded: If the tensor grid is > 1 along the
Runtime
- Device Creation: The ttnn runtime will wholesale switch to working with
mesh devices via api
ttnn::multi_device::open_mesh_device, this is possible because a 1x1 mesh device is a valid single device. The mesh shape during device open will always be1xNwhereNis the number of deviceIds in the array. Note that this shape can be reinterpreted by flatbuffer programs on the fly withSubMeshAPI. - Tensor Creation: Tensor creation in a multi-device system is a bit more
involved. In order to upload a multi-device tensor to the mesh, the host
tensor much first be created with
MultiDeviceHostStorage. The ttnn runtime can automatically do this duringhandleToHostMemoryConfigOp:- Regular host tensor will bounce through new tensor with
MultiDeviceHostStoragetype. tensor.to(mesh_device)will allocate/move the tensor to the mesh device.
- Regular host tensor will bounce through new tensor with
Lowering to TTMetal
In TTMetal dialect we are only constrained by what we've implemented in the tt-mlir compiler, this means it is much more flexible and can theoretically support any of the grid interpretations above.
Test Plan
test/python/device_attr.pycovers all of the examples above and asserts the IR is correctly generated.- Additional functional unit tests will be added as op and runtime support is added.
Concerns
ttcore.deviceis very flexible, but with this flexibility comes the potential for misuse. It's important that the compiler is able to validate the legal configurations of this attribute for the target backend.
TTNN Optimizer
TL;DR
TTNNOptimizer performs two key optimizations for TTNN operations:
- Maximizes L1 memory usage — keeps intermediate tensors in fast on-chip L1 memory instead of slow DRAM
- Optimizes op-specific configurations — selects optimal parameters for operations (e.g., Conv2d block sizes, activation handling)
It achieves this via:
- Layout Generation: Enumerate valid tensor layouts per op
- DFShardingPolicy: Build L1 chains in DFS order
- ShardSolver: Constraint satisfaction to find compatible configs
- Graph Transformation: Apply configs and insert reshards
Key limitation: Only tracks first operand; single edge failure breaks entire chain.
Table of Contents
- Introduction & Goals
- Architecture Overview
- Current Design - Core Components
- 3.1 Layout Generation Pipeline
- 3.2 DFShardingPolicy
- 3.3 ShardSolver
- 3.4 OpModel Integration
- 3.5 Graph Transformation
- Future Work / Proposed Refactors
- Proposed Refactoring: Pass-Based Architecture
- 5.1 Summary
- 5.2 Motivation
- 5.3 Design Philosophy
- 5.4 Problems with Current Approach
- 5.5 Empirical Findings
- 5.6 Proposed Architecture
- 5.7 Simplicity Benefits
- 5.8 Optimization Strategies
1. Introduction & Goals
1.1 Purpose
The TTNNOptimizer pass determines optimal memory layouts and op configurations for TTNN operations to maximize performance on Tenstorrent hardware. The fundamental goal is to maximize data residency in L1 memory while maintaining correctness.
1.2 Memory Hierarchy Context
Tenstorrent devices feature a two-level memory hierarchy:
┌───────────────────────────────────────────────┐
│ Tensix Cores: [L1] [L1] [L1] ... [L1] │
│ │ │ │ │ │
│ └─────┴─────┴───────┘ │
│ │ │
│ NoC (Network on Chip) │
│ │ │
│ ┌──────┴──────┐ │
│ │ DRAM │ │
│ └─────────────┘ │
└───────────────────────────────────────────────┘
| Memory | Size | Latency | Use Case |
|---|---|---|---|
| L1 (SRAM) | ~1.5 MB per core | Low | Hot data, intermediate tensors within compute chains |
| DRAM | ~12 GB total | High | Large tensors, model weights, spill buffer |
1.3 Optimization Goals
-
Maximize L1 Residency: keep intermediate tensors in L1 as long as possible to avoid costly DRAM round-trips.
-
Enable Sharding: distribute tensors across multiple cores' L1 to enable parallel computation and fit larger tensors.
-
Minimize Resharding: when sharding layouts differ between producer and consumer ops, avoid unnecessary
ToLayoutOpinsertions. -
Maximize Core Utilization: prefer configurations that use more cores (larger grids) for better parallelism.
-
Maintain Correctness: only choose configurations validated by the backend (via OpModel).
1.4 Key Trade-offs
| Decision | Benefit | Cost |
|---|---|---|
| L1 Sharded | Fastest compute, parallel execution | Limited capacity, layout constraints |
| L1 Interleaved | Simpler, no sharding constraints | Less parallelism than sharded |
| DRAM Interleaved | Unlimited capacity | Slowest, memory bandwidth bound |
2. Architecture Overview
2.1 High-Level Component Diagram
┌─────────────────────────────────────────────────────────────────────────────┐
│ TTNNOptimizer Pass │
│ │
│ ┌────────────────────────────────────────────────────────────────────────┐ │
│ │ Analysis Pipeline │ │
│ │ │ │
│ │ ┌─────────────────────┐ ┌─────────────────────┐ │ │
│ │ │ ScalarDataType │ ───▶│ LegalTensorLayout │ │ │
│ │ │ Analysis │ │ Analysis │ │ │
│ │ │ │ │ │ │ │
│ │ │ Collects all scalar │ │ Generates ALL │ │ │
│ │ │ types in graph │ │ possible layouts │ │ │
│ │ └─────────────────────┘ │ for each tensor │ │ │
│ │ │ type │ │ │
│ │ └──────────┬──────────┘ │ │
│ │ │ │ │
│ │ ▼ │ │
│ │ ┌───────────────────────────┐ │ │
│ │ │ LegalOpLayoutAnalysis │ │ │
│ │ │ (per-op) │ │ │
│ │ │ │ │ │
│ │ │ Filters layouts via │ │ │
│ │ │ OpModel validation │ │ │
│ │ └─────────────┬─────────────┘ │ │
│ │ │ │ │
│ │ ▼ │ │
│ │ ┌───────────────────────────┐ │ │
│ │ │ LegalOpConfigAnalysis │ │ │
│ │ │ (per-op) │ │ │
│ │ │ │ │ │
│ │ │ Expands op-specific │ │ │
│ │ │ configs (Conv2dConfig) │ │ │
│ │ └─────────────┬─────────────┘ │ │
│ │ │ │ │
│ └───────────────────────────────────────┼────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌────────────────────────────────────────────────────────────────────────┐ │
│ │ MemoryLayoutAnalysis │ │
│ │ │ │
│ │ ┌──────────────────────────────────────────────────────────────────┐ │ │
│ │ │ Memory Layout Policy (Pluggable) │ │ │
│ │ │ │ │ │
│ │ │ ┌──────────────────┐ │ │ │
│ │ │ │ DFShardingPolicy │◀── Default, production-ready │ │ │
│ │ │ │ │ │ │ │
│ │ │ │ • DFS scheduling│ │ │ │
│ │ │ │ • L1 chain │ │ │ │
│ │ │ │ building │ ┌──────────────────────┐ │ │ │
│ │ │ │ • ShardSolver │────▶│ ShardSolver │ │ │ │
│ │ │ │ resolution │ │ │ │ │ │
│ │ │ └──────────────────┘ │ • Constraint SAT │ │ │ │
│ │ │ │ • Bitset tracking │ │ │ │
│ │ │ │ • Reshard insertion │ │ │ │
│ │ │ │ • Core usage max │ │ │ │
│ │ │ └──────────────────────┘ │ │ │
│ │ └──────────────────────────────────────────────────────────────────┘ │ │
│ │ │ │
│ └────────────────────────────────────────┬───────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌───────────────────────────────────────────────────────────────────────┐ │
│ │ OpConfigAnalysis │ │
│ │ │ │
│ │ Picks single final config per op from remaining valid set │ │
│ └────────────────────────────────────────┬──────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌───────────────────────────────────────────────────────────────────────┐ │
│ │ Graph Transformation │ │
│ │ │ │
│ │ • Apply layout attributes to ops │ │
│ │ • Set op-specific configs (Conv2dConfigAttr) │ │
│ │ • Insert ToLayoutOp for resharding │ │
│ │ • Process spill-to-DRAM ops │ │
│ │ • L1 Interleaved fallback (optional upgrade from DRAM) │ │
│ └───────────────────────────────────────────────────────────────────────┘ │
│ │
└────────────────────────────────────────────────────────────────────────────┘
3. Current Design - Core Components
3.1 Layout Generation Pipeline
The layout generation pipeline creates the search space of valid configurations for each operation.
3.1.1 ScalarDataTypeAnalysis
Purpose: Collect all scalar element types used across the graph.
Input Graph:
%0 = ttnn.conv2d(...) : tensor<1x32x32x64xbf16>
%1 = ttnn.relu(%0) : tensor<1x32x32x64xbf16>
%2 = ttnn.matmul(...) : tensor<1x32x32x128xf32>
Output:
scalarTypes = {bf16, f32}
This analysis respects layout overrides specified by the user.
3.1.2 LegalTensorLayoutAnalysis
Purpose: Generate all possible TTNNLayoutAttr combinations for each tensor type.
For each (TensorType, ScalarType) pair, generates layouts across these dimensions:
TensorPageLayout:
├── Tiled (32x32 tiles)
└── RowMajor (if enabled via --row-major-enabled)
TensorMemoryLayout:
├── Interleaved (data spread across cores round-robin)
└── Sharded (data explicitly partitioned per core)
BufferType:
├── L1 (SRAM, local to Tensix core)
└── DRAM (shared, accessed via NoC)
Grid (for sharded only):
Various grid dimensions based on device worker grid
e.g., 1x1, 1x8, 8x1, 8x8, etc.
3.1.3 LegalOpLayoutAnalysis
Purpose: Select tensor layouts for each operation from the pre-generated layout pool.
This per-op analysis picks layouts from the tensor type layouts generated in the previous step, associating them with specific operations. Results are bounded by maxLegalLayouts to limit the search space.
3.1.4 LegalOpConfigAnalysis
Purpose: Expand layouts with op-specific configuration parameters.
For operations like Conv2d, there are additional configuration knobs beyond just the output layout (e.g., activation block sizes, memory deallocation options). This analysis expands each legal layout by generating the cartesian product with op-specific parameter values, producing the full configuration search space.
3.1.5 Configuration Flow Diagram
┌────────────────────┐
│ tensor<1x64x64xbf16>│
└─────────┬──────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ LegalTensorLayoutAnalysis │
│ │
│ Generates ~100s of layouts: │
│ • L1-Sharded-1x8, L1-Sharded-8x1, L1-Sharded-8x8, ... │
│ • L1-Interleaved │
│ • DRAM-Interleaved │
└─────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ LegalOpLayoutAnalysis (per-op) │
│ │
│ For ttnn.matmul: │
│ Valid: L1-Sharded-8x8, L1-Interleaved, DRAM-Inter... │
│ Invalid: L1-Sharded-1x1 (not enough parallelism) │
│ │
│ Filtered to maxLegalLayouts = 8 │
└─────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ LegalOpConfigAnalysis (per-op) │
│ │
│ For ops with extra config knobs (e.g., Conv2d): │
│ Expand each layout with op-specific parameters │
│ │
│ N layouts × M parameter combinations = configs │
└─────────────────────────────────────────────────────────┘
│
▼
legalConfigs[op] = vector<OpConfig>
3.2 DFShardingPolicy
Purpose: Build and resolve L1 chains by processing ops in DFS-schedulable order.
3.2.1 L1 Chain Concept
An L1 chain is a sequence of operations whose intermediate tensors can reside in L1 memory. The goal is to identify maximal chains where data flows through L1 without spilling to DRAM.
Example L1 Chain:
DRAM Input
│
▼
┌─────────┐
│ Conv2d │ ─┐
└─────────┘ │
│ │
▼ │ L1 Chain
┌─────────┐ │ (all intermediates in L1)
│ ReLU │ │
└─────────┘ │
│ │
▼ │
┌─────────┐ ─┘
│ Add │
└─────────┘
│
▼
DRAM Output (spill)
3.2.2 Chain Building Algorithm
The policy walks the graph in DFS (Depth-First Search) schedulable order:
Algorithm: DFShardingPolicy.run()
1. Schedule ops in DFS order
2. For each op:
a. Add to chain if shardable with legal configs
b. Continue chain if: (1) next op uses this as operand[0], AND (2) single use
c. Otherwise: finalize chain, start new one
3. Resolve each chain with ShardSolver
4. Select config maximizing core usage
3.2.3 Chain Building Rules
| Rule | Rationale |
|---|---|
| Single-use only | If currentOp.hasOneUse() is false (fork), chain breaks to avoid complex dataflow |
| First operand | nextOp.operand[0] must be currentOp - ensures linear chain structure |
| Shardable ops only | Only specific ops support L1 sharding (Conv2d, Matmul, elementwise ops, etc.) |
| Has legal configs | Op must have at least one valid sharded configuration |
3.2.4 L1ChainConfig State Machine
┌──────────────┐
│ InBuild │ Initial state, ops can be added
└──────┬───────┘
│ build()
▼
┌──────────────┐
│ Built │ Ops finalized, ready for ShardSolver
└──────┬───────┘
│ resolveWithSolver()
▼
┌──────────────┐ ┌──────────────┐
│ Resolved │────────▶│ Failed │ If solver finds no solution
└──────┬───────┘ └──────────────┘
│ complete()
▼
┌──────────────┐
│ Completed │ Single config selected per op
└──────────────┘
3.3 ShardSolver
Purpose: Solve the constraint satisfaction problem of finding compatible sharding configurations for adjacent operations in an L1 chain.
3.3.1 Problem Formulation
Given an L1 chain of N operations, each with K_i valid configurations, find a selection of one configuration per operation such that:
- Edge Compatibility: For each producer→consumer edge, the producer's output layout is compatible with the consumer's input requirements
- Memory Fit: All selected configurations fit within L1 capacity
- Maximize Core Usage: Among valid solutions, prefer those using more cores
3.3.2 Bitset-Based Constraint Tracking
ShardSolver uses fixed-size bitsets to efficiently track which configurations remain valid for each operation. Each bit position represents a configuration index—a set bit means the config is still valid, a cleared bit means it has been eliminated.
The bitset size is chosen to accommodate the expanded configuration space. While maxLegalLayouts bounds the number of tensor layouts, op-specific attributes (e.g., Conv2d block sizes) multiply the total configs per operation into the hundreds.
3.3.3 PathSet Graph
The solver maintains a graph of valid "paths" between adjacent operations. A path connects a producer config index to a consumer config index, indicating that the producer's output layout is compatible with the consumer's input requirements for those specific configurations.
For each edge in the chain, the solver stores a PathSet containing all valid producer-consumer config pairs. As constraints propagate, paths are removed when either endpoint's config becomes invalid.
3.3.4 Resolution Algorithm
The solver processes the chain in order, building PathSets for each edge:
- Preprocess first op: Determine which configs can accept external (typically DRAM interleaved) input
- Build paths: For each edge, validate all producer-consumer config combinations via OpModel
- Handle incompatibility: If no valid paths exist for an edge, attempt to insert a reshard
- Update bitsets: Narrow each operation's valid configs based on which have valid paths
- Propagate constraints: Iteratively propagate until the constraint graph stabilizes
If any edge ends up with zero valid paths, the entire chain fails.
3.3.5 First Op Preprocessing
The first operation receives input from outside the chain. The solver checks which of its configs can accept interleaved input and produce sharded output. If none can, a reshard is inserted at chain entry.
3.3.6 Reshard Insertion
When adjacent operations have incompatible layouts, the solver inserts a reshard (ToLayoutOp). It searches all possible sharded layouts that could bridge the gap, recording which consumer configs each reshard layout enables. Multiple valid reshard layouts may exist per consumer config, providing flexibility during final resolution.
3.3.7 Constraint Propagation
After initial path construction, constraints propagate bidirectionally through the graph until convergence. When a config is eliminated from one operation, all paths involving that config are removed, which may eliminate configs from adjacent operations, triggering further propagation.
This continues until no more changes occur or an edge loses all paths (failure).
3.3.8 Core Usage Maximization
After constraints are resolved, the solver selects the final configuration for each operation. It computes accumulated core usage by walking the chain backward, summing each operation's grid volume with its downstream usage. The configuration path with highest total core usage is selected, preferring solutions that maximize parallelism across the entire chain.
3.3.9 Shortcomings and Limitations
The current ShardSolver design has several significant limitations:
1. Reshard Insertion is Reactive (Primary Limitation)
Reshards are only inserted when direct compatibility fails:
- No proactive optimization of reshard placement
- Cannot reason about whether a reshard earlier in the chain would enable better configurations downstream
- A strategically placed reshard might unlock better overall configurations, but the solver only reacts to failures
2. First Operand Only
ShardSolver only tracks and resolves constraints along the first operand (operand[0]) of each operation. This means:
- Operations with multiple activation tensor inputs (e.g., binary ops where both inputs come from the chain) cannot have both inputs properly constrained
- The second operand's layout is not considered during constraint propagation
- This fundamentally limits the solver to linear chains where data flows through the first operand
3. Single Edge Failure Breaks Entire Chain
If constraint resolution fails on any single edge in the chain, the entire chain fails:
- No partial solutions are possible
- A chain of 10 ops will completely fall back to DRAM if one edge cannot be resolved
- This leads to suboptimal results for graphs that could benefit from partial L1 placement
4. Local Optimization Only
Each L1 chain is solved independently:
- No global view of memory pressure across chains
- Cannot make trade-offs between chains (e.g., shrink one chain to benefit another)
- Chains are built greedily without considering downstream implications
5. Complex Constraint Propagation
The PathSet-based constraint propagation adds significant complexity:
- Bidirectional updates between producer and consumer bitsets
- Iterative propagation until convergence
- Difficult to reason about and debug when constraints conflict
- The
updateSolverloop can visit the same operations multiple times
3.4 OpModel Integration
Purpose: Query the tt-metal backend for operation validity, memory requirements, and actual output layouts.
The OpModel provides a validation interface that checks if an operation can execute with given input layouts and configuration. It returns whether the configuration is valid, memory usage information, and the actual output layout the backend will produce. This validation is called extensively during layout generation and constraint resolution to ensure only valid configurations are considered.
3.5 Graph Transformation
Purpose: Apply the chosen configurations to the IR and insert necessary memory reconfiguration operations.
After all analysis phases complete, the optimizer transforms the IR by applying the resolved layout and op-specific configurations to each operation. Where adjacent operations have incompatible layouts (as determined by ShardSolver), ToLayoutOp reshards are inserted to bridge the gap. Chain outputs that cannot remain in L1 are spilled to DRAM. Finally, operations are reordered according to the computed schedule to ensure memory-efficient execution.
Transformation Example
Before Optimization:
%0 = ttnn.conv2d(%input, %weight) : tensor<1x64x64x128xbf16> [DRAM Interleaved]
%1 = ttnn.relu(%0) : tensor<1x64x64x128xbf16> [DRAM Interleaved]
return %1
After Optimization:
%0 = ttnn.conv2d(%input, %weight)
{conv2d_config = #ttnn.conv2d_config<actBlockHOverride = 32>}
: tensor<1x64x64x128xbf16, #layout<L1, Sharded, 8x8>>
%1 = ttnn.relu(%0) : tensor<1x64x64x128xbf16, #layout<L1, Sharded, 8x8>>
// Inserted spill to DRAM for function return
%2 = ttnn.to_layout(%1) {memory_config = #ttnn.memory_config<DRAM, Interleaved>}
: tensor<1x64x64x128xbf16, #layout<DRAM, Interleaved>>
return %2
4. Future Work / Proposed Refactors
4.1 DFSharding 2.0: Chain Merging and L1 Saturation
Goal: Maximize L1 utilization by keeping chain outputs in L1 when possible, avoiding unnecessary DRAM spills.
4.1.1 Motivation
The current DFSharding policy builds isolated L1 chains, where each chain's output spills to DRAM before the next chain begins. This wastes L1 capacity and introduces DRAM latency when:
- Chain A → Chain B: Chain A's output could stay in L1 for Chain B to consume directly
- Fork operations: An op with multiple users spills to DRAM, causing all consumers to read from slow DRAM
- Concat operations: All input chains spill to DRAM, then concat reads them back
Current Behavior (wasteful):
Chain A: [Conv2d → Relu]
│
▼ spill to DRAM
─────────────────────
│
▼ reload from DRAM
Chain B: [Add → Matmul]
Desired Behavior (Chain Merging):
Chain A: [Conv2d → Relu]
│
│ stays in L1 ────────┐
▼ │
Chain B: [Add → Matmul] ←──┘
4.1.2 Chain Merging Types
1. Simple A→B Merge
Chain A's output stays in L1 and is consumed by Chain B on any operand.
Chain A ────┐
│ (operand 1)
▼
┌─────────┐
│ Add │ Chain B first op
└─────────┘
│
▼
[...] Chain B continues
Validation: All ops scheduled between Chain A's last op and the join point must be re-validated with Chain A's output size as additional L1 usage. This includes any scheduled op in that window, regardless of whether it belongs to an L1 chain.
2. 3-Way Merge
When Chain B's first op has two operands from different chains, both can stay in L1.
Chain A (operand 0) ───┐
│
┌────┴────┐
│ Add │ Chain B first op
└────┬────┘
│
Chain C (operand 1) ───┘
Execution order: Chain A executes first, then Chain C executes while Chain A's output stays in L1, then Chain B's first op consumes both.
Validation: Chain C must be validated to execute with Chain A's output as additional L1 pressure.
3. N-Way Merge (Concat)
Concat operations consume multiple inputs. All input chains can stay in L1 if:
- All input chains complete successfully (state = Completed)
- All inputs have compatible sharding (based on concat dimension)
- Concat can consume all L1-sharded inputs directly
Chain 1 ────┐
│
Chain 2 ────┼───▶ [Concat] ───▶ Chain output
│
Chain 3 ────┘
Concat sharding constraints:
- Width concat (dim = last): requires HEIGHT_SHARDED inputs
- Height concat (dim = second-to-last): requires WIDTH_SHARDED inputs
- BLOCK_SHARDED is NOT supported for concat
Validation: Chains feeding into concat execute in schedule order. All scheduled ops between the first chain's completion and concat execution must be validated with cumulative L1 pressure:
- Chain 1 executes normally
- All ops scheduled after Chain 1 (including Chain 2) are validated with Chain 1's output as additional L1
- All ops scheduled after Chain 2 (including Chain 3) are validated with (Chain 1 + Chain 2) outputs as additional L1
- And so on until concat, which must fit all N inputs in L1 simultaneously
4.1.3 L1 Reservation Timeline
To validate merges, we track L1 memory usage across the schedule timeline. Each reservation records which operation's output is being held in L1, the schedule positions where the reservation is active (from production to last use), and the size in bytes. When validating any operation, we query active reservations at that schedule position to determine total L1 pressure from merged chain outputs.
4.1.4 Fork Op L1 Optimization
Operations with multiple users (forks) traditionally spill to DRAM, causing all consumers to read from slow memory. This refactor tries to keep forked outputs in L1.
Algorithm:
For each chain that spills to DRAM with forked output:
1. Try keeping SHARDED layout:
- Check all consumers can accept sharded input
- Validate memory pressure across fork span
- If valid: spillLocation = None, create L1 reservation
2. Fallback to L1 INTERLEAVED:
- Validate op can produce L1 interleaved output
- Check all consumers can accept L1 interleaved input
- Validate memory pressure
- If valid: spillLocation = L1Interleaved, create L1 reservation
3. If both fail: keep DRAM spill
4.1.5 Merge Validation Process
Critical Insight: Chain merging validation must cover ALL scheduled ops between the source chain's last op and the join point, not just ops in L1 chains. This is implemented via validateScheduleRangeWithReservation.
L1 Residents Layout Map:
Tracks layouts of chain outputs that stay in L1 after merging. Updated incrementally as merges are applied, so subsequent validations see actual sharded layouts from merged chains instead of IR's DRAM layouts.
validateScheduleRangeWithReservation() (core validation function):
For each op in schedule range [startPos, endPos]:
1. Calculate total additional L1 at this position:
totalAdditionalL1 = getActiveL1Reservations(pos) + additionalL1
2. If op is in a chain:
- Build input layouts from resolved configs + l1ResidentsLayoutMap
- Validate with chain's resolved config
3. If op is NOT in a chain:
- Extract layouts from IR
- Override inputs with l1ResidentsLayoutMap where applicable
- Validate with IR config
4. If validation fails: reject merge
validateChainBWithMergedInput():
1. Validate intermediate ops between source chain and join op:
validateScheduleRangeWithReservation(startPos+1, joinOpPos-1, sourceOutputSize)
2. For each op in Chain B (up to join op):
- Build input layouts from resolved configs + l1ResidentsLayoutMap
- At join op: replace operand layout with source chain's output
- Calculate total additional L1
- Validate operation
validateChainWithPredecessorInL1() (for 3-way merge):
For each op in Chain C:
1. Build input layouts from resolved configs + l1ResidentsLayoutMap
2. Calculate total additional L1:
additionalL1 = predecessorOutputSize + getActiveL1Reservations(opPos)
3. Call validateOperation(op, inputLayouts, config, additionalL1)
4. If validation fails: reject merge
validateThreeWayMergeJoinOp() (3-way merge join validation):
The join op must be revalidated with BOTH sharded inputs:
1. Build input layouts starting from IR
2. Replace operand 0 with Chain A's sharded output layout
3. Replace operand 1 with Chain C's sharded output layout
4. Validate join op with both sharded inputs
This is critical because the join op was originally validated with interleaved inputs during chain resolution.
4.1.6 Concat Chain Resolution
Concat ops are isolated into single-op chains and resolved after regular chains:
Chain Building:
When encountering ConcatOp:
1. Finalize current chain
2. Create single-op chain with isConcatChain = true
3. Start new chain for subsequent ops
setConcatChainPreferences() (pre-resolution):
For each concat chain:
1. Determine required input memory layout from concat dim
2. Set preferredOutputMemLayout on all input chains
3. Set preferredOutputMemLayout on consumer chain
resolveConcatChains() (post regular chain resolution):
For each concat chain:
1. Check all input chains are Completed
2. Check all inputs have compatible sharding
3. Validate concat with L1-sharded inputs
4. If valid:
- Set spillLocation = None on input chains
- Complete concat chain with L1-sharded output
4.1.7 Data Flow with Merging
┌─────────────────────────────────────────────────────────────────────────┐
│ DFShardingPolicy with Chain Merging │
│ │
│ 1. Build chains (unchanged, but ConcatOp gets isolated chains) │
│ │ │
│ ▼ │
│ 2. setConcatChainPreferences() │
│ Set preferred sharding for chains feeding into concat │
│ │ │
│ ▼ │
│ 3. Resolve regular chains with ShardSolver │
│ (preferredOutputMemLayout influences config selection) │
│ │ │
│ ▼ │
│ 4. resolveConcatChains() │
│ Validate concat can consume L1-sharded inputs │
│ │ │
│ ▼ │
│ 5. applyL1ReservationsForReshapes() │
│ Keep reshape outputs in L1 when feeding interleaved consumers │
│ │ │
│ ▼ │
│ 6. applyL1ReservationsForForkOps() │
│ Keep forked outputs in L1 (sharded or interleaved) │
│ │ │
│ ▼ │
│ 7. applyChainMerges() │
│ Merge chains where outputs can stay in L1 │
│ - Simple A→B merges │
│ - 3-way merges │
│ │ │
│ ▼ │
│ Output: Chains with spillLocation set (None, L1Interleaved, or DRAM) │
└─────────────────────────────────────────────────────────────────────────┘
4.1.8 Future: Towards Global Optimization
Chain merging is a step towards global optimization but still operates on pre-built chains. Future work may:
- Remove L1 chain concept entirely - treat graph as a whole
- Global memory pressure analysis - consider all ops simultaneously
- Cost-based optimization - evaluate trade-offs between L1 placement and reshards
- Deprecate ShardSolver - replace with simpler per-edge validation
The L1 reservation timeline mechanism introduced here provides the foundation for global memory tracking.
5. Proposed Refactoring: Pass-Based Architecture
5.1 Summary
We propose removing the DFShardingPolicy, ShardSolver, and most of the TTNNOptimizer analysis pipeline, replacing them with a simpler pass-based architecture. Our empirical analysis across 50+ models shows that a greedy approach can match or exceed current performance while being significantly easier to understand and maintain.
5.2 Motivation
The current optimizer architecture has grown complex over time. The combination of L1 chain building, chain merging, and ShardSolver constraint propagation creates a system that is difficult to reason about, debug, and extend. More importantly, our analysis reveals that this complexity doesn't translate to better results—the sophisticated backtracking mechanism rarely provides practical benefit.
5.3 Design Philosophy
- Simple mental model: "Keep data in L1 unless an operation requires otherwise, then return to L1 as soon as possible."
- Defer to the backend: Let the backend decide optimal configs and layouts via its query APIs. The optimizer's job is to respect those choices, not second-guess them.
5.4 Problems with Current Approach
5.4.1 Operand 0 Limitation
The ShardSolver only propagates sharding decisions through operand 0 edges. This means that for binary operations like subtract(a, b), if operand 0 cannot be sharded, the solver ignores operand 1 entirely—even if it's perfectly valid to keep operand 1 in L1. Our analysis found this causes significant unnecessary spills.
5.4.2 All-or-Nothing Chain Failure
When any edge in an L1 chain fails validation, the entire chain spills to DRAM. There's no mechanism for partial success—a single incompatible operation forces all connected operations out of L1 memory.
5.4.3 Designed for Linear Chains
The ShardSolver's bitset-based constraint propagation assumes linear chain structure. Complex graph topologies like forks, joins, and diamonds require special-case handling outside the solver, adding to the overall complexity.
5.4.4 Solving a Problem That Rarely Exists
The ShardSolver is designed to solve the case where an operation has multiple valid output layouts for a given sharded input, and the choice matters because it affects downstream compatibility. The constraint propagation and backtracking machinery exists to navigate this combinatorial space. In practice, however, most operations produce a single valid output layout for a given input—there is rarely a meaningful choice to optimize over. The solver's complexity addresses a theoretical problem that empirically almost never arises.
5.4.5 Precomputed Layout Pool Discards Valid Results
The current pipeline precomputes a fixed pool of candidate layouts (via LegalTensorLayoutAnalysis) before any per-op validation. When the backend's op constraints API is queried, it may return a valid sharded output layout that was not in this precomputed pool—and the optimizer silently discards it. This means the solver operates over an incomplete search space: valid, potentially optimal configurations are rejected simply because they were not anticipated during layout enumeration. The proposed architecture avoids this by accepting whatever layout the backend returns rather than filtering against a precomputed set.
5.5 Empirical Findings
We analyzed the compiled IR for 50+ models including Segformer, ResNet50, and 45 LLM variants (Llama, Falcon, Gemma, Phi, Qwen). Key findings:
Memory pressure is rare at current batch sizes. All tested models show 40-94% L1 headroom. The L1 budget of ~1364 KB per core is rarely stressed. This could change for CNN models at larger batch sizes, where activation tensors grow significantly. LLM decode paths should remain comfortable since activations stay relatively small regardless of batch size.
Spills are constraint-driven, not memory-driven. The vast majority of spills occur because specific operations require DRAM inputs (reduce ops, permute, reshape), not because L1 is full.
Unnecessary spills have clear causes:
- Operand 0 limitation: 36-65 spills per model in patterns where one operand is DRAM while another could stay in L1
- Fork handling: 15 spills in ResNet50 residual connections that could remain in L1 with proper liveness tracking
Greedy decisions would have been correct. In every case we analyzed, the optimal choice was apparent from local information—no backtracking was needed to find it.
5.6 Proposed Architecture
We propose two independent passes with clear responsibilities:
5.6.1 Pass 1: Layout Propagation
An edge-based layout picker that processes each operation in schedule order and selects the best valid layout through backend validation. For each operation:
- Look at input edges and their current layouts
- Enumerate candidate (config, layout) pairs for the op
- Validate each candidate against the backend (OpModel) given the actual input layouts
- Pick the best valid candidate using a scoring heuristic (e.g., maximize core usage)
- If no valid L1 sharded layout exists, fall back to L1 Interleaved
- If L1 Interleaved is also not valid, fall back to DRAM Interleaved
This pass considers all operands (fixing the operand 0 limitation) but has no notion of memory pressure across multiple live tensors—it only validates that each individual op-to-op transition is valid. It propagates layouts edge by edge, inserting reshards where adjacent ops have incompatible layouts.
Reshard exploration: Even when a reshard-free path exists between two operations, a reshard may enable a better downstream layout (e.g., more cores). This pass can explore reshard paths alongside direct paths and use its scoring heuristic to decide which is better. This is where beam search (Section 5.8.1) becomes valuable—it preserves multiple candidates to avoid committing to a locally convenient but globally suboptimal choice.
Inline reshard validation: Instead of precomputing all possible layouts upfront (as the current LegalTensorLayoutAnalysis does), reshard candidates can be generated and validated inline in two steps:
- Given the producer's output tensor shape, use
create_sharded_memory_config(from tt-metal) with different core grids and shard strategies (height, width, block) to generate candidate memory configs for the reshard target. - For each candidate, validate the consumer op via
query_op_constraintswith the resharded tensor as input.
This eliminates the precomputed layout pool entirely (fixing the problem described in Section 5.4.5) and generates reshard targets on demand based on the actual tensor shape at each point in the graph.
Note: Because this pass does not track global L1 pressure, it may leave the graph in a state where OOM is expected at runtime—multiple simultaneously live tensors may each be assigned L1 layouts that are individually valid but collectively exceed the L1 budget. This is by design; Pass 2 (L1 Spill Management) is responsible for resolving these conflicts.
Op-specific configs: This pass also selects op-specific configs (conv2d, matmul, compute configs). Today, we generate these configs ourselves because the backend's query APIs use a dummy allocator that cannot auto-select optimal configs. Once the allocator is integrated into the query path, both layouts and op configs will become fully backend-driven, and this pass will simply ask the backend "given these inputs, what is the best config?" instead of enumerating candidates.
5.6.2 Pass 2: L1 Spill Management
Pass 1 validates each op-to-op edge in isolation—it confirms that a single producer-consumer pair can both fit in L1, but does not account for other tensors that are simultaneously live. Pass 2 takes the L1 layout assignments from Pass 1 and adjusts them based on global memory pressure.
Core strategy:
- Walk the schedule and track all live tensors and their L1 sizes at each point
- When total L1 usage at any point exceeds the memory budget, spill tensors to free space
- Spill the tensor with the longest remaining lifetime first (furthest next use)
- Spilled tensors move to DRAM Interleaved (or L1 Interleaved where possible)
Fork handling (borrowed from DF sharding 2.0):
- Allow fork tensors to stay in L1 for their full lifetime when space permits
- Modify op configs as needed (e.g., conv2d
deallocate_activation=falsefor fork inputs)
Key distinction from Pass 1: Pass 1 only falls back to DRAM when no valid L1 layout exists for an operation. Pass 2 may undo an L1 decision that Pass 1 made, because the cumulative L1 pressure from multiple simultaneously live tensors exceeds the budget—even though each individual op-to-op edge was valid in isolation.
5.7 Simplicity Benefits
The proposed architecture is substantially simpler:
- No chain state machine or chain merging logic
- No bitset-based constraint solver
- Each pass has a single, well-defined responsibility
- Decisions are local and easy to trace
- Fewer special cases for graph patterns
This simplicity translates to faster development, easier debugging, and more predictable behavior.
5.8 Optimization Strategies
While greedy allocation provides a functional baseline, the pass-based architecture enables more sophisticated strategies to reach parity with the current optimizer.
5.8.1 Beam Search for Layout Propagation (Pass 1 Enhancement)
Pure greedy (K=1) can lock in suboptimal choices early. For example, an early op might choose 32-core sharding because it avoids a reshard, but this propagates forward and forces downstream matmuls to also use 32 cores—losing significant compute throughput.
The problem: Greedy's strategy is "use working config without reshard, fall back to reshard only if none exists." This avoids reshards but may miss globally better paths.
Solution: Beam search with K candidates (e.g., K=4 or K=8) per op. Beam search has two phases:
Forward phase (candidate selection): Process ops in schedule order. For each op:
- Enumerate candidates from configs compatible with input layouts (no reshard) and configs requiring reshards but enabling more cores
- For binary ops, consider combinations from both inputs (K × K pairs)
- Score all candidates, keep top K
- Store back-pointers to parent candidates
Backward phase (trace-back): Starting from leaf nodes, trace back through best candidates to reconstruct the optimal path. At fork points, resolve conflicts (see below).
Scoring (heuristic mode): Without device access, use core count as proxy:
- Primary: maximize
minCores(bottleneck core count on path) - Tiebreaker: minimize
reshardCount
Scoring (cost mode, opt level 3): With device access, use getOpRuntime() for actual runtime estimates. Score = accumulated runtime. This enables precise tradeoffs but is slower and requires device.
Complexity: O(K² × n) where K = beam width, n = number of ops. The K² factor comes from binary ops where we evaluate K × K input combinations. For ops with more inputs (e.g., concat with 4-5 operands), the combinations remain tractable since K is small (4-8).
Why this reaches parity with current optimizer: ShardSolver explores configurations via constraint propagation and backtracking. Beam search achieves similar exploration with bounded complexity, but considers all operands and doesn't suffer from chain-level failures.
Handling fork points: During backward trace-back, different consumer paths may prefer different layouts from a forked tensor:
fork_op (keeps K candidates: [HS, BS, WS, ...])
/ \
consumer_A consumer_B
(path wants HS) (path wants BS)
At each fork during trace-back:
- Collect what layout each consumer path wants
- For each of fork's K candidates, compute total reshard cost to satisfy all consumers
- Pick the candidate with minimum total reshard cost
This is a local decision—no tree traversal needed. Beam search reduces the global problem to local decisions by preserving K candidates at each op.
5.8.2 Dynamic Programming for Optimal Spill Selection (Pass 2 Enhancement)
When L1 pressure exists and multiple tensors compete for limited space, the spill decision becomes a classic register allocation problem. A DP-based approach can find the globally optimal set of tensors to keep in L1:
Problem formulation: Given a schedule of operations and their tensor lifetimes, select which tensors to keep in L1 at each point such that total memory never exceeds budget and total spill cost is minimized.
DP state: At each operation in the schedule, track which subset of live tensors are in L1. Transitions occur when tensors become live (allocate or spill) or die (deallocate).
Cost model: Assign costs to spills based on tensor size and access patterns. Tensors accessed multiple times have higher spill cost than single-use tensors.
This approach guarantees optimal allocation but has exponential complexity in the number of simultaneously live tensors. For most models this is tractable (typically 5-15 live tensors), but may need pruning heuristics for complex graphs.
5.8.3 Progression Path
Each phase delivers a complete optimizer (both Pass 1 and Pass 2). The phases represent increasing sophistication in the strategies used within each pass.
Phase 1 - Greedy (MVP): Pass 1 uses pure greedy layout propagation (K=1). Pass 2 uses greedy spill management with liveness tracking. Together, this already fixes the operand 0 limitation (Pass 1 considers all operands) and fork handling (Pass 2 tracks tensor lifetimes). Validates the pass-based architecture with minimal complexity. Sufficient for models where early layout choices don't constrain downstream ops.
Phase 2 - Beam Search with Heuristics (Parity): Upgrade Pass 1 to beam search (K=4 or K=8) with heuristic scoring: maximize cores, break ties by reshard count. Explores reshard paths even when reshard-free paths exist. No device access needed, fast. Pass 2 remains greedy. Expected to match or exceed current optimizer quality.
Phase 3 - Beam Search with Cost Mode (Opt Level 3): Upgrade Pass 1's scoring to use getOpRuntime() for actual runtime estimates. Precise cost-based tradeoffs between reshards and compute. Requires device access, slower, but more accurate for complex models.
Phase 4 - DP Extensions (Edge Cases): Upgrade Pass 2 to use DP-based spill selection for models with genuine memory pressure. Our empirical data (40-94% headroom) suggests this is rarely needed, but the architecture supports it.
'd2m' Dialect
Direct-to-metal subset of D2M
The D2M dialect contains the subset of D2M used by the direct-to-metal lowering path (TTMetal). It hosts generic dispatch ops and related region ops required post D2MToD2MGeneric.
[TOC]
d2m.composite_view (tt::d2m::CompositeViewOp)
Piecewise view over multiple input tensors
Represents a piecewise-affine view that aggregates multiple input tensors
along a certain dimension.
The optional logicalSizes attribute records the logical sizes of the
inputs along dim, which is required for row-major inputs.
Traits: AlwaysSpeculatableImplTrait
Interfaces: BufferizableOpInterface, ConditionallySpeculatable, D2M_ViewOpInterface, NoMemoryEffect (MemoryEffectOpInterface), ViewOpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim | ::mlir::IntegerAttr | 32-bit signed integer attribute |
logicalSizes | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of ranked tensor of any type values or non-0-ranked.memref of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values or non-0-ranked.memref of any type values |
d2m.create_global_semaphore (tt::d2m::CreateGlobalSemaphoreOp)
Global semaphore allocation operation (D2M).
Syntax:
operation ::= `d2m.create_global_semaphore` `(` $input `)` attr-dict `:` type($input) `->` type($result)
Create an uninitialized global semaphore with the specified core range.
Interfaces: BufferizableOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
value | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values or non-0-ranked.memref of any type values |
Results:
| Result | Description |
|---|---|
result | D2M global semaphore type. |
d2m.create_local_semaphore (tt::d2m::CreateLocalSemaphoreOp)
Create local semaphore op.
Syntax:
operation ::= `d2m.create_local_semaphore` prop-dict attr-dict `->` type($result)
This operation is a representational op. It creates a local semaphore in the core range within the generic op in which it is consumed.
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
initialValue | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Results:
| Result | Description |
|---|---|
result | D2M local semaphore type. |
d2m.empty (tt::d2m::EmptyOp)
Empty tensor allocation operation (D2M).
Syntax:
operation ::= `d2m.empty` `(` `)` attr-dict `:` type($result)
Create an uninitialized tensor with the specified shape, element type and encoding.
Optionally, the virtualGridInverseMapping attribute stores the inverse affine
map (physical to virtual grid coordinates) and virtualGridForwardMapping
stores the forward affine map (virtual to physical grid coordinates).
Interfaces: BufferizableOpInterface, MemoryEffectOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
virtualGridInverseMapping | ::mlir::AffineMapAttr | AffineMap attribute |
virtualGridForwardMapping | ::mlir::AffineMapAttr | AffineMap attribute |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
d2m.generic (tt::d2m::GenericOp)
Generically dispatch work to a grid of cores (D2M).
Same semantics as D2M generic; carries regions for compute/datamovement to be consumed by the metal path.
Traits: AttrSizedOperandSegments, NoTerminator
Interfaces: BufferizableOpInterface, DestinationStyleOpInterface, MemoryEffectOpInterface, OpAsmOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
grid | ::mlir::tt::ttcore::GridAttr | TT grid attribute{{% markdown %}} TT grid attribute {{% /markdown %}} |
block_factors | ::mlir::ArrayAttr | 64-bit integer array attribute |
indexing_maps | ::mlir::ArrayAttr | AffineMap array attribute |
iterator_types | ::mlir::ArrayAttr | |
threads | ::mlir::ArrayAttr | |
fabricConnectionConfig | ::mlir::tt::ttcore::FabricConnectionConfigAttr | Fabric Connection Config attribute.{{% markdown %}} Structure for configuring fabric connections for worker cores (in CCL ops). {{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of ranked tensor of any type values or non-0-ranked.memref of any type values |
outputs | variadic of ranked tensor of any type values or non-0-ranked.memref of any type values |
additionalArgs | variadic of any type |
Results:
| Result | Description |
|---|---|
results | variadic of ranked tensor of any type values |
d2m.mask (tt::d2m::MaskOp)
Mask tensor padding outside logical bounds with a fill value
Syntax:
operation ::= `d2m.mask` $input `,` $output `logical_shape` `=` $logicalShape `fill_value` `=` $fill_value attr-dict `:` type($input) `into` type($output) `->` type($result)
d2m.mask materializes a padding contract for a tiled tensor. Elements
outside logicalShape are replaced with fill_value; elements inside
the logical bounds are copied from input.
This is a tensor-level operation. d2m-decompose-masking lowers it to
explicit per-core masking loops after bufferization.
Interfaces: BufferizableOpInterface, MemoryEffectOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
logicalShape | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
fill_value | ::mlir::tt::ttcore::OOBValAttr | TT OOBVal |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values or non-0-ranked.memref of any type values |
output | ranked tensor of any type values or non-0-ranked.memref of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values or non-0-ranked.memref of any type values |
d2m.mesh_shard (tt::d2m::MeshShardOp)
Mesh shard operation (D2M).
Syntax:
operation ::= `d2m.mesh_shard` $input attr-dict `:` type($input) `->` type($result)
MeshShard op shards the inputs (FullToShard) or concatenates the outputs (ShardToFull) for ccl ops.
Traits: AlwaysSpeculatableImplTrait
Interfaces: BufferizableOpInterface, ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
shard_type | ::mlir::tt::ttcore::MeshShardTypeAttr | MeshShard shard_type attribute in TT dialect{{% markdown %}} Define sharded tensor data of mesh_shard op. - Identity: input and output tensors are pre-sharded (same data) and no sharding is required. - Replicate: all of the devices has full tensor (same data). - Maximal: one or part of the devcices has full tensor (same data). - Devices: all or part of the devices has sharded (partial) tensor (different data). {{% /markdown %}} |
shard_direction | ::mlir::tt::ttcore::MeshShardDirectionAttr | TT MeshShardDirection |
shard_shape | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
shard_dims | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values or non-0-ranked.memref of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values or non-0-ranked.memref of any type values |
d2m.reset_global_semaphore (tt::d2m::ResetGlobalSemaphoreOp)
Global semaphore reset operation (D2M).
Syntax:
operation ::= `d2m.reset_global_semaphore` `(` $semaphore `)` attr-dict `:` type($semaphore)
Reset global semaphore to a specific value. This operation blocks until the value has been set.
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
value | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
semaphore | D2M global semaphore type. |
d2m.spatial (tt::d2m::SpatialOp)
Execute multiple d2m.generic ops simultaneously on disjoint grid ranges of the device.
Syntax:
operation ::= `d2m.spatial` attr-dict `\n`
` ` ` ` ` ` ` ` `ins` `(` $inputs (`:` type($inputs)^)? `)` `\n`
` ` ` ` ` ` ` ` `outs` `(` $outputs `:` type($outputs) `)` ` ` $regions (`:` type($results)^ )?
Execute multiple d2m.generic ops simultaneously on disjoint parts of the physical
device. Each region corresponds to one grid range in grid_ranges and contains
exactly one d2m.generic op. Grid ranges must be non-overlapping and contained
in the device.
Traits: AttrSizedOperandSegments, NoTerminator
Interfaces: BufferizableOpInterface, DestinationStyleOpInterface, MemoryEffectOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
grid_ranges | ::mlir::ArrayAttr | ordered array of ttcore core_range attributes |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of ranked tensor of any type values or non-0-ranked.memref of any type values |
outputs | variadic of ranked tensor of any type values or non-0-ranked.memref of any type values |
Results:
| Result | Description |
|---|---|
results | variadic of ranked tensor of any type values |
d2m.to_device (tt::d2m::ToDeviceOp)
Transfer data from host to device.
Syntax:
operation ::= `d2m.to_device` $input `,` $output `layout` `=` $layout attr-dict `:` type($input) `into` type($output) (`->` type($results)^)?
ToDevice operation transfers tensor data from host (system) memory to device memory. This is the explicit host-to-device data movement operation that replaces the overloaded system transfer case of ToLayoutOp.
The layout attribute stores the device layout information needed for the transfer.
#layout = #ttcore.metal_layout<logical_shape = 64x128, dim_alignments = 32x32, collapsed_intervals = dense<[[0, 1], [1, 2]]> : tensor<2x2xi64>, l1, sharded>
%1 = d2m.to_device %arg0, %0 layout = #layout : tensor<64x128xf32> into tensor<64x128xf32, #layout>
Interfaces: BufferizableOpInterface, MemoryEffectOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
layout | ::mlir::tt::ttcore::MetalLayoutAttr | Tensor layout attribute with explicit physical shape{{% markdown %}} The tensor layout attribute captures how tensor data is sharded across a grid of devices/cores and is laid out in memory. Note that the presence of this attribute implies that the tensor shape includes sharding (i.e. the first half of the tensor shape represents the grid shape).{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values or memref of any type values |
output | ranked tensor of any type values or memref of any type values |
Results:
| Result | Description |
|---|---|
results | variadic of ranked tensor of any type values |
d2m.to_host (tt::d2m::ToHostOp)
Transfer data from device to host.
Syntax:
operation ::= `d2m.to_host` $input `,` $output `layout` `=` $layout attr-dict `:` type($input) `into` type($output) (`->` type($results)^)?
ToHost operation transfers tensor data from device memory to host (system) memory. This is the explicit device-to-host data movement operation that replaces the overloaded system transfer case of ToLayoutOp.
The layout attribute stores the device layout information needed for the transfer.
#layout = #ttcore.metal_layout<logical_shape = 64x128, dim_alignments = 32x32, collapsed_intervals = dense<[[0, 1], [1, 2]]> : tensor<2x2xi64>, l1, sharded>
%1 = d2m.to_host %arg0, %0 layout = #layout : tensor<64x128xf32, #layout> into tensor<64x128xf32>
Interfaces: BufferizableOpInterface, MemoryEffectOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
layout | ::mlir::tt::ttcore::MetalLayoutAttr | Tensor layout attribute with explicit physical shape{{% markdown %}} The tensor layout attribute captures how tensor data is sharded across a grid of devices/cores and is laid out in memory. Note that the presence of this attribute implies that the tensor shape includes sharding (i.e. the first half of the tensor shape represents the grid shape).{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values or memref of any type values |
output | ranked tensor of any type values or memref of any type values |
Results:
| Result | Description |
|---|---|
results | variadic of ranked tensor of any type values |
d2m.to_layout (tt::d2m::ToLayoutOp)
Layout op.
Syntax:
operation ::= `d2m.to_layout` $input `,` $output `:` type($input) `into` type($output) attr-dict (`->` type($results)^)?
ToLayout operation, transition tensors from one layout to another. Some examples include:
- Transitioning between different memory spaces, e.g. DRAM to L1.
- Transitioning between different data types, e.g. f32 to f16.
- Transitioning between different tile sizes, e.g. 1x16 to 32x32
- Transitioning between different tensor sharding
- Some combination of the above
#layout = #ttcore.metal_layout<logical_shape = 64x128, dim_alignments = 32x32, collapsed_intervals = dense<[[0, 1], [1, 2]]> : tensor<2x2xi64>, system, sharded>
#layout1 = #ttcore.metal_layout<logical_shape = 64x128, dim_alignments = 32x32, collapsed_intervals = dense<[[0, 1], [1, 2]]> : tensor<2x2xi64>, l1, sharded>
%1 = "d2m.to_layout"(%arg0, %0) : (tensor<64x128xf32, #layout>, tensor<64x128xf32, #layout1>) -> tensor<64x128xf32, #layout1>
Interfaces: BufferizableOpInterface, MemoryEffectOpInterface
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values or non-0-ranked.memref of any type values |
output | ranked tensor of any type values or non-0-ranked.memref of any type values |
Results:
| Result | Description |
|---|---|
results | variadic of ranked tensor of any type values |
d2m.view_layout (tt::d2m::ViewLayoutOp)
View Layout op (D2M subset)
Syntax:
operation ::= `d2m.view_layout` $input `remapping` `=` $remapping attr-dict `:` type($input) `->` type($result)
Create a representational view of a tensor/memref with a different layout. This is a no-op for codegen; consumers are expected to compose layouts.
The remapping attr describes the exact remapping this op represents.
Traits: AlwaysSpeculatableImplTrait
Interfaces: BufferizableOpInterface, ConditionallySpeculatable, D2M_ViewOpInterface, NoMemoryEffect (MemoryEffectOpInterface), OpAsmOpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
remapping | ::mlir::AffineMapAttr | AffineMap attribute |
reinterpretLayout | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values or non-0-ranked.memref of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values or non-0-ranked.memref of any type values |
'emitpy' Dialect
Dialect to generate Python from MLIR.
[TOC]
emitpy.assign_global (tt::emitpy::AssignGlobalOp)
Assign a value to a global variable
The emitpy.assign_global assigns the value to an existing named global variable.
Example:
emitpy.assign_global @value = %arg0 : !emitpy.opaque<"[ttnn.Tensor]">
Interfaces: SymbolUserOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
name | ::mlir::FlatSymbolRefAttr | flat symbol reference attribute |
Operands:
| Operand | Description |
|---|---|
value | any type |
emitpy.assign (tt::emitpy::AssignOp)
Assign operation
The emitpy.assign operation represents Python variable assignment.
For subscript assignment (e.g., dict[5] = value), wrap the subscript
in an emitpy.expression and use its result as the assign target.
The expression computes the lvalue; the assign performs the write.
Examples:
// Simple assignment
emitpy.assign %target = %value : (!emitpy.opaque<"int">, !emitpy.opaque<"int">)
...
// Subscript assignment (expression computes subscript lvalue)
%dict = emitpy.create_dict "dict" {literal_expr = "{}"} : () -> !emitpy.dict
%key = emitpy.literal "5" : index
%sub = emitpy.expression(%dict, %key) : (!emitpy.dict, index) -> !emitpy.opaque<"[ttnn.Tensor]"> {
^bb0(%d: !emitpy.dict, %k: index):
%s = emitpy.subscript %d[%k] : (!emitpy.dict, index) -> !emitpy.opaque<"[ttnn.Tensor]">
emitpy.yield %s : !emitpy.opaque<"[ttnn.Tensor]">
}
emitpy.assign %sub = %value : (!emitpy.opaque<"[ttnn.Tensor]">, !emitpy.opaque<"[ttnn.Tensor]">)
# Code emitted:
target = value
...
dict[5] = value
Interfaces: MemoryEffectOpInterface
Operands:
| Operand | Description |
|---|---|
target | EmitPy opaque type or EmitPy class type or EmitPy dictionary type or EmitPy string type. |
value | EmitPy opaque type or EmitPy class type or EmitPy dictionary type or EmitPy string type. |
emitpy.call_opaque (tt::emitpy::CallOpaqueOp)
Opaque call operation
Syntax:
operation ::= `emitpy.call_opaque` $callee `(` $operands `)` attr-dict `:` functional-type($operands, results)
The emitpy.call_opaque operation represents a Python function call. The callee
can be an arbitrary non-empty string.
Example:
%2 = emitpy.call_opaque "ttnn.add"(%0, %1) {args = [0 : index, 1 : index, #emitpy.opaque<"ttnn.DataType.BFLOAT16">, #emitpy.opaque<"ttnn.MemoryConfig(ttnn.TensorMemoryLayout.INTERLEAVED, ttnn.BufferType.DRAM, None)">], keyword_args = ["", "", "dtype", "memory_config"]} : (!emitpy.opaque<"ttnn.Tensor">, !emitpy.opaque<"ttnn.Tensor">) -> !emitpy.opaque<"ttnn.Tensor">
Interfaces: PyExpressionInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
callee | ::mlir::StringAttr | string attribute |
args | ::mlir::ArrayAttr | array attribute |
keyword_args | ::mlir::ArrayAttr | string array attribute |
Operands:
| Operand | Description |
|---|---|
operands | variadic of any type |
Results:
| Result | Description |
|---|---|
| «unnamed» | variadic of any type |
emitpy.class (tt::emitpy::ClassOp)
Class definition
The emitpy.class operation represents a Python class definition.
It is a symbol and contains a single-region body with class members.
Class verification enforces:
- At most one
__init__method. __init__returns nothing and is an instance method.- Methods can be annotated with
emitpy.method_kindattribute onfunc.funcusing one of:instance,staticmethod,classmethod. - Instance and class methods must have a receiver argument as the first
argument; if named, it must be
self(instance) orcls(classmethod).
Example:
emitpy.class @Model(#emitpy.opaque<"torch.nn.Module">) {
func.func @__init__(%self: !emitpy.class<"Model">) {
%w = emitpy.call_opaque "ttnn.load_weight"() : () -> !emitpy.opaque<"ttnn.Tensor">
emitpy.set_attr %self, "weight", %w : (!emitpy.class<"Model">, !emitpy.opaque<"ttnn.Tensor">)
return
}
}
Traits: IsolatedFromAbove, NoTerminator, SingleBlock, SymbolTable
Interfaces: Symbol
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
sym_name | ::mlir::StringAttr | string attribute |
base_classes | ::mlir::ArrayAttr | array attribute |
emitpy.constant (tt::emitpy::ConstantOp)
Constant operation
The emitpy.constant operation produces an SSA value equal to some constant
specified by an attribute. This can be used to form simple integer and
floating point constants, as well as more exotic things like tensor
constants.
Traits: ConstantLike
Interfaces: PyExpressionInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
value | ::mlir::Attribute | An opaque attribute or TypedAttr instance |
Results:
| Result | Description |
|---|---|
result | any type |
emitpy.create_dict (tt::emitpy::CreateDictOp)
Create dictionary operation
Syntax:
operation ::= `emitpy.create_dict` $dict_name (`(` $items^ `)`)? attr-dict `:` functional-type(operands, results)
Creates a Python dictionary with a specified name.
Can be created in two ways:
- From key-value pairs (items operands) - pairs are alternating key, value
- From a Python literal expression (literal_expr attribute)
When literal_expr is provided, items must be empty. When items are provided, they must be even count (key-value pairs).
Example:
// Empty dict using literal_expr
%dict1 = emitpy.create_dict "my_dict" {literal_expr = "{}"} : () -> !emitpy.dict
// Dict from key-value operands
%dict2 = emitpy.create_dict "cache" (%k0, %v0) : (index, !emitpy.opaque<"None">) -> !emitpy.dict
// Dict from literal expression (most compact for complex dicts)
%dict3 = emitpy.create_dict "_CONST_EVAL_CACHE" {literal_expr = "{i: None for i in range(133)}"} : () -> !emitpy.dict
# Code emitted for the operations above:
my_dict = {}
cache = {0: None}
_CONST_EVAL_CACHE = {i: None for i in range(133)}
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dict_name | ::mlir::StringAttr | string attribute |
literal_expr | ::mlir::StringAttr | string attribute |
Operands:
| Operand | Description |
|---|---|
items | variadic of any type |
Results:
| Result | Description |
|---|---|
result | EmitPy dictionary type |
emitpy.expression (tt::emitpy::ExpressionOp)
Expression operation to inline Python code
The emitpy.expression operation returns a single SSA value yielded by its
single-basic-block region. The operations inside the region must form a DAG
(directed acyclic graph) of computations that produces a single result value.
The expression's operands are mapped to block arguments and can be used
within the expression body.
When generating Python code, operations within the expression body are emitted inline without intermediate variable assignments, producing cleaner code.
The optional do_not_inline attribute can be used to force the translator to
emit the expression as separate statements rather than inline.
Example:
%expression = emitpy.expression(%a, %b) : (!emitpy.opaque, !emitpy.opaque) -> !emitpy.opaque {
^bb0(%arg0: !emitpy.opaque, %arg1: !emitpy.opaque):
%0 = emitpy.call_opaque "ttnn.mul"(%arg0, %arg1) : (!emitpy.opaque, !emitpy.opaque) -> !emitpy.opaque
%1 = emitpy.call_opaque "ttnn.add"(%0, %arg1) : (!emitpy.opaque, !emitpy.opaque) -> !emitpy.opaque
emitpy.yield %1 : !emitpy.opaque
}
return %expression : !emitpy.opaque
This would generate:
return ttnn.add(ttnn.mul(a, b), b)
If the do_not_inline attribute is set:
%expression = ttnn.add(ttnn.mul(a, b), b)
return %expression
Traits: HasOnlyGraphRegion, IsolatedFromAbove, SingleBlockImplicitTerminator<YieldOp>, SingleBlock
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
do_not_inline | ::mlir::UnitAttr | unit attribute |
Operands:
| Operand | Description |
|---|---|
operands | variadic of any type |
Results:
| Result | Description |
|---|---|
result | any type |
emitpy.file (tt::emitpy::FileOp)
A file container operation
Syntax:
operation ::= `emitpy.file` $id attr-dict-with-keyword $bodyRegion
A file represents a single Python file.
If -emitpy-file-id=id flag is used with ttmlir-translate,
then only the matching emitpy.file op is emitted.
Example:
emitpy.file "main" {
emitpy.func @func_one() {
emitpy.return
}
}
Traits: IsolatedFromAbove, NoRegionArguments, NoTerminator, SymbolTable
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
id | ::mlir::StringAttr | An Attribute containing a string{{% markdown %}} Syntax:{{% /markdown %}} |
emitpy.get_attr (tt::emitpy::GetAttrOp)
Get attribute from an object
Syntax:
operation ::= `emitpy.get_attr` $object `,` $attr_name attr-dict `:` functional-type(operands, results)
The emitpy.get_attr operation represents Python attribute access
via the dot operator.
Example:
%w = emitpy.get_attr %self, "weight" : (!emitpy.class<"Model">) -> !emitpy.opaque<"ttnn.Tensor">
# Code emitted:
w = self.weight
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), PyExpressionInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
attr_name | ::mlir::StringAttr | string attribute |
Operands:
| Operand | Description |
|---|---|
object | any type |
Results:
| Result | Description |
|---|---|
result | any type |
emitpy.global (tt::emitpy::GlobalOp)
A global variable
Syntax:
operation ::= `emitpy.global` $sym_name custom<EmitPyGlobalOpInitialValue>($initial_value) attr-dict
The emitpy.global operation defines a named global variable.
Example:
emitpy.global @x : #emitpy.opaque<"[]">
Interfaces: Symbol
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
sym_name | ::mlir::StringAttr | string attribute |
initial_value | ::mlir::Attribute | An opaque attribute or TypedAttr instance |
emitpy.global_statement (tt::emitpy::GlobalStatementOp)
Marks a variable as global for the current function scope
Syntax:
operation ::= `emitpy.global_statement` $name `:` type($result) attr-dict
The emitpy.global_statement operation represents a Python global
statement.
It marks an identifier, specified by its symbol @name, as
referring to a variable in the global (module) scope, rather
than a new local variable.
Example:
%0 = emitpy.global_statement @x : !emitpy.opaque<"[ttnn.Tensor]">
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), SymbolUserOpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
name | ::mlir::FlatSymbolRefAttr | flat symbol reference attribute |
Results:
| Result | Description |
|---|---|
result | any type |
emitpy.if (tt::emitpy::IfOp)
If statement with optional else
Syntax:
operation ::= `emitpy.if` $condition (`args` $cond_args^ `:` `(` type($cond_args) `)`)? $thenRegion
(`else` $elseRegion^)? attr-dict
The emitpy.if operation represents a Python if statement with an
optional else clause. The condition is a format string with {}
placeholders that are replaced by the condition arguments.
An elif chain is represented by nesting an emitpy.if as the sole
operation inside the else region without its own else clause. The Python
emitter detects this pattern and emits elif instead of else: if.
Example:
emitpy.if "not {}" args %dict : (!emitpy.dict) {
// then body
}
emitpy.if "{} > {}" args %a, %b : (index, index) {
// then body
} else {
// else body
}
emitpy.if "{}" args %a : (!emitpy.opaque<"dict">) {
// then body
} else {
emitpy.if "{} > 0" args %b : (!emitpy.opaque<"int">) {
// elif body
}
}
# Code emitted:
if not dict:
# then body
if a > b:
# then body
else:
# else body
if a:
# then body
elif b > 0:
# elif body
Traits: NoTerminator
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
condition | ::mlir::StringAttr | string attribute |
Operands:
| Operand | Description |
|---|---|
cond_args | variadic of any type |
emitpy.import (tt::emitpy::ImportOp)
Import operation
The emitpy.import operation allows to define a Python module import
via various forms of the import statement.
Example:
emitpy.import import "ttnn"
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
module_name | ::mlir::StringAttr | string attribute |
module_alias | ::mlir::StringAttr | string attribute |
members_to_import | ::mlir::ArrayAttr | string array attribute |
member_aliases | ::mlir::ArrayAttr | string array attribute |
import_all | ::mlir::UnitAttr | unit attribute |
emitpy.literal (tt::emitpy::LiteralOp)
Literal operation
Syntax:
operation ::= `emitpy.literal` $value attr-dict `:` type($result)
The emitpy.literal operation produces an SSA value equal to some constant
specified by an attribute.
Example:
%0 = emitpy.literal "0" : index
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), PyExpressionInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
value | ::mlir::StringAttr | string attribute |
Results:
| Result | Description |
|---|---|
result | index |
emitpy.set_attr (tt::emitpy::SetAttrOp)
Set attribute on an object
Syntax:
operation ::= `emitpy.set_attr` $object `,` $attr_name `,` $value attr-dict `:` `(` type($object) `,` type($value) `)`
The emitpy.set_attr operation represents Python attribute assignment
via the dot operator.
Example:
emitpy.set_attr %self, "weight", %w : (!emitpy.opaque<"Model">, !emitpy.opaque<"ttnn.Tensor">)
# Code emitted:
self.weight = w
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
attr_name | ::mlir::StringAttr | string attribute |
Operands:
| Operand | Description |
|---|---|
object | any type |
value | any type |
emitpy.subscript (tt::emitpy::SubscriptOp)
Subscript operation
Syntax:
operation ::= `emitpy.subscript` $container `[` $index `]` attr-dict `:` functional-type(operands, results)
The emitpy.subscript operation represents Python subscript access.
This is the read counterpart to emitpy.assign.
Supports reading from any subscriptable object (e.g. arrays, dicts) with integer or string keys.
Example:
%0 = emitpy.literal "0" : index
%1 = emitpy.subscript %arg0[%0] : (!emitpy.opaque<"[ttnn.Tensor]">, index) -> !emitpy.opaque<"ttnn.Tensor">
...
%dict = emitpy.global_statement @_CONST_EVAL_CACHE : !emitpy.dict
%key = emitpy.literal "5" : index
%tensors = emitpy.subscript %dict[%key] : (!emitpy.dict, index) -> !emitpy.opaque<"[ttnn.Tensor]">
# Code emitted:
var_0 = subscript_arg[0]
...
tensors = _CONST_EVAL_CACHE[5]
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), PyExpressionInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
container | EmitPy opaque type or EmitPy dictionary type |
index | index or EmitPy string type. |
Results:
| Result | Description |
|---|---|
result | EmitPy opaque type or EmitPy class type or EmitPy dictionary type or EmitPy string type. |
emitpy.verbatim (tt::emitpy::VerbatimOp)
Verbatim operation
Syntax:
operation ::= `emitpy.verbatim` $value (`args` $fmtArgs^ `:` type($fmtArgs))? attr-dict
The emitpy.verbatim operation produces no results and the value is emitted as is
followed by a line break ('\n' character) during translation.
This operation can be used in situations where a more suitable operation is not yet implemented in the dialect.
Note: Use with caution. This operation can have arbitrary effects on the semantics of the emitted code. Use semantically more meaningful operations whenever possible. Additionally this op is NOT intended to be used to inject large snippets of code.
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
value | ::mlir::StringAttr | string attribute |
Operands:
| Operand | Description |
|---|---|
fmtArgs | variadic of any type |
emitpy.yield (tt::emitpy::YieldOp)
Yield operation for expression termination
Syntax:
operation ::= `emitpy.yield` $result attr-dict `:` type($result)
The emitpy.yield terminates its parent EmitPy operation's region, optionally yielding
an SSA value. The semantics of how the values are yielded is defined by the
parent operation.
Example:
%0 = emitpy.expression(%arg0, %arg1) : (!emitpy.opaque, !emitpy.opaque) -> !emitpy.opaque {
^bb0(%a: !emitpy.opaque, %b: !emitpy.opaque):
%1 = emitpy.call_opaque "foo"(%a, %b) : (!emitpy.opaque, !emitpy.opaque) -> !emitpy.opaque
emitpy.yield %1 : !emitpy.opaque
}
Traits: AlwaysSpeculatableImplTrait, HasParent<ExpressionOp>, ReturnLike, Terminator
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), RegionBranchTerminatorOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
result | any type |
'ttcore' Dialect
TT core types and attributes common to all TT dialects.
This dialect defines types and attributes common to all TT dialects.
[TOC]
ArchAttr
TT Arch
Syntax:
#ttcore.arch<
::mlir::tt::ttcore::Arch # value
>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| value | ::mlir::tt::ttcore::Arch | an enum of type Arch |
ArgumentAllocationAttr
Argument allocation attribute in TT dialect
Syntax:
#ttcore.arg_alloc<
uint64_t, # address
uint64_t, # size
MemorySpace # memorySpace
>
Holds the metadata for the allocation of an function argument i.e. for graph inputs.
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| address | uint64_t | |
| size | uint64_t | |
| memorySpace | MemorySpace |
ArgumentTypeAttr
Argument Type
Syntax:
#ttcore.argument_type<
::mlir::tt::ttcore::ArgumentType # value
>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| value | ::mlir::tt::ttcore::ArgumentType | an enum of type ArgumentType |
CBLayoutAttr
Circular buffer layout attribute for core-local buffers.
Syntax:
#ttcore.cb_layout<
::llvm::ArrayRef<int64_t>, # stride
uint32_t # buffers
>
Describes the layout of a core-local circular buffer in L1 memory. Unlike ShardLayoutAttr, this layout does not imply a grid+shard shape split — the entire memref shape is the per-core local buffer shape. CBs are always core-local (implicitly 1x1 grid).
- Stride: Stride of each dimension in bytes.
- Buffers: Number of backing buffers (1 = single, 2 = double-buffered, etc.)
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| stride | ::llvm::ArrayRef<int64_t> | |
| buffers | uint32_t |
CPUDescAttr
TT cpu_desc attribute
Syntax:
#ttcore.cpu_desc<
CPURole, # role
StringAttr # target_triple
>
TT cpu_desc attribute
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| role | CPURole | |
| target_triple | StringAttr |
CPURoleAttr
TT CPU Role
Syntax:
#ttcore.cpu_role<
::mlir::tt::ttcore::CPURole # value
>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| value | ::mlir::tt::ttcore::CPURole | an enum of type CPURole |
ChipChannelAttr
TT chip_channel attribute
Syntax:
#ttcore.chip_channel<
unsigned, # deviceId0
::llvm::ArrayRef<int64_t>, # ethernetCoreCoord0
unsigned, # deviceId1
::llvm::ArrayRef<int64_t> # ethernetCoreCoord1
>
TT chip_channel attribute
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| deviceId0 | unsigned | |
| ethernetCoreCoord0 | ::llvm::ArrayRef<int64_t> | |
| deviceId1 | unsigned | |
| ethernetCoreCoord1 | ::llvm::ArrayRef<int64_t> |
ChipCoordAttr
TT chip_coord attribute
Syntax:
#ttcore.chip_coord<
unsigned, # rack
unsigned, # shelf
unsigned, # y
unsigned # x
>
TT chip_coord attribute
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| rack | unsigned | |
| shelf | unsigned | |
| y | unsigned | |
| x | unsigned |
ChipDescAttr
TT chip_desc attribute
Syntax:
#ttcore.chip_desc<
ArchAttr, # arch
::llvm::ArrayRef<int64_t>, # grid
::llvm::ArrayRef<int64_t>, # coordTranslationOffsets
unsigned, # l1Size
unsigned, # numDramChannels
unsigned, # dramChannelSize
unsigned, # nocL1AddressAlignBytes
unsigned, # pcieAddressAlignBytes
unsigned, # nocDRAMAddressAlignBytes
unsigned, # l1UnreservedBase
unsigned, # eriscL1UnreservedBase
unsigned, # dramUnreservedBase
unsigned, # dramUnreservedEnd
::llvm::ArrayRef<DataTypeAttr>, # supportedDataTypes
::llvm::ArrayRef<TileSizeAttr>, # supportedTileSizes
unsigned, # dstPhysicalSizeTiles
unsigned, # numCBs
unsigned, # numComputeThreads
unsigned, # numDatamovementThreads
::llvm::ArrayRef<int64_t>, # dramGrid
::llvm::ArrayRef<CoreCoordAttr>, # dramBankToLogicalWorkerNoc0
::llvm::ArrayRef<CoreCoordAttr> # dramBankToLogicalWorkerNoc1
>
TT chip_desc attribute
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| arch | ArchAttr | |
| grid | ::llvm::ArrayRef<int64_t> | |
| coordTranslationOffsets | ::llvm::ArrayRef<int64_t> | |
| l1Size | unsigned | |
| numDramChannels | unsigned | |
| dramChannelSize | unsigned | |
| nocL1AddressAlignBytes | unsigned | |
| pcieAddressAlignBytes | unsigned | |
| nocDRAMAddressAlignBytes | unsigned | |
| l1UnreservedBase | unsigned | |
| eriscL1UnreservedBase | unsigned | |
| dramUnreservedBase | unsigned | |
| dramUnreservedEnd | unsigned | |
| supportedDataTypes | ::llvm::ArrayRef<DataTypeAttr> | |
| supportedTileSizes | ::llvm::ArrayRef<TileSizeAttr> | |
| dstPhysicalSizeTiles | unsigned | |
| numCBs | unsigned | |
| numComputeThreads | unsigned | |
| numDatamovementThreads | unsigned | |
| dramGrid | ::llvm::ArrayRef<int64_t> | |
| dramBankToLogicalWorkerNoc0 | ::llvm::ArrayRef<CoreCoordAttr> | |
| dramBankToLogicalWorkerNoc1 | ::llvm::ArrayRef<CoreCoordAttr> |
CoreCoordAttr
TT core_coord attribute
Syntax:
#ttcore.core_coord<
int64_t, # y
int64_t # x
>
TT core_coord attribute containing a single physical core coordinate.
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| y | int64_t | |
| x | int64_t |
CoreRangeAttr
A range of cores in the core grid
Syntax:
#ttcore.core_range<
CoreCoordAttr, # start_coord
CoreCoordAttr # end_coord
>
Defines a range of cores in the core grid.
Parameters:
start_coord: Lower-left corner of the core rangeend_coord: Upper-right corner of the core range
Constraints:
start_coordandend_coordmust use non-negative core indices (lowering uses unsigned TTNN core coordinates; negative values can wrap).- The condition
start_coord<=end_coordmust be satisfied
Example:
// Define a core range spanning from (1,1) to (3,4)
// This represents a 3x4 rectangular grid of cores
#core_range = #ttcore.core_range<(1, 1), (3, 4)>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| start_coord | CoreCoordAttr | |
| end_coord | CoreCoordAttr |
DataTypeAttr
TT DataTypes
Syntax:
#ttcore.supportedDataTypes<
::mlir::tt::ttcore::DataType # value
>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| value | ::mlir::tt::ttcore::DataType | an enum of type DataType |
DeviceAttr
Device attribute in TT dialect.
Syntax:
#ttcore.device<
::mlir::tt::ttcore::GridAttr, # workerGrid
::mlir::tt::ttcore::GridAttr, # dramGrid
AffineMap, # l1Map
AffineMap, # dramMap
::llvm::ArrayRef<int64_t>, # meshShape
::llvm::ArrayRef<unsigned>, # chipIds
::llvm::ArrayRef<Topology> # meshTopology
>
Describes the physical layout of a device in the system and is made up of a few components:
- A grid attribute that describes the device's compute grid shape. It not only describes the shape of the compute grid, but also carries an affine map that describes how the logical grid maps to the physical grid.
- Two affine maps that describe how a tensor layout's linear attribute maps to the L1 and DRAM memory spaces.
- A mesh shape that describes the virtual layout of the chips with respect to each other. Note that in a multi-chip system, this grid encapsulates the entire system's grid shape, e.g. 8x16 grid could be made up of a 1x2 mesh of chips side-by-side. The mesh attribute configures how the above grid/map attributes are created such that they implement this mesh topology.
- An array of chip ids that this device is made up of. This array's length must match the volume of the mesh shape and should be interpreted in row-major order.
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| workerGrid | ::mlir::tt::ttcore::GridAttr | TT grid attribute |
| dramGrid | ::mlir::tt::ttcore::GridAttr | TT grid attribute |
| l1Map | AffineMap | |
| dramMap | AffineMap | |
| meshShape | ::llvm::ArrayRef<int64_t> | |
| chipIds | ::llvm::ArrayRef<unsigned> | |
| meshTopology | ::llvm::ArrayRef<Topology> |
FabricConnectionConfigAttr
Fabric Connection Config attribute.
Syntax:
#ttcore.fabric_connection_config<
NocIndex, # noc_index
Topology, # topology
uint32_t, # cluster_axis
RoutingMode, # routing_mode
uint32_t # num_links
>
Structure for configuring fabric connections for worker cores (in CCL ops).
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| noc_index | NocIndex | |
| topology | Topology | |
| cluster_axis | uint32_t | |
| routing_mode | RoutingMode | |
| num_links | uint32_t |
GridAttr
TT grid attribute
Syntax:
#ttcore.grid<
::llvm::ArrayRef<int64_t>, # shape
AffineMap, # virtToPhysicalMap
AffineMap # physicalToVirtMap
>
TT grid attribute
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| shape | ::llvm::ArrayRef<int64_t> | |
| virtToPhysicalMap | AffineMap | |
| physicalToVirtMap | AffineMap |
HostLayoutAttr
Host-side memref layout attribute with padding support.
Syntax:
#ttcore.host_layout<
::llvm::ArrayRef<int64_t>, # logical_shape
::llvm::ArrayRef<int64_t>, # host_strides
int64_t, # host_volume
TensorMeshAttr # mesh
>
Describes a host-side memref layout with a logical shape where each dimension may be padded up to a requested alignment. This attribute encodes row-major strides and volume of the aligned shape, both computed in the bufferization pass to match the corresponding device memref's shape.
This allows host memrefs to reflect the padded footprint required by the
device while preserving the original logical shape, enabling I/O for
unaligned densly-packed shapes (e.g., non-multiples of 32×32 tiles). The
correct element placement in data copies between padded and unpadded host
memrefs is ensured by the strided-memcpy of the runtime's memref.copy
implementation.
- logical_shape: The unpadded logical shape in elements.
- host_strides: Per-dimension alignment in elements used to compute aligned shapes for stride calculation.
- host_volume: The (potentially padded) volume in elements.
- optional(mesh): The mesh that a memref lives on. No mesh indicates single device.
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| logical_shape | ::llvm::ArrayRef<int64_t> | |
| host_strides | ::llvm::ArrayRef<int64_t> | |
| host_volume | int64_t | |
| mesh | TensorMeshAttr |
InterleavedLayoutAttr
Interleaved layout attribute in TT dialect
Syntax:
#ttcore.interleaved<
::llvm::ArrayRef<int64_t> # stride
>
Describes overall layout of an interleaved memref buffer.
- Stride: Stride of each dim in bytes.
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| stride | ::llvm::ArrayRef<int64_t> |
IteratorTypeAttr
TT IteratorType
Syntax:
#ttcore.iterator_type<
::mlir::tt::ttcore::IteratorType # value
>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| value | ::mlir::tt::ttcore::IteratorType | an enum of type IteratorType |
LocalShapeAttr
Local shape of an argument/result in multi-device context
Syntax:
#ttcore.local_shape<
RankedTensorType # localShape
>
This attribute can be applied to arguments + results to signify their local shape in multi-device context. Any tool built on top of mlir runtime needs to know how to generate the inputs (unsharded or presharded), and this attribute encapsulates that information. There is a strict contract between local shape and shard status. The shard status influences the compiler and the runtime needs to be given the correct tensors (single device or multi-device).
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| localShape | RankedTensorType |
MemorySpaceAttr
TT MemorySpace
Syntax:
#ttcore.memory_space<
::mlir::tt::ttcore::MemorySpace # value
>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| value | ::mlir::tt::ttcore::MemorySpace | an enum of type MemorySpace |
MeshAttr
Mesh reference attribute in TT dialect.
Syntax:
#ttcore.mesh<
StringAttr, # name
::llvm::ArrayRef<int64_t> # shape
>
Describes a mesh config including name and shape.
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| name | StringAttr | |
| shape | ::llvm::ArrayRef<int64_t> |
MeshShardDirectionAttr
TT MeshShardDirection
Syntax:
#ttcore.shard_direction<
::mlir::tt::ttcore::MeshShardDirection # value
>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| value | ::mlir::tt::ttcore::MeshShardDirection | an enum of type MeshShardDirection |
MeshShardTypeAttr
MeshShard shard_type attribute in TT dialect
Syntax:
#ttcore.shard_type<
::mlir::tt::ttcore::MeshShardType # value
>
Define sharded tensor data of mesh_shard op.
- Identity: input and output tensors are pre-sharded (same data) and no sharding is required.
- Replicate: all of the devices has full tensor (same data).
- Maximal: one or part of the devcices has full tensor (same data).
- Devices: all or part of the devices has sharded (partial) tensor (different data).
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| value | ::mlir::tt::ttcore::MeshShardType | an enum of type MeshShardType |
MeshTopologyAttr
Per-axis topology for a mesh.
Syntax:
#ttcore.mesh_topology<
::llvm::ArrayRef<Topology> # topologies
>
Describes a topology for each axis of a mesh.
Example: #ttcore.mesh_topology<[ring, linear]>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| topologies | ::llvm::ArrayRef<Topology> |
MeshesAttr
TT system meshes attribute.
Syntax:
#ttcore.meshes<
::llvm::ArrayRef<MeshAttr> # meshes
>
TT system meshes attribute includes one or more mesh configs used for networks.
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| meshes | ::llvm::ArrayRef<MeshAttr> |
MetalLayoutAttr
Tensor layout attribute with explicit physical shape
Syntax:
#ttcore.metal_layout<
::llvm::ArrayRef<int64_t>, # logical_shape
::llvm::ArrayRef<int64_t>, # dim_alignments
DenseIntElementsAttr, # collapsed_intervals
MemorySpace, # memory_space
TensorMemoryLayout # memory_layout
>
The tensor layout attribute captures how tensor data is sharded across a grid of devices/cores and is laid out in memory. Note that the presence of this attribute implies that the tensor shape includes sharding (i.e. the first half of the tensor shape represents the grid shape).
Some high level goals:
- Logical shapes: Store the original tensor shape and rank intact and agnostic to underlying storage layout. Keeping the logical shapes not only makes some graph transformations vastly simpler, in particular convs, but it makes the lowered IR much easier to read and reason about. The original tensor shapes leave breadcrumbs that make it much easier to map back to the input representation.
- Collapsed dims: We may collapse dimensions during transformation, but it is important we capture this information such that it is not lost during tensor transformation. The collapsed_intervals field stores the collapses performed during conversion from logical_shape to physical tensor shape.
- Padding: store the desired alignments s.t. padding can be simply encoded; dim_alignments field represents alignment along each logical dim during collapse.
- Memref translation: ensure we have all necessary info s.t. we can trivially lower a tensor into a memref without any intermediate passes.
For a logical tensor of shape [H, W] distributed across a grid [GY, GX], the tensor shape would be:
- Without tiling: [GY, GX, H/GY, W/GX]
- With tiling: [GY, GX, H/GY/TH, W/GX/TW, TH, TW] where TH,TW are tile dimensions
This makes the representation 1:1 with memrefs and eliminates the need for shape conversion passes.
Examples:
// Logical 8x300 tensor distributed across 1x2 grid:
// tensor<1x2x8x150xf32, #tt.metal_layout<logical_shape=8x300, ...>>
// Logical 1024x1024 tensor distributed across 2x2 grid with 32x32 tiles:
// tensor<2x2x16x16x!ttcore.tile<32x32xf32>, #tt.metal_layout<logical_shape=1024x1024, ...>>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| logical_shape | ::llvm::ArrayRef<int64_t> | |
| dim_alignments | ::llvm::ArrayRef<int64_t> | |
| collapsed_intervals | DenseIntElementsAttr | Intervals of dims to collapse |
| memory_space | MemorySpace | |
| memory_layout | TensorMemoryLayout | Tensor memory layout |
MoEActivationFunctionAttr
Activation function for the MoE expert FFN
Syntax:
#ttcore.moe_activation_function<
::mlir::tt::ttcore::MoEActivationFunction # value
>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| value | ::mlir::tt::ttcore::MoEActivationFunction | an enum of type MoEActivationFunction |
OOBValAttr
TT OOBVal
Syntax:
#ttcore.oob_val<
::mlir::tt::ttcore::OOBVal # value
>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| value | ::mlir::tt::ttcore::OOBVal | an enum of type OOBVal |
ReduceTypeAttr
TT Reduce Type
Syntax:
#ttcore.reduce_type<
::mlir::tt::ttcore::ReduceType # value
>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| value | ::mlir::tt::ttcore::ReduceType | an enum of type ReduceType |
ShardLayoutAttr
Shard layout attribute in TT dialect
Syntax:
#ttcore.shard<
::llvm::ArrayRef<int64_t>, # stride
uint32_t # buffers
>
Describes shard layout of a memref buffer.
- Stride: Stride of each dim in bytes.
- Buffers: Number of back buffers used for double buffering, I/O latency hiding, etc
The shard layout attribute is a description of how each shard of a memref is laid out in memory. Memref's with this layout type implicitly mean their data is distributed across a grid of cores.
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| stride | ::llvm::ArrayRef<int64_t> | |
| buffers | uint32_t |
ShardStatusAttr
Shard Status Type
Syntax:
#ttcore.shard_status<
::mlir::tt::ttcore::ShardStatus # value
>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| value | ::mlir::tt::ttcore::ShardStatus | an enum of type ShardStatus |
SystemDescAttr
TT system_desc attribute
Syntax:
#ttcore.system_desc<
::llvm::ArrayRef<CPUDescAttr>, # cpuDescs
::llvm::ArrayRef<ChipDescAttr>, # chipDescs
::llvm::ArrayRef<unsigned>, # chipDescIndices
::llvm::ArrayRef<ChipCapabilityAttr>, # chipCapabilities
::llvm::ArrayRef<ChipCoordAttr>, # chipCoords
::llvm::ArrayRef<ChipChannelAttr> # chipChannels
>
TT system_desc attribute
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| cpuDescs | ::llvm::ArrayRef<CPUDescAttr> | |
| chipDescs | ::llvm::ArrayRef<ChipDescAttr> | |
| chipDescIndices | ::llvm::ArrayRef<unsigned> | |
| chipCapabilities | ::llvm::ArrayRef<ChipCapabilityAttr> | |
| chipCoords | ::llvm::ArrayRef<ChipCoordAttr> | |
| chipChannels | ::llvm::ArrayRef<ChipChannelAttr> |
TensorMemoryLayoutAttr
TTCore Tensor Memory Layout
Syntax:
#ttcore.tensor_memory_layout<
::mlir::tt::ttcore::TensorMemoryLayout # value
>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| value | ::mlir::tt::ttcore::TensorMemoryLayout | an enum of type TensorMemoryLayout |
TensorMeshAttr
Tensor mesh in TT dialect.
Syntax:
#ttcore.tensor_mesh<
StringAttr # name
>
Describes what mesh a tensor lives on.
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| name | StringAttr |
TileSizeAttr
TT tile_size attribute
Syntax:
#ttcore.tile_size<
int64_t, # y
int64_t # x
>
TT tile_size attribute containing a supported Tensix tile shape.
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| y | int64_t | |
| x | int64_t |
TopologyAttr
CCL Topology Type
Syntax:
#ttcore.topology<
::mlir::tt::ttcore::Topology # value
>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| value | ::mlir::tt::ttcore::Topology | an enum of type Topology |
ViewLayoutAttr
View layout attribute in TT dialect
Syntax:
#ttcore.view<
unsigned # rank
>
Placeholder attr to indicate a view layout of a memref buffer. Actual affine map is encoded on the view_layout op itself.
Only the view_layout op should return memref's with this attribute. The view layout attribute is necessary for two reasons:
- It provides a way to reblock the data view into a different shape (via affine map). Usually this would be some subblock of the original backing memory to chunk the data into smaller pieces.
- The type itself is a signal to datamovement passes that the memref is a view and should be treated as such.
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| rank | unsigned |
ttcore.cpu_module (tt::ttcore::CPUModuleOp)
Module-wrapper operation for CPU ops
Syntax:
operation ::= `ttcore.cpu_module` attr-dict-with-keyword regions
Custom module operation that can a single ModuleOp, which should contain all funcs which should be run on CPU.
Example:
ttcore.cpu_module {
module {
func.func foo() { ... }
}
}
Traits: IsolatedFromAbove, NoRegionArguments, NoTerminator, SingleBlock, SymbolTable
ttcore.composite (tt::ttcore::CompositeOp)
A named composite operation with an inlineable decomposition.
A composite operation that carries a named fused pattern along with a reference to a decomposition function. During lowering, the composite is either promoted to a typed backend op (if validation succeeds) or its decomposition body is inlined as a fallback.
Example:
%indices, %weights = ttcore.composite "topk_router_gpt"
(%input, %weight, %bias)
decomposition(@topk_router_gpt_decomp)
composite_attributes = {k = 4 : i32, num_experts = 128 : i32}
: (tensor<32x64xbf16>, tensor<64x128xbf16>, tensor<32x128xbf16>)
-> (tensor<32x4xui16>, tensor<32x4xbf16>)
func.func private @topk_router_gpt_decomp(
%arg0: tensor<32x64xbf16>,
%arg1: tensor<64x128xbf16>,
%arg2: tensor<32x128xbf16>)
-> (tensor<32x4xui16>, tensor<32x4xbf16>) {
// ... sequence of primitive ops ...
}
Traits: TTCore_NonCacheableTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
composite_name | ::mlir::StringAttr | string attribute |
decomposition | ::mlir::FlatSymbolRefAttr | flat symbol reference attribute |
composite_attributes | ::mlir::DictionaryAttr | dictionary of named attribute values |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
results | variadic of ranked tensor of any type values |
ttcore.device_module (tt::ttcore::DeviceModuleOp)
Module-wrapper operation for device ops
Syntax:
operation ::= `ttcore.device_module` attr-dict-with-keyword $bodyRegion
Custom module operation that can a single ModuleOp, which should contain all funcs which should be run on device.
Example:
ttcore.device_module {
module {
func.func foo() { ... }
}
}
Traits: IsolatedFromAbove, NoRegionArguments, NoTerminator, SingleBlock, SymbolTable
ttcore.device (tt::ttcore::DeviceOp)
Named device
Syntax:
operation ::= `ttcore.device` $sym_name `=` $device_attr attr-dict
Interfaces: Symbol
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
sym_name | ::mlir::StringAttr | string attribute |
device_attr | ::mlir::tt::ttcore::DeviceAttr | Device attribute in TT dialect.{{% markdown %}} Describes the physical layout of a device in the system and is made up of a few components: - A grid attribute that describes the device's compute grid shape. It not only describes the shape of the compute grid, but also carries an affine map that describes how the logical grid maps to the physical grid. - Two affine maps that describe how a tensor layout's linear attribute maps to the L1 and DRAM memory spaces. - A mesh shape that describes the virtual layout of the chips with respect to each other. Note that in a multi-chip system, this grid encapsulates the entire system's grid shape, e.g. 8x16 grid could be made up of a 1x2 mesh of chips side-by-side. The mesh attribute configures how the above grid/map attributes are created such that they implement this mesh topology. - An array of chip ids that this device is made up of. This array's length must match the volume of the mesh shape and should be interpreted in row-major order. {{% /markdown %}} |
ttcore.get_global (tt::ttcore::GetGlobalOp)
Named global
Syntax:
operation ::= `ttcore.get_global` $sym_name attr-dict `:` type($result)
Retrieves a named global value declared with ttcore.global
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
sym_name | ::mlir::StringAttr | string attribute |
Results:
| Result | Description |
|---|---|
result | any type |
ttcore.get_key_value (tt::ttcore::GetKeyValueOp)
Get dictionary value
Syntax:
operation ::= `ttcore.get_key_value` $dict `[` $key `]` attr-dict `:`
functional-type(operands, results)
Retrieves the value(s) stored under the given key from the dictionary. The key can either be a string or an index.
Example:
%0 = ttcore.get_key_value %dict[3 : index] : (!ttcore.dict) -> tensor<32x32xbf16>
%0, %1 = ttcore.get_key_value %dict["key"]
: (!ttcore.dict) -> (tensor<32x32xbf16>, tensor<64x64xbf16>)
Interfaces: MemoryEffectOpInterface (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{MemoryEffects::Read on ::mlir::SideEffects::DefaultResource}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
key | ::mlir::Attribute | string attribute or index attribute |
Operands:
| Operand | Description |
|---|---|
dict | TTCore dictionary type |
Results:
| Result | Description |
|---|---|
results | variadic of any type |
ttcore.get_tuple_element (tt::ttcore::GetTupleElementOp)
GetTupleElement operation
Syntax:
operation ::= `ttcore.get_tuple_element` $operand `[` $index `]` attr-dict `:` functional-type(operands, results)
Extracts element at index position of the operand tuple and produces a result.
Example:
%result = ttcore.get_tuple_element %operand[0] : (tuple<tensor<32x32xbf16>, tensor<1x32xf32>>) -> tensor<32x32xbf16>
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, InferTypeOpInterface, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
index | ::mlir::IntegerAttr | 32-bit signless integer attribute whose value is non-negative |
Operands:
| Operand | Description |
|---|---|
operand | nested tuple with any combination of ranked tensor of any type values values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttcore.global (tt::ttcore::GlobalOp)
Named global
Syntax:
operation ::= `ttcore.global` $sym_name `=` $type (` ` `[` $index^ `]`)? attr-dict
Declares a global variable with an optional index.
Interfaces: Symbol
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
sym_name | ::mlir::StringAttr | string attribute |
type | ::mlir::TypeAttr | any type attribute |
index | ::mlir::IntegerAttr | 32-bit signed integer attribute |
ttcore.load_cached (tt::ttcore::LoadCachedOp)
Load cached results from a previously computed function
Syntax:
operation ::= `ttcore.load_cached` `(` $callee `,` `[` $inputs `]` `)` attr-dict `:` functional-type($inputs, $results)
The load_cached operation calls a precomputed function with given arguments and returns its results. This is typically used to load constant or hoisted computation results.
Example:
%0, %1, %2 = "ttcore.load_cached"(@forward_const_eval_1, [%arg0, %arg2])
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
callee | ::mlir::FlatSymbolRefAttr | flat symbol reference attribute |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
results | variadic of ranked tensor of any type values |
ttcore.optimization_barrier (tt::ttcore::OptimizationBarrierOp)
Optimization barrier operation.
The optimization_barrier operation prevents compiler optimizations from reordering or eliminating
the values passed through it. It acts as a barrier for optimization passes.
Inputs:
inputs(Variadic): Values of tensor type.
Outputs:
results(Variadic): Same values as inputs, passed through unchanged.
Interfaces: MemoryEffectOpInterface (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{MemoryEffects::Read on ::mlir::SideEffects::DefaultResource, MemoryEffects::Write on ::mlir::SideEffects::DefaultResource}
Operands:
| Operand | Description |
|---|---|
inputs | variadic of ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
results | variadic of ranked tensor of any type values |
ttcore.set_key_value (tt::ttcore::SetKeyValueOp)
Set or update dictionary value
Syntax:
operation ::= `ttcore.set_key_value` $dict `[` $key `]` `=` $values attr-dict `:`
type($dict) `,` type($values)
Sets or updates a value(s) for the given key in the dictionary. The key can either be a string or an index.
Example:
ttcore.set_key_value %dict[3 : index] = %0
: !ttcore.dict, tensor<32x32xbf16>
ttcore.set_key_value %dict["key"] = %0, %1
: !ttcore.dict, tensor<32x32xbf16>, tensor<64x64xbf16>
Interfaces: MemoryEffectOpInterface (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{MemoryEffects::Write on ::mlir::SideEffects::DefaultResource}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
key | ::mlir::Attribute | string attribute or index attribute |
Operands:
| Operand | Description |
|---|---|
dict | TTCore dictionary type |
values | variadic of any type |
ttcore.tuple (tt::ttcore::TupleOp)
Tuple operation
Syntax:
operation ::= `ttcore.tuple` $operands attr-dict `:` custom<TupleOpType>(type($operands), type($result))
Produces a result tuple from operands operands.
Example:
%result = ttcore.tuple %operand0, %operand1 : tuple<tensor<32xbf16, tensor<1x32xf32>>
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, InferTypeOpInterface, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
operands | variadic of ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | nested tuple with any combination of ranked tensor of any type values values |
BFloat16Type
Bfloat16 floating-point type
ComplexType
Complex number with a parameterized element type
Syntax:
complex-type ::= `complex` `<` type `>`
The value of complex type represents a complex number with a parameterized
element type, which is composed of a real and imaginary value of that
element type. The element must be a floating point or integer scalar type.
Example:
complex<f32>
complex<i32>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| elementType | Type |
Float4E2M1FNType
4-bit floating point with 2-bit exponent and 1-bit mantissa
An 4-bit floating point type with 1 sign bit, 2 bits exponent and 1 bit mantissa. This is not a standard type as defined by IEEE-754, but it follows similar conventions with the following characteristics:
- bit encoding: S1E2M1
- exponent bias: 1
- infinities: Not supported
- NaNs: Not supported
- denormals when exponent is 0
Open Compute Project (OCP) microscaling formats (MX) specification: https://www.opencompute.org/documents/ocp-microscaling-formats-mx-v1-0-spec-final-pdf
Float6E2M3FNType
6-bit floating point with 2-bit exponent and 3-bit mantissa
An 6-bit floating point type with 1 sign bit, 2 bits exponent and 3 bits mantissa. This is not a standard type as defined by IEEE-754, but it follows similar conventions with the following characteristics:
- bit encoding: S1E2M3
- exponent bias: 1
- infinities: Not supported
- NaNs: Not supported
- denormals when exponent is 0
Open Compute Project (OCP) microscaling formats (MX) specification: https://www.opencompute.org/documents/ocp-microscaling-formats-mx-v1-0-spec-final-pdf
Float6E3M2FNType
6-bit floating point with 3-bit exponent and 2-bit mantissa
An 6-bit floating point type with 1 sign bit, 3 bits exponent and 2 bits mantissa. This is not a standard type as defined by IEEE-754, but it follows similar conventions with the following characteristics:
- bit encoding: S1E3M2
- exponent bias: 3
- infinities: Not supported
- NaNs: Not supported
- denormals when exponent is 0
Open Compute Project (OCP) microscaling formats (MX) specification: https://www.opencompute.org/documents/ocp-microscaling-formats-mx-v1-0-spec-final-pdf
Float8E3M4Type
8-bit floating point with 3 bits exponent and 4 bit mantissa
An 8-bit floating point type with 1 sign bit, 3 bits exponent and 4 bits mantissa. This is not a standard type as defined by IEEE-754, but it follows similar conventions with the following characteristics:
- bit encoding: S1E3M4
- exponent bias: 3
- infinities: supported with exponent set to all 1s and mantissa 0s
- NaNs: supported with exponent bits set to all 1s and mantissa values of {0,1}⁴ except S.111.0000
- denormals when exponent is 0
Float8E4M3Type
8-bit floating point with 3 bit mantissa
An 8-bit floating point type with 1 sign bit, 4 bits exponent and 3 bits mantissa. This is not a standard type as defined by IEEE-754, but it follows similar conventions with the following characteristics:
- bit encoding: S1E4M3
- exponent bias: 7
- infinities: supported with exponent set to all 1s and mantissa 0s
- NaNs: supported with exponent bits set to all 1s and mantissa of (001, 010, 011, 100, 101, 110, 111)
- denormals when exponent is 0
Float8E4M3B11FNUZType
8-bit floating point with 3 bit mantissa
An 8-bit floating point type with 1 sign bit, 4 bits exponent and 3 bits mantissa. This is not a standard type as defined by IEEE-754, but it follows similar conventions, with the exception that there are no infinity values, no negative zero, and only one NaN representation. This type has the following characteristics:
- bit encoding: S1E4M3
- exponent bias: 11
- infinities: Not supported
- NaNs: Supported with sign bit set to 1, exponent bits and mantissa bits set to all 0s
- denormals when exponent is 0
Related to: https://dl.acm.org/doi/10.5555/3454287.3454728
Float8E4M3FNType
8-bit floating point with 3 bit mantissa
An 8-bit floating point type with 1 sign bit, 4 bits exponent and 3 bits mantissa. This is not a standard type as defined by IEEE-754, but it follows similar conventions, with the exception that there are no infinity values and only two NaN representations. This type has the following characteristics:
- bit encoding: S1E4M3
- exponent bias: 7
- infinities: Not supported
- NaNs: supported with exponent bits and mantissa bits set to all 1s
- denormals when exponent is 0
Described in: https://arxiv.org/abs/2209.05433
Float8E4M3FNUZType
8-bit floating point with 3 bit mantissa
An 8-bit floating point type with 1 sign bit, 4 bits exponent and 3 bits mantissa. This is not a standard type as defined by IEEE-754, but it follows similar conventions, with the exception that there are no infinity values, no negative zero, and only one NaN representation. This type has the following characteristics:
- bit encoding: S1E4M3
- exponent bias: 8
- infinities: Not supported
- NaNs: Supported with sign bit set to 1, exponent bits and mantissa bits set to all 0s
- denormals when exponent is 0
Described in: https://arxiv.org/abs/2209.05433
Float8E5M2Type
8-bit floating point with 2 bit mantissa
An 8-bit floating point type with 1 sign bit, 5 bits exponent and 2 bits mantissa. This is not a standard type as defined by IEEE-754, but it follows similar conventions with the following characteristics:
- bit encoding: S1E5M2
- exponent bias: 15
- infinities: supported with exponent set to all 1s and mantissa 0s
- NaNs: supported with exponent bits set to all 1s and mantissa of (01, 10, or 11)
- denormals when exponent is 0
Described in: https://arxiv.org/abs/2209.05433
Float8E5M2FNUZType
8-bit floating point with 2 bit mantissa
An 8-bit floating point type with 1 sign bit, 5 bits exponent and 2 bits mantissa. This is not a standard type as defined by IEEE-754, but it follows similar conventions, with the exception that there are no infinity values, no negative zero, and only one NaN representation. This type has the following characteristics:
- bit encoding: S1E5M2
- exponent bias: 16
- infinities: Not supported
- NaNs: Supported with sign bit set to 1, exponent bits and mantissa bits set to all 0s
- denormals when exponent is 0
Described in: https://arxiv.org/abs/2206.02915
Float8E8M0FNUType
8-bit floating point with 8-bit exponent, no mantissa or sign
An 8-bit floating point type with no sign bit, 8 bits exponent and no mantissa. This is not a standard type as defined by IEEE-754; it is intended to be used for representing scaling factors, so it cannot represent zeros and negative numbers. The values it can represent are powers of two in the range [-127,127] and NaN.
- bit encoding: S0E8M0
- exponent bias: 127
- infinities: Not supported
- NaNs: Supported with all bits set to 1
- denormals: Not supported
Open Compute Project (OCP) microscaling formats (MX) specification: https://www.opencompute.org/documents/ocp-microscaling-formats-mx-v1-0-spec-final-pdf
Float16Type
16-bit floating-point type
Float32Type
32-bit floating-point type
Float64Type
64-bit floating-point type
Float80Type
80-bit floating-point type
Float128Type
128-bit floating-point type
FloatTF32Type
TF32 floating-point type
FunctionType
Map from a list of inputs to a list of results
Syntax:
// Function types may have multiple results.
function-result-type ::= type-list-parens | non-function-type
function-type ::= type-list-parens `->` function-result-type
The function type can be thought of as a function signature. It consists of a list of formal parameter types and a list of formal result types.
Example:
func.func @add_one(%arg0 : i64) -> i64 {
%c1 = arith.constant 1 : i64
%0 = arith.addi %arg0, %c1 : i64
return %0 : i64
}
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| inputs | ArrayRef<Type> | |
| results | ArrayRef<Type> |
GraphType
Map from a list of inputs to a list of results
Syntax:
// Function types may have multiple results.
function-result-type ::= type-list-parens | non-function-type
function-type ::= type-list-parens `->` function-result-type
The function type can be thought of as a function signature. It consists of a list of formal parameter types and a list of formal result types.
Example:
func.func @add_one(%arg0 : i64) -> i64 {
%c1 = arith.constant 1 : i64
%0 = arith.addi %arg0, %c1 : i64
return %0 : i64
}
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| inputs | ArrayRef<Type> | |
| results | ArrayRef<Type> |
IndexType
Integer-like type with unknown platform-dependent bit width
Syntax:
// Target word-sized integer.
index-type ::= `index`
The index type is a signless integer whose size is equal to the natural machine word of the target ( rationale ) and is used by the affine constructs in MLIR.
Rationale: integers of platform-specific bit widths are practical to express sizes, dimensionalities and subscripts.
IntegerType
Integer type with arbitrary precision up to a fixed limit
Syntax:
// Sized integers like i1, i4, i8, i16, i32.
signed-integer-type ::= `si` [1-9][0-9]*
unsigned-integer-type ::= `ui` [1-9][0-9]*
signless-integer-type ::= `i` [1-9][0-9]*
integer-type ::= signed-integer-type |
unsigned-integer-type |
signless-integer-type
Integer types have a designated bit width and may optionally have signedness semantics.
Rationale: low precision integers (like i2, i4 etc) are useful for
low-precision inference chips, and arbitrary precision integers are useful
for hardware synthesis (where a 13 bit multiplier is a lot cheaper/smaller
than a 16 bit one).
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| width | unsigned | |
| signedness | SignednessSemantics |
MemRefType
Shaped reference to a region of memory
Syntax:
layout-specification ::= attribute-value
memory-space ::= attribute-value
memref-type ::= `memref` `<` dimension-list-ranked type
(`,` layout-specification)? (`,` memory-space)? `>`
A memref type is a reference to a region of memory (similar to a buffer
pointer, but more powerful). The buffer pointed to by a memref can be
allocated, aliased and deallocated. A memref can be used to read and write
data from/to the memory region which it references. Memref types use the
same shape specifier as tensor types. Note that memref<f32>,
memref<0 x f32>, memref<1 x 0 x f32>, and memref<0 x 1 x f32> are all
different types.
A memref is allowed to have an unknown rank (e.g. memref<*xf32>). The
purpose of unranked memrefs is to allow external library functions to
receive memref arguments of any rank without versioning the functions based
on the rank. Other uses of this type are disallowed or will have undefined
behavior.
Are accepted as elements:
- built-in integer types;
- built-in index type;
- built-in floating point types;
- built-in vector types with elements of the above types;
- another memref type;
- any other type implementing
MemRefElementTypeInterface.
Layout
A memref may optionally have a layout that indicates how indices are
transformed from the multi-dimensional form into a linear address. The
layout must avoid internal aliasing, i.e., two distinct tuples of
in-bounds indices must be pointing to different elements in memory. The
layout is an attribute that implements MemRefLayoutAttrInterface. The
bulitin dialect offers two kinds of layouts: strided and affine map, each
of which is available as an attribute. Other attributes may be used to
represent the layout as long as they can be converted to a
semi-affine map and implement the required
interface. Users of memref are expected to fallback to the affine
representation when handling unknown memref layouts. Multi-dimensional
affine forms are interpreted in row-major fashion.
In absence of an explicit layout, a memref is considered to have a
multi-dimensional identity affine map layout. Identity layout maps do not
contribute to the MemRef type identification and are discarded on
construction. That is, a type with an explicit identity map is
memref<?x?xf32, (i,j)->(i,j)> is strictly the same as the one without a
layout, memref<?x?xf32>.
Affine Map Layout
The layout may be represented directly as an affine map from the index space
to the storage space. For example, the following figure shows an index map
which maps a 2-dimensional index from a 2x2 index space to a 3x3 index
space, using symbols S0 and S1 as offsets.

Semi-affine maps are sufficiently flexible to represent a wide variety of dense storage layouts, including row- and column-major and tiled:
// MxN matrix stored in row major layout in memory:
#layout_map_row_major = (i, j) -> (i, j)
// MxN matrix stored in column major layout in memory:
#layout_map_col_major = (i, j) -> (j, i)
// MxN matrix stored in a 2-d blocked/tiled layout with 64x64 tiles.
#layout_tiled = (i, j) -> (i floordiv 64, j floordiv 64, i mod 64, j mod 64)
Strided Layout
Memref layout can be expressed using strides to encode the distance, in
number of elements, in (linear) memory between successive entries along a
particular dimension. For example, a row-major strided layout for
memref<2x3x4xf32> is strided<[12, 4, 1]>, where the last dimension is
contiguous as indicated by the unit stride and the remaining strides are
products of the sizes of faster-variying dimensions. Strided layout can also
express non-contiguity, e.g., memref<2x3, strided<[6, 2]>> only accesses
even elements of the dense consecutive storage along the innermost
dimension.
The strided layout supports an optional offset that indicates the
distance, in the number of elements, between the beginning of the memref
and the first accessed element. When omitted, the offset is considered to
be zero. That is, memref<2, strided<[2], offset: 0>> and
memref<2, strided<[2]>> are strictly the same type.
Both offsets and strides may be dynamic, that is, unknown at compile time.
This is represented by using a question mark (?) instead of the value in
the textual form of the IR.
The strided layout converts into the following canonical one-dimensional affine form through explicit linearization:
affine_map<(d0, ... dN)[offset, stride0, ... strideN] ->
(offset + d0 * stride0 + ... dN * strideN)>
Therefore, it is never subject to the implicit row-major layout interpretation.
Codegen of Unranked Memref
Using unranked memref in codegen besides the case mentioned above is highly discouraged. Codegen is concerned with generating loop nests and specialized instructions for high-performance, unranked memref is concerned with hiding the rank and thus, the number of enclosing loops required to iterate over the data. However, if there is a need to code-gen unranked memref, one possible path is to cast into a static ranked type based on the dynamic rank. Another possible path is to emit a single while loop conditioned on a linear index and perform delinearization of the linear index to a dynamic array containing the (unranked) indices. While this is possible, it is expected to not be a good idea to perform this during codegen as the cost of the translations is expected to be prohibitive and optimizations at this level are not expected to be worthwhile. If expressiveness is the main concern, irrespective of performance, passing unranked memrefs to an external C++ library and implementing rank-agnostic logic there is expected to be significantly simpler.
Unranked memrefs may provide expressiveness gains in the future and help bridge the gap with unranked tensors. Unranked memrefs will not be expected to be exposed to codegen but one may query the rank of an unranked memref (a special op will be needed for this purpose) and perform a switch and cast to a ranked memref as a prerequisite to codegen.
Example:
// With static ranks, we need a function for each possible argument type
%A = alloc() : memref<16x32xf32>
%B = alloc() : memref<16x32x64xf32>
call @helper_2D(%A) : (memref<16x32xf32>)->()
call @helper_3D(%B) : (memref<16x32x64xf32>)->()
// With unknown rank, the functions can be unified under one unranked type
%A = alloc() : memref<16x32xf32>
%B = alloc() : memref<16x32x64xf32>
// Remove rank info
%A_u = memref_cast %A : memref<16x32xf32> -> memref<*xf32>
%B_u = memref_cast %B : memref<16x32x64xf32> -> memref<*xf32>
// call same function with dynamic ranks
call @helper(%A_u) : (memref<*xf32>)->()
call @helper(%B_u) : (memref<*xf32>)->()
The core syntax and representation of a layout specification is a
semi-affine map. Additionally,
syntactic sugar is supported to make certain layout specifications more
intuitive to read. For the moment, a memref supports parsing a strided
form which is converted to a semi-affine map automatically.
The memory space of a memref is specified by a target-specific attribute. It might be an integer value, string, dictionary or custom dialect attribute. The empty memory space (attribute is None) is target specific.
The notionally dynamic value of a memref value includes the address of the buffer allocated, as well as the symbols referred to by the shape, layout map, and index maps.
Examples of memref static type
// Identity index/layout map
#identity = affine_map<(d0, d1) -> (d0, d1)>
// Column major layout.
#col_major = affine_map<(d0, d1, d2) -> (d2, d1, d0)>
// A 2-d tiled layout with tiles of size 128 x 256.
#tiled_2d_128x256 = affine_map<(d0, d1) -> (d0 div 128, d1 div 256, d0 mod 128, d1 mod 256)>
// A tiled data layout with non-constant tile sizes.
#tiled_dynamic = affine_map<(d0, d1)[s0, s1] -> (d0 floordiv s0, d1 floordiv s1,
d0 mod s0, d1 mod s1)>
// A layout that yields a padding on two at either end of the minor dimension.
#padded = affine_map<(d0, d1) -> (d0, (d1 + 2) floordiv 2, (d1 + 2) mod 2)>
// The dimension list "16x32" defines the following 2D index space:
//
// { (i, j) : 0 <= i < 16, 0 <= j < 32 }
//
memref<16x32xf32, #identity>
// The dimension list "16x4x?" defines the following 3D index space:
//
// { (i, j, k) : 0 <= i < 16, 0 <= j < 4, 0 <= k < N }
//
// where N is a symbol which represents the runtime value of the size of
// the third dimension.
//
// %N here binds to the size of the third dimension.
%A = alloc(%N) : memref<16x4x?xf32, #col_major>
// A 2-d dynamic shaped memref that also has a dynamically sized tiled
// layout. The memref index space is of size %M x %N, while %B1 and %B2
// bind to the symbols s0, s1 respectively of the layout map #tiled_dynamic.
// Data tiles of size %B1 x %B2 in the logical space will be stored
// contiguously in memory. The allocation size will be
// (%M ceildiv %B1) * %B1 * (%N ceildiv %B2) * %B2 f32 elements.
%T = alloc(%M, %N) [%B1, %B2] : memref<?x?xf32, #tiled_dynamic>
// A memref that has a two-element padding at either end. The allocation
// size will fit 16 * 64 float elements of data.
%P = alloc() : memref<16x64xf32, #padded>
// Affine map with symbol 's0' used as offset for the first dimension.
#imapS = affine_map<(d0, d1) [s0] -> (d0 + s0, d1)>
// Allocate memref and bind the following symbols:
// '%n' is bound to the dynamic second dimension of the memref type.
// '%o' is bound to the symbol 's0' in the affine map of the memref type.
%n = ...
%o = ...
%A = alloc (%n)[%o] : <16x?xf32, #imapS>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| shape | ::llvm::ArrayRef<int64_t> | |
| elementType | Type | |
| layout | MemRefLayoutAttrInterface | |
| memorySpace | Attribute |
NoneType
A unit type
Syntax:
none-type ::= `none`
NoneType is a unit type, i.e. a type with exactly one possible value, where its value does not have a defined dynamic representation.
Example:
func.func @none_type() {
%none_val = "foo.unknown_op"() : () -> none
return
}
OpaqueType
Type of a non-registered dialect
Syntax:
opaque-type ::= `opaque` `<` type `>`
Opaque types represent types of non-registered dialects. These are types represented in their raw string form, and can only usefully be tested for type equality.
Example:
opaque<"llvm", "struct<(i32, float)>">
opaque<"pdl", "value">
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| dialectNamespace | StringAttr | |
| typeData | ::llvm::StringRef |
RankedTensorType
Multi-dimensional array with a fixed number of dimensions
Syntax:
tensor-type ::= `tensor` `<` dimension-list type (`,` encoding)? `>`
dimension-list ::= (dimension `x`)*
dimension ::= `?` | decimal-literal
encoding ::= attribute-value
Values with tensor type represents aggregate N-dimensional data values, and
have a known element type and a fixed rank with a list of dimensions. Each
dimension may be a static non-negative decimal constant or be dynamically
determined (indicated by ?).
The runtime representation of the MLIR tensor type is intentionally
abstracted - you cannot control layout or get a pointer to the data. For
low level buffer access, MLIR has a memref type. This
abstracted runtime representation holds both the tensor data values as well
as information about the (potentially dynamic) shape of the tensor. The
dim operation returns the size of a
dimension from a value of tensor type.
The encoding attribute provides additional information on the tensor.
An empty attribute denotes a straightforward tensor without any specific
structure. But particular properties, like sparsity or other specific
characteristics of the data of the tensor can be encoded through this
attribute. The semantics are defined by a type and attribute interface
and must be respected by all passes that operate on tensor types.
TODO: provide this interface, and document it further.
Note: hexadecimal integer literals are not allowed in tensor type
declarations to avoid confusion between 0xf32 and 0 x f32. Zero sizes
are allowed in tensors and treated as other sizes, e.g.,
tensor<0 x 1 x i32> and tensor<1 x 0 x i32> are different types. Since
zero sizes are not allowed in some other types, such tensors should be
optimized away before lowering tensors to vectors.
Example:
// Known rank but unknown dimensions.
tensor<? x ? x ? x ? x f32>
// Partially known dimensions.
tensor<? x ? x 13 x ? x f32>
// Full static shape.
tensor<17 x 4 x 13 x 4 x f32>
// Tensor with rank zero. Represents a scalar.
tensor<f32>
// Zero-element dimensions are allowed.
tensor<0 x 42 x f32>
// Zero-element tensor of f32 type (hexadecimal literals not allowed here).
tensor<0xf32>
// Tensor with an encoding attribute (where #ENCODING is a named alias).
tensor<?x?xf64, #ENCODING>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| shape | ::llvm::ArrayRef<int64_t> | |
| elementType | Type | |
| encoding | Attribute |
TupleType
Fixed-sized collection of other types
Syntax:
tuple-type ::= `tuple` `<` (type ( `,` type)*)? `>`
The value of tuple type represents a fixed-size collection of elements,
where each element may be of a different type.
Rationale: Though this type is first class in the type system, MLIR
provides no standard operations for operating on tuple types
(rationale).
Example:
// Empty tuple.
tuple<>
// Single element
tuple<f32>
// Many elements.
tuple<i32, f32, tensor<i1>, i5>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| types | ArrayRef<Type> |
UnrankedMemRefType
Shaped reference, with unknown rank, to a region of memory
Syntax:
unranked-memref-type ::= `memref` `<*x` type (`,` memory-space)? `>`
memory-space ::= attribute-value
A memref type with an unknown rank (e.g. memref<*xf32>). The purpose of
unranked memrefs is to allow external library functions to receive memref
arguments of any rank without versioning the functions based on the rank.
Other uses of this type are disallowed or will have undefined behavior.
See MemRefType for more information on memref types.
Examples:
memref<*f32>
// An unranked memref with a memory space of 10.
memref<*f32, 10>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| elementType | Type | |
| memorySpace | Attribute |
UnrankedTensorType
Multi-dimensional array with unknown dimensions
Syntax:
tensor-type ::= `tensor` `<` `*` `x` type `>`
An unranked tensor is a type of tensor in which the set of dimensions have unknown rank. See RankedTensorType for more information on tensor types.
Examples:
tensor<*xf32>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| elementType | Type |
VectorType
Multi-dimensional SIMD vector type
Syntax:
vector-type ::= `vector` `<` vector-dim-list vector-element-type `>`
vector-element-type ::= float-type | integer-type | index-type
vector-dim-list := (static-dim-list `x`)?
static-dim-list ::= static-dim (`x` static-dim)*
static-dim ::= (decimal-literal | `[` decimal-literal `]`)
The vector type represents a SIMD style vector used by target-specific operation sets like AVX or SVE. While the most common use is for 1D vectors (e.g. vector<16 x f32>) we also support multidimensional registers on targets that support them (like TPUs). The dimensions of a vector type can be fixed-length, scalable, or a combination of the two. The scalable dimensions in a vector are indicated between square brackets ([ ]).
Vector shapes must be positive decimal integers. 0D vectors are allowed by
omitting the dimension: vector<f32>.
Note: hexadecimal integer literals are not allowed in vector type
declarations, vector<0x42xi32> is invalid because it is interpreted as a
2D vector with shape (0, 42) and zero shapes are not allowed.
Examples:
// A 2D fixed-length vector of 3x42 i32 elements.
vector<3x42xi32>
// A 1D scalable-length vector that contains a multiple of 4 f32 elements.
vector<[4]xf32>
// A 2D scalable-length vector that contains a multiple of 2x8 f32 elements.
vector<[2]x[8]xf32>
// A 2D mixed fixed/scalable vector that contains 4 scalable vectors of 4 f32 elements.
vector<4x[4]xf32>
// A 3D mixed fixed/scalable vector in which only the inner dimension is
// scalable.
vector<2x[4]x8xf32>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| shape | ::llvm::ArrayRef<int64_t> | |
| elementType | ::mlir::Type | VectorElementTypeInterface instance |
| scalableDims | ::llvm::ArrayRef<bool> |
DictType
TTCore dictionary type
Syntax: !ttcore.dict
A type representing a dictionary.
Example:
!ttcore.dict
TileType
TT tile
Syntax:
!ttcore.tile<
::llvm::ArrayRef<int64_t>, # shape
DataType # dataType
>
Tile type in TT dialect
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| shape | ::llvm::ArrayRef<int64_t> | |
| dataType | DataType |
'ttir' Dialect
TTIR dialect provides high level semantics for dispatching work to TT HW.
This dialect provides high level semantics for dispatching work to TT HW. It defines a set of declarative/high level operations that are used to describe the dispatch, but is largely agnostic to the set of operations or dialects that are actually supported by a consuming backend.
[TOC]
ttir.abs (tt::ttir::AbsOp)
Elementwise absolute value operation.
The abs operation computes the absolute value of each element in the input tensor.
For each element, it returns the magnitude of the value without regard to its sign:
- For real numbers, it returns |x| (the non-negative value without sign)
This operation has the idempotence property, meaning that applying it multiple times produces the same result as applying it once: abs(abs(x)) = abs(x). The operation preserves the data type of the input.
Example:
// Compute absolute values of all elements in %input
%result = ttir.abs(%input) : tensor<4x4xf32> -> tensor<4x4xf32>
// Input tensor:
// [[-2.5, 3.7, 0.0, 1.2], ... ]
// Output tensor:
// [[2.5, 3.7, 0.0, 1.2], ... ]
// Example with integer tensor
%result = ttir.abs(%int_input) : (tensor<10xi32>) -> tensor<10xi32>
// Input tensor:
// [-5, 0, 3, -2, ...]
// Output tensor:
// [5, 0, 3, 2, ...]
Mathematical definition: abs(x) = |x| = { x if x ≥ 0 -x if x < 0 }
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable, TTIR_Idempotence
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.acos (tt::ttir::AcosOp)
Eltwise arccosine op.
The acos operation computes the arccosine (inverse cosine) of each element in the input tensor.
For each element, it returns the angle in radians whose cosine is the input value. The operation returns values in the range [0, π]. Inputs are expected to lie in [-1, 1].
Example:
// Compute arccosine of all elements in %input
%result = ttir.acos(%input) : (tensor<4xf32>) -> tensor<4xf32>
// Input tensor:
// [1.0, 0.5, 0.0, -1.0]
// Output tensor:
// [0.0, 1.047, 1.571, 3.142] // values in radians
// Example with different values
%result = ttir.acos(%float_input) : (tensor<3xf32>) -> tensor<3xf32>
// Input tensor:
// [0.707, 0.0, -0.5]
// Output tensor:
// [0.785, 1.571, 2.094] // acos(√2/2) = π/4, acos(0) = π/2, acos(-0.5) = 2π/3
Mathematical definition: acos(x) = cos⁻¹(x), where the result is in the range [0, π]
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.add (tt::ttir::AddOp)
Elementwise addition operation.
The add operation performs an elementwise addition between two tensors.
For each pair of corresponding elements, it adds the elements and places the result in the output tensor.
Example:
// Addition operation
%result = ttir.add(%lhs, %rhs) : (tensor<3xi32>, tensor<3xi32>) -> tensor<3xi32>
// Input tensors:
// %lhs: [10, 20, 30]
// %rhs: [1, 2, 3]
// Output tensor:
// [11, 22, 33]
// Example with floating point values
%result = ttir.add(%float_lhs, %float_rhs) : (tensor<3xf32>, tensor<3xf32>) -> tensor<3xf32>
// Input tensors:
// %float_lhs: [3.5, 0.0, -1.2]
// %float_rhs: [1.5, 2.0, -3.2]
// Output tensor:
// [5.0, 2.0, -2.0]
Note: The data type of the output tensor matches the data type of the input tensors.
Mathematical definition: add(x, y) = x + y
Traits: AlwaysSpeculatableImplTrait, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), QuantizableOpInterface, TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.all_gather (tt::ttir::AllGatherOp)
All gather operation.
All gather op.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_CCL
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
all_gather_dim | ::mlir::IntegerAttr | 32-bit signed integer attribute |
cluster_axis | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.all_reduce_async (tt::ttir::AllReduceAsyncOp)
Asynchronous AllReduce operation.
Asynchronous all-reduce collective communication operation. Performs a reduction (e.g. sum) across all devices in a mesh and distributes the result back to all devices, using async execution to overlap communication with computation.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_CCL
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
reduce_type | ::mlir::tt::ttcore::ReduceTypeAttr | TT Reduce Type |
cluster_axis | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.all_reduce (tt::ttir::AllReduceOp)
AllReduce operation.
AllReduce op.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_CCL
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
reduce_type | ::mlir::tt::ttcore::ReduceTypeAttr | TT Reduce Type |
cluster_axis | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.all_to_all_combine (tt::ttir::AllToAllCombineOp)
Combine expert outputs back to original token positions.
Inverse of dispatch: gathers expert computation results from expert devices and restores tokens to their original device and order.
Input shapes:
- input_tensor: [E_local, B*D, S, H]
- expert_metadata: [1, B*D, S, K]
- expert_mapping: [1, 1, E, D]
Output shape:
- result: [K, B, S, H]
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_CCL
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
num_devices | ::mlir::IntegerAttr | 64-bit signless integer attribute |
cluster_axis | ::mlir::IntegerAttr | 64-bit signless integer attribute |
num_experts_per_tok | ::mlir::IntegerAttr | 64-bit signless integer attribute |
output_shard_dim | ::mlir::IntegerAttr | 64-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
input_tensor | ranked tensor of any type values |
expert_metadata | ranked tensor of any type values |
expert_mapping | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.all_to_all_dispatch_metadata (tt::ttir::AllToAllDispatchMetadataOp)
Dispatch tokens with metadata to expert devices for MoE computation.
Routes tokens along with expert scores to devices holding their selected experts via all-to-all communication within a ring (cluster_axis). Returns dispatched tokens (sparse — only routed token slots are filled), all-gathered expert indices, and all-gathered expert scores.
Dimensions: M = tokens per ring device K = selected experts per token D = total devices E = total experts
Input shapes (per device, after mesh sharding):
- input_tensor: [1, 1, M, H]
- expert_indices: [1, 1, M, K]
- expert_scores: [1, 1, M, K]
- expert_mapping: [1, 1, D, E] Each entry [d, e] is the device ID that owns expert e.
Output shapes (3D, per device, num_devices * M = tokens_global):
- dispatched: [1, tokens_global, H]
- indices: [1, tokens_global, K] (all-gathered across ring)
- scores: [1, tokens_global, K] (all-gathered across ring)
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_CCL
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
num_devices | ::mlir::IntegerAttr | 64-bit signless integer attribute |
cluster_axis | ::mlir::IntegerAttr | 64-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
input_tensor | ranked tensor of any type values |
expert_indices | ranked tensor of any type values |
expert_scores | ranked tensor of any type values |
expert_mapping | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
dispatched | ranked tensor of any type values |
indices | ranked tensor of any type values |
scores | ranked tensor of any type values |
ttir.all_to_all_dispatch (tt::ttir::AllToAllDispatchOp)
Dispatch tokens to expert devices for MoE computation.
Routes tokens to devices holding their selected experts via all-to-all communication. Used before sparse_matmul in the MoE dispatch/combine flow.
Input shapes:
- input_tensor: [B, S, 1, H]
- expert_indices: [B, S, 1, K]
- expert_mapping: [1, 1, E, D]
Output shapes:
- dispatched: [1, B*D, S, H]
- metadata: [1, B*D, S, K]
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_CCL
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
num_devices | ::mlir::IntegerAttr | 64-bit signless integer attribute |
cluster_axis | ::mlir::IntegerAttr | 64-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
input_tensor | ranked tensor of any type values |
expert_indices | ranked tensor of any type values |
expert_mapping | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
dispatched | ranked tensor of any type values |
metadata | ranked tensor of any type values |
ttir.all_to_all (tt::ttir::AllToAllOp)
All to All operation.
The all_to_all operation redistributes slices of a tensor across a cluster of devices. It splits each local tensor along split_dimension, sends the resulting slices to other devices along cluster_axis, and then concatenates the received slices along concat_dimension.
Example: For a 1x2 mesh and a local input of shape [8, 4]: - split_dimension = 1 - concat_dimension = 0 - split_count = 2 - cluster_axis = 1
Each device splits its [8, 4] tensor into two [8, 2] slices. After the exchange, each device concatenates the two received [8, 2] slices into a [16, 2] output tensor.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_CCL
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
split_dim | ::mlir::IntegerAttr | 32-bit signed integer attribute |
concat_dim | ::mlir::IntegerAttr | 32-bit signed integer attribute |
split_count | ::mlir::IntegerAttr | 32-bit signed integer attribute |
replica_groups | ::mlir::DenseIntElementsAttr | 64-bit signless integer elements attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.alloc (tt::ttir::AllocOp)
Alloc op.
Tensor Alloc operation
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
address | ::mlir::IntegerAttr | 64-bit signless integer attribute |
size | ::mlir::IntegerAttr | 64-bit signless integer attribute |
memory_space | ::mlir::tt::ttcore::MemorySpaceAttr | TT MemorySpace |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.arange (tt::ttir::ArangeOp)
Tensor range generation operation.
The arange operation generates a tensor with evenly spaced values within a given interval.
This operation creates a tensor with values from start to end (exclusive) with a step size of step,
along the dimension specified by arange_dimension. It's similar to NumPy's arange function and is useful
for creating tensors with regular sequences of values.
Example:
// Generate a 1D tensor with values [0, 1, 2, 3, 4]
%result = ttir.arange() {
start = 0 : si64,
end = 5 : si64,
step = 1 : si64,
arange_dimension = 0 : i64
} : () -> tensor<5xi64>
// Generate a 1D tensor with values [0.0, 2.0, 4.0, 6.0, 8.0]
%result = ttir.arange() {
start = 0 : si64,
end = 10 : si64,
step = 2 : si64,
arange_dimension = 0 : i64
} : () -> tensor<5xf32>
// Generate a 2D tensor with the sequence along dimension 0
%result = ttir.arange() {
start = 0 : si64,
end = 5 : si64,
step = 1 : si64,
arange_dimension = 0 : i64
} : () -> tensor<5x3xi64>
// Result:
// [[0, 0, 0],
// [1, 1, 1],
// [2, 2, 2],
// [3, 3, 3],
// [4, 4, 4]]
// Generate a 2D tensor with the sequence along dimension 1
%result = ttir.arange() {
start = 0 : si64,
end = 3 : si64,
step = 1 : si64,
arange_dimension = 1 : i64
} : () -> tensor<5x3xi64>
// Result:
// [[0, 1, 2],
// [0, 1, 2],
// [0, 1, 2],
// [0, 1, 2],
// [0, 1, 2]]
Attributes:
start(Integer): The start value of the sequence.end(Integer): The end value of the sequence (exclusive).step(Integer): The step size between values in the sequence.arange_dimension(Integer): The dimension along which to generate the sequence.
Output:
result(Tensor): The generated tensor containing the sequence.
Traits: AlwaysSpeculatableImplTrait, TTCore_CreationOpTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
start | ::mlir::IntegerAttr | 64-bit signed integer attribute |
end | ::mlir::IntegerAttr | 64-bit signed integer attribute |
step | ::mlir::IntegerAttr | 64-bit signed integer attribute |
arange_dimension | ::mlir::IntegerAttr | 64-bit signless integer attribute |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.argmax (tt::ttir::ArgMaxOp)
Argmax reduction op.
Determine the indices of the maximum values along a specified dimension of a tensor or over all elements in a tensor.
This operation reduces the input tensor by finding the index of the maximum value along the dimensions
specified in dim_arg. If dim_arg is not provided, the argmax is computed over all dimensions,
resulting in a scalar index. If keep_dim is set to true, the reduced dimensions are retained
with a size of 1.
Example IR Usage:
// Argmax along dimension 1
%input = ... : tensor<2x3xf32>
%result = ttir.argmax(%input) {keep_dim = false, dim_arg = [1: i32]} : (tensor<2x3xf32>) -> tensor<2xi32>
// Input tensor:
// [[1.0, 5.0, 3.0],
// [2.0, 4.0, 6.0]]
// Output tensor:
// [1, 2] // Index of maximum value in each row (5.0 in first row, 6.0 in second row)
// Argmax along dimension 0
%input = ... : tensor<2x3xf32>
%result = ttir.argmax(%input) {keep_dim = false, dim_arg = [0: i32]} : (tensor<2x3xf32>) -> tensor<3xi32>
// Input tensor:
// [[1.0, 5.0, 3.0],
// [2.0, 4.0, 6.0]]
// Output tensor:
// [1, 0, 1] // Index of maximum value in each column
// Argmax over all dimensions
%input = ... : tensor<2x3xf32>
%result = ttir.argmax(%input) {keep_dim = false} : (tensor<2x3xf32>) -> tensor<i32>
// Input tensor:
// [[1.0, 5.0, 3.0],
// [2.0, 4.0, 6.0]]
// Output tensor:
// 5 // Flattened index of the maximum value (6.0)
Inputs:
input(Tensor): The input tensor.
Attributes:
keep_dim(Bool): Whether to keep the reduced dimensions or not.dim_arg(Array of Int32): Dimensions to reduce along.
Output:
result(Tensor): The result tensor after applying the reduction.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
keep_dim | ::mlir::BoolAttr | bool attribute |
dim_arg | ::mlir::ArrayAttr | 32-bit integer array attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.asin (tt::ttir::AsinOp)
Eltwise arcsine op.
The asin operation computes the arcsine (inverse sine) of each element in the input tensor.
For each element, it returns the angle in radians whose sine is the input value. The operation returns values in the range [-π/2, π/2]. Inputs are expected to lie in [-1, 1].
Example:
// Compute arcsine of all elements in %input
%result = ttir.asin(%input) : (tensor<4xf32>) -> tensor<4xf32>
// Input tensor:
// [0.0, 0.5, 1.0, -1.0]
// Output tensor:
// [0.0, 0.524, 1.571, -1.571] // values in radians
// Example with different values
%result = ttir.asin(%float_input) : (tensor<3xf32>) -> tensor<3xf32>
// Input tensor:
// [-0.5, 0.0, 0.707]
// Output tensor:
// [-0.524, 0.0, 0.785] // asin(√2/2) = π/4
Mathematical definition: asin(x) = sin⁻¹(x), where the result is in the range [-π/2, π/2]
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.asinh (tt::ttir::AsinhOp)
Eltwise inverse hyperbolic sine op.
The asinh operation computes the inverse hyperbolic sine of each element in the input tensor.
For each element, it returns the value whose hyperbolic sine is the input value. Unlike asin,
this function accepts all real numbers as input.
Example:
// Compute inverse hyperbolic sine of all elements in %input
%result = ttir.asinh(%input) : (tensor<4xf32>) -> tensor<4xf32>
// Input tensor:
// [0.0, 1.0, -1.0, 10.0]
// Output tensor:
// [0.0, 0.8814, -0.8814, 2.9982]
Mathematical definition: asinh(x) = ln(x + √(x² + 1))
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.atan2 (tt::ttir::Atan2Op)
Elementwise atan2 operation.
The atan2 operation performs an elementwise arc tangent (inverse tangent) operation between two tensors.
For each pair of corresponding elements, it computes the angle in radians between the positive x-axis and the vector from the origin to the point (x, y) in the Cartesian plane. This operation is typically used in trigonometric calculations and supports partial broadcasting, allowing operands of different shapes to be combined.
Example:
// %lhs: [0.0, 1.0, -1.0]
// %rhs: [1.0, 0.0, 0.0]
%result = ttir.atan2(%lhs, %rhs) : (tensor<3xf64>, tensor<3xf64>) -> tensor<3xf64>
// %result: [0.0, 1.57079637, -1.57079637] // [0.0, pi/2, -pi/2]
Mathematical definition: atan2(x, y) = arctan(y / x)
Traits: AlwaysSpeculatableImplTrait, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.atan (tt::ttir::AtanOp)
Eltwise arctangent op.
The atan operation computes the arctangent (inverse tangent) of each element in the input tensor.
For each element, it returns the angle in radians whose tangent is the input value. The operation returns values in the range [-π/2, π/2].
Example:
// Compute arctangent of all elements in %input
%result = ttir.atan(%input) : (tensor<4xf32>) -> tensor<4xf32>
// Input tensor:
// [1.0, 0.5, 0.0, -1.0]
// Output tensor:
// [0.785, 0.464, 0.0, -0.785] // values in radians
// Example with different values
%result = ttir.atan(%float_input) : (tensor<3xf32>) -> tensor<3xf32>
// Input tensor:
// [0.0, 1.0, 1000.0]
// Output tensor:
// [0.0, 0.785, 1.571] // values approach π/2 as input grows
Mathematical definition: atan(x) = tan⁻¹(x), where the result is in the range [-π/2, π/2]
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.avg_pool2d (tt::ttir::AvgPool2dOp)
2D average pooling operation.
The avg_pool2d operation applies a 2D average pooling over an input tensor composed of several input planes.
This operation performs downsampling by dividing the input into local regions and computing the average value of each region. It reduces the spatial dimensions (height and width) of an input tensor while preserving the batch and channel dimensions. This is commonly used in neural networks to reduce the spatial size of feature maps.
Example:
// Basic 2D average pooling with a 2x2 kernel and stride 1
%input = ... : tensor<1x3x3x1xf32> // 3x3 input tensor with values:
// [[[1, 2, 3],
// [4, 5, 6],
// [7, 8, 9]]]
%result = ttir.avg_pool2d(%input) {
kernel = [2, 2],
stride = [1, 1],
dilation = [1, 1],
padding = [0, 0, 0, 0],
ceil_mode = false
} : (tensor<1x3x3x1xf32>) -> tensor<1x2x2x1xf32>
// Result: [[[3, 4],
// [6, 7]]]
// Where: 3 = (1+2+4+5)/4, 4 = (2+3+5+6)/4, 6 = (4+5+7+8)/4, 7 = (5+6+8+9)/4
Inputs:
input(Tensor): Input tensor in NHWC format (batch, height, width, channels).
Attributes:
kernel(i32 | array<2xi32>):- i32: Same kernel size for height and width dimensions (kH = kW = value).
- array<2xi32>: [kH, kW] where kH is kernel size for height and kW is kernel size for width.
stride(i32 | array<2xi32>):- i32: Same stride for height and width dimensions (sH = sW = value).
- array<2xi32>: [sH, sW] where sH is stride for height and sW is stride for width.
dilation(i32 | array<2xi32>):- i32: Same dilation for height and width dimensions (dH = dW = value).
- array<2xi32>: [dH, dW] where dH is dilation for height and dW is dilation for width.
padding(i32 | array<2xi32> | array<4xi32>):- i32: Same padding for all sides (pT = pL = pB = pR = value).
- array<2xi32>: [pH, pW] where pH is padding for height (top/bottom) and pW is padding for width (left/right).
- array<4xi32>: [pT, pL, pB, pR] for top, left, bottom, and right padding respectively.
ceil_mode(Boolean): When true, uses ceil instead of floor for output shape calculation.count_include_pad(Boolean): When true, include padding in the average calculation (default: True)
Output:
result(Tensor): Output tensor after average pooling.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), QuantizableOpInterface, TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
kernel | ::mlir::Attribute | 32-bit signless integer attribute or i32 dense array attribute |
stride | ::mlir::Attribute | 32-bit signless integer attribute or i32 dense array attribute |
dilation | ::mlir::Attribute | 32-bit signless integer attribute or i32 dense array attribute |
padding | ::mlir::Attribute | 32-bit signless integer attribute or i32 dense array attribute |
ceil_mode | ::mlir::BoolAttr | bool attribute |
count_include_pad | ::mlir::BoolAttr | bool attribute |
flattened_compat_info | ::mlir::tt::ttir::FlattenedCompatInfoAttr | Information for sliding window operations with tensors flattened to (1, 1, N*H*W, C){{% markdown %}} This attribute marks operations that are compatible with flattened tensors. It is used as a marker and doesn't carry any additional data. {{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.batch_norm_inference (tt::ttir::BatchNormInferenceOp)
BatchNormInference operation
Performs batch normalization inference on the input tensor. Normalizes the operand tensor
across all dimensions except for the specified dimension (feature dimension) and
produces the normalized result using pre-computed mean and variance.
Inputs:
operand(Tensor): The input tensor to be normalized.scale(Tensor): The scale parameter (gamma).offset(Tensor): The offset parameter (beta).mean(Tensor): The pre-computed mean of the input.variance(Tensor): The pre-computed variance of the input.
Attributes:
epsilonis a small constant added to variance for numerical stability.dimensionspecifies which dimension represents the features/channels.
Output:
result(Tensor): The normalized output tensor.
Example:
// Normalize a batch of activations
%result = ttir.batch_norm(%operand, %scale, %offset, %mean, %variance,
epsilon = 0.001, dimension = 1) :
(tensor<8x16x32x32xf32>, tensor<16xf32>, tensor<16xf32>,
tensor<16xf32>, tensor<16xf32>) -> tensor<8x16x32x32xf32>
Mathematical definition: batch_norm(x, scale, offset, mean, variance, epsilon, dimension) = (x - mean) / sqrt(variance + epsilon) * scale + offset
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
epsilon | ::mlir::FloatAttr | 32-bit float attribute |
dimension | ::mlir::IntegerAttr | 32-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
operand | ranked tensor of any type values |
scale | ranked tensor of any type values |
offset | ranked tensor of any type values |
mean | ranked tensor of any type values |
variance | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.batch_norm_training (tt::ttir::BatchNormTrainingOp)
BatchNormTraining operation
Performs batch normalization during training on the input tensor. Normalizes the operand tensor
across all dimensions except for the specified dimension (feature dimension) and
produces the normalized result along with batch statistics. Updates the running mean and variance.
Inputs:
operand(Tensor): The input tensor to be normalized.scale(Tensor): The scale parameter (gamma).offset(Tensor): The offset parameter (beta).running_mean(Tensor): The running mean (updated during training).running_variance(Tensor): The running variance (updated during training).
Attributes:
epsilonis a small constant added to variance for numerical stability.dimensionspecifies which dimension represents the features/channels.momentumis the momentum factor for updating running statistics.
Outputs:
result(Tensor): The normalized output tensor.batch_mean(Tensor): The computed batch mean.batch_variance(Tensor): The computed batch variance.
Example:
// Normalize a batch of activations (training)
%result, %batch_mean, %batch_variance = ttir.batch_norm_training(%operand, %scale, %offset, %running_mean, %running_variance,
%output, %batch_mean_output, %batch_variance_output :
epsilon = 0.001, dimension = 1, momentum = 0.1) :
(tensor<8x16x32x32xf32>, tensor<16xf32>, tensor<16xf32>,
tensor<16xf32>, tensor<16xf32>, tensor<8x16x32x32xf32>,
tensor<16xf32>, tensor<16xf32>, tensor<16xf32>, tensor<16xf32>) ->
(tensor<8x16x32x32xf32>, tensor<16xf32>, tensor<16xf32>)
Mathematical definition: batch_mean = mean(x, dimension) batch_variance = variance(x, dimension) normalized = (x - batch_mean) / sqrt(batch_variance + epsilon) * scale + offset running_mean = momentum * batch_mean + (1 - momentum) * running_mean running_variance = momentum * batch_variance + (1 - momentum) * running_variance
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
epsilon | ::mlir::FloatAttr | 32-bit float attribute |
dimension | ::mlir::IntegerAttr | 32-bit signless integer attribute |
momentum | ::mlir::FloatAttr | 32-bit float attribute |
Operands:
| Operand | Description |
|---|---|
operand | ranked tensor of any type values |
scale | ranked tensor of any type values |
offset | ranked tensor of any type values |
running_mean | ranked tensor of any type values |
running_variance | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
batch_mean | ranked tensor of any type values |
batch_variance | ranked tensor of any type values |
ttir.bitcast_convert (tt::ttir::BitcastConvertOp)
Elementwise bitcast operation.
The bitcast_convert operation reinterprets the bits of each element in
the input tensor as a data type of the output tensor. This leads to change
in numerical values in data.
Only same-bit-width element types are supported (e.g. ui32 -> f32).
Example:
// Reinterpret the raw bits of each ui32 element as f32.
// Input: [0x3F800000, 0x40000000] (ui32)
// Output: [1.0, 2.0 ] (f32) — same bits, read as float
%result = ttir.bitcast_convert(%input) : (tensor<16384xui32>) -> tensor<16384xf32>
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.bitwise_and (tt::ttir::BitwiseAndOp)
Elementwise bitwise AND.
The bitwise_and operation performs an elementwise bitwise AND operation between two tensors.
For each pair of corresponding elements, it computes the bitwise AND of their binary representations. This operation is typically used with integer data types and has the idempotence property, meaning that applying it twice with the same second operand returns the original result: bitwise_and(bitwise_and(x, y), y) = bitwise_and(x, y).
Example:
// Bitwise AND operation
%result = ttir.bitwise_and(%lhs, %rhs) : (tensor<2x2xi32>, tensor<2x2xi32>) -> tensor<2x2xi32>
// Input tensors:
// %lhs: [[1, 2], [3, 4]]
// %rhs: [[5, 6], [7, 8]]
// Output tensor:
// [[1, 2], [3, 0]]
// Example with binary representation (for 8-bit integers)
%result = ttir.bitwise_and(%int8_lhs, %int8_rhs) : (tensor<4xi8>, tensor<4xi8>) -> tensor<4xi8>
// Input tensors:
// %int8_lhs: [0x0F, 0xAA, 0xFF, 0x00] (binary: [00001111, 10101010, 11111111, 00000000])
// %int8_rhs: [0xF0, 0x55, 0xFF, 0x00] (binary: [11110000, 01010101, 11111111, 00000000])
// Output tensor:
// [0x00, 0x00, 0xFF, 0x00] (binary: [00000000, 00000000, 11111111, 00000000])
Mathematical definition: bitwise_and(x, y) = x & y
Traits: AlwaysSpeculatableImplTrait, TTIR_BinaryIdempotence, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.bitwise_not (tt::ttir::BitwiseNotOp)
Elementwise bitwise NOT.
The bitwise_not operation computes the bitwise NOT (one's complement) of each element in the input tensor.
For each element, it flips all the bits in the binary representation of the value. This operation is typically used with integer data types and has the involution property, meaning that applying it twice returns the original value: bitwise_not(bitwise_not(x)) = x.
Example:
// Bitwise operation with with integer tensors
%result = "ttir.bitwise_not"(%operand) : (tensor<2x2xi32>) -> tensor<2x2xi32>
// %operand: [[1, 2], [3, 4]]
// %result: [[-2, -3], [-4, -5]]
// Example with binary representation (for 8-bit integers)
%result = ttir.bitwise_not(%int8_input) : (tensor<3xi8>) -> tensor<3xi8>
// Input %int8_input:
// [0, 5, 255] (binary: [00000000, 00000101, 11111111])
// Output %int8_output:
// [255, 250, 0] (binary: [11111111, 11111010, 00000000])
Mathematical definition: bitwise_not(x) = ~x
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable, TTIR_Involution
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.bitwise_or (tt::ttir::BitwiseOrOp)
Elementwise bitwise OR operation.
The bitwise_or operation performs an elementwise bitwise OR operation between two tensors.
For each pair of corresponding elements, it computes the bitwise OR of their binary representations. This operation is typically used with integer data types and has the idempotence property, meaning that applying it twice with the same second operand returns the original result: bitwise_or(bitwise_or(x, y), y) = bitwise_or(x, y).
Example:
// Bitwise OR operation
%result = ttir.bitwise_or(%lhs, %rhs) : (tensor<2x2xi32>, tensor<2x2xi32>) -> tensor<2x2xi32>
// Input tensors:
// %lhs: [[1, 2], [3, 4]]
// %rhs: [[5, 6], [7, 8]]
// Output tensor:
// [[5, 6], [7, 12]]
// Example with binary representation (for 8-bit integers)
%result = ttir.bitwise_or(%int8_lhs, %int8_rhs) : (tensor<4xi8>, tensor<4xi8>) -> tensor<4xi8>
// Input tensors:
// %int8_lhs: [0x0F, 0xAA, 0x00, 0x55] (binary: [00001111, 10101010, 00000000, 01010101])
// %int8_rhs: [0xF0, 0x55, 0x00, 0xAA] (binary: [11110000, 01010101, 00000000, 10101010])
// Output tensor:
// [0xFF, 0xFF, 0x00, 0xFF] (binary: [11111111, 11111111, 00000000, 11111111])
Mathematical definition: bitwise_or(x, y) = x | y
Traits: AlwaysSpeculatableImplTrait, TTIR_BinaryIdempotence, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.bitwise_xor (tt::ttir::BitwiseXorOp)
Elementwise bitwise XOR operation.
The bitwise_xor operation performs an elementwise bitwise XOR (exclusive OR) operation between two tensors.
For each pair of corresponding elements, it computes the bitwise XOR of their binary representations. This operation is typically used with integer data types and has the property that when applied twice with the same second operand, it returns the original input: bitwise_xor(bitwise_xor(x, y), y) = x.
Example:
// Bitwise XOR operation
%result = ttir.bitwise_xor(%lhs, %rhs) : (tensor<2x2xi32>, tensor<2x2xi32>) -> tensor<2x2xi32>
// Input tensors:
// %lhs: [[1, 2], [3, 4]]
// %rhs: [[5, 6], [7, 8]]
// Output tensor:
// [[4, 4], [4, 12]]
// Example with binary representation (for 8-bit integers)
%result = ttir.bitwise_xor(%int8_lhs, %int8_rhs) : (tensor<4xi8>, tensor<4xi8>) -> tensor<4xi8>
// Input tensors:
// %int8_lhs: [0x0F, 0xAA, 0xFF, 0x00] (binary: [00001111, 10101010, 11111111, 00000000])
// %int8_rhs: [0xF0, 0x55, 0xFF, 0x00] (binary: [11110000, 01010101, 11111111, 00000000])
// Output tensor:
// [0xFF, 0xFF, 0x00, 0x00] (binary: [11111111, 11111111, 00000000, 00000000])
Mathematical definition: bitwise_xor(x, y) = x ^ y
Traits: AlwaysSpeculatableImplTrait, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.broadcast (tt::ttir::BroadcastOp)
Broadcast operation.
The broadcast operation expands the dimensions of an input tensor according to specified broadcast dimensions.
This operation takes an input tensor and broadcasts it to a larger shape by repeating elements along dimensions where the input has size 1 and the output has a larger size. This is commonly used to make tensors compatible for elementwise operations.
Example:
// Broadcast a tensor from shape [1, 1, 32] to [1, 16, 32]
%input = ... : tensor<1x1x32xf32>
%result = ttir.broadcast(%input) {broadcast_dimensions = [1, 16, 1]} : (tensor<1x1x32xf32>) -> tensor<1x16x32xf32>
// The input tensor is repeated 16 times along the second dimension
// Broadcast a tensor from shape [1, 3] to [2, 3]
%input = ... : tensor<1x3xf32>
%result = ttir.broadcast(%input) {broadcast_dimensions = [2, 1]} : (tensor<1x3xf32>) -> tensor<2x3xf32>
// The input tensor is repeated 2 times along the first dimension
Note: Currently, when generating a TTNN executable, the broadcast and repeat operations share the same semantics due to the lack of tensor view support in TTNN. As a result, the broadcast operation is lowered to a repeat operation in the TTNN compilation pipeline.
Inputs:
input(Tensor): The input tensor to broadcast.
Attributes:
broadcast_dimensions(Array of Integer): The number of times to broadcast the tensor along each dimension.
Output:
result(Tensor): The broadcasted tensor.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
broadcast_dimensions | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.cbrt (tt::ttir::CbrtOp)
Elementwise cubic root operation.
The cbrt operation computes the cubic root (∛) of each element in the input tensor.
For each element, it returns the real-valued number that, when cubed, equals the input value. Unlike square root, cubic root is defined for negative numbers as well as positive numbers.
Example:
// Compute cubic root of all elements in %input
%result = ttir.cbrt(%input) : (tensor<4x4xf32>) -> tensor<4x4xf32>
// Input tensor:
// [[8.0, 27.0, -8.0, 1.0], ... ]
// Output tensor:
// [[2.0, 3.0, -2.0, 1.0], ... ]
// Example with different values
%result = ttir.cbrt(%float_input) : (tensor<3x2xf32>) -> tensor<3x2xf32>
// Input tensor:
// [[125.0, -27.0],
// [0.0, 0.001],
// [1000.0, -1.0]]
// Output tensor:
// [[5.0, -3.0],
// [0.0, 0.1],
// [10.0, -1.0]]
Mathematical definition: cbrt(x) = ∛x = x^(1/3)
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.ceil (tt::ttir::CeilOp)
Elementwise ceiling operation.
The ceil operation computes the ceiling (smallest integer greater than or equal to x)
of each element in the input tensor.
For each element, it rounds the value up to the nearest integer. The operation preserves the data type of the input.
This operation has the idempotence property, meaning that applying it multiple times produces the same result as applying it once: ceil(ceil(x)) = ceil(x).
Example:
// Compute ceiling of all elements in %input
%result = ttir.ceil(%input) : (tensor<4x4xf32>) -> tensor<4x4xf32>
// Input tensor:
// [[1.7, 2.0, -0.3, 4.5], ... ]
// Output tensor:
// [[2.0, 2.0, 0.0, 5.0], ... ]
// Example with different values
%result = ttir.ceil(%float_input) : (tensor<3x2xf32>) -> tensor<3x2xf32>
// Input tensor:
// [[3.14, -2.5],
// [0.0, 0.001],
// [9.999, -0.0]]
// Output tensor:
// [[4.0, -2.0],
// [0.0, 1.0],
// [10.0, 0.0]]
Mathematical definition: ceil(x) = ⌈x⌉ = min{n ∈ ℤ | n ≥ x}
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable, TTIR_Idempotence
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.clamp_scalar (tt::ttir::ClampScalarOp)
Scalar value clamping operation.
The clamp_scalar operation constrains all elements of a tensor to be within a specified range.
This operation applies element-wise clamping to the input tensor, ensuring that all values fall within
the range [min, max]. Values less than min are set to min, and values greater than max are set to max.
This is commonly used to ensure that tensor values stay within a valid range.
Example:
// Clamp values to the range [2.0, 5.0]
%input = ... : tensor<1x8xf32> // Input tensor with values:
// [[0, 1, 2, 3, 4, 5, 6, 7]]
%result = ttir.clamp_scalar(%input) {
min = 2.0 : f32, // Minimum value
max = 5.0 : f32 // Maximum value
} : (tensor<1x8xf32>) -> tensor<1x8xf32>
// Result: [[2, 2, 2, 3, 4, 5, 5, 5]]
// Values < 2.0 are clamped to 2.0, values > 5.0 are clamped to 5.0
Inputs:
input(Tensor): The input tensor to clamp.
Attributes:
min(Float): The minimum value for clamping.max(Float): The maximum value for clamping.
Output:
result(Tensor): The clamped tensor.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
min | ::mlir::Attribute | 32-bit float attribute or 32-bit signless integer attribute |
max | ::mlir::Attribute | 32-bit float attribute or 32-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.clamp_tensor (tt::ttir::ClampTensorOp)
Tensor value clamping operation.
The clamp_tensor operation constrains elements of a tensor to be within ranges specified by min and max tensors.
Unlike clamp_scalar, which uses scalar values for min and max, this operation uses tensor values for
element-wise clamping. Each element in the input tensor is clamped between the corresponding elements
in the min and max tensors. This allows for different clamping ranges for different elements.
Example:
// Clamp values using min and max tensors
%input = ... : tensor<1x8xf32> // Input tensor with values:
// [[0, 1, 2, 3, 4, 5, 6, 7]]
%min = ... : tensor<1x8xf32> // Min tensor with values:
// [[2, 2, 2, 3, 3, 3, 0, 0]]
%max = ... : tensor<1x8xf32> // Max tensor with values:
// [[5, 5, 5, 9, 9, 9, 6, 6]]
%result = ttir.clamp_tensor(%input, %min, %max) :
(tensor<1x8xf32>, tensor<1x8xf32>, tensor<1x8xf32>) -> tensor<1x8xf32>
// Result: [[2, 2, 2, 3, 4, 5, 6, 6]]
// Each element is clamped between its corresponding min and max values
Inputs:
input(Tensor): The input tensor to clamp.min(Tensor): The tensor containing minimum values for clamping.max(Tensor): The tensor containing maximum values for clamping.
Output:
result(Tensor): The clamped tensor.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
min | ranked tensor of any type values |
max | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.collective_broadcast (tt::ttir::CollectiveBroadcastOp)
Collective Broadcast op
The collective_broadcast operation distributes a tensor from a single source device to all other devices within each replica group. Each replica group defines a subset of devices that participate in the broadcast, and the operation is applied independently within each group.
By convention, the first device listed in each replica group is treated as the broadcast source.
The value of the input tensor on that source device is sent to all other devices in the same
group. The input tensor values on non-source devices are ignored and will be overwritten
during the operation.
Inputs:
- input: The tensor to broadcast. Only the value on the first device of each replica group (the source) is used; values on other devices are ignored.
- replica_groups: A list of replica groups. Each group is a list of device IDs, and the first ID in each group is treated as the broadcast source for that group.
Result:
- result: The output tensor containing the broadcasted value, identical across all devices in the same replica group.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_CCL
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
replica_groups | ::mlir::DenseIntElementsAttr | 64-bit signless integer elements attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.collective_permute (tt::ttir::CollectivePermuteOp)
Collective permute operation.
Collective permute op. This operation ingests a multi-device tensor spread across multi-devices and will shuffle the data according to source_target_pairs [['src', 'dest']].
Example: For a 1x2 mesh, the following will take the device shard living in device 0 and move it to device 1. The device shard living in device 1 will move to device 0. %source_target_pairs: [[0, 1], [1, 0]]
In the case of missing 'dest', the device shard living on that device will contain values of 0. For example, device shard living in device 0 will contain 0 values. %source_target_pairs: [[0, 1]]
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_CCL
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
source_target_pairs | ::mlir::DenseIntElementsAttr | 64-bit signless integer elements attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.concat (tt::ttir::ConcatOp)
Tensor concatenation operation.
The concat operation joins multiple tensors along a specified dimension.
This operation concatenates a list of tensors along the dimension specified by dim.
All input tensors must have the same shape except for the dimension being concatenated,
and the output tensor's shape will match the input tensors except for the concatenated
dimension, which will be the sum of the input dimensions.
Example:
// Concatenate along dimension 0
%input1 = ... : tensor<2x3xf32>
%input2 = ... : tensor<3x3xf32>
%result = ttir.concat(%input1, %input2) {dim = 0 : i32} : (tensor<2x3xf32>, tensor<3x3xf32>) -> tensor<5x3xf32>
// Input1 shape: [2, 3]
// Input2 shape: [3, 3]
// Output shape: [5, 3]
// Concatenate along dimension 1
%input1 = ... : tensor<2x3xf32>
%input2 = ... : tensor<2x2xf32>
%result = ttir.concat(%input1, %input2) {dim = 1 : i32} : (tensor<2x3xf32>, tensor<2x2xf32>) -> tensor<2x5xf32>
// Input1 shape: [2, 3]
// Input2 shape: [2, 2]
// Output shape: [2, 5]
Inputs:
inputs(Variadic Tensor): A list of input tensors to concatenate.
Attributes:
dim(Integer): The dimension along which to concatenate the tensors.
Output:
result(Tensor): The concatenated tensor.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim | ::mlir::IntegerAttr | 32-bit signed integer attribute |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.concatenate_heads (tt::ttir::ConcatenateHeadsOp)
Concatenate heads operation.
The concatenate_heads operation concatenates multiple heads of a multi-head attention tensor into a single tensor.
This operation is typically used in transformer models where the attention mechanism is split into multiple heads. It combines the outputs of these heads into a single tensor, allowing further processing.
It takes an input tensor with shape [batch_size, num_heads, sequence_size, head_size]
and produces an output tensor with shape [batch_size, sequence_size, num_heads * head_size].
It corresponds to a sequence of permute and reshape operations.
Example:
// Concatenate heads from a multi-head attention output
%input = ... : tensor<1x24x32x128xbf16> // batch_size: 1, num_heads: 24, sequence_size: 32, head_size: 128
%result = ttir.concatenate_heads(%input) : (tensor<1x24x32x128xbf16>) -> tensor<1x32x3072xbf16>
// Input tensor shape: [1, 24, 32, 128]
// Output tensor shape: [1, 32, 3072]
Inputs:
input(Tensor): The input tensor containing multiple heads.
Output:
result(Tensor): The concatenated output tensor.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.constant (tt::ttir::ConstantOp)
Tensor constant creation operation.
The constant operation creates a tensor with values specified by a constant attribute.
This operation is used to create tensors with predefined values that remain constant throughout program execution. It's commonly used for initializing model weights, biases, and other fixed parameters in neural networks.
Example:
// Create a 2D tensor of zeros
%result = ttir.constant() {
value = dense<0> : tensor<2x3xi32>
} : () -> tensor<2x3xi32>
// Result: [[0, 0, 0], [0, 0, 0]]
// Create a 1D tensor with specific floating-point values
%result = ttir.constant() {
value = dense<[0.2, 1.3]> : tensor<2xf32>
} : () -> tensor<2xf32>
// Result: [0.2, 1.3]
// Create a scalar constant
%result = ttir.constant() {
value = dense<5.0> : tensor<f32>
} : () -> tensor<f32>
// Result: 5.0
// Create a 2D tensor with different values
%result = ttir.constant() {
value = dense<[[1, 2, 3], [4, 5, 6]]> : tensor<2x3xi32>
} : () -> tensor<2x3xi32>
// Result: [[1, 2, 3], [4, 5, 6]]
Attributes:
value(DenseElementsAttr): The constant value of the tensor.
Output:
result(Tensor): The tensor with the specified constant values.
Note: The shape and element type of the result tensor are determined by the value attribute.
The constant operation is typically folded during compilation, allowing for optimizations
such as constant propagation.
Traits: AlwaysSpeculatableImplTrait, ConstantLike, TTCore_CreationOpTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
value | ::mlir::ElementsAttr | constant vector/tensor attribute |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.conv2d (tt::ttir::Conv2dOp)
Conv2d operation.
Applies a 2D convolution over an input image composed of several input planes.
This operation performs a 2D convolution on the input tensor using the provided weight tensor and optional bias. It supports configurable stride, padding, dilation, and grouping parameters to control the convolution behavior.
Example:
// Basic 2D convolution
%input = ... : tensor<1x28x28x3xf32> // Batch size 1, 28x28 image, 3 channels
%weight = ... : tensor<16x3x3x3xf32> // 16 output channels, 3 input channels, 3x3 kernel
%bias = ... : tensor<1x1x1x16xf32> // Bias for 16 output channels
%result = ttir.conv2d(%input, %weight, %bias) {
stride = [1, 1],
padding = [0, 0, 0, 0],
dilation = [1, 1],
groups = 1
} : (tensor<1x28x28x3xf32>, tensor<16x3x3x3xf32>, tensor<1x1x1x16xf32>) -> tensor<1x26x26x16xf32>
// Convolution with stride 2 and padding
%input = ... : tensor<1x28x28x3xf32> // Batch size 1, 28x28 image, 3 channels
%weight = ... : tensor<16x3x3x3xf32> // 16 output channels, 3 input channels, 3x3 kernel
%bias = ... : tensor<1x1x1x16xf32> // Bias for 16 output channels
%result = ttir.conv2d(%input, %weight, %bias) {
stride = [2, 2],
padding = [1, 1, 1, 1],
dilation = [1, 1],
groups = 1
} : (tensor<1x28x28x3xf32>, tensor<16x3x3x3xf32>, tensor<1x1x1x16xf32>) -> tensor<1x14x14x16xf32>
Inputs:
input(AnyRankedTensor): 4D tensor where dimension indices are controlled bybatch_dim,height_dim,width_dim, andchannel_dimattributes. Default layout is NHWC (N, H_in, W_in, C) where:- N is the batch size
- H_in is the height of the input planes
- W_in is the width of the input planes
- C is the number of channels
weight(AnyRankedTensor): expected in the following format (O, C/G, K_H, K_W) where:- C is the number of input channels
- O is the number of output channels
- G is the number of groups
- K_H is the height of the kernel
- K_W is the width of the kernel
biasOptional: bias tensor with output channels at position specified by channel_dim. Default format is (1, 1, 1, O).
Attributes:
stride(i32 | array<2xi32>):- i32: Same stride for height and width dimensions (sH = sW = value).
- array<2xi32>: [sH, sW] where sH is stride for height and sW is stride for width.
padding(i32 | array<2xi32> | array<4xi32>):- i32: Same padding for all sides (pT = pL = pB = pR = value).
- array<2xi32>: [pH, pW] where pH is padding for height (top/bottom) and pW is padding for width (left/right).
- array<4xi32>: [pT, pL, pB, pR] for top, left, bottom, and right padding respectively.
dilation(i32 | array<2xi32>): Spacing between kernel elements.- i32: Same dilation for height and width dimensions (dH = dW = value).
- array<2xi32>: [dH, dW] where dH is dilation for height and dW is dilation for width.
groups(i32): Number of blocked connections from input channels to output channels. Input and output channels must both be divisible by groups.batch_dim(i64): Index of the batch dimension in input/output tensors. Default: 0.height_dim(i64): Index of the height dimension in input/output tensors. Default: 1.width_dim(i64): Index of the width dimension in input/output tensors. Default: 2.channel_dim(i64): Index of the channel dimension in input/output tensors. Default: 3.
Output:
resultAnyRankedTensor: 4D tensor with same layout as input (controlled by dimension attributes). Default format is (N, H_out, W_out, O) where:H_out = (H_in + pT + pB - dH * (K_H - 1) - 1) / sH + 1W_out = (W_in + pL + pR - dW * (K_W - 1) - 1) / sW + 1
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), QuantizableOpInterface, TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
stride | ::mlir::Attribute | 32-bit signless integer attribute or i32 dense array attribute |
padding | ::mlir::Attribute | 32-bit signless integer attribute or i32 dense array attribute |
dilation | ::mlir::Attribute | 32-bit signless integer attribute or i32 dense array attribute |
groups | ::mlir::IntegerAttr | 32-bit signless integer attribute |
batch_dim | ::mlir::IntegerAttr | 64-bit signless integer attribute |
height_dim | ::mlir::IntegerAttr | 64-bit signless integer attribute |
width_dim | ::mlir::IntegerAttr | 64-bit signless integer attribute |
channel_dim | ::mlir::IntegerAttr | 64-bit signless integer attribute |
flattened_compat_info | ::mlir::tt::ttir::FlattenedCompatInfoAttr | Information for sliding window operations with tensors flattened to (1, 1, N*H*W, C){{% markdown %}} This attribute marks operations that are compatible with flattened tensors. It is used as a marker and doesn't carry any additional data. {{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
weight | ranked tensor of any type values |
bias | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.conv3d (tt::ttir::Conv3dOp)
Conv3d operation.
Applies a 3D convolution over an input volume composed of several input planes.
This operation performs a 3D convolution on the input tensor using the provided weight tensor and optional bias. It supports configurable stride, padding, padding_mode and grouping parameters to control the convolution behavior. This is commonly used for video or volumetric data processing.
Example:
// Basic 3D convolution with 3x3x3 kernel
%input = ... : tensor<1x8x28x28x4xf32> // Batch=1, Depth=8, H=28, W=28, Channels=4
%weight = ... : tensor<16x4x3x3x3xf32> // 16 output channels, 4 input channels, 3x3x3 kernel
%bias = ... : tensor<1x1x1x1x16xf32> // Bias for 16 output channels
%result = ttir.conv3d(%input, %weight, %bias) {
stride = [1, 1, 1],
padding = [0, 0, 0],
groups = 1,
padding_mode = "zeros"
} : (tensor<1x8x28x28x4xf32>, tensor<16x4x3x3x3xf32>, tensor<1x1x1x1x16xf32>) -> tensor<1x6x26x26x16xf32>
// Convolution with stride 2 and padding
%input = ... : tensor<1x8x28x28x4xf32> // Batch size 1, Depth=8, H=28, W=28, Channels=4
%weight = ... : tensor<16x4x3x3x3xf32> // 16 output channels, 4 input channels, 3x3x3 kernel
%bias = ... : tensor<1x1x1x1x16xf32> // Bias for 16 output channels
%result = ttir.conv3d(%input, %weight, %bias) {
stride = [2, 2, 2],
padding = [1, 1, 1],
groups = 1,
padding_mode = "zeros"
} : (tensor<1x8x28x28x4xf32>, tensor<16x4x3x3x3xf32>, tensor<1x1x1x1x16xf32>) -> tensor<1x4x14x14x16xf32>
Inputs:
input(AnyRankedTensor): expected in the following format (N, D, H, W, C) where:- N is the batch size
- D is the depth of the input volume
- H is the height of the input planes
- W is the width of the input planes
- C is the number of input channels
weight(AnyRankedTensor): expected in the following format (C_out, C_in, K_D, K_H, K_W) where:- C_out is the number of output channels
- C_in is the number of input channels
- K_D is the depth of the kernel
- K_H is the height of the kernel
- K_W is the width of the kernel
biasOptional: expected in the following format (1, 1, 1, 1, C_out).
Attributes:
stride(i32 | array<3xi32>): [sD, sH, sW] where sD is stride for depth, sH for height, sW for width.padding(i32 |array<3xi32>): [pD, pH, pW] where pD is padding for depth, pH for height, pW for width. Padding is symmetric (same on both sides of each dimension).padding_mode(StrAttr): "zeros" or "replicate" - padding fill strategy.groups(i32): Number of blocked connections from input channels to output channels.
Output:
resultAnyRankedTensor: 5D tensor in format (N, D_out, H_out, W_out, C_out) where:D_out = (D_in + 2*pD - K_D) / sD + 1H_out = (H_in + 2*pH - K_H) / sH + 1W_out = (W_in + 2*pW - K_W) / sW + 1
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
stride | ::mlir::Attribute | 32-bit signless integer attribute or i32 dense array attribute |
padding | ::mlir::Attribute | 32-bit signless integer attribute or i32 dense array attribute |
groups | ::mlir::IntegerAttr | 32-bit signless integer attribute |
batch_dim | ::mlir::IntegerAttr | 64-bit signless integer attribute |
depth_dim | ::mlir::IntegerAttr | 64-bit signless integer attribute |
height_dim | ::mlir::IntegerAttr | 64-bit signless integer attribute |
width_dim | ::mlir::IntegerAttr | 64-bit signless integer attribute |
channel_dim | ::mlir::IntegerAttr | 64-bit signless integer attribute |
padding_mode | ::mlir::StringAttr | string attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
weight | ranked tensor of any type values |
bias | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.conv_transpose2d (tt::ttir::ConvTranspose2dOp)
ConvTranspose2d operation.
Applies a 2D transposed convolution operator over an input image composed of several input planes.
This operation performs the gradient of a 2D convolution with respect to the input, which is useful for tasks like upsampling feature maps in neural networks. It supports configurable stride, padding, dilation, output padding, and grouping parameters.
Example:
// Basic 2D transposed convolution
%input = ... : tensor<1x14x14x16xf32> // Batch size 1, 14x14 feature map, 16 channels
%weight = ... : tensor<16x8x3x3xf32> // 16 input channels, 8 output channels, 3x3 kernel
%bias = ... : tensor<1x1x1x8xf32> // Bias for 8 output channels
%result = ttir.conv_transpose2d(%input, %weight, %bias) {
stride = [2, 2],
padding = [0, 0, 0, 0],
dilation = [1, 1],
output_padding = [0, 0],
groups = 1
} : (tensor<1x14x14x16xf32>, tensor<16x8x3x3xf32>, tensor<1x1x1x8xf32>) -> tensor<1x28x28x8xf32>
// Transposed convolution with padding and output padding
%input = ... : tensor<1x14x14x16xf32> // Batch size 1, 14x14 feature map, 16 channels
%weight = ... : tensor<16x8x4x4xf32> // 16 input channels, 8 output channels, 4x4 kernel
%bias = ... : tensor<1x1x1x8xf32> // Bias for 8 output channels
%result = ttir.conv_transpose2d(%input, %weight, %bias) {
stride = [2, 2],
padding = [1, 1, 1, 1],
dilation = [1, 1],
output_padding = [1, 1],
groups = 1
} : (tensor<1x14x14x16xf32>, tensor<16x8x4x4xf32>, tensor<1x1x1x8xf32>) -> tensor<1x29x29x8xf32>
Inputs:
inputAnyRankedTensor: 4D tensor where dimension indices are controlled bybatch_dim,height_dim,width_dim, andchannel_dimattributes. Default layout is NHWC (N, H_in, W_in, C) where:- N is the batch size
- H_in is the height of the input planes
- W_in is the width of the input planes
- C is the number of channels
weight(AnyRankedTensor): expected in the following format (C, O/G, K_H, K_W) where:- C is the number of input channels
- O is the number of output channels
- G is the number of groups
- K_H is the height of the kernel
- K_W is the width of the kernel
biasOptional: bias tensor with output channels at position specified by channel_dim. Default format is (1, 1, 1, O).
Attributes:
stride(i32 | array<2xi32>): Controls the stride for the cross-correlation.padding(i32 | array<2xi32> | array<4xi32>): Controls the amount of implicit zero padding on both sides for dilation * (kernel_size - 1) - padding number of points.output_padding(i32 | array<2xi32>): Controls the additional size added to one side of the output shape.dilation(i32 | array<2xi32>): Controls the spacing between the kernel pointsgroupsi32: Controls the connections between inputs and outputs. Must be divisible by input and output channels.batch_dim(i64): Index of the batch dimension in input/output tensors. Default: 0.height_dim(i64): Index of the height dimension in input/output tensors. Default: 1.width_dim(i64): Index of the width dimension in input/output tensors. Default: 2.channel_dim(i64): Index of the channel dimension in input/output tensors. Default: 3.
Output:
resultAnyRankedTensor: 4D tensor with same layout as input (controlled by dimension attributes). Default format is (N, H_out, W_out, O) where:- H_out = (H_in - 1) * stride[0] - (padding_top + padding_bottom) + dilation[0] * (K_H - 1) + output_padding[0] + 1
- W_out = (W_in - 1) * stride[1] - (padding_left + padding_right) + dilation[1] * (K_W - 1) + output_padding[1] + 1
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), QuantizableOpInterface, TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
stride | ::mlir::Attribute | 32-bit signless integer attribute or i32 dense array attribute |
padding | ::mlir::Attribute | 32-bit signless integer attribute or i32 dense array attribute |
output_padding | ::mlir::Attribute | 32-bit signless integer attribute or i32 dense array attribute |
dilation | ::mlir::Attribute | 32-bit signless integer attribute or i32 dense array attribute |
groups | ::mlir::IntegerAttr | 32-bit signless integer attribute |
batch_dim | ::mlir::IntegerAttr | 64-bit signless integer attribute |
height_dim | ::mlir::IntegerAttr | 64-bit signless integer attribute |
width_dim | ::mlir::IntegerAttr | 64-bit signless integer attribute |
channel_dim | ::mlir::IntegerAttr | 64-bit signless integer attribute |
flattened_compat_info | ::mlir::tt::ttir::FlattenedCompatInfoAttr | Information for sliding window operations with tensors flattened to (1, 1, N*H*W, C){{% markdown %}} This attribute marks operations that are compatible with flattened tensors. It is used as a marker and doesn't carry any additional data. {{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
weight | ranked tensor of any type values |
bias | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.cos (tt::ttir::CosOp)
Elementwise cosine operation.
The cos operation computes the cosine of each element in the input tensor.
For each element, it returns the cosine of the angle in radians.
Example:
// Compute cosine of all elements in %input
%result = ttir.cos(%input) : (tensor<4x4xf32>) -> tensor<4x4xf32>
// Input tensor:
// [[1.7, 2.0, -0.3, 4.5], ... ]
// Output tensor:
// [[0.9601, 0.5403, -0.9553, -0.1365], ... ]
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.cumprod (tt::ttir::CumProdOp)
Cumulative product operation.
The cumprod operation computes the cumulative product of elements along a specified dimension of the input tensor.
For each position in the output tensor, this operation computes the product of all elements in the input tensor along the specified dimension up to and including that position. The shape of the output tensor matches the shape of the input tensor.
Example:
// Cumulative product along dimension 0
%input = ... : tensor<2x3xf32>
%result = ttir.cumprod(%input) {dim = 0 : i64} : (tensor<2x3xf32>) -> tensor<2x3xf32>
// Input tensor:
// [[2, 3, 4],
// [5, 6, 7]]
// Output tensor:
// [[2, 3, 4], // first row remains the same
// [10, 18, 28]] // each element is the product of the corresponding column up to this point
// Cumulative product along dimension 1
%input = ... : tensor<2x3xf32>
%result = ttir.cumprod(%input) {dim = 1 : i64} : (tensor<2x3xf32>) -> tensor<2x3xf32>
// Input tensor:
// [[2, 3, 4],
// [5, 6, 7]]
// Output tensor:
// [[2, 6, 24], // each element is the product of the corresponding row up to this point
// [5, 30, 210]]
Inputs:
input(Tensor): The input tensor.
Attributes:
dim(Integer): The dimension along which to compute the cumulative product.
Output:
result(Tensor): The tensor containing the cumulative products.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim | ::mlir::IntegerAttr | 64-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.cumsum (tt::ttir::CumSumOp)
Cumulative sum operation.
The cumsum operation computes the cumulative sum of elements along a specified dimension of the input tensor.
For each position in the output tensor, this operation computes the sum of all elements in the input tensor along the specified dimension up to and including that position. The shape of the output tensor matches the shape of the input tensor.
Example:
// Cumulative sum along dimension 0
%input = ... : tensor<2x3xf32>
%result = ttir.cumsum(%input) {dim = 0 : i64} : (tensor<2x3xf32>) -> tensor<2x3xf32>
// Input tensor:
// [[1, 2, 3],
// [4, 5, 6]]
// Output tensor:
// [[1, 2, 3], // first row remains the same
// [5, 7, 9]] // each element is the sum of the corresponding column up to this point
// Cumulative sum along dimension 1
%input = ... : tensor<2x3xf32>
%result = ttir.cumsum(%input) {dim = 1 : i64} : (tensor<2x3xf32>) -> tensor<2x3xf32>
// Input tensor:
// [[1, 2, 3],
// [4, 5, 6]]
// Output tensor:
// [[1, 3, 6], // each element is the sum of the corresponding row up to this point
// [4, 9, 15]]
Inputs:
input(Tensor): The input tensor.
Attributes:
dim(Integer): The dimension along which to compute the cumulative sum.
Output:
result(Tensor): The tensor containing the cumulative sums.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim | ::mlir::IntegerAttr | 64-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.dealloc (tt::ttir::DeallocOp)
Dealloc op.
Tensor Dealloc operation
Operands:
| Operand | Description |
|---|---|
result | ranked tensor of any type values |
ttir.dequantize (tt::ttir::DequantizeOp)
Dequantize operation.
The Dequantize operation converts a quantized tensor back into a floating-point tensor using the quant.uniform type from the MLIR Quant dialect.
The input tensor is expected to be of type quant.uniform.
The output tensor will be a floating-point tensor, where each element is computed as:
output[i] = (input[i] - zero_point) * scale
Example:
%input = ttir.empty() : () -> tensor<64x128x!quant.uniform<i32:f32, 0.1>>
%dequantized = "ttir.dequantize"(%input) : (tensor<64x128x!quant.uniform<i32:f32, 0.1>>) -> tensor<64x128xf32>
// In this example:
// - The input is a 64x128 tensor of 32-bit quantized values
// - The output is a 64x128 tensor of 32-bit floating-point values
// - The scale is 0.1 (each step represents 0.1 in the original scale)
// - The zero point is 128 (the value 128 in the quantized space represents 0.0 in the original space)
Inputs:
input(Quantized Tensor): The quantized tensor to be dequantized.
Results:
result(Tensor): The floating-point tensor after dequantization.
Note: The quantization parameters (scale and zero point) are specified in the input tensor type. Dequantization is the reverse process of quantization, converting quantized values back to floating-point values.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.dequantize_unrolled (tt::ttir::DequantizeUnrolledOp)
Dequantize operation unrolled (scale and zero point as input operands).
The DequantizeUnrolledOp dequantizes a tensor using the scale and zero point provided as input operands.
Inputs:
inputAnyRankedTensor: The input tensor to be dequantized. Must have quantized element type.scaleAnyRankedTensor: The scale factor (or factors for per-axis quantization).zero_pointAnyRankedTensor: The zero point value (or values for per-axis quantization). Must be in range of the quantized storage type.axisOptional: The axis along which quantization is applied. Must be in range [0, rank) where rank is the rank of the input tensor.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
axis | ::mlir::IntegerAttr | 32-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
scale | ranked tensor of any type values |
zero_point | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.distributed_layer_norm (tt::ttir::DistributedLayerNormOp)
Distributed layer normalization with all-gather operation
Fused distributed layer normalization across mesh devices. Each device computes local partial statistics (sum of x and sum of x²), the statistics are all-gathered along cluster_axis to obtain globally-correct mean and variance, and each device then normalizes its local shard. The steps are:
- Optional residual addition: norm_input = input + residual
- Compute local partial statistics and all-gather across cluster_axis
- Layer normalization: output = (norm_input - mean) / sqrt(var + epsilon) * weight + bias
Only statistics are communicated across devices — the input data itself is not all-gathered. Each device's output shape equals its input shape.
This is a multi-device operation that requires the tensor to be sharded across a device mesh along the normalized (last) dimension.
Decomposes in the TTNN dialect into: layer_norm_pre_all_gather → all_gather → layer_norm_post_all_gather.
Inputs:
input(Tensor): The input tensor to be normalized.weight(Optional Tensor): The scale parameter (gamma).bias(Optional Tensor): The shift parameter (beta).residual(Optional Tensor): Residual tensor for fused add before normalization.
Attributes:
cluster_axisspecifies which mesh dimension to all-gather the statistics across (0 or 1).epsilonis a small constant added for numerical stability (default: 1e-05).
Output:
result(Tensor): The normalized output tensor (same shape as input).
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
cluster_axis | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
epsilon | ::mlir::FloatAttr | 32-bit float attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
weight | ranked tensor of any type values |
bias | ranked tensor of any type values |
residual | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.distributed_rms_norm (tt::ttir::DistributedRMSNormOp)
Distributed RMS normalization with all-gather operation
Fused distributed RMS normalization across mesh devices. Each device computes local RMS statistics (E(x²)), the statistics are all-gathered along cluster_axis to obtain globally-correct values, and each device then normalizes its local shard. The steps are:
- Optional residual addition (input + residual)
- Compute local E(x²) and all-gather statistics across cluster_axis
- RMS normalization: output = input * rsqrt(E(x²) + epsilon) * weight
Only statistics are communicated across devices — the input data itself is not all-gathered. Each device's output shape equals its input shape.
This is a multi-device operation that requires the tensor to be sharded across a device mesh.
Inputs:
input(Tensor): The input tensor to be normalized.weight(Optional Tensor): The scale parameter (gamma).residual(Optional Tensor): Residual tensor for fused add before normalization.
Attributes:
cluster_axisspecifies which mesh dimension to all-gather the statistics across (0 or 1).epsilonis a small constant added for numerical stability (default: 1e-05).
Output:
result(Tensor): The normalized output tensor (same shape as input).
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
cluster_axis | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
epsilon | ::mlir::FloatAttr | 32-bit float attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
weight | ranked tensor of any type values |
residual | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.div (tt::ttir::DivOp)
Elementwise division operation.
The div operation performs an elementwise division between two tensors.
For each pair of corresponding elements, it divides the element in the first tensor (dividend) by the element in the second tensor (divisor) and places the result in the output tensor.
Example:
// Division operation
%result = ttir.div(%lhs, %rhs) : (tensor<3xi32>, tensor<3xi32>) -> tensor<3xi32>
// Input tensors:
// %lhs: [10, 20, 20]
// %rhs: [1, 2, 3]
// Output tensor:
// [10, 10, 6]
// Example with floating point values
%result = ttir.div(%float_lhs, %float_rhs) : (tensor<3xf32>, tensor<3xf32>) -> tensor<3xf32>
// Input tensors:
// %float_lhs: [3.5, 0.0, -1.2]
// %float_rhs: [1.5, 2.0, -3.2]
// Output tensor:
// [2.333333333, 0.0, -0.375]
Note: Division by zero typically results in undefined behavior or NaN for floating-point types.
Mathematical definition: div(x, y) = x / y
Traits: AlwaysSpeculatableImplTrait, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.dot_general (tt::ttir::DotGeneralOp)
Dot general operation.
Flexible tensor operation that generalizes matrix multiplication by allowing user to specify which dimensions of two tensors to contract. Matrix multiplication is a special case of this operation, where the contraction happens along the last axis of the first tensor and the second-to-last axis of the second tensor. From StableHLO DotGeneral Op https://openxla.org/stablehlo/spec#dot_general
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
batch_dims_lhs | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
contract_dims_lhs | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
batch_dims_rhs | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
contract_dims_rhs | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.dropout (tt::ttir::DropoutOp)
Dropout operation.
Applies dropout to the input tensor element-wise.
During training, randomly zeroes some elements of the input tensor with
probability prob using samples from a Bernoulli distribution. The
remaining elements are scaled by scale (typically 1/(1-prob)) to maintain
the expected sum.
Example: %result = "ttir.dropout"(%input) <{prob = 0.2 : f32, scale = 1.25 : f32, seed = 42 : ui32}> : (tensor<64x128xbf16>) -> tensor<64x128xbf16>
Attributes:
prob(Float): Dropout probability. Elements are zeroed with this probability [Default: 0.0].scale(Float): Scale factor applied to non-zeroed elements. Typically 1/(1-prob) [Default: 1.0].seed(Integer): Seed for the random number generator [Default: 0].use_per_device_seed(Bool): Whether to use a different seed per device [Default: true].
Inputs:
input(Tensor): The input tensor.
Output:
result(Tensor): The output tensor with dropout applied.
Traits: TTCore_NonCacheableTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
prob | ::mlir::FloatAttr | 32-bit float attribute |
scale | ::mlir::FloatAttr | 32-bit float attribute |
seed | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
use_per_device_seed | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.embedding_backward (tt::ttir::EmbeddingBackwardOp)
Embedding backward operation.
The embedding_backward operation computes the gradient of the embedding operation with respect to the weight tensor.
This operation takes an input tensor of indices, the original weight tensor, and the gradient tensor from previous backpropagation steps. It computes how the embedding weights should be updated during backpropagation by accumulating gradients at the appropriate indices in the weight tensor.
Example:
// Embedding backward
%input = ... : tensor<2x3xi32> // Original indices used in the forward pass
%weight = ... : tensor<10x4xf32> // Original embedding table
%in_gradient = ... : tensor<2x3x4xf32> // Gradient from previous backpropagation steps
%result = ttir.embedding_backward(%input, %weight, %in_gradient) :
(tensor<2x3xi32>, tensor<10x4xf32>, tensor<2x3x4xf32>) -> tensor<10x4xf32>
// Input tensor (indices):
// [[0, 2, 5],
// [7, 1, 9]]
// Input gradient tensor (from previous backpropagation steps):
// [[[0.1, 0.2, 0.3, 0.4], // gradient for embedding of index 0
// [0.5, 0.6, 0.7, 0.8], // gradient for embedding of index 2
// [...]], // gradient for embedding of index 5
// [[...], // gradient for embedding of index 7
// [0.9, 1.0, 1.1, 1.2], // gradient for embedding of index 1
// [...]]] // gradient for embedding of index 9
// Output tensor (gradient for the embedding table):
// The gradients are accumulated at the corresponding indices in the weight tensor.
// For example, at index 0, the gradient is [0.1, 0.2, 0.3, 0.4]
Note: If the same index appears multiple times in the input tensor, the gradients are accumulated (added) at that index in the output tensor.
Inputs:
input(Tensor): The original input tensor containing indices used in the forward pass.weight(Tensor): The original embedding table tensor.in_gradient(Tensor): The gradient tensor from the forward pass.
Output:
result(Tensor): The gradient tensor for the embedding table.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
weight | ranked tensor of any type values |
in_gradient | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.embedding (tt::ttir::EmbeddingOp)
Embedding lookup operation.
The embedding operation performs a lookup in an embedding table (weight matrix) using integer indices.
This operation takes an input tensor of indices and a weight tensor representing the embedding table. For each index in the input tensor, it retrieves the corresponding row from the weight tensor. The result is a tensor where each input index is replaced by its corresponding embedding vector.
Example:
// Embedding lookup
%input = ... : tensor<2x3xi32> // Batch of indices
%weight = ... : tensor<10x4xf32> // Embedding table with 10 entries of dimension 4
%result = ttir.embedding(%input, %weight) : (tensor<2x3xi32>, tensor<10x4xf32>) -> tensor<2x3x4xf32>
// Input tensor (indices):
// [[0, 2, 5],
// [7, 1, 9]]
// Weight tensor (embedding table):
// [[0.1, 0.2, 0.3, 0.4], // embedding vector for index 0
// [0.5, 0.6, 0.7, 0.8], // embedding vector for index 1
// [0.9, 1.0, 1.1, 1.2], // embedding vector for index 2
// ...
// [1.7, 1.8, 1.9, 2.0]] // embedding vector for index 9
// Output tensor:
// [[[0.1, 0.2, 0.3, 0.4], // embedding for index 0
// [0.9, 1.0, 1.1, 1.2], // embedding for index 2
// [...]], // embedding for index 5
// [[...], // embedding for index 7
// [0.5, 0.6, 0.7, 0.8], // embedding for index 1
// [...]]] // embedding for index 9
Note: The indices in the input tensor must be valid indices into the first dimension of the weight tensor.
Inputs:
input(Tensor): The input tensor containing indices.weight(Tensor): The embedding table tensor.
Output:
result(Tensor): The resulting tensor containing the embeddings.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
weight | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.empty (tt::ttir::EmptyOp)
Empty tensor allocation operation.
Syntax:
operation ::= `ttir.empty` `(` `)` attr-dict `:` type($result)
The empty operation creates an uninitialized tensor with the specified shape and element type.
This operation allocates memory for a tensor but does not initialize its values. It's commonly used as a first step before filling the tensor with computed values. The shape and element type of the tensor are determined by the return type.
Example:
// Create an uninitialized 2D tensor with shape [3, 4]
%result = ttir.empty() : tensor<3x4xf32>
// Create an uninitialized 3D tensor with shape [2, 3, 4]
%result = ttir.empty() : tensor<2x3x4xi32>
// Use empty to create a tensor for storing computation results
%input = ... : tensor<10x20xf32>
%result = ttir.some_computation(%input) : (tensor<10x20xf32>) -> tensor<10x20xf32>
Output:
result(Tensor): The uninitialized tensor.
Note: Since the tensor is uninitialized, reading from it before writing may yield undefined values.
This operation is typically used in conjunction with other operations that will fill the tensor with
meaningful values. The empty operation is more efficient than zeros or ones when the tensor
will be completely overwritten, as it avoids the initialization step.
Traits: TTCore_CreationOpTrait, TTCore_NonCacheableTrait
Interfaces: MemoryEffectOpInterface
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.eq (tt::ttir::EqualOp)
Elementwise equality comparison operation.
The eq operation performs an elementwise equality comparison between two tensors.
For each pair of corresponding elements, it returns:
- 1 (true) if the elements are equal
- 0 (false) if the elements are not equal
Note that special handling may be required for floating-point NaN values, as NaN is not equal to any value, including itself.
Example:
// Compare elements for equality
%result = ttir.eq(%lhs, %rhs) : (tensor<4x4xf32>, tensor<4x4xf32>) -> tensor<4x4xi1>
// Input tensors:
// %lhs: [[1.0, 2.0, 3.0, 2.0], ... ]
// %rhs: [[1.0, 2.0, 4.0, 5.0], ... ]
// Output tensor:
// [[1, 1, 0, 0], ... ] // 1 where equal, 0 where not equal
// Example with integer tensors
%result = ttir.eq(%int_lhs, %int_rhs) : (tensor<3xi32>, tensor<3xi32>) -> tensor<3xi1>
// Input tensors:
// %int_lhs: [10, -5, 0]
// %int_rhs: [10, 5, 1]
// Output tensor:
// [1, 0, 0] // Only the first elements are equal
Mathematical definition: equal(x, y) = x == y
Traits: AlwaysSpeculatableImplTrait, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.erf (tt::ttir::ErfOp)
Element-wise error function operation.
Element-wise error function (erf) operation. Calculates erf(x) for each element of the input tensor.
Example:
// Compute error function for all elements in %input
%result = ttir.erf(%input) : (tensor<4x4xf32>) -> tensor<4x4xf32>
// Input tensor with values [0.0, 1.0, -1.0, 2.0]
// Output tensor with values [0.0, 0.8427, -0.8427, 0.9953]
Mathematical definition: erf(x) = (2/√π) ∫₀ˣ e^(-t²) dt
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.erfc (tt::ttir::ErfcOp)
Element-wise complementary error function operation.
Element-wise complementary error function (erfc) operation. Calculates erfc(x) = 1 - erf(x) for each element of the input tensor.
Example:
// Compute complementary error function for all elements in %input
%result = ttir.erfc(%input) : (tensor<4x4xf32>) -> tensor<4x4xf32>
// Input tensor with values [0.0, 1.0, -1.0, 2.0]
// Output tensor with values [1.0, 0.1573, 1.8427, 0.0047]
Mathematical definition: erfc(x) = 1 - erf(x) = 1 - (2/√π) ∫ₓ^∞ e^(-t²) dt
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.exp2 (tt::ttir::Exp2Op)
Elementwise base-2 exponential.
For each element x, returns 2^x.
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.exp (tt::ttir::ExpOp)
Elementwise exponential op.
The exp operation computes the exponential of each element in the input tensor.
For each element, it returns e^x, where e is the base of natural logarithms (approximately 2.71828).
Example:
// Compute exponential of all elements in %input
%result = ttir.exp(%input) : (tensor<4x4xf32>) -> tensor<4x4xf32>
// Input tensor:
// [[1.0, 2.0, -3.0, 4.0], ... ]
// Output tensor:
// [[2.71828, 7.389056, 0.090031, 54.59815], ... ]
Mathematical definition: exp(x) = e^x
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.expm1 (tt::ttir::Expm1Op)
Elementwise exponential minus one operation.
The expm1 operation computes the exponential of each element in the input tensor and subtracts one.
For each element x, it returns e^x - 1. This operation is more accurate than computing exp(x) - 1 directly for x values close to zero, where catastrophic cancellation can occur in the subtraction.
Example:
// Compute expm1 of all elements in %input
%result = ttir.expm1(%input) : (tensor<2x2xf32>) -> tensor<2x2xf32>
// Input tensor:
// [[0.0, 1.0],
// [0.0, 0.0]]
// Output tensor:
// [[0.0, 1.71828],
// [0.0, 0.0]]
// Example with small values where expm1 is more accurate than exp(x)-1
%result = ttir.expm1(%small_input) : (tensor<3xf32>) -> tensor<3xf32>
// Input tensor:
// [1e-10, 1e-7, 1e-5]
// Output tensor:
// [1e-10, 1e-7, 1e-5] // Approximately equal to the input for very small values
Mathematical definition: expm1(x) = e^x - 1
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.fill_cache (tt::ttir::FillCacheOp)
Cache filling operation.
The fill_cache operation fills a cache tensor with values from an input tensor.
Unlike update_cache which updates specific positions, this operation fills the entire cache
or a contiguous section of it with values from the input tensor. This is commonly used to
initialize a cache in sequence models.
Example:
// Fill cache with input values
%cache = ... : tensor<2x16x64xf32> // Batch size 2, sequence length 16, hidden dim 64
%input = ... : tensor<2x16x64xf32> // Initial values for the entire cache
%result = ttir.fill_cache(%cache, %input) {batch_offset = 0 : i32} :
tensor<2x16x64xf32>, tensor<2x16x64xf32> -> tensor<2x16x64xf32>
// The entire cache tensor is filled with values from input
// Fill a portion of the cache
%cache = ... : tensor<2x16x64xf32> // Batch size 2, sequence length 16, hidden dim 64
%input = ... : tensor<2x8x64xf32> // Values for half of the cache
%result = ttir.fill_cache(%cache, %input) {batch_offset = 0 : i32} :
tensor<2x16x64xf32>, tensor<2x8x64xf32> -> tensor<2x16x64xf32>
// The first 8 positions of the cache are filled with values from input
Inputs:
cache(Tensor): The cache tensor to be filled.input(Tensor): The input tensor containing the values to fill the cache with.
Attributes:
batch_offset(Integer): Offset in the batch dimension.
Output:
result(Tensor): The filled cache tensor.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_CacheOpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
batch_offset | ::mlir::IntegerAttr | 32-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
cache | ranked tensor of any type values |
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.floor (tt::ttir::FloorOp)
Elementwise floor operation.
The floor operation computes the floor (greatest integer less than or equal to x)
of each element in the input tensor.
For each element, it rounds the value down to the nearest integer. The operation preserves the data type of the input.
This operation has the idempotence property, meaning that applying it multiple times produces the same result as applying it once: floor(floor(x)) = floor(x).
Example:
// Compute floor of all elements in %input
%result = ttir.floor(%input) : (tensor<4x4xf32>) -> tensor<4x4xf32>
// Input tensor:
// [[1.7, 2.0, -0.3, 4.5], ... ]
// Output tensor:
// [[1.0, 2.0, -1.0, 4.0], ... ]
Mathematical definition: floor(x) = ⌊x⌋ = max{n ∈ ℤ | n ≤ x}
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable, TTIR_Idempotence
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.frac (tt::ttir::FracOp)
Elementwise fractional part operation.
For each element x, returns the fractional part x - trunc(x), matching common floating-point library semantics.
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.full (tt::ttir::FullOp)
Creates a tensor filled with the specified value
Tensor operation to create a tensor filled with a specified value.
Given a shape and a fill_value, produces a tensor with the shape, filled with the specified value.
Example: %0 = "ttir.full"() <{shape = array<i32: 64, 32, 32>, fill_value = 7 : i32}> : () -> tensor<64x32x32xi32> // %0: [[[7, 7, 7, ..., 7], [7, 7, 7, ..., 7], ..., [7, 7, 7, ..., 7]]]
Traits: AlwaysSpeculatableImplTrait, ConstantLike, TTCore_CreationOpTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
shape | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
fill_value | ::mlir::Attribute | 32-bit float attribute or 32-bit signless integer attribute |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.gather (tt::ttir::GatherOp)
Gather operation along a single dimension
The gather operation gathers values from an input tensor along a
given dimension using an index tensor. This corresponds to torch.gather
semantics and maps directly to the tt-metal ttnn::gather device op.
Parameters:
input(Tensor): The source tensor to gather from.index(Tensor): Indices specifying which values to gather.dim(int32_t): The dimension along which to gather.
Example:
%result = "ttir.gather"(%input, %index)
<{dim = 0 : i32}> : (tensor<4x4xbf16>, tensor<2x4xi32>) -> tensor<2x4xbf16>
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim | ::mlir::IntegerAttr | 32-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
index | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.gelu_bw (tt::ttir::GeluBackwardOp)
Backward pass operation for the GELU activation function.
The gelu_bw operation computes the gradient of the GELU (Gaussian Error Linear Unit)
activation function with respect to its input during backpropagation. This is an elementwise
binary operation that multiplies the incoming gradient with the derivative of GELU.
Inputs:
lhs(Tensor): The gradient tensor flowing back from the loss (grad_output).rhs(Tensor): The original input tensor that was fed to the forward GELU operation.
Attributes:
approximate(string): The GELU approximation algorithm to use. Can be "none" (exact) or "tanh" (tanh approximation). Defaults to "none".
Output:
result(Tensor): The gradient with respect to the input tensor.
Example:
// Compute GELU backward pass
%result = ttir.gelu_bw(%grad, %input) :
(tensor<4x4xf32>, tensor<4x4xf32>, tensor<4x4xf32>) -> tensor<4x4xf32>
// With tanh approximation
%result = ttir.gelu_bw(%grad, %input) {approximate = "tanh"} :
(tensor<4x4xf32>, tensor<4x4xf32>, tensor<4x4xf32>) -> tensor<4x4xf32>
Mathematical definition (approximate = "none"): gelu_bw(grad, x) = grad * (cdf(x) + x * pdf(x)) where cdf is the cumulative distribution function and pdf is the probability density function of the standard normal distribution.
Mathematical definition (approximate = "tanh"): gelu_bw(grad, x) = grad * d/dx[0.5 * x * (1 + tanh(sqrt(2/pi) * (x + 0.044715 * x^3)))]
Traits: AlwaysSpeculatableImplTrait, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
approximate | ::mlir::StringAttr | string attribute |
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.gelu (tt::ttir::GeluOp)
Elementwise GELU operation.
The gelu operation computes the GELU (Gaussian Error Linear Unit) of each element in the input tensor.
For each element, it returns the GELU value, which is a smooth, non-monotonic function that approximates the cumulative distribution function of a standard normal distribution. The operation preserves the data type of the input.
Example:
// Compute GELU of all elements in %input
%result = ttir.gelu(%input) : (tensor<4x4xf32>) -> tensor<4x4xf32>
// Input tensor:
// [[1.7, 2.0, -0.3, 4.5], ... ]
// Output tensor:
// [[0.9601, 0.5403, -0.3, 4.5], ... ]
Mathematical definition: gelu(x) = 0.5 * x * (1 + erf(x / sqrt(2)))
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.get_dimension_size (tt::ttir::GetDimensionSizeOp)
GetDimensionSize op.
Produces the size of the given dimension of the operand.
Example: %operand: [[3, 2, 7], [1, 4, 4]] "ttir.get_dimension_size"(%operand, value = dense<0>, %out) -> %out: [[3]]
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dimension | ::mlir::IntegerAttr | 32-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
operand | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.global_avg_pool2d (tt::ttir::GlobalAvgPool2dOp)
A global average pooling 2d operation
The global_avg_pool2d operation applies global average pooling over the spatial dimensions
(height and width) of a 4D input tensor. In essence, it should be realised as the sum-reduce style operation
under the hood, for performance reasons (since we include all elements, there is no need for kernel allocation).
It reduces spatial dimensions to 1.
This operation yields the same result as the standard avg_pool_2d operation when kernel_size == [input_height, input_width]. However, it is much more memory efficient, as the underlying implementation doesn't need to allocate the kernel for pooling (since the operation boils down to a simple sum-reduce).
Example:
// Basic global average pooling reducing 32x32 spatial dimensions to 1x1
%input = ... : tensor<1x32x32x64xbf16> // Input tensor with values in NHWC format
// N=1 (batch), H=32 (height), W=32 (width), C=64 (channels)
%result = "ttir.global_avg_pool2d"(%input) : (tensor<1x32x32x64xbf16>) -> tensor<1x1x1x64xbf16>
// Result: tensor<1x1x1x64xbf16> where each channel contains the average of all 32*32=1024 spatial locations
// Example with different input sizes
%large_input = ... : tensor<1x128x128x32xbf16> // Large spatial dimensions
%large_result = "ttir.global_avg_pool2d"(%large_input) : (tensor<1x128x128x32xbf16>) -> tensor<1x1x1x32xbf16>
// Each output channel averages across 128*128=16384 spatial locations
Inputs:
input: 4D tensor with shape [N, H, W, C] where N is batch size, H is height, W is width, and C is channelsoutput: Pre-allocated output tensor with shape [N, 1, 1, C] to store the result
Attributes:
- None (this operation has no configurable attributes, unlike regular pooling operations)
Outputs:
result: 4D tensor with shape [N, 1, 1, C] containing the global average pooled values
Note: The operation reduces spatial dimensions (H, W) to (1, 1) by computing the average across all spatial locations for each channel independently. This is equivalent to avg_pool2d with kernel_size=[H, W], stride=[1, 1], and no padding, but implemented more efficiently.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.ge (tt::ttir::GreaterEqualOp)
Elementwise greater than or equal to.
The ge operation performs an elementwise greater than or equal to comparison between two tensors.
For each pair of corresponding elements, it returns:
- 1 (true) if the left element is greater than or equal to the right element
- 0 (false) if the left element is less than the right element
Example:
// Compare elements for greater than or equal to
%result = ttir.ge(%lhs, %rhs) : (tensor<4x4xf32>, tensor<4x4xf32>) -> tensor<4x4xi1>
// Input tensors:
// %lhs: [[1.0, 2.0, 3.0, 2.0], ... ]
// %rhs: [[1.0, 2.0, 4.0, 5.0], ... ]
// Output tensor:
// [[1, 1, 0, 0], ... ] // 1 where greater or equal, 0 where less
// Example with integer tensors
%result = ttir.ge(%int_lhs, %int_rhs) : (tensor<3xi32>, tensor<3xi32>) -> tensor<3xi1>
// Input tensors:
// %int_lhs: [10, -5, 0]
// %int_rhs: [10, 5, 1]
// Output tensor:
// [1, 0, 0] // Only the first elements are greater or equal
Mathematical definition: greater_equal(x, y) = x >= y
Traits: AlwaysSpeculatableImplTrait, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.gt (tt::ttir::GreaterThanOp)
Elementwise greater than.
The gt operation performs an elementwise greater than comparison between two tensors.
For each pair of corresponding elements, it returns:
- 1 (true) if the left element is greater than the right element
- 0 (false) if the left element is less than or equal to the right element
Example:
// Compare elements for greater than
%result = ttir.gt(%lhs, %rhs) : (tensor<4x4xf32>, tensor<4x4xf32>) -> tensor<4x4xi1>
// Input tensors:
// %lhs: [[1.0, 2.0, 3.0, 2.0], ... ]
// %rhs: [[1.0, 2.0, 4.0, 5.0], ... ]
// Output tensor:
// [[0, 0, 0, 1], ... ] // 1 where greater, 0 where less or equal
// Example with integer tensors
%result = ttir.gt(%int_lhs, %int_rhs) : (tensor<3xi32>, tensor<3xi32>) -> tensor<3xi1>
// Input tensors:
// %int_lhs: [10, -5, 0]
// %int_rhs: [10, 5, 1]
// Output tensor:
// [0, 0, 0] // Only the last element is greater
Mathematical definition: greater_than(x, y) = x > y
Traits: AlwaysSpeculatableImplTrait, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.group_norm (tt::ttir::GroupNormOp)
Group normalization operation
Computes group normalization over the input tensor. The input tensor's channels are split into groups, and mean and variance are computed per group. The result is normalized by subtracting the mean and dividing by the standard deviation, then optionally scaled and shifted by weight (gamma) and bias (beta).
Input tensor must be at least 4D. Common shapes include [N, C, H, W] (4D) and [N, C, D, H, W] (5D for 3D convolutions). During TTIR-to-TTNN conversion, inputs are permuted and reshaped to [N, 1, H*W, C] based on the channel_dim attribute.
Inputs:
input(Tensor): The input tensor to be normalized (at least 4D).input_mask(Optional Tensor): When processing the inputs, the mask is used to only look at the elements of the current group. Defaults to None.weight(Optional Tensor): The scale parameter (gamma). If provided, the normalized result is element-wise multiplied by this weight.bias(Optional Tensor): The shift parameter (beta). If provided, this bias is added to the scaled result.
Attributes:
num_groups(int): Number of groups to split the tensor's channels into. C must divide evenly into num_groups.epsilon: Small constant added for numerical stability (default: 1e-12).channel_dim(int): The index of the channel dimension in the input tensor. Default is 3 (channels-last / NHWC). Set to 1 for NCHW layout. During TTIR-to-TTNN conversion, the input is permuted and reshaped to [N, 1, H*W, C] based on this attribute.
Output:
result(Tensor): The group normalized output tensor.
Example:
// Group norm with 8 groups, input shape [1, 1, 64, 480]
%result = ttir.group_norm(%input, %input_mask, %weight, %bias) : <{ num_groups = 8, epsilon = 1e-12 }> :
(tensor<1x1x64x480xf32>, tensor<1x8x32x32xf32>, tensor<1x1x15x32xf32>, tensor<1x1x15x32xf32>) -> tensor<1x1x64x480xf32>
Mathematical definition: group_norm(x, weight, bias, epsilon) = ((x - mu) / sqrt(sigma^2 + epsilon)) * weight + bias where mu and sigma^2 are the mean and variance computed per group.
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
num_groups | ::mlir::IntegerAttr | 64-bit signless integer attribute |
epsilon | ::mlir::FloatAttr | 32-bit float attribute |
channel_dim | ::mlir::IntegerAttr | 64-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
input_mask | ranked tensor of any type values |
weight | ranked tensor of any type values |
bias | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.hardsigmoid (tt::ttir::HardsigmoidOp)
Elementwise hard sigmoid operation.
The hardsigmoid operation computes the hard sigmoid activation function of each element in the input tensor.
The hard sigmoid function is a piecewise linear approximation of the sigmoid function that is computationally more efficient. It is defined as:
- 0 if x <= -3
- (x + 3) / 6 if -3 < x < 3
- 1 if x >= 3
This activation function is commonly used in neural networks as a computationally efficient alternative to the standard sigmoid function, particularly in mobile and embedded applications where computational resources are limited.
Example:
// Compute hard sigmoid of all elements in %input
%result = ttir.hardsigmoid(%input, %output) : tensor<4x4xf32>, tensor<4x4xf32> -> tensor<4x4xf32>
// Input tensor:
// [-3.0, -1.0, 0.0, 3.0]
// Output tensor:
// [0.0, 0.333, 0.5, 1.0]
Mathematical definition: hardsigmoid(x) = max(0, min(1, (x + 3) / 6))
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.index (tt::ttir::IndexOp)
Tensor indexing operation.
The index operation extracts a sub-tensor (slice) from the input tensor along a specified dimension.
This operation selects elements from the input tensor along a single dimension based on the specified
begin, end, and step indices. It's similar to Python's slicing notation tensor[:, begin:end:step, :]
where the slicing is applied only to the specified dimension.
Example:
// Extract elements with indices 1, 3, 5 from dimension 0 of a 1D tensor
%input = ... : tensor<6xf32> // Input tensor with values: [1, 2, 3, 4, 5, 6]
%result = ttir.index(%input) {
dim = 0 : i32, // Dimension to index
begin = 1 : i32, // Start index
end = 6 : i32, // End index (exclusive)
step = 2 : i32 // Step size
} : (tensor<6xf32>) -> tensor<3xf32>
// Result: [2, 4, 6]
// Extract columns 0 and 2 from a 2D tensor
%input = ... : tensor<3x4xf32> // Input tensor with values:
// [[1, 2, 3, 4],
// [5, 6, 7, 8],
// [9, 10, 11, 12]]
%result = ttir.index(%input) {
dim = 1 : i32, // Index along columns (dimension 1)
begin = 0 : i32, // Start from first column
end = 3 : i32, // End at third column (exclusive)
step = 2 : i32 // Take every other column
} : (tensor<3x4xf32>) -> tensor<3x2xf32>
// Result:
// [[1, 3],
// [5, 7],
// [9, 11]]
Inputs:
input(Tensor): The input tensor to index.
Attributes:
dim(Integer): The dimension along which to index.begin(Integer): The starting index.end(Integer): The ending index (exclusive).step(Integer): The step size between indices.
Output:
result(Tensor): The indexed tensor.
Note: The shape of the output tensor is the same as the input tensor except for the indexed dimension,
which will have size ceil((end - begin) / step). The indices selected will be begin, begin + step,
begin + 2*step, etc., up to but not including end.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim | ::mlir::IntegerAttr | 32-bit signless integer attribute |
begin | ::mlir::IntegerAttr | 32-bit signless integer attribute |
end | ::mlir::IntegerAttr | 32-bit signless integer attribute |
step | ::mlir::IntegerAttr | 32-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.index_select (tt::ttir::IndexSelectOp)
Tensor selection operation.
The index_select operation extracts a sub-tensor (slice) from the input tensor along a specified dimension.
Unlike the more general slice operation, index_select operates on a single dimension with a specified
starting index, length, and optional stride. This is useful for extracting specific segments of a tensor
along a particular axis.
Example:
// Select elements 2, 3, 4 from a 1D tensor along dimension 0
%input = ... : tensor<6xf32> // Input tensor with values: [1, 2, 3, 4, 5, 6]
%result = ttir.index_select(%input) {
dim = 0 : i32, // Dimension to select from
begin = 2 : i32, // Start index
length = 3 : i32, // Number of elements to select
stride = 0 : i32 // No stride (consecutive elements)
} : (tensor<6xf32>) -> tensor<3xf32>
// Result: [3, 4, 5]
// Select every other row from a 2D tensor
%input = ... : tensor<4x3xf32> // Input tensor with values:
// [[1, 2, 3],
// [4, 5, 6],
// [7, 8, 9],
// [10, 11, 12]]
%result = ttir.index_select(%input) {
dim = 0 : i32, // Select along rows
begin = 0 : i32, // Start from the first row
length = 2 : i32, // Select 2 rows
stride = 2 : i32 // Select every other row
} : (tensor<4x3xf32>) -> tensor<2x3xf32>
// Result:
// [[1, 2, 3],
// [7, 8, 9]]
Inputs:
input(Tensor): The input tensor to select from.
Attributes:
dim(Integer): The dimension along which to select elements.begin(Integer): The starting index for selection.length(Integer): The number of elements to select.stride(Integer, default=0): The step size for selection. A value of 0 means no stride (consecutive elements).
Output:
result(Tensor): The selected tensor.
Note: The shape of the output tensor is the same as the input tensor except for the selected dimension,
which will have size length. If stride is non-zero, the elements selected will be at indices
begin, begin + stride, begin + 2*stride, etc., up to length elements.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim | ::mlir::IntegerAttr | 32-bit signed integer attribute |
begin | ::mlir::IntegerAttr | 32-bit signed integer attribute |
length | ::mlir::IntegerAttr | 32-bit signed integer attribute |
stride | ::mlir::IntegerAttr | 32-bit signed integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.isfinite (tt::ttir::IsFiniteOp)
Elementwise isfinite operation.
The isfinite operation checks if each element in the input tensor is finite (neither infinite nor NaN).
For each element, it returns a boolean value indicating whether the element is finite.
Example:
// Check if all elements in %input are finite
%result = ttir.isfinite(%input) : (tensor<4x4xf32>) -> tensor<4x4xf32>
// Input tensor:
// [[1.7, 2.0, Inf, 4.5], ... ]
// Output tensor:
// [[true, true, false, true], ... ]
Mathematical definition: isfinite(x) = x ∈ ℝ
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.layer_norm (tt::ttir::LayerNormOp)
Layer normalization operation
Performs layer normalization on the input tensor. This operation normalizes the input tensor by computing the mean and variance of elements across the specified dimensions, then normalizes by subtracting the mean and dividing by the standard deviation, optionally scaling and shifting the result.
Inputs:
input(Tensor): The input tensor to be normalized.weight(Optional Tensor): The scale parameter (gamma). If provided, the normalized result is element-wise multiplied by this weight.bias(Optional Tensor): The shift parameter (beta). If provided, this bias is added to the scaled result.
Attributes:
normalized_shapespecifies the dimensions over which to normalize. Typically the last few dimensions of the input tensor.epsilonis a small constant added for numerical stability (default: 1e-05).
Output:
result(Tensor): The layer normalized output tensor.
Example:
// Layer normalization over last dimension (shape: [2, 4, 8] -> normalize over [8])
%result = ttir.layer_norm(%input, %weight, %bias) : <{ normalized_shape = [8], epsilon = 1e-05 }> :
(tensor<2x4x8xf32>, tensor<2x4x8xf32>, tensor<8xf32>) -> tensor<2x4x8xf32>
// Layer normalization over last two dimensions (shape: [2, 4, 8] -> normalize over [4, 8])
%result = ttir.layer_norm(%input, %weight, %bias) : <{ normalized_shape = [4, 8], epsilon = 1e-05 }> :
(tensor<2x4x8xf32>, tensor<2x4x8xf32>, tensor<4x8xf32>) -> tensor<2x4x8xf32>
Mathematical definition: layer_norm(x, weight, bias, epsilon) = ((x - mean(x, dims=normalized_dims)) / sqrt(var(x, dims=normalized_dims) + epsilon)) * weight + bias
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
normalized_shape | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
epsilon | ::mlir::FloatAttr | 32-bit float attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
weight | ranked tensor of any type values |
bias | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.leaky_relu (tt::ttir::LeakyReluOp)
Eltwise leaky relu operation.
The Leaky ReLU (Rectified Linear Unit) operation computes an element-wise activation function over its input tensor. It is defined as:
y = x if x > 0 y = parameter * x if x <= 0
where parameter is a small, user-defined constant that determines the slope for
negative inputs.
Inputs:
input(Tensor): The input tensor to be activated.
Output:
result(Tensor): The tensor after applying the Leaky ReLU activation.
Attributes:
parameter(float): The slope for negative values.
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
parameter | ::mlir::FloatAttr | 32-bit float attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.le (tt::ttir::LessEqualOp)
Elementwise less than or equal to.
The le operation performs an elementwise less than or equal to comparison between two tensors.
For each pair of corresponding elements, it returns:
- 1 (true) if the left element is less than or equal to the right element
- 0 (false) if the left element is greater than the right element
Example:
// Compare elements for less than or equal to
%result = ttir.le(%lhs, %rhs) : (tensor<4x4xf32>, tensor<4x4xf32>) -> tensor<4x4xi1>
// Input tensors:
// %lhs: [[1.0, 2.0, 3.0, 2.0], ... ]
// %rhs: [[1.0, 2.0, 4.0, 5.0], ... ]
// Output tensor:
// [[1, 1, 1, 0], ... ] // 1 where less or equal, 0 where greater
// Example with integer tensors
%result = ttir.le(%int_lhs, %int_rhs) : (tensor<3xi32>, tensor<3xi32>) -> tensor<3xi1>
// Input tensors:
// %int_lhs: [10, -5, 0]
// %int_rhs: [10, 5, 1]
// Output tensor:
// [1, 1, 1] // All elements are less or equal
Mathematical definition: less_equal(x, y) = x <= y
Traits: AlwaysSpeculatableImplTrait, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.lt (tt::ttir::LessThanOp)
Elementwise less than.
The lt operation performs an elementwise less than comparison between two tensors.
For each pair of corresponding elements, it returns:
- 1 (true) if the left element is less than the right element
- 0 (false) if the left element is greater than or equal to the right element
Example:
// Compare elements for less than
%result = ttir.lt(%lhs, %rhs) : (tensor<4x4xf32>, tensor<4x4xf32>) -> tensor<4x4xi1>
// Input tensors:
// %lhs: [[1.0, 2.0, 3.0, 2.0], ... ]
// %rhs: [[1.0, 2.0, 4.0, 5.0], ... ]
// Output tensor:
// [[0, 0, 0, 1], ... ] // 1 where less, 0 where greater or equal
// Example with integer tensors
%result = ttir.lt(%int_lhs, %int_rhs) : (tensor<3xi32>, tensor<3xi32>) -> tensor<3xi1>
// Input tensors:
// %int_lhs: [10, -5, 0]
// %int_rhs: [10, 5, 1]
// Output tensor:
// [0, 0, 0] // Only the last element is less
Mathematical definition: less_than(x, y) = x < y
Traits: AlwaysSpeculatableImplTrait, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.linear (tt::ttir::LinearOp)
Linear transformation operation.
The linear operation performs a linear transformation by computing the matrix multiplication
of tensors a and b with an optional addition of a bias tensor.
This operation is commonly used in neural networks to implement fully connected layers. It computes the matrix multiplication of the input tensor with a weight tensor and adds an optional bias.
Example:
// Linear transformation with bias
%a = ... : tensor<10x64x32xbf16> // Input tensor: batch_size=10, sequence_length=64, input_dim=32
%b = ... : tensor<32x128xbf16> // Weight tensor: input_dim=32, output_dim=128
%bias = ... : tensor<128xbf16> // Bias tensor: output_dim=128
%result = ttir.linear(%a, %b, %bias) :
(tensor<10x64x32xbf16>, tensor<32x128xbf16>, tensor<128xbf16>) -> tensor<10x64x128xbf16>
// Linear transformation without bias
%a = ... : tensor<10x64x32xf32> // Input tensor
%b = ... : tensor<32x128xf32> // Weight tensor
%result = ttir.linear(%a, %b) :
(tensor<10x64x32xf32>, tensor<32x128xf32>) -> tensor<10x64x128xf32>
Inputs:
a(Tensor): The input tensor.b(Tensor): The weight tensor.bias(Optional Tensor): The bias tensor to add to the result of the matrix multiplication.
Attributes:
transpose_a(Boolean, default=false): Whether to transpose tensorabefore multiplication.transpose_b(Boolean, default=false): Whether to transpose tensorbbefore multiplication.
Output:
result(Tensor): The result of the linear transformation.
The operation computes: result = matmul(a, b) + bias
Note: The shapes of the tensors must be compatible for matrix multiplication. For a 3D input tensor with shape [batch_size, sequence_length, input_dim], the weight tensor should have shape [input_dim, output_dim], and the bias tensor should have shape [output_dim]. The resulting tensor will have shape [batch_size, sequence_length, output_dim].
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
transpose_a | ::mlir::BoolAttr | bool attribute |
transpose_b | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
a | ranked tensor of any type values |
b | ranked tensor of any type values |
bias | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.log1p (tt::ttir::Log1pOp)
Elementwise natural logarithm of one plus input operation.
The log1p operation computes the natural logarithm of one plus each element in the input tensor.
For each element x, it returns ln(1 + x). This operation is more accurate than computing log(1 + x) directly for x values close to zero, and it is defined for x > -1. For values less than or equal to -1, the behavior depends on the implementation (may return NaN or negative infinity).
Example:
// Compute log1p of all elements in %input
%result = ttir.log1p(%input) : (tensor<5xf32>) -> tensor<5xf32>
// Input tensor:
// [0.0, -0.999, 7.0, 6.38905621, 15.0]
// Output tensor:
// [0.0, -6.90776825, 2.07944155, 2.0, 2.77258873]
// Example with small values where log1p is more accurate than log(1+x)
%result = ttir.log1p(%small_input) : (tensor<3xf32>) -> tensor<3xf32>
// Input tensor:
// [1e-10, 1e-7, 1e-5]
// Output tensor:
// [1e-10, 1e-7, 1e-5] // Approximately equal to the input for very small values
Mathematical definition: log1p(x) = ln(1 + x)
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.log (tt::ttir::LogOp)
Elementwise natural logarithm operation.
The log operation computes the natural logarithm of each element in the input tensor.
For each element, it returns the natural logarithm (base e) of the value. This operation is defined only for positive values; the behavior for zero or negative inputs depends on the implementation (may return NaN, infinity, or other special values).
Example:
// Compute natural logarithm of all elements in %input
%result = ttir.log(%input) : (tensor<4x4xf32>) -> tensor<4x4xf32>
// Input tensor:
// [[1.0, 2.718, 7.389, 20.086], ... ]
// Output tensor:
// [[0.0, 1.0, 2.0, 3.0], ... ]
// Example with different values
%result = ttir.log(%float_input) : (tensor<3xf32>) -> tensor<3xf32>
// Input tensor:
// [10.0, 100.0, 1000.0]
// Output tensor:
// [2.303, 4.605, 6.908] // ln(10), ln(100), ln(1000)
Mathematical definition: log(x) = ln(x), where ln is the natural logarithm
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.logical_and (tt::ttir::LogicalAndOp)
Elementwise logical and.
The logical_and operation performs an elementwise logical AND operation between two tensors.
For each pair of corresponding elements, it returns:
- 1 (true) if both elements are 1 (true)
- 0 (false) if at least one element is 0 (false)
Example:
// Logical AND operation
%result = ttir.logical_and(%lhs, %rhs) : (tensor<4x4xi1>, tensor<4x4xi1>) -> tensor<4x4xi1>
// Input tensors:
// %lhs: [[1, 0, 1, 0], ... ]
// %rhs: [[1, 1, 0, 1], ... ]
// Output tensor:
// [[1, 0, 0, 0], ... ] // 1 where both are 1, 0 otherwise
// Example with integer tensors
%result = ttir.logical_and(%int_lhs, %int_rhs) : (tensor<3xi32>, tensor<3xi32>) -> tensor<3xi1>
// Input tensors:
// %int_lhs: [10, 0, 0]
// %int_rhs: [10, 5, 1]
// Output tensor:
// [1, 0, 0] // Only the first element is true
Mathematical definition: logical_and(x, y) = x && y
Traits: AlwaysSpeculatableImplTrait, TTIR_BinaryIdempotence, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.logical_left_shift (tt::ttir::LogicalLeftShiftOp)
Eltwise Logical Left Shift operation
The logical_left_shift operation performs an elementwise logical left shift
on the elements of the first tensor by the corresponding shift amounts in the
second tensor.
Traits: AlwaysSpeculatableImplTrait, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.logical_not (tt::ttir::LogicalNotOp)
Elementwise logical not operation.
The logical_not operation computes the logical negation of each element in the input tensor.
For each element, it returns a boolean value indicating whether the element is false (zero) or true (non-zero).
Example:
// Compute logical negation of all elements in %input
%result = ttir.logical_not(%input) : (tensor<4x4xf32>) -> tensor<4x4xf32>
// Input tensor:
// [[1.7, 2.0, -0.0, 4.5], ... ]
// Output tensor:
// [[false, false, true, false], ... ]
Mathematical definition: logical_not(x) = !x
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.logical_or (tt::ttir::LogicalOrOp)
Elementwise logical or.
The logical_or operation performs an elementwise logical OR operation between two tensors.
For each pair of corresponding elements, it returns:
- 1 (true) if at least one element is 1 (true)
- 0 (false) if both elements are 0 (false)
Example:
// Logical OR operation
%result = ttir.logical_or(%lhs, %rhs) : (tensor<4x4xi1>, tensor<4x4xi1>) -> tensor<4x4xi1>
// Input tensors:
// %lhs: [[1, 0, 1, 0], ... ]
// %rhs: [[1, 1, 0, 1], ... ]
// Output tensor:
// [[1, 1, 1, 1], ... ] // 1 where at least one is 1, 0 otherwise
// Example with integer tensors
%result = ttir.logical_or(%int_lhs, %int_rhs) : (tensor<3xi32>, tensor<3xi32>) -> tensor<3xi1>
// Input tensors:
// %int_lhs: [10, 0, 0]
// %int_rhs: [10, 5, 1]
// Output tensor:
// [1, 1, 1] // All elements are true
Mathematical definition: logical_or(x, y) = x || y
Traits: AlwaysSpeculatableImplTrait, TTIR_BinaryIdempotence, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.logical_right_shift (tt::ttir::LogicalRightShiftOp)
Eltwise Logical Right Shift operation
The logical_right_shift operation performs an elementwise logical right shift
on the elements of the first tensor by the corresponding shift amounts in the
second tensor.
Traits: AlwaysSpeculatableImplTrait, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.logical_xor (tt::ttir::LogicalXorOp)
Elementwise logical xor.
The logical_xor operation performs an elementwise logical XOR operation between two tensors.
For each pair of corresponding elements, it returns:
- 1 (true) if exactly one element is 1 (true)
- 0 (false) if both elements are 0 (false) or both are 1 (true)
Example:
// Logical XOR operation
%result = ttir.logical_xor(%lhs, %rhs) : (tensor<4x4xi1>, tensor<4x4xi1>) -> tensor<4x4xi1>
// Input tensors:
// %lhs: [[1, 0, 1, 0], ... ]
// %rhs: [[1, 1, 0, 1], ... ]
// Output tensor:
// [[0, 1, 1, 1], ... ] // 1 where exactly one is 1, 0 otherwise
// Example with integer tensors
%result = ttir.logical_xor(%int_lhs, %int_rhs) : (tensor<3xi32>, tensor<3xi32>) -> tensor<3xi1>
// Input tensors:
// %int_lhs: [10, 0, 0]
// %int_rhs: [10, 5, 1]
// Output tensor:
// [0, 1, 1] // Only the last element is true
Mathematical definition: logical_xor(x, y) = x ^^ y
Traits: AlwaysSpeculatableImplTrait, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.matmul (tt::ttir::MatmulOp)
Matrix multiplication operation.
The matmul operation computes the matrix multiplication of two tensors.
This operation performs matrix multiplication between tensors a and b. It supports optional
transposition of either input tensor before multiplication. For 2D tensors, this computes the standard
matrix product. For tensors with more dimensions, it applies batched matrix multiplication.
Example:
// Basic matrix multiplication of 2D tensors
%a = ... : tensor<3x4xf32> // Matrix A with shape [3,4]
%b = ... : tensor<4x5xf32> // Matrix B with shape [4,5]
%result = ttir.matmul(%a, %b) :
(tensor<3x4xf32>, tensor<4x5xf32>) -> tensor<3x5xf32>
// Batched matrix multiplication with transposition
%a = ... : tensor<2x3x4xf32> // Batch of 2 matrices with shape [3,4]
%b = ... : tensor<2x5x4xf32> // Batch of 2 matrices with shape [5,4]
%result = ttir.matmul(%a, %b) {
transpose_a = false, // Don't transpose A
transpose_b = true // Transpose B before multiplication
} : (tensor<2x3x4xf32>, tensor<2x5x4xf32>) -> tensor<2x3x5xf32>
Inputs:
a(Tensor): The first input tensor.b(Tensor): The second input tensor.
Attributes:
transpose_a(Boolean, default=false): Whether to transpose tensorabefore multiplication.transpose_b(Boolean, default=false): Whether to transpose tensorbbefore multiplication.
Output:
result(Tensor): The result of the matrix multiplication.
Note: The inner dimensions of the input tensors must be compatible for matrix multiplication.
If a has shape [..., m, k] and b has shape [..., k, n], then the result will have shape [..., m, n].
If transpose_a is true, then a is treated as having shape [..., k, m].
If transpose_b is true, then b is treated as having shape [..., n, k].
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
transpose_a | ::mlir::BoolAttr | bool attribute |
transpose_b | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
a | ranked tensor of any type values |
b | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.max (tt::ttir::MaxOp)
Maximum reduction operation.
The max operation computes the maximum value of elements along specified dimensions of the input tensor.
This operation reduces the input tensor by finding the maximum value of all elements along the dimensions
specified in dim_arg. If dim_arg is not provided, the maximum is computed over all dimensions,
resulting in a scalar value. If keep_dim is set to true, the reduced dimensions are retained
with a size of 1.
Example:
// Maximum along dimension 1
%input = ... : tensor<2x3xf32>
%result = ttir.max(%input) {keep_dim = false, dim_arg = [1: i32]} : (tensor<2x3xf32>) -> tensor<2xf32>
// Input tensor:
// [[1.0, 5.0, 3.0],
// [4.0, 2.0, 6.0]]
// Output tensor:
// [5.0, 6.0] // Maximum of each row
// Maximum along dimension 0
%input = ... : tensor<2x3xf32>
%result = ttir.max(%input) {keep_dim = false, dim_arg = [0: i32]} : (tensor<2x3xf32>) -> tensor<3xf32>
// Input tensor:
// [[1.0, 5.0, 3.0],
// [4.0, 2.0, 6.0]]
// Output tensor:
// [4.0, 5.0, 6.0] // Maximum of each column
// Maximum over all dimensions
%input = ... : tensor<2x3xf32>
%result = ttir.max(%input) {keep_dim = false} : (tensor<2x3xf32>) -> tensor<f32>
// Input tensor:
// [[1.0, 5.0, 3.0],
// [4.0, 2.0, 6.0]]
// Output tensor:
// 6.0 // Maximum of all elements
Note: When comparing with NaN values, NaN is typically not selected as the maximum value.
Mathematical definition: max(x, dim) = max(x[i]) for all i in dimension dim
Inputs:
input(Tensor): The input tensor.
Attributes:
keep_dim(Bool): Whether to keep the reduced dimensions or not.dim_arg(Array of Int32): Dimensions to reduce along.
Output:
result(Tensor): The result tensor after applying the reduction.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
keep_dim | ::mlir::BoolAttr | bool attribute |
dim_arg | ::mlir::ArrayAttr | 32-bit integer array attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.max_pool2d (tt::ttir::MaxPool2dOp)
2D maximum pooling operation.
The max_pool2d operation applies a 2D maximum pooling over an input tensor composed of several input planes.
This operation performs downsampling by dividing the input into local regions and computing the maximum value of each region. It reduces the spatial dimensions (height and width) of an input tensor while preserving the batch and channel dimensions. This is commonly used in neural networks to reduce the spatial size of feature maps while retaining the most important features.
Example:
// Basic 2D max pooling with a 2x2 kernel and stride 1
%input = ... : tensor<1x3x3x1xf32> // 3x3 input tensor with values:
// [[[1, 2, 3],
// [4, 5, 6],
// [7, 8, 9]]]
%result = ttir.max_pool2d(%input) {
kernel = [2, 2],
stride = [1, 1],
dilation = [1, 1],
padding = [0, 0, 0, 0],
ceil_mode = false
} : (tensor<1x3x3x1xf32>) -> tensor<1x2x2x1xf32>
// Result: [[[5, 6],
// [8, 9]]]
// Where: 5 = max(1,2,4,5), 6 = max(2,3,5,6), 8 = max(4,5,7,8), 9 = max(5,6,8,9)
Inputs:
input(Tensor): Input tensor in NHWC format (batch, height, width, channels).
Attributes:
kernel(i32 | array<2xi32>):- i32: Same kernel size for height and width dimensions (kH = kW = value).
- array<2xi32>: [kH, kW] where kH is kernel size for height and kW is kernel size for width.
stride(i32 | array<2xi32>):- i32: Same stride for height and width dimensions (sH = sW = value).
- array<2xi32>: [sH, sW] where sH is stride for height and sW is stride for width.
dilation(i32 | array<2xi32>):- i32: Same dilation for height and width dimensions (dH = dW = value).
- array<2xi32>: [dH, dW] where dH is dilation for height and dW is dilation for width.
padding(i32 | array<2xi32> | array<4xi32>):- i32: Same padding for all sides (pT = pL = pB = pR = value).
- array<2xi32>: [pH, pW] where pH is padding for height (top/bottom) and pW is padding for width (left/right).
- array<4xi32>: [pT, pL, pB, pR] for top, left, bottom, and right padding respectively.
ceil_mode(Boolean): When true, uses ceil instead of floor for output shape calculation.
Output:
result(Tensor): Output tensor after maximum pooling.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), QuantizableOpInterface, TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
kernel | ::mlir::Attribute | 32-bit signless integer attribute or i32 dense array attribute |
stride | ::mlir::Attribute | 32-bit signless integer attribute or i32 dense array attribute |
dilation | ::mlir::Attribute | 32-bit signless integer attribute or i32 dense array attribute |
padding | ::mlir::Attribute | 32-bit signless integer attribute or i32 dense array attribute |
ceil_mode | ::mlir::BoolAttr | bool attribute |
flattened_compat_info | ::mlir::tt::ttir::FlattenedCompatInfoAttr | Information for sliding window operations with tensors flattened to (1, 1, N*H*W, C){{% markdown %}} This attribute marks operations that are compatible with flattened tensors. It is used as a marker and doesn't carry any additional data. {{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.max_pool2d_with_indices (tt::ttir::MaxPool2dWithIndicesOp)
2D maximum pooling operation with indices.
The max_pool2d_with_indices operation applies a 2D maximum pooling over an input tensor composed of several input planes
and also returns the indices of the maximum values within each pooling window.
This operation performs downsampling by dividing the input into local regions and computing the maximum value of each region, along with the index (location) of that maximum value within the original input tensor. It reduces the spatial dimensions (height and width) of an input tensor while preserving the batch and channel dimensions. This is commonly used in neural networks to reduce the spatial size of feature maps while retaining the most important features, and the indices can be used for unpooling operations or gradient computation.
Example:
// Basic 2D max pooling with indices using a 2x2 kernel and stride 1
%input = ... : tensor<1x3x3x1xf32> // 3x3 input tensor with values:
// [[[1, 2, 3],
// [4, 5, 6],
// [7, 8, 9]]]]
%output = ttir.empty() : tensor<1x2x2x1xf32>
%indices_output = ttir.empty() : tensor<1x2x2x1xi32>
%result, %indices = ttir.max_pool2d_with_indices(%input, %output, %indices_output) {
kernel = [2, 2],
stride = [1, 1],
dilation = [1, 1],
padding = [0, 0, 0, 0],
ceil_mode = false
} : tensor<1x3x3x1xf32>, tensor<1x2x2x1xf32>, tensor<1x2x2x1xi32> -> tensor<1x2x2x1xf32>, tensor<1x2x2x1xi32>
// Result values: [[[5, 6],
// [8, 9]]]]
// Result indices: [[[4, 5], // 5 is at index 4, 6 is at index 5
// [7, 8]]]] // 8 is at index 7, 9 is at index 8
// Where: 5 = max(1,2,4,5), 6 = max(2,3,5,6), 8 = max(4,5,7,8), 9 = max(5,6,8,9)
Inputs:
input(Tensor): Input tensor in NHWC format (batch, height, width, channels).output(Tensor): Output tensor for the pooled values.indices_output(Tensor): Output tensor for the indices of maximum values.
Attributes:
kernel(i32 | array<2xi32>):- i32: Same kernel size for height and width dimensions (kH = kW = value).
- array<2xi32>: [kH, kW] where kH is kernel size for height and kW is kernel size for width.
stride(i32 | array<2xi32>):- i32: Same stride for height and width dimensions (sH = sW = value).
- array<2xi32>: [sH, sW] where sH is stride for height and sW is stride for width.
dilation(i32 | array<2xi32>):- i32: Same dilation for height and width dimensions (dH = dW = value).
- array<2xi32>: [dH, dW] where dH is dilation for height and dW is dilation for width.
padding(i32 | array<2xi32> | array<4xi32>):- i32: Same padding for all sides (pT = pL = pB = pR = value).
- array<2xi32>: [pH, pW] where pH is padding for height (top/bottom) and pW is padding for width (left/right).
- array<4xi32>: [pT, pL, pB, pR] for top, left, bottom, and right padding respectively.
ceil_mode(Boolean): When true, uses ceil instead of floor for output shape calculation.
Outputs:
result(Tensor): Output tensor after maximum pooling.indices(Tensor): Output tensor containing the indices of the maximum values in the input tensor.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
kernel | ::mlir::Attribute | 32-bit signless integer attribute or i32 dense array attribute |
stride | ::mlir::Attribute | 32-bit signless integer attribute or i32 dense array attribute |
dilation | ::mlir::Attribute | 32-bit signless integer attribute or i32 dense array attribute |
padding | ::mlir::Attribute | 32-bit signless integer attribute or i32 dense array attribute |
ceil_mode | ::mlir::BoolAttr | bool attribute |
flattened_compat_info | ::mlir::tt::ttir::FlattenedCompatInfoAttr | Information for sliding window operations with tensors flattened to (1, 1, N*H*W, C){{% markdown %}} This attribute marks operations that are compatible with flattened tensors. It is used as a marker and doesn't carry any additional data. {{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
output | variadic of ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
result_indices | ranked tensor of any type values |
ttir.maximum (tt::ttir::MaximumOp)
Elementwise maximum operation.
The maximum operation calculates the elementwise maximum between two tensors.
For each pair of corresponding elements, it selects the larger value and places it in the output tensor. This operation has the idempotence property, meaning that applying it twice with the same second operand returns the original result: maximum(maximum(x, y), y) = maximum(x, y).
Example:
// Maximum operation
%result = ttir.maximum(%lhs, %rhs) : (tensor<3x3xi32>, tensor<3x3xi32>) -> tensor<3x3xi32>
// Input tensors:
// %lhs: [[3, 2, 7], [1, 4, 4]]
// %rhs: [[1, 4, 2], [1, 2, 3]]
// Output tensor:
// [[3, 4, 7], [1, 4, 4]]
Note: When comparing with NaN values, NaN is typically not selected as the maximum value.
Mathematical definition: maximum(x, y) = max(x, y)
Traits: AlwaysSpeculatableImplTrait, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.mean (tt::ttir::MeanOp)
Mean reduction op.
The mean operation computes the arithmetic mean of elements along specified dimensions of the input tensor.
This operation reduces the input tensor by computing the average of all elements along the dimensions
specified in dim_arg. If dim_arg is not provided, the mean is computed over all dimensions,
resulting in a scalar value. If keep_dim is set to true, the reduced dimensions are retained
with a size of 1.
Example:
// Mean along dimension 1
%input = ... : tensor<2x3xf32>
%result = ttir.mean(%input) {keep_dim = false, dim_arg = [1: i32]} : (tensor<2x3xf32>) -> tensor<2xf32>
// Input tensor:
// [[1.0, 2.0, 3.0],
// [4.0, 5.0, 6.0]]
// Output tensor:
// [2.0, 5.0] // Mean of each row
// Mean along dimension 0
%input = ... : tensor<2x3xf32>
%result = ttir.mean(%input) {keep_dim = false, dim_arg = [0: i32]} : (tensor<2x3xf32>) -> tensor<3xf32>
// Input tensor:
// [[1.0, 2.0, 3.0],
// [4.0, 5.0, 6.0]]
// Output tensor:
// [2.5, 3.5, 4.5] // Mean of each column
// Mean over all dimensions
%input = ... : tensor<2x3xf32>
%result = ttir.mean(%input) {keep_dim = false} : (tensor<2x3xf32>) -> tensor<f32>
// Input tensor:
// [[1.0, 2.0, 3.0],
// [4.0, 5.0, 6.0]]
// Output tensor:
// 3.5 // Mean of all elements
Note: For integer input tensors, the result is typically rounded to the nearest integer according to the rounding mode.
Mathematical definition: mean(x, dim) = (∑ x[i]) / n for all i in dimension dim, where n is the number of elements in dimension dim
Inputs:
input(Tensor): The input tensor.
Attributes:
keep_dim(Bool): Whether to keep the reduced dimensions or not.dim_arg(Array of Int32): Dimensions to reduce along.
Output:
result(Tensor): The result tensor after applying the reduction.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
keep_dim | ::mlir::BoolAttr | bool attribute |
dim_arg | ::mlir::ArrayAttr | 32-bit integer array attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.mesh_partition (tt::ttir::MeshPartitionOp)
Mesh partition operation.
Mesh partition op.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim | ::mlir::IntegerAttr | 32-bit signed integer attribute |
cluster_axis | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.mesh_shard (tt::ttir::MeshShardOp)
Mesh shard operation.
MeshShard op shards the inputs (FullToShard) or concatnates the outputs (ShardToFull) for ccl ops.
shard_direction attribute determines whether to shard or concat.
shard_type attribute determines how to shard or concat. manual: no sharding replicate: all devices have identical data maximal: only one device contains full data devices: shard_shape/shard_dims determine particular sharding
shard_dims attribute determines row and column sharding dimension of input tensor
For example, on 2x4 mesh hardware, following op shards arg0 to 8 slices, row divided by 2 and col divided by 4.
%1 = "ttir.mesh_shard"(%arg0) <
{... shard_direction = #ttcore.shard_direction<full_to_shard>,
shard_shape = array<i64: 2, 4>,
shard_dims = array<i64: 0, 1>,
shard_type = #ttcore.shard_type
On the other hand, this op concatnates %4 to single tensor by concatnating one of the top row tensor with one of the bottom row tensor.
%6 = "ttir.mesh_shard"(%4) <
{..., shard_direction = #ttcore.shard_direction<shard_to_full>,
shard_shape = array<i64: 2, 1>,
shard_dims = array<i64: 1, -1>,
shard_type = #ttcore.shard_type
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
shard_type | ::mlir::tt::ttcore::MeshShardTypeAttr | MeshShard shard_type attribute in TT dialect{{% markdown %}} Define sharded tensor data of mesh_shard op. - Identity: input and output tensors are pre-sharded (same data) and no sharding is required. - Replicate: all of the devices has full tensor (same data). - Maximal: one or part of the devcices has full tensor (same data). - Devices: all or part of the devices has sharded (partial) tensor (different data). {{% /markdown %}} |
shard_direction | ::mlir::tt::ttcore::MeshShardDirectionAttr | TT MeshShardDirection |
shard_shape | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
shard_dims | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values or non-0-ranked.memref of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values or non-0-ranked.memref of any type values |
ttir.min (tt::ttir::MinOp)
Minimum reduction operation.
The min operation computes the minimum value of elements along specified dimensions of the input tensor.
This operation reduces the input tensor by finding the minimum value of all elements along the dimensions
specified in dim_arg. If dim_arg is not provided, the minimum is computed over all dimensions,
resulting in a scalar value. If keep_dim is set to true, the reduced dimensions are retained
with a size of 1.
Example:
// Minimum along dimension 1
%input = ... : tensor<2x3xf32>
%result = ttir.min(%input) {keep_dim = false, dim_arg = [1: i32]} : (tensor<2x3xf32>) -> tensor<2xf32>
// Input tensor:
// [[1.0, 5.0, 3.0],
// [4.0, 2.0, 6.0]]
// Output tensor:
// [1.0, 2.0] // Minimum of each row
// Minimum along dimension 0
%input = ... : tensor<2x3xf32>
%result = ttir.min(%input) {keep_dim = false, dim_arg = [0: i32]} : (tensor<2x3xf32>) -> tensor<3xf32>
// Input tensor:
// [[1.0, 5.0, 3.0],
// [4.0, 2.0, 6.0]]
// Output tensor:
// [1.0, 2.0, 3.0] // Minimum of each column
// Minimum over all dimensions
%input = ... : tensor<2x3xf32>
%result = ttir.min(%input) {keep_dim = false} : (tensor<2x3xf32>) -> tensor<f32>
// Input tensor:
// [[1.0, 5.0, 3.0],
// [4.0, 2.0, 6.0]]
// Output tensor:
// 1.0 // Minimum of all elements
Note: When comparing with NaN values, NaN is typically not selected as the minimum value.
Mathematical definition: min(x, dim) = min(x[i]) for all i in dimension dim
Inputs:
input(Tensor): The input tensor.
Attributes:
keep_dim(Bool): Whether to keep the reduced dimensions or not.dim_arg(Array of Int32): Dimensions to reduce along.
Output:
result(Tensor): The result tensor after applying the reduction.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
keep_dim | ::mlir::BoolAttr | bool attribute |
dim_arg | ::mlir::ArrayAttr | 32-bit integer array attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.minimum (tt::ttir::MinimumOp)
Elementwise minimum operation.
The minimum operation computes the elementwise minimum between two tensors.
For each pair of corresponding elements, it selects the smaller value and places it in the output tensor. This operation has the idempotence property, meaning that applying it twice with the same second operand returns the original result: minimum(minimum(x, y), y) = minimum(x, y).
Example:
// Minimum operation
%result = ttir.minimum(%lhs, %rhs) : (tensor<2x3xi32>, tensor<2x3xi32>) -> tensor<2x3xi32>
// Input tensors:
// %lhs: [[3, 2, 7], [1, 4, 4]]
// %rhs: [[1, 4, 2], [1, 2, 3]]
// Output tensor:
// [[1, 2, 2], [1, 2, 3]]
// Example with floating point values
%result = ttir.minimum(%float_lhs, %float_rhs) : (tensor<3xf32>, tensor<3xf32>) -> tensor<3xf32>
// Input tensors:
// %float_lhs: [3.5, -2.1, 0.0]
// %float_rhs: [1.2, -5.0, 0.0]
// Output tensor:
// [1.2, -5.0, 0.0]
Note: When comparing with NaN values, NaN is typically not selected as the minimum value.
Mathematical definition: minimum(x, y) = min(x, y)
Traits: AlwaysSpeculatableImplTrait, TTIR_BinaryIdempotence, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.mish (tt::ttir::MishOp)
Elementwise Mish activation operation.
The mish operation computes the Mish activation function of each element in the input tensor.
Mish is a smooth, self-regularized, non-monotonic activation function that combines properties of both ReLU-like and smooth activation functions. It has been shown to improve performance in deep learning applications, particularly in computer vision tasks.
Example:
// Compute Mish of all elements in %input
%result = ttir.mish(%input, %output) : tensor<4x4xf32>, tensor<4x4xf32> -> tensor<4x4xf32>
// Input tensor:
// [[-2.0, -1.0, 0.0, 1.0], ... ]
// Output tensor:
// [[-0.252, -0.303, 0.0, 0.865], ... ]
Mathematical definition: mish(x) = x * tanh(softplus(x)) = x * tanh(ln(1 + e^x))
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.moe_compute (tt::ttir::MoeComputeOp)
Fused MoE expert compute (selective tilize + experts + combine).
Composite operation that performs the MoE expert FFN in a single fused
kernel: selective tilize of dispatched tokens, the gate/up matmul (W0/W1)
followed by SILU or SwiGLU activation, the down matmul (W2), and an
A2A selective-reduce-combine. Maps to
ttnn.experimental.moe_compute at runtime.
Takes the raw per-expert weights w0 / w1 / w2 (logical shapes
(L, E, K, N), (L, E, K, N), (L, E, N, K) with K = hidden_size,
N = intermediate_size) and optional per-expert biases bias_0 /
bias_1 / bias_2.
Inputs:
tilize_input_tensor: dense per-token activations dispatched via all_to_all_dispatch.tilize_expert_indices_tensor: per-token expert indices.tilize_expert_scores_tensor: per-token expert routing scores.tilize_expert_mapping_tensor: global expert-to-device mapping.w0/w1/w2: raw per-expert gate / up / down weights.bias_0/bias_1/bias_2: optional per-expert biases.
Outputs (6, in declaration order):
0. per_expert_total_tokens routing metadata: per-expert token counts
expert_activationrouting metadata: per-token activation recordsexpert_to_tokenrouting metadata: per-expert token liststilize_outputselective-tilize staging buffermatmul_outputexpert-FFN result (final output in compute_only)combine_outputA2A-combined result (aliases matmul_output in compute_only)
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_CCL
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
layer_id | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
output_height_shard_dim | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
intermediate_size | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
activation_function | ::mlir::tt::ttcore::MoEActivationFunctionAttr | Activation function for the MoE expert FFN |
bh_ring_size | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
compute_only | ::mlir::BoolAttr | bool attribute |
cluster_axis | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
tilize_input_tensor | ranked tensor of any type values |
tilize_expert_indices_tensor | ranked tensor of any type values |
tilize_expert_scores_tensor | ranked tensor of any type values |
tilize_expert_mapping_tensor | ranked tensor of any type values |
w0 | ranked tensor of any type values |
w1 | ranked tensor of any type values |
w2 | ranked tensor of any type values |
bias_0 | ranked tensor of any type values |
bias_1 | ranked tensor of any type values |
bias_2 | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
per_expert_total_tokens | ranked tensor of any type values |
expert_activation | ranked tensor of any type values |
expert_to_token | ranked tensor of any type values |
tilize_output | ranked tensor of any type values |
matmul_output | ranked tensor of any type values |
combine_output | ranked tensor of any type values |
ttir.moe_expert_token_remap (tt::ttir::MoeExpertTokenRemapOp)
Remap global expert routing to local device experts with sparsity.
Converts global expert routing scores to local per-device expert mapping and creates a sparsity pattern for efficient sparse_matmul. Used after all_to_all_dispatch in the MoE dispatch/compute/combine flow.
Input shapes:
- topk_tensor: [D, B, S, E] (bf16 routing scores)
- expert_mapping: [1, 1, E, D] (uint16 one-hot mapping)
- expert_metadata: [D, B, S, K] (uint16 expert indices)
Output shapes:
- mapping: [1, B, S, E_local] (bf16 local routing weights)
- reduced: [1, 1, ceil(B*S/reduction_size), E_local] (uint16 sparsity)
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
reduction_size | ::mlir::IntegerAttr | 64-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
topk_tensor | ranked tensor of any type values |
expert_mapping | ranked tensor of any type values |
expert_metadata | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
mapping | ranked tensor of any type values |
reduced | ranked tensor of any type values |
ttir.moe_gpt (tt::ttir::MoeGptOp)
Fused MoE compute kernel for GPT-OSS models.
Fused Mixture-of-Experts compute kernel for GPT-OSS-style models. Performs the full MoE compute pipeline in a single kernel: selective tilize, gate/up projection (w0_w1), SwiGLU activation, all-to-all ring exchange, down projection (w2), and combine. Typically follows all_to_all_dispatch_metadata in the MoE dispatch/compute/combine flow.
Dimensions: T = total_tokens across the dispatch ring K = hidden_size N = intermediate_size K_sel = selected experts per token (top-k) E = experts per device D = total devices C_dram = DRAM-bank-aligned compute cores used for weight sharding C_worker = worker cores in the compute grid L = layers per weight tensor (typically 1) G = weight groups per core (gate/up interleaved pairs) TILE_SIZE = compute tile size L1_ALIGN = L1 alignment
Input shapes (per device, after mesh sharding):
- input_tensor: [T, K] (bf16)
- expert_indices: [T, K_sel] (uint16)
- expert_scores: [T, K_sel] (bf16)
- expert_mapping: [1, E*D] (uint16; flattened mapping, entry [0, i] = device ID owning expert i)
- w0_w1_tensor: [C_dram, L, E, G, K, 4*TILE_SIZE] (interleaved gate+up)
- w2_tensor: [C_dram, L, E, 2, N, 4*TILE_SIZE] (down projection)
Output shapes:
- token_counts: [1, align(E*sizeof(u32), L1_ALIGN) / sizeof(u32)] (uint32)
- activation_records: [1, (T+1) * align((2*E+1)*sizeof(u32), L1_ALIGN) / sizeof(u32)] (uint32)
- token_indices: [E, (T+1) * align(sizeof(u32), L1_ALIGN) / sizeof(u32)] (uint32)
- tilize_out: [C_worker, 2, TILE_SIZE, K] (bf16, tiled)
- tilize_out_rm: [C_worker, 2, TILE_SIZE, K] (bf16, row-major) where align(n, a) = ceil(n/a) * a.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
output_height_shard_dim | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
output_width_shard_dim | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
hidden_size | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
cluster_axis | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
input_tensor | ranked tensor of any type values |
expert_indices | ranked tensor of any type values |
expert_scores | ranked tensor of any type values |
expert_mapping | ranked tensor of any type values |
w0_w1_tensor | ranked tensor of any type values |
w2_tensor | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
token_counts | ranked tensor of any type values |
activation_records | ranked tensor of any type values |
token_indices | ranked tensor of any type values |
tilize_out | ranked tensor of any type values |
tilize_out_rm | ranked tensor of any type values |
ttir.multiply (tt::ttir::MultiplyOp)
Elementwise multiplication operation.
The multiply operation performs an elementwise multiplication between two tensors.
For each pair of corresponding elements, it multiplies the elements and places the result in the output tensor.
Example:
// Multiplication operation
%result = ttir.multiply(%lhs, %rhs) : (tensor<3xi32>, tensor<3xi32>) -> tensor<3xi32>
// Input tensors:
// %lhs: [10, 20, 30]
// %rhs: [1, 2, 3]
// Output tensor:
// [10, 40, 90]
// Example with floating point values
%result = ttir.multiply(%float_lhs, %float_rhs) : (tensor<3xf32>, tensor<3xf32>) -> tensor<3xf32>
// Input tensors:
// %float_lhs: [3.5, 0.0, -1.2]
// %float_rhs: [1.5, 2.0, -3.2]
// Output tensor:
// [5.25, 0.0, -3.84]
Note: The data type of the output tensor matches the data type of the input tensors.
Mathematical definition: multiply(x, y) = x * y
Traits: AlwaysSpeculatableImplTrait, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.neg (tt::ttir::NegOp)
Elementwise negate operation.
The neg operation negates each element in the input tensor.
For each element, it returns the negation of the value. The operation preserves the data type of the input.
Example:
// Compute negation of all elements in %input
%result = ttir.neg(%input) : (tensor<4x4xf32>) -> tensor<4x4xf32>
// Input tensor:
// [[1.7, 2.0, -0.3, 4.5], ... ]
// Output tensor:
// [[-1.7, -2.0, 0.3, -4.5], ... ]
Mathematical definition: neg(x) = -x
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable, TTIR_Involution
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.ne (tt::ttir::NotEqualOp)
Elementwise inequality comparison operation.
The ne operation performs an elementwise inequality comparison between two tensors.
For each pair of corresponding elements, it returns:
- 1 (true) if the elements are not equal
- 0 (false) if the elements are equal
Note that special handling may be required for floating-point NaN values, as NaN is not equal to any value, including itself. This means ne(NaN, NaN) should return true.
Example:
// Compare elements for inequality
%result = ttir.ne(%lhs, %rhs) : (tensor<4x4xf32>, tensor<4x4xf32>) -> tensor<4x4xi1>
// Input tensors:
// %lhs: [[1.0, 2.0, 3.0, 2.0], ... ]
// %rhs: [[1.0, 2.0, 4.0, 5.0], ... ]
// Output tensor:
// [[0, 0, 1, 1], ... ] // 0 where equal, 1 where not equal
// Example with integer tensors
%result = ttir.ne(%int_lhs, %int_rhs) : (tensor<3xi32>, tensor<3xi32>) -> tensor<3xi1>
// Input tensors:
// %int_lhs: [10, -5, 0]
// %int_rhs: [10, 5, 1]
// Output tensor:
// [0, 1, 1] // Only the first elements are equal, so their result is 0
Mathematical definition: not_equal(x, y) = x != y
Traits: AlwaysSpeculatableImplTrait, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.ones (tt::ttir::OnesOp)
Creates a tensor filled with ones.
The ones operation creates a tensor filled with ones of the specified shape.
This operation is commonly used to initialize tensors with one values. It takes a shape attribute and produces a tensor of that shape with all elements set to one.
Example:
// Create a 3D tensor of ones with shape [64, 28, 28]
%result = ttir.ones() {
shape = [64, 28, 28]
} : () -> tensor<64x28x28xbf16>
// Result: A tensor of shape [64, 28, 28] filled with ones
// Create a 2D tensor of ones with shape [3, 4]
%result = ttir.ones() {
shape = [3, 4]
} : () -> tensor<3x4xf32>
// Result: [[1.0, 1.0, 1.0, 1.0],
// [1.0, 1.0, 1.0, 1.0],
// [1.0, 1.0, 1.0, 1.0]]
Attributes:
shape(Array of Integer): The shape of the tensor to create.
Output:
result(Tensor): The tensor filled with ones.
Note: The element type of the result tensor is determined by the return type specified in the operation. This operation is useful for initializing tensors before scaling them or as a starting point for operations that require tensors filled with ones, such as creating masks or constant multipliers.
Traits: AlwaysSpeculatableImplTrait, ConstantLike, TTCore_CreationOpTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
shape | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.pad (tt::ttir::PadOp)
Tensor padding operation.
The pad operation adds padding to the edges of an input tensor with a specified constant value.
This operation extends the dimensions of the input tensor by adding padding elements with a constant value. The padding is specified for each dimension as the number of elements to add at the beginning (low) and end (high) of that dimension.
The padding attribute must be a sequence of integers that is twice the size as the rank of the input.
Each pair of integers in the padding attribute represents the amount of padding to add to the low and high
of that dimension. For example, for a 2D tensor, the padding attribute would have 4 values: [dim0_low, dim0_high, dim1_low, dim1_high].
Example:
// Pad a 2x3 tensor with different padding on each dimension
%input = ... : tensor<2x3xf32> // Input tensor with values:
// [[1, 2, 3],
// [4, 5, 6]]
%result = ttir.pad(%input) {
padding = [1, 0, 1, 1], // Format: [dim0_low, dim0_high, dim1_low, dim1_high]
value = 0.0 : f32
} : (tensor<2x3xf32>) -> tensor<3x5xf32>
// Result:
// [[0, 0, 0, 0, 0],
// [0, 1, 2, 3, 0],
// [0, 4, 5, 6, 0]]
Inputs:
input(Tensor): The input tensor to pad.
Attributes:
padding(Array of Integer): The padding values for each dimension, specified as [dim0_low, dim0_high, dim1_low, dim1_high, ...].value(Float): The constant value to use for the padding elements.
Output:
result(Tensor): The padded tensor.
Note: The shape of the output tensor must match the shape of the input tensor plus the padding specified in the padding attribute. For example, if the input shape is [2,3] and the padding is [1,0,1,1], then the output shape must be [3,5].
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
padding | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
value | ::mlir::FloatAttr | 32-bit float attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.paged_fill_cache (tt::ttir::PagedFillCacheOp)
Paged fill cache op.
Fills the cache tensor in-place with values from input at batch_idx_tensor.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_CacheOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
cache | ranked tensor of any type values |
input | ranked tensor of any type values |
page_table | ranked tensor of any type values |
batch_idx_tensor | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.paged_flash_multi_latent_attention_decode (tt::ttir::PagedFlashMultiLatentAttentionDecodeOp)
Paged flash multi-latent attention decode operation.
Paged flash Multi-Latent Attention (MLA) for the decode phase. This is a specialized attention kernel that combines flash attention with multi-latent attention and paged KV cache support, optimized for single-token decode.
MLA compresses the KV cache using low-rank projections, significantly reducing memory requirements for long-context inference. The paged variant manages cache memory in fixed-size pages.
Key difference from PagedScaledDotProductAttentionDecode: the value tensor is optional (may be null for latent-only MLA) and head_dim_v specifies the value head dimension separately.
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
head_dim_v | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
is_causal | ::mlir::BoolAttr | bool attribute |
scale | ::mlir::FloatAttr | 32-bit float attribute |
Operands:
| Operand | Description |
|---|---|
query | ranked tensor of any type values |
key | ranked tensor of any type values |
value | ranked tensor of any type values |
page_table | ranked tensor of any type values |
attention_mask | ranked tensor of any type values |
cur_pos_tensor | ranked tensor of any type values |
attention_sink | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.paged_scaled_dot_product_attention_decode (tt::ttir::PagedScaledDotProductAttentionDecodeOp)
Paged scaled dot product attention decode operation.
Paged scaled dot product attention decode operation.
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
is_causal | ::mlir::BoolAttr | bool attribute |
scale | ::mlir::FloatAttr | 32-bit float attribute |
sliding_window_size | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
query | ranked tensor of any type values |
key | ranked tensor of any type values |
value | ranked tensor of any type values |
page_table | ranked tensor of any type values |
output | ranked tensor of any type values |
attention_mask | ranked tensor of any type values |
cur_pos_tensor | ranked tensor of any type values |
attention_sink | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.paged_update_cache (tt::ttir::PagedUpdateCacheOp)
Paged update cache op.
Inputs:
cache: The cache tensor to be updated. This tensor is modified in place [max_num_blocks, num_heads, block_size, head_dim]input: The input tensor containing new values. [1, num_users, num_heads (padded to 32), head_dim]update_index: Indices specifying where to update the cache. [num_users]share_cache: Whether the cache tensors share memory regions. Defaults to False.page_table: The page table for managing memory regions during updates. [num_users, max_num_blocks_per_seq]
Outputs:
result: The updated cache tensor.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_CacheOpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
share_cache | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
cache | ranked tensor of any type values |
input | ranked tensor of any type values |
update_index | ranked tensor of any type values |
page_table | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.permute (tt::ttir::PermuteOp)
Tensor dimension permutation operation.
The permute operation reorders the dimensions of the input tensor according to the specified permutation.
This operation is similar to transpose but generalizes to tensors of any rank. It rearranges the dimensions of the input tensor based on the permutation attribute, which specifies the new order of dimensions.
Example:
// Transpose a 2D tensor (swap dimensions 0 and 1)
%input = ... : tensor<3x4xf32> // Input tensor with shape [3,4]
%result = ttir.permute(%input) {
permutation = [1, 0] // Swap dimensions 0 and 1
} : (tensor<3x4xf32>) -> tensor<4x3xf32>
// Result: tensor with shape [4,3], equivalent to transposing the input
// Permute a 3D tensor
%input = ... : tensor<2x3x4xf32> // Input tensor with shape [2,3,4]
%result = ttir.permute(%input) {
permutation = [1, 2, 0] // Reorder dimensions to [1,2,0]
} : (tensor<2x3x4xf32>) -> tensor<3x4x2xf32>
// Result: tensor with shape [3,4,2]
Inputs:
input(Tensor): The input tensor to permute.
Attributes:
permutation(Array of Integer): The permutation of the input tensor dimensions. This must be a valid permutation of the indices [0, 1, ..., rank-1].
Output:
result(Tensor): The permuted tensor.
Note: The permutation attribute must contain exactly one occurrence of each integer in the range [0, rank-1], where rank is the number of dimensions in the input tensor. The shape of the output tensor is determined by permuting the dimensions of the input tensor according to the permutation. For example, if the input shape is [2,3,4] and the permutation is [1,2,0], then the output shape will be [3,4,2].
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_TensorManipulation
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
permutation | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.pow (tt::ttir::PowOp)
Elementwise power operation.
The pow operation performs an elementwise exponentiation between two tensors.
For each pair of corresponding elements, it raises the element in the first tensor (base) to the power of the element in the second tensor (exponent) and places the result in the output tensor.
Example:
// Power operation
%result = ttir.pow(%lhs, %rhs) : (tensor<3xf32>, tensor<3xf32>) -> tensor<3xf32>
// Input tensors:
// %lhs: [2.0, 3.0, 4.0] // Bases
// %rhs: [2.0, 2.0, 0.5] // Exponents
// Output tensor:
// [4.0, 9.0, 2.0]
// Example with integer values
%result = ttir.pow(%int_lhs, %int_rhs) : (tensor<3xi32>, tensor<3xi32>) -> tensor<3xi32>
// Input tensors:
// %int_lhs: [2, 3, 5]
// %int_rhs: [3, 2, 1]
// Output tensor:
// [8, 9, 5]
Special cases:
- 0^0 is typically defined as 1
- For integer types, negative bases with non-integer exponents may result in complex numbers, which are typically not supported and may result in undefined behavior
Mathematical definition: pow(x, y) = x^y
Traits: AlwaysSpeculatableImplTrait, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.prod (tt::ttir::ProdOp)
Product reduction op.
The `prod` operation computes the product of elements along specified dimensions of the input tensor.
This operation reduces the input tensor by multiplying all elements along the dimensions
specified in dim_arg. If dim_arg is not provided, the product is computed over all dimensions,
resulting in a scalar value. If keep_dim is set to true, the reduced dimensions are retained
with a size of 1.
Example:
// Product along dimension 0
%input = ... : tensor<2x3xi32>
%result = ttir.prod(%input) {keep_dim = false, dim_arg = [0: i32]} : (tensor<2x3xi32>) -> tensor<3xi32>
// Input tensor:
// [[1, 2, 3],
// [4, 5, 6]]
// Output tensor:
// [4, 10, 18] // Product of each column
// Product along dimension 1
%input = ... : tensor<2x3xi32>
%result = ttir.prod(%input) {keep_dim = false, dim_arg = [1: i32]} : (tensor<2x3xi32>) -> tensor<2xi32>
// Input tensor:
// [[1, 2, 3],
// [4, 5, 6]]
// Output tensor:
// [6, 120] // Product of each row
// Product over all dimensions
%input = ... : tensor<2x3xi32>
%result = ttir.prod(%input) {keep_dim = false} : (tensor<2x3xi32>) -> tensor<i32>
// Input tensor:
// [[1, 2, 3],
// [4, 5, 6]]
// Output tensor:
// 720 // Product of all elements
Note: For floating-point inputs, the order of multiplication may affect the result due to floating-point precision issues.
Mathematical definition: prod(x, dim) = ∏ x[i] for all i in dimension dim
Inputs:
input(Tensor): The input tensor.
Attributes:
keep_dim(Bool): Whether to keep the reduced dimensions or not.dim_arg(Array of Int32): Dimensions to reduce along.
Output:
result(Tensor): The result tensor after applying the reduction.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
keep_dim | ::mlir::BoolAttr | bool attribute |
dim_arg | ::mlir::ArrayAttr | 32-bit integer array attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.quantize (tt::ttir::QuantizeOp)
Quantize operation.
The Quantize operation converts a tensor into a quantized tensor using the quant.uniform type from the MLIR Quant dialect.
This type encapsulates the scale and zero-point metadata directly within the tensor type.
The output tensor will be of type 'quant.uniform', where each element is computed as:
output[i] = (input[i] / scale) + zero_point
Example:
%input = ttir.empty() : () -> tensor<64x128xf32>
%quantized = "ttir.quantize"(%input) : (tensor<64x128xf32>) -> tensor<64x128x!quant.uniform<i32:f32, 0.1>>
// In this example:
// - The input is a 64x128 tensor of 32-bit floating-point values
// - The output is a 64x128 tensor of 32-bit quantized values
// - The scale is 0.1 (each step represents 0.1 in the original scale)
// - The zero point is 128 (the value 128 in the quantized space represents 0.0 in the original space)
Inputs:
input(Tensor): Input tensor to be quantized.
Results:
result(Quantized Tensor): The quantized tensor with typequant.uniform.
Note: The quantization parameters (scale and zero point) are specified in the result type. Quantization helps reduce model size and computational requirements by representing floating-point values with lower-precision integers, which is particularly useful for deployment on resource-constrained devices.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.quantize_unrolled (tt::ttir::QuantizeUnrolledOp)
Quantize operation unrolled (scale and zero point as input operands).
The QuantizeUnrolledOp quantizes a tensor using the scale and zero point provided as input operands.
Inputs:
inputAnyRankedTensor: The input tensor to be quantized. Must have floating-point element type.scaleAnyRankedTensor: The scale factor (or factors for per-axis quantization). Must be either a scalar (for per-tensor quantization) or a 1D tensor with size matching the dimension of the specified axis (for per-axis quantization).zero_pointAnyRankedTensor: The zero point value (or values for per-axis quantization). Must be in range of the quantized storage type.axisOptional: The axis along which quantization is applied. Must be in range [0, rank) where rank is the rank of the input tensor.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
axis | ::mlir::IntegerAttr | 32-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
scale | ranked tensor of any type values |
zero_point | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.rms_norm (tt::ttir::RMSNormOp)
RMS normalization operation
Performs RMS (Root Mean Square) normalization on the input tensor. This operation normalizes the input tensor by computing the root mean square of elements across the specified dimensions and dividing by that value, optionally scaling and shifting the result.
Inputs:
input(Tensor): The input tensor to be normalized.weight(Optional Tensor): The scale parameter (gamma). If provided, the normalized result is element-wise multiplied by this weight.bias(Optional Tensor): The shift parameter (beta). If provided, this bias is added to the scaled result.
Attributes:
normalized_shapespecifies the dimensions over which to normalize. Typically the last few dimensions of the input tensor.epsilonis a small constant added for numerical stability (default: 1e-05).
Output:
result(Tensor): The RMS normalized output tensor.
Example:
// RMS normalization over last dimension (shape: [2, 4, 8] -> normalize over [8])
%result = ttir.rms_norm(%input, %weight, %bias) : <{ normalized_shape = [8], epsilon = 1e-05 }> :
(tensor<2x4x8xf32>, tensor<2x4x8xf32>, tensor<8xf32>) -> tensor<2x4x8xf32>
// RMS normalization over last two dimensions (shape: [2, 4, 8] -> normalize over [4, 8])
%result = ttir.rms_norm(%input, %weight, %bias) : <{ normalized_shape = [4, 8], epsilon = 1e-05) }> :
(tensor<2x4x8xf32>, tensor<2x4x8xf32>, tensor<4x8xf32>) -> tensor<2x4x8xf32>
Mathematical definition: rms_norm(x, weight, bias, epsilon) = (x / sqrt(mean(x^2, dims=normalized_dims) + epsilon)) * weight + bias
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
normalized_shape | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
epsilon | ::mlir::FloatAttr | 32-bit float attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
weight | ranked tensor of any type values |
bias | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.rand (tt::ttir::RandOp)
Random number generation operation.
Returns a tensor filled with random numbers drawn from a uniform distribution over given interval [low, high) [Default: [0, 1)].
Example: %0 = "ttir.rand"() <{high = 1.000000e+00 : f32, low = 0.000000e+00 : f32, seed = 0 : ui32, size = [32 : i32, 32 : i32]}> : () -> tensor<32x32xbf16>
Attributes:
size(Array of Integer): The shape of the tensor to create.low(Float): The lower bound of the range (inclusive) [Default: 0.0].high(Float): The upper bound of the range (exclusive) [Default: 1.0].seed(Integer): Value to initialize the random number generator for reproducible results [Default: 0].
Output:
result(Tensor): The generated tensor containing the random values.
Traits: AlwaysSpeculatableImplTrait, TTCore_CreationOpTrait, TTCore_NonCacheableTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
size | ::mlir::ArrayAttr | 32-bit integer array attribute |
low | ::mlir::FloatAttr | 32-bit float attribute |
high | ::mlir::FloatAttr | 32-bit float attribute |
seed | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.rearrange (tt::ttir::RearrangeOp)
Tensor rearrange operation.
The rearrange operation reshapes, transposes, and reorganizes tensor dimensions using an
intuitive notation inspired by Einstein notation. This operation takes an input tensor and
transforms it according to a pattern string that describes how dimensions should be rearranged.
The pattern uses named axes and supports splitting, merging, and reordering dimensions in a
single operation. This operation is commonly used in neural networks for dimension manipulation,
such as converting between different data layouts, splitting/merging dimensions, or transposing
axes.
Example:
// Transpose a 2D tensor (equivalent to transpose)
%input = ... : tensor<2x3xf32> // Input tensor with shape [2,3]
%result = ttir.rearrange(%input) {pattern = "h w -> w h"} : (tensor<2x3xf32>) -> tensor<3x2xf32>
// Flatten spatial dimensions of a 4D tensor (batch, channel, height, width)
%input = ... : tensor<1x3x4x4xf32> // Input tensor with shape [1,3,4,4]
%result = ttir.rearrange(%input) {pattern = "b c h w -> b c (h w)"} :
(tensor<1x3x4x4xf32>) -> tensor<1x3x16xf32>
// Split a dimension into two dimensions
%input = ... : tensor<2x12xf32> // Input tensor with shape [2,12]
%result = ttir.rearrange(%input) {pattern = "b (h w) -> b h w", axes_lengths = {h = 3, w = 4}} :
(tensor<2x12xf32>) -> tensor<2x3x4xf32>
// Rearrange image patches (batch, height, width, channels) to sequence format
%input = ... : tensor<8x16x16x3xf32> // Input tensor with shape [8,16,16,3]
%result = ttir.rearrange(%input) {pattern = "b h w c -> b (h w) c"} :
(tensor<8x16x16x3xf32>) -> tensor<8x256x3xf32>
Inputs:
input(Tensor): The input tensor to rearrange.
Attributes:
pattern(String): A string describing the rearrangement pattern. The pattern consists of two parts separated by "->": the left side describes the input axes and the right side describes the output axes. Named axes can be reordered, merged using parentheses "()", or split using parentheses with known dimensions. Examples: "b c h w -> b (c h w)", "b (h w) -> b h w", "h w c -> c h w".axes_lengths(UNSUPPORTED #6339): A mapping of axis names to their lengths when splitting dimensions. Required when decomposing a dimension into multiple dimensions. Example: {h = 3, w = 4} when splitting a dimension of size 12 into h and w.
Output:
result(Tensor): The rearranged tensor.
Note: The total number of elements in the input tensor must equal the total number of elements in the output tensor. When merging dimensions, their sizes are multiplied. When splitting dimensions, the product of the split dimensions must equal the original dimension size. All axis names in the pattern must be unique within each side of the arrow, and axes can be reordered freely between input and output patterns.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_TensorManipulation
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
pattern | ::mlir::StringAttr | An Attribute containing a string{{% markdown %}} Syntax:{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.reciprocal (tt::ttir::ReciprocalOp)
Eltwise reciprocal.
The reciprocal operation computes the reciprocal (1/x) of each element in the input tensor.
For each element, it returns the reciprocal of the value.
Example:
// Compute reciprocal of all elements in %input
%result = ttir.reciprocal(%input) : (tensor<4x4xf32>) -> tensor<4x4xf32>
// Input tensor:
// [[1.7, 2.0, -0.3, 4.5], ... ]
// Output tensor:
// [[0.5882, 0.5, -3.3333, 0.2173], ... ]
Mathematical definition: reciprocal(x) = 1 / x
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable, TTIR_Involution
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.reduce_and (tt::ttir::ReduceAndOp)
Logical AND reduction operation.
The reduce_and operation performs a logical AND reduction along specified dimensions of the input tensor.
This operation reduces the input tensor by applying a logical AND operation to all elements along the dimensions
specified in dim_arg. If dim_arg is not provided, the reduction is computed over all dimensions,
resulting in a scalar value. If keep_dim is set to true, the reduced dimensions are retained
with a size of 1.
The operation treats non-zero values as True and zero values as False when performing the logical AND.
Example:
// Logical AND reduction along dimension 0
%input = ... : tensor<4x4xi1>
%result = ttir.reduce_and(%input) {keep_dim = false, dim_arg = [0: i32]} : (tensor<4x4xi1>) -> tensor<4xi1>
// Input tensor (where 1 represents True and 0 represents False):
// [[1, 0, 1, 0],
// [1, 1, 1, 1],
// [0, 0, 1, 1],
// [0, 1, 1, 0]]
// Output tensor:
// [0, 0, 1, 0] // Logical AND of each column
// Logical AND reduction along dimension 1
%input = ... : tensor<4x4xi1>
%result = ttir.reduce_and(%input) {keep_dim = false, dim_arg = [1: i32]} : (tensor<4x4xi1>) -> tensor<4xi1>
// Input tensor:
// [[1, 0, 1, 0],
// [1, 1, 1, 1],
// [0, 0, 1, 1],
// [0, 1, 1, 0]]
// Output tensor:
// [0, 1, 0, 0] // Logical AND of each row
// Logical AND reduction over all dimensions
%input = ... : tensor<4x4xi1>
%result = ttir.reduce_and(%input) {keep_dim = false} : (tensor<4x4xi1>) -> tensor<i1>
// Input tensor:
// [[1, 0, 1, 0],
// [1, 1, 1, 1],
// [0, 0, 1, 1],
// [0, 1, 1, 0]]
// Output tensor:
// 0 // Logical AND of all elements
Mathematical definition: reduce_and(x, dim) = AND(x[i]) for all i in dimension dim
Inputs:
input(Tensor): The input tensor.
Attributes:
keep_dim(Bool): Whether to keep the reduced dimensions or not.dim_arg(Array of Int32): Dimensions to reduce along.
Output:
result(Tensor): The result tensor after applying the reduction.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
keep_dim | ::mlir::BoolAttr | bool attribute |
dim_arg | ::mlir::ArrayAttr | 32-bit integer array attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.reduce_or (tt::ttir::ReduceOrOp)
Logical OR reduction operation.
The reduce_or operation performs a logical OR reduction along specified dimensions of the input tensor.
This operation reduces the input tensor by applying a logical OR operation to all elements along the dimensions
specified in dim_arg. If dim_arg is not provided, the reduction is computed over all dimensions,
resulting in a scalar value. If keep_dim is set to true, the reduced dimensions are retained
with a size of 1.
The operation treats non-zero values as True and zero values as False when performing the logical OR.
Example:
// Logical OR reduction along dimension 0
%input = ... : tensor<4x4xi1>
%result = ttir.reduce_or(%input) {keep_dim = false, dim_arg = [0: i32]} : (tensor<4x4xi1>) -> tensor<4xi1>
// Input tensor (where 1 represents True and 0 represents False):
// [[1, 0, 0, 0],
// [1, 1, 0, 1],
// [0, 0, 0, 1],
// [0, 0, 0, 0]]
// Output tensor:
// [1, 1, 0, 1] // Logical OR of each column
// Logical OR reduction along dimension 1
%input = ... : tensor<4x4xi1>
%result = ttir.reduce_or(%input) {keep_dim = false, dim_arg = [1: i32]} : (tensor<4x4xi1>) -> tensor<4xi1>
// Input tensor:
// [[1, 0, 0, 0],
// [1, 1, 0, 1],
// [0, 0, 0, 1],
// [0, 0, 0, 0]]
// Output tensor:
// [1, 1, 1, 0] // Logical OR of each row
// Logical OR reduction over all dimensions
%input = ... : tensor<4x4xi1>
%result = ttir.reduce_or(%input) {keep_dim = false} : (tensor<4x4xi1>) -> tensor<i1>
// Input tensor:
// [[1, 0, 0, 0],
// [1, 1, 0, 1],
// [0, 0, 0, 1],
// [0, 0, 0, 0]]
// Output tensor:
// 1 // Logical OR of all elements
Mathematical definition: reduce_or(x, dim) = OR(x[i]) for all i in dimension dim
Inputs:
input(Tensor): The input tensor.
Attributes:
keep_dim(Bool): Whether to keep the reduced dimensions or not.dim_arg(Array of Int32): Dimensions to reduce along.
Output:
result(Tensor): The result tensor after applying the reduction.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
keep_dim | ::mlir::BoolAttr | bool attribute |
dim_arg | ::mlir::ArrayAttr | 32-bit integer array attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.reduce_scatter (tt::ttir::ReduceScatterOp)
Reduce scatter operation.
Reduce scatter op.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_CCL
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
reduce_type | ::mlir::tt::ttcore::ReduceTypeAttr | TT Reduce Type |
scatter_dim | ::mlir::IntegerAttr | 32-bit signed integer attribute |
cluster_axis | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.relu6 (tt::ttir::Relu6Op)
Eltwise ReLU6.
The relu6 operation computes the ReLU6 activation function of each element in the input tensor.
For each element, it returns the minimum of 6 and the maximum of 0 and the value. The operation preserves the data type of the input.
This operation has the idempotence property, meaning that applying it multiple times produces the same result as applying it once: relu6(relu6(x)) = relu6(x).
Example:
// Compute ReLU6 of all elements in %input
%result = ttir.relu6(%input, %output) : tensor<4x4xf32>, tensor<4x4xf32> -> tensor<4x4xf32>
// Input tensor:
// [[1.7, 2.0, -0.3, 7.0], ... ]
// Output tensor:
// [[1.7, 2.0, 0.0, 6.0], ... ]
Mathematical definition: relu6(x) = min(6, max(0, x))
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable, TTIR_Idempotence
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.relu (tt::ttir::ReluOp)
Eltwise ReLU.
The relu operation computes the rectified linear unit (ReLU) of each element in the input tensor.
For each element, it returns the maximum of 0 and the value. The operation preserves the data type of the input.
Example:
// Compute ReLU of all elements in %input
%result = ttir.relu(%input) : (tensor<4x4xf32>) -> tensor<4x4xf32>
// Input tensor:
// [[1.7, 2.0, -0.3, 4.5], ... ]
// Output tensor:
// [[1.7, 2.0, 0.0, 4.5], ... ]
Mathematical definition: relu(x) = max(0, x)
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable, TTIR_Idempotence
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.remainder (tt::ttir::RemainderOp)
Elementwise remainder operation.
The remainder operation performs an elementwise remainder (modulo) operation between two tensors.
For each pair of corresponding elements, it computes the remainder when dividing the element in the first tensor (dividend) by the element in the second tensor (divisor) and places the result in the output tensor.
Example:
// Remainder operation
%result = ttir.remainder(%lhs, %rhs) : (tensor<4xi64>, tensor<4xi64>) -> tensor<4xi64>
// Input tensors:
// %lhs: [17, -17, 17, -17] // Dividends
// %rhs: [3, 3, -3, -3] // Divisors
// Output tensor:
// [2, -2, 2, -2]
// Example with floating point values
%result = ttir.remainder(%float_lhs, %float_rhs) : (tensor<3xf32>, tensor<3xf32>) -> tensor<3xf32>
// Input tensors:
// %float_lhs: [10.5, -10.5, 3.0]
// %float_rhs: [3.0, 3.0, 2.0]
// Output tensor:
// [1.5, -1.5, 1.0]
Note: Division by zero typically results in undefined behavior or NaN for floating-point types.
Mathematical definition: remainder(x, y) = x % y (where % is the remainder operator)
Traits: AlwaysSpeculatableImplTrait, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.repeat_interleave (tt::ttir::RepeatInterleaveOp)
Tensor repeat interleave operation.
The repeat_interleave operation repeats elements of a tensor along a specified dimension.
Unlike the repeat operation which repeats the entire tensor, this operation repeats each individual
element of the input tensor the specified number of times along the given dimension. This creates an
interleaved pattern of repeated values.
Example:
// Repeat interleave along dimension 0 with repeats=2
%input = ... : tensor<2x3xf32>
%result = ttir.repeat_interleave(%input) {repeats = 2 : ui32, dim = 0 : i32} : (tensor<2x3xf32>) -> tensor<4x3xf32>
// Input tensor:
// [[1.0, 2.0, 3.0],
// [4.0, 5.0, 6.0]]
// Output tensor:
// [[1.0, 2.0, 3.0], // First row repeated
// [1.0, 2.0, 3.0],
// [4.0, 5.0, 6.0], // Second row repeated
// [4.0, 5.0, 6.0]]
// Repeat interleave along dimension 1 with repeats=3
%input = ... : tensor<2x2xf32>
%result = ttir.repeat_interleave(%input) {repeats = 3 : ui32, dim = 1 : i32} : (tensor<2x2xf32>) -> tensor<2x6xf32>
// Input tensor:
// [[1.0, 2.0],
// [3.0, 4.0]]
// Output tensor:
// [[1.0, 1.0, 1.0, 2.0, 2.0, 2.0], // Each element repeated 3 times
// [3.0, 3.0, 3.0, 4.0, 4.0, 4.0]]
Inputs:
input(Tensor): The input tensor.
Attributes:
repeats(Integer): The number of times to repeat each element.dim(Integer): The dimension along which to repeat elements.
Output:
result(Tensor): The tensor with repeated elements.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
repeats | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
dim | ::mlir::IntegerAttr | 32-bit signed integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.repeat (tt::ttir::RepeatOp)
Repeat operation.
The repeat operation creates a new tensor by replicating the input tensor's elements
along specified dimensions.
This operation repeats the entire input tensor along each dimension according to the
values specified in the repeat_dimensions attribute. The resulting tensor's shape
is the product of the input tensor's shape and the corresponding repeat values.
Example:
// Repeat a 2x3 tensor with repeat dimensions [2, 2]
%input = ... : tensor<2x3xf32>
%result = ttir.repeat(%input) {repeat_dimensions = [2, 2]} : (tensor<2x3xf32>) -> tensor<4x6xf32>
// Input tensor:
// [[1.0, 2.0, 3.0],
// [4.0, 5.0, 6.0]]
// Output tensor:
// [[1.0, 2.0, 3.0, 1.0, 2.0, 3.0],
// [4.0, 5.0, 6.0, 4.0, 5.0, 6.0],
// [1.0, 2.0, 3.0, 1.0, 2.0, 3.0],
// [4.0, 5.0, 6.0, 4.0, 5.0, 6.0]]
// Repeat a 2x2 tensor with repeat dimensions [1, 3]
%input = ... : tensor<2x2xf32>
%result = ttir.repeat(%input) {repeat_dimensions = [1, 3]} : (tensor<2x2xf32>) -> tensor<2x6xf32>
// Input tensor:
// [[1.0, 2.0],
// [3.0, 4.0]]
// Output tensor:
// [[1.0, 2.0, 1.0, 2.0, 1.0, 2.0],
// [3.0, 4.0, 3.0, 4.0, 3.0, 4.0]]
Inputs:
input(Tensor): The input tensor to repeat.
Attributes:
repeat_dimensions(Array of Integer): The number of times to repeat the tensor along each dimension.
Output:
result(Tensor): The repeated tensor.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
repeat_dimensions | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.requantize (tt::ttir::RequantizeOp)
Requantize operation.
The Requantize operation converts a quantized tensor from one scale and zero-point to another, using the quant.uniform type from the MLIR Quant dialect.
The input tensor is expected to be of type quant.uniform.
The output tensor will also be of type quant.uniform.
Each element in the output tensor is computed as:
output[i] = round((input[i] - input_zero_point) * (input_scale / output_scale)) + output_zero_point
Example:
%input = ttir.empty() : () -> tensor<64x128x!quant.uniform<i32:f32, 0.1>>
%requantized = "ttir.requantize"(%input) : (tensor<64x128x!quant.uniform<i32:f32, 0.1>>) -> tensor<64x128x!quant.uniform<i32:f32, 0.2>>
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.requantize_unrolled (tt::ttir::RequantizeUnrolledOp)
Requantize operation unrolled (scale and zero point as input operands).
The RequantizeUnrolledOp requantizes a tensor using the scale and zero point provided as input operands.
Inputs:
inputAnyRankedTensor: The input tensor to be requantized. Must have quantized element type.in_scaleAnyRankedTensor: The input scale factor (or factors for per-axis quantization). Must be either a scalar (for per-tensor quantization) or a 1D tensor with size matching the dimension of the specified axis (for per-axis quantization).in_zero_pointAnyRankedTensor: The input zero point value (or values for per-axis quantization). Must be in range of the quantized storage type.out_scaleAnyRankedTensor: The output scale factor (or factors for per-axis quantization). Must be either a scalar (for per-tensor quantization) or a 1D tensor with size matching the dimension of the specified axis (for per-axis quantization).out_zero_pointAnyRankedTensor: The output zero point value (or values for per-axis quantization). Must be in range of the quantized storage type.axisOptional: The axis along which quantization is applied. Must be in range [0, rank) where rank is the rank of the input tensor.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
axis | ::mlir::IntegerAttr | 32-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
in_scale | ranked tensor of any type values |
in_zero_point | ranked tensor of any type values |
out_scale | ranked tensor of any type values |
out_zero_point | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.reshape (tt::ttir::ReshapeOp)
Tensor reshape operation.
The reshape operation changes the shape of a tensor without changing the data or number of elements.
This operation takes an input tensor and reshapes it to a new shape specified by the shape attribute. The total number of elements in the tensor must remain the same after reshaping. This operation is commonly used in neural networks to change the dimensionality of tensors between layers.
Example:
// Reshape a 2x3 tensor to a 1x6 tensor
%input = ... : tensor<2x3xf32> // Input tensor with shape [2,3]
%result = ttir.reshape(%input) {shape = [1, 6]} : (tensor<2x3xf32>) -> tensor<1x6xf32>
// Reshape a 3D tensor to a 2D tensor
%input = ... : tensor<2x3x4xf32> // Input tensor with shape [2,3,4]
%result = ttir.reshape(%input) {shape = [6, 4]} : (tensor<2x3x4xf32>) -> tensor<6x4xf32>
Inputs:
input(Tensor): The input tensor to reshape.
Attributes:
shape(Array of Integer): The new shape for the tensor.
Output:
result(Tensor): The reshaped tensor.
Note: The total number of elements in the input tensor must equal the total number of elements in the output tensor. For example, a tensor of shape [2,3] (6 elements) can be reshaped to [1,6], [6,1], [2,1,3], etc., but not to [2,4] (8 elements).
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_TensorManipulation
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
shape | ::mlir::ArrayAttr | 32-bit integer array attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.reverse (tt::ttir::ReverseOp)
Tensor reversal operation.
The reverse operation reverses the order of elements in the input tensor along the specified dimensions.
This operation flips the elements of a tensor along one or more axes, which is useful for operations like sequence reversal, matrix transposition with reversal, and other tensor manipulations that require changing the order of elements.
Example:
// Reverse a 3x2 tensor along dimension 1 (columns)
%input = ... : tensor<3x2xi32> // Input tensor with values:
// [[1, 2],
// [3, 4],
// [5, 6]]
%result = ttir.reverse(%input) {
dimensions = [1] // Reverse along columns
} : (tensor<3x2xi32>) -> tensor<3x2xi32>
// Result:
// [[2, 1],
// [4, 3],
// [6, 5]]
// Reverse a 3x2 tensor along both dimensions
%input = ... : tensor<3x2xi64> // Input tensor with values:
// [[1, 2],
// [3, 4],
// [5, 6]]
%result = ttir.reverse(%input) {
dimensions = [0, 1] // Reverse along both rows and columns
} : (tensor<3x2xi64>) -> tensor<3x2xi64>
// Result:
// [[6, 5],
// [4, 3],
// [2, 1]]
Inputs:
input(Tensor): The input tensor to reverse.
Attributes:
dimensions(Array of Integer): The dimensions along which to reverse the tensor.
Output:
result(Tensor): The reversed tensor.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dimensions | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.right_shift (tt::ttir::RightShiftOp)
Eltwise Arithmetic Right Shift operation
The right_shift operation performs an elementwise arithmetic right shift
on the elements of the first tensor by the corresponding shift amounts in the
second tensor.
Traits: AlwaysSpeculatableImplTrait, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.rsqrt (tt::ttir::RsqrtOp)
Eltwise reciprocal square root.
The rsqrt operation computes the reciprocal square root of each element in the input tensor.
For each element, it returns the reciprocal of the square root of the value.
Example:
// Compute reciprocal square root of all elements in %input
%result = ttir.rsqrt(%input) : (tensor<4x4xf32>) -> tensor<4x4xf32>
// Input tensor:
// [[1.7, 2.0, -0.3, 4.5], ... ]
// Output tensor:
// [[0.5882, 0.5, -3.3333, 0.2173], ... ]
Mathematical definition: rsqrt(x) = 1 / sqrt(x)
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.sampling (tt::ttir::SamplingOp)
Sampling operation.
Performs fused top-k + top-p + multinomial sampling on pre-filtered candidate logits. Takes the top-k values and their global vocab indices (from a prior topk stage), per-request top-k, top-p, temperature parameters, and an optional random seed. Returns one sampled global token index per request.
Inputs:
input_values: Pre-filtered candidate logit values [batch, candidates] bf16input_indices: Global vocab indices for each candidate [batch, candidates] int32k: Per-request top-k values [batch] uint32p: Per-request top-p values [batch] bf16temp: Per-request temperature values [batch] bf16seed: Optional random seed (uint32 scalar attribute)
Output:
result: Sampled global token indices [batch] int32
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
seed | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
input_values | ranked tensor of any type values |
input_indices | ranked tensor of any type values |
k | ranked tensor of any type values |
p | ranked tensor of any type values |
temp | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.scaled_dot_product_attention_decode (tt::ttir::ScaledDotProductAttentionDecodeOp)
A version of scaled dot product attention specifically for decode.
Flash-Decode SDPA for single-query-token decode. Supports MQA and GQA.
Shapes use B (batch), Hq/Hkv (query/kv heads), Sk (kv seq len),
D (head size).
Args:
query (AnyRankedTensor): [1 x B x Hq x D]. Dim 0 must be 1.
key (AnyRankedTensor): [B x Hkv x Sk x D].
value (AnyRankedTensor): [B x Hkv x Sk x D]. Same type as key.
is_causal (bool, optional): Defaults to true. Mutually exclusive
with attention_mask.
attention_mask (AnyRankedTensor, optional): [1|B x 1 x 1|Hq x Sk].
Dim 0 broadcasts batch, dim 2 broadcasts heads. Only valid when
is_causal is false.
cur_pos_tensor (AnyRankedTensor): 1D [B] integer tensor of decode
positions.
attention_sink (AnyRankedTensor, optional): [Hq x 32], single tile
wide.
scale (float, optional): Softmax scale. Defaults to 1 / sqrt(D).
Returns:
AnyRankedTensor: [1 x B x Hq x D] (same type as query).
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
is_causal | ::mlir::BoolAttr | bool attribute |
scale | ::mlir::FloatAttr | 32-bit float attribute |
Operands:
| Operand | Description |
|---|---|
query | ranked tensor of any type values |
key | ranked tensor of any type values |
value | ranked tensor of any type values |
attention_mask | ranked tensor of any type values |
cur_pos_tensor | ranked tensor of any type values |
attention_sink | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.scaled_dot_product_attention (tt::ttir::ScaledDotProductAttentionOp)
Scaled dot product attention operation.
FlashAttention-2 SDPA. Supports MHA, MQA, and GQA.
Lowering to TTNN dispatches on Sq: Sq > 1 lowers to
ttnn.scaled_dot_product_attention (prefill), while Sq == 1 lowers to
ttnn.scaled_dot_product_attention_decode (decode, with the necessary Q
and mask permutations applied at the conversion boundary).
Shapes use B (batch), Hq/Hkv (query/kv heads), Sq/Sk (query/kv
seq len), D (head size).
Args:
query (AnyRankedTensor): [B x Hq x Sq x D].
key (AnyRankedTensor): [B x Hkv x Sk x D].
value (AnyRankedTensor): [B x Hkv x Sk x D]. Same type as key.
attention_mask (AnyRankedTensor, optional): [1|B x 1|Hq x Sq x Sk].
Dim 0 broadcasts batch, dim 1 broadcasts heads. Only valid when
is_causal is false. Defaults to None.
is_causal (bool): Defaults to true. Requires Sq == Sk and no
attention_mask.
scale (float, optional): Softmax scale. Defaults to 1 / sqrt(D).
sliding_window_size (uint, optional): If is_causal, attends to the
last N tokens; otherwise attends to a window of size N centered at
the current position. Defaults to None.
attention_sink (AnyRankedTensor, optional): [1 x Hq x 1 x 1], one
value per query head broadcast across batch and tile dims.
Defaults to None.
Returns:
AnyRankedTensor: [B x Hq x Sq x D] (same type as query).
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
is_causal | ::mlir::BoolAttr | bool attribute |
scale | ::mlir::FloatAttr | 32-bit float attribute |
sliding_window_size | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
query | ranked tensor of any type values |
key | ranked tensor of any type values |
value | ranked tensor of any type values |
attention_mask | ranked tensor of any type values |
attention_sink | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.scatter (tt::ttir::ScatterOp)
Scatter operation with simplified dimension attributes
The scatter operation introduces torch style scatter in TTIR so that
we can lower ttir scatter -> ttnn scatter.
Embeds the values of the source tensor into the input tensor at locations specified by the index tensor along the given dimension.
This is a simplified scatter operation that operates along a single dimension, making it more straightforward to use than the general scatter operation when you only need to scatter along one axis.
Parameters:
input(Tensor): The tensor being updated.index(Tensor): Indices where values will be written to.source(Tensor): The values to scatter into the input tensor.dim(int32_t): The dimension along which to scatter.scatter_reduce_type(Enum): The scatter reduce type to use (SUM, PROD, MIN, MAX, INVALID).
Example:
// Scatter values along dimension 0
%input = ... : tensor<8xf32> // Input tensor
%indices = ... : tensor<3xi32> // Indices tensor
%source = ... : tensor<3xf32> // Source values to scatter
%result = ttir.scatter_in_dim(%input, %indices, %source) {
dim = 0, scatter_reduce_type = "SUM"
} : tensor<8xf32>, tensor<3xi32>, tensor<3xf32> -> tensor<8xf32>
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim | ::mlir::IntegerAttr | 32-bit signless integer attribute |
scatter_reduce_type | ::mlir::tt::ttcore::ReduceTypeAttr | TT Reduce Type |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
index | ranked tensor of any type values |
source | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.selective_reduce_combine (tt::ttir::SelectiveReduceCombineOp)
Reduce and combine phase of the MoE pipeline.
Takes dense blocks of expert-computed tokens from the MoE compute kernel, sparsifies them, and sends tokens back to their originating devices via fabric.
Input shapes:
- dense_input_tensor: dense expert output
- dense_activations_tensor: activation metadata
- dense_token_maps_tensor: token routing maps
- dense_token_counts_tensor: token counts per expert
Output shape:
- result: combined expert contributions
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_CCL
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
hidden_size | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
batch_size | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
seq_size | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
select_experts_k | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
experts | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
dense_input_tensor | ranked tensor of any type values |
dense_activations_tensor | ranked tensor of any type values |
dense_token_maps_tensor | ranked tensor of any type values |
dense_token_counts_tensor | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.selu (tt::ttir::SeluOp)
Elementwise scaled exponential linear unit (SELU).
Applies SELU activation elementwise. scale and alpha follow the same role as in
the standard SELU definition and default to PyTorch's torch.nn.functional.selu values.
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
scale | ::mlir::FloatAttr | 32-bit float attribute |
alpha | ::mlir::FloatAttr | 32-bit float attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.sigmoid (tt::ttir::SigmoidOp)
Eltwise sigmoid.
The sigmoid operation computes the sigmoid of each element in the input tensor.
For each element, it returns the sigmoid of the value.
Example:
// Compute sigmoid of all elements in %input
%result = ttir.sigmoid(%input) : (tensor<4x4xf32>) -> tensor<4x4xf32>
// Input tensor:
// [[1.7, 2.0, -0.3, 4.5], ... ]
// Output tensor:
// [[0.8391, 0.9641, 0.5793, 0.9899], ... ]
Mathematical definition: sigmoid(x) = 1 / (1 + exp(-x))
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.sign (tt::ttir::SignOp)
Eltwise sign operation.
The sign operation computes the sign of each element in the input tensor.
For each element, it returns:
- 1 if the value is positive
- 0 if the value is zero
- -1 if the value is negative
This operation has the idempotence property, meaning that applying it multiple times produces the same result as applying it once: sign(sign(x)) = sign(x).
Example:
// Compute sign of all elements in %input
%result = ttir.sign(%input) : (tensor<2x3xi32>) -> tensor<2x3xi32>
// Input tensor:
// [[3, -2, 0],
// [1, -4, 4]]
// Output tensor:
// [[1, -1, 0],
// [1, -1, 1]]
// Example with floating-point values
%result = ttir.sign(%float_input) : (tensor<4xf32>) -> tensor<4xf32>
// Input tensor:
// [5.7, -0.0, 0.001, -3.14]
// Output tensor:
// [1.0, 0.0, 1.0, -1.0]
Mathematical definition: sign(x) = { 1 if x > 0 0 if x = 0 -1 if x < 0 }
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable, TTIR_Idempotence
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.signbit (tt::ttir::SignbitOp)
Elementwise IEEE-754 sign bit as 0.0 or 1.0.
For each element, returns 0.0 if the sign bit is clear and 1.0 if set, matching IEEE 754 signbit semantics in the element type of the result tensor.
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.silu (tt::ttir::SiluOp)
Elementwise SiLU (Sigmoid Linear Unit) operation.
The silu operation computes the SiLU (Sigmoid Linear Unit) activation function of each element in the input tensor.
SiLU, also known as Swish, is defined as x * sigmoid(x). It combines the properties of both linear and sigmoid functions, providing smooth, non-monotonic activation that has shown good performance in deep learning applications.
Example:
// Compute SiLU of all elements in %input
%result = ttir.silu(%input, %output) : tensor<4x4xf32>, tensor<4x4xf32> -> tensor<4x4xf32>
// Input tensor:
// [[-2.0, -1.0, 0.0, 1.0], ... ]
// Output tensor:
// [[-0.238, -0.269, 0.0, 0.731], ... ]
Mathematical definition: silu(x) = x * sigmoid(x) = x * (1 / (1 + exp(-x)))
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.sin (tt::ttir::SinOp)
Eltwise sin operation.
The sin operation computes the sine of each element in the input tensor.
For each element, it returns the sine of the angle in radians.
Example:
// Compute sine of all elements in %input
%result = ttir.sin(%input) : (tensor<4x4xf32>) -> tensor<4x4xf32>
// Input tensor:
// [[1.7, 2.0, -0.3, 4.5], ... ]
// Output tensor:
// [[0.9601, 0.5403, -0.3, 4.5], ... ]
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.slice_dynamic (tt::ttir::SliceDynamicOp)
Tensor slice operation with dynamic parameters.
The slice_dynamic operation extracts a sub-tensor (slice) from the input tensor across one or more dimensions.
This operation selects a subset of elements from the input tensor based on the specified begin, end, and
step indices for each dimension. It's similar to Python's slicing notation tensor[begin:end:step] but
extended to multiple dimensions. The begins and ends parameters are tensor inputs determined at runtime.
Example:
// Extract a 2x2 slice from a 4x4 tensor with dynamic begin/end indices
%input = ... : tensor<4x4xf32> // Input tensor with values:
// [[1, 2, 3, 4],
// [5, 6, 7, 8],
// [9, 10, 11, 12],
// [13, 14, 15, 16]]
%begins = ... : tensor<2xi32> // Tensor with values [1, 1]
%ends = ... : tensor<2xi32> // Tensor with values [3, 3]
%result = ttir.slice_dynamic(%input, %begins, %ends) <{
step = [1, 1] // Step size for each dimension
}> : (tensor<4x4xf32>, tensor<2xi32>, tensor<2xi32>) -> tensor<2x2xf32>
// Result:
// [[6, 7],
// [10, 11]]
// Extract elements with a step of 2 using dynamic indices
%input = ... : tensor<5xf32> // Input tensor with values: [1, 2, 3, 4, 5]
%begins = ... : tensor<1xi32> // Tensor with values [0]
%ends = ... : tensor<1xi32> // Tensor with values [5]
%result = ttir.slice_dynamic(%input, %begins, %ends) <{
step = [2] // Step size
}> : (tensor<5xf32>, tensor<1xi32>, tensor<1xi32>) -> tensor<3xf32>
// Result: [1, 3, 5]
Inputs:
input(Tensor): The input tensor to slice.begins(Tensor): The starting indices for the slice in each dimension.ends(Tensor): The ending indices (exclusive) for the slice in each dimension.
Attributes:
step(Array of Integer): The step sizes for the slice in each dimension.
Outputs:
result(Tensor): The sliced tensor.
Note: The begins and ends tensors must have the same length as the rank of the input tensor.
The output tensor shape may contain dynamic dimensions when slice parameters are runtime-determined.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
step | ::mlir::ArrayAttr | 32-bit integer array attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
begins | ranked tensor of any type values |
ends | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.slice_static (tt::ttir::SliceStaticOp)
Tensor slice operation with constant parameters.
The slice_static operation extracts a sub-tensor (slice) from the input tensor across one or more dimensions.
This operation selects a subset of elements from the input tensor based on the specified begin, end, and
step indices for each dimension. It's similar to Python's slicing notation tensor[begin:end:step] but
extended to multiple dimensions. The begins and ends parameters are attributes with fixed values.
Example:
// Extract a 2x2 slice from a 4x4 tensor
%input = ... : tensor<4x4xf32> // Input tensor with values:
// [[1, 2, 3, 4],
// [5, 6, 7, 8],
// [9, 10, 11, 12],
// [13, 14, 15, 16]]
%result = ttir.slice_static(%input) {
begins = [1, 1], // Start indices for each dimension
ends = [3, 3], // End indices for each dimension (exclusive)
step = [1, 1] // Step size for each dimension
} : (tensor<4x4xf32>) -> tensor<2x2xf32>
// Result:
// [[6, 7],
// [10, 11]]
// Extract elements with a step of 2
%input = ... : tensor<5xf32> // Input tensor with values: [1, 2, 3, 4, 5]
%result = ttir.slice_static(%input) {
begins = [0], // Start index
ends = [5], // End index (exclusive)
step = [2] // Step size
} : (tensor<5xf32>) -> tensor<3xf32>
// Result: [1, 3, 5]
Inputs:
input(Tensor): The input tensor to slice.
Attributes:
begins(Array of Integer): The starting indices for the slice in each dimension.ends(Array of Integer): The ending indices (exclusive) for the slice in each dimension.step(Array of Integer): The step sizes for the slice in each dimension.
Output:
result(Tensor): The sliced tensor.
Note: The shape of the output tensor is determined by the slice parameters. For each dimension i,
the output size is calculated as ceil((ends[i] - begins[i]) / step[i]). The begins, ends, and
step arrays must have the same length as the rank of the input tensor.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
begins | ::mlir::ArrayAttr | 32-bit integer array attribute |
ends | ::mlir::ArrayAttr | 32-bit integer array attribute |
step | ::mlir::ArrayAttr | 32-bit integer array attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.softmax (tt::ttir::SoftmaxOp)
Softmax normalization operation.
The softmax operation applies the softmax function along a specified dimension of the input tensor.
The softmax function transforms each element of the input tensor to a value between 0 and 1, such that the sum of all elements along the specified dimension equals 1. This is commonly used to convert a vector of real numbers into a probability distribution.
The softmax function is defined as: softmax(x_i) = exp(x_i) / sum(exp(x_j)) for all j in the specified dimension
Example:
// Softmax along dimension 1
%input = ... : tensor<2x3xf32>
%result = ttir.softmax(%input) {dimension = 1 : i32} : (tensor<2x3xf32>) -> tensor<2x3xf32>
// Input tensor:
// [[1.0, 2.0, 3.0],
// [4.0, 1.0, 2.0]]
// Output tensor (approximate values):
// [[0.09, 0.24, 0.67], // sum = 1.0
// [0.71, 0.09, 0.20]] // sum = 1.0
Note: For numerical stability, the implementation typically subtracts the maximum value in each slice before applying the exponential function.
Inputs:
input(Tensor): The input tensor.
Attributes:
dimension(Integer): The dimension along which to apply the softmax function.numericStable(Boolean, default=false): Whether to use numerically stable computation.
Output:
result(Tensor): The tensor after applying the softmax function.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dimension | ::mlir::IntegerAttr | 32-bit signed integer attribute |
numericStable | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.softsign (tt::ttir::SoftsignOp)
Elementwise softsign activation.
For each element x, returns x / (1 + |x|).
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.sort (tt::ttir::SortOp)
Sort operation.
Sorts elements of a tensor along a given dimension.
Input:
- input: AnyRankedTensor
Attributes:
- dim (int32): The dimension to sort along (default: -1, the last dim).
- descending (bool): If True, sort in descending order (default: False).
- stable (bool): If True, ensures stable sort (equal elements keep order).
Returns a tuple:
- values: the sorted tensor.
- indices: the original indices of the sorted values.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim | ::mlir::IntegerAttr | 32-bit signed integer attribute |
descending | ::mlir::BoolAttr | bool attribute |
stable | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
values | ranked tensor of any type values |
indices | ranked tensor of any type values |
ttir.sparse_matmul (tt::ttir::SparseMatmulOp)
Sparse block matrix multiplication with sparsity mask.
The sparse_matmul operation performs batched matrix multiplication where
computation is selectively skipped for blocks marked as zero in the sparsity
tensor. Input b is organized as a collection of weight matrices indexed by
a block dimension (dim 1), and the sparsity tensor controls which blocks
participate in the computation.
The operation supports three sparsity modes that determine which input carries the block structure:
Inputs:
a(Tensor): The first input tensor (activations or sparse input).b(Tensor): The second input tensor, always [1, num_blocks, K, N].sparsity(Tensor): 4D binary mask indicating active blocks.
Attributes:
is_input_a_sparse(Boolean, default=false): Whetherahas block structure.is_input_b_sparse(Boolean, default=true): Whetherbhas block structure.nnz(Optional Integer): Number of non-zero blocks per row. If absent, it is inferred at runtime.
Supported Modes:
- is_input_a_sparse=false, is_input_b_sparse=true (column-parallel): a: [A, B, M, K], b: [1, E, K, N], sparsity: [A, B, 1, E] -> output: [A, B, 1, E, M, N]
- is_input_a_sparse=true, is_input_b_sparse=false (row-parallel): a: [A, E, M, K], b: [1, E, K, N], sparsity: [1, 1, A, E] -> output: [A, E, M, N]
- is_input_a_sparse=true, is_input_b_sparse=true (both sparse): a: [1, E, M, K], b: [1, E, K, N], sparsity: [1, 1, 1, E] -> output: [1, E, M, N]
Example (Mixture of Experts gate/up projection):
%result = "ttir.sparse_matmul"(%activations, %expert_weights, %sparsity) <{
is_input_a_sparse = false, is_input_b_sparse = true, nnz = 2
}> : (tensor<2x4x32x2880xbf16>, tensor<1x4x2880x5760xbf16>,
tensor<2x4x1x4xbf16>) -> tensor<2x4x1x4x32x5760xbf16>
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
is_input_a_sparse | ::mlir::BoolAttr | bool attribute |
is_input_b_sparse | ::mlir::BoolAttr | bool attribute |
nnz | ::mlir::IntegerAttr | 64-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
a | ranked tensor of any type values |
b | ranked tensor of any type values |
sparsity | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.split_query_key_value_and_split_heads (tt::ttir::SplitQueryKeyValueAndSplitHeadsOp)
Split query, key, values and split heads op used in attention layer.
Splits input_tensor of shape [batch_size, sequence_size, 3 * hidden_size] into 3 tensors (Query, Key, Value) of shape [batch_size, sequence_size, hidden_size]. Then, reshapes and permutes the output tensors, to make them ready for computing attention scores. If kv_input_tensor is passed in, then input_tensor of shape [batch_size, sequence_size, hidden_size] is only used for Query, and kv_input_tensor of shape [batch_size, sequence_size, 2 * hidden_size] is used for Key and Value. For the sharded implementation, the input query, key and value are expected to be concatenated such that the heads are interleaved (q1 k1 v1…qn kn vn).
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
num_heads | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
num_kv_heads | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
transpose_key | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
input_tensor | ranked tensor of any type values |
kv_input_tensor | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
query | ranked tensor of any type values |
key | ranked tensor of any type values |
value | ranked tensor of any type values |
ttir.sqrt (tt::ttir::SqrtOp)
Eltwise square root.
The sqrt operation computes the square root of each element in the input tensor.
For each element, it returns the square root of the value.
Example:
// Compute square root of all elements in %input
%result = ttir.sqrt(%input) : (tensor<4x4xf32>) -> tensor<4x4xf32>
// Input tensor:
// [[1.7, 2.0, -0.3, 4.5], ... ]
// Output tensor:
// [[0.5882, 0.5, -3.3333, 0.2173], ... ]
Mathematical definition: sqrt(x) = √x
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.square (tt::ttir::SquareOp)
Eltwise square.
The square operation computes the square of each element in the input tensor (x * x).
Example:
%result = ttir.square(%input) : (tensor<4x4xf32>) -> tensor<4x4xf32>
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.squeeze (tt::ttir::SqueezeOp)
Tensor dimension squeezing operation.
The squeeze operation removes a dimension of size 1 from the shape of a tensor.
This operation is commonly used to eliminate unnecessary singleton dimensions from a tensor's shape.
It specifies which dimension to remove using the dim attribute. The specified dimension must have size 1.
Example:
// Squeeze dimension 0 from a tensor of shape [1, 3, 4]
%input = ... : tensor<1x3x4xf32> // Input tensor with shape [1, 3, 4]
%result = ttir.squeeze(%input) {
dim = 0 : i32 // Dimension to squeeze
} : (tensor<1x3x4xf32>) -> tensor<3x4xf32>
// Result: tensor with shape [3, 4]
// Squeeze dimension 1 from a tensor of shape [2, 1, 3]
%input = ... : tensor<2x1x3xf32> // Input tensor with shape [2, 1, 3]
%result = ttir.squeeze(%input) {
dim = 1 : i32 // Dimension to squeeze
} : (tensor<2x1x3xf32>) -> tensor<2x3xf32>
// Result: tensor with shape [2, 3]
Inputs:
input(Tensor): The input tensor to squeeze.
Attributes:
dim(Integer): The dimension to squeeze.
Output:
result(Tensor): The squeezed tensor.
Note: The specified dimension must have size 1. The shape of the output tensor is the same as the input tensor with the specified dimension removed. For example, squeezing dimension 1 of a tensor with shape [2, 1, 3] results in a tensor with shape [2, 3].
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim | ::mlir::IntegerAttr | 32-bit signed integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.subtract (tt::ttir::SubtractOp)
Elementwise subtract operation.
The subtract operation performs an elementwise subtraction between two tensors.
For each pair of corresponding elements, it subtracts the element in the second tensor from the element in the first tensor and places the result in the output tensor.
Example:
// Subtraction operation
%result = ttir.subtract(%lhs, %rhs) : (tensor<3xi32>, tensor<3xi32>) -> tensor<3xi32>
// Input tensors:
// %lhs: [10, 20, 30]
// %rhs: [1, 2, 3]
// Output tensor:
// [9, 18, 27]
// Example with floating point values
%result = ttir.subtract(%float_lhs, %float_rhs) : (tensor<3xf32>, tensor<3xf32>) -> tensor<3xf32>
// Input tensors:
// %float_lhs: [3.5, 0.0, -1.2]
// %float_rhs: [1.5, 2.0, -3.2]
// Output tensor:
// [2.0, -2.0, 2.0]
Note: The data type of the output tensor matches the data type of the input tensors.
Mathematical definition: subtract(x, y) = x - y
Traits: AlwaysSpeculatableImplTrait, TTIR_Broadcastable, TwoOperands
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseBinary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.sum (tt::ttir::SumOp)
Sum reduction operation.
The sum operation computes the sum of elements along specified dimensions of the input tensor.
This operation reduces the input tensor by computing the sum of all elements along the dimensions
specified in dim_arg. If dim_arg is not provided, the sum is computed over all dimensions,
resulting in a scalar value. If keep_dim is set to true, the reduced dimensions are retained
with a size of 1.
Example:
// Sum along dimension 1
%input = ... : tensor<2x3xf32>
%result = ttir.sum(%input) {keep_dim = false, dim_arg = [1: i32]} : (tensor<2x3xf32>) -> tensor<2xf32>
// Input tensor:
// [[1.0, 2.0, 3.0],
// [4.0, 5.0, 6.0]]
// Output tensor:
// [6.0, 15.0] // Sum of each row
// Sum along dimension 0
%input = ... : tensor<2x3xf32>
%result = ttir.sum(%input) {keep_dim = false, dim_arg = [0: i32]} : (tensor<2x3xf32>) -> tensor<3xf32>
// Input tensor:
// [[1.0, 2.0, 3.0],
// [4.0, 5.0, 6.0]]
// Output tensor:
// [5.0, 7.0, 9.0] // Sum of each column
// Sum over all dimensions
%input = ... : tensor<2x3xf32>
%result = ttir.sum(%input) {keep_dim = false} : (tensor<2x3xf32>) -> tensor<f32>
// Input tensor:
// [[1.0, 2.0, 3.0],
// [4.0, 5.0, 6.0]]
// Output tensor:
// 21.0 // Sum of all elements
Mathematical definition: sum(x, dim) = ∑ x[i] for all i in dimension dim
Inputs:
input(Tensor): The input tensor.
Attributes:
keep_dim(Bool): Whether to keep the reduced dimensions or not.dim_arg(Array of Int32): Dimensions to reduce along.
Output:
result(Tensor): The result tensor after applying the reduction.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
keep_dim | ::mlir::BoolAttr | bool attribute |
dim_arg | ::mlir::ArrayAttr | 32-bit integer array attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.ttnn_metal_layout_cast (tt::ttir::TTNNMetalLayoutCastOp)
Cast TTNN layout-encoded tensor to/from TTCore metal layout-encoded tensor
Syntax:
operation ::= `ttir.ttnn_metal_layout_cast` $input attr-dict `:` type($input) `->` type($result)
Purely representational op that reinterprets a tensor's layout encoding from #ttnn.ttnn_layout<...>
to/from #ttcore.metal_layout<...> without modifying the underlying data.
Pre-bufferization, the input and output must be a RankedTensorType where one holds a
ttnn::TTNNLayoutAttr and the other, a ttcore::MetalLayoutAttr. Post bufferization,
the tensor encoded with a ttcore::MetalLayoutAttr is bufferized to a memref.
Examples:
%cast_to_metal = ttir.ttnn_metal_layout_cast %arg0
: tensor<32x32xf32, #ttnn.ttnn_layout<...>>
-> tensor<32x32xf32, #ttcore.metal_layout<...>>
%cast_to_metal_bufferized = ttir.ttnn_metal_layout_cast %arg0
: tensor<32x32xf32, #ttnn.ttnn_layout<...>>
-> memref<32x32xf32, ...>
%cast_to_ttnn = ttir.ttnn_metal_layout_cast %arg0
: tensor<32x32xf32, #ttcore.metal_layout<...>>
-> tensor<32x32xf32, #ttnn.ttnn_layout<...>>
%cast_to_ttnn_bufferized = ttir.ttnn_metal_layout_cast %arg0
: memref<32x32xf32, ...>
-> tensor<32x32xf32, #ttnn.ttnn_layout<...>>
Traits: AlwaysSpeculatableImplTrait
Interfaces: BufferizableOpInterface, ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpAsmOpInterface, TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
virtual_grid_inverse_mapping | ::mlir::AffineMapAttr | AffineMap attribute |
virtual_grid_forward_mapping | ::mlir::AffineMapAttr | AffineMap attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values or non-0-ranked.memref of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values or non-0-ranked.memref of any type values |
ttir.tan (tt::ttir::TanOp)
Elementwise tan operation.
The tan operation computes the tangent of each element in the input tensor.
For each element, it returns the tangent of the angle in radians.
Example:
// Compute tangent of all elements in %input
%result = ttir.tan(%input) : (tensor<4x4xf32>) -> tensor<4x4xf32>
// Input tensor:
// [[1.7, 2.0, -0.3, 4.5], ... ]
// Output tensor:
// [[0.9601, 0.5403, -0.3, 4.5], ... ]
Mathematical definition: tan(x) = sin(x) / cos(x)
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.tanh (tt::ttir::TanhOp)
Elementwise hyperbolic tangent operation.
The tanh operation computes the hyperbolic tangent of each element in the input tensor.
For each element, it returns the hyperbolic tangent of the value.
Example:
// Compute hyperbolic tangent of all elements in %input
%result = ttir.tanh(%input) : (tensor<4x4xf32>) -> tensor<4x4xf32>
// Input tensor:
// [[1.7, 2.0, -0.3, 4.5], ... ]
// Output tensor:
// [[0.9601, 0.5403, -0.3, 4.5], ... ]
Mathematical definition: tanh(x) = (e^x - e^-x) / (e^x + e^-x)
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.to_layout (tt::ttir::ToLayoutOp)
Layout op.
Syntax:
operation ::= `ttir.to_layout` $input `,` $output `:` type($input) `into` type($output) (`hostInfo` `=` $layout^)? attr-dict (`->` type($results)^)?
ToLayout operation, transition tensors from one layout to another. Some examples include:
- Transitioning between different memory spaces, e.g. DRAM to L1.
- Transitioning between different data types, e.g. f32 to f16.
- Transitioning between different tile sizes, e.g. 1x16 to 32x32
- Transitioning between different tensor sharding
- Some combination of the above
#layout = #ttcore.metal_layout<logical_shape = 64x128, dim_alignments = 32x32, collapsed_intervals = dense<[[0, 1], [1, 2]]> : tensor<2x2xi64>, system, sharded>
#layout1 = #ttcore.metal_layout<logical_shape = 64x128, dim_alignments = 32x32, collapsed_intervals = dense<[[0, 1], [1, 2]]> : tensor<2x2xi64>, l1, sharded>
%1 = "ttir.to_layout"(%arg0, %0) : (tensor<64x128xf32, #layout>, tensor<64x128xf32, #layout1>) -> tensor<64x128xf32, #layout1>
Interfaces: DestinationStyleOpInterface, MemoryEffectOpInterface, TTIROpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
layout | ::mlir::tt::ttcore::MetalLayoutAttr | Tensor layout attribute with explicit physical shape{{% markdown %}} The tensor layout attribute captures how tensor data is sharded across a grid of devices/cores and is laid out in memory. Note that the presence of this attribute implies that the tensor shape includes sharding (i.e. the first half of the tensor shape represents the grid shape).{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values or non-0-ranked.memref of any type values |
output | ranked tensor of any type values or non-0-ranked.memref of any type values |
Results:
| Result | Description |
|---|---|
results | variadic of ranked tensor of any type values |
ttir.topk (tt::ttir::TopKOp)
Top-K selection operation.
Returns the k largest or k smallest elements of the input_tensor along a given dimension dim.
If dim is not provided, the last dimension of the input_tensor is used.
If largest is True, the k largest elements are returned. Otherwise, the k smallest elements are returned.
The boolean option sorted if True, will make sure that the returned k elements are sorted.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
k | ::mlir::IntegerAttr | 32-bit signless integer attribute |
dim | ::mlir::IntegerAttr | 32-bit signless integer attribute |
largest | ::mlir::BoolAttr | bool attribute |
sorted | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
input_tensor | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
values | ranked tensor of any type values |
indices | ranked tensor of any type values |
ttir.topk_router_gpt (tt::ttir::TopKRouterGptOp)
Fused router linear layer for GPT-style mixture-of-experts models.
A fused multi-core matmul + top-k for the GPT-OSS MoE router. Computes the router logits via a linear projection (input @ weight + bias) and returns the top-k expert indices and weights for each token.
Inputs:
- input: [B, hidden_dim] bf16 hidden states
- weight: [hidden_dim, num_experts] bf16 router weight matrix
- bias: [B, num_experts] bf16 router bias (pre-broadcast across batch)
Outputs:
- expert_indices: [B, k_padded] ui16 top-k expert indices
- expert_weights: [B, k_padded] bf16 top-k router weights
where k_padded = round_up(k, 8).
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
k | ::mlir::IntegerAttr | 32-bit signless integer attribute |
num_experts | ::mlir::IntegerAttr | 32-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
weight | ranked tensor of any type values |
bias | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
expert_indices | ranked tensor of any type values |
expert_weights | ranked tensor of any type values |
ttir.transpose (tt::ttir::TransposeOp)
Tensor transpose operation.
The transpose operation swaps two dimensions of a tensor.
This operation exchanges the positions of two specified dimensions in the input tensor,
effectively transposing those dimensions. The shape of the output tensor is the same as
the input tensor, except that the dimensions specified by dim0 and dim1 are swapped.
Example:
// Transpose dimensions 0 and 1
%input = ... : tensor<2x3x4xf32>
%result = ttir.transpose(%input) {dim0 = 0 : i32, dim1 = 1 : i32} : (tensor<2x3x4xf32>) -> tensor<3x2x4xf32>
// Input tensor shape: [2, 3, 4]
// Output tensor shape: [3, 2, 4]
// Transpose dimensions 1 and 2
%input = ... : tensor<2x3x4xf32>
%result = ttir.transpose(%input) {dim0 = 1 : i32, dim1 = 2 : i32} : (tensor<2x3x4xf32>) -> tensor<2x4x3xf32>
// Input tensor shape: [2, 3, 4]
// Output tensor shape: [2, 4, 3]
Inputs:
input(Tensor): The input tensor.
Attributes:
dim0(Integer): The first dimension to swap.dim1(Integer): The second dimension to swap.
Output:
result(Tensor): The transposed tensor.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_TensorManipulation
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim0 | ::mlir::IntegerAttr | 32-bit signed integer attribute |
dim1 | ::mlir::IntegerAttr | 32-bit signed integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.trunc (tt::ttir::TruncOp)
Elementwise truncation toward zero.
For each element x, returns the value truncated toward zero (round toward zero), preserving the tensor element type.
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.typecast (tt::ttir::TypecastOp)
Elementwise type casting operation.
The typecast operation converts each element in the input tensor to a different data type.
This operation performs element-wise type conversion, such as converting from integers to floating-point values or between different floating-point precisions. The conversion follows the standard type conversion rules for the target platform.
Example:
// Cast from int32 to float32
%result = ttir.typecast(%input) : (tensor<4x4xi32>) -> tensor<4x4xf32>
// Input tensor:
// [[1, 2, -3, 4], ... ]
// Output tensor:
// [[1.0, 2.0, -3.0, 4.0], ... ]
// Cast from float32 to int32
%result = ttir.typecast(%float_input) : (tensor<3xf32>) -> tensor<3xi32>
// Input tensor:
// [1.7, -2.3, 3.0]
// Output tensor:
// [1, -2, 3] // Note: truncation, not rounding
// Cast from float32 to float64 (higher precision)
%result = ttir.typecast(%f32_input) : (tensor<2xf32>) -> tensor<2xf64>
// Input tensor:
// [3.14159, 2.71828]
// Output tensor:
// [3.14159, 2.71828] // Same values but with higher precision
Traits: AlwaysSpeculatableImplTrait, OneOperand, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseUnary, TTIR_QuantizableOpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
conservative_folding | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.unsqueeze (tt::ttir::UnsqueezeOp)
Tensor dimension insertion operation.
The unsqueeze operation inserts a dimension of size 1 into the shape of a tensor.
This operation is the inverse of the squeeze operation and is commonly used to add a singleton dimension
to a tensor's shape. It specifies which position to insert the new dimension using the dim attribute.
Example:
// Insert a dimension at position 0 of a tensor with shape [3, 4]
%input = ... : tensor<3x4xf32> // Input tensor with shape [3, 4]
%result = ttir.unsqueeze(%input) {
dim = 0 : i32 // Position to insert the new dimension
} : (tensor<3x4xf32>) -> tensor<1x3x4xf32>
// Result: tensor with shape [1, 3, 4]
// Insert a dimension at position 1 of a tensor with shape [2, 3]
%input = ... : tensor<2x3xf32> // Input tensor with shape [2, 3]
%result = ttir.unsqueeze(%input) {
dim = 1 : i32 // Position to insert the new dimension
} : (tensor<2x3xf32>) -> tensor<2x1x3xf32>
// Result: tensor with shape [2, 1, 3]
Inputs:
input(Tensor): The input tensor to unsqueeze.
Attributes:
dim(Integer): The position to insert the new dimension.
Output:
result(Tensor): The unsqueezed tensor.
Note: The shape of the output tensor is the same as the input tensor with a new dimension of size 1 inserted at the specified position. For example, unsqueezing at position 1 of a tensor with shape [2, 3] results in a tensor with shape [2, 1, 3].
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim | ::mlir::IntegerAttr | 32-bit signed integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.update_cache (tt::ttir::UpdateCacheOp)
Cache update operation.
The update_cache operation updates a cache tensor with values from an input tensor at specific indices.
This operation is commonly used in sequence models like transformers to update a key-value cache with new token information. It takes a cache tensor, an input tensor, and update indices, and updates the cache at the specified positions.
Example:
// Update cache at specific indices
%cache = ... : tensor<2x16x64xf32> // Batch size 2, sequence length 16, hidden dim 64
%input = ... : tensor<2x1x64xf32> // New token embeddings
%update_index = ... : tensor<1xi32> // Update at position [15]
%result = ttir.update_cache(%cache, %input, %update_index) {batch_offset = 0 : i32} :
tensor<2x16x64xf32>, tensor<2x1x64xf32>, tensor<1xi32> -> tensor<2x16x64xf32>
// The cache tensor is updated at position 15 for both batches with the values from input
Inputs:
cache(Tensor): The cache tensor to be updated.input(Tensor): The input tensor containing new values.update_index(Tensor): Indices specifying where to update the cache.
Attributes:
batch_offset(Integer): Offset in the batch dimension.
Output:
result(Tensor): The updated cache tensor.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_CacheOpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
batch_offset | ::mlir::IntegerAttr | 32-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
cache | ranked tensor of any type values |
input | ranked tensor of any type values |
update_index | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.upsample2d (tt::ttir::Upsample2dOp)
Upsample 2D operation.
The upsample2d operation increases the spatial dimensions (height and width) of an input tensor.
This operation is commonly used in neural networks to increase the spatial resolution of feature maps. It supports different upsampling algorithms such as "nearest" and "bilinear" interpolation. The input tensor is assumed to be in NHWC format (batch, height, width, channels).
Example:
// Upsample a tensor with different scale factors for height and width
%input = ... : tensor<10x64x32x3xbf16> // Input tensor: [batch=10, height=64, width=32, channels=3]
%result = ttir.upsample2d(%input) {
scale_factor = [2, 4], // Scale height by 2, width by 4
mode = "bilinear" // Use bilinear interpolation
} : (tensor<10x64x32x3xbf16>) -> tensor<10x128x128x3xbf16>
// Result: tensor with shape [10,128,128,3]
// Upsample with the same scale factor for both dimensions
%input = ... : tensor<1x32x32x16xf32> // Input tensor
%result = ttir.upsample2d(%input) {
scale_factor = 2, // Scale both height and width by 2
mode = "nearest" // Use nearest neighbor interpolation
} : (tensor<1x32x32x16xf32>) -> tensor<1x64x64x16xf32>
// Result: tensor with shape [1,64,64,16]
Inputs:
input(Tensor): The input tensor to upsample, in NHWC format.
Attributes:
scale_factor(Integer or Array of Integer): The scale factor for upsampling in height and width dimensions. If a single integer is provided, it's used for both dimensions. If an array is provided, the first value is used for height and the second for width.mode(String, default="nearest"): The upsampling algorithm to use. Currently supported values are "nearest" for nearest neighbor interpolation and "bilinear" for bilinear interpolation.
Output:
result(Tensor): The upsampled tensor.
Note: The output height is calculated as input_height * scale_factor[0] and the output width as input_width * scale_factor[1]. The batch and channel dimensions remain unchanged.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
scale_factor | ::mlir::Attribute | 32-bit signed integer attribute or i32 dense array attribute |
mode | ::mlir::StringAttr | string attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.where (tt::ttir::WhereOp)
Elementwise conditional selection operation based on a predicate.
The where operation performs element-wise conditional selection based on a predicate.
For each element position, it selects between two values based on a boolean condition in first tensor:
- If the condition is true (non-zero), it selects the corresponding element from the second tensor
- If the condition is false (zero), it selects the corresponding element from the third tensor
This operation supports broadcasting, allowing inputs of different shapes to be combined according to standard broadcasting rules.
Example:
// Select elements from %true_values where %condition is true,
// otherwise select from %false_values
%result = ttir.where(%condition, %true_values, %false_values) : (tensor<4x4xi1>, tensor<4x4xf32>, tensor<4x4xf32>) -> tensor<4x4xf32>
// With broadcasting (condition is a scalar)
%result = ttir.where(%scalar_condition, %true_values, %false_values) : (tensor<1xi1>, tensor<4x4xf32>, tensor<4x4xf32>) -> tensor<4x4xf32>
This operation is equivalent to the ternary conditional operator (condition ? true_value : false_value)
in many programming languages, applied elementwise across tensors.
Traits: AlwaysSpeculatableImplTrait, TTIR_Broadcastable
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTIROpInterface, TTIR_ElementwiseTernary
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
first | ranked tensor of any type values |
second | ranked tensor of any type values |
third | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttir.zeros (tt::ttir::ZerosOp)
Creates a tensor filled with zeros.
The zeros operation creates a tensor filled with zeros of the specified shape.
This operation is commonly used to initialize tensors with zero values. It takes a shape attribute and produces a tensor of that shape with all elements set to zero.
Example:
// Create a 3D tensor of zeros with shape [64, 28, 28]
%result = ttir.zeros() {
shape = [64, 28, 28]
} : () -> tensor<64x28x28xbf16>
// Result: A tensor of shape [64, 28, 28] filled with zeros
// Create a 2D tensor of zeros with shape [3, 4]
%result = ttir.zeros() {
shape = [3, 4]
} : () -> tensor<3x4xf32>
// Result: [[0.0, 0.0, 0.0, 0.0],
// [0.0, 0.0, 0.0, 0.0],
// [0.0, 0.0, 0.0, 0.0]]
Attributes:
shape(Array of Integer): The shape of the tensor to create.
Output:
result(Tensor): The tensor filled with zeros.
Note: The element type of the result tensor is determined by the return type specified in the operation. This operation is useful for initializing tensors before filling them with computed values or as a starting point for accumulation operations.
Traits: AlwaysSpeculatableImplTrait, ConstantLike, TTCore_CreationOpTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
shape | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
'ttkernel' Dialect
A TTKernel out-of-tree MLIR dialect.
This dialect is an example of an out-of-tree MLIR dialect designed to illustrate the basic setup required to develop MLIR-based tools without working inside of the LLVM source tree.
[TOC]
ArgAttr
Kernel argument.
Syntax:
#ttkernel.arg<
ArgType, # arg_type
size_t, # operand_index
bool, # is_uniform
StringAttr # argument_name
>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| arg_type | ArgType | |
| operand_index | size_t | |
| is_uniform | bool | |
| argument_name | StringAttr |
ArgSpecAttr
Kernel argument specification.
Syntax:
#ttkernel.arg_spec<
::llvm::ArrayRef<ArgAttr>, # rt_args
::llvm::ArrayRef<ArgAttr> # ct_args
>
A list of argument attributes, of which form the argument specification for this kernel.
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| rt_args | ::llvm::ArrayRef<ArgAttr> | |
| ct_args | ::llvm::ArrayRef<ArgAttr> |
BcastTypeAttr
TTKernel Broadcast Types
Syntax:
#ttkernel.bcast_type<
::mlir::tt::ttkernel::BcastType # value
>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| value | ::mlir::tt::ttkernel::BcastType | an enum of type BcastType |
BinaryDestReuseTypeAttr
TTKernel Binary Dest Reuse Types
Syntax:
#ttkernel.reuse_type<
::mlir::tt::ttkernel::BinaryDestReuseType # value
>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| value | ::mlir::tt::ttkernel::BinaryDestReuseType | an enum of type BinaryDestReuseType |
EltwiseBinaryTypeAttr
TTKernel Elementwise Binary Op Types
Syntax:
#ttkernel.eltwise_binary_type<
::mlir::tt::ttkernel::EltwiseBinaryType # value
>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| value | ::mlir::tt::ttkernel::EltwiseBinaryType | an enum of type EltwiseBinaryType |
InputClampingAttr
TTKernel SFPU Input Clamping Modes
Syntax:
#ttkernel.input_clamping<
::mlir::tt::ttkernel::InputClamping # value
>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| value | ::mlir::tt::ttkernel::InputClamping | an enum of type InputClamping |
ReduceDimAttr
TTKernel Reduce Dimensions
Syntax:
#ttkernel.reduce_dim<
::mlir::tt::ttkernel::ReduceDim # value
>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| value | ::mlir::tt::ttkernel::ReduceDim | an enum of type ReduceDim |
ReduceTypeAttr
TTKernel Reduce Types
Syntax:
#ttkernel.reduce_type<
::mlir::tt::ttkernel::ReduceType # value
>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| value | ::mlir::tt::ttkernel::ReduceType | an enum of type ReduceType |
ThreadTypeAttr
TTKernel ThreadTypes
Syntax:
#ttkernel.thread<
::mlir::tt::ttkernel::ThreadType # value
>
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| value | ::mlir::tt::ttkernel::ThreadType | an enum of type ThreadType |
ttkernel.abs_tile_int32 (tt::ttkernel::AbsTileI32Op)
Absolute value i32 tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.abs_tile_int32` `(` $dst0_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of absolute value operation DST[dst0_index] <- abs(DST[dst0_index]) on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.abs_tile_init (tt::ttkernel::AbsTileInitOp)
Init function for abs_tile operation. Refer to documentation for any init function.
Syntax:
operation ::= `ttkernel.abs_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before abs_tile.
Traits: TTKernel_InitOpTrait
ttkernel.abs_tile (tt::ttkernel::AbsTileOp)
Absolute value tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.abs_tile` `(` $dst0_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of absolute value operation DST[dst0_index] <- abs(DST[dst0_index]) on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.acos_tile_init (tt::ttkernel::AcosTileInitOp)
Init function for acos_tile operation. Refer to documentation for any init function.
Syntax:
operation ::= `ttkernel.acos_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before acos_tile.
Traits: TTKernel_InitOpTrait
ttkernel.acos_tile (tt::ttkernel::AcosTileOp)
Arccosine tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.acos_tile` `(` $dst0_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of arccosine operation DST[dst0_index] <- acos(DST[dst0_index]) on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.add_binary_tile_init (tt::ttkernel::AddBinaryTilesInitOp)
Short init function
Syntax:
operation ::= `ttkernel.add_binary_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before add_binary_tile.
Traits: TTKernel_InitOpTrait
ttkernel.add_binary_tile (tt::ttkernel::AddBinaryTilesOp)
Addition operation between two tiles
Syntax:
operation ::= `ttkernel.add_binary_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of addition operation DST[odst_index] <- DST[dst0_index] + DST[dst1_index] on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.add_int_tile_init (tt::ttkernel::AddIntTileInitOp)
Short init function
Syntax:
operation ::= `ttkernel.add_int_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before add_int_tile.
Traits: TTKernel_InitOpTrait
ttkernel.add_int_tile (tt::ttkernel::AddIntTileOp)
Integer addition operation between two tiles
Syntax:
operation ::= `ttkernel.add_int_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `,` $dtype `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of integer addition operation DST[odst_index] <- DST[dst0_index] + DST[dst1_index] on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call. Supported data formats are: Int32, UInt32, UInt16.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.add_tiles_init (tt::ttkernel::AddTilesInitOp)
Short init function
Syntax:
operation ::= `ttkernel.add_tiles_init` `(` $in0_cb `,` $in1_cb `)` attr-dict `:` functional-type(operands, results)
Must be run before add_tiles.
Traits: TTKernel_InitOpTrait
Operands:
| Operand | Description |
|---|---|
in0_cb | TTKernel cb |
in1_cb | TTKernel cb |
ttkernel.add_tiles (tt::ttkernel::AddTilesOp)
Add operation
Syntax:
operation ::= `ttkernel.add_tiles` `(` $in0_cb `,` $in1_cb `,` $in0_tile_index `,` $in1_tile_index `,` $dst_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise addition C=A+B of tiles in two CBs at given indices and writes the result to the DST register at index dst_tile_index. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_BinaryOpTrait, TTKernel_FPUOpTrait
Operands:
| Operand | Description |
|---|---|
in0_cb | TTKernel cb |
in1_cb | TTKernel cb |
in0_tile_index | index or 32-bit signless integer |
in1_tile_index | index or 32-bit signless integer |
dst_index | index or 32-bit signless integer |
ttkernel.add_unary_tile_int32 (tt::ttkernel::AddUnaryTileInt32Op)
Add by int32 scalar operation
Syntax:
operation ::= `ttkernel.add_unary_tile_int32` `(` $dst0_index `,` $param `)` attr-dict `:` functional-type(operands, results)
Performs element-wise addition of an int32 tile by an int32 scalar value. DST[dst0_index] <- DST[dst0_index] + scalar The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
param | 32-bit signless integer |
ttkernel.add_unary_tile (tt::ttkernel::AddUnaryTileOp)
Add by scalar operation
Syntax:
operation ::= `ttkernel.add_unary_tile` `(` $dst0_index `,` $param `)` attr-dict `:` functional-type(operands, results)
Performs element-wise addition of a tile by a scalar value. DST[dst0_index] <- DST[dst0_index] + scalar The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
param | 32-bit signless integer |
ttkernel.asin_tile_init (tt::ttkernel::AsinTileInitOp)
Init function for asin_tile operation. Refer to documentation for any init function.
Syntax:
operation ::= `ttkernel.asin_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before asin_tile.
Traits: TTKernel_InitOpTrait
ttkernel.asin_tile (tt::ttkernel::AsinTileOp)
Arcsine tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.asin_tile` `(` $dst0_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of arcsine operation DST[dst0_index] <- asin(DST[dst0_index]) on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.atan2_binary_tile_init (tt::ttkernel::Atan2BinaryTilesInitOp)
Short init function
Syntax:
operation ::= `ttkernel.atan2_binary_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before atan2_binary_tile.
Traits: TTKernel_InitOpTrait
ttkernel.atan2_binary_tile (tt::ttkernel::Atan2BinaryTilesOp)
Elementwise atan2 operation between two tiles
Syntax:
operation ::= `ttkernel.atan2_binary_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of atan2 operation DST[odst_index] <- atan2(DST[dst0_index], DST[dst1_index]) on DST register operands. The DST register buffer must be in acquired state via acquire_dst call.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.atan_tile_init (tt::ttkernel::AtanTileInitOp)
Init function for atan_tile operation. Refer to documentation for any init function.
Syntax:
operation ::= `ttkernel.atan_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before atan_tile.
Traits: TTKernel_InitOpTrait
ttkernel.atan_tile (tt::ttkernel::AtanTileOp)
Arctangent tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.atan_tile` `(` $dst0_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of arctangent operation DST[dst0_index] <- atan(DST[dst0_index]) on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.bfloat16_greater (tt::ttkernel::Bfloat16GreaterOp)
Compare two bfloat16 values using integer arithmetic.
Syntax:
operation ::= `ttkernel.bfloat16_greater` `(` $bf16_a `,` $bf16_b `)` attr-dict `:` functional-type(operands, results)
Returns true if bf16_a > bf16_b. Operates on raw bits in int16 format representation. Maps to bfloat16_greater() in device code.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, InferTypeOpInterface, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
bf16_a | 16-bit signless integer |
bf16_b | 16-bit signless integer |
Results:
| Result | Description |
|---|---|
result | 1-bit signless integer |
ttkernel.binary_bitwise_tile_init (tt::ttkernel::BinaryBitwiseTileInitOp)
Init function for binary bitwise operations (AND, OR, XOR). Refer to documentation for any init function.
Syntax:
operation ::= `ttkernel.binary_bitwise_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before bitwise_and_binary_tile, bitwise_or_binary_tile, or bitwise_xor_binary_tile.
Traits: TTKernel_InitOpTrait
ttkernel.binary_dest_reuse_tiles_init (tt::ttkernel::BinaryDestReuseTilesInitOp)
Init for binary op with dest reuse
Syntax:
operation ::= `ttkernel.binary_dest_reuse_tiles_init` `(` $in_cb `,` $eltwise_binary_type `,` $reuse_type `)` attr-dict `:` functional-type(operands, results)
Init function for binary_dest_reuse_tiles operation.
Must be run before binary_dest_reuse_tiles.
eltwise_binary_type specifies the operation (add/sub/mul).
reuse_type specifies which source register gets the DST operand.
Traits: TTKernel_InitOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
eltwise_binary_type | ::mlir::tt::ttkernel::EltwiseBinaryTypeAttr | TTKernel Elementwise Binary Op Types |
reuse_type | ::mlir::tt::ttkernel::BinaryDestReuseTypeAttr | TTKernel Binary Dest Reuse Types |
Operands:
| Operand | Description |
|---|---|
in_cb | TTKernel cb |
ttkernel.binary_dest_reuse_tiles (tt::ttkernel::BinaryDestReuseTilesOp)
Binary op with one operand from DST
Syntax:
operation ::= `ttkernel.binary_dest_reuse_tiles` `(` $in_cb `,` $in_tile_index `,` $dst_tile_index `,` $eltwise_binary_type `,` $reuse_type `)` attr-dict `:` functional-type(operands, results)
Performs element-wise binary op where one operand comes from DST and one
from a CB. If reuse_type is dest_to_srca, DST[dst_tile_index] is loaded
to SRCA and CB tile is loaded to SRCB. If dest_to_srcb, the opposite.
Result is written back to DST[dst_tile_index].
The DST register buffer must be in acquired state via tile_regs_acquire call.
eltwise_binary_type specifies the operation (add/sub/mul).
Traits: TTKernel_FPUOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
eltwise_binary_type | ::mlir::tt::ttkernel::EltwiseBinaryTypeAttr | TTKernel Elementwise Binary Op Types |
reuse_type | ::mlir::tt::ttkernel::BinaryDestReuseTypeAttr | TTKernel Binary Dest Reuse Types |
Operands:
| Operand | Description |
|---|---|
in_cb | TTKernel cb |
in_tile_index | index or 32-bit signless integer |
dst_tile_index | index or 32-bit signless integer |
ttkernel.binary_left_shift_tile (tt::ttkernel::BinaryLeftShiftTileOp)
Elementwise left shift between two tiles
Syntax:
operation ::= `ttkernel.binary_left_shift_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `,` $dtype `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of a left shift operation DST[odst_index] <- DST[dst0_index] << DST[dst1_index] on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.binary_logical_right_shift_tile (tt::ttkernel::BinaryLogicalRightShiftTileOp)
Elementwise logical right shift between two tiles
Syntax:
operation ::= `ttkernel.binary_logical_right_shift_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `,` $dtype `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of a logical right shift operation DST[odst_index] <- DST[dst0_index] >> DST[dst1_index] (zero-filled) on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.binary_max_int32_tile_init (tt::ttkernel::BinaryMaxInt32TileInitOp)
Short init function
Syntax:
operation ::= `ttkernel.binary_max_int32_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before binary_max_int32_tile.
Traits: TTKernel_InitOpTrait
ttkernel.binary_max_int32_tile (tt::ttkernel::BinaryMaxInt32TileOp)
Integer elementwise maximum operation between two tiles
Syntax:
operation ::= `ttkernel.binary_max_int32_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of integer maximum operation DST[odst_index] <- max(DST[dst0_index], DST[dst1_index]) on DST register operands. The DST register buffer must be in acquired state via acquire_dst call.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.binary_max_tile_init (tt::ttkernel::BinaryMaxTileInitOp)
Short init function
Syntax:
operation ::= `ttkernel.binary_max_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before binary_max_tile.
Traits: TTKernel_InitOpTrait
ttkernel.binary_max_tile (tt::ttkernel::BinaryMaxTileOp)
Elementwise maximum operation
Syntax:
operation ::= `ttkernel.binary_max_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of maximum operation DST[odst_index] <- max(DST[dst0_index], DST[dst1_index]) on DST register operands. The DST register buffer must be in acquired state via acquire_dst call.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.binary_min_int32_tile_init (tt::ttkernel::BinaryMinInt32TileInitOp)
Short init function
Syntax:
operation ::= `ttkernel.binary_min_int32_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before binary_min_int32_tile.
Traits: TTKernel_InitOpTrait
ttkernel.binary_min_int32_tile (tt::ttkernel::BinaryMinInt32TileOp)
Integer elementwise minimum operation between two tiles
Syntax:
operation ::= `ttkernel.binary_min_int32_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of integer minimum operation DST[odst_index] <- min(DST[dst0_index], DST[dst1_index]) on DST register operands. The DST register buffer must be in acquired state via acquire_dst call.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.binary_min_tile_init (tt::ttkernel::BinaryMinTileInitOp)
Short init function
Syntax:
operation ::= `ttkernel.binary_min_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before binary_min_tile.
Traits: TTKernel_InitOpTrait
ttkernel.binary_min_tile (tt::ttkernel::BinaryMinTileOp)
Elementwise minimum operation
Syntax:
operation ::= `ttkernel.binary_min_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of minimum operation DST[odst_index] <- min(DST[dst0_index], DST[dst1_index]) on DST register operands. The DST register buffer must be in acquired state via acquire_dst call.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.binary_op_init_common (tt::ttkernel::BinaryOpInitCommonOp)
Init function for all binary ops
Syntax:
operation ::= `ttkernel.binary_op_init_common` `(` $in0_cb `,` $in1_cb `,` $out_cb `)` attr-dict `:` functional-type(operands, results)
Followed by the specific init required with an opcode (binrary_op_specific_init).
Traits: TTKernel_InitOpTrait
Operands:
| Operand | Description |
|---|---|
in0_cb | TTKernel cb |
in1_cb | TTKernel cb |
out_cb | TTKernel cb |
ttkernel.binary_right_shift_tile (tt::ttkernel::BinaryRightShiftTileOp)
Elementwise arithmetic right shift between two tiles
Syntax:
operation ::= `ttkernel.binary_right_shift_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `,` $dtype `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of an arithmetic right shift operation DST[odst_index] <- DST[dst0_index] >> DST[dst1_index] (sign-preserving) on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.binary_shift_tile_init (tt::ttkernel::BinaryShiftTileInitOp)
Init function for binary shift tile operations (left / right / logical right). Refer to documentation for any init function.
Syntax:
operation ::= `ttkernel.binary_shift_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before binary_left_shift_tile, binary_right_shift_tile, or binary_logical_right_shift_tile.
Traits: TTKernel_InitOpTrait
ttkernel.binop_with_scalar_tile_init (tt::ttkernel::BinopWithScalarTileInitOp)
Init function for binary operations with scalar tile operations.
Syntax:
operation ::= `ttkernel.binop_with_scalar_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before binary operations with scalar like mul_unary_tile.
Traits: TTKernel_InitOpTrait
ttkernel.bitcast (tt::ttkernel::BitcastOp)
Reinterpret a ui32 compile-time arg value as a scalar type.
Syntax:
operation ::= `ttkernel.bitcast` $input `:` type($input) `to` type($result) attr-dict
Reinterprets the bits of a ui32 compile-time arg as the given type. Used to recover typed scalar kernel arguments after reading them from the compile-time arg slot (which always stores ui32).
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | 32-bit unsigned integer |
Results:
| Result | Description |
|---|---|
result | any type |
ttkernel.bitwise_and_binary_tile (tt::ttkernel::BitwiseAndBinaryTilesOp)
Bitwise AND operation between two tiles
Syntax:
operation ::= `ttkernel.bitwise_and_binary_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `,` $dtype `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of bitwise AND operation DST[odst_index] <- DST[dst0_index] & DST[dst1_index] on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.bitwise_not_tile_init (tt::ttkernel::BitwiseNotTileInitOp)
Init function for bitwise_not_tile operation. Refer to documentation for any init function.
Syntax:
operation ::= `ttkernel.bitwise_not_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before bitwise_not_tile.
Traits: TTKernel_InitOpTrait
ttkernel.bitwise_not_tile (tt::ttkernel::BitwiseNotTileOp)
Bitwise Not operation on tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.bitwise_not_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of sign operation DST[tile_index] <- bitwise_not(DST[tile_index]) on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.bitwise_or_binary_tile (tt::ttkernel::BitwiseOrBinaryTilesOp)
Bitwise OR operation between two tiles
Syntax:
operation ::= `ttkernel.bitwise_or_binary_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `,` $dtype `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of bitwise OR operation DST[odst_index] <- DST[dst0_index] | DST[dst1_index] on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.bitwise_xor_binary_tile (tt::ttkernel::BitwiseXorBinaryTilesOp)
Bitwise XOR operation between two tiles
Syntax:
operation ::= `ttkernel.bitwise_xor_binary_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `,` $dtype `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of bitwise XOR operation DST[odst_index] <- DST[dst0_index] ^ DST[dst1_index] on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.cb_pop_front (tt::ttkernel::CBPopFrontOp)
CBPopFront call.
Syntax:
operation ::= `ttkernel.cb_pop_front` `(` $cb `,` $numPages `)` attr-dict `:` functional-type(operands, results)
CBPopFront operation
Operands:
| Operand | Description |
|---|---|
cb | TTKernel cb |
numPages | 32-bit signless integer |
ttkernel.cb_push_back (tt::ttkernel::CBPushBackOp)
CBPushBack call.
Syntax:
operation ::= `ttkernel.cb_push_back` `(` $cb `,` $numPages `)` attr-dict `:` functional-type(operands, results)
CBPushBack operation
Operands:
| Operand | Description |
|---|---|
cb | TTKernel cb |
numPages | 32-bit signless integer |
ttkernel.cb_reserve_back (tt::ttkernel::CBReserveBackOp)
CBReserveBack call.
Syntax:
operation ::= `ttkernel.cb_reserve_back` `(` $cb `,` $numPages `)` attr-dict `:` functional-type(operands, results)
CBReserveBack operation
Traits: TTKernel_DeviceZoneOpTrait
Operands:
| Operand | Description |
|---|---|
cb | TTKernel cb |
numPages | 32-bit signless integer |
ttkernel.cb_wait_front (tt::ttkernel::CBWaitFrontOp)
CBWaitFront call.
Syntax:
operation ::= `ttkernel.cb_wait_front` `(` $cb `,` $numPages `)` attr-dict `:` functional-type(operands, results)
CBWaitFront operation
Traits: TTKernel_DeviceZoneOpTrait
Operands:
| Operand | Description |
|---|---|
cb | TTKernel cb |
numPages | 32-bit signless integer |
ttkernel.reinterpret_cast (tt::ttkernel::CastToL1PtrOp)
CastToL1Ptr
Syntax:
operation ::= `ttkernel.reinterpret_cast` `(` $addr `)` attr-dict `:` functional-type(operands, results)
Cast specified addr to L1 pointer.
Operands:
| Operand | Description |
|---|---|
addr | 32-bit signless integer or TTKernel l1 address or TTKernel semaphore |
Results:
| Result | Description |
|---|---|
l1_ptr | TTKernel l1 address pointer |
ttkernel.ceil_tile (tt::ttkernel::CeilTileOp)
Ceil tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.ceil_tile` `(` $dst0_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of ceil operation DST[dst0_index] <- ceil(DST[dst0_index]) on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.clamp_tile_init (tt::ttkernel::ClampScalarTileInitOp)
Init function for clamp_scalar_tile operation.
Syntax:
operation ::= `ttkernel.clamp_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before clamp_scalar_tile.
Traits: TTKernel_InitOpTrait
ttkernel.clamp_tile_int32 (tt::ttkernel::ClampScalarTileInt32Op)
Clamp int32 tile elements to scalar range
Syntax:
operation ::= `ttkernel.clamp_tile_int32` `(` $dst_index `,` $min_param `,` $max_param `)` attr-dict `:` functional-type(operands, results)
Performs element-wise clamping of int32 tile values to the range [min, max] DST[dst_index] <- clamp(DST[dst_index], min, max) on DST register operand. The DST register buffer must be in acquired state via tile_regs_acquire call. min and max are int32 values.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst_index | index or 32-bit signless integer |
min_param | 32-bit signless integer |
max_param | 32-bit signless integer |
ttkernel.clamp_tile (tt::ttkernel::ClampScalarTileOp)
Clamp tile elements to scalar range
Syntax:
operation ::= `ttkernel.clamp_tile` `(` $dst_index `,` $min_param `,` $max_param `)` attr-dict `:` functional-type(operands, results)
Performs element-wise clamping of tile values to the range [min, max] DST[dst_index] <- clamp(DST[dst_index], min, max) on DST register operand. The DST register buffer must be in acquired state via tile_regs_acquire call. min and max are uint 32-bit representations of the float values.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst_index | index or 32-bit signless integer |
min_param | 32-bit signless integer |
max_param | 32-bit signless integer |
ttkernel.experimental.close_fabric_connections (tt::ttkernel::CloseFabricConnectionsOp)
CloseFabricConnections
Syntax:
operation ::= `ttkernel.experimental.close_fabric_connections` `(` $fabric_connection_manager `)` attr-dict `:` functional-type(operands, results)
Close fabric connections.
Operands:
| Operand | Description |
|---|---|
fabric_connection_manager | TTKernel fabric connection manager |
ttkernel.compute_kernel_hw_startup (tt::ttkernel::ComputeKernelHWStartupOp)
Compute_kernel_hw_startup
Must be run at the start of compute kernel.
Traits: TTKernel_InitOpTrait
Operands:
| Operand | Description |
|---|---|
icb0 | TTKernel cb |
icb1 | TTKernel cb |
ocb | TTKernel cb |
ttkernel.experimental.convert_logical_x_to_translated (tt::ttkernel::ConvertLogicalXToTranslatedOp)
ConvertLogicalToTranslatedX
Syntax:
operation ::= `ttkernel.experimental.convert_logical_x_to_translated` `(` $logical_x `)` attr-dict `:` functional-type(operands, results)
this converts the x coordinate from the LOGICAL coordinate system to TRANSLATED
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
logical_x | index or 32-bit signless integer |
Results:
| Result | Description |
|---|---|
virtual_x | index or 32-bit signless integer |
ttkernel.experimental.convert_logical_y_to_translated (tt::ttkernel::ConvertLogicalYToTranslatedOp)
ConvertLogicalToTranslatedY
Syntax:
operation ::= `ttkernel.experimental.convert_logical_y_to_translated` `(` $logical_y `)` attr-dict `:` functional-type(operands, results)
this converts the y coordinate from the LOGICAL coordinate system to TRANSLATED
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
logical_y | index or 32-bit signless integer |
Results:
| Result | Description |
|---|---|
virtual_y | index or 32-bit signless integer |
ttkernel.copy_block_matmul_partials (tt::ttkernel::CopyBlockMatmulPartialsOp)
CopyBlockMatmulPartials op.
Syntax:
operation ::= `ttkernel.copy_block_matmul_partials` `(` $cb `,` $start_tile_index `,` $start_dst_index `,` $ntiles `)` attr-dict `:` functional-type(operands, results)
Copies ntiles consecutive tiles from a specified circular buffer starting at start_tile_index to consecutive DST register slots starting at start_dst_index. The function employs the unpacker to first unpack into SRC registers and then move into DST registers.
The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
A typical use case is reloading partial matmul results from a CB back into DST for further accumulation. The consumer first calls cb_wait_front to ensure tiles are available, then calls copy_block_matmul_partials to load the block into DST, accumulates with subsequent matmul operations, and finally packs the results back to a CB.
Operands:
| Operand | Description |
|---|---|
cb | TTKernel cb |
start_tile_index | index or 32-bit signless integer |
start_dst_index | index or 32-bit signless integer |
ntiles | index or 32-bit signless integer |
ttkernel.copy_dest_values_init (tt::ttkernel::CopyDestValuesInitOp)
Short init function
Syntax:
operation ::= `ttkernel.copy_dest_values_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before copy_dest_values.
Traits: TTKernel_InitOpTrait
ttkernel.copy_dest_values (tt::ttkernel::CopyDestValuesOp)
Copies all values from the tile at idst_in to the tile at idst_out in the DST register buffer.
Syntax:
operation ::= `ttkernel.copy_dest_values` `(` $idst_in `,` $idst_out `,` $data_format `)` attr-dict `:` functional-type(operands, results)
Copies all values from the tile at idst_in to the tile at idst_out in the DST register buffer. Performs element-wise copy: DST[idst_out] <- DST[idst_in]. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Lowers to: copy_dest_values
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
data_format | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
Operands:
| Operand | Description |
|---|---|
idst_in | index or 32-bit signless integer |
idst_out | index or 32-bit signless integer |
ttkernel.copy_tile_init (tt::ttkernel::CopyTileInitOp)
Perform the init for copy tile. This does not reconfigure the unpacker data types.
Syntax:
operation ::= `ttkernel.copy_tile_init` `(` $cb0 `)` attr-dict `:` functional-type(operands, results)
Must be called before copy_tile.
Traits: TTKernel_InitOpTrait
Operands:
| Operand | Description |
|---|---|
cb0 | TTKernel cb |
ttkernel.copy_tile (tt::ttkernel::CopyTileOp)
Copy tile from specified CB to DST.
Syntax:
operation ::= `ttkernel.copy_tile` `(` $cb0 `,` $tile_index_cb `,` $tile_index_dst `)` attr-dict `:` functional-type(operands, results)
Copies a single tile from the specified input CB and writes the result to DST at a specified index. The function will employ unpacker to first unpack into SRC registers and then perform move into DST registers, at a specified index. For the in_tile_index to be valid for this call, cb_wait_front(n) had to be previously called to ensure that at least some number n>0 of tiles are available in the input CB. The CB index 0 then references the first tile in the received section of the CB, up to index n-1 (in a FIFO order). The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Operands:
| Operand | Description |
|---|---|
cb0 | TTKernel cb |
tile_index_cb | index or 32-bit signless integer |
tile_index_dst | index or 32-bit signless integer |
ttkernel.cos_tile_init (tt::ttkernel::CosTileInitOp)
Short init function which configures compute unit for execution of cos_tile.
Syntax:
operation ::= `ttkernel.cos_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before cos_tile.
Traits: TTKernel_InitOpTrait
ttkernel.cos_tile (tt::ttkernel::CosTileOp)
Cos operation
Syntax:
operation ::= `ttkernel.cos_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of the trigonometric cosine operation on each element of a tile in DST register at index tile_index. The DST register buffer must be in acquired state via acquire_dst call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.experimental.create_fabric_connection_manager (tt::ttkernel::CreateFabricConnectionManagerOp)
CreateFabricConnectionManager
Syntax:
operation ::= `ttkernel.experimental.create_fabric_connection_manager` `(` `)` attr-dict `:` functional-type(operands, results)
Create fabric connection manager. The fabric connection manager is required for all fabric operations.
Interfaces: InferTypeOpInterface
Results:
| Result | Description |
|---|---|
fabric_connection_manager | TTKernel fabric connection manager |
ttkernel.dprint (tt::ttkernel::DPrintOp)
Print to output stream from kernel.
Syntax:
operation ::= `ttkernel.dprint` `(` $fmt (`,` $argv^)? `)` attr-dict `:` functional-type($argv, results)
std::format style format string:
rewriter.create<ttkernel::DPrintOp>(loc, "nocY={} nocX={} addr={}\\n",
nocY, nocX, addr);
ttkernel.dprint("virtY {} virtX {} addr {}\\n", %14, %15, %13) : (index, index, i32)
Notes:
- Only trivial format specifier currently supported, i.e.
{}. - Must double escape newline character or other special characters.
- When a CB operand is provided, calls print_cb_details, printing underlying CB pointers and details.
Interfaces: MemoryEffectOpInterface (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{MemoryEffects::Read on ::mlir::SideEffects::DefaultResource, MemoryEffects::Write on ::mlir::SideEffects::DefaultResource}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
fmt | ::mlir::StringAttr | string attribute |
Operands:
| Operand | Description |
|---|---|
argv | variadic of any type |
ttkernel.div_binary_tile_init (tt::ttkernel::DivBinaryTilesInitOp)
Short init function
Syntax:
operation ::= `ttkernel.div_binary_tile_init` `(` `)` attr-dict `:`functional-type(operands, results)
Must be run before div_binary_tile.
Traits: TTKernel_InitOpTrait
ttkernel.div_binary_tile (tt::ttkernel::DivBinaryTilesOp)
Divide operation between two tiles
Syntax:
operation ::= `ttkernel.div_binary_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of division operation DST[odst_index] <- DST[dst0_index] / DST[dst1_index] on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.div_unary_tile (tt::ttkernel::DivUnaryTileOp)
Divide by scalar operation
Syntax:
operation ::= `ttkernel.div_unary_tile` `(` $dst0_index `,` $param `)` attr-dict `:` functional-type(operands, results)
Performs element-wise division of a tile by a scalar value. DST[dst0_index] <- DST[dst0_index] / scalar The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
param | 32-bit signless integer |
ttkernel.eq_binary_tile_init (tt::ttkernel::EqBinaryTilesInitOp)
Short init function
Syntax:
operation ::= `ttkernel.eq_binary_tile_init` `(` `)` attr-dict `:`functional-type(operands, results)
Must be run before eq_binary_tile.
Traits: TTKernel_InitOpTrait
ttkernel.eq_binary_tile (tt::ttkernel::EqBinaryTilesOp)
Equality operation between two tiles
Syntax:
operation ::= `ttkernel.eq_binary_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of equality operation DST[odst_index] <- DST[dst0_index] == DST[dst1_index] on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.eqz_tile_int32 (tt::ttkernel::EqzTileI32Op)
Equal to zero tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.eqz_tile_int32` `(` $dst0_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise equality on DST register tiles for int32 data type. DST[dst0_index] <- (DST[dst0_index] == 0) The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.eqz_tile_init (tt::ttkernel::EqzTileInitOp)
Init function for eqz() operation. Refer to documentation for any init function.
Syntax:
operation ::= `ttkernel.eqz_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before eqz_tile.
Traits: TTKernel_InitOpTrait
ttkernel.eqz_tile (tt::ttkernel::EqzTileOp)
Equal to zero tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.eqz_tile` `(` $dst0_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise equality on DST register tiles. DST[dst0_index] <- (DST[dst0_index] == 0) The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.erf_tile_init (tt::ttkernel::ErfTileInitOp)
Short init function which configures compute unit for execution of erf_tile.
Syntax:
operation ::= `ttkernel.erf_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before erf_tile.
Traits: TTKernel_InitOpTrait
ttkernel.erf_tile (tt::ttkernel::ErfTileOp)
Erf operation
Syntax:
operation ::= `ttkernel.erf_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of error function (erf) on each element of a tile in DST register at index tile_index. The DST register buffer must be in acquired state via acquire_dst call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.erfc_tile_init (tt::ttkernel::ErfcTileInitOp)
Short init function which configures compute unit for execution of erfc_tile.
Syntax:
operation ::= `ttkernel.erfc_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before erfc_tile.
Traits: TTKernel_InitOpTrait
ttkernel.erfc_tile (tt::ttkernel::ErfcTileOp)
Erfc operation
Syntax:
operation ::= `ttkernel.erfc_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of complementary error function (erfc) on each element of a tile in DST register at index tile_index. The DST register buffer must be in acquired state via acquire_dst call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.exp2_tile_init (tt::ttkernel::Exp2TileInitOp)
Short init function which configures compute unit for execution of exp2_tile.
Syntax:
operation ::= `ttkernel.exp2_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before exp2_tile.
Traits: TTKernel_InitOpTrait
ttkernel.exp2_tile (tt::ttkernel::Exp2TileOp)
Exp2 operation
Syntax:
operation ::= `ttkernel.exp2_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of base-2 exponential (2^x) on each element of a tile in DST register at index tile_index. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.exp_tile_init (tt::ttkernel::ExpTileInitOp)
Short init function which configures compute unit for execution of exp_tile.
Syntax:
operation ::= `ttkernel.exp_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before exp_tile.
The optional attributes map onto the metal template parameters
exp_tile_init<bool approx, uint32_t scale, InputClamping input_clamping>().
When all attributes are omitted the op lowers to a bare exp_tile_init()
call, preserving the metal defaults
(approx=false, scale=0x3F800000, input_clamping=ClampToNegative).
Traits: TTKernel_InitOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
approx | ::mlir::BoolAttr | bool attribute |
scale | ::mlir::IntegerAttr | 32-bit signless integer attribute |
input_clamping | ::mlir::tt::ttkernel::InputClampingAttr | TTKernel SFPU Input Clamping Modes |
ttkernel.exp_tile (tt::ttkernel::ExpTileOp)
Exp operation
Syntax:
operation ::= `ttkernel.exp_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of exponential on each element of a tile in DST register at index tile_index. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
The optional attributes map onto the metal template parameters
exp_tile<bool approx, bool scale_en, InputClamping input_clamping, int iterations>(idst, vector_mode, scale).
When all attributes are omitted the op lowers to a bare exp_tile(idst)
call, preserving the metal defaults
(approx=false, scale_en=false, input_clamping=ClampToNegative, iterations=8).
scale holds the runtime scale argument; when present and not equal to
the default 1.0 value it enables metal's scale_en template parameter and
is emitted as the third positional argument with vector_mode defaulted
to VectorMode::RC.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
approx | ::mlir::BoolAttr | bool attribute |
input_clamping | ::mlir::tt::ttkernel::InputClampingAttr | TTKernel SFPU Input Clamping Modes |
iterations | ::mlir::IntegerAttr | 32-bit signless integer attribute |
scale | ::mlir::IntegerAttr | 32-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.experimental.fill_arange_tile (tt::ttkernel::ExperimentalFillArangeTileOp)
Experimental Write Full Linear Index Tile Op
Syntax:
operation ::= `ttkernel.experimental.fill_arange_tile` `(` $cb `)` attr-dict `:` functional-type(operands, results)
Writes a full linear index tile pattern to a CB, where element[i,j] = i * 32 + j (0-1023) in the CB's native data format (Float32, Float16_b, or Int32).
The resulting tile looks like: [[ 0, 1, 2, ..., 31], [ 32, 33, 34, ..., 63], ... [992, 993, 994, ..., 1023]]
Operands:
| Operand | Description |
|---|---|
cb | TTKernel cb |
ttkernel.experimental.matmul_block (tt::ttkernel::ExperimentalMatmulBlockOp)
Matmul tiles operation
Performs block-sized matrix multiplication C=A*B between the blocks in two
different input CBs and writes the result to DST. The DST register buffer
must be in acquired state via acquire_dst call. in1_k_stride is the
source-tile stride between consecutive K tiles in input 1. This call is
blocking and is only available on the compute engine.
Traits: TTKernel_FPUOpTrait, TTKernel_TernaryOpTrait
Operands:
| Operand | Description |
|---|---|
in0_cb_id | TTKernel cb |
in1_cb_id | TTKernel cb |
in0_tile_idx | index or 32-bit signless integer |
in1_tile_idx | index or 32-bit signless integer |
dst_tile_idx | index or 32-bit signless integer |
transpose | 32-bit signless integer |
ct_dim | 32-bit signless integer |
rt_dim | 32-bit signless integer |
kt_dim | 32-bit signless integer |
in1_k_stride | 32-bit signless integer |
ttkernel.experimental.pack_untilize_block (tt::ttkernel::ExperimentalPackUntilizeBlockOp)
Experimental PackUntilizeBlockOp call.
Syntax:
operation ::= `ttkernel.experimental.pack_untilize_block` `(` $cbIn `,` $cbOut `,` $blockR `,` $blockC `)` attr-dict `:` functional-type(operands, results)
Custom pack untilize block LLK that takes the dimensions of the block.
Uses pack_untilize_init for initialization and calls
pack_untilize_block<cols_per_dst_pass, total_col_tiles>(icb, ocb, block_r, block_c).
cols_per_dst_pass is the number of column tiles processed per DST pass
(constrained by DST capacity), and total_col_tiles is the total number
of column tiles in the untilized row.
For correctness, cols_per_dst_pass must divide total_col_tiles, and
block_c is expected to be compatible with the chosen
cols_per_dst_pass (the implementation processes
block_c / cols_per_dst_pass column blocks).
Use this op in the sequence:
pack_untilize_init -> experimental.pack_untilize_block -> pack_untilize_uninit.
Traits: TTKernel_LayoutOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
colsPerDstPass | ::mlir::IntegerAttr | 32-bit signless integer attribute |
totalColTiles | ::mlir::IntegerAttr | 32-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
cbIn | TTKernel cb |
cbOut | TTKernel cb |
blockR | 32-bit signless integer |
blockC | 32-bit signless integer |
ttkernel.experimental.tilize_block (tt::ttkernel::ExperimentalTilizeBlockOp)
Experimental TilizeBlockOp call.
Syntax:
operation ::= `ttkernel.experimental.tilize_block` `(` $cbIn `,` $cbOut `,` $blockR `,` $blockC `)` attr-dict `:` functional-type(operands, results)
This is a custom tilize block LLK that takes the dimensions of the block, and properly tilizes each row.
Traits: TTKernel_LayoutOpTrait
Operands:
| Operand | Description |
|---|---|
cbIn | TTKernel cb |
cbOut | TTKernel cb |
blockR | 32-bit signless integer |
blockC | 32-bit signless integer |
ttkernel.experimental.untilize_block (tt::ttkernel::ExperimentalUntilizeBlockOp)
Experimental UntilizeBlockOp call.
Syntax:
operation ::= `ttkernel.experimental.untilize_block` `(` $cbIn `,` $cbOut `,` $blockR `,` $blockC `)` attr-dict `:` functional-type(operands, results)
This is a custom untilize block LLK that takes the dimensions of the block.
Traits: TTKernel_LayoutOpTrait
Operands:
| Operand | Description |
|---|---|
cbIn | TTKernel cb |
cbOut | TTKernel cb |
blockR | 32-bit signless integer |
blockC | 32-bit signless integer |
ttkernel.experimental.write_col_mask_tile (tt::ttkernel::ExperimentalWriteColMaskTileOp)
Experimental Write Col Mask Tile Op
Syntax:
operation ::= `ttkernel.experimental.write_col_mask_tile` `(` $validCols `,` $cb `)` attr-dict `:` functional-type(operands, results)
Writes a column mask tile pattern to a CB, where element[i,j] = 1.0 if j < validCols, else 0.0. This is used in dataflow kernels to generate OOB mask tiles directly in L1 memory, avoiding DST register pressure in the compute kernel.
Operands:
| Operand | Description |
|---|---|
validCols | 32-bit signless integer |
cb | TTKernel cb |
ttkernel.experimental.write_row_mask_tile (tt::ttkernel::ExperimentalWriteRowMaskTileOp)
Experimental Write Row Mask Tile Op
Syntax:
operation ::= `ttkernel.experimental.write_row_mask_tile` `(` $validRows `,` $cb `)` attr-dict `:` functional-type(operands, results)
Writes a row mask tile pattern to a CB, where element[i,j] = 1.0 if i < validRows, else 0.0. This is used in dataflow kernels to generate OOB mask tiles directly in L1 memory, avoiding DST register pressure in the compute kernel.
Operands:
| Operand | Description |
|---|---|
validRows | 32-bit signless integer |
cb | TTKernel cb |
ttkernel.expm1_tile_init (tt::ttkernel::Expm1TileInitOp)
Short init function which configures compute unit for execution of expm1_tile.
Syntax:
operation ::= `ttkernel.expm1_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before expm1_tile.
Traits: TTKernel_InitOpTrait
ttkernel.expm1_tile (tt::ttkernel::Expm1TileOp)
Expm1 operation
Syntax:
operation ::= `ttkernel.expm1_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of exp(x)-1 on each element of a tile in DST register at index tile_index. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.experimental.fabric_mcast_sem_inc (tt::ttkernel::FabricMulticastSemIncOp)
FabricMulticastSemIncOp
Syntax:
operation ::= `ttkernel.experimental.fabric_mcast_sem_inc` `(` $fabric_connection_manager `,` $dst_mesh_id `,` $dst_dev_id_start `,` $dst_dev_id_end `,` $semaphore_addr `,` $incr `)` attr-dict `:` functional-type(operands, results)
FabricMulticastSemIncOp. This operation increments a semaphore on a range of remote devices.
Operands:
| Operand | Description |
|---|---|
fabric_connection_manager | TTKernel fabric connection manager |
dst_mesh_id | 16-bit signless integer |
dst_dev_id_start | 16-bit signless integer |
dst_dev_id_end | 16-bit signless integer |
semaphore_addr | TTKernel noc address |
incr | index or 32-bit signless integer |
ttkernel.experimental.fabric_mcast_fast_write_any_len (tt::ttkernel::FabricMulticastWriteOp)
FabricMulticastWriteOp
Syntax:
operation ::= `ttkernel.experimental.fabric_mcast_fast_write_any_len` `(` $fabric_connection_manager `,` $dst_mesh_id `,` $dst_dev_id_start `,` $dst_dev_id_end `,` $dst_addr `,` $src_addr `,` $len_bytes `)` attr-dict `:` functional-type(operands, results)
FabricMulticastWriteOp
Operands:
| Operand | Description |
|---|---|
fabric_connection_manager | TTKernel fabric connection manager |
dst_mesh_id | 16-bit signless integer |
dst_dev_id_start | 16-bit signless integer |
dst_dev_id_end | 16-bit signless integer |
dst_addr | TTKernel noc address |
src_addr | 32-bit signless integer |
len_bytes | 32-bit signless integer |
ttkernel.experimental.fabric_sem_inc (tt::ttkernel::FabricSemIncOp)
FabricSemIncOp
Syntax:
operation ::= `ttkernel.experimental.fabric_sem_inc` `(` $fabric_connection_manager `,` $dst_mesh_id `,` $dst_dev_id `,` $semaphore_addr `,` $incr `)` attr-dict `:` functional-type(operands, results)
FabricSemIncOp. This operation increments a semaphore on a remote device.
Operands:
| Operand | Description |
|---|---|
fabric_connection_manager | TTKernel fabric connection manager |
dst_mesh_id | 16-bit signless integer |
dst_dev_id | 16-bit signless integer |
semaphore_addr | TTKernel noc address |
incr | index or 32-bit signless integer |
ttkernel.experimental.fabric_fast_write_any_len (tt::ttkernel::FabricWriteOp)
FabricWriteOp
Syntax:
operation ::= `ttkernel.experimental.fabric_fast_write_any_len` `(` $fabric_connection_manager `,` $dst_mesh_id `,` $dst_dev_id `,` $dst_addr `,` $src_addr `,` $len_bytes `)` attr-dict `:` functional-type(operands, results)
FabricWriteOp
Operands:
| Operand | Description |
|---|---|
fabric_connection_manager | TTKernel fabric connection manager |
dst_mesh_id | 16-bit signless integer |
dst_dev_id | 16-bit signless integer |
dst_addr | TTKernel noc address |
src_addr | 32-bit signless integer |
len_bytes | 32-bit signless integer |
ttkernel.fill_tile_init (tt::ttkernel::FillTileInitOp)
Init function for fill_tile operation. Refer to documentation for any init function.
Syntax:
operation ::= `ttkernel.fill_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before fill_tile.
Traits: TTKernel_InitOpTrait
ttkernel.fill_tile_int (tt::ttkernel::FillTileIntOp)
Fill tile with specified int32 value.
Syntax:
operation ::= `ttkernel.fill_tile_int` `(` $dst_index `,` $value `)` attr-dict `:` functional-type(operands, results)
Fills supplied DST register tile with a supplied i32 value. The DST register must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst_index | index or 32-bit signless integer |
value | 32-bit signless integer |
ttkernel.fill_tile (tt::ttkernel::FillTileOp)
Fill tile with specified value.
Syntax:
operation ::= `ttkernel.fill_tile` `(` $dst_index `,` $value `)` attr-dict `:` functional-type(operands, results)
Fills supplied DST register tile with a supplied f32 value. The DST register must be in acquired state via tile_regs_acquire call.
Example:
ttkernel.fill_tile(%dst_index, %value);
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst_index | index or 32-bit signless integer |
value | 32-bit float |
ttkernel.float32_greater (tt::ttkernel::Float32GreaterOp)
Compare two float32 values using integer arithmetic.
Syntax:
operation ::= `ttkernel.float32_greater` `(` $f32_a `,` $f32_b `)` attr-dict `:` functional-type(operands, results)
Returns true if f32_a > f32_b. Operates on raw bits in int32 format. Maps to float32_greater() in device code.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, InferTypeOpInterface, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
f32_a | 32-bit signless integer |
f32_b | 32-bit signless integer |
Results:
| Result | Description |
|---|---|
result | 1-bit signless integer |
ttkernel.floor_tile (tt::ttkernel::FloorTileOp)
Floor tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.floor_tile` `(` $dst0_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of floor operation DST[dst0_index] <- floor(DST[dst0_index]) on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.frac_tile (tt::ttkernel::FracTileOp)
Frac operation
Syntax:
operation ::= `ttkernel.frac_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of the fractional part (x - trunc(x)) on each element of a tile in DST register at index tile_index. Requires rounding_op_tile_init to be called first. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.ge_binary_tile_init (tt::ttkernel::GeBinaryTilesInitOp)
Short init function
Syntax:
operation ::= `ttkernel.ge_binary_tile_init` `(` `)` attr-dict `:`functional-type(operands, results)
Must be run before ge_binary_tile.
Traits: TTKernel_InitOpTrait
ttkernel.ge_binary_tile (tt::ttkernel::GeBinaryTilesOp)
Greater-than-or-equal operation between two tiles
Syntax:
operation ::= `ttkernel.ge_binary_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of greater-than-or-equal operation DST[odst_index] <- DST[dst0_index] >= DST[dst1_index] on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.gelu_tile_init (tt::ttkernel::GeluTileInitOp)
Short init function which configures compute unit for execution of gelu_tile.
Syntax:
operation ::= `ttkernel.gelu_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before gelu_tile.
Traits: TTKernel_InitOpTrait
ttkernel.gelu_tile (tt::ttkernel::GeluTileOp)
GELU operation
Syntax:
operation ::= `ttkernel.gelu_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of GELU on each element of a tile in DST register at index tile_index. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.get_arg_val (tt::ttkernel::GetArgValOp)
Get runtime arg value.
Syntax:
operation ::= `ttkernel.get_arg_val` `(` $arg_index `)` attr-dict `:` functional-type(operands, results)
Get runtime argument value at specified index.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
arg_index | index or 32-bit signless integer |
Results:
| Result | Description |
|---|---|
arg_val | index or 32-bit signless integer or 32-bit unsigned integer or TTKernel cb or TTKernel l1 address |
ttkernel.get_common_arg_val (tt::ttkernel::GetCommonArgValOp)
Get common runtime arg value.
Syntax:
operation ::= `ttkernel.get_common_arg_val` `(` $arg_index `)` attr-dict `:` functional-type(operands, results)
Get runtime argument value at specified index. (Indexes from different location compared to get_arg_val)
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
arg_index | index or 32-bit signless integer |
Results:
| Result | Description |
|---|---|
arg_val | index or 32-bit signless integer or 32-bit unsigned integer or TTKernel cb or TTKernel l1 address |
ttkernel.get_compile_time_arg_val (tt::ttkernel::GetCompileArgValOp)
Get compile-time arg value.
Syntax:
operation ::= `ttkernel.get_compile_time_arg_val` `(` $arg_index `)` attr-dict `:` functional-type(operands, results)
Get compile-time argument value at specified index.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
arg_index | ::mlir::IntegerAttr | 32-bit signless integer attribute |
Results:
| Result | Description |
|---|---|
arg_val | index or 32-bit signless integer or 32-bit unsigned integer or TTKernel cb or TTKernel l1 address |
ttkernel.get_dataformat (tt::ttkernel::GetDataFormatOp)
Get the data format of a given CB
Syntax:
operation ::= `ttkernel.get_dataformat` `(` $cb `)` attr-dict `:` functional-type(operands, results)
get_dataformat operation
Interfaces: InferTypeOpInterface
Operands:
| Operand | Description |
|---|---|
cb | TTKernel cb |
Results:
| Result | Description |
|---|---|
dataFormat | TTKernel compute data format type |
ttkernel.experimental.get_device_id_from_logical_mesh_position (tt::ttkernel::GetDeviceIdFromLogicalMeshPositionOp)
GetDeviceIdFromLogicalMeshPosition
Syntax:
operation ::= `ttkernel.experimental.get_device_id_from_logical_mesh_position` `(` $fcm `,` $position_indices `)` attr-dict `:` functional-type(operands, results)
Get the device ID for a given logical mesh position. Takes a list of indices representing the logical mesh position and returns the corresponding device ID. Maps to get_device_id_from_logical_mesh_position(fcm, position) in device code.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, InferTypeOpInterface, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
fcm | TTKernel fabric connection manager |
position_indices | variadic of index |
Results:
| Result | Description |
|---|---|
device_id | 16-bit signless integer |
ttkernel.experimental.get_my_device_id (tt::ttkernel::GetMyDeviceIdOp)
GetMyDeviceId
Syntax:
operation ::= `ttkernel.experimental.get_my_device_id` `(` `)` attr-dict `:` functional-type(operands, results)
Get my device id. This is a 16 bit value.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, InferTypeOpInterface, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Results:
| Result | Description |
|---|---|
my_device_id | 16-bit signless integer |
ttkernel.experimental.get_my_logical_mesh_position (tt::ttkernel::GetMyLogicalMeshPositionOp)
GetMyLogicalMeshPosition
Syntax:
operation ::= `ttkernel.experimental.get_my_logical_mesh_position` `(` $fcm `)` attr-dict `:` functional-type(operands, results)
Get the mesh position for the current device at the given dimension.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, InferTypeOpInterface, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim | ::mlir::IntegerAttr | 64-bit signless integer attribute whose minimum value is 0 |
Operands:
| Operand | Description |
|---|---|
fcm | TTKernel fabric connection manager |
Results:
| Result | Description |
|---|---|
result | index |
ttkernel.get_noc_addr_from_bank_id (tt::ttkernel::GetNocAddrFromBankIDOp)
GetNocAddrFromBankID
Syntax:
operation ::= `ttkernel.get_noc_addr_from_bank_id` `(` $bank_id `,` $bankAddressOffset `)` attr-dict `:` functional-type(operands, results)
GetNocAddrFromBankID api
Interfaces: InferTypeOpInterface
Operands:
| Operand | Description |
|---|---|
bank_id | 32-bit signless integer |
bankAddressOffset | 32-bit signless integer |
Results:
| Result | Description |
|---|---|
nocAddr | TTKernel noc address |
ttkernel.get_noc_addr (tt::ttkernel::GetNocAddrOp)
GetNocAddr
Syntax:
operation ::= `ttkernel.get_noc_addr` `(` $x `,` $y `,` $l1Address (`,` $noc^)? `)` attr-dict `:` functional-type(operands, results)
GetNocAddr api including core coordinates.
Interfaces: InferTypeOpInterface
Operands:
| Operand | Description |
|---|---|
x | index or 32-bit signless integer |
y | index or 32-bit signless integer |
l1Address | 32-bit signless integer or TTKernel l1 address or TTKernel semaphore |
noc | 8-bit signless integer |
Results:
| Result | Description |
|---|---|
nocAddr | TTKernel noc address |
ttkernel.get_noc_multicast_addr (tt::ttkernel::GetNocMulticastAddrOp)
GetNocMulticastAddr
Syntax:
operation ::= `ttkernel.get_noc_multicast_addr` `(` $noc_x_start `,` $noc_y_start `,` $noc_x_end `,` $noc_y_end `,` $addr (`,` $noc^)? `)` attr-dict `:` functional-type(operands, results)
Default tt-metal get_noc_multicast_addr.
The caller must make sure the start and end coordinates are flipped on
WH/BH's NoC1, especially when the optional noc operand is absent.
Interfaces: InferTypeOpInterface
Operands:
| Operand | Description |
|---|---|
noc_x_start | index or 32-bit signless integer |
noc_y_start | index or 32-bit signless integer |
noc_x_end | index or 32-bit signless integer |
noc_y_end | index or 32-bit signless integer |
addr | 32-bit signless integer or TTKernel l1 address or TTKernel semaphore |
noc | 8-bit signless integer |
Results:
| Result | Description |
|---|---|
mcastNocAddr | TTKernel noc address |
ttkernel.get_read_ptr (tt::ttkernel::GetReadPtrOp)
GetReadPtr
Syntax:
operation ::= `ttkernel.get_read_ptr` `(` $cb `)` attr-dict `:` functional-type(operands, results)
GetReadPtr operation
Interfaces: InferTypeOpInterface
Operands:
| Operand | Description |
|---|---|
cb | TTKernel cb |
Results:
| Result | Description |
|---|---|
readPtr | 32-bit signless integer |
ttkernel.get_semaphore (tt::ttkernel::GetSemaphoreOp)
GetSemaphoreOp
Syntax:
operation ::= `ttkernel.get_semaphore` `(` $semaphore `)` attr-dict `:` functional-type(operands, results)
Get L1 addr of the semaphore with specified semaphore id
Interfaces: InferTypeOpInterface
Operands:
| Operand | Description |
|---|---|
semaphore | index or 32-bit signless integer |
Results:
| Result | Description |
|---|---|
sem_addr | TTKernel semaphore |
ttkernel.get_tile_size (tt::ttkernel::GetTileSizeOp)
Get the tile size in bytes of a given CB
Syntax:
operation ::= `ttkernel.get_tile_size` `(` $cb `)` attr-dict `:` functional-type(operands, results)
get_tile_size operation
Interfaces: InferTypeOpInterface
Operands:
| Operand | Description |
|---|---|
cb | TTKernel cb |
Results:
| Result | Description |
|---|---|
tileSizeBytes | 32-bit signless integer |
ttkernel.get_write_ptr (tt::ttkernel::GetWritePtrOp)
GetWritePtr
Syntax:
operation ::= `ttkernel.get_write_ptr` `(` $cb `)` attr-dict `:` functional-type(operands, results)
GetWritePtr operation
Interfaces: InferTypeOpInterface
Operands:
| Operand | Description |
|---|---|
cb | TTKernel cb |
Results:
| Result | Description |
|---|---|
writePtr | 32-bit signless integer |
ttkernel.gez_tile_int32 (tt::ttkernel::GezTileI32Op)
Greater than or equal to zero tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.gez_tile_int32` `(` $dst0_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise greater than or equal to zero comparison on DST register tiles for int32 data type. DST[dst0_index] <- (DST[dst0_index] >= 0) The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.gez_tile_init (tt::ttkernel::GezTileInitOp)
Init function for gez() operation. Refer to documentation for any init function.
Syntax:
operation ::= `ttkernel.gez_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before gez_tile.
Traits: TTKernel_InitOpTrait
ttkernel.gez_tile (tt::ttkernel::GezTileOp)
Greater than or equal to zero tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.gez_tile` `(` $dst0_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise greater than or equal to zero comparison on DST register tiles. DST[dst0_index] <- (DST[dst0_index] >= 0) The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.gt_binary_tile_init (tt::ttkernel::GtBinaryTilesInitOp)
Short init function
Syntax:
operation ::= `ttkernel.gt_binary_tile_init` `(` `)` attr-dict `:`functional-type(operands, results)
Must be run before gt_binary_tile.
Traits: TTKernel_InitOpTrait
ttkernel.gt_binary_tile (tt::ttkernel::GtBinaryTilesOp)
Greater-than operation between two tiles
Syntax:
operation ::= `ttkernel.gt_binary_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of greater-than operation DST[odst_index] <- DST[dst0_index] > DST[dst1_index] on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.gtz_tile_int32 (tt::ttkernel::GtzTileI32Op)
Greater than zero tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.gtz_tile_int32` `(` $dst0_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise greater than zero comparison on DST register tiles for int32 data type. DST[dst0_index] <- (DST[dst0_index] > 0) The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.gtz_tile_init (tt::ttkernel::GtzTileInitOp)
Init function for gtz() operation. Refer to documentation for any init function.
Syntax:
operation ::= `ttkernel.gtz_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before gtz_tile.
Traits: TTKernel_InitOpTrait
ttkernel.gtz_tile (tt::ttkernel::GtzTileOp)
Greater than zero tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.gtz_tile` `(` $dst0_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise greater than zero comparison on DST register tiles. DST[dst0_index] <- (DST[dst0_index] > 0) The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.hardsigmoid_tile_init (tt::ttkernel::HardsigmoidTileInitOp)
Short init function which configures compute unit for execution of hardsigmoid_tile.
Syntax:
operation ::= `ttkernel.hardsigmoid_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before hardsigmoid_tile.
Traits: TTKernel_InitOpTrait
ttkernel.hardsigmoid_tile (tt::ttkernel::HardsigmoidTileOp)
Hardsigmoid operation
Syntax:
operation ::= `ttkernel.hardsigmoid_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of hardsigmoid on each element of a tile in DST register at index tile_index. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.init_sfpu (tt::ttkernel::InitSFPUOp)
Initialization function for SFPU operations.
Syntax:
operation ::= `ttkernel.init_sfpu` `(` $icb `,` $ocb `)` attr-dict `:` functional-type(operands, results)
This operation initializes all necessary components for SFPU operations, including unpacking, packing, and math configurations.
Traits: TTKernel_InitOpTrait
Operands:
| Operand | Description |
|---|---|
icb | TTKernel cb |
ocb | TTKernel cb |
ttkernel.invoke_sfpi (tt::ttkernel::InvokeSFPIOp)
Syntax:
operation ::= `ttkernel.invoke_sfpi` attr-dict-with-keyword $region
Traits: NoTerminator, TTKernel_SFPUOpTrait
ttkernel.le_binary_tile_init (tt::ttkernel::LeBinaryTilesInitOp)
Short init function
Syntax:
operation ::= `ttkernel.le_binary_tile_init` `(` `)` attr-dict `:`functional-type(operands, results)
Must be run before le_binary_tile.
Traits: TTKernel_InitOpTrait
ttkernel.le_binary_tile (tt::ttkernel::LeBinaryTilesOp)
Less-than-or-equal operation between two tiles
Syntax:
operation ::= `ttkernel.le_binary_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of less-than-or-equal operation DST[odst_index] <- DST[dst0_index] <= DST[dst1_index] on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.lez_tile_int32 (tt::ttkernel::LezTileI32Op)
Less than or equal to zero tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.lez_tile_int32` `(` $dst0_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise less than or equal to zero comparison on DST register tiles for int32 data type. DST[dst0_index] <- (DST[dst0_index] <= 0) The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.lez_tile_init (tt::ttkernel::LezTileInitOp)
Init function for lez() operation. Refer to documentation for any init function.
Syntax:
operation ::= `ttkernel.lez_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before lez_tile.
Traits: TTKernel_InitOpTrait
ttkernel.lez_tile (tt::ttkernel::LezTileOp)
Less than or equal to zero tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.lez_tile` `(` $dst0_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise less than or equal to zero comparison on DST register tiles. DST[dst0_index] <- (DST[dst0_index] <= 0) The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.load_from_l1 (tt::ttkernel::LoadFromL1Op)
LoadFromL1
Syntax:
operation ::= `ttkernel.load_from_l1` `(` $l1_ptr `,` $offset `)` attr-dict `:` functional-type(operands, results)
Load value from L1.
Operands:
| Operand | Description |
|---|---|
l1_ptr | TTKernel l1 address pointer |
offset | 32-bit signless integer |
Results:
| Result | Description |
|---|---|
value | 8-bit signless integer or 16-bit signless integer or 32-bit signless integer |
ttkernel.log1p_tile_init (tt::ttkernel::Log1pTileInitOp)
Short init function which configures compute unit for execution of log1p_tile.
Syntax:
operation ::= `ttkernel.log1p_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before log1p_tile.
Traits: TTKernel_InitOpTrait
ttkernel.log1p_tile (tt::ttkernel::Log1pTileOp)
Log1p operation
Syntax:
operation ::= `ttkernel.log1p_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of log(1+x) on each element of a tile in DST register at index tile_index. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.log_tile_init (tt::ttkernel::LogTileInitOp)
Short init function which configures compute unit for execution of log_tile.
Syntax:
operation ::= `ttkernel.log_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before log_tile.
Traits: TTKernel_InitOpTrait
ttkernel.log_tile (tt::ttkernel::LogTileOp)
Log operation
Syntax:
operation ::= `ttkernel.log_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of log on each element of a tile in DST register at index tile_index. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.logical_not_tile_init (tt::ttkernel::LogicalNotTileInitOp)
Init function for logical_not_tile operation. Refer to documentation for any init function.
Syntax:
operation ::= `ttkernel.logical_not_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before logical_not_tile.
Traits: TTKernel_InitOpTrait
ttkernel.logical_not_tile (tt::ttkernel::LogicalNotTileOp)
Logical negation tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.logical_not_tile` `(` $dst0_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of logical negation operation DST[dst0_index] <- !DST[dst0_index] on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call. The DataFormat template parameter specifies the data type.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.lt_binary_tile_init (tt::ttkernel::LtBinaryTilesInitOp)
Short init function
Syntax:
operation ::= `ttkernel.lt_binary_tile_init` `(` `)` attr-dict `:`functional-type(operands, results)
Must be run before lt_binary_tile.
Traits: TTKernel_InitOpTrait
ttkernel.lt_binary_tile (tt::ttkernel::LtBinaryTilesOp)
Less-than operation between two tiles
Syntax:
operation ::= `ttkernel.lt_binary_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of less-than operation DST[odst_index] <- DST[dst0_index] < DST[dst1_index] on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.ltz_tile_int32 (tt::ttkernel::LtzTileI32Op)
Less than zero tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.ltz_tile_int32` `(` $dst0_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise less than zero comparison on DST register tiles for int32 data type. DST[dst0_index] <- (DST[dst0_index] < 0) The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.ltz_tile_init (tt::ttkernel::LtzTileInitOp)
Init function for ltz() operation. Refer to documentation for any init function.
Syntax:
operation ::= `ttkernel.ltz_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before ltz_tile.
Traits: TTKernel_InitOpTrait
ttkernel.ltz_tile (tt::ttkernel::LtzTileOp)
Less than zero tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.ltz_tile` `(` $dst0_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise less than zero comparison on DST register tiles. DST[dst0_index] <- (DST[dst0_index] < 0) The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.mm_block_init (tt::ttkernel::MatmulBlockInitOp)
Matmul init function
Initialization for matmul_block operation. Must be called before matmul_block.
Traits: TTKernel_InitOpTrait
Operands:
| Operand | Description |
|---|---|
in0_cb | TTKernel cb |
in1_cb | TTKernel cb |
out_cb | TTKernel cb |
transpose | 32-bit signless integer |
ct_dim | 32-bit signless integer |
rt_dim | 32-bit signless integer |
kt_dim | 32-bit signless integer |
ttkernel.mm_block_init_short (tt::ttkernel::MatmulBlockInitShortOp)
Matmul short init function
A short version of matmul_block initialization.
Traits: TTKernel_InitOpTrait
Operands:
| Operand | Description |
|---|---|
in0_cb | TTKernel cb |
in1_cb | TTKernel cb |
transpose | 32-bit signless integer |
ct_dim | 32-bit signless integer |
rt_dim | 32-bit signless integer |
kt_dim | 32-bit signless integer |
ttkernel.matmul_block (tt::ttkernel::MatmulBlockOp)
Block matmul operation
Syntax:
operation ::= `ttkernel.matmul_block` `(` $in0_cb_id `,` $in1_cb_id `,` $in0_tile_idx `,` $in1_tile_idx `,` $dst_tile_idx `,` $transpose `,` $ct_dim `,` $rt_dim `,` $kt_dim `)` attr-dict `:` functional-type(operands, results)
Performs block-sized matrix multiplication C=A*B between blocks of tiles in two input CBs and accumulates the result into DST. Block dimensions are specified by ct_dim (output columns in tiles), rt_dim (output rows in tiles), and kt_dim (inner dimension in tiles). The transpose flag controls whether input 1 is transposed. The DST register buffer must be in acquired state via ttkernel.tile_regs_acquire. Blocking; compute engine only.
Traits: TTKernel_FPUOpTrait, TTKernel_TernaryOpTrait
Operands:
| Operand | Description |
|---|---|
in0_cb_id | TTKernel cb |
in1_cb_id | TTKernel cb |
in0_tile_idx | index or 32-bit signless integer |
in1_tile_idx | index or 32-bit signless integer |
dst_tile_idx | index or 32-bit signless integer |
transpose | 32-bit signless integer |
ct_dim | 32-bit signless integer |
rt_dim | 32-bit signless integer |
kt_dim | 32-bit signless integer |
ttkernel.mm_init (tt::ttkernel::MatmulInitOp)
Matmul init function
Syntax:
operation ::= `ttkernel.mm_init` `(` $in0_cb `,` $in1_cb `,` $out_cb `,` $transpose `)` attr-dict `:` functional-type(operands, results)
Can only be run ONCE per kernel. Should be run before matmul.
Traits: TTKernel_InitOpTrait
Operands:
| Operand | Description |
|---|---|
in0_cb | TTKernel cb |
in1_cb | TTKernel cb |
out_cb | TTKernel cb |
transpose | 32-bit signless integer |
ttkernel.mm_init_short (tt::ttkernel::MatmulInitShortOp)
Matmul short init function
Syntax:
operation ::= `ttkernel.mm_init_short` `(` $in0_cb `,` $in1_cb `,` $transpose `)` attr-dict `:` functional-type(operands, results)
Can be run MULTIPLE times per kernel. Should be run before matmul. Use this if some other init was called between mm_init and matmul_tiles. (i.e. in a loop)
Traits: TTKernel_InitOpTrait
Operands:
| Operand | Description |
|---|---|
in0_cb | TTKernel cb |
in1_cb | TTKernel cb |
transpose | 32-bit signless integer |
ttkernel.matmul_tiles (tt::ttkernel::MatmulTilesOp)
Matmul tiles operation
Syntax:
operation ::= `ttkernel.matmul_tiles` `(` $in0_cb_id `,` $in1_cb_id `,` $in0_tile_idx `,` $in1_tile_idx `,` $dst_tile_idx `)` attr-dict `:` functional-type(operands, results)
Performs tile-sized matrix multiplication C=A*B between the tiles in two specified input CBs and writes the result to DST. The DST register buffer must be in acquired state via ttkernel.tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_FPUOpTrait, TTKernel_TernaryOpTrait
Operands:
| Operand | Description |
|---|---|
in0_cb_id | TTKernel cb |
in1_cb_id | TTKernel cb |
in0_tile_idx | index or 32-bit signless integer |
in1_tile_idx | index or 32-bit signless integer |
dst_tile_idx | index or 32-bit signless integer |
ttkernel.mem_zeros_base (tt::ttkernel::MemZerosBaseOp)
Op corresponding to MEM_ZEROS_BASE macro in kernels.
Syntax:
operation ::= `ttkernel.mem_zeros_base` `(` `)` attr-dict `:` functional-type(operands, results)
Op corresponding to MEM_ZEROS_BASE macro in kernels.
Interfaces: InferTypeOpInterface
Results:
| Result | Description |
|---|---|
result | 32-bit signless integer |
ttkernel.mem_zeros_size (tt::ttkernel::MemZerosSizeOp)
Op corresponding to MEM_ZEROS_SIZE macro in kernels.
Syntax:
operation ::= `ttkernel.mem_zeros_size` `(` `)` attr-dict `:` functional-type(operands, results)
Op corresponding to MEM_ZEROS_SIZE macro in kernels.
Interfaces: InferTypeOpInterface
Results:
| Result | Description |
|---|---|
result | 32-bit signless integer |
ttkernel.mul_binary_tile_init (tt::ttkernel::MulBinaryTilesInitOp)
Short init function
Syntax:
operation ::= `ttkernel.mul_binary_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before mul_binary_tile.
Traits: TTKernel_InitOpTrait
ttkernel.mul_binary_tile (tt::ttkernel::MulBinaryTilesOp)
Multiplication operation between two tiles
Syntax:
operation ::= `ttkernel.mul_binary_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of multiplication operation DST[odst_index] <- DST[dst0_index] * DST[dst1_index] on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.mul_int_tile_init (tt::ttkernel::MulIntTileInitOp)
Short init function
Syntax:
operation ::= `ttkernel.mul_int_tile_init` `(` $dtype `)` attr-dict `:` functional-type(operands, results)
Must be run before mul_int_tile.
Traits: TTKernel_InitOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
ttkernel.mul_int_tile (tt::ttkernel::MulIntTileOp)
Integer multiplication operation between two tiles
Syntax:
operation ::= `ttkernel.mul_int_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `,` $dtype `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of integer multiplication operation DST[odst_index] <- DST[dst0_index] * DST[dst1_index] on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call. Supported data formats are: Int32, UInt32, UInt16.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.mul_tiles_init (tt::ttkernel::MulTilesInitOp)
Short init function
Syntax:
operation ::= `ttkernel.mul_tiles_init` `(` $in0_cb `,` $in1_cb `)` attr-dict `:` functional-type(operands, results)
Must be run before mul_tiles.
Traits: TTKernel_InitOpTrait
Operands:
| Operand | Description |
|---|---|
in0_cb | TTKernel cb |
in1_cb | TTKernel cb |
ttkernel.mul_tiles (tt::ttkernel::MulTilesOp)
Mul operation
Syntax:
operation ::= `ttkernel.mul_tiles` `(` $in0_cb `,` $in1_cb `,` $in0_tile_index `,` $in1_tile_index `,` $dst_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise multiplication C=A*B of tiles in two CBs at given indices and writes the result to the DST register at index dst_tile_index. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_BinaryOpTrait, TTKernel_FPUOpTrait
Operands:
| Operand | Description |
|---|---|
in0_cb | TTKernel cb |
in1_cb | TTKernel cb |
in0_tile_index | index or 32-bit signless integer |
in1_tile_index | index or 32-bit signless integer |
dst_index | index or 32-bit signless integer |
ttkernel.mul_unary_tile (tt::ttkernel::MulUnaryTileOp)
Multiply by scalar operation
Syntax:
operation ::= `ttkernel.mul_unary_tile` `(` $dst0_index `,` $param `)` attr-dict `:` functional-type(operands, results)
Performs element-wise multiplication of a tile by a scalar value. DST[dst0_index] <- DST[dst0_index] * scalar The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
param | 32-bit signless integer |
ttkernel.my_logical_x_ (tt::ttkernel::MyLogicalXOp)
MyLogicalX
Syntax:
operation ::= `ttkernel.my_logical_x_` attr-dict `:` functional-type(operands, results)
Lowers to the tt-metal supported my_logical_x_ global. This represents the logical X coordinate of the current core.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, InferIntRangeInterface, InferTypeOpInterface, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Results:
| Result | Description |
|---|---|
x | index |
ttkernel.my_logical_y_ (tt::ttkernel::MyLogicalYOp)
MyLogicalY
Syntax:
operation ::= `ttkernel.my_logical_y_` attr-dict `:` functional-type(operands, results)
Lowers to the tt-metal supported my_logical_y_ global. This represents the logical Y coordinate of the current core.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, InferIntRangeInterface, InferTypeOpInterface, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Results:
| Result | Description |
|---|---|
y | index |
ttkernel.my_x (tt::ttkernel::MyXOp)
MyX
Syntax:
operation ::= `ttkernel.my_x` `(` ($noc^)? `)` attr-dict `:` functional-type(operands, results)
Lowers to the tt-metal supported MY_X macro. This represents the virtual X coordinate of the current core.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, InferTypeOpInterface, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
noc | 8-bit signless integer |
Results:
| Result | Description |
|---|---|
x | index |
ttkernel.my_y (tt::ttkernel::MyYOp)
MyY
Syntax:
operation ::= `ttkernel.my_y` `(` ($noc^)? `)` attr-dict `:` functional-type(operands, results)
Lowers to the tt-metal supported MY_Y macro. This represents the virtual Y coordinate of the current core.
Traits: AlwaysSpeculatableImplTrait
Interfaces: ConditionallySpeculatable, InferTypeOpInterface, NoMemoryEffect (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
noc | 8-bit signless integer |
Results:
| Result | Description |
|---|---|
y | index |
ttkernel.ne_binary_tile_init (tt::ttkernel::NeBinaryTilesInitOp)
Short init function
Syntax:
operation ::= `ttkernel.ne_binary_tile_init` `(` `)` attr-dict `:`functional-type(operands, results)
Must be run before ne_binary_tile.
Traits: TTKernel_InitOpTrait
ttkernel.ne_binary_tile (tt::ttkernel::NeBinaryTilesOp)
Inequality operation between two tiles
Syntax:
operation ::= `ttkernel.ne_binary_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of inequality operation DST[odst_index] <- DST[dst0_index] != DST[dst1_index] on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.negative_tile_init (tt::ttkernel::NegativeTileInitOp)
Short init function which configures compute unit for execution of negative_tile.
Syntax:
operation ::= `ttkernel.negative_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before negative_tile.
Traits: TTKernel_InitOpTrait
ttkernel.negative_tile_int32 (tt::ttkernel::NegativeTileInt32Op)
Negative i32 tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.negative_tile_int32` `(` $dst0_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of negation operation DST[dst0_index] <- -DST[dst0_index] on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.negative_tile (tt::ttkernel::NegativeTileOp)
Negative operation
Syntax:
operation ::= `ttkernel.negative_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of the negative on each element of a tile in DST register at index tile_index. The DST register buffer must be in acquired state via acquire_dst call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.nez_tile_int32 (tt::ttkernel::NezTileI32Op)
Not equal to zero tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.nez_tile_int32` `(` $dst0_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise inequality on DST register tiles for int32 data type. DST[dst0_index] <- (DST[dst0_index] != 0) The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.nez_tile_init (tt::ttkernel::NezTileInitOp)
Init function for nez() operation. Refer to documentation for any init function.
Syntax:
operation ::= `ttkernel.nez_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before nez_tile.
Traits: TTKernel_InitOpTrait
ttkernel.nez_tile (tt::ttkernel::NezTileOp)
Not equal to zero tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.nez_tile` `(` $dst0_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise inequality on DST register tiles. DST[dst0_index] <- (DST[dst0_index] != 0) The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.noc_async_atomic_barrier (tt::ttkernel::NocAsyncAtomicBarrierOp)
NocAsyncAtomicBarrier
Syntax:
operation ::= `ttkernel.noc_async_atomic_barrier` `(` ($noc^)? `)` attr-dict `:` functional-type(operands, results)
Block until all outstanding non-posted atomic operations on the given
NOC have flushed. Pairs with noc_semaphore_inc and
noc_semaphore_inc_multicast.
Operands:
| Operand | Description |
|---|---|
noc | 8-bit signless integer |
ttkernel.noc_async_read_barrier (tt::ttkernel::NocAsyncReadBarrierOp)
NocAsyncReadBarrier
Syntax:
operation ::= `ttkernel.noc_async_read_barrier` `(` ($noc^)? `)` attr-dict `:` functional-type(operands, results)
Waits for all outstanding read transactions on the given NOC.
Traits: TTKernel_DeviceZoneOpTrait
Operands:
| Operand | Description |
|---|---|
noc | 8-bit signless integer |
ttkernel.noc_async_read_barrier_with_trid (tt::ttkernel::NocAsyncReadBarrierWithTridOp)
NocAsyncReadBarrierWithTrid
Syntax:
operation ::= `ttkernel.noc_async_read_barrier_with_trid` `(` $trid (`,` $noc^)? `)` attr-dict `:` functional-type(operands, results)
Waits for outstanding read transactions matching a transaction ID. TRID is 0-15, NOC is 0 or 1.
Example:
ttkernel.noc_async_read_barrier_with_trid(%trid, %noc_idx) : (i32, i8) -> ()
Traits: TTKernel_DeviceZoneOpTrait, TTKernel_TridNocOpTrait
Operands:
| Operand | Description |
|---|---|
trid | 32-bit signless integer |
noc | 8-bit signless integer |
ttkernel.noc_async_read_one_packet_set_state (tt::ttkernel::NocAsyncReadOnePacketSetStateOp)
NocAsyncReadOnePacketSetState
Syntax:
operation ::= `ttkernel.noc_async_read_one_packet_set_state` `(` (`core` `[` $srcCoreXY^ `]`)? (`bank` `[` $srcBankId^ `]`)? `,` $srcAddress `,` $size (`,` `noc` $noc^)? `)` attr-dict `:` functional-type(operands, results)
NocAsyncReadOnePacketSetState
Traits: AttrSizedOperandSegments
Operands:
| Operand | Description |
|---|---|
srcCoreXY | variadic of index or 32-bit signless integer |
srcBankId | variadic of 32-bit signless integer |
srcAddress | 32-bit signless integer |
size | 32-bit signless integer |
noc | 8-bit signless integer |
ttkernel.noc_async_read_one_packet_with_state (tt::ttkernel::NocAsyncReadOnePacketWithStateOp)
NocAsyncReadOnePacketWithState
Syntax:
operation ::= `ttkernel.noc_async_read_one_packet_with_state` `(` (`core` `[` $srcCoreXY^ `]`)? (`bank` `[` $srcBankId^ `]`)? `,` $srcAddress `,` $dstLocalL1Addr `,` $size (`,` `noc` $noc^)? `)` attr-dict `:` functional-type(operands, results)
NocAsyncReadOnePacketWithState
Traits: AttrSizedOperandSegments
Operands:
| Operand | Description |
|---|---|
srcCoreXY | variadic of index or 32-bit signless integer |
srcBankId | variadic of 32-bit signless integer |
srcAddress | 32-bit signless integer |
dstLocalL1Addr | 32-bit signless integer or TTKernel l1 address |
size | 32-bit signless integer |
noc | 8-bit signless integer |
ttkernel.noc_async_read (tt::ttkernel::NocAsyncReadOp)
NocAsyncRead
Syntax:
operation ::= `ttkernel.noc_async_read` (`core` `[` $srcCoreXY^ `]`)? (`bank` `[` $srcBankId^ `]`)? `,` $srcAddress `,` $dstLocalL1Addr `,` $size (`,` `noc` $noc^)? attr-dict `:` functional-type(operands, results)
NocAsyncRead from either an L1 core coordinate or a DRAM bank.
Traits: AttrSizedOperandSegments
Operands:
| Operand | Description |
|---|---|
srcCoreXY | variadic of index or 32-bit signless integer |
srcBankId | variadic of 32-bit signless integer |
srcAddress | 32-bit signless integer |
dstLocalL1Addr | 32-bit signless integer |
size | 32-bit signless integer |
noc | 8-bit signless integer |
ttkernel.noc_async_read_tile (tt::ttkernel::NocAsyncReadTileOp)
NocAsyncReadTile
Syntax:
operation ::= `ttkernel.noc_async_read_tile` `(` $id `,` $addrGenStruct `,` $dstLocalL1Addr (`,` $noc^)? `)` attr-dict `:` functional-type(operands, results)
NocAsyncReadTile
Operands:
| Operand | Description |
|---|---|
id | 32-bit signless integer |
addrGenStruct | TensorAccessor type |
dstLocalL1Addr | 32-bit signless integer |
noc | 8-bit signless integer |
ttkernel.noc_async_write_barrier (tt::ttkernel::NocAsyncWriteBarrierOp)
NocAsyncWriteBarrier
Syntax:
operation ::= `ttkernel.noc_async_write_barrier` `(` ($noc^)? `)` attr-dict `:` functional-type(operands, results)
Waits for all outstanding write transactions on the given NOC.
Traits: TTKernel_DeviceZoneOpTrait
Operands:
| Operand | Description |
|---|---|
noc | 8-bit signless integer |
ttkernel.noc_async_write_barrier_with_trid (tt::ttkernel::NocAsyncWriteBarrierWithTridOp)
NocAsyncWriteBarrierWithTrid
Syntax:
operation ::= `ttkernel.noc_async_write_barrier_with_trid` `(` $trid (`,` $noc^)? `)` attr-dict `:` functional-type(operands, results)
Waits for outstanding write transactions matching a transaction ID. TRID is 0-15, NOC is 0 or 1.
Example:
ttkernel.noc_async_write_barrier_with_trid(%trid, %noc_idx) : (i32, i8) -> ()
Traits: TTKernel_DeviceZoneOpTrait, TTKernel_TridNocOpTrait
Operands:
| Operand | Description |
|---|---|
trid | 32-bit signless integer |
noc | 8-bit signless integer |
ttkernel.noc_async_write_multicast_loopback_src (tt::ttkernel::NocAsyncWriteMulticastLoopbackSrcOp)
NocAsyncWriteMulticastLoopbackSrc
Syntax:
operation ::= `ttkernel.noc_async_write_multicast_loopback_src` `(` $srcLocalL1Addr `,` $size `,` $num_dests `,`
`start_xy` `[` $dstNocXStart `,` $dstNocYStart `]` `,`
`end_xy` `[` $dstNocXEnd `,` $dstNocYEnd `]` `,`
$dstLocalL1Addr (`,` `noc` $noc^)? (`,` `linked` $linked^)? `)` attr-dict `:` functional-type(operands, results)
Multicast write that allows the sender to be part of the destinations.
The caller must make sure the start and end coordinates are flipped on
WH/BH's NoC1, especially when the optional noc operand is absent.
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
linked | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
srcLocalL1Addr | 32-bit signless integer |
size | 32-bit signless integer |
num_dests | 32-bit signless integer |
dstNocXStart | index or 32-bit signless integer |
dstNocYStart | index or 32-bit signless integer |
dstNocXEnd | index or 32-bit signless integer |
dstNocYEnd | index or 32-bit signless integer |
dstLocalL1Addr | 32-bit signless integer |
noc | 8-bit signless integer |
ttkernel.noc_async_write_multicast_one_packet (tt::ttkernel::NocAsyncWriteMulticastOnePacketOp)
NocAsyncWriteMulticastOnePacket
Syntax:
operation ::= `ttkernel.noc_async_write_multicast_one_packet` `(` $srcLocalL1Addr `,` $size `,` $num_dests `,`
`start_xy` `[` $dstNocXStart `,` $dstNocYStart `]` `,`
`end_xy` `[` $dstNocXEnd `,` $dstNocYEnd `]` `,`
$dstLocalL1Addr (`,` `noc` $noc^)? (`,` `linked` $linked^)? `)` attr-dict `:` functional-type(operands, results)
NocAsyncWriteMulticastOnePacket this issues only a single packet with size <= NOC_MAX_BURST_SIZE (ie maximum packet size)
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
linked | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
srcLocalL1Addr | 32-bit signless integer |
size | 32-bit signless integer |
num_dests | 32-bit signless integer |
dstNocXStart | index or 32-bit signless integer |
dstNocYStart | index or 32-bit signless integer |
dstNocXEnd | index or 32-bit signless integer |
dstNocYEnd | index or 32-bit signless integer |
dstLocalL1Addr | 32-bit signless integer |
noc | 8-bit signless integer |
ttkernel.noc_async_write_multicast (tt::ttkernel::NocAsyncWriteMulticastOp)
NocAsyncWriteMulticast
Syntax:
operation ::= `ttkernel.noc_async_write_multicast` `(` $srcLocalL1Addr `,` $size `,` $num_dests `,`
`start_xy` `[` $dstNocXStart `,` $dstNocYStart `]` `,`
`end_xy` `[` $dstNocXEnd `,` $dstNocYEnd `]` `,`
$dstLocalL1Addr (`,` `noc` $noc^)? (`,` `linked` $linked^)? `)` attr-dict `:` functional-type(operands, results)
Initiates an asynchronous write from a source address in L1 memory on the Tensix core executing this function call to a rectangular destination grid. The destinations are specified using an on-chip grid of nodes located at NOC coordinate range (x_start,y_start,x_end,y_end) and a local address. Also, see noc_async_write_barrier.
The caller must make sure the start and end coordinates are flipped on
WH/BH's NoC1, especially when the optional noc operand is absent.
The destination nodes can only be a set of Tensix cores + L1 memory address. The destination nodes must form a rectangular grid. The destination L1 memory address must be the same on all destination nodes.
With this API, the multicast sender cannot be part of the multicast destinations. If the multicast sender has to be in the multicast destinations (i.e. must perform a local L1 write), the other API variant noc_async_write_multicast_loopback_src can be used.
Note: The number of destinations needs to be non-zero. Besides that, there is no restriction on the number of destinations, i.e. the multicast destinations can span the full chip. However, as mentioned previously, the multicast source cannot be part of the destinations. So, the maximum number of destinations is 119.
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
linked | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
srcLocalL1Addr | 32-bit signless integer |
size | 32-bit signless integer |
num_dests | 32-bit signless integer |
dstNocXStart | index or 32-bit signless integer |
dstNocYStart | index or 32-bit signless integer |
dstNocXEnd | index or 32-bit signless integer |
dstNocYEnd | index or 32-bit signless integer |
dstLocalL1Addr | 32-bit signless integer |
noc | 8-bit signless integer |
ttkernel.noc_async_write_one_packet_with_trid (tt::ttkernel::NocAsyncWriteOnePacketWithTridOp)
NocAsyncWriteOnePacketWithTrid
Syntax:
operation ::= `ttkernel.noc_async_write_one_packet_with_trid` `(` $srcLocalL1Addr `,` (`core` `[` $dstCoreXY^ `]`)? (`bank` `[` $dstBankId^ `]`)? `,` $dstAddress `,` $size `,` $trid (`,` `noc` $noc^)? `)` attr-dict `:` functional-type(operands, results)
Issues a one-packet NOC write with a specific transaction ID. TRID is 0-15, NOC is 0 or 1.
Example:
ttkernel.noc_async_write_one_packet_with_trid(%l1_src, core[%x, %y], %dst_addr, %size, %trid, noc %noc_idx) : (i32, index, index, i32, i32, i32, i8) -> ()
// TRID-specific barrier should follow.
// ttkernel.noc_async_write_barrier_with_trid(%trid, %noc_idx) : (i32, i8) -> ()
Traits: AttrSizedOperandSegments, TTKernel_TridNocOpTrait
Operands:
| Operand | Description |
|---|---|
srcLocalL1Addr | 32-bit signless integer |
dstCoreXY | variadic of index or 32-bit signless integer |
dstBankId | variadic of 32-bit signless integer |
dstAddress | 32-bit signless integer |
size | 32-bit signless integer |
trid | 32-bit signless integer |
noc | 8-bit signless integer |
ttkernel.noc_async_write (tt::ttkernel::NocAsyncWriteOp)
NocAsyncWrite
Syntax:
operation ::= `ttkernel.noc_async_write` $srcLocalL1Addr `,` (`core` `[` $dstCoreXY^ `]`)? (`bank` `[` $dstBankId^ `]`)? `,` $dstAddress `,` $size (`,` `noc` $noc^)? attr-dict `:` functional-type(operands, results)
NocAsyncWrite to either an L1 core coordinate or a DRAM bank.
Traits: AttrSizedOperandSegments
Operands:
| Operand | Description |
|---|---|
srcLocalL1Addr | 32-bit signless integer |
dstCoreXY | variadic of index or 32-bit signless integer |
dstBankId | variadic of 32-bit signless integer |
dstAddress | 32-bit signless integer |
size | 32-bit signless integer |
noc | 8-bit signless integer |
ttkernel.noc_async_write_tile (tt::ttkernel::NocAsyncWriteTileOp)
NocAsyncWriteTile
Syntax:
operation ::= `ttkernel.noc_async_write_tile` `(` $id `,` $addrGenStruct `,` $srcLocalL1Addr (`,` $noc^)? `)` attr-dict `:` functional-type(operands, results)
NocAsyncWriteTilie
Operands:
| Operand | Description |
|---|---|
id | index or 32-bit signless integer |
addrGenStruct | TensorAccessor type |
srcLocalL1Addr | 32-bit signless integer |
noc | 8-bit signless integer |
ttkernel.noc_inline_dw_write (tt::ttkernel::NocInlineDwWriteOp)
NocInlineDwWrite
Syntax:
operation ::= `ttkernel.noc_inline_dw_write` `(` `core` `[` $dstNocX `,` $dstNocY `]` `,` $dstAddress `,` $val `,` $byte_enable (`,` `noc` $noc^)? `)` attr-dict `:` functional-type(operands, results)
Initiates an inline 32-bit NOC write to a remote L1 address. The value is provided as an SSA value, so the operation does not require a local SRAM staging word.
Operands:
| Operand | Description |
|---|---|
dstNocX | index or 32-bit signless integer |
dstNocY | index or 32-bit signless integer |
dstAddress | 32-bit signless integer |
val | 32-bit signless integer |
byte_enable | 8-bit signless integer |
noc | 8-bit signless integer |
ttkernel.noc_semaphore_inc_multicast (tt::ttkernel::NocSemaphoreIncMulticastOp)
NocSemaphoreIncMulticast
Syntax:
operation ::= `ttkernel.noc_semaphore_inc_multicast` `(` $addr `,` $incr `,` $num_dests (`,` $noc^)? `)` (`posted` $posted^)? attr-dict `:` functional-type(operands, results)
Initiates an atomic increment (with 32-bit wrap) of a 4-byte L1 semaphore on every core in a rectangular destination grid. The destinations are encoded in a uint64_t produced by get_noc_multicast_addr covering the NOC coordinate range (x_start, y_start, x_end, y_end) and the target L1 address. Used for cumulative synchronization across multiple senders sharing receivers, paired with experimental.semaphore_wait_min.
The sender must not be a member of the multicast destination set; for including the sender there is no corresponding loopback variant in tt-metal at this time.
The posted attribute mirrors the semantics of noc_semaphore_inc's
posted template parameter. Posted multicast is currently restricted
on some architectures in the underlying tt-metal (cf. the assertion in
the v2 Noc::async_write_multicast API); leave unset when in doubt.
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
posted | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
addr | TTKernel noc address |
incr | index or 32-bit signless integer |
num_dests | 32-bit signless integer |
noc | 8-bit signless integer |
ttkernel.noc_semaphore_inc (tt::ttkernel::NocSemaphoreIncOp)
NocSemaphoreInc
Syntax:
operation ::= `ttkernel.noc_semaphore_inc` `(` $addr `,` $incr (`,` $noc^)? `)` (`posted` $posted^)? attr-dict `:` functional-type(operands, results)
The Tensix core executing this function call initiates an atomic increment (with 32-bit wrap) of a remote Tensix core L1 memory address. This L1 memory address is used as a semaphore of size 4 Bytes, as a synchronization mechanism.
The posted attribute selects the NOC transaction response mode and
maps to the homonymous template parameter of noc_semaphore_inc in
tt-metal. When unset or false, the transaction is non-posted: the
receiver returns an acknowledgement and the sender's outstanding-atomics
counter tracks completion. When true, the transaction is posted: no
acknowledgement is returned, the sender's counter is not updated, and
synchronization must be receiver-driven.
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
posted | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
addr | TTKernel noc address |
incr | index or 32-bit signless integer |
noc | 8-bit signless integer |
ttkernel.noc_semaphore_set_multicast_loopback_src (tt::ttkernel::NocSemaphoreSetMulticastLoopbackOp)
NocSemaphoreSetMulticastLoopback
Syntax:
operation ::= `ttkernel.noc_semaphore_set_multicast_loopback_src` `(` $src_local_l1_addr `,` $dst_noc_addr_multicast `,` $num_dests (`,` $linked^)? `)` attr-dict `:` functional-type(operands, results)
Initiates an asynchronous write from a source address in L1 memory on the Tensix core executing this function call to a rectangular destination grid. The destinations are specified using a uint64_t encoding referencing an on-chip grid of nodes located at NOC coordinate range (x_start,y_start,x_end,y_end) and a local address created using get_noc_multicast_addr function. The size of data that is sent is 4 Bytes. This is usually used to set a semaphore value at the destination nodes, as a way of a synchronization mechanism. The same as noc_async_write_multicast with preset size of 4 Bytes. Note: With this API, sending data only to the source node (when num_dests is 1) may result in unexpected behaviour. For some parameters, hangs have been observed. For some other parameters, nothing may happen. Consider using regular non multicast operations such as noc_async_write in this case.
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
linked | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
src_local_l1_addr | TTKernel l1 address or TTKernel semaphore |
dst_noc_addr_multicast | TTKernel noc address |
num_dests | 32-bit signless integer |
ttkernel.noc_semaphore_set_multicast (tt::ttkernel::NocSemaphoreSetMulticastOp)
NocSemaphoreSetMulticast
Syntax:
operation ::= `ttkernel.noc_semaphore_set_multicast` `(` $src_local_l1_addr `,` $dst_noc_addr_multicast `,` $num_dests (`,` $linked^)? `)` attr-dict `:` functional-type(operands, results)
Initiates an asynchronous write from a source address in L1 memory on the Tensix core executing this function call to a rectangular destination grid. The destinations are specified using a uint64_t encoding referencing an on-chip grid of nodes located at NOC coordinate range (x_start,y_start,x_end,y_end) and a local address created using get_noc_multicast_addr function. The size of data that is sent is 4 Bytes. This is usually used to set a semaphore value at the destination nodes, as a way of a synchronization mechanism. The same as noc_async_write_multicast with preset size of 4 Bytes. With this API, the multicast sender cannot be part of the multicast destinations. If the multicast sender has to be in the multicast destinations (i.e. must perform a local L1 write), the other API variant noc_semaphore_set_multicast_loopback_src can be used.
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
linked | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
src_local_l1_addr | TTKernel l1 address or TTKernel semaphore |
dst_noc_addr_multicast | TTKernel noc address |
num_dests | 32-bit signless integer |
ttkernel.noc_semaphore_set (tt::ttkernel::NocSemaphoreSetOp)
NocSemaphoreSet
Syntax:
operation ::= `ttkernel.noc_semaphore_set` `(` $sem_addr `,` $val `)` attr-dict `:` functional-type(operands, results)
Sets the value of a local L1 memory address on the Tensix core executing this function to a specific value. This L1 memory address is used as a semaphore of size 4 Bytes, as a synchronization mechanism. Also, see noc_semaphore_wait.
Operands:
| Operand | Description |
|---|---|
sem_addr | TTKernel l1 address pointer |
val | index or 32-bit signless integer |
ttkernel.pack_reconfig_data_format (tt::ttkernel::PackReconfigDataFormatOp)
Reconfigure packer data format for the given output CB.
Syntax:
operation ::= `ttkernel.pack_reconfig_data_format` `(` $out_cb `)` attr-dict `:` functional-type(operands, results)
Reconfigures the packer data format to match the output circular buffer. Must be called before pack_reconfig_l1_acc to ensure format consistency during L1 accumulation.
Operands:
| Operand | Description |
|---|---|
out_cb | TTKernel cb |
ttkernel.pack_reconfig_l1_acc (tt::ttkernel::PackReconfigL1AccOp)
Reconfigure packer to L1 accumulation mode.
Syntax:
operation ::= `ttkernel.pack_reconfig_l1_acc` `(` $l1_acc_en `)` attr-dict `:` functional-type(operands, results)
Reconfigures the packer to accumulate when packing from DST to L1.
Operands:
| Operand | Description |
|---|---|
l1_acc_en | 32-bit signless integer |
ttkernel.pack_tile_block (tt::ttkernel::PackTileBlockOp)
PackTileBlock op.
Syntax:
operation ::= `ttkernel.pack_tile_block` `(` $dst_index `,` $out_cb `,` $ntiles `)` attr-dict `:` functional-type(operands, results)
Copies a contiguous block of ntiles tiles from the DST register buffer, starting at dst_index through dst_index + ntiles - 1, to a specified output CB. Unlike pack_tile, which copies a single tile and supports out-of-order packing, this copies tiles sequentially from contiguous DST slots. The CB write pointer advances by ntiles after each call and resets after cb_push_back.
The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Operates in tandem with functions cb_reserve_back and cb_push_back.
A typical use case is packing an entire block of computed tiles from DST to an output CB in one call, rather than issuing pack_tile for each tile individually. The producer first reserves space via cb_reserve_back, then calls pack_tile_block to copy all ntiles at once, and finally calls cb_push_back to make the block visible to the consumer.
Operands:
| Operand | Description |
|---|---|
dst_index | index or 32-bit signless integer |
out_cb | TTKernel cb |
ntiles | index or 32-bit signless integer |
ttkernel.pack_tile (tt::ttkernel::PackTileOp)
PackTile op.
Syntax:
operation ::= `ttkernel.pack_tile` `(` $dst_index `,` $out_cb `,` $out_index `,` $out_of_order`)` attr-dict `:` functional-type(operands, results)
Copies a single tile from the DST register buffer at a specified index to a specified CB at a given index. For the out_tile_index to be valid for this call, cb_reserve_back(n) has to be called first to reserve at least some number n > 0 of tiles in the output CB. out_tile_index = 0 then references the first tile in the reserved section of the CB, up to index n - 1, which will then be visible to the consumer in the same order after a cb_push_back call. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Each subsequent pack call will increment the write pointer in the cb by single tile size. The pointer is then again set to a valid position with space for n reserved tiles by another cb_reserve_back call.
Operates in tandem with functions cb_reserve_back and cb_push_back.
A typical use case is first the producer ensures that there is a number of tiles available in the buffer via cb_reserve_back, then the producer uses the pack_tile call to copy a tile from one of DST slots to a slot in reserved space and finally cb_push_back is called to announce visibility of the reserved section of the circular buffer to the consumer.
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
out_of_order | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
dst_index | index or 32-bit signless integer |
out_cb | TTKernel cb |
out_index | index or 32-bit signless integer |
ttkernel.pack_untilize_init (tt::ttkernel::PackUntilizeInitOp)
PackUntilizeInitOp call.
Syntax:
operation ::= `ttkernel.pack_untilize_init` `(` $cbIn `,` $cbOut `)` attr-dict `:` functional-type(operands, results)
Initializes UNPACK, MATH, and PACK threads for the pack untilize
operation. Maps to the official tt-metal
pack_untilize_init<block_ct_dim, full_ct_dim>(icb, ocb) API.
cols_per_dst_pass is the number of column tiles processed per DST pass
(block_ct_dim in the tt-metal template), and total_col_tiles is the
total number of column tiles (full_ct_dim in the tt-metal template).
For correctness, cols_per_dst_pass must divide total_col_tiles, and
cols_per_dst_pass must fit
in DST capacity for the target data type. Both default to 1.
This op is expected to be paired with
experimental.pack_untilize_block and finalized by
pack_untilize_uninit.
Traits: TTKernel_InitOpTrait, TTKernel_LayoutOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
colsPerDstPass | ::mlir::IntegerAttr | 32-bit signless integer attribute |
totalColTiles | ::mlir::IntegerAttr | 32-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
cbIn | TTKernel cb |
cbOut | TTKernel cb |
ttkernel.pack_untilize_uninit (tt::ttkernel::PackUntilizeUninitOp)
PackUntilizeUninitOp call.
Syntax:
operation ::= `ttkernel.pack_untilize_uninit` `(` $cbOut `)` attr-dict `:` functional-type(operands, results)
Uninitializes the pack untilize operation. Maps to the official tt-metal
pack_untilize_uninit(ocb) API.
Traits: TTKernel_LayoutOpTrait
Operands:
| Operand | Description |
|---|---|
cbOut | TTKernel cb |
ttkernel.power_binary_tile_init (tt::ttkernel::PowBinaryTilesInitOp)
Short init function which configures compute unit for execution of power_binary_tile.
Syntax:
operation ::= `ttkernel.power_binary_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before power_binary_tile.
Traits: TTKernel_InitOpTrait
ttkernel.power_binary_tile (tt::ttkernel::PowBinaryTilesOp)
Power operation between two tiles
Syntax:
operation ::= `ttkernel.power_binary_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of power operation DST[odst_index] <- DST[dst0_index] ^ DST[dst1_index] on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.power_tile (tt::ttkernel::PowUnaryTileOp)
Power by scalar operation
Syntax:
operation ::= `ttkernel.power_tile` `(` $dst0_index `,` $param `)` attr-dict `:` functional-type(operands, results)
Performs element-wise exponentiation of a tile by a scalar value. DST[dst0_index] <- DST[dst0_index] ^ scalar The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
param | 32-bit signless integer |
ttkernel.power_tile_init (tt::ttkernel::PowerTileInitOp)
Init function for power_tile operation.
Syntax:
operation ::= `ttkernel.power_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before power_tile.
Traits: TTKernel_InitOpTrait
ttkernel.rand_tile_init (tt::ttkernel::RandTileInitOp)
Init function for rand_tile operation. Refer to documentation for any init function.
Syntax:
operation ::= `ttkernel.rand_tile_init` `(` $seed `)` attr-dict `:` functional-type(operands, results)
Initializes the PRNG seed for the SFPU. Must be run before rand_tile.
Traits: TTKernel_InitOpTrait
Operands:
| Operand | Description |
|---|---|
seed | index or 32-bit signless integer |
ttkernel.rand_tile (tt::ttkernel::RandTileOp)
Rand tile operation
Syntax:
operation ::= `ttkernel.rand_tile` `(` $tile_index `,` $from `,` $scale `)` attr-dict `:` functional-type(operands, results)
Performs element-wise rand on each element of a tile in DST register at index tile_index. That is each element is overwritten with a randomly generated float in the range [from, from + scale).
from and scale are passed as the uint32_t bit pattern of their
corresponding f32 values. The DST register buffer must be in acquired
state via tile_regs_acquire call.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
from | index or 32-bit signless integer |
scale | index or 32-bit signless integer |
ttkernel.recip_tile_init (tt::ttkernel::RecipTileInitOp)
Init function for recip_tile operation. Refer to documentation for any init function.
Syntax:
operation ::= `ttkernel.recip_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be called before recip_tile function.
Traits: TTKernel_InitOpTrait
ttkernel.recip_tile (tt::ttkernel::RecipTileOp)
Recip tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.recip_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of the reciprocal on each element of a tile in DST register at index tile_index. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine. Only works for Float32, Float16_b, Bfp8_b data formats for full accuracy.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.reduce_init (tt::ttkernel::ReduceInitOp)
Init function
Syntax:
operation ::= `ttkernel.reduce_init` `(` $in_cb `,` $scaling_cb `,` $out_cb `,` $reduce_type `,` $reduce_dim `)` attr-dict `:` functional-type(operands, results)
Must be run before reduce_tile.
Traits: TTKernel_InitOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
reduce_type | ::mlir::tt::ttkernel::ReduceTypeAttr | TTKernel Reduce Types |
reduce_dim | ::mlir::tt::ttkernel::ReduceDimAttr | TTKernel Reduce Dimensions |
full_fp32 | ::mlir::UnitAttr | unit attribute |
Operands:
| Operand | Description |
|---|---|
in_cb | TTKernel cb |
scaling_cb | TTKernel cb |
out_cb | TTKernel cb |
ttkernel.reduce_tile (tt::ttkernel::ReduceTileOp)
Reduce operation
Syntax:
operation ::= `ttkernel.reduce_tile` `(` $in_cb `,` $scaling_cb `,` $in_tile_index `,` $scaling_tile_index `,` $dst_index `,` $reduce_type `,` $reduce_dim `)` attr-dict `:` functional-type(operands, results)
Performs a reduction operation B = reduce(A) using reduce_func for dimension reduction on a tile in the CB at a given index and writes the result to the DST register at index dst_tile_index. Reduction can be either of type Reduce::R, Reduce::C or Reduce::RC, identifying the dimension(s) to be reduced in size to 1. The DST register buffer must be in acquired state via tile_regs_acquire call. The templates takes reduce_type which can be ReduceFunc::Sum, ReduceFunc::Max and reduce_dim which can be Reduce::R, Reduce::C, Reduce::RC. They can also be specified by defines REDUCE_OP and REDUCE_DIM. This call is blocking and is only available on the compute engine.
Traits: TTKernel_FPUOpTrait, TTKernel_TernaryOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
reduce_type | ::mlir::tt::ttkernel::ReduceTypeAttr | TTKernel Reduce Types |
reduce_dim | ::mlir::tt::ttkernel::ReduceDimAttr | TTKernel Reduce Dimensions |
full_fp32 | ::mlir::UnitAttr | unit attribute |
Operands:
| Operand | Description |
|---|---|
in_cb | TTKernel cb |
scaling_cb | TTKernel cb |
in_tile_index | index or 32-bit signless integer |
scaling_tile_index | index or 32-bit signless integer |
dst_index | index or 32-bit signless integer |
ttkernel.reduce_uninit (tt::ttkernel::ReduceUninitOp)
Init function for reduce_uninit operation.
Syntax:
operation ::= `ttkernel.reduce_uninit` `(` `)` attr-dict `:` functional-type(operands, results)
Resets the packer edge mask configuration to its default state by clearing any previously set masks. Needs to be called after reduce_tile if the next operation requires default packer state. In case that the next operation is reduce operation across the same dimension, this call can be omitted. If this function is not called, the packer will continue to use the edge masks set by the latest reduce_init call, which may lead to incorrect packing behavior in subsequent operations.
The full_fp32 attribute emits reduce_uninit
This function is not in line with our programming mode. To be removed by end of 2025. tt-metal#22904.
Traits: TTKernel_InitOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
full_fp32 | ::mlir::UnitAttr | unit attribute |
ttkernel.relu_tile_int32 (tt::ttkernel::ReluTileI32Op)
Relu operation (for int32 type)
Syntax:
operation ::= `ttkernel.relu_tile_int32` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of relu on each element of a tile in DST register at index tile_index. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.relu_tile_init (tt::ttkernel::ReluTileInitOp)
_Short init function which configures compute unit for execution of relu_tile(int32).
Syntax:
operation ::= `ttkernel.relu_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before relu_tile(_int32).
Traits: TTKernel_InitOpTrait
ttkernel.relu_tile (tt::ttkernel::ReluTileOp)
Relu operation
Syntax:
operation ::= `ttkernel.relu_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of relu on each element of a tile in DST register at index tile_index. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.remote_sram_write_u32 (tt::ttkernel::RemoteSramWriteU32Op)
RemoteSramWriteU32
Syntax:
operation ::= `ttkernel.remote_sram_write_u32` `(` $src_sram_addr `,` $dst_remote_addr (`,` $noc^)? `)` attr-dict `:` functional-type(operands, results)
Initiates a 4-byte remote SRAM write of the u32 value stored at a local SRAM address on the Tensix core executing this function call. The source SRAM word may be referenced by a typed SRAM address, a computed i32 SRAM address, or a local semaphore handle.
Operands:
| Operand | Description |
|---|---|
src_sram_addr | 32-bit signless integer or TTKernel l1 address or TTKernel semaphore |
dst_remote_addr | TTKernel noc address |
noc | 8-bit signless integer |
ttkernel.rounding_op_tile_init (tt::ttkernel::RoundingTileInitOp)
Init function for ceil/floor/round_tile operation. Refer to documentation for any init function.
Syntax:
operation ::= `ttkernel.rounding_op_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before ceil/floor/round_tile.
Traits: TTKernel_InitOpTrait
ttkernel.rsqrt_tile_init (tt::ttkernel::RsqrtTileInitOp)
Short init function which configures compute unit for execution of rsqrt_tile.
Syntax:
operation ::= `ttkernel.rsqrt_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before rsqrt_tile.
Traits: TTKernel_InitOpTrait
ttkernel.rsqrt_tile (tt::ttkernel::RsqrtTileOp)
Rsqrt operation
Syntax:
operation ::= `ttkernel.rsqrt_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of reciprocal sqrt on each element of a tile in DST register at index tile_index. The DST register buffer must be in acquired state via acquire_dst call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.sfpu_reduce_init (tt::ttkernel::SFPUReduceInitOp)
Init for sfpu_reduce.
Syntax:
operation ::= `ttkernel.sfpu_reduce_init` `(` $reduce_type `,` $data_format `)` attr-dict `:` functional-type(operands, results)
Initializes the SFPU reduce kernel. Must be called before sfpu_reduce. Unlike reduce_init this call carries no CB/DST operands: it only configures the SFPU for the given PoolType and DataFormat.
Only Sum/Max reductions over Int32 tiles are supported today; the verifier enforces this.
Lowers to: sfpu_reduce_init<PoolType, DataFormat>().
Traits: TTKernel_InitOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
reduce_type | ::mlir::tt::ttkernel::ReduceTypeAttr | TTKernel Reduce Types |
data_format | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
ttkernel.sfpu_reduce (tt::ttkernel::SFPUReduceTileOp)
SFPU reduce operation on a tile in DST.
Syntax:
operation ::= `ttkernel.sfpu_reduce` `(` $dst_index `,` $reduce_type `,` $data_format `,` $reduce_dim `)` attr-dict `:` functional-type(operands, results)
Performs an intra-tile reduction on the tile at index dst_index in the
DST register using the SFPU path. The input tile must already be loaded
into DST (e.g. via copy_tile). The reduction is performed in-place on
that DST slot, writing the result into the first row (REDUCE_COL) or
first column (REDUCE_ROW) of the same tile.
Only 32x32 tile dimensions are supported.
Only Sum/Max reductions over Int32 tiles are supported today, and reduce_dim must be Row or Col (Scalar must be decomposed into Col + Row by the caller); the verifier enforces these constraints.
Lowers to: sfpu_reduce<PoolType, DataFormat, ReduceDim>(dst_index).
Traits: TTKernel_SFPUOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
reduce_type | ::mlir::tt::ttkernel::ReduceTypeAttr | TTKernel Reduce Types |
data_format | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
reduce_dim | ::mlir::tt::ttkernel::ReduceDimAttr | TTKernel Reduce Dimensions |
Operands:
| Operand | Description |
|---|---|
dst_index | index or 32-bit signless integer |
ttkernel.selu_tile_init (tt::ttkernel::SeluTileInitOp)
Short init function which configures compute unit for execution of selu_tile.
Syntax:
operation ::= `ttkernel.selu_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before selu_tile.
Traits: TTKernel_InitOpTrait
ttkernel.selu_tile (tt::ttkernel::SeluTileOp)
Selu operation
Syntax:
operation ::= `ttkernel.selu_tile` `(` $tile_index `,` $scale `,` $alpha `)` attr-dict `:` functional-type(operands, results)
Performs element-wise SELU activation: scale*(max(0,x) + min(0,alpha*(exp(x)-1))) on each element of a tile in DST register at index tile_index. scale and alpha are uint32 bit-cast representations of bf16 float values. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
scale | 32-bit signless integer |
alpha | 32-bit signless integer |
ttkernel.experimental.semaphore_wait_min (tt::ttkernel::SemaphoreWaitMinOp)
SemaphoreWaitMin
Syntax:
operation ::= `ttkernel.experimental.semaphore_wait_min` `(` $sem_addr `,` $val `)` attr-dict `:` functional-type(operands, results)
A blocking call that waits until the value of a local L1 memory address on the Tensix core executing this function becomes equal or greater than a target value. This L1 memory address is used as a semaphore of size 4 Bytes, as a synchronization mechanism. Also, see noc_semaphore_set.
Operands:
| Operand | Description |
|---|---|
sem_addr | TTKernel l1 address pointer |
val | 32-bit signless integer |
ttkernel.experimental.semaphore_wait (tt::ttkernel::SemaphoreWaitOp)
SemaphoreWait
Syntax:
operation ::= `ttkernel.experimental.semaphore_wait` `(` $sem_addr `,` $val `)` attr-dict `:` functional-type(operands, results)
A blocking call that waits until the value of a local L1 memory address on the Tensix core executing this function becomes equal to a target value. This L1 memory address is used as a semaphore of size 4 Bytes, as a synchronization mechanism. Also, see noc_semaphore_set.
Operands:
| Operand | Description |
|---|---|
sem_addr | TTKernel l1 address pointer |
val | index or 32-bit signless integer |
ttkernel.experimental.setup_fabric_connections (tt::ttkernel::SetupFabricConnectionsOp)
SetupFabricConnections
Syntax:
operation ::= `ttkernel.experimental.setup_fabric_connections` `(` $fabric_connection_manager `)` attr-dict `:` functional-type(operands, results)
Setup fabric connections for inter-device communication. The connection scheme
is derived from the attribute TTMetal_FabricConnectionConfigAttr in the
EnqueueProgramOp.
TTMetal_FabricConnectionConfigAttr specifies:
noc_index: Which NOC the fabric uses (must match kernel's NocConfig)topology: The routing scheme to use for the mesh device (e.g. Line, Ring)cluster_axis: The axis along which the to route for 1D topologiesnum_links: Number of routing planes (connections to fabric routers)
After setup, the FabricConnectionManager can be used with ops like
fabric_fast_write_any_len to send data to other devices in the mesh.
Operands:
| Operand | Description |
|---|---|
fabric_connection_manager | TTKernel fabric connection manager |
ttkernel.sigmoid_tile_init (tt::ttkernel::SigmoidTileInitOp)
Short init function which configures compute unit for execution of sigmoid_tile.
Syntax:
operation ::= `ttkernel.sigmoid_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before sigmoid_tile.
Traits: TTKernel_InitOpTrait
ttkernel.sigmoid_tile (tt::ttkernel::SigmoidTileOp)
Sigmoid operation
Syntax:
operation ::= `ttkernel.sigmoid_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of sigmoid on each element of a tile in DST register at index tile_index. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.sign_tile_init (tt::ttkernel::SignTileInitOp)
Init function for sign_tile operation. Refer to documentation for any init function.
Syntax:
operation ::= `ttkernel.sign_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before sign_tile.
Traits: TTKernel_InitOpTrait
ttkernel.sign_tile (tt::ttkernel::SignTileOp)
Sign operation
Syntax:
operation ::= `ttkernel.sign_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of sign on each element of a tile in DST register at index tile_index. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.signbit_tile_init (tt::ttkernel::SignbitTileInitOp)
Short init function which configures compute unit for execution of signbit_tile.
Syntax:
operation ::= `ttkernel.signbit_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before signbit_tile.
Traits: TTKernel_InitOpTrait
ttkernel.signbit_tile (tt::ttkernel::SignbitTileOp)
Signbit operation
Syntax:
operation ::= `ttkernel.signbit_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise sign bit extraction on each element of a tile in DST register at index tile_index, returning 0.0 if the sign bit is clear and 1.0 if it is set (matching IEEE 754 signbit semantics). The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.silu_tile_init (tt::ttkernel::SiluTileInitOp)
Short init function which configures compute unit for execution of silu_tile.
Syntax:
operation ::= `ttkernel.silu_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before silu_tile.
Traits: TTKernel_InitOpTrait
ttkernel.silu_tile (tt::ttkernel::SiluTileOp)
Silu operation
Syntax:
operation ::= `ttkernel.silu_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of silu on each element of a tile in DST register at index tile_index. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.sin_tile_init (tt::ttkernel::SinTileInitOp)
Init function for sin_tile operation. Refer to documentation for any init function.
Syntax:
operation ::= `ttkernel.sin_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before sin_tile.
Traits: TTKernel_InitOpTrait
ttkernel.sin_tile (tt::ttkernel::SinTileOp)
Sine tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.sin_tile` `(` $dst0_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of sine operation DST[dst0_index] <- sin(DST[dst0_index]) on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.softsign_tile_init (tt::ttkernel::SoftsignTileInitOp)
Short init function which configures compute unit for execution of softsign_tile.
Syntax:
operation ::= `ttkernel.softsign_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before softsign_tile.
Traits: TTKernel_InitOpTrait
ttkernel.softsign_tile (tt::ttkernel::SoftsignTileOp)
Softsign operation
Syntax:
operation ::= `ttkernel.softsign_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of x/(1+|x|) on each element of a tile in DST register at index tile_index. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.sqrt_tile_init (tt::ttkernel::SqrtTileInitOp)
Short init function which configures compute unit for execution of sqrt_tile.
Syntax:
operation ::= `ttkernel.sqrt_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before sqrt_tile.
Traits: TTKernel_InitOpTrait
ttkernel.sqrt_tile (tt::ttkernel::SqrtTileOp)
Sqrt operation
Syntax:
operation ::= `ttkernel.sqrt_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of sqrt on each element of a tile in DST register at index tile_index. The DST register buffer must be in acquired state via acquire_dst call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.square_tile_init (tt::ttkernel::SquareTileInitOp)
Short init function which configures compute unit for execution of square_tile.
Syntax:
operation ::= `ttkernel.square_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before square_tile.
Traits: TTKernel_InitOpTrait
ttkernel.square_tile (tt::ttkernel::SquareTileOp)
Square operation
Syntax:
operation ::= `ttkernel.square_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of x^2 on each element of a tile in DST register at index tile_index. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.store_to_l1 (tt::ttkernel::StoreToL1Op)
StoreToL1
Syntax:
operation ::= `ttkernel.store_to_l1` `(` $value `,` $l1_ptr `,` $offset `)` attr-dict `:` functional-type(operands, results)
Store value to L1.
Operands:
| Operand | Description |
|---|---|
value | 8-bit signless integer or 16-bit signless integer or 32-bit signless integer |
l1_ptr | TTKernel l1 address pointer |
offset | 32-bit signless integer |
ttkernel.sub_binary_tile_init (tt::ttkernel::SubBinaryTilesInitOp)
Short init function
Syntax:
operation ::= `ttkernel.sub_binary_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before sub_binary_tile.
Traits: TTKernel_InitOpTrait
ttkernel.sub_binary_tile (tt::ttkernel::SubBinaryTilesOp)
Subtraction operation between two tiles
Syntax:
operation ::= `ttkernel.sub_binary_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of subtraction operation DST[odst_index] <- DST[dst0_index] - DST[dst1_index] on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.sub_int_tile_init (tt::ttkernel::SubIntTileInitOp)
Short init function
Syntax:
operation ::= `ttkernel.sub_int_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before sub_int_tile.
Traits: TTKernel_InitOpTrait
ttkernel.sub_int_tile (tt::ttkernel::SubIntTileOp)
Integer subtraction operation between two tiles
Syntax:
operation ::= `ttkernel.sub_int_tile` `(` $dst0_index `,` $dst1_index `,` $odst_index `,` $dtype `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of integer subtraction operation DST[odst_index] <- DST[dst0_index] - DST[dst1_index] on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call. Supported data formats are: Int32, UInt32, UInt16.
Traits: TTKernel_BinaryOpTrait, TTKernel_SFPUOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
dst1_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
ttkernel.sub_tiles_init (tt::ttkernel::SubTilesInitOp)
Short init function
Syntax:
operation ::= `ttkernel.sub_tiles_init` `(` $in0_cb `,` $in1_cb `)` attr-dict `:` functional-type(operands, results)
Must be run before sub_tiles.
Traits: TTKernel_InitOpTrait
Operands:
| Operand | Description |
|---|---|
in0_cb | TTKernel cb |
in1_cb | TTKernel cb |
ttkernel.sub_tiles (tt::ttkernel::SubTilesOp)
Sub operation
Syntax:
operation ::= `ttkernel.sub_tiles` `(` $in0_cb `,` $in1_cb `,` $in0_tile_index `,` $in1_tile_index `,` $dst_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise subtraction C=A-B of tiles in two CBs at given indices and writes the result to the DST register at index dst_tile_index. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_BinaryOpTrait, TTKernel_FPUOpTrait
Operands:
| Operand | Description |
|---|---|
in0_cb | TTKernel cb |
in1_cb | TTKernel cb |
in0_tile_index | index or 32-bit signless integer |
in1_tile_index | index or 32-bit signless integer |
dst_index | index or 32-bit signless integer |
ttkernel.sub_unary_tile_int32 (tt::ttkernel::SubUnaryTileInt32Op)
Subtract by int32 scalar operation
Syntax:
operation ::= `ttkernel.sub_unary_tile_int32` `(` $dst0_index `,` $param `)` attr-dict `:` functional-type(operands, results)
Performs element-wise subtraction of an int32 tile by an int32 scalar value. DST[dst0_index] <- DST[dst0_index] - scalar The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
param | 32-bit signless integer |
ttkernel.sub_unary_tile (tt::ttkernel::SubUnaryTileOp)
Subtract by scalar operation
Syntax:
operation ::= `ttkernel.sub_unary_tile` `(` $dst0_index `,` $param `)` attr-dict `:` functional-type(operands, results)
Performs element-wise subtraction of a tile by a scalar value. DST[dst0_index] <- DST[dst0_index] - scalar The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
param | 32-bit signless integer |
ttkernel.tan_tile_init (tt::ttkernel::TanTileInitOp)
Short init function which configures compute unit for execution of tan_tile.
Syntax:
operation ::= `ttkernel.tan_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before tan_tile.
Traits: TTKernel_InitOpTrait
ttkernel.tan_tile (tt::ttkernel::TanTileOp)
Tan operation
Syntax:
operation ::= `ttkernel.tan_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of the trigonometric tangent operation on each element of a tile in DST register at index tile_index. The DST register buffer must be in acquired state via acquire_dst call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.tanh_tile_init (tt::ttkernel::TanhTileInitOp)
Short init function which configures compute unit for execution of tanh_tile.
Syntax:
operation ::= `ttkernel.tanh_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before tanh_tile.
Traits: TTKernel_InitOpTrait
ttkernel.tanh_tile (tt::ttkernel::TanhTileOp)
Tanh operation
Syntax:
operation ::= `ttkernel.tanh_tile` `(` $dst0_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise computation of the hyperbolic tangent operation on each element of a tile in DST register at index tile_index. The DST register buffer must be in acquired state via acquire_dst call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.TensorAccessorArgs (tt::ttkernel::TensorAccessorArgsOp)
TensorAccessorArgs
TensorAccessorArgs struct constructor.
CTA (compile-time args) and CRTA (compile/runtime args) offsets are determined as follows.
- If cta_expr is provided: use the constexpr string expression.
- Else if
prev_argsis provided, use chaining:prev_args.next_compile_time_args_offset()(for CTA) orprev_args.next_common_runtime_args_offset()(for CRTA). - Otherwise, use cta_base/crta_base integer constants.
Examples:
// Literal offsets
%c0 = arith.constant 0 : i32
%args = ttkernel.TensorAccessorArgs(%c0, %c0) : (i32, i32) -> !ttkernel.TensorAccessorArgs
// Generates: TensorAccessorArgs<0, 0>()
// CTA+CRTA chaining (common pattern)
%args_src = ttkernel.TensorAccessorArgs(%c0, %c0) : (i32, i32) -> !ttkernel.TensorAccessorArgs
%args_dst = ttkernel.TensorAccessorArgs(prev = %args_src) : (!ttkernel.TensorAccessorArgs) -> !ttkernel.TensorAccessorArgs
// Generates: TensorAccessorArgs<args_src.next_compile_time_args_offset(), args_src.next_common_runtime_args_offset()>()
// Selective override: chain CTA from prev, use literal CRTA
%args_custom = ttkernel.TensorAccessorArgs(prev = %args_src) {crta_expr = "0"} : (!ttkernel.TensorAccessorArgs) -> !ttkernel.TensorAccessorArgs
// Generates: TensorAccessorArgs<args_src.next_compile_time_args_offset(), 0>()
// Constexpr expression (no chaining)
%args_expr = ttkernel.TensorAccessorArgs(%c0, %c0) {cta_expr = "get_offset()"} : (i32, i32) -> !ttkernel.TensorAccessorArgs
// Generates: TensorAccessorArgs<get_offset(), 0>()
Traits: AttrSizedOperandSegments
Interfaces: InferTypeOpInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
cta_expr | ::mlir::StringAttr | string attribute |
crta_expr | ::mlir::StringAttr | string attribute |
Operands:
| Operand | Description |
|---|---|
cta_base | 32-bit signless integer |
crta_base | 32-bit signless integer |
prev_args | TensorAccessorArgs type |
Results:
| Result | Description |
|---|---|
result | TensorAccessorArgs type |
ttkernel.tensor_accessor.get_bank_and_offset (tt::ttkernel::TensorAccessorGetBankAndOffsetOp)
TensorAccessor's get_bank_and_offset
Syntax:
operation ::= `ttkernel.tensor_accessor.get_bank_and_offset` `(` $tensor_accessor `,` $page_id `)` attr-dict `:` functional-type(operands, results)
Returns bank id and page offset.
Interfaces: InferTypeOpInterface
Operands:
| Operand | Description |
|---|---|
tensor_accessor | TensorAccessor type |
page_id | 32-bit signless integer |
Results:
| Result | Description |
|---|---|
bank_id_and_offset | TensorAccessor PageMapping struct |
ttkernel.tensor_accessor.get_noc_addr (tt::ttkernel::TensorAccessorGetNocAddrOp)
TensorAccessor's get_noc_addr
Syntax:
operation ::= `ttkernel.tensor_accessor.get_noc_addr` `(` $tensor_accessor `,` $id `,` $offset (`,` $noc^)? `)` attr-dict `:` functional-type(operands, results)
get_noc_addr using information stored in the TensorAccessor.
Interfaces: InferTypeOpInterface
Operands:
| Operand | Description |
|---|---|
tensor_accessor | TensorAccessor type |
id | 32-bit signless integer |
offset | 32-bit signless integer |
noc | 8-bit signless integer |
Results:
| Result | Description |
|---|---|
nocAddr | TTKernel noc address |
ttkernel.tensor_accessor.get_shard_noc_addr (tt::ttkernel::TensorAccessorGetShardNocAddrOp)
TensorAccessor's get_shard_noc_addr
Syntax:
operation ::= `ttkernel.tensor_accessor.get_shard_noc_addr` `(` $tensor_accessor `,` $shard_id `,` $offset (`,` $noc^)? `)` attr-dict `:` functional-type(operands, results)
Returns noc addr of a shard.
Interfaces: InferTypeOpInterface
Operands:
| Operand | Description |
|---|---|
tensor_accessor | TensorAccessor type |
shard_id | 32-bit signless integer |
offset | 32-bit signless integer |
noc | 8-bit signless integer |
Results:
| Result | Description |
|---|---|
shardNocAddr | 32-bit signless integer |
ttkernel.tensor_accessor.is_local_addr (tt::ttkernel::TensorAccessorIsLocalAddrOp)
TensorAccessor's is_local_addr
Syntax:
operation ::= `ttkernel.tensor_accessor.is_local_addr` `(` $tensor_accessor `,` $virtual_x `,` $virtual_y (`,` $noc^)? `)` attr-dict `:` functional-type(operands, results)
Returns bool indicating addr locality.
Interfaces: InferTypeOpInterface
Operands:
| Operand | Description |
|---|---|
tensor_accessor | TensorAccessor type |
virtual_x | 32-bit signless integer |
virtual_y | 32-bit signless integer |
noc | 8-bit signless integer |
Results:
| Result | Description |
|---|---|
result | 1-bit signless integer |
ttkernel.tensor_accessor.is_local_bank (tt::ttkernel::TensorAccessorIsLocalBankOp)
TensorAccessor's is_local_bank
Syntax:
operation ::= `ttkernel.tensor_accessor.is_local_bank` `(` $tensor_accessor `,` $id `,` $offset (`,` $noc^)? `)` attr-dict `:` functional-type(operands, results)
Returns bool indicating bank locality.
Interfaces: InferTypeOpInterface
Operands:
| Operand | Description |
|---|---|
tensor_accessor | TensorAccessor type |
id | 32-bit signless integer |
offset | 32-bit signless integer |
noc | 8-bit signless integer |
Results:
| Result | Description |
|---|---|
result | 1-bit signless integer |
ttkernel.tensor_accessor.is_local_page (tt::ttkernel::TensorAccessorIsLocalPageOp)
TensorAccessor's is_local_page
Syntax:
operation ::= `ttkernel.tensor_accessor.is_local_page` `(` $tensor_accessor `,` $page_id (`,` $noc^)? `)` attr-dict `:` functional-type(operands, results)
Returns bool indicating page locality.
Interfaces: InferTypeOpInterface
Operands:
| Operand | Description |
|---|---|
tensor_accessor | TensorAccessor type |
page_id | 32-bit signless integer |
noc | 8-bit signless integer |
Results:
| Result | Description |
|---|---|
result | 1-bit signless integer |
ttkernel.tensor_accessor.is_local_shard (tt::ttkernel::TensorAccessorIsLocalShardOp)
TensorAccessor's is_local_shard
Syntax:
operation ::= `ttkernel.tensor_accessor.is_local_shard` `(` $tensor_accessor `,` $shard_id (`,` $noc^)? `)` attr-dict `:` functional-type(operands, results)
Returns bool indicating shard locality.
Interfaces: InferTypeOpInterface
Operands:
| Operand | Description |
|---|---|
tensor_accessor | TensorAccessor type |
shard_id | 32-bit signless integer |
noc | 8-bit signless integer |
Results:
| Result | Description |
|---|---|
result | 1-bit signless integer |
ttkernel.TensorAccessor (tt::ttkernel::TensorAccessorOp)
MakeTensorAccessorFromArgs
Syntax:
operation ::= `ttkernel.TensorAccessor` `(` $args `,` $bank_base_address_in `,` $page_size_in `)` attr-dict `:` functional-type(operands, results)
TensorAccessor constructor.
Interfaces: InferTypeOpInterface
Operands:
| Operand | Description |
|---|---|
args | TensorAccessorArgs type |
bank_base_address_in | 32-bit signless integer |
page_size_in | 32-bit signless integer |
Results:
| Result | Description |
|---|---|
result | TensorAccessor type |
ttkernel.tile_regs_acquire (tt::ttkernel::TileRegsAcquireOp)
Tile_regs_acquire
Syntax:
operation ::= `ttkernel.tile_regs_acquire` `(` `)` attr-dict `:` functional-type(operands, results)
Acquire an exclusive lock on the DST register for the MATH thread. This register is an array of 16 tiles of 32x32 elements each. This is a blocking function, i.e. this function will wait until the lock is acquired.
Traits: TTKernel_DeviceZoneOpTrait
ttkernel.tile_regs_commit (tt::ttkernel::TileRegsCommitOp)
Tile_regs_commit
Syntax:
operation ::= `ttkernel.tile_regs_commit` `(` `)` attr-dict `:` functional-type(operands, results)
Release lock on DST register by MATH thread. The lock had to be previously acquired with tile_regs_acquire.
ttkernel.tile_regs_release (tt::ttkernel::TileRegsReleaseOp)
Tile_regs_release
Syntax:
operation ::= `ttkernel.tile_regs_release` `(` `)` attr-dict `:` functional-type(operands, results)
Release lock on DST register by PACK thread. The lock had to be previously acquired with tile_regs_wait.
ttkernel.tile_regs_wait (tt::ttkernel::TileRegsWaitOp)
Tile_regs_wait
Syntax:
operation ::= `ttkernel.tile_regs_wait` `(` `)` attr-dict `:` functional-type(operands, results)
Acquire an exclusive lock on the DST register for the PACK thread. It waits for the MATH thread to commit the DST register. This is a blocking function, i.e. this function will wait until the lock is acquired.
Traits: TTKernel_DeviceZoneOpTrait
ttkernel.tilize_block (tt::ttkernel::TilizeBlockOp)
TilizeBlockOp call.
Syntax:
operation ::= `ttkernel.tilize_block` `(` $cbIn `,` $numTiles `,` $cbOut `)` attr-dict `:` functional-type(operands, results)
TilizeBlockOp operation
Traits: TTKernel_LayoutOpTrait
Operands:
| Operand | Description |
|---|---|
cbIn | TTKernel cb |
numTiles | 32-bit signless integer |
cbOut | TTKernel cb |
ttkernel.tilize_init (tt::ttkernel::TilizeInitOp)
TilizeInitOp call.
Syntax:
operation ::= `ttkernel.tilize_init` `(` $cbIn `,` $numTiles `,` $cbOut `)` attr-dict `:` functional-type(operands, results)
Initialize the tilize operation. To be called once at beginning of a kernel.
Traits: TTKernel_InitOpTrait, TTKernel_LayoutOpTrait
Operands:
| Operand | Description |
|---|---|
cbIn | TTKernel cb |
numTiles | 32-bit signless integer |
cbOut | TTKernel cb |
ttkernel.tilize_uninit (tt::ttkernel::TilizeUninitOp)
TilizeUninitOp call.
Syntax:
operation ::= `ttkernel.tilize_uninit` `(` $cbI `,` $cbOut `)` attr-dict `:` functional-type(operands, results)
Uninitialize tilize operation before re-initializing for another operation.
Traits: TTKernel_LayoutOpTrait
Operands:
| Operand | Description |
|---|---|
cbI | TTKernel cb |
cbOut | TTKernel cb |
ttkernel.transpose_wh_init (tt::ttkernel::TransposeInitOp)
TransposeInitOp call.
Syntax:
operation ::= `ttkernel.transpose_wh_init` `(` $cbIn `,` $cbOut `)` attr-dict `:` functional-type(operands, results)
Initialize the transpose operation. To be called once at beginning of a kernel before transpose operations.
Operands:
| Operand | Description |
|---|---|
cbIn | TTKernel cb |
cbOut | TTKernel cb |
ttkernel.transpose_wh_tile (tt::ttkernel::TransposeTileOp)
Transpose WH tile operation
Syntax:
operation ::= `ttkernel.transpose_wh_tile` `(` $icb `,` $itile `,` $idst `)` attr-dict `:` functional-type(operands, results)
Performs a 32x32 transpose operation on a tile in the CB at a given index and writes the result to the DST register at index dst_tile_index.
Operands:
| Operand | Description |
|---|---|
icb | TTKernel cb |
itile | index or 32-bit signless integer |
idst | index or 32-bit signless integer |
ttkernel.trunc_tile (tt::ttkernel::TruncTileOp)
Trunc operation
Syntax:
operation ::= `ttkernel.trunc_tile` `(` $tile_index `)` attr-dict `:` functional-type(operands, results)
Performs element-wise truncation toward zero on each element of a tile in DST register at index tile_index. Requires rounding_op_tile_init to be called first. The DST register buffer must be in acquired state via tile_regs_acquire call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Operands:
| Operand | Description |
|---|---|
tile_index | index or 32-bit signless integer |
ttkernel.typecast_tile_init (tt::ttkernel::TypecastTileInitOp)
Init function for typecast_tile operation. Refer to documentation for any init function.
Syntax:
operation ::= `ttkernel.typecast_tile_init` `(` $in_dtype `,` $out_dtype `)` attr-dict `:` functional-type(operands, results)
Must be run before typecast_tile.
Traits: TTKernel_InitOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
in_dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
out_dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
ttkernel.typecast_tile (tt::ttkernel::TypecastTileOp)
Cast the dataformat of the tile in the DST at specified index.
Syntax:
operation ::= `ttkernel.typecast_tile` `(` $dst0_index `,` $in_dtype `,` $out_dtype `)` attr-dict `:` functional-type(operands, results)
Performs element-wise typecast operation DST[dst0_index] <- typecast<in_dataformat, out_dataformat>(DST[dst0_index]) on DST register operands. The DST register buffer must be in acquired state via tile_regs_acquire call.
Traits: TTKernel_SFPUOpTrait, TTKernel_UnaryOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
in_dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
out_dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
Operands:
| Operand | Description |
|---|---|
dst0_index | index or 32-bit signless integer |
ttkernel.unary_bcast_init (tt::ttkernel::UnaryBcastInitOp)
Init function
Syntax:
operation ::= `ttkernel.unary_bcast_init` `(` $in_cb `,` $out_cb `,` $bcast_type `)` attr-dict `:` functional-type(operands, results)
Must be run before bcast_tile.
Traits: TTKernel_InitOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
bcast_type | ::mlir::tt::ttkernel::BcastTypeAttr | TTKernel Broadcast Types |
Operands:
| Operand | Description |
|---|---|
in_cb | TTKernel cb |
out_cb | TTKernel cb |
ttkernel.unary_bcast (tt::ttkernel::UnaryBcastTileOp)
Broadcast operation
Syntax:
operation ::= `ttkernel.unary_bcast` `(` $in_cb `,` $in_tile_index `,` $dst_tile_index `,` $bcast_type `)` attr-dict `:` functional-type(operands, results)
Performs a broadcast operation B = broadcast(A) using bcast_dim for
dimension expansion on a tile in the CB at a given index and writes the
result to the DST register at index dst_tile_index. The supported
broadcast dimensions are row, col, scalar (both row and column). The
DST register buffer must be in acquired state via tile_regs_acquire
call. This call is blocking and is only available on the compute engine.
Traits: TTKernel_FPUOpTrait, TTKernel_UnaryOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
bcast_type | ::mlir::tt::ttkernel::BcastTypeAttr | TTKernel Broadcast Types |
Operands:
| Operand | Description |
|---|---|
in_cb | TTKernel cb |
in_tile_index | index or 32-bit signless integer |
dst_tile_index | index or 32-bit signless integer |
ttkernel.unary_op_init_common (tt::ttkernel::UnaryOpInitCommonOp)
Initialization function for unary operations.
Syntax:
operation ::= `ttkernel.unary_op_init_common` `(` $icb `,` $ocb `)` attr-dict `:` functional-type(operands, results)
This operation initializes all necessary components for unary operations, including unpacking, packing, and math configurations.
Traits: TTKernel_InitOpTrait
Operands:
| Operand | Description |
|---|---|
icb | TTKernel cb |
ocb | TTKernel cb |
ttkernel.experimental.unpack_stall_on_pack (tt::ttkernel::UnpackStallOnPackOp)
Stall UNPACK thread until previous PACK write is committed to L1.
Syntax:
operation ::= `ttkernel.experimental.unpack_stall_on_pack` attr-dict
Issues a hardware semaphore wait on the MATH_PACK semaphore from the UNPACK thread, blocking until the previous packer cycle's write to L1 is visible. Used between consecutive linalg.generics sharing an intermediate L1 buffer in the single-tile shard path.
ttkernel.unreachable (tt::ttkernel::UnreachableOp)
Unreachable op.
Syntax:
operation ::= `ttkernel.unreachable` `(` `)` attr-dict `:` functional-type(operands, results)
Unreachable operation
Traits: AlwaysSpeculatableImplTrait, ReturnLike, Terminator
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), RegionBranchTerminatorOpInterface
Effects: MemoryEffects::Effect{}
ttkernel.untilize_block (tt::ttkernel::UntilizeBlockOp)
UntilizeBlockOp call.
Syntax:
operation ::= `ttkernel.untilize_block` `(` $cbIn `,` $numTiles `,` $cbOut `)` attr-dict `:` functional-type(operands, results)
UntilizeBlockOp operation
Traits: TTKernel_LayoutOpTrait
Operands:
| Operand | Description |
|---|---|
cbIn | TTKernel cb |
numTiles | 32-bit signless integer |
cbOut | TTKernel cb |
ttkernel.untilize_init (tt::ttkernel::UntilizeInitOp)
UntilizeInitOp call.
Syntax:
operation ::= `ttkernel.untilize_init` `(` $cbIn `)` attr-dict `:` functional-type(operands, results)
Init function for untilize operations, to be used at the beginning of the kernel.
Traits: TTKernel_InitOpTrait, TTKernel_LayoutOpTrait
Operands:
| Operand | Description |
|---|---|
cbIn | TTKernel cb |
ttkernel.untilize_uninit (tt::ttkernel::UntilizeUninitOp)
UntilizeUninitOp call.
Syntax:
operation ::= `ttkernel.untilize_uninit` `(` $cbIn `)` attr-dict `:` functional-type(operands, results)
Uninitialize untilize operation, to allow initializing another operation.
Traits: TTKernel_LayoutOpTrait
Operands:
| Operand | Description |
|---|---|
cbIn | TTKernel cb |
ttkernel.where_tile_init (tt::ttkernel::WhereTileInitOp)
Short init function
Syntax:
operation ::= `ttkernel.where_tile_init` `(` `)` attr-dict `:` functional-type(operands, results)
Must be run before where_tile.
Traits: TTKernel_InitOpTrait
ttkernel.where_tile (tt::ttkernel::WhereTileOp)
Conditional selection operation
Syntax:
operation ::= `ttkernel.where_tile` `(` $dst_cond_index `,` $dst_true_index `,` $dst_false_index `,` $odst_index `,` $dtype `)` attr-dict `:` functional-type(operands, results)
Performs element-wise conditional selection DST[odst_index] <- condition ? DST[dst_true_index] : DST[dst_false_index] For each element, if condition is non-zero, selects from dst_true_index, otherwise selects from dst_false_index. The DST register buffer must be in acquired state via acquire_dst call.
Traits: TTKernel_SFPUOpTrait, TTKernel_TernaryOpTrait
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
Operands:
| Operand | Description |
|---|---|
dst_cond_index | index or 32-bit signless integer |
dst_true_index | index or 32-bit signless integer |
dst_false_index | index or 32-bit signless integer |
odst_index | index or 32-bit signless integer |
CBType
TTKernel cb
Syntax:
!ttkernel.cb<
int64_t, # num_elements
Type # element_type
>
Circular buffer type in TTKernel dialect
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| num_elements | int64_t | |
| element_type | Type |
DataFormatType
TTKernel compute data format type
Syntax: !ttkernel.DataFormat
Data format type in TTKernel dialect
FabricConnectionManagerType
TTKernel fabric connection manager
Syntax: !ttkernel.fabric_connection_manager
Fabric connection manager type in TTKernel dialect
L1AddrType
TTKernel l1 address
Syntax: !ttkernel.l1_addr
L1 address type in TTKernel dialect
L1AddrPtrType
TTKernel l1 address pointer
Syntax:
!ttkernel.l1_addr_ptr<
unsigned # elementWidth
>
L1 pointer address type in TTKernel dialect
Parameters:
| Parameter | C++ type | Description |
|---|---|---|
| elementWidth | unsigned |
LocalSemaphoreType
TTKernel semaphore
Syntax: !ttkernel.local_semaphore
Local semaphore type in TTKernel dialect
MeshPositionType
TTKernel logical mesh position
Syntax: !ttkernel.mesh_position
A logical mesh position representing a coordinate in the device mesh.
NocAddrType
TTKernel noc address
Syntax: !ttkernel.noc_addr
Noc address type in TTKernel dialect
TensorAccessorType
TensorAccessor type
Syntax: !ttkernel.TensorAccessor
Accessor that encapsulates logic to access tensor information
TensorAccessorArgsType
TensorAccessorArgs type
Syntax: !ttkernel.TensorAccessorArgs
TensorAccessor args type that stores compile + runtime information
TensorAccessorPageMappingType
TensorAccessor PageMapping struct
Syntax: !ttkernel.PageMapping
TensorAccessor struct that holds bank_id and bank_page_offset
'ttmetal' Dialect
A TTMetal out-of-tree MLIR dialect.
This dialect is an example of an out-of-tree MLIR dialect designed to illustrate the basic setup required to develop MLIR-based tools without working inside of the LLVM source tree.
[TOC]
ttmetal.create_buffer (tt::ttmetal::CreateBufferOp)
Create buffer op.
Create buffer operation.
When this buffer uses a virtual grid, virtualGridInverseMapping stores the
inverse affine map (physical to virtual grid coordinates) and
virtualGridForwardMapping stores the forward affine map (virtual to
physical grid coordinates). Both are propagated from d2m.empty through
bufferization.
Interfaces: MemoryEffectOpInterface (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{MemoryEffects::Allocate on ::mlir::SideEffects::DefaultResource}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
address | ::mlir::IntegerAttr | 64-bit signless integer attribute |
virtualGridInverseMapping | ::mlir::AffineMapAttr | AffineMap attribute |
virtualGridForwardMapping | ::mlir::AffineMapAttr | AffineMap attribute |
Results:
| Result | Description |
|---|---|
result | non-0-ranked.memref of any type values |
ttmetal.create_global_semaphore (tt::ttmetal::CreateGlobalSemaphoreOp)
Create global semaphore op.
Create global semaphore operation
Interfaces: InferTypeOpInterface, MemoryEffectOpInterface (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{MemoryEffects::Write on ::mlir::SideEffects::DefaultResource}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
address | ::mlir::IntegerAttr | 64-bit signless integer attribute |
initial_value | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
core_range | ::mlir::tt::ttmetal::CoreRangeAttr | TTMetal grid attribute{{% markdown %}} TTMetal grid attribute {{% /markdown %}} |
Results:
| Result | Description |
|---|---|
result | TTMetal global semaphore |
ttmetal.create_local_semaphore (tt::ttmetal::CreateLocalSemaphoreOp)
Create local semaphore op.
Create local semaphore operation
Interfaces: InferTypeOpInterface, MemoryEffectOpInterface (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{MemoryEffects::Allocate on ::mlir::SideEffects::DefaultResource}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
initial_value | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Results:
| Result | Description |
|---|---|
result | TTMetal local semaphore |
ttmetal.deallocate_buffer (tt::ttmetal::DeallocateBufferOp)
Deallocate buffer op.
Deallocate buffer operation
Interfaces: MemoryEffectOpInterface (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{MemoryEffects::Free on ::mlir::SideEffects::DefaultResource}
Operands:
| Operand | Description |
|---|---|
input | non-0-ranked.memref of any type values |
ttmetal.enqueue_program (tt::ttmetal::EnqueueProgramOp)
Enqueue program op.
Enqueue program operation
Traits: AttrSizedOperandSegments
Interfaces: MemoryEffectOpInterface (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{MemoryEffects::Read on ::mlir::SideEffects::DefaultResource, MemoryEffects::Write on ::mlir::SideEffects::DefaultResource}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
cb_ports | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
kernelConfigs | ::mlir::ArrayAttr | |
fabricConnectionConfig | ::mlir::tt::ttcore::FabricConnectionConfigAttr | Fabric Connection Config attribute.{{% markdown %}} Structure for configuring fabric connections for worker cores (in CCL ops). {{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
args | variadic of any type |
cbs | variadic of non-0-ranked.memref of any type values |
ttmetal.enqueue_read_buffer (tt::ttmetal::EnqueueReadBufferOp)
Enqueue read buffer op.
Enqueue read buffer operation
Interfaces: MemoryEffectOpInterface (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{MemoryEffects::Read on ::mlir::SideEffects::DefaultResource, MemoryEffects::Write on ::mlir::SideEffects::DefaultResource}
Operands:
| Operand | Description |
|---|---|
input | non-0-ranked.memref of any type values |
output | memref of any type values |
ttmetal.enqueue_write_buffer (tt::ttmetal::EnqueueWriteBufferOp)
Enqueue write buffer op.
Enqueue write buffer operation
Interfaces: MemoryEffectOpInterface (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{MemoryEffects::Read on ::mlir::SideEffects::DefaultResource, MemoryEffects::Write on ::mlir::SideEffects::DefaultResource}
Operands:
| Operand | Description |
|---|---|
input | memref of any type values |
output | non-0-ranked.memref of any type values |
ttmetal.finish (tt::ttmetal::FinishOp)
Finish op for command queue.
Global barrier op, used to wait for all commands on queue to finish.
Interfaces: MemoryEffectOpInterface (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{MemoryEffects::Read on ::mlir::SideEffects::DefaultResource, MemoryEffects::Write on ::mlir::SideEffects::DefaultResource}
ttmetal.mesh_shard (tt::ttmetal::MeshShardOp)
Nd sharding or (partial) concat op
Nd sharding or (partial) concat op in D2M runtime. ShardToFull: Nd sharding in host memory. FullToshard: (partial) concat in host memory.
Interfaces: MemoryEffectOpInterface (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{MemoryEffects::Read on ::mlir::SideEffects::DefaultResource, MemoryEffects::Allocate on ::mlir::SideEffects::DefaultResource}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
shard_type | ::mlir::tt::ttcore::MeshShardTypeAttr | MeshShard shard_type attribute in TT dialect{{% markdown %}} Define sharded tensor data of mesh_shard op. - Identity: input and output tensors are pre-sharded (same data) and no sharding is required. - Replicate: all of the devices has full tensor (same data). - Maximal: one or part of the devcices has full tensor (same data). - Devices: all or part of the devices has sharded (partial) tensor (different data). {{% /markdown %}} |
shard_direction | ::mlir::tt::ttcore::MeshShardDirectionAttr | TT MeshShardDirection |
shard_shape | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
shard_dims | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
Operands:
| Operand | Description |
|---|---|
input | non-0-ranked.memref of any type values |
Results:
| Result | Description |
|---|---|
result | non-0-ranked.memref of any type values |
ttmetal.reset_global_semaphore (tt::ttmetal::ResetGlobalSemaphoreOp)
Reset global semaphore op.
Reset global semaphore operation
Interfaces: MemoryEffectOpInterface (MemoryEffectOpInterface)
Effects: MemoryEffects::Effect{MemoryEffects::Write on ::mlir::SideEffects::DefaultResource}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
value | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
semaphore | TTMetal global semaphore |
'ttnn' Dialect
A TTNN out-of-tree MLIR dialect.
This dialect is an example of an out-of-tree MLIR dialect designed to illustrate the basic setup required to develop MLIR-based tools without working inside of the LLVM source tree.
[TOC]
ttnn.nlp_create_qkv_heads_decode (tt::ttnn::NLPCreateQKVHeadsDecodeOp)
Nlp_create_qkv_heads_decode op in TTNN dialect.
Shuffles [1, S=1, B, head_dim * (num_heads + 2*num_kv_heads)] fused qkv matrix into Q, K, and V heads with shape [S, B, num_heads, head_dim] for Q and [S, B, num_kv_heads, head_dim] for K and V, where num_heads and num_kv_heads will be padded to nearest 32.
- Input must be sharded, B=32 and S=1.
- overlap_qk_coregrid is a boolean flag that determines whether the output Q and K heads are on same core grid. If true, then Q, K, and V heads are on the same core grid. If false, the Q and K heads are on non-overlapping core-grid useful for processing Q and K in parallel.
- Batch offset is used to fuse batch slicing. If provided slice size must also be provided in which batch dim of QKV output will be slice_size.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
num_heads | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
num_kv_heads | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
overlap_qk_coregrid | ::mlir::BoolAttr | bool attribute |
slice_size | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
batch_offset | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
query | ranked tensor of any type values |
key | ranked tensor of any type values |
value | ranked tensor of any type values |
ttnn.abs (tt::ttnn::AbsOp)
Eltwise absolute.
Eltwise absolute operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.acos (tt::ttnn::AcosOp)
Eltwise arccosine op.
Performs an elementwise arccosine (acos) on the input tensor; result
range [0, π] for inputs in [-1, 1]. Floating-point tensors.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.add (tt::ttnn::AddOp)
Eltwise add.
Eltwise add operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseBinary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.aggregate_tensor (tt::ttnn::AggregateTensorOp)
Aggregate distributed tensor back to host
Aggregates a multi-device tensor back into a single host-side tensor according to the specified composer configuration.
This operation takes a distributed tensor and creates a single-device host tensor aggregated according to the MeshComposerConfig configuration.
// Note: In the ttnn API, the aggregate_tensor op takes an input tensor and a MeshToTensor object as its arguments. // To create a MeshToTensor object, the API create_mesh_composer is used, which requires both MeshComposerConfig and MeshDevice. // Instead of modeling create_mesh_composer as a separate op in the IR, these two strongly coupled APIs are combined into one aggregate_tensor op // to keep the IR simple and less cluttered. If a clear need arises in the future, splitting them into separate ops can be considered.
Example:
%result = "ttnn.aggregate_tensor"(%input, %device) <{
composer_config = #ttnn.mesh_composer_config<
dims = [1],
mesh_shape_override = #ttnn.mesh_shape<2x2>
>
}> : (tensor<32x64xbf16>, !ttnn.device) -> tensor<32x64xbf16>
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait, OpModelExempt
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
composer_config | ::mlir::tt::ttnn::MeshComposerConfigAttr | Mesh composer configuration for tensor aggregation{{% markdown %}} Configuration for how a distributed tensor should be aggregated back. Specifies which dimensions to concatenate. {{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
mesh_device | TTNN device |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.all_gather (tt::ttnn::AllGatherOp)
All gather op.
Tensor All Gather operation
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait, OpModelExempt
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
all_gather_dim | ::mlir::IntegerAttr | 32-bit signed integer attribute |
cluster_axis | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
sub_device_id | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
num_links | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
topology | ::mlir::tt::ttcore::TopologyAttr | CCL Topology Type |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.all_reduce_async (tt::ttnn::AllReduceAsyncOp)
Asynchronous all reduce op.
Asynchronous all-reduce collective communication operation. Performs a reduction (e.g. sum) across all devices in a mesh and distributes the result back to all devices, using async execution to overlap communication with computation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait, OpModelExempt
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
reduce_type | ::mlir::tt::ttcore::ReduceTypeAttr | TT Reduce Type |
cluster_axis | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
sub_device_id | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
num_links | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
topology | ::mlir::tt::ttcore::TopologyAttr | CCL Topology Type |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.all_reduce (tt::ttnn::AllReduceOp)
All reduce op.
Tensor All Reduce operation
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait, OpModelExempt
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
reduce_type | ::mlir::tt::ttcore::ReduceTypeAttr | TT Reduce Type |
cluster_axis | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
sub_device_id | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
num_links | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
topology | ::mlir::tt::ttcore::TopologyAttr | CCL Topology Type |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.all_to_all_combine (tt::ttnn::AllToAllCombineOp)
Combine expert outputs back to original token positions.
Inverse of dispatch: gathers expert computation results from expert devices and restores tokens to their original device and order.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait, OpModelExempt
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
num_devices | ::mlir::IntegerAttr | 64-bit signless integer attribute |
cluster_axis | ::mlir::IntegerAttr | 64-bit signless integer attribute |
num_experts_per_tok | ::mlir::IntegerAttr | 64-bit signless integer attribute |
output_shard_dim | ::mlir::IntegerAttr | 64-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
input_tensor | ranked tensor of any type values |
expert_metadata | ranked tensor of any type values |
expert_mapping | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.all_to_all_dispatch_metadata (tt::ttnn::AllToAllDispatchMetadataOp)
Dispatch tokens with metadata to expert devices for MoE computation.
Routes tokens along with expert scores to devices holding their selected experts via all-to-all communication within a ring (cluster_axis). Returns dispatched tokens (sparse — only routed token slots are filled), all-gathered expert indices, and all-gathered expert scores.
Dimensions: M = tokens per ring device K = selected experts per token D = total devices, E = total experts
Input shapes (per device, after mesh sharding):
- input_tensor: [1, 1, M, H]
- expert_indices: [1, 1, M, K]
- expert_scores: [1, 1, M, K]
- expert_mapping: [D, E] entry [d, e] = device ID owning expert e
Output shapes (per device, num_devices * M = tokens_global):
- dispatched: [1, tokens_global, H]
- indices: [1, tokens_global, K] (all-gathered across ring)
- scores: [1, tokens_global, K] (all-gathered across ring)
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait, OpModelExempt
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
num_devices | ::mlir::IntegerAttr | 64-bit signless integer attribute |
cluster_axis | ::mlir::IntegerAttr | 64-bit signless integer attribute |
drain_core | ::mlir::tt::ttnn::CoreCoordAttr | A 2D coordinate of a core in the core grid{{% markdown %}} Specifies a coordinate representing a specific core{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input_tensor | ranked tensor of any type values |
expert_indices | ranked tensor of any type values |
expert_scores | ranked tensor of any type values |
expert_mapping | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
dispatched | ranked tensor of any type values |
indices | ranked tensor of any type values |
scores | ranked tensor of any type values |
ttnn.all_to_all_dispatch (tt::ttnn::AllToAllDispatchOp)
Dispatch tokens to expert devices for MoE computation.
Routes tokens to devices holding their selected experts via all-to-all communication. Used before sparse_matmul in the MoE dispatch/combine flow.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait, OpModelExempt
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
num_devices | ::mlir::IntegerAttr | 64-bit signless integer attribute |
cluster_axis | ::mlir::IntegerAttr | 64-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
input_tensor | ranked tensor of any type values |
expert_indices | ranked tensor of any type values |
expert_mapping | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
dispatched | ranked tensor of any type values |
metadata | ranked tensor of any type values |
ttnn.alloc (tt::ttnn::AllocOp)
Alloc op.
Tensor Alloc operation
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait, OpModelExempt, TTCore_CreationOpTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
address | ::mlir::IntegerAttr | 64-bit signless integer attribute |
size | ::mlir::IntegerAttr | 64-bit signless integer attribute |
buffer_type | ::mlir::tt::ttnn::BufferTypeAttr | TTNN Buffer Type |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.arange (tt::ttnn::ArangeOp)
Arange operation.
Tensor arange operation.
Produces a (1, 1, 1, N)-shaped tensor with values from start to end (exclusive) with a step size of step.
Examples: %0 = "ttnn.arange"() {start = 0 : i64, end = 5 : i64 step = 1 : i64} : () -> tensor<1x1x1x5xi64> // %0: [[[[0, 1, 2, 3, 4]]]]
%1 = "ttnn.arange"() {start = 0 : i64, end = 10 : i64, step = 2 : i64} : () -> tensor<1x1x1x5xf32> // %1: [[[[0.0, 2.0, 4.0, 6.0, 8.0]]]]
Traits: AlwaysSpeculatableImplTrait, CanExecuteOnHostTrait, CheckTileTypeTrait, TTCore_CreationOpTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_DeviceOperandInterface, TTNN_DtypeOpInterface, TTNN_LayoutOpInterface, TTNN_MemoryConfigOpInterface, TTNN_TensorSpecInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
start | ::mlir::IntegerAttr | 64-bit signless integer attribute |
end | ::mlir::IntegerAttr | 64-bit signless integer attribute |
step | ::mlir::IntegerAttr | 64-bit signless integer attribute |
layout | ::mlir::tt::ttnn::LayoutAttr | TTNN Layout |
Operands:
| Operand | Description |
|---|---|
device | TTNN device |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.argmax (tt::ttnn::ArgMaxOp)
Argmax reduction op.
Determine the indices of the maximum values along a specified dimension of a tensor or over all elements in a tensor.
Parameters:
input: The input tensor.dim: Specifies the dimension along which the argmax is applied.keep_dim: If set to true, the output tensor will have the same number of dimensions as the input tensor.use_multicore: Whether to use multiple cores or not.
IR usage: // Input tensor of shape (128, 28, 28, 64) %input = ... : tensor<128x28x28x64xbf16>
%empty = "ttnn.empty"(%0) <{....}> : -> tensor<128x28x28xi32> %4 = "ttnn.argmax"(%input, %empty) <{dim = 3 : i32, use_multicore = false}> : (tensor<128x28x28xbf16>, tensor<128x28x28xi32) -> tensor<128x28x28xi32>
Example: input: [[1, 5, 3], [2, 4, 6]]
// Computing along dim 0 output: [1, 0, 1]
// Computing along dim 1 output: [1, 2]
// Computing for entire tensor output: 5
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim | ::mlir::IntegerAttr | 32-bit signless integer attribute |
keep_dim | ::mlir::BoolAttr | bool attribute |
use_multicore | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.asin (tt::ttnn::AsinOp)
Eltwise arcsine op.
Performs an elementwise arcsine (asin) on the input tensor; result
range [-π/2, π/2] for inputs in [-1, 1]. Floating-point tensors.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.asinh (tt::ttnn::AsinhOp)
Eltwise inverse hyperbolic sine op.
Performs an elementwise inverse hyperbolic sine (asinh) on the input
tensor. Accepts all real-valued inputs. Floating-point tensors.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.assign (tt::ttnn::AssignOp)
Assign Tensor
Returns a new tensor which is a new copy of input tensor.
Alternatively, copies input tensor input to optional_output_tensor
if their shapes and memory layouts match, and returns input_b tensor.
Input tensors can be of any data type.
Output tensor will be of same data type as Input tensor.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.atan2 (tt::ttnn::Atan2Op)
Eltwise atan2 OP.
Performs element-wise atan2 operation on lhs and rhs tensor and produces a result tensor.
Example:
// %lhs: [0.0, 1.0, -1.0]
// %rhs: [1.0, 0.0, 0.0]
%result = "ttnn.atan2"(%lhs, %rhs) : (tensor<3xf64>, tensor<3xf64>) -> tensor<3xf64>
// %result: [0.0, 1.57079637, -1.57079637] // [0.0, pi/2, -pi/2]
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.atan (tt::ttnn::AtanOp)
Eltwise arctangent op.
Performs an elementwise arctangent (atan) operation on the input tensor.
This operation computes the inverse tangent of each element, returning
values in the range [-π/2, π/2]. Supports floating-point tensor types.
Example:
%input = tensor<4xf32> {1.0, 0.5, 0.0, -1.0}
%result = "ttir.atan"(%input) : (tensor<4xf32>) -> tensor<4xf32>
Given the input [1.0, 0.5, 0.0, -1.0], the result would be approximately:
[0.785, 0.464, 0.0, -0.785] (values in radians).
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.avg_pool2d (tt::ttnn::AvgPool2dOp)
Applies a 2D average pooling over an input signal composed of several input planes.
It is a downsampling operation to reduce the spatial dimensions (height and width) of a input tensor by computing averages with in a window.
Example: // 3x3 input tensor input: [[1, 2, 3], [4, 5, 6], [7, 8, 9]] kernel_height: 2 kernel_width: 2 stride_height: 1 stride_width: 1 dilation_height: 1 dilation_width: 1 output: [[3, 4], [6, 7]]
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
batch_size | ::mlir::IntegerAttr | 32-bit signed integer attribute |
input_height | ::mlir::IntegerAttr | 32-bit signed integer attribute |
input_width | ::mlir::IntegerAttr | 32-bit signed integer attribute |
channels | ::mlir::IntegerAttr | 32-bit signed integer attribute |
kernel_size | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
stride | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
padding | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
dilation | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
applied_shard_scheme | ::mlir::tt::ttnn::TensorMemoryLayoutAttr | TTNN Tensor Memory Layout |
ceil_mode | ::mlir::BoolAttr | bool attribute |
reallocate_halo_output | ::mlir::BoolAttr | bool attribute |
count_include_pad | ::mlir::BoolAttr | bool attribute |
config_tensors_in_dram | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.batch_norm_inference (tt::ttnn::BatchNormInferenceOp)
Batch normalization inference op.
Batch normalization operation for inference over each channel on input tensor. Uses pre-computed mean and variance.
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
epsilon | ::mlir::FloatAttr | 32-bit float attribute |
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
running_mean | ranked tensor of any type values |
running_var | ranked tensor of any type values |
weight | ranked tensor of any type values |
bias | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.batch_norm_training (tt::ttnn::BatchNormTrainingOp)
Batch normalization training op.
Batch normalization operation for training over each channel on input tensor. Computes batch statistics and updates running mean and variance.
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
epsilon | ::mlir::FloatAttr | 32-bit float attribute |
momentum | ::mlir::FloatAttr | 32-bit float attribute |
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
running_mean | ranked tensor of any type values |
running_var | ranked tensor of any type values |
weight | ranked tensor of any type values |
bias | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.begin_trace_capture (tt::ttnn::BeginTraceCaptureOp)
Begin trace capture.
Begins trace capture. Returns a scalar tensor containing the trace id. Inputs:
deviceTTNN_Device: The device to capture the trace on.cq_idui32: The command queue to capture the trace with. Must be 0 or 1. Outputs:trace_idAnyRankedTensor: The scalar trace id tensor containing the trace id.
Traits: OpModelExempt
Interfaces: MemoryEffectOpInterface, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
cq_id | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
device | TTNN device |
Results:
| Result | Description |
|---|---|
trace_id | ranked tensor of any type values |
ttnn.bitcast_convert (tt::ttnn::BitcastConvertOp)
Bitcast_convert op.
This op reinterprets the bits of each element in the input tensor as a data type of the output tensor.
The output data type is derived from the result tensor's TTNNLayoutAttr encoding via the TTNN_DtypeOpInterface.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.bitwise_and (tt::ttnn::BitwiseAndOp)
Eltwise bitwise AND.
Performs element-wise bitwise AND of two tensors lhs and rhs
and produces a result tensor.
Example: // %lhs: [[1, 2], [3, 4]] // %rhs: [[5, 6], [7, 8]] %result = "ttnn.bitwise_and"(%lhs, %rhs) : (tensor<2x2xi32>, tensor<2x2xi32>) -> tensor<2x2xi32> // %result: [[1, 2], [3, 0]]
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.bitwise_not (tt::ttnn::BitwiseNotOp)
Eltwise bitwise NOT.
Performs element-wise NOT of tensor operand and produces a result tensor.
Example: // Bitwise operation with with integer tensors // %operand: [[1, 2], [3, 4]] %result = "ttnn.bitwise_not"(%operand) : (tensor<2x2xi32>) -> tensor<2x2xi32> // %result: [[-2, -3], [-4, -5]]
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.bitwise_or (tt::ttnn::BitwiseOrOp)
Eltwise bitwise OR.
Performs element-wise bitwise OR of two tensors lhs and rhs
and produces a result tensor.
Example: // %lhs: [[1, 2], [3, 4]] // %rhs: [[5, 6], [7, 8]] %result = "ttnn.bitwise_or"(%lhs, %rhs) : (tensor<2x2xi32>, tensor<2x2xi32>) -> tensor<2x2xi32> // %result: [[5, 6], [7, 12]]
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.bitwise_xor (tt::ttnn::BitwiseXorOp)
Eltwise bitwise XOR.
Performs element-wise bitwise XOR of two tensors lhs and rhs
and produces a result tensor.
Example: // %lhs: [[1, 2], [3, 4]] // %rhs: [[5, 6], [7, 8]] %result = "ttnn.bitwise_xor"(%lhs, %rhs) : (tensor<2x2xi32>, tensor<2x2xi32>) -> tensor<2x2xi32> // %result: [[4, 4], [4, 12]]
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.capture_or_execute_trace (tt::ttnn::CaptureOrExecuteTraceOp)
Capture or execute trace.
Captures or executes the trace. Will have read/write memory effects on the cached trace data. If the trace data exists (meaning the trace was captured previously), it will be executed with the execute_callee function. Otherwise, the trace will be captured with the capture_callee function.
Inputs:
deviceTTNN_Device: The device where the trace was captured.capture_calleeFlatSymbolRefAttr: The symbol of the capture trace function.execute_calleeFlatSymbolRefAttr: The symbol of the execute trace function.inputsVariadic: The input tensors to the trace function. semaphore_inputsVariadic<TTNN_GlobalSemaphore>: Global semaphores forwarded into the capture/execute programs. Outputs:resultsVariadic: The output tensors from the trace function.
Traits: AttrSizedOperandSegments, OpModelExempt
Interfaces: MemoryEffectOpInterface, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
capture_callee | ::mlir::FlatSymbolRefAttr | flat symbol reference attribute |
execute_callee | ::mlir::FlatSymbolRefAttr | flat symbol reference attribute |
Operands:
| Operand | Description |
|---|---|
device | TTNN device |
inputs | variadic of ranked tensor of any type values |
semaphore_inputs | variadic of TTNN global semaphore. |
Results:
| Result | Description |
|---|---|
results | variadic of ranked tensor of any type values |
ttnn.cbrt (tt::ttnn::CbrtOp)
Eltwise cubic root.
Eltwise cubic root operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.ceil (tt::ttnn::CeilOp)
Eltwise ceil.
Eltwise ceil operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.clamp_scalar (tt::ttnn::ClampScalarOp)
Clamp op.
Clamp tensor values to a specified range.
Example: min: 2.000000+00 input: [[0, 1, 2, 3, 4, 5, 6, 7]] max: 5.000000+00
"ttnn.clamp_scalar"(%arg0) <{max = 2.000000e+00 : f32, min = 5.000000e+00 : f32}> -> %out = [[2, 2, 2, 3, 4, 5, 5, 5]]
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
min | ::mlir::Attribute | 32-bit float attribute or 32-bit signless integer attribute |
max | ::mlir::Attribute | 32-bit float attribute or 32-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.clamp_tensor (tt::ttnn::ClampTensorOp)
Clamp op.
Clamp tensor values to a specified range using min/max as tensor.
Example: min: [[2, 2, 2, 3, 3, 3, 0, 0]] input: [[0, 1, 2, 3, 4, 5, 6, 7]] max: [[5, 5, 5, 9, 9, 9, 6, 6]]
"ttnn.clamp_tensor"(%input, %min, %max) %out: [[2, 2, 2, 3, 4, 5, 6, 6]]
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
min | ranked tensor of any type values |
max | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.concat (tt::ttnn::ConcatOp)
Concat op.
Concat tensors along a given dimension.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim | ::mlir::IntegerAttr | 32-bit signed integer attribute |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.concatenate_heads (tt::ttnn::ConcatenateHeadsOp)
Concatenate heads op used in attention layer.
Takes in a tensor of shape [batch_size, num_heads, sequence_size, head_size], concatenates heads back along the width dimension and returns the tensor of shape [batch_size, sequence_size, num_heads * head_size].
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.constant (tt::ttnn::ConstantOp)
Constant op.
Produces tensor filled with given constant value.
Examples: %0 = "ttnn.constant"() {value = dense<[[3, 4, 2], [1, 7, 8]]> : tensor<2x3xui16>} : () -> tensor<2x3xui16> // %0: [[3, 4, 2], [1, 7, 8]] %1 = "ttnn.constant"() {value = dense<[0.2, 1.3]> : tensor<2xf32>} : () -> tensor<2xf32> // %1: [0.2, 1.3]
Traits: AlwaysSpeculatableImplTrait, CanExecuteOnHostTrait, CheckTileTypeTrait, TTCore_CreationOpTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_DeviceOperandInterface, TTNN_DtypeOpInterface, TTNN_LayoutOpInterface, TTNN_MemoryConfigOpInterface, TTNN_TensorSpecInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
value | ::mlir::ElementsAttr | constant vector/tensor attribute |
layout | ::mlir::tt::ttnn::LayoutAttr | TTNN Layout |
Operands:
| Operand | Description |
|---|---|
device | TTNN device |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.conv2d (tt::ttnn::Conv2dOp)
Conv2d operation.
Applies a 2D convolution over an input image composed of several input planes.
Inputs:
input(AnyRankedTensor): expected in the following flattened format (1, 1, N * H_in * W_in, C) where:- N is the batch size
- H_in is the height of the input planes
- W_in is the width of the input planes
- C is the number of channels
weight(AnyRankedTensor): expected in the following format (O, C/G, K_H, K_W).bias(Optional): expected in the following format (1, 1, 1, O) where: - C is the number of input channels
- O is the number of output channels
- G is the number of groups
- K_H is the height of the kernel
- K_W is the width of the kernel
Attributes:
in_channels(i32): The number of input channels.out_channels(i32): The number of output channels.batch_size(i32): The batch size.input_height(i32): The input height.input_width(i32): The input width.kernel_size(array<2xi32>): [K_H, K_W] where K_H is the kernel height and K_W is the kernel width.stride(array<2xi32>): [sH, sW] where sH is stride for height and sW is stride for width.padding(array<2xi32> | array<4xi32>):- array<2xi32>: [pH, pW] where pH is padding for height (top/bottom) and pW is padding for width (left/right).
- array<4xi32>: [pT, pB, pL, pR] for top, bottom, left, and right padding respectively.
dilation(array<2xi32>): [dH, dW] where dH is dilation for height and dW is dilation for width.groups(i32): Number of blocked connections from input channels to output channels. Input and output channels must both be divisible by groups.
Outputs:
result(AnyRankedTensor): returned in the following flattened format (1, 1, N * H_out * W_out, O) where:H_out = (H_in + pT + pB - dH * (K_H - 1) - 1) / sH + 1W_out = (W_in + pL + pR - dW * (K_W - 1) - 1) / sW + 1
Example: %input = ttir.empty() : () -> tensor<1x1x1024x64xbf16> %weight = ttir.empty() : () -> tensor<64x64x3x3xbf16> %bias = ttir.empty() : () -> tensor<1x1x1x64xbf16> %device = "ttnn.get_device"() <{mesh_shape = #ttnn<mesh_shape 1x1>}> : () -> !ttnn.device %0 = "ttnn.conv2d"(%input, %weight, %bias, %device) <{ in_channels = 64: i32, out_channels = 64: i32, batch_size = 1: i32, input_height = 32: i32, input_width = 32: i32, kernel_size = array<i32: 3, 3>, stride = array<i32: 1, 1>, padding = array<i32: 0, 0>, dilation = array<i32: 1, 1>, groups = 1: i32 }> : (tensor<1x1x1024x64xbf16>, tensor<64x64x3x3xbf16>, tensor<1x1x1x64xbf16>, !ttnn.device) -> tensor<1x1x900x64xbf16>
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
in_channels | ::mlir::IntegerAttr | 32-bit signless integer attribute |
out_channels | ::mlir::IntegerAttr | 32-bit signless integer attribute |
batch_size | ::mlir::IntegerAttr | 32-bit signless integer attribute |
input_height | ::mlir::IntegerAttr | 32-bit signless integer attribute |
input_width | ::mlir::IntegerAttr | 32-bit signless integer attribute |
kernel_size | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
stride | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
padding | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
dilation | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
groups | ::mlir::IntegerAttr | 32-bit signless integer attribute |
conv2d_config | ::mlir::tt::ttnn::Conv2dConfigAttr | TTNN Conv2dConfig attribute{{% markdown %}} Configuration parameters for TTNN conv2d operations that control memory usage, performance optimizations, and execution behavior.{{% /markdown %}} |
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
conv2d_slice_config | ::mlir::tt::ttnn::Conv2dSliceConfigAttr | TTNN Conv2d slice configuration attribute{{% markdown %}} Conv2d slice configuration specifying slice type and number of slices. {{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
weight | ranked tensor of any type values |
bias | ranked tensor of any type values |
device | TTNN device |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.conv3d (tt::ttnn::Conv3dOp)
Conv3d operation.
Applies a 3D convolution over an input volume composed of several input planes.
Inputs:
input(AnyRankedTensor): expected in the following format (N, D, H, W, C) where:- N is the batch size
- D is the depth of the input volume
- H is the height of the input planes
- W is the width of the input planes
- C is the number of input channels
weight(AnyRankedTensor): expected in the following format (K_D * K_H * K_W * C / G, O) where:- K_D is the depth of the kernel
- K_H is the height of the kernel
- K_W is the width of the kernel
- C is the number of input channels
- O is the number of output channels
- G is the number of groups The spatial kernel dimensions and input channels are flattened together into a 2D tensor.
bias(Optional): expected in the following format (1, O) where: - O is the number of output channels
Attributes:
in_channels(i32): The number of input channels.out_channels(i32): The number of output channels.batch_size(i32): The batch size.input_depth(i32): The input depth.input_height(i32): The input height.input_width(i32): The input width.kernel_size(array<3xi32>): [K_D, K_H, K_W] where K_D is the kernel depth, K_H is the kernel height and K_W is the kernel width.stride(array<3xi32>): [sD, sH, sW] where sD is stride for depth, sH for height and sW is stride for width.padding(array<3xi32>): [pD, pH, pW] where pD is padding for depth, pH is padding for height and pW is padding for width. Padding is symmetric (same on both sides of each dimension).padding_mode(StrAttr): "zeros" or "replicate" - padding fill strategy.groups(i32): Number of blocked connections from input channels to output channels. Input and output channels must both be divisible by groups.
Outputs:
result(AnyRankedTensor): returned in the following format (N, D_out, H_out, W_out, O) where:D_out = (D_in + 2*pD - K_D) / sD + 1H_out = (H_in + 2*pH - K_H) / sH + 1W_out = (W_in + 2*pW - K_W) / sW + 1
Example: %input = ttir.empty() : () -> tensor<1x28x28x28x32xbf16> %weight = ttir.empty() : () -> tensor<864x64xbf16> // 864 = 333*32 (2D tensor) %bias = ttir.empty() : () -> tensor<1x64xbf16> // 2D tensor %device = "ttnn.get_device"() <{mesh_shape = #ttnn<mesh_shape 1x1>}> : () -> !ttnn.device %0 = "ttnn.conv3d"(%input, %weight, %bias, %device) <{ in_channels = 32: i32, out_channels = 64: i32, batch_size = 1: i32, input_depth = 28: i32, input_height = 28: i32, input_width = 28: i32, kernel_size = array<i32: 3, 3, 3>, stride = array<i32: 1, 1, 1>, padding = array<i32: 0, 0, 0>, padding_mode = "zeros", groups = 1: i32 }> : (tensor<1x28x28x28x32xbf16>, tensor<864x64xbf16>, tensor<1x64xbf16>, !ttnn.device) -> tensor<1x26x26x26x64xbf16>
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
in_channels | ::mlir::IntegerAttr | 32-bit signless integer attribute |
out_channels | ::mlir::IntegerAttr | 32-bit signless integer attribute |
batch_size | ::mlir::IntegerAttr | 32-bit signless integer attribute |
input_depth | ::mlir::IntegerAttr | 32-bit signless integer attribute |
input_height | ::mlir::IntegerAttr | 32-bit signless integer attribute |
input_width | ::mlir::IntegerAttr | 32-bit signless integer attribute |
kernel_size | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
stride | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
padding | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
padding_mode | ::mlir::StringAttr | string attribute |
groups | ::mlir::IntegerAttr | 32-bit signless integer attribute |
conv3d_config | ::mlir::tt::ttnn::Conv3dConfigAttr | TTNN Conv3dConfig attribute{{% markdown %}} Configuration parameters for TTNN conv3d operations. Controls performance tuning parameters like block sizes, data formats, and grid configuration. {{% /markdown %}} |
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
weight | ranked tensor of any type values |
bias | ranked tensor of any type values |
device | TTNN device |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.conv_transpose2d (tt::ttnn::ConvTranspose2dOp)
ConvTranspose2d operation.
Applies a 2D transposed convolution operator over an input image composed of several input planes.
Inputs:
-
inputAnyRankedTensor: expected in the following format (N, H_in, W_in, C) where:- N is the batch size
- H_in is the height of the input planes
- W_in is the width of the input planes
- C is the number of channels
-
weightAnyRankedTensor: expected in the following format (C, O/G, K_H, K_W). -
biasOptional: expected in the following format (1, 1, 1, O) where: - C is the number of input channels
- O is the number of output channels
- G is the number of groups
- K_H is the height of the kernel
- K_W is the width of the kernel
-
outputAnyRankedTensor: expected in the following format (N, H_out, W_out, O) where:- H_out = (H_in - 1) * stride[0] - 2 * padding[0] + dilation[0] * (K_H - 1) + output_padding[0] + 1
- W_out = (W_in - 1) * stride[1] - 2 * padding[1] + dilation[1] * (K_W - 1) + output_padding[1] + 1
Attributes:
in_channelsi32: The number of input channels.out_channelsi32: The number of output channels.batch_sizei32: The batch size.input_heighti32: The input height.input_widthi32: The input width.kernel_sizearray<2xi32>: The kernel size.stridearray<2xi32>: Controls the stride for the cross-correlation.paddingarray<2xi32>: Controls the amount of implicit zero padding on both sides for dilation * (kernel_size - 1) - padding number of points.output_paddingarray<2xi32>: Controls the additional size added to one side of the output shape.dilationarray<2xi32>: Controls the spacing between the kernel pointsgroupsi32: Controls the connections between inputs and outputs. Must be divisible by input and output channels.
Example: // %input: tensor<3x8x8x256xbf16> // %weight: tensor<256x256x3x3xbf16> // %bias: tensor<1x1x1x256xbf16> // %output: tensor<3x10x10x256xbf16> %0 = "ttnn.conv_transpose2d"(%input, %weight, %bias, %output, %device) <{ batch_size = 3: i32, dilation = array<i32: 1, 1>, groups = 1: i32, in_channels = 256: i32, input_height = 8: i32, input_width = 8: i32, kernel_size = array<i32: 3, 3>, out_channels = 256: i32, output_padding = array<i32: 0, 0>, padding = array<i32: 0, 0>, stride = array<i32: 1, 1> }> : (tensor<3x8x8x256xbf16>, tensor<256x256x3x3xbf16>, tensor<1x1x1x256xbf16>, tensor<3x10x10x256xbf16>) -> tensor<3x10x10x256xbf16>
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
in_channels | ::mlir::IntegerAttr | 32-bit signless integer attribute |
out_channels | ::mlir::IntegerAttr | 32-bit signless integer attribute |
batch_size | ::mlir::IntegerAttr | 32-bit signless integer attribute |
input_height | ::mlir::IntegerAttr | 32-bit signless integer attribute |
input_width | ::mlir::IntegerAttr | 32-bit signless integer attribute |
kernel_size | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
stride | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
padding | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
output_padding | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
dilation | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
groups | ::mlir::IntegerAttr | 32-bit signless integer attribute |
conv2d_config | ::mlir::tt::ttnn::Conv2dConfigAttr | TTNN Conv2dConfig attribute{{% markdown %}} Configuration parameters for TTNN conv2d operations that control memory usage, performance optimizations, and execution behavior.{{% /markdown %}} |
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
conv2d_slice_config | ::mlir::tt::ttnn::Conv2dSliceConfigAttr | TTNN Conv2d slice configuration attribute{{% markdown %}} Conv2d slice configuration specifying slice type and number of slices. {{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
weight | ranked tensor of any type values |
bias | ranked tensor of any type values |
device | TTNN device |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.cos (tt::ttnn::CosOp)
Eltwise cosine.
Eltwise cosine operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.create_global_semaphore (tt::ttnn::CreateGlobalSemaphoreOp)
Create global semaphore op.
Creates a global semaphore with the specified core range and initial value.
Global semaphores are similar to normal semaphores but differ in a couple of ways:
- their lifetime exists beyond the scope of an op (and thus must created/deallocated separately like tensors)
- they can be initialized before an op is even dispatched (whereas normal semaphores are initialized at dispatch time)
This is needed for CCLs (and multichip communication in general) to synchronize devices or for normal signalling where normal semaphores cannot be used. This is because the different devices in a mesh are not running ops in a synchronized manner (devices can be running different ops in the program) so the existence/initialization of normal semaphores cannot be guaranteed on a different device that we need to communicate with.
For example, if we have to run a matmul then an all gather, device x could be doing the matmul whereas device y has completed the matmul and begun an all gather. Now, if device y has to do a remote semaphore increment on device x as part of the all gather, this would lead to undefined behaviour since device x is still executing the matmul and it's semaphore for the all gather op does not even exist yet.
Example:
%semaphore = "ttnn.create_global_semaphore"(%device) <{core_range_set = #ttnn.core_range_set<[#ttnn.core_range<(0,0), (7,7)>]>, initial_value = 0 : ui32}> : (!ttnn.device) -> !ttnn.global_semaphore
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait, OpModelExempt, TTCore_CreationOpTrait, TTCore_NonCacheableTrait
Interfaces: ConditionallySpeculatable, InferTypeOpInterface, NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
initial_value | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
core_range_set | ::mlir::tt::ttnn::CoreRangeSetAttr | Represents a set of core ranges in the core grid{{% markdown %}} Defines a collection of core ranges within the core grid. No two core ranges in the set should intersect.{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
device | TTNN device |
Results:
| Result | Description |
|---|---|
result | TTNN global semaphore. |
ttnn.cumprod (tt::ttnn::CumProdOp)
Cumulative product op.
Computes the cumulative product of elements of a tensor along specified dimension.
Example: input: [[2, 3, 4], [5, 6, 7]]
// Cumulative product along dim=0: output: [[2, 3, 4], [10, 18, 28]]
// Cumulative product along dim=1: output: [[2, 6, 24], [5, 30, 210]]
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim | ::mlir::IntegerAttr | 32-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.cumsum (tt::ttnn::CumSumOp)
Cumulative sum op.
Computes the cumulative sum of elements of a tensor along specified dimension.
Example: input: [[1, 2, 3], [4, 5, 6]]
// Cumulative sum along dim=0: output: [[1, 2, 3], [5, 7, 9]]
// Cumulative sum along dim=1: output: [[1, 3, 6], [4, 9, 15]]
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim | ::mlir::IntegerAttr | 32-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.d2m_subgraph (tt::ttnn::D2MSubgraphOp)
Dispatch D2M compiled subgraph.
Syntax:
operation ::= `ttnn.d2m_subgraph` $d2m_func attr-dict `\n`
`ins` `(` $inputs `:` type($inputs) `)` `\n`
`outs` `(` $outputs `:` type($outputs) `)` (`:` type($results)^)?
References a D2M-compiled subgraph function containing ttnn.generic ops. The function is a private function in the same module.
Before TTNNMaterializeD2M runs, the referenced function contains a TTNN subgraph to be compiled via D2M.
After TTNNMaterializeD2M runs, the referenced function contains:
- ttnn.generic ops (the compiled subgraph)
- Kernel functions are generated at module scope
TTNNCollaspeD2M will inline the D2M function body at the call site.
Example:
// Before D2M compilation
%result = ttnn.d2m_subgraph @d2m_subgraph
ins(%a : tensor<...>)
outs(%out : tensor<...>) : tensor<...>
func.func private @d2m_subgraph(...) -> tensor<...> {
// ttnn subgraph
}
// After D2M compilation
%result = ttnn.d2m_subgraph @d2m_subgraph
ins(%a : tensor<...>)
outs(%out : tensor<...>) : tensor<...>
func.func private @d2m_subgraph(...) -> tensor<...> {
ttnn.generic ...
// more generic ops if subgraph didn't fully fuse
}
func.func private @kernel0() { ... }
... other kernel functions at module scope
Traits: AttrSizedOperandSegments
Interfaces: MemoryEffectOpInterface, OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
d2m_func | ::mlir::SymbolRefAttr | symbol reference attribute |
Operands:
| Operand | Description |
|---|---|
inputs | variadic of ranked tensor of any type values |
outputs | variadic of ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
results | variadic of ranked tensor of any type values |
ttnn.deallocate (tt::ttnn::DeallocateOp)
Deallocate op.
Tensor Deallocate operation
Interfaces: MemoryEffectOpInterface (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{MemoryEffects::Free on ::mlir::SideEffects::DefaultResource}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
force | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
ttnn.dequantize (tt::ttnn::DequantizeOp)
Dequantize operation.
Applies dequantization to the input tensor.
Inputs:
inputAnyRankedTensor: The input tensor to be dequantized. Must have quantized element type.scaleAnyRankedTensor: The scale factor (or factors for per-axis quantization).zero_pointAnyRankedTensor: The zero point value (or values for per-axis quantization). Must be in range of the quantized storage type.axisOptional: The axis along which quantization is applied. Must be in range [0, rank) where rank is the rank of the input tensor. output_dtypeOptional<TTCore_DataTypeAttr>: The data type of the output tensor.
// For per-tensor dequantization:
output[i] = (input[i] - zero_point) * scale
// For per-axis dequantization:
output[i0, i1, ..., ia, ..., in] = (input[i0, i1, ..., ia, ..., in] - zero_point[ia]) * scale[ia]
Example:
%input = ttir.empty() : () -> tensor<64x128x!quant.uniform<i32:f32, 0.1>>
%output = ttir.empty() : () -> tensor<64x128xf32>
%dequantized = "ttnn.dequantize"(%input, %output) : (tensor<64x128x!quant.uniform<i32:f32, 0.1>, tensor<64x128xf32>) -> tensor<64x128xf32>
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
axis | ::mlir::IntegerAttr | 32-bit signless integer attribute |
output_dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
scale | ranked tensor of any type values |
zero_point | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.distribute_tensor (tt::ttnn::DistributeTensorOp)
Distribute tensor across mesh devices
Distributes a host-side tensor across multiple devices in a mesh according to the specified mapping configuration.
This operation takes a single-device tensor and creates a multi-device tensor distributed according to the MeshMapperConfig configuration.
// Note: In the ttnn API, the distribute_tensor op takes an input tensor and a TensorToMesh object as its arguments. // To create a TensorToMesh object, the API create_mesh_mapper is used, which requires both MeshMapperConfig and MeshDevice. // Instead of modeling create_mesh_mapper as a separate op in the IR, these two strongly coupled APIs are combined into one distribute_tensor op // to keep the IR simple and less cluttered. If a clear need arises in the future, splitting them into separate ops can be considered.
Example:
%result = "ttnn.distribute_tensor"(%input, %device) <{
mapper_config = #ttnn.mesh_mapper_config<
placements = [#ttnn.placement<replicate>, #ttnn.placement<shard, 1>],
mesh_shape_override = #ttnn.mesh_shape<2x2>
>,
cq_id = 0 : ui32
}> : (tensor<32x64xbf16>, !ttnn.device) -> tensor<32x64xbf16>
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait, OpModelExempt
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
mapper_config | ::mlir::tt::ttnn::MeshMapperConfigAttr | Mesh mapper configuration for tensor distribution{{% markdown %}} Configuration for how a tensor should be distributed across a mesh. Specifies placement strategy for each mesh dimension. {{% /markdown %}} |
cq_id | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
mesh_device | TTNN device |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.distributed_layer_norm (tt::ttnn::DistributedLayerNormOp)
Distributed layer normalization with all-gather op.
Intermediate TTNN op for distributed layer normalization across mesh devices.
Always decomposes into: layer_norm_pre_all_gather + all_gather + layer_norm_post_all_gather.
Does not reach serialization — no flatbuffer/runtime/EmitC needed.
Inputs:
- input: Input tensor, width-sharded across mesh devices along the normalized (last) dimension.
- weight: Optional gamma (scale) tensor applied after normalization.
- bias: Optional beta (shift) tensor applied after normalization.
- residual: Optional residual tensor to add to input before normalization. norm_input = input + residual.
Attributes:
- cluster_axis: Mesh dimension (0 or 1) along which to all-gather the partial statistics across devices.
- epsilon: Small constant added to the denominator for numerical stability. Defaults to 1e-05.
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments, CheckTileTypeTrait, OpModelExempt
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
cluster_axis | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
epsilon | ::mlir::FloatAttr | 32-bit float attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
weight | ranked tensor of any type values |
bias | ranked tensor of any type values |
residual | ranked tensor of any type values |
device | TTNN device |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.distributed_rms_norm (tt::ttnn::DistributedRMSNormOp)
Distributed RMS normalization with all-gather op.
Fused distributed RMS normalization operation across mesh devices. Computes local RMS statistics (the mean of squared values, E(x²)), all-gathers the statistics along the specified cluster_axis to obtain globally-correct values, then normalizes each element by x / sqrt(E(x²) + epsilon) and applies optional weight scaling locally on each device.
Only statistics are communicated across devices — the input data itself is not all-gathered. Each device's output shape equals its input shape.
Maps to ttnn::fused_rms_minimal at runtime.
This operation requires the input tensor to be width-sharded across devices.
Inputs:
- input: Input tensor. Must be width-sharded in L1 with shape (1,1,32,M) where M is a multiple of 32. Tiled layout required.
- weight: Optional gamma (scale) tensor applied after normalization. Must be in ROW_MAJOR layout with width equal to tile_width (32), i.e. reshaped from 1D (N,) to 2D (N/32, 32).
- residual: Optional residual tensor to add to input before normalization (x + residual). Must have the same shard spec as input.
- stats: Scratch tensor for intermediate RMS statistics exchanged across devices via all-gather. Shape (1,1,32,32), width-sharded on core (0,0) in L1. Dtype is Float32 when fp32_dest_acc_en is set, otherwise BFloat16.
Attributes:
- cluster_axis: Mesh dimension (0 or 1) along which to all-gather the RMS statistics across devices.
- epsilon: Small constant added to the denominator for numerical stability. Defaults to 1e-12.
- sub_device_id: Optional sub-device targeting for kernel placement.
- num_links: Optional number of links for the all-gather communication.
- topology: CCL topology for all-gather (Linear or Ring).
- compute_config: Device compute kernel configuration. Controls math fidelity, fp32_dest_acc_en, and packer L1 accumulation.
- program_config: LayerNormShardedMultiCoreProgramConfig derived from the input's shard spec (core grid, block_h, block_w).
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments, CheckTileTypeTrait, OpModelExempt
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_DistributedOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
cluster_axis | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
epsilon | ::mlir::FloatAttr | 32-bit float attribute |
sub_device_id | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
num_links | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
topology | ::mlir::tt::ttcore::TopologyAttr | CCL Topology Type |
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
program_config | ::mlir::tt::ttnn::LayerNormShardedMultiCoreProgramConfigAttr | TTNN LayerNorm Sharded Multi-Core Program Config{{% markdown %}} Configuration for sharded multi-core layer norm / RMS norm operations.{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
weight | ranked tensor of any type values |
residual | ranked tensor of any type values |
stats | ranked tensor of any type values |
semaphore | TTNN global semaphore. |
device | TTNN device |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.divide (tt::ttnn::DivideOp)
Eltwise divide.
Eltwise divide operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseBinary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.dropout (tt::ttnn::DropoutOp)
Dropout operation.
Applies dropout to the input tensor element-wise.
Example: %result = "ttnn.dropout"(%input) <{prob = 0.2 : f32, scale = 1.25 : f32, seed = 42 : ui32}> : (tensor<64x128xbf16>) -> tensor<64x128xbf16>
Attributes:
prob(Float): Dropout probability. Elements are zeroed with this probability [Default: 0.0].scale(Float): Scale factor applied to non-zeroed elements. Typically 1/(1-prob) [Default: 1.0].seed(Integer): Seed for the random number generator [Default: 0].use_per_device_seed(Bool): Whether to use a different seed per device [Default: true].
Inputs:
input(Tensor): The input tensor.
Output:
result(Tensor): The output tensor with dropout applied.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait, TTCore_NonCacheableTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
prob | ::mlir::FloatAttr | 32-bit float attribute |
scale | ::mlir::FloatAttr | 32-bit float attribute |
seed | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
use_per_device_seed | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.dump_tensor (tt::ttnn::DumpTensorOp)
Saves a tensor to disk in the TTNN binary format
Saves a tensor to disk in the TTNN binary format. Files must use the .tensorbin extension.
Inputs:
file_pathStrAttr: Path of the file where tensor should be dumped. Must end with.tensorbinextension.inputAnyRankedTensor: Tensor to serialize.
Traits: OpModelExempt
Interfaces: MemoryEffectOpInterface (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{MemoryEffects::Write on ::mlir::SideEffects::DefaultResource}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
file_path | ::mlir::StringAttr | string attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
ttnn.embedding_bw (tt::ttnn::EmbeddingBackwardOp)
Embedding backward op.
Embedding backward operation. Generates the gradient of the embedding operation with respect to the input.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
weight | ranked tensor of any type values |
in_gradient | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.embedding (tt::ttnn::EmbeddingOp)
Embedding op.
Embedding operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
weight | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.empty (tt::ttnn::EmptyOp)
Empty op.
Tensor empty operation
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait, TTCore_CreationOpTrait, TTCore_NonCacheableTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_DeviceOperandInterface, TTNN_DtypeOpInterface, TTNN_LayoutOpInterface, TTNN_MemoryConfigOpInterface, TTNN_TensorSpecInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
shape | ::mlir::tt::ttnn::ShapeAttr | TTNN Shape attribute{{% markdown %}} TTNN shape attribute {{% /markdown %}} |
layout | ::mlir::tt::ttnn::LayoutAttr | TTNN Layout |
Operands:
| Operand | Description |
|---|---|
device | TTNN device |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.end_trace_capture (tt::ttnn::EndTraceCaptureOp)
End trace capture.
Ends trace capture for the given trace id. Consumes a scalar tensor containing the trace id. Has no output, but will have memory effects on the trace region of the device, modelled by trace resource in the compiler. Inputs:
deviceTTNN_Device: The device to end the trace capture on.trace_idAnyRankedTensor: The trace id tensor to end the capture for. Must be a scalar.cq_idui32: The command queue to end the capture with. Must be 0 or 1.
Traits: OpModelExempt
Interfaces: MemoryEffectOpInterface, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
cq_id | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
device | TTNN device |
trace_id | ranked tensor of any type values |
ttnn.eq (tt::ttnn::EqualOp)
Eltwise equal to.
Eltwise equal to operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseBinary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.erf (tt::ttnn::ErfOp)
Eltwise erf op.
Eltwise erf operation. Calculates erf(x) for each element of the input tensor.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.erfc (tt::ttnn::ErfcOp)
Eltwise erfc op.
Eltwise erfc operation. Calculates erfc(x) for each element of the input tensor.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.execute_trace (tt::ttnn::ExecuteTraceOp)
Execute trace.
Executes the captured trace. Consumes a scalar tensor containing the trace id. Has no output, but will have read/write memory effects on the cached trace input/output tensors created when capturing the trace. Inputs:
deviceTTNN_Device: The device where the trace was captured.trace_idAnyRankedTensor: The trace id tensor to execute. Must be a scalar.cq_idui32: The command queue to execute the trace with. Must be 0 or 1.blockingbool: Whether the trace should be executed synchronously.
Traits: OpModelExempt
Interfaces: MemoryEffectOpInterface, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
cq_id | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
blocking | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
device | TTNN device |
trace_id | ranked tensor of any type values |
ttnn.exp (tt::ttnn::ExpOp)
Eltwise exponential.
Eltwise exponential operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.expm1 (tt::ttnn::Expm1Op)
Eltwise unary op.
Performs element-wise exponential minus one operation on operand tensor
and stores the result in the output tensor.
Example: %a: [[0, 1], [0, 0]] "ttnn.exmp1"(%a, %out) -> %out: [[0, 1.71828], [0, 0]]
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.fill_cache (tt::ttnn::FillCacheOp)
Fill static cache tensor.
Fills the cache tensor in-place with values from input at batch_offset.
Interfaces: MemoryEffectOpInterface (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{MemoryEffects::Write on ::mlir::SideEffects::DefaultResource}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
batch_offset | ::mlir::IntegerAttr | 32-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
cache | ranked tensor of any type values |
input | ranked tensor of any type values |
ttnn.flash_mla_prefill (tt::ttnn::FlashMlaPrefillOp)
Flash Multi-head Latent Attention prefill operation.
Multi-head Latent Attention (MLA) prefill. Mirrors
ttnn::transformer::flash_mla_prefill.
Shapes use B (batch), Hq/Hkv (query/kv heads), Sq (sequence
length; must equal Sk for prefill), dh_qk (Q/K head size), and
head_dim_v (V/output head size).
Args:
query (AnyRankedTensor): [B x Hq x Sq x dh_qk].
key (AnyRankedTensor): [B x Hkv x Sq x dh_qk].
value (AnyRankedTensor, optional): [B x Hkv x Sq x head_dim_v].
When absent (MLA-from-latent), V is taken from the first
head_dim_v features of K.
attention_mask (AnyRankedTensor, optional): [1|B x 1 x Sq x Sq].
Only valid when is_causal is false.
head_dim_v (uint): Head dimension of V/output.
is_causal (bool): Defaults to true. Cannot be true when
attention_mask is provided.
scale (float, optional): Softmax scale. Defaults to 1 / sqrt(dh_qk).
Returns:
AnyRankedTensor: [B x Hq x Sq x head_dim_v] (same dtype as query).
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
head_dim_v | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
is_causal | ::mlir::BoolAttr | bool attribute |
scale | ::mlir::FloatAttr | 32-bit float attribute |
Operands:
| Operand | Description |
|---|---|
query | ranked tensor of any type values |
key | ranked tensor of any type values |
value | ranked tensor of any type values |
attention_mask | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.floor (tt::ttnn::FloorOp)
Eltwise floor op.
Eltwise floor operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.from_device (tt::ttnn::FromDeviceOp)
FromDevice op.
This op retrieves the input tensor from the given device.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait, OpModelExempt
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.full (tt::ttnn::FullOp)
Creates a tensor filled with the specified value
Tensor operation to create a tensor filled with a specified value.
Given a shape and a fill_value, produces a tensor with the shape, filled
with the specified value.
Example:
%0 = "ttnn.full"() <{
fill_value = 7 : i32,
layout = #ttnn.layout
Traits: AlwaysSpeculatableImplTrait, CanExecuteOnHostTrait, CheckTileTypeTrait, TTCore_CreationOpTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_DeviceOperandInterface, TTNN_DtypeOpInterface, TTNN_LayoutOpInterface, TTNN_MemoryConfigOpInterface, TTNN_TensorSpecInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
shape | ::mlir::tt::ttnn::ShapeAttr | TTNN Shape attribute{{% markdown %}} TTNN shape attribute {{% /markdown %}} |
fill_value | ::mlir::Attribute | 32-bit float attribute or 32-bit signless integer attribute |
layout | ::mlir::tt::ttnn::LayoutAttr | TTNN Layout |
Operands:
| Operand | Description |
|---|---|
device | TTNN device |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.gather (tt::ttnn::GatherOp)
Gather op.
Gathers values from the input tensor along the given dimension using an
index tensor. This corresponds to torch.gather semantics and maps
directly to the tt-metal ttnn::gather device op.
Parameters:
input(ttnn.Tensor): The source tensor to gather from.index(ttnn.Tensor): Indices specifying which values to gather.dim(int32_t): The dimension along which to gather.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim | ::mlir::IntegerAttr | 32-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
index | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.gelu_bw (tt::ttnn::GeluBackwardOp)
Backward pass operation for the GELU activation function.
Computes the gradient of the GELU (Gaussian Error Linear Unit) activation function with respect to its input during backpropagation.
This operation corresponds to ttnn.experimental.gelu_bw.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseBinary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
approximate | ::mlir::StringAttr | string attribute |
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.gelu (tt::ttnn::GeluOp)
Eltwise GELU.
Eltwise GELU operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.generic (tt::ttnn::GenericOp)
Generic operation.
Generic operation capable of running a program with custom kernels. Each kernel is described with a
symbol reference to its function in EmitC dialect plus compile and runtime arguments. Generic operation
is supplied with concatenated input and output ios tensors.
Inputs:
inputs_and_outputsVariadic: The input and output tensors. programProgramAttr: Program descriptor that includes a description of each kernels, array of CBs and array of semaphores.
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments, CheckTileTypeTrait, OpModelExempt, TTCore_NonCacheableTrait
Interfaces: ConditionallySpeculatable, MemoryEffectOpInterface (MemoryEffectOpInterface), NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{MemoryEffects::Read on ::mlir::SideEffects::DefaultResource, MemoryEffects::Write on ::mlir::SideEffects::DefaultResource}, MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
program | ::mlir::Attribute | Program or Mesh program descriptor |
Operands:
| Operand | Description |
|---|---|
inputs_and_outputs | variadic of ranked tensor of any type values |
additional_args | variadic of any type |
ttnn.get_device (tt::ttnn::GetDeviceOp)
Get Device op.
This op returns a submesh carved out from the parent runtime device. Mesh shape and mesh offset define the size and offset of the submesh.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait, OpModelExempt, TTCore_DuplicateConstEvalTrait
Interfaces: ConditionallySpeculatable, InferTypeOpInterface, NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
mesh_shape | ::mlir::tt::ttnn::MeshShapeAttr | TTNN Mesh Shape{{% markdown %}} TTNN mesh shape representing the dimensions of a 2D mesh. {{% /markdown %}} |
mesh_offset | ::mlir::tt::ttnn::MeshOffsetAttr | TTNN Mesh Offset{{% markdown %}} TTNN mesh offset representing the starting coordinates in a 2D mesh. {{% /markdown %}} |
Results:
| Result | Description |
|---|---|
device | TTNN device |
ttnn.global_avg_pool2d (tt::ttnn::GlobalAvgPool2dOp)
A global average pooling 2d operation
The global_avg_pool2d operation applies global average pooling over the spatial dimensions
(height and width) of a 4D input tensor. In essence, it should be realised as the sum-reduce style operation
under the hood, for performance reasons (since we include all elements, there is no need for kernel allocation).
It reduces spatial dimensions to 1.
Example:
%device = "ttnn.get_device"() <{mesh_shape = #ttnn<mesh_shape 1x1>}> : () -> !ttnn.device
%result = "ttnn.global_avg_pool2d"(%input)
: (tensor<1x128x128x32xbf16>) -> tensor<1x1x1x32xbf16>
Inputs:
input: 4D tensor with shape [N, H, W, C] where N is batch size, H is height, W is width, and C is channels
Outputs:
result: 4D tensor with shape [N, 1, 1, C] containing the global average pooled values
Note: The operation reduces spatial dimensions (H, W) to (1, 1) by computing the average across all spatial locations for each channel independently.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.ge (tt::ttnn::GreaterEqualOp)
Eltwise greater than or equal to.
Eltwise greater than or equal to operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseBinary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.gt (tt::ttnn::GreaterThanOp)
Eltwise greater than.
Eltwise greater than operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseBinary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.group_norm (tt::ttnn::GroupNormOp)
Group normalization op.
Computes group normalization over the input tensor. The input tensor's channels are split into groups, and mean and variance are computed per group. The result is normalized by subtracting the mean and dividing by the standard deviation, then optionally scaled and shifted by weight (gamma) and bias (beta).
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
num_groups | ::mlir::IntegerAttr | 64-bit signless integer attribute |
epsilon | ::mlir::FloatAttr | 32-bit float attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
input_mask | ranked tensor of any type values |
weight | ranked tensor of any type values |
bias | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.hardsigmoid (tt::ttnn::HardsigmoidOp)
Eltwise hardsigmoid.
Eltwise hardsigmoid operation. Computes hardsigmoid(x) = max(0, min(1, (x + 3) / 6)).
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.isfinite (tt::ttnn::IsFiniteOp)
Eltwise isfinite op.
Eltwise isfinite operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.layer_norm (tt::ttnn::LayerNormOp)
Layer normalization op.
Performs layer normalization on the input tensor. This operation normalizes the input tensor by computing the mean and variance of elements across the specified dimensions, then normalizes by subtracting the mean and dividing by the standard deviation, optionally scaling and shifting the result.
This operation performs normalization over the last dimension of the input tensor, matching the TTNN runtime implementation.
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
epsilon | ::mlir::FloatAttr | 32-bit float attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
weight | ranked tensor of any type values |
bias | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.layer_norm_post_all_gather (tt::ttnn::LayerNormPostAllGatherOp)
Layer normalization post-all-gather op.
Applies normalization using gathered statistics from a distributed layer normalization pipeline. Takes the original input tensor and the all-gathered partial statistics, computes the final normalized output, and optionally scales by weight and shifts by bias.
Inputs:
- input: Original input tensor.
- stats: All-gathered statistics tensor from pre-all-gather phase.
- weight: Optional scale (gamma) tensor.
- bias: Optional shift (beta) tensor.
Attributes:
- epsilon: Small constant for numerical stability (default 1e-12).
- compute_config: Optional device compute kernel configuration.
- program_config: Optional LayerNormShardedMultiCoreProgramConfig.
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
epsilon | ::mlir::FloatAttr | 32-bit float attribute |
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
program_config | ::mlir::tt::ttnn::LayerNormShardedMultiCoreProgramConfigAttr | TTNN LayerNorm Sharded Multi-Core Program Config{{% markdown %}} Configuration for sharded multi-core layer norm / RMS norm operations.{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
stats | ranked tensor of any type values |
weight | ranked tensor of any type values |
bias | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.layer_norm_pre_all_gather (tt::ttnn::LayerNormPreAllGatherOp)
Layer normalization pre-all-gather op.
Computes local partial statistics (Welford) for distributed layer normalization on a width-sharded input tensor. Produces partial statistics that should be all-gathered across devices before being consumed by a post-all-gather normalization op.
Inputs:
- input: Input tensor (width-sharded in L1).
- residual_input: Optional residual tensor to add before computing statistics. Must have the same shape as input.
- recip: Optional precomputed reciprocal tensor.
Attributes:
- compute_config: Optional device compute kernel configuration.
- program_config: Optional LayerNormShardedMultiCoreProgramConfig.
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
program_config | ::mlir::tt::ttnn::LayerNormShardedMultiCoreProgramConfigAttr | TTNN LayerNorm Sharded Multi-Core Program Config{{% markdown %}} Configuration for sharded multi-core layer norm / RMS norm operations.{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
residual_input | ranked tensor of any type values |
recip | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.leaky_relu (tt::ttnn::LeakyReluOp)
Eltwise leaky relu operation.
The Leaky ReLU (Rectified Linear Unit) operation computes an element-wise activation function over its input tensor. It is defined as:
y = x if x > 0 y = parameter * x if x <= 0
where parameter is a small, user-defined constant that determines the slope for
negative inputs.
Attributes:
parameter(float): The slope for negative values.
Inputs:
input(Tensor): The input tensor to be activated.
Outputs:
output(Tensor): The tensor after applying the Leaky ReLU activation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
parameter | ::mlir::FloatAttr | 32-bit float attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.le (tt::ttnn::LessEqualOp)
Eltwise less than or equal to.
Eltwise less than or equal to operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseBinary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.lt (tt::ttnn::LessThanOp)
Eltwise less than.
Eltwise less than operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseBinary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.linear (tt::ttnn::LinearOp)
Linear transformation of inputs.
Produces the matmul of tensors a and b with optional addition with bias.
Example: // %a = [[1., 2.], [2., 1.]] // %b = [[0., 1.], [1., 0.]] // %bias = [[1.]] "ttnn.linear"(%a, %b, %bias, %result) : (tensor<2x2xf16>, tensor<2x2xf16>, tensor<1xf16>, tensor<2x2xf16>) -> tensor<2x2xf16> // %result = [[3., 2.], [2., 3.]]
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
transpose_a | ::mlir::BoolAttr | bool attribute |
transpose_b | ::mlir::BoolAttr | bool attribute |
matmul_program_config | ::mlir::Attribute | TTNN MatmulMultiCoreReuseProgramConfig or TTNN MatmulMultiCoreReuseMultiCastProgramConfig or TTNN MatmulMultiCoreReuseMultiCast1DProgramConfig or TTNN MatmulMultiCoreReuseMultiCastDRAMShardedProgramConfig |
activation | ::mlir::StringAttr | string attribute |
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
a | ranked tensor of any type values |
b | ranked tensor of any type values |
bias | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.load_tensor (tt::ttnn::LoadTensorOp)
Loads a tensor from disk
Loads a tensor from disk, optionally placing it directly on a device.
Inputs:
file_pathStrAttr: Path of the file of the serialized tensor. Must end with.tensorbinextension.deviceOptional<TTNN_Device>: Device where tensor should be deserialized. It has to be provided iff the serialized tensor is a device tensor. Outputs:resultAnyRankedTensor: Deserialized tensor from thefile_path.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait, OpModelExempt
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
file_path | ::mlir::StringAttr | string attribute |
Operands:
| Operand | Description |
|---|---|
device | TTNN device |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.log1p (tt::ttnn::Log1pOp)
Eltwise log1p operation.
Performs element-wise logarithm plus one operation on operand tensor and
puts the result in the output tensor.
Example: %a: [0.0, -0.999, 7.0, 6.38905621, 15.0] "ttnn.logp1"(%a, %out) -> %out: [0.0, -6.90776825, 2.07944155, 2.0, 2.77258873]
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.log (tt::ttnn::LogOp)
Eltwise logarithm.
Eltwise logarithm operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.logical_and (tt::ttnn::LogicalAndOp)
Eltwise logical and.
Eltwise logical and operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseBinary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.logical_left_shift (tt::ttnn::LogicalLeftShiftOp)
Eltwise Logical Left Shift operation
The logical_left_shift operation performs an elementwise logical left shift
on the elements of the first tensor by the corresponding shift amounts in the
second tensor.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.logical_not (tt::ttnn::LogicalNotOp)
Eltwise logical not op.
Eltwise logical not operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.logical_or (tt::ttnn::LogicalOrOp)
Eltwise logical or.
Eltwise logical or operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseBinary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.logical_right_shift (tt::ttnn::LogicalRightShiftOp)
Eltwise Logical Right Shift operation
The logical_right_shift operation performs an elementwise logical right shift
on the elements of the first tensor by the corresponding shift amounts in the
second tensor.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseBinary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.logical_xor (tt::ttnn::LogicalXorOp)
Eltwise logical xor.
Eltwise logical xor operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseBinary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.matmul (tt::ttnn::MatmulOp)
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
transpose_a | ::mlir::BoolAttr | bool attribute |
transpose_b | ::mlir::BoolAttr | bool attribute |
matmul_program_config | ::mlir::Attribute | TTNN MatmulMultiCoreReuseProgramConfig or TTNN MatmulMultiCoreReuseMultiCastProgramConfig or TTNN MatmulMultiCoreReuseMultiCast1DProgramConfig or TTNN MatmulMultiCoreReuseMultiCastDRAMShardedProgramConfig |
activation | ::mlir::StringAttr | string attribute |
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
a | ranked tensor of any type values |
b | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.max (tt::ttnn::MaxOp)
Max reduction op.
Max reduction op.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
keep_dim | ::mlir::BoolAttr | bool attribute |
dim_arg | ::mlir::ArrayAttr | 32-bit integer array attribute |
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.max_pool2d (tt::ttnn::MaxPool2dOp)
Applies a 2D max pooling over an input signal composed of several input planes.
Applies a 2D max pooling over an input signal composed of several input planes.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
batch_size | ::mlir::IntegerAttr | 32-bit signed integer attribute |
input_height | ::mlir::IntegerAttr | 32-bit signed integer attribute |
input_width | ::mlir::IntegerAttr | 32-bit signed integer attribute |
channels | ::mlir::IntegerAttr | 32-bit signed integer attribute |
kernel_size | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
stride | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
padding | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
dilation | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
applied_shard_scheme | ::mlir::tt::ttnn::TensorMemoryLayoutAttr | TTNN Tensor Memory Layout |
ceil_mode | ::mlir::BoolAttr | bool attribute |
reallocate_halo_output | ::mlir::BoolAttr | bool attribute |
config_tensors_in_dram | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.max_pool2d_with_indices (tt::ttnn::MaxPool2dWithIndicesOp)
Applies a 2D max pooling over an input signal composed of several input planes, returning both values and indices.
Applies a 2D max pooling over an input signal composed of several input planes. Returns both the maximum values and the indices of where those values were found in the input tensor. The indices can be used for unpooling operations or gradient computation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
batch_size | ::mlir::IntegerAttr | 32-bit signed integer attribute |
input_height | ::mlir::IntegerAttr | 32-bit signed integer attribute |
input_width | ::mlir::IntegerAttr | 32-bit signed integer attribute |
channels | ::mlir::IntegerAttr | 32-bit signed integer attribute |
kernel_size | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
stride | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
padding | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
dilation | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
applied_shard_scheme | ::mlir::tt::ttnn::TensorMemoryLayoutAttr | TTNN Tensor Memory Layout |
ceil_mode | ::mlir::BoolAttr | bool attribute |
reallocate_halo_output | ::mlir::BoolAttr | bool attribute |
config_tensors_in_dram | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
result_indices | ranked tensor of any type values |
ttnn.maximum (tt::ttnn::MaximumOp)
Eltwise maximum OP.
Calculates maximum of input tensors' values element-wise and stores result in output tensor.
Example: %lhs: [[3, 2, 7], [1, 4, 4]] %rhs: [[1, 4, 2], [1, 2, 3]] "ttnn.maximum"(%lhs, %rhs, %out) -> %out: [[3, 4, 7], [1, 4, 4]]
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.mean (tt::ttnn::MeanOp)
Mean reduction op.
Mean reduction op.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
keep_dim | ::mlir::BoolAttr | bool attribute |
dim_arg | ::mlir::ArrayAttr | 32-bit integer array attribute |
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.mesh_partition (tt::ttnn::MeshPartitionOp)
Mesh partition operation.
Mesh partition op.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim | ::mlir::IntegerAttr | 32-bit signed integer attribute |
cluster_axis | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.min (tt::ttnn::MinOp)
Min reduction op.
This op computes the minimum of all elements of the tensor or along specified dimension.
Example: input: [[1, 5, 3], [4, 2, 6]]
// Computing along dim 0 output: [1, 2, 3]
// Computing along dim 1 output: [1, 2]
// Computing for entire tensor output: 1
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
keep_dim | ::mlir::BoolAttr | bool attribute |
dim_arg | ::mlir::ArrayAttr | 32-bit integer array attribute |
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.minimum (tt::ttnn::MinimumOp)
Eltwise minimum OP.
Calculates minimum of input tensors' values element-wise and stores result in output tensor.
Example: %lhs: [[3, 2, 7], [1, 4, 4]] %rhs: [[1, 4, 2], [1, 2, 3]] "ttnn.minimum"(%lhs, %rhs, %out) -> %out: [[1, 2, 2], [1, 2, 3]]
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.mish (tt::ttnn::MishOp)
Eltwise Mish.
Eltwise Mish operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.moe_compute (tt::ttnn::MoeComputeOp)
Fused MoE expert compute (selective tilize + experts + combine).
Composite operation that performs the MoE expert FFN in a single fused
kernel: selective tilize of dispatched tokens, the gate/up matmul (W0/W1)
followed by SILU or SwiGLU activation, the down matmul (W2), and an
A2A selective-reduce-combine. Maps to
ttnn::experimental::moe_compute at runtime.
optional_output_tensor is the caller-allocated combine-output buffer;
cross_device_semaphore synchronizes the A2A combine across devices.
Both are optional in source MLIR but must be bound before the runtime
can lower the op. They are populated by the
TTNNAllocateDistributedOpBuffers / TTNNAllocateDistributedOpSemaphores
passes via the DistributedOpInterface.
When compute_only is set, the A2A combine is skipped (single-device /
no-CCL bring-up): tt-metal returns only the first five tensors and
matmul_output is the final user-visible output. In that mode
cluster_axis, topology, num_links, mux_core_range_set,
optional_output_tensor, and cross_device_semaphore are unused, and
combine_output aliases matmul_output. bh_ring_size pins the
Blackhole matmul ring size (8, 12, or 16; default 12) and is ignored on
Wormhole.
See TTIR_MoeComputeOp for input/output shapes and dtypes.
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments, CheckTileTypeTrait, OpModelExempt
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_DistributedOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
layer_id | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
output_height_shard_dim | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
intermediate_size | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
has_bias | ::mlir::BoolAttr | bool attribute |
activation_function | ::mlir::tt::ttcore::MoEActivationFunctionAttr | Activation function for the MoE expert FFN |
bh_ring_size | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
compute_only | ::mlir::BoolAttr | bool attribute |
cluster_axis | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
num_links | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
topology | ::mlir::tt::ttcore::TopologyAttr | CCL Topology Type |
mux_core_range_set | ::mlir::tt::ttnn::CoreRangeSetAttr | Represents a set of core ranges in the core grid{{% markdown %}} Defines a collection of core ranges within the core grid. No two core ranges in the set should intersect.{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
tilize_input_tensor | ranked tensor of any type values |
tilize_expert_indices_tensor | ranked tensor of any type values |
tilize_expert_scores_tensor | ranked tensor of any type values |
tilize_expert_mapping_tensor | ranked tensor of any type values |
matmul_w0_w1_tensor | ranked tensor of any type values |
matmul_w2_tensor | ranked tensor of any type values |
optional_output_tensor | ranked tensor of any type values |
cross_device_semaphore | TTNN global semaphore. |
device | TTNN device |
Results:
| Result | Description |
|---|---|
per_expert_total_tokens | ranked tensor of any type values |
expert_activation | ranked tensor of any type values |
expert_to_token | ranked tensor of any type values |
tilize_output | ranked tensor of any type values |
matmul_output | ranked tensor of any type values |
combine_output | ranked tensor of any type values |
ttnn.moe_expert_token_remap (tt::ttnn::MoeExpertTokenRemapOp)
Remap global expert routing to local device experts with sparsity.
Converts global expert routing scores to local per-device expert mapping and creates a sparsity pattern for efficient sparse_matmul.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait, OpModelExempt
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
reduction_size | ::mlir::IntegerAttr | 64-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
topk_tensor | ranked tensor of any type values |
expert_mapping | ranked tensor of any type values |
expert_metadata | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
mapping | ranked tensor of any type values |
reduced | ranked tensor of any type values |
ttnn.moe_gpt (tt::ttnn::MoeGptOp)
Fused MoE compute kernel for GPT-OSS models.
Fused Mixture-of-Experts compute kernel for GPT-OSS-style models. Runs the full MoE compute pipeline in a single kernel: selective tilize, gate/up projection (w0_w1), SwiGLU activation, all-to-all ring exchange along cluster_axis, down projection (w2), and combine. Typically follows ttnn.all_to_all_dispatch_metadata in the MoE dispatch/compute/combine flow.
Dimensions: T = total_tokens across the dispatch ring K = hidden_size N = intermediate_size K_sel = selected experts per token (top-k) E = experts per device D = total devices C_dram = DRAM-bank-aligned compute cores used for weight sharding C_worker = worker cores in the compute grid L = layers per weight tensor (typically 1) G = weight groups per core (gate/up interleaved pairs) TILE_SIZE = compute tile size L1_ALIGN = L1 alignment
Input shapes and layouts (per device, after mesh sharding; enforced by TTNNWorkaroundsPass to match kernel expectations):
- input_tensor: [T, K] bf16, ROW_MAJOR (kernel tilizes internally)
- expert_indices: [T, K_sel] uint16, ROW_MAJOR, L1 HEIGHT_SHARDED
- expert_scores: [T, K_sel] bf16, ROW_MAJOR, L1 HEIGHT_SHARDED
- expert_mapping: [1, ED] uint16, ROW_MAJOR (flattened mapping, entry [0, i] = device ID owning expert i; the tilize_reader kernel casts the buffer to uint16_t)
- w0_w1_tensor: [C_dram, L, E, G, K, 4*TILE_SIZE] (interleaved gate+up)
- w2_tensor: [C_dram, L, E, 2, N, 4*TILE_SIZE] (down projection)
Output shapes:
- token_counts: [1, align(E*sizeof(u32), L1_ALIGN) / sizeof(u32)] uint32
- activation_records: [1, (T+1) * align((2*E+1)*sizeof(u32), L1_ALIGN) / sizeof(u32)] uint32
- token_indices: [E, (T+1) * align(sizeof(u32), L1_ALIGN) / sizeof(u32)] uint32
- tilize_out: [C_worker, 2, TILE_SIZE, K] bf16, TILE
- tilize_out_rm: [C_worker, 2, TILE_SIZE, K] bf16, ROW_MAJOR where align(n, a) = ceil(n/a) * a.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
output_height_shard_dim | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
output_width_shard_dim | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
hidden_size | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
cluster_axis | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
input_tensor | ranked tensor of any type values |
expert_indices | ranked tensor of any type values |
expert_scores | ranked tensor of any type values |
expert_mapping | ranked tensor of any type values |
w0_w1_tensor | ranked tensor of any type values |
w2_tensor | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
token_counts | ranked tensor of any type values |
activation_records | ranked tensor of any type values |
token_indices | ranked tensor of any type values |
tilize_out | ranked tensor of any type values |
tilize_out_rm | ranked tensor of any type values |
ttnn.multiply (tt::ttnn::MultiplyOp)
Eltwise multiply.
Eltwise multiply operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseBinary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.nlp_concat_heads_decode (tt::ttnn::NLPConcatHeadsDecodeOp)
Concatenate heads op used in attention layer.
Shuffles [S=1, B=32, 32(num_heads), head_dim] tensor into tensor with shape [S=1, 1, B=32, num_heads * head_dim].
This operation assumes that input num_heads is padded to at most 32. When invoking this op,
we specify the actual num_heads via the attribute num_heads and it should be less than input padded num_heads.
Operation will unpad the input num_heads to the actual num_heads.
The output is default width sharded by num heads.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
num_heads | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.nlp_concat_heads (tt::ttnn::NLPConcatHeadsOp)
Nlp_concat_heads op in TTNN dialect.
"This op targets specific case of concatenate heads operation where input tensor [B, num_heads, S, head_dim] is permuted and reshaped into [B, 1, S, num_heads * head_dim]."
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.neg (tt::ttnn::NegOp)
Eltwise negate.
Eltwise negate operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.ne (tt::ttnn::NotEqualOp)
Eltwise not equal to.
Eltwise not equal to operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseBinary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.ones (tt::ttnn::OnesOp)
Creates a tensor filled with ones.
Tensor operation to create a tensor filled with ones.
Given a ShapeAttr shape, produces a tensor with the same shape, filled with ones.
Example: %0 = "ttnn.ones"() <{shape = array<i32:64, 28, 28>}> : () -> tensor<64x28x28xbf16> // %0: [[[1, 1, 1, ..., 1], [1, 1, 1, ..., 1], ..., [1, 1, 1, ..., 1]]]
Traits: AlwaysSpeculatableImplTrait, CanExecuteOnHostTrait, CheckTileTypeTrait, TTCore_CreationOpTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_DeviceOperandInterface, TTNN_DtypeOpInterface, TTNN_LayoutOpInterface, TTNN_MemoryConfigOpInterface, TTNN_TensorSpecInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
shape | ::mlir::tt::ttnn::ShapeAttr | TTNN Shape attribute{{% markdown %}} TTNN shape attribute {{% /markdown %}} |
layout | ::mlir::tt::ttnn::LayoutAttr | TTNN Layout |
Operands:
| Operand | Description |
|---|---|
device | TTNN device |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.pad (tt::ttnn::PadOp)
Pad op.
Pad input tensor by padding the input_shape to output_shape using the provided value.
The padding attribute must be a sequence of integers that is twice the size as the rank of the input.
Each pair of integers in the padding attribute represents the amount of padding to add to the low and high of that dimension.
I.e: an input tensor of shape <1x30x30x64xf32> with padding attribute <0, 0, 1, 1, 1, 1, 0, 0> will return a tensor of shape <1x32x32x64xf32>,
and so will a padding attribute of <0, 0, 0, 2, 0, 2, 0, 0>.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
padding | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
value | ::mlir::FloatAttr | 32-bit float attribute |
use_multicore | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.paged_fill_cache (tt::ttnn::PagedFillCacheOp)
Paged fill cache op.
Fills the cache tensor in-place with values from input at batch_offset.
Interfaces: MemoryEffectOpInterface (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{MemoryEffects::Write on ::mlir::SideEffects::DefaultResource}
Operands:
| Operand | Description |
|---|---|
cache | ranked tensor of any type values |
input | ranked tensor of any type values |
page_table | ranked tensor of any type values |
batch_idx_tensor | ranked tensor of any type values |
ttnn.paged_flash_multi_latent_attention_decode (tt::ttnn::PagedFlashMultiLatentAttentionDecodeOp)
Paged flash multi-latent attention decode operation.
Paged flash Multi-Latent Attention (MLA) for the decode phase. Combines flash attention with multi-latent attention and paged KV cache support, optimized for single-token decode.
Key difference from PagedScaledDotProductAttentionDecode: the value tensor is optional (may be null for latent-only MLA) and head_dim_v specifies the value head dimension separately.
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
head_dim_v | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
is_causal | ::mlir::BoolAttr | bool attribute |
scale | ::mlir::FloatAttr | 32-bit float attribute |
Operands:
| Operand | Description |
|---|---|
query | ranked tensor of any type values |
key | ranked tensor of any type values |
value | ranked tensor of any type values |
page_table | ranked tensor of any type values |
attention_mask | ranked tensor of any type values |
cur_pos_tensor | ranked tensor of any type values |
attention_sink | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.paged_scaled_dot_product_attention_decode (tt::ttnn::PagedScaledDotProductAttentionDecodeOp)
Paged scaled dot product attention decode operation.
Paged scaled dot product attention decode operation.
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
is_causal | ::mlir::BoolAttr | bool attribute |
scale | ::mlir::FloatAttr | 32-bit float attribute |
sliding_window_size | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
program_config | ::mlir::tt::ttnn::SDPAProgramConfigAttr | TTNN SDPA (Scaled Dot Product Attention) Program Config{{% markdown %}} Configuration for Scaled Dot Product Attention (SDPA) operations.{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
query | ranked tensor of any type values |
key | ranked tensor of any type values |
value | ranked tensor of any type values |
page_table | ranked tensor of any type values |
attention_mask | ranked tensor of any type values |
cur_pos_tensor | ranked tensor of any type values |
attention_sink | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.paged_update_cache (tt::ttnn::PagedUpdateCacheOp)
Paged update cache op.
Inputs:
cache: The cache tensor to be updated. This tensor is modified in place [max_num_blocks, num_heads, block_size, head_dim]input: The input tensor containing new values. [1, num_users, num_heads (padded to 32), head_dim]update_index: Indices specifying where to update the cache. [num_users]share_cache: Whether the cache tensors share memory regions. Defaults to False.page_table: The page table for managing memory regions during updates. [num_users, max_num_blocks_per_seq]
Interfaces: MemoryEffectOpInterface (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{MemoryEffects::Write on ::mlir::SideEffects::DefaultResource}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
share_cache | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
cache | ranked tensor of any type values |
input | ranked tensor of any type values |
update_index | ranked tensor of any type values |
page_table | ranked tensor of any type values |
ttnn.permute (tt::ttnn::PermuteOp)
Permute operation.
Permute input tensor dimensions.
Attributes:
permutationarray: The permutation of the input tensor dimensions.
Example: %a = ttir.empty() : () -> tensor<2x3x4xi32> %0 = "ttir.permute"(%a) {permutation = array<i64: 1, 2, 0>} : (tensor<2x3x4xi32>) -> tensor<3x4x2xi32>
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
permutation | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
pad_value | ::mlir::FloatAttr | 32-bit float attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.point_to_point (tt::ttnn::PointToPointOp)
Point To Point operation.
Performs point-to-point communication by copying a tensor shard from one device to another within a multi-device mesh. This operation is typically used for explicit data movement in distributed tensor computations, where a specific device (send_coord) sends its local tensor data to a target device (receive_coord).
If optional_output_tensor is not provided, a new output tensor will be allocated automatically
at the receiver. If provided, the data will be written into the specified output tensor.
The operation returns a multi-device tensor whose buffer layout follows the mesh configuration.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait, OpModelExempt
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
sender_coord | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
receiver_coord | ::mlir::DenseI64ArrayAttr | i64 dense array attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
optional_output_tensor | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.pow_scalar (tt::ttnn::PowScalarOp)
Eltwise power OP.
The pow_scalar operation performs an exponentiation of each element of an
input tensor with a scalar exponent and returns the result.
Example:
%result = ttnn.pow_scalar(%input) <{exponent = 2.0 : f32}> : tensor<4xf32>, tensor<4xf32> -> tensor<4xf32>
// Input tensors:
// %input: [2.0, 3.0, 4.0, 5.0] // Bases
// %exponent: 2.0 // Power
// Output tensor: [4.0, 9.0, 16.0, 25.0]
Restriction: TTNN API supports expoenent ≥ 0 only.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
rhs | ::mlir::Attribute | 32-bit float attribute or 32-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.pow_tensor (tt::ttnn::PowTensorOp)
Eltwise power OP.
Performs element-wise exponentiation of lhs tensor by rhs tensor and produces a result tensor. Tensors must be of same shape.
Example:
%result = "ttnn.pow_tensor"(%lhs, %rhs) : (tensor<6xf64>, tensor<6xf64>) -> tensor<6xf64>
%lhs: [-2.0, -0.0, -36.0, 5.0, 3.0, 10000.0]
%rhs: [2.0, 2.0, 1.1, 2.0, -1.0, 10.0]
%result: [4.0, 0.0, -nan, 25.0, 0.333333343, inf]
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.prepare_conv2d_bias (tt::ttnn::PrepareConv2dBiasOp)
Prepares conv2d bias so that it can be consumed by the conv2d op.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
input_memory_config | ::mlir::tt::ttnn::MemoryConfigAttr | TTNN MemoryConfig attribute{{% markdown %}} The `MemoryConfigAttr` defines how a tensor is stored in memory on Tenstorrent hardware.{{% /markdown %}} |
input_tensor_layout | ::mlir::tt::ttnn::LayoutAttr | TTNN Layout |
in_channels | ::mlir::IntegerAttr | 32-bit signless integer attribute |
out_channels | ::mlir::IntegerAttr | 32-bit signless integer attribute |
batch_size | ::mlir::IntegerAttr | 32-bit signless integer attribute |
input_height | ::mlir::IntegerAttr | 32-bit signless integer attribute |
input_width | ::mlir::IntegerAttr | 32-bit signless integer attribute |
kernel_size | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
stride | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
padding | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
dilation | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
groups | ::mlir::IntegerAttr | 32-bit signless integer attribute |
input_dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
output_dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
conv2d_config | ::mlir::tt::ttnn::Conv2dConfigAttr | TTNN Conv2dConfig attribute{{% markdown %}} Configuration parameters for TTNN conv2d operations that control memory usage, performance optimizations, and execution behavior.{{% /markdown %}} |
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
conv2d_slice_config | ::mlir::tt::ttnn::Conv2dSliceConfigAttr | TTNN Conv2d slice configuration attribute{{% markdown %}} Conv2d slice configuration specifying slice type and number of slices. {{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
bias_tensor | ranked tensor of any type values |
device | TTNN device |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.prepare_conv2d_weights (tt::ttnn::PrepareConv2dWeightsOp)
Prepares conv2d weights so that they can be consumed by the conv2d op.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
input_memory_config | ::mlir::tt::ttnn::MemoryConfigAttr | TTNN MemoryConfig attribute{{% markdown %}} The `MemoryConfigAttr` defines how a tensor is stored in memory on Tenstorrent hardware.{{% /markdown %}} |
input_tensor_layout | ::mlir::tt::ttnn::LayoutAttr | TTNN Layout |
weights_format | ::mlir::StringAttr | string attribute |
in_channels | ::mlir::IntegerAttr | 32-bit signless integer attribute |
out_channels | ::mlir::IntegerAttr | 32-bit signless integer attribute |
batch_size | ::mlir::IntegerAttr | 32-bit signless integer attribute |
input_height | ::mlir::IntegerAttr | 32-bit signless integer attribute |
input_width | ::mlir::IntegerAttr | 32-bit signless integer attribute |
kernel_size | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
stride | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
padding | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
dilation | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
has_bias | ::mlir::BoolAttr | bool attribute |
groups | ::mlir::IntegerAttr | 32-bit signless integer attribute |
input_dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
output_dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
conv2d_config | ::mlir::tt::ttnn::Conv2dConfigAttr | TTNN Conv2dConfig attribute{{% markdown %}} Configuration parameters for TTNN conv2d operations that control memory usage, performance optimizations, and execution behavior.{{% /markdown %}} |
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
conv2d_slice_config | ::mlir::tt::ttnn::Conv2dSliceConfigAttr | TTNN Conv2d slice configuration attribute{{% markdown %}} Conv2d slice configuration specifying slice type and number of slices. {{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
weight_tensor | ranked tensor of any type values |
device | TTNN device |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.prepare_conv3d_weights (tt::ttnn::PrepareConv3dWeightsOp)
Prepares conv3d weights so that they can be consumed by the conv3d op.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
groups | ::mlir::IntegerAttr | 32-bit signless integer attribute |
c_in_block | ::mlir::IntegerAttr | 32-bit signless integer attribute |
alignment | ::mlir::IntegerAttr | 32-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
weight_tensor | ranked tensor of any type values |
device | TTNN device |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.prepare_conv_transpose2d_bias (tt::ttnn::PrepareConvTranspose2dBiasOp)
Prepares conv_transpose2d bias so that it can be consumed by the conv_transpose2d op.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
input_memory_config | ::mlir::tt::ttnn::MemoryConfigAttr | TTNN MemoryConfig attribute{{% markdown %}} The `MemoryConfigAttr` defines how a tensor is stored in memory on Tenstorrent hardware.{{% /markdown %}} |
input_tensor_layout | ::mlir::tt::ttnn::LayoutAttr | TTNN Layout |
in_channels | ::mlir::IntegerAttr | 32-bit signless integer attribute |
out_channels | ::mlir::IntegerAttr | 32-bit signless integer attribute |
batch_size | ::mlir::IntegerAttr | 32-bit signless integer attribute |
input_height | ::mlir::IntegerAttr | 32-bit signless integer attribute |
input_width | ::mlir::IntegerAttr | 32-bit signless integer attribute |
kernel_size | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
stride | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
padding | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
dilation | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
groups | ::mlir::IntegerAttr | 32-bit signless integer attribute |
input_dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
output_dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
conv2d_config | ::mlir::tt::ttnn::Conv2dConfigAttr | TTNN Conv2dConfig attribute{{% markdown %}} Configuration parameters for TTNN conv2d operations that control memory usage, performance optimizations, and execution behavior.{{% /markdown %}} |
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
conv2d_slice_config | ::mlir::tt::ttnn::Conv2dSliceConfigAttr | TTNN Conv2d slice configuration attribute{{% markdown %}} Conv2d slice configuration specifying slice type and number of slices. {{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
bias_tensor | ranked tensor of any type values |
device | TTNN device |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.prepare_conv_transpose2d_weights (tt::ttnn::PrepareConvTranspose2dWeightsOp)
Prepares conv_transpose2d weights so that they can be consumed by the conv_transpose2d op.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
input_memory_config | ::mlir::tt::ttnn::MemoryConfigAttr | TTNN MemoryConfig attribute{{% markdown %}} The `MemoryConfigAttr` defines how a tensor is stored in memory on Tenstorrent hardware.{{% /markdown %}} |
input_tensor_layout | ::mlir::tt::ttnn::LayoutAttr | TTNN Layout |
weights_format | ::mlir::StringAttr | string attribute |
in_channels | ::mlir::IntegerAttr | 32-bit signless integer attribute |
out_channels | ::mlir::IntegerAttr | 32-bit signless integer attribute |
batch_size | ::mlir::IntegerAttr | 32-bit signless integer attribute |
input_height | ::mlir::IntegerAttr | 32-bit signless integer attribute |
input_width | ::mlir::IntegerAttr | 32-bit signless integer attribute |
kernel_size | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
stride | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
padding | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
dilation | ::mlir::DenseI32ArrayAttr | i32 dense array attribute |
has_bias | ::mlir::BoolAttr | bool attribute |
groups | ::mlir::IntegerAttr | 32-bit signless integer attribute |
input_dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
output_dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
conv2d_config | ::mlir::tt::ttnn::Conv2dConfigAttr | TTNN Conv2dConfig attribute{{% markdown %}} Configuration parameters for TTNN conv2d operations that control memory usage, performance optimizations, and execution behavior.{{% /markdown %}} |
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
conv2d_slice_config | ::mlir::tt::ttnn::Conv2dSliceConfigAttr | TTNN Conv2d slice configuration attribute{{% markdown %}} Conv2d slice configuration specifying slice type and number of slices. {{% /markdown %}} |
mirror_kernel | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
weight_tensor | ranked tensor of any type values |
device | TTNN device |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.prepare_moe_compute_w0_w1_weights (tt::ttnn::PrepareMoEComputeW0W1WeightsOp)
Prepack gate (W0) and up (W1) expert weights for moe_compute.
Interleaves W0 / W1 and reorders the result into the bank-aware sharded
layout ttnn.moe_compute's matmul_w0_w1_tensor operand consumes.
Optional bias_0 / bias_1 fuse per-expert biases along K (their
presence must match has_bias on the downstream moe_compute). The
result shape and memory layout are derived at compile time by the
TTNNDeduceMoEComputeLayouts pass via a TTNN graph-capture query.
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
hidden_size | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
intermediate_size | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
bh_ring_size | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
w0 | ranked tensor of any type values |
w1 | ranked tensor of any type values |
bias_0 | ranked tensor of any type values |
bias_1 | ranked tensor of any type values |
device | TTNN device |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.prepare_moe_compute_w2_weights (tt::ttnn::PrepareMoEComputeW2WeightsOp)
Prepack down (W2) expert weight for moe_compute.
Reorders W2 into the bank-aware sharded layout ttnn.moe_compute's
matmul_w2_tensor operand consumes. Optional bias_2 fuses the
per-expert bias along N without ring-rotation (its presence must match
has_bias on the downstream moe_compute). Result shape comes from the
TTNN graph capture query.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
hidden_size | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
intermediate_size | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
bh_ring_size | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
w2 | ranked tensor of any type values |
bias_2 | ranked tensor of any type values |
device | TTNN device |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.prod (tt::ttnn::ProdOp)
Product reduction op.
This op computes the product of all elements of the tensor (full product) or along a specific dimension.
Example: input: [[1, 2, 3], [4, 5, 6]]
// Computing along dim 0 output: [4, 10, 18]
// Computing along dim 1 output: [6, 120]
// Computing full product output: 720
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim_arg | ::mlir::IntegerAttr | 64-bit signless integer attribute |
keep_dim | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.quantize (tt::ttnn::QuantizeOp)
Quantize operation.
Applies quantization to the input tensor.
Inputs:
inputAnyRankedTensor: The input tensor to be quantized. Must have floating-point element type.scaleAnyRankedTensor: The scale factor (or factors for per-axis quantization). Must be either a scalar (for per-tensor quantization) or a 1D tensor with size matching the dimension of the specified axis (for per-axis quantization).zero_pointAnyRankedTensor: The zero point value (or values for per-axis quantization). Must be in range of the quantized storage type.axisOptional: The axis along which quantization is applied. Must be in range [0, rank) where rank is the rank of the input tensor. output_dtypeOptional<TTCore_DataTypeAttr>: The data type of the output tensor.
// For per-tensor quantization:
output[i] = round(input[i] / scale) + zero_point
// For per-axis quantization:
output[i0, i1, ..., ia, ..., in] = round(input[i0, i1, ..., ia, ..., in] / scale[ia]) + zero_point[ia]
Example:
%input = ttir.empty() : () -> tensor<64x128xf32>
%output = ttir.empty() : () -> tensor<64x128x!quant.uniform<i32:f32, 0.1>>
%quantized = "ttir.quantize"(%input, %output) : (tensor<64x128xf32>, tensor<64x128x!quant.uniform<i32:f32, 0.1>>) -> tensor<64x128x!quant.uniform<i32:f32, 0.1>>
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
axis | ::mlir::IntegerAttr | 32-bit signless integer attribute |
output_dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
scale | ranked tensor of any type values |
zero_point | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.rms_norm (tt::ttnn::RMSNormOp)
RMS normalization op.
RMS (Root Mean Square) normalization operation over the input tensor. Normalizes the input by computing the root mean square of elements and dividing by that value, optionally scaling and shifting the result.
This operation performs normalization over the last dimension of the input tensor, matching the TTNN runtime implementation.
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
epsilon | ::mlir::FloatAttr | 32-bit float attribute |
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
weight | ranked tensor of any type values |
bias | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.rms_norm_pre_all_gather (tt::ttnn::RMSNormPreAllGatherOp)
Pre all-gather RMS normalization op.
Computes local partial statistics for distributed RMS normalization across mesh devices. This op performs the local pre-processing stage of RMSNorm when the normalized dimension is sharded across devices. It computes the local RMS statistics (partial/local sum(x) and sum(x²)) needed to form the globally-correct RMS normalization factor, before an all-gather collects these statistics along the specified cluster_axis.
The gathered statistics are then consumed by the corresponding post-all-gather op, which computes the final normalization factor ( x / sqrt(E(x²) + epsilon) ) and applies normalization and optional weight scaling locally on each device.
Only statistics are communicated across devices; the input tensor itself is not all-gathered.
Maps to ttnn::rms_norm_pre_all_gather at runtime.
This operation requires the input tensor to be width-sharded across devices.
Inputs:
- input: Input tensor. Must be width-sharded in L1. Tiled layout required.
- residual: Optional Residual Input Tensor to add to input before normalization (x + residual). If provided, it must match input's padded shape and sharding.
Outputs:
- result: Intermediate/local statistics tensor that is later aggregated across devices via all-gather. The result is in TILE layout.
Attributes:
- compute_config: Device compute kernel configuration. Controls math fidelity, fp32_dest_acc_en, and packer L1 accumulation.
- program_config: LayerNormShardedMultiCoreProgramConfig derived from the input's shard spec (core grid, block_h, block_w).
- use_2d_core_grid: Optional flag controlling 2D core-grid execution. Defaults to None
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
program_config | ::mlir::tt::ttnn::LayerNormShardedMultiCoreProgramConfigAttr | TTNN LayerNorm Sharded Multi-Core Program Config{{% markdown %}} Configuration for sharded multi-core layer norm / RMS norm operations.{{% /markdown %}} |
use_2d_core_grid | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
residual | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.rand (tt::ttnn::RandOp)
Random number generation operation.
Returns a tensor filled with random numbers drawn from a uniform distribution over given interval [low, high) [Default: [0, 1)].
Example:
%0 = "ttnn.get_device"() <{mesh_offset = #ttnn<mesh_offset 0x0>, mesh_shape = #ttnn<mesh_shape 1x1>}> : () -> !ttnn.device
%1 = "ttnn.rand"(%0) <{high = 1.000000e+00 : f32, layout = #ttnn.layout
Attributes:
size(TTNN_ShapeAttr): The shape of the tensor to create.device(TTNN_Device): The device where the trace was captured.layout(TTNN_LayoutAttr): The layout for the output tensor.low(Float): The lower bound of the range (inclusive) [Default: 0.0].high(Float): The upper bound of the range (exclusive) [Default: 1.0].seed(Integer): Value to initialize the random number generator for reproducible results [Default: 0].
Outputs:
result(Tensor): The generated tensor containing the random values.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait, TTCore_CreationOpTrait, TTCore_NonCacheableTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_DeviceOperandInterface, TTNN_DtypeOpInterface, TTNN_LayoutOpInterface, TTNN_MemoryConfigOpInterface, TTNN_TensorSpecInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
size | ::mlir::tt::ttnn::ShapeAttr | TTNN Shape attribute{{% markdown %}} TTNN shape attribute {{% /markdown %}} |
low | ::mlir::FloatAttr | 32-bit float attribute |
high | ::mlir::FloatAttr | 32-bit float attribute |
seed | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
layout | ::mlir::tt::ttnn::LayoutAttr | TTNN Layout |
Operands:
| Operand | Description |
|---|---|
device | TTNN device |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.reciprocal (tt::ttnn::ReciprocalOp)
Eltwise reciprocal.
Eltwise reciprocal operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.reduce_scatter (tt::ttnn::ReduceScatterOp)
Reduce scatter op.
Tensor Reduce Scatter operation
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait, OpModelExempt
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
reduce_type | ::mlir::tt::ttcore::ReduceTypeAttr | TT Reduce Type |
scatter_dim | ::mlir::IntegerAttr | 32-bit signed integer attribute |
cluster_axis | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
sub_device_id | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
num_links | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
topology | ::mlir::tt::ttcore::TopologyAttr | CCL Topology Type |
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.relu6 (tt::ttnn::Relu6Op)
Eltwise ReLU6.
Eltwise ReLU6 operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.relu (tt::ttnn::ReluOp)
Eltwise ReLU.
Eltwise ReLU operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.remainder (tt::ttnn::RemainderOp)
Eltwise remainder.
Performs element-wise remainder of dividend lhs and divisor rhs tensors and produces a result tensor.
Example:
// %lhs: [17, -17, 17, -17] // %rhs: [3, 3, -3, -3] %result = "ttnn.remainder"(%lhs, %rhs) : (tensor<4xi64>, tensor<4xi64>) -> tensor<4xi64> // %result: [2, -2, 2, -2]
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.repeat_interleave (tt::ttnn::RepeatInterleaveOp)
Repeat interleave op.
Repeats elements of a tensor along a specified dimension. It allows for flexible repetition patterns, where each element can be repeated a different number of times. This is particularly useful for tasks that require duplicating elements in a non-uniform manner.
Parameters:
input: The input tensor.repeats: Specifies the number of repetitions for each element, each element is repeated that number of times.dim: The dimension along which to repeat values.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
repeats | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
dim | ::mlir::IntegerAttr | 32-bit signed integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.repeat (tt::ttnn::RepeatOp)
Repeat op.
Returns a new tensor filled with repetition of input tensor according to number of times specified in repeat_dims.
Parameters:
input_tensor(ttnn.Tensor): the input tensor.repeat_dims(number): The number of repetitions for each element.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
repeat_dims | ::mlir::tt::ttnn::ShapeAttr | TTNN Shape attribute{{% markdown %}} TTNN shape attribute {{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.requantize (tt::ttnn::RequantizeOp)
Requantize operation.
Applies requantization to the input tensor.
Inputs:
inputAnyRankedTensor: The input tensor to be requantized. Must have quantized element type.in_scaleAnyRankedTensor: The input scale factor (or factors for per-axis quantization). Must be either a scalar (for per-tensor quantization) or a 1D tensor with size matching the dimension of the specified axis (for per-axis quantization).in_zero_pointAnyRankedTensor: The input zero point value (or values for per-axis quantization). Must be in range of the quantized storage type.out_scaleAnyRankedTensor: The output scale factor (or factors for per-axis quantization). Must be either a scalar (for per-tensor quantization) or a 1D tensor with size matching the dimension of the specified axis (for per-axis quantization).out_zero_pointAnyRankedTensor: The output zero point value (or values for per-axis quantization). Must be in range of the quantized storage type.axisOptional: The axis along which quantization is applied. Must be in range [0, rank) where rank is the rank of the input tensor. output_dtypeOptional<TTCore_DataTypeAttr>: The data type of the output tensor.
// For per-tensor requantization:
output[i] = round((input[i] - input_zero_point) * (input_scale / output_scale)) + output_zero_point
// For per-axis requantization:
output[i0, i1, ..., ia, ..., in] = round((input[i0, i1, ..., ia, ..., in] - in_zero_point[ia]) * (in_scale[ia] / out_scale[ia])) + out_zero_point[ia]
Example:
%input = ttir.empty() : () -> tensor<64x128x!quant.uniform<i32:f32, 0.1>>
%output = ttir.empty() : () -> tensor<64x128x!quant.uniform<i32:f32, 0.2>>
%requantized = "ttnn.requantize"(%input, %output) : (tensor<64x128x!quant.uniform<i32:f32, 0.1>, tensor<64x128x!quant.uniform<i32:f32, 0.2>>) -> tensor<64x128x!quant.uniform<i32:f32, 0.2>>
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
axis | ::mlir::IntegerAttr | 32-bit signless integer attribute |
output_dtype | ::mlir::tt::ttcore::DataTypeAttr | TT DataTypes |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
in_scale | ranked tensor of any type values |
in_zero_point | ranked tensor of any type values |
out_scale | ranked tensor of any type values |
out_zero_point | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.reset_global_semaphore (tt::ttnn::ResetGlobalSemaphoreOp)
Reset global semaphore op.
Resets a global semaphore to the specified value.
Example:
"ttnn.reset_global_semaphore"(%semaphore) <{value = 0 : ui32}> : (!ttnn.global_semaphore) -> ()
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait, OpModelExempt
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
value | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
semaphore | TTNN global semaphore. |
ttnn.reshape (tt::ttnn::ReshapeOp)
Reshape op.
Reshape tensor.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
shape | ::mlir::ArrayAttr | 32-bit integer array attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.rotary_embedding_llama (tt::ttnn::RotaryEmbeddingLlamaOp)
Rotary embedding llama operation.
Applies rotary embedding to the input tensor using precomputed cosine and sine caches along with a transformation matrix.
The operation supports both prefill and decode modes:
- Prefill mode: Uses interleaved memory layout
- Decode mode: Uses height-sharded memory layout
Example:
%result = ttnn.rotary_embedding_llama(%input, %cos_cache, %sin_cache, %trans_mat)
{is_decode_mode = false}
: tensor<1x32x128xbf16>, tensor<1x32x128xbf16>, tensor<1x32x128xbf16>,
tensor<1x1x32x32xbf16> -> tensor<1x32x128xbf16>
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
is_decode_mode | ::mlir::BoolAttr | bool attribute |
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
cos_cache | ranked tensor of any type values |
sin_cache | ranked tensor of any type values |
trans_mat | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.rotary_embedding (tt::ttnn::RotaryEmbeddingOp)
Rotary embedding op in TTNN dialect.
Applies rotary embedding to the input tensor using precomputed cosine and sine caches. Formula used: x_rotated = x * cos + rotate_half(x) * sin where rotate_half(x) swaps the first and second halves of the last dimension of x.
Example:
%result = ttnn.rotary_embedding(%input, %cos_cache, %sin_cache)
: tensor<1x32x1024x64xf16>, tensor<1x1x1024x64xf16>, tensor<1x1x1024x64xf16>
-> tensor<1x32x1024x64xf16>
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
token_index | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
cos_cache | ranked tensor of any type values |
sin_cache | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.rsqrt (tt::ttnn::RsqrtOp)
Eltwise rsqrt.
Eltwise rsqrt operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.sampling (tt::ttnn::SamplingOp)
Sampling operation.
Performs fused top-k + top-p + multinomial sampling on pre-filtered candidate logits using the ttnn::sampling kernel.
Inputs:
input_values: Pre-filtered candidate logit values [batch, candidates] bf16, TILE layoutinput_indices: Global vocab indices for each candidate [batch, candidates] int32, ROW_MAJORk: Per-request top-k values [batch] uint32, ROW_MAJORp: Per-request top-p values [batch] bf16, ROW_MAJORtemp: Per-request temperature values [batch] bf16, ROW_MAJORseed: Optional random seed (uint32 scalar attribute)
Output:
result: Sampled global token indices [batch] int32, ROW_MAJOR
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
seed | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
input_values | ranked tensor of any type values |
input_indices | ranked tensor of any type values |
k | ranked tensor of any type values |
p | ranked tensor of any type values |
temp | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.scaled_dot_product_attention_decode (tt::ttnn::ScaledDotProductAttentionDecodeOp)
A version of scaled dot product attention specifically for decode.
Flash-Decode SDPA for single-query-token decode. Supports MQA and GQA.
Shapes use B (batch), Hq/Hkv (query/kv heads), Sk (kv seq len),
D (head size).
Args:
query (AnyRankedTensor): [1 x B x Hq x D]. Dim 0 must be 1.
key (AnyRankedTensor): [B x Hkv x Sk x D].
value (AnyRankedTensor): [B x Hkv x Sk x D]. Same type as key.
is_causal (bool, optional): Defaults to true. Mutually exclusive
with attention_mask.
attention_mask (AnyRankedTensor, optional): [1|B x 1 x 1|Hq x Sk].
Dim 0 broadcasts batch, dim 2 broadcasts heads. Only valid when
is_causal is false.
cur_pos_tensor (AnyRankedTensor): 1D [B] integer tensor of decode
positions.
attention_sink (AnyRankedTensor, optional): [Hq x 32], single tile
wide.
scale (float, optional): Softmax scale. Defaults to 1 / sqrt(D).
Returns:
AnyRankedTensor: [1 x B x Hq x D] (same type as query).
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
is_causal | ::mlir::BoolAttr | bool attribute |
scale | ::mlir::FloatAttr | 32-bit float attribute |
program_config | ::mlir::tt::ttnn::SDPAProgramConfigAttr | TTNN SDPA (Scaled Dot Product Attention) Program Config{{% markdown %}} Configuration for Scaled Dot Product Attention (SDPA) operations.{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
query | ranked tensor of any type values |
key | ranked tensor of any type values |
value | ranked tensor of any type values |
attention_mask | ranked tensor of any type values |
cur_pos_tensor | ranked tensor of any type values |
attention_sink | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.scaled_dot_product_attention (tt::ttnn::ScaledDotProductAttentionOp)
Scaled dot product attention operation.
FlashAttention-2 SDPA. Supports MHA, MQA, and GQA.
Shapes use B (batch), Hq/Hkv (query/kv heads), Sq/Sk (query/kv
seq len), D (head size).
Args:
query (AnyRankedTensor): [B x Hq x Sq x D].
key (AnyRankedTensor): [B x Hkv x Sk x D].
value (AnyRankedTensor): [B x Hkv x Sk x D]. Same type as key.
attention_mask (AnyRankedTensor, optional): [1|B x 1|Hq x Sq x Sk].
Dim 0 broadcasts batch, dim 1 broadcasts heads. Only valid when
is_causal is false. Defaults to None.
is_causal (bool): Defaults to true. Requires Sq == Sk and no
attention_mask.
scale (float, optional): Softmax scale. Defaults to 1 / sqrt(D).
sliding_window_size (uint, optional): If is_causal, attends to the
last N tokens; otherwise attends to a window of size N centered at
the current position. Defaults to None.
attention_sink (AnyRankedTensor, optional): [1 x Hq x 1 x 1], one
value per query head broadcast across batch and tile dims.
Defaults to None.
Returns:
AnyRankedTensor: [B x Hq x Sq x D] (same type as query).
Traits: AlwaysSpeculatableImplTrait, AttrSizedOperandSegments, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
is_causal | ::mlir::BoolAttr | bool attribute |
scale | ::mlir::FloatAttr | 32-bit float attribute |
sliding_window_size | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
query | ranked tensor of any type values |
key | ranked tensor of any type values |
value | ranked tensor of any type values |
attention_mask | ranked tensor of any type values |
attention_sink | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.scatter (tt::ttnn::ScatterOp)
Scatter op.
Embeds the values of the source tensor into the input tensor at locations specified by the index tensor along the given dimension.
Parameters:
input(ttnn.Tensor): The tensor being updated.index(ttnn.Tensor): Indices where values will be written to.source(ttnn.Tensor): The values to scatter into the input tensor.dim(int32_t): The dimension along which to scatter.scatter_reduce_type(Enum): The scatter reduce type to use (SUM, PROD, MIN, MAX, INVALID).
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim | ::mlir::IntegerAttr | 32-bit signless integer attribute |
scatter_reduce_type | ::mlir::tt::ttcore::ReduceTypeAttr | TT Reduce Type |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
index | ranked tensor of any type values |
source | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.selective_reduce_combine (tt::ttnn::SelectiveReduceCombineOp)
Reduce and combine phase of the MoE pipeline.
Takes dense blocks of expert-computed tokens from the MoE compute kernel, sparsifies them, and sends tokens back to their originating devices via fabric.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait, OpModelExempt
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
hidden_size | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
batch_size | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
seq_size | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
select_experts_k | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
experts | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
dense_input_tensor | ranked tensor of any type values |
dense_activations_tensor | ranked tensor of any type values |
dense_token_maps_tensor | ranked tensor of any type values |
dense_token_counts_tensor | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.sigmoid (tt::ttnn::SigmoidOp)
Eltwise sigmoid.
Eltwise sigmoid operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.sign (tt::ttnn::SignOp)
Eltwise sign operation.
Returns the sign of the operand element-wise and produces a result
tensor.
Example: %a: [[3, -2, 0], [1, -4, 4]] "ttnn.sign"(%a, %out) -> %out: [[1, -1, 0], [1, -1, 1]]
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.silu (tt::ttnn::SiluOp)
Eltwise SiLU.
Eltwise SiLU (Swish) operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.sin (tt::ttnn::SinOp)
Eltwise sine.
Eltwise sine operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.slice_dynamic (tt::ttnn::SliceDynamicOp)
Dynamic slice op.
Extract a portion of a tensor based on the specified start (begins), stop (ends), and step
indices for each dimension. Maps to ttnn::slice.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
step | ::mlir::ArrayAttr | 32-bit integer array attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
begins | ranked tensor of any type values |
ends | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.slice_static (tt::ttnn::SliceStaticOp)
Slice op.
Extract a portion of a tensor based on the specified start (begins), stop (ends), and step
indices for each dimension. The begins and ends parameters are attributes with fixed values.
Maps to ttnn::slice.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
begins | ::mlir::ArrayAttr | 32-bit integer array attribute |
ends | ::mlir::ArrayAttr | 32-bit integer array attribute |
step | ::mlir::ArrayAttr | 32-bit integer array attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.softmax (tt::ttnn::SoftmaxOp)
Softmax op.
Softmax operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dimension | ::mlir::IntegerAttr | 32-bit signed integer attribute |
numericStable | ::mlir::BoolAttr | bool attribute |
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.sort (tt::ttnn::SortOp)
Sort op.
Sorts elements of a tensor along a given dimension.
Input:
- input: AnyRankedTensor
Attributes:
- dim (int8): The dimension to sort along (default: -1, the last dim).
- descending (bool): If True, sort in descending order (default: False).
- stable (bool): If True, ensures stable sort (equal elements keep order).
Returns a tuple:
- values: the sorted tensor.
- indices: the original indices of the sorted values.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim | ::mlir::IntegerAttr | 8-bit signed integer attribute |
descending | ::mlir::BoolAttr | bool attribute |
stable | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
values | ranked tensor of any type values |
indices | ranked tensor of any type values |
ttnn.sparse_matmul (tt::ttnn::SparseMatmulOp)
Sparse block matrix multiplication with sparsity mask.
The sparse_matmul operation performs batched matrix multiplication where
computation is selectively skipped for blocks marked as zero in the sparsity
tensor. Input b is organized as a collection of weight matrices indexed by
a block dimension (dim 1), and the sparsity tensor controls which blocks
participate in the computation.
Supported Modes:
- is_input_a_sparse=false, is_input_b_sparse=true (column-parallel): a: [A, B, M, K], b: [1, E, K, N], sparsity: [A, B, 1, E] -> output: [A, B, 1, E, M, N]
- is_input_a_sparse=true, is_input_b_sparse=false (row-parallel): a: [A, E, M, K], b: [1, E, K, N], sparsity: [1, 1, A, E] -> output: [A, E, M, N]
- is_input_a_sparse=true, is_input_b_sparse=true (both sparse): a: [1, E, M, K], b: [1, E, K, N], sparsity: [1, 1, 1, E] -> output: [1, E, M, N]
Example:
%result = "ttnn.sparse_matmul"(%activations, %weights, %sparsity) <{
is_input_a_sparse = false, is_input_b_sparse = true, nnz = 2
}> : (tensor<2x4x32x2880xbf16>, tensor<1x4x2880x5760xbf16>,
tensor<2x4x1x4xbf16>) -> tensor<2x4x1x4x32x5760xbf16>
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait, OpModelExempt
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
is_input_a_sparse | ::mlir::BoolAttr | bool attribute |
is_input_b_sparse | ::mlir::BoolAttr | bool attribute |
nnz | ::mlir::IntegerAttr | 64-bit signless integer attribute |
program_config | ::mlir::tt::ttnn::MatmulMultiCoreReuseMultiCast1DProgramConfigAttr | TTNN MatmulMultiCoreReuseMultiCast1DProgramConfig{{% markdown %}} TTNN MatmulMultiCoreReuseMultiCast1DProgramConfig{{% /markdown %}} |
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
a | ranked tensor of any type values |
b | ranked tensor of any type values |
sparsity | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.split_query_key_value_and_split_heads (tt::ttnn::SplitQueryKeyValueAndSplitHeadsOp)
Split query, key, values and split heads op used in attention layer.
Splits input_tensor of shape [batch_size, sequence_size, 3 * hidden_size] into 3 tensors (Query, Key, Value) of shape [batch_size, sequence_size, hidden_size]. Then, reshapes and permutes the output tensors, to make them ready for computing attention scores. If kv_input_tensor is passed in, then input_tensor of shape [batch_size, sequence_size, hidden_size] is only used for Query, and kv_input_tensor of shape [batch_size, sequence_size, 2 * hidden_size] is used for Key and Value. For the sharded implementation, the input query, key and value are expected to be concatenated such that the heads are interleaved (q1 k1 v1…qn kn vn).
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
num_heads | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
num_kv_heads | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
transpose_key | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
input_tensor | ranked tensor of any type values |
kv_input_tensor | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
query | ranked tensor of any type values |
key | ranked tensor of any type values |
value | ranked tensor of any type values |
ttnn.sqrt (tt::ttnn::SqrtOp)
Eltwise sqrt.
Eltwise sqrt operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.subtract (tt::ttnn::SubtractOp)
Eltwise subtract.
Eltwise subtract operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseBinary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
lhs | ranked tensor of any type values |
rhs | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.sum (tt::ttnn::SumOp)
Sum reduction op.
Sum reduction op.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ComputeKernelConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
keep_dim | ::mlir::BoolAttr | bool attribute |
dim_arg | ::mlir::ArrayAttr | 32-bit integer array attribute |
compute_config | ::mlir::tt::ttnn::DeviceComputeKernelConfigAttr | TTNN DeviceComputeKernelConfig attribute{{% markdown %}} The TTNN_DeviceComputeKernelConfig attribute configures compute kernel execution parameters for tensor operations on Tenstorrent devices. This attribute provides fine-grained control over mathematical precision, memory usage, and synchronization behavior during compute operations.{{% /markdown %}} |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.tan (tt::ttnn::TanOp)
Eltwise tan op.
Eltwise tan operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.tanh (tt::ttnn::TanhOp)
Eltwise tanh op.
Eltwise tanh operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_ElementwiseUnary, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.to_device (tt::ttnn::ToDeviceOp)
ToDevice op.
This op sends the input tensor to the given device with the given memory config.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait, OpModelExempt
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
device | TTNN device |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.to_layout (tt::ttnn::ToLayoutOp)
ToLayout op.
This op wraps all layout information gathered from ttir.toLayout. It is used/updated by the optimizer to perform optimizations, and later broken down into specific memory/layout operations (toDevice, toMemoryConfig etc.). Currently in the TTNN backend, we use this op solely for tilize/untilize, therefore marking all other attrs as optional. Once ttnn::to_layout supports other attrs, we can remove the optional tag.
The output data type is derived from the result tensor's TTNNLayoutAttr
encoding via the TTNN_DtypeOpInterface. Whether this op actually changes dtype can
be queried via hasDtypeChange().
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
layout | ::mlir::tt::ttnn::LayoutAttr | TTNN Layout |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.to_memory_config (tt::ttnn::ToMemoryConfigOp)
ToMemoryConfig op.
This op converts the memory config of the input tensor based on the given memory config. It handles:
- Dram to L1
- L1 to Dram
- Interleaved to sharded
- Sharded to interleaved
- Sharded to sharded (reshard)
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.topk (tt::ttnn::TopKOp)
Top-K selection operation.
Returns the k largest or k smallest elements of the input_tensor along a given dimension dim.
If dim is not provided, the last dimension of the input_tensor is used.
If largest is True, the k largest elements are returned. Otherwise, the k smallest elements are returned.
The boolean option sorted if True, will make sure that the returned k elements are sorted.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
k | ::mlir::IntegerAttr | 32-bit signless integer attribute |
dim | ::mlir::IntegerAttr | 32-bit signless integer attribute |
largest | ::mlir::BoolAttr | bool attribute |
sorted | ::mlir::BoolAttr | bool attribute |
Operands:
| Operand | Description |
|---|---|
input_tensor | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
values | ranked tensor of any type values |
indices | ranked tensor of any type values |
ttnn.topk_router_gpt (tt::ttnn::TopKRouterGptOp)
Fused router linear layer for GPT-style mixture-of-experts models.
A fused multi-core matmul + top-k for the GPT-OSS MoE router. Computes the router logits via a linear projection (input @ weight + bias) and returns the top-k expert indices and weights for each token.
Inputs:
- input: [B, hidden_dim] bf16 hidden states
- weight: [hidden_dim, num_experts] bf16 router weight matrix
- bias: [B, num_experts] bf16 router bias (pre-broadcast across batch)
Outputs:
- expert_indices: [B, k] ui16 top-k expert indices (ROW_MAJOR)
- expert_weights: [B, k] bf16 top-k router weights (ROW_MAJOR)
num_experts must be 128. B must be 32.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
k | ::mlir::IntegerAttr | 32-bit signless integer attribute |
num_experts | ::mlir::IntegerAttr | 32-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
weight | ranked tensor of any type values |
bias | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
expert_indices | ranked tensor of any type values |
expert_weights | ranked tensor of any type values |
ttnn.transpose (tt::ttnn::TransposeOp)
Transpose op.
Transpose tensor along two given dimensions.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
dim0 | ::mlir::IntegerAttr | 32-bit signed integer attribute |
dim1 | ::mlir::IntegerAttr | 32-bit signed integer attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.typecast (tt::ttnn::TypecastOp)
Typecast op.
This op converts the data type of the input tensor based on the given data type. It handles:
- conversions of data types.
The output data type is derived from the result tensor's TTNNLayoutAttr encoding via the TTNN_DtypeOpInterface.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.update_cache (tt::ttnn::UpdateCacheOp)
Update static cache tensor.
Updates the cache tensor in-place with values from input at update_index and batch_offset.
Interfaces: MemoryEffectOpInterface (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{MemoryEffects::Write on ::mlir::SideEffects::DefaultResource}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
batch_offset | ::mlir::IntegerAttr | 32-bit signless integer attribute |
Operands:
| Operand | Description |
|---|---|
cache | ranked tensor of any type values |
input | ranked tensor of any type values |
update_index | ranked tensor of any type values |
ttnn.upsample (tt::ttnn::UpsampleOp)
Upsample 2D op.
Upsample 2D operation. Input tensor is assumed to be in NHWC format.
Attributes:
scale_factor(si32 | array): The scale factor for upsampling in H and W dimensions respectively. mode(str): The upsampling algorithm. Currently only "nearest" and "bilinear" are supported. Default is "nearest".
Example: // %a: tensor<10x64x32xbf16> %0 = "ttnn.upsample"(%a) <{scale_factor = array<i32: 2, 4>}> : (tensor<10x64x32x3xbf16>) -> tensor<10x128x128x3xbf16>
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
scale_factor | ::mlir::Attribute | 32-bit signed integer attribute or i32 dense array attribute |
mode | ::mlir::StringAttr | string attribute |
Operands:
| Operand | Description |
|---|---|
input | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.where (tt::ttnn::WhereOp)
Eltwise where.
Eltwise where operation.
Traits: AlwaysSpeculatableImplTrait, CheckTileTypeTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Operands:
| Operand | Description |
|---|---|
first | ranked tensor of any type values |
second | ranked tensor of any type values |
third | ranked tensor of any type values |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |
ttnn.write_tensor (tt::ttnn::WriteTensorOp)
Write tensor op.
Copies host_tensor data into device_tensor through cq_id. Memory copy is done in place, thus no output is returned. Inputs:
host_tensorAnyRankedTensor: The host tensor to copy.device_tensorAnyRankedTensor: The device tensor to copy into.blockingbool: Whether the copy should be executed synchronously.cq_idi32: The command queue to copy the tensor with. Must be 0 or 1.
Traits: OpModelExempt
Interfaces: MemoryEffectOpInterface (MemoryEffectOpInterface), TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{MemoryEffects::Write on ::mlir::SideEffects::DefaultResource}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
blocking | ::mlir::BoolAttr | bool attribute |
cq_id | ::mlir::IntegerAttr | 32-bit unsigned integer attribute |
Operands:
| Operand | Description |
|---|---|
host_tensor | ranked tensor of any type values |
device_tensor | ranked tensor of any type values |
ttnn.zeros (tt::ttnn::ZerosOp)
Creates a tensor filled with zeros.
Tensor operation to create a tensor filled with zeros.
Given a ShapeAttr shape, produces a tensor with the same shape, filled with zeros.
Example: %0 = "ttnn.zeros"() <{shape = array<i32:64, 28, 28>}> : () -> tensor<64x28x28xbf16> // %0: [[[0, 0, 0, ..., 0], [0, 0, 0, ..., 0], ..., [0, 0, 0, ..., 0]]]
Traits: AlwaysSpeculatableImplTrait, CanExecuteOnHostTrait, CheckTileTypeTrait, TTCore_CreationOpTrait
Interfaces: ConditionallySpeculatable, NoMemoryEffect (MemoryEffectOpInterface), OpModel, TTNNDtypeOpInterface, TTNNMemoryConfigOpInterface, TTNN_DeviceOperandInterface, TTNN_DtypeOpInterface, TTNN_LayoutOpInterface, TTNN_MemoryConfigOpInterface, TTNN_TensorSpecInterface, TTNN_WorkaroundInterface
Effects: MemoryEffects::Effect{}
Attributes:
| Attribute | MLIR Type | Description |
|---|---|---|
shape | ::mlir::tt::ttnn::ShapeAttr | TTNN Shape attribute{{% markdown %}} TTNN shape attribute {{% /markdown %}} |
layout | ::mlir::tt::ttnn::LayoutAttr | TTNN Layout |
Operands:
| Operand | Description |
|---|---|
device | TTNN device |
Results:
| Result | Description |
|---|---|
result | ranked tensor of any type values |