SaProt-1.3b was running on fabricated weights due to a config mismatch that strict=False happily hid—the checkpoint has 66 layers at 1280 hidden dim, not 40 layers at 2560—and now from_pretrained reads the real config and refuses to build on shape mismatches, bringing the model to near-parity (X_emb=0.99508, just shy of the 0.9987–0.9996 ESMC band due to bf16 accumulation over those 66 residual layers). Perf-gate false positives between machines of the same card type are fixed by adding machine-id (socket.gethostname()) under the card-type baseline block. The release adds multi-card data-parallel fanout for SaProt embeddings via --devices, seeds perf baselines for esmc-300m, esmc-6b, saprot-650m, and boltz2-affinity (activating their regression gates), hardens the Boltz-2 and Protenix-v2 flagship legs with 5+5 seeds and alignment-free metrics (TM-score, CA-lDDT), widens the Boltz-2 affinity leg to three targets with pose and pocket metrics, root-causes and fixes a FKBP12 affinity GAP from unseeded global RNG draws in the worker, and adds HSA (L585) as the first L300–800 pharma-realistic target—plus drops ProteinMPNN entirely (CPU-only, redundant with BoltzGen's inverse-fold path).
A hidden dimension of Tenstorrent awesomeness
A curated directory of projects, tools, models, and research for Tenstorrent hardware — contributed by the community and our team. Browse by category or search across all entries.
Planet Tenstorrent is the ecosystem's live feed — new releases, articles, papers, talks, and community posts from across the Tenstorrent world, gathered in one place and updated daily. The latest five:
This release brings two new capabilities that expand tt-bio's toolkit for protein design workflows: SaProt structure-aware embeddings and ProteinMPNN inverse folding for fixed-backbone design. SaProt fuses amino-acid and Foldseek-3Di vocabularies into an ESM-2 encoder, letting you embed proteins with awareness of their 3D structure; ProteinMPNN then lets you generate sequences that fold back to a given backbone—the natural next step after running a structure predictor like Boltz-2 or bringing your own backbone. Both features are fully gated and validated on Blackhole P150a hardware with no performance regression across the existing model lineup (Boltz-2, ESMFold2, Protenix-v2, OpenDDE, ESMC), embedding parity tests confirm numerical accuracy, and ProteinMPNN runs on CPU via data-parallel fanout rather than on-device porting. See docs/proteinmpnn-port.md for details on the design choice.
This release brings antibody-antigen co-folding via OpenDDE (built on Protenix-v2 with a structural-token expander) alongside a fused-RoPE attention kernel that speeds up embedding without accuracy loss, plus optional diffusion trace replay that collapses per-step host dispatch overhead across Boltz-2, BoltzGen, Protenix-v2, and OpenDDE. The release also establishes perf and UX regression gates as standing test legs, fixing two release-blocking issues: OF3 pairformer gates now gracefully skip when missing host keys, and the perf gate now compares against hardware-specific baselines so P150a runs aren't falsely judged against P300c numbers. All shipped models pass gate thresholds with no performance regressions observed.
The release introduces HivemindSweeper, a new mode for system monitoring, alongside a shift to distributing packages via ppa.tenstorrent.com for easier installation.
The VS Code toolkit now includes a comprehensive guide to joyfully monkeypatching TT-NN without modifying your precious tt-metal checkouts.
This site is two old traditions sharing one orbit: an awesome list and a planet. Open source is an ecosystem the way space is — moonshot projects igniting into galaxies of forks and stars, and planet sites keeping the whole universe in view. (Around here the metaphor is load-bearing: we ship hardware called Galaxy.) Both traditions are gifts from decades of that culture, and both deserve some tribute.
🕶 The awesome list
Humans curating links for other humans is the oldest genre on the web —
Yahoo! began life in 1994 as "Jerry and David's Guide to the World
Wide Web", and the volunteer-run
DMOZ / Open Directory Project
kept hand-sorted order for two decades. In 2014, Sindre Sorhus distilled
that instinct into a GitHub-native microformat with
sindresorhus/awesome:
one README, a ruthless curation bar ("only awesome things"), and pull
requests as the editorial process. The
awesome manifesto
turned list-making into a commons — thousands of lists,
lists of lists,
and giants like
awesome-python,
awesome-selfhosted, and
awesome-go.
Synth heads are gloriously covered too:
awesome-musicdsp,
awesome-audio-dsp,
awesome-webaudio, and
awesome-supercollider.
Because the format is halfway to being a database, people have long
rendered lists into websites — tt-awesome just commits to the bit:
every entry is a JSON file, and the README, this site,
data.json, and the feeds are all built from the same source.
🪐 The planet
In the early 2000s, Jeff Waugh and Scott James Remnant wrote Planet, a little Python feed aggregator that river-merged a community's blogs into one page — and free software communities never looked back. Planet GNOME, Planet KDE, Planet Debian, Planet Gentoo, Planet Ubuntu, Planet Fedora (the Red Hat family), and Planet Mozilla are all still ticking decades later, many having passed through Sam Ruby's Planet Venus rewrite along the way. The lineage runs deeper still: before planets there were blogrolls, and before blogrolls, web rings — WebRing was built in 1995 by a teenaged Sage Weil, who grew up to create Ceph, which is about as open-source-full-circle as a story gets. Planet Tenstorrent carries that torch for this ecosystem.
⚡ Why we bother
Curated commons like these only exist because communities keep them alive in the open. That's not nostalgia to us — it's the plan. Open source is our past, present, and future.
No entries match the current filters.
Select an entry to see details
tt-metal
officialTT-NN operator library and TT-Metalium low-level kernel programming model. The primary SDK for developing on Tenstorrent hardware — from high-level tensor ops to bare-metal RISC-V kernels.
5 previous releases
tt-forge
official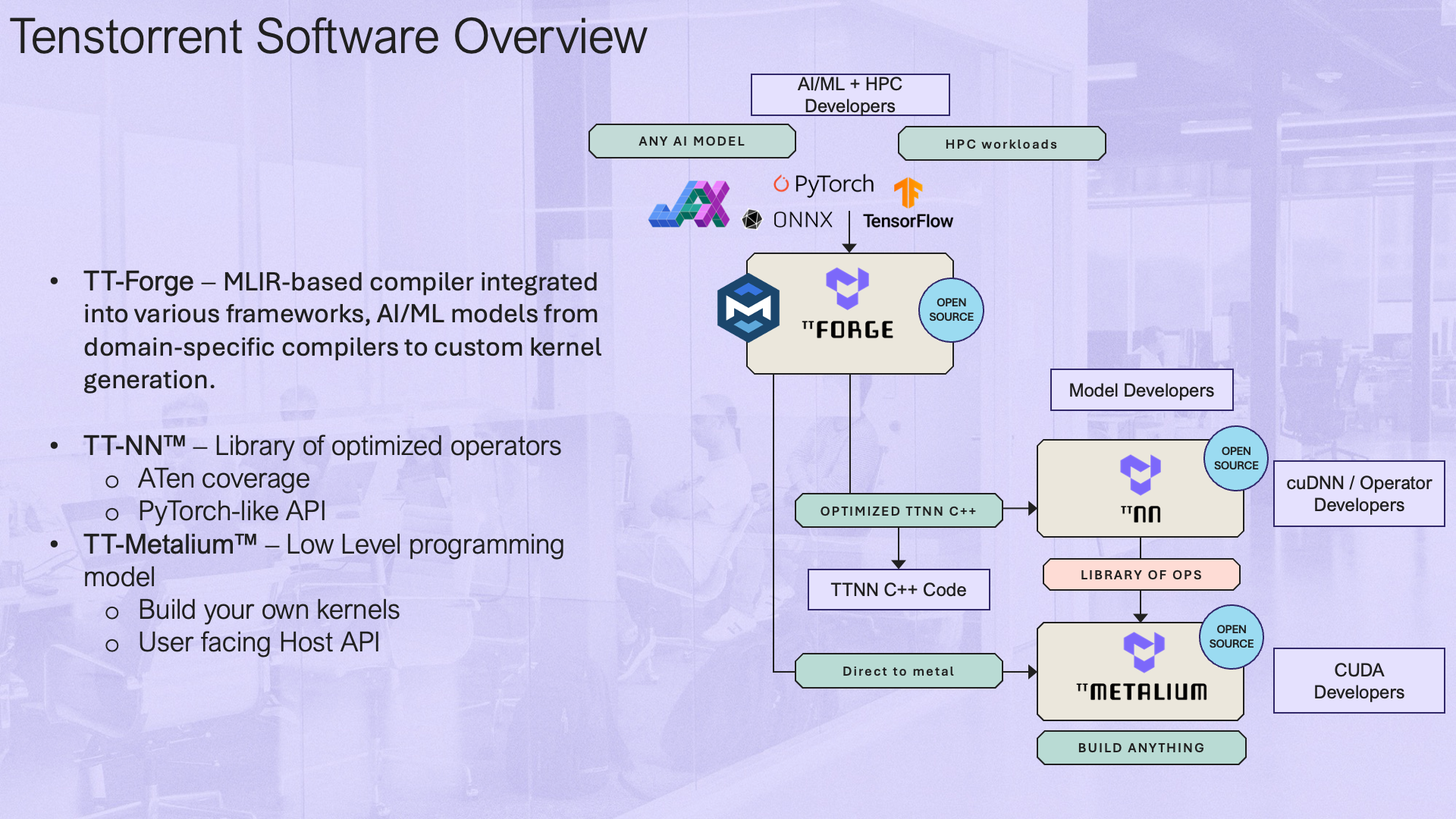
Tenstorrent's MLIR-based compiler frontend. Enables running AI workloads from PyTorch, ONNX, and other frameworks on all Tenstorrent hardware configurations through an open-source, general, and performant compiler.
5 previous releases
tt-buda
officialTT-BUDA: Tenstorrent's original Python compiler and runtime for AI workloads. Legacy stack — tt-forge is the recommended successor, but tt-buda has the largest model demo library.
4 previous releases
tt-mlir
officialTenstorrent MLIR compiler — the core compiler infrastructure shared by tt-forge and other frontends. Handles graph optimization, lowering, and code generation for Tensix hardware.
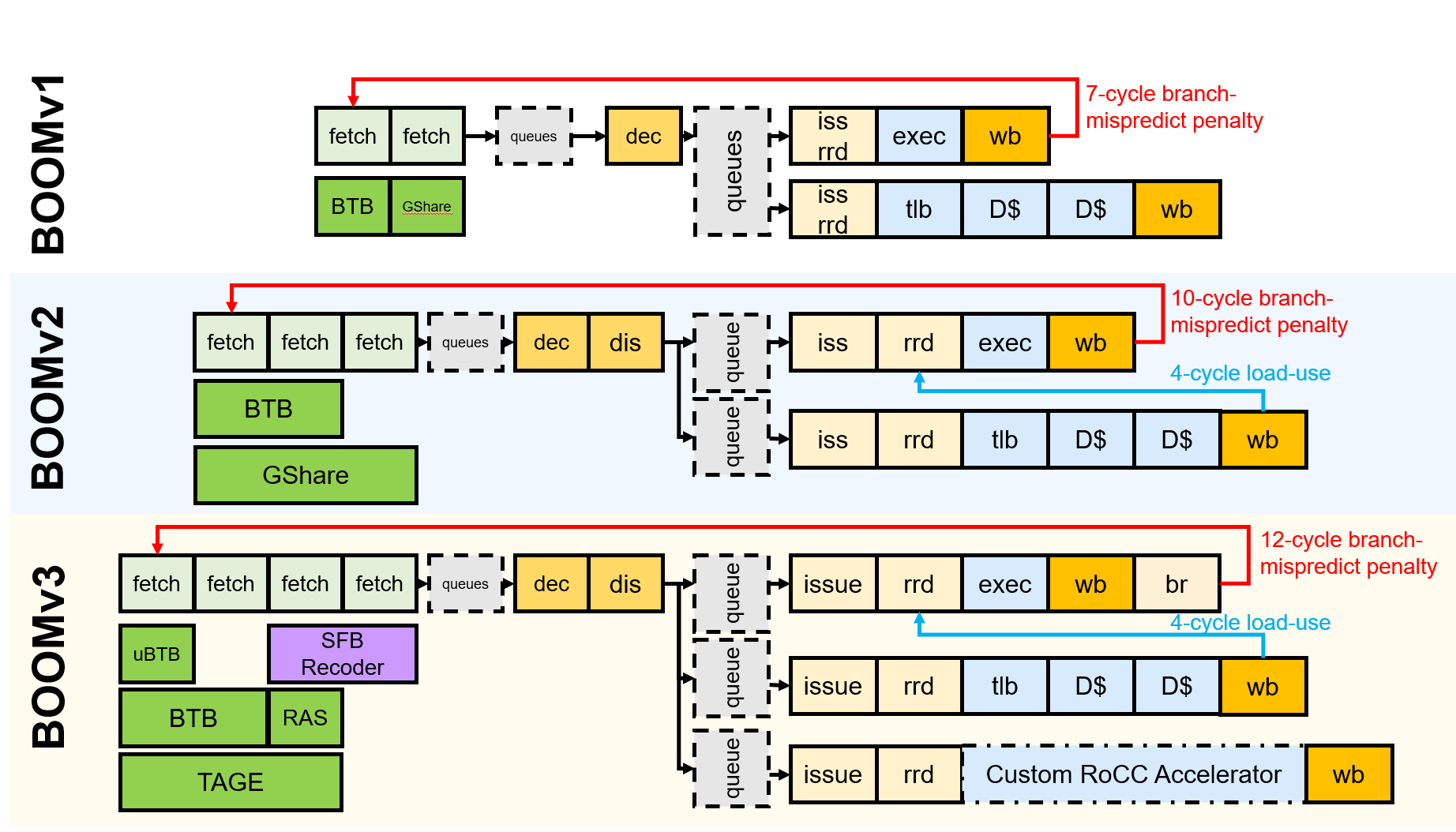
The Berkeley Out-of-Order Machine with V-EXT (RISC-V Vector Extension) support. Tenstorrent's research-grade out-of-order RISC-V core with vector extension.
ttsim
officialFast full-system simulator of Tenstorrent Wormhole and Blackhole hardware. Runs TT-Metalium workloads on any Linux/x86_64 system without physical silicon. Bit-exact results relative to hardware.
riscv_arch_tests
officialRISC-V architectural self-checking directed tests — randomly-generated register operands and data with low-level OS code for test scheduling and self-checking, runnable on a RISC-V design or an ISS such as Whisper or Spike. Generated by an internal Tenstorrent tool from the official RISC-V ISA spec.
tt-isa-documentation
officialLow-level ISA and microarchitecture documentation for Tenstorrent AI architectures (Grayskull, Wormhole, Blackhole) — the authoritative hardware reference beneath the tt-forge / tt-metal software stack.
RISC-V Instruction Set Simulator (ISS) used by Tenstorrent for processor verification. Powers the co-simulation architecture checker.
tt-xla
officialPJRT device plugin for Tenstorrent hardware. Enables JAX, PyTorch/XLA, and other XLA-based frameworks to target TT accelerators.
5 previous releases
tt-kmd
officialTenstorrent kernel module driver. The Linux kernel module required to interface with Tenstorrent PCIe accelerator cards.
4 previous releases
RiESCUE
officialRISC-V Directed Test Framework and Compliance Suite. Comprehensive test infrastructure for verifying RISC-V processor implementations against the specification.
tt-inference-server
officialProduction-ready model serving for Tenstorrent hardware with OpenAI-compatible REST API. Supports continuous batching, multiple models, and all TT hardware configurations.
tt-forge-onnx
officialONNX graph compiler for Tenstorrent hardware. Optimizes and transforms ONNX model graphs for efficient execution on Tensix accelerators. Used as a backend by tt-forge for ONNX model ingestion.
5 previous releases
tt-buda-demos
officialRepository of model demos using TT-Buda. The largest collection of pre-compiled model examples for Tenstorrent hardware — BERT, ResNet, YOLO, GPT-2, Whisper, and many more.
tt-smi
official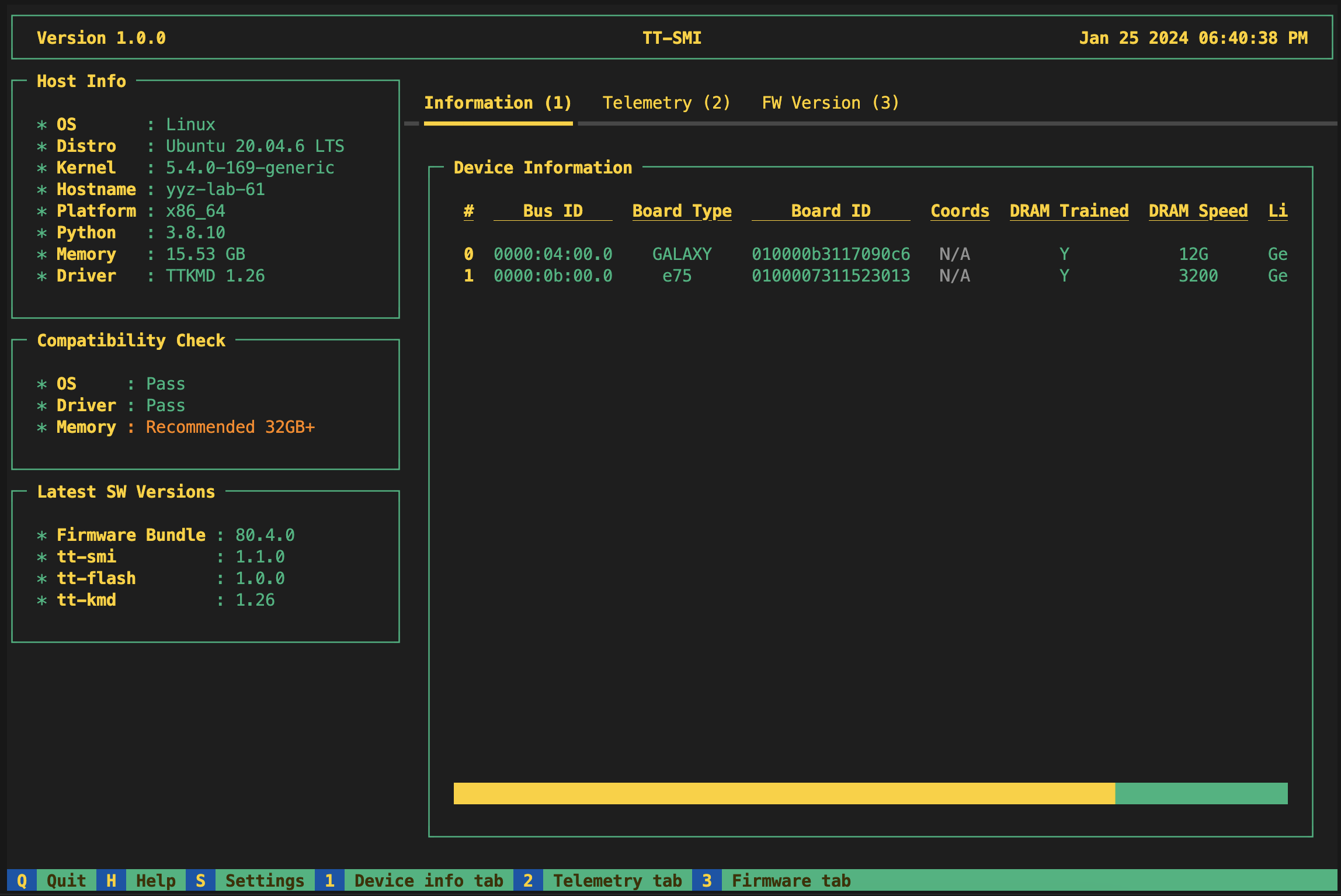
Tenstorrent System Management Interface — monitor device telemetry, issue board-level resets, and inspect hardware health. The nvidia-smi equivalent for Tenstorrent hardware.
📋 Changelog
# Changelog All notable changes to this project will be documented in this file. The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/), and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html). ## 3.0.26 - 29/07/25 - Added single tray galaxy reset option - Bumped luwen from 0.7.5 -> 0.7.10 - Chip detect now doesn't wait for eth to train for the 6U galaxy's, allowing multi tray resets to happen independently - Updated readme with the new reset option ## 3.0.25 - 29/07/25 - Added packaging ## 3.0.24 - 04/07/25 - Now users have 2 galay reset modes available - glx_reset: resets the galaxy, informs users if there has been an eth failure - glx_reset_auto: resets the galaxy upto 3 times if eth failures are detected ## 3.0.23 - 03/07/25 - Bumped luwen 0.7.3 -> 0.7.5 to fix cargo lock compatibilty issue ## 3.0.22 - 02/07/25 - Bumped tt-tools-common 1.4.16 -> 1.4.17 - Bumped luwen 0.7.2 -> 0.7.3 - Bumped smi 3.0.21 -> 3.0.22 ## 3.0.21 - 26/06/25 - Added option to not re-init chips after reset - Updated galaxy 6u reset option from --ubb_reset to -glx_reset - Removed the a3 arc message before doing a 6u reset, meaning we can reset even when chips are not pcie accessible - Added eth link check and return failure if any of the eth links have a LINK_INACTIVE_FAIL_DUMMY_PACKET failure ## 3.0.20 - 04/06/25 - Chore - bumped tt-tools-common version to fix driver version check for compatability with tt-kmd 2.0.0 ## 3.0.19 - 30/04/25 - Fixed an issue preventing the telemetry thread from being dispatched when the user clicked tab 2 ## 3.0.18 - 22/05/25 - Added BH and WH UBB board type support - Removed the dependency on tt-tools-common for this info ## 3.0.17 - 13/05/25 - Added proper telemetry heartbeat checks for Grayskull ## 3.0.16 - 12/05/25 - Used new ResetTypes from tools-common to simplify reset code - Added a heartbeat spinner to the telemetry pane. We expect this spinner to update about twice per second. If the spinner is not moving, this indicates new telemetry is not being fetched. ## 3.0.15 - 24/04/25 - Patch for the ubb_reset to just discover local only post reset. Looks like eth port status 2 has been re-used to mean connected and pyluwen waits for it to clear, leading to eth timeout. ## 3.0.14 - 21/04/25 - Added wh ubb reset via command line `tt-smi --ubb_reset`. Intention is that this command line option will be removed and integrated into `tt-smi -r` after we update board detection with the correct external naming. - Removed some unused imports and code - no functional changes ## 3.0.13 - 21/03/25 - Removed get\_sw\_versions ## 3.0.12 - 21/03/25 - Chore - bumped luwen version to include eth fw version check fix ## 3.0.11 - 13/03/25 - Chore - bumped luwen version to include enable chips with external connections but no routing ## 3.0.10 - 10/03/25 - Chore - bumped luwen version to include protoc lib detection check ## 3.0.9 - 07/03/25 - Chore - bumped luwen v
tt-bh-linux
official★ featured
Linux demo for the Tenstorrent Blackhole P100/P150 card RISC-V cores. Boot a real Linux kernel on the 16 high-performance RISC-V cores built into the Blackhole chip.
tt-lang
official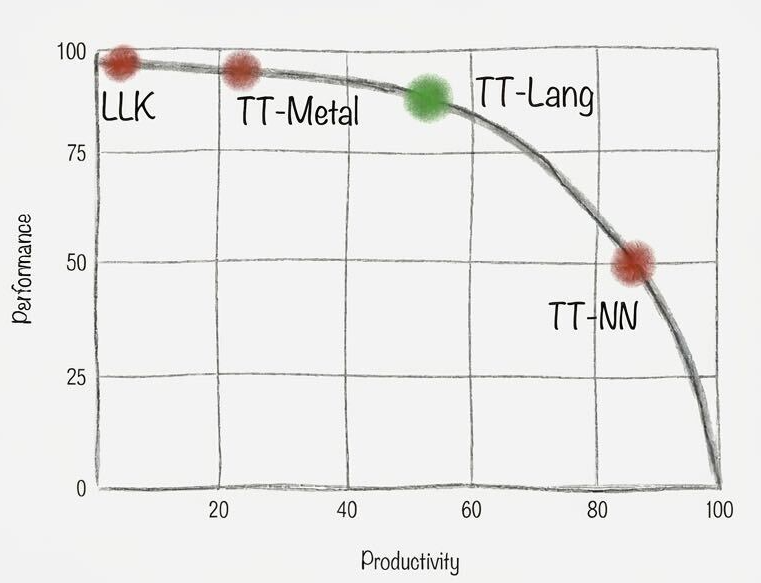
Python-based DSL that sits between TT-NN and TT-Metalium — expresses custom fused kernels with progressive disclosure, compiling directly to Tensix. Ships an integrated functional simulator (no hardware needed), line-by-line performance metrics, and AI-agent-friendly tooling. Two packages: tt-lang (compiler + hardware, requires ttnn) and tt-lang-sim (simulator only, works on Linux/macOS without Tenstorrent hardware).
📋 Changelog
# Changelog All notable changes to TT-Lang will be documented in this file. The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/), and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html). ## Version 1.1.1 ### Compiler - Fix for live-interval boundary computation (issue [#536](../../issues/536)) - Fix for all-zero results in FP32 reductions (issue # [#533](../../issues/533)) - Fix for inferred `pop` and `push` (issues [#536](../../issues/536), [#554](../../issues/554)) - Fix for write pointer tracking on pipe sender accross iterations (issue [#578](../../issues/578)) - Fix to report data type mismatch error - Fix to report DFB over allocation error (issue [#511](../../issues/511)) - Support for pipenet predicates `is_src`, `is_dst` and `is_active` (issue [#541](../../issues/541)) - Support for `ttl.math.typecast` ### Simulator - Support for inferred `pop`, `push` and `copy`'s transfer handle `wait` - Support for pipenet predicates `is_src`, `is_dst` and `is_active` - Support `all_gather` - Support `bfloat8_b` - Improved/actionable error messages - Improved performance by simulating math in FP32 ### Infrastructure - TT-Lang installable with `pip install tt-lang` for full installation and `pip install tt-lang-sim` for simulator only - [Matmul benchmarks](benchmarks/matmul/README.md) ## Version 1.0.0 ### Compiler - Support `+=` syntax in conjunction with dot product (`@`) lowered to packer L1 accumulation - Support implicit temporary compute-kernel-local DFBs - Support `ttl.Pipenet` - Support implicit `ttl.Block.push` and `ttl.Block.pop` - Support implicit `ttl.Transfer.wait` - Support for `expm1`, `exp2`, `ceil`, `sign`, `gelu`, `silu`, `hardsigmoid`, `square`, `softsign`, `signbit`, `frac`, `trunc` in `ttl.math` ### Simulator - Support for `ttl.GroupTransfer` - SPMD and mesh device simulation support - Support for `ttnn.all_reduce` CCLs - Use tracing to report statistics with `tt-lang-sim-stats` - Remote L1 reads/writes statistics ### Examples and documentation - Matmul tutorial ## Version 0.1.8 ### Compiler - Support for dot product operator (`@`) with lowering to [`ckernel::matmul_block`](https://docs.tenstorrent.com/tt-metal/v0.55.0/tt-metalium/tt_metal/apis/kernel_apis/compute/matmul_block.html) - Support for fusing matmul and certain elementwise operations - Support lowering to `pack_tile_block` - Support for `ttl.math.fill`, `ttl.math.reduce_sum`, `ttl.math.reduce_max`, and `ttl.math.transpose` - Support for arbitrary sub-blocking including dot product K-dimension to allow maximizing L1 usage and reuse - Support for `sin`, `cos`, `tan`, `asin`, `acos`, `atan` in `ttl.math` - Support for L1 sharded tensors - Support for tensors with BF8 data type - SPMD support (`ttnn.open_mesh_device`) ### Simulator - Track L1 space and number of DFBs usage and warn when exceeded - Support for tensors with row-major layout - Support for L1 sharded tensors ### Examples and documentat
tt-llk
officialTenstorrent Low-Level Kernels: the C++ library that directly programs the RISC-V cores inside each Tensix compute engine. TRISC0 (unpack), TRISC1 (math/FPU/SFPU), and TRISC2 (pack) are all programmed through this layer — it is the interface between TT-Metal kernel code and bare silicon.
ttnn-visualizer
officialComprehensive tool for visualizing and analyzing model execution on Tenstorrent hardware. Interactive graphs, memory plots, tensor details, buffer overviews, operation flow graphs, and multi-instance support.
WallaBMC
official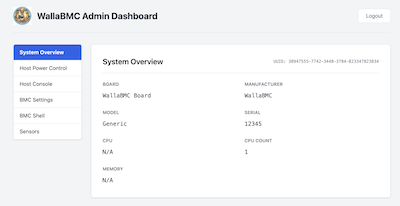
Lightweight BMC (Baseboard Management Controller) for STM32 and similar MCUs, with Web UI, Redfish API, and HTTPS support. Built on Zephyr RTOS. Used in Tenstorrent systems.
TT-Studio
officialWeb-based GUI for deploying and chatting with AI models on Tenstorrent hardware. Handles all technical setup automatically — deploy models, run inference, and explore capabilities through a simple browser interface.
tt-umd
officialUser-mode driver for Tenstorrent hardware. The userspace layer that sits between the kernel module and higher-level SDKs.
4 previous releases
📋 Changelog
# Changelog ## [0.9.5] - 2026-05-12 ### Changed Hardware hang detection for NOC and PCIe. Tracy profiler integration with instrumentation across TLB, PCIe and sysmem paths. DeviceProtocol ported to TTDevice, including DMA migration. SocDescriptor split into static (SocArchDescriptor) and runtime parts. LITERAL coordinate system in CoreCoord. Multicast to all TENSIX cores. SMN support. SWEmuleChip software emulation chip and Quasar simulation support (incl. 4GB TLB). Unified UmdException/UMD_ASSERT/UMD_THROW error handling across the codebase. ## [0.9.4] - 2026-03-18 ### Changed TopologyDiscoveryOptions refactoring. TopologyDiscoveryOption to retrain ETH links on 6u. TLBs for TTsim. DRAM retrain support. DeviceProtocol changes. Simulator in TTDevice changes. ETH heartbeat check. ## [0.9.3] - 2026-02-24 ### Changed Sigbus safe read write API. Remove 4U related code. Implement BH SPI as well, so full SPI support. P150 expects harvested cores. TT_VISIBLE_DEVICES uses logical IDs. ## [0.9.2] - 2026-02-09 ### Changed SPI interface for Wormhole. PCI BDF based sorting and filtering. Multicast PCI DMA. Support Blackhole loudbox. Many code fixes and test enhancements. ## [0.9.1] - 2026-01-23 ### Changed Started publishing to pypi. ## [0.9.0] - 2026-01-23 ### Changed Warm reset notification and callback implementation. ## [0.8.6] - 2026-01-20 ### Changed Make predicting ETH FW from CMFW optional in TopologyDiscovery. ## [0.8.4] - 2026-01-16 ### Changed Use older manylinux image ## [0.8.3] - 2026-01-15 ### Changed Reverted remote discovery issue ## [0.8.2] - 2026-01-15 ### Changed Support warm reset without secondary bus reset. Expose subsystem vendor id. ## [0.8.1] - 2026-01-15 ### Changed Support dma functions on TTDevice layer ## [0.8.0] - 2026-01-14 ### Changed Many functional fixes and minor changes. Final fixes needed for integration into tt-smi. Also contains adjustments needed for integration into exalens. ## [0.7.0] - 2025-11-29 ### Changed Changed to a more generic arc_msg API. ## [0.6.0] - 2025-11-24 ### Changed Change the usage of TLBs such that KMD is in control of TLB allocation instead of UMD. TLBs are now allocated using KMD's dedicated API. ## [0.5.3] - 2025-11-14 ### Changed Added generation of .deb and .rpm packages. Added three separate packages (runtime, development and python). ## [0.5.1] - 2025-11-12 ### Changed Manylinux builds and Pypi test publishing. Many smaller fixes and improvements. ## [0.4.0] - 2025-10-18 ### Changed Removed old type names. ## [0.3.0] - 2025-10-17 ### Changed Many smaller fixes and improvements. TTsim support improvements. JTAG support improvement. Fixing CMake install path. Further work on integrating new KMD TLBs. ## [0.2.0] - 2025-09-15 ### Changed A couple of smaller fixes and improvements, including L2CPU harvesting, fixes for new FW. Better TTSim support. Further JTAG support. Introduced new soft reset API. Introduced lite fabric initial version.
tt-system-firmware
official
System firmware for Tenstorrent hardware. Low-level system initialization and control firmware that runs on-device.
4 previous releases
polaris
officialA high-level AI simulator from Tenstorrent for modeling and exploring AI accelerator and workload performance.
luwen
officialTenstorrent system interface library written in Rust. Low-level Rust bindings for communicating with and managing TT hardware.
tt-tvm
officialTVM for Tenstorrent ASICs. Brings the Apache TVM compiler stack to Tenstorrent hardware, enabling model compilation from TensorFlow, PyTorch, ONNX, and more.
tensix-isa-simulator
officialISA-level simulator for the Tensix compute engine. Simulates the matrix, vector, and scalar units inside each Tensix core.
tt-torch
officialFrontend integration for PyTorch with tt-mlir. Compile PyTorch models directly to Tenstorrent hardware via torch.compile integration.
tt-firmware
officialTenstorrent firmware repository. Board management and control firmware for Tenstorrent accelerator cards.
tt-installer
officialInstall the complete Tenstorrent software stack with one command. Handles drivers, firmware, Python environment, and SDK setup automatically.
tt-exalens
officialLow-level hardware debugger for Tenstorrent devices. Inspect register state, memory contents, and kernel execution at the hardware level.
4 previous releases
tt-blacksmith
officialOptimized training recipes for a variety of ML models on Tenstorrent hardware, powered by the TT-Forge compiler stack. Reference implementations for fine-tuning and training from scratch.
tt-topology
official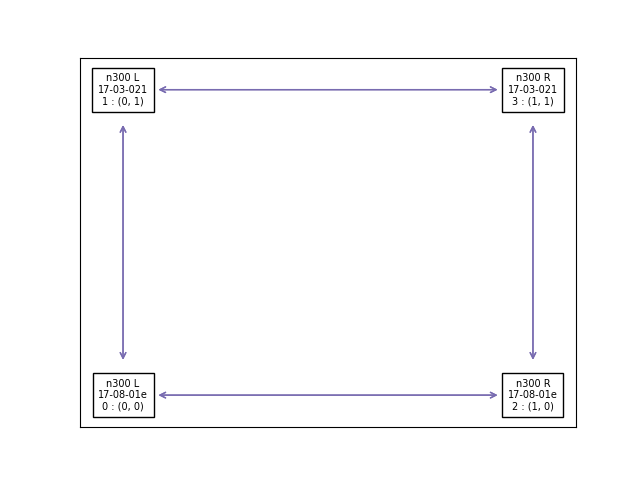
Configure Ethernet routing on multi-card Tenstorrent systems. Flash NB cards to use specific ETH routing configurations for scale-out deployments.
4 previous releases
📋 Changelog
# Changelog All notable changes to this project will be documented in this file. The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/), and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html). ## 1.2.11 - 17/06/2025 ### Updated - Updated mesh coord generation to be connection type agnostic - Added failure and exit if mesh type detected, but not enough connections - Added warning in README about lack of supoort for BH and 6U boards ## 1.2.10 - 05/06/2025 ### Updated - Bumped tt-tools-common version to fix driver version check for compatability with tt-kmd 2.0.0 ## 1.2.9 - 30/05/2025 ### Updated - Bug fix for https://github.com/tenstorrent/tt-topology/issues/39. Now the tool will use a DFS longest path to determine a linear layout if its not a fully connected graph. - Updated initial device detection - now it needs full noc access for octopus and list options ## 1.2.8 - 08/05/2025 ### Updated - Fixed issue where tool would fail when PCI interfaces don't start from ID 0 - Now using actual PCI interface IDs from devices instead of assuming sequential numbering ## 1.2.7 - 07/05/2025 ### Updated - Use tools-common 1.4.15 - Use type checking in octopus reset ## 1.2.6 - 05/05/2025 ### Updated - Bug fix: added "ignore-eth" flag to first chip detect to avoid eth training loops forever and truly detect pcie only chips - Chore: bumped luwen ## 1.2.5 - 15/04/2025 ### Updated - When flashing to isolated mode, we now flash the WH ethernet ports to a disabled state, in order to prevent their use. ## 1.2.4 - 02/04/2025 ### Updated - You can now run `tt-topology -l isolated` to flash cards to the default (non-connected) state - Users are now warned about missing or loose cables ## 1.2.3 - 21/03/2025 ### Fixed - Bumped luwen (0.6.2 -> 0.6.3) to include eth version check bug for TG setup ## 1.2.2 - 13/03/2025 ### Fixed - Bumped luwen version to make it more robust against eth fw updates ## 1.2.1 - 13/03/2025 ### Fixed - Moved the spi reads after the reset to increase stability during M3 L2R copy - Bumped luwen version ## 1.2.0 - 06/03/2025 ### Fixed - Updated how local eth board info is calculated to make it agnostic to eth fw version - bumped tt-tools-common version - Added traceback printing when catching exceptions in main. ## 1.1.5 - 14/05/2024 ### Updated - Bumped luwen (0.3.8) and tt_tools_common (1.4.3) lib versions - Removed unused python libraries ## 1.1.4 - 25/03/2024 ### Fixed - Changed detect_chips with detect_chips_with_callback to enable detailed debug info. ## 1.1.3 - 22/03/2024 ### Fixed - Bumped tt-tools-common version to avoid pip discrepancy. ## 1.1.2 - 22/03/2024 ### Fixed - Fixed command line bug when no args are provided. ## 1.1.1 - 21/03/2024 ### Fixed - Fixed reference to pyluwen lib ## 1.1.0 - 12/03/2024 ### Added - Octopus Configuration (4 n150s connected to 1 galaxy) ## 1.0.2 - 12/03/2024 ### Fixed - Dependency bug with tt_tools
tt-npe
official
Network-on-chip Performance Estimator for Tenstorrent Tensix-based devices. Model and estimate NoC utilization before running kernels on hardware.
tt-flash
officialTenstorrent firmware update utility. Flash new firmware onto Tenstorrent accelerator cards from the command line.
📋 Changelog
# Changelog All notable changes to this project will be documented in this file. The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/), and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html). ## 3.4.0 - 30/07/25 - Bump pyyaml 6.0.1 -> 6.0.2 - Improve error message formatting - No longer have to use --force for flashing BH cards ## 3.3.5 - 03/07/25 - Bump luwen 0.7.3 -> 0.7.5 ## 3.3.4 - 02/07/25 - Bump tt-tools-common 1.4.16 -> 1.4.17 - Bump luwen 0.6.4 -> 0.7.3 ## 3.3.3 - 05/06/2025 - Bumped tt-tools-common version to fix driver version check for compatability with tt-kmd 2.0.0 ## 3.3.2 - 14/05/2025 - Bump tt-tools-common version to latest ## 3.2.0 - 12/03/2025 ### Updated - luwen version bump to bring inline with tt-smi; provides stability fixes ## 3.1.3 - 06/03/2025 ### Added - luwen version bump to include bh arc init checks ## 3.1.2 - 28/02/2025 ### Added - Support for more BH cards: p100a, p150, and p150c ## 3.1.1 - 06/01/2025 ### Updated - Bumped luwen version to accomodate Maturin updates ## 3.1.0 - 29/10/2024 ### Added - Support for flashing the BH tt-boot-fs file format - Bumped luwen version to 0.4.6 to allow resets when chip is inaccessible ## 3.0.2 - 17/10/2024 ### Fixed - Unbound variable when exception is thrown when getting current fw-version ## 3.0.1 - 16/10/2024 ### Changed - Bumped luwen version to 0.4.5 to resolve false positives on bad chip detection ## 3.0.0 - 23/08/2024 - NO BREAKING CHANGES! Major version bump to signify new generation of product. - Added support for p100 ## 2.2.0 - 19/07/2024 ### Updated - Added support for an alternative spi flash configuration via a new version of luwen ## 2.0.8 - 14/05/2024 ### Updated - Bumped luwen (0.3.8) and tt_tools_common (1.4.3) lib versions ## 2.0.1 - 2.0.7 - Dependency updates ## 2.0.0 - WH flash release ## 1.0.0 - GS flash release
SFPI
officialTenstorrent SFPU programming interface — TT-enhanced RISC-V GCC and binutils plus header files for programming the Tensix SFPU (vector engine) from kernel code. The compiler toolchain underneath TT-Metalium's SFPU ops.
4 previous releases
tt-example-apps
officialEnd-to-end AI applications running on Tenstorrent AI accelerators. Complete application examples from retrieval-augmented generation to image generation pipelines.
tt-forge-models
officialA shared repository of model implementations used across TT-Forge frontends — a single source of truth for the models used in testing and benchmarking, rather than duplicating them across frontend repos.
tt-perf-report
official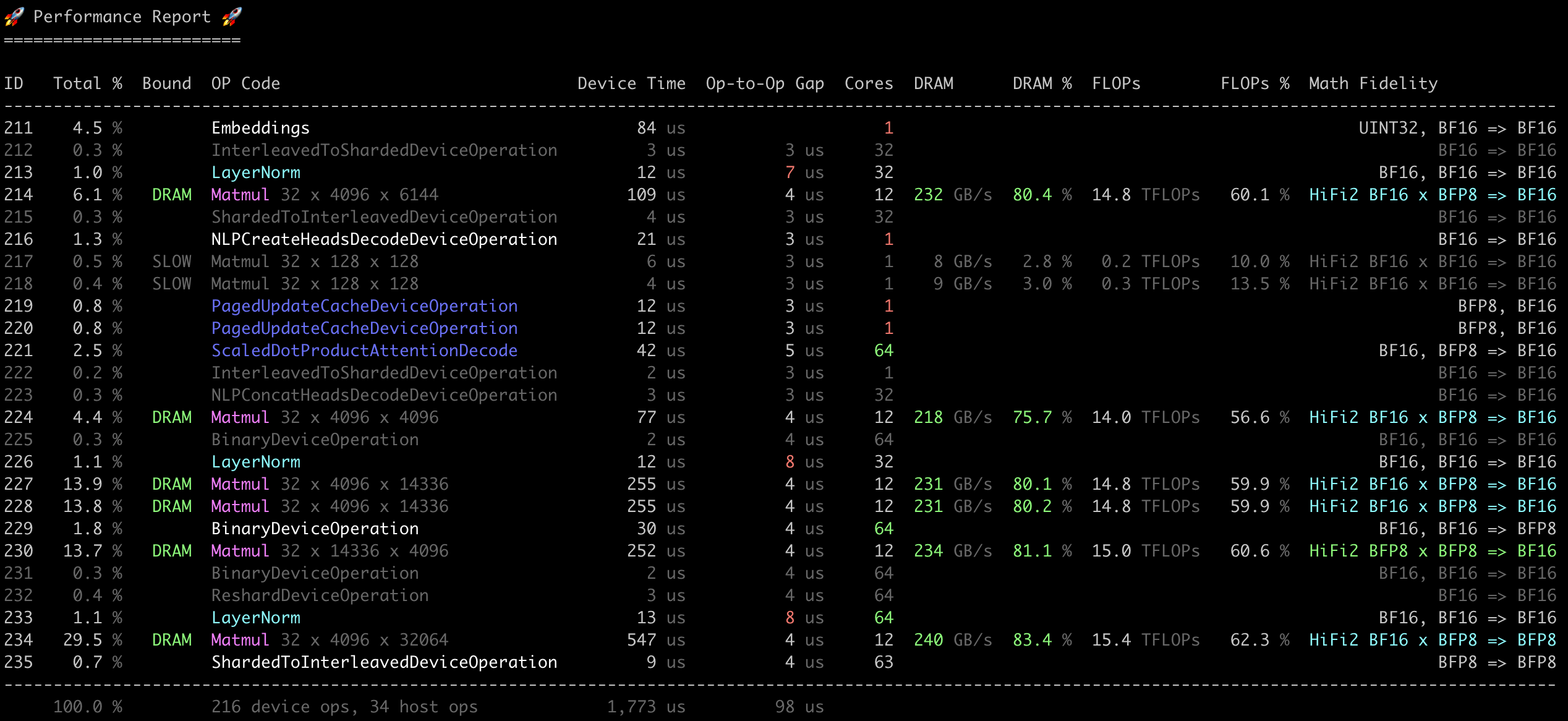
Performance report analysis tool for Tenstorrent Metal operations — analyzes perf traces to surface throughput, bottlenecks, and optimization opportunities.
tt-vscode-toolkit
official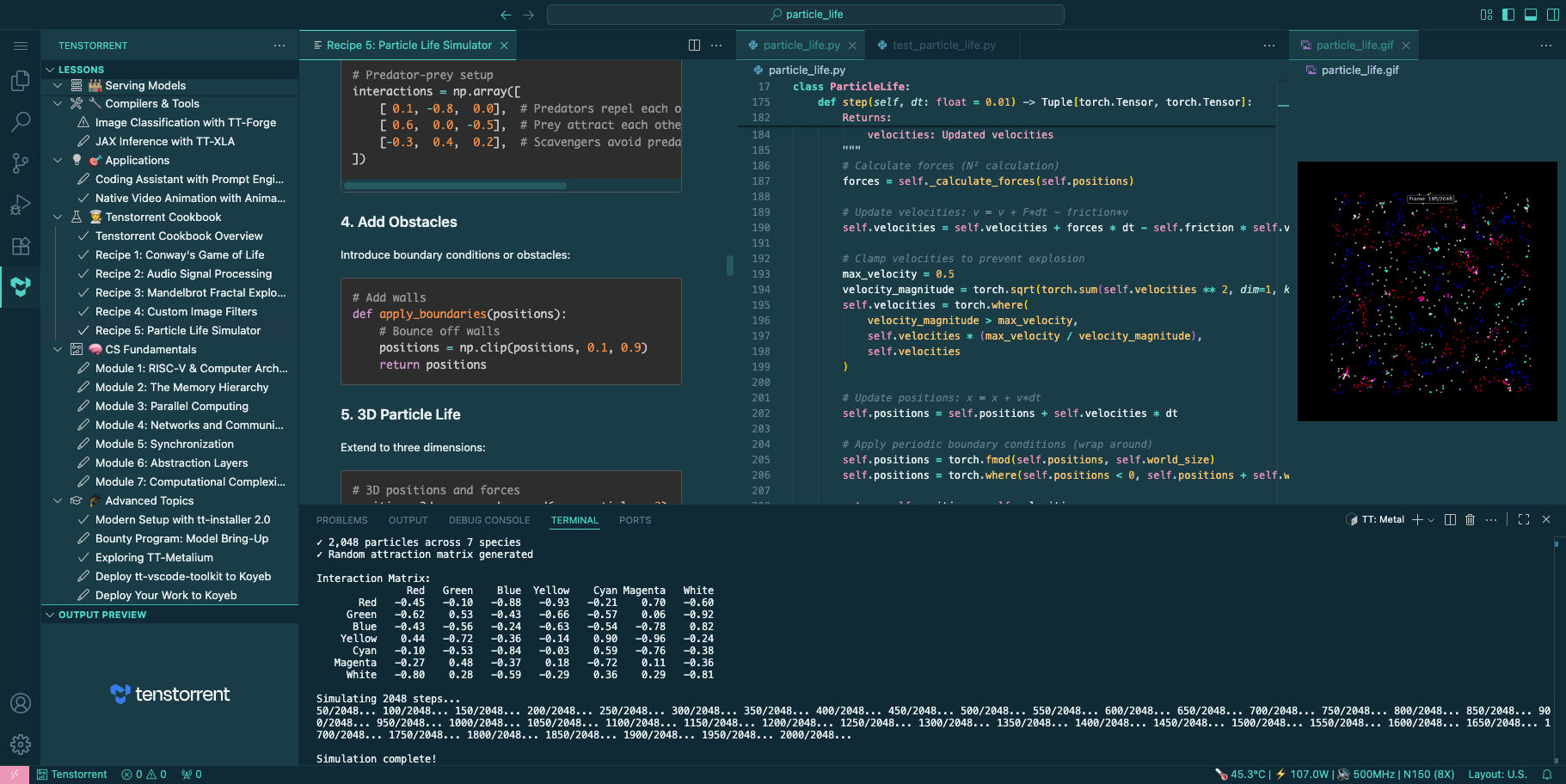
48 interactive lessons covering the full Tenstorrent developer path — from hardware detection to custom training — with click-to-run commands and hardware auto-detection. Available in VSCode and code-server.
📋 Changelog
# Changelog All notable changes to the TT-VSCode-Toolkit will be documented in this file. The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/), and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html). --- ## [0.1.19] - 2026-07-16 ### Added - **New advanced lesson "Monkeypatching TT-NN"** (order 16, after "Exploring TT-Metalium") — upgrade-safe, smallest-trace patching of TT-NN / TT-Metalium organized by developer goal (observe; fix a bug early; change a default; add something new; and a last-resort source-diff escape hatch), for the TT-QuietBox 2 case where `ttnn` is an installed package with no `~/tt-metal` source tree. Covers the env + import-order rule, the "patch to change behavior, wrap to add behavior" principle (citing Martin Chang's non-invasive `ttPseudoRowMajor` and upstream-first ggml backend), and an AI-agent verification recipe. Validated on p300c — all 19 lesson patterns exercised against real `ttnn` on a TT-QuietBox 2. - **New reusable template `content/templates/monkeypatch/tt_patches.py`** — a dependency-free patch harness (save/restore `wrap` and `set_default`, `patched` context manager, `version_at_most` guard that zero-pads unequal-length versions, and a `verify` probe helper) with fail-loud missing-target detection, shipped with a self-contained hardware-free `test_tt_patches.py` and a usage README. The lesson embeds the full harness source in a collapsible section for transparency. - **`tenstorrent.monkeypatch.copyHarness` command** — copies the harness folder into `~/tt-scratchpad/monkeypatch/`, replacing any prior copy (with confirmation) so it mirrors the shipped template, and offers an "Open tt_patches.py" follow-up. Wired into the lesson as a click-to-copy button. - **`check:monkeypatch-drift` script** (wired into the pre-commit hook) fails if the `tt_patches.py` source embedded in the lesson diverges from the template file. ### Changed - Excluded `.superpowers/` from the packaged `.vsix` via `.vscodeignore` (was shipping ~1.9 MB of session artifacts). ## [0.1.18] - 2026-07-13 ### Fixed - **PRD-246 — Jeremy's QB2 testing feedback on the first-inference lesson flow:** - `download-model` — fixed the broken "Step 3: Download the Model" skip link. The anchor pointed to `#step-3-download-qwen3-0-6b`, but the "Step 3: Download Qwen3-0.6B" heading slugs to `#step-3-download-qwen3-06b` (the `.` in `0.6B` is dropped, not turned into a hyphen). - `download-model` — consolidated the repeated, scattered Hugging Face auth flow. Removed the standalone "Already Authenticated?" pre-check and folded the `hf auth whoami` check into Step 2, so authentication reads as a single sequence (set token → check → log in) instead of appearing in multiple places. - `hardware-detection` — marked "Check 4: Device Reset" as optional; it is a recovery action, not part of normal detection, and a healthy device never needs it. - `tt-installer` — removed the redundant `tt-smi` hardwar
tt-tools-common
officialShared helper library of common utilities used across Tenstorrent system tools such as tt-smi, tt-flash, and tt-topology. A dependency rather than a standalone tool.
4 previous releases
📋 Changelog
# Changelog
All notable changes to this project will be documented in this file.
The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/),
and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html).
## 1.4.17 - 02/07/2025
### Changed
- Loosened requirements on pyproject.toml to make it more compatible in different venvs
## 1.4.15 - 05/05/2025
### Changed
- parse\_reset\_json now returns a ResetInput with stricter typing
## 1.4.14 - 04/02/2025
### Added
- New flags in reset config file generation to disable sw\_version reporting
## 1.4.13 - 23/1/2025
- Removed nr\_hugepages count from compatibility, as hugepages allocation is tricky
and deserves its own widget elsewhere.
## 1.4.12 - 16/1/2025
- Added TTHostCompatibilityMenu to replace Host Info and Compatibility boxes
- Added a count of nr\_hugepages to the TTHostCompatibilityMenu
## 1.4.11 - 30/12/2025
- Updated Luwen version to fix Maturin issue
## 1.4.10 - 16/12/2024
### Changed
- detect\_chips\_with\_callback now takes a print\_status arg
## 1.4.9 - 11/12/2024
### Changed
- A failed reset now results in a fail exit code on BH
## 1.4.8 - 11/10/2024
### Changed
- Updated reset completion logic to handle the case where the bmfw needs to upgrade itself
## 1.4.7 - 11/10/2024
### Added
- Implemented m3 reset option for Blackhole
### Fixed
- Fixed crash during driver version dection when the "extraversion" field is used
- i.e. 1.28-bh
## 1.4.6 - 17/07/2024
### Added
- Reset support of Blackhole
## 1.4.5 - 11/07/2024
### Added
- Bump pyluwen library version (v0.3.8 -> v0.3.11)
- Moved pyluwen v0.3.11 to optional dependencies in pyproject.toml
## 1.4.4 - 21/06/2024
### Added
- Version bump of python dependencies in pyproject.toml (dependabot)
- requests (2.31.0 -> 2.32.0)
- tqdm (4.66.1 -> 4.66.3)
- Pydantic library version bump (1.* -> >=1.2) to resolve: [TT-SMI issue #27](https://github.com/tenstorrent/tt-smi/issues/27)
## 1.4.3 - 14/05/2024
### Added
- Arm platform check and warning for WH device resets in compatibility menu
- Added check for WH device init after reset and prompt user to reboot host if chips are still non recoverable
- Bumped textual (0.59.0) and luwen (0.3.8) lib versions
## 1.4.2 - 04/04/2024
### Added
- Added "silent" flag to WH and GS resets to make them more versatile for use in other tools
## 1.4.1 - 22/03/2024
### Fixed
- removed pyluwen version to avoid dependency issues in other repos
## 1.4.0 - 19/03/2024
### Added
- detect_device_fallible that will provide feedback about chip state during init
### Fixed
- Update min driver version to 1.26 to perform lds reset
- Reset config file uses dev/tenstorrent id
- Catch JSON errors in reset config parsing
- Make nested dirs when initializing reset config path
## 1.3.0 - 06/03/2024
### Added
- Migrated GS Tensix reset to tools_common
- Migrated all related GS data files
- Functions to fetch arc and eth fw versions from telemetry
tt-toplike
official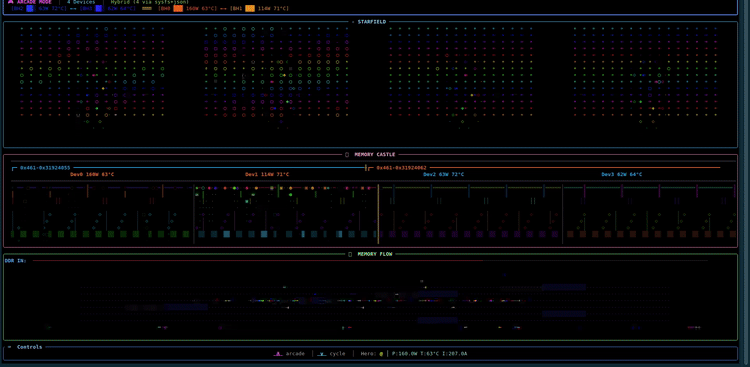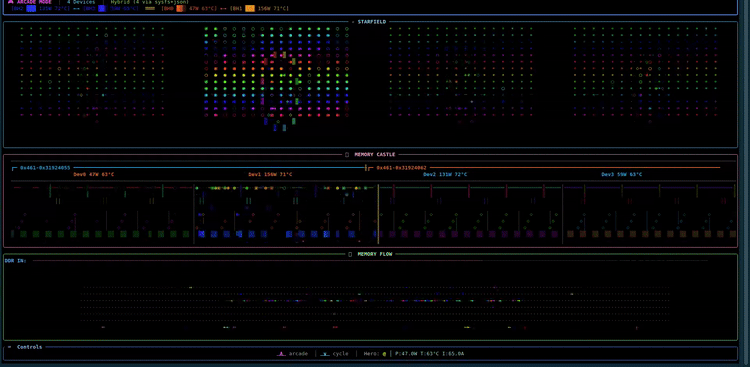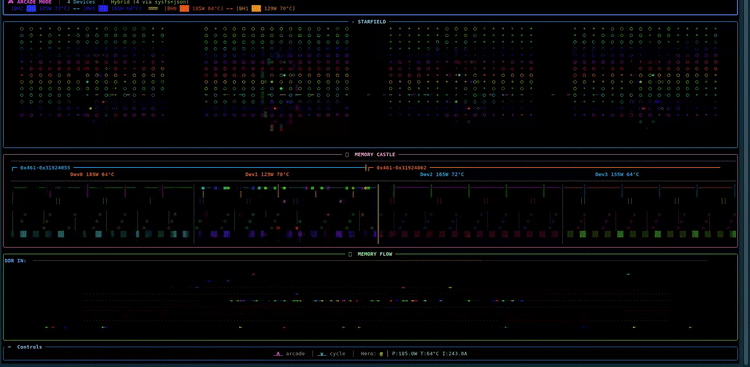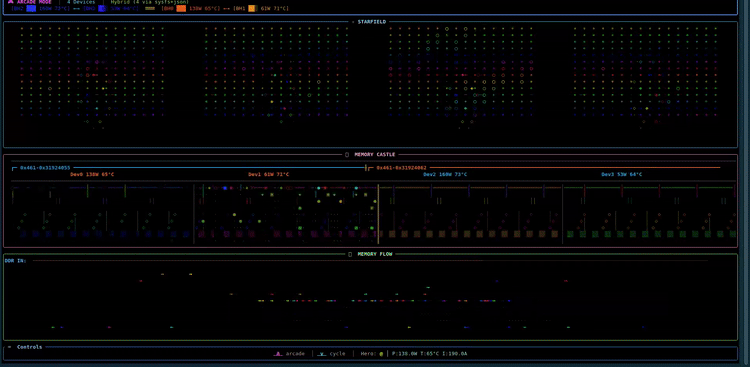
A vibrant htop-style visualizer for Tenstorrent hardware written in Rust. Real-time process and utilization view for TT accelerators.
4 previous releases
📋 Changelog
# Changelog The **canonical, complete release log lives in [`debian/changelog`](debian/changelog)** — that's the file the `.deb` packages are built from and where every release is recorded in full. This file is a friendly pointer plus a summary of the most recent releases; it deliberately does not duplicate the whole history. To see everything: ```bash less debian/changelog # full history git tag # released versions ``` ## Recent releases ### 0.7.33 - **[i] media/diffusion monitoring** — SkyReels / SDXL / z-image servers (tt-media-inference-server) now show live telemetry instead of a blank panel. They expose a `tt_media_server_*` Prometheus namespace (not `vllm:`), so a dedicated parser reads completed generations, the **in-flight `jobs_in_progress` gauge**, and per-generation timing. The Feeding snake is reused: headline is generations/min + seconds-per-gen, the body tracks in-flight jobs, and the panel shows in-flight/done + stage times (no tok/s). Verified against a live 0.15.0 SkyReels box; dedupes the duplicate series that build emits. - Fix: the legend / help / explain overlay panel truncated its own text (fixed 42-col width vs 50–66-col content, and `Paragraph` clips instead of wrapping). It now measures its widest line and sizes to fit, clamped to the terminal. ### 0.7.18 - **`--remote <host[:port]>`** — watch a remote QuietBox's telemetry over a WebSocket stream (plaintext, unauthed: trusted-LAN only). Every visualization runs against the remote chips; the process panel and `[i]` inference monitor still describe the **local** machine. - Remote hardening: the process panel no longer TT-filters local processes under `--remote`, the Arcade `⚔` duel is suppressed under `--remote`, and backend status reports last-frame age / flags a stale stream. - Packaging: WS support is a default-on `remote` cargo feature (opt out with `--no-default-features`). ### 0.7.17 - **Arcade duel** — the hero now duels the inference snake: a telemetry-true tug-of-war strip when a model is serving, the `⚔` marker sliding toward whichever side dominates (chip power/util vs tokens/s + queue depth). - Per-device power/temp now shows once as a shared strip instead of per section. - Memory Castle gains a compact 8-column tier before the fleet-grid fallback. - 1990s BBS/demoscene ANSI chrome (`╔══[ SECTION ]══▓▒░`), themed under grayskull. ### 0.7.16 - **`/theme grayskull`** — an app-wide grayscale palette (a thousand shades of grey, cyan/purple accents, hot pink as the only hot color). `/theme default` restores full color; bare `/theme` toggles.
tt-system-tools
officialSystem setup and support utilities for Tenstorrent hardware — hugepages-setup configures the 1GB hugepages TT ASICs need, and tt-oops collects diagnostic data for troubleshooting. Ships as the tenstorrent-tools deb/rpm.
4 previous releases
tt-emule
officialA C++ software emulator of the Tenstorrent device-level kernel and host APIs. Run tt-metal kernel and host code on a standard x86-64 Linux machine — no Tenstorrent hardware required.
tt-local-generator
official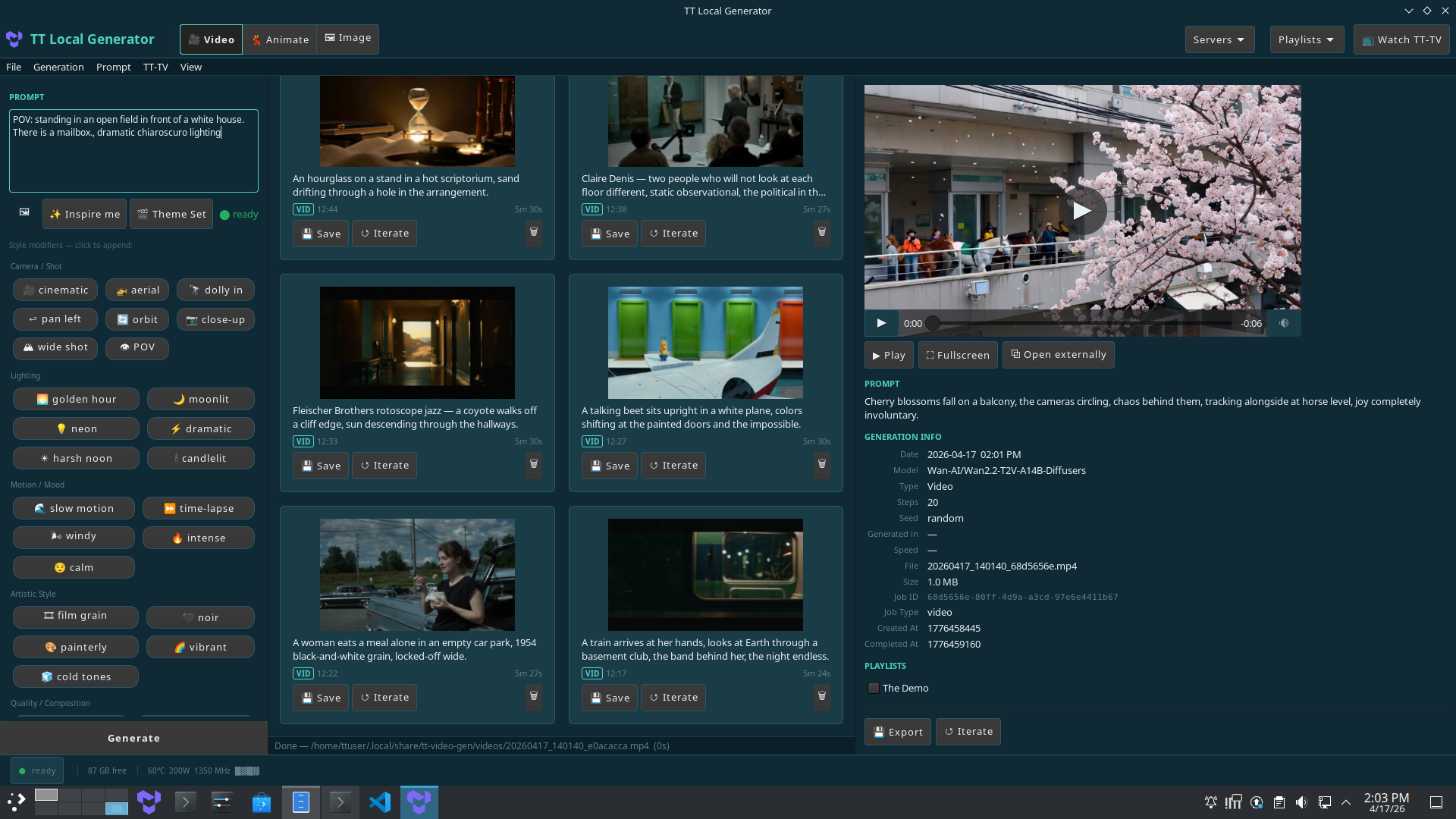
Generate infinite videos and images (and imaginative prompts to inspire them) on Tenstorrent's Quietbox 2. Fully local generative media pipeline.
4 previous releases
tt-burnin
officialCommand-line utility that runs a high power-consumption workload on Tenstorrent devices — used for chip testing, burn-in, and validating a system's power delivery and cooling under sustained load.
4 previous releases
📋 Changelog
# Changelog All notable changes to this project will be documented in this file. The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/), and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html). ## 0.2.2 - 31/07/2024 ### Added - Added glx reset support - Threaded start and end of burnin to increase burnin speed - Added prints to indicate which chip we are currently running on - Added support for bh harvesting ## 0.2.1 - 16/01/2024 ### Bug fix - Fix for https://github.com/tenstorrent/tt-burnin/issues/6 - BH reports asic temperature as a signed 16_16 int unlike GS and WH - Added missing support to report BH asic temperatre ## 0.2.0 - 29/10/2024 ### Added - BH burnin support ## 0.1.1 - 14/05/2024 ### Updated - Bumped luwen (0.3.8) and tt_tools_common (1.4.3) lib versions ## 0.1.0 - 04/04/2024 First release of opensource tt-burnin ### Added - GS and WH burnin support
tt-animatediff
official
Generates short, temporally coherent animated GIFs using the AnimateDiff model on Tenstorrent hardware. Phase 1 runs the correct SD 1.4 + MotionAdapter architecture on CPU; Phase 2 accelerates spatial denoising on Blackhole using the TTNN UNet. Produces vibrant 8-frame animations in ~15 s/frame on a P300C.
Cloud-Native Support
officialOfficial documentation hub for running Tenstorrent accelerators on Kubernetes. Centers on tt-operator (the umbrella Helm chart) and covers Node Feature Discovery, kernel-mode driver (tt-kmd) management, firmware flashing, Prometheus telemetry, Fabric Manager topology resolution, Dynamic Resource Allocation, and multi-node scheduling via JobSet and PMIx.
TT Console
official★ featuredBrowser-based cloud console for exploring AI on Tenstorrent hardware. Run LLM inference, image and video generation, and browse the supported model catalog in-browser — backed by Tenstorrent accelerators. Cloud hardware access and advanced workflows (deployments, agents) available in staged rollout.
tt-operator
officialKubernetes operator that automates installation and lifecycle management of the full software stack needed to run Tenstorrent workloads on a cluster. Distributed as an umbrella Helm chart coordinating driver (tt-kmd) management, Node Feature Discovery, firmware flashing, Prometheus telemetry, fabric/topology resolution, and device allocation with multi-node scheduling (JobSet/PMIx).
TT-QuietBox 2 Guide
officialOfficial setup and onboarding guide for the TT-QuietBox 2 — a compact, liquid-cooled AI workstation with four Blackhole accelerators, an AMD Ryzen CPU, 256GB RAM, and 4TB NVMe. Covers hardware specs, first-boot setup, and hands-on learning paths for running pre-loaded models like Qwen3-32B and serving text, image, video, and speech models via tt-inference-server.
Tenstorrent's fork of QEMU that provides the full-system emulation layer behind ttsim. Models the RISC-V cores and system devices of Wormhole and Blackhole so TT-Metalium workloads can boot and run without physical silicon.
tt-bio
affiliated★ featuredBoltz-2 biomolecular model for drug discovery on Tenstorrent Blackhole. Supports single-card and multi-card configurations — QuietBox (4×) and Galaxy (32×). Approaches physics-based FEP accuracy at 1000× the speed.
📋 Changelog
# Changelog All notable changes to TT-Bio are recorded here. Versioning is [SemVer](https://semver.org); releases are cut from a commit that has passed the on-hardware test suite (see `RELEASING.md`). ## [Unreleased] ## [0.3.2] - 2026-07-20 ### Fixed - **SaProt-1.3b config bug** — `CONFIGS["saprot-1.3b"]` carried a fabricated arch (hidden=2560 / n_heads=40 / n_layers=40 / intermediate=10240) that does not match the real `westlake-repl/SaProt_1.3B_AF2` checkpoint (1280 / 20 / 66 / 5120 — the 650m width with double the layers). `load_state_dict(..., strict=False)` silently masked the mismatch, so the device ran with effectively untrained weights and the 1.3b leg read as a parity failure. Config corrected; `Saprot.from_pretrained` now reads the checkpoint's `config.json` and refuses to build on an arch mismatch. With correct shapes saprot-1.3b reaches X_emb=0.99508 / X_logits=0.99895 (deterministic, qb1 card 1) — a near-pass; the per-residue embedding PCC lands just below the 0.9987–0.9996 ESMC band (bf16 accumulation over 66 residual layers), so no clean PASS row is added to `docs/pharma-benchmark.md`. See `docs/saprot-parity.md`. - **Perf-gate within-card-type false positives** — the perf-regression gate keyed baselines by card type only, so two machines with the same card type (pc vs qb1, both p150a) read as false ~30–36% regressions against each other. Added a machine-id layer under card type (`socket.gethostname()`), with backward-compatible fallback to the card-type block. `--update-baseline` now writes to the detected machine's block. ### Added - **`tt-bio saprot --devices`** — multi-card data-parallel fanout for SaProt embeddings (one pinned worker per card, sequences sharded by length, results reassembled in input order), mirroring the ESMC `--devices` path. Row-independent: a sequence's output is identical to running it on one card. - **esmc-300m and esmc-6b perf-gate baselines seeded** (esmc-300m 33.17 seq/s on p300c, esmc-6b 3.17 seq/s on p150a), activating the perf-regression legs specced in 0.3.1. - **Release-gate perf + UX coverage for SaProt and Boltz-2 affinity** — both shipped in 0.3.1 with accuracy-leg coverage but no perf/UX gate legs; saprot-650m (222.69 seq/s, qb1 p150a) and boltz2-affinity (0.014319 affinities/s, p300c) baselines seeded. ### Removed - **ProteinMPNN** — the `tt-bio design` inverse-folding port is dropped entirely. It ran CPU-only (dispatch-bound, no TT-card use), duplicated BoltzGen's inverse-fold capability, and reimplemented the mature upstream `dauparas/ProteinMPNN`. SaProt is untouched. ### Verify / benchmark hardening - **Boltz-2 and Protenix-v2 ubiquitin flagship legs hardened 2+2 → 5+5 seeds** (seeds 0–4 both sides): R and D are now 10 pairwise distances each, so the parity verdict is a real statistical statement rather than a single-pair coincidence. Both PASS within floor on CA-RMSD and TM-score; CA-lDDT misses on Boltz-2 (a bf16 narrow
grayskull-attention
affiliatedFlashAttention-style attention kernel implemented entirely in on-chip SRAM on the Tenstorrent Grayskull chip using TT-Metalium. Pioneering work in low-level attention on TT hardware.
tt-atom
affiliated
Meta's UMA interatomic potential running on Tenstorrent Blackhole — energy, forces, and stress for molecules and periodic materials behind an ASE calculator. Its per-edge Wigner rotation runs as a custom tt-metal kernel for a highest-performance uma-s build.
📋 Changelog
# Changelog All notable changes to TT-Atom are recorded here. Versioning is [SemVer](https://semver.org); releases are cut only from a commit that has passed the on-hardware release gate — accuracy parity, no OOM across the supported size range, and no perf regression (see `RELEASING.md`). ## [Unreleased] ### Fixed - `tt_atom.batch.MultiCard` now builds the Orb-v3/OrbMol backbone when given Orb weights. The worker previously hardcoded the UMA path (`WeightBundle` + eSCN-MD `Backbone`), so pointing it at an Orb weights file built the wrong model silently. It now dispatches on the loaded bundle's `config` (the same UMA/Orb family split `tt_atom.auto` exposes by name) and runs the `Encoder`/`AttentionInteractionLayer`/`EnergyHead` forward for Orb. Verified bit-exact vs the single-card `OrbCalculator` on `orb-v3-conservative-inf-omat` (energy diff 0 eV on H2O / ethanol / benzene). `tests/test_multicard_orb.py` mirrors the UMA `test_multicard.py` sharded-vs- sequential parity shape (auto-skips below 2 cards). ### Notes - The v0.2.0 scope note below flagged Orb multi-card as "not independently re-run — same scheduler as UMA". That understated the gap: at v0.2.0 the worker was UMA-only, so Orb multi-card did not work at all (not merely unmeasured). Fixed here. - No real-weights multi-card *scaling* number is re-reported this pass: pc has a single Tenstorrent card, so N>1 scaling cannot be measured on it. The one honest datapoint measured here is the per-card baseline: Orb (`conservative-inf-omat`, real weights) on one card at ~128-atom Si supercells — 0.37 Medges/s. The earlier 2.95x@4cards figure (commit 43e981b) used the synthetic `examples/model_tiny_demo.npz` UMA bundle, not real weights and not Orb, so it is not a real-weights scaling number for either family. ## [0.2.0] - 2026-07-11 A second model family, additive to v0.1.0: **Orb-v3** (Orbital Materials) and **OrbMol**, its charge/spin-conditioned molecular variant. UMA/eSEN code paths are untouched (byte-identical to v0.1.0) — see full history and numbers in `docs/orb-port.md`. ### Added - **Orb-v3** (`orb-v3-conservative-inf-omat`, `orb-v3-direct-20-omat`): a non-equivariant, attention-MPNN backbone, ported bottom-up (encoder, 5-layer backbone, energy/force/stress heads, ZBL pair repulsion, periodic images, disjoint-union batching). None of UMA's four custom kernels transfer (Orb has no equivariant hidden representation) — this path runs on stock `ttnn` ops only, no source tt-metal build required for Orb-only use. - **OrbMol** (`orb-v3-conservative-omol`, `orb-v3-direct-omol`): the OMol25-trained, charge/spin- conditioned checkpoints. Reuses the Orb-v3 backbone unmodified plus a closed-form, node-only charge/spin embedding (zero learned matmuls) — no new forward/backward machinery. - `OrbTracedEngine` (`tt_atom/orb_trace.py`): trace-capture for the Orb-v3 forward(+analytic-VJP backward), refreshing only the two pos-dependent device inputs per MD/
tt-lang-models
affiliated
A growing collection of models that use tt-lang for some or all of their implementation. Reference implementations for bringing modern models to the tt-lang DSL.

A Tenstorrent fork of Infocom's Zork I (and more!), running a Z-machine interpreter at least four different ways on TT hardware. The most fun you can have with an AI accelerator.
tt-qb-lights
affiliatedSync your Tenstorrent Quietbox's RGB lighting to accelerator utilization status. Visual feedback for hardware activity in real time.
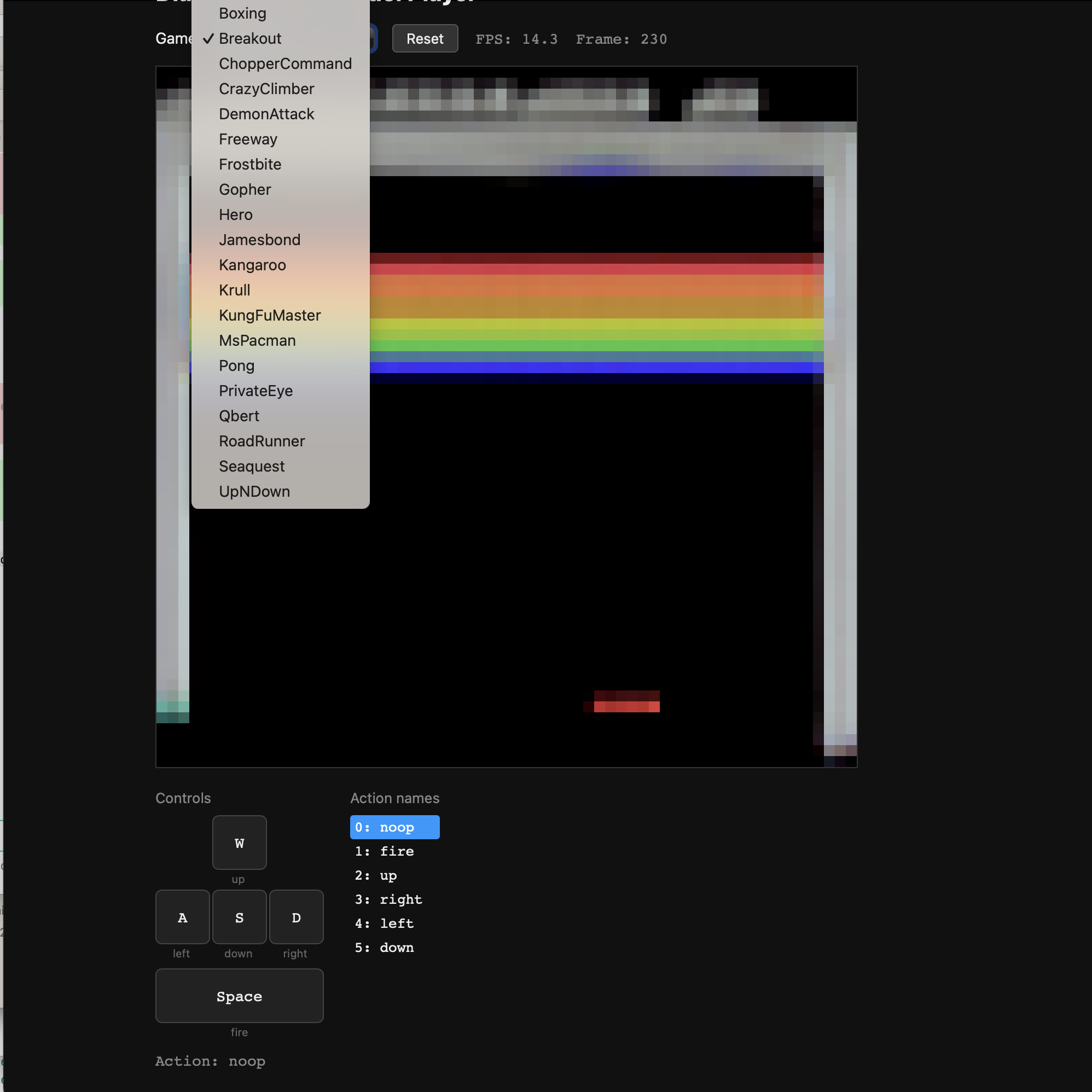
DIAMOND: Atari game-playing agent implemented on Tenstorrent hardware via tt-lang. Diffusion-based world model for reinforcement learning.
gemma4
affiliatedGemma 4 language model implemented in tt-lang (e4b variant) for direct execution on Tenstorrent hardware.
tt-lang inference script for Oasis 500M — an interactive video world model running on Tenstorrent hardware via the tt-lang DSL.
tt-model-runner
affiliatedDiscover, load, and benchmark models with a GUI and TUI for tt-inference-server. Makes exploring available models on Tenstorrent hardware as easy as browsing a catalog.
tt-claw
affiliatedA Tenstorrent-powered claw machine that rewards players with real prizes. The QuietBox 2 runs local AI inference to act as an agent controlling the claw hardware — the OpenClaw AI assistant lesson builds directly on this project.
Local AI Agents on Tenstorrent
affiliated★ featuredThree agentic projects running fully on-device: local AI agents on QuietBox 2, a coding assistant powered by Aider against a local inference server, and the OpenClaw AI assistant on QuietBox 2. No cloud APIs — all inference runs on TT hardware.
DFlash: Block Diffusion for Flash Speculative Decoding on Tenstorrent hardware using tt-lang. Combines block diffusion with speculative decoding for faster inference.
A Tenstorrent port of the DeepSeek Engram model using tt-lang. Brings DeepSeek's memory-efficient architecture to TT hardware.
Stable Diffusion XL on Tenstorrent
affiliatedOn-device image generation with Stable Diffusion XL running entirely on Tenstorrent hardware. Full inference pipeline with no cloud dependency.
Video Generation on Tenstorrent
affiliated★ featuredThree lesson-projects covering on-device video synthesis: frame-by-frame diffusion with tt-local-generator, native AnimateDiff video animation, and video generation on QuietBox 2. All run entirely on TT hardware with no cloud dependency.
tt-forge-compiletron
affiliated
Compile more than 100 models on tt-forge in a display format suitable for demos. Comprehensive showcase of tt-forge model compatibility.
📋 Changelog
# Changelog
All notable changes to tt-forge-compiletron are documented here.
## [Unreleased]
### Added
- `docs/kv-cache-bench.md` — teaching companion for the StaticCache KV cache
benchmark, explaining the two-graph pattern and why static shapes matter
---
## [1.6.0] — 2026-06-30
### Added
- **StaticCache KV cache decode benchmarking** — `bench_decode.py` now compiles
a second forge graph for the decode step using `transformers.StaticCache`.
The StaticCache is embedded in `KVDecodeWrapper` as a submodule so forge
traces K/V tensors as model state and emits `FillCache`/`UpdateCache` ops.
Falls back to full-recompute for models that don't support `cache_position`.
- `_try_kv_decode()` function — detects model dtype to avoid bfloat16/float32
mismatches, resolves tokenizer from loader or AutoTokenizer, pre-fills cache
on CPU before forge compilation.
- Bestiary `decode_note` field now records the method used per model
("StaticCache KV cache" vs "no KV cache — full recompute per step").
### Changed
- Decode results updated for all 5 stages — GPT-2 2.30→5.52 tok/s, OPT
3.98→5.05 tok/s, Phi-2 1.48 tok/s (new), Falcon 3.30 tok/s (new),
LLaMA-LoRA 2.86 tok/s (new), Gemma-LoRA 2.40 tok/s (new), and more.
---
## [1.5.0] — 2026-06-30
### Added
- **`scripts/bench_decode.py`** — dedicated LLM decode benchmark measuring
TTFT, prefill tok/s, and decode tok/s for all compiled causal LMs.
Subprocess isolation + tt-smi health check prevent hardware lockups.
- **Leaderboard columns** — TTFT, Prefill tok/s, Decode tok/s, Params (M)
replace the old Infer p50 / Throughput columns in `docs/leaderboard.html`.
- 5 benchmark stages: Stage 1 (GPT-2, OPT), Stage 2 (Phi-2, BLOOM, CodeGen),
Stage 3 (Falcon, Allam, LLaMA-LoRA, Gemma-LoRA), Stage 4 (Qwen 2.5,
Phi-1 LoRA), Stage 5 (DeepCogito, DeepSeek Coder, frontier models).
- `params_m` field added to all benchmarked bestiary entries.
- `hf:` loader prefix for frontier HuggingFace models loaded without a
tt-forge-models seed loader.
### Changed
- Bestiary `throughput_unit` relabeled from generic `tok/s` → `prefill_tok/s`
for all 54 causal LM entries to prevent confusion with decode throughput.
---
## [1.4.0] — 2026-06-29
### Added
- **`scripts/install.sh`** — turn-key smart installer: hardware pre-check,
hugepages, disk space, forge venv, XLA venv, mesh descriptor probe,
tt-forge-models clone, stale-shm cleanup. Outputs color-coded summary table.
- **RAM/DRAM budget calculator** — skips models whose weights exceed available
system RAM + per-chip DRAM; prevents OOM crashes at load time.
- **`scripts/setup-venvs.sh`** — minimal venv setup script for clean Ubuntu
24.04 installs on Tenstorrent Blackhole hardware.
- Self-contained patches directory — tt-forge-models fixes applied at
expedition startup without modifying upstream.
- `--ephemeral` / `--evict-failures` flags — evict HF weight cache after
each model to reclaim disk space on small-storage machines.
### Changed
Image Classification with TT-Forge
affiliatedEnd-to-end image classification project using TT-Forge — compile and run a PyTorch classification model on Tenstorrent hardware with no kernel authoring required.
tensix-viz
affiliated★ featured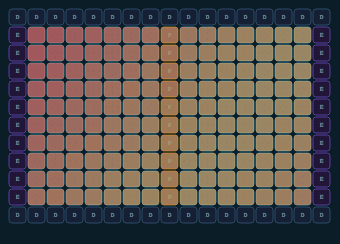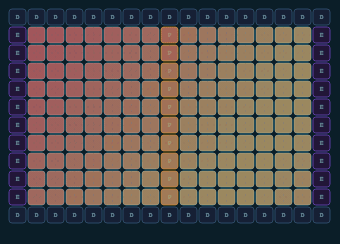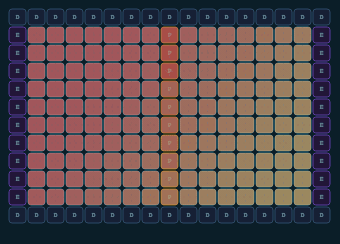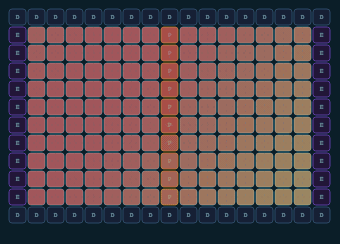
Hardware topology visualizer for Tenstorrent chips — from individual chip to full cluster. Interactive JavaScript visualization of Tensix core layout and NoC connections.
📋 Changelog
# Changelog
All notable changes to tensix-viz are documented here.
## [1.1.2] - 2026-06-29
### Fixed
- **`TensixViz.autoInit()` is idempotent for `.tensix-viz-container` elements** (`src/chip.js`)
1.1.1 made the `[data-viz]` path idempotent but left the legacy single-chip path unguarded. When
`autoInit()` ran twice (the bundle's self-init plus an explicit host-page call), each
`.tensix-viz-container` canvas received a second `TensixViz` instance — two animation loops drawing
on one canvas, which renders as a doubled/overlapping grid. `TensixViz.autoInit()` now skips any
container already initialized (`container._tensixViz`) and records the instance on it.
### Added
- **Responsive multi-chip canvas** (`tensix-viz.css`)
`.tv-chip-wrapper canvas { max-width: 100%; height: auto; }` — card/system canvases (created
without the `.tensix-viz-canvas` class) now scale to fit a narrow column instead of being clipped
by `.tv-card`'s overflow. Previously this rule had to be patched in by downstream consumers.
## [1.1.1] - 2026-06-25
### Fixed
- **Animation player accepts both script schemas** (`src/chip.js` `_execStep`)
The player dispatched on `step.step` and read `step.cores` only, so scripts authored with the
alternate `{ action, coords }` schema ran zero steps — the Play button (and auto-play) appeared
dead. `_execStep` now dispatches on `step.step || step.action` and falls back `coords → cores`,
so blocks written in either schema animate.
- **`autoInit()` is idempotent for `[data-viz]` elements** (`src/index.js`)
`autoInit()` can run more than once (the bundle's self-init plus an explicit call). For `card`
and `system` vizzes — which append their render into the host element — the second run appended
a duplicate set of chips. `autoInit()` now skips any element already initialized (`el._tensixViz`).
## [1.1.0] - 2026-06-09
### Fixed
- **Heatmap: non-tensix cells no longer painted by heat overlay** (`src/chip.js` `_drawHeatmap`)
Commit 76dca80 added `coreType !== 'tensix'` guards to the pre-built artifacts but never to
the source. The guards are now in `src/chip.js` so the next build preserves them. Without this
fix, DRAM (col 5 on Wormhole), ETH (row 6 on Wormhole), and PCIe (col 8 on Blackhole) cells
were colored by the heatmap overlay and could inflate `maxVal`, compressing the visible range
for all tensix cells.
- **Memory overlay: stale phase not rendered after `reset()` on `showMemory: true` instances**
(`src/chip.js` `reset()` and constructor)
After calling `viz.activate(mode)` followed by `viz.reset()` on a canvas created with
`showMemory: true`, `_memPhase` retained the frozen `_mem` object from the animation closure.
`reset()` calls `render()` at the end, which caused `_drawMemoryLayer()` to run with stale data,
producing a faint DRAM glow and L1 fill bars on an otherwise blank chip. `reset()` now sets
`this._memPhase = null`; the field is also explicitly initialized to `null` in t
tt-warp
affiliatedWarp terminal plugin for Tenstorrent — integrates hardware status, model management, and developer workflows directly into the Warp terminal.
Tensix Grid Playground
affiliatedInteractive browser-based visualizer of the Tenstorrent Tensix grid architecture. Explore the NoC, core layout, and dataflow patterns without hardware — a great companion for learning kernel programming.
Tenstorrent Cookbook: Conway's Game of Life
affiliatedTT-Metalium implementation of Conway's Game of Life as a cookbook recipe. Each generation is a full parallel kernel dispatch over the grid — a clean introduction to stateful compute on Tensix cores.
Tenstorrent Cookbook: Particle Life Simulator
affiliated★ featuredParticle Life simulation on Tenstorrent hardware — an emergent-behavior N-body system where simple attraction/repulsion rules between species produce complex lifelike patterns. Cookbook recipe demonstrating parallel N-body compute on Tensix.
CS Fundamentals on Tenstorrent Hardware
affiliated★ featuredSeven-module computer science curriculum taught on real Tenstorrent hardware. Covers RISC-V architecture, memory hierarchy, parallel computing, networks and NoC, synchronization, abstraction layers, and computational complexity — all grounded in what is physically happening on the chip.
Custom Model Training on Tenstorrent
affiliatedEight-lesson series covering the full custom training workflow on TT hardware: dataset fundamentals, configuration patterns, fine-tuning, multi-device distributed training, experiment tracking, model architecture basics, and training from scratch.
Tenstorrent Cookbook: Core Recipes
affiliatedThree hands-on TT-Metalium kernel recipes: a Mandelbrot fractal explorer, real-time audio signal processing pipeline, and custom image filter stack. Each recipe is a complete kernel project with full source in the lesson.
nvtop
community★ featured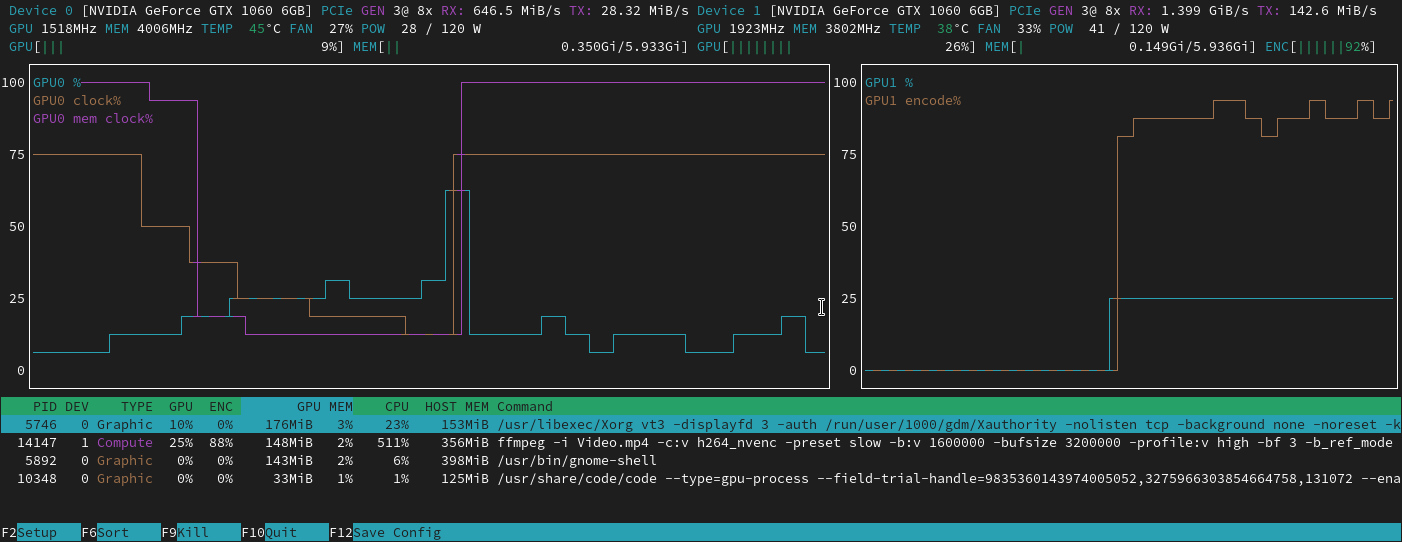
htop-style process monitor for GPUs and AI accelerators. Supports AMD, Apple, Huawei, Intel, NVIDIA, Qualcomm — and Tenstorrent. Real-time utilization, memory, and process info in a terminal UI.
dstack
community★ featuredVendor-agnostic orchestration for training, inference, and agentic workloads across NVIDIA, AMD, TPU, and Tenstorrent on clouds, Kubernetes, and bare metal.
4 previous releases
BarraCUDA
community★ featuredOpen-source CUDA compiler targeting multiple GPU architectures including Tenstorrent. Compiles .cu files to run on AMD and Tenstorrent hardware without modification.
tt-tiny
community★ featuredMinimal Python code to access and program the Tenstorrent Blackhole chip directly — George Hotz's exploration of TT hardware programmability with pointed commentary on the architecture.
zyx
community
A complete ML library and compiler in Rust — "from assembly to neural networks" — with a native Tenstorrent backend (src/backend/tenstorrent), autograd, custom kernels, multi-backend support, and Python bindings.
tt-twitch
communityA Tenstorrent Grayskull kernel written live on Twitch by George Hotz. 120-core grid demonstration of live kernel programming.
koyeb/tenstorrent-examples
communityExample applications and deployment configurations for running AI workloads on Tenstorrent hardware via Koyeb's cloud platform.
blackhole-py
communityPure Python driver for Tenstorrent Blackhole cards providing direct low-level hardware access without going through the full TT-Metal stack.
tenstorrent-tiny-examples
communitySimple C++ kernel experiments on a GraySkull e75 chip. Hands-on examples for learning the TT-Metal programming model at the metal level.
ttnn-helloworld-cpp
communityMinimal working example of using Tenstorrent TTNN in C++. The simplest possible starting point for C++ developers targeting TT hardware with TTNN.
tt-sim
community★ featuredCommunity-built Tenstorrent architecture simulator written in Python. Runs without hardware — useful for researchers and developers exploring the Tensix architecture offline.
tt-iree
community★ featuredIREE (Intermediate Representation Execution Environment) ML compiler ported to Tenstorrent AI accelerators. Brings the IREE compiler ecosystem to TT hardware.
TT-GoL
community
Conway's Game of Life implemented on Tenstorrent hardware using TT-Metal kernels.
triton-tenstorrent
community★ featuredOpenAI Triton compiler plugin for Tenstorrent hardware. Write Triton kernels and target Tensix cores — brings the Triton ML kernel ecosystem to TT devices.
tenstorrent.nix
communityNix flake packaging the Tenstorrent software stack for NixOS and Nix users. Reproducible, declarative installation of TT drivers and tools.
ttMandelbrot
communityMandelbrot Set fractal renderer running on Tenstorrent hardware. A classic demo showcasing parallel compute on Tensix cores.
TT-Metal Mini Template
communityMinimal working CMake project template for starting a new TT-Metal project from scratch. Good starting point for community kernel development.
tt-tutorial (HPC)
communityTutorial on Tenstorrent hardware for HPC researchers from the RISC-V Testbed project at Edinburgh/EPCC. Covers Wormhole from an HPC parallel-computing perspective.
ttPEAK
communityclpeak-style peak-performance benchmark for Tenstorrent devices using TT-Metalium. Measures theoretical peak throughput across operations — useful for hardware characterization.
current
communityHigh-level parallel programming framework for Tenstorrent accelerators, abstracting TT-Metal into a research-oriented programming model for parallel computation.
ttVecAdd
communityMinimal vector-addition example on Tenstorrent devices using TT-Metalium. A clean hello-world for the TT-Metal kernel programming model in C++.
bhx
community★ featuredBoot stock Linux cloud images on the SiFive X280 RISC-V cores inside Tenstorrent Blackhole AI accelerators. Per-card Rust daemon with virtio-mmio block/net/console and U-Boot/EFI support.
📋 Changelog
# Changelog Notable changes per release. Format loosely follows [Keep a Changelog](https://keepachangelog.com/en/1.1.0/); this project does not yet promise SemVer compatibility on the RPC wire format or library API surface (we're not 1.0). ## Unreleased V2 virtio-dispatch redesign. The kick ring + completion ring + host- side throttle that grew up around #184 are gone; in their place is a per-(slot, queue) dirty bitmap in BRISC L1. The bitmap is level- sensitive — guest QUEUE_NOTIFY storms coalesce into a single set byte, so the dispatch path can't fall behind under any burst. Wire incompatible with 0.9.0; `TENSIX_PROTOCOL_VERSION` bumped 4 → 5. ### Added - **V2 dirty-bitmap dispatch** (`#187` / `#188` / `#189`). BRISC writes 1 to `CTRL_OFF_DIRTY[slot][queue]` on every guest QUEUE_NOTIFY; the daemon's `Dispatcher` clears the byte and dispatches each pass. Replaces V1's 2048-entry kick ring + daemon-side `consume_kick_ring_pass` consumer. - **V2 processed-cursor table** at `CTRL_OFF_PROCESSED`. Daemon publishes `used.idx` after each successful dispatch so warm-resume reads cursors directly without re-probing guest DRAM. - **`bhx_notify_events_total`, `bhx_dispatch_passes_total`, `bhx_dispatch_queues_drained`** Prometheus counters surface the new dispatch path. The burst regression test (`scripts/ soak_virtio_burst.py`) asserts `dispatch_passes_total > 0` to confirm the workload reached the new path. - **`scripts/soak_virtio_burst.py`** — multi-queue burst regression test. Sustains 16-job direct=1 fio randwrite + a tight `printf` loop to `/dev/console`, samples `/metrics` every 1 s, and verifies the daemon log contains zero `kick.*drop|rescue|throttle.*ENGAGE` matches. - **`DaemonState.chip_reset_this_session`** flag — gates `maybe_opportunistic_reset_board` so 4-way parallel cold boots reset the chip exactly once, not once per L2CPU. Without this the second-and-later resets blip the chip while earlier-booted L2CPUs hold mmap pages, SIGBUSing their workers. - **`Dispatcher` (was `KickPoller`)** with documented testability seam (`CtrlL1Access` trait); `drain_dirty_bitmap` is unit-tested against an in-memory L1 fake covering all five visit/clear semantics cases plus the address-formula pins. ### Changed - **`KickPoller` → `Dispatcher`**, plus `kick_poller` → `dispatcher` field on `DaemonState`, `tensix-kick-poller` → `tensix-dispatcher` thread name, `[kick-poller]` → `[dispatcher]` log tag, `kicks_consumed` → `dispatches_total`, `last_kick_slot_queue` → `last_dispatch_slot_queue`. Pure rename; no behavior change. V1 vocabulary scrubbed throughout the codebase (firmware, daemon, scripts, docs). - **`CTRL_SIZE` shrinks 36 KiB → 4 KiB**. V2 footprint is ~1.5 KiB; the rest is reserved for future fields. - **Stats-page offsets repacked** — V1 `STATS_OFF_KICK_DROPS`, `STATS_OFF_COMPL_EVENTS`, `STATS_OFF_LAST_COMPL` retired with V1 (#190); deprecated PRECAP / BLINDCAP / POSTCAP slots dropp
ttas
communityttas is a hacker-friendly assembler/disassembler for Tensix on Wormhole. It turns assembly into the exact 32-bit words the hardware runs, and turns binaries back into readable instructions using the same shared instruction table.
tt-tutorial (Korean)
communityComprehensive tutorials for the Tenstorrent software stack in Korean. Jupyter notebooks covering the full developer path from hardware setup to model inference.
Collective Operations on Wormhole n150 (Sapienza University of Rome)
communityMaster's thesis implementing and benchmarking five allreduce algorithms (Swing, Recursive Doubling, Bandwidth Optimal, Latency Optimal, Shared Memory) on the Wormhole n150. Bandwidth Optimal achieved best performance, approaching within 2× of theoretical optimal.
libtt-metal-cxx
communityRust crate that exposes the TT-Metal host API through a C++ bridge via cxx.rs — covering device management, program/kernel creation (from source file or inline string), circular buffers, semaphores, runtime arguments, sharded buffers, and MeshDevice workflows, with hardware-backed integration tests.
tetsuh/tt-metal-community-distro-matrix
community
A compatibility guardrail that continuously monitors whether [tt-metal](https://github.com/tenstorrent/tt-metal) and the official [tt-installer](https://github.com/tenstorrent/tt-installer) build successfully on community Linux distributions that are not part of Tenstorrent's official CI.
libtt
communityA Bazel-built PJRT plugin (libtt.so) providing an XLA backend for Tenstorrent devices. Bundles the tt-xla PJRT implementation with tt-mlir and tt-metal into a single shared object so JAX code runs on Tenstorrent hardware, with patches so sglang-jax works out of the box.
tt-splat — matrix-native 3D Gaussian Splatting on Blackhole
community
3D Gaussian Splatting rewritten to run on the matrix engine: a polynomial splat and order-independent weighted-sum blending replace exp and depth-sorted alpha, so the pipeline becomes GEMM → activation → GEMM. Renderer + trainer, trained device-resident on a Blackhole p150a.
ttPseudoRowMajor
communityA small TTNN-facing C++ library (ttprm) for running view-shaped tensor work without first materializing the view in DRAM. Targets Tenstorrent TILE tensors and uses cached device operations to gather/scatter through layout views.
gsplat_tt
communityPort of Gaussian Splatting (3D scene reconstruction from 2D images) to Tenstorrent hardware.
A Gentle Guide: Tenstorrent Card on Arch Linux with Metalium
communityStep-by-step guide to getting a Tenstorrent card running on Arch Linux with the full Metalium stack. Practical troubleshooting from someone who did it the hard way first.
Thoughts and Logs After Messing with Tenstorrent Grayskull
communityHonest field notes from getting a Grayskull card running and writing first Metalium kernels. Covers setup pitfalls, processor hangs, memory protection quirks, and what makes Metalium compelling despite early rough edges.
Programming Tenstorrent Processors
community★ featuredDeep-dive into the Tenstorrent architecture and Metalium programming model — circular buffers, kernel synchronization, NoC routing, and where the footguns are. The honest guide to thinking in Tensix.
Tenstorrent Architecture — W&M CSCI654 Advanced Computer Architecture
communityLecture 20 from William & Mary's graduate Computer Architecture course. Frames Tenstorrent in the landscape between GPUs and TPUs, draws comparisons to Cerebras and SambaNova, then dives deep into the Wormhole chip and Tensix core: the 5 RISC-V core design, SFPU, NoC, and dataflow execution model.
Tenstorrent SFPU Kernel Series — Jason Davies
community★ featuredSponsored series of deep technical articles on implementing optimal SFPU kernels for the Tenstorrent Wormhole and Blackhole vector units. Covers where, typecasting, 16/32-bit integer multiplication, cube root, and accurate sin/cos/tan — with cycle counts, assembly walkthroughs, and Blackhole vs Wormhole comparisons throughout.
tt-rqm-kernels
communityStructured quaternion, rotor, and phase-aware tensor kernels — operations on 3D rotation and orientation data packed into ordinary `[N, 4]` float tensors — plus StructuredBench, a benchmark suite for these workloads. Provides CPU/PyTorch reference implementations and an optional TT-Lang simulator prototype for the quaternion multiply (`qmul`) kernel as a first step toward Tenstorrent hardware support.
Attention in SRAM on Tenstorrent Grayskull
communityA fused kernel for the Grayskull architecture implementing Transformer self-attention entirely within SRAM. Combines matrix multiply, attention score scaling, and Softmax without DRAM accesses, achieving significant speedups over non-fused implementations.
Exploring Fast Fourier Transforms on the Tenstorrent Wormhole
communityPorts the Cooley-Tukey FFT algorithm to the Wormhole n300 RISC-V accelerator. The Wormhole draws 8× less power and consumes 2.8× less energy than a 24-core Xeon Platinum for a 2D FFT. ISC 2025.
Assessing Tenstorrent Grayskull RISC-V MatMul Acceleration for LLMs
communityEvaluates the Tenstorrent Grayskull e75 RISC-V accelerator for matrix multiplication at reduced numerical precision (BFP8 and LoFi), a fundamental kernel in LLM inference computation.
Porting Strategies for Gravitational N-Body Simulations on Tenstorrent Wormhole
communityEvaluates three strategies for scaling an N-body code across multiple Tenstorrent Wormhole accelerators. Builds on the established performance of single-card N-body work to explore parallelism via the on-chip NoC and multi-accelerator configurations.
Accelerating Gravitational N-Body Simulations on Tenstorrent Wormhole
communityAccelerates an astrophysical N-body simulation on the Wormhole n300. Achieves 2× speedup and 2× energy savings over a highly optimized CPU implementation. SC '25 Workshop.
Numerical Kernels on a Spatial Accelerator: Tenstorrent Wormhole
communityImplements three numerical kernels and composes them into a conjugate gradient solver on Wormhole. Demonstrates AI accelerators merit consideration for HPC workloads traditionally dominated by CPUs and GPUs. 2026.
Accelerating Stencils on the Tenstorrent Grayskull RISC-V Accelerator
communityExplores stencil computation on the Grayskull PCIe RISC-V accelerator. Early academic work examining TT hardware for HPC stencil workloads. 2024.
Stencil Computations on Tenstorrent Wormhole
communityMaps 2D 5-point stencil computations onto the Tenstorrent Wormhole RISC-V AI dataflow accelerator via two implementations: element-wise decomposition (Axpy) and matrix-multiplication reformulation (MatMul). Profiling shows the isolated Wormhole kernel is competitive with CPU execution, with PCIe transfers and initialization driving end-to-end overhead; Axpy achieves lower energy than the CPU baseline at large scales. Identifies architectural and software directions for making AI accelerators viable for HPC stencil workloads. 2025.
SwiftNPU: Scalable Shape-Flexible Allocation for Inter-Core Connected NPUs
communityMakes multi-tenant NPU sharing practical for Blackhole-class hardware using polynomial-time allocation algorithms. Delivers up to 1.37× higher utilization and 1.14× faster workload completion. Up to 890,000× faster than NP-hard baselines.
TileLoom: Automatic Dataflow Planning for Spatial Dataflow Accelerators
communityCompiler system that automatically generates efficient dataflow plans for tile-based languages on spatial accelerators including Tenstorrent Wormhole. Exploits on-chip network forwarding between processing elements to reduce DRAM pressure.
Rewriting TTS Inference Economics: Lightning V2 on Tenstorrent vs. NVIDIA L40S
communityShows that Text-to-Speech inference on Tenstorrent Lightning V2 achieves 4× lower cost than NVIDIA L40S. Applies BlockFloat8 (BFP8) and low-fidelity (LoFi) precision strategies to TTS despite their greater numerical fragility compared to LLMs.
Tenstorrent Blackhole Architecture Guide
community★ featuredA 6,500-word community deep dive into the Blackhole p100a architecture: the tile model (Tensix, DRAM, SiFive x280 L2CPU, Ethernet, PCIe, NoC arc), firmware startup sequence, MOP micro-op processor, replay buffer, FPU/SFPU sync, and the anatomy of a kernel. From the author of blackhole-py.